
Abstract
In this paper, a video-based behavioural recognition dataset for beef cattle is constructed. The dataset covers five behaviours of beef cattle: standing, lying, drinking, feeding, and ruminating. Six beef cows in a captive barn were selected and monitored for 168 h. Different light conditions and nighttime data were considered. The dataset was collected by one surveillance video camera. The data collection process required deploying cameras, memory, routers and laptops. Data annotation was automated using the YOLOv8 target detection model and the ByteTrack multi-target tracking algorithm to annotate each beef cow’s coordinates and identity codes. The FFmpeg tool cut out individual beef cow video clips and manually annotated them with behavioural labels. The dataset includes 500 video clips, 2000 image recognition samples, over 4000 target tracking samples, and over 10G of frame sequence images. 4974 video data of different behavioural types are labelled, totalling about 14 h. Based on this, a TimeSformer multi-behaviour recognition model for beef cattle based on video understanding is proposed as a baseline evaluation model. The experimental results show that the model can effectively learn the corresponding category labels from the behavioural category data of the dataset, with an average recognition accuracy of 90.33% on the test set. In addition, a data enhancement and oversampling strategy was adopted to solve the data imbalance problem and reduce the risk of model overfitting. The dataset provides a data basis for studying beef cattle behaviour recognition. It is of great significance for the intelligent perception of beef cattle health status and improvement of farming efficiency.
Similar content being viewed by others

Introduction
Using computer vision, deep learning, and video understanding technologies makes it possible to quickly, accurately, and contactlessly identify cattle behaviours. Farmers can use video analysis to make decisions to improve agricultural management, and detection data can be rapidly adjusted to the livestock environment. These developments are crucial for advancing livestock farming towards precision, intelligence, modernisation, and scale.
With its expansive grasslands and favourable climate and ecology, Yunnan, which borders China to the southwest, has made beef cattle rearing one of its most significant enterprises. In 2023, the province’s cattle inventory of 8,973,900 heads, an increase of 2.1% year-on-year, ranked first in the country; 3,647,600 heads of cattle slaughtered, a rise of 1.3%, ranked second in the country; and beef production of 447,400 tonnes.
While the beef cattle industry achieves precise poverty alleviation, articulates rural revitalisation, and promotes farmers’ income, it also faces challenges such as reducing feed costs, improving feeding efficiency, preventing and managing diseases, and advancing farming towards modernisation and scaling up1. Among these pressing issues, the importance of understanding beef cattle behaviour is increasing, and the creation of beef cattle behaviour datasets is becoming more necessary to help develop more accurate identification models to address these issues.
Datasets of captive beef cattle behaviour can improve the performance and generalisation of models, and accurate animal detection and identification have an irreplaceable role in safeguarding animal health and improving livestock productivity and product quality. Researchers can collect diverse and large-scale information more easily and accurately through video collection.
To address the lack of video datasets of beef cattle behaviour, a data acquisition system integrating cameras, memory, routers and laptops was deployed, resulting in the development of datasets adapted to real farm environments. To solve the problem of tedious and time-consuming manual video data annotation, the YOLOv8 target detection model and ByteTrack multi-target tracking algorithm were applied to automate the annotation of spatial and temporal information of beef cattle. The dataset was also refined by manually labelling single beef cattle video clips. In addition, data enhancement and oversampling methods were utilised to reduce the impact of data imbalance on model training. Establishing a dataset based on real farming environments is important in improving beef cattle welfare and promoting sustainable development2.
Thus, this study created a dataset on the behaviour of captive beef cattle. This dataset served as a standard for the behavioural identification of captive beef cattle. The dataset contains five behavioural categories: standing, lying, eating, drinking and rumination. These five behavioural categories integrate postures and states, embrace basic daily activities, and apply them to real-life scenarios.
Through in-depth research, five categories of behaviours that can generally reflect the daily behavioural habits of beef cattle have been identified, which can help farmers understand the living standards and health status of beef cattle. This dataset will provide a database for beef cattle detection, tracking and multi-behavioural identification, and promote innovation in animal identification. Therefore, the main contributions of this paper are as follows:
-
(1)
500 video clips, 2000 image recognition samples, over 4000 target tracking samples, over 10G of frame sequence images, and 4974 video data of five behavior kinds make up the video dataset we created for this work. Data augmentation and oversampling were employed to increase the dataset, lower the danger of model overfitting, and guarantee data standardization and diversity. The dataset was collected using a video camera to watch captive beef cattle for 168 h, covering various light conditions and nighttime data.
-
(2)
In the data annotation stage, we proposed a semi-automatic annotation method that innovatively combines target detection and multi-target tracking algorithms to achieve the ID and coordinate positioning of beef cows. After cutting the video through the code development process, the approach manually annotates individual beef cows, resulting in an 83.34% reduction in the burden associated with manual annotation.
-
(3)
Finally, we present a baseline recognition model’s adaptation and training using the new Time–Space transformer (TimeSformer) video understanding architecture. The model can recognise and analyse beef cattle behaviour in standardised captive environments, using TimeSformer’s separate time–space attention mechanism to reduce the model’s temporal complexity and improve recognition accuracy, thereby increasing the utility of behavioural analysis on real farms.
The rest of the paper is organised as follows. ‘Related work’ is a literature review of beef cattle behavioural video datasets. In ‘Materials and methods’, we introduce the data collection steps used in this study, the steps and methods of data annotation, and the baseline framework and principles of the behaviour recognition model. The statistical analysis of the dataset and the experimental outcomes of the models trained on the dataset created in this work are provided in the ‘Results’ section, which also examines the experimental errors and the quantity of dataset annotations. The ‘Discussion’ section discusses future research directions and the application value of this study. Finally, we give the conclusion of this study in the ‘Conclusion’ section.
Related work
Research on behaviour recognition in beef cattle falls into two main categories: contact sensor technology and computer perception technology. The contact method is to attach the sensor to the animal or implant it in the animal for data acquisition, and use algorithms to achieve animal behaviour recognition3. Zehner et al.4 used nasal band pressure sensors to acquire behaviours such as feeding and rumination in cows. Chelotti et al.5 used sound sensors to collect feeding data from cattle and classify feeding behaviour. Achour et al.6 Automatic detection of cow behaviour using a fixed inertial measurement unit on the back of the cow. Hosseininoorbin et al.7 Recognition of multiple behaviours in beef cattle by wearing triaxial acceleration sensors on their necks and incorporating deep learning techniques.
In machine vision, one approach is to achieve relevant behavioural detection by obtaining bio-visual features of a target from an image. Classification of cow riding behaviour was achieved by extracting geometric and optical flow features of the cow region by background subtraction algorithm and inter-frame differencing by Guo et al.8 Recognition of rumination behaviour was achieved by extracting visual features of the cow’s mouth using a convolutional neural networks (CNN) model by Ayadi et al.9 Another approach is to extract spatiotemporal features of animals to achieve recognition and classification of behaviours. A behavioural recognition detection framework combining frame-level detection and spatiotemporal information to achieve real-time multi-behavioural recognition of cattle was proposed by Fuentes et al.10 Wu et al.11 implemented the recognition of cow behaviour based on CNN and long short-term memory (LSTM). Li et al.12 proposed a beef cattle behaviour recognition method based on dynamic serpentine convolution and BiFormer attention mechanism enhancement.
To perform effective video behaviour recognition, researchers usually rely on behaviour recognition datasets, through which researchers can train and evaluate behaviour recognition models to improve performance and generalisation13. Chen et al.14 constructed a large-scale video dataset of mammalian behaviour that compensates for the shortcomings of previous datasets but suffers from dataset bias. Li et al.15 constructed a new benchmark dataset for cow behavioural recognition research that fills the gap in video cow behaviour datasets under standardised pasture conditions but suffers from data imbalances.
As the availability of public datasets is relatively limited, we constructed a video behavioural dataset containing five daily behaviours of beef cattle collected from a real farm. Standing, lying down, drinking, feeding, and rumination were recorded in detail, and we also utilised data enhancement and oversampling to address data imbalance. Our approach establishes the groundwork for future video-based behavioural identification research in captive beef cattle while simultaneously improving data quality, reducing noise, lowering labour costs, and increasing the efficiency of data annotation. We compared our dataset with some cutting-edge datasets on livestock video behavior, and the comparison is shown in Table 1.
Methods and materials
Beef cattle behaviour selection
Animal Behaviour provides a theoretical basis for computer vision-based animal behaviour recognition research, helping us to understand the nature and laws of animal behaviour17.To identify specific behaviours, research was carried out to identify five key behaviours necessary to study beef cattle.
Table 2 explains the behaviour of beef cattle used in this survey. By studying and identifying these behaviours, it is possible to improve feeding management techniques, reduce the incidence and spread of diseases, help farmers make decisions, and make it easier to conduct follow-up studies to identify advanced behaviours (e.g. lameness, estrus) in beef cattle.
Data collection
To collect data on the behaviour of beef cattle, we built a data acquisition system in the farm, including cameras, memory, routers and laptops, and the devices are connected through Power over Ethernet (POE) power supply technology. The camera used in this study was a Hikvision Network 4MP camera (model DS-2CD3T47WD-LU) with a resolution of 1920 × 1080 pixels and a frame rate of 25fps.
The camera was fixed in a specific location, as shown in Fig. 1 to capture the cattle’s behavior. It was determined to shoot from the side of the cattle because shooting directly at the cattle could potentially damage the camera power cord and network cable. After testing, the cattle factory shed pillar height of roughly two meters was chosen because it allowed six cows to cover the shooting angle at the fixed camera location.

Schematic diagram of a cow barn. The blue area captured by the camera is responsible for capturing the daily behavior of the beef cattle.
This beef cattle behavioural data was collected based on the above equipment and environment, the collection time was July 2023, all-day 24-h monitoring, the collection duration was one week, a total of 420G raw video data was obtained, the experimental collection of video format is MP4, the video resolution is 1920 × 1080, the frame rate is 25 frames per second, these video data will be used as the basic data of the experiment for the subsequent beef cattle image dataset and video behaviour dataset construction.
Data annotation
After capturing the video data, to reduce the workload of manual annotation, this study proposes a new annotation method, which is chosen to combine target detection, target tracking and manual behavioural annotation to achieve semi-automatic annotation of video data.
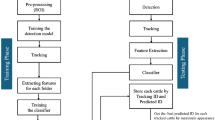
Figure 2 illustrates the particular data annotation procedure. Three components make up this process: YOLOv8 beef cattle target detection, BateTrack beef cattle target tracking, and manual beef cattle behaviour annotation.

Dataset construction and annotation process.
In this study, 2000 images of beef cattle randomly selected from 168 h of raw video data over different periods were used to construct a target detection dataset, and the photos were labelled using Make Sense software, defining the unique annotation category ‘COW’, creating bounding-box annotations around the cattle, and exporting the YOLO format label file after the annotation was completed. After data enhancement, the annotated images were expanded to 4500 images, divided into a training set (3600 images) and a validation set (900 images) according to the ratio of 8:2.
To further improve the generalisation ability and accuracy of the detection model, data enhancement operations were performed on the annotated images18. Five data enhancement methods were used. These data augmentation operations—scale transformation, horizontal flipping, scaling and rotation, noise addition, and color jittering—are part of our image preprocessing pipeline aimed at improving detection model performance. The results are shown in Fig. 3.

Comparison of data enhancement effects on image recognition datasets.
Target detection19 aims to accurately locate and identify the position and class of multiple target objects from an image or video, and in this study target detection is one of the key steps in building a behavioural dataset. YOLOv8 is the target detection model used in this study to locate the position of captive beef cattle. To detect targets at different scales, the model uses a deep convolutional network as its backbone in conjunction with a feature pyramid network to achieve multi-scale feature fusion20. On the target detection dataset established in this study, the average accuracy of detection of the model after 150 rounds of iteration can reach 99.48%. The effect of target detection in beef cattle is shown in Fig. 4.

Effectiveness of target detection in beef cattle.
ByteTrack, a multi-target tracking algorithm based on Track-by-Detection, was chosen for this experiment to track beef cattle21. ByteTrack can achieve better tracking performance with lower computational resource consumption and has already achieved excellent performance on several public datasets, outperforming most existing multiple object tracking (MOT) algorithms and becoming a new benchmark method in the field of target tracking22. Bytetrack requires no training, as long as the detection model is trained and the algorithm uses the results of the target detection as input.
Before performing target detection and tracking, the original video data is subjected to a preprocessing operation, where the video that may affect the model training is removed by data cleaning, and then the cleaned video is subjected to a frame extraction operation, where the video is cropped to a sequence of frames. The trained YOLOv8 model is used to detect beef cattle targets using the saved frame sequences, and the detection results are input to the ByteTrack tracker for multi-target tracking.
The tracking process is shown in Fig. 5. The ByteTrack tracking algorithm is divided into the following four steps, firstly, based on the YOLOv8 detection scores and ByteTrack thresholds, the detection frames are divided into two categories: high and low scores. Then the first correlation is performed, followed by the second correlation, and finally after post-processing the target tracking can be achieved. The tracking threshold set for this experiment is 0.5 (if the match between the target and the existing track is higher than this threshold, the target is considered to be associated with the existing track). The high threshold is 0.6 (if the detected target does not match any existing trajectory and its matching degree is higher than this threshold, a new trajectory is initialised for it). The match threshold is 0.8 (a target is considered to be associated with an existing trajectory only if the target matches an existing trajectory above this threshold). The time buffer size for removing trajectories is 30 (if an unmatched tracking target is not matched successfully after 30 frames, the tracking target is deleted). The results of target localisation and tracking of beef cattle are shown in Fig. 6. ByteTrack performed well in tracking animals even with partial occlusion, maintaining the animals’ identities. However, in cases of full occlusion or close proximity between animals, tracking accuracy can decrease, and identity switching may occur. To address these challenges, future work will explore improving the robustness of ByteTrack, potentially through the integration of appearance-based methods or more advanced tracking algorithms.

ByteTrack tracking process.

The effect of automated labelling of beef cattle locations.
Through the detection and tracking technology of YOLOv8 and ByteTrack, the location of each beef cow in the video and its unique identification code (ID) were accurately captured, and based on the above information, the video clips of a single beef cow were extracted using FFmpeg. Adjusting all videos to a resolution of 224 × 224 and image filling using Letterbox technology ensured the clarity and quality of the adjusted videos, which is very important for preserving the details and features of the video content. The final step was a manual behavioural annotation of the video clips, where each video clip was classified according to five behaviours: stand, lie, eat, drink and ruminate. The manual annotation process was performed independently by two researchers who each annotated the behavioral events in the video. To ensure the quality of the annotation, we implemented a consistency (IAA) procedure and resolved any discrepancies through discussion. At the same time, we calculated the Kappa coefficient to quantify the level of consistency between the annotators, with a final result of 0.95.
Baseline assessment
Video understanding refers to analysing and interpreting video clips, which is an important research direction in computer vision. Unlike image data, video data contains a temporal dimension in addition to a spatial dimension, so the dynamic information in video data needs to be taken into account. We chose to use the TimeSformer model for this task.
Before choosing the TimeSformer model, we delved into the shortcomings of other behaviour recognition models for processing video datasets. The traditional 2DCNN is mainly used to extract spatial features of the image, with insufficient consideration of temporal correlation23. 3DCNN adds the temporal dimension to 2D CNN, thus achieving simultaneous convolution of spatiotemporal dimensions, but suffers from high computational cost and low training efficiency24.
TimeSformer is the first video behaviour recognition architecture based entirely on Transformer, enabling better processing of temporal data by using the self-attention mechanism in Transformer25. TimeSformer’s scalability allows it to train larger models on longer video clips. TimeSformer has achieved significant results on several challenging behavioural recognition datasets (e.g., Kinetics-400, Kinetics-600, Something-v2 and HowTo100M datasets.).
Details of the TimeSformer model
The backbone network of TimeSformer is a vision transformer (ViT), and the schematic diagram of the ViT network is shown in Fig. 7 ViT converts the image classification problem into a sequence problem by converting the image blocks into a sequence of tokens, and using the Transformer’s self-attention mechanism for feature extraction and learning.

ViT schematic.
If ViT is directly used for video recognition, the amount of computation is unacceptable. To alleviate this problem, TimeSformer reduces the computation in two ways, one is to disassemble the video into a subset of disjoint image block sequences, and the other is to propose a divided space–time (T + S) attention mechanism to obtain temporal and spatial features based on the ViT model. The TimeSformer model treats the input video as a spatiotemporal sequence of image blocks extracted from each frame, and the model obtains the semantics of each image block by comparing the semantics of each image block with the other image blocks in the video to capture both local dependencies between neighbouring image blocks and global dependencies of distant image blocks.
Results
The dataset consists of labelled data, frame sequence images and raw video clips obtained from the installed camera. Figure 8 shows two types of images in the dataset for ‘postural behaviour’: standing and lying down. Figure 9 shows three categories of images in the dataset for ‘state behaviour’: eating, drinking and rumination. The dataset contains a total of 2000 target detection image samples, over 4000 target tracking samples, and 4974 classified video clips, as well as over 10G of frame sequence image samples used to extract keyframes for annotation. The target tracking samples are divided into training, validation and test sets, and the video samples are not separated into training and test sets, so users can divide them according to their needs.

Two samples of the postural behaviour of beef cattle in the dataset.

Sample behaviour of beef cattle in three states in the dataset.
The dataset consists of seven folders, namely ‘videos’, ‘video_cut’, ‘Target detection dataset ’, ‘Target tracking dataset’, ‘Labelframes’, ‘Category Videos’. Where videos denote the original video, and video_cut is a 10 s video clip after cropping based on the original video. The ‘Target detection dataset’ is the image dataset used to train YOLOv8, including the training set, validation set, and test set divided according to the Ultralytics framework, corresponding to the image and label files.Target tracking dataset is the sample images of YOLOv8 after training and validation tests, which can be used as samples for ByteTrack multi-target tracking, Labelframes are the images used to extract the key frames for labelling, and Category Videos are the labelled video clips of a single beef cow with five different behavioural categories.
Analysis of data sets
As illustrated in Fig. 10, which lists the percentages of the composition of each catogory, we performed a discrete statistical analysis of the dataset’s five behavioral categories.

Proportional composition of samples of five categorical behaviours.
Figure 11 displays the number of occurrences of each behaviour in the sample files and provides a thorough depiction of the distribution of the 4974 single-head beef cattle video clips in the dataset based on the category labels in the annotated files.

Counting statistics for five types of behaviour.
Observation of the data reveals that the number of videos for standing and rumination behaviours is high, lying and feeding videos are in the middle while drinking behaviour has the least number of videos, which is a large difference compared to the amount of data for the other behaviours, which is an obvious data imbalance problem. This may result in the model being trained with excessive focus on most other categories and ignoring the category of drinking behaviour, where features are not adequately learned and thus biased in prediction. Such a scenario will also result in issues including biased model evaluation metrics and diminished recognition accuracy.
We used a combination of random oversampling26 and data augmentation to deal with the data imbalance problem after evaluating three types of solution strategies: the training strategy side, the data side and the model network module. Oversampling a few classes of samples without introducing too much complexity increases their sample size, and then data augmentation is performed on all samples to generate more diverse and realistic samples and to make the number of samples in each class tend to be close to each other, to improve the model’s ability to recognise a few classes and to enhance the model’s ability to generalise27. Finally, the video data was expanded to 10,577 items, and the comparison between before and after data expansion is shown in Fig. 12.

Comparison chart before and after data expansion.
Analysis of dataset annotation volume
The beef cattle video behaviour dataset constructed by the semi-automated annotation method proposed in this paper contains a total of 4974 video data with a total duration of about 14 h. Referring to the publicly available behaviour recognition dataset, for each piece of data, the annotation data includes at least six key information: the location information, ID, behaviour category, behaviour start and end time points, and duration of each beef cow. For the 4974 data in this paper, the total amount of annotation will be at least 29,844 when manually annotated according to the above criteria. However, by using semi-automatic annotation, the manual annotation work focuses only on the behavioral category of a single beef cow, and the amount of annotation is only 4974, which reduces the workload by about 83.34%, and improves the efficiency of annotation while ensuring the quality of the annotation.
Analysis of experimental results
In this study, the model’s performance is measured in terms of accuracy, model computation and number of parameters. Mean average precision (mAP) is a comprehensive assessment of the overall performance of the model on different categories. FLOPs and Params are two important metrics for measuring the complexity of deep learning algorithms, and they can be used to evaluate the performance and usefulness of a model.
To understand the impact of video data size on model performance, this experiment trained the TimeSformer model on different subsets of the created dataset, and the results are shown in Table 3. The accuracy of the model steadily improves as the number of samples rises. The model performed best on the test set when the dataset size was 100%, achieving an average accuracy of 90.33%. Therefore, the dataset size for all subsequent tests was 10,577. To investigate overfitting, we compared the performance of the model on both the training and test sets. The model achieved an mAP of 90.45% on the training set and 90.33% on the test set, with a relatively small difference, suggesting that the model is not overfitting. However, due to limited resources, we did not perform additional cross-validation experiments. In future work, we aim to implement techniques such as dropout and early stopping to further mitigate the risk of overfitting.
To explore the effect of image size on the model, the size of the video frames in the dataset was reduced and enlarged from the original 224 × 224 to 112 × 112 and 336 × 336 sizes, respectively, in this experiment. To make sure their initial scales didn’t alter, the Letterbox image processing technique was used for the processing. In terms of model accuracy and computation, when the size of the input video frame is reduced to 112 × 112, the average recognition accuracy of the TimeSformer model decreases by 1.13%, and the computation is reduced by 75%; when the size of the video frame is enlarged to 336 × 336, the average recognition accuracy of the model is only increased by 0.64%, but the computation is increased by more than one times. The experimental results are shown in Table 4. The experimental results show that 224 × 224 size video frames are enough to be used in the actual production of cattle farms, while 112 × 112 can also meet the needs of breeding scenarios with limited computational resources and low requirements for accuracy.
Comparative experimental results analysis
To highlight the advantages of our proposed model, we compared it with the advanced model SlowFast28 in the field of video behavior recognition. The experimental results show that TimeSformer outperforms SlowFast in terms of accuracy, especially as the dataset size increases. Furthermore, TimeSformer achieves higher accuracy with lower computational costs, making it more suitable for high-precision and large-scale learning applications.
With a video frame size of 224 × 224, the results from testing both models on the smallest dataset (25% dataset) are compared, and the accuracy of the models under different dataset sizes is shown in Fig. 13.

Comparison of model accuracy for different dataset sizes.
The dataset size experiment shows that when the dataset is expanded from 2645 to 5289 samples (50% dataset) and 10,577 samples (100% dataset), the average recognition accuracy of the SlowFast model increases from 86.94 to 87.44% and 88.79%, respectively, with an improvement of 0.5% and 1.35%. In contrast, the accuracy of the TimeSformer model increases from 87.40 to 88.07% and 90.33%, improving by 0.67% and 2.26%, indicating that TimeSformer is more capable of handling large-scale data, especially when the dataset is larger, showing more significant performance improvement.
When the dataset size is 100% and with 224 × 224 input feature maps (i.e., video frames), the results from training both models are compared, and the accuracy and computational cost of the models under different input feature map sizes are shown in Fig. 14, with the overall performance of the models shown in Table 5.

Comparison of model accuracy at different video frame sizes.
The feature map size experiment shows that both the dataset size and the input feature map size significantly affect model accuracy and computational resource requirements. As shown in Fig. 14, when the input feature map size increases from 224 × 224 to 336 × 336, the accuracy of SlowFast increases from 88.79 to 89.35%, while TimeSformer increases from 90.33 to 90.97%. Although increasing the feature map size improves accuracy, it also leads to an increase in computational cost. Specifically, with an input size of 112 × 112, SlowFast reduces the computational cost by 67%, while TimeSformer reduces it by 75%.
Table 5 shows the overall performance comparison between the two models. In terms of parameters, the SlowFast model is relatively lightweight, while the TimeSformer model has four times more parameters, making it more computationally complex. However, TimeSformer still outperforms in terms of accuracy and maintains higher inference efficiency with relatively lower computational cost, making it more suitable for large-scale learning tasks.
The dataset size experiment results demonstrate that large labeled datasets are essential for video behavior recognition tasks to learn more samples and spatial variation information, thereby improving behavior recognition ability29,30. Compared to the two models, TimeSformer has higher accuracy, and its accuracy increases more significantly as the sample data increases, showing better performance when the dataset is large25. Additionally, the feature map size experiment shows that both increasing the dataset size and the feature map size lead to richer input information for the model, which is more conducive to improving model accuracy31,32. The size of the input feature map directly affects the model’s computational complexity and performance. Increasing the feature map size increases the computational load, as SlowFast requires more convolutions and pooling operations on larger images, thus increasing the computational burden. In contrast, for TimeSformer, when the size of each image block remains unchanged, increasing the image size results in more image blocks, requiring more computational resources.
Considering both model performance and computational resource requirements, although TimeSformer has a larger learning capacity, the SlowFast model is relatively lightweight25. However, TimeSformer has higher accuracy while maintaining lower inference costs, making it more suitable for large-scale learning environments25. In contrast, the high computational cost of existing 3D convolution models makes it difficult to increase model capacity while maintaining efficiency. Therefore, TimeSformer is more suitable for practical livestock farming scenarios, and when the input feature map size is reduced to 112 × 112, the computational cost of the model is significantly reduced by 75%, with only a 1.13% decrease in accuracy, resulting in better performance in beef cattle behavior recognition tasks.
To analyze the effect of model application in real scenarios, we use the trained beef cattle behavior recognition model in combination with YOLOv8 and ByteTrack beef cattle detection and tracking model to randomly select several video clips from the original video within different periods for beef cattle behavior recognition. The detection results include both posture-related and state behaviors of six beef cows. Figure 15 visualizes the results of these evaluations, demonstrating the effectiveness of our approach.

Results of five behavioural tests in beef cattle: (A) Daytime effect. (B) Night effect.
Error analysis
From videos of different periods, the model is relatively good for recognition in daytime videos and less effective at night. The model’s accuracy is greatly influenced by the illumination, which is often darker at night. This lowers video quality, which causes feature information to be lost and makes it more challenging for the model to correctly detect behaviors. In addition, the training dataset has relatively fewer video data in the night scene, which leads to the model’s insufficient generalisation ability and lack of sufficient robustness under night conditions.
From the perspective of each beef cow in the video screen, the closer the distance to the camera, the better the model’s effect on its behavioural recognition. While the feature information of the beef cows at a far distance is relatively fuzzy and the occlusion problem is more severe, making it more difficult for the model to detect and recognize them, the feature information of the cows at a close distance is richer and makes it easier for the model to extract their keyfeatures.
From the various types of behaviour of beef cattle, there is a misjudgment of ruminating behaviour during feeding and drinking. Beef cattle ruminating will repeatedly chew the food that has been swallowed, the opening and closing of the mouth in this process has a certain regularity; beef cattle in the feeding is first lowered with the tongue rolled in the pasture, and then chewed, the opening and closing of the mouth of the beef cattle is more frequent and forceful; drinking is lowered with the tongue licking the water inhaled into the oral cavity, and there is a more frequent swallowing action. However, there are intermittent moments of raising the head during the process of eating or drinking in beef cattle, while the range of the mouth area is relatively small, and the different features of the mouth are relatively difficult to extract, which leads to the difficulty of the model to differentiate, and then misjudgement.
Discussion
To address the above challenges, future research efforts can be improved in the following ways: (1) Improvement of night data quality through the use of fill-in lights; (2) Optimisation of tracking algorithms combined with other feature fusion strategies to improve the accuracy of long-range target detection and identification33; (3) Optimise the model structure by adding some post-processing strategies34, such as behavioural filtering based on temporal continuity and threshold judgement based on behavioural probability, to the output part of the model to reduce misjudgement35; (4) Further collection of more data from different perspectives, scenarios, and nights, combined with more data preprocessing strategies to expand the richness and size of the sample.
Moreover, the main outcome of this study is the proposal of a semi-automatic video behavior annotation method, which significantly reduces the burden of manual labeling by combining YOLOv8 target detection and ByteTrack multi-target tracking algorithms. However, this method still has some limitations. Firstly, it relies on the accuracy of target detection and tracking. Secondly, the model may fail to accurately recognize cattle behaviors in crowded environments or when there are significant changes in behavioral expressions. To address these limitations, future work should focus on enhancing the robustness of the model to improve behavior recognition accuracy. Additionally, developing automated annotation systems to reduce the need for manual validation and expanding the dataset to improve the model’s generalization ability in various complex environments should be prioritized.
Although the current model has been trained with data containing occlusion, pose variation, scale differences, and low illumination, a systematic robustness analysis remains necessary. Future work should consider simulating more controlled image degradation scenarios—such as additive Gaussian noise36, and cluttered backgrounds37—to evaluate the model’s stability under challenging conditions. We have reviewed the work by Mon et al.35, which proposes an AI-enhanced real-time cattle identification system using YOLOv8 for detection, a custom tracking algorithm, and SVM for recognition. This approach has demonstrated effective performance in real-time tracking across various environments. We plan to build on this work by exploring how combining appearance-based methods and advanced tracking algorithms can enhance the robustness of our model in cases of occlusion or close proximity of animals. Furthermore, future work will consider multi-camera setups and deep learning-based tracking to improve the model’s performance in complex environments.
Overall, this dataset has an important value. This data set is quite valuable overall. In addition to offering a more accurate foundation for animal behavior recognition tasks, the behavior recognition method based on temporal and spatial characteristics can simultaneously extract the features of video data in both time and space dimensions. This helps breeders create more scientific breeding plans and management strategies, increase breeding efficiency, and lower breeding costs. It is a crucial tool for enhancing the financial gains of the beef cow breeding sector and for advancing the industry’s sustainable growth, both of which are crucial in the current beef cattle breeding landscape.
Conclusion
In this paper, we construct a captive beef cattle behaviour dataset that integrates image and video data from five categories of daily behaviour of beef cattle. The dataset includes 500 recorded video clips, 2000 target detection image samples, over 4000 target tracking image samples, over 10G video frame sequences, and 4979 carefully processed and classified behavioural video clips.
We trained the dataset using the TimeSformer model to improve the accuracy of beef cow behavior recognition in order to thoroughly confirm the dataset’s validity. Experiments show that the model not only performs well in accurately identifying the behaviour of beef cattle but also demonstrates advantages in balancing model parameters and efficiency.
We believe that this dataset constitutes a key benchmark for behavioural recognition research in beef cattle, while our proposed semi-automated annotation method for video data based on YOLOv8 and ByteTrack contributes to advances in object detection and tracking. By providing this innovative video data construction and annotation method, we aim to inspire more scientists to study the complexity of animal behaviour in greater depth and promote innovation in animal welfare science.
Data availability
Our dataset is publicly available for download on Kaggle (https://www.kaggle.com/datasets/lucyfirst/beef-cattle-behavior-data-set).
References
Chouhan, G. K. et al. Phytomicrobiome for promoting sustainable agriculture and food security: Opportunities, challenges, and solutions. Microbiol. Res. 248, 126763 (2021).
Bai, Q. et al. X3DFast model for classifying dairy cow behaviors based on a two-pathway architecture. Sci. Rep. 13, 20519 (2023).
Smith, D. et al. Behavior classification of cows fitted with motion collars: Decomposing multi-class classification into a set of binary problems. Comput. Electron. Agric. 131, 40–50 (2016).
Zehner, N., Umstätter, C., Niederhauser, J. J. & Schick, M. System specification and validation of a noseband pressure sensor for measurement of ruminating and eating behavior in stable-fed cows. Comput. Electron. Agric. 136, 31–41 (2017).
Chelotti, J. O., Vanrell, S. R., Galli, J. R., Giovanini, L. L. & Rufiner, H. L. A pattern recognition approach for detecting and classifying jaw movements in grazing cattle. Comput. Electron. Agric. 145, 83–91 (2018).
Achour, B., Belkadi, M., Aoudjit, R. & Laghrouche, M. Unsupervised automated monitoring of dairy cows’ behavior based on inertial measurement unit attached to their back. Comput. Electron. Agric. 167, 105068 (2019).
Hosseininoorbin, S. et al. Deep learning-based cattle behaviour classification using joint time-frequency data representation. Comput. Electron. Agric. 187, 106241 (2021).
Guo, Y., Zhang, Z., He, D., Niu, J. & Tan, Y. Detection of cow mounting behavior using region geometry and optical flow characteristics. Comput. Electron. Agric. 163, 104828 (2019).
Distributed Computing for Emerging Smart Networks: Second International Workshop, DiCES-N 2020, Bizerte, Tunisia, December 18, 2020, Proceedings, Vol. 1348 (Springer International Publishing, Cham, 2020).
Fuentes, A., Yoon, S., Park, J. & Park, D. S. Deep learning-based hierarchical cattle behavior recognition with spatio-temporal information. Comput. Electron. Agric. 177, 105627 (2020).
Wu, D. et al. Using a CNN-LSTM for basic behaviors detection of a single dairy cow in a complex environment. Comput. Electron. Agric. 182, 106016 (2021).
Li, G., Shi, G. & Zhu, C. Dynamic serpentine convolution with attention mechanism enhancement for beef cattle behavior recognition. Animals 14, 466 (2024).
Kulsoom, F. et al. A review of machine learning-based human activity recognition for diverse applications. Neural Comput. Appl. 34, 18289–18324 (2022).
Chen, J. et al. MammalNet: A large-scale video benchmark for mammal recognition and behavior understanding. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 13052–13061 (IEEE, Vancouver, BC, Canada, 2023). https://doi.org/10.1109/CVPR52729.2023.01254.
Li, K., Fan, D., Wu, H. & Zhao, A. A new dataset for video-based cow behavior recognition. Sci. Rep. 14, 18702 (2024).
Qiao, Y., Guo, Y., Yu, K. & He, D. C3D-ConvLSTM based cow behaviour classification using video data for precision livestock farming. Comput. Electron. Agric. 193, 106650 (2022).
Bao, J. & Xie, Q. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 331, 129956 (2022).
Shorten, C. & Khoshgoftaar, T. M. A survey on image data augmentation for deep learning. J. Big Data 6, 60 (2019).
Zhao, Z.-Q., Zheng, P., Xu, S.-T. & Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 30, 3212–3232 (2019).
Safaldin, M., Zaghden, N. & Mejdoub, M. An improved YOLOv8 to detect moving objects. IEEE Access 12, 59782–59806 (2024).
Wang, Y. & Mariano, V. Y. A multi object tracking framework based on YOLOv8s and bytetrack algorithm. IEEE Access 12, 120711–120719 (2024).
Berk, D., Adak, M., Adak, B., Celik, C. & Ateş, H. F. Real-time multi-object tracking with YOLOv8. In 2024 32nd Signal Processing and Communications Applications Conference (SIU) 1–4 (IEEE, Mersin, Turkiye, 2024). https://doi.org/10.1109/SIU61531.2024.10600933.
Yao, G., Lei, T. & Zhong, J. A review of convolutional-neural-network-based action recognition. Pattern Recognit. Lett. 118, 14–22 (2019).
Li, Z., Liu, F., Yang, W., Peng, S. & Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 33, 6999–7019 (2022).
Bertasius, G., Wang, H. & Torresani, L. Is space-time attention all you need for video understanding?. ICML 2, 4 (2021).
Leevy, J. L., Khoshgoftaar, T. M., Bauder, R. A. & Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 5, 42 (2018).
Johnson, J. M. & Khoshgoftaar, T. M. Survey on deep learning with class imbalance. J. Big Data 6, 27 (2019).
Feichtenhofer, C., Fan, H., Malik, J. & He, K. SlowFast networks for video recognition. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV) 6201–6210 (IEEE, Seoul, Korea (South), 2019). https://doi.org/10.1109/ICCV.2019.00630.
Zhu, Y. et al. A comprehensive study of deep video action recognition. Preprint at https://doi.org/10.48550/arXiv.2012.06567 (2020).
Barulina, M. et al. Method for preprocessing video data for training deep-learning models for identifying behavioral events in bio-objects. Mathematics 12, 3978 (2024).
Advances in Information Retrieval: 41st European Conference on IR Research, ECIR 2019, Cologne, Germany, April 14–18, 2019, Proceedings, Part I. vol. 11437 (Springer International Publishing, Cham, 2019).
Luke, J. J., Joseph, R. & Balaji, M. Impact of image size on accuracy and generalization of convolutional neural networks. 6, (2019).
Li, D. et al. Cattle identification based on multiple feature decision layer fusion. Sci. Rep. 14, 26631 (2024).
Wang, R. et al. A lightweight cow mounting behavior recognition system based on improved YOLOv5s. Sci. Rep. 13, 17418 (2023).
Mon, S. L. et al. AI-enhanced real-time cattle identification system through tracking across various environments. Sci. Rep. 14, 17779 (2024).
Ahmed, A., Yousif, H., Kays, R. & He, Z. Animal species classification using deep neural networks with noise labels. Ecol. Inf. 57, 101063 (2020).
Jiang, L. & Wu, L. Enhanced Yolov8 network with extended kalman filter for wildlife detection and tracking in complex environments. Ecol. Inf. 84, 102856 (2024).
Acknowledgements
We want to express our gratitude to the relevant personnel at Longfeng Biological Technology Co., Ltd. farm in Xianggelila, Yunnan Province, who provided us with all the necessary assistance and valuable advice for our research there.
Author information
Authors and Affiliations
Contributions
The authors are involved in the conceptualisation, survey design, data collection, methodology, validation, formal analysis, data curation, writing, editing and revision of this manuscript as follows: Z. C. and C.L.: conceptualisation, survey design, data collection, formal analysis, data curation, writing, editing and revision X.Y.: conceptualisation, survey design, data collection, writing and revision S.Z.: methodology, formal analysis, editing and revision L.L.: data collection, methodology, validation, writing H.W.: methodology, writing H.Z: conceptualisation, data curation, project administration, editing and revision The authors also declare that they have no conflict of interest.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cao, Z., Li, C., Yang, X. et al. Semi-automated annotation for video-based beef cattle behavior recognition. Sci Rep 15, 17131 (2025). https://doi.org/10.1038/s41598-025-01948-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-01948-6
Keywords
This article is cited by
-
An efficient and consistent framework for multi-rank taxonomic identification in wildlife images
Scientific Reports (2026)
