
Abstract
Federated learning is widely used for collaborative training of human activity recognition models across multiple devices with limited local data. However, label noise caused by human and time constraints during data annotation is common and severely limits model performance. Existing studies mainly address this through client selection and sample filtering, but still face key limitations: (1) insufficient granularity in client quality evaluation; (2) aggregation methods ignoring data quality differences; (3) client drift under non-IID data distribution. To overcome these challenges of complex label noise and feature drift, this paper proposes LN-FHAR, a two-stage federated learning framework with label noise robustness. This framework effectively mitigates the coupling problem of noise and data heterogeneity by assessing client data quality and designing differentiated training strategies. In the client selection stage, clients are graded based on class-level loss analysis and a Gaussian Mixture Model. In the noise-robust training stage, reliable neighbors are introduced to collaboratively filter clean samples, and prototype regularization is employed to constrain the consistency between local models and global feature representations. Additionally, a data-aware aggregation method is designed, which assigns weights based on both the quality and quantity of client data, reducing the negative impact of noisy clients. Experimental results demonstrate that LN-FHAR has robustness and generalization ability in complex noise environments.
Similar content being viewed by others
Introduction
Human Activity Recognition (HAR) based on sensors, as a core technology in the field of smart sensing, demonstrates broad application prospects in scenarios such as medical monitoring, industrial control, and smart homes. By collecting data from sensors like accelerometers and gyroscopes, the system can analyze user behavior patterns in real time, providing support for precise decision-making. Currently, with the widespread adoption of sensor devices and innovations in artificial intelligence algorithms, HAR based on sensors has become a continuous hot topic of research in the field, showing enormous application potential and prospects1. However, there are three core challenges in practical deployment: insufficient data samples on edge devices, stringent privacy protection requirements, and the prevalent issue of label noise.
Human physiological activity signals contain sensitive information such as user activity trajectories, preferences, and health status. The need for privacy protection, coupled with threats of cyberattacks, communication bandwidth usage, and computational cost constraints, makes the willingness to share raw data on edge devices extremely low. The traditional centralized data storage and model training approach in data centers is challenged. However, data from a single edge device often cannot effectively support the model training and testing process. To address the challenges of distributed data processing and data privacy protection, Google proposed the federated learning framework2. This framework shifts model training tasks from the cloud to clients closer to users through a distributed collaborative training model. Each client is responsible for training a local model and only transmits the model’s parameter information to the server for aggregation, resulting in a global model, which is then shared with other clients. This approach reduces the risk of sensitive user information leakage and allows user data resources to be used for model training in a "usable but invisible" manner, which is difficult to achieve with traditional centralized methods.
Federated Human Activity Recognition (HAR) based on sensors faces multiple challenges, including personalized demands3,4,5,6, scarce annotations7, and limited communication resources8,9. Most existing research is based on the idealized assumption that clients are completely reliable and training data is free from labeling errors. However, during the data collection process, user behavior data inevitably contains a significant amount of noise due to factors such as file corruption, sensor malfunctions, and user mistake operations. This noise mainly includes feature noise and label noise10 . Label noise blurs the connection between data samples and their true categories, distorting the model’s feature learning process and significantly reducing its generalization ability, making it more harmful 11. In a federated setting, noise can spread to the global model through the aggregation mechanism, further exacerbating performance degradation. Moreover, compared to image or text data, physiological data used for activity recognition is not intuitive and difficult to annotate, especially when data quality relies on user self-observation or reporting, making the issue of noisy labels particularly prominent12. Additionally, data from different clients may have different noise distributions, i.e., significant differences in data quality, which further complicates the problem and makes it difficult for federated HAR based on sensors to achieve the desired results.
Existing federated noise learning methods mainly focus on two strategies: clients selection and samples filtering13. The clients selection strategy14,15,16,17 indirectly assesses data quality by evaluating the performance of local models, assigning higher aggregation weights to high-quality clients. The samples filtering strategy13,18,19,20,21, on the other hand, uses loss thresholds to distinguish between noisy and clean samples. The theoretical basis for this strategy is that deep neural networks tend to learn simple and general patterns first, and then gradually overfit to all noise patterns22. The memorization effect is independent of the optimizer or neural network architecture used during training. Before overfitting occurs, the learning process differs, leading to distinct training loss curves for clean and noisy samples. Samples with higher training losses are typically considered as noisy, and targeted strategies are designed accordingly, such as semi-supervised learning.
However, these methods face the following limitations in sensor-based HAR tasks: (1) Coarse-grained client quality assessment. Most works do not differentiate the heterogeneity of noise distributions among clients and adopt a unified processing strategy for all clients19,21 , resulting in noisy samples from low-quality clients not being effectively suppressed, while clean samples from high-quality clients may be excessively corrected as noisy ones. (2) Unreasonable allocation of aggregation weights. Some works use the traditional FedAvg algorithm, which only considers data volume as the weight18,19,21,23,24, ignoring the differences in data quality among clients, thereby amplifying the negative impact of high-noise clients on the global model. (3) Poor adaptability to non-IID data. The differences in user behavior lead to highly heterogeneous data distributions and feature drift among clients. Existing methods18,19,23,24,25 do not adequately address the issue of client drift26. (4) Current research mainly focuses on tasks such as image classification, and there is insufficient research on scenarios specific to sensor-based human activity recognition tasks.
In this study, we design a two-stage federated training architecture, LN-FHAR, for sensor-based human activity recognition tasks with labeled noisy sample data. In the client selection stage, the average loss value per class for each client, calculated using an initial model, is used to identify low-quality clients. In the noise-robust training stage, different training strategies are adopted for high-quality and low-quality clients. The main contributions of this paper are summarized as follows:
First, considering label noise and client drift to simulate real-world federated learning scenarios, we introduce a two-stage federated learning approach to the sensor-based HAR field for the first time. By separating the dynamic assessment of client quality and noise-robust training for optimized performance, we address the coupled challenges of noise and data heterogeneity. In the first stage, low-quality clients are identified based on class-level loss analysis. In the second stage, differentiated training strategies are designed for high- and low-quality clients to prevent the global model from being dominated by noise.
Second, we introduce a reliable neighbor selection method based on data quality and distribution similarity, leveraging prior knowledge from high-quality clients to assist low-quality clients in filtering clean samples. Additionally, by incorporating prototype regularization to constrain the alignment of local representations with global prototypes, we effectively mitigate client drift.
Third, we design a weight allocation method that considers both data quality and quantity, optimizing the aggregation process using client training accuracy as a quality indicator. This reduces the negative impact of noisy clients and enhances the robustness of the global model.
Fourth, we compare our method with eight baseline approaches and validate its superiority in human activity recognition tasks through extensive experiments on multiple label noise scenarios from two benchmark datasets.
The subsequent sections of this paper are organized as follows: Section "Related work" reviews related work on federated HAR and noise learning; Section "Preliminaries" introduces the reliable neighbor selection and prototype regularization methods; Section "Proposed method" details the design of the LN-FHAR framework; Section "Evaluation" verifies the effectiveness of the method through experiments; Section "Discussion" discusses the experimental methods; Section "Conclusion" summarizes the paper.
Related work
Sensor based federated human activity recognition
Current federated human activity recognition focuses on personalized needs27, aiming to generalize global models to individual users or those with heterogeneous data. Li et al. proposed the Meta-HAR framework5, where a signal embedding network is meta-trained via federated learning, and the learned signal representations are fed into personalized classification networks for each user. To enhance the generalization of the embedding network, each user’s task is treated as independent and trained using a model-agnostic meta-learning framework, enabling adaptability to heterogeneous users. Tu et al. introduced a dynamic layer-sharing scheme24 that builds a global model by learning user similarities, forming a shared structure and aggregating models layer-by-layer in a bottom-up manner. Bu et al. developed an attention-based group-driven method28, revealing client similarity relationships through attention-based message passing and enabling pairwise collaboration. This approach improves model generalization, reduces overfitting risks, and suits scenarios with limited activity labels. While a few studies have applied federated learning to human activity recognition, detailed analyses of how personalized algorithms affect generalization performance remain insufficient28. Additionally, personalized solutions require substantial high-quality labeled data for classifier training, but the non-intuitive nature of sensor data makes manual annotation challenging for large-scale datasets.
Noisy label learning
Deep neural networks, with their large number of parameters, tend to overfit noisy data, leading to incorrect optimization of model parameters. In centralized settings, current research strategies include robust architecture design, robust regularization methods, robust loss function design, and sample selection29. To handle complex noise environments, many studies adopt sample selection strategies: leveraging the memory effect of neural networks to identify correctly labeled samples from noisy datasets while discarding potentially mislabeled ones. However, when ambiguous classes exist in training data, sample selection may cause cumulative errors due to incorrect choices. To address this, multiple deep neural networks are often employed collaboratively. Additionally, semi-supervised learning has been combined with sample selection to extract richer features from mislabeled samples.
While these methods can be applied to local training in federated learning, their applicability is often limited in distributed training environments with complex and varying data distributions.
Federated noisy label learning
Clients selection strategy
Current federated noisy label learning mainly focuses on client selection and sample selection strategies13. In federated security contexts, low-quality clients are treated as malicious, and multiple defense mechanisms are proposed against them, such as loss-based defenses, outlier-based defenses, and norm-bounding defenses30. For loss-based defenses, Fang et al. use loss values from a server validation dataset to filter clients with the highest losses during aggregation31. However, this requires knowing the number of malicious clients in advance, which is often impractical, and fully validating each client’s updates adds heavy computational costs. For outlier-based defenses, the FoolsGold algorithm32 detects label-flipping attacks using cosine similarity based on client contribution diversity during training rounds, even when the number of malicious clients is unknown. Gupta et al. cluster clients by applying clustering algorithms to their historical short- and long-term gradients33. However, existing methods poorly tolerate noisy or heterogeneous data, increasing the risk of misclassifying benign clients as malicious. Norm-bounding defenses[34]restrict the norm of client updates, forcing malicious clients to use larger weights to push the model in wrong directions. Yet, these defenses struggle against advanced attacks. Client selection strategies do not directly address label noise, leading to significant performance drops when clients contain widespread noisy data.
Samples filtering strategy
When federated security is not prioritized, research shifts to sample selection strategies combined with semi-supervised or unsupervised learning to integrate noisy data into training for richer feature extraction. Some studies first identify low-quality clients for targeted training. Jiang et al. introduce FedELC20, a two-stage framework where the first stage detects low-quality clients, and the second optimizes their labels via end-to-end correction. Dunkin et al. proposed the MgCNL35. A label confidence evaluation approach based on multi-granularity balls is introduced, which integrates supervised learning with contrastive learning to enhance representation learning using unlabeled data. This provides a highly robust solution for industrial fault diagnosis. Zhang et al. proposed the PSSCL method 36, which replaces the traditional Cross-Entropy loss with Generalized Cross-Entropy loss to mitigate overfitting to noisy labels. By employing a Gaussian Mixture Model (GMM) and a sliding window strategy, they effectively filter high-confidence clean sample sets to ensure stability in the learning process. However, these strategies heavily rely on robust initial models with minimal accumulated errors, making them vulnerable to data complexity and error accumulation. Data augmentation and regularization struggle to effectively address overfitting issues caused by noisy labels.
All these methods fail when handling clients with extremely high noise rates. To address this challenge, FedNed37 introduces a “negative distillation” mechanism, repurposing extreme noise clients as negative knowledge sources instead of discarding them. It balances noise impact and information utilization by combining MC Dropout uncertainty estimation with dual local training. However, FedNed degrades to FedAvg when no extreme noise clients exist, requiring integration with other methods for mixed noise scenarios. FedFixer38 pioneers dual-model collaboration and dual regularization to balance global consistency and local specificity, effectively resolving heterogeneous noise issues through dynamic sample filtering and parameter constraints. This approach avoids overfitting and error accumulation in traditional methods, achieving strong performance in high-noise scenarios. However, its dual-model structure significantly increases local computation and communication costs. Miao et al. proposed the Collaborative Sample Selection framework39, which combines CLIP’s zero-shot classification probabilities with DNN classifiers’ cross-entropy loss to construct 2D feature vectors. These vectors are analyzed via a 2D Gaussian Mixture Model to distinguish clean and noisy samples. The framework introduces unsupervised contrastive loss to minimize feature distances between augmented views of the same image, improving noise robustness. This design mitigates the vicious cycle of error accumulation in traditional methods and enhances model performance under high-noise scenarios.
Preliminaries
We assume the federated learning system consists of \(N\) clients belonging to set \(C\) and one server, where each client \(c_{k} \in C\) contains a local dataset \(D_{k} = \left\{ {(x_{i} ,y_{i} )} \right\}_{i = 1}^{{n_{k} }}\) comprising \(n_{k} = \left| {D_{k} } \right|\) samples. In this setup, local datasets are non-IID and lack certain classes, and the sample size of any local dataset is limited, insufficient for training a high-accuracy model individually.
FedAvg coordinates multiple clients to collaboratively train a global model while protecting data privacy. In each round of communication \(t\), a subset of clients \(C_{t}\) is selected to optimize their local models \(\theta_{k}^{t}\), after which the server updates the global model \(\theta^{G}\) using the local model parameters sent by the client subset:
where \(n_{t} = \sum\limits_{{c_{k} \in C_{t} }} {\left| {{\text{D}}_{k} } \right|}\) is the total number of data samples from the client subset.
Prototype regularization
Deep learning models can be divided into representation and classifier layers. The representation layer uses an embedding function \(f(\theta )\) to map instance input x from the original feature space \({\mathbb{R}}^{d}\) to a low-dimensional representation space \({\mathbb{R}}^{k}\), obtaining embedding vectors. The classifier layer uses fully connected layers to make classification decisions for given learning tasks, mapping the low-dimensional representation space \({\mathbb{R}}^{k}\) to the label space \({\mathbb{R}}^{q}\)40.
The prototype is the output of the model’s representation layer, denoted as \(P_{k,i}^{j} = f_{k} (x_{i}^{j} ;\theta_{k} )\), \(x_{i}^{j}\) is the \(i - {\text{th}}\) sample of class \(j\). Since local datasets of two clients may have different label distributions, the average prototype representation is obtained by averaging the embedding vectors of all instances in this category.
where \(D_{k,j}\) consisting of training instances belonging to class \(j\) is the subset of the local dataset \(D_{k}\).
Given a set of action prototypes \({\mathbb{P}} = \left\{ {P^{1} ,P^{2} , \ldots ,P^{j} , \ldots } \right\}\), for a certain class of activity \(j\) , the server receives prototype sets from the selected client subset \(C_{t}\) in the current round. After the prototype aggregation operation, a global prototype \(P_{{}}^{j}\) is generated for each activity class \(j\). The server must maintain the set of action prototypes \({\mathbb{P}}\), while each client only needs to maintain a subset of activity classes that constitute the activity prototype set \({\mathbb{P}}\), which can be different and overlapping across clients. During each communication round, the global prototype is dynamically updated using similarity-based weighting. Before the next training round begins, this updated prototype is shared with all clients. This helps reduce differences between model parameters and brings local models closer to the global model’s behavior. By aligning local and global updates, it prevents models from drifting away from convergence, improving overall stability and generalization. To handle potential noise instances in clients, we aggregate client prototypes using cosine similarity to adjust the global prototypes, giving more weight to client prototypes similar to the global prototypes, thereby reducing the influence of noise instances on global prototypes:
At the beginning of training, deep neural networks tend to prioritize learning simple and clean instances. We leverage this characteristic to form global prototypes. Additionally, global prototype updating based on similarity can reduce the weight contribution of prototypes with large differences, further mitigating the interference of potential noise samples on global prototypes. Note that after normalization, sensor signals are projected into a unit hypersphere space. Here, differences between samples mainly depend on the direction of feature vectors, not their absolute distances. Cosine similarity naturally aligns with this direction-based discrimination, effectively capturing spatial consistency patterns of similar behaviors across devices. Unlike norm-based distance comparisons (which focus on raw parameter differences), prototype similarity emphasizes semantic-level feature distributions. By measuring directional alignment, it improves tolerance to noise while preserving shared behavioral patterns. This design handles scenarios with highly diverse client data distributions and complex local label noise. It mitigates feature drift caused by non-IID data, whereas norm-based metrics may amplify minor parameter shifts into unstable feature space changes. Cosine similarity better corrects directional biases caused by noise, ensuring reliable prototype alignment.
In human activity recognition tasks, data heterogeneity exists across users. Learning a generalizable representation technique that can handle noise samples and client drift is crucial. This paper introduces prototype regularization40,41 and correction vectors42 to narrow the distance between local and global representations, utilizing global prototypes as penalty terms to jointly optimize the distributed learning problem.
Reliable neighbors
Reliable neighbors are defined as clients that share both high data quality and high distribution similarity with the target client. Their models are considered more reliable in identifying clean samples and can assist the target client’s model in jointly fitting a Gaussian mixture model. This models the loss distributions of clean and noisy samples, helping the target model distinguish clean samples from training data for more robust training21. The quality of reliable neighbors is determined jointly by the data quality score and data distribution similarity score.
Data quality score
Deep neural networks (DNNs) tend to learn simple and general patterns first. If a client has clean local data, its model will achieve higher training accuracy in identifying clean datasets. After the server aggregates local models into a global model, all clients use this global model to compute their local training accuracy. These accuracy values are then sent to the server, indirectly measuring data quality without violating privacy.
Data distribution similarity score
The data distribution similarity score is measured using the prediction difference of \(c_{b} ,c_{a}\) client models, with a smaller difference indicating higher similarity. During the local model update phase, two clients generate the same Gaussian random noise \(\tilde{x}\) as input to obtain outputs \(p(\tilde{x},\theta_{b} )\) and \(p(\tilde{x},\theta_{a} )\), which are then transmitted to the server to calculate their cosine similarity. For the target client, its cosine similarity with itself is 1:
Apply min–max normalization to the training accuracy and cosine similarity scores of the \(N\) clients. This removes scale differences in accuracy across clients and ensures scores fall within [0,1]. The results are the data quality score \(Q\) (from accuracy) and the data distribution similarity score \(S\) (from cosine similarity).
Comprehensive evaluation score
In a federated system with client set \(C\), for target client \(c_{a}\), the evaluation score \(G(c_{b} ,c_{a} )\) for another client \(c_{b} \left( {c_{b} \in C - \left\{ {c_{a} } \right\}} \right)\) combines its data quality score \(Q{(}c_{b} {)}\) and data distribution similarity score \(S{(}c_{a} ,c_{b} {)}\) , weighted by a balancing factor \(\alpha\).
For target client \(c_{a}\), the \(M\) clients with the highest evaluation score \(G\) are its reliable neighbors \(r_{1}^{a} ,r_{2}^{a} , \ldots ,r_{M}^{a}\). These neighbors have high data quality and high model similarity to the target client. They help client a filter out noisy samples, preserving high-quality data contributions while reducing the impact of noisy data. This reduces performance gaps between clients with varying data quality and leads to a more reliable global model.
Proposed method
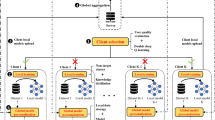
As shown in Fig. 1, the proposed framework has two stages: client selection and noise-robust training.

Overview of LN-FHAR: First, an initial model is trained to cluster clients using GMM. Second, reliable neighbors are inducted to assist low-quality clients select clean samples. Prototype regularization and data quality-aware aggregation strategy are adopted to generate a robust global model.
Client selection stage.
-
(1)
Use FedAvg for initial training to obtain a base model.
-
(2)
Calculate each client’s per-class average loss and training accuracy, then upload these metrics to the server.
-
(3)
Apply a Gaussian Mixture Model (GMM) to split clients into high-quality and low-quality groups.
Noise-robust training stage.
-
(1)
For low-quality clients, identify clean samples using their reliable neighbors (selected via evaluation scores) and include these samples in training.
-
(2)
During local training, use prototype regularization and a similarity-based global prototype aggregation strategy to handle client drift and potential noisy samples.
-
(3)
Finally, apply a data-aware model aggregation method, which combines client sample size and quality scores to assign aggregation weights, generating a robust global model.
Stage 1: client selection
To filter noisy data, LN-FHAR first identifies clients with large amounts of low-quality data. However, due to federated learning’s privacy constraints, the server cannot directly access clients’ private data (e.g., label noise or data distribution). This makes locating low-quality clients challenging. To address this, we train an initial model using FedAvg with cross-entropy loss for \(T\) rounds. Then, we compute each client’s per-class average loss and obtain the model training accuracy \(ACC{ = }\left( {acc_{1} ,acc_{2} , \ldots ,acc_{N} } \right)\) on their local data. Finally, we use these metrics to split clients into high- and low-quality groups via a Gaussian Mixture Model (GMM).
Single-round loss values can be unstable (due to limitations of the small-loss trick) and may misclassify correctly labeled hard samples (e.g., rare-class samples), which often have high loss in early training43. Thus, we replace instantaneous loss with the average loss over multiple iterations for reliability.
We calculate the average loss value for each category on each client separately, rather than averaging the loss across all sample categories. This approach is grounded in our ob-servation from human activity recognition tasks: although samples across categories are non-IID, most users still share some similar basic features within the same activity category. This is because data collection typically follows certain standards, and the generation and transition of user actions also adhere to certain patterns, with similar sensor device configu-rations and fixed positions. For example, when collecting data using smartphones, most us-ers tend to place their phones in their shirt or trouser pockets, which are usually near the hip area; when using smartwatches, the devices are typically worn on the wrist. In cases where specialized equipment and collection procedures are used, the sensor placement and data collection are even more standardized. When focusing on specific categories within each client’s local data, the basic features of the data are similar. Therefore, for any given category, if the average loss of a particular category on a certain client is significantly different from that of other clients, that client can be identified as a low-quality client. Furthermore, under label noise heterogeneity, noisy samples across clients may be assigned to different noisy labels, making it insufficient to rely on the loss of any single category to identify low-quality clients. Therefore, the average loss values across all categories on each client are used for identification.
where the superscript denotes the class index, and \(H\) is the total number of classes; the subscript denotes the client index, and \(N\) is the total number of clients.
Considering the issue of class absence in heterogeneous data, where specific classes may not exist on certain clients, implying no noisy samples in such classes, we employ the minimum average loss value of this class from other clients to fill in the gap. Taking into account the variation in learning difficulties among different classes, which can lead to significant differences in loss value ranges, we perform max–min normalization on the average loss of all classes for each client to obtain \(Loss_{{{\text{norm}}}}\). This ensures that all classes contribute equally to the identification of noisy clients, rather than being dominated by specific classes. Subsequently, the processed loss vectors for each class are deployed onto a two-component Gaussian Mixture Model (GMM) to divide the \(N\) clients into two subsets: \(C_{{\text{High }}}\) and \(C_{{{\text{Low}}}}\).
Stage 2: noise-robust training
The client drift challenge in this paper arises from two aspects: differences in user behavior patterns and the impact of noisy labels. Different users exhibit personalized variations in the amplitude, frequency, and duration when performing the same actions (e.g., gait patterns or exercise habits). Local models in noisy clients (containing high proportions of mislabeled data) learn incorrect feature-label mappings, resulting in systematic deviations in their parameter update directions compared to clean clients. Noisy labels may confuse action categories (e.g., mislabeling “rope jumping” as “running”), causing divergent feature representations of the same action across different clients. To address this, we adopt prototype regularization and a reliable neighbor collaboration strategy to mitigate client drift.
As shown in Fig. 2, two characteristics exist in each user’s activity records: 1) Most users typically only record a subset of all activity types, leading to imbalanced label distributions in local datasets. 2) Significant differences in signal distributions occur even when performing identical activities across users. This label distribution heterogeneity severely impacts the performance of the global model, and this impact intensifies as more participating users join. For instance, two users may demonstrate distinct walking patterns: one with wide strides and another with higher step frequency but shorter stride length.

The client drift phenomenon in human activity recognition.
Although different users’ sensor recordings of the same activity show highly heterogeneous signal distributions, most clients still retain similar features within the same activity category. In the second phase, we introduce prototype regularization to collect feature representations of same-class samples from heterogeneous clients and average them to obtain potential prototype knowledge. By sharing a common prototype across heterogeneous clients, this method constrains data points in the embedding space near their closest prototypes, thereby reducing the adverse effects of client drift. Specifically, we design a prototype exchange mechanism between clients and the server: 1) Generate client prototypes from local activity prototypes of each client; 2) Aggregate client prototypes using cosine similarity to adjust the global prototype, assigning higher weights to client prototypes more similar to the global prototype to reduce noise impact; 3) Broadcast these global prototypes to all clients to guide their local representation training. This approach simultaneously captures common knowledge across clients and addresses both client drift and noisy sample interference.
In Noise-Robust Training, we use the following loss function:
where \(l_{CE}\) is the cross-entropy loss, \(l_{P}\) is the prototype penalty loss defined in Eq. (4), and \(l_{E}\) is the entropy regularization loss. This strategy generates global prototypes by aggregating local feature prototypes from clients and constrains local model representations to align with these global prototypes. By leveraging similarities in the feature space, it suppresses interference from noisy samples during parameter updates and enhances the model’s generalization capability across heterogeneous data.
Target clients may simultaneously possess low-quality data and data that may be absent in other normal clients. Therefore, directly removing the contributions of entire target clients could potentially decrease, rather than increase, the accuracy of the global model. To address this, the concept of reliable neighbors is introduced for low-quality clients. Reliable neighbors are other clients that have similar data class distributions to the target client and better-performing local models, and they collaborate with the target client’s model to identify clean samples. For low-quality clients, the server sends a notification to each target client, and in each round of communication, the target client receives \(M\) reliable neighbor models from high-quality clients to identify clean samples from noisy training samples for robust training. This approach retains the contributions of high-quality data while reducing the impact of noisy data, thereby mitigating performance disparities among clients with varying data quality and obtaining a more reliable global model. We calculate reliable neighbor scores only using high-quality clients identified after client selection and the target client itself. This ensures all \(M\) selected neighbors are high-quality clients, excluding low-quality ones from the selection process to reduce unnecessary computational overhead.
The \(M + 1\) model consists of \(M\) models from a set of reliable neighbors \(C_{R}^{a}\) and the target client \(c_{a}\). In this paper, we estimate the probability of each training sample being a clean sample using \(M + 1\) model with different reliability scores. Assist low-quality clients in filtering clean samples through multi-model voting and probability fusion mechanisms. Before local training begins, a two-component GMM is fitted to the loss distribution of all training samples in the target client using the Expectation–Maximization (EM) algorithm. For a given sample x, its posterior probability of being a clean sample (i.e., having a smaller loss) is taken as the probability of it being a clean sample.
\(\mu_{1} < \mu_{2}\), low-loss models \({\mathcal{N}}(\mu_{1} ,\sigma_{1}^{2} )\) correspond to clean samples while high-loss models \({\mathcal{N}}(\mu_{2} ,\sigma_{2}^{2} )\) correspond to noisy samples. Parameters are estimated via the Expectation–Maximization (EM) algorithm.
For a given sample x, its posterior probability of being a clean sample (i.e., having a smaller loss) is taken as the probability of it being a clean sample.
where \(h\) denotes the Gaussian modality with a smaller mean (i.e.,smaller loss) and \(l\) is the loss function.
Then, the probabilities of each sample being a clean sample across various models are combined with the reliability score \(G_{M + 1}\) to obtain a composite probability, assigning more weight to reliable neighbors with better data quality:
Based on the above results, samples with a clean probability greater than 0.5 are selected as clean samples to construct the clean dataset \(D_{a}^{{{\text{clean}}}} = \left\{ {(x_{i} ,y_{i} )} \right\}_{i = 1}^{{\tilde{n}_{k} }}\) for the target noisy client \(c_{a}\). During local training, only the clean dataset is used, discarding potentially noisy samples to enable robust learning. This reduces the proportion of noisy samples from low-quality clients participating in training and minimizes error gradient propagation. Through knowledge sharing among neighboring clients, the update direction of local models is adjusted to enhance learning accuracy.
Clients’ data-aware model aggregation
Clients with varying data quality contribute differently to the global model. Some works18,21,23,44 use FedAvg to aggregate local models during the global model aggregation phase, neglecting the consideration of different data quality among clients. Other works17,20 employ model distance-aware aggregation methods to dynamically adjust the weights of low-quality clients in model aggregation, but frequently calculating the distance between model parameters incurs significant computational overhead. In this paper, leveraging the memory effect of deep neural networks, we indirectly measure the data quality of clients using the client training accuracy \(ACC{ = }\left( {acc_{1} ,acc_{2} , \ldots ,acc_{N} } \right)\) obtained during the client selection phase. After the client selection stage, we assign weights \(\tilde{w}_{k}\) to client models based on a combination of their data quality and the number of client samples.

LN-FHAR Pseudocode.
Evaluation
Experiment
Data sets and preprocessing
We validate the proposed method using two commonly used datasets, PAMAP2 and OPPORTUNITY. Initially, the raw data undergoes preprocessing steps such as removing redundant attributes and data, linear interpolation, downsampling, and segmenting the data using sliding windows. Additionally, wavelet threshold denoising is applied for smoothing, with a wavelet level of 3, and the threshold function and formula detailed in reference45. Both datasets are randomly split into training and testing sets in a 7:3 ratio.
PAMAP246: This physical activity monitoring dataset comprises data on 18 different daily activities and exercises (such as cleaning, ironing, jump rope, playing soccer, brisk walking, etc.) performed by 9 subjects wearing 3 inertial measurement units and a heart rate monitor. The devices are attached to the subjects’ chest, hand, and ankle. For ease of analysis, the sampling rate of 100 Hz is downsampled to 33.3 Hz. The large size of the sliding window is 171.
OPPORTUNITY47: This dataset is generated by 4 subjects performing 17 types of daily activities (such as closing doors, opening fridges, cleaning tables, drinking coffee, etc.) in a simulated studio environment. The data on daily activities is collected from wireless wearable devices, including 7 inertial measurement units, 12 accelerometers, and 4 localizers. The size of the sliding window is 342.
The direct website link to access PAMAP2 dataset: https://archive.ics.uci.edu/dataset/231/pamap2+physical+activity+monitoring. The direct website link to access OPPORTUNITY dataset: https://archive.ics.uci.edu/dataset/226/opportunity+activity+recognition.
In addition to the non-IID nature inherent in these two datasets, the total data is allocated to different clients using a Dirichlet distribution, with each client having missing classes. The data allocation results are fixed by a random seed.
To simulate label noise in real-world data, we adopted a common approach. Manual label noise is injected into the original data using a symmetric flipping approach, where the original class label is flipped to any incorrect class label with equal probability. Let \(\eta\) be the noisy client rate (i.e., the proportion of clients containing noisy data), and \(\eta \cdot N\) clients are randomly selected as noisy clients. Given the lower bound \(\mu\) and upper bound \(\nu\) of the data noise ratio for a client, the data noise ratio \(\varepsilon\) for the client is determined by randomly sampling from a uniform distribution \(U(\mu ,\nu )\). That is, a total of \(\varepsilon \cdot n_{k}\) sample labels in the local dataset are symmetrically flipped to other labels.
Baselines and model
We implements three noise learning methods (Co-teaching48, SELFIE49, DivideMix50), three federated noisy learning methods (Robust FL19, FedCorr18, FedNoRo17), one sensor-based federated human activity recognition method (ProtoHAR41), and FedProx51, by referring to their official open-source codes. The three noise learning methods are integrated into client-side local training to align with the federated training framework.
The backbone classification network employs a simple convolutional neural network consisting of three convolutional layers, two max-pooling layers, two fully connected layers, and a softmax layer.
The hyperparameter configurations for the baseline methods are consistent with the literature. This paper specifies the key hyperparameter settings for all baseline algorithms as Table 1.
Experiment setup
The experiments were conducted on the Ubuntu 22.4 system with 32 GB of memory, using CUDA 12.4, Python 3.9, an Nvidia RTX 4080SUPER GPU, and an Intel i7-13700KF CPU. The evaluation metrics used were the average accuracy, F1 score, and recall of the global model over the last 20 rounds. All experiments were run with three random seeds and averaged for a fair comparison. In the second phase, the number of reliable neighbors was set to 2, with \(\lambda\) set to 0.01 and \(\alpha\) set to 0.5. For the PAMAP2, 10 clients were configured with a prototype dimension of 512; for the OPPORTUNITY, 20 clients were set up with a prototype dimension of 128. All clients participated in global aggregation in each round. Local training at each client consisted of 3 rounds with a batch size of 32, using the SGD optimizer with a learning rate of 0.001, momentum of 0.5, and a decay rate of 0.1. The stage1 lasted for 5 rounds, and stage2 for 95 rounds to ensure convergence for all baselines. We set two noisy client rates of 0.4 and 0.8, respectively. The noise rate for each noisy client’s data was determined by random sampling from uniform distributions \(U(0.1,0.4)\) and \(U(0.4,0.8)\), resulting in four groups of noise patterns. The Dirichlet distribution parameter was set to 0.8,
Result analysis
The superiority of NL-FHAR over the other eight methods was verified using two synthetic noisy datasets under non-IID setting and four label noise scenarios. The experimental results are shown in Tables 2 and 3.
For the PAMAP2 dataset, LN-FHAR achieves the best performance across most metrics under identical noise settings. With a noisy client rate of 0.4 and client data noise rates of (0.1,0.4), LN-FHAR ranks second in accuracy, F1-score, and recall rate compared to FedELC. With a noisy client rate of 0.4 and client data noise rates of (0.4, 0.8), LN-FHAR outperforms the second-best method by 1.76%, 1.76%, and 1.02%. With a noisy client rate of 0.7 and client data noise rates of (0.1, 0.4), LN-FHAR shows 0.42% higher accuracy, 0.81% better F1-score, and 0.87% improved recall than the second-best approach. With a noisy client rate of 0.7 and client data noise rates of (0.4, 0.8), the improvements were 1.47%、0.44%、0.83%, respectively.
For OPPORTUNITY, with a noisy client rate of 0.4 and client data noise rates of (0.1, 0.4), LN-FHAR improved accuracy, F1 score, and recall by 0.4%, 0.45%, and 0.2%, respectively, compared to the second-best method. With a noisy client rate of 0.4 and client data noise rates of (0.4, 0.8), the improvements were 1.83%, 1.11%, and 1.08%, respectively. With a noisy client rate of 0.7 and client data noise rates of (0.1, 0.4), LN-FHAR improved accuracy by 0.4%, although the F1 score and recall were slightly lower than those of Robust FL. With a noisy client rate of 0.7 and client data noise rates of (0.4, 0.8), the improvements were 0.87%, 1.72%, and 1.12%, respectively.
The experimental results demonstrate that the LN-FHAR method exhibits superior performance in most settings. Although the difference between LN-FHAR and the second-best method is not significant when client data noise rates are low, as the noise level increases, the metrics of all methods decline, and the advantage of LN-FHAR becomes particularly evident. This proves its robustness and effectiveness in dealing with high-noise environments. Since the datasets are non-IID, the good F1 score of LN-FHAR indicates that the model has strong recognition capabilities for positive and minority classes, and it achieves a good balance between accuracy and recall, demonstrating strong comprehensive performance in complex scenarios.
Ablation experiments
Under the settings of a noisy client rate of 0.7 and client data noise rates ranging from 0.1 to 0.4, we conducted experiments by removing prototype regularization and data quality-aware aggregation methods to verify the effectiveness of our proposed approach. The experimental results are shown in Table 4. The results indicate that removing each technique leads to a decrease in performance, which reflects the effectiveness of these methods.
Analysis of prototype regularization
Prototype regularization aims tstage, we assign weights o reduce differences between model parameters by penalizing the discrepancies between the sample features extracted by the local model and the global class feature centers. This encourages local models to align more closely with the global model, preventing parameters from deviating from convergence points and improving stability and generalization.
In practice, data across clients often contains varying noise distributions. Simply averaging prototypes can weaken convergence due to noise interference. To address this, our method aggregates prototypes based on class feature similarity. During early training, local and global class feature centers are primarily trained on clean samples, allowing them to accurately represent true class characteristics. When clean samples are abundant, these centers show strong consistency in convergence direction. By reinforcing well-aligned feature centers and suppressing those that deviate, we enhance convergence stability and ensure the model reliably approaches optimal solutions.
Analysis of clients’ data-aware model aggregation
Figure 3a and Fig. 3b show the relationship between client data noise rates and training accuracy under settings where 70% of clients are noisy, with client noise rates ranging from 0.1 to 0.4. The results indicate a negative correlation: higher client noise rates typically lead to lower training accuracy.

The relationship between client data noise rate and client training accuracy.
When label noise exists in client data, the model attempts to fit incorrect label-feature mappings. For example, if a sample’s true label is ‘walking’ but is mislabeled as ‘running’, the model incorrectly associates certain motion features with ‘running’, causing confusion in classification boundaries during training. Noisy labels create inconsistencies between the model’s predictions and incorrect labels on local data, reducing training accuracy (the model’s accuracy on its own data). For instance, with high noise rates, the model struggles to fit both correct and noisy samples, leading to significant drops in accuracy.
If client data distributions vary significantly (e.g., different user behavior patterns), even with correct labels, the model may perform poorly due to its inability to capture global patterns, slightly lowering training accuracy. However, the impact of non-IID data (data distribution differences) and label noise remains distinct: non-IID data challenges generalization, while label noise teaches incorrect patterns. Thus, early-stage training accuracy can indirectly reflect data quality.
In FedAvg, client weights are determined by sample size, ignoring differences in contributions from noisy versus clean clients. Noisy clients with heavily flawed data might unfairly dominate global model updates. By using client accuracy as a weight indicator during aggregation, we reduce the influence of noisy clients and their negative impact. This weight adjustment mechanism balances both data quantity and quality, improving overall performance.
Robustness experiments
Under settings with a noisy client ratio of 0.7 and client data noise rates ranging from 0.1 to 0.4, experiments were conducted by adjusting the number of clients and the degree of non-IID (non-independent and identically distributed) data to validate the method’s robustness across different configurations. Results are shown in Table 5.
As the number of clients increases, the non-IID nature of their data becomes more complex. With more clients, each client’s data volume decreases. Data fragmentation leads to insufficient local training samples. When sample sizes are small, models struggle to capture statistical patterns, making them prone to overfitting (and more sensitive to noise).
With more clients, each client’s data distribution is more likely to deviate from the global distribution (e.g., some clients may only contain data from a single class). Local models overfit to local features, making it harder to align parameter updates from different directions during aggregation. Although performance declines slightly due to the distributed training framework, the proposed method maintained reasonable robustness even as the number of clients increased.
Hyperparameters sensitivity experiments
We investigated the robustness of our method by tuning hyperparameters \(\alpha\) and \(\lambda\) under a noise client ratio of 0.7 with client data noise rates ranging from 0.1 to 0.4. Parameter \(\alpha\) controls the balance between data quality and model prediction similarity in selecting reliable neighbors: \(\alpha\) = 0 prioritizes clients with top-k model prediction similarity, while \(\alpha\) = 1 focuses on top-k data quality. Table 6 reveals that relying solely on either factor degrades neighbor selection quality, confirming the necessity of both metrics. Meanwhile, Table 7 demonstrates that excessively high \(\lambda\) values impair performance, emphasizing the need for careful parameter tuning within practical limits.
Discussion
Method analysis
This study finds that directly applying noisy label learning methods from centralized settings to federated learning frameworks often yields unsatisfactory results. This is mainly because data distribution in federated learning environments is far more complex and variable than in centralized settings. In federated learning, data is distributed across multiple clients, and each client’s data distribution may differ significantly. Such heterogeneous data distribution poses serious challenges for noisy label learning. Directly transplanting centralized methods overlooks the dynamic and localized nature of federated scenarios, requiring collaborative algorithm design (such as coupling noise handling with federated optimization) to achieve more robust solutions.
Existing federated noisy learning methods improve model noise resistance by filtering noisy samples for semi-supervised learning, conducting robust training for high-noise clients, or similar approaches. These methods show competitive performance when client data has low noise rates. However, when handling high-noise data, they remain vulnerable to issues like error accumulation and model overfitting due to retained noisy samples. Although techniques like pseudo-labeling and knowledge distillation have been applied, overfitting persists. Noisy samples continue to misguide models during training, causing noticeable accuracy drops and fluctuations. This suggests that discarding noisy data without significantly damaging data features can indeed achieve better performance. Removing noisy samples reduces training interference, thereby improving model generalization and stability, though careful sample selection remains crucial.
The small-loss trick, which updates neural networks using samples with minimal losses during training iterations (typically treated as clean data), shows performance variations in experiments. While outperforming FedProx and ProtoHAR overall, significant performance gaps persist between high-quality and low-quality clients. Therefore, improving underperforming local models while identifying clean samples from noisy data is essential for enhancing federated learning robustness with noisy labels. When high-quality and low-quality clients coexist, leveraging high-quality clients to assist low-quality ones and assigning client weights based on data quality during model aggregation can strengthen global model robustness.
Time complexity
While the proposed LN-FHAR framework achieves robustness against label noise and client drift, its computational demands must be evaluated for deployment on resource-constrained IoT devices.
In client selection stage, each client trains an initial model for \(T\) rounds using FedAvg. The local training involves forward–backward passes with cross-entropy loss, requiring \(O(K \cdot N \cdot D)\) operations for all clients, where \(N\) is the number of samples and \(K\) is the number of clients ,\(D\) is the model dimension. Calculating per-class average losses and training accuracy adds \(O(C \cdot N)\) operations, where \(C\) is the number of classes. However, this step is lightweight compared to full model training. In noise-robust training stage, computing local prototypes involves averaging embeddings for each class, requiring \(O(N_{c} \cdot d)\) operations per client, where \(N_{c}\) is the number of samples per class and \(d\) is the embedding dimension. Global prototype aggregation via cosine similarity introduces \(O(C \cdot K \cdot d)\) operations on the server, where \(K\) is the number of clients. For each low-quality client, calculating data distribution similarity scores involves generating Gaussian noise-augmented predictions and computing pairwise cosine similarities. When calculating reliable neighbor scores, we only use high-quality clients from the selection phase and the target client. This step increases computational cost \(O(L \cdot H \cdot d)\) by \(L\)(number of low-quality clients) multiplied by \(H\) (number of high-quality clients). The EM algorithm for GMM fitting on loss distributions has a complexity of \(O(N \cdot I)\), where \(I\) is the number of EM iterations. The complexity of selecting M neighbors for each low-quality client is \(O(K \cdot \log K)\). It can be seen that the time complexity of model computation primarily stems from model training and prototype computation.
The main computational complexity comes from model training, prototype computation, and pairwise cosine similarity calculations during neighbor selection. To reduce costs when client numbers are large, some optimizations are applied, including simplifying neural network parameters and restricting reliable neighbor selection to a subset of Top-k high-quality clients, thereby minimizing pairwise comparisons. Dimensionality reduction techniques like PCA compress model outputs to accelerate individual similarity computations. Additionally, periodic neighbor updates, instead of per-round recalculations, combined with a sliding window strategy to reuse historical similarity results significantly reduce processing frequency while maintaining system effectiveness.
Conclusion
This paper proposes LN-FHAR, a two-stage sensor-based federated training framework for human activity recognition tasks with noisy labels. LN-FHAR identifies clean samples through reliable neighbor collaboration and trains models on the purified dataset. During local training, it leverages global activity prototype knowledge shared across clients to correct local model representations. In the model aggregation phase, client weights are determined by jointly considering data quality and quantity contributions, ensuring robust global model performance even under high label noise levels. Experimental results validate the effectiveness of the proposed method. The approach demonstrates promising application potential in scenarios with noisy client data sources. For instance, in healthcare settings such as patient status monitoring and recognition tasks, LN-FHAR can addresses challenges including privacy preservation, limited learnable samples from individual data sources, and label noise contamination, offering technical and methodological support for building intelligent healthcare systems.
Data availability
The data presented in this study are available on request from corresponding author.
References
Chen, K. X. et al. Deep learning for sensor-based human activity recognition: overview, challenges, and opportunities. ACM Comput. Surv. 54, 1–40 (2021).
McMahan, H. B. et al. Communication-efficient learning of deep networks from decentralized data. Proceedings 20th Int. Conf. Artif. Intell. Stat. 1273–1282 (2017).
Wu, Q., Chen, X., Zhou, Z. & Zhang, J. Fedhome: Cloud-edge based personalized federated learning for in-home health monitoring. IEEE Trans. Mob. Comput. 21, 2818–2832 (2020).
Presotto, R., Civitarese, G. & Bettini, C. FedCLAR: Federated clustering for personalized sensor-based human activity recognition. Proceedings IEEE PerCom. 227–236 (2022).
Li, C., Niu, D., Jiang, B., Zuo, X. & Yang, J. Meta-HAR: Federated representation learning for human activity recognition. Proceedings Web Conf 912–922 (2021).
Shen, Q. et al. Federated multi-task attention for cross-individual human activity recognition. Proceedings IJCAI 3423–3429 (2022).
Yu, H. Z. et al. FedHAR: Semi-supervised online learning for personalized federated human activity recognition. IEEE Trans. Mob. Comput. 22, 3318–3332 (2023).
Imteaj, A., Alabagi, R. & Amini, M. H. Exploiting federated learning technique to recognize human activities in resource-constrained environment. International Conference on Intelligent Human Computer Interaction. 659–672 (2021).
Gad, G., Fadlullah, Z. M., Rabie, K. & Fouda, M. M. Communication-efficient privacy-preserving federated learning via knowledge distillation for human activity recognition systems. Proceedings IEEE ICC 1572–1578 (2023).
Zhu, X. Q. & Wu, X. D. Class noise vs. attribute noise: A quantitative study. Artif. Intell. Rev. 22, 177–210 (2004).
Sáez, J. A., Galar, M., Luengo, J. & Herrera, F. Analyzing the presence of noise in multi-class problems: Alleviating its influence with the One-vs-One decomposition. Knowl. Inf. Syst. 38, 179–206 (2014).
Atkinson, G. & Metsis, V. Identifying label noise in time-series datasets. Proceedings ACM UbiComp/ISWC 238–243 (2020).
Duan, S. M., Liu, C. Y., Cao, Z. S., Jin, X. P. & Han, P. Y. Fed-DR-Filter: Using global data representation to reduce the impact of noisy labels on the performance of federated learning. Future Gener. Comput. Syst. 136, 336–348 (2022).
Zhuo, Y. & Li, B. FedNS: Improving federated learning for collaborative image classification on mobile clients. Proceedings IEEE ICME 1–6 (2021).
Wu, W. T., He, L. G., Lin, W. W. & Maple, C. FedProf: Selective federated learning based on distributional representation profiling. IEEE Trans. Parallel Distrib. Syst. 34, 1942–1953 (2023).
Yang, M., Qian, H., Wang, X. M., Zhou, Y. & Zhu, H. B. Client selection for federated learning with label noise. IEEE Trans. Veh. Technol. 71, 2193–2197 (2022).
Wu, N. N., Yu, L., Jiang, X. F., Cheng, K.-T. & Yan, Z. Q. FedNoRo: Towards noise-robust federated learning by addressing class imbalance and label noise heterogeneity. Proceedings IJCAI 4424–4432 (2023).
Tang, M. et al. FedCor: Correlation-based active client selection strategy for heterogeneous federated learning. Proceedings IEEE CVPR 10092–10101 (2022).
Yang, S. H., Park, H. S., Byun, J. Y. & Kim, C. G. Robust federated learning with noisy labels. IEEE Intell. Syst. 37, 35–43 (2022).
Jiang, X. F., Sun, S., Li, J. & Xue, J. J. Tackling noisy clients in federated learning with end-to-end label correction. Proceedings ACM CIKM 1015–1026 (2024).
Kim, S. M., Shin, W., Jang, S., Song, H. & Yun, S. Y. FedRN: Exploiting k-reliable neighbors towards robust federated learning. Proceedings ACM CIKM 972–981 (2022).
Liu, S., Jonathan, N.-W., Razavian, N. & Carlos. F-G. Early-learning regularization prevents memorization of noisy labels. Proceedings NeurIPS 20331–20342 (2020).
Jiang, X. F., Sun, S., Wang, Y. W. & Liu, M. Towards federated learning against noisy labels via local self-regularization. Proceedings ACM CIKM 862–873 (2022).
Gao, L. et al. FedDC: Federated learning with non-IID data via local drift decoupling and correction. Proceedings IEEE CVPR 10102–10111 (2022).
Fang, X. W. & Ye, M. Robust federated learning with noisy and heterogeneous clients. Proceedings IEEE CVPR 10062–10071 (2022).
Zhao, H. W. et al. Community awareness personalized federated learning for defect detection. IEEE Trans. Comput. Soc. Syst. 11(6), 8064–8077 (2024).
Zhao, H.W. et al. Personalized fuzzy federated prompt tuning for Re-Identification. DTPI 110–115(2024)
Bu, C. et al. Learn from others and be yourself in federated human activity recognition via attention-based pairwise collaborations. IEEE Trans. Instrum. Meas. 73, 1–15 (2024).
Song, H., Kim, M., Park, D., Shin, Y. & Lee, J.-G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 34, 8135–8153 (2023).
Valadi, V., Qiu, X. C., Gusmao, P. P. B. D., Lane, N. D. & Alibeigi, M. FedVal: Different good or different bad in federated learning. Proceedings USENIX Secur. 6365–6380 (2023).
Fang, M. H., Cao, X. Y., Jia, J. Y. & Gong, N. Z. Local model poisoning attacks to Byzantine-Robust federated learning. Proceedings USENIX Secur. 1623–1630 (2020).
Fung, C., Yoon, C. J. M. & Beschastnikh, I. The limitations of federated learning in Sybil settings. Proceedings RAID 301–316 (2020).
Gupta, A. Luo, T., Ngo, M. V. & Das, S. K. Long-short history of gradients is all you need: Detecting malicious and unreliable clients in federated learning. Proceedings ESORICS 445–465 (2022).
Sun, Z., Kairouz, P., Suresh, A. & Mcmahan, T. H. B. Can you really backdoor federated learning? (2019).
Dunkin, F. et al. MgCNL: A sample separation approach via multi-granularity balls for fault diagnosis with the interference of noisy labels. IEEE Trans. Autom. Sci. Eng. 22, 7748–7761 (2025).
Zhang, Q., Zhu, Y., Cordeiro, F. R. & Chen, Q. PSSCL: A progressive sample selection framework with contrastive loss designed for noisy labels. Pattern Recogn. 161, 111284 (2025).
Lu, Y. et al. Federated learning with extremely noisy clients via negative distillation. Proceedings. AAAI 38,14184-14192(2024).
Ji, X. Y. et al. FedFixer: Mitigating heterogeneous label noise in federated learning. Proceedings AAAI 38, 12830-12838(2024).
Miao, Q. et al. Learning with noisy labels using collaborative sample selection and contrastive semi-supervised learning. Knowl.Based Syst. 296, 111860 (2024).
Tan, Y. et al. FedProto: Federated prototype learning across heterogeneous clients. Proceedings AAAI 8432–8440 (2022).
Cheng, D. Z. et al. ProtoHAR: Prototype guided personalized federated learning for human activity recognition. IEEE J. Biomed. Health Inform. 27, 3900–3911 (2023).
Karimireddy, S. P. et al. SCAFFOLD: Stochastic controlled averaging for federated learning. Proceedings ICML 5132–5143 (2020).
Xiao, B. X. et al. Sample selection with uncertainty of losses for learning with noisy labels. (2021).
Li, J. C., Li, G. B., Cheng, H., Liao, Z. C. & Yu, Y. Z. FedDiv: Collaborative noise filtering for federated learning with noisy labels. Proceedings AAAI 3118–3126 (2024).
Lu, J. Y., Lin, H., Dong, Y. & Zhang, Y. S. A new wavelet threshold function and de-noising application. Math. Probl. Eng. 2016, 1–8 (2016).
Reiss, A. & Stricker, D. Introducing a new benchmarked dataset for activity monitoring. Proceedings ISWC 108–109 (2012).
Roggen, D. et al. Collecting complex activity datasets in highly rich networked sensor environments. Proceedings INSS 233–240 (2010).
Han, B. et al. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Proceedings NeurIPS 8536–8546 (2018).
Song, H. J., Kim, M.-S. & Lee, J.-G. SELFIE: Refurbishing unclean samples for robust deep learning. Proceedings ICML 5907–5915 (2019).
Li, J. N., Socher, R. & Hoi, S. C. H. Dividemix: Learning with noisy labels as semi-supervised learning. (2020).
Sahu, A. et al. Federated optimization in heterogeneous networks. Proceedings MLSys. 429-450 (2020).
Funding
This research is Supported by the China Postdoctoral Science Foundation (Grant No.2024M754275), the National Natural Science Foundation of China (Grant No. 62401609) and Natural Science Basis Research Plan in Shaanxi Province of China (Grant No. 2024JC-YBQN-0628).
Author information
Authors and Affiliations
Contributions
S.H.F. and L.X.J. contributed to the experimental coding, manuscript , and figure preparation. G.H.Y. was responsible for data curation and funding acquisition. Y.J.P. and L.Y.F. participated in manuscript review and editing. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sun, H., Yao, J., Li, X. et al. Robust two stages federated learning for sensor based human activity recognition with label noise. Sci Rep 15, 17227 (2025). https://doi.org/10.1038/s41598-025-02395-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02395-z
