
Abstract
Image steganography is a process of embedding a secret image into a cover image to achieve secret transmission and accurately recovering a secret image from a stego image. To further investigate the high invisibility and extraction accuracy of steganography, this study presents RISRANet, a reversible image steganography network utilizing residual structure and mixed attention mechanism, markedly enhancing both the fidelity of stego image and the accuracy of restoring secret image. The network uses INN as the overall framework, adopts a double-branch structure, extracts deep features using the mixed attention mechanism, and employs channel shuffle to promote information interaction between different features. This paper introduces dilated convolution to design a multi-scale convolution attention module that combines feature information from different scales, highlights essential features, and precisely locates the ideal embedding position. In addition, the residual structure is constructed to allow for feature reuse, and the structural similarity is introduced into the loss function to improve the accuracy of information recovery. The experimental results suggest that the framework achieves secure hiding and lossless extraction of secret images, superior to comparative algorithms in multiple evaluation metrics.
Similar content being viewed by others

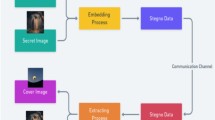
Introduction
The rapid advance of Internet technology has facilitated information transmission but also raised security risks, making secure transmission a major concern. Information-hiding technology is a common information security technology.Image steganography is a special information-hiding technology that conceals images within images.
Given the advantages of neural networks for feature extraction, a growing amount of researchers have applied neural networks to information hiding and achieved excellent results. Baluja1 was the first to use neural networks to conceal a full-color image within a similar-sized image. Zhu et al.2 inserted a noise layer between the encoder and decoder networks and proposed a HiDDeN network, finally confirming the contribution of adversarial training to the appearance of the encoded image. Rehman et al.3 designed a universal end-to-end CNN-based encoder-decoder architecture. Yu et al.4 reported a non-embedded information-hiding strategy that constructs on the attentional mechanism and generative adversarial network. Duan et al.5 introduced a double-layer U-Net structure, cascaded convolution and attention mechanism to fully extract features, and improve image appearance.
Although these algorithms above have achieved good performance, the feature extraction and fusion in the hiding and recovery process are not effective enough. The feature mapping of each channel in the image is treated equally, and the attention to the texture area of the carrier image is insufficient, so the features of the texture area cannot be better learned, and the secret information is embedded into the complex texture area. In addition, some multi-scale spatial information features on the feature map are ignored, so that the spatial information features are not fully utilized, which limits the quality of the stego image and the further improvement of the recovery accuracy of the secret image.
Based on the above problems, this research presents a reversible image steganography method founded on residual structure and attention mechanism. Image hiding and recovery are accomplished by utilizing an invertible neural network. Shuffle attention6 is imported to focus on inter-channel dependencies and inter-pixel relationship capture, while the “channel shuffle” is employed to implement the information interaction. Multi-scale convolution is proposed for effective feature extraction, and skip connections are used to transfer features across layers to better utilize features. Experimental results show significant improvements in the quality of generated images, ensuring strong security and invisibility.
The following is a summary of this study’s primary contributions:
-
We present RISRANet, a reversible steganography model built on residual structure and attention mechanism, which is capable of generating higher-quality stego image, recovering more accurate secret image, and providing strong security.
-
We employ hybrid attention to adjust the importance of different locations and channels dynamically; “channel shuffle” is performed to accomplish the information interaction, enhancing the feature representation.
-
We design a multi-scale attention component that makes use of dilated convolutions with various dilation coefficients and attention mechanism, effectively increases the network receptive field, and strengthens the model’s capacity for generalization.
-
We use the residual structure to better convey feature information, and the structural similarity index is introduced to construct a hybrid loss function for recovering higher-quality secret image.
Related works
Image steganography based on residual structure
The ResNet network7 was proposed by He et al. in 2015. This network adds a skip connection branch between the second convolutional layer and the activation function, resolving the model degradation issue that often occurs in deep networks. Duan et al.8 applied the residual blocks to the hidden structure, which considerably optimized the visual effect of the picture. Wu et al.9 proposed a steganography technique named a Generative Feedback Residual Network (GFR-Net) that improves the hiding capacity.
Image steganography based on invertible neural networks
Invertible Neural Network (INN) is presented by Dinh et al.10 initially, due to its bijective construction and efficient invertibility, INN is extensively applied to various inference tasks. Jing et al.11 proposed applying INN to the image steganography task initially, treating image concealment and restoration as a forward and reverse process of a single INN to assure reversibility. Yang et al. proposed the PRIS12 algorithm, which introduced two enhancement modules before and after the recovery process, allowing steganography to withstand various attacks. Huo et al.13 designed a new fitting module that generates a variable at the receiver to simulate the lost information, and overcome the data loss. All the above demonstrate the excellence of INN in image steganography.
Methods
Overview
The RISRANet’s general design is depicted in Figure 1, which is made up of N identical invertible blocks. In the concealing procedure, the secret and cover images are first preprocessed by DWT, and the obtained feature maps are input into a series of invertible blocks, and finally the stego image and the lost information are obtained by IWT. In the reverse recovery process,a random normal distribution tensor is used to replace the lost information. The stego image serves as the combined input for recovery. They are first pre-processed with a DWT, then passed through the invertible blocks, and finally, the secret and cover images are recovered using an IWT. The overall hiding and recovery procedure can be expressed as the below formula:
where NINV and \(NINV^{-1}\) represent the processing functions of the forward hiding and backward recovery processes respectively; DWT represent the Discrete Wavelet Transform, it is a widely used image processing technique that converts image data from the spatial domain into the frequency domain, IWT represent the Inverse Discrete Wavelet Transform. We present the hiding and the recovery processes respectively in Algorithms 1, 2 to further illustrate the input, output, and process of the proposed method.

The structure of RISRANet.

Hiding process

Recovery process
In the hiding operation, the inputs of the ith invertible block are defined as \(x_{cover}^{i}\) and \(x_{secret}^{i}\), and the corresponding outputs are defined as \(x_{cover}^{i+1}\) and \(x_{secret}^{i+1}\). The specific calculating technique is shown in the following formula:
where \(\sigma (\cdot )\) represents the sigmoid activation function scaled by a constant factor, \(\Phi (\cdot )\), \(\rho (\cdot )\), and \(\eta (\cdot )\) represent arbitrary functions. In this study, we design a residual shuffle attention module and apply it to the arbitrary functions. The module’s structure is depicted in Figure 2, including three sub-modules: Convolutional Shuffle Attention Module, Dense convolution Shuffle Attention Module, and Multi-scale Shuffle Attention Module, hereinafter referred to as the CSA module, DSA module, and MSA module, respectively.

Residual shuffle attention module structure \(\Phi (\cdot )\), \(\rho (\cdot )\), and \(\eta (\cdot )\).
In the recovery operation, the inputs of the (i+1)th invertible block are defined as \(x_{stego}^{i+1}\) and \(g^{i+1}\), and the corresponding outputs are \(x_{stego}^{i}\) and \(g^{i}\). The g is added to replace r since the distribution of the lost information r in the concealing procedure is uncertain. In this study, g is set to the noise randomly selected from the Gaussian distribution.
Convolutional shuffle attention
Ordinary convolutional models cannot efficiently distinguish the importance of features, resulting in some useful information being neglected. Hence, we import hybrid attention to design a CSA module, ensuring the model recognizes the crucial parts of the image, generating higher-quality images, and reducing visual distortion.
Figure 3 depicts the specific structure of the CSA module. In the beginning, the 1x1 convolution layer reduces the feature dimension, next, the 3x3 convolution layer increases the dimension to 32, thereby decreasing the amount of computation and parameters when deepening the network. This helps the model grasp more complex features, and then later by the Shuffle Attention module, hereinafter referred to as the SA module, which is used to highlight the important features and suppress the other features, thus generating higher quality images. In which the SA module divides the input feature mapping into numerous sub-features first, afterward using channel segmentation to handle each group’s sub-features concurrently. The sub-features of every group are then combined, the channel shuffle operator is utilized to actualize the information interaction between various features, and the channel attention and spatial attention are subsequently merged into a block of every group with a concatenation operation. The module’s specific structure is depicted in the lower part of Fig. 3, which consists primarily of four components: feature grouping, channel attention, spatial attention, and aggregation operation, which will be detailed in detail next.
Feature Grouping: Let \(X\in R^{C\times H\times W}\) be set as the input feature, in this context, C, H, and W denote the amount of input channels, image’s height and width, correspondingly. X is first grouped according to the channel dimension, and each group’s channels become C/G, where G is the number of groups, that is, \(X=\begin{bmatrix}X_1,X_2,...,X_G\end{bmatrix}\), \(X_{k}\in R^{C/G\times H\times W}\), during the training process, each sub-feature \(X_{k}\) will gradually learn and capture specific semantic information, and then assign corresponding weight coefficients to these sub-features through the attention module. Specifically, after feature grouping, each group of features will be split into two branches on the channel dimension, respectively \(X_{k1}, X_{k2}\in R^{C/2G\times H\times W}\), as shown in Figure 3. The two branches focus on the relationship between different channels of image features and the relationship within the space, respectively, and generate the corresponding feature maps, which makes the model concentrate on identifying valid information on the feature maps and where the valid information is located.

The architecture of the CSA module.
Channel attention: in this study, the method initially incorporates global information through Global Average Pooling (GAP). This technique generates a channel statistic \(c\in R^{C/2G\times 1\times 1}\) by summing and averaging all elements of the feature map \(X_{k1}\) in the spatial dimension H\(\times\)W, as indicated in Eq. (9):
The channel vectors are then scaled and shifted using a pair of parameters through a gating mechanism that employs a sigmoid function, generating a compact feature representation for accurate and adaptive selection guidance, as indicated in Eq. (10):
where \(X_{k1}'\) is the ultimate result of the channel attention part. The parameters \(w_{1}\in R^{C/2G\times 1\times 1}\), \(b_{1}\in R^{C/2G\times 1\times 1}\) are utilized to scale and offset c.
Spatial Attention: Unlike channel attention, spatial attention centers on “which regions” contain crucial information, thus complementing channel attention. In this paper, group normalization (GN) is applied to the input \(X_{k2}\) to generate a spatial statistic s. Then, similar to the channel statistic, the spatial vectors are then scaled and shifted using a set of parameters to refine the representation of \(X_{k2}\). The ultimate result of the spatial attention part is given by the below equations:
where the parameters \(w_{2}\) and \(b_{2}\) have the shape \(R^{C/2G\times 1\times 1}\).
To maintain an equal number of output channels as input channels in every group, the outputs from the channel attention and spatial attention parts are connected by concatenation operation, that is, \(X_{k}^{\prime }=\begin{bmatrix}X_{k1}^{\prime }, X_{k2}^{\prime }\end{bmatrix}\in R^{C/G\times H\times W}\).
Aggregation: The Aggregation operation is utilized to aggregate the features of every group. The “channel shuffle” is applied to realize group cross-attention, this allows for effective feature fusion and interchange across channels to optimize feature representation.
Figure 4 depicts the specific architecture of the DSA module, and Table 1 displays the precise DSA network structure and parameters.

The architecture of the DSA module.
Multi-scale convolutional shuffle attention
In this study, we designed a multi-scale shuffle convolutional attention module, as illustrated in Fig. 5. By using dilated convolution in parallel and setting different dilation rates of 1, 2, and 5, we enable the network to gather a broader range of contextual information and decrease information loss. Meanwhile, the dilated convolution can gather multi-scale features in the image using different dilation rates, providing a rich feature space for steganography. By incorporating the attention mechanism, the network is better able to concentrate on the most significant features which results in higher visual quality.

The structure of the MSA module.
Residual structure
Residual connection is a common concept in deep learning and has produced excellent results in computer vision tasks. The proposed method fused the output features of the double branches by addition and then input them into the MSA module for further multi-scale feature extraction, and skipped the MSA module scaffold through the residual connection to input into the next arbitrary function, ensuring that the information of the two branches could be effectively transmitted and retained in the network, avoiding the loss of significant features in the information embedding and recovery steps. Ensure that the network can make full use of the information from each layer. The insertion of residual structure reduces damage to the image’s original features while improving the robustness of embedding and recovery. Simultaneously, the problem of gradient vanishing in the network is alleviated, allowing the network to learn deep features more effectively. The design of multiple branch structures and feature fusion renders the network to capture more diverse features, which can enhance model’s generalization capacity.
Loss function
The total loss function adopted in the training process is composed of four components: hiding loss, recovery loss, low-frequency wavelet loss, and structural similarity loss, which is included to increase the recovered secret information’s correctness.
Hiding loss: The hiding loss is formulated below:
where, MSE stands for Mean squared Error loss, N denotes the quantity of training images in a batch.
Recovery loss: The recovery loss is described below:
Low-frequency wavelet loss: The DWT process breaks the image down into low- and high-frequency sub-bands. Since the high-frequency sub-bands hold more intricate image details, embedding secret information in these sub-bands helps reduce the effect on the image’s visual quality. To ensure that the secret information is predominantly embedded within the high-frequency sub-bands, minimizing the disparity between the low-frequency sub-bands of the stego image and the cover image is crucial. Accordingly, the low-frequency wavelet loss is described below:
where, \(DWT(\cdot )_{LL}\) represents the extraction of the low-frequency sub-bands from the image following the DWT.
Structural similarity loss: To maximize the similarity between the recovered secret image and the original secret image, we incorporate the structural similarity index into total loss. The formula is expressed as below:
where, \(\alpha\) and \(\beta\) are hyperparameters that balance the two sub-losses.
Total loss: The formula is detailed below:
where \(\lambda _{h}\), \(\lambda _{r}\), \(\lambda _{f}\) and \(\lambda _{s}\) are hyperparameters that balance the weights of different loss terms.
Experimental results and analysis
Experiment settings
Datasets: The suggested approach’s datasets include DIV2K, COCO, CelebA, and Pascal VOC2012. The DIV2K dataset contains 900 high-resolution images, 800 of which are selected as our training dataset and randomly cropped to 256\(\times\)256 size, and the remaining 100 of which are used as the test dataset, which are cropped to 1024\(\times\)1024 size by using center cropping. The test datasets also consist of 5000 randomly selected images from the COCO dataset, 2000 from the CelebA dataset, and 2000 from the Pascal VOC2012 dataset; these images are cropped to 256\(\times\)256, 178\(\times\)178, and 256\(\times\)256 resolutions using center cropping, respectively.
Experimental setups: During model training, we set the quantity of invertible blocks to 8, the batch-size to 8, the groups G to 16, the loss weights \(\lambda _{h}\), \(\lambda _{r}\), \(\lambda _{f}\), \(\lambda _{s}\), \(\alpha\) and \(\beta\) to 11, 12, 12, 1, 2, and 2.5, respectively. During training, the Adam optimization algorithm performs 270K iterations, , with a starting learning rate set to 1\(\times\) \(10^{-4.5}\). To demonstrate the effectiveness of the presented approach, we conduct a comparison against five schemes, namely HiDDeN2, Weng et al.14, Baluja15, HiNet11, StegGAN16, CAISFormer17 and HiiT18.
Subjective analysis
The subjective evaluation of image steganography is a crucial aspect of ensuring the utility of steganography. As shown in Fig. 6, the cover image, stego image, secret image, recovered secret image are arranged from left to right. The result reveals no discernible distinction between the stego image produced by the proposed method and the original cover image. Similarly, the secret image and its recovered counterpart exhibit no visible discrepancies, suggesting that the method effectively generates a high-quality stego image and achieves near-perfect recovery of the hidden information.

Visualizations generated by the presented approach on the DIV2K dataset.
Figure 7 compares the visual effects generated by the suggested approach, HiNet11 and StegGAN16, on the DIV2K dataset, as well as the related residual maps. The residual maps are used to compare pixel differences between the two images, \(\times\)20 represents the effect after 20 times magnification. The images produced by StegGAN16 have observable defects, including color distortion and irregular textures, among other things. The generated stego image is visually ineffective and cannot recover the secret image well. Additionally, noticeable texture from the secret image is evident in the residual maps between the stego images and cover images for both StegGAN16 and HiNet11. Such distinct residuals make it possible for a third party to swiftly detect the embedded secret information, thus undermining the security of these methods. Compared to StegGAN16 and HiNet11, the suggested approach provides that the visual appearances of the stego image and the restored secret image closely resemble the original image. This indicates the enhanced quality of the images produced by our approach. Furthermore, the residual maps are entirely black, signifying that the proposed method is more secure and challenging to detect.

Visualizations and residual maps of RISRANet and other comparison algorithms on the DIV2K dataset.
Objective analysis
The Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) are widely regarded as essential objective indicators for evaluating image quality.
As shown in Table 2, we compared with HiDDeN2, Weng et al.14, Baluja15, HiNet11, and StegGAN16 algorithms on the DIV2K and COCO datasets, respectively, and the findings indicate that the RISRANet exceeds the other algorithms on all four metrics. Specifically, the PSNR values of the cover-stego image pair of RISRANet reach 57.20 dB and 51.20 dB on the DIV2K and COCO datasets, respectively, which are improved by 8.21 dB and 4.68 dB relative to the second-best algorithm, and the SSIM values reach 0.9994 and 0.9978, respectively, which are 0.0023 and 0.0017 higher than the second-best algorithm. The PSNR values of secret-recovered secret image pair on the DIV2K and COCO datasets reach 57.02 dB and 50.01 dB, respectively, which are 4.16 dB and 3.03 dB higher than the second-best algorithm, and the SSIM values reach 0.9994, 0.9969, respectively, which are 0.0002 and 0.0012 higher than the second-best algorithm. The RISRANet achieves considerably better outcomes than other deep learning-based SOTA algorithms, indicating that the RISRANet enhances image steganography’s performance and security.
Figure 8 depicts the experimental images randomly selected by the proposed method from the DIV2K dataset, and their RGB histograms. The results indicate no difference between the RGB histograms of the cover image and stego image, preventing third parties from determining secret information, hence improving security. The RGB histogram of the recovered secret image is also identical to the original secret image, underscoring the algorithm’s effectiveness in recovery. This consistency further validates the imperceptibility and security of the RISRANet.

Comparison of RGB three-channel histograms of experimental images.
Ablation experiment
To validate the significance of multi-scale attention, convolutional shuffle attention, and structural similarity loss for the RISRANet, we design the ablation experiment, as shown in Table 3. Compared to the baseline, the algorithm with the addition of the shuffle attention module and the CSA branch generates improvements of 7.11 dB in PSNR for cover-stego image pairs, 0.0021 in SSIM; 2.66 dB in PSNR for secret-recovered secret image pairs. This enhancement is largely due to the multi-branch structure with attention, which captures diverse features and minimizes information loss. To further improve algorithm’s performance, we incorporate structural similarity into loss function, and the evaluation index between image pairs is further improved. To effectively obtain the image’s multi-scale features, we also design multi-scale convolution attention, further improve model performance. Finally, compared to the baseline, the PSNR and SSIM values for the two image pairs are improved by 8.21 dB, 0.0023, and 4.16 dB, 0.0002, respectively.
Generalizability analysis
We evaluated the RISRANet’s generalization performance on various datasets, Table 4 depicts the findings. The PSNR values on all datasets are all greater than 50 dB, indicating that the produced image is of extremely high quality. All of them have a high SSIM value, indicating that the suggested approach has outstanding generalization capabilities and performs well even when applied to unknown data.
Analysis on model complexity and computational complexity
In this section, we compare the computational complexity and model complexity of different deep learning-based image steganography algorithms. The computational complexity is measured by calculating the FLOPs of all convolutional layers, and the model complexity is measured by the number of parameters of the model. The experimental results are shown in Table 5. Among them, the author of CAISFormer did not provide source code and only provided the number of model parameters in the paper, so FLOPs of this paper was replaced by / in the table.
It can be seen from the Table 5 that the proposed method achieves suboptimal results in terms of computation and parameters, which is only higher than the computational complexity and model complexity of Baluja15. The reason may be that in the image steganography method based on reversible neural network, the hiding network and recovery network are composed of multiple affine coupling blocks, including multiple learning functions, which increases the computational cost. However, the quality of the images generated by the proposed method is much higher than that of Baluja15. Compared with HiNet11 and CAISFormer17, the proposed method has lower computational cost and model Parameters. Specifically, the FLOPs of the proposed method is reduced by 12.4\(\%\) compared with HiNet11, and the parameters of the proposed method are reduced by 12.3\(\%\) and 41.5\(\%\) compared with HiNet11 and CAISFormer17, respectively. This indicates that our method can achieve higher steganography performance while ensuring a lower amount of computation and parameters.
Security analysis
To illustrate the RISRANer’s security, we employ three tools to perform steganalysis on it. The first tool is StegExpose19, we randomly select 2000 images from the COCO dataset to generate stego images, and then use StegExpose19 to generate the ROC detection curve. According to Figure 9, the results show that the AUC value is 0.5010, which is nearly identical to 0.50, showing that the RISRANet method’s detection effect is almost the same as that of random guess (0.50). This suggests that the stego images produced by RISRANet are nearly indistinguishable from the cover image when analyzed by StegExpose19, demonstrating that RISRANet significantly improves steganographic security.

ROC curve generated by StegExpose for RISRANet.
The second tool is ManTraNet20, which can further localize specific tampered regions of the stego image. Figure 10 depicts the detection results. The mask image represents the tampered image generated by ManTraNet20, and the white areas indicate the tampered areas detected. Figure suggests that the stego image generated by RISRANet has the least detected areas and does not expose any secret image information, while the stego images generated by HiNet11 and StegGAN16 have a great number of tampered regions detected, and also expose some secret image contour information, implying that our approach is much more secure than other approaches.

The detection results of ManTraNet.
The third tools are SRNet21 and ZhuNet22, which are an image steganalysis network to distinguish the cover image from the stego image, when the detection accuracy is high, it means that the generated stego image can be easily detected to contain secret information. In other words, when the detection accuracy is lower, the stego image generated by the image steganography algorithm is more secure. Table 6 and Table 7 show the detection accuracy of steganographic images generated by different steganography algorithms using SRNet and ZhuNet. It can be seen from the tables that our method has the lowest probability of detection 50.40 and 50.03, which are significantly better than other algorithms, which means that the steganographic images generated by us have higher quality and the model can better extract the features of the images. The attention mechanism can guide the secret information to be embedded into the complex texture area of the carrier image, making the secret information more hidden and difficult to be detected, and the algorithm has better security.
Conclusion
In this study, we apply the INN framework for image steganography, capturing the diverse features of the image via the double-branch structure, which can efficiently reuse multi-level features and enhance the ability to capture local details and textures by densely connecting the branches, while the ordinary convolutional branch is more adept at extracting global semantic features, and the features of the two branches can form a complement when fused while retaining the details and semantic information, which improves the model’s ability to characterize the complex scene. After fusion, multi-scale convolution and attention mechanism were combined to significantly improve the expression ability of fusion features. Simultaneously, the residual structure is used to realize feature reuse, and the structural similarity loss is introduced to train the RISRANet to increase information recovery precision. The studies indicate that the suggested approach performs well on PSNR and SSIM evaluation metrics, outperforms other approaches with respect to imperceptibility, security, and steganography extraction precision, and performs excellently on different datasets with good generalization ability. However, this method has limited hiding capacity, and in the future, we will further explore higher capacity hiding methods to achieve multiple image hiding.
Data availability
The datasets used and/or analysed during the current study are publicly available on Kaggle (under the terms specified by the Kaggle platform). It can be accessed via the link https://www.kaggle.com/datasets.
References
Baluja, S. Hiding images in plain sight: Deep steganography. Adv. Neural Inf. Process. Syst. 30 (2017).
Zhu, J. Hidden: Hiding data with deep networks. arXiv preprint arXiv:1807.09937 (2018).
ur Rehman, A., Rahim, R., Nadeem, S. & ul Hussain, S. End-to-end trained cnn encoder-decoder networks for image steganography. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops. https://doi.org/10.1007/978-3-030-11018-5_64 (2018).
Yu, C. et al. An improved steganography without embedding based on attention GAN. Peer-to-Peer Netw. Appl. 14, 1446–1457. https://doi.org/10.1007/s12083-020-01033-x (2021).
Duan, X., Wu, G., Li, C., Li, Z. & Qin, C. Duianet: A double layer u-net image hiding method based on improved inception module and attention mechanism. J. Vis. Commun. Image Represent. 98, 104035. https://doi.org/10.1016/j.jvcir.2023.104035 (2024).
Zhang, Q.-L. & Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2235–2239. https://doi.org/10.1109/ICASSP39728.2021.9414568 (IEEE, 2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778. https://doi.org/10.1109/cvpr.2016.90 (2016).
Duan, X., Li, B., Xie, Z., Yue, D. & Ma, Y. High-capacity information hiding based on residual network. IETE Tech. Rev. 38, 172–183. https://doi.org/10.1080/02564602.2020.1808097 (2021).
Wu, J., Lai, Z. & Zhu, X. Generative feedback residual network for high-capacity image hiding. J. Mod. Opt. 69, 870–886. https://doi.org/10.1080/09500340.2022.2093415 (2022).
Dinh, L., Krueger, D. & Bengio, Y. Nice: Non-linear independent components estimation. arXiv preprint, arXiv:1410.8516 (2014).
Jing, J., Deng, X., Xu, M., Wang, J. & Guan, Z. Hinet: Deep image hiding by invertible network. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4733–4742 (2021).
Yang, H., Xu, Y., Liu, X. & Ma, X. PRIS: Practical robust invertible network for image steganography. Eng. Appl. Artif. Intell. 133, 108419. https://doi.org/10.1016/j.engappai.2024.108419 (2024).
Huo, L., Huang, L., Gan, Z. & Chen, R. P. A fitting model with optimal multiple image hiding effect. Neurocomputing 571, 127146. https://doi.org/10.1016/j.neucom.2023.127146 (2024).
Weng, X., Li, Y., Chi, L. & Mu, Y. High-capacity convolutional video steganography with temporal residual modeling. In Proceedings of the 2019 on International Conference on Multimedia Retrieval. 87–95. https://doi.org/10.1145/3323873.3325011 (2019).
Baluja, S. Hiding images within images. IEEE Trans. Pattern Anal. Mach. Intell. 42, 1685–1697. https://doi.org/10.1109/TPAMI.2019.2901877 (2019).
Singh, B., Sharma, P. K., Huddedar, S. A., Sur, A. & Mitra, P. Steggan: Hiding image within image using conditional generative adversarial networks. Multimed. Tools Appl. 81, 40511–40533. https://doi.org/10.1007/s11042-022-13172-9 (2022).
Zhou, Y. et al. Caisformer: Channel-wise attention transformer for image steganography. Neurocomputing 603, 128295. https://doi.org/10.1016/j.neucom.2024.128295 (2024).
Dong, Y. et al. Hiding image with inception transformer. IET Image Process. 18, 3961–3975. https://doi.org/10.1049/ipr2.13225 (2024).
Boroumand, M., Chen, M. & Fridrich, J. Deep residual network for steganalysis of digital images. IEEE Trans. Inf. For. Secur. 14, 1181–1193. https://doi.org/10.1109/TIFS.2018.2871749 (2018).
Wu, Y., AbdAlmageed, W. & Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9543–9552 (2019).
Boroumand, M., Chen, M. & Fridrich, J. Deep residual network for steganalysis of digital images. In IEEE Transactions on Information Forensics and Security. 1181-1193. https://doi.org/10.1109/tifs.2018.2871749 (2019).
Zhang, R., Zhu, F., Liu, J. & Liu, G. Depth-wise separable convolutions and multi-level pooling for an efficient spatial cnn-based steganalysis. In IEEE Transactions on Information Forensics and Security. 1138-1150. https://doi.org/10.1109/tifs.2019.2936913 (2020).
Acknowledgements
This work was supported by the Shandong Province Natural Science Foundation (Grant numbers ZR2022MF277) and the joint Fund of Natural Science Foundation of Shandong province (Grant numbers ZR202209070011).
Author information
Authors and Affiliations
Contributions
Lianshan Liu contributed to the Conceptualization, Formal analysis, Methodology, Investigation, Writing - original draft, Writing - review and editing, Funding acquisition. Shanshan Tong contributed to the Conceptualization, Formal analysis, Methodology, Investigation, Writing - original draft, Writing - review and editing, Software. Qianwen Xue contributed to the Conceptualization, Formal analysis, Methodology, Investigation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, L., Tong, S. & Xue, Q. Reversible image steganography based on residual structure and attention mechanism. Sci Rep 15, 19355 (2025). https://doi.org/10.1038/s41598-025-04441-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-04441-2
