
Abstract
In the human body, the skin is the main organ. Nearly 30–70% of individuals globally have skin-related health issues, for whom efficient and effective analysis is essential. A general method dermatologists use for analyzing skin illnesses is dermoscopy, which permits surveillance of the hidden structures of skin injuries, i.e., an area suffering from an illness whose effects are unseen to the naked eye. Dermoscopy is generally employed for cancers and other kinds of skin cancers with pigment. Yet, access to a dermoscopy is demanding in resource-poor areas and unnecessary for many general skin diseases. So, developing an effective skin disease analysis method that depends upon effortlessly accessible clinical imaging would be helpful and deliver lower-cost, common access to many individuals. Recently, computer-aided diagnosis (CAD) approaches have been effectively employed to detect skin cancers in dermatoscopic imaging. The CAD-based techniques will be beneficial for helping professionals detect and classify skin lesions. This paper presents an Advanced Skin Lesion Classification using Block-Scrambling-Based Encryption with a Fusion of Transfer Learning Models and a Hippopotamus Optimization (SLCBSBE-FTLHO) model. The main aim of the SLCBSBE-FTLHO model relies on automating the diagnostic procedures of skin lesions using optimal DL approaches. At first, the block-scrambling-based encryption (BSBE) technique is utilized in the image encryption pre-processing stage, and then the decryption process is performed. The feature extraction process employs the fusion of MobileNetV2, GoogLeNet, and AlexNet techniques. Furthermore, the conditional variational autoencoder (CVAE) method is implemented for skin lesion classification. To optimize the CVAE model performance, the hippopotamus optimization (HO) model is utilized for hyperparameter tuning to ensure that the optimum hyperparameters are chosen for enhanced accuracy. To exhibit the improved performance of the SLCBSBE-FTLHO approach, a comprehensive experimental analysis is conducted under the skin cancer ISIC dataset. The comparative study of the SLCBSBE-FTLHO approach portrayed a superior accuracy value of 99.48% over existing models.
Similar content being viewed by others
Introduction
Generally, the skin is the largest organ that covers bones, muscles, and all over the body. The function of the skin in the human body has greater significance because minor changes in its functioning may affect other body parts1. Skin is uncovered, which is why many infections and skin diseases occur. Therefore, skin diseases need the utmost attention. The infected area on the skin is referred to as a lesion2. The skin is exposed directly to the atmosphere, which leads to more skin diseases. It infuses all cultures, arises at all ages, and affects the health of over 30–70% of people3. The epidermis has melanocytes, which produce melanin at a very unusual rate under any circumstance. A widespread method dermatologists utilize for identifying skin infections is dermoscopy, which allows observation of the hidden structures of skin lesions, for example, an area that suffers from disease, whose effects are unseen to the naked eye4. Dermoscopy is typically employed for melanomas and other types of skin cancers with pigment. However, accessing a dermoscopy in needy places is hard and pointless for more common skin diseases5. Hence, advancing the efficient skin disease diagnosis method based on easily retrieved medical images is beneficial and provides cheap and worldwide access to many individuals. Dermoscopy uses polarised light that reduces the stratum corneum’s translucency6. Appropriate analysis of these dermoscopic images leads to improved medical analytic precision. Initial analysis of skin lesions is crucial for improved treatment7. Currently, the medical sector relies more on computer-aided diagnosis (CAD). The initial recognition of skin disease is more difficult for inexperienced dermatologists. Integrating digital image processing for skin cancer recognition can diagnose without physical contact with the skin8. Hence, advancing the CAD System has become an important research area in the medical field. An early study on the CAD methods for skin lesions generally connects with pigmented skin disease (e.g., melanoma) classification and detection, whose predicted or detected results did not accurately advance the doctors’ diagnosis. With the improvement of CV and AI, many investigations use computers to analyze anatomical data9. DL and ML are crucial in the medical domain for automating many procedures. It revealed that dermoscopy may worsen the diagnostic precision for inexperienced dermatologists. The growth of automatic diagnostic systems for skin lesion screening10. It provides promising reproducibility of analytical outcomes and increases the speed of the diagnosis procedure. Moreover, automated diagnosis applications have aided in reducing first-time diagnostic faults.
This paper presents an Advanced Skin Lesion Classification using Block-Scrambling-Based Encryption with a Fusion of Transfer Learning Models and a Hippopotamus Optimization (SLCBSBE-FTLHO) model. The main aim of the SLCBSBE-FTLHO model relies on automating the diagnostic procedures of skin lesions using optimal DL approaches. At first, the block-scrambling-based encryption (BSBE) technique is utilized in the image encryption pre-processing stage, and then the decryption process is performed. The feature extraction process employs the fusion of MobileNetV2, GoogLeNet, and AlexNet techniques. Furthermore, the conditional variational autoencoder (CVAE) method is implemented for skin lesion classification. To optimize the CVAE model performance, the hippopotamus optimization (HO) model is utilized for hyperparameter tuning to ensure that the optimum hyperparameters are chosen for enhanced accuracy. To exhibit the improved performance of the SLCBSBE-FTLHO approach, a comprehensive experimental analysis is conducted under the skin cancer ISIC dataset.
-
The SLCBSBE-FTLHO model utilizes the BSBE method for pre-processing to secure medical image data and ensure confidentiality. This approach improves the protection of sensitive medical images during transmission and storage. By integrating BSBE, the model strengthens privacy while maintaining the integrity of the data for additional analysis.
-
The SLCBSBE-FTLHO approach integrates MobileNetV2, GoogLeNet, and AlexNet to extract features from skin lesion images effectively, enhancing accuracy and efficiency. This fusion model utilizes the merits of each network to capture diverse and relevant features. It improves the overall robustness of the model in detecting key patterns in medical image analysis.
-
The SLCBSBE-FTLHO method employs the CVAE technique for precise skin lesion classification, enabling accurate differentiation between diverse lesion types. The CVAE improves classification performance under varying conditions by conditioning the extracted features. This approach confirms reliable and efficient skin lesion diagnosis.
-
The SLCBSBE-FTLHO methodology implements the HO technique to fine-tune model parameters, enhancing the overall classification accuracy. Using this optimization technique, the model effectively explores the parameter space for optimal performance. HO improves the robustness and precision of the classification task.
-
The SLCBSBE-FTLHO model integrates BSBE for secure data encryption, incorporating advanced DL methods such as MobileNetV2, GoogLeNet, and AlexNet for effective feature extraction. The model utilizes CVAE for accurate skin lesion classification while presenting a novel HO-based tuning method to optimize model parameters. This novel integration ensures improved security and performance, addressing critical challenges in medical image analysis.
Review of literature
In11, a BC-based method is planned to classify skin diseases aided by an enhanced DL technique. The skin disease is identified depending on the skin images kept in the BC in a dataset. Additionally, a fresh segmentation method was established to excerpt the lesions from the surroundings of the skin. DeepJoint segmentation, adapted by the presence of the Kumar-Hassebrooks distance, is used for segmentation. Afterwards, feature extraction and data augmentation were implemented, and the attributes defined were exposed to the LeNet for identification. Pingulkar et al.12 proposed an automatic classification method to detect skin disease that uses DL procedures to diagnose skin lesions precisely. This method enables the sharing of secure diagnostic data between clinical experts, supporting the cooperative planning of the treatment. Identifying the profound significance of confidentiality and data security in the medical field, the classification uses advanced security measures for protecting the patient’s sensitive information while transferring medical data. Kolluri et al.13 aimed to transform the estimation of skin diseases in patients. The Convolutional Neural Network method and Exception models are combined through transfer learning (TL) to provide a sturdy estimation structure. The TL model utilizes pre-trained techniques on patient-specific information to stimulate training and improve accuracy. This study attains a new tactic to address data security problems by using BC technology to secure patient data by ensuring integrity and transparency. Rajeshkumar et al.14 proposed a BC-aided Homomorphic Encryption Method for Skin Lesion Diagnosis employing an Optimum DL (BHESKD-ODL) technique. The proposed BHESKD-ODL method accomplishes security and appropriate identification of skin lesion images, utilizing BC to store the patient’s medical image to limit accessibility to intruders or third-party users. Furthermore, the BHESKD-ODL model safeguards medical images through the Mayfly Optimization (MFO) procedure by the Homomorphic Encryption (HE) method. Thwin and Park15 introduced a skin lesion detection model, which connects the abilities of 3 progressed DL methods: Inception-V3, ResNet-50, and VGG16. Incorporating these techniques within the ensemble, this method optimizes their strengths for improved identification precision and sturdiness. Each method in the ensemble makes its characteristic contributions and has experienced pretraining on ImageNet and consequent fine-tuning through dermoscopic images. Islam et al.16 presented a sophisticated pipeline for building an excellent healthcare system by combining security. DL was introduced recently in skin lesion classification. There are several mechanisms to build CAD for skin lesions. A CAD system detects skin cancer with the help of a smartphone camera. The authors17 investigated a convolutional neural network method to categorize skin illnesses depending on the fusion model. The fusion model and deep feature fusion reinforce the capability of the feature extraction model.
Khan et al.18 proposed a new DL procedure for detecting skin cancer. The CAD skin system categorizes and detects skin lesions through AEs and DCNN. The CAD was developed and designed using the current pre-processing method. It is a fusion of gamma correction, multiscale retinex, contrast-limited adaptive histogram equalization, and sharp masking. They executed data augmentation strategies to deal with the unstable dataset. Moreover, a Quantum SVM (QSVM) procedure is incorporated into the last detection step. Dharani Devi and Jeyalakshmi19 present a TL–based FL approach utilizing ResNet and domain adversarial training across decentralized medical centres while preserving data privacy and addressing domain shift challenges. Amaizu et al.20 propose FedViTBloc. This secure framework incorporates FL, ViT, and blockchain (BC) to enable decentralized medical image analysis while conserving patient privacy through homomorphic encryption and differential privacy. Bárcena et al.21 present an FL approach by utilizing a fuzzy regression tree (FRT) model to improve model interpretability and privacy, and compare its performance with a multilayer perceptron neural network (MLP-NN), illustrating competitive RMSE scores and improved generalization in distributed settings. Yao et al.22 proposed the federated learning (FL) with a shuffle model and differential privacy in edge computing environments (FedShufde) framework. Gamiz et al.23 presented a privacy-preserving and robust FL (PRoT-FL) framework that coordinates multiple training sessions using a secure protocol integrated with BC for auditability, ensuring protection against privacy attacks and maintaining model accuracy. Bezanjani, Ghafouri, and Gholamrezaei24 introduce a three-phase method integrating BC-based encryption for secure data transactions, request pattern recognition for detecting unauthorized access, and bidirectional long short-term memory (BiLSTM)-based feature selection. Xu et al.25 propose AAQ-PEKS, a lattice-based, quantum-resistant searchable encryption scheme with attribute-based access control for secure EMR sharing in IoMT, ensuring IND-CPA and IND-CKA security with superior efficiency. Khan et al.26 present Fed-Inforce-Fusion, a privacy-preserving FL-based intrusion detection system for IoMT networks, incorporating reinforcement learning (RL) to capture medical data patterns and a dynamic client fusion strategy. Shukla et al.27 present a privacy-preserving breast cancer detection method utilizing FL with a differential privacy model. Abidi, Alkhalefah, and Aboudaif28 propose a crossover-based multilayer perceptron (CMLP) model to detect adversarial attacks on medical records. Haripriya, Khare, and Pandey29 introduce a privacy-preserving medical image classification framework integrating TL and FL, introducing an adaptive aggregation method to improve model accuracy, scalability, and convergence across diverse medical datasets. Huang et al.30 present a personalized federated TL (PFTL) framework that integrates pre-trained global models with client-specific fine-tuning and dynamic aggregation, utilizing attention mechanisms for customized health prognosis across heterogeneous clients.
Despite crucial BC, FL, and DL improvements for skin disease detection and medical data privacy, interoperability, model generalizability, and real-time scalability exist. Many works depend on single or limited datasets, mitigating robustness across diverse domains. Privacy techniques, namely HE and DP, are integrated but often lack alignment with explainability and interpretability requirements. Furthermore, ensemble or TL models may suffer high computational costs, restricting deployment in low-resource environments. A research gap remains in developing lightweight, interpretable, and privacy-preserving frameworks that balance security, accuracy, and real-time performance in dispersed healthcare systems.
Proposed methodology
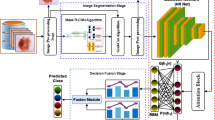
This paper presents an SLCBSBE-FTLHO approach. The approach’s primary goal is to automate the diagnostic procedures of skin lesions utilizing optimal DL models. The proposed SLCBSBE-FTLHO model involves various stages: image pre-processing, feature extraction, classification, and parameter tuning. Figure 1 depicts the overall working flow process of the SLCBSBE-FTLHO model.

Overall working flow of the SLCBSBE-FTLHO model.
Image pre-processing
At first, the BSBE technique is utilized in the image encryption pre-processing stage, and then the decryption process occurs31. The model is chosen for its robust mechanism for scrambling image data, which adds an extra layer of protection against potential data breaches or unauthorized access. The technique also exhibits robust safety capabilities, ensuring that medical image data remains encrypted during transmission and storage. This technique confirms that sensitive patient data remains secure without compromising the image quality for additional processing. Moreover, BSBE operates efficiently, mitigating the computational overhead usually associated with other encryption methods. The capacity to maintain data confidentiality while conserving crucial image features for analysis makes BSBE an ideal choice for medical applications, specifically in scenarios where privacy is paramount. This makes it highly appropriate for integration into sensitive domains such as medical image classification, where security and performance must be balanced. Figure 2 illustrates the BSBE framework.

Framework of BSBE method.
The BSBE model is applied to ensure the image is encrypted safely. Using this BSBE method, a consumer should strongly transfer image \(\:I\) to observers by applying virtual networking providers. However, suppose the customer fails to give the private key \(\:K\) to the virtual networking providers. In that case, the confidentiality of the image, which was distributed to users, is safe, while the virtual networking providers recompress the image \(\:I\). This approach mainly divided an image with \(\:X\)x\(\:Y\) pixels into non-overlapped blocks using \(\:{B}_{x}\text{x}{B}_{y}\). Then, four block‐scrambling‐based handling phases were implemented to separate the images. The method to implement the encryption image was given as shown:
Step1: Separate the image into \(\:X\text{x}Y\) pixels as blocks and all blocks by \(\:{B}_{x}\text{x}{B}_{y}\) pixels. Furthermore, the divided block is changed randomly using a random integer produced by the private key \(\:{K}_{1},L\) bit per pixel. \(\:{K}_{1}\) has commonly been used for all colour components.
Step2: Invert and rotate each block randomly using a random integer produced by the key \(\:{K}_{2}\), which has typically been applied for all colour elements.
Step3: Implement negative-positive change for each of the blocks by \(\:{K}_{3}\). However, \(\:{K}_{3}\) is usually used for all colour components. The converted value of a pixel from the \(\:{i}^{th}\) block \(\:{B}_{i},{p}^{{\prime\:}}\), is measured as provided under
Now, \(\:r\left(i\right)\) suggests a random binary integer generated by \(\:{K}_{3}\), and \(\:p\in\:{B}_{i}\) indicates the pixel value of the new image using \(\:L\) bit per pixel. The occurrence probability value \(\:P\left(r\left(i\right)\right)=0.5\) is applied to invert the bits randomly
Step4: Rearrange the three colour components from each block using a number randomly selected between 6 integers by key \(\:{K}_{4}.\)
The sample of the image encryption is \(\:({B}_{x}={B}_{y}=16)\). So, it is connected to the BSBE image for the following purposes.
-
(i)
The encrypted images are suitable for JPEG.
-
(ii)
The compression efficiency for encrypting the images is equal to that of the novel in JPEG.
-
(iii)
Sturdiness against some assaults is determined.
Fusion-based feature extraction process
The feature extraction model employs the fusion of the MobileNetV2, GoogLeNet, and AlexNet techniques. MobileNetV2 is lightweight and effective, making it ideal for resource-constrained environments while maintaining high performance in feature extraction. GoogLeNet, with its Inception module, outperforms in capturing multiscale features, allowing it to process complex and varied image patterns effectively. AlexNet, though older, has proven to be highly efficient in extracting deep features from images, giving robust baseline performance. Integrating these models ensures robustness in feature extraction, as each model compensates for the limitations of the others, resulting in more accurate and comprehensive representations of skin lesion images. This fusion not only enhances classification accuracy but also improves the capability of the model to generalize across diverse datasets, making it an ideal choice for medical image analysis.
MobileNetV2 model
The MobileNetV2 framework is applied to images given as input. This model starts with the image phase, whereas the images with dissimilar shapes and textures are gathered as input data for the method. Then, a pre-trained MobileNetV2 method is loaded to remove the main characteristics from the input images32. During this training stage, the MobileNetV2 structure incorporates some major modules. Initially, feature extraction is carried out to remove essential features from the images utilizing a primary convolution with a 3×3 filter. A main module in this phase is the inverted Residual Blocks, which are convolutional blocks that use depth-wise separable convolution to decrease the parameter counts and enhance computational complexity. These blocks utilize shortcut links to preserve feature information in the propagation method. Then, the bottleneck layers act as the basis for MobileNetV2. These layers use inverted residual links, which permit information to remain unchanged efficiently regardless of the small parameter counts. These layers further improve the feature representation ability without considerably increasing computational cost. Afterwards, the features are well‐removed; the following phase is the fully connected layers in charge of the last classification. During this layer, the ReLU is applied in the feature mapping process. Figure 3 indicates the MobileNetV2 framework.

Architecture of MobileNetV2 model.
GoogLeNet method
The GoogLeNet Architecture is applied to classify images into some types according to visual features removed by the method. This model starts with the image phase, where different images with dissimilar textures and shapes are gathered as input data. Then, a pre-trained GoogLeNet method is loaded, acting as a feature extractor in the training stage. According to CNN, GoogLeNet is a well-known DL method for its Inception structure, which aims to improve computational complexity while preserving higher image precision. During this training stage, GoogLeNet contains key layers important in feature extraction. The model begins with convolutional layers that use many receptive fields to incorporate 1×1, 3×3, and 5×5 convolutions inside inception elements. This allows the model to capture feature information at different scales without considerably increasing the parameter counts. Furthermore, the ReLU is applied to present non‐linearity in the network and enhance feature representation abilities. Then, the removed features are handled through inception Components, which create the basis of GoogLeNet. These components use parallel convolutional filters to capture textural and spatial features at various detail levels in the input image. This incorporation gives higher flexibility in processing objects with composite texture and shape variations. After that, the pooling procedure is performed, whereas numerous pooling layers with max-pooling are applied to reduce feature sizes without losing significant information. This pooling targets to enhance computational cost and decrease the probability of overfitting. Moreover, a dropout layer is added to alleviate overfitting in training, thus improving the generalization method to novel data. After passing through some feature extraction phases, the process utilizes the softmax activation function to make likelihoods for every class in the multi-classification phase. Figure 4 specifies the GoogLeNet model.

Architecture of the GoogLeNet method.
AlexNet model.
AlexNet is a deeper CNN structure that significantly improves computer vision (CV) tasks. This architecture has eight fully connected layers and five convolutional layers. To gather lower-level characteristics, the initial convolutional layer benefits from the revolutionary receptive field for CV tasks, namely, the image category33. The first convolutional layer uses a wide receptive field to collect low-level features, which is revolutionary for computer vision tasks like picture categorization. The following layers use small receptive fields to capture complex and conceptual components. In contrast, the first convolutional layer applies a larger receptive field for recording lower-level features such as textures and edges. AlexNet primarily used the ReLU. Furthermore, dropout regularization is used to stop overfitting after training. The success of AlexNet on the ImageNet dataset, consisting of more than a million images, shows the ability of deeper neural networks in image classification tasks and opens the vision field. Figure 5 portrays the flow of the AlexNet technique.

Flow of the AlexNet method.
Classification model using CVAE technique
In this section, the SLCBSBE-FTLHO model employs the CVAE method for the skin lesion classification34. This model is chosen because it can generate highly accurate, probabilistic, and interpretable outputs. Unlike conventional classifiers, this technique can model intrinsic and diverse data dispersions by learning latent variables that capture the underlying features of skin lesions. This enables the model to classify images more robustly, without noise or limited data. The conditional aspect of CVAE allows it to condition the output based on specific attributes (e.g., lesion characteristics), making it highly appropriate for medical image classification where context and condition are crucial. Furthermore, CVAE’s generative nature improves its capability to handle data variability and enhance classification performance over standard discriminative models. This flexibility and capacity to generate realistic samples make CVAE appropriate for skin lesion classification tasks. Figure 6 signifies the structure of the CVAE model.

Structure of the CVAE model.
AE is a neural network that reconstructs and compresses original data. An AE contains a decoder \(\:{p}_{\theta\:}\left(x|z\right)\:\)and an encoder \(\:q\varphi\:\left(z|x\right)\). The encoder compresses the input \(\:x\) into latent variables \(\:z\), and the decoder rebuilds the input \(\:x\) from \(\:z\). The AE aims to learn parameters \(\:\theta\:\) and \(\:\varphi\:\) to reduce the dissimilarity between the input and the recreated output. Meanwhile, \(\:z\) contains a smaller dimension than \(\:x\), so it cannot easily output the input copy. Then, the encoding is learned to function as the feature extractor and the decoder as the generator. AE’s variants consist of VAE and CVAE.
VAE also learns the dispersal of latent variables \(\:{p}_{\theta\:}\left(z\right|x)\) from the input \(\:x\); however, in VAE, this distribution is demonstrated as a Gaussian distribution. The encoding outputs the variance vector \(\:{\sigma\:}^{2},\:\)the mean vector \(\:\mu\:\), and the latent variables \(\:z\) are tested depending on these, as presented as:
The decoder then recreates the latent variables \(\:z\) to the original sizes. The VAE’s loss function is stated as:
The amount of KL divergence \(\:{D}_{KL}\left(q\left(z|x\right)p\left(z\right)\right)\) among the latent distribution \(\:p\left(zx\right)\) and the previous distribution \(\:p\left(z\right)\), and the reconstruction error. This guarantees that the latent variables follow a Gaussian distribution, permitting closer latent variables to make related outputs. CVAE extends VAE to make data according to particular conditions (for example, classes). The loss function for CVAE in training provided classes \(\:c\) is stated as:
Unlike VAE networks, CVAE inputs classes into the encoder and decoder. A model for connecting class \(\:c\) with input \(\:x\) and the latent variables \(\:z\) was presented. Including the class in the training makes producing data from the distribution according to the specified class after training promising.
HO-based parameter tuning model
For optimizing the CVAE model performance, the HO approach is utilized for hyperparameter tuning to ensure that the best hyperparameters are selected for enhanced accuracy35. This approach is chosen due to its effectiveness in exploring massive, complex search spaces and for model parameter tuning. Unlike conventional optimization algorithms, this model replicates the adaptive behaviour of hippopotamuses in nature, allowing it to balance exploration and exploitation during the search process effectively. This results in faster convergence and better optimization outcomes, specifically for complex DL models. The robustness of the HO model in avoiding local minima and its capability to fine-tune parameters with minimal computational overhead make it highly appropriate for optimizing skin lesion classification models. HO has illustrated superior accuracy and efficiency in tasks requiring fine-tuning multiple hyperparameters compared to other techniques. Its unique behaviour ensures enhanced model performance, contributing to faster and more reliable predictions. Figure 7 depicts the steps involved in the HO technique.

Steps involved in the HO methodology.
HO is stimulated by hippopotamuses’ social behaviour and defence procedures. Like other optimizer techniques, the Hippopotamus’s location is a candidate solution to an issue. The Hippopotamus’s initial location is random, as assumed below.
Here, \(\:H{O}_{ij}\) represents the location of the Hippopotamus in the \(\:{j}^{th}\) dimension. \(\:{U}_{j}\:\)and\(\:\:{L}_{j}\) represent the upper and lower limits for dimension \(\:j\), respectively. \(\:rand\) is a randomly generated number between \(\:0\) and 1. Equation (7) provides matrix for \(\:M\) hippopotamus in dimension\(\:\:N\).
The Hippopotamus’s location upgrade to discover the searching space contains three stages. Stage 1 displays the exploration utilizing the Hippopotamus’s social behaviour. The mathematical formulation is shown in Eq. (8).
Meanwhile, \(\:H{O}^{c},\:H{O}^{f},\:H{O}^{L}\), and \(\:H{O}^{m}\) correspondingly embody the calves, females, leaders, and male hippopotamuses. Every Hippopotamus is considered \(\:H{O}^{\:f}or\) \(\:H{O}^{c}\), \(\:H{O}^{m}\), or \(\:H{O}^{L}\), depending upon its fitness value. For the male Hippopotamus, the location upgrade in the water bodies is set by Eq. (9).
Here, \(\:{C}_{1}\) denotes a constant number between 1 and 2. For female hippopotamuses, the location upgrade and calves, i.e., \(\:H{O}^{fc}={H}^{f}\cup\:{H}^{c}\), are determined by Eq. (10).
While \(\:i=1,2,3,\dots\:,\:{[}^{M}{/}_{2}]\) and \(\:j=1, 2,3,\dots\:N\). \(\:{v}_{1},{v}_{2}\) are produced utilizing Eq. (11), \(\:T\) is made by employing Eq. (12). \(\:{C}_{2}\) denotes a constant number between 1 and 2. \(\:R{G}^{m}\) indicates the mean of the chosen Hippopotamus randomly from the accessible \(\:M\) hippopotamus.
\(\:Cu{r}_{itr}\) and \(\:{\text{Max}}_{itr}\) denote the present and maximum iterations, respectively. \(\:{\vartheta\:}_{1},{\vartheta\:}_{2}\) denote randomly generated numerals between \(\:0\) and 1. Equations (13) and (14) will recognize the upgraded location of the Hippopotamus.
While \(\:fit\left(\right)\) denotes a fitness function. Stage 2 shows exploration and represents the protection method against hunters. The predator location is set by Eq. (15).
Utilizing Eq. (16), the distance of a precise hippopotamus from the hunter originated.
The Hippopotamus selects its protective activity depending on the \(\:\overrightarrow{\text{Dist}}\) value. Suppose it is in the adjacent locality of predator-fit \(\:\left({P}_{j}\right)<\text{fit}\left(HO\right)\). In that case, the Hippopotamus will tackle or travel near the predator, as presented in Eq. (17).
Here \(\:i={[}^{M}{/}_{2}]+1,\:{[}^{M}{/}_{2}]+2,\dots\:,M\:\text{ and }\:j=1, 2,3,\dots\:N.\)
If the fitness value is superior to the current fitness value, then the upgraded location of the Hippopotamus is accepted as assumed by Eq. (18).
Stage 3 displays the exploitation of the predator’s escape behaviour. Hippopotamuses usually hunt for adjacent water bodies to escape from the hunter. The local lower and upper limits are obtained utilizing Eq. (19).
The upgraded location of the Hippopotamus is set by Eq. (20).
Here, the \(\:\alpha\:\) formulation is shown in Eq. (21).
Meanwhile, \(\:\overrightarrow{randn}\) provides a randomly generated number. If the fitness value is superior to the present, it will travel to a safer location as set by Eq. (22).
Algorithm 1 specifies the HO model.

HO technique.
Fitness selection is a significant influence on manipulating the HO technique performance. The hyperparameter range process comprises the solution-encoded system to evaluate the candidate solution efficiency. The HO model studies accuracy as the primary criterion for designing the fitness function as follows:
Here, \(\:TP\) and \(\:FP\) mean the optimistic value of true and false.
Experimental analysis
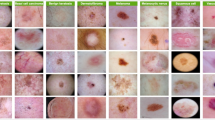
The experimental study of the SLCBSBE-FTLHO model is examined under the skin cancer ISIC dataset36. The technique is simulated using the Python 3.6.5 tool on a PC with an i5-8600k, 250GB SSD, GeForce 1050Ti 4GB, 16GB RAM, and 1 TB HDD. The parameter settings are provided: learning rate: 0.01, activation: ReLU, epoch count: 50, dropout: 0.5, and batch size: 5. This dataset holds 2239 no. of images under nine classes. The complete details of this dataset are depicted in Table 1. Figure 8 signifies the sample images. The encryption and decryption images are shown in Fig. 9.
The model’s performance is assessed using the metrics derived from the confusion matrix37. This matrix reveals the values for true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN), which are crucial for computing key evaluation metrics such as accuracy, recall, precision, and F-measure. These metrics play a significant role in thoroughly evaluating the model. These metrics’ success rates are computed using the mathematical expressions provided in Eqs. 25–2838.

Sample images.

(a) Original images, (b) Encrypted images.
Figure 10 illustrates the classification performance of the SLCBSBE-FTLHO model under 70%TRAPHA and 30%TESPHA on a multi-class dataset comprising nine classes labelled C1 to C9. In TRAPHA, the figure illustrates robust diagonal dominance, showing accurate predictions for most classes with minimal misclassifications. Likewise, the TESPHA reflects consistent performance, with high true positive values for major classes and limited off-diagonal entries, highlighting the superior generalizability of the model. Classes C4 and C5 also exhibit excellent precision and recall, with minimal confusion with other classes. Misclassifications are sparse and mostly occur between neighbouring classes with similar features. The model depicts high classification accuracy and robust generalization across all class categories.

80%TRAPHA and 20%TESPHA of (a, b) confusion matrices, (c) curve of PR, and (d) curve of ROC.
Table 2; Fig. 11 represent the detection of skin cancer by the SLCBSBE-FTLHO method under 80% TRAPHA and 20% TESPHA. The result implies that the SLCBSBE-FTLHO procedure appropriately recognized the instances. By 80%TRAPHA, the SLCBSBE-FTLHO method provides an average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F}_{Measure}\), and \(\:MCC\) of 99.48%, 97.40%, 95.86%, 96.59%, and 96.32%, correspondingly. Additionally, with 20%TESPHA, the SLCBSBE-FTLHO approach offers average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F}_{Measure}\), and \(\:MCC\) of 99.16%, 94.45%, 94.66%, 94.44%, and 94.02%, respectively.

Average of SLCBSBE-FTLHO model under (a, b) 80%TRAPHA and 20%TESPHA.
Figure 12 demonstrates the training (TRAN) \(\:acc{u}_{y}\) and validation (VALN) \(\:acc{u}_{y}\) findings of the SLCBSBE-FTLHO method under 80:20. The \(\:acc{u}_{y}\:\)values are intended through the 0–25 epochs interval. The figure highlighted that both the \(\:acc{u}_{y}\) values exhibit an increasing propensity that informed the capability of the SLCBSBE-FTLHO method with enhanced performance through numerous iterations. Additionally, both \(\:acc{u}_{y}\) remain near over the epochs, which suggests marginal overfitting and demonstrates improved performance of the SLCBSBE-FTLHO method, ensuring reliable estimation on invisible samples.

\(\:Acc{u}_{y}\) curve of SLCBSBE-FTLHO method under 80:20
In Fig. 13, the TRAN loss (TRANLOS) and VAL loss (VALNLOS) graph of the SLCBSBE-FTLHO design under 80:20 is exhibited. The loss values are figured for 0–25 epochs. Both values exemplify a reducing propensity, notifying the ability of the SLCBSBE-FTLHO method to balance a trade-off. The constant reduction in loss values assures the enhanced performance of the SLCBSBE-FTLHO method.

Loss curve of SLCBSBE-FTLHO method under 80:20.
Figure 14 illustrates the classification performance of the SLCBSBE-FTLHO model under 70%TRAPHA and 30%TESPHA on a multi-class dataset comprising nine classes labelled C1 to C9. In TRAPHA, most classes show high true positive counts, particularly C4, C5, and C6, indicating effective learning and minimal misclassifications. The TESPHA maintains this trend with notable accuracy for classes C2, C4, C5, C6, and C9, highlighting robust diagonal dominance. Although minor misclassifications are present in classes such as C3 and C7, they are relatively limited and do not significantly affect the overall performance. The model depicts consistent generalization capability, a good balance between precision and recall, and promising classification stability across the dataset.

70%TRAPHA and 30%TESPHA of (a, b) confusion matrices, (c) curve of PR, and (d) curve of ROC.
Table 3; Fig. 15 represent the skin cancer detection by the SLCBSBE-FTLHO method under 70%TRAPHA and 30%TESPHA. The table values indicate that the SLCBSBE-FTLHO model correctly recognized the samples. By 70%TRAPHA, the SLCBSBE-FTLHO model bids average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F}_{Measure}\), and \(\:MCC\) of 99.15%, 95.78%, 92.78%, 94.13%, and 93.73%, correspondingly. Likewise, with 30%TESPHA, the SLCBSBE-FTLHO method offers average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F}_{Measure}\), and \(\:MCC\) of 99.17%, 96.60%, 93.22%, 94.70%, and 94.34%, respectively.

Average of SLCBSBE-FTLHO model under 70%TRAPHA and 30%TESPHA.
Figure 16 shows the TRAN \(\:acc{u}_{y}\) and VALN \(\:acc{u}_{y}\) results of the SLCBSBE-FTLHO technique under 70:30. The \(\:acc{u}_{y}\:\)values are estimated through an interval of 0–25 epochs. The figure emphasized that both \(\:acc{u}_{y}\) Values exhibit a growing tendency, which indicates the capacity of the SLCBSBE-FTLHO technique with improved outcomes over some iterations. Additionally, both \(\:acc{u}_{y}\) stays closer on the epochs, which states the least overfitting and reveals boosted performance of the SLCBSBE-FTLHO model, ensuring consistent prediction on unseen samples.

\(\:Acc{u}_{y}\) curve of SLCBSBE-FTLHO model under 70:30
Figure 17 portrays the TRANLOS and VALNLOS chart of the SLCBSBE-FTLHO method under 70:30. The loss values are computed over 0–25 epochs. Both values exemplify a declining leaning that indicates the competence of the SLCBSBE-FTLHO technique in equalizing a trade-off. The continuous decrease in loss values guarantees the enhanced performance of the SLCBSBE-FTLHO technique.

Loss curve of SLCBSBE-FTLHO method under 70:30.
Table 4; Fig. 18 compare the SLCBSBE-FTLHO structure with recent techniques proven20,21,22,23,39,40,41. The findings underlined that the current methods like Deep CNN, AlexNet CNN, DenseNet77-UNET, FCNs, LinkNet-B7, ResNet152, InceptionV3, FedViTBloc, FRT, MLP-NN, FedShufde, and PRoT-FL exhibited worst performance. But, the presented SLCBSBE-FTLHO technique stated upgraded performance by maximum \(\:acc{u}_{y}\) of 99.48%, \(\:pre{c}_{n}\) of 97.40%, \(\:rec{a}_{l}\) of 95.86%, and \(\:{F}_{Measure}\) of 96.59%.

Comparison study of the SLCBSBE-FTLHO approach with existing models.
In Table 5; Fig. 19, the execution time (ET) result of the SLCBSBE-FTLHO method with recent models is presented. The introduced SLCBSBE-FTLHO technique presents less ET of 8.85 s, while the Deep CNN, AlexNet CNN, DenseNet77-UNET, FCNs, LinkNet-B7, ResNet152, InceptionV3, FedViTBloc, FRT, MLP-NN, FedShufde, and PRoT-FL procedures accomplish larger ET of 17.75 s, 11.02 s, 13.95 s, 15.10 s, 20.61 s, 23.52 s, 17.92 s, 12.78 s, 15.00 s, 13.91 s, 15.00 s, and 12.90 s, correspondingly.

ET outcome of SLCBSBE-FTLHO methodology with existing methods.
Table 6; Fig. 20 demonstrate the ablation study of the SLCBSBE-FTLHO approach. The BSBE encryption and decryption stages achieved \(\:acc{u}_{y}\) of 95.09% and 95.66% with \(\:{F}_{Measure}\) of 91.55% and 92.35%, respectively. Furthermore, MobileNetV2 reached an \(\:acc{u}_{y}\) of 96.35% and \(\:{F}_{Measure}\) of 93.11%, while AlexNet exhibited improved \(\:acc{u}_{y}\) of 97.55% and 94.42% F1-score. The HO illustrated an \(\:acc{u}_{y}\) of 98.29% and \(\:{F}_{Measure}\) of 95.03%. With the addition of the CVAE, an \(\:acc{u}_{y}\) of 98.98% and \(\:{F}_{Measure}\) of 95.79% is attained. Finally, the SLCBSBE-FTLHO model achieved the highest \(\:acc{u}_{y}\) of 99.48% and \(\:{F}_{Measure}\) of 96.59%, highlighting the superiority of the integrated approach in improving classification performance. This analysis emphasizes the individual impact of each component, illustrating how their combination significantly improves overall performance.

Result analysis of the ablation study of SLCBSBE-FTLHO approach.
Conclusion
This paper presents an SLCBSBE-FTLHO model. The main goal of the SLCBSBE-FTLHO model relies on automating the diagnostic procedures of skin lesions utilizing optimal DL models. At first, the BSBE technique is used in the image encryption pre-processing stage, and then the decryption process is performed. The feature extraction process employs the fusion of MobileNetV2, GoogLeNet, and AlexNet techniques. Furthermore, the CVAE method employs the SLCBSBE-FTLHO model for the skin lesion classification. To further optimize the CVAE model performance, the HO model is utilized for hyperparameter tuning to ensure that the optimum hyperparameters are chosen for enhanced accuracy. To exhibit the improved performance of the SLCBSBE-FTLHO approach, a comprehensive experimental analysis is conducted under the skin cancer ISIC dataset. The comparative study of the SLCBSBE-FTLHO approach portrayed a superior accuracy value of 99.48% over existing models. The limitations of the SLCBSBE-FTLHO approach include reliance on a fixed dataset, which may not generalize well to various skin tones, lighting conditions, or imaging devices. Furthermore, the model may encounter difficulty in precisely classifying rare or less common skin diseases due to data imbalance. The encryption and decryption stages may present computational overhead, affecting real-time deployment in low-resource settings. The framework does not integrate patient metadata, which may improve the prediction accuracy. Also, there is limited exploration of explainability, which is significant for clinical acceptance. A research gap exists in computing the system’s robustness against adversarial attacks. Future works may explore incorporating massive and more diverse datasets, enhancing computational efficiency, and integrating explainable AI techniques for greater transparency.
Data availability
The data supporting this study’s findings are openly available in the Kaggle repository at https://www.kaggle.com/datasets/nodoubttome/skin-cancer9-classesisic, reference number36.
References
Kassem, M. A., Hosny, K. M., Damaševičius, R. & Eltoukhy, M. M. Machine learning and deep learning methods for skin lesion classification and diagnosis: a systematic review. Diagnostics. 11(8), 1390. (2021).
Barata, C., Celebi, M. E. & Marques, J. S. Explainable skin lesion diagnosis using taxonomies. Pattern Recogn. 110, 107413. (2021).
Reshma, G. et al. Deep learning-based skin lesion diagnosis model using dermoscopic images. Intell. Autom. Soft Comput. 31(1). (2022).
Wang, S., Yin, Y., Wang, D., Wang, Y. & Jin, Y. Interpretability-based multimodal convolutional neural networks for skin lesion diagnosis. IEEE Trans. Cybern.. 52 (12), 12623–12637 (2021).
Jin, Q., Cui, H., Sun, C., Meng, Z. & Su, R. Cascade knowledge diffusion network for skin lesion diagnosis and segmentation. Appl. Soft Comput. 99, 106881. (2021).
Gessert, N. et al. Skin lesion classification using CNNs with patch-based attention and diagnosis-guided loss weighting. IEEE Trans. Biomed. Eng. 67 (2), 495–503 (2019).
Mirikharaji, Z. et al. A survey on deep learning for skin lesion segmentation. Med. Image Anal. 88, 102863. (2023).
Goyal, M., Knackstedt, T., Yan, S. & Hassanpour, S. Artificial intelligence-based image classification methods for diagnosis of skin cancer: Challenges and opportunities. Comput. Biol. Med. 127, 104065. (2020).
Al-Masni, M. A., Kim, D. H. & Kim, T. S. Multiple skin lesions diagnostics via integrated deep convolutional networks for segmentation and classification. Comput. Methods Programs Biomed. 190, 105351. (2020).
Al-Hatab, M. M. M., Al-Obaidi, A. S. I. & Al-Hashim, M. A. Exploring CIE lab color characteristics for skin lesion images detection: a novel image analysis methodology incorporating color-based segmentation and luminosity analysis. Fusion: Pract. Appl. 15 (1), 88–97 (2024).
Rokade, S. & Mishra, N. A blockchain-based deep learning system with optimization for skin disease classification. Biomed. Signal Process.Control. 95, 106380. (2024).
Pingulkar, S., Divekar, D. & Tiwary, A. Deep learning for skin disease diagnosis with end-to-end data security. In 2023 Second International Conference on Informatics (ICI) (pp. 1–6). IEEE. (2023).
Kolluri, R., Dargar, S. K., Kumar, S. S., Chouhan, A. S. & Gupta, A. Robust Xception-based skin disease classification system with blockchain integration. In 2024 7th International Conference on Contemporary Computing and Informatics (IC3I) (Vol. 7, pp. 292–297). IEEE. (2024).
Rajeshkumar, K., Ananth, C. & Mohananthini, N. Blockchain-assisted homomorphic encryption approach for skin lesion diagnosis using optimal deep learning model. Eng. Technol. Appl. Sci. Res. 13 (3), 10978–10983 (2023).
Thwin, S. M. & Park, H. S. Skin lesion classification using a deep ensemble model. Appl. Sci. 14(13), 5599. (2024).
Islam, K. et al. IoT and deep Learning-Based smart healthcare with an integrated security system to detect various skin lesions. In Artificial Intelligence for Disease Diagnosis and Prognosis in Smart Healthcare (219–242). CRC. (2023).
Wei, M. et al. A skin disease classification model based on densenet and convnext fusion. Electronics. 12(2), 438. (2023).
Khan, A., Sajid, M. Z., Khan, N. A., Mahgoub, A. Y. & Abbas, Q. CAD-Skin: a hybrid convolutional Neural Network–autoencoder framework for precise detection and classification of skin lesions and cancer. Bioengineering. 12(4), 326. (2025).
Dharani Devi, G. & Jeyalakshmi, J. Privacy-Preserving breast cancer classification: a federated transfer learning approach. J. Imaging Inf. Med. 37 (4), 1488–1504 (2024).
Amaizu, G. C. et al. FedViTBloc: secure and privacy-enhanced medical image analysis with federated vision transformer and blockchain. High-Confidence Comput., 100302. (2025).
Bárcena, J. L. C., Ducange, P., Marcelloni, F. & Renda, A. Increasing trust in AI through privacy preservation and model explainability: federated learning of fuzzy regression trees. Inf. Fusion. 113, 102598. (2025).
Yao, A. et al. FedShufde: a privacy preserving framework of federated learning for edge-based smart UAV delivery system. Future Gener. Comput. Syst. 166, 107706. (2025).
Gamiz, I., Regueiro, C., Jacob, E., Lage, O. & Higuero, M. PRoT-FL: a privacy-preserving and robust training manager for federated learning. Inf. Process. Manage. 62(1), 103929. (2025).
Bezanjani, B. R., Ghafouri, S. H. & Gholamrezaei, R. Fusion of machine learning and blockchain-based privacy-preserving approach for healthcare data in the internet of things. J. Supercomput. 80 (17), 24975–25003 (2024).
Xu, G. et al. AAQ-PEKS: an Attribute-based anti-Quantum public key encryption scheme with keyword search for E-healthcare scenarios. Peer-to-Peer Netw. Appl. 18 (2), 1–21 (2025).
Khan, I. A. et al. Fed-inforce-fusion: a federated reinforcement-based fusion model for security and privacy protection of IoMT networks against cyber-attacks. Inf. Fusion. 101, 102002. (2024).
Shukla, S. et al. Federated learning with differential privacy for breast cancer diagnosis, enabling secure data sharing and model integrity. Scientific Reports, 15(1), 13061. (2025).
Abidi, M. H., Alkhalefah, H. & Aboudaif, M. K. Enhancing healthcare data security and disease detection using Crossover-Based multilayer perceptron in smart healthcare systems. CMES-Comput. Model. Eng. Sci. 139(1). (2024).
Haripriya, R., Khare, N. & Pandey, M. Privacy-preserving federated learning for collaborative medical data mining in multi-institutional settings. Scientific Reports, 15(1), 12482. (2025).
Huang, C. G., Li, H., Peng, W., Tang, L. C. & Ye, Z. S. Personalized federated transfer learning for Cycle-Life prediction of Lithium-Ion batteries in heterogeneous clients with data privacy protection. IEEE Internet Things J. (2024).
Alsubaei, F. S., Alneil, A. A., Mohamed, A. & Mustafa Hilal, A. Block-scrambling-based encryption with DL-driven remote sensing image classification. Remote Sens. 15(4), 1022. (2023).
Pratomo, Y., Roseno, M. T., Syaputra, H. & Antoni, D. Performance analysis of convolutional neural network in Pempek food image classification with MobileNetV2 and GoogLeNet architecture. J. Inform. Syst. Inf. 7 (1), 556–571 (2025).
Sanjaya, C. B., Rosadi, M. I., Lutfi, M. & Hakim, L. Comparison of transfer learning model performance for breast Cancer type classification in mammogram images. Jurnal RESTI (Rekayasa Sistem Dan. Teknologi Informasi). 9 (1), 130–136 (2025).
Yasui, D. & Sato, H. Improving local fidelity and interpretability of LIME by replacing only the sampling process with CVAE. IEEE Access (2025).
Minocha, S., Sharma, S. R., Singh, B. & Gandomi, A. H. Adaptive image encryption approach using an enhanced swarm intelligence algorithm. Scientific Reports. 15(1), 9476. (2025).
https://www.kaggle.com/datasets/nodoubttome/skin-cancer9-classesisic
Sertkaya, M. E., Ergen, B. & Togacar, M. June. Diagnosis of eye retinal diseases based on convolutional neural networks using optical coherence images. In 2019 23rd International Conference Electronics (pp. 1–5). IEEE. (2019).
Başaran, E. et al. September. Chronic tympanic membrane diagnosis based on deep convolutional neural network. In 2019 4th International Conference on Computer Science and Engineering (UBMK) (pp. 1–4). IEEE. (2019).
Mridha, K., Uddin, M. M., Shin, J., Khadka, S. & Mridha, M. F. An interpretable skin cancer classification using optimized convolutional neural network for a smart healthcare system. IEEE Access. 11, 41003–41018 (2023).
Sara, U., Das, U. K., Sikder, J. & Chowdhury, S. R. Automated skin Cancer classification and detection using convolutional neural networks and dermoscopy images. Procedia Comput. Sci. 252, 108–117 (2025).
Adamu, S. et al. Unleashing the power of Manta Rays Foraging Optimizer: A novel approach for hyper-parameter optimization in skin cancer classification. Biomed. Signal Process. Control. 99, 106855. (2025).
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/344/46. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R809), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors extend their appreciation to Northern Border University, Saudi Arabia, for supporting this work through project number (NBU-CRP-2025-2903). The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program. The Authors would like to thank the Deanship of Scientific Research at Majmaah University for supporting this work under Project No. R-2025-1832.
Author information
Authors and Affiliations
Contributions
Ghada Moh. Samir Elhessewi: Conceptualization, methodology development, experiment, formal analysis, investigation, writing. Mohammed Yahya Alzahrani: Formal analysis, investigation, validation, visualization, writing. Mohammad Alamgeer: Formal analysis, review and editing. Da’ad Albalawneh: Methodology, investigation. Mohammed Alqahtani: Review and editing.Mutasim Al Sadig: Discussion, review and editing. Sultan Alanazi: Discussion, review and editing. Abdulbasit A. Darem: Conceptualization, methodology development, investigation, supervision, review and editing.All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
This article contains no studies with human participants performed by any authors.
Consent to participate
Not applicable.
Informed consent
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elhessewi, G.M.S., Alzahrani, M.Y., Alamgeer, M. et al. Design of Block-Scrambling-Based privacy protection mechanism in healthcare using fusion of transfer learning models with Hippopotamus optimization algorithm. Sci Rep 15, 20893 (2025). https://doi.org/10.1038/s41598-025-04931-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-04931-3
