
Abstract
Zeolites, known for their extensive surface area and customizable adsorption characteristics, demonstrate significant efficiency in adsorptive desulfurization. This research investigates the application of Response Surface Methodology (RSM) and Artificial Neural Networks (ANN) for modeling and optimizing the sulfur adsorption performance of modified zeolites. Key structural and operational parameters were investigated, including surface area, micropore volume, temperature, time, and sulfur compound molecular weight. Using the central composite design (CCD), RSM modeled the adsorption process by fitting experimental data through least-squares regression, providing valuable insights into parameter effects. The quadratic model achieved an adjusted correlation coefficient (R2) value of 0.9502 and a predicted R2 value of 0.9475, indicating excellent predictive accuracy. While RSM highlighted significant trends, its limitations in capturing complex nonlinear interactions led to the adoption of ANN for more accurate predictions. The Radial Basis Function (RBF) and Multilayer Perceptron (MLP) models were developed among various ANN architectures. The RBF network achieved superior precision with an R2 of 0.9951 and a mean square error (MSE) of 0.0015, outperforming the MLP. Furthermore, a global sensitivity analysis (GSA) was performed to identify the most influential input parameters, highlighting micropore volume as the dominant factor. An uncertainty analysis based on Monte Carlo simulations also confirmed the robustness and predictive stability of the optimized MLP model. Validation with new datasets confirmed ANN’s reliability, making it a robust alternative to traditional modeling techniques. This study demonstrates ANN’s potential as a powerful tool for optimizing adsorptive desulfurization processes. The findings pave the way for achieving ultra-low sulfur fuels through efficient and scalable approaches, reducing experimental efforts while enhancing process insights.
Similar content being viewed by others

Introduction
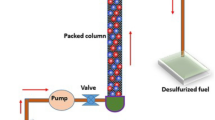
In recent years, the rapid growth of the global economy has resulted in increased emissions of sulfur oxides (SOx) from the combustion of sulfur-containing compounds in fuel oil. These emissions contribute significantly to air pollution, causing environmental issues such as acid rain and forest damage. Additionally, sulfur can cause corrosion in process equipment, such as pumps, pipelines, and refinery units, posing significant challenges for fuel processing and reforming systems1,2. Current regulations limit sulfur content to 10 ppmw in gasoline and 15 ppmw in diesel3. Consequently, achieving ultra-deep desulfurization of liquid fuels has become a global research priority, with numerous studies dedicated to developing methods for reducing fuel sulfur levels4. Various forms of Sulfur Compounds, such as sulfides and disulfides, also organosulfur compounds, including mercaptans, thiophene (Th), benzothiophene (BT), benzonaphthothiophene (BNT), dibenzothiophene (DBT), and 4,6-dimethyl dibenzothiophene (4,6-DMDBT)5. Several desulfurization techniques are proposed, such as hydrodesulfurization (HDS)6, extractive desulfurization (EDS)7, biodesulfurization (BDS)8, oxidative desulfurization (ODS)9, and adsorptive desulfurization (ADS)10. Because of its effective effect on removing mercaptans and sulfides, HDS is currently the most popular technology and a widely adopted approach for lowering sulfur levels in fuels at refineries globally11. However, despite the high consumption of hydrogen and performance in high temperature and pressure conditions, HDS has a limited effect on the elimination of refractory sulfur compounds, including benzothiophene, thiophene, and their derivatives, which include most of the sulfur compounds in the fuel12,13. Moreover, HDS produces hydrogen sulfide, another sulfur-containing compound that must be separated14. Among these methods, ADS is considered a well-known technique10. Particularly for ultralow sulfur levels because of its mild process conditions, low operating costs, economical and environmentally friendly, and excellent preservation of fuel quality15. Figure 1 is a simplified illustration of the ADS process. The system includes a feed tank, air compressor, ADS reactor, and condenser. Sulfur-containing fuel flows through the packed-bed reactor packed with a porous zeolite adsorbent, where sulfur impurities are removed. The magnified section indicates the internal structure of the zeolite, with particular focus on its porosity and surface activity, both of which are critical for the efficiency of adsorption. The effectiveness and cost-efficiency of ADS in removing sulfur from oil largely depend on choosing the right adsorbent, as it determines the process’s overall efficiency and flexibility16. Porous materials, including zeolite-based materials17, activated carbons (AC)18, aluminas19, Mesoporous silicates20, metal–organic frameworks (MOFs)21, and metal oxides22, are used for adsorption desulfurization. Zeolites are particularly suitable adsorbents due to their unique physical and chemical properties, such as high adsorption capacity, selectivity, specific surface area, and regenerability22,23. Faujasite (FAU) zeolites with different Si ratios, such as NaX and NaY, are widely studied for their effectiveness in adsorptive desulfurization due to their high porosity and surface area. Their ion-exchange capability and tunable structures lead to the high flexibility of zeolites in adsorption capacity and selectivity24. The schematic structure of the FAU zeolite with metal ion exchange is shown in Fig. 2.

Schematic of ADS process25.

Metal-containing FAU-type zeolite.
Numerous investigations have explored using zeolites for desulfurizing liquid hydrocarbon fuels13,14,15. The zeolite’s porous structure, characterized by microcavities, constrains the adsorption of sulfur compounds26. Creating mesoporous zeolites through various structural modification processes, including desilication and dealumination, mitigates diffusion limitations, allowing refractory sulfur compounds to access internal adsorption sites without compromising the zeolite’s structure27. Dealumination refers to removing aluminum species from the framework, typically carried out through steaming, acid treatment, and chemical treatment.28. Numerous attributes have been cited as crucial for determining the adsorption efficiency of zeolites, but there is no clear consensus on which factors are most impactful. This disparity likely arises due to the differing operating conditions and zeolite properties, resulting in the predominant factor or condition influencing the adsorption rate to vary accordingly29. The Si/Al ratio impacts the catalytic performance of Fe-ZSM-12, according to Akopyan et al. The activity was increased by raising the Si/Al ratio, which they linked to a decrease in weak acid sites and a minor increase in strong acid sites following iron deposition30.
On the other hand, Mahmoudi and Falamaki reported an increase in activity when the Si/Al ratio was lower31. Various metal ions, such as copper, nickel, and cerium, are applied as single metals or in bimetallic combinations to modify adsorbents through ion exchange or impregnation to increase adsorption capacity.15,16,32. It has been discovered that the kind of sulfur component being removed affects how well adsorption works. According to Zhou et al., BT was the most selectively adsorbed compound, followed by TH and DBT33. According to Akopyan et al. Organosulfur compounds have different levels of activity. DBT has the most activity, followed by 4,6-DMDBT, and BT has the lowest. They concluded that steric hindrances and the electron density surrounding the sulfur atom are the main factors influencing this tendency, consistent with earlier research findings.30. The link between zeolite properties and adsorption capacity during desulfurization is well-documented. However, these properties’ relative importance and interplay in adsorption processes are poorly understood and have not been specifically studied. Identifying the key process parameters is crucial for enhancing the ADS process. Although experimental approaches can determine the effects of zeolite properties and process conditions on adsorption capacity, these experiments are often challenging due to their complexity and the substantial resources required, making them impractical for many researchers. Consequently, many unanswered questions remain about how zeolites’ properties, like their Brunauer–Emmett–Teller (BET) surface area and pore volume, impact their capacity to adsorb sulfur. Response Surface Methodology (RSM) has garnered significant interest among researchers because it effectively manages several variables with limited data. This technique excels at identifying the specific interactions between independent variables34.
Utilizing RSM as a statistical approach allows for creating effective empirical models. The choice of response surface designs varies based on the experimental aims and conditions35. Although RSM shows limitations in effectively addressing nonlinear issues in multicomponent systems, advanced techniques can tackle these challenges. Artificial Neural Networks (ANN) can model complex and nonlinear problems36. Research in this field has been limited, with few studies to date. A recent survey by Mguni et al. investigated ADS using zeolite-based adsorbents, noting challenges in screening zeolites and the lack of consensus on key parameters. They applied machine learning techniques, specifically multiple linear regression (MLR) and random forest (RF) regression, to analyze ADS processes. The RF model showed better predictive performance (R2 = 0.9300) compared to the MLR model (R2 = 0.8800)29. Despite increased research interest in employing ANN and RSM in simulating adsorption processes, relatively little effort has been made with their employment in simulating ADS using zeolites, with a focus particularly on the twin aspects of fuel properties, operational conditions, and adsorbent structure. In this paper, we set up a modeling platform that includes operational parameters (reaction time and temperature), fuel-specific descriptors (sulfur compound molecular weight), and zeolite structural parameters (micropore volume and BET surface area) to predict sulfur adsorption capacity precisely. In addition to comparing the optimized multilayer perceptron (MLP) and radial basis function (RBF) neural network performance, model interpretability was enhanced through 3D surface plots and global sensitivity analysis (GSA) to investigate variable interactions and identify important factors affecting sulfur uptake. The approach provides improved insight into the adsorption behavior and allows for more targeted experimental design. An uncertainty analysis was also performed on the optimized MLP model using a Monte Carlo-based approach, calculating mean predictions and 95% confidence intervals to validate the model’s reliability further. In this work, a neural network model for predicting sulfur adsorption capacity on modified zeolites will be developed, and its outcomes will be compared with those of the RSM model. Using statistical analysis and comparison, the study aims to provide a comprehensive investigation of the correctness of both models utilizing the mean square error (MSE) and coefficient of determination (R2). This approach can potentially reduce the need for extensive experimental screening, thereby saving time and resources while offering valuable insights into the mechanisms of adsorption desulfurization.
Materials and methods
Data collection
The dataset, which included 317 data points, was taken from earlier experimental investigations and utilized to train and test the models. To reduce data inconsistency in the results obtained, only research under batch and atmospheric pressure was utilized. Besides, data from a similar temperature range, time, and model fuel type were utilized. Physical properties of the zeolites, i.e., micropore volume and BET surface area, were also considered and utilized as model input parameters so that comparison could be performed consistently for various zeolites. All experimental data used in this study were collected from previously published studies and are summarized in Table 1, which presents the types of zeolites used, their structural characteristics, pore properties, operating conditions (e.g., temperature and time), and the specific sulfur compounds used in the model fuels.
Statistical properties of data
Data normalization was performed to ensure precise neural network outcomes. All data were scaled to a range of -1 to + 1 using Eq. (1).
Xnorm represents the normalized data in this context. At the same time, the input variable is indicated by X. The maximum and minimum values of the data are represented by Xmax and Xmin, respectively. Minimizing the predicted network error at each iteration is essential to get ideal network parameter values during training. The criteria employed for this purpose include the MSE, R2, and the total absolute average relative deviation (AARD%). The mathematical expressions for MSE, R2, and AARD are given in the following equations45,46:
Yactual stands for the experimental value, and Ypredicted for the value the artificial neural network anticipated.
Response surface methodology (RSM)
RSM is a widely used statistical method and the key to identifying the interrelationships between process variables and the desired outcomes in cases of, for example, sulfur removal efficiency. RSM models the complex system with the minimum number of operations and applies regression modeling and nonlinear analysis. Therefore, it is also the experimental design47. This was mainly due to the research of Box and Behnken, which is known for its effectiveness and frugality, as well as its capability to test out the effect of separate and together elements47. The RSM process has three main stages: developing foolproof tests, building exact mathematical models, and finding the best conditions to reach the highest or lowest problems. RSM plays a crucial role in process improvement, reiterating excellent product quality, reducing costs, and facilitating extensive and skilled teaching of process interactions to the students through its visual and multivariable analysis capabilities.34,48. The quadratic polynomial equation is the most frequently utilized model for fitting experimental data34. This study examined and used a quadratic polynomial model by reviewing existing models, shown in Eq. (5)49.
where \({\beta }_{0}\) indicates the intercept or constant term, \({\beta }_{i}\) Is the coefficient for the linear terms and \({\beta }_{ij}\) represents the interaction coefficients between the variables, \(Y\) represents the expected response (Adsorption Capacity) in this equation. Epsilon represents the residual error, while \({X}_{i}\) and \({X}_{j}\) stand for the input parameters. Table 2 compiles the independent variables’ lowest, maximum, and average values.
The curvature of the response surface can be identified in RSM modeling when the coefficients for quadratic components are computed using the experimental design’s central points. On the other hand, factorial points, which show the direct linear correlations between input variables and the answer, are used to derive the coefficients of linear terms. Building a trustworthy forecasting model requires accurate calculation of these coefficients50. Table 2 highlights the process factors examined in the RSM framework. These factors were analyzed to determine how they affected adsorption capacity and maximize efficiency (see Table 3). While the predicted optimum lies within the boundaries of the input variable limits, it slightly exceeds the maximum value observed in the experimental data. This common trend in RSM-based models reflects a potentially improved combination of parameters. These predictions are mathematically derived from the quadratic regression surface, which can identify optimum regions not directly represented by the experimental points. Nonetheless, further experimental testing may be considered in future research to confirm the empirical validity of this prediction.
Artificial neural network (ANN) theory
ANNs, which are powerful computations emulating human brain operations, are thus called. These networks impersonate the brain network architecture of biological systems by embracing layers of connected nodes, namely an input layer, one or more hidden layers, and an output layer. Such models are chiefly applied to difficult, nonlinear systems, where they are excellent at extracting information and analyzing the data to reveal patterns and relationships. ANNs may accomplish complicated tasks like language translation and image processing by joining these layers to mimic the activity of organic neurons. The ability of ANNs to model complex systems and forecast outcomes in various industries, such as technology, healthcare, and finance, makes them essential in artificial intelligence and machine learning. In particular, feed-forward ANNs perform exceptionally well at approximating smooth functions when given enough neurons and training conditions. These networks are frequently used in chemical engineering to improve the accuracy of regression and classification issues, supporting tasks like system optimization, process modeling, and surrogate model creation.34,51,52.
To save time and money on computation, neural networks concentrate on determining the optimal weights (w) for their functions (f). They accomplish this by applying the associated weights (w) to each input (xi), adding a bias factor (b), and then summing these products, as shown in Eq. (6).53.
The outcomes are derived using the transfer function (f), as shown in Eq. (7), which varies in form. The data is divided randomly, with 70% used for training, 15% for validating, and 15% for testing. This process is illustrated in the schematic view of the work cycle of an ANN, as shown in Fig. 3.

Schematic representation of the work cycle of an ANN.
Multilayer perceptron (MLP)
Supervised learning will be performed based on the feed-forward architecture of the MLP networks. Generally, ANNs have one input layer to accept data and an output layer to provide the final ranked outputs, and there might be one or more hidden layers to process the data in various ways. While fully modeling the relationships in data, the hidden neurons use various nonlinear activation functions, including the hyperbolic tangent and sigmoid. The MLP uses a back-propagation technique on weights during training to fine-tune these and reduce error functions and values. The output generation step is non-linear because of an activation function, the addition of bias terms, the weighing of inputs, and the sum of contributions from all hidden neurons. This systematic procedure allows MLP networks to perform consistently on various tasks, from different predictions to classification tasks54,55. The MLP network structure is shown in Fig. 4.

MLP network structure.
In Eq. (8), the output vector \(g\) of the MLP neural network is defined with \({x}_{i}\) representing the reference vector, \(w\) denoting the coefficient weighting vector and \(\theta\) Symbolizing the threshold limit. These variables are fundamental in describing the MLP neural network’s output.
In Eq. (9), \({\gamma }_{jk}\) and \({\beta }_{jk}\) represent the contribution of neuron \(j\) from layer \(k\) and its corresponding bias weight, respectively. The weights of the connections are denoted by \({w}_{ij}\), \({F}_{k}\) while signifies the nonlinear activation transfer function.
Radial basis function (RBF)
The RBF network uses radial basis functions, which are one of the feed-forward networks with a single hidden layer. The radial basis function is used as the activation function in the RBF network’s single hidden layer structure, which is an advantage. An input layer, a hidden layer with a non-linear RBF activation function, typically a Gaussian function, and an output layer made up of linear combinations make up the standard configuration of RBF networks, as seen in Fig. 5. An RBF unit is a fixed point or reference point for the distance between the input data and the center point; Euclidean distances can be used to calculate the amount of this distance. The ultimate response is obtained by a linear combination of the radial basis functions obtained as the output of each RBF unit56,57.

RBF network structure.
In Eq. (10), the RBF network’s output layer functions through a linear combination. Here, \(N\) refers to the total number of training samples, \({w}_{ij}\) represents the weight applied to each hidden layer neuron, \(x\) stands for the input variable, \({c}_{i}\) indicates the center points, and \(b\) is the bias term. The Gaussian function is then applied to derive the centralized response from the hidden neurons, as shown in Eq. (11).
The parameter \({\sigma }_{i}\) determines the width of the Gaussian function, while \(t\) describes the extent of \(\left\| {x - c_{i} } \right\|\) in the input space that triggers the RBF neuron’s response. This setup ensures that the network’s neurons are finely tuned to react within specific regions of the input space.
ANN model design
Figure 3 gives a suggested algorithm where the first step is to compile all the experimental data, which includes variables such as a, Vp, T, t, and MW as inputs and qe as output. The second step uses normalized data for inputs and outputs; then, the learning algorithm is properly chosen to build the network structure. For the ANN model, 70% of the dataset is used for training to optimize network parameters such as weights, biases, and thresholds to improve the model’s performance. Besides, 15% of the dataset is used in validation, and the remaining 15% is used for testing. When evaluating the model’s accuracy, comparisons between expected and actual data are used to calculate statistical measures such as the R2 value and MSE. By experimenting with different numbers of hidden layers and neurons in each layer, as well as other training procedures, the optimal MLP configuration is achieved. Trial and error is typically used to determine the number of neurons in the RBF network, starting with a large number and reducing it to a level that yields the lowest MSE. The training is terminated when the optimal error is reached.
Results and discussion
RSM results
Variance analysis (ANOVA)
Table 5 shows the ANOVA results from evaluating the experimental data. The F-value indicates the overall significance of the model, and the P-value indicates the probability associated with the ANOVA analysis. P-values of less than 0.05 indicate that a term is statistically significant within the model. P-values above 0.1, however, suggest that the terms are not statistically significant.46,58. The model’s F-value was determined to be 404.99, suggesting a high degree of significance. This suggests there is only a 0.01% chance that such a large F-value could occur due to random noise. P-values for variables A, B, C, D, and E are less than 0.05, indicating they are significant and influential on the dependent variable. Variables A and E have the lowest P-values and the highest F-values among individual parameters, suggesting they have the most important effect on q. The Adjusted R2 is 0.9502, and the Predicted R2 is 0.9475, showing a close agreement with a difference of less than 0.2, indicating that the model effectively predicts new data while fitting the existing data well. Adeq. Precision measuring the signal-to-noise rate is 90.5336, significantly above the desirable threshold of 4, demonstrating a strong signal. The parameters for the response’s fit statistics are shown in Table 4, which was obtained from analyzing 317 observations (Table 5).
Perturbation plots
An important tool for assessing how different process parameters affect both qe at the central point is that the perturbation plot enables each component’s impact to be observed using a single visual representation. Figure 6 demonstrates the perturbation plot for q, effectively showing how this method visualizes the influence of each parameter on the process. As illustrated in the plot, the surface area exhibits a direct and linear relationship with the adsorption capacity, showing a relatively steep slope; an increase in surface area results in higher adsorption capacity. In contrast, the micropore volume demonstrates an inverse relationship, where increased volume leads to decreased adsorption capacity. The plot for the temperature parameter presents a parabolic trend, initially showing a positive effect on adsorption with growing time but eventually leading to a decrease in capacity as time progresses. The impact of time on adsorption capacity starts as a positive relationship; initially, as time increases, so does the adsorption. But as time goes on, this impact tapers off and even slightly reverses, creating a parabolic shape. This trend likely occurs because, after a while, the adsorption sites on the surface become saturated, which naturally slows down further adsorption. At this stage, slight desorption can also happen due to repulsive interactions or shifts in surface stability. On the other hand, the molecular weight of sulfur compounds in the fuel has a direct, linear relationship with adsorption capacity. As we move from thiophene to benzothiophene, the additional benzene ring in heavier compounds encourages π-π interactions with the adsorbent, leading to improved adsorption.

Variation curves of Adsorption capacity based on a coded factor.
Pearson correlation matrix
Figure 7 shows the Heat correlation matrix, a square matrix representing correlation coefficients between feature pairs within a dataset. These coefficients, ranging from -1 to + 1, indicate the strength and direction of linear relationships: 0 indicates no correlation, -1 indicates a perfect negative correlation, and + 1 indicates a perfect positive correlation. Diagonal elements are always 1, representing a feature’s correlation with itself. This matrix provides insights into the dataset’s structure, as the sign and magnitude of coefficients reveal the nature of relationships between variables.

Heat correlation matrix between any two variables.
Interaction of factors
This study used Design-Expert software, version 13.0, to divide data and create three-dimensional (3D) response surfaces. The 3D plots assessed the sulfur compounds’ surface area, pore volume, temperature, duration, and MW to maximize their adsorption capability. These visual aids were also used to determine the ranges of parameters that would maximize the capacity of sulfur adsorption. Figure 8 illustrates sulfur adsorption capability using color codes and labeled lines.


Response surfaces plots of Sulfur adsorption capacity influence of (a) a and Vp, (b) a and T, (c) a and t, (d) a and S-compound MW, (e) S-compound MW and Vp, (f) S-compound MW and T, and (g) S-compound MW and t.
As shown in Fig. 8a–d, increasing surface area enhances adsorption capacity, benefiting sulfur removal by providing more active sites for sulfur molecules. Figure 8a indicates that reducing micropore volume can enhance adsorption, likely due to metal ions introduced into the zeolite structure. These ions occupy micropores and promote sulfur adsorption through strong interactions, including π-complexes or metal-sulfur bonds. Modifications such as dealumination or metal impregnation can reduce micropore volume while creating mesopores, thereby increasing surface area and enhancing sulfur capture, consistent with previous studies. Figure 8b shows that while an initial temperature increase boosts adsorption by enhancing molecular mobility, further increases reduce adsorption since it is an exothermic process. As seen in Fig. 8c, increasing adsorption time initially improves capacity until saturation is reached, after which further time yields diminishing returns due to potential desorption. Finally, Fig. 8d–g illustrates that the molecular weight of sulfur compounds positively affects desulfurization. Higher molecular weight, as seen with benzothiophene, enhances adsorption efficiency compared to thiophene, likely due to its additional aromatic ring facilitating stronger π-complex interactions with metal ions.
ANN results
Prediction and optimization
317 data points were used to create the neural network, 70% of which were used for training, and the final 30% were split between 15% for testing and 15% for validation. Critical elements, including the number of neurons and layers, activation functions, training epochs, and training methods, were all considered to get the best performance out of the test data’s MLP network architecture. A comprehensive evaluation was conducted to identify each model’s most effective configurations and activation functions. In this regard, twelve backpropagation algorithms were investigated, including the Bayesian Regularization (trainbr)59, Scaled Conjugate Gradient (trainscg) method60, and Levenberg–Marquardt (trainlm) algorithm61. The study looked at MLP designs with two or three hidden layers and a range of 15 to 30 neurons. It was discovered that adding more neurons or layers up to this point did not enhance performance but contributed significantly to training time and the possibility of overfitting, primarily due to the constrained dataset size. The output layer was subjected to the linear function (purelin), while the hidden layers were activated using the sigmoid function (tansig). The selection of the tansig activation function for hidden layers and the purelin function for the output layer was also motivated by relevant literature in the modeling of adsorption. For instance, Kolbadinejad et al.62 employed a two-hidden-layer MLP structure with tansig and purelin functions to predict gas adsorption on zeolites and activated carbon and achieved an R2 of 0.9998. As a result of the similarity in adsorption mechanism and use of zeolite-based adsorbents, such an ANN configuration was considered appropriate for modeling adsorptive desulfurization of model fuels in the present research. Initial weights and biases were randomly initialized using MATLAB. Each network architecture was trained at least three times to account for potential variability due to these random initializations. The most optimal results from these repetitions were selected for further analysis. This approach mitigated the influence of initial weight and bias settings on the outcomes and ensured that the resulting models exhibited superior accuracy and robustness. By thoroughly examining various configurations and training conditions, the proposed MLP architecture effectively addressed the inherent variations in the training process, thereby enhancing the reliability of the results. The results of the network evaluation are summarized in Table 6, which presents detailed performance metrics for each tested algorithm. The table includes the following parameters: the algorithm name, optimal network architecture, and performance measurements like MSE and R2 for the training, validation, test, and overall datasets. Additionally, it provides information about the training time (in seconds) and the number of epochs required for convergence.
Based on the results presented in the table, the Levenberg–Marquardt (LM) method stands out as the top performer, achieving the highest accuracy (R2 = 0.9919) and the lowest mean squared error (MSE = 0.0025) across all datasets, training, validation, and test. This impressive performance highlights LM’s effectiveness in optimizing neural networks, especially given its ability to converge within just 15 epochs. In comparison, Bayesian Regularization (BR) also performs well, reaching an overall accuracy of 0.9910 and an MSE of 0.0030. However, BR requires much larger epochs (300) and a longer runtime, indicating a heavier computational demand. Meanwhile, the Scaled Conjugate Gradient (SCG) algorithm emerges as the most time-efficient approach, delivering solid performance with an accuracy of 0.9824 and an MSE of 0.0058, all while completing training in a swift 1.5940 s and requiring only 68 epochs. This makes SCG particularly attractive for applications where time efficiency is essential. On the other hand, BFG has a notably longer runtime (2.7350 s) yet achieves high test accuracy (R2 = 0.9900), reflecting its optimization strategy’s complexity and computational intensity. Gradient Descent with Momentum and an Adaptive Learning Rate (GDX) benefits from adaptive learning and momentum, achieving a reasonable accuracy of 0.9711. However, it’s less efficient than other algorithms, taking 3.0290 s to complete. Regarding convergence, GD and GDA (Gradient Descent Adaptive) stand out for a less desirable reason: both reach the maximum allowed epochs (300) without achieving satisfactory accuracy, underlining their limitations in navigating the optimization landscape effectively. In contrast, LM’s rapid convergence within a limited number of epochs reaffirms its stability and robustness in training neural networks. LM is the preferred choice due to its high accuracy, low MSE, and rapid convergence, making it especially suitable for applications that demand precision and stable performance. Although SCG offers a faster runtime, LM’s superior accuracy and consistency in convergence make it the better option for applications focused on reliability. Figure 9(a) presents how the mean square error changes with the number of data steps, where the best MLP model reaches its best validation performance of 0.0023 at 15 epochs. Meanwhile, the regression outcomes of the best MLP network are shown in Fig. 10.

MSE as a function of epochs for adsorption capacity datasets in (a) MLP, (b) RBF.

Comparing the experimental data with the results of the MLP neural network model with the (a) training, (b) validation, (c) test, and (d) total data.
The optimization of the RBF neural network is critical for accurate predictions, requiring adjustments to parameters such as the spread value, training functions, and number of neurons. The optimal RBF model, with 228 neurons in its hidden layer, achieved a mean square error of 0.0015 (Fig. 9b) and a strong correlation with experimental data (R2 = 0.9951, Fig. 11). As shown in Fig. 12, the MSE varies with different values of spread and neuron counts. The MSE generally decreases as the number of neurons increases up to around 50, and the best performance is observed with a lower spread value (e.g., 0.1) and 228 neurons. Beyond this point, the MSE tends to stabilize and sometimes slightly increase, likely due to overfitting. To prevent overtraining and improve generalizability, the network’s runtime was reduced, and its accuracy was validated using data not included in the training.

Comparing the experimental data with the results of the RBF neural network model.

MSE variation across different neuron counts and spread values in the RBF neural network.
Global sensitivity analysis
To investigate the influence of the individual input parameters on the predicted sulfur adsorption capacity, global sensitivity analysis (GSA) was performed for the optimized MLP neural network model trained with the trainlm algorithm63,64. The GSA was done through a variance-based method with Monte Carlo sampling over normalized ranges of inputs. The results showed that the micropore volume made the largest output variation (sensitivity index = 0.5918), demonstrating its predominant role in adsorption. The other parameters, including BET surface area, reaction time, temperature, and molecular weight of sulfur compounds, were much smaller in sensitivity indices, which determined the structural characteristics of the zeolite as the most predominant factor in the process of adsorption-based desulfurization. The detailed results of this analysis are illustrated in Fig. 13.

Variance-based global sensitivity analysis showing the influence of input variables on sulfur adsorption capacity.
Uncertainty analysis
An uncertainty analysis was performed on the optimized MLP model to determine the robustness and predictive stability of the trained neural network. The analysis computes the sensitivity of the model predictions to random variability in initial weight settings and plots a statistical confidence interval around predicted values65. From the comparison of training algorithms (refer to Section “ANN results”), the LM method was selected as the best training method because it performed better. Therefore, the uncertainty analysis was performed for the MLP model trained using LM. The model was trained 20 times with different random initializations, and the mean predicted adsorption capacity and 95% confidence interval were computed. This was done using a Monte Carlo-based method to achieve the statistical variability of the model. The findings on the whole dataset are presented in Fig. 14, showing that the model has stable predictions with small uncertainty bounds for most of the data points.

Uncertainty analysis of optimized MLP model.
3D response surfaces
The response surfaces of an ANN model using an MLP technique to predict adsorption capacity are depicted in three-dimensional plots in Fig. 15. These plots highlight the impact of changes in five factors while keeping the other two factors fixed to evaluate their combined influence on the output. A comparison between RSM and ANN results reveals that, while both exhibit similar trends, the ANN model is more effective in predicting the interactions among the parameters, providing more accurate insights. In Fig. 15a, it can be observed that an increase in surface area enhances adsorption due to the presence of more active sites for sulfur compounds. However, reducing the micropore volume can also improve adsorption efficiency, likely due to the incorporation of metal ions within the zeolite structure. These ions occupy micropores and facilitate sulfur uptake through mechanisms such as π-complex interactions and metal-sulfur bonding. Introducing mesopores, often achieved through dealumination or metal impregnation, further improves adsorption by increasing surface area. As shown in Fig. 15b and f, an initial increase in temperature promotes adsorption by enhancing molecular mobility; however, since the adsorption process is typically exothermic, a further temperature increase leads to decreased adsorption due to desorption effects. Figure 15c reveals that while extending adsorption time initially increases Adsorption capacity, this effect plateaus once saturation is reached, as prolonged exposure may result in desorption. Figure 15d–g also highlights that sulfur compounds with higher molecular weights exhibit better adsorption performance. Compounds like benzothiophene, with an additional aromatic ring, demonstrate stronger interactions with metal sites than lighter compounds like thiophene, thus enhancing adsorption through more robust π-complexation.

3D response surface plots generated by the MLP model to provide adsorption capacity for analyzing the influence of (a) a and Vp, (b) a and T, (c) a and t, (d) a and S-compound MW, (e) S-compound MW and Vp, (f) S-compound MW and T, and (g) S-compound MW and t.
Prediction of Adsorption capacity with new data
The MLP and RBF networks were examined using a different set of 17 experimental data points that had been removed from the original dataset to evaluate the performance of the created neural network models. The adsorption capacities predicted by these models were then compared with the actual experimental measurements. For further evaluation, an additional random subset of experimental data was used to compare the accuracy of the MLP and RBF networks. This accuracy was quantified by comparing the predicted outputs with the experimental values and calculating the %AARD. As highlighted in Table 7 and Fig. 16, the RBF model achieved a higher R2 value of 0.9803, outperforming the MLP network, which had an R2 value of 0.9775. This indicates that the RBF network demonstrated superior accuracy in predicting adsorption capacities, showcasing its better ability to capture underlying patterns within the dataset. These 17 data points were selected at approximately equal intervals across the entire dataset and were excluded from all training, validation, and internal testing phases. This sampling strategy ensured that the final evaluation was based on unseen and independently distributed data, offering a reliable assessment of the models’ generalization performance.

Linear regression between new experimental data and (a) RBF and (b) MLP outputs.
Conclusion
Sulfur removal from fuels remains a critical challenge to mitigate environmental damage, and zeolites, with their tailored adsorption properties and high surface area, play a vital role in achieving effective desulfurization. This study employed RSM to examine the impact of surface area, micropore volume, temperature, time, and sulfur compound molecular weight on adsorption capacity. The quadratic model achieved high predictive accuracy, with an adjusted R2 of 0.9502 and a predicted R2 of 0.9475, indicating excellent alignment with experimental data. Perturbation plots and Pearson correlation analysis further highlighted the significant effects of individual parameters. ANN models were developed as robust predictive tools to overcome RSM’s limitations in addressing nonlinear interactions. Among twelve learning algorithms tested for the MLP network, the TrainLM algorithm emerged as the most effective, achieving an R2 value of 0.9919 and an MSE of 0.0023 after just 15 epochs. The optimal MLP model incorporated two hidden layers with 45 neurons each, utilizing purelin for the output and the Tansig activation function in hidden layers. RBF model surpassed the MLP in accuracy, delivering an R2 value of 0.9951 and an MSE of 0.0015. Validation with new datasets confirmed the reliability of both networks, with the RBF model achieving an R2 value of 0.9803 compared to the MLP’s 0.9775. These results underline the ANN’s superior capability to handle complex nonlinear relationships, making it a valuable alternative to RSM. Additionally, GSA identified micropore volume as the most influential factor governing sulfur adsorption, while uncertainty analysis confirmed the stability and robustness of the optimized MLP model through narrow confidence intervals across repeated runs. In conclusion, this study demonstrates the potential of ANN, particularly the RBF network, in optimizing adsorptive desulfurization processes. By reducing experimental requirements and enhancing predictive capabilities, these models open pathways for advancing environmental technologies and achieving ultra-low sulfur fuels with greater efficiency.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Abbreviations
- a:
-
Surface area, (m2/g)
- Vp :
-
Micro volume, (cm3/g)
- T:
-
Temperature, (°C)
- t:
-
Time, (min)
- q:
-
Adsorption capacity, (mg/g)
- i:
-
Number of neurons in the hidden layer
- N:
-
Number of neurons
- R2 :
-
Correlation coefficient
- w:
-
Weight factor (-)
- wij :
-
Weight related to each hidden neuron (-)
- wik :
-
Weight connecting the ith neuron to the kth neuron
- x:
-
Input variable (-)
- xi :
-
Input examples (attributes)
- X:
-
Independent variable of RSM method
- x(j) :
-
Input of jth layer
- xk (j) :
-
Value of the kth neuron in the jth layer
- b:
-
Bias
- bi :
-
Bias value associated with the i th neuron
- β0 :
-
Constant term of quadratic equation
- βi :
-
Linear coefficients of quadratic equation
- βii :
-
Quadratic coefficients of quadratic equation
- βij :
-
Interaction coefficients of quadratic equation
- λ:
-
Regularization parameter
- ε:
-
Error
- φ:
-
Activated function
- ANN:
-
Artificial neural networks
- BET:
-
Brunauer–Emmett–Teller
- CCD:
-
Central composite design
- MLP:
-
Multi-layer perceptron
- MSE:
-
Mean square error
- RBF:
-
Radial base function
- RSM:
-
Response surface model
- AARD%:
-
Average absolute relative deviation percentage
- BP:
-
Backpropagation
- GD:
-
Gradient descent
- GDA:
-
Gradient descent with adaptive learning rate backpropagation
- GDX:
-
Gradient descent with momentum and adaptive learning rate backpropagation
- GSA:
-
Global sensitivity analysis
- RP:
-
Resilient backpropagation
- CGF:
-
Fletcher–Powell conjugate gradient
- CGP:
-
Polak–Ribiere conjugate gradient
- CGB:
-
Conjugate gradient with Powell–Beal restarts
- SCG:
-
Scaled conjugate gradient
- OSS:
-
One step secant
- BR:
-
Bayesian regularization
- LM:
-
Levenberg–Marquardt
- BFGS:
-
Broyden–Fletcher–Goldfarb–Shanno
- Activation function:
-
The activation function is a mathematical function situated between the input received by the present neuron and the output transmitted to the subsequent layer
- Bias:
-
Bias is a constant that aids the model in optimizing its fit to the provided data
- Neurons:
-
Neurons serve as fundamental units within a complex neural network
- Epoch:
-
Training involves inputs and outputs fed into iterative steps, compared to target values for error calculation. Weights and biases are computed and adjusted at each epoch.
- Weight:
-
Describes the significance and strengths of the input to the Neurons
References
Lee, K. X. & Valla, J. A. Adsorptive desulfurization of liquid hydrocarbons using zeolite-based sorbents: A comprehensive review. React. Chem. Eng. 4(8), 1357–1386 (2019).
Song, X., Pang, Y. & Gao, L. Preparation of bimetal modified HMS molecular sieve and its desulfurization performance mechanism. Appl. Organomet. Chem. 35(11), e6393 (2021).
Hessou, E. P., Jabraoui, H., Khalil, I., Dziurla, M.-A. & Badawi, M. Ab initio screening of zeolite Y formulations for efficient adsorption of thiophene in presence of benzene. Appl. Surf. Sci. 541, 148515 (2021).
Fu, H., Wang, Y., Zhang, T., Yang, C. & Shan, H. Adsorption and separation mechanism of thiophene/benzene in MFI zeolite: A GCMC study. J. Phys. Chem. C 121(46), 25818–25826 (2017).
Shang, H., Zhang, H., Du, W. & Liu, Z. Development of microwave assisted oxidative desulfurization of petroleum oils: A review. J. Ind. Eng. Chem. 19(5), 1426–1432 (2013).
Méndez, F. J. et al. Dibenzothiophene hydrodesulfurization with NiMo and CoMo catalysts supported on niobium-modified MCM-41. Appl. Catal. B 219, 479–491 (2017).
Wu, J. et al. Extraction desulphurization of fuels using ZIF-8-based porous liquid. Fuel 300, 121013 (2021).
Mohebali, G. & Ball, A. S. Biodesulfurization of diesel fuels–past, present and future perspectives. Int. Biodeterior. Biodegrad. 110, 163–180 (2016).
Boshagh, F., Rahmani, M., Rostami, K. & Yousefifar, M. Key factors affecting the development of oxidative desulfurization of liquid fuels: A critical review. Energy Fuels 36(1), 98–132 (2021).
Lin, X. et al. Selective adsorptive desulfurization with alkaline-earth metal-modified zeolites in oil in the presence of olefin. ACS Omega 8(48), 45976–45984 (2023).
Wang, J. et al. Insight into the relationship between effective active sites and ultra-deep adsorption desulfurization performance of CuCeY with different Cu precursors. Fuel Process. Technol. 250, 107930 (2023).
Ahmadpour, J., Ahmadi, M. & Javdani, A. Hydrodesulfurization unit for natural gas condensate: Simulation based on Aspen Plus software. J. Therm. Anal. Calorim. 135, 1943–1949 (2019).
Subhan, F. et al. Confinement of mesopores within ZSM-5 and functionalization with Ni NPs for deep desulfurization. Chem. Eng. J. 354, 706–715 (2018).
Liu, X., Yi, D., Cui, Y., Shi, L. & Meng, X. Adsorption desulfurization and weak competitive behavior from 1-hexene over cesium-exchanged Y zeolites (CsY). J. Energy Chem. 27(1), 271–277 (2018).
Song, H. et al. Deep desulfurization of model gasoline by selective adsorption over Cu–Ce bimetal ion-exchanged Y zeolite. Fuel Process. Technol. 116, 52–62 (2013).
Mohammed, M. M., Alalwan, H. A., Alminshid, A., Hussein, S. A. M. & Mohammed, M. F. Desulfurization of heavy naphtha by oxidation-adsorption process using iron-promoted activated carbon and Cu+2-promoted zeolite 13X. Catal. Commun. 169, 106473 (2022).
Jafarabadi, H., Mansouri, M., Shayanmehr, M. & Ghaemi, A. Mechanisms, challenges, and future perspectives of adsorptive desulfurization using zeolite-based adsorbents: A review. Environ. Sci. Pollut. Res. 1–53 (2025).
Fotiadis, K., Kostoglou, M., Baltzopoulou, P., Zaspalis, V. & Karagiannakis, G. Activated carbon modification for real diesel adsorptive deep desulfurization: experiments and modeling. Chem. Eng. Commun. 211(9), 1319–1335 (2024).
Zhu, J. et al. 3D printing of hierarchically porous lightweight activated carbon/alumina monolithic adsorbent for adsorptive desulfurization of hydrogenated diesel. Sep. Purif. Technol. 330, 125334 (2024).
Wu, J.-Q. et al. Construction of large-aperture mesoporous silica spheres supported polyoxometalate heterogeneous catalysts and their high-efficiency for the ultra-deep desulfurization. Fuel 371, 131902 (2024).
Shayanmehr, M., Aarabi, S., Ghaemi, A. & Hemmati, A. A data driven machine learning approach for predicting and optimizing sulfur compound adsorption on metal organic frameworks. Sci. Rep. 15(1), 3138 (2025).
Liu, Y. et al. Morphology-controlled construction and aerobic oxidative desulfurization of hierarchical hollow Co–Ni–Mo–O mixed metal-oxide nanotubes. Ind. Eng. Chem. Res. 59(14), 6488–6496 (2020).
Dashtpeyma, G., Shabanian, S. R., Ahmadpour, J. & Nikzad, M. Effect of desilication of NaY zeolite on sulfur content reduction of gasoline model in presence of toluene and cyclohexene. Chem. Eng. Res. Des. 178, 523–539 (2022).
Kulawong, S., Artkla, R., Sriprapakhan, P. & Maneechot, P. Biogas purification by adsorption of hydrogen sulphide on NaX and Ag-exchanged NaX zeolites. Biomass Bioenergy 159, 106417 (2022).
Salehi, E., Askari, M., Afshar, S., Eidi, B. & Aliee, M. H. Adsorptive desulfurization of wild naphtha using magnesium hydroxide-coated ceramic foam filters in pilot scale: Process optimization and sensitivity analysis. Chem. Eng. Process. Process Intensif. 152, 107937 (2020).
Zhang, R. et al. Using ultrasound to improve the sequential post-synthesis modification method for making mesoporous Y zeolites. Front. Chem. Sci. Eng. 14, 275–287 (2020).
Ma, Q. et al. Development of mesoporous ZSM-5 zeolite with microporosity preservation through induced desilication. J. Mater. Sci. 55, 11870–11890 (2020).
Kerr, G. T. Chemistry of crystalline aluminosilicates. V. Preparation of aluminum-deficient faujasites. J. Phys. Chem. 72(7), 2594–2596 (1968).
Mguni, L. L., Ndhlovu, A., Liu, X., Hildebrandt, D. & Yao, Y. Insight into adsorptive desulfurization by zeolites: A machine learning exploration. Energy Fuels 36(8), 4427–4438 (2022).
Akopyan, A. V. et al. Deep aerobic desulfurization of fuels over iron–containing zeolite based catalysts. Chem. Eng. J. Adv. 12, 100385 (2022).
Mahmoudi, R. & Falamaki, C. A systematic study on the effect of desilication of clinoptilolite zeolite on its deep-desulfurization characteristics. Nanochem. Res. 1(2), 205–213 (2016).
Lee, K. X., Wang, H., Karakalos, S., Tsilomelekis, G. & Valla, J. A. Adsorptive desulfurization of 4, 6-dimethyldibenzothiophene on bimetallic mesoporous Y zeolites: Effects of Cu and Ce composition and configuration. Ind. Eng. Chem. Res. 58(39), 18301–18312 (2019).
Zhou, D., Wang, Y., He, N. & Yang, G. The pi-complexation mechanisms of Cu (I), Ag (I)/zeolites for desulfurization. Acta Physicochim. Sin. 22(5), 542 (2006).
Ghaemi, A., Dehnavi, M. K. & Khoshraftar, Z. Exploring artificial neural network approach and RSM modeling in the prediction of CO2 capture using carbon molecular sieves. Case Stud. Chem. Environ. Eng. 7, 100310 (2023).
Mosallanezhad, A. & Kalantariasl, A. Performance prediction of ion-engineered water injection (EWI) in chalk reservoirs using Response Surface Methodology (RSM). Energy Rep. 7, 2916–2929 (2021).
Hussain, S., Khan, H., Gul, S., Steter, J. R. & Motheo, A. J. Modeling of photolytic degradation of sulfamethoxazole using boosted regression tree (BRT), artificial neural network (ANN) and response surface methodology (RSM); energy consumption and intermediates study. Chemosphere 276, 130151 (2021).
Lu, Y., Wang, R., Nan, Y., Liu, F. & Yang, X. Removal of sulphur from model gasoline by CuAgY zeolite: Equilibrium, thermodynamics and kinetics. RSC Adv. 7(81), 51528–51537 (2017).
Song, H. et al. Equilibrium, kinetic, and thermodynamic studies on adsorptive desulfurization onto CuICeIVY zeolite. Ind. Eng. Chem. Res. 53(14), 5701–5708 (2014).
Song, H. et al. Kinetic and thermodynamic studies on adsorption of thiophene and benzothiophene onto AgCeY Zeolite. J. Taiwan Inst. Chem. Eng. 63, 125–132 (2016).
Fei, L., Rui, J., Wang, R., Lu, Y. & Yang, X. Equilibrium and kinetic studies on the adsorption of thiophene and benzothiophene onto NiCeY zeolites. RSC Adv. 7(37), 23011–23020 (2017).
Dashtpeyma, G., Shabanian, S. R., Ahmadpour, J. & Nikzad, M. The investigation of adsorption desulphurization performance using bimetallic CuCe and NiCe mesoporous Y zeolites: Modification of Y zeolite by H4EDTA-NaOH sequential treatment. Fuel Process. Technol. 235, 107379 (2022).
Tian, F., Shen, Q., Fu, Z., Wu, Y. & Jia, C. Enhanced adsorption desulfurization performance over hierarchically structured zeolite Y. Fuel Process. Technol. 128, 176–182 (2014).
Li, H. et al. Competitive adsorption desulfurization performance over K-Doped NiY zeolite. J. Colloid Interface Sci. 483, 102–108 (2016).
Shi, Y. et al. Effect of cyclohexene on thiophene adsorption over NaY and LaNaY zeolites. Fuel Process. Technol. 110, 24–32 (2013).
Khoshraftar, Z. & Ghaemi, A. Evaluation of pistachio shells as solid wastes to produce activated carbon for CO2 capture: Isotherm, response surface methodology (RSM) and artificial neural network (ANN) modeling. Curr. Res. Green Sustain. Chem. 5, 100342 (2022).
Naderi, K., Foroughi, A. & Ghaemi, A. Analysis of hydraulic performance in a structured packing column for air/water system: RSM and ANN modeling. Chem. Eng. Process. Process Intensif. 193, 109521 (2023).
Bruns, R. E., Scarminio, I. S. & de Barros Neto, B. Statistical Design-Chemometrics (Elsevier, 2006).
Mu’azu, N. D. & Olatunji, S. O. K-nearest neighbor based computational intelligence and RSM predictive models for extraction of Cadmium from contaminated soil. Ain Shams Eng. J. 14(4), 101944 (2023).
Myers, R. H., Montgomery, D. C. & Anderson-Cook, C. M. Response Surface Methodology: Process and Product Optimization Using Designed Experiments (John Wiley & Sons, 2016).
Leonzio, G. Optimization through response surface methodology of a reactor producing methanol by the hydrogenation of carbon dioxide. Processes 5(4), 62 (2017).
Arora, A., Iyer, S. S. & Hasan, M. F. Computational material screening using artificial neural networks for adsorption gas separation. J. Phys. Chem. C 124(39), 21446–21460 (2020).
Agatonovic-Kustrin, S. & Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 22(5), 717–727 (2000).
Khoshraftar, Z. & Ghaemi, A. Preparation of activated carbon from Entada Africana Guill. & Perr for CO2 capture: Artificial neural network and isotherm modeling. J. Chem. Pet. Eng. 56(1), 165–180 (2022).
Murtagh, F. Multilayer perceptrons for classification and regression. Neurocomputing 2(5–6), 183–197 (1991).
Siddique, N. & Adeli, H. Computational Intelligence: Synergies of Fuzzy, Logic Neural Networks and Evolutionary Computing (John Wiley & Sons, 2013).
Zhang, D., Zhang, N., Ye, N., Fang, J. & Han, X. Hybrid learning algorithm of radial basis function networks for reliability analysis. IEEE Trans. Reliab. 70(3), 887–900 (2020).
Ganguly, S. Prediction of VLE data using radial basis function network. Comput. Chem. Eng. 27(10), 1445–1454 (2003).
Bahmanzadegan, F. & Ghaemi, A. Exploring the effect of zeolite’s structural parameters on the CO2 capture efficiency using RSM and ANN methodologies. Case Stud. Chem. Environ. Eng. 9, 100595 (2024).
Shi, J., Zhu, Y., Khan, F. & Chen, G. Application of Bayesian Regularization Artificial Neural Network in explosion risk analysis of fixed offshore platform. J. Loss Prev. Process Ind. 57, 131–141 (2019).
Gopalakrishnan, K. Effect of training algorithms on neural networks aided pavement diagnosis. Int. J. Eng. Sci. Technol. 2(2), 83–92 (2010).
Mukherjee, I. & Routroy, S. Comparing the performance of neural networks developed by using Levenberg–Marquardt and Quasi-Newton with the gradient descent algorithm for modelling a multiple response grinding process. Expert Syst. Appl. 39(3), 2397–2407 (2012).
Kolbadinejad, S., Mashhadimoslem, H., Ghaemi, A. & Bastos-Neto, M. Deep learning analysis of Ar, Xe, Kr, and O2 adsorption on activated carbon and zeolites using ANN approach. Chem. Eng. Process. Process Intensif. 170, 108662 (2022).
Saltelli, A. et al. Global Sensitivity Analysis: The Primer (John Wiley & Sons, 2008).
Sobol, I. M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 55(1–3), 271–280 (2001).
Gawlikowski, J. et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 56(Suppl 1), 1513–1589 (2023).
Author information
Authors and Affiliations
Contributions
A.G.: Conceptualization, Methodology, Software, Conceived and designed the experiments, Validation, Formal analysis, Investigation, Resources, Data curation, Writing—original draft, Writing—review & editing, Supervision Visualization, Project administration, Supervision, Funding acquisition. M.M.: Conceptualization, Methodology, Conceived and designed the experiments, Validation, Formal analysis, Investigation, Resources, Writing—original draft, Writing—review & editing. M.S.: Conceptualization, Methodology, Conceived and designed the experiments, Validation, Formal analysis, Investigation, Resources, Writing—original draft, Writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mansouri, M., Shayanmehr, M. & Ghaemi, A. Exploring the adsorption desulfurization efficiency using RSM and ANN methodologies. Sci Rep 15, 20869 (2025). https://doi.org/10.1038/s41598-025-05688-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05688-5
