
Abstract
Reliable recognition of geochemical anomalies linked to ore deposits is one of the most significant challenges in mineral exploration. Several advanced machine learning (AML) algorithms have recently been applied to recognize multi-element geochemical anomalies. Performance of the AML algorithms are extremely dependent to values of their hyperparameters. Because, conclusions of their application can significantly be differed tuning hyperparameters. Tuning hyperparameters through trial-and-error way is a labor-intensive and time-consuming procedure which is not mostly eventuated to reliable results. In this regard, applying an AML model decreases training time and assists to achieve optimized values of hyperparameters yielding reasonable potential maps. Hence, execution of an AML model mitigates the biasness problem and uncertainties with recognition of multi-element geochemical anomalies. In this study, Harris hawks optimization (HHO) algorithm was employed to optimize known hyperparameters of the random forest (RF) method for detecting multi-element geochemical anomalies related to mineralization occurrences in the Feyzabad district of the Razavi Khorasan province, NE Iran. This research demonstrates that Harris hawks optimized random forest (HHORF) model is a vigorous procedure to identify multi-element geochemical anomalies. Because, the HHORF model has recognized 86.53% mineralization occurrences through 30% corresponding area while the RF method has catched 80.14% mineralization occurrences up via same corresponding area.
Similar content being viewed by others

Introduction
Decreasing uncertainty of multi-element geochemical anomaly mapping is a challenging procedure. Decreasing uncertainty is so necessary for geochemical anomaly mapping in a study area. Because, recognition of multi-element geochemical anomalies can facilitate to detect hidden deposits1. In regional scale, multi-element geochemical anomaly detection is performed employing stream sediments geochemical data. The stream sediments geochemical data is extremely under efficacy of complex geological features2,3,4,5. Hence, this data is a nonlinear multivariate input which requires capable processing models5,6. Whereas, traditional procedures have not necessary capability to process them but advanced machine learning (AML) frameworks are appropriate substitutes to perform this task1,3,7,8,9,10,11,12,13,14. Among applied machine learning models, random forest (RF), artificial neural networks and support vector machine were the most useful methods for multi-element geochemical anomaly detection15,16,17. The RF method is a developed form of decision trees which can be applied for classification and regression18,19,20,21. Three known hyperparameters of the RF comprising number of trees (NT), number of splits (NS) and depth (D) extremely need to be optimized for reduction of uncertainties in multi-element geochemical anomaly detection. Although, applied ML models have better conclusions than traditional methods but majority users tune their hyperparameters through performing trial-and-error procedure. While, applying trial-and-error is an onerous and time-consuming way which can not be eventuated to reliable results22,23,24. Fortunately, numerous nature-inspired optimization techniques have been designed to remove trial-and-error procedure of tuning stage of the ML hyperparameters in recent decade. These techniques commonly inspire by the social life behavior of creatures. In this regard, firefly algorithm25,26, dolphin echolocation27,28, cuckoo search29, bat algorithm30, whale optimization algorithm24 and grey wolf optimizer31, wild horse optimizer32, Harris hawks optimization (HHO) algorithm23 and so on were introduced to optimize ML models applied in medical, industrial, agriculture and geoscience fields33,34,35,36. Indeed, these optimization techniques have been widely regarded due to i) inspiring from nature, ii) considering problems as black boxes, iii) avoidance of falling to great local optima, iv) containing gradient-free mechanism37. Optimization techniques are usually selected based on: 1) which does hyperparameter of a specific ML model need to be optimized? and 2) should that hyperparameter be maximized or minimized? In recent decade, several AML frameworks were constructed hybridizing the ML models with nature-inspired optimization techniques to recognize multi-element geochemical anomalies38,39,40. Accordingly, research proposal is integration of the RF model due to its popularity, computational attractiveness, great inference power with the HHO algorithm due to its robust conclusions in comparison to 11 optimization algorithms23. In fact, hybridization of the RF model with HHO was applied to eliminate trial-and-error of training stages and decreases uncertainties of geochemical anomaly mapping. It is noteworthy, results demonstrate effect of eliminating trial-and-error procedure in tuning hyperparameters of the RF model. Difference of performance of the AML model applied to conventional RF model is rather than 6% which can be confirmed considering success-rate curves.
Region of interest
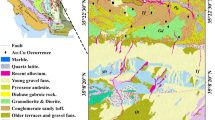
A main mineral potential zone from NE Iran is the Feyzabad district. The Feyzabad is known as a high potential area of the iron oxide copper–gold (IOCG) and vein-type Au-Cu mineralizations which is restricted between 58° 30´ 0˝ E and 59° 0´ 0˝ E longitudes and 35° 0´ 0˝ N and 35° 30´ 0˝ N latitudes4,41. Its significant mineralization occurrences are Zarmehr (IOCG), Tanourjeh (vein-type), Baharieh (IOCG), Sarsefidal (IOCG), Kamarmard (IOCG) and Kalateh timor. This area is a segment of the boundaries of the internal Iranian microcontinent which places between the Loot Block and the Central Iran zones. It is seen, numerous faults and fractures are related to mineralization occurrences in this area. In this regard, the darouneh fault as the longest fracture plays a significant role in forming deposits of the Feyzabad district. Granodiorite, diorite, pyroxene andesite and diabase gabbroic rock are the most significant volcanic structures which are frequently observed there (Fig. 1). Also, alternations of sedimentary and carbonated rock units comprising reddish and sandstone conglomerate, gypsiferous marl, dolomitic limestone, silty shale and quartz latite which belong to middle- to upper-Cambrian era and accompany mentioned volcanic rock units (Fig. 1)42. The vein-type Au-Cu and the IOCG deposits are mainly hosted by diorite and granodiorite intrusions of Eocene–Oligocene age in this area. Elements Au, Cu, Bi, Pb, Zn, Sb and As demonstrated spatial correlation to mineralization occurrences. But, Appropriate pathfinder elements Au, Cu, Sb, Zn and Pb with specific thresholds were chosen based on a novel deep framework presented by7,18 to trace mineralization occurrences in the study area43.

Simplified geological map (1:100,000) of the Feyzabad district, NE Iran. This map is an improved version of its original version presented by geological survey & mineral exploration organization from Iran as public (https://gsi.ir/). This version has been improved applying GIS software 10.6 toolbox.
Methods and materials
Conventional random forest method
The RF method is applied for classification and regression which was first introduced by44. Training process in the RF method is performed applying “bagging” procedure. This method creates many decision trees and integrates them to predict information precisely. Each decision tree is trained by a random sample of inputs. Within the forest, a sample is classified into a class which get majority votes of overall decision trees. A schematic flowchart of the conventional RF classification algorithm has been shown in Fig. 2. Three hyperparameters of the RF comprising NT, NS and D should be tuned to present reliable data classification. In this concept, increasing NT value can increase accuracy of classification but value of the NT should be optimized because additional NT wastes training time. Unsuitable NS value can create under-fitting problem in prediction procedure45. Because, each decision tree with rather splits is considered deeper. Also, unsuitable D value can create over-fitting problem in training procedure45. More information of the conventional RF methodology can be investigated in10,40,44,46,47,48.

Flowchart of classification procedure applying the CRF algorithm.
Harris hawks optimization algorithm
Superb performance of the HHO algorithm in comparison to 11 powerful optimization algorithms was demonstrated by23. Harris hawk is a predator bird in the Arizona, USA. Because, this creature seeks, attacks and shares victims with other family members. Nature-inspired algorithms generally include two stages comprising exploration and exploitation. In the exploration stage, Harris hawks seek and find the prey from the highest altitude applying their eyes in a desert region. In this regard, the best location of the Harris hawks to the prey is the closest distance to it which can be mathematically simulated as follow:
where r1, r2, r3, r4 and q (perching chance of the Harris hawks) are the random values in range (0, 1) and LB, UB, Xprey, Xrand, X(t) and X(t + 1) are lower bound, upper bound, location of the prey in the t iteration, randomly chosen Harris hawk in the current population, location of the Harris hawk in the t iteration and t + 1 iteration respectively. Also, Xm(t) as mean location of the Harris hawks should be calculated as follow:
where Xi(t) is location of each Harris hawk in iteration t and N is number of Harris hawks. It is noteworthy, fleeing condition of the prey can change response of the Harris hawks in the HHO algorithm. In this case, escaping energy factor can be defined using Eq. (3). While, escaping energy parameter be \(\text{E}\ge 1\), seeking for the prey is continued by Harris hawks but the exploitation behavior is started when escaping energy parameter is \(\text{E}<1\).
where T is maximum number of iteration. E and E0 are escaping energy in iteration t and initial escaping energy respectively. For each iteration, E0 varies inside range (− 1, 1). Decreasing E0 from 0 to − 1 demonstrates exhausting the prey and increasing E0 from 0 to 1 demonstrates strengthening of the prey. In the exploitation stage, Harris hawks have targeted their prey and intend to attack it. Consequently, targeted prey tries to flee the surprising pounce by performing random jumps. In this regard, the prey chance for successful feeling can be considered as r < 0.5 and while fleeing be not successful r ≥ 0.5. Based on different fleeing chances and escaping energy factor of the prey, four possible strategies are mathematically simulated in the HHO algorithm. At the first strategy (\(r \ge 0.5\) and \(\left| E \right| \ge 0.5\)), Harris hawks intend to tire the prey before attacking because the prey still has enough escaping energy but it will be eventually capitulated. In this strategy which named soft besiege, location of the Harris hawks in iteration t + 1 is expressed as follow:
where r5 is also a random value in (0, 1) and J is random jump strength of the prey during fleeing procedure which varies in each iteration randomly to model the nature of the prey movements. At the second strategy (\(r \ge 0.5\) and \(\left| E \right| < 0.5\)), the prey has been capitulated and Harris hawk can apply surprising pounce. In this strategy (hard besiege), locations of the Harris hawks in iteration t + 1 can also be considered by following equation:
At the third strategy (\(r < 0.5\) and \(\left| E \right| \ge 0.5\)), the prey has enough escaping energy and a soft besiege can still be performed before surprising pounce. This stage (soft besiege with progressive rapid dives) is rather intelligent than the first stage. Accordingly, locations of Harris hawks are updated via Eqs. (8–10):
The Harris hawks compare previous motion of the prey to their previous dive, whether was dive response appropriate or not? Accordingly, along deceptive movements of the prey, those also carry irregular, suddenly and rapid dives out. In23 suggested an LF(x) function to consider various dives of the Harris hawks along zigzag deceptive movements of the prey during scape as follow:
where LF(x) named levy flight function and β value is equal to 1.5 and Г is Gamma function. Also, u, ω and S are the random value in range (0, 1) and a random vector respectively. Eventually, location of the Harris hawk in iteration t + 1 can be expressed as follow:
At the forth strategy (\(r<0․5\) and \(\left|E\right|<0․5\)), the prey has been exhausted and the escaping chance is very low. Accordingly, the Harris hawks apply hard besiege behavior with progressive rapid dives which can be simulated as:
Examples of the soft and hard besiege behaviors have been presented in Fig. 3.

Some cases of exploitation phase, (a) example of overall vectors in the case of hard besiege, (b) example of overall vectors in the case of soft besiege with progressive rapid dives.
Appropriate validation
Area under the receiver operating characteristic (ROC) curve (AUC) was employed as aggregated classification method to validate geochemical samples classified. The AUC value mostly lies in range [0.5, 1]. While, the AUC values be 0.5, performance of applied machine learning model is similar to guess randomly. Also, performance of applied machine learning model is completed if its AUC values be 1. In other word, applied machine learning model has been perfectly trained. The success-rate curve method was initially presented to evaluate spatial accuracy of targeting models employed by49. In this validation tool, proportion of mineralization occurrences which have correctly placed within recognized anomaly zones is exhibited in the vertical axis. In contrast, proportion of the corresponding study area is exhibited in the horizontal axis. A diagonal gauge line is discriminant factor of inefficiency and efficiency of applied targeting model and its geochemical map produced. If, success-rate curve of an employed model be above the gauge line meaning a strong spatial correlation between its geochemical map produced and mineralization occurrences. While, success-rate curve of an employed model be below the gauge line meaning a weak spatial correlation between its geochemical map produced and mineralization occurrences. Indeed, each curve which be higher than other includes more prediction ability.
Geochemical sample preparation and analysis
The study area has dimensions of 44 × 54 km2 which a dense sampling grid (1.4 × 1.4 km2) has been performed there. Stream sediments samples (1033) were collected to check changing rate of concentrations of 27 elements across the Feyzabad district. Collected geochemical samples were analyzed using a combined inductively coupled plasma-optic emission spectroscopy (ICP-OES) after a near-total 4-acid digestion (hydrochloric, nitric, perchloric, and hydrofluoric acids)50. Also, analyzing precision (< 10%) was measured applying duplicated sub-samples for each 20 measurements.
Prepare training data
Classification of the stream sediments geochemical data is critical for producing requirement geochemical layers. Stream sediments geochemical data includes inherent closure problem5,51. Hence, the centered log-ratio (clr) transformation was performed to eliminate data closure problem using Eq. (15).
where x, xD and g(x) are vector of the composition with D dimensions, Euclidean distances between distinct variables and geometric mean of the composition x respectively52. Then, data table values were transformed in range [0, 1]. Accordingly, a geochemical data table comprising transformed values of elements Au, Cu, Sb, Zn and Pb was classified to map geochemical anomalies in the study area. Indeed, a geochemical data table with 5 columns including transformed values of pathfinder elements with 1 column including their labels for whole of 1033 collected samples was constructed to train model (Fig. 4). For assigning pre-defined labels of training data, we applied several ranges of transformed values (Table 1). Accordingly, geochemical data table was consisted of the four class types comprising strong anomaly, weak anomaly, high background and low background based on suggested ranges and their labels were allocated to samples. Accordingly, for instance, a geochemical sample which is contained transformed values Au = 0.648, Cu = 0.703, Sb = 0.927, Zn = 0.811 and Pb = 0.806 has a great spatial correlation to close mineralization occurrences and is member of the strong anomaly population and achieves label 4 (Table 1). In this research, we also implemented a cost function of root mean squared error (RMSE) values during the training procedure based on Eq. (16).
where n, CR and Cp are number of samples, allocated real class to sample and predicted class respectively.

Hybridization of the RF model with the HHO algorithm using training and testing data.
Results and discussion
Training conventional RF
In this regard, the MATLAB R2022a environment was applied to conduct conventional RF (CRF) and Harris hawks optimized random forest (HHORF) networks. 70% samples (in-bag data) were randomly applied to train and 30% samples (out-of-bag data) were employed to test networks designed. For training conventional RF network, relevant hyperparameters NT, NS and D were experimentally assigned in range 1–300, 1–8 and 1–4 respectively. These tuned hyperparameters using trial-and-error procedure were presented in Table 2. Optimum value of the parameter NT (280) was applied to train CRF with tenfold cross-validation. It is noteworthy, increasing the NT value is not necessarily eventuated to decrease the uncertainties but also increases the calculating time. Furthermore, NS and D values were chosen 5 and 2 respectively while these parameters include lower impact on the CRF performance (Table 2).
Training HHORF and comparison
A schematic flowchart of the hybridization of the HHO algorithm with the RF method has been presented in Fig. 4. Here, the HHO is fittingly attracted to optimal solutions in the best locations of the search spaces, and the number of random parameters is restricted in the HHO. Therefore, the initial population of Harris hawks is significant in this algorithm. Before optimizing hyperparameters of the HHORF model, appropriate number of iterations (100), Harris hawks population (30), lower bound value (100) and upper bound value (1) with tenfold cross-validation were set. In the HHORF procedure, the best location of the prey (Xprey) is considered as relevant hyperparameters of the RF method in the selected features for all cross validation folds. Tuned hyperparameters of the RF by employing HHO algorithm were demonstrated as NT = 636, NS = 7 and D = 3 (Table 2). Cost function of optimizing procedure for all iterations has also been exhibited in Fig. 5. It is displayed, minimizing procedure is finalized after 58th iteration with a cost value 0.466. Indeed, stable part of the cost function after 58th iteration with the lowest cost value can insure perfect tuning of the model hyperparameters. The AUCs presented in Fig. 6 can compare prediction ability of the trained models in this research. It is cleared, the HHORF has rather accuracy than the CRF method. The AUC values of classified samples (class 4 = 0.931, class 3 = 0.937, class 2 = 0.943, class 1 = 0.925) by applying the HHORF (Fig. 6b) are greater than the AUC values of the classified samples (class 4 = 0.811, class 3 = 0.916, class 2 = 0.802, class 1 = 0.797) through the CRF (Fig. 6a; Table 3).

Minimizing procedure of the cost values in whole of iterations.


Area under the receiver operating characteristic curve (AUC) for geochemical data classified via employing, (a) the CRF model and (b) the HHORF model.
Multi-element geochemical anomaly mapping and validation
Testing data classified were applied to map multi-element geochemical anomalies through inverse distance weighted (IDW) interpolation tool in the GIS software 10.6 toolbox (Fig. 7). Due to greater classification accuracy of the HHORF procedure, map plotted of its samples classified obviously presents better prediction of the geochemical anomalies linked to the mineralization occurrences. In other word, high potential zones of multi-element geochemical map produced through HHORF approach (Fig. 7b) has catched up more mineralization occurrences. This claim can also be demonstrated regarding the success-rate curves achieved for both plots (Fig. 8). In this concept, two cases are regardable. The first, both success-rate curves are meaningfully above the diagonal gauge line meaning both produced maps have acceptable ability in predicting geochemical anomalies. The second, success-rate curve of the produced map by classified samples of the HHORF procedure is above other curve. It is meaning, prediction ability of the HHORF procedure is greater due to higher proportion of the mineralization occurrences have detected in lower proportion of the corresponding area. For instance, the HHORF has predicted 86.53% mineralization occurrences in the 30% corresponded area while the CRF has predicted 80.14% mineralization occurrences in same corresponding area (Fig. 8).


Multi-element geochemical anomaly maps plotted applying, (a) the CRF model and (b) the HHORF model.

The success-rate curve for achieved results employing, (a) the CRF model and (b) the HHORF model.
Conclusions
In this research, a hybridized random forest model was successfully constructed to classify multi-element geochemical data table linked to the mineralization occurrences in the Feyzabad district, NE Iran. Accordingly, conclusion remarks are presented as follow:
-
The CRF is a powerful and popular method for classification of geochemical data which its relevant hyperparameters extremely require to be optimized for achieving reliable conclusions.
-
Optimization of hyperparameters of the CRF method is time consuming and onerous while trial-and-error procedure be executed.
-
A nature-inspired procedure named Harris hawks optimization algorithm could reliably tune hyperparameters of the CRF without wasting a lot time.
-
Advanced machine learning frameworks can be constructed hybridizing appropriate optimization algorithms with powerful machine learning models.
-
Advanced machine learning frameworks can meaningfully decrease uncertainties yielding reasonable geochemical anomaly maps.
Data availability
The datasets used during the current study available from the corresponding author on reasonable request.
References
Zuo, R. & Carranza, E. J. M. Support vector machine: A tool for mapping mineral prospectivity. Comput. Geosci. 37(12), 1967–1975 (2011).
Zuo, R. et al. A geologically constrained variational autoencoder for mineral prospectivity mapping. Nat. Resour. Res. 31(3), 1121–1133 (2022).
Zhang, C. et al. A geologically-constrained deep learning algorithm for recognizing geochemical anomalies. Comput. Geosci. 162, 105100 (2022).
Sabbaghi, H., Tabatabaei, S. H. & Fathianpour, N. Geologically-constrained GANomaly network for mineral prospectivity mapping through frequency domain training data. Sci. Rep. 14(1), 6236 (2024).
Sadeghi, B., Molayemat, H. & Pawlowsky-Glahn, V. How to choose a proper representation of compositional data for mineral exploration? J. Geochem. Exp., p. 107425 (2024).
Qaderi, S., et al., Translation of mineral system components into time step-based ore-forming events and evidence maps for mineral exploration: Intelligent mineral prospectivity mapping through adaptation of recurrent neural networks and random forest algorithm. Ore Geol. Rev., p. 106537 (2025).
Sabbaghi, H. & Tabatabaei, S. H. Regimentation of geochemical indicator elements employing convolutional deep learning algorithm. Front. Environ. Sci. 11, 1076302 (2023).
Sabbaghi, H. & Tabatabaei, S. H. A combinative knowledge-driven integration method for integrating geophysical layers with geological and geochemical datasets. J. Appl. Geophys. 172, 103915 (2020).
Xiong, Y. & Zuo, R. Recognition of geochemical anomalies using a deep autoencoder network. Comput. Geosci. 86, 75–82 (2016).
Wang, J., Zuo, R. & Xiong, Y. Mapping mineral prospectivity via semi-supervised random forest. Nat. Resour. Res. 29, 189–202 (2020).
Sabbaghi, H. & Tabatabaei, S. H. Application of the most competent knowledge-driven integration method for deposit-scale studies. Arab. J. Geosci. 15(11), 1–10 (2022).
Sabbaghi, H. & Tabatabaei, S. H. Execution of an applicable hybrid integration procedure for mineral prospectivity mapping. Arab. J. Geosci. 16(1), 1–13 (2023).
Yousefi, M., Kamkar-Rouhani, A. & Carranza, E. J. M. Geochemical mineralization probability index (GMPI): A new approach to generate enhanced stream sediment geochemical evidential map for increasing probability of success in mineral potential mapping. J. Geochem. Exp. 115, 24–35 (2012).
Parsa, M. et al. Prospectivity modeling of porphyry-Cu deposits by identification and integration of efficient mono-elemental geochemical signatures. J. Afr. Earth Sci. 114, 228–241 (2016).
Gonbadi, A. M., Tabatabaei, S. H. & Carranza, E. J. M. Supervised geochemical anomaly detection by pattern recognition. J. Geochem. Exp. 157, 81–91 (2015).
Geranian, H. et al. Application of discriminant analysis and support vector machine in mapping gold potential areas for further drilling in the Sari-Gunay gold deposit NW Iran. Nat. Resour. Res. 25(2), 145–159 (2016).
Abedi, M., Norouzi, G.-H. & Bahroudi, A. Support vector machine for multi-classification of mineral prospectivity areas. Comput. Geosci. 46, 272–283 (2012).
Sabbaghi, H., Recognition of multi-element geochemical anomalies related to Pb–Zn mineralization applying upgraded support vector machine in the Varcheh district of Iran. Model. Earth Syst. Environ., p. 1–14 (2024).
Sakizadeh, M. & Milewski, A. Quantifying LULC changes in Urmia Lake Basin using machine learning techniques, intensity analysis and a combined method of cellular automata (CA) and artificial neural networks (ANN)(CA-ANN). Model. Earth Syst. Environ. 10(2), 2011–2030 (2024).
Arshad, A. et al. Reconstructing high-resolution groundwater level data using a hybrid random forest model to quantify distributed groundwater changes in the Indus Basin. J. Hydrol. 628, 130535 (2024).
Sabbaghi, H., Tabatabaei, S. H. & Fathianpour, N. Optimization of multi-element geochemical anomaly recognition in the Takht-e Soleyman area of northwestern Iran using swarm-intelligence support vector machine. Front. Earth Sci. 13, 1352912 (2025).
Sabbaghi, H. & Tabatabaei, S. H. Data-driven logistic function for weighting of geophysical evidence layers in mineral prospectivity mapping. J. Appl. Geophys. 212, 104986 (2023).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 97, 849–872 (2019).
Mirjalili, S., et al. Whale optimization algorithm: Theory, literature review, and application in designing photonic crystal filters. In Nature-inspired optimizers: theories, literature reviews and applications, p. 219–238 (2020).
Yang, X.-S. & Deb, S. Eagle strategy using Lévy walk and firefly algorithms for stochastic optimization. In Nature inspired cooperative strategies for optimization (NICSO 2010) 101–111 (Springer, 2010).
Yang, X.-S., Firefly algorithm, stochastic test functions and design optimisation. arXiv preprint arXiv:1003.1409, 2010.
Kaveh, A. & Farhoudi, N. Dolphin monitoring for enhancing metaheuristic algorithms: Layout optimization of braced frames. Comput. Struct. 165, 1–9 (2016).
Kaveh, A. & Farhoudi, N. A new optimization method: Dolphin echolocation. Adv. Eng. Softw. 59, 53–70 (2013).
Yang, X.-S. & Deb, S. Cuckoo search via Lévy flights. In 2009 World congress on nature & biologically inspired computing (NaBIC). (2009. IEEE).
Yang, X.-S. A new metaheuristic bat-inspired algorithm. In Nature inspired cooperative strategies for optimization (NICSO 2010) 65–74 (Springer, 2010).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Naruei, I. & Keynia, F. Wild horse optimizer: A new meta-heuristic algorithm for solving engineering optimization problems. Eng. Comput. 38(Suppl 4), 3025–3056 (2022).
Zareie, A., Sheikhahmadi, A. & Jalili, M. Identification of influential users in social network using gray wolf optimization algorithm. Expert Syst. Appl. 142, 112971 (2020).
Saravanan, G. et al. Improved wild horse optimization with levy flight algorithm for effective task scheduling in cloud computing. J. Cloud Comput. 12(1), 24 (2023).
Ali, E. Optimization of power system stabilizers using BAT search algorithm. Int. J. Electr. Power Energy Syst. 61, 683–690 (2014).
Wachs-Lopes, G. A. et al. Recent nature-Inspired algorithms for medical image segmentation based on tsallis statistics. Commun. Nonlinear Sci. Numer. Simul. 88, 105256 (2020).
Saremi, S., Mirjalili, S. & Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 105, 30–47 (2017).
Roshanravan, B. et al. Cuckoo optimization algorithm for support vector regression potential analysis: An example from the Granites-Tanami Orogen, Australia. J. Geochem. Exp. 230, 106858 (2021).
Ghezelbash, R. et al. Incorporating the genetic and firefly optimization algorithms into K-means clustering method for detection of porphyry and skarn Cu-related geochemical footprints in Baft district, Kerman, Iran. Appl. Geochem. 148, 105538 (2023).
Daviran, M. et al. A new strategy for spatial predictive mapping of mineral prospectivity: Automated hyperparameter tuning of random forest approach. Comput. Geosci. 148, 104688 (2021).
Hoseinzade, Z. & Bazoobandi, M. H. Deep embedded clustering: Delineating multivariate geochemical anomalies in the Feizabad region. Geochemistry 84(4), 126208 (2024).
Sabbaghi, H. & Moradzadeh, A. ASTER spectral analysis for host rock associated with porphyry copper-molybdenum mineralization. J. Geol. Soc. India 91(5), 627–638 (2018).
Skirrow, R. G. Iron oxide copper-gold (IOCG) deposits–A review (part 1): Settings, mineralogy, ore geochemistry and classification. Ore Geol. Rev. 140, 104569 (2022).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Carranza, E. J. M. & Laborte, A. G. Data-driven predictive mapping of gold prospectivity, Baguio district, Philippines: Application of random forests algorithm. Ore Geol. Rev. 71, 777–787 (2015).
Liaw, A. & Wiener, M. Classification and regression by randomForest. R News 2(3), 18–22 (2002).
Zuo, R. Machine learning of mineralization-related geochemical anomalies: A review of potential methods. Nat. Resour. Res. 26, 457–464 (2017).
Gao, Y. et al. Mapping mineral prospectivity for Cu polymetallic mineralization in southwest Fujian Province, China. Ore Geol. Rev. 75, 16–28 (2016).
Agterberg, F. P. & Bonham-Carter, G. F. Measuring the performance of mineral-potential maps. Nat. Resour. Res. 14, 1–17 (2005).
Sabbaghi, H. A combinative technique to recognise and discriminate turquoise stone. Vib. Spectrosc. 99, 93–99 (2018).
Wang, W., Zhao, J. & Cheng, Q. Mapping of Fe mineralization-associated geochemical signatures using logratio transformed stream sediment geochemical data in eastern Tianshan, China. J. Geochem. Exp. 141, 6–14 (2014).
Aitchison, J. et al. Logratio analysis and compositional distance. Math. Geol. 32, 271–275 (2000).
Acknowledgements
Authors intend to thank geological survey & mineral exploration organization from Iran for presenting geochemical samples collected to this manuscript.
Funding
The authors declare that no financial support was received for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
H.S. conceived the research idea, developed the computer code, performed the numerical experiments, derived the models, wrote the paper and interpretation of the results. NF: supervision, writing–review and editing.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sabbaghi, H., Fathianpour, N. Hybrid Harris hawks-optimized random forest model for detecting multi-element geochemical anomalies related to mineralization. Sci Rep 15, 23662 (2025). https://doi.org/10.1038/s41598-025-07534-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-07534-0
