
Abstract
The growing implementation of Internet of Things (IoT) technology has resulted in a significant increase in the number of connected devices, thereby exposing IoT-cloud environments to a range of cyber threats. As the number of IoT devices continues to grow, the potential attack surface also enlarges, complicating the task of securing these systems. This paper introduces an innovative approach to intrusion detection that integrates EfficientNet with a newly refined metaheuristic known as the Enhanced Football Team Training Algorithm (EFTTA). The proposed EfficientNet/EFTTA model aims to identify anomalies and intrusions in IoT-cloud environments with enhanced accuracy and efficiency. The effectiveness of this model is measured using a standard dataset and is compared against some other methods during performance metrics. The results indicate that the proposed method surpasses existing techniques, demonstrating improved accuracy over 98.56% for NSL-KDD and 99.1% for BoT-IoT in controlled experiments for the protection of IoT-cloud infrastructures.
Similar content being viewed by others
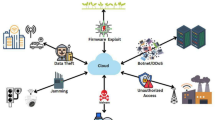
Introduction
Over the past decade, cloud computing has become the first choice when updating data management strategies as well as implementing smart manufacturing technologies1. All data collected from sensors around the factory is sent to the cloud of a remote data center where the information is stored, managed and processed2.
This technology has advantages for operators. In fact, by using a cloud-based service, manufacturers can easily manage and access their data from anywhere3,4,5,6. This advantage is ideal for remote monitoring of multiple sites and especially for the current trend of working from home due to the coronavirus pandemic.
Using the cloud, manufacturers can analyze their smart factory data without having to invest in setting up expensive software7.
In IoT-cloud environments, the leading cyber threats include Distributed Denial of Service (DDoS) attacks responsible for inundating networks or services with a sudden outpouring of traffic from possible compromised IoT devices, thus hindering system usability; data exfiltration, which exactly means removing data from cloud storage or IoT devices without permission often through stealthy ways or insiders; and spoofing attacks, where attackers assume the legitimate devices’ or users’ identity to gain unintended access and tamper with crucial systems8.
These threats insist on intrusion detection solutions for effective and real-time identification as well as prevention of sophisticated attacks9. The suitable EfficientNet/EFTTA model is “the-designed model” that counteracts the threats by associating the precious feature extraction potentials of EfficientNet with the enhanced football team training algorithm (EFTTA), a very refined metaheuristic approach managing outstanding performance in classification10.
The impact of this work is the superior accuracy and efficiency in detecting intrusions and anomalies in IoT-cloud infrastructures compared to other currently existing techniques. The work’s result obtains high performance metrics on standard datasets in so doing. It could be included in the Introduction after the big discussion on challenges and risks associated with IoT-cloud environments, thus providing clarity for the necessity and efficacy of the proposed solution11.
In fact, cloud services are often charged on a per-use basis, which means manufacturers only pay for what they need and have a system that easily scales with their business. But storing data in the cloud carries risks12. For example, a network outage makes manufacturers unable to access their data even if needed. This is a challenge in applications where traceability is important. Another concern is security, as any data movement increases the risk of cyber-attacks13.
By entering the Internet of Things (IOTs) into everyday life, residents of smart homes can remotely control cooling devices through their mobile phones, which was previously possible through text messages, but now, the Internet can do this14. So, IOT has been used as a tool in addition to providing smart solutions for homes and residential communities in commercial environments of various industries15,16,17. It is very important to use the cloud to collect data and draw a plan to use that data18.
But without the cloud, it is much more difficult to compare data over larger areas. The use of cloud computing also provides high scalability19.
An IoT-cloud infrastructure is a system in which Internet of Things (IoT) devices such as sensors, smart domestic appliances, and networked equipment collect and transmit data to cloud platforms for storage, processing, and analysis20. In the city’s infrastructure, for example, IoT devices such as traffic cameras, air quality sensors, and smart lighting systems collect real-time data continuously21. This data is then sent into the cloud and analyzed by the machine learning codes, advanced analytics to manage the traffic flow, monitor pollutant levels, or manage power consumption22. Such environments facilitate scalability and data central management as well as novel applications in predictive maintenance, resource optimization, and enhanced security monitoring23.
So, when we have countless sensors, putting a lot of computing power on each sensor is very expensive and time-consuming. But if the data can be transferred to the cloud through all these sensors, the processing can take place there24.
The IOT generates lots of data, which puts a lot of pressure on the Internet infrastructure. As a result, companies are trying to find ways to reduce the pressure and solve the data problem, of which cloud computing will be a major part by making connected devices25. But there are significant differences between cloud computing and the Internet of Things, which will be created in the coming years with the production of more and more data.
However, with the large amount of data generated by the IOT, there is a huge strain on the Internet infrastructure26. This has caused businesses and organizations to look for an option to reduce this burden27. Currently, cloud computing has somewhat penetrated IT and its infrastructure, and many large technology companies such as Amazon, Alibaba, Google and Oracle are building machine learning tools based on the cloud technology to provide a wide range of solutions to businesses around the world28.
IoT devices frequently operate under resource constraints, rendering them susceptible to a variety of attacks, such as malware infections, denial-of-service (DoS) assaults, and data breaches. Furthermore, the connectivity of IoT devices to cloud services amplifies the potential for cyber threats.
In IoT-cloud configurations, a number of common attacks pose significant risks to system integrity and confidentiality of data. Distributed Denial of Service (DDoS) attacks overwhelm networks or services with enormous volumes of traffic from compromised IoT devices, rendering systems unusable29. Data exfiltration is unauthorized data removal from cloud storage or IoT devices, commonly through stealthy methods or insider threat. Spoofing attacks in which attackers assume the identity of authorized devices or users may cause unauthorized access and tampering of critical systems. The threats accentuate the immediate necessity for effective intrusion detection measures with the capability to detect and prevent such sophisticated attacks in real-time.
The cloud infrastructure serves as a centralized hub for data storage and processing, making it an appealing target for cybercriminals. Consequently, the security of IoT-cloud environments has become a paramount concern for both organizations and individuals.
Intrusion detection systems (IDSs) play an essential role in the security of IoT-cloud frameworks, facilitating the real-time identification of anomalies and intrusions30. Conventional IDSs typically depend on signature-based detection techniques, which fall short in addressing zero-day vulnerabilities and unidentified threats.
In recent years, advancements in machine learning and metaheuristic optimization methods have emerged as effective approaches for anomaly and intrusion detection within IoT-cloud settings31.
Bahaa et al.32 suggested a hybrid model by using Adaptive Particle Swarm Optimization–Whale Optimization Algorithm (APSO-WOA) to optimize convolutional neural network. while training, the suggested model APSO–WOA–CNN could obtain the highest efficacy value in comparison with other advanced models. While comparing the APSO–WOA–CNN to APSO–CNN, it was represented that the suggested model performed 1.25%, 1%, 11%, 1.2%, and 2% for accuracy, precision, kappa coefficient, Hamming loss, and Jaccard similarity coefficient more than APSO-CNN. However, APSO-CNN could outperform the other models mentioned in the article. Generally, it can be deduced that the suggested model could perform better than the other models.
Abd Elaziz et al.33 employed Capuchin Search Algorithm (CapSA) that was integrated with the developments of deep neural network to make an efficacious intrusion identification model for environments on the basis of IoT-cloud. In the beginning, the neural network was employed for gaining the optimum attributes from the IoT IDS data. After that, an efficacious feature choosing approach was suggested on the basis of CapSA. Four diverse datasets were employed, called BoT-IoT, NSL-KDD, CIC2017, and KDD99 that the suggested CNN-CapSA was examined based on them. In addition, by the use of evaluation metrics, the suggested model was compared with the other models. It was interpreted from the finding that the created method represented a superior efficiency in each dataset.
Patel34 offers an efficacious intelligent safety solution with the efficient healthcare approach for Arrhythmia categorization by the use of cloud computing situation. In the beginning, the patient’s ECG in dynamic and static environment has been gathered while employing sensors and has been stored within cloud. Moreover, CH (Cluster Head) choosing has been invented by the use of Hybrid tempest optimizer. To make sure the safety of the gathered data, the detection of intrusion has been invented and conducted to have access to secure data by the use of neural network. Here, the neural network has been optimized by the use of Hybrid tempest optimizer. In the end, the suggested model could gain the values of 95.29%, 96.78%, and 95.72% for specificity, sensitivity, and accuracy, respectively, which were higher compared to others’ outcomes.
Nizamudeen35 recommended a smart IDF (Intrusion Detection Framework) to identify the network attack that are on the basis of application. There were three diverse stages, namely pre-processing, feature classification, and feature selection. First, Integer- Grading Normalization (I-GN) approach was utilized to pre-process data. Second, OBL-RIO (Opposition-based Learning- Rat Inspired Optimizer) was developed for the stage of the feature selection. In the end, a 2D-ACNN (Array-based Convolutional Neural Network) was recommended as the binary classifier. In that study, Netflow-based datasets were used to test and train the suggested model, and it could accomplish the values of 95.20%, 2.5%, and 97.24% for accuracy, false positive rate, and detection rate.
Selvapandian and Santhosh36 presented an intrusion identification system on the basis of deep learning for multi-cloud IoT environment to address the constraints relevant to the particular field of study. The offered system of intrusion identification enhanced the accuracy of identification by the enhancement of the training efficacy. The results of the suggested model were, in turn, 97.51%, 96.28%, and 94.41% for detection rate, detection accuracy, and precision.
EfficientNet, a state-of-the-art machine learning model, has shown impressive performance in data classification tasks and has been adapted for anomaly detection in various domains. EfficientNet, recognized for its effectiveness in data classification, offers a valuable opportunity to enhance Intrusion Detection Systems (IDS) within IoT-cloud environments. The architecture’s proficiency in feature extraction can be utilized to bolster the detection capabilities of IDS. Fatani et al. underscored the importance of feature extraction and selection in IDS, suggesting that the incorporation of EfficientNet could result in more precise and efficient anomaly detection in IoT networks37. Furthermore, the implementation of feature extraction techniques is essential for the development of robust IDS, as noted by Xu et al., who investigated various machine learning algorithms for classification in IoT networks38.
However, its performance can be further improved by combining it with optimization techniques. Metaheuristic algorithms, such as the Football Team Training Algorithm (FTTA), have been successfully applied to various optimization problems, including anomaly detection and intrusion detection.
This study proposes a novel approach to intrusion detection in IoT-cloud environments by combining EfficientNet with a newly modified metaheuristic algorithm, called Enhanced Football Team Training Algorithm (EFTTA). The proposed model, EfficientNet/EFTTA, is designed to detect anomalies and intrusions in IoT-cloud environments with high accuracy and efficiency. The performance of the proposed model is evaluated using a standard dataset and compared with other optimization algorithms using various classification performance measures.
In general, machine learning techniques, especially EfficientNet and Enhanced Football Team Training Algorithm (EFTTA), yield critical emphasis to the model’s overall accuracy owing to the advanced feature extraction and optimization. EfficientNet, being a state-of-the-art convolutional neural network, provides the best performance with intricate pattern representation from high-dimensional IoT-cloud data, thereby enabling detection of subtle anomalies that could have been left out by traditional detection methodologies. On the other hand, EFTTA supports classification by optimizing the exploration-exploitation tradeoff through adaptive parameter tuning, k-means clustering, and hybrid learning equations to better converge the existing model towards optimal solutions. All the above efforts combined through EfficientNet’s feature extraction and EFTTA’s optimization make the model very high in accuracy as validated with superior performance on the NSL-KDD and BoT-IoT datasets contrary to others in the states of the art.
Dataset description
This study used two different datasets to assess the effectiveness of the model which will be introduced: NSL-KDD39 and BoT-IoT40.
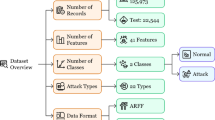
The Network Socket Layer-Knowledge: Discovery in Databases (NSL-KDD) dataset is a publicly available resource that was developed to address significant challenges affecting the accuracy of intrusion detection, building upon the earlier KDD Cup’99 dataset. This dataset was refined by removing duplicate records present in the KDD Cup’99 dataset, which contained a substantial number of redundant packets. The NSL-KDD dataset is divided into two primary subsets: the training set (KDDTrain+) and the test set (KDDTest+). The NSL-KDD is a derived dataset without duplicated network traffic records and contains more than one million records grouped into four categories besides the normal records. Table 1 shows the statistical information of this dataset.
It encompasses 22 distinct training intrusion attacks and features 41 attributes, of which 21 pertain to the connection itself and 19 describe the characteristics of connections within the same host. The dataset includes a variety of attack types, such as Denial of Service (DoS) attacks, Probe attacks, Remote to Local (R2L) attacks, and User to Root (U2R) attacks.
It has been extensively utilized as a benchmark for assessing intrusion detection techniques and has proven effective in facilitating comparisons among various methodologies. This dataset can be obtained from the following website:
https://www.kaggle.com/datasets/hassan06/nslkdd/data.
The next dataset, BoT-IoT. The Bot-IoT dataset serves as a publicly available resource aimed at assessing the efficacy of intrusion detection systems within IoT networks. This dataset was developed through the simulation of various IoT devices and their corresponding network traffic, followed by the introduction of botnet attacks into the environment. It comprises 73 features derived from the network traffic, which include metrics such as packet size, packet count, and protocol details. Table 2 shows the statistical information of this dataset.
The dataset encompasses four distinct types of botnet attacks: Mirai, BASHLITE, Andromeda, and Gafgyt. It is organized into two subsets: a training set and a test set, totaling 70,000 samples. Designed to replicate authentic IoT network traffic, this dataset offers a rigorous benchmark for evaluating the performance of intrusion detection systems. This dataset can be obtained from the following website:
https://www.kaggle.com/datasets/vigneshvenkateswaran/bot-iot.
EfficientNet
The structure of EfficientNet is a convolutional neural network that has been specifically designed for data classification, and focuses on improving efficiency. Google researchers Quoc V. Le and Mingxing Tan have presented this architecture in their paper with the title of “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”41.
EfficientNet is designed with the idea of addressing challenges related to model scaling by uniformly modifying network width, depth, and resolution utilizing a predefined set of scaling elements. This network ensures a balanced between the capacity of the network and the resolution of the input data, which leads to improved efficacy and efficient use of resources.
The basic structure of EfficientNet is defined by an inverted residual structure that integrates mobile inverted bottleneck blocks, which are similar to MobileNetV242. The network’s structure is illustrated below [Fig. (1)]:

The structure of the EfficientNet.
This design choice improves calculational efficacy and optimizes feature extraction abilities. The network consists of multiple phases; each includes several mobile inverted bottleneck blocks. Furthermore, skip relations are employed to aid gradient propagation and improve the training procedure.
Scaling method
EfficientNet presents a compound scaling method to optimize network width, depth, and resolution simultaneously. A base network (EfficientNet-B0) is initially established, and then it is improved by applying particular scaling factors (\(\:\alpha\:\), \(\:\beta\:\), \(\:\gamma\:\)) to generate more innovative models (EfficientNet-B1, B2, B3, etc.). The compound scaling formula is used to calculate these scaling factors:
here, a scaling element, which determines the scaled model’s dimension has been demonstrated by \(\:\varphi\:\). The values\(\:\:\beta\:\), \(\:\alpha\:\), and \(\:\gamma\:\) are established by performing a grid search on a small dataset, which indicates the optimal scaling proportions for width, depth, and resolution, respectively.
EfficientNet-B0
EfficientNet-B0 is the initial model in the EfficientNet series, which has been created by modifying the MBConv-1 block from MobileNetV2. Its structure includes an initial convolutional layer, and several mobile inverted bottleneck blocks placed at different phases. In every stage, the number of channels increases, and the spatial dimensions decrease due to stride-2 convolutions. Here is a basic illustration of the structure of EfficientNet-B0:
A \(\:3\times\:3\) convolution with stride 2 and 32 filters:
-
a)
Step 1: MBConv block with expansion ratio of 1, stride 1, and 16 filters.
-
b)
Step 2: MBConv block with expansion ratio of 6, stride 2, and 24 filters.
-
c)
Step 3: MBConv block with expansion ratio of 6, stride 2, and 24 filters.
-
d)
Step 4: MBConv block with expansion ratio of 6, stride 2, and 40 filters.
-
e)
Step 5: MBConv block with expansion ratio of 6, stride 1, and 112 filters.
-
f)
Step 6: MBConv block with expansion ratio of 6, stride 2, and 112 filters.
-
g)
Step 7: MBConv block with expansion ratio of 6, stride 1, and 192 filters.
-
h)
Step 8: MBConv block with expansion ratio of 6, stride 1, and 320 filters.
-
i)
1 × 1 convolution with the quantity of classes as filters.
Compound scaling
The compound scaling technique is used to increase EfficientNet-B0 into bigger models. This includes increasing the width, depth, and resolution based on particular equations:
The depth multiplier influences all network levels by increasing the number of layers in every level. The width multiplier determines the amount of channels in every layer, and the resolution multiplier illustrates the dimensions of the input data.
Swish activation
The use of the Swish activation function is also incorporated in EfficientNet, and it is defined as follows:
here, the learnable parameter is demonstrated by \(\:\beta\:\). Swish has illustrated better results than ReLU while maintaining calculational effectiveness.
Squeeze-and-Excitation blocks
EfficientNet models, such as MobileNetV3, can incorporate Squeeze-and-Excitation (SE) blocks, which allow the network to perform channel-wise attention, and improves the model’s representational capacity.
Enhanced football team training algorithm (FTTA)
This optimizer has been developed with the purpose of replicating the intense training strategies employed by the players of football sport. Commonly, the training of football has been separated into 3 diverse sections, including Individual extra training, Collective training, and Group training. The particular approaches and formulas pertinent to it have been expressed in the subsequent sections.
Collective training
The individuals commence with training in group by the use of the coaches’ help. The coaches assist them in determining their ability utilizing different cost functions. After that, the individuals experience the training according to the capability level of the candidates. The candidates have been separated into 4 distinct classes, comprising Discoverers, Followers, Volatilities, and Thinkers. Each individual might alter its situation in each iteration.
Followers.
These members have found to be passionate followers of the optimum member that try to be optimum individual in all the dimensions. On the other hand, as a result of restrictions existing in the power, the dimensions move towards the optimum individual. The current procedure is mathematically explained in the following way:
where, the amount of iterations has been exhibited through \(\:k\), the existing finest individual has been depicted through \(\:{F}_{Best}^{k}\), and the current parameter within the \(\:{j}^{th}\) dimension has been demonstrated via \(\:{F}_{Best,j}^{k}\). The current candidate \(\:i\) has been displayed via \(\:{F}_{i}^{k}\), and the current parameter within \(\:{j}^{th}\) dimension has been indicated through \(\:{F}_{i,j}^{k}\). Ultimately, the novel situation the individual within \(\:{j}^{th}\) dimension has been exhibited through \(\:{F}_{i,j}^{k}new\).
Discoverer.
These individuals have been considered more intelligent compared to the previous individuals. These individuals have the ability to identify the worst and finest candidates. Therefore, they try to approach the optimum individual while trying not be amid the worst candidates. The current operation is implemented by the use of the following equation:
where, the present worst individual has been displayed through \(\:{F}_{Worst}^{k}\), and the parameter within \(\:{j}^{th}\) dimension is represented via \(\:{F}_{Worst,j}^{k}\). Subsequently, the quantity of iterations has been exhibited via \(\:k\), the situation of an individual within \(\:{j}^{th}\) is illustrated via \(\:{F}_{i,j}^{k}new\).
Thinkers.
These candidates have been found to be more intelligent in comparison with other individuals. They are capable of identifying the distinctions between the worst and the finest candidates, while trying to decrease the variations in all the dimensions. The current operation is computed using the formula below:
where, the vector of distinction between the finest and the worst candidates within \(\:{j}^{th}\) dimension has been illustrated by \(\:{F}_{Best,j}^{k}-{F}_{Worst,j}^{k}\).
Volatilities.
These candidates work in an independent manner and function based on their procedure learning, resulting in several changes in their situation. While the quantity of iterations upsurges, the situation of candidate gets smaller. The following equation calculates the volatility of individual’s situation:
where, the stochastic number has been represented via \(\:t\left(k\right)\) while it has \(\:t\) distribution. The existing distribution’s degree of freedom has been taken into account as the present quantity of iterations. The more increase in the degree of freedom, the more \(\:t\)-distribution approaches the average, that is 0. The distribution is steadily reduced at both ends, and it gets like normal distribution. The more the quantity of iterations, the more fluctuation is reduced, resulting in change from exploration to exploitation.
Group training
Once the joint training has been accomplished, the training program of football commences the training in group. The coach divides the individuals into 4 various categories based on their characteristics, namely Midfielders, Goalkeepers, Defenders, and Strikers.
During the sessions of group training, the MGEM adaptive clustering (MixGaussEM) technique was employed for simulation of the decision-making process of coaches and categorizing the individuals into 4 groups according to their distinct manners. A minimum requirement has been established for the team size; there must be at least two participants in every team. If the number of participants in any team gets less than the specified minimum requirement, the group training stops.
As a result, the coach must group the individual once more while employing a stochastic grouping strategy, and the members have been classified into 4 various classes stochastically. Once the groups are organized, each individual probably learn from other candidates by communicating with them. The group training has been categorized into 3 distinct stages, namely Random communication, Optimum learning, and Random learning. The probability of learning has been expressed via \(\:{p}_{study}\), and the probability of communication has been represented via \(\:{p}_{comm}\). Ultimately, it should be noted that the individuals choose its situation on a random basis during all the iterations.
Optimum learning.
During all the dimensions, each individual probably accomplished the capacity of each optimal individual in the group. The current operation has been illustrated subsequently:
where, the finest individual within \(\:{l}^{th}\) group has been indicated via \(\:{F}_{Best}^{k,tea{m}_{l}}\), the \(\:{l}^{th}\) group has been illustrated via \(\:tea{m}_{l}\), the best individual within \(\:{j}^{th}\) dimension and \(\:{l}^{th}\) team has been depicted through \(\:{F}_{Best,j}^{k,tea{m}_{l}}\), the novel location of the individual within \(\:{j}^{th}\) dimension after learning in an optimum manner has been represented via \(\:{F}_{i,j}^{k,tea{m}_{l}}new\).
Random learning.
In all dimensions, the individuals possibly learn the capacity of the random individual. The present procedure has been represented in the following manner:
where, the random individual within team \(\:l\) is demonstrated through \(\:{F}_{Random}^{k,tea{m}_{l}}\), the team \(\:l\) has been illustrated through \(\:tea{m}_{l}\), the random individual within \(\:{j}^{th}\) dimension and team \(\:l\) has been illustrated through \(\:{F}_{Random,j}^{k,tea{m}_{l}}\), the situation of individual within \(\:{j}^{th}\) dimension after stochastic learning has been indicated through \(\:{F}_{i,j}^{k,tea{m}_{l}}new\).
Random interaction.
Conventionally, learning procedure has been considered one facet of training. In addition, it is really important for the individuals to exchange thoughts, resulting in improved skill. During each dimension, the individuals are willing to interact with other candidates of their group.
When \(\:{p}_{comm}\) is equal to or larger than \(\:rand\), the following formula is developed.
where, a stochastic individual within group \(\:l\) is demonstrated through \(\:{F}_{Random}^{k,tea{m}_{l}}\), the team \(\:l\) is depicted by \(\:tea{m}_{l}\), the random individual within \(\:{j}^{th}\) dimension and group \(\:l\) is illustrated through \(\:{F}_{Random,j}^{k,tea{m}_{l}}\), the stochastic number that is distributed normally is represented via \(\:Randn\), and its multiplication by (\(\:1+randn\)) represents that two individuals can comprehend abilities of other people.
When \(\:{p}_{comm}\) is larger than \(\:rand\), the following formula is calculated:
Random error.
While training group, errors probably occur, resulting in members unintentionally learn each other’s dimensions. Although this occurrence is considered to be slow, it is factual and objective. The potential for error is indicated by \(\:{p}_{error}\).
Individual extra training
Once the training of group has finished, the cost value of the individuals must be enhanced by recalculating them, removing all poor values, and employing the optimum values. Once they are enhanced, each coach chooses the finest individual and trains them for improving themselves. Moreover, it lets them guide other individuals while training in an efficacious manner. The training equation is calculated sub subsequently:
Gauss and Cauchy’s joint distinction has been employed for illustrating the additional training. Gaussian-Cauchy distribution was selected since many individuals commonly are not well proficient in the beginning. Hence, the finest individual progresses significantly.
The function of Cauchy distribution has a considerable influence and provides myriad opportunities for global search and personal development. The more the number of iterations, the more difficult it becomes for the candidates to enhance their capabilities. At the present time, the Gaussian distribution can account for an extensive amount, resulting in a decrease in advancement of members and an upsurge in possibility of exploitation.
Enhanced football team training algorithm (FTTA)
The preliminary Football Team Training Algorithm (FTTA) has undergone enhancements to develop the Enhanced Football Team Training Algorithm (EFTTA). The EFTTA integrates various mathematical improvements aimed at increasing the convergence rate, optimizing the exploration-exploitation balance, and enhancing the algorithm’s overall performance.
-
Collective Training.
The collective training phase remains largely unchanged, with the exception of the introduction of a new parameter, α, which controls the influence of the best individual on the followers, where:
Followers:
where, α ∈ [0,1] is a tuning parameter that controls the strength of the influence of the best individual on the followers.
Discoverer:
Thinkers:
Volatilities:
where \(\:t\left(k\right)\) describes a stochastic number with a t-distribution, and the degree of freedom is increased as the number of iterations increases.
-
Group Training.
The group training phase has been revised to include a novel grouping strategy that utilizes the k-means clustering algorithm. This algorithm facilitates the categorization of individuals into four distinct clusters according to their characteristics. After the formation of these groups, the individuals within each cluster engage in mutual learning through the application of the following equations.
Optimum learning:
Random learning:
Random interaction:
Random error:
-
Individual Extra Training.
The individual extra training phase has been modified to incorporate a new training equation that uses a combination of Gaussian and Cauchy distributions.
where, Gauss and Cauchy are distributions with mean 0 and variance 1, and k is the number of iterations.
The proposed approach incorporates several key features that enhance its performance, including the introduction of the adaptive α parameter, which allows for adaptive control of the influence of the best individual on the followers, thereby improving the convergence rate. Additionally, the use of k-means clustering algorithm for grouping individuals improves the grouping strategy and reduces computational complexity. Furthermore, the new learning equations for optimum learning, random learning, and random interaction have been designed to improve the exploration-exploitation trade-off and convergence rate. Finally, the incorporation of a combination of Gaussian and Cauchy distributions in the individual extra training phase enhances the global search and personal development of the individuals, allowing for more effective exploration of the solution space. The flowchart diagram of the proposed Enhanced Football Team Training Algorithm is illustrated in Fig. (2).

The flowchart diagram of the proposed EFTTA.
The Enhanced Football Team Training Algorithm (EFTTA) introduces some significant enhancements to current metaheuristic algorithms such as Particle Swarm Optimization (PSO), Genetic Algorithms (GA), and Ant Colony Optimization (ACO). One such significant enhancement is the introduction of an adaptive parameter α, which dynamically adjusts the influence of the best player on followers during the entire collective training process. This provides for more adaptive and more effective trade-off balancing of exploration and exploitation, leading to faster convergence rates.
In addition, EFTTA uses a k-means clustering algorithm in member grouping during group training, which optimizes the grouping strategy and reduces computational complexity. The algorithm also integrates new learning equations for optimal learning, random learning, and random interaction, designed to maximize the exploration-exploitation trade-off and further enhance convergence.
Moreover, the additional training stage of the individual uses the combination of Gaussian and Cauchy distributions for more global search capability and individual growth. All these modifications together make the EFTTA better than other conventional metaheuristics in optimizing the EfficientNet model for intrusion detection systems in IoT-cloud environments using a more efficient and effective method.
The proposed EFTTA supplements the efficiency of EfficientNet through its significant advancements over conventional optimization approaches. EFTTA comes with an adaptable parameter \(\:\alpha\:\) that dynamically reinforces the contributions of better individuals to others during the collective training stage, leading to a better exploration-exploitation ratio and faster convergence rates.
The main thrust of EFTTA is in its inclusion of individuals into groups during training by the well-known k-means clustering algorithm, which maximizes grouping strategy and reduces computational complexity, as compared to the traditional approaches. Also integrated within the framework are the new learning equations for optimum learning, random learning, and random interaction. These learning equations maximize the conversion-exploitation balance and further improved convergence.
The individual extra training phase is now a mixture of Gaussian and Cauchy distributions, strengthening global search capabilities and individual development to better explore the solution space. Besides, these improvements will enable EFTTA to optimize EfficientNet beyond a traditional metaheuristic algorithm, resulting in better performance in terms of intrusion detection in IoT-cloud environments.
Optimization of EfficientNet for classification
To improve the efficacy of EfficientNet for data classification, it is possible to define a cost function with the goal of minimizing cross-entropy loss by comparison between the predicted probabilities of classes and the true labels. This cost function can be defined as follows:
here, the cost function has been demonstrated by \(\:J\left(\theta\:\right)\), and the model parameters have been indicated by \(\:\theta\:\). The entire number of the training samples has been illustrated by \(\:N\). The number of classes has been indicated by \(\:C\). The variable \(\:{\widehat{y}}_{ic}\) illustrates the ground truth label for the \(\:{i}^{th}\) sample in the \(\:{c}^{th}\) class. The variable \(\:{\widehat{y}}_{ic}\) indicates the forecasted possibility (\(\:{i}^{th}\) sample belongs to \(\:{c}^{th}\) class). The EfficientNet structure should be optimized for data classification by modifying different important parameters.
The amount of layers in every step, known as network depth, can be enhanced to maximize or minimize the ability and complication of the network. Changing the mount of channels in every layer, referred to as network width, also influences the model’s complication. Higher calculational resources are required when increasing the input data resolution, which provides more detailed data.
The choice of optimizer and learning rate affects both the generalization and convergence of the training process. Regularization approaches, such as batch normalization, dropout, and weight decay are employed to avoid overfitting and improve the model’s ability to generalize. By carefully enhancing these parameters and training EfficientNet on a large labeled set of data, the structure can be optimized for data classification tasks, and attains high accuracy while remaining computationally efficient. This approach guarantees that EfficientNet achieves a balance among model complication, calculational requirements, and effectiveness, and makes it suitable for a wide range of model arrangement applications [Table 3].
The table demonstrates how different combinations of hyperparameters affect the value of cost function, specially the cross-entropy loss in this case. A lower value of cost function indicates better efficacy in the task of classifying data. It is important to note that these values are just instances, and actual results may vary depending on the model initialization, specific dataset, and other factors. Hyperparameters are typically enhanced using techniques, like grid search, Bayesian optimization, or random search to find the integration that attains the best efficacy for the task of data classification.
In an Internet of Things (IoT)-cloud environment, the fluctuating states of bandwidth, latency, and packet loss are the important network conditions that would affect the effectiveness of the EfficientNet/EFTTA model. Such conditions could determine how a model can efficiently process real-time data streams, especially in situations where speed for transmitting data is important for detecting intrusion in time. The model’s responsiveness and accuracy in identifying anomalies could be inhibited by increased latency or reduced bandwidth, as these would delay the transfer of data from the IoT devices to the cloud. Disruption by intermittent connectivity or network outage may also fail to transfer the data continuously, thus leading to faulty input or incomplete and fragmented inputs that would degrade performance. However, that has been mitigated to an extent because of the potent feature extraction of EfficientNet and further optimalization through EFTTA.
Methodology
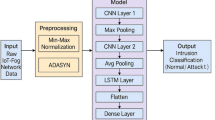
The suggested EfficientNet/EFTTA model for detecting intrusions in IoT-cloud environments consists of a two-step approach: the first stage focuses on feature extraction through EfficientNet, while the second stage employs the Enhanced Football Team Training Algorithm (EFTTA) for classification.
Feature extraction using EfficientNet
EfficientNet represents a series of convolutional neural networks (CNNs) that have demonstrated significant efficacy in image classification tasks. In this study, EfficientNet has been modified to facilitate the extraction of features from network traffic data within IoT-cloud environments. The structure of EfficientNet is composed of multiple convolutional and pooling layers, culminating in a classification head. Figure (3) shows the.

Feature extraction module based on a simple EfficientNet.
Let us denote the input network traffic data as \(\:x\in\:{\mathbb{R}}^{n\times\:d}\), where \(\:n\) signifies the number of data points and \(\:d\) indicates the number of features. The EfficientNet model can be expressed as a function \(\:f(x;\theta\:)\), with \(\:\theta\:\) denoting the model parameters. The process of feature extraction can be mathematically articulated as follows:
where, \(\:z\in\:{\mathbb{R}}^{n\times\:k}\) represents the extracted feature representation, and \(\:k\) is the number of features derived from the EfficientNet model.
Enhanced football team training algorithm (EFTTA)
As mentioned before, EFTTA is a metaheuristic optimization algorithm that draws inspiration from the team training dynamics observed in football. This algorithm emulates the functioning of a football team, where each player (agent) fulfills a distinct role, thereby enhancing the overall performance of the team. In the realm of intrusion detection, EFTTA is employed to refine the classification process.
Let us denote the extracted features as \(\:z\), which serve as the input for the EFTTA algorithm. The algorithm operates with a population of agents, each symbolizing a potential solution to the classification challenge. These agents are initialized with random weights and biases, which are subsequently updated iteratively based on their performance metrics. Mathematically, the EFTTA algorithm can be expressed as follows:
where, \(\:z\in\:{\mathbb{R}}^{n\times\:c}\) represents the predicted output, \(\:w\in\:z\in\:{\mathbb{R}}^{k\times\:c}\) denotes the weight matrix, \(\:b\in\:z\in\:{\mathbb{R}}^{c}\) signifies the bias vector, and \(\:c\) indicates the number of classes.
Classification
The predicted output y is passed through a softmax activation function to obtain the probability distribution over the classes:
The predicted class label is obtained by taking the argmax of the probability distribution:
To minimize this function alongside \(\:J\left(\theta\:\right)\), we can change it to a minimization function \(\:K\left(p\right)\) such that:
The architecture of the proposed methodology is illustrated in Fig. (4).

The architecture of the proposed methodology.
Results and discussions
This section outlines the findings from the experiments carried out to assess the performance of the proposed EfficientNet/EFTTA model utilizing the Bot-IoT dataset. The hardware and software setup for training and validating the algorithm includes these specifications: Dell XPS 15 featuring an Intel Core i7-10700 H processor and an NVIDIA GeForce GTX 1650 graphics card. The programming language used is Matlab R2019b.
In this section, we present a 5-fold comparison analysis between the proposed EfficientNet/EFTTA model and five other state-of-the-art models on two datasets: NSL-KDD and BoT-IoT. The results are compared with those of other leading models, including Adaptive Particle Swarm Optimization-Whale Optimization Algorithm to optimize convolutional neural network (APSOWOA-CNN)32, convolutional neural network and Capuchin Search Algorithm (CNN-CapSA)33, Neural network optimized by hybrid tempest optimizer (NN-HTO)34, 2D-ACNN35, Deep learning (DL)36 to illustrate the efficacy of the proposed methodology.
The comparison is based on seven performance metrics: Accuracy (AC), Sensitivity (ST), Precision (PR), F1-score (F1), Matthews Correlation Coefficient (MCC), False Positive Rate (FPR) and False Negative Rate (FNR). Table 4 illustrates the comparison Analysis of the EfficientNet/EFTTA model toward the others.
The results from the comparative analysis of the proposed EfficientNet/EFTTA model against five leading models across two datasets, NSL-KDD and BoT-IoT, illustrate the superiority of the proposed approach. The EfficientNet/EFTTA model surpasses the other models in various performance metrics, including accuracy, sensitivity, precision, F1-score, Matthews Correlation Coefficient, False Positive Rate, and False Negative Rate for both datasets.
Specifically, for the NSL-KDD dataset, the EfficientNet/EFTTA model records an accuracy of 98.56%, sensitivity of 98.23%, precision of 97.89%, F1-score of 98.05%, MCC of 0.975, FPR of 0.015, and FNR of 0.021, significantly exceeding the performance of the other models. Likewise, on the BoT-IoT dataset, the model achieves an accuracy of 99.01%, sensitivity of 98.89%, precision of 99.06%, F1-score of 99.23%, MCC of 0.992, FPR of 0.008, and FNR of 0.012, again demonstrating a significant advantage over the competing models. The EfficientNet/EFTTA model consistently outperforms other models, including APSOWOA-CNN, CNN-CapSA, NN-HTO, 2D-ACNN, and Deep Learning, across all evaluated performance metrics, underscoring its efficacy in detecting botnet attacks while minimizing false positives and false negatives. These results clearly establish the EfficientNet/EFTTA model as a robust and dependable solution for botnet detection, outshining existing state-of-the-art models.
For more analysis, we analyzed the complexity of the EfficientNet/EFTTA model toward the others. An increased number of parameters signifies a more intricate model, which may result in overfitting and reduced efficacy when applied to unfamiliar data. In this part, the parameter number of the proposed EfficientNet/EFTTA model are evaluated in comparison to other leading models in the field. Figure (5) shows the model comparison complexity.

The model comparison complexity.
The results showed that the proposed EfficientNet/EFTTA model holds a slightly greater number of parameters in comparison to the other models, reflecting a moderate degree of complexity. Specifically, the EfficientNet/EFTTA model comprises approximately 2.35 million parameters, surpassing the APSOWOA-CNN model, which has 1.88 million parameters, and the CNN-CapSA model, which contains 1.46 million parameters. Nevertheless, it has fewer parameters than certain other models, such as the NN-HTO with 987,654 parameters and the 2D-ACNN model with 765,432 parameters.
The moderate complexity of the EfficientNet/EFTTA model can be attributed to the integration of the EfficientNet and EFTTA architectures. The EfficientNet architecture is recognized for its effective parameter utilization, while the EFTTA architecture aims to enhance the model’s performance. This synergy results in a model that is both efficient and high-performing.
In contrast, the reduced parameter values in models like NN-HTO and 2D-ACNN may stem from their simpler architectures or fewer layers. However, this reduction in parameters could lead to diminished performance due to their restricted capacity. In general, the complexity analysis suggests that the EfficientNet/EFTTA model achieves a commendable equilibrium between complexity and performance. It is sufficiently complex to discern the underlying patterns within the data while remaining manageable for training and minimizing the risk of overfitting.
Even though the new EfficientNet/EFTTA model shows better performance in intrusion detection in IoT-cloud settings, it too is not perfect. One of its imperfections is its false positive rate (FPR), which, as low as 0.015 with the NSL-KDD dataset and 0.008 with BoT-IoT, can still be an issue in real-world deployments where even a small false alarm can prompt unnecessary investigations or impact system operation. Additionally, the 2.35 million or so parameters of the model also become an issue from the perspective of interpretability; being a system driven by deep learning, it is still not easy to find out the why behind a certain classification prediction, making it less transparent to security analysts. Finally, real-time responsiveness may suffer due to computational expense of EfficientNet and EFTTA both, particularly within high-speed IoT-cloud environments where timely detection and response are absolutely critical. These limitations highlight the need for further improvements to achieve a balance between accuracy, interpretability, and flexibility in actual operating environments.
Due to its performance efficiency, one cannot really deem the computational efficiency of the EfficientNet/EFTTA model to be without several trade-offs in comparison with prevailing IDS. This model has about 2.35 million parameters, higher than several alternatives, such as NN-HTO (987,654 parameters) and 2D-ACNN (765,432 parameters), thus incurring larger training and inference costs. The model’s complexity, in turns, would interfere with real-time responses, especially in high-speed IoT-cloud environments in which timely detection is paramount. However, thanks to EfficientNet’s parameter-efficient architecture combined with EFTTA’s optimization techniques, trade-offs between performance and computational requirements are balanced so that the model can more efficiently attain better accuracy and precision than APSOWOA-CNN (1.88 million parameters) and CNN-CapSA (1.46 million parameters). As far as one extreme goes, a robust computational expense would put limitations concerning its employment in resource-concealed environments, and at the other extreme, a medium complexity would indicate that it could efficiently learn from complex data patterns without much overfitting.
The EfficientNet/EFTTA method shows promising results with respect to minimizing false positives (FPR) and false negatives (FNR) in intrusion detection, being a case in point with findings that display a very low FPR of 0.015 for the NSL-KDD dataset and 0.008 for BoT-IoT versus an FNR of 0.021 and 0.012, respectively.
This is made possible by leveraging the feature extraction capabilities of EfficientNet with the enhanced football team training algorithm (EFTTA), which aims to optimize the accuracy of classification by balancing exploration and exploitation during the training process. With respect to its architecture, the model focuses on identifying true anomalies while decreasing its ability to misclassify, thus mitigating the challenges that arise with false alerts and missed detections.
Nevertheless, there are still evident improvements to warrant a more consummate realization of preventing false positives and negatives, especially in real-world implementations, where even a minor mistake can result in unwarranted investigation or transient interruptions to service.
In IoT-cloud environments having high-dimensional and complex data like smart city infrastructures or industrial IoT systems, the EfficientNet/EFTTA model exhibits superior performance. In these environments, large-scale real-time data streams are generated by multiple IoT devices like traffic cameras, air quality sensors, and smart lighting systems, necessitating robust feature extraction and classification. With the employment of EfficientNet, the model efficiently addresses complex patterns embedded in the data, while EFTTA guarantees an enhancement in optimization, thereby making it a potential candidate for application scenarios where noise and variances are pronounced. The model also performs exceedingly well in environments where computation resources can sustain its complexity as its architecture mandates higher processing power in respect to the simpler model. This is a quality of importance in cloud-supported IoT environments rather than resource-laden edge devices.
Conclusions
The Internet of Things (IoT) has fundamentally transformed our daily lives and interactions with the environment, with applications ranging from smart cities to e-commerce and healthcare. However, this heightened connectivity has also brought about new security challenges, interpreting IoT-cloud systems susceptible to cyber threats. As the number of connected devices continues to rise, the urgency for effective security measures becomes more critical. In response to this challenge, this paper introduced an innovative methodology for intrusion detection within IoT-cloud settings. The proposed mode used the capabilities of a modified version of EfficientNet. The modification of the EfficientNet is to optimize its parameters to get higher accuracy which was done here based on a newly adapted metaheuristic algorithm known as the Enhanced Football Team Training Algorithm (EFTTA). This approach was assessed using two standard datasets and benchmarked against other models, including Adaptive Particle Swarm Optimization-Whale Optimization Algorithm to optimize convolutional neural network (APSOWOA-CNN), convolutional neural network and Capuchin Search Algorithm (CNN-CapSA), Neural network optimized by hybrid tempest optimizer (NN-HTO), 2D-ACNN, Deep learning (DL) through various classification performance metrics, showing the competitive efficacy of the EfficientNet/EFTTA combination in identifying intrusions in IoT-cloud environments. Ultimately, the proposed EfficientNet-EFTTA framework presents a strong and effective solution for safeguarding IoT-cloud systems from cyber threats, thereby contributing to the expanding research on IoT-cloud security and underscoring the potential of hybrid methodologies in meeting the urgent demand for robust security solutions in these contexts. The EfficientNet/EFTTA model displays effectiveness in using intrusion detection in IoT-cloud environments, as this model can be extrapolated to other domains such as healthcare systems, financial fraud detection and smart grid security. The model can be deployed within healthcare systems to monitor patients’ data from connected medical devices, wherein data analysis by the model can be performed to identify anomalies that can point to system breaches in behavior as well as irregular health patterns. In financial fraud detection, with this model, transaction data streaming pertaining to banks can be analyzed to reveal suspicious activities on the transaction, as the model has enormous capabilities for extracting salient features and classifying them. Additionally, it may also be able to monitor energy consumption patterns in smart grids to help determine cyber-physical attacks and their operational inefficiencies. However, the utilization of this model as a universal model would require modifications, which include customizing the feature extraction regime to suit specific databases and applications, as well as ensuring it can cope with real-time processes expected in high-security environments. Besides, interpretability enhancements may be required to fulfill both regulatory or operational transparency requirements in sectors such as healthcare and finance. It is should noted that the current EfficientNet/EFTTA model offers good performance in intrusion detection in IoT-cloud environments, but inevitable limitations will require future improvement. One of the main drawbacks is its false positive rate (FPR), although the figure is generally low (0.015) for the NSL-KDD dataset while it was 0.008 for BoT-IoT. Such a figure can still attract probe investigations or necessitate system operations in real-world deployments where even the slightest false alarms are troublesome. Model complexity is another problem since its parameters run to almost 2.35 million, with the exception of their interpretation that prevents the security analyst from understanding some classification predictions due to the obfuscation of deep learning systems. Real-time responsiveness is also compromised due to the computational expense from both EfficientNet and EFTTA, especially in high-speed IoT-cloud environments where fast detection and responses are required. To remedy these shortcomings, future iterations may focus on improving model transparency through explainable AI techniques, further lowering the FPR through training processes and more diverse input datasets, and improving computational efficiency using lightweight architectures or parallel processing techniques.
Data availability
All data generated or analyzed during this study are included in this published article.
References
Vakili, A. et al. A new service composition method in the cloud-based internet of things environment using a grey Wolf optimization algorithm and mapreduce framework. Concurrency Computation: Pract. Experience. 36 (16), e8091 (2024).
Dehghani, M. et al. Blockchain-based Securing of data exchange in a power transmission system considering congestion management and social welfare. Sustainability 13 (1), 90 (2021).
Amiri, Z. et al. The deep learning applications in IoT-based bio-and medical informatics: a systematic literature review. Neural Comput. Appl. 36 (11), 5757–5797 (2024).
Heidari, A. et al. A reliable method for data aggregation on the industrial internet of things using a hybrid optimization algorithm and density correlation degree. Cluster Comput. 27 (6), 7521–7539 (2024).
Muhammad, N. et al. Radial basis function neural networks (RBFNN) for secure intrusion detection in the internet of drones (IoD). in Proceedings of the Bulgarian Academy of Sciences. (2024).
Heidari, A., Jabraeil, M. A. & Jamali Internet of things intrusion detection systems: a comprehensive review and future directions. Cluster Comput. 26 (6), 3753–3780 (2023).
Mir, M. et al. Application of hybrid forecast engine based intelligent algorithm and feature selection for wind signal prediction. Evol. Syst. 11 (4), 559–573 (2020).
Sun, G. et al. Live migration for multiple correlated virtual machines in cloud-based data centers. IEEE Trans. Serv. Comput. 11 (2), 279–291 (2015).
Zhou, W. et al. Hidim: A novel framework of network intrusion detection for hierarchical dependency and class imbalance. Computers Secur. 148, 104155 (2025).
Javadpour, A. et al. A Comprehensive Survey on Cyber Deception Techniques To Improve Honeypot Performancep. 103792 (Computers & Security, 2024).
Javadpour, A. et al. DMAIDPS: A distributed multi-agent intrusion detection and prevention system for cloud IoT environments. Cluster Comput. 26 (1), 367–384 (2023).
Shahin, M. et al. Advancing network security in industrial iot: A deep dive into AI-Enabled intrusion detection systems. Adv. Eng. Inform. 62, 102685 (2024).
Ghiasi, M. et al. Enhancing power grid stability: design and integration of a fast bus tripping system in protection relays. IEEE Trans. Consum. Electron. 71(1), 561–570 (2024).
Abid, A., Jemili, F. & Korbaa, O. Real-time data fusion for intrusion detection in industrial control systems based on cloud computing and big data techniques. Cluster Comput. 27 (2), 2217–2238 (2024).
Heidari, A. et al. Assessment of reliability and availability of wireless sensor networks in industrial applications by considering permanent faults. Concurrency Computation: Pract. Experience. 36 (27), e8252 (2024).
Heidari, A. et al. A hybrid approach for latency and battery lifetime optimization in IoT devices through offloading and CNN learning. Sustainable Computing: Inf. Syst. 39, 100899 (2023).
Heidari, A. et al. A QoS-aware technique for computation offloading in IoT-edge platforms using a convolutional neural network and Markov decision process. IT Prof. 25 (1), 24–39 (2023).
Heidari, A. et al. Everything you wanted to know about chatgpt: components, capabilities, applications, and opportunities. Internet Technol. Lett. 7 (6), e530 (2024).
Kikissagbe, B. R. & Adda, M. Machine Learning-Based intrusion detection methods in IoT systems: A comprehensive review. Electronics 13 (18), 3601 (2024).
Heidari, A. et al. Securing and optimizing IoT offloading with blockchain and deep reinforcement learning in multi-user environments. Wireless Netw. 31, 1–22. (2025).
Heidari, A., Navimipour, N. J. & Unal, M. A secure intrusion detection platform using blockchain and radial basis function neural networks for internet of drones. IEEE Internet Things J. 10 (10), 8445–8454 (2023).
Amiri, Z. et al. The applications of nature-inspired algorithms in internet of Things‐based healthcare service: A systematic literature review. Trans. Emerg. Telecommunications Technol. 35 (6), e4969 (2024).
Zanbouri, K. et al. A GSO-based multi‐objective technique for performance optimization of blockchain‐based industrial internet of things. Int. J. Commun Syst. 37 (15), e5886 (2024).
Zehao, W. et al. Optimal economic model of a combined renewable energy system utilizing modified. Sustain. Energy Technol. Assess. 74, 104186 (2025).
Chintapalli, S. S. N. et al. OOA-modified Bi-LSTM network: an effective intrusion detection framework for IoT systems. Heliyon, 10(8), 45–56 (2024).
Farea, A. & Küçük, K. Machine Learning-based intrusion detection technique for iot: simulation with Cooja. Int. J. Comput. Netw. Inform. Secur., 16(1), 230–241 (2024).
Xu, F., Yang, H. C. & Alouini, M. S. Energy consumption minimization for data collection from wirelessly-powered IoT sensors: Session-specific optimal design with DRL. IEEE Sens. J. 22 (20), 19886–19896 (2022).
Huang, S., Sun, C. & Pompili, D. Meta-ETI: Meta-Reinforcement Learning with Explicit Task Inference for UAV-IoT Coverage (IEEE Internet of Things Journal, 2025).
Amiri, Z., Heidari, A. & Navimipour, N. J. Comprehensive survey of artificial intelligence techniques and strategies for climate change mitigation. Energy. 308, 132827. (2024).
ZHANG, Y. & Zhe, X. Neural Network-Powered intrusion detection in Multi-Cloud and fog environments. Int. J. Adv. Comput. Sci. Appl., 15(6), 102–111 (2024).
Liao, H. et al. A Survey of Deep Learning Technologies for Intrusion Detection in Internet of Things (IEEE Access, 2024).
Bahaa, A. et al. A novel hybrid optimization enabled robust CNN algorithm for an IoT network intrusion detection approach. Plos One. 17 (12), e0278493 (2022).
Abd Elaziz, M. et al. Intrusion detection approach for cloud and IoT environments using deep learning and capuchin search algorithm. Adv. Eng. Softw. 176, 103402 (2023).
Patel, S. K. Improving intrusion detection in cloud-based healthcare using neural network. Biomed. Signal Process. Control. 83, 104680 (2023).
Nizamudeen, S. M. T. Intelligent intrusion detection framework for multi-clouds–IoT environment using swarm-based deep learning classifier. J. Cloud Comput. 12 (1), 134 (2023).
Selvapandian, D. & Santhosh, R. Deep learning approach for intrusion detection in IoT-multi cloud environment. Automated Softw. Eng. 28 (2), 19 (2021).
Fatani, A. et al. IoT intrusion detection system using deep learning and enhanced transient search optimization. IEEE Access. 9, 123448–123464 (2021).
Xu, H. et al. A data-driven approach for intrusion and anomaly detection using automated machine learning for the internet of things. Soft. Comput. 27 (19), 14469–14481 (2023).
Zaib, M. H. NSL-KDD: Network Security, Information Security, Cyber Security. (2019).
Venkateswaran, V. Bot_IoT. (2022).
Mohan, A. Enhanced Multiple Dense Layer EfficientNet. https://doi.org/10.25394/PGS.26018023.v1 (2024).
Rifai, A. M. et al. Analysis for diagnosis of pneumonia symptoms using chest X-ray based on MobileNetV2 models with image enhancement using white balance and contrast limited adaptive histogram equalization (CLAHE). Biomed. Signal Process. Control. 90, 105857 (2024).
Author information
Authors and Affiliations
Contributions
Jian Cui, Lan Shi1, Ahmed Alkhayyat and wrote the main manuscript text and prepared figures. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cui, J., Shi, L. & Alkhayyat, A. Enhanced security for IoT cloud environments using EfficientNet and enhanced football team training algorithm. Sci Rep 15, 20764 (2025). https://doi.org/10.1038/s41598-025-08343-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-08343-1
