
Abstract
The precise diagnosis of heart disease represents a significant obstacle within the medical field, demanding the implementation of advanced diagnostic instruments and methodologies. This article conducts an extensive examination of the efficacy of different machine learning (ML) and deep learning (DL) models in forecasting heart disease using tabular dataset, with a particular focus on a binary classification task. An extensive array of preprocessing techniques is thoroughly examined in order to optimize the predictive models’ quality and performance. Our study employs a wide range of ML algorithms, such as Logistic Regression (LR), Naive Bayes (NB), Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), K-Nearest Neibors (KNN), AdaBoost (AB), Gradient Boosting Machine (GBM), Light Gradient Boosting Machine (LGBM), CatBoost (CB), Linear Discriminant Analysis (LDA), and Artificial Neural Network (ANN) to assess the predictive performance of these algorithms in the context of heart disease detection. By subjecting the ML models to exhaustive experimentation, this study evaluates the effects of different feature scaling, namely standardization, minmax scaling, and normalization technique on their performance. The assessment takes into account various parameters including accuracy (Acc), precision (Pre), recall (Rec), F1 score (F1), Area Under Curve (AUC), Cohen’s Kappa (CK)and Logloss. The results of this research not only illuminate the optimal scaling methods and ML models for forecasting heart disease, but also offer valuable perspectives on the pragmatic ramifications of implementing these models within a healthcare environment. The research endeavors to make a scholarly contribution to the field of cardiology by utilizing predictive analytics to pave the way for improved early detection and diagnosis of heart disease. This is critical information for coordinating treatment and ensuring opportune intervention.
Similar content being viewed by others

Introduction
The opportune identification of heart disease is a critical component of preventive healthcare, as it facilitates effective interventions that have the potential to greatly enhance patient diagnosis. Heart disease, which is classified as a complex clinical syndrome, can be caused by an extensive variety of factors such as hypertension, coronary artery disease, valvular heart diseases, and cardiomyopathies1,2,3,4. These aforementioned conditions result in a compromised cardiac function, which significantly impairs the heart’s capacity to adequately circulate blood to satisfy the demands of the body5,6,7,8. Modernly, cardiovascular disease stands as the primary cause of mortality. The World Health Organization estimates that cardiac disorders contribute to 12 million fatalities annually across the globe. In 2017, there were 10.6 million newly reported cases of coronary heart disease worldwide, resulting in the unfortunate loss of 8.9 million lives. 126.5 million individuals were diagnosed with coronary heart disease in 20179,10,11,12,13. It is predicted that cardiac disease-related medical costs in the United States will increase by 41% between 2010 and 2040, from $126.2 billion to $177.5 billion14. There are numerous complications that can result from the progression of heart disease, including a substantial increase in mortality rates, recurrent hospitalizations, and diminished quality of life15. Due to the complex characteristics of cardiovascular disease and its significant ramifications for global public health, there is an increasing need for more precise and timely detection techniques16.
Cardiovascular disease continues to be a prominent contributor to mortality on a global scale, underscoring the criticality for sophisticated diagnostic instruments capable of accurately and efficiently prognosticating heart disease. The increasing sense of urgency has generated a burgeoning fascination with the application of ML17,18,19and Deep Learning (DL)20 methods to improve the predictive precision and effectiveness of heart disease detection. ML and DL, which falls under the category of artificial intelligence (AI)21,22,23,24provides robust functionalities for the examination of intricate datasets. It facilitates the detection of correlations and patterns that may elude human analysts at first glance. ML algorithms have the capability to analyze extensive quantities of patient data, including clinical symptoms, medical histories, laboratory results, and imaging studies, in order to forecast the probability of heart disease with an unprecedented degree of precision that was hitherto unattainable using only conventional statistical approaches. ML and DL have been utilized in various fields, including handwritten digit recognition,
disease diagnosis25,26,27depression detection28,29,30,31language processing32,object detection33,34and suspicious activity detection35,36etc. Furthermore, the capacity of ML models to consistently acquire knowledge from fresh data offers a prospect for the creation of dynamic diagnostic instruments that can progress in tandem with emergent patterns in the manifestation of cardiac disease and the results of treatments37. Accurate predictions in this domain necessitate the integration of complex data. Therefore, the incorporation of ML methods into the diagnostic procedure signifies a substantial progression in the domain of cardiology, holding the potential to revolutionize the existing strategy for identifying and treating heart disease. Through the optimization of diagnostic instruments’ predictive accuracy and efficiency, ML possesses the capacity to enable timely interventions, customize treatment approaches according to unique patient profiles, and ultimately enhance the prognosis for those susceptible to heart disease. Through the utilization of ML models’ predictive functionalities, healthcare providers are able to detect individuals who are at risk of developing a particular condition prematurely and execute intervention strategies that are tailored to target the distinct factors that contribute to each patient’s condition. As a whole, the introduction of ML and AI into the field of cardiology signifies a turning point in the battle against heart disease. Through the utilization of these technologies to analyze intricate medical data, the medical community has achieved an unprecedented level of capability in promptly identifying individuals who are at risk of developing heart disease and in formulating individualized treatment approaches that have the potential to substantially transform the trajectory of this perilous condition. For this, a through study on ML algorithms and various preprocessing techniques must be explored. In this study, we have addressed the following issues. The main contribution of this study includes:
-
1.
An extensive examination is conducted on a range of data preprocessing methods and their influence on the predictive efficacy of ML models with respect to heart disease.
-
2.
This study performs a comprehensive analysis of 12 different ML models, encompassing both conventional algorithms like SVM and DT, and more sophisticated methodologies like neural networks. We make a scholarly contribution to the field of medical diagnostics by identifying the most effective algorithms for predicting heart disease through an evaluation of these models.
-
3.
By addressing the difficulties associated with deploying ML solutions in real-world scenarios, our research provides recommendations for optimizing their effects on patient care and outcomes.
-
4.
Lastly, this study establishes a foundation for subsequent investigations concerning ML and the detection of cardiac disease. By identifying deficiencies in the existing body of literature and proposing potential avenues for additional research, our objective is to stimulate ongoing innovation and inquiry into the utilization of artificial intelligence in the context of cardiovascular health.
The remaining sections of this paper are structured as follows: Section two presents an outline of the most prevalent techniques for detecting and analyzing heart disease. Section three details the datasets, experimental procedure, and ML and DL techniques employed in this research. The outcomes of multiple experiments are presented in Section four. Finally, Section five highlights potential challenges and future avenues for the application of ML and DL in heart disease detection.
Literature review
Scientists have used several ML approaches to construct a model for forecasting cardiac disease. Lakshmanarao et al.6 suggest using ML techniques such as RF, NB, LR, and DT for the purpose of diagnosing cardiac problems. The UCI ML repository was used as the primary data source for this inquiry. Jindal et al.38 advocate using machine-learning techniques, such as LR and KNN, for the purpose of predicting and classifying individuals with cardiac disease. The analysis has shown that the K-NN algorithm has superior performance, with an accuracy rate over 88%. Sahoo et al.39 proposed using a variety of techniques, such as Naïve Bayes, SVM, DT, K-NN, and LR, to evaluate coronary artery disease data obtained from the UCI repository. The dataset consists of 13 important attributes. Based on the data analysis, it has been determined that the SVM approach has attained an accuracy of more than 85%, making it the most accurate method. Uyar et al.40 have developed a Genetic Algorithm (GA) that utilizes trained recurrent fuzzy neural networks (RFNN) to evaluate cardiac disorders. The UCI heart disease dataset was used in the research [23. Out of the 297 instances of patient data, 257 are allocated for training purposes, while 45 are specifically chosen for testing. The results indicated that the testing set had an accuracy percentage of 97.78%. Gupta et al.41 used a dataset sourced from the University of California, Irvine (UCI) repository to forecast the occurrence of heart illness. LR (LR) demonstrated superior performance compared to other supervised classifiers, including NB, SVM, KNN, DT, and RF. LR achieved higher precision, accuracy, specificity, F1 score, and sensitivity (or recall), with an accuracy rate of 92.30%. The heart disease dataset from UCI has been often used in past research works. Patil et al.42 used the LR method to construct a ML model that predicts the risk of cardiovascular disease (CVD) using the Cleveland dataset. The user inputs the medical data of the.
patient into the computer, after which the system analyzes and predicts the result. Reddy et al.43 introduced prediction models for the Heart disease Dataset (HFD) that use DT and NB algorithms. These models have the potential to provide valuable insights and improve outcomes in the clinical sector. The use of NB and DT algorithms on the High Frequency Dataset (HFD) resulted in accuracies of 86% and 82%, respectively. Kumar et al.44 examined the enhanced k-means neighbor classifier and contrasted it with the original k-means neighbor classifier. It was noted that the enhanced classifier had reduced risk since the occurrence of false negatives was decreased in the confusion matrix.Arabasadi et al.45 have developed an accurate hybrid method for identifying coronary heart disease. The technique may improve the performance of the neural network by about 10% by upgrading its initial weights using a genetic algorithm that proposes more favorable outcomes for the neural network. By using their methodology on the Z-Alizadeh Sani dataset, they have attained accuracy, sensitivity, and specificity rates of 93.85%, 97.5%, and 92.5%, correspondingly. Sonawane and Patil46 have developed a Multilayer Perceptron (MLP) neural network-based prediction technique for heart disease. The neural network of the system receives input from 13 clinical criteria. With a maximum precision of 98%, it is taught to use the back-propagation method to ascertain if the patient is afflicted with heart disease.
P.K. Anooj47 used a weighted fuzzy rule-based system to automatically collect data from the patient’s information in order to identify heart disease. The suggested approach for predicting heart disease involves two stages: an automated process for producing weighted fuzzy rules and developing a decision support system based on fuzzy rules. During the first phase, the process of data mining involves using a technique to choose attributes and assign weights to them in order to build weighted fuzzy rules. The selected weighted fuzzy rules and features are then used to build the fuzzy system. Jan et al.48utilized a combination of five distinct classification techniques, namely RF, neural network, NB, classification via regression analysis, and SVM, to construct a data mining strategy. This strategy was implemented on two benchmark datasets, specifically the Cleveland and Hungarian datasets, which were obtained from a UCI repository. In the analysis, it was shown that regression techniques were the least successful algorithm. However, RF algorithm achieved a very high accuracy of 98.136%. In49the feature extraction process used the correlation coefficient technique, followed by the application of ML algorithms like as SVM, LR (LR), and RF to predict cardiovascular disease (CVD) using the dataset from the Svetlana Ulianova research group. The results indicate that the SVM-based method attained an average area under the ROC curve of 78.84% using 5-fold cross-validation. This demonstrates that SVM performed better than LR and RF for the given data. A variety of ML techniques were used by Jindal et al. to forecast cardiac illness using the Cleveland dataset obtained from the UCI ML repository38. The LR, KNN, and RF classifiers were used to detect the illnesses. The mean accuracy of these models was 87.5%. The study conducted by Ghosh et al.50 used popular supervised algorithms, including DT, AB, GBM, RF, and KNN, in conjunction with composite classifiers. These methods were applied to the Cleveland dataset. The models used the bagging and boosting strategies. In addition, the comparison was made using runtime, computational complexity, and hyperparameter adjustment, resulting in an accuracy of 99.05%. From the review, it can be seen that most of the studies utilized only a few number of ML models and feature scaling techniques. In this study, we have utilized 12 ML models and 3 different feature scaling for heart disease detection.
Methodology
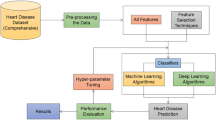
This task comprises several essential stages. The comprehensive workflow is illustrated in Fig. 1. We began by amassing the publicly accessible benchmark datasets. Once that is determined, the datasets are examined for missing values. In order to convert the categorical values present in the datasets to numeric values. After that, the input features are normalized. Following the conclusion of the preprocessing stage, PCA was utilized to extract the significant features. Following this, ML and DL models are developed. Subsequently, the models undergo testing using the test data after being instructed using the training data.
Dataset
A publicly available datasets has been used in this work. The dataset has been collected from UCI data repository51. This dataset was formed by amalgamating distinct datasets previously available separately but had not been joined previously51,52. Four cardiac datasets (Cleveland, Hungary, Switzerland, and the VA Long Beach) have been merged based on 14 shared characteristics in this dataset. Table 1 presents the features present on the dataset and their characteristics.
Data preprocessing
Data preparation is the first step in creating a ML model, signaling the beginning of the process. Real-world data is frequently insufficient, inconsistent, inaccurate, and lacks essential attribute values. Data preparation involves cleaning, organizing, and formatting raw data to be suitable for ML models. In this study, we have employed a variety of data preparation approaches and MI Score of the features which are presented in Figs. 2(a) and 2(b) respectively.

The workflow of the proposed methodology. The workflow begins with dataset collection. Then the data has been preproccessed. The various ML models has been developed after that. Finally, the models has been trained, and tested using various metrics.

This figure presents (a) workflow of data preprocessing, and (a) MI Score of the features.
Categorical data encoding
Category data encoding is the process of converting categorical variables into numerical variables to make them usable in ML models. Categorical data comprises variables grouped into different categories, such colors, locations, or types of items as shown in Table 1. Given that the majority of ML models rely on mathematical equations, it is essential to transform categorical data into numerical data to prevent any issues. We have converted the category data in the datasets into numerical values. We utilized the LabelEncoder() function from the sklearn package for this task.
Handling class imbalance
SMOTE has been employed as a means to rectify the class imbalance. SMOTE, which stands for Synthetic Minority Oversampling Technique, is a technique implemented in the domain of supervised learning to rectify class imbalances in datasets. As opposed to producing duplicates, it generates synthetic samples from the minority class, thereby circumventing the overfitting issue associated with random oversampling. SMOTE generates a more diverse set of examples compared to a straightforward duplication of minority class samples by generating synthetic samples as a linear combination of the original samples and their neighbors. We obtained a balanced dataset with an equal number of samples in each class after implementing SMOTE. Balancing the dataset using SMOTE was essential for this study because imbalanced datasets can lead to biased model performance, where the model favors the majority class. This bias often results in poor recall for the minority class, which is particularly problematic in heart disease detection as it may lead to misclassification of patients at risk. By creating a balanced dataset, we ensured that the models had an equal opportunity to learn patterns from both classes, leading to fairer and more reliable performance metrics.
Feature correlation analysis
A critical aspect of statistical analysis and data exploration is the comprehension of the interrelationships among variables. In pursuit of this objective, we utilized the Pearson correlation coefficient, a commonly employed technique for quantifying the linear association between two continuous variables within our dataset. The range of values for the Pearson correlation coefficient (r) is -1 to + 153. The intensity of the correlation is denoted by the magnitude of the coefficient, whereas the direction is indicated by the sign. The Pearson correlation method was utilized to examine the relationships between every pair of continuous variables in the dataset54. Through the identification of substantially correlated variables, one can acquire valuable insights into latent patterns and connections that may serve as indicators of intrinsic causal relationships or interdependencies within the dataset. The correlation matrix is presented in Fig. 3.
Feature importance analysis
Feature Importance Calculation: When constructing predictive models, it is critical to comprehend the significance of every feature in relation to the target variable. An efficacious approach to assess this level of importance is by employing the computation of Mutual Information (MI) scores. In contrast to more straightforward linear metrics, MI offers a broader measure that can encompass any type of relationship between variables, whether it be nonlinear or linear55. If two variables are independent, then the score is zero. Conversely, a larger score signifies an enhanced interdependence or correlation among the variables. The MI score of a feature with respect to the target variable indicates, in the context of feature selection, the degree to which knowledge of the feature reduces uncertainty regarding the target. The feature importance graph is presented in Fig. 2(b).

Feature correlation analysis using pearson correlation.
Feature scaling
An integral part of our research was preparing the data, with a special emphasis on feature scaling. Feature scaling is essential in ML models to standardize the range of independent variables, which aids algorithms in converging faster and achieving higher performance. Scaling the characteristics of our dataset assures that no one feature has a dominant influence because of its scale, considering the dataset’s heterogeneous nature. We tested four distinct feature scaling methods in comparison to a baseline model without any feature scaling to assess their influence on the efficacy of ML models in predicting heart disease. The Standard Scaler method was used to standardize the feature distribution by removing the mean and dividing by the standard deviation, resulting in features centered around zero and with a standard deviation of one56. This approach is very efficient when the features are normally distributed, although it may be used with any distribution57. Standard scaling helps stabilize the convergence of gradient descent algorithms by ensuring all features are on a comparable scale. It can be represented as:
Min-Max Scaling was used to standardize the features to a certain range, usually [0, 158. We standardized each characteristic by deleting its minimum value and dividing by the range to guarantee equal contribution to the final forecast. This method is beneficial for situations where the parameters must fall inside a certain range and is commonly employed when the distribution is non-Gaussian.
Normalization, specifically L2 scaling, was employed to adjust individual samples to have a norm of one59,60. This method is beneficial in situations where the Euclidean distance between instances is significant61. This scaling approach improves the efficiency of algorithms that use distance between instances by normalizing each instance’s feature vector to have a Euclidean length of one. Models were trained without applying any scaling to the dataset to evaluate the inherent impact of feature scaling.
This method enabled a straightforward comparison to assess the efficacy of each scaling methodology in improving model performance. Integrating these feature scaling strategies into our preprocessing workflow allowed for a thorough assessment of their impact on model correctness and convergence. We compared heart disease prediction models with and without feature scaling to determine the benefits of each strategy and find the best preprocessing procedures for this particular application. The comparative analysis emphasized the significance of feature scaling in ML pipelines and offered guidance on choosing suitable scaling strategies depending on the data properties and model needs. Tables 2, 3 and 4, and 5 depicted the results found from the ML models without feature scaling, standardization, minmax scaling, and normalization conditions.
Machine learning models
In this investigation, we implemented ML techniques that are widely utilized across industries due to their straightforwardness and ability to generalize. The methodologies employed in this investigation are delineated as follows:
Logistic regression
As a predictive analysis algorithm, LR is predominantly applied to problems involving binary classification62. It operates by employing a logistic function, which is bounded between 0 and 1, to estimate probabilities. This feature renders it an exceptional instrument in situations where the probability of an occurrence must be predicted, such as determining the spam status of an email or the malignant or benign nature of a tumor. Logistic regression is fundamentally concerned with generating probability scores for observations and classifying them into two distinct categories via a decision threshold (typically set at 0.5).
Naive Bayes
NB is an algorithm for ML and predictive modeling that is both straightforward and potent63. It operates under the assumption that the existence of a specific feature in a given class is independent of the existence of any other feature (hence the term “naive”). It is founded upon Bayes’ theorem. Although NB simplifies the process, the resulting models can be quite accurate, particularly when used for tasks such as sentiment analysis, spam detection, and document classification. Known for its efficiency and speed, the algorithm is well-suited for high-dimensional data and is frequently employed in text classification tasks involving sizable datasets, where the algorithm’s simplicity can confer a substantial benefit.
Decision tree
A DT is an algorithm for supervised learning that is non-parametric and is utilized for both classification and regression tasks64. A DT, at its essence, employs a tree-like representation of choices and their potential ramifications, encompassing resource expenses, utility, and random event outcomes. It commences with a solitary node that branches into potential outcomes; each of those branches subsequently connects to additional nodes that branch off into additional possibilities. The aforementioned procedure persists until it reaches a leaf node, which subsequently yields the DT’s output pertaining to the corresponding input features. The routes connecting the root to the leaf signifies classification rules or regression routes. At each node, a determination is executed using regression estimates or the attribute that provides the most effective separation of classes, as determined by a specific criterion. The straightforwardness of DTs facilitates their comprehension, representation, and elucidation, thereby substantially bolstering their prevalence in decision-making endeavors that demand transparency.
Random forest
The RF algorithm is frequently utilized by data scientists and is one of the most widely recognized algorithms65,66. A frequently employed Supervised ML Algorithm, it is utilized to tackle problems related to classification and regression. The algorithm is composed of a multitude of DTs, with each DT analyzing a unique subset of the dataset and computing the mean in order to enhance the precision of the prediction. Multiple classifiers are integrated into the EL strategy in order to tackle a complex problem and improve the performance of the model. By aggregating the results, RF is an ensemble technique that reduces overfitting and outperforms a single DT.
Support vector machine
Support Vector Machine (SVM) is a potent supervised ML technique utilized for classification and regression tasks67. Never- theless, it is predominantly utilized in categorization difficulties68. SVM classifies data by identifying the hyperplane that most effectively separates the dataset into different groups. SVM aims to find the best hyperplane that optimizes the margin between various classes in the training dataset. Support vectors are the data points nearest to the hyperplane and have a significant impact on the hyperplane’s location and orientation. SVM enhances classification accuracy by increasing the margin between classes through the use of support vectors69. The SVM technique is adaptable and can handle linear and non-linear separations using kernel functions, making it suitable for a broad range of data formats and prediction problems.
K-Nearest neighbors
K-Nearest Neighbors (KNN) is an instance-based or lazy learning technique that approximates the function locally and delays all computation until function evaluation70. It is a versatile tool utilized for both classification and regression problems because to its simplicity and effectiveness. The K-NN algorithm operates by calculating the distances between a query and all data instances, choosing the designated number “K” of the nearest examples, and then either picking the most common label (for classification) or averaging the labels (for regression). Choosing the parameter K is crucial. A lower K number increases the impact of noise on the output, while a large value leads to increased computational costs and potential inclusion of points from other classes71. KNN is obvious and simple to understand, however its computational speed decreases notably as the dataset size increases.

Confusion matrix obtained from (a) LR, (b) NB, (c) DT, (d) RF, (e) SVM, (f) KNN, (g) GBM, (h) LGBM, (i) AB, (j) CB, (k) LDA, and (l) ANN without any feature scaling.
AdaBoost
AB, also known as Adaptive Boosting72,73is an ensemble learning technique mainly utilized for binary classification tasks. AB’s fundamental concept is amalgamating several weak classifiers to form a robust classifier. A weak classifier is a classifier that performs marginally better than random guessing. AB gives weights to each training instance and adjusts them as training advances. Classifiers are trained successively, with each new classifier emphasizing the training cases that were misclassified by preceding classifiers. The final prediction is generated by combining the predictions of all classifiers using a weighted majority vote or total. Boosting’s adaptability stems from its emphasis on challenging examples to classify and its strategy of assigning greater weight to classifiers with superior performance. AB enhances the accuracy of weak learning models, making it a potent tool for enhancing model performance.
Gradient boosting machine
Gradient Boosting Machine (GBM)74,75is a potent ML method that enhances DTs by adding weak learners sequentially to form a robust prediction model. Every new tree aims to rectify the mistakes of the trees constructed before it. Gradient Boosting Machine (GBM) employs the gradient descent approach to reduce errors in sequential models. It modifies the importance of a data point according on its prior categorization. When an observation is misclassified, its weight is increased, and vice versa. This method enables the model to focus more on challenging situations for classification, leading to enhanced accuracy. Gradient Boosting Machine (GBM) is versatile, being applicable to both regression and classification tasks, and has proven effective in addressing several real-world situations. GBM is a popular choice among data scientists for achieving excellent performance in predictive jobs due to its ability to handle different types of data and produce strong predictions.

Confusion matrix obtained from (a) LR, (b) NB, (c) DT, (d) RF, (e) SVM, (f) KNN, (g) GBM, (h) LGBM, (i) AB, (j) CB, (k) LDA, and (l) ANN with standard sca.
Light gradient boosting machine
LGBM, akin to alternative gradient-boosting methodologies, employs an incremental model construction approach76. It constructs a series of DTs, wherein each succeeding tree is designed to correct the errors committed by its antecedent. Assembled from the final model, this weighted sum of the individual trees. The model is denoted as follows:
where N represents the quantity of trees and fi(x) denotes the forecast of the i-th tree. The process of training entails the minimization of a loss function. In LightGBM, the objective function is composed of two components: the regularization term and the loss function77. The training process involves minimizing a loss function that measures the difference between the predicted and actual values. In LightGBM, the objective function is defined as:
Here, the loss function ensures the model’s predictions align closely with the target values, while the regularization term is included to prevent overfitting by penalizing overly complex models.
CatBoost
CatBoost (CB) is a gradient boosting algorithm that has been purposefully developed to efficiently process categorical features78. The system integrates novel methodologies to attain optimal performance and resilience, specifically when confronted with situations involving diverse data types and extensive datasets. CB minimizes a differentiable loss function L(yi,F(xi)), where xi is the feature vector, yi is the target variable, and F(xi) is the predicted value for the i-th instance. To minimize the loss function, CB assembles an ensemble of DTs in a sequential fashion. The model acquires knowledge of the gradient of the loss function in relation to the preceding predictions at each iteration t.

Confusion matrix obtained from (a) LR, (b) NB, (c) DT, (d) RF, (e) SVM, (f) KNN, (g) GBM, (h) LGBM, (i) AB, (j) CB, (k) LDA, and (l) ANN with minmax scaling.
CatBoost is a library for gradient boosting that has been purposefully developed to handle categorical features. It employs a gradient boosting implementation with DT and integrates innovative methods to efficiently manage categorical variables79.
Linear discriminant analysis
LDA80,81is a supervised ML technique specifically designed for classification applications. It is a method employed to identify a linear combination of characteristics that most effectively distinguishes the different classes within a dataset. LDA functions by mapping the data onto a reduced-dimensional space that optimizes the distance between the different classes. It does this by identifying a group of linear discriminants that optimize the ratio of variance across classes to variance within classes. It identifies the directions in the feature space that most effectively distinguish between the various data classes. LDA presupposes that the data follows a Gaussian distribution and that the covariance matrices of the various classes are identical. The assumption is that the data is linearly separable, allowing a linear decision boundary to effectively categorize the various classes.
Artificial neural network
A feed-forward Neural Network (FFN) is a type of network that creates a directed graph with nodes and edges. Data is transmitted along these edges from a node to the next without forming a cycle. The ANN82,83is a variant of FFN with three or more layers: an input layer, one or more hidden layers, and an output layer. Each of these layers contains many neurons or units, as defined in mathematical notation. To determine the number of hidden layers in an ANN, a hyperparameter tuning strategy is employed84,85. Information is transferred from one layer to the next without taking into account previous values, and all neurons in each layer are connected, as documented in sources86,87. ANN with n hidden layers may be expressed mathematically as follows:

Confusion matrix obtained from (a) LR, (b) NB, (c) DT, (d) RF, (e) SVM, (f) KNN, (g) GBM, (h) LGBM, (i) AB, (j) CB, (k) LDA, and (l) ANN with normalization.
Evaluation
Evaluation metrics
A variety of metrics were utilized to assess the performance of the models, with the primary ones being accuracy, recall, precision, and F1-score. The accuracy metric quantifies the proportion of correct predictions relative to the total number of predictions. The metric of accuracy quantifies the proportion of correct positive predictions relative to the overall number of positive predictions. Recall can be conceptualized as the ratio of precise positive forecasts to the sum of precise positive forecasts and erroneous negative predictions. The harmonic means of recall and precision constitutes the F1-score. The Area Under the Curve (AUC) is a metric utilized to assess the binary classification model’s performance. As the AUC increases, so does the model’s ability to distinguish between positive and negative instances. It is a prevalent metric utilized in ML to evaluate the performance of classification algorithms.
Result analysis
The experiment findings are divided into two parts based on the datasets. It is essential for computational models in ML to accurately generalize the obtained properties. Overtraining a model leads to the identification of a disrupted generalization during training. Data segmentation is commonly used to prevent overtraining. The categorization process involves finding a model or mapping function that divides data into many classes. We have tested several split ratios between training and testing to avoid overfitting. The train-test-split is set to 80%-20%.
Figures 4, 5 and 6, and 7 present the confusion matrix obtained from the ML models without feature scaling, standardization, minmax scaling, and normalization. Figure 8 presents the ROC curve obtained from the ML models without feature scaling, standardization, minmax scaling, and normalization. Tables 2, 3 and 4, and 5 present the results obtained from the ML models without feature scaling, standardization, minmax scaling, and normalization. At first, we experimented without applying any feature scaling to the features. The performance metrics of LR and ANN were found to be indistinguishable. Specifically, LR and ANN attained F1 Scores of around 0.8480 and 0.8480, respectively. A Cohen’s Kappa of 0.6898 further validates the substantial agreement between the two networks, which defies random variation. The individuals’ Log Loss values of 0.3781 and 0.3860, respectively, demonstrated their aptitude for precisely estimating probabilities. Accuracy and Recall for NB and LGBM were both 0.8824, while Precision and F1 Score were 0.8822 and 0.8822, respectively. The models demonstrated a considerable degree of accuracy in their forecasts, which was further supported by a Cohen’s Kappa value of 0.7595, which underscored their resilience. LGBM exhibited a marginally more advantageous Log Loss value of 0.2801, indicating a marginally superior capacity for probability calibration in comparison to NB’s 0.5216. SVM achieved an accuracy of 0.8676 and a precision of 0.8701, which is marginally greater. With an F1 Score of 0.8662 and Cohen’s Kappa of 0.7261, the results suggest a high degree of concurrence and a well-rounded performance among the classes. In our evaluation, the Log Loss was deemed inapplicable to this particular model. The DT demonstrated inferior accuracy and precision (0.8039), which were accompanied by a correspondingly moderate F1 Score and Cohen’s Kappa, thus indicating a more moderate level of performance. Significantly elevated at 7.0674, the Log Loss indicated less dependability in probability estimation. The efficacy of RF and ET was virtually identical, with ET marginally outperforming RF in terms of precision. Both models exhibited high Cohen’s Kappa scores (greater than 0.73), and their Log Loss values were comparatively low, which underscored their efficacy in estimating probabilities and accurately classifying data. XGBoost demonstrated comparable accuracy and recall to RF, while boasting a slightly superior Cohen’s Kappa of 0.7505 and a Log Loss of 0.3154. These metrics establish XGBoost as a model that is highly competitive with respect to both prediction accuracy and reliability. CB demonstrated superior performance by attaining the highest values for Accuracy (0.8971), Precision (0.8973), Cohen’s Kappa (0.7887), and Log Loss (0.2735). These results underscore CB’s exceptional capability to produce probabilistic predictions that are both accurate and dependable. Although KNN attained an Accuracy and Recall of 0.8725, its Precision and Cohen’s Kappa score were marginally higher at 0.7366 and 1.1207, respectively. These results indicate potential constraints in the estimation of probabilities using KNN. The GBM outperformed all other models in terms of Accuracy, Precision, and F1 Score, attaining values exceeding 0.90 for each metric. Furthermore, it exhibited the highest Cohen’s Kappa (0.7991), further emphasizing its remarkable capability to accurately model and predict binary outcomes with a high degree of dependability and precision. The efficacy of AB, LDA, SGD, and RC exhibited considerable variation, as evidenced by their varying accuracy values (0.8186 to 0.8431) and Cohen’s Kappa values (moderate to substantial agreement). Although their efficacy may not be the highest, it is evident that they are useful in certain circumstances, especially when their computational efficiency and model simplicity are taken into account as illustrated in Fig. 9.

ROC-AUC curve of ML models (a) without any feature scaling, (b) Standadization, (c) Minmax Scaling, (c) Robust Scaling, and (d) Normalization.
Then, we applied standardization on the features. In terms of Accuracy, Precision, Recall, and F1 Score, LR and ANN demonstrated indistinguishable performance, with all four metrics equaling 0.8431 and a Cohen’s Kappa of 0.6803. This finding suggests a significant level of concurrence in their forecasts that is not attributable to chance, as evidenced by a Log Loss of around 0.396, which signifies accurate estimation of probability. The NB model demonstrated noteworthy performance,

Results obtained from the ML models without any feature scaling implying (a) Accuracy, (b) Precision, (c) Recall, and (d) F1-score.
achieving Accuracy and Recall of 0.8824 and Precision of 0.8822. The predictive consistency of the model is indicated by a high Cohen’s Kappa value of 0.7595, while its F1 Score reflects its Precision. The logarithmic loss of 0.5216, while greater than certain models, indicates the model’s proficiency in estimating class probabilities. The SVM demonstrated a dependable performance, as evidenced by its Accuracy of 0.8627, Precision of 0.8629, and Cohen’s Kappa of 0.7179; however, the Log Loss metric is not relevant in this context. DT exhibited suboptimal performance metrics, as evidenced by their Accuracy of 0.7990 and Precision of marginally lower. The F1 Score exhibits a strong correlation with Precision, and its Cohen’s Kappa of 0.5886 and Log Loss of 7.2441 are both relatively low, indicating that the F1 Score has restricted predictive reliability. The performance of RF exhibited high Cohen’s Kappa values, which indicate precise predictions, and demonstrated some of the lowest Log Loss values, which indicate exceptional capability in estimating probabilities. LGBM emerged as the most effective, with CB attaining the highest Accuracy (0.8971) and Precision (0.8973). High Cohen’s Kappa values were exhibited by both models, signifying their superior predictive accuracy. CB demonstrated an exceptionally low Log Loss value of 0.2741, which underscored its adeptness in making precise probability predictions. KNN demonstrated comparable accuracy and precision to NB and LGBM. However, it exhibited a greater Log Loss of 0.9503, suggesting potential difficulties in estimating probabilities, notwithstanding its notable Cohen’s Kappa of 0.7608. GBM demonstrated its superior prediction and classification capabilities by attaining the highest Accuracy (0.9020), Precision (0.9021), and the highest Cohen’s Kappa (0.7991). Furthermore, it maintained a low Log Loss of 0.2773. The performance of AB, and LDA was inconsistent, with accuracy values ranging from 0.8186 to 0.8431 as depicted in Fig. 10. The models demonstrated a considerable level of concurrence in their predictions, as evidenced by their Cohen’s Kappa scores; however, they differed in the extent of Log Loss, which signifies variations in the precision of their probability estimations.
After that, we have applied minmax scaling on the features. In all aspects, LR and ANN achieved consistent performance, as evidenced by their identical F1 Scores, Accuracy, Precision, Recall, and F1 Score of around 0.848, accompanied by Cohen’s Kappa of 0.6898. This indicates a significant concurrence in forecasts that surpasses the element of chance. Their Log Loss values of 0.3781 and 0.3860, respectively, demonstrate their proficiency in estimating probabilities with precision. Accuracy was 0.8824 for both NB and LGBM, while Precision and F1 Score were marginally lower at 0.8822. The models exhibited considerable accuracy in their forecasts, as evidenced by a Cohen’s Kappa of 0.7595 for both of them, which indicates resilience. In contrast, LGBM exhibited a more favorable Log Loss of 0.2801, signifying superior probability calibration, in contrast to NB’s 0.5216. The SVM achieved an accuracy of 0.8676 and a precision that was marginally higher at 0.8701. Cohen’s Kappa was 0.7261, and the F1 Score was 0.8662, both of which were substantial, signifying remarkable performance across all courses. Log loss was not a relevant factor in evaluating SVM in this study. The Performance of DT was deemed moderate, as evidenced by their Accuracy of 0.8137 and Precision of 0.8152. Additionally, they exhibited a Cohen’s Kappa of 0.6224 and a comparatively high Log Loss of 6.7140, which indicated a diminished capacity for accurate probability estimation and prediction. RF exhibited robust performance in terms of accuracy (0.8873). RF exhibited meritorious Cohen’s Kappa scores (exceeding 0.73) and Log minimal Loss values, signifying their effectiveness in estimating probabilities and classification accuracy. The CB model demonstrated superior performance, attaining the highest values of Accuracy (0.8971), Precision (0.8973), and an impressive Cohen’s Kappa of 0.7887. Furthermore, it exhibited the most minimal Log Loss (0.2735) in comparison to all other models, underscoring its exceptional probabilistic prediction precision. The KNN algorithm demonstrated a marginally higher precision of 0.7366 and an accuracy of 0.8725. However, it incurred a significantly high log loss of 1.1207, which implies that its capability to estimate probabilities may be limited. GBM distinguished itself with the maximum values of Accuracy (0.9020), Precision (0.9021), and Cohen’s Kappa (0.7991), in addition to a minimal Log Loss of 0.2774. These results underscore the GBM’s outstanding capabilities in prediction, classification, and dependability. The performance of AB, LDA varied considerably. Accuracy ranged from 0.7696 for LDA to 0.8431 for AB, while Cohen’s Kappa indicated moderate to substantial agreement in predictions for all three methods. Lastly, we applied normalization in our features. The performance of LR and ANN was deemed moderate, as LR attained an Accuracy value of 0.6225 and ANN marginally surpassed it at 0.6618. The difficulty in prediction under normalization is reflected in their Precision and F1 Scores, while Cohen’s Kappa scores suggest negligible to low agreement beyond what would be expected by chance. The Log Loss values were comparatively large, which suggests that the probability estimates were not entirely precise. The performance of NB was significantly enhanced, as evidenced by its Accuracy of 0.7745 and Precision of 0.7885. The Cohen’s Kappa value of 0.5514 and the Log Loss of 1.0875 indicate a moderate degree of accuracy in estimating probabilities and predictive reliability, respectively. Both KNN and SVM demonstrated inferior performance metrics, as evidenced by KNN’s 0.6765 Accuracy and SVM’s 0.6814 Accuracy as depicted in Fig. 11.

Results obtained from the ML models after applying standardization implying (a) Accuracy, (b) Precision, (c) Recall, and (d) F1-score.
The higher Log Loss (for KNN) and Cohen’s Kappa values suggest that attaining dependable prediction and probability estimation under normalization conditions presents difficulties. Although DT demonstrated an enhancement in accuracy to 0.8088, they still encountered certain drawbacks, as evidenced by a greater log loss of 6.8907. However, a respectable Cohen’s Kappa of 0.6108 provided some reassurance regarding the predictions. RF demonstrated robust performance by attaining an impressive Accuracy value of 0.8824. RF demonstrated significant agreement in predictions, as evidenced by their high Cohen’s Kappa scores (above 0.72). Its relatively low Log Loss values highlighted the efficacy in classification accuracy and probability estimation. Among the best performers, LGBM, and CB all achieved an accuracy greater than 0.8627. The models above exhibited significant Cohen’s Kappa values, which signify strong agreement beyond mere chance. Also, they maintained low Log Loss values, particularly CB at 0.2872, which underscores their exceptional capability in estimating probabilities. AB and GBM both demonstrated strong performance, as evidenced by their respective Accuracy values of 0.8725 and 0.8824. The model demonstrated robust Cohen’s Kappa values and comparatively modest Log Loss values (particularly GBM’s 0.3130), suggesting that it could accurately predict and classify outcomes. The LDA model demonstrated a commendable performance, as evidenced by its Accuracy of 0.8235 and Precision of 0.8290. Furthermore, it achieved a moderate Log Loss of 0.3977 and a Cohen’s Kappa of 0.6451, all of which contributed to the LDA’s good predictive reliability as shown in Fig. 12.

Results obtained from the ML models after applying minmax scaling implying (a) Accuracy, (b) Precision, (c) Recall, and (d) F1-score.

Results obtained from the ML models after applying normalization implying (a) Accuracy, (b) Precision, (c) Recall, and (d) F1-score.
Conclusion
This paper undertook an exhaustive investigation of ML approaches to accurately predict heart disease, a challenge in binary classification that utilized tabular datasets. By conducting an extensive examination, this study scrutinized a variety of preprocessing methods that sought to enhance the performance of the models by optimizing the data. Additionally, it utilized a range of ML models to determine their effectiveness in detecting heart disease. Evaluation metrics, which are fundamental for validating the performance of models, were meticulously implemented in order to guarantee a strong assessment of the predictive capability of each model. The results of our study emphasize the considerable capacity of ML to improve the prediction of heart disease. The investigation unveiled that specific preprocessing methods, such as feature selection, normalization, and absent data management, significantly impacted model results. This underscores the paramount significance of conscientious data preparation when constructing predictive models that are efficacious. In addition, the examination of ML models in comparison shed light on the diverse performance exhibited by various algorithms, wherein certain models showcased enhanced accuracy and dependability in the prediction of heart disease. The presence of this variation highlights the criticality of choosing a suitable model in accordance with the particular attributes and specifications of the given dataset.
A comprehensive assessment of the predictive performance of the models was obtained by evaluating them using various metrics, including accuracy, precision, recall, and F1 score. In this study, the GBM, CB, and LGBM emerged as the most effective models for heart disease prediction, with their performance varying depending on the preprocessing method applied. The GBM demonstrated the highest overall classification accuracy (90.20%) under min-max scaling, highlighting its robustness and suitability for tasks requiring high predictive accuracy. CB excelled in probabilistic prediction, achieving the lowest log loss (0.2734) and a high Cohen’s Kappa score (0.7887) under standardization, making it an ideal choice for scenarios demanding precise probability calibration. LGBM exhibited versatility, maintaining consistently strong performance across all preprocessing techniques, with a notable balance between accuracy (88.73%) and probability estimation (logarithmic loss of 0.2801). These findings underscore the importance of selecting an appropriate combination of machine learning model and data preprocessing technique to achieve optimal performance in heart disease prediction tasks. Adopting a comprehensive approach to evaluating models is essential in order to gain a thorough comprehension of their merits and drawbacks. This process aids in determining which models are most appropriate for the detection of heart disease. In summary, this research provides significant contributions to the understanding of how ML can be effectively utilized to predict cardiac disease. This emphasizes the critical significance of preprocessing in the preparation of data, reveals the varying levels of performance exhibited by different ML models, and drives home the need for exhaustive evaluation metrics to assess the effectiveness of models. With the ongoing evolution of the healthcare sector, the incorporation of ML presents a potentially fruitful pathway towards augmenting diagnostic precision and enhancing patient results.
Data availability
Availability of data and materialOur objective is to maintain control over unsupervised usage that may lead to unintentional duplication of research efforts or reduced novelty in future studies. however, the dataset will be provided upon request. Please contact Waleed Alsabhan (email: walsabhan@Alfaisal.edu) if anyone needs the data for this study.
References
Tan, L. B., Williams, S. G., Tan, D. K. & Cohen-Solal, A. So many definitions of heart failure: are they all universally valid? A critical appraisal. Expert Rev. Cardiovasc. Ther. 8 (2), 217–228. https://doi.org/10.1586/erc.09.187 (2010). From NLM.
Bing, P. et al. A novel approach for denoising electrocardiogram signals to detect cardiovascular diseases using an efficient hybrid scheme. Front. Cardiovasc. Med. 11 https://doi.org/10.3389/fcvm.2024.1277123 (2024). Original Research.
Li, C., Bian, Y., Zhao, Z., Liu, Y. & Guo, Y. Advances in biointegrated wearable and implantable optoelectronic devices for cardiac healthcare. Cyborg Bionic Syst. 5, 0172. https://doi.org/10.34133/cbsystems.0172 (2024).
Li, W. Q. et al. Calcitonin gene-related peptide inhibits the cardiac fibroblasts senescence in cardiac fibrosis via up-regulating Klotho expression. Eur. J. Pharmacol. 843, 96–103. https://doi.org/10.1016/j.ejphar.2018.10.023 (2019).
Chamberlain, A. M. et al. Burden and timing of hospitalizations in heart failure: A community study. Mayo Clin. Proc 2017, 92 (2), 184–192. https://doi.org/10.1016/j.mayocp.2016.11.009 From NLM.
Qian, K. et al. Learning representations from heart sound: A comparative study on shallow and deep models. Cyborg Bionic Syst. 5, 0075. https://doi.org/10.34133/cbsystems.0075 (2024).
Qiu, W. et al. Federated abnormal heart sound detection with weak to no labels. Cyborg Bionic Syst. 5, 0152. https://doi.org/10.34133/cbsystems.0152 (2024).
Liu, Q. et al. Weight status change during four years and left ventricular hypertrophy in Chinese children. Front. Pead. 12 https://doi.org/10.3389/fped.2024.1371286 (2024). Original Research.
Odden, M. C. et al. The impact of the aging population on coronary heart disease in the united States. Am. J. Med. 124 (9), 827–833e825. https://doi.org/10.1016/j.amjmed.2011.04.010 (2011). From NLM.
Zhang, Z. et al. A case of pioneering subcutaneous implantable cardioverter defibrillator intervention in timothy syndrome. BMC Pediatr. 24 (1), 729. https://doi.org/10.1186/s12887-024-05216-w (2024).
Xu, A. et al. NF-κB pathway activation during endothelial-to-mesenchymal transition in a rat model of doxorubicin-induced cardiotoxicity. Biomed. Pharmacother. 130, 110525. https://doi.org/10.1016/j.biopha.2020.110525 (2020).
Pu, X., Sheng, S., Fu, Y., Yang, Y. & Xu, G. Construction of circRNA–miRNA–mRNA CeRNA regulatory network and screening of diagnostic targets for tuberculosis. Ann. Med. 56 (1), 2416604. https://doi.org/10.1080/07853890.2024.2416604 (2024).
Hu, F., Qiu, L. & Zhou, H. Medical device product innovation choices in asia: an empirical analysis based on product space. Front. Public. Health. 10 https://doi.org/10.3389/fpubh.2022.871575 (2022). Original Research.
Dai, H. et al. Global, regional, and National burden of ischaemic heart disease and its attributable risk factors, 1990–2017: results from the global burden of disease study 2017. Eur. Heart J. - Qual. Care Clin. Outcomes. 8 (1), 50–60. https://doi.org/10.1093/ehjqcco/qcaa076 (2022).
O’Connor, C. M. et al. Causes of death and rehospitalization in patients hospitalized with worsening heart failure and reduced left ventricular ejection fraction: results from efficacy of vasopressin antagonism in heart failure outcome study with Tolvaptan (EVEREST) program. Am. Heart J. 159 (5), 841–849e841. https://doi.org/10.1016/j.ahj.2010.02.023 (2010). From NLM.
Dharmarajan, K. et al. Diagnoses and timing of 30-day readmissions after hospitalization for heart failure, acute myocardial infarction, or pneumonia. Jama 309 (4), 355–363. https://doi.org/10.1001/jama.2012.216476 (2013). From NLM.
Jordan, M. I. & Mitchell, T. M. Machine learning: trends, perspectives, and prospects. Science 349 (6245), 255–260. https://doi.org/10.1126/science.aaa8415 (2015). From NLM.
Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. (IJSR) [Internet]. 9 (1), 381–386 (2020).
Zhou, Z. H. Machine Learning (Springer nature, 2021).
Bengio, Y., Goodfellow, I. & Courville, A. Deep Learning (MIT press Cambridge, 2017).
Nilsson, N. J. Principles of Artificial Intelligence (Morgan Kaufmann, 2014).
Mishra, M. Quantifying compressive strength in limestone powder incorporated concrete with incorporating various machine learning algorithms with SHAP analysis. Asian J Civ Eng 26, 731–746 (2025). https://doi.org/10.1007/s42107-024-01219-1
Wang, J. et al. Deep learning for strain field customization in bioreactor with dielectric elastomer actuator array. Cyborg Bionic Syst. 5, 0155. https://doi.org/10.34133/cbsystems.0155 (2024).
Huang, H., Wu, N., Liang, Y., Peng, X. & Shu, J. S. L. N. L. A novel method for gene selection and phenotype classification. Int. J. Intell. Syst. 37 (9), 6283–6304. https://doi.org/10.1002/int.22844 (2022).
Mumenin, N., Islam, M. F., Chowdhury, M. R. Z. & Yousuf, M. A. Diagnosis of Autism Spectrum Disorder Through Eye Movement Tracking Using Deep Learning. In Proceedings of International Conference on Information and Communication Technology for Development, Singapore, 2023; Ahmad, M., Uddin, M. S., Jang, Y. M., Eds.; Springer Nature Singapore: pp 251–262. (2023).
Lee, J., Kang, E., Heo, D. W. & Suk, H. I. Site-Invariant Meta-Modulation learning for multisite autism spectrum disorders diagnosis. IEEE Trans. Neural Netw. Learn. Syst. https://doi.org/10.1109/tnnls.2023.3311195 (2023). From NLMPp.
Mumenin, N. et al. A robust involution-based architecture for diagnosis of autism spectrum disorder utilising eye-tracking technology. IET Comput. Vision. 18 (5), 666–681. https://doi.org/10.1049/cvi2.12271 (2024). (acccessed 2025/01/25).
Mumenin, N. et al. Screening depression among university students utilizing GHQ-12 and machine learning. Heliyon 10 (17), e37182. https://doi.org/10.1016/j.heliyon.2024.e37182 (2024).
Kang, W. Factor structure of the GHQ-12 and their applicability to epilepsy patients for screening mental health problems. Healthc. (Basel). 11 (15). https://doi.org/10.3390/healthcare11152209 (2023). From NLM.
Hasib, K. M. et al. An Interrogative Survey. IEEE Trans. Comput. Social Syst. 10 (4), 1568–1586. https://doi.org/10.1109/TCSS.2023.3263128 (2023). Depression Detection From Social Networks Data Based on Machine Learning and Deep Learning Techniques:.
Mumenin, N. et al. Suicidal Ideation Detection from Social Media Texts Using an Interpretable Hybrid Model. In 6th International Conference on Electrical Information and Communication Technology (EICT), 7–9 Dec. 2023, 2023; pp 1–6., 7–9 Dec. 2023, 2023; pp 1–6. (2023). https://doi.org/10.1109/EICT61409.2023.10427944
Chowdhury, M. A. H., Mumenin, N., Taus, M. & Yousuf, M. A. Detection of Compatibility, Proximity and Expectancy of Bengali Sentences using Long Short Term Memory. In 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), 5–7 Jan. 2021, 2021; pp 233–237., 5–7 Jan. 2021, 2021; pp 233–237. (2021). https://doi.org/10.1109/ICREST51555.2021.9331057
Chen, S., Sun, P., Song, Y., Luo, P. & DiffusionDet Diffusion Model for Object Detection. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp 19773–19786. (2023). https://doi.org/10.1109/ICCV51070.2023.01816
Kaur, R. & Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Proc. 132, 103812. https://doi.org/10.1016/j.dsp.2022.103812 (2023).
Ghadekar, P. et al. Suspicious Activity Detection in Adverse Weather Conditions using YOLOv7. Grenze International Journal of Engineering & Technology (GIJET) 10, p2914. (2024).
Buttar, A. M., Bano, M., Akbar, M. A., Alabrah, A. & Gumaei, A. H. RETRACTED ARTICLE: toward trustworthy human suspicious activity detection from surveillance videos using deep learning. Soft. Comput. 28 (2), 467–467. https://doi.org/10.1007/s00500-023-07971-x (2024).
Jiang, C. et al. Xanthohumol inhibits TGF-β1-Induced cardiac fibroblasts activation via mediating pten/akt/mtor signaling pathway. Drug. Des. Devel. Ther. 14 (null), 5431–5439. https://doi.org/10.2147/DDDT.S282206 (2020).
Jindal, H., Agrawal, S., Khera, R., Jain, R. & Nagrath, P. Heart disease prediction using machine learning algorithms. In IOP conference series: materials science and engineering, ; IOP Publishing: Vol. 1022, p 012072. (2021).
Sahoo, P. K. & Jeripothula, P. Heart Failure Prediction Using Machine Learning Techniques. Available at SSRN: http://dx.doi.org/10.2139/ssrn.3759562 (2020).
Uyar, K. & İlhan, A. Diagnosis of heart disease using genetic algorithm based trained recurrent fuzzy neural networks. Procedia Comput. Sci. 120, 588–593. https://doi.org/10.1016/j.procs.2017.11.283 (2017).
Gupta, G., Adarsh, U., Subba Reddy, N. V. & Ashwath Rao, B. Comparison of various machine learning approaches uses in heart ailments prediction. Journal of Physics: Conference Series 2161 (1), 012010. (2022). https://doi.org/10.1088/1742-6596/2161/1/012010
Patil, A., Sonawane, O. & Sopan, V. Risk prediction of cardiovascular disease using logistic regression machine learning algorithm. Int Res. J. Mod. Eng. Technol. Sci 4 (1), 1-7 (2022).
Reddy, S. K., Meghana, V., Subba Reddy, P. & Ashwath Rao, N. V. B. Prediction on Cardiovascular disease using Decision tree and Naïve Bayes classifiers. Journal of Physics: Conference Series 2161 (1), 012015. (2022). https://doi.org/10.1088/1742-6596/2161/1/012015
Kumar, V. D. A. et al. Prediction of cardiovascular disease using machine learning technique—A modern approach. Computers Mater. Continua. 71 (1), 855–869 (2022).
Arabasadi, Z., Alizadehsani, R., Roshanzamir, M., Moosaei, H. & Yarifard, A. A. Computer aided decision making for heart disease detection using hybrid neural network-Genetic algorithm. Comput. Methods Programs Biomed. 141, 19–26. https://doi.org/10.1016/j.cmpb.2017.01.004 (2017). From NLM.
Sonawane, J. S. & Patil, D. R. Prediction of heart disease using multilayer perceptron neural network. In International Conference on Information Communication and Embedded Systems (ICICES2014), 27–28 Feb. 2014; pp 1–6. (2014). https://doi.org/10.1109/ICICES.2014.7033860
Anooj, P. K. Clinical decision support system: risk level prediction of heart disease using weighted fuzzy rules. J. King Saud Univ. - Comput. Inform. Sci. 24 (1), 27–40. https://doi.org/10.1016/j.jksuci.2011.09.002 (2012).
Jan, M., Awan, A. A., Khalid, M. S. & Nisar, S. Ensemble approach for developing a smart heart disease prediction system using classification algorithms. Res. Rep. Clin. Cardiol. 9 (null), 33–45. https://doi.org/10.2147/RRCC.S172035 (2018).
Sun, W., Zhang, P., Wang, Z. & Li, D. Prediction of cardiovascular diseases based on machine learning. ASP Trans. Internet Things. 1 (1), 30–35 (2021).
Ghosh, P. et al. Efficient prediction of cardiovascular disease using machine learning algorithms with relief and LASSO feature selection techniques. IEEE Access. 9, 19304–19326. https://doi.org/10.1109/ACCESS.2021.3053759 (2021).
Detrano, R. et al. Heart Disease—UCI Machine Learning Repository. American Journal of Cardiology: New York, NY, USA (1989).
Janosi, S. W. P. M. & Detrano, R. ras Heart disease. UCI machine learning repository UCI machine learning repository (1988). https://doi.org/10.24432/C52P4X
Sedgwick, P. (2012) Pearson’s Correlation Coefficient. BMJ, 345, e4483-e4483. https://doi.org/10.1136/bmj.e4483
Obilor, E. I. & Amadi, E. C. Test for significance of pearson’s correlation coefficient. Int. J. Innovative Math. Stat. Energy Policies. 6 (1), 11–23 (2018).
Liu, S. & Motani, M. Exploring Unique Relevance for Mutual Information based Feature Selection. In 2020 IEEE International Symposium on Information Theory (ISIT), 21–26 June 2020; pp 2747–2752. (2020). https://doi.org/10.1109/ISIT44484.2020.9174304
Shanker, M., Hu, M. Y. & Hung, M. S. Effect of data standardization on neural network training. Omega 24 (4), 385–397. https://doi.org/10.1016/0305-0483(96)00010-2 (1996).
de Amorim, L. B. V., Cavalcanti, G. D. C. & Cruz, R. M. O. The choice of scaling technique matters for classification performance. Appl. Soft Comput. 133, 109924. https://doi.org/10.1016/j.asoc.2022.109924 (2023).
Cao, X. H., Stojkovic, I. & Obradovic, Z. A robust data scaling algorithm to improve classification accuracies in biomedical data. BMC Bioinform. 17 (1), 359. https://doi.org/10.1186/s12859-016-1236-x (2016).
Singh, D. & Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 97, 105524. https://doi.org/10.1016/j.asoc.2019.105524 (2020).
Li, B., Wu, F., Lim, S., Belongie, S. & Weinberger, K. Q. On Feature Normalization and Data Augmentation. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20–25 June 2021, ; pp 12378–12387. (2021). https://doi.org/10.1109/CVPR46437.2021.01220
Singh, D. & Singh, B. Feature wise normalization: an effective way of normalizing data. Pattern Recogn. 122, 108307. https://doi.org/10.1016/j.patcog.2021.108307 (2022).
LaValley, M. Logistic regression. Circulation 117 (18), 2395–2399 (2008).
Rish, I. An empirical study of the naive Bayes classifier. In IJCAI 2001 workshop on empirical methods in artificial intelligence, ; Seattle, WA, USA;: Vol. 3, pp 41–46. (2001).
Song, Y. Y. & Lu, Y. Decision tree methods: applications for classification and prediction. Shanghai Arch. Psychiatry. 27 (2), 130–135. https://doi.org/10.11919/j.issn.1002-0829.215044 (2015). From NLM.
Biau, G. & Scornet, E. A random forest guided tour. TEST 25 (2), 197–227. https://doi.org/10.1007/s11749-016-0481-7 (2016).
Rigatti, S. J. Random forest. J. Insur. Med. 47 (1), 31–39 (2017).
Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J. & Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 13 (4), 18–28 (1998).
Steinwart, I. & Christmann, A. Support Vector Machines (Springer Publishing Company, 2008).
Suthaharan, S. & Suthaharan, S. Support vector machine. Machine learning models and algorithms for big data classification: thinking with examples for effective learning 207–235 (2016).
Guo, G., Wang, H., Bell, D., Bi, Y. & Greer, K. KNN Model-Based Approach in Classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, Berlin, Heidelberg, 2003//, 2003; Meersman, R., Tari, Z., Schmidt, D. C., Eds.; Springer Berlin Heidelberg: pp 986–996.
Zhang, S., Li, X., Zong, M., Zhu, X. & Wang, R. Efficient kNN classification with different numbers of nearest neighbors. IEEE Trans. Neural Networks Learn. Syst. 29 (5), 1774–1785. https://doi.org/10.1109/TNNLS.2017.2673241 (2018).
Cao, Y., Miao, Q. G., Liu, J. C. & Gao, L. Advance and prospects of adaboost algorithm. Acta Automatica Sinica. 39 (6), 745–758. https://doi.org/10.1016/S1874-1029(13)60052-X (2013).
Hastie, T., Rosset, S., Zhu, J. & Zou, H. Multi-class adaboost. Stat. Its Interface. 2 (3), 349–360 (2009).
Natekin, A. & Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 7, 21. https://doi.org/10.3389/fnbot.2013.00021 (2013). From NLM.
Ayyadevara, V. Gradient boosting machine BT—Pro machine learning algorithms: A Hands-On approach to implementing algorithms in Python and R. Pro Mach. Learn. Algorithms (2018).
Taha, A. A. & Malebary, S. J. An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine. IEEE Access. 8, 25579–25587. https://doi.org/10.1109/ACCESS.2020.2971354 (2020).
Alzamzami, F., Hoda, M. & Saddik, A. E. Light gradient boosting machine for general sentiment classification on short texts: A comparative evaluation. IEEE Access. 8, 101840–101858. https://doi.org/10.1109/ACCESS.2020.2997330 (2020).
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. Advances in neural information processing systems 31, (2018).
Hancock, J. T. & Khoshgoftaar, T. M. CatBoost for big data: an interdisciplinary review. J. Big Data. 7 (1), 94. https://doi.org/10.1186/s40537-020-00369-8 (2020).
Balakrishnama, S. & Ganapathiraju, A. Linear discriminant analysis-a brief tutorial. Institute for Signal and information Processing 18 (1998), 1–8. (1998).
Tharwat, A., Gaber, T., Ibrahim, A. & Hassanien, A. E. Linear discriminant analysis: A detailed tutorial. AI Commun. 30 (2), 169–190 (2017).
Hassoun, M. Fundamentals of Artificial Neural Networks (The MIT Press, 1995).
Wang, S. C. & Wang, S. C. Artificial neural network. Interdisciplinary Comput. Java Programming (Chapter 5), Kluwer Academic Publishers, 81–100. (2003). https://doi.org/10.1007/978-1-4615-0377-4_5
Wu, Y. & Feng, J. Development and application of artificial neural network. Wireless Pers. Commun. 102 (2), 1645–1656. https://doi.org/10.1007/s11277-017-5224-x (2018).
Abiodun, O. I. et al. State-of-the-art in artificial neural network applications: A survey. Heliyon 4 (11), e00938. https://doi.org/10.1016/j.heliyon.2018.e00938 (2018).
Goodfellow, I. Deep Learning (MIT Press, 2016).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521 (7553), 436–444 (2015).
Acknowledgements
The research was conducted at the Department of Software Engineering, College of Engineering, Alfaisal University, Riyadh, Saudi Arabia.
Funding
There is no specific funding for this manuscript.
Author information
Authors and Affiliations
Contributions
Waleed Alsabhan: Conceptualization, Methodology, Validation, Formal analysis, Writing - original draft, Writing - review & editing. Abdullah Alfadhly: Conceptualization, Methodology, Validation, Formal analysis, Supervision, Writing - original draft, Writing - review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alsabhan, W., Alfadhly, A. Effectiveness of machine learning models in diagnosis of heart disease: a comparative study. Sci Rep 15, 24568 (2025). https://doi.org/10.1038/s41598-025-09423-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-09423-y
