
Abstract
T2DM is a major risk factor for CHD. In recent years, machine learning algorithms have demonstrated significant advantages in improving predictive accuracy; however, studies applying these methods for clinical prediction and diagnosis of CHD-DM2 remain limited. This study aims to evaluate the performance of machine learning models and to develop an interpretable model to identify critical risk factors of CHD-DM2, thereby supporting clinical decision-making. Data were collected from cardiovascular inpatients admitted to the First Affiliated Hospital of Xinjiang Medical University between 2001 and 2018. A total of 12,400 patients were included, comprising 10,257 cases of CHD and 2143 cases of CHD-DM2.To address the class imbalance in the dataset, the SMOTENC algorithm was applied in conjunction with the themis package for data preprocessing. Final predictors were identified through a combined approach of univariate analysis and Lasso regression. We then developed and validated seven machine learning models: Logistic, Logistic_Lasso, KNN, SVM, XGBoost, RF, and LightGBM. The predictive performance of the five models was compared using evaluation metrics including accuracy, sensitivity, specificity, AUC, ROC and DCA. Additionally, SHAP values were employed to provide interpretability of the model outputs. The dataset was split into a training set (n = 8460) and a validation set (n = 3680) at a 7:3 ratio. A total of 25 predictive variables were ultimately identified through Lasso regression analysis. Among the seven machine learning models, the RF model demonstrated significantly superior performance and achieved the highest net benefit in the DCA. According to SHAP analysis, Diabetes.History, BG, and HbA1c were identified as the top contributors to CHD-DM2 risk. This study identified Diabetes.History, blood glucose (BG), and HbA1c as the primary risk factors for CHD-DM2. It is recommended that hospitals enhance monitoring of such patients, document the presence of high-risk factors, and implement targeted intervention strategies accordingly.
Similar content being viewed by others


Introduction
With the accelerating pace of population aging in China, the prevalence of multimorbidity among older adults is becoming increasingly prominent. Multimorbidity refers to the co-existence of two or more chronic diseases or conditions1. Among individuals aged 65 years and older, the prevalence of multimorbidity reaches 64.7%2. The co-occurrence of coronary heart disease (CHD) and diabetes mellitus (DM) is one of the most common combinations in the elderly population.CHD is a major subtype within the spectrum of cardiovascular diseases. Its underlying mechanism involves organic stenosis or obstruction of the coronary arteries, leading to myocardial ischemia, hypoxia, and even necrosis. Therefore, it is often referred to as ischemic heart disease3. Clinical manifestations include angina pectoris, arrhythmias, myocardial infarction, and even sudden cardiac death4.
One of the major and modifiable risk factors for CHD that can be addressed at the population level is hyperglycemia or diabetes mellitus5.In recent years, Type 2 Diabetes Mellitus (T2DM) has become one of the most significant comorbidities of CHD, with its incidence steadily increasing6 and being associated with patient mortality7.In terms of diagnosis, conventional techniques include coronary angiography, coronary CT angiography (CTA), electrocardiography, and echocardiography. However, these methods require specialized equipment and trained personnel, making them costly and less accessible. Therefore, developing low-cost, convenient, and effective non-invasive diagnostic tools is crucial for the early detection of CHD-DM2 and may significantly reduce patient mortality.
Data indicate that glucose metabolism disorders are common among patients undergoing coronary angiography. Among 1040 patients with CHD, 62.2% exhibited abnormal glucose metabolism.The integrated management of CHD and T2DM, along with the identification of patients at risk for multiple comorbidities, is a high priority in clinical practice8.Currently, machine learning algorithms have been proven to be highly effective in predicting cardiovascular diseases9. In the medical field, the application of machine learning is rapidly permeating all aspects of clinical practice—from preprocessing clinical data to precise patient stratification and the personalization of treatment strategies—demonstrating an increasingly significant impact. Specifically, machine learning has played a significant role in disease diagnosis, treatment risk assessment, drug development, and medical data analysis10.
At present, no dedicated model exists for predicting the risk of diabetes in patients with CHD. This study employs machine learning algorithms to develop a clinical risk prediction model for CHD-DM2. By deeply mining and integrating clinical data from CHD-DM2 patients and systematically analyzing the key factors contributing to disease development, this model provides a solid foundation for early intervention and treatment. The incorporation of machine learning enables more precise individual risk assessment and offers new perspectives and possibilities for disease management, highlighting promising clinical applications.
Materials and methods
Study population
A retrospective collection of clinical data was conducted on 29,960 cardiovascular disease patients admitted to the First Affiliated Hospital of Xinjiang Medical University between January 1, 2001, and December 31, 2018. The collected data included: basic demographic information (gender, age, education level, occupation); personal lifestyle history (smoking, alcohol consumption); family history (presence of diabetes, hypertension, hyperlipidemia); and laboratory tests such as complete blood count (WBC, NE, LY, MO, EO, BA, NE1, LY1, etc.).
Inclusion criteria were as follows: ① CHD patients: Diagnosed with CHD by coronary angiography (CAG) or CTA, with clear clinical manifestations such as angina pectoris or other ischemic symptoms; age ≥ 18 years. ② CHD-DM2 patients: Met all inclusion criteria for CHD. Diagnosed with T2DM based on indicators such as C-peptide level, islet autoantibody testing, or age at diabetes onset. Complete glycemic control records were available, including data on glycated hemoglobin (HbA1c).
Exclusion criteria included: ① Incomplete or erroneous data: Patients with missing key clinical information, such as diagnostic records, or those with significant data inconsistencies. ② Severe comorbidities: Patients with serious hepatic or renal dysfunction, or other systemic diseases that could interfere with study validity. Individuals with active malignancies receiving chemotherapy or radiotherapy were also excluded.Based on the above inclusion and exclusion criteria, a total of 12,400 eligible patients with CHD and CHD-DM2 were ultimately included in the study.
This study is a retrospective analysis, with data sourced from the medical records of cardiovascular disease patients admitted to the First Affiliated Hospital of Xinjiang Medical University from January 1, 2001, to December 31, 2018. The study protocol was reviewed and approved by the Ethics Committee of Xinjiang Medical University (Approval Number: XJYKDXR20250515001), and exemption from informed consent was granted. The decision to exempt informed consent was based on the following criteria: 1. International ethical guidelines In accordance with Article 32 of the Declaration of Helsinki (2013 revised edition), informed consent may be waived in the following circumstances: ① The research risk is extremely low. This study only involves statistical analysis of anonymized medical record data and does not involve any intervention measures. According to the ethics committee’s risk assessment, the risk level of this study is “lowest,” which complies with the core principle of the Declaration that “the research risk is no greater than the minimum risk.” ② The reasonableness of secondary use of data: The research data is derived from medical records generated during the diagnostic and treatment process, constituting lawful and compliant secondary use. The data has undergone double anonymization (removal of direct and indirect identifiers such as names, ID numbers, and hospital admission numbers), ensuring it cannot be traced back to individuals, in accordance with the Declaration’s requirement that “exemption from informed consent shall not adversely affect the rights and health of research participants.” ③ Objective limitations in contacting participants: Due to the study’s long time span of 18 years (2001–2018), after verification by the hospital’s medical records department, over 85% of patients’ contact information was found to be invalid or changed, meeting the exception in the Declaration that “if requiring informed consent would prevent the study from being conducted.” II. Legal Basis in China According to Article 23 of the “Ethical Review Measures for Life Sciences and Medical Research Involving Human Subjects” jointly issued by the National Health Commission and three other ministries in 2023 (National Health Commission Science and Education Development [2023] No. 4), an ethics committee may approve research exempt from informed consent if the following conditions are met: ① Risk controllability: The research poses extremely low risk and participants cannot be contacted (e.g., in this study, patients became unreachable due to the time span), meeting the criteria of Item (i) of this provision. ② Anonymization standards: Data has been thoroughly anonymized in accordance with the requirements of the Personal Information Protection Law, with all identifiable information removed, meeting the standard of “cannot be traced back to an individual” specified in Item (ii) of this provision. ② Protective measures for rights and interests: The study does not involve risks of personal privacy breaches or conflicts of commercial interest, meeting the requirements of subparagraph (3) of this clause. Therefore, this study strictly adheres to the principle of “minimizing risks and maximizing rights and interests,” and the decision to waive informed consent complies with international ethical guidelines and Chinese laws and regulations.
Data preprocessing
To ensure the integrity and accuracy of the analysis, we used the dplyr package in R (version 3.6.1) to identify variables with more than 30% missing values (e.g., Age, Educational Level), which were excluded from the final dataset. For variables with a missing rate below 30%, the mice package was employed to perform multiple imputation, effectively estimating and replacing missing data to retain dataset completeness and continuity (Fig. 1).The dummyVars function from the caret package in R was used to generate dummy variables for categorical data. For instance: Male (female = 0, male = 1); Educational Level (below high school = 1, high school or GED = 2, vocational school = 3, university = 4); Professional (mental worker = 0, manual worker = 1); Current Smoker (no = 0, yes = 1); Current Drinker (no = 0, yes = 1); Hypertensive History (no = 0, yes = 1); Diabetes History (no = 0, yes = 1); Pro (negative = 0, positive = 1); and Glu (negative = 0, positive = 1).In clinical data research, missing values can degrade model accuracy and may even result in misleading conclusions. Moreover, due to objective differences in disease prevalence, imbalanced distributions between positive and negative cases are common in medical datasets11, leading to poor classification performance for minority class samples12. To address the issue of data imbalance, this study employed the SMOTENC algorithm in combination with the themis package in R for data preprocessing. SMOTENC was used to generate synthetic samples for the minority class in order to balance the class distribution within the dataset.

Visualization of missing value patterns.
Feature selection
Feature selection is an important and commonly used dimensionality reduction technique that aims to identify an optimal subset of features by removing irrelevant and redundant information from the dataset13,14. By interpreting the most relevant features, deeper insights into the problem can be obtained15. The LASSO regression algorithm enables dimensionality reduction and variable selection for high-dimensional data16. In this study, a combined approach of univariate analysis and LASSO regression was employed. Potential candidate features were initially identified using univariate analysis with the nortest package in R, selecting variables with statistical significance (P < 0.05). These candidates were further refined using LASSO regression via the glmnet package in R, which introduces a penalty term to reduce model complexity and ultimately selects the most predictive feature set.
Model construction
In recent years, Machine Learning (ML) techniques have been widely applied in medical research, leveraging large datasets to uncover complex patterns that may not be readily identifiable by human observers, thereby offering a promising alternative approach17. In this study, seven machine learning models—XGBoost, Random Forest (RF), LightGBM, Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Logistic Regression, and Logistic_Lasso—were used to construct predictive models. These algorithms are commonly applied to binary classification tasks in coronary heart disease and diabetes-related research18.
XGBoost algorithm
XGBoost is an extended implementation of the Boosting ensemble algorithm. By integrating multiple weak classifiers, it constructs an efficient decision tree–based ensemble learning framework, significantly reducing computational complexity and runtime while improving algorithmic efficiency. The objective function consists of two key components: a loss term that measures the difference between predicted and actual values, and a regularization term that controls model complexity and prevents overfitting. The objective function is expressed as:
Here, \({\text{y}}_{\text{i}}\) denotes the true value, and \({\hat{\text{y}}}_{\text{i}}\) represents the predicted value. The function l refers to the loss function, commonly mean squared error (MSE) or log loss. \({\text{f}}_{\text{k}}\) denotes the k-th decision tree, and \(\Omega\) is the regularization term used to control model complexity.
RF algorithm
RF is an ensemble learning algorithm composed of multiple decision trees. It enhances model stability and predictive performance by constructing a multitude of trees. The core idea is to aggregate several weak classifiers (decision trees) into a strong classifier, improving prediction accuracy through majority voting or averaging. It can handle various types of features and reduces overfitting by randomly selecting features and training data subsets for each tree19. The RF model can be expressed as:
Here, B is the number of decision trees in the forest, and \({h}_{i}\)(x) indicates the output of the i-th tree for a given input x.
LightGBM algorithm
LightGBM is based on the Gradient Boosting Decision Tree (GBDT) framework, an ensemble learning method that iteratively adds new trees to correct errors made by the previous ones, thereby enhancing predictive performance. By leveraging histogram-based algorithms, leaf-wise growth strategies with depth constraints, and parallel optimization, LightGBM achieves significant advantages in training speed, memory efficiency, and scalability for large-scale distributed data processing20. The objective function is defined as:
In this expression, \({\text{l}}\left( {{\text{y}}_{{\text{i}}} ,{{\hat{\text{y}}}}_{{\text{i}}} } \right)\) refers to the individual sample loss, while Ω \(\left(\text{T}\right)\) serves as a regularization component to control model complexity and reduce the risk of overfitting.
SVM algorithm
SVM is a classification method based on the principle of structural risk minimization. Its core idea is to find the optimal hyperplane that maximizes the margin between different classes, effectively separating them while maximizing the distance from the hyperplane to the nearest data points—known as support vectors. For datasets that are not linearly separable in the original feature space, SVM employs kernel functions to map the data into a higher-dimensional space where linear separation becomes feasible21. The SVM model can be expressed as:
W is the weight vector, \({\varnothing }\left(\text{X}\right)\) denotes the mapping function that transforms the input sample into a high-dimensional feature space, b is the bias term, and \(\text{y}\left(\text{x}\right)\) represents the predicted value for sample x.
KNN algorithm
KNN algorithm is a non-parametric and intuitive supervised learning method. Its core idea is that if the majority of a sample’s k nearest neighbors in the feature space belong to a particular class, the sample is also assigned to that class and is expected to share its characteristics. It determines the closest instances by calculating the distance between the query sample and all samples in the training dataset22. The distance between test and training samples is computed using the following formula:
Here, m denotes the number of features. After computing the distances, the k nearest samples with the smallest distances are selected, and their labels or values are used to predict the outcome of the test sample.
Logistic regression algorithm
Logistic regression is a widely used statistical model for binary classification tasks. Its core concept involves applying the sigmoid function to a linear combination of input features, thereby transforming regression outputs into probability values between 0 and 1 and effectively converting a regression problem into a classification task23.
In this expression, \({\text{h}}_{\uptheta }\left(\text{X}\right)\) represents the predicted probability of the input sample. X is the feature vector, and \(\theta\) is the parameter vector of the model, where each parameter corresponds to the weight of an input feature.
Model performance assessment
To ensure optimal performance and robustness, tenfold cross-validation was employed on the training dataset. This method averages performance metrics across multiple trials to provide a more reliable assessment of model performance. The model’s predictive ability was evaluated using the confusion matrix, area under the receiver operating characteristic curve (AUC), Receiver Operating Characteristic Curve(ROC),sensitivity, specificity, and precision. Clinical utility was further assessed using decision curve analysis (DCA). Feature importance analysis was conducted for the selected models to determine the contribution of each variable to the prediction24, thereby evaluating model reliability and clinical applicability, as well as identifying net benefit.
Model interpretability
SHAP was used to analyze and interpret the results of the machine learning models. As an advanced interpretable machine learning framework, SHAP provides detailed explanations for individual model predictions, enhancing the transparency of ML models and facilitating the adoption of AI technologies in clinical practice25. Its capabilities include quantifying the overall contribution of each feature, illustrating their specific influence on individual predictions, examining feature interactions, and analyzing the combined effects of feature dependencies26. It enables the visualization of feature importance relationships and supports comprehensive interpretation of model behavior.In R, the average absolute SHAP values were visualized to rank the relative importance of each variable in the model, providing a comprehensive understanding of their individual contributions to the predictions27. The SHAP beeswarm plot offers an intuitive visualization of how all variables influence model predictions. The SHAP waterfall plot illustrates the direction and magnitude of each feature’s contribution to the final prediction for an individual case. The SHAP dependence plot allows exploration of the relationship between a given variable and its SHAP value, as well as interactions between variables. These visualizations enable unbiased evaluation of each variable’s contribution within the system, allowing the impact of individual variable values on model output to be considered independently28.
Results
Baseline characteristics analysis
A total of 29,960 patients with cardiovascular disease were screened according to strict inclusion and exclusion criteria and subjected to multiple imputation (see Fig. 1). Baseline analysis was conducted on the remaining 12,400 eligible patients. Among them, 10,257 patients (82.7%) were in the CHD group, and 2,143 patients (17.2%) were in the CHD-DM2 group. Detailed results are presented in Table 1.
In this study, a comprehensive and systematic comparison of baseline characteristics was conducted between the CHD-DM2 group and the CHD group. The results showed significant differences in 62 baseline indicators between the two groups. Specifically, the CHD-DM2 group had a lower median weight compared to the CHD group (74 kg [65.0; 83.0] vs 75 kg [66.0; 82.0], P < 0.05). Regarding professional status, the proportion of mental workers in the CHD-DM2 group was higher (81.9%) than in the CHD group (77.8%) (P < 0.01), which may be related to differences in lifestyle, dietary habits, and occupational stress among specific professional groups.The CHD-DM2 group showed a markedly higher prevalence of hypertensive history than the CHD group (62.2% vs 46.0%, P < 0.001). Additional analyses identified significant intergroup differences in laboratory measures such as WBC count, MO1 count, hemoglobin levels, MCV, and MCH (all P < 0.05). These findings may indicate the multifaceted influence of T2DM on the physiological status of individuals with CHD.It is noteworthy that MPV and PDW levels were significantly elevated in the CHD-DM2 group compared to the CHD group (P < 0.001), indicating potential alterations in platelet function or activity associated with diabetes. Furthermore, the CHD-DM2 group showed higher positivity rates for Pro and Glu than the CHD group (8.91% vs 5.43%; 27.5% vs 5.87%; P < 0.001), highlighting the specific effects of T2DM on renal function and glycometabolic regulation.In terms of coagulation function, the CHD-DM2 group had a higher PT.Activity than the CHD group (105% vs 102%, P < 0.001), which may be associated with diabetes-related imbalance in the coagulation and fibrinolytic systems. Regarding biochemical markers, the CHD-DM2 group showed a slightly lower BUN level (5.36 mmol/L vs 5.20 mmol/L, P < 0.001), suggesting differences in metabolic status. Finally, BG levels were significantly lower in the CHD-DM2 group than in the CHD group (6.81 mmol/L vs 5.05 mmol/L, P < 0.001), directly reflecting the diagnostic characteristics of diabetes and the strict requirements for glycemic control. Detailed data are presented in Table 1.
Class imbalance handling
Table 2 presents a comparison between the original and balanced datasets obtained using the SMOTENC algorithm. As shown in Table 2, the original dataset exhibited a substantial class imbalance with an imbalance ratio of 4.786. To address this issue and prevent bias in the results, we used the smotenc() function from the themis package in R (version 3.6.1) to balance the data. Based on statistical considerations, the number of neighbors k was set to 10, and different k values were tested across datasets. The parameter over_ratio was set to 1, representing the target ratio between the majority and minority classes. Oversampling was applied to the minority class and undersampling to the majority class, resulting in a balanced distribution of CHD cases (10,257) and CHD-DM2 cases (2,143). Detailed distributions of class observations in both balanced and imbalanced training sets are shown in Table 2 and Fig. 2.

Visualization of the original and balanced datasets using the SMOTENC algorithm.
Feature selection
We employed a comprehensive strategy that effectively combined univariate analysis with LASSO regression to achieve efficient and accurate feature selection. Initially, univariate analysis was used as a preliminary screening step, narrowing down the original pool of variables to 62 promising candidates. During this process, the error rate was carefully controlled to ensure robustness in feature selection. Subsequently, LASSO regression was introduced to further refine the feature set and enhance model performance. A rigorous ten-fold cross-validation procedure was implemented to evaluate model performance across different data subsets. Features with non-zero regression coefficients under cross-validation were retained, resulting in a final set of 25 key predictors out of the 62 initial variables. These predictors—Hypertensive.history, Diabetes.history, Weight, MCH, MCHC, PDW, Pro, ISR, Glu, BG, HbA1c, TG, LDL, APO.B, MVE, LVES, MVA, MVEA, SV, LAD, LCX, OM, and RCA—were identified as having the most significant influence on model predictive performance (Fig. 3A and B).

Importance of each predictor in the LASSO model. (A) Coefficient profile plot for the LASSO regression model. (B) Optimal parameter selection via ten-fold cross-validation.
Model construction and evaluation
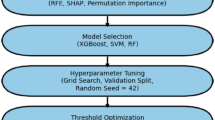
The study population (n = 12,400) was randomly divided into a training set (n = 8460) and a test set (n = 3680) in a 7:3 ratio. The training set was used to develop predictive models, and the test set was used for further validation.Participants were categorized into a CHD group (n = 10,257) and a CHD-DM2 group (n = 2,143), with model prediction based on CHD-DM2 status. The overall research workflow is illustrated in Fig. 4, which clearly outlines the steps of data partitioning, model construction, and validation.

Workflow diagram of the machine learning procedures in this study.
Seven widely used machine learning models were constructed and validated using the training and test datasets, including Logistic, Logistic_Lasso, SVM, KNN, XGBoost, RF, and LightGBM. When models were trained and tested on the original dataset, as shown in Table 3, the RF model demonstrated the best performance, with AUCs of 1.0000 and 0.9985, and accuracies of 0.9502 and 0.9282 in the training and test sets, respectively. The XGBoost model also showed superior performance compared to other models in both datasets. As shown in Table 4, RF achieved the highest values in the balanced dataset, with AUC, accuracy, sensitivity, and specificity values of 1 on both the training and test sets, indicating its strong discriminative capability in classification tasks. Next are the LightGBM and XGBoost models, which also perform well, with AUC values of 0.9816, 0.9683, 0.9869, and 0.91, and accuracy rates of 0.9289, 0.8367, 0.9439, and 0.8703 on the training and test sets, respectively. Figure 5 presents radar plots that visually demonstrate the positive impact of data balancing on both datasets and model performance. Compared with the imbalanced dataset, all seven models exhibited significantly reduced errors when trained on the balanced dataset, further underscoring the critical role of class balancing in improving model performance. On the balanced dataset, the RF model exhibited well-balanced and high values across accuracy, AUC, specificity, sensitivity, recall, and precision, indicating strong overall performance.

Radar plots of seven machine learning models. (A) Radar plot of models on the training set from the original dataset; (B) Radar plot of models on the test set from the original dataset; (C) Radar plot of models on the training set from the balanced dataset; (D) Radar plot of models on the test set from the balanced dataset.
Figure 6 shows the ROC curves of five machine learning models trained on both balanced and imbalanced datasets. All models demonstrated superior performance when trained on the balanced dataset. On the imbalanced dataset, the XGBoost model achieved an AUC of 0.8706, outperforming the other four models (Fig. 4A). On the balanced dataset, the AUC of the XGBoost model increased to 0.9594, again surpassing the performance of the other four models (Fig. 4B). The DCA curves illustrate the clinical utility of the predictive models by evaluating net benefits across different probability thresholds29.

ROC curve analysis of seven machine learning models. (A) ROC curves of models trained on the original dataset; (B) ROC curves of models tested on the original dataset; (C) ROC curves of models trained on the balanced dataset; (D) ROC curves of models tested on the balanced dataset.
Figure 7 displays the DCA curves of the seven models trained on both the original and balanced datasets. Compared to the original dataset, all models trained on the balanced dataset exhibited improved performance. Each of the seven models is represented by a distinct colored curve in the figure. Two benchmark lines—“All” (assuming all patients are high-risk) and “None” (assuming all patients are low-risk)—are also shown. A higher curve indicates greater net benefit at a given threshold. The RF (pink), LightGBM (yellow), and XGBoost (green) models showed higher curves, suggesting superior clinical utility at corresponding thresholds.

Decision curve analysis (DCA) of seven machine learning models. (A) DCA curves for models trained on the original dataset; (B) DCA curves for models tested on the original dataset; (C) DCA curves for models trained on the balanced dataset; (D) DCA curves for models tested on the balanced dataset.
Analysis of feature importance
Figure 8 illustrates the key contributions of various variables across the seven predictive models trained on the balanced dataset. In the kNN model, Diabetes history, BG, HbA1c, LAD, RCA, LCX, Glu, Hypertensive history, MVEA, and MVA were identified as the most important predictors. Similarly, for the SVM model, Diabetes history, BG, HbA1c, LAD, RCA, LCX, Glu, Hypertensive history, MVEA, and MVA were also regarded as critical predictive factors. In the XGBoost model, Diabetes history, BG, HbA1c, and PDW emerged as key predictive factors. By contrast, the logistic regression model highlighted the high importance of Diabetes history, LAD, Glu, LCX, Pro, and TG. Moreover, the logistic Lasso model underscored the significance of Diabetes history, LAD, Glu, LCX, RCA, and PDW.

Variable importance across seven machine learning models trained on the balanced dataset.
In summary, variables such as Diabetes history, BG level, HbA1c, and LAD consistently emerged as important across different models. This highlights their significance in influencing the risk of CHD-DM2 and suggests they are key targets for risk assessment and potential intervention strategies.
Interpretability of the model
To provide a more intuitive understanding of the contribution of selected variables in predicting CHD-DM2, we applied SHAP-based interpretability analysis. Figure 9 displays the top ten features ranked by importance, with Diabetes history, LVES, ISR, BG, and HbA1c identified as key factors, and LAD, Weight, CH, and MVA as additional important features. In the SHAP summary plot, each feature’s contribution to the prediction is visualized using colored dots, with variables listed in descending order of importance. Each dot represents an individual patient, with the x-axis indicating the magnitude of the Shapley value. The grey vertical line separates positive from negative impacts: positive Shapley values indicate a positive contribution to prediction, while negative values indicate a negative effect. Darker purple dots denote higher Shapley values, and yellow represents lower values. The top three most influential variables in the model were Diabetes history, LVES, and ISR.

Visualization of SHAP values. (A) SHAP beeswarm plot displaying feature contributions across all samples; (B) Bar plot ranking features by mean absolute SHAP values.
To assess the individual contributions of each feature to model output, SHAP waterfall plots were generated for the two outcome variables. The y-axis indicates feature names, while the x-axis represents SHAP values. In Fig. 10, purple bars denote negative contributions to the predicted value, whereas yellow bars indicate positive contributions. Labels on the bars show the deviation of each feature’s value from the model’s base value. Features are ranked in descending order of absolute contribution. In Fig. 10A, the ISR feature value is 2.31, contributing + 0.248 to a base value of 1.5. In Fig. 10B, Diabetes.history contributes − 0.153 to the prediction.

SHAP waterfall plots illustrating individual-level model predictions. (A) SHAP-based explanation of a representative CHD patient. (B) SHAP-based explanation of a representative CHD-DM2 patient.
In Fig. 11, the baseline value is \(\text{E}[\text{f}(\text{X})]=1.5\), which, as in the previous waterfall plots, approximates the average predicted value across the entire training dataset. The model output value \(\text{f}(\text{X})=1.\) 71 is also shown in the figure. Feature names and their values are shown at the top of the plot; features with positive contributions are marked in yellow, while negative contributions are shown in purple-red bars. All yellow bars on the left side represent features that positively shift the prediction from the baseline. The names of the features are located at the top of each bar in the chart. The length of each bar reflects the magnitude of the feature’s contribution. All purplish-red bars on the right side represent features that negatively influence the deviation from the baseline; feature names are shown at the top of the bars, and bar length reflects the size of the contribution.

SHAP force plot indicating feature-level contributions for a case predicted to survive.
Discussion
In recent years, large-scale bioinformatics analyses have increasingly focused on identifying key biomarkers, garnering unprecedented attention30,31. The growing scale and inherent complexity of biological data have driven the widespread application of machine learning in biological research32. Artificial intelligence (AI) approaches offer considerable advantages in predictive accuracy and operational efficiency over traditional and domain-specific methods33. As a powerful family of algorithms, machine learning enables the precise identification of complex patterns in data to perform key tasks such as prediction and classification. With the explosive growth of data availability and computing power, machine learning has been extensively applied and deeply integrated across both industry and natural sciences, demonstrating its irreplaceable value and potential34,35.
In this study, the SMOTENC algorithm was integrated with state-of-the-art machine learning approaches to mitigate class imbalance and reduce bias in the analysis. The algorithm minimized the likelihood of overfitting by avoiding redundant sampling of minority class instances36. Comparative analyses of seven machine learning models before and after data balancing (KNN, SVM, XGBoost, Logistic_Lasso, Logistic, RF, LightGBM) demonstrated substantial improvements in predictive performance following the application of balancing methods. Notably, the RF, LightGBM, and XGBoost models exhibited the best predictive metrics on the balanced dataset, achieving the highest levels of precision, recall, and AUC.
CHD develops through a multifactorial process shaped by interactions between genetic predisposition and environmental exposures, with numerous variables contributing simultaneously. Extensive prior research has revealed numerous critical CHD risk factors, such as age, gender, hypertension, diabetes, smoking behavior, and abnormal lipid profiles37. To gain insights into the contribution of these selected variables to the CHD-DM2 prediction model, we applied SHAP (Shapley Additive Explanations) to interpret feature importance. SHAP values provide interpretability by quantifying each feature’s contribution to the model’s prediction, thereby revealing the most predictive variables in CHD. This method not only improves interpretability but also guides subsequent investigation and clinical strategies38. Our findings highlight diabetes history, BG, and HbA1c as key determinants of CHD-DM2 risk. Given their influence, more attention should be devoted to mitigating cardiovascular risk in T2DM populations39. T2DM is marked by chronic hyperglycemia and metabolic dysregulation due to insulin resistance and deficient insulin production, frequently resulting in sustained increases in blood pressure, lipid levels, and glucose, thereby impairing systemic metabolic balance. Epidemiological data indicate that elevated glucose levels—even below the diabetic threshold—significantly raise the risk of cardiovascular events40. In this context, effective glycemic and lipid management in individuals with CHD-DM2 is essential. Maintaining blood glucose within target levels through consistent monitoring and dietary control can alleviate irreversible damage from chronic hyperglycemia and hyperlipidemia, ultimately enhancing patient outcomes and delaying disease advancement.
In recent years, both domestic and international experts have widely acknowledged the strong association between CHD and hypertension and hyperglycemia, prompting active research into therapeutic strategies for CHD-DM2.These advancements warrant urgent clinical attention and translation into practical applications. Specifically, clinicians should closely monitor and document high-risk factors in patients with CHD-DM2 and implement tailored interventions accordingly. With continuous advancements in medical infrastructure and research, we anticipate the development of more effective and evidence-based strategies for the control and treatment of CHD-DM2, ultimately improving patient care and outcomes.
Data availability
The study selected detailed clinical data from a total of 29,960 cardiovascular disease patients admitted to the First Affiliated Hospital of Xinjiang Medical University between January 1, 2001, and December 31, 2018 as the research subjects.If anyone wishes to request data from this study, please contact the author, Dandan Tang (Email ID:18,299,062,172@163.com).
Abbreviations
- T2DM:
-
Type 2 diabetes
- CHD:
-
Coronary heart disease
- CHD-DM2:
-
Coronary heart disease combined with type 2 diabetes
References
Xu, H. et al. Establishment of a diagnostic model of coronary heart disease in elderly patients with diabetes mellitus based on machine learning algorithms. J. Geriatr. Cardiol. 19(6), 445–455 (2022).
Bähler, C., Huber, C. A., Brüngger, B. & Reich, O. Multimorbidity, health care utilization and costs in an elderly community-dwelling population: A claims data based observational study. BMC Health Serv. Res. 22(15), 23 (2015).
Sagris, M. et al. Inflammation in coronary microvascular dysfunction. Int. J. Mol. Sci. 22(24), 13471 (2021).
Stone, P. H., Libby, P. & Boden, W. E. Fundamental pathobiology of coronary atherosclerosis and clinical implications for chronic ischemic heart disease management-the plaque hypothesis: A narrative review. JAMA Cardiol. 8(2), 192–201 (2023).
Turin, T. C. et al. Diabetes and lifetime risk of coronary heart disease. Prim. Care Diabetes 11(5), 461–466 (2017).
Aronson, D. & Edelman, E. R. Coronary artery disease and diabetes mellitus. Cardiol. Clin. 32(3), 439–455 (2014).
Xu, Q. et al. Prediction of atrial fibrillation in hospitalized elderly patients with coronary heart disease and type 2 diabetes mellitus using machine learning: A multicenter retrospective study. Front. Public Health 4(10), 842104 (2022).
Xiao, H. et al. Disease patterns of coronary heart disease and type 2 diabetes harbored distinct and shared genetic architecture. Cardiovasc. Diabetol. 21(1), 276 (2022).
Mirjalili, S. R. et al. An innovative model for predicting coronary heart disease using triglyceride-glucose index: A machine learning-based cohort study. Cardiovasc. Diabetol. 22(1), 200 (2023).
Forrest, I. S. et al. Machine learning-based marker for coronary artery disease: Derivation and validation in two longitudinal cohorts. Lancet 401(10372), 215–225 (2023).
Rahman, M. M. & Davis, D. N. Addressing the class imbalance problem in medical datasets. Int. J. Mach. Learn. Comput. 3(2), 224 (2013).
Thabtah, F. et al. Data imbalance in classification: Experimental evaluation. Inf. Sci. 513, 429–441 (2020).
Abdel Majeed, Y., Awadalla, S. S. & Patton, J. L. Regression techniques employing feature selection to predict clinical outcomes in stroke. PLoS ONE 13(10), e0205639 (2018).
Wei, H. et al. Environmental chemical exposure dynamics and machine learning-based prediction of diabetes mellitus. Sci. Total Environ. 806(Pt 2), 150674 (2022).
Alizadehsani, R. et al. Machine learning-based coronary artery disease diagnosis: A comprehensive review. Comput. Biol. Med. 111, 103346 (2019).
Shao, L. et al. LASSO-derived nomogram predicting new-onset diabetes mellitus in patients with kidney disease receiving immunosuppressive drugs. J. Clin. Pharm. Ther. 47(10), 1627–1635 (2022).
Huang, Y., Li, J., Li, M. & Aparasu, R. R. Application of machine learning in predicting survival outcomes involving real-world data: A scoping review. BMC Med. Res. Methodol. 23(1), 268 (2023).
Mujeeb Rahman, K. K. Automatic screening of diabetic retinopathy using fundus images and machine learning algorithms. Diagnostics (Basel) 12(9), 2292 (2022).
Ou-Yang, Y. et al. Explaining basketball game performance with SHAP: Insights from Chinese Basketball Association. Sci. Rep. 15, 13793 (2025).
Ke, G. et al. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, 3149–3157 (2017).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Peterson, L. E. K-nearest neighbor. Scholarpedia 4, 1883 (2009).
Hosmer, D. W. Jr., Lemeshow, S. & Sturdivant, R. X. Applied Logistic Regression (Wiley, 2013).
Ma, Y. et al. Explainable machine learning model reveals its decision-making process in identifying patients with paroxysmal atrial fibrillation at high risk for recurrence after catheter ablation. BMC Cardiovasc. Disord. 23(1), 91 (2023).
Yuan, Z. et al. A predictive model for hospital death in cancer patients with acute pulmonary embolism using XGBoost machine learning and SHAP interpretation. Sci. Rep. 15, 18268 (2025).
El-Sappagh, S., Alonso, J. M., Islam, S. M. R., Sultan, A. M. & Kwak, K. S. A multilayer multimodal detection and prediction model based on explainable artificial intelligence for Alzheimer’s disease. Sci. Rep. 11(1), 2660 (2021).
Parsa, A. B., Movahedi, A., Taghipour, H., Derrible, S. & Mohammadian, A. K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 136, 105405 (2020).
Mangiagalli, M., Miccolis, I., Maffé, P., Pogliani, E. M. & Corneo, G. Role of granulocyte colony-stimulating factor in relapsed/resistant intermediate and high-grade non-Hodgkin’s lymphoma patients treated with the E-SHAP regimen. Tumori J. 81(2), 91–95 (1995).
Kondo, T. et al. Predicting stroke in heart failure and preserved ejection fraction without atrial fibrillation. Circ. Heart Fail. 16(7), e010377 (2023).
Thapa, R. et al. Predicting falls in long-term care facilities: Machine learning study. JMIR Aging 5(2), e353731 (2022).
Wu, X. N. et al. Identified lung adenocarcinoma metabolic phenotypes and their association with tumor immune microenvironment. Cancer Immunol. Immunother. 70(10), 2835–2850 (2021).
Greener, J. G., Kandathil, S. M., Moffat, L. & Jones, D. T. A guide to machine learning for biologists. Nat. Rev. Mol. Cell Biol. 23(1), 40–55 (2022).
Martin-Morales, A. et al. Predicting cardiovascular disease mortality: Leveraging machine learning for comprehensive assessment of health and nutrition variables. Nutrients 15(18), 3937 (2023).
Zhang, H. et al. PTX3 mediates the infiltration, migration, and inflammation-resolving-polarization of macrophages in glioblastoma. CNS Neurosci. Ther. 28(11), 1748–1766 (2022).
Hu, M. et al. A risk prediction model based on machine learning for cognitive impairment among Chinese community-dwelling elderly people with normal cognition: Development and validation study. J. Med. Internet Res. 23(2), e202981 (2021).
Thakur, V. S., Kankar, P. K., Parey, A., Jain, A. & Jain, P. K. The implication of oversampling on the effectiveness of force signals in the fault detection of endodontic instruments during RCT. Proc. Inst. Mech. Eng. H 237(8), 958–974 (2023).
Feitosa, M. F. et al. Heterogeneity of the predictive polygenic risk scores for coronary heart disease age-at-onset in three different coronary heart disease family-based ascertainments. Circ. Genom. Precis. Med. 14(3), e003201 (2021).
Li, X. et al. Development of an interpretable machine learning model associated with heavy metals’ exposure to identify coronary heart disease among US adults via SHAP: Findings of the US NHANES from 2003 to 2018. Chemosphere 311(Pt 1), 137039 (2023).
Tian, X. et al. The association between serum Sestrin2 and the risk of coronary heart disease in patients with type 2 diabetes mellitus. BMC Cardiovasc. Disord. 22(1), 281 (2022).
Nathan, D. M. et al. Diabetes Control and Complications Trial/Epidemiology of Diabetes Interventions and Complications (DCCT/EDIC) Study Research Group. Intensive diabetes treatment and cardiovascular disease in patients with type 1 diabetes. N. Engl. J. Med. 353(25), 2643–2653 (2005).
Funding
The present paper was supported by the following funding: (1)Youth Science Fund of the Natural Science Foundation of Xinjiang Uyghur Autonomous Region; Project Number: 2022D01C718; Project Title:"Developing a Risk Prediction Model for Concurrent Diabetes in Coronary Heart Disease Patients Using Multimodal Data and Machine Learning".(2)Special Funds for Talents of Xinjiang Medical University; Project Number: 0103010211.
Author information
Authors and Affiliations
Contributions
Dandan Tang was responsible for conceptualization, methodology, research design, data analysis, and article writing; Fengwei Liang was responsible for clinical data curation, algorithm development, SHAP implementation, statistical validation; Xingli Gu was responsible for data compilation and statistical analysis; Yuanyuan Jin was responsible for research coordination and material support; Xuanjie Hu was responsible for data collection and compilation; Fen Liu was responsible for clinical interpretation, biomarker analysis, revealing research results; Yining Yang was responsible for study design, funding acquisition, manuscript supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and consent to participate
The Xinjiang Medical University Ethics Committee approved this study, approval number: XJYKDXR20250515001 (date:May 15, 2025). This study used a retrospective design and did not require written informed consent to participate. The study was conducted in accordance with national legislation and institutional requirements. No conflict of interest exits in the submission of this manuscript, and manuscript is approved by all authors for publication. I would like to declare on behalf of my co-authors that the work described was original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part.All the authors listed have approved the manuscript that is enclosed.That its publication has been approved by the responsible authorities at the institution where the work carried out.
Consent for publication
The co-authors agreed to publication in “Scientific Reports”.The copyright to the article is transferred to “Scientific Reports” effective if and when the article is accepted for publication. The author warrants that his/her contribution is original and that he/she has full power to make this grant. The author signs for and accepts responsibility for releasing this material on behalf of any and all co-authors.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tang, D., Liang, F., Gu, X. et al. Exploration and analysis of risk factors for coronary artery disease with type 2 diabetes based on SHAP explainable machine learning algorithm. Sci Rep 15, 29521 (2025). https://doi.org/10.1038/s41598-025-11142-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11142-3
