
Abstract
The human auditory system’s ability to accurately localize sounds is essential for navigating and interpreting our environment. However, modern hearing aids and cochlear implants often disrupt critical binaural hearing cues, posing challenges for individuals with hearing impairments. Additionally, precise sound localization is vital for technologies such as smart-home devices, autonomous vehicles, and robotics. In this work we introduce a brain-inspired neural network model, utilizing sparse coding techniques, that can achieve high accuracy in azimuthal sound localization by leveraging binaural and spectral auditory cues. The proposed model achieves a localization accuracy of 95%, comparable to human performance, through a novel application of the Locally Competitive Algorithm (LCA) for efficient sparse coding of auditory signals. This approach not only enhances our understanding of neural auditory processing but also holds promise for improving hearing aids and other auditory-based technologies, thereby advancing individual well-being and technological interactions within complex auditory environments.
Similar content being viewed by others

Introduction
The human brain’s ability to perform sound localization in diverse auditory environments is a complex process that integrates audio information from both ears. This binaural hearing allows the auditory system to determine the position and distance of sounds through the use of certain auditory cues. The binaural cues of interaural time difference (ITD) and interaural level difference (ILD) contain information about the difference in arrival time and intensity of a sound between the ears. Spectral filtering from the outer ear (pinna) provides additional frequency-based information that helps to distinguish ambiguities in ITD/ILD cues and to determine elevation. These binaural and spectral cues are processed along the auditory pathway to perform both horizontal and vertical localization of sounds1,2,3,4.
Developing accurate and efficient models can help us to improve assistive hearing devices and to develop vital technologies that improve safety and well-being. Modern hearing aids and cochlear implants often alter or destroy the binaural cues that are essential for accurate sound localization and spatial hearing, making it harder for users to navigate complex auditory environments5,6,7. Furthermore, technologies such as smart-home devices, autonomous vehicles, and robotics rely on advanced sensing and processing of audio signals to produce an accurate understanding of their surroundings8,9,10. Computational models inspired by the human auditory system can help to improve our understanding of neural auditory processing characteristics, and lead to the development of efficient, neuromorphic approaches that can be integrated into technologies requiring precise and reliable sound localization. In this work we propose a brain-inspired neural network model for sound localization based on sparse coding techniques, which provides high localization accuracy while maintaining a small and efficient network size. Our model mimics characteristics of human auditory processing while producing robust and accurate predictions of sound location.
Recent studies have investigated the use of machine learning models for understanding and modeling aspects of the brain, including sound localization within the auditory system. Prior works have explored the use of deep neural networks (DNNs) to perform brain-inspired sound localization using architectures such as feedforward networks11,12, convolutional neural networks (CNNs)13,14,15,16, and autoencoders17. While these models can reveal interesting parallels to neural functioning and leverage binaural information for performing localization tasks, they often lack the biological plausibility needed to effectively represent the important mechanisms and characteristics within the human brain. Specifically, they do not mimic the sparse and efficient coding strategies present in neural processing18,19,20, and their architectures miss key features of neural dynamics such as neuron inhibition and complex processing pathways21.
Other classes of localization models take a more biologically focused approach by modeling specific structures and dynamics of the auditory pathway. For instance, spiking neural network models that mimic the medial superior olive and other auditory structures have been proposed to capture the temporal precision and spatial tuning seen in biological neurons22,23. Additionally, probabilistic models that calculate ITD and ILD cues offer robustness in localization but still do not fully integrate these cues in a biologically plausible manner24. These models often rely on explicitly calculating binaural cues such as ITDs and ILDs to perform localization tasks, disregarding the importance of other auditory cues processed within the brain.
In this work, we propose a model of auditory processing for azimuthal sound localization in the brain derived from temporal sparse coding via a neural network based on the locally competitive algorithm (LCA). Prior studies have shown the effectiveness of sparse coding for representing cortical and auditory processing in the brain19,20,25 and have investigated sparse coding for spatial hearing with binaural audio signals26. The LCA, in particular, has been shown to learn receptive fields that are similar to the receptive fields of neurons within the Inferior Colliculus (IC) and Auditory Cortex27,28 when provided with audio inputs, suggesting that it may be well-suited for modeling auditory neuron behavior in the brain. However, these models are limited in their similarity to human auditory processing because they require the entire audio sample to be available at once, processing it as if it were a static image rather than a temporal signal. In contrast, our model processes audio in sequential time-steps, mimicking the real-time processing of the human auditory system. This approach allows for a more accurate representation of how the brain processes and localizes sound, improving the model’s biological plausibility and applicability to real-world auditory tasks.
The LCA has advantages over conventional machine learning approaches to auditory modeling, because it incorporates more aspects of a biological network of neurons, extracts features of input signals in a sparse manner, and aligns more closely with the natural processing pathways observed in the human auditory system. The dynamics of neurons within the LCA are similar to integrate-and-fire neurons and include inhibition between neurons, which mimics the inhibitory processes in the brain that are necessary for neural computation. The LCA performs sparse coding of inputs through unsupervised learning, enabling our model to independently detect and leverage relevant auditory features. In this work, we present the first use of the neural-inspired LCA as part of our model for performing sound localization on binaural audio and investigate the auditory cues utilized by the model in performing this localization task. This approach produces an efficient and effective model that parallels the behavior of the brain when performing sound localization, and has promising applications for use in hearing technologies. Unlike other neural network-based models for sound localization, our results show the ability of our model to independently learn to leverage specific auditory cues in a similar manner to the human brain, while providing excellent localization accuracy.
Results
Auditory model architecture
Cochlear front-end
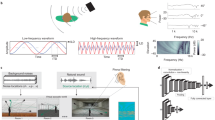
The first stage of our auditory model consists of a front-end based on the auditory periphery. This front-end converts the audio input to a time-frequency representation (Fig. 1) to mimic the behavior of the cochlea and auditory nerve. The binaural audio is converted into a spectrogram using a Short-Time Fourier Transform (STFT) in MATLAB. Each frame of the spectrogram is set to 16 ms with an 8 ms overlap to balance temporal resolution with computational efficiency while preserving the timing dynamics necessary for sound localization, resulting in 30 time-steps. We filter the magnitude spectrograms into 64 channels using a log-scaled Mel filterbank with center frequencies ranging from 50 Hz to 8 kHz. This configuration is chosen to mimic the frequency selectivity that is characteristic of the human cochlea29. To further improve localization accuracy, the phase information for frequencies below 1.5 kHz is retained from the STFT from both the right and left ear audio signals. The difference between the phase of the audio from the two ears is calculated which allows the model to utilize timing information as a cue for azimuth determination. The phase information is limited to frequencies below 1.5 kHz to both limit the input size to the LCA network and to reflect the human auditory system’s primary dependence on interaural phase differences at frequencies below this threshold, as phase cues become ambiguous at higher frequencies. However, limiting the phase content does exclude potential information from amplitude modulated high frequency signals in human speech, where humans have shown sensitivity to interaural phase differences between envelopes of high-frequency signals1. The magnitude spectrograms from the right and left ears are concatenated with the phase difference, resulting in a total input size of 177 values over the 30 time-steps. The cochlear stage extracts initial features from the audio inputs to provide the necessary time, frequency, and magnitude information for subsequent stages of the auditory model (Fig. 2a). Our model splits the computations relating to ITD and ILD that typically occur in the brainstem30 between the cochlear front-end and the auditory midbrain stages. In addition to providing the frequency filtering of the cochlea, the front-end of the model also synthesizes ITD information by taking the phase difference between the right and left ear signals. Magnitude information is passed to the midbrain stage, where ILD is processed.

Processing of the binaural audio inputs to produce magnitude spectrograms and phase difference information for use in later stages of the model. Binaural audio is converted to a time-frequency representation using a Short-Time Fourier Transform (STFT). Magnitude spectrograms are filtered into 64 channels using a log-scaled Mel filterbank, and phase differences for frequencies below 1.5 kHz are calculated. This results in a total input size of 177 values over 30 time-steps, providing time, frequency, and magnitude information for subsequent stages of the auditory model.
Sparse coding auditory midbrain via the locally competitive algorithm
Following initial processing of the binaural audio by the cochlear model, we next perform sparse coding of the audio in our auditory midbrain stage using a form of the LCA based on biologically plausible spiking leaky integrate-and-fire (LIF) neurons (Fig. 2b). This sparse coding allows for efficient representation of the input signal in an overcomplete dictionary of neurons, in a similar approach to how the brain encodes sensory information in an efficient manner18,19,20.
The LCA is a recursive neural network that performs sparse coding through networks of neurons that compete to fire31. The biologically inspired dynamics of the LCA make it an attractive candidate for modeling sparse coding in the brain. Each neuron within the LCA behaves as a leaky integrate and fire neuron, where inputs charge the neuron potentials until they reach a firing threshold. Competition in the form of inhibition between neurons allows stronger neurons to suppress those that are weaker from reaching the firing threshold, producing a sparse output representation.
In this work, we use a version of the LCA consisting of spiking neurons, where neurons communicate through discrete spikes instead of continuous signals32. The final output of the spiking LCA network is the spike rate of the neurons averaged over the run-time of the network. This spiking approach is well-suited for our application because it more closely aligns with neural activity in the brain, enhancing the biological plausibility and efficiency of the model while reducing computational complexity.
In prior work using LCA for sparse coding of natural images and audio spectrograms, the inputs are typically flattened, meaning that the multidimensional data is converted into a one-dimensional format before being fed to the input layer of LCA neurons. This approach treats the input as a single time step, with no subsequent inputs during the network activity. As a result, the LCA network must be very large because effective sparse coding requires an overcomplete dictionary of neurons. This large network size leads to prohibitively long training times for the dictionary and significant computational overhead. Additionally, flattening the spectrogram reduces the resemblance to auditory processing in the brain, which does not have access to the entire audio sequence at each stage of processing. Previous studies using audio spectrogram inputs for sparse coding algorithms to explore similarities to neural auditory processing apply dimensionality reduction via principal component analysis (PCA) to the spectrogram to reduce the input size26,27,28. However, this approach reduces the information available to the LCA and lacks a straightforward biological analogy.
In this work, we provide sequential time-steps of the spectrogram as input to the LCA, allowing it to process each time-step individually before moving on to the next, rather than providing the entire flattened spectrogram in a single step. This approach mimics the temporal processing of auditory information in the brain, enabling each time-step to be evaluated in sequence. Neuron potentials are not reset between spectrogram slices to maintain the continuity of neural states between consecutive time steps. This ensures that while the LCA only operates on a single time-step of the input, it maintains a temporal memory of the previous time-steps, allowing it to evaluate the current spectrogram slice in the context of previous inputs. We use a network size of 200 neurons to form an overcomplete dictionary for our input of size 177. In comparison, flattening the 2D spectrogram to a 1D input vector would require an overcomplete dictionary of neurons to be greater than 5,310 (177 × 30). Providing the spectrogram to the LCA in this way allows us to maintain the resolution of the spectrogram while limiting the size of the LCA network, and ensures better biological plausibility.
Cortical processing by a machine learning classifier
After the LCA stage extracts relevant features from auditory inputs through sparse coding, a feedforward classifier mimics higher-level cortical processing to determine sound location (Fig. 2c). Previous studies have shown that simple models can effectively represent spatial processing in the brain using the responses of auditory neurons33,34,35. This supports our approach of using a basic classifier to mimic the neural mechanisms involved in spatial localization during higher-level auditory processing.
This stage of our model consists of a feedforward neural network classifier with a single hidden layer of 32 neurons, to balance simplicity and computational efficiency. Because of the efficient feature extraction in preceding stages, a small classifier size is sufficient for synthesizing the sparse information generated by the LCA and producing accurate predictions about the auditory scene. Before input to the classifier, neural activity from each LCA neuron is averaged over the time period of the spectrogram to produce the relative neural activity during the auditory scene. The classifier outputs the most probable location of the sound’s origin, utilizing a softmax layer to handle classification among potential sound locations.

An overview of the localization architecture. a, In the frequency selective cochlear frontend, binaural audio inputs are filtered and converted into a time-frequency representation to form a spectrogram. b, Magnitude and phase difference are input sequentially to the sparse coding auditory midbrain stage consisting of a spiking LCA. c, Average neuron spike rates are used by a feedforward neural network to simulate higher-level cortical processing for classifying sound location.
Model implementation and evaluation
In this work, we propose a computational model for binaural sound localization based on characteristics of the auditory pathway. We implement and evaluate the three-stage architecture described in Sect."Auditory model architecture"—consisting of the cochlear front-end, the LCA-based sparse coding midbrain, and the cortical classifier—using human speech audio from the Google Speech Commands dataset36. The speech samples are shortened to 0.25 s clips and filtered with a Head-Related Transfer Function (HRTF) to create spatialized binaural audio. The HRTF is the measured response of how an individual’s head and ears filter a sound coming from a specific location37. It includes interaural time and level differences as well as the spectral changes introduced by the head and pinna, providing important auditory cues for our model. The binaural audio is simulated at 36 locations spaced in 10o increments around the head. The audio set is split into a training set of 90,000 samples and a testing set of 10,000 samples. Training is performed using gradient descent to learn the LCA dictionary and the weights for the classifier network.
Along with measuring the overall localization accuracy, we also modify the auditory cues of ITD, ILD, and spectral information to investigate how each cue impacts the model’s performance. Additionally, we compare the location tuning of neurons within the LCA with the responses of neurons in the cat auditory midbrain, highlighting similarities in their tuning patterns.
Speaker localization performance of auditory model
Our model achieves an overall accuracy of 95% for localizing the audio samples and displays similar behavior to results observed in human sound localization38,39. This high level of accuracy for performing sound localization from binaural audio demonstrates the model’s effectiveness in learning underlying features present due to the filtering of audio by the human head, similar to the features leveraged by the auditory system in the human brain. Localization accuracy at each speaker location is determined by the fraction of trials for that location that are classified correctly, i.e., the number of correct classifications divided by the total number of trials. Figure 3a shows a confusion matrix of the model’s accuracy at correctly identifying sound locations 360o around the head in 10o increments. Figure 3b displays the corresponding accuracy at each location.

(a) Confusion matrix for sound location predictions. The proposed model exhibits high accuracy at categorizing the location of a sound from 360o around the head in increments of 10o, including performing front/back discrimination. Highest confusion is observed near 90o and 270o (in-line with the right and left ears), as well as a small number of front/back reversals, in a similar manner observed in human sound localization performance38,39. (b) A plot showing the percentage of correct localization of sounds at each azimuth.
The results from our model display similar levels of localization accuracy as observed in humans. A study testing human sound localization accuracy for broadband sounds in the front hemisphere found localization accuracy of 99% for azimuths surrounding the midline of the listener, with accuracy dropping to the range of 60-70% for locations closer to the right or left ear40.
Similar to the auditory localization limitations experienced by humans, the model exhibits the lowest accuracy in areas directly in-line with the right and left ears on the interaural axis, often called the “cone of confusion”, where binaural localization cues are less useful for sound location discrimination38,39. A small number of front/back reversals are also observed around these angles, which is characteristic of human auditory perception. Azimuths near 90° and 270° exhibit lower accuracy, which improves as the source moves toward the centerline, as shown in Fig. 3b. Localization accuracy is strongest directly in front of and behind the head, areas where ITD, ILD, and spectral cues all provide distinct information for sound localization. These results highlight the model’s dependence on binaural and spectral auditory cues to discriminate sound location in a similar manner to the human auditory system.
Unlike other machine learning based localization algorithms that are restricted to only the front or rear hemisphere because of their dependence on only ITD or ILD auditory cues22,23,24, our model naturally leverages multiple auditory cues including spectral cues to perform effective front-back localization. This allows our model to distinguish sounds from a full 360o around the head, demonstrating its advanced auditory scene analysis and improved biological plausibility.
Impact of modified auditory cues on model performance
Next, we assess the use of specific binaural and spectral auditory cues in the trained localization model by testing it with modified binaural audio signals. The individual impact of ITD, ILD, and spectral cues on model performance is evaluated by modifying the HRTFs to destroy or modify the time difference, level difference, or spectral differences between the two binaural audio signals. The results show that each modified auditory cue degrades the performance of the model to some extent, however modifying ITD caused the largest impact to the model’s localization ability (Fig. 4). To compare the localization behavior of the model, confusion matrices showing the classification accuracy for the unmodified binaural audio (Fig. 5a) and for each modified cue (Fig. 5b-f) are plotted. Setting the ITD to 0 s for each sample reduced the localization accuracy to only 5%. As shown in Fig. 5b, most samples are classified as located near 0o or 180o, where the ITD is naturally 0 s, demonstrating the strong effect that ITD has on the model’s ability to localize the speech. Additionally, shifting the ITD of each sample by 30o reduces the localization accuracy even more to 1%. The confusion matrix for this test set (Fig. 5c) shows that the model often mis-classifies the samples as originating from 30o clockwise. These results reveal the overwhelming dependence of the model on ITD cues for accurate sound localization.
Modifications to ILDs and spectral cues also lead to a smaller but still significant degradation of localization accuracy. Altering the spectral characteristics of the samples, by flattening the spectral cues, results in an accuracy of 66%. Additionally, normalizing the ILD between the left and right ears causes a localization accuracy of 67%, and adjusting the ILD cues to match those from a sound source displaced by 30o clockwise results in the smallest impact on performance, reducing accuracy to 78%. The confusion matrices for these test sets (Fig. 5d-f) show that most errors in classification occur as front/back reversals, which agrees with the physiological importance of these cues for front/back discrimination in humans34,38,39.
These findings show a stark contrast in the effects of modifying ITD versus ILD and spectral cues, highlighting a primary dependence of the model on ITD for accurate sound localization. This dependency mirrors the human auditory system’s use of ITD, which primarily uses the ITD for localization of audio with frequency content that is less than 1.5 kHz, while ILD is more dominant for use in localization of higher frequency sounds1,41. Additionally, studies have found that ITD is the dominant auditory cue even in broadband audio containing low-frequency content (like human speech, which contains broadband content but has most energy concentrated below 4 kHz42), and when ITD conflicts with other cues, it typically overrides them43.
The main misclassifications that are observed in the samples with modified ILD or spectral cues are front-back reversals, as shown in the confusion matrices for the modified cue test sets (Fig. 5d-f). These results align with the importance of ILD and spectral cues for front-back discrimination of sounds, since the ITDs of these sounds are identical34,38.
Overall, the results from tests with modified auditory cues validate the model’s ability to mirror key aspects of human auditory processing such as the use of specific binaural and spectral cues, and emphasize the importance of all three cues for the effective localization of sound sources.

(a) A graph of the overall accuracy of correct location classification for different test sets. Accuracy of the model for the unmodified testing data is shown in blue, with an overall accuracy of 95%. The results for samples with zeroed or shifted ITD cues are shown in orange, with an accuracy of 5% and 1% respectively. Modified ILD cues are shown in yellow with accuracies of 67% and 78%, and the modified spectral cues are shown in purple with an accuracy of 66%. (b) Box plots showing the distribution of absolute error of angle classifications by the model. Highest MAE was observed in the modified ITD test sets, while the other modified cue test sets show MAE in the range of 10o to 20o.

Confusion matrices for each test set showing the predicted locations by the model vs. the actual sound locations. The original confusion matrix from Fig. 3a with unmodified cues is shown in plot a as a comparison to the modified cue tests. b-c, show confusion matrix results for modified ITD cues, which exhibit the largest localization errors. d-e, maintain strong localization accuracy along the midline but have increased front/back reversals due to modification of ILD and spectral cues.
Individual neuron location sensitivity
In addition to assessing overall model localization performance, we also investigate the specialization of the leaky integrate-and-fire (LIF) neurons within the sparse coding model for performing spatial discrimination. When presented with audio originating from different source locations, the responses of individual neurons within the LCA show varying sensitivity, indicating that they have independently learned spatial tuning. We analyze the correlation between the left and right half of the neuron receptive fields corresponding to the magnitude spectrograms of the left and right ears to determine the sensitivity of the neurons to differences in binaural signals. We test the response of individual neurons by taking the average of the spike rate of individual neurons to audio samples from each location over the entire test set.
Our findings show that neurons with the highest correlation in their receptive fields maintain a roughly constant activity level across all azimuths. In contrast, neurons with receptive fields that have lower correlation exhibit activity levels that are tuned to peak at specific azimuths. These results indicate that certain neurons within the LCA have learned to modulate their activity levels based on the location of a sound.
This pattern of location tuning is similar to the activity observed in auditory neurons in the brains of mammals, where some neurons have low spatial tuning, where activity is not modulated by sound azimuth, and some neurons are highly spatially tuned showing large fluctuations in activity based on sound azimuth44,45. Similar to the behavior of the sparse coding LIF neurons observed in our model, biological neurons in the auditory midbrain which are thought to contribute to sound localization exhibit much higher activity over a range of azimuths, often tuned for maximum activity centered in either the left or right hemisphere46,47,48.
Patterns of neuron activity over different sound azimuths are shown in Fig. 6, where activity of neurons from our model are compared to measured neurons in the inferior colliculus (IC) of cats48. The four patterns of activity observed in the IC neurons of cats match similar patterns of activity observed in neurons from our model. Neurons displayed activity tuned strongly to the right or left hemisphere, activity centered near the midline, location insensitivity, or multiple peaks of location activity. In the IC of cats, the observed neuron activity shows similar location tuning, as shown in the top row of plots in Fig. 6. Neurons showing activity tuned to the ipsilateral hemisphere were not observed in this study48. Ipsilateral tuning has been observed in a small number of IC neurons49 as well as being present in the auditory cortex50. Our model differs from typical IC behavior in that groups of neurons are tuned to the right or left hemispheres in similar quantities. Our model likely shows this behavior because it receives signals in the same way from both ears. The similar patterns of location tuning learned by the neurons in our model supports its biological plausibility and its potential for further exploration in bio-inspired auditory processing models.

Comparison of model results (bottom row) with experimental data from the inferior colliculus (IC) of a cat48 (top row). The neurons from the sparse coding stage of the model learn similar patterns of activity tuning curves as those observed in the IC of the cat. The experimental data were extracted from [Aitkin et al. 1985] using WebPlotDigitizer51.
Discussion
In this work we propose a novel sparse coding neural network model to mimic properties of sound localization in the human brain. We provide binaural audio of human speech to the model to observe its sound localization performance in the azimuthal plane. Specific auditory cues that are known to be essential for sound localization in the brain are isolated and modified to observe the response of the model to ITD, ILD, and spectral modifications. We observe that while all cues are necessary for the best performance, the model exhibits the strongest dependence on ITD which mimics the human brain’s dependence on ITD for localization of sounds containing low frequencies41,43. Additionally, we probe the response of individual neurons within the sparse coding stage of the model and observe that these neurons display activity over the azimuthal plane that matches biological neural activity observed in the mammalian auditory pathway44,45,46,47,48. These results demonstrate the effectiveness of our model at performing sound localization using binaural audio streams, and its similarity to aspects of sound localization in the human brain.
Prior neural network models have been used to model aspects of human audition and specifically sound localization. However, these models often rely on explicitly calculated auditory cues such as ITD and ILD22,23,24. In contrast, our model implicitly learns to extract features from binaural audio in an unsupervised manner, leveraging these cues without explicit calculation. Unlike previous models that use DNN architectures11,12,13,14,15,16,17, our approach incorporates spiking behavior, sparse encoding, and recurrent inhibition between neurons, providing a closer approximation to biological neural functioning.
While our proposed model does provide improved biological plausibility over traditional deep neural networks, and prior works have shown the similarity of receptive fields learned by neurons within an LCA to biological neurons within the IC and auditory cortex in humans when presented with monaural audio stimuli27,28, the architecture of the LCA lacks some features of biological neural networks within the auditory pathway. First, neurons within the LCA include both excitatory and inhibitory properties, while neurons within the brain typically produce purely excitatory or inhibitory activity. However, prior works have modified the LCA and similar algorithms to include populations of purely inhibitory or excitatory neurons and reported overall behavior comparable to the classic LCA52,53. Because these works found similar sparse coding results, we chose to use traditional LCA neurons for our model. Nonetheless, future work could explore whether this separation provides additional insights into auditory processing or further biological plausibility.
Additionally, the neuron dictionary in our model, which determines the strength of both feedforward and inhibitory connections between neurons, is pre-trained using gradient descent and then remains static during the run-time of the model. In biological neural networks, neural plasticity is an important characteristic of neural pathways that allows structures in the brain to dynamically learn and adapt to new information. Incorporating spike-dependent plasticity into the LCA could improve its biological plausibility and allow our model to dynamically adapt to new sounds and auditory scenes.
Because of its basis on the LCA and shallow neural networks, this architecture is well-suited for use in hardware applications. Its efficiency can be leveraged in low-power audio processing applications, making it an excellent candidate for integration into listening devices such as hearing aids and cochlear implants. These devices can benefit from more sophisticated sound localization, improving the quality of life for individuals with hearing impairments. Additionally, the efficient nature of this model makes it well-suited for a wide range of additional technologies. For instance, in smart home devices, efficient audio localization can improve voice command recognition and spatial awareness, leading to more responsive and accurate interactions. In robotics, environmental awareness and navigation can be improved by accurately and efficiently localizing sounds, which is crucial for tasks such as search and rescue, human-robot interaction, and autonomous operations in complex environments. Overall, the accuracy and efficiency of this architecture open up numerous potential applications beyond traditional auditory processing.
Methods
Audio dataset generation and model training
In this study we use the Google Speech Commands dataset36, which consists of 1 s long recordings of English keywords spoken by 2,618 different speakers. The recordings have a sample rate of 16 kHz. To create spatialized binaural audio recordings, the speech is pre-processed using a head-related-transfer function from the SADIE II database37 in MATLAB. The generated binaural audio samples are located in a plane around the head at a distance of 1.2 m. Possible speaker locations are spaced at 10o intervals, 360o around the head for a total of 36 azimuths. The orientation of the speaker azimuths relative to the head is shown in Fig. 7. The binaural audio clips are shortened to 0.25 s for input to the model.

Audio sources are spaced at 10o intervals in a plane 1.2 m from the head.
Dynamics of the locally competitive algorithm
The dynamics of the LCA are described by the ordinary differential equation (ODE) in (1), where u(t) represents the neuron potentials, s(t) is the input signal, and a(t) is the output of the neurons. The dictionary, D, contains the receptive fields of the neurons. The spectrogram input s(t) causes the neuron potentials to charge. The thresholding function in (2) determines if the neuron potential has reached the firing threshold λ, producing a neuron output a(t) when the threshold is reached.
We use a spiking version of the LCA, in which all neuron outputs and inter-neuron communications occur through spiking, acting as leaky-integrate and fire (LIF) neurons32. The spiking LCA produces sparse features that are equivalent to those of the non-spiking version, but provides improved computational efficiency and greater biological plausibility. In this version, the output of the LCA is the neurons’ spike rate over the network’s operating time.
Model training
The binaural audio samples are split into 90,000 training samples and 10,000 testing samples. Our model undergoes two phases of training. First, the training set is processed by the cochlear stage and then used to train the dictionary of the LCA via gradient descent using the cost function shown in (3), where y(t) is the output of the LCA (the spike rate of the neurons), D is the dictionary, and s(t) is the input to the LCA.
In the second training phase, the output of the previously trained LCA on the training set is used to produce inputs to train the classifier stage. The classifier training is performed using ADAM optimization in MATLAB for 700 epochs or until convergence is reached. To test the model, the samples from the test set are passed through the entire auditory model to analyze sound localization performance.
Auditory cue modifications
In order to understand the impact of specific auditory cues on the performance of our model, we create five additional testing datasets, each containing 10,000 audio samples. Each dataset contains binaural audio where one cue (ITD, ILD, or spectral filtering) is modified, while leaving the other cues intact. These datasets follow the same process described above for producing binaural audio samples, but the impulse responses of the HRTFs are modified to have shifted or zeroed ITD and ILD or flattened spectral cues. To modify the ILD cues we produce two test sets; in the first the ILD of each sample is equalized between the left and right ears (i.e. there is no amplitude difference between the audio signals at the two ears), and in the second the ILD of each sample is modified to be equal to the ILD of the unmodified HRTF location that is 30o clockwise. Similarly, two test sets are produced for the modified ITD cues, one where the ITD of each sample is set to zero (i.e. there is no time difference between the audio signals at the two ears), and the second where the ITD of each sample is set to the corresponding ITD of a sample that is 30o clockwise. Spectral cues are modified in a test set that contains samples where the frequency spectrum is “flattened” so that the HRTF has a constant frequency response at each speaker location. Characteristics of the original and modified binaural and spectral cues are shown in Fig. 8. To test the response of our model to the modified cues, we first train the model on the unmodified training set and then record the testing results from each modified testing set. By isolating specific auditory cues that are used in the brain to perform sound localization, we are able to probe the use of each cue in our model and compare this cue utilization to behavior in the human auditory system.

Calculated ITDs and ILDs from original and modified test sets. The top row shows the ITD (left) and ILD (right) for original, zeroed, and shifted test sets across different azimuths. The bottom row depicts the original (top) and modified (bottom) frequency spectrums. These modifications isolate the impact of specific auditory cues on the model’s performance by setting ITD or ILD to zero, shifting ITD or ILD by 30o, and flattening the spectral cues, providing insights into the model’s cue utilization and comparison to human auditory processing.
Neural activity from auditory cortex neurons in a Cat
In Sect. “Individual Neuron Location Sensitivity” of Results, neural activity responses to different azimuths in our model are compared to experimental results from neurons in the cat inferior colliculus48. Original data from [Aitkin et al., 1985] were extracted using WebPlotDigitizer51. The extracted data were normalized to align with our experimental results for comparative analysis of the impact of sound source location on auditory neuron activity in Fig. 6.
Statistical analysis
To evaluate the accuracy of the neural network model across the modified cue datasets (Fig. 4a), bootstrapping was used to estimate the error bars on the accuracy bar graph. For each of the 1,000 bootstrap samples, the accuracy was calculated as the proportion of correct predictions. The standard error of these bootstrap accuracies was used to create error bars, reflecting the variability in accuracy across different datasets.
For the analysis of prediction errors in Fig. 4b, bootstrapping was also used to estimate the Mean Absolute Error (MAE) across different datasets. Specifically, 1,000 bootstrap samples were generated by resampling the test set with replacement. The MAE was calculated as the mean of the absolute differences between predicted and actual angles. This approach allowed us to estimate the variability of the MAE, with the results visualized as box plots.
Confusion matrices (Figs. 3 and 5) were computed for each dataset by comparing the predicted labels to the actual labels. These matrices were normalized to reflect the percentage of predictions for each actual class and visualized as heatmaps.
Data availability
This work uses publicly available data from the Google Speech Commands dataset and the SADIE II database. The code for the sparse coding model and specific binaural dataset that was analysed is available from the corresponding author on reasonable request.
References
Middlebrooks, J. C. & Green, D. M. Sound localization by human listeners. Annu. Rev. Psychol. 42, 135–159 (1991).
Schnupp, A. & Carr, J. C. On hearing with more than one ear: lessons from evolution. Nat. Neurosci. 12, 692–697 (2009).
Musicant, A. D. & Butler, R. A. The influence of pinnae-based spectral cues on sound localization. J. Acoust. Soc. Am. 75 (4), 1195–1200 (1984).
Grothe, B., Pecka, M. & McAlpine, D. Mechanisms of sound localization in mammals. Physiol. Rev. 90, 3, 983–1012 (2010).
Zheng, Y., Swanson, J., Koehnke, J. & Guan, J. Sound localization of listeners with normal hearing, impaired hearing, hearing aids, bone-anchored hearing instruments, and cochlear implants: a review. Am. J. Audiol. 31, 3, 819–834 (2022).
Arras, T. et al. Longitudinal auditory data of children with prelingual single-sided deafness managed with early cochlear implantation. Sci. Rep. 12, 9376 (2022).
Dorman, M. F., Loiselle, L. H., Cook, S. J., Yost, W. A. & Gifford, R. H. Sound source localization by Normal-Hearing listeners, Hearing-Impaired listeners and cochlear implant listeners. Audiol. Neurootol. 21 (3), 127–131 (2016).
Schoepe, T. et al. Neuromorphic Sensory Integration for Combining Sound Source Localization and Collision Avoidance. IEEE Biomedical Circuits and Systems Conference (BioCAS) 1–4 (2019). 1–4 (2019). (2019).
Dávila-Chacón, J., Liu, J. & Wermter, S. Enhanced robot speech recognition using biomimetic binaural sound source localization. IEEE Trans. Neural Networks Learn. Syst. 30 (1), 138–150 (2019).
Latif, T., Whitmire, E., Novak, T. & Bozkurt, A. Sound localization sensors for search and rescue biobots. IEEE Sens. J. 16, 10, 3444–3453 (2016).
Roden, R., Moritz, N., Gerlach, S., Weinzierl, S. & Goetze, S. On sound source localization of speech signals using deep neural networks. Fortschritte der Akustik–DAGA 2015 41, 1510–1513 (2015).
Chung, W., Carlile, S. & Leong, P. A performance adequate computational model for auditory localization. J. Acoust. Soc. Am. 107 (1), 432–445 (2000).
Francl, A. & McDermott, J. H. Deep neural network models of sound localization reveal how perception is adapted to real-world environments. Nat. Hum. Behav. 6, 111–133 (2022).
Tan, T. H., Lin, Y. T., Chang, Y. L. & Alkhaleefah, M. Sound source localization using a convolutional neural network and regression model. Sensors 21, 238031 (2021).
Jacome, K. G. R., Grijalva, F. L. & Masiero, B. S. Sound events localization and detection using Bio-Inspired Gammatone filters and Temporal convolutional neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 31, 2314–2324 (2023).
Jiang, S., Wu, L., Yuan, P., Sun, Y. & Liu, H. Deep and CNN fusion method for binaural sound source localisation. J. Eng. 2020, 511–515 (2020).
Smith, S. S., Sollini, J. & Akeroyd, M. A. Inferring the basis of binaural detection with a modified autoencoder. Front. Neurosci. 17, 1000079 (2023).
Laughlin, S. B. & Sejnowski, T. J. Communication in neuronal networks. Science 301, 1870–1874 (2003).
Lewicki, M. S. Efficient coding of natural sounds. Nat. Neurosci. 5, 356–1111 (2002).
Smith, E. C. & Lewicki, M. S. Efficient auditory coding. Nature 439, 978–982 (2006).
Frisina, R. D. Subcortical neural coding mechanisms for auditory Temporal processing. Hear. Res. 158, 1–27 (2001).
Liu, J., Perez-Gonzalez, D., Rees, A., Erwin, H. & Wermter A biologically inspired spiking neural network model of the auditory midbrain for sound source localization. Neurocomputing 74, 129–139 (2010).
Glackin, B., Wall, J. A., McGinnity, T. M., Maguire, L. P. & McDaid, L. J. A spiking neural network model of the medial superior Olive using Spike timing dependent plasticity for sound localization. Front. Comput. Neurosci. 4, 18 (2010).
May, T., van de Par, S. & Kohlrausch, A. A. Probabilistic model for robust localization based on a binaural auditory Front-End. IEEE Trans. Audio Speech Lang. Process. 19, 1–13 (2011).
Olshausen, B. A. & Field, D. J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 381, 607–609 (1996).
Młynarski, W. Efficient coding of spectrotemporal binaural sounds leads to emergence of the auditory space representation. Front. Comput. Neurosci. 8, 26 (2014).
Carlson, N. L., Ming, V. L. & DeWeese, M. R. Sparse codes for speech predict spectrotemporal receptive fields in the inferior colliculus. PLoS Comput. Biol. 8, e1002594 (2012).
Dodds, E. M. & DeWeese, M. R. On the sparse structure of natural sounds and natural images: similarities, differences, and implications for neural coding. Front. Comput. Neurosci. 13, 39 (2019).
Robles, L. & Ruggero, M. A. Mechanics of the mammalian cochlea. Physiol. Rev. 81, 1305–1352 (2001).
Yin, T. C. T. Neural mechanisms of encoding binaural localization cues in the auditory brainstem. In Integrative Functions in the Mammalian Auditory Pathway. Springer Handbook of Auditory Research Vol. 15 (eds Oertel, D. et al.) (Springer, 2002).
Rozell, C. J., Johnson, D. H., Baraniuk, R. G. & Olshausen, B. A. Sparse coding via thresholding and local competition in neural circuits. Neural Comput. 20, 2526–2563 (2008).
Shapero, S., Zhu, M., Hasler, J. & Rozell, C. Optimal sparse approximation with integrate and fire neurons. Int. J. Neural Syst. 24, 1440001 (2014).
Slee, S. J. & Young, E. D. Linear processing of interaural level difference underlies Spatial tuning in the nucleus of the brachium of the inferior colliculus. J. Neurosci. 33, 3891–3904 (2013).
van der Heijden, K. et al. Cortical mechanisms of Spatial hearing. Nat. Rev. Neurosci. 20, 609–623 (2019).
Pena, J. L. & Konishi, M. Robustness of multiplicative processes in auditory Spatial tuning. J. Neurosci. 24, 8907–8910 (2004).
Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. ArXiv Preprint arXiv:1804.03209 (2018).
Armstrong, C., Thresh, L., Murphy, D. & Kearney, G. A. Perceptual evaluation of individual and Non-Individual hrtfs: A case study of the SADIE II database. Appl. Sci. 8, 2029 (2018).
Makous, J. C. & Middlebrooks, J. C. Two-dimensional sound localization by human listeners. J. Acoust. Soc. Am. 87, 2188–2200 (1990).
Shinn-Cunningham, B. G., Santarelli, S. & Kopco, N. Tori of confusion: binaural localization cues for sources within reach of a listener. J. Acoust. Soc. Am. 107, 1627–1636 (2000).
Yost, W. A., Loiselle, L., Dorman, M., Burns, J. & Brown, C. A. Sound source localization of filtered noises by listeners with normal hearing: a statistical analysis. J. Acoust. Soc. Am. 133, 2876–2882 (2013).
Rayleigh, L. On our perception of sound direction. Lond. Edinb. Dublin Philos. Mag J. Sci. 13, 214–232 (1907).
Monson, B. B., Hunter, E. J., Lotto, A. J. & Story, B. H. The perceptual significance of high-frequency energy in the human voice. Front. Psychol. 5, 587 (2014).
Wightman, F. L. & Kistler, D. J. The dominant role of low-frequency interaural time differences in sound localization. J. Acoust. Soc. Am. 91, 1648–1661 (1992).
Middlebrooks, J. C. & Pettigrew, J. D. Functional classes of neurons in primary auditory cortex of the Cat distinguished by sensitivity to sound location. J. Neurosci. 1, 107–120 (1981).
Aitkin, L. M., Gates, G. R. & Phillips, S. C. Responses of neurons in inferior colliculus to variations in sound-source azimuth. J. Neurophysiol. 52, 1–17 (1984).
Fitzpatrick, D. C., Batra, R., Stanford, T. R. & Kuwada, S. A neuronal population code for sound localization. Nature 388, 871–874 (1997).
McAlpine, D., Jiang, D. & Palmer, A. A neural code for low-frequency sound localization in mammals. Nat. Neurosci. 4, 396–401 (2001).
Aitkin, L. M., Pettigrew, J. D., Calford, M. B., Phillips, S. C. & Wise, L. Z. Representation of stimulus azimuth by low-frequency neurons in inferior colliculus of the Cat. J. Neurophysiol. 53, 43–59 (1985).
Delgutte, B., Joris, P. X., Litovsky, R. Y. & Yin, T. C. Receptive fields and binaural interactions for virtual-space stimuli in the Cat inferior colliculus. J. Neurophysiol. 81, 2833–2851 (1999).
Rajan, R., Aitkin, L. M., Irvine, D. R. F. & McKay, J. Azimuthal sensitivity of neurons in primary auditory cortex of cats. I. Types of sensitivity and the effects of variations in stimulus parameters. J. Neurophysiol. 64, 872–887 (1990).
Rohatgi, A. & WebPlotDigitizer Version 4.4 [Software]. (2020). Available from http://arohatgi.info/WebPlotDigitizer
Zhu, M. & Rozell, C. J. Modeling inhibitory interneurons in efficient sensory coding models. PLoS Comput. Biol. 11, e1004353 (2015).
King, P. D., Zylberberg, J. & DeWeese, M. R. Inhibitory interneurons decorrelate excitatory cells to drive sparse code formation in a spiking model of V1. J. Neurosci. 33, 5475–5485 (2013).
Author information
Authors and Affiliations
Contributions
Conceptualization and design: EW, MF. Code development and data analysis: EW. Result interpretation: MR, MF, EW. Project guidance: MF. Initial manuscript draft: EW. Manuscript editing: MF, MR, EW. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ware, E.E., Roberts, M.T. & Flynn, M.P. A multi-stage auditory model for binaural sound localization using the locally competitive algorithm. Sci Rep 15, 27048 (2025). https://doi.org/10.1038/s41598-025-11613-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11613-7
