
Abstract
The foundational segmentation models, segmenting anything model (SAM) and SAM 2, have transformed segmentation by enabling remarkable zero-shot performance across diverse domains. In this study, we evaluate SAM 2 for surgical scene understanding by examining its semantic segmentation capabilities for organs/tissues both in zero-shot scenarios and after fine-tuning. We utilized five public datasets to evaluate and fine-tune SAM 2 for segmenting anatomical tissues in surgical videos/images. Fine-tuning was applied to the image encoder and mask decoder. We limited training subsets from 50 to 400 samples per class to better model real-world constraints with data acquisition. The impact of dataset size on fine-tuning performance was evaluated with weighted mean dice coefficient (WMDC), and the results were also compared against previously reported state-of-the-art (SOTA) results. SurgiSAM 2, a fine-tuned SAM 2 model, demonstrated significant improvements in segmentation performance, achieving a 17.9% relative WMDC gain compared to the baseline SAM 2. Increasing prompt points from 1 to 10 and training data scale from 50/class to 400/class enhanced performance; the best WMDC of 0.92 on the validation subset was achieved with 10 prompt points and 400 samples per class. On the test subset, this model outperformed prior SOTA methods in 24/30 (80%) of the classes with a WMDC of 0.91 using 10-point prompts. Notably, SurgiSAM 2 generalized effectively to unseen organ classes, achieving SOTA on 7/9 (77.8%) of them. Heavily dissected tissues and similar appearing organs such as small and large intestines remained challenging. SAM 2 achieves remarkable zero-shot and fine-tuned performance for surgical scene segmentation, surpassing prior SOTA models across several organ classes of diverse datasets. This suggests immense potential for enabling automated/semi-automated annotation pipelines, thereby decreasing the burden of annotations facilitating several surgical applications.
Similar content being viewed by others
Introduction
Foundational models have transformed the field of natural language processing1,2. These models, pre-trained on massive datasets in a task-agnostic manner, can be fine-tuned for downstream tasks that differ from their initial training objectives. Their ability to generalize and deliver remarkable zero-shot performance on novel tasks, i.e. perform tasks without any prior task-specific training, offers substantial advantages in reducing the need for expensive dataset creation and curation. Computer vision has benefited by leveraging large general-purpose models for generative purposes3 and achieving state-of-the-art (SOTA) performance on other vision tasks such as image classification and object detection4,5,6. Recently, with the release of Segment Anything Model (SAM)7 and SAM 28 by Meta, this approach has been applied to semantic segmentation, shifting away from the traditional method of developing task-specific models9. This enables generalization to unseen datasets and tasks for various biomedical and clinical applications with minimal adaptation.
In biomedicine, semantic segmentation is indispensable, particularly in medical imaging for disease diagnosis, treatment planning, and disease monitoring. However, as noted, the field is currently dominated by inflexible, task-specific models. The zero-shot performance of SAM and SAM 2 on medical images has been modest10, with inconsistent results across datasets and tasks. Low contrast, indistinct borders, small, or amorphous objects11,12,13 and other complexities of medical imaging contribute to these limitations. However, SAM and SAM 2 have demonstrated the potential to surpass SOTA performance in tasks involving large, well-defined objects14,15. Moreover, several studies leveraging large-scale medical datasets have shown significant performance improvements by fine-tuning various components of SAM—image encoder and mask decoder in Biomedical SAM 216, mask decoder only in MedSAM17, low-rank-adaptation (LoRA) fine-tuning in SAMed18, and customized adapter modules in Medical SAM Adapter19. This yielded impressive outcomes, often matching or surpassing SOTA fully supervised task-specific models.
While SAM and SAM 2 have primarily been evaluated for applications in computer-aided diagnosis, semantic segmentation may serve another critical medical application—surgical scene understanding. Achieving pixel-perfect identification of structures is essential for accurately interpreting surgical scenes. Success with this could greatly advance the future of surgery and surgical education, enabling precise spatio-temporal tracking of tools, tissues, and their interactions that can facilitate downstream applications such as real-time surgical navigation, automated skill assessment, and even, ultimately, autonomous robotic surgery.
Tool segmentation has been relatively straightforward due to tools’ distinct boundaries and striking contrast against background tissues20,21. However, the zero-shot performance of SAM 2 on surgical segmentation tasks involving live tissues in a surgical context remains unexplored. Furthermore, the limited representation of surgical data in the training sources of both SAM and SAM 2 presents an opportunity to significantly improve performance by fine-tuning SAM 2 on surgical video data. Given the cumbersome and costly nature of obtaining labeled training images in this domain, we utilized public surgical segmentation datasets to comprehensively evaluate SAM 2’s capabilities.
The contributions of this paper are as follows:
We evaluated zero-shot promptable segmentation capabilities of SAM 2 for anatomical tissues in surgical videos.
-
We fine-tuned SAM 2 on public surgical segmentation datasets, achieving SOTA performance across multiple organ classes included in the fine-tuning process, while also demonstrating generalization to several unseen organ classes that were not part of the fine-tuning process.
-
We evaluated the impact of constrained datasets on fine-tuning performance to mimic real-world challenges associated with obtaining labeled surgical video datasets for segmentation. We demonstrate that substantial fine-tuning performance gains can be achieved with as few as 50 images per class.
-
A generalized foundation model can greatly aid surgical scene understanding, where labeled datasets are scarce, and segmentation is challenging due to the need for time-consuming and expensive annotations. This fine-tuned model could significantly improve annotation efficiency in creating surgical video datasets and thereby facilitate adoption of computer vision models for various biomedical and clinical applications.
Methods
Preliminary SAM 2 architecture
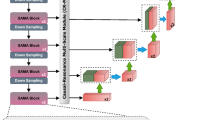
The SAM 2 architecture is a versatile segmentation model designed for both image and video segmentation tasks. It builds upon SAM by integrating advanced capabilities for temporal image processing. The core components of the SAM 2 architecture include an image encoder, prompt encoder, and mask decoder, with novel components such as memory encoder, memory attention mechanism, and memory bank to enhance segmentation performance in videos (Fig. 1). While SAM 2 allows modeling of temporal context across frames in a video, we utilized it exclusively for the segmentation of individual images in this study.

Diagrammatic representation of the SAM 2 model and its components.
Dataset characteristics
To comprehensively assess the segmentation performance of SAM 2 over surgical scenes, we utilized five surgical video datasets with varying numbers of annotations for several organ/tissue classes from different surgical specialties. These datasets were chosen based on a literature review of prior studies with publicly available surgical video datasets. These datasets are as follows:
-
1.
CholecSeg8k22 comprises 8,080 unique laparoscopic images focused on cholecystectomy procedures. It includes 12 segmentation classes—abdominal wall, blood, connective tissue, cystic duct, fat, gallbladder, gastrointestinal tract, grasper, hepatic vein, L-hook electrocautery, liver, and liver ligament.
-
2.
Dresden23 comprises 2,431 unique laparoscopic images focused on colorectal procedures. It includes 11 classes—abdominal wall, colon, inferior mesenteric artery, intestinal veins, liver, pancreas, small intestine, spleen, stomach, ureter, and vesicular glands.
-
3.
UreterUD24 comprises 586 unique laparoscopic images focused on urological procedures. It includes 3 classes—ureter, uterine artery, and nerves.
-
4.
Endoscapes25 comprises 493 unique laparoscopic images focused on cholecystectomy. It includes 6 classes—cystic duct, cystic artery, cystic plate, gallbladder, hepatocystic triangle, and instruments.
-
5.
m2caiSeg26 comprises 299 unique images from minimally invasive abdominal surgeries. It includes 17 classes—artery, bile, bipolar, blood, clipper, fat, gallbladder, grasper, hook, intestine, irrigator, liver, scissors, specimen-bag, trocar, unknown, and upper wall.
These datasets represent a diverse set of challenges in terms of class complexity, number of classes, and surgical context, providing a comprehensive evaluation framework for fine-tuning SAM 2 for surgical scene segmentation tasks and determining its capabilities for surgical scene understanding. Instrument classes, when present in the dataset, were segmented but were excluded from the weighted mean Dice coefficient (WMDC). These results are reported in Supplementary file 1.
Dataset preprocessing and splitting
The images/frames in the datasets were utilized in their original form without any pre-processing. The multi-class masks were split into individual class-wise masks for all datasets. The dataset preprocessing scripts/notebooks are provided in the Github repository (https://github.com/Devanish31/SurgiSAM2).
All datasets were split into train, validation, and test subsets, ensuring patient-wise splitting across all classes within each dataset. The splits were as follows: CholecSeg8k [13/2/2 (patients)], Dresden [90/5/5 (%)], Endoscapes [201/41/40(patients)], UreterUD [70/15/15 (%)], and m2caiSeg [80/10/10 (%)]. Additional quality-control was performed in the m2caiSeg dataset to remove poor-quality masks with issues such as empty masks, mismatch between mask and image sizes, and masks with < 50 pixels mask area.
Evaluation pipeline and training data
We randomly extracted points from the ground truth masks to mimic the user interactively providing points for prompting SAM 2 for segmentation. Points were sampled incrementally from 1 to 10, and the zero-shot segmentation performance on the validation subsets was evaluated in intervals of 2. We did not explore additional prompt variations, such as combining positive and negative prompts or incorporating bounding box prompts, as the primary focus of this study was not on prompt engineering but rather to evaluate model performance. Nonetheless, these other approaches could potentially enhance performance.
The training subsets were used for fine-tuning the SAM 2 model, with segmentation performance tracked on the validation subsets using 10-point prompts. To investigate the impact of data scale, fine-tuning was performed using varying amounts of data per class (50, 100, 200, and 400 samples) from the training subset, assessing whether increased data volume improves performance. We deliberately restricted the dataset to fewer than 400 samples for two reasons: (1) the primary goal was to investigate SAM 2 under real-world conditions where surgical training data is typically scarce; and (2) limiting to 400 samples per class ensured a more balanced representation across all classes because several categories lacked sufficient masks at data scales of 200 and 400 avoiding a larger class imbalance beyond 400 per class.
A total of 21 unique organ/tissue classes were selected from the overall 30 organ/tissue classes across the datasets and chosen for fine-tuning. The segmentation performance with 10-point prompts was compared against the baseline SAM 2 model’s performance under similar conditions.
The best-performing fine-tuned model checkpoint across all data scales was evaluated on the test subset. Its performance was compared across various classes and tasks to that of other algorithms or model architectures reported in the original dataset papers.
Segmentation performance metrics, analyses, and visualization
Segmentation quality was determined using several standard metrics to evaluate the overlap/ agreement between predicted and ground truth masks. The following metrics were computed:
Intersection over union (IoU)
IoU measures the overlap between the predicted mask and the ground truth mask, calculated as the ratio of their intersection to their union.
Specifically, it is defined as:

IoU provides a robust measure of agreement by penalizing both false positives and false negatives.
Dice coefficient
The Dice coefficient evaluates the similarity between the predicted and ground truth masks, calculated as:
The Dice coefficient is defined as:

This metric emphasizes overlap by weighting the intersection relative to the total size of the predicted and ground truth masks.
Precision
Precision quantifies the proportion of correctly predicted pixels among all pixels in the predicted mask [True positive/(True positive + False positive)], defined as:
It is defined as:

High precision indicates fewer false positives.
Recall
Recall measures the proportion of correctly predicted pixels out of all pixels in the ground truth mask [True positive/(True positive + False negative)], calculated as:
It is defined as:

High recall indicates fewer false negatives.
These metrics were computed for all examples/masks across the validation and test subsets and averaged for each class. While all metrics were calculated, the most commonly used segmentation metric, Dice coefficient is presented in the main text for brevity. Additionally, a weighted mean of the Dice coefficient was calculated as the WMDC with the results of tissue classes of all datasets, with weights determined by the number of examples in each class.
The average Dice coefficient for each class (Dicei) is computed as:

Where:
Dicei,j: Dice coefficient for the j-th example in class i.
ni: Total number of examples in class i.
The overall WMDC (Diceweighted) is then calculated as:

Where:
N: Total number of examples across all classes, defined as \(N = \sum\limits_{i = 1}^{C} {n_{i} }\).
C: Total number of classes.
\(n_{i} \cdot {\text{Dice}}_{i}\): Weighted contribution of class i to the overall Dice coefficient, based on the number of examples in that class.
Fine-tuning details and hyperparameters
We followed the fine-tuning specifications outlined in the SAM 2 Github repository (https://github.com/facebookresearch/sam2). The SAM 2 model was fine-tuned using the AdamW optimizer with a base learning rate of 5.0 × 10−6 and a cosine scheduler. The vision specific learning rate was 3.0 × 10–6. The weight decay was set at 0.1. The loss function incorporated mask loss, Dice loss, IoU loss, and class loss with weights of 20, 1, 1, and 1, respectively. This was consistent with the original SAM/SAM 2 training approach. Training was conducted for 30 epochs with a batch size of 1, employing data augmentation techniques such as horizontal flips, affine transformations, resizing, and color jittering. Fine-tuning was conducted using the pre-trained SAM 2.1 checkpoint (SAM 2-Hiera-B +), optimizing only the image encoder and mask decoder. All experiments were performed on a single NVIDIA A100 GPU, saving checkpoints every two epochs. Fine-tuning was carried out across varying training data scales (50, 100, 200, and 400 samples per class) including 21 unique organ/tissue classes, completing each scale within 3, 6, 11, and 16 h, respectively. Checkpoints were saved every fifth epoch for each training scale, and the WMDC across all tissue classes was analyzed to identify the best checkpoint for each scale.
Ablation studies
To better understand the contribution of each model component in the fine-tuning performance, we conducted ablation studies on the SAM 2 model by selectively excluding one component at a time. Specifically, we evaluated the impact of fine-tuning combinations of the image encoder, mask decoder, and prompt encoder on segmentation performance using 400 samples per class across 21 tissue classes.
Assessing generalizability of fine-tuned model
To preserve SAM 2’s generalized segmentation capabilities and mitigate catastrophic forgetting, we employed a low learning rate and limited the number of training epochs. We performed multi-dataset training to improve generalization across datasets and minimize overfitting to a single dataset. To determine generalizability, we assessed the segmentation performance of the best fine-tuned model checkpoint on an unseen test subset of all datasets that were split patient-wise for all classes across all datasets. We also assessed the fine-tuned model’s performance on unseen/untrained classes of the datasets (majorly m2caiSeg).
Additionally, we also evaluated the segmentation performance of SurgiSAM 2 against another biomedical foundational segmentation model, MedSAM.
Preliminary evaluation of tissue tracking in videos: baseline SAM 2 vs. SurgiSAM 2
We conducted an evaluation of tissue tracking performance for both the baseline and fine-tuned SAM 2 models using surgical videos from four distinct procedures. These videos, sourced from YouTube under a Creative Commons license, featured tissues and organs not included in the training dataset: the lung in lobectomy, the ovary in hysterectomy, the appendix in appendectomy, and the spleen in renal cyst enucleation. From each video, we extracted 7–8 short segments of 0.5 s in duration, resulting in approximately 100 frames per tissue class and a total of ~ 400 frames. To simulate a manual segmentation workflow, the first frame of each segment was prompted with 1 to 10 points, and the resulting mask generated by the video predictor model was propagated across the remaining frames. The Dice coefficient was then calculated for each organ class to compare the tracking performance of the baseline and fine-tuned models.
Additionally, we evaluated organ tracking performance on the CholecSegTrack dataset, which we curated from CholecSeg8k. The CholecSegTrack consists of video clips from 17 laparoscopic cholecystectomy procedures. Each clip spans 3–4 s (~ 80 frames at 25 fps) and contains continuous, frame-level segmentations for seven abdominal structures: cystic duct, gall bladder, liver, gastrointestinal tract, fat, liver ligament, and hepatic vein. For each organ, only clips from procedures excluded from its training set were used. Tracking performance was evaluated by computing the mean Dice score across each clip for all clips of a given organ class, under 1-, 5-, and 10-point prompt conditions. Prompts were applied only to the first frame, and the resulting masks were propagated throughout the clip for both Baseline SAM 2 and SurgiSAM 2.
Results
Dataset characteristics
The dataset characteristics of all included datasets are presented in (Table 1, Fig. 2). The five datasets, CholecSeg8k, Dresden, Endoscapes, UreterUD, and m2caiSeg include 45,635 annotated masks across 12 segmentation classes, 13,138 annotated masks across 11 segmentation classes, 648 annotated masks across 3 segmentation classes, 1,911 masks across 6 segmentation classes, 2,044 masks across 17 segmentation classes, respectively.

The number of annotated masks (x-axis) for the five datasets (CholecSeg8k, Dresden, Endoscapes, UreterUD, and m2caiSeg), categorized by training, validation, and testing splits across all organ/tissue classes (y-axis). The CholecSeg8k dataset constituted the largest portion across all dataset splits.
Zero-shot evaluation: impact of model backbone and prompt quantity
The performance of baseline SAM 2 was evaluated using Hiera Large and Hiera Base Plus backbones with 1 to 10 prompt points (Table 2). The WMDC improved progressively with increasing numbers of prompts, reaching the highest performance at 10 points for both models (Fig. 3). Hiera Large consistently outperformed Hiera Base Plus across most classes, with overall WMDC of 0.84 and 0.78, respectively with 10 prompt points (Fig. 3). The largest performance gains were observed in structures such as cystic artery (+ 0.36), cystic plate (+ 0.74), and the liver (+ 0.27), and vesicular glands (+ 0.19). Following this, segmentation was only performed with the Hiera Base Plus model for computational purposes.

Performance comparison of Hiera Large and Hiera Base Plus backbones using weighted mean Dice coefficient (x-axis), evaluated with 1 to 10 prompt points (y-axis) across segmentation tasks. The performance of Hiera-Large and Hiera-Base-Plus increases with progressively increasing number of prompts plateauing near the higher number of prompts.
Fine-tuning performance across training data scales
Fine-tuning SAM 2 (SurgiSAM 2) resulted in an absolute WMDC improvement of 0.14, representing a 17.9% relative improvement over the baseline SAM 2 Base Plus model across all tissue classes. The most substantial performance gains occurred within the first six epochs across all data scales, after which improvements were marginal (Fig. 4). The effect of training data scale on model performance was assessed by fine-tuning SAM 2 with different sample sizes per class (50, 100, 200, and 400). For each data scale, the best-performing model checkpoint was identified based on the WMDC at 5-epoch intervals and used for further comparison. Notably, for all data scales (50 to 400 samples per class), performance improved only marginally beyond the 6th epoch (Supplementary file 2).

Weighted mean Dice coefficient improvements (y-axis) during fine-tuning of SAM 2 with different training data scales (50, 100, 200, and 400 samples per class) (x-axis) across epochs. While all the training data scales demonstrate significant improvement from the baseline, there remains a performance gap even after prolonged training between 50 and 400 examples per class. In addition, most of the performance gains of fine-tuning are achieved as early as 6 epochs.
Regarding training data scale, increasing the number of samples per class beyond 50 resulted in minimal enhancement in segmentation performance. The highest performance was recorded with 400 samples per class and 10 prompts, achieving a WMDC of 0.92 (Fig. 4). The benefits of data scaling were consistent across various organs and structures. Scaling the training data improved WMDC across tissue classes; however, the WMDC reduced when also considering instrument classes, given the model shift towards specifically segmenting tissues/organs (Fig. 5).

Weighted mean Dice coefficients (y-axis) for “Tissues Classes Only” and “Tissues Plus Instruments Classes” scenarios with single point prompt and 10-point prompts and progressively increasing training data scale (x-axis). In both the “Tissues Classes Only” and the “Tissues Plus Instruments Classes”, performance progressively increases with increasing scale of data, but only marginally. *Segmentation metrics of the instrument classes are reported in the Supplementary files 1 & 2.
Comparison against prior SOTA and other SAM models
SurgiSAM2’s performance was evaluated against prior SOTA methods using both 1-point and 10-point prompts on test subsets. Fine-tuned SAM 2 (SurgiSAM 2) achieved substantial improvements in segmentation accuracy and consistently outperformed prior SOTA methods with 10-point prompts (24/30 classes, 80%) and even 1-point prompt (20/30 classes, 66.6%) (Table 3). Interestingly, SurgiSAM2 also outperformed the medical segmentation-specific model, MedSAM, over all organ classes (Fig. 6). SurgiSAM 2 excelled in segmenting smaller and more challenging structures, with the most significant gain in organs such as the inferior mesenteric artery, cystic duct, cystic artery, uterine artery, and vesicular glands, with average Dice coefficient improvements of 0.43, 0.37, 0.32, 0.29, and 0.28, respectively. However, certain classes, including gallbladder, abdominal wall, and liver, showed only marginal improvements due to their impressive baseline performance. These findings highlight SAM’s capability in handling complex segmentation tasks, especially smaller and anatomically intricate structures, reinforcing its potential as a reliable and adaptable model for surgical scene understanding.

Multi-class segmentation performance of different models in surgical images. Comparison of prior SOTA (state-of-the-art) (grey), MedSAM (red), baseline SAM2 (orange), and SurgiSAM2 (green) across several anatomical structures. Values shown as percentages on radial axes range from 0–100% (0.0–1.0 mean Dice scores for the organ class). SurgiSAM 2 outperforms all other models across the majority of organ and tissue classes. (*MedSAM 2 was not employed in this study due to the fine-tuning being conducted on the smaller variant of SAM 2, containing 39 million parameters. Comparing this version to the base-plus model, which has 89 million parameters and was fine-tuned in this study, may not provide a fair assessment).
Generalization capability
A strict, patient-wise split for training, validation, and testing was implemented to prevent data leakage. No appreciable decline in performance was observed in the test subset relative to the training subset, further supporting the model’s capacity to generalize effectively to unseen examples and patients. Fine-tuning SAM 2 on 21 selected tissue classes out of the available 30, also resulted in improved Dice scores across the remaining 9 unseen classes, with an average increase of 0.17 compared to the baseline SAM 2. Notably, it achieved SOTA performance on 7 of these 9 unseen classes (77.8%). The unseen classes primarily consisted of organ-redundant categories across different datasets of the training data. This highlights the model’s capacity to generalize to similar classes (organs/tissues) beyond the training datasets, demonstrating strong cross-dataset transfer.
Qualitative assessment of successful and edge cases
To clearly demonstrate the segmentation efficacy, we performed visualization experiments showcasing examples of both the best and worst segmented cases, as determined by Dice metric, across various classes and datasets. The results are presented in (Fig. 7). Other than the reasons mentioned in the figure, failure cases also stemmed from factors such as obscured anatomical boundaries under dim lighting (e.g., abdominal wall vs. liver) and minor inconsistencies in ground truth annotations (e.g., gallbladder masks, fat vs. abdominal wall). For small or fragmented structures (e.g., ureter, intestinal veins), over-labeling may have caused prompt points to be sampled beyond their anatomical boundaries, potentially introducing ambiguity and impairing model performance. Additionally, the absence of temporal context in single-frame images likely contributed to misclassification of adjacent, visually similar structures—errors that might have been mitigated with temporal continuity available in video-based tracking. A more detailed breakdown of these failure cases is provided in the supplementary materials.

Qualitative assessment of SAM’s segmentation performance, illustrating best-performing (left) and worst-performing (right) predictions across different datasets and anatomical structures. SurgiSAM 2 performs exceedingly well even with smaller organs (spleen, ureter), discontinuous organs (liver), and deformed organs (gallbladder when being handled). SurgiSAM 2 may struggle when smaller organs undergo heavy dissection (cystic artery, cystic duct, intestinal veins), abstract anatomical concepts like hepatocystic triangle, and similar looking organs (small intestine and large intestine).
Preliminary evaluation of tissue tracking in videos: baseline SAM 2 vs. SurgiSAM 2
SurgiSAM 2 demonstrated a modest improvement over the baseline SAM 2 model (Fig. 8A) across all classes when using between 1–10 prompt points, while performing comparably at certain prompt point counts. Notably, the baseline model itself showed robust performance, with results progressively improving with increasing number of prompt points. The superior baseline performance on these videos, compared to other image datasets, can be attributed to several factors. First, the use of masks as prompts provides a dense representation of organ classes. Second, the short duration of the videos (0.5 s) results in minimal frame-to-frame variation. Lastly, the organs evaluated—characterized by their sharp borders—are inherently easier to segment. This experiment served as a preliminary assessment of the models’ tissue tracking capabilities, which have the potential to significantly enhance annotation workflows, rather than a comprehensive evaluation of the baseline and fine-tuned SAM 2 models.

Comparative video tracking performance of baseline SAM 2 and SurgiSAM 2 using mean Dice scores (y-axis). The dashed line represents the performance of the baseline SAM 2 model, while the solid line corresponds to the fine-tuned SurgiSAM 2 model. Both models exhibit improved segmentation accuracy with an increasing number of point prompts (x-axis). (A) YouTubeTrack dataset—SurgiSAM 2 marginally outperformed the baseline model across most prompt counts, achieving higher Dice scores. Performance of both models plateaus around 8–10-point prompts, with SurgiSAM 2 maintaining marginally superior Dice score. (B) CholecSegTrack dataset—SurgiSAM 2 outperformed the baseline model across all prompt counts, achieving higher Dice scores.
For the CholecSegTrack dataset, SurgiSAM 2 consistently outperformed Baseline SAM 2 across all organs, in Dice scores (Fig. 8B), with the largest gains observed under the 1-point prompt condition. Mean Dice scores generally increased with more point prompts, but SurgiSAM 2 maintained a performance advantage at all prompt levels (Table 4). These results highlight the model’s robustness in tracking anatomical structures across real-world surgical video scenarios.
Ablation studies
Ablation studies demonstrated that freezing the image encoder led to a substantial drop in WMDC by 5%, while excluding other components had minimal impact (Table 5). This suggests that the image encoder, which comprises a large portion of the model’s parameters, plays a key role in adapting the model to domain-specific surgical features. Fine-tuning this component appears essential for optimal segmentation performance.
Discussion
This study demonstrates the adaptability of foundational models like SAM 2 to specialized surgical data, achieving SOTA segmentation performance across a wide range of organs and tissues. Fine-tuning SAM 2 on surgical datasets delivered remarkable accuracy and generalization, often surpassing task-specific models, while requiring significantly fewer labeled samples. Unlike traditional task-specific models that demand extensive labeled datasets for each task/application, SurgiSAM 2 can leverage its generalized segmentation capabilities to provide a scalable, resource-efficient solution for fully automated or semi-automated segmentation pipelines for surgical applications. This is particularly important given how labor intensive it is to annotate surgical videos, the need for busy, trained surgeons to do this annotation, and the resulting scarcity of annotated videos.
Our findings align with recent advancements in medical image segmentation with SAM, where fine-tuning foundational models have shown significant promise, particularly when both the image encoder and the mask decoder are fine-tuned. Similar to prior research suggesting that models fine-tuned solely on the mask decoder deliver inferior performance, our ablation study found that freezing the image encoder alone led to a significant drop in WMDC of 5%, whereas freezing the mask decoder or prompt encoder had minimal impact on overall performance underscoring the critical role of the image encoder in adapting SAM 2 to surgical video data16. While we performed full fine-tuning of SAM 2, Wang et al. proposed SurgicalSAM using LoRA to adapt SAM for robotic surgery27. LoRA updates only low-rank matrices, typically training fewer than 1% of the model’s parameters, making it highly efficient. In contrast, our full fine-tuning approach, though more resource-intensive, usually provides greater robustness and generalization28, making it more suitable for complex, real-world scenarios such as unstructured surgical videos. However, since full fine-tuning updates all parameters, it is also more prone to catastrophic forgetting of pre-trained features, a risk that is mitigated with LoRA28. Ultimately, the choice between LoRA and full fine-tuning should be guided by the specific use case, available computational resources, and the desired trade-off between efficiency and performance. Our fine-tuning approach showed a 17.9% relative improvement over baseline SAM 2 and consistently outperformed prior SOTA models across most tissue classes, without significant performance degradation on the instrument classes. Although using bounding boxes or learned feature vectors as prompts could further enhance performance29,30,31, this work focused on evaluating SurgiSAM 2’s potential for surgical scene segmentation rather than optimizing prompt engineering.
Remarkably, these results were achieved with only 50–400 labeled samples per class. Even with just 50 samples per class, fine-tuning resulted in only marginal performance degradation compared to using 400 samples per class. This represents a reduction of one to two orders of magnitude in training data requirements compared to fully supervised task-specific models like nnU-Net32, while delivering comparable or slightly superior performance. Furthermore, SurgiSAM 2 excelled at generalizing to unseen tasks and datasets, achieving SOTA performance on 77.8% of unseen redundant classes from other datasets. This underscores its ability to effectively capture both low-level features and high-level organ-specific semantic features across diverse anatomical structures. The model’s capacity to generalize across datasets without retraining is particularly advantageous in the surgical setting, where video annotations are costly, time-consuming, and access to highly skilled annotators is limited.
Another critical finding is SurgiSAM 2’s ability to effectively segment discontinuous or amorphous structures (as shown with liver in Fig. 6) that are common in surgical data but remain difficult to segment accurately. This was also observable with a single point prompt. Despite all these strengths and notable performance improvements with challenging structures such as the gastrointestinal tract, ureter, and vesicular glands, certain challenges remained. SurgiSAM 2 performed poorly on small organs that were heavily dissected, such as the cystic plate, cystic artery, cystic duct, and intestinal veins in (Fig. 6). Tissue dissection can unpredictably alter the appearance and feature representation of organs, making it challenging for models to accurately identify them. The presence of adipose tissue overlying abdominal organs can also complicate annotation and hinder the model’s performance, as it may be challenging to distinguish and label pixels accurately as either the organ or adipose tissue. Additionally, the small intestine was sometimes misclassified as the colon when both appeared in the same frame, likely due to their similar visual characteristics or due to the class, gastrointestinal tract, in CholecSeg8k dataset having examples from both small and large intestine. Furthermore, the segmentation of abstract and dynamic anatomical concepts, such as the hepatocystic triangle, remained a significant challenge. It may be that some of the tissues that could be of greatest benefit to surgeons (and their patients) to be able to identify using segmentation models such as the common bile duct during a cholecystectomy and a ureter during a colon resection, may prove in many cases to be the most difficult to identify using segmentation models. Finally, other challenges include poor illumination and smoke from surgical cauterization that affect image quality and model performance.
Further enhancements to SurgiSAM 2’s performance could be achieved by incorporating the larger image encoder, such as Hiera Large, and exploring prompting strategies such as: combination of positive and negative prompts, avoiding border regions for sampling prompts points, bounding boxes, and high dimensional learned organ-specific feature vectors33,34. Moreover, adopting multi-frame segmentation approaches to leverage temporal information in videos, rather than relying solely on isolated images as in this study, could further enhance segmentation. Memory optimization methods, such as efficient frame pruning35, could further facilitate surgical video segmentation in intraoperative settings.
The ability of SurgiSAM 2 to generalize and perform well even with limited training data has significant clinical implications. By enabling segmentation in scenarios where annotated datasets are scarce, SurgiSAM 2 addresses a critical bottleneck in the adoption of CV models for surgical applications. Currently, the rate-limiting step for integrating AI into surgical workflows is the need for extensive manual annotation of training data, which is both time-consuming and resource-intensive. With SurgiSAM 2’s remarkable segmentation capabilities, surgeons can leverage AI to enhance surgical scene understanding, even in underrepresented or novel surgical scenarios. This reduces the dependency on large-scale annotation efforts, paving the way for broader clinical adoption of artificial intelligence-driven tools in surgical applications such as real-time intraoperative guidance, automated skill assessment, and robotic surgery.
The limitations of this study are herein acknowledged. While this study utilized all public datasets with segmentation masks for tissues, these likely do not comprehensively represent the full diversity of organs and structures encountered during surgical procedures. This may limit the generalizability of SurgiSAM2 to the more broader range of procedures and anatomical structures encountered in surgical settings. Moreover, the random convenient sampling of frames from the original datasets for the range of training data scales may overrepresent scenes from certain aspects of surgery. Incorporating a more representative dataset through manual curation by surgeons, or automated sampling of images based on methods such as cosine similarity for clustering, could further improve performance. Finally, the potential for achieving higher performance with the full dataset scale was not evaluated due to computational constraints.
Conclusion
In conclusion, SAM 2 demonstrates remarkable zero-shot performance and exhibits significant improvements with fine-tuning across multiple organ classes from diverse datasets (Table 5). The fine-tuned SAM 2, SurgiSAM 2 underscores the potential of foundational segmentation models to offer robust, generalizable, and cost-effective solutions for surgical scene segmentation, even with limited training data. SurgiSAM 2 paves the way for scalable segmentation solutions by enabling semi-automatic pipelines that significantly reduce manual annotation requirements. This holds immense potential for surgical scene understanding, by facilitating accurate spatio-temporal tracking of tissues and instruments, thereby enabling clinical applications such as real-time surgical navigation, automated skill assessment and autonomous robotic surgery.
Data availability
The underlying code [and training/validation/test splits of all datasets] for this study and data with the final fine-tuned checkpoint are available on Github [https://github.com/Devanish31/SurgiSAM2] and Figshare [https://doi.org/10.6084/m9.figshare.28489961], respectively.
References
Radford, A., et al. Learning transferable visual models from natural language supervision. Preprint at https://arxiv.org/abs/2103.00020 (2021).
Brown, T.B., et al. Language models are few-shot learners. https://arxiv.org/abs/2005.14165 (2020).
Shi, Z., Zhou, X., Qiu, X. & Zhu, X. Improving image captioning with better use of captions. Preprint at https://arxiv.org/abs/2006.11807 (2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. Preprint at https://arxiv.org/abs/1512.03385 (2015).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at https://arxiv.org/abs/1409.1556 (2015).
Szegedy, C., Liu, W., Jia, Y., et al. Going deeper with convolutions. Preprint at https://arxiv.org/abs/1409.4842 (2014).
Kirillov, A., et al. Segment anything. Preprint at https://arxiv.org/abs/2304.02643 (2023).
Ravi, N., et al. SAM 2: Segment anything in images and videos. Preprint at https://arxiv.org/abs/2408.00714 (2024).
Kamtam, D.N., et al. Deep learning approaches to surgical video segmentation and object detection: A scoping review. Preprint at https://arxiv.org/abs/2502.16459 (2025).
Gu, H., Dong, H., Yang, J. & Mazurowski, M.A. How to build the best medical image segmentation algorithm using foundation models: a comprehensive empirical study with segment anything model. Preprint at https://arxiv.org/abs/2404.09957 (2024).
Zhang, Y. & Shen, Z. Unleashing the potential of SAM2 for biomedical images and videos: A survey. Preprint at https://arxiv.org/abs/2408.12889 (2024).
Shen, C., Li, W., Shi, Y. & Wang, X. Interactive 3D medical image segmentation with SAM 2. Preprint at https://arxiv.org/abs/2408.02635 (2024).
Deng, R., et al. Segment anything model (SAM) for digital pathology: Assess zero-shot segmentation on whole slide imaging. Preprint at https://arxiv.org/abs/2304.04155 (2023).
Mazurowski, M. A. et al. Segment anything model for medical image analysis: an experimental study. Med. Image Anal. 89, 102918 (2023).
Yamagishi, Y., et al. Zero-shot 3D segmentation of abdominal organs in CT scans using segment anything model 2. Preprint at https://arxiv.org/abs/2408.06170 (2024).
Yan, Z., et al. Biomedical SAM 2: Segment anything in biomedical images and videos. Preprint at https://arxiv.org/abs/2408.03286 (2024).
Ma, J. et al. Segment anything in medical images. Nat. Commun. 15, 654 (2024).
Zhang, K., Liu, D. Customized segment anything model for medical image segmentation. Preprint at https://arxiv.org/abs/2304.13785 (2024).
Wu, J., et al. Medical SAM adapter: Adapting segment anything model for medical image segmentation. Preprint at https://arxiv.org/abs/2304.12620 (2024).
Lou, A., Li, Y., Zhang, Y., Labadie, R.F., Noble, J. Zero-shot surgical tool segmentation in monocular video using segment anything model 2. Preprint at https://arxiv.org/abs/2408.01648 (2024).
Yu, J., et al. SAM 2 in robotic surgery: An empirical evaluation for robustness and generalization in surgical video segmentation. Preprint at https://arxiv.org/abs/2408.04593 (2024).
Hong, W.Y., et al. CholecSeg8k: A semantic segmentation dataset for laparoscopic cholecystectomy based on Cholec80. Preprint at https://arxiv.org/abs/2012.12453 (2020).
Carstens, M. et al. The dresden surgical anatomy dataset for abdominal organ segmentation in surgical data science. Sci. Data 10, 3 (2023).
Serban, N., Kupas, D., Hajdu, A., Török, P. & Harangi, B. Distinguishing the uterine artery, the ureter, and nerves in laparoscopic surgical images using ensembles of binary semantic segmentation networks. Sensors 24, 2926 (2024).
Murali, A., et al. Latent graph representations for critical view of safety assessment. Preprint at https://arxiv.org/abs/2212.04155 (2023).
Maqbool, S., Riaz, A., Sajid, H. & Hasan, O. m2caiSeg: Semantic segmentation of laparoscopic images using convolutional neural networks. Preprint at https://arxiv.org/abs/2008.10134 (2020).
Wang, A., Islam, M., Xu, M., Zhang, Y. & Ren, H. SAM meets robotic surgery: An empirical study on generalization, robustness adaptation. MICCAI https://doi.org/10.1007/978-3-031-47401-9_23 (2023).
Shuttleworth, R., Andreas, J., Torralba, A. & Sharma, P. LoRA vs full fine-tuning: An illusion of equivalence. Preprint at https://arxiv.org/abs/2410.21228 (2024).
Xie, W., Willems, N., Patil, S., Li, Y. & Kumar, M. SAM fewshot finetuning for anatomical segmentation in medical images. Preprint at https://arxiv.org/abs/2407.04651 (2024).
Dong, H., et al. Segment anything model 2: an application to 2D and 3D medical images. Preprint at https://arxiv.org/abs/2408.00756 (2024).
Zhao, X., et al. Inspiring the next generation of segment anything models: Comprehensively evaluate SAM and SAM 2 with diverse prompts towards context-dependent concepts under different scenes. Preprint at https://arxiv.org/abs/2412.01240 (2024).
Isensee, F., et al. nnU-Net: Self-adapting framework for U-Net-based medical image segmentation. Preprint at https://arxiv.org/abs/1809.10486 (2018).
Silva, B., et al., Analysis of Current Deep LearningNetworks for Semantic Segmentation of AnatomicalStructures in Laparoscopic Surgery, 44th AnnualInternational Conference of the IEEE Engineering inMedicine & Biology Society (EMBC), Glasgow, Scotland,United Kingdom. pp. 3502–3505. https://doi.org/10.1109/EMBC48229.2022.9871583 (2022).
Yunfan, L., et al. Automated Assessment of Critical View of Safety in Laparoscopic Cholecystectomy. https://doi.org/10.48550/arXiv.2309.07330 (2023).
Ouyang, S., He B., Luo H., & Jia F. SwinD-Net: alightweight segmentation network for laparoscopic liversegmentation. Comput Assist Surg (Abingdon). 29(1), 2329675. https://doi.org/10.1080/24699322.2024.2329675 (2024).
Kolbinger, F. R., et al. Anatomy segmentation in laparoscopicsurgery: comparison of machine learning and humanexpertise – an experimental study. Int. Jour. Surg. 109(10), p 2962–2974. https://doi.org/10.1097/JS9.0000000000000595 (2024).
Author information
Authors and Affiliations
Contributions
DNK—Conceptualization, Data curation, Formal analysis, Methodology, Supervision, Writing—original draft, Writing—review and editing; JBS—Conceptualization, Methodology, Supervision, Writing—review and editing; SDM—Conceptualization, Data curation, Writing—original draft, Writing—review and editing; XW—Conceptualization, Methodology, Supervision, Writing—review and editing; NL—Conceptualization, Methodology, Writing—review and editing; JJC—Conceptualization, Data curation, Methodology, Writing—review and editing; SY—Conceptualization, Methodology, Supervision, Writing—review and editing; CH—Conceptualization, Methodology, Supervision, Writing—review and editing. All authors read and approved of the final manuscript.
Corresponding author
Ethics declarations
Competing interests
Joseph Shrager: Consulting—Becton Dickinson; Lungpacer; Serena Yeung—Research collaborations with Intuitive Surgical Inc. and Surgical Safety Technologies; Clarence Hu: Founder – Hotpot.ai; Other authors have nothing to declare.
Declarations of generative AI and AI-assisted technologies
During the preparation of this work, the author(s) utilized ChatGPT to assist with rephrasing and refining the writing in the manuscript. After using this tool/service, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the published article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kamtam, D.N., Shrager, J.B., Malla, S.D. et al. A fine-tuned foundational model SurgiSAM2 for surgical video anatomy segmentation and detection. Sci Rep 15, 35961 (2025). https://doi.org/10.1038/s41598-025-11759-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11759-4
