
Abstract
Landslides are a frequent geohazard within the Himalayas, threatening human lives, infrastructure, and indigenous economies. Traditional subsidence velocity forecasting models, however, typically rely on either satellite remote sensing data or geotechnical parameters in isolation, which limits their predictive power and applicability. This work bridges this gap by suggesting an interpretable data-driven model that systematically integrates traditional soil information with geotechnical features for improved prediction. A stacking ensemble regression model called Forecasting Data-Driven Regression Learning (FDRL) was developed on the basis of the last machine learning breakthroughs, including feature selection techniques such as Pearson correlation and mutual information scores. The model combined both quantitative variables (e.g., specific gravity and plasticity index) and qualitative indicators based on conventional soil evaluation procedures (e.g., water retention, odor, and soil color). The FDRL model outperformed baseline regression models with a training Root Mean Squared Error (RMSE) of 1.11 mm/year and a test RMSE of 1.32 mm/year. Explainability analysis with SHAP showed that geotechnical as well as traditional soil characteristics significantly contributed to model predictions, confirming the utility of this hybrid combination. By demonstrating the explanatory potential of traditional soil indicators, typically excluded from scientific models, this study bridges local knowledge systems with modern data science. The method provides a scalable, interpretable, and locally implementable approach to early warning of slope creep and long-term deformation trends, facilitating proactive landslide risk management.
Similar content being viewed by others

Introduction
Landslides are among the most destructive natural disasters, causing significant fatalities, infrastructure damage, and long-term environmental deterioration. Because of a combination of steep topography, intense precipitation, deforestation, and seismic activity, the Himalayan region, particularly Himachal Pradesh in India, frequently experiences landslides. These events seriously disrupt transportation networks, isolate communities, and endanger lives, underscoring the urgent need for precise forecasting and mitigation strategies1. This research particularly addresses rainfall-triggered landslides, which are the most common and usually take place during monsoons, when continuous rain increases pore-water pressure and decreases soil shear strength. Predicting subsidence velocities, a crucial symptom of slope instability, remains challenging, even with advancements in monitoring and modeling methods.
Subsidence velocities, representing surface deformation rates, serve as early indicators of landslide activity. Ground deformation monitoring has been transformed using methods such as Interferometric Synthetic Aperture Radar (InSAR), which offers millimetric accuracy across large regions. InSAR has been applied to mining zones, urban areas, and landslide-prone regions to identify and assess slow-moving landslides2. These applications are primarily post-event or observational, though, with little incorporation into anticipatory frameworks that can inform risk reduction. Current InSAR-based approaches tend to focus on post-event analysis or isolated case studies, rather than combining diverse data sources for predictive modeling3.
Understanding slope stability and simulating soil behavior under stress requires geotechnical data such as soil density, porosity, shear strength, and fine content. Research has indicated their significance in areas susceptible to landslides; however, there is still a lack of integration with remote sensing datasets4. For instance, geotechnical analyses provide localized information on soil stability but lack the spatial coverage provided by remote sensing techniques such as InSAR5. Therefore, integrating these complementary datasets to enhance the prediction of subsidence velocities represents a significant research gap. Combining these data sources allows for a more comprehensive understanding of the slope instability.
The fusion of contemporary scientific methods with traditional knowledge systems is another unexplored path. Traditional knowledge emphasizes qualitative soil characteristics, such as color, texture, and fragrance, which are often overlooked in conventional geotechnical investigations. These culturally embedded indicators historically utilized by local societies can potentially capture hydrological or stability-concerned soil behavior that eludes conventional metrics. In regions such as the Himalayas, these traditional indicators can offer region-specific insights into soil behavior6. For example, brown and yellow soil colors frequently suggest inadequate drainage and specific odors may indicate anaerobic conditions, both of which are important aspects of slope stability7. Ancient liquid organic manure, known as Kunapajala, is well known for its ability to improve soil fertility and promote sustainable farming practices, both of which can indirectly enhance slope stability8. However, the predictive value of these traditional soil traits remains largely untested, creating a significant gap in literature.
Recent developments in machine learning (ML) have enabled the integration of diverse datasets to improve subsidence velocities predictions. Ensemble ML models, such as random forests (RF), support vector machines (SVM), and neural networks (NN), have demonstrated exceptional performance in processing complex datasets, especially in geologically challenging terrains9. However, most ML applications in landslide studies concentrate on mapping susceptibility or classifying regions at risk, often neglecting the prediction of quantitative measures, such as subsidence velocities10. In addition, interpretable hybrid models that integrate geotechnical, satellite, and local knowledge into a single, understandable pipeline remain to be developed. Recent studies have applied similar approaches to landslide hazard mapping and remote sensing integration, offering a comparative foundation for this work11,12,13.
Several approaches have been developed for modeling landslide and subsurface instability, including traditional geotechnical analysis, remote sensing-based monitoring, and machine learning. Geotechnical methods offer detailed site-specific measurements of soil strength and deformation, while remote sensing techniques such as InSAR provide spatially extensive insights into surface displacement patterns. Machine learning approaches, including decision trees, random forests, and neural networks, have enabled the analysis of high-dimensional and nonlinear data. Recent efforts have also explored hybrid models that combine multiple data sources or techniques. However, the integration of qualitative traditional indicators into predictive models remains limited. Table 1 presents a comparison of key methods used in subsurface and landslide modeling.
As indicated in Table 1, every modeling method has unique strengths and compromises. Geotechnical analysis is the current gold standard for site-specific precision but is limited by logistical and budgetary restrictions, particularly in mountainous and inaccessible areas. Remote sensing, especially with InSAR, allows for extensive spatial reach and high-resolution monitoring of the surface deformation. Remote sensing is mostly retrospective and does not provide information on subsurface conditions or future deformation unless provided with additional data inputs. Machine learning algorithms based only on geotechnical features have the advantage of interpretability and the capacity to capture nonlinear correlations but tend to lack generalization across regions. ML models applied with remote sensing inputs have the advantage of scalable insights for landscape but tend to lack adequate ground-truth support. The hybrid solution presented in this paper (see Table 1) has the advantage of a comprehensive solution by integrating geotechnical features, indigenous knowledge, and remote sensing into one predictive pipeline. Furthermore, although machine learning models have shown promise in handling high-dimensional and nonlinear geohazard data, their application in combining traditional and conventional features remains limited. Existing studies often focus on classification-based landslide susceptibility mapping, and few explore regression-based predictions of quantitative ground movements. There is also a lack of interpretable hybrid frameworks that integrate indigenous soil indicators with geotechnical and remote sensing data in a structured and explainable manner. Addressing these limitations can contribute to both methodological advancement and practical decision support for landslide-prone regions, such as the Himalayas.
To fill these gaps, this research presents a new stacking ensemble regression model Forecasting Data-Driven Regression Learning (FDRL) that combines geotechnical attributes, InSAR-based deformation data, and organized conventional soil expertise. The model identifies the most pertinent soil characteristics by utilizing feature selection techniques, such as Pearson correlation and mutual information coefficients. These techniques include both traditional indicators (e.g., color and smell) and conventional geotechnical parameters (e.g., soil density and porosity). Achieving RMSE values of 1.11 mm/year for training and 1.32 mm/year for testing, this multidisciplinary method provides a robust framework for predicting subsidence velocities with greater accuracy than standalone models14.
This study is significant because it connects conventional geotechnical and remote-sensing methods with traditional knowledge systems. By improving the accuracy of subsidence velocity predictions, the results contribute to the creation of early warning systems, proactive landslide mitigation plans, and sustainable land use strategies in the Himalayas and beyond. It further shows that native signs can be translated and understood in a contemporary, explainable AI framework. In addition to advancing scientific knowledge, this innovative integration of diverse data sources into a machine learning framework has significant potential for reducing disaster risks in geologically unstable areas15.
Despite extensive research on susceptibility mapping and hazard modeling, most existing approaches rely solely on geotechnical or remote sensing data, often overlooking qualitative indicators derived from traditional soil knowledge. There has been limited exploration of how traditional knowledge systems can be systematically integrated with modern quantitative features in predictive models. This study addresses this gap by proposing a novel machine learning framework that combines geotechnical parameters with traditional soil features, selected using both Mutual Information and Pearson Correlation techniques. A stacking ensemble model (FDRL) is developed and evaluated to improve prediction of subsidence velocities in landslide-prone regions.
The novelty of this study lies in the structured integration of traditional knowledge into a quantitative machine-learning pipeline supported by explainable AI methods such as SHAP for model interpretability. This study contributes a replicable, interpretable, and hybrid knowledge-based approach to geohazard prediction that extends beyond the conventional data sources and modelling techniques used in prior studies.
The study’s methodology, findings, and wider ramifications are described in depth in the parts that follow. These sections also provide insights into how multidisciplinary methods might revolutionize subsidence velocities prediction and management in high-risk areas.
Materials and methods
Study area
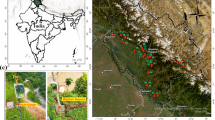
The study was conducted in Himachal Pradesh, India, focusing on the Mandi region in the mid-Himalayan range (Fig. 1). It is most prone to landsliding in the western Himalayas owing to an incidence of topographical steepness, year-round heavy precipitation, active tectonics, and widespread man-induced modifications. These factors make the region ideal for investigating slope instability and the effectiveness of predictive modeling strategies. The research area of specific concern slices a 50-kilometer highway from Mandi town to Kamand town, and these elevations range from sea level to 1,250 to 850 m. The geographic extent is defined by coordinates 76°55′54″E to 76°59′42″E and 31°42′25″N to 31°46′26″N. This corridor has seen recurring slope failure during monsoon seasons, and hence it is a high-hazard terrain for transport and infrastructure.
The geology of the area is a mix of metamorphic and sedimentary rocks capped by overlying colluvial soil covers of varying proportions of silt, sand, clay, and gravel. This diversity affects the mechanical strength and permeability of the soil, two of the primary parameters that control slope stability. The area also features steep elevation gradients with slopes frequently in excess of 30°, which affect surface runoff kinematics as well as infiltration rates. The area experiences a mean annual rainfall of about 1,380 mm, of which most occurs during July to September. Seasonal rains increase pore-water pressure and reduce shear strength of soil, both of which are two important causes of landslides triggered by rainfalls. In addition to hydrometeorological drivers, slope-cutting for roads, deforestation, and unregulated construction further exacerbate slope instability.
Both shallow and deep-seated landslides have been reported in the region. Historical information of disaster management authorities and on-site surveys support multiple slope failure in the research area, particularly during monsoons. Several of these events have resulted in road blockages, damaged infrastructure, and temporary isolation of villages. A total of 55 landslide-prone locations were selected along the study route. The following places were chosen based on documented landslide histories, field accessibility, and regional representativeness of the study area regarding geological, hydrological, and vegetation diversity. Soil samples were collected from each site, integrating both conventional geotechnical protocols and traditional knowledge indicators to create a comprehensive feature set for slope stability assessment.

Location of the Mandi region on Google Maps. The map illustrates locations in Mandi District where data were collected. The base map was generated using ArcGIS Pro version 3.2 (https://www.esri.com/arcgis-blog/products/arcgis-pro/announcements/whats-new-in-arcgis-pro-3-2/.
Data attributes
This study employed the Small Baseline Subset Interferometric SAR (SBAS-InSAR) technique, which is well known for its high precision in detecting and tracking surface deformations over time. To enhance both temporal coherence and spatial granularity, SBAS-InSAR was supplemented with Persistent Scatterer Interferometry (PS-InSAR), which provided millimetric-level accuracy for the quantification of ground displacement16. This integration allowed for comprehensive geohazard monitoring and provided deformation patterns that were crucial for subsidence velocity predictions.
Sentinel-1 SAR data, captured in the Interferometric Wide (IW) swath mode, were used for their ability to cover large geographic areas with high spatial resolution. Operating at a 5.4 GHz frequency (C-band) with a 5.6 cm wavelength, this mode offered detailed deformation mapping across the 250 km2 Kamand Valley region. The data spanned from December 2022 to December 2023, enabling temporal analysis of deformation trends6.
DInSAR processing was conducted using SARSCAPE software, which facilitates the generation of differential interferograms. Primary and secondary images were carefully paired based on stack coherence and geometric alignment, and the Goldstein filtering technique was applied to reduce phase noise and enhance the accuracy of subsidence velocity measurements17.
The SBAS module of the SARSCAPE platform’s automated detection of the most coherent image pairs ensured stable generation of interferograms and minimized decorrelation noise in image stacks18,19. The SBAS-InSAR-derived subsidence velocities were integrated into the FDRL model, enriching its predictive capability by providing early indicators of deformation.
This integration of satellite-based deformation monitoring with machine learning is a data-driven, scalable method for predicting slope instability in mountain terrain. The inclusion of the SBAS algorithm in SARSCAPE ensures reliable interferogram generation by selecting the most coherent SAR data pairs18,19.
This study illustrates the significance of integrating high-resolution SAR techniques with ground soil proxies to model geohazards. The combination of SBAS–InSAR’s proven accuracy and the FDRL model enhanced forecasting precision and risk mitigation applications in the Himalayan region20.
Although the SAR data spanned a 12-month observation period, subsidence velocities were derived as cumulative or average values for each location rather than as a continuous time series. Therefore, the data structure does not support a time-series modelling approach. The predictive modelling task was framed as a standard regression problem to estimate the average subsidence velocity using static soil properties, consistent with the input data design.
Data collection and preprocessing
Soil samples were collected from 55 locations in the study area of Kamand Valley, Mandi district, Himachal Pradesh, India. Selection of these locations was based on a history of frequent landslides and to represent the geological and climatic diversity of the region. The dataset used in this study included 53 features.
These are divided into conventional geotechnical features such as plasticity index, liquid limit, specific gravity, saturated water content, fine content, and others and traditional soil features, including soil color, smell, water retention, fertility, and vegetation cover. Conventional features are standard parameters in soil mechanics and engineering.
Traditional features follow the principles of traditional knowledge, which considers qualitative traits such as color and smell for insights into soil stability. These qualitative indicators such as soil color, smell, water retention, and texture originate from traditional knowledge practices used by communities to assess soil fertility, drainage potential, and general health.
Although conventionally not incorporated into engineering models, these experience-based indicators were methodically coded and added to this research to assess their complementary value in predictive slope instability modeling.Each traditional feature was categorized and structured for use in the regression framework alongside quantitative geotechnical data. The purpose of combining these feature categories is to explore whether including traditional knowledge with standard geotechnical data can improve the prediction of landslide-related soil movement.
Natural water content and water retention variables associated with moisture were measured by standard gravimetric methods. Soil samples collected from each site were weighed before and after oven-drying, and water retention was assessed using drainage behavior under standard conditions. These controlled measurements guaranteed reproducibility between field sites and produced hydrological indicators reflective of actual slope saturation potential.
All features included in the analysis are listed in Table 2. The dataset also integrates subsidence velocity measurements derived from remote sensing data. This variable serves as the output for the predictive modeling task.
Experimental setup
This study applied machine learning models to predict subsidence velocity at landslide-prone locations using both geotechnical and traditional soil features as input variables (see Table 1). The output variable is the subsidence velocity at each location, which reflects the rate of ground movement observed from satellite remote sensing.
To facilitate dimensionality reduction and enhance model interpretability, feature selection methods including Mutual Information and Pearson Correlation Coefficient were used to rank the predictive ability of the entire 53 input features. Feature selection methods, including Mutual Information and Pearson Correlation, were used to identify the most informative predictors among the 53 features. Both the full set and a subset of top features were considered for model training and evaluation. The analysis was structured to compare models trained with modern geotechnical features, traditional features, and their combinations.
Experiment design compared model performance systematically across three feature scenarios: geotechnical-only, traditional-only, and a combined feature set. The objective is to assess whether the integration of traditional soil indicators with standard geotechnical data enhances predictive accuracy for landslide risk assessment in this region. The experimental process included normalization of data, feature selection, and evaluation of multiple regression models for performance in predicting subsidence velocity.
The data pipeline had three principal steps: normalization, feature selection, and supervised regression modeling.Results from these experiments form the basis for further discussion of subsidence velocity forecasting approaches.
Normalization
Normalization was applied to the dataset to ensure that all features contributed equally during the model training. Normalization was performed to scale all input variables, including the target variable (subsidence velocity), to the range of [− 1, 1]. Scaling features to a common range helps improve the numerical stability of machine learning models and speeds up convergence during training. Without normalization, features with larger numerical ranges can dominate the learning process, leading to biased model behavior.
Min-Max normalization was used and calculated using the following formula:
where x is the original value, and xmin and xmax are the feature’s minimum and maximum values. This conversion standardizes all input features onto a single scale, reducing skewness and promoting evenly balanced gradient updates during learning. This preprocessing step ensures uniformity across features, facilitating faster model convergence and reducing numerical instability.
Feature engineering
High-dimensional datasets often present significant computational challenges in training regression and classification algorithms. These datasets often contain redundant or irrelevant features that can lead to overfitting and introduce noise, which adversely affects the performance of machine learning (ML) models21. Consequently, classifiers or regressors may generate erroneous predictions or rely on misleading features14,22.
Feature selection is an important step in ML workflows to enhance model performance by identifying and retaining only the most relevant features. This process reduces computational costs while improving the accuracy and interpretability of the model9,23.
To accurately predict subsidence velocities, this study selected a subset of 53 features from the dataset instead of using the entire feature set. Two established selection methods were utilized: Mutual Information (MI), which is capable of capturing nonlinear relationships between features and the target, and Pearson Correlation Coefficient (PCC), detecting linear relationships and assisting in minimizing multicollinearity.
Only features with the highest predictive value were retained because these techniques were tailored to suit the characteristics of the dataset9,24. This hybrid feature engineering strategy allowed for both improved model robustness and interpretability, especially in the context of integrating qualitative traditional indicators with quantitative geotechnical variables. The hybrid feature engineering approach enabled both enhanced model robustness as well as interpretability, particularly when considering combining qualitative conventional indicators with quantitative geotechnical variables.
Train-test splits
To evaluate the performance of the machine learning models, this study applied a train-test split method. 85% of the dataset was used for training, and the remaining 15% was reserved for testing. Random shuffling was applied before the split to ensure that the data were uniformly distributed across both sets. The 85/15 split was selected to balance the need for sufficient data during model training while maintaining an independent set for reliable performance evaluation. The use of a dedicated testing set allowed the assessment of the model’s generalization ability for unseen data. This split ratio was selected to ensure that the model had access to sufficient data during training to learn complex patterns, while retaining a representative portion for testing. It strikes a balance between maximizing training efficiency and validating performance robustness.
Pearson correlation
Pearson correlation coefficient (PCC) between the variables was determined in an effort to measure direction as well as strength of their linear relationship25. PCC is a common statistical parameter describing the extent to which two variables co-vary. The correlation coefficient runs from − 1 to 1; values close to − 1 indicate the strong negative correlation and 1 indicates a strong positive correlation between variables; a value of 0 denotes no correlation between variables. The PCC for qualities between two variables x and y can be computed using the following equation:
where \(\:\underset{\_}{x}\) and \(\:\underset{\_}{y}\) are the means of variable x and y, respectively, and n is the number of data points. The numerator records the co-variation of the two variables, while the denominator reduces the outcome so that it becomes scale-independent. After determining the PCC of each attribute to the target variable (subsidence velocity), attributes were ranked in the order of the absolute value of their correlation coefficients. Attributes with the strongest correlations (closer to ± 1) were given a higher score, while those closer to 0scored lower. An ensuing score makes it possible to rank attributes that are more linearly predictive and thus best suited to follow-up modeling exercises.
Mutual information coefficients
The Mutual Information (MI) concept was used to guide the selection of features using Mutual Information coefficient (MIC) methods24. MI is a useful technique for determining the feature relevance to the target variable because it quantifies the amount of information that one random variable contains about another. Unlike linear techniques like correlation, MI is able to capture linear and nonlinear relationships between variables, which makes it an effective method for selecting features that might not show evident correlations.
The most informative features are highlighted in the MIC techniques by ranking them according to their MI scores with the target variable. A higher MI score represents features that add more novel information towards predicting the target. MIC produces a score ranging between 0 and 1, where 0 indicates no relationship between the variables, and 1 indicates a strong relationship, which could be either linear or non-linear. The formula for MI between two variables, a and b, is given by:
where (p (x, y)) is the joint probability function of x and y, and (p(x)) and (p(y)) are the marginal probability functions of x and y, respectively. After calculating the MIC, the features were sorted based on their MIC values, with the highest values (close to 1) ranked first, and those closer to 0 ranked last.
Feature selection
For building a good and simple feature set, we employed a two-stage feature selection approach. First, pairwise Pearson Correlation Coefficient (PCC) analysis was carried out to assess the linear relationships between all features. Features with a high correlation (PCC ≥ 0.78) were grouped, and one feature from each highly correlated pair or group was removed. This was necessary to remove duplicate information and minimize multicollinearity in the regression model. Subsequently, Mutual Information (MI) was calculated between each remaining feature and the target variable. This step captures the nonlinear relationships between features and the target. Sixteen features with the highest MI scores were selected for the final model.
The ultimate set of chosen features was a compromise of physical significance and statistical robustness. These consisted of geotechnical properties (e.g., cohesiveness, dry density, angle of internal friction), conventional soil indicators (e.g., color, texture, odor), and environmental factors (e.g., moisture retention, drainage characteristics). Through the combination of domain expertise with data-driven feature selection, this cross-disciplinary pipeline preserved geophysical interpretability while improving model predictive accuracy for subsidence velocity estimation.
Machine learning algorithms
This study trained several regression models to predict subsidence velocities using both the complete feature set and a feature-engineered subset. The machine learning models used include K-Nearest Neighbors Regression (KNR), Support Vector Regression (SVR), Decision Tree Regression (DTR), Random Forest Regression (RFR), Linear Regression (LR), Lasso Regression, and Elastic Net Regression26. These models were selected to represent a range of learning approaches suitable for small-to-medium-sized datasets with potential nonlinear relationships between features and the target variable. KNR and SVR are capable of modeling complex, non-linear patterns, while DTR and RFR offer interpretability and robustness against overfitting. LR, Lasso, and Elastic Net provide baseline comparisons based on linear assumptions and regularization techniques. Hyperparameter tuning was performed for each model to optimize the predictive performance and minimize the risk of overfitting across both datasets.
K-nearest neighbors’ regression (KNR)
Using the average of the values of its k-nearest neighbors of the current instance in the feature space for the regression problems, this model predicts the output for a given input. According to this theory, the input points that are similar have similar output points. It uses the closeness of the data points to make estimates. KNR is based on the hypothesis that spatially or feature-wise proximal observations exhibit similar output behavior and thus is well-suited for datasets where local structure is important. This balances the trade-off between bias and variance using a suitable value of k, thereby offering simple predictive modeling27.
Support vector regression (SVR)
SVR is a supervised learning model for regression tasks. It tries to find a hyperplane in a high-dimensional space that best fits the data points to minimize prediction error within a specified margin. Kernel functions are used to handle non-linear relationships. By considering only the support vectors observations nearest to the margin SVR yields a sparse, computationally efficient model with good generalization even in high-dimensional feature spaces. By optimizing the margin and using support vectors, SVR balances model prediction accuracy and complexity28.
Decision tree regression (DTR)
Decision tree regression is a non-linear model and their potential outcomes using a tree structure. To create a tree with each leaf node representing a predicted value, it recursively divides the data into subsets according to the feature values that minimize the variance. This technique captures intricate linkages and interactions between features without requiring a linear shape. However, DTR models are highly sensitive to training data and may overfit if not pruned or regularized properly. If not appropriately trimmed, it may start overfitting29.
Random forest regression (RFR)
Breiman developed the RF model for classification and regression problems in 2001. During the RF training time, several decision trees are randomly created. The RF either gives out the majority class (classification) or the number that is the mean of the predictions made by each tree (regression). RFR minimizes variance of each tree by ensemble averaging and enhances overall model stability. The RF model fixes the overfitting problem in decision trees by aggregation30.
Stacking ensemble regression
This ML model combines multiple regression models to improve prediction performance. It trains with several base models and then uses a meta-model to predict, often through weighted averaging or voting. Stacking is distinct from bagging and boosting in that it learns to best combine the base models explicitly using a meta-learner, thus enhancing the adaptability of the ensemble across datasets. This method uses the advantages of several models, lowering individual flaws and improving general accuracy. Stacking produces a stable and adaptable model ensemble by combining several methods and learning paradigms31.
Linear regression (LR)
A basic statistical model for simulating the relationship between a dependent variable and one or more independent variables is called linear regression. A linear equation is fitted to the observed data points to minimize the sum of squared discrepancies between the observed and anticipated values. This approach yields interpretable coefficients showing the direction and intensity of the correlations between the variables under the assumption that a linear relationship exists between them. Even with its simplicity and clarity, LR can be restricted in the presence of multicollinearity or nonlinearity in difficult datasets. However, it may not capture complex nonlinear relationships present in the data22.
Lasso regression
Least absolute shrinkage and selection operator is a linear regression model that performs variable selection and regularization to improve accuracy. It works by increasing the regression model’s penalty by an amount equal to the absolute value of the magnitude of the coefficients. Lasso’s L1 regularization prevents overfitting in high-dimensional data by reducing some coefficients to zero, thus regularizing the model and enhancing generalization. By setting some of the coefficients to zero, this penalty term promotes sparsity and helps choose a less complex model that prevents overfitting32.
Elastic net
Elastic Net is a regularized regression model that linearly combines the penalties of the Lasso and Ridge regression methods. It functions by including in the regression model the L1 penalty, the absolute value of the coefficient magnitude, and the L2 penalty, which is the squared coefficient magnitude. Elastic Net is especially useful when predictors are highly correlated since it can pick groups of correlated variables and balance between model complexity and variance. This combination balances the stability of Ridge regression and the sparse solutions of Lasso, enabling Elastic Net to execute variable selection while successfully handling correlated predictors23.
Forecasting data-driven regression learning (FDLR) model
This study developed a novel Forecasting Data-Driven Regression Learning (FDRL) model based on a stacking ensemble regression approach. The FDRL model was designed to integrate multiple machine learning algorithms to improve the prediction accuracy of subsidence velocities in landslide-prone areas.
Model architecture
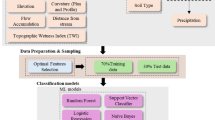
The FDRL model’s architecture is depicted in Fig. 2, which also shows the model’s sequential processing from feature engineering to the final prediction. The FDRL model offers a strong and dependable tool for predicting subsidence velocities by integrating numerous regressions approaches inside a stacking ensemble framework, which helps to improve landslide risk management and mitigation tactics. Such stacked architecture not only enables improved generalization but also utilizes the diversity of base models to learn disparate patterns from diverse feature types. The FDRL model architecture is organized to systematically process and assess a mix of geotechnical data and conventional soil features to predict subsidence velocity profiles derived from satellite-based observations, as shown in Fig. 2.
The FDRL model uses a stacking ensemble approach to improve the accuracy of subsidence velocity predictions. The first step in this ensemble is the combination of DTR and RFR. A DTR model is developed to identify non-linear relationships in the data. Separately, an RFR model is developed due to its ability to manage complex datasets. It operates by creating multiple decision trees during the training. This method, known as bootstrap aggregation, helps to reduce the risk of overfitting by averaging the predictions of multiple trees. SVR was included because of its ability to model both linear and nonlinear patterns in the data using kernel functions. Combined, these base learners work as first-level predictors that learn representative functional dependencies among the input features and target variable. By combining these models, the FDRL framework improves the accuracy and reliability of predictions.
After generating predictions from the DTR and RFR, these predictions were passed through a LR model in FDLR. The role of this LR model is to combine the outputs from the DTR and RFR, thereby improving the overall prediction by balancing any biases or variances that might exist between the two. This intermediate linear layer is a calibrator that smoothing the tree learners’ outputs prior to further blending.
The final step in the FDRL technique involves passing the combined predictions from DTR, RFR, and KNR through another LR model. This second LR model integrates the outputs from all models in the ensemble, resulting in a final prediction that leverages the strengths of each method. This second-order LR aggregator ensures that data from various predictive styles proximity-based (KNR), structure-based (RFR/DTR), and margin-based (SVR) are systematically integrated to provide strong and accurate subsidence velocity estimates. The stacking ensemble approach in the FDRL technique was designed to utilize different machine learning models in a systematic manner, leading to more accurate predictions of subsidence velocities.
The FDRL model predicts subsidence velocities with a high degree of accuracy. When compared to standalone models, the FDRL model considerably increases prediction accuracy by combining several machine learning techniques and utilizing both conventional and contemporary soil data. Its hybrid architecture makes it especially well-suited to geologically heterogeneous environments such as the Himalayas, where high-dimensional data and intricate interactions overwhelm conventional predictive methods. Applications in areas like the Himalayas, where complicated geotechnical conditions and high-dimensional data present major hurdles, are especially well-suited for this concept.

Architecture for landslide subsidence velocities prediction using FDRL ML model.
Model selection and optimization
To identify the most effective models for predicting subsidence velocities, this study performed comparative evaluations of multiple regression algorithms. Hyperparameter tuning was conducted to optimize each model’s performance and to reduce the risk of overfitting33. Hyperparameter optimization focused on achieving a balance between model complexity and generalization ability across different training and testing sets. This was particularly necessary in view of the existence of high-dimensional, mixed-type data that entailed conventional and geotechnical soil predictors. Stacking ensemble methods have been employed to combine the strengths of individual models while minimizing their weaknesses, thereby creating a more reliable prediction framework. All models were evaluated consistently using the Mean Squared Error (MSE) metric to compare predictive accuracy and robustness. Table 3 lists the optimized parameters for the different models.
DTR
In DTR, the minimum samples split parameter was set to 10 and maximum depth was set to 5. These features were chosen to improve decision tree splits and reduce overfitting. This setting was chosen in order to avoid excessively complex trees and better generalize while maintaining the important nonlinear patterns.
KNR
For KNR, the number of Neighbors was set to 5, and the weight function was set to uniform. These features were tuned to enhance model performance by considering 5 nearest neighbors with uniform weighting. This configuration enabled the model to make predictions locally from the data structure without biasing the estimate towards closer or more distant neighbors.
SVR
In SVR, the regularization parameter (C) was set to 1, the epsilon (ε) value was set to 0.8, and the kernel function was Radial Basis Function (RBF). Performance and generalization were enhanced by the optimization of these parameters. The RBF kernel was chosen because of its ability to model both global and local feature effects, suitable to the variation in soil properties.
RFR
The number of trees in RFR was set to 100 and the maximum depth set to 5. The configuration of these features results in a strong ensemble model. Such configuration guaranteed enough variety among the trees but limited their depth to prevent overfitting and enhance model stability.
Error measures
The root-mean-square error was used to calculate the difference between the expected and actual values (RMSE). RMSE is calculated as follows:
where yi represents the actual data point, (\(\:\widehat{y}\)i ) signifies the value predicted by the model, and “n” denotes the total count of data points. This metric penalizes larger deviations more heavily than smaller ones, making it a preferred choice when the objective is to minimize substantial prediction errors. RMSE was utilized uniformly in all model comparisons so that one could accurately compare the forecasts of subsidence velocities. Its ease of interpretation in the same units as the target variable (i.e., mm/year) also rendered it an effective measure to communicate results in geotechnical as well as environmental applications. Other than RMSE, Mean Absolute Error (MAE) and the coefficient of determination (R2) were also calculated to give a better overview of model performance.
Mean Absolute Error (MAE) measures the average magnitude of the errors between predicted and actual values, without considering their direction. It is defined as:
MAE is less sensitive to outliers compared to RMSE and provides a direct interpretation of average error magnitude, making it particularly suitable for communicating average prediction performance.
The coefficient of determination (R2) quantifies the proportion of variance in the dependent variable that is predictable from the input features. It is calculated as:
where is the mean of the observed values.
An R2 value closer to 1 indicates a stronger model fit. In this study, R2 was used to interpret the explanatory power of the regression models and evaluate their generalization capability. Together, these three metrics RMSE, MAE, and R2 provided a balanced view of model accuracy, robustness, and explanatory power, ensuring a thorough evaluation of predictive performance across all approaches.
Results
A total of 55 sites were selected along the study route, identified based on their history of frequent landslides and accessibility for data collection. Figure 3 displays the spatial distribution of these sites within the Mandi valley, illustrating a diverse topographical spread for sampling.

Map of the study area in Mandi district, Himachal Pradesh, India, showing the 55 landslide-prone locations along the Mandi–Kamand valley. The map was generated using ArcGIS Pro version 3.2 (https://www.esri.com/arcgis-blog/products/arcgis-pro/announcements/whats-new-in-arcgis-pro-3-2/).
By combining PCC and MI, the selected features reflect both linear and nonlinear dependencies on the target variable, enhancing the interpretability and predictive power of the model. As shown in Table 4, the selected feature set included 11 modern geotechnical features: plasticity index, liquid limit, cohesion (C, kPa), fine content (%), angle of internal friction (degrees), sand (%), density (kN/m3), silt (%), natural water content (%), gravel (%), and specific gravity. Traditional features include water retention, moisture, sweet taste, clay content and gravel content of soil. This hybrid set of predictors ensured both empirical strength (from geotechnical indicators) and contextual relevance (from traditional knowledge), improving the model’s ability to reflect real-world slope conditions in the Himalayan region.
Machine learning is suitable for this study because it can capture complex, nonlinear relationships between multiple geotechnical and soil features and the target variable, subsidence velocity. Unlike traditional deterministic models, which often require predefined physical relationships and site-specific slope parameters, ML models learn patterns directly from data and are better suited for integrating diverse feature types. This makes ML effective for regional-scale predictions, where direct mechanistic modelling is not always practical.
Regression model for predicting soil velocity.
Regression models were evaluated on both the data with feature engineering and on the entire datasets. The models like LR, SVR, Lasso Regression, Elastic Net, DTR, KNR, RFR, and stacked ensemble were trained to predict soil velocity with 16 engineered features (see Table 5). The results demonstrate the efficacy of different regression techniques in modeling soil velocity based on engineered features. Among the tested models, the Forecasting Data-Driven Regression Learning (FDRL) approach clearly yielded the most accurate predictions. The results indicated that the FDLR model performed the best among the tested models. It achieved a training RMSE of 1.11 mm/year and a test RMSE of 1.32 mm/year. This model outperformed others like DTR, RFR, and KNN, which had training RMSEs ranging from 1.13 to 2.43 mm/year and test RMSEs from 1.77 to 2.79 mm/year.
The performance metrics of various regression models on the complete datasets are summarized in Table 6. The regression models, when trained using all features instead of only the top 16, showed lower performance across all models. Compared with Table 5, the DTR model had a training RMSE of 2.50 mm/year and a test RMSE of 2.89 mm/year when using all features, whereas it achieved a better training RMSE of 2.43 mm/year and a test RMSE of 2.79 mm/year with the top 16 features in Table 5. Similarly, RFR had a training RMSE of 1.99 mm/year and a test RMSE of 2.40 mm/year with all features in Table 5, compared to a better training RMSE of 1.74 mm/year and a test RMSE of 1.98 mm/year in Table 5. These findings underscore that parsimonious, well-curated feature sets can outperform full-dimensional datasets by reducing overfitting and enhancing generalization.
When comparing Table 5 (models with the top 16 features) and Table 6 (models with all features), it is clear that feature selection greatly enhances model performance. The models trained on the top 16 features consistently had lower RMSE values, indicating more accurate predictions. This highlights the importance of feature selection for reducing model complexity and improving accuracy by focusing on the most relevant data.
The RMSE and model performance were evaluated using the Mean Absolute Error (MAE) and coefficient of determination (R2). The FDRL model achieved an MAE of 0.95 mm/year and an R2 of 0.89 on the test set, indicating strong agreement between predicted and actual values with minimal average error. These metrics were also calculated for all baseline models and are summarized in Table 7 for comparison. Together, RMSE, MAE, and R2 offer a well-rounded diagnostic of model precision (RMSE), consistency (MAE), and explanatory strength (R2). The FDRL model emerges as a clear leader across all three.
To visualize the model performance, a scatter plot was created to compare the actual versus predicted subsidence velocities for both the training and testing datasets (Fig. 4). In both cases, the data points align closely along the 1:1 reference line, indicating that the FDRL model effectively captures the underlying deformation patterns. The tight clustering in the training plot and consistent alignment in the testing plot highlight the model’s ability to generalize well to unseen data. Such visual validation reinforces the numerical strength of the model, making the case for its deployment in regional slope monitoring and landslide early-warning systems.

The scatter plots show the actual versus predicted subsidence velocities for the training (left, blue) and test (right, green) sets.
The SHapley Additive exPlanations (SHAP) beeswarm plot (Lundberg and Lee 2017) was created, and it illustrates the influence of various features on the stacking regression model used for predicting subsidence velocity for the entire dataset (see Fig. 5). As seen in Fig. 5, key features such as Gravel (%), Natural water content (%), Silt (%), and Density (kN/m3) have a significant impact on the model output, as evidenced by their widespread SHAP values. High Gravel (%) values tend to negatively affect predictions, whereas lower values contribute positively. Features such as Specific Gravity, Cohesion (C, kPa), and Plasticity Index exhibit relatively smaller impacts than others. Traditional soil features, including Water retention, Moisture and Clay content in the soil, also contribute to the predictions, indicating their potential role in improving the model performance by complementing modern geotechnical parameters. SHAP’s explainability confirms that both mechanistic and qualitative indicators add value, particularly in geologically complex settings like the Himalayas. This analysis highlights the importance of integrating traditional and modern features to enhance predictive accuracy. The top-ranked features identified through statistical methods in Table 4, such as gravel (%), Natural Water Content (%), silt (%), and density (kN/m3), also demonstrated strong influence in the SHAP analysis (Fig. 5). This alignment between quantitative ranking and SHAP interpretability confirms the robustness of the feature selection process. This further illustrates how both geotechnical and traditional soil features meaningfully contribute to the model’s predictions of subsidence velocity.

The SHAP beeswarm plot showing feature importance.
Discussion
This paper presents a novel approach for predicting subsidence velocities by integrating conventional geotechnical parameters, traditional soil features, and SBAS-InSAR-derived deformation data into a Forecasting Data-Driven Regression Learning (FDRL) model. This integrated methodology reflects a significant step toward addressing the challenges of high-dimensional, heterogeneous datasets in geohazard prediction. These findings demonstrate that this integrated framework effectively addresses the challenges associated with high-dimensional datasets for geohazard prediction. By combining mutual information and Pearson correlation methods for feature selection, this study identified and retained the most relevant features, thereby enhancing the model’s accuracy and interpretability. The inclusion of traditional soil features marks a theoretical and methodological advancement, extending the conventional understanding of landslide dynamics and highlighting the complementary role of local experiential knowledge in modern AI-driven frameworks. Similar approaches have shown promise in recent studies, such as that of Wen et al., who incorporated SHAP analysis into backpropagation neural networks for landslide hazard evaluation34.
The FDRL model achieved an RMSE of 1.32 mm/year on the testing set, surpassing traditional machine learning models such as Random Forest (1.45 mm/year) and SVR (1.50 mm/year). This improvement is not just marginal but methodologically meaningful, as it validates the hypothesis that integrating traditional soil indicators with geotechnical parameters strengthens forecasting performance9,21.
The differences in model performance can be explained by the underlying architecture and learning strategies of each method. Linear Regression and Lasso Regression assume linear relationships between input features and the target variable, which may not hold for complex, high-dimensional landslide data involving both geotechnical and traditional qualitative soil properties22. These models are less capable of capturing feature interactions or nonlinear effects, leading to higher error rates.
Decision Tree Regression (DTR) improves upon this by learning simple decision rules, but it tends to overfit when data are noisy or limited, as seen in its relatively high RMSE29. Random Forest Regression (RFR), in contrast, uses multiple decision trees and averages their outputs, which reduces variance and helps generalize better to unseen data30. Support Vector Regression (SVR) performed competitively, likely owing to its capacity to model non-linear relationships through kernel functions, although its sensitivity to hyperparameters and scale may have limited its effectiveness with the full dataset28.
The superior performance of the FDRL model lies in its ensemble strategy, which aggregates predictions from base learners (SVR, KNR, DTR, and RFR), effectively balancing bias and variance. This stacking approach allows the model to capitalize on the strengths of each individual regressor while mitigating their individual weaknesses, thereby producing more robust and generalized predictions across diverse data types.
For instance, SHAP analysis revealed that Gravel and Natural water content were the most influential geotechnical features, whereas water retention, Moisture and Clay content in the soil contributed significantly to the predictive power of the model, collectively accounting for 17% of the feature importance. These results mirror the findings of Hsiao et al., who used SHAP to interpret the role of soil parameters in liquefaction-induced lateral spreading, thereby emphasizing the growing relevance of explainable AI in geohazard prediction35.
SHAP analysis not only explains model decisions but bridges the gap between empirical AI and domain theory by assigning measurable importance to traditionally qualitative features. Unlike prior models, which often operate as black-box systems, the FDRL framework offers insights into the relative importance of individual features. For example, the high SHAP value of the fine content corroborates its role in slope stability, as reported in earlier studies, whereas the significance of the sweet taste of soil as a predictor represents a novel finding in landslide research21. The practical relevance of the model is equally noteworthy. These findings are consistent with recent advancements in the integration of physical and machine-learning models for enhanced subsidence velocities prediction36.
The results of this study have practical implications in landslide risk management. The integration of geotechnical and traditional features into a single predictive framework offers a scalable solution that can be adapted for diverse geological contexts. The ability of the FDRL model to achieve high predictive accuracy while maintaining interpretability makes it a valuable tool for disaster-management authorities and policymakers. By highlighting the contributions of specific soil features, the model provides actionable insights that can guide early warning systems, land-use planning, and mitigation strategies in landslide-prone regions. This adaptability aligns with recent trends in geohazard modeling, in which interdisciplinary approaches have proven successful in addressing complex environmental challenges37.
This study contributes to theoretical advancement by demonstrating that qualitative traditional soil indicators often excluded from conventional models can be quantitatively encoded and systematically evaluated alongside geotechnical and remote sensing data. By encoding soil color, smell, and water retention into structured inputs for machine learning, this research expands the variable space used in geohazard forecasting. The use of SHAP analysis further strengthens this contribution by quantifying the relative influence of each feature, showing that some traditional indicators hold comparable importance to standard geotechnical parameters. Such an approach paves the way for inclusive modeling frameworks that respect both scientific rigor and traditional knowledge systems.
Despite these contributions, the study has several limitations. The dataset includes only 55 landslide-prone sites within a single geographic area, which may limit the generalizability of the model to other regions. The spatial resolution of the InSAR data, while adequate for this study, may not capture rapid or highly localized ground changes. Additionally, the influence of dynamic factors, such as rainfall intensity and vegetation cover, was not explicitly modelled. The cross-regional transferability of traditional indicators also remains an open question, as their interpretation may vary with cultural, ecological, or linguistic context.
Future research should address these limitations by expanding the dataset to include samples from other landslide-prone regions with varied geological and cultural characteristics. Incorporating real-time IoT-based sensors could enhance the temporal granularity of the data and allow for continuous monitoring. Additional traditional indicators should be documented through participatory rural appraisal techniques to better understand their broader applicability. Integration of SBAS-InSAR with environmental indices such as NDVI, rainfall, and land-use data could further enhance predictive strength by accounting for ecological seasonality. It is important to note that this model is optimized for creep-induced deformation rather than sudden failure events. Features such as cohesion, water retention, and fine content act as proxies for long-term slope weakening. While dynamic triggers like rainfall are not directly modeled, the SBAS-InSAR-derived velocity captures their cumulative impact on surface movement, enabling early detection of slow-moving landslides.
In summary, this study advances the field of subsidence velocities prediction by bridging traditional and conventional methodologies within an interpretable machine learning framework. This demonstrates that traditional soil knowledge, which is often overlooked in contemporary research, can complement geotechnical parameters to enhance the predictive accuracy. By combining explainable AI with traditional insights, this study established a foundation for culturally and scientifically inclusive geohazard models, contributing to both theoretical advancements and practical applications.
Conclusions
This study presents a hybrid machine learning framework for predicting subsidence velocities by integrating traditional soil knowledge, geotechnical parameters, and SBAS-InSAR data. The Forecasting Data-Driven Regression Learning (FDRL) model demonstrated high predictive accuracy and interpretability, supported by feature selection and explainable AI techniques. The fusion of qualitative traditional indicators with quantitative engineering features marks a substantial methodological evolution in landslide forecasting.
The SHAP analysis confirmed the predictive relevance of both traditional and modern features, reinforcing the value of culturally inclusive data sources in environmental modelling. Future studies should focus on expanding the dataset across diverse geographic regions, incorporating real-time sensor inputs, and testing additional traditional indicators. This framework lays the groundwork for interpretable, locally informed, and scientifically robust geohazard prediction models, adaptable to both Himalayan and global contexts.
Data availability
The corresponding author will provide access to the raw data supporting the conclusions of this article upon request without unnecessary restrictions.
References
Tonini, M., Pecoraro, G., Romailler, K. & Calvello, M. Spatio-temporal cluster analysis of recent Italian landslides. Georisk: Assess. Manag. Risk Eng. Syst. Geohazards. 16 (3), 536–554 (2022).
Solari, L., Feyzullahoglu, A. N., Raspini, F., Ciampalini, A. & Moretti, S. Mapping urban ground subsidence in Italy using InSAR techniques. Eur. J. Remote Sens. 51 (1), 182–197 (2018).
Morishita, Y. et al. LiCSBAS: an open-source InSAR time series analysis package integrated with the LiCSAR automated Sentinel-1 InSAR processor. Remote Sens. 12 (3), 424 (2020).
Kamaruszaman, N. A., Abdullah, N. A. & Hasbollah, R. Geological influences on slope stability: A review of significant factors and case studies. J. Appl. Geol. 12 (2), 95–110 (2021).
Gao, F., He, X. & Zhang, S. Pumping effect of rainfall-induced excess pore pressure on particle migration. Transp. Geotech. 31, 100669 (2021).
Sarkar, S., Kundu, S. S. & Ghorai, D. Validation of Ancient Liquid Organics-Panchagavya and Kunapajala as plant growth promoters (2014).
Biswas, S. & Das, R. Kunapajala: A Traditional Organic Formulation for Improving Agricultural Productivity: A Review (Agricultural Reviews, 2023).
Nene, Y. L. The concept and formulation of kunapajala, the world’s oldest fermented liquid organic manure. Asian Agri-History 22 (1), 1–7 (2018).
Kumar, P., Priyanka, P., Dhanya, J., Uday, K. V. & Dutt, V. Analyzing the performance of univariate and multivariate machine learning models in soil movement prediction: A comparative study. IEEE Access (2023).
Dal Seno, N., Evangelista, D., Piccolomini, E. & Berti, M. Comparative analysis of conventional and machine learning techniques for rainfall threshold evaluation under complex geological conditions. Landslides 21 (12), 2893–2911 (2024).
Ebrahim, K. M., Gomaa, S. M., Zayed, T. & Alfalah, G. Recent phenomenal and investigational subsurface landslide monitoring techniques: A mixed review. Remote Sens. 16 (2), 385 (2024).
Ebrahim, K. M., Fares, A., Faris, N. & Zayed, T. Exploring time series models for landslide prediction: A literature review. Geoenviron. Disasters. 11 (1), 25 (2024).
Ebrahim, K. M., Gomaa, S. M., Zayed, T. & Alfalah, G. Rainfall-induced landslide prediction models, part ii: Deterministic physical and phenomenologically models. Bull. Eng. Geol. Environ. 83 (3), 85 (2024).
Mali, N., Dutt, V. & Uday, K. V. Determining the geotechnical slope failure factors via ensemble and non-ensemble machine learning: A case study in mandi, India. Front. Earth Sci. 9, 824 (2021).
Searle, M. P. & Treloar, P. J. Introduction to Himalayan tectonics: a modern synthesis. Geol. Soc. Lond. Spec. Publ. 483 (1), 1–17 (2019).
Pawluszek-Filipiak, K. & Borkowski, A. Integration of DInSAR and SBAS techniques to determine mining-related deformations using Sentinel-1 data: The case study of Rydułtowy mine in Poland. Remote Sens. 12 (2), 242 (2020).
Goldstein, R. M. & Werner, C. L. Radar interferogram filtering for geophysical applications. Geophys. Res. Lett. 25 (21), 4035–4038 (1998).
Sharma, N. & Saharia, M. ML-CASCADE: A machine learning and cloud computing-based tool for rapid and automated mapping of landslides using Earth observation data. Landslides, 1–13. (2024).
Bonì, R. et al. Assessment of the Sentinel-1 based ground motion data feasibility for large scale landslide monitoring. Landslides 17 (9), 2287–2299 (2020).
Chen, Y. et al. Research on time series monitoring of surface deformation in Tongliao urban area based on SBAS-PS-DS-InSAR. Sensors 24 (4), 1169 (2024).
Cao, Y., Chen, Z., Belkin, M. & Gu, Q. Benign overfitting in two-layer convolutional neural networks. Adv. Neural. Inf. Process. Syst. 35, 25237–25250 (2022).
Kibria, B. G. & Lukman, A. F. A new ridge-type estimator for the linear regression model: simulations and applications. Scientifica 2020 (1), 9758378 (2020).
Zou, H. & Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.). 67 (2), 301–320 (2005).
Gao, L. & Wu, W. Relevance assignation feature selection method based on mutual information for machine learning. Knowl. Based Syst. 209, 106439 (2020).
Baak, M., Koopman, R., Snoek, H. & Klous, S. A new correlation coefficient between categorical, ordinal and interval variables with pearson characteristics. Comput. Stat. Data Anal. 152, 107043 (2020).
Egwim, C. N., Alaka, H., Egunjobi, O. O., Gomes, A. & Mporas, I. Comparison of machine learning algorithms for evaluating Building energy efficiency using big data analytics. J. Eng. Des. Technol. 22 (4), 1325–1350 (2024).
Hamed, Y., Alzahrani, A. I., Mustaffa, Z., Ismail, M. C. & Eng, K. K. Two steps hybrid calibration algorithm of support vector regression and K-nearest neighbors. Alex. Eng. J. 59 (3), 1181–1190 (2020).
Tran, N. K., Kühle, L. C. & Klau, G. W. A Critical Review of Multi-output Support Vector Regression (Pattern Recognition Letters, 2023).
Balogun, A. L. & Tella, A. Modelling and investigating the impacts of Climatic variables on Ozone concentration in Malaysia using correlation analysis with random forest, decision tree regression, linear regression, and support vector regression. Chemosphere 299, 134250 (2022).
Zhou, X., Lu, P., Zheng, Z., Tolliver, D. & Keramati, A. Accident prediction accuracy assessment for highway-rail grade crossings using random forest algorithm compared with decision tree. Reliab. Eng. Syst. Saf. 200, 106931 (2020).
Gupta, R., Yadav, A. K., Jha, S. K. & Pathak, P. K. A robust regressor model for estimating solar radiation using an ensemble stacking approach based on machine learning. Int. J. Green Energy. 21 (8), 1853–1873 (2024).
Li, Y., Lu, F. & Yin, Y. Applying logistic LASSO regression for the diagnosis of atypical crohn’s disease. Sci. Rep. 12 (1), 11340 (2022).
Hua, H., Li, X., Dou, D., Xu, C. Z. & Luo, J. Improving pretrained Language model fine-tuning with noise stability regularization. IEEE Trans. Neural Netw. Learn. Syst. (2023).
Wen, H., Liu, B., Di, M., Li, J. & Zhou, X. A SHAP-enhanced XGBoost model for interpretable prediction of coseismic landslides. Adv. Space Res. 74 (8), 3826–3854 (2024).
Hsiao, C. H., Kumar, K. & Rathje, E. M. Explainable AI models for predicting liquefaction-induced lateral spreading. Front. Built Environ. 10, 1387953 (2024).
Al-Najjar, H. A. et al. Integrating physical and machine learning models for enhanced landslide prediction in data-scarce environments. Earth Syst. Environ. 1–28 (2024).
Dey, S., Das, S. & Roy, S. K. Landslide susceptibility assessment in Eastern himalayas, India: A comprehensive exploration of four novel hybrid ensemble data driven techniques integrating explainable artificial intelligence approach. Environ. Earth Sci. 83 (22), 1–25 (2024).
Acknowledgements
This work was supported by the Indian Institute of Technology Mandi, who provided the necessary financial and computational resources for this experiment. Also, this project was partially supported by a grant from national mission on himalayan studies (NMHS) to VD.
Author information
Authors and Affiliations
Contributions
SS designed the experiment, collected data, performed analyses, and drafted the manuscript. PK contributed to the coding and implementation of the machine learning models. AK assisted in editing the manuscript. AS contributed to editing and finalizing the manuscript. KV provided expertise in geotechnical aspects, assisted in data analysis, and contributed to the interpretation of results. VD, as the principal investigator, conceived the study and provided continuous guidance. All authors contributed to the manuscript and approved the submitted version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
All authors have reviewed and approved the manuscript and consent to its submission to the Landslides Journal.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sankhyan, S., Kumar, A., Kumar, P. et al. FDRL: a data-driven algorithm for forecasting subsidence velocities in Himalayas using conventional and traditional soil features. Sci Rep 15, 29742 (2025). https://doi.org/10.1038/s41598-025-12932-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-12932-5
