
Abstract
Accurate prediction of hydraulic support pressure is crucial for ensuring coal mine safety. With increasing mining depths and increasingly complex operating environments, precise prediction faces greater challenges. To address these challenges, this study proposes an LSTM-PatchTST prediction method based on multi-dimensional feature dependency fusion: First, Pearson correlation analysis is used to screen key features, and Gaussian moving average filtering optimizes the data; Subsequently, the preprocessed time series is input to the LSTM network, where the forget gate and input gate capture short-term fluctuations and long-term trends respectively, while residual connections ensure complete preservation of multi-layer temporal features; Then, the dynamic features extracted by LSTM are passed to the PatchTST module, which divides the sequence into local patches, with a multi-layer self-attention encoder simultaneously modeling local details and global dependencies, achieving deep feature fusion. The model’s performance is validated using actual pressure data from Fucun Coal Mine in Zaozhuang, Shandong. Experimental results show that, compared to pure PatchTST and Transformer + LSTM models, the proposed model reduces RMSE by approximately 48.6% and 30.0%, and MAE by approximately 58.7% and 38.8%, respectively. Finally, to further verify the model’s generalization ability, the trained model was transferred to a dataset from Gengcun Coal Mine in Yima, Henan, where compared to pure PatchTST and Transformer + LSTM models, the proposed model reduces RMSE by approximately 34.6% and 31.4%, and MAE by approximately 35.7% and 29.9%, respectively.
Similar content being viewed by others

Introduction
In modern mining operations, hydraulic supports are key equipment for ensuring mine safety and improving production efficiency1,2,3,4. However, due to the extremely complex underground environment, pressure variations are influenced by multiple factors, making it difficult for traditional methods to accurately model and predict changes, resulting in support failure and posing significant threats to miners’ safety5–6. Therefore, developing pressure prediction methods capable of adapting to complex working conditions with high precision has become a critical scientific problem requiring urgent resolution.
As research on hydraulic support pressure manifestation patterns has deepened, scholars both at home and abroad have conducted extensive studies on pressure prediction in fully mechanized mining faces, which can be categorized into three main approaches: methods based on physical models and mechanical principles7–8, such as finite element analysis and mechanical analytical models, which reflect physical processes but struggle to handle complex, variable field environments and are highly parameter-dependent; non-deterministic methods based on fuzzy logic and statistical analysis9–10, such as grey systems and regression analysis, which can accommodate a certain degree of data uncertainty but have limited prediction accuracy when facing high-dimensional, strongly nonlinear actual working conditions; and machine learning and deep learning technologies, which have been widely applied in mine pressure prediction and have gradually become mainstream prediction tools due to their powerful feature learning and pattern recognition capabilities, overcoming to some extent the limitations of the first two methods.
With the development of artificial intelligence, machine learning and deep learning methods have been widely applied to various time series prediction tasks. For example, in fields such as battery life prediction11–12 and photovoltaic power output prediction13–14, deep neural networks have effectively mined complex dynamic features and nonlinear patterns in data, significantly enhancing prediction performance. In highly dynamic time series data modeling such as network traffic and financial markets, researchers have adopted diversified modeling strategies. Cortez et al.15 achieved effective network traffic prediction based on multi-time scale sampling and ARMA models, while Yang Yujun et al.16 predicted stock market indices by combining regression analysis and support vector machines (SVM). For common issues in time series data such as noise, trends, and non-stationarity, preprocessing methods like particle filtering17–18 and weighted average filtering19–20 have been widely applied for data denoising and feature extraction, providing a more reliable data foundation for subsequent model training. In the field of hydraulic support pressure prediction, relevant research has gradually increased. Lai Xingping et al.21 proposed a BP neural network based on immune algorithm-particle swarm optimization (IA-PSO), enhancing model convergence speed and global optimization capability through hyperparameter optimization, significantly reducing prediction errors. Wang Ke et al.22 proposed a coal mine roof pressure prediction method based on grey neural networks, combining grey theory with neural network algorithms, using multi-factor data affecting roof pressure as a foundation, through improved grey models and optimized neural networks, using GM(1,n) models and adjusted BP neural networks to achieve coal mine roof pressure prediction. Although this method achieved certain results, BP neural networks have limitations in handling long-term dependencies. Subsequently, Long Short-Term Memory networks (LSTM) gradually became the mainstream method for processing time series data. Zhao Yixin et al.23 effectively captured long-term dependency features in time series data by using LSTM to predict pressure with normalized hydraulic support pressure as input data. Qin Changkun et al.24 combined transfer learning with LSTM, enhancing prediction performance when monitoring data is missing by utilizing data from adjacent sensors, expanding the model’s applicable scenarios. Jie Lu et al.25 proposed the Nadam-LSTM model, further improving pressure prediction accuracy and robustness through optimization algorithms and multi-factor inputs. However, LSTM’s ability to process global features remains insufficient. Addressing this limitation, Li Zexi et al.26 proposed an ensemble learning model based on variable temporal shift Transformer + LSTM, utilizing multi-head attention mechanisms and LSTM modules to capture dynamic features of hydraulic support pressure changes, effectively capturing both long-term and short-term fluctuations. Hao-jie Li et al.27 achieved high-precision classification of hydraulic support quality by optimizing the LeNet-5 network and introducing spatiotemporal pressure matrices. In summary, although existing methods provide valuable references for model design and feature extraction in hydraulic support pressure prediction, they still have the following limitations: first, most models focus only on single feature dimensions, failing to fully explore the dynamic interaction relationships between multi-dimensional features; second, they have relatively weak adaptability to extreme working conditions or abnormal pressure changes, making it difficult to meet prediction requirements in complex real-world scenarios.
Hydraulic support pressure data typically contains both significant short-term fluctuations and long-term trends. In the dynamic feature dimension, these fluctuations are reflected as rapid changes and instantaneous jumps in pressure values over time28–29; while in the static feature dimension, they manifest as global pressure change trends and their influence on local fluctuations30–31. Therefore, accurately modeling long-term and short-term dependency relationships in hydraulic support pressure sequences, as well as the interaction between global and local features, is crucial for improving prediction accuracy. Existing methods often focus on only a single dimension or dependency, making it difficult to simultaneously capture multi-scale, multi-dimensional dynamic characteristics, and their adaptability to extreme working conditions is limited. Addressing these issues, this paper proposes a multi-dimensional feature dependency fusion model (LSTM-PatchTST) combining LSTM and PatchTST. This model utilizes LSTM’s powerful temporal feature extraction capability to capture long-term and short-term dependencies in hydraulic support pressure data; while simultaneously leveraging PatchTST network’s advantages in global and local feature fusion to achieve deep interactive modeling of multi-dimensional features, thereby enhancing modeling capability for complex pressure change patterns and prediction accuracy. The main innovations and contributions of this paper are as follows:
Addressing the complex dynamic characteristics of hydraulic support pressure sequences, we designed multi-dimensional feature extraction and fusion strategies, effectively enhancing the model’s adaptability to extreme working conditions and abnormal pressure changes.
We constructed a novel LSTM-PatchTST model, combining LSTM’s temporal dependency feature extraction capability with PatchTST’s advantages in global and local feature fusion, and selected actual pressure data from Fucun Coal Mine in Zaozhuang City, Shandong Province, China to validate the model’s prediction performance. Through comparison with other methods (such as LSTM, PatchTST, Informer, and Transformer + LSTM), experimental results demonstrate that the LSTM-PatchTST model exhibits superior performance in hydraulic support pressure prediction.
We introduced a transfer learning mechanism, transferring the model trained on Fucun Coal Mine data to the dataset from Gengcun Coal Mine in Yima, Henan Province. Experimental results show that the proposed model maintains high prediction accuracy in the new mining area, fully validating the model’s cross-regional generalization ability and practical application value.
The remainder of this study is organized as follows: Sect. 1 describes the data processing methodology. Section 2 presents the details of the proposed method. Section 3 provides an analysis and comparison of experimental results. Section 4 concludes with findings and recommendations for future research and practical applications.
Related work
LSTM
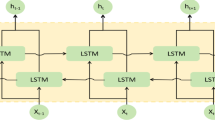
LSTM (Long Short-Term Memory Network)32 is designed to solve the gradient vanishing and gradient explosion problems when processing long sequences by RNN (Recurrent Neural Network), and it has good results in hydraulic support pressure prediction. It mainly contains an input gate, forgetting gate, and output gate components and the information of the 3-gate structure is expressed as follows:
Where the subscript t is the time step, \(t=1,2 \ldots n\); \({f_t}\) denotes the forgetting gate that determines the information that should be removed from the cell state by accepting the previous hidden layer state \({h_{t - 1}}\) and the current input \({x_t}\) and generating a value between 0 and 1 for each element in the cell state \({C_t}\), \({i_t}\) denotes the input gate that determines how much information should be transmitted to update the long-term memory, \({o_t}\) denotes the output gate that determines how much potential memory should be passed as the hidden state should be transferred to \({h_t}\), or used as a prediction for the next time step, \({\mathop C\limits^{\sim } _t}\)denotes the candidate cell state, which represents a candidate representation of the current input information, \({C_t}\) denotes the cell state, which is responsible for remembering the information, \({h_t}\) denotes the output of the hidden state, and \({h_{t - 1}}\) is the intermediate output; \({b_f},{b_i},{b_c},{b_o}\) denote the bias matrices of the forgetting gate, the input gate, the cell state, and the output gate respectively; \({W_f},{W_i},{W_c},{W_o}\) denote the weight matrices of the forgetting gate, input gate, cell state and output gate, respectively. The basic LSTM neural network was built as shown in Fig. 1.\(\sigma\) is the Sigmoid activation function.

The LSTM model structure.
PatchTST
In hydraulic support pressure prediction for coal mines, neural network models effectively capture data flow and trends, thereby enhancing prediction accuracy. The Transformer model’s approach to data capture differs from LSTM’s sequential data processing method, as it inputs predivided three-dimensional tensors into the model simultaneously. From a static feature dimension perspective, while this approach can capture global features and reveal overall trends, directly inputting large volumes of data increases computational complexity and may result in the loss of critical local information. To address this issue, PatchTST33, a variant of the Transformer model, divides input data into multiple-scale blocks, with each block serving as a carrier of local features. This enables dependency processing within smaller ranges, preventing information loss. Specifically, each time series is first divided into multiple blocks, which represent the patch length and denote the stride (the non-overlapping region between two consecutive patches). This patching process generates a series of patches \({\text{x}}_{{\text{p}}}^{{{\text{(i)}}}} \in {R^{P \times N}}\)
where \({\text{N}}\) is the number of patches as shown in Eq. (7).
After dividing the patch, the repeated number \({\text{S}}\) of the last value \({\text{x}}_{{\text{L}}}^{{{\text{(i)}}}} \in R\) is padded to the end of the original sequence to ensure that the length of the sequence is adapted to the patch division. Where \({\text{L}}\) denotes the univariate time series length.
Subsequently, The shallow encoder processes internal dependencies within local blocks. As data propagates through network layers, the deep encoder becomes engaged, handling both intra-block dependencies and inter-block relationships. This enables the model to capture global features of hydraulic support pressure data holistically, revealing long-term trends and global variation patterns. The steps are:
1)At the shallow coding layer, the time series that have been divided into patches are subjected to a linear projection matrix \({W_p}\), and \({W_{pos}} \in {R^{D \times N}}\) is applied as the bias matrix as shown in Eq. (8).
where \(x_{p}^{{(i)}}\) is the encoder input.
2)Each head \({\text{h}} \in (1,H)\) in the multihead attention is transformed into a query matrix, a key matrix and a value matrix, i.e.;
where \(W_{h}^{Q},W_{h}^{K} \in {R^{D \times {d_k}}}\), \(W_{h}^{V} \in {R^{D \times D}}\), \({d_k}\) refers to the dimensions of the key vector.
3)The attention output result \(O_{h}^{{(i)}} \in {R^{D \times N}}\) is obtained by scaling the dot product computation, i.e.:
The deep coding layer gradually extracts more complex features by reusing the output of the shallow coding layer. Finally, the output is obtained by dimensionality reduction, using the smoothing and linear layers, and the structure of the PatchTST model is shown in Fig. 2.

The PatchTST model structure.
Method
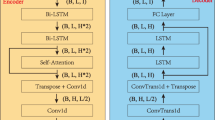
Long Short-Term Memory (LSTM) and PatchTST are neural network models designed for time series data processing. LSTM automatically extracts temporal dependencies through its distinctive gated architecture and recurrent input. When hydraulic support pressure data flows into LSTM, the model employs memory cells to capture correlations between consecutive data points. The forget gate determines the significance of historical information, the input gate regulates the incorporation of new information, and the output gate determines the current time step’s output. This architecture enables LSTM to effectively retain critical historical information, capturing both long-term dependencies and short-term variations in dynamic features. In contrast, the PatchTST model overcomes LSTM’s sequential processing constraints and addresses Transformer’s limitations in local feature extraction through its “patching” approach and self-attention mechanism. Consequently, this study combines LSTM with PatchTST to leverage their respective advantages for time series prediction. The operational principle of this hybrid model is illustrated in Fig. 3. The LSTM-PatchTST architecture consists of two core components:

The LSTM-patchts model structure.
Following filtering, the data dimensions become (11286, 4). To efficiently input data into the model, a batching strategy is implemented. Specifically, the data is divided into multiple batches with dimensions of (32, 96, 4), where 32 represents the batch size, indicating the number of data samples input to the model at each iteration; 96 represents the sequence length, denoting the number of time steps in each sample; and 4 represents the feature vector dimension, reflecting features related to four hydraulic supports. In the LSTM layer, data is processed sequentially by time steps. At each time step, LSTM updates its hidden state and effectively captures and preserves both long-term and short-term dependencies in the sequence through residual connections.
The PatchTST layer receives output from the LSTM layer with dimensions (32, 96, 4). Initially, the “patching” mechanism subdivides each data point and generates data with dimensions (32, 4, 12, 16). Subsequently, through a multilayer encoding structure, the model develops a deep understanding of data characteristics, enabling more accurate capture of complex time series patterns. After processing through the smoothing layer, the data dimensions transform to (32, 4, 6144), where 6144 represents the flattened feature dimension. Finally, the linear layer outputs results with dimensions (32, 4, 12), where 12 represents the prediction step length, which can be adjusted according to specific application requirements. This design enables the PatchTST layer to effectively integrate long-term and short-term dependencies extracted by LSTM at both global and local levels.
Experimental settings
Data preprocessing
Data analysis
This study utilizes one month of monitoring data from hydraulic supports on a fully mechanized mining face at Fucun Coal Mine in Zaozhuang City, Shandong Province, China. The working face comprises 154 hydraulic supports, with pressure sensors recording data every 5 min for each support, resulting in a total of 778,408 data points. To analyze the pressure correlation between hydraulic supports, this study employed the Pearson Correlation Coefficient for correlation analysis.
The Pearson Correlation Coefficient is a widely used statistical measure that evaluates the linear relationship between two variables. It ranges from − 1 to 1, where values closer to either 1 or -1 indicate stronger correlations between variables, while a value of 0 suggests no linear correlation. Specifically, a coefficient of 1 represents a perfect positive correlation, while − 1 indicates a perfect negative correlation. Due to its computational simplicity and interpretability, the Pearson Correlation Coefficient is extensively employed in various correlation analyses. Based on these advantages, this study selected this coefficient to analyze pressure correlations between hydraulic supports, as shown in Eq. (11).
where \({\rho _{X,Y}}\) is the Pearson correlation coefficient, \(\operatorname{cov} (X,Y)\) is the covariance, and \({\sigma _X}\), \({\sigma _Y}\) are the standard deviations between variables X and Y. As shown in Fig. 4.

The related heatmap zoom.
Based on the figure, data sets 2, 3, 4, and 5 exhibit the highest correlation coefficients among all pairs. Consequently, these four data sets were selected as the final dataset. The resulting dataset comprises 11,286 samples, with each sample consisting of four data points.
Data processing
Because of the intense roof movements caused by complex geological conditions near the coal mine and mining activities, the pressure sensor of the hydraulic support is often disturbed by vibration noise when collecting the pressure data of the roof, which affects the accuracy and prediction effect of the data. To address this issue, a Gaussian moving average filtering method34–35 is employed. The method weights data points according to their distance from the current time point, making the hydraulic support pressure data smoother and more stable. When filtering the hydraulic support pressure data with dimensions of 11,286 × 4, discrete weights for each time point are first calculated, whichk represents the window half-width, as shown in Eq. (12).
\(\omega [i]\) is the Gaussian weight at relative position i within the window, and i takes the value range of \(\left( { - k,k} \right)\); \(\sigma\) is the standard deviation parameter controlling the spread of the Gaussian function. The exponential term ensures that weights decrease as distance from the center increases
After that, the normalized weights are calculated as:
\(\sum\limits_{{j= - {\text{k}}}}^{k} {\omega [j]}\) represents the sum of all discretized weights, and \(\omega ^{'} [i]\) represents the normalized weight at relative position i.
Finally, weighting is applied to each data point as shown in Eq. (14).
\(y[t]\) represents the position of the smoothed data at time point t, \(x[t+i]\) represents the original data value at time point \(t+i\).
To better demonstrate the filtering effect, we compared hydraulic support pressure data from 3,000 time points before and after Gaussian moving average filtering. To avoid data redundancy and improve storage and computational efficiency, pressure data recorded every 5 min was considered as one step (i.e., one time point). To evaluate the impact of different parameters on noise removal effectiveness, we conducted comparative analysis of hydraulic support pressure data with different window values and standard deviation values. The window length setting during filtering determines how many time points (including the current point and certain points before and after it) will be referenced when calculating the average for the current point. The standard deviation determines the decay rate of data points in the weight distribution. As shown in Fig. 5, where the horizontal axis represents time points (i.e., number of samples) and the vertical axis represents hydraulic support pressure in MPa. The figure shows that when window length and standard deviation are small (Figure 5a), the filtering effect is too strong, resulting in loss of significant hydraulic support pressure data; when window length and standard deviation are large (Figure 5b), too much noise is retained. In comparison, Figure 5c shows the filtering parameters selected in this paper, which successfully removed most noise while preserving critical hydraulic support pressure data.

The comparison of hydraulic bracket pressure data before and after filtering with different window values and standard deviation values. (a) Before and after filtering of hydraulic bracket pressure data with a window length of 20 and standard deviation of 4. (b) Before and after filtering of hydraulic bracket pressure data with window length 5 and standard deviation 1. (c) Before and after filtering of hydraulic bracket pressure data with a window length of 10 and standard deviation of 2.
Design of loss function
In this study, we primarily used Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and Weighted Mean Absolute Error (Weighted MAE) to evaluate and analyze model performance. RMSE and MAE are the most commonly used evaluation metrics for regression problems. RMSE is more sensitive to larger errors, amplifying the impact of extreme predicted values, which helps reduce large errors during model training. MAE treats all errors equally, exhibiting good robustness and reflecting the model’s overall average prediction deviation. Their calculation formulas are as follows:
In the hydraulic support pressure prediction task for coal mines, prediction errors for certain anomalous pressure values have more critical implications for system safety. Traditional Mean Absolute Error (MAE) assigns equal weights across all samples, making it difficult to reflect the model’s actual performance in safety-critical intervals. Therefore, this paper introduces Weighted Mean Absolute Error (Weighted MAE, WMAE) as an evaluation metric, assigning higher weights to prediction errors of anomalous values, thereby more accurately reflecting model performance under high-risk operating conditions. Its calculation formula is as follows:
Based on the prediction requirements of safety-critical engineering systems, this research proposes a differentiated weight MAE evaluation mechanism. This weight allocation strategy is guided by engineering safety risk considerations, precisely classifying 2,240 hydraulic support samples in the test set. Through systematic analysis, data points with pressure values significantly above the 95% quantile threshold (approximately 5% of samples) were identified as “safety-critical intervals” and assigned 5-fold weights, while the remaining normal samples maintained baseline weights. This weighted configuration mechanism is established on the foundation of mining safety engineering practices: anomalous hydraulic support pressure values typically indicate major safety hazards such as surrounding rock instability, roof disasters, or structural instability. The weight ratio (5:1) selection ensures special attention to critical safety points while avoiding excessive bias toward anomalous samples that might affect overall prediction performance.
Hyperparameter settings
To enhance the performance of the proposed LSTM-PatchTST model in complex hydraulic support pressure sequence prediction tasks and fully leverage its multidimensional feature fusion and spatiotemporal dependency modeling capabilities, we conducted systematic optimization of key hyperparameters. The tuning work focused on Batch Size, LSTM Hidden Units and Layers, PatchTST Patch Size, Encoder Layers, and Attention Heads. We employed a multi-stage optimization strategy: first determining reasonable value ranges for each hyperparameter through Grid Search, then further refining parameter selection within these preliminary ranges using Random Search. To ensure evaluation fairness and reliability, the training set was divided in an 8:2 ratio, with 20% serving as the validation set. Model performance was evaluated based on metrics including RMSE and MAE on the validation set. Although we introduced safety-weighted MAE (SWMAE, with a weight ratio of 5:1) in the overall model evaluation to emphasize prediction capability for safety-critical anomalous samples, considering the consistent trends between SWMAE and MAE observed during validation, we primarily used RMSE and MAE as core metrics for parameter selection to ensure reliability and interpretability of the hyperparameter optimization process.
Table 1 lists model prediction performance on the test set from Fucun Coal Mine in Zaozhuang, Shandong under various key hyperparameter combinations, with W-MAE representing Weighted_MAE values. Bold indicates optimal configuration. Experimental results indicate that optimal performance across all evaluation metrics was achieved when LSTM hidden units were set to 64, patch size to 16, encoder layers to 2, attention heads to 8, and batch size to 32.
The analysis of factors affecting the prediction of hydraulic support pressure data
Comparison of model performance with different training sets
To effectively predict the hydraulic bracket pressure data and consider the influence of different dataset divisions on the results of the prediction model, this study adopts a 6-step length as a benchmark. As shown in Fig. 6. Since this section aims to assess the generalization performance of the model across different training set proportions, only RMSE and MAE are considered.

The effect of different training set share.
It can be seen that the model works best when the ratio of the training set to the test set is 0.8:0.2.
Gaussian filtering and LSTM-patchTST for coal mine sensor noise mitigation
To thoroughly investigate how the combination of Gaussian moving average filtering and our proposed model addresses sensor noise challenges in coal mine environments, this study conducted comparative analysis between original hydraulic support pressure data and data processed with Gaussian moving average filtering. The original data naturally contains various noise sources inherent to underground coal mining operations, including equipment vibration, electromagnetic interference, and environmental disturbances in hydraulic support systems. The experimental analysis employed three evaluation metrics: RMSE, MAE, and weighted MAE (with normal samples weighted 1 and anomalous samples weighted 5 to emphasize safety-critical detection). This comprehensive assessment approach ensures thorough evaluation of filtering technique effectiveness and the model’s noise processing capabilities across different performance aspects.

Performance comparison of the proposed model on raw and Gaussian filtered hydraulic support pressure data (6-step prediction).
Figure 7 provides detailed comparative results for 6-step prediction performance. Prediction results for hydraulic support original noisy data showed RMSE of 2.45, MAE of 1.78, and weighted MAE of 1.92, reflecting the challenging nature of real coal mine environments where sensor noise significantly impacts prediction accuracy. After applying Gaussian moving average filtering, these metrics improved to RMSE of 0.54, MAE of 0.356, and weighted MAE of 0.419, representing improvements of 78%, 80.0%, and 78.2% respectively. The results demonstrate that the synergistic combination of Gaussian moving average filtering and our proposed model effectively addresses sensor noise challenges in coal mine environments. The filtering technique successfully mitigates noise interference while the model maintains robust prediction performance, significantly enhancing reliability and accuracy for multi-step pressure prediction and safety monitoring applications.
Comparative analysis of prediction performance across different models
To further validate the performance of the LSTM-PatchTST hybrid model in hydraulic support pressure prediction, this study conducted comparative experiments with GRU, LSTM, PatchTST, Informer, Transformer + LSTM hybrid model, and the proposed LSTM-PatchTST model. To ensure the fairness and scientific validity of the comparison, all models were trained and tested on the same dataset, with identical data preprocessing procedures, feature inputs, and hyperparameter tuning strategies. This consistent experimental setup guarantees that the observed performance differences are attributable to the models themselves rather than external factors. In practical applications, short-term prediction facilitates rapid response and prevention of emergencies, medium-term prediction supports operational adjustments, and long-term prediction aids in planned maintenance and decision-making. Based on these requirements, the hydraulic support pressure data in the coal mining face was modeled for predicting pressure values at 1 time step (5 min), 6 time steps (30 min), and 12 time steps (1 h). Table 2 presents the performance evaluation results for each model, with the optimal values highlighted in bold.
Based on the comprehensive data presented in Table 2, the LSTM-PatchTST model demonstrates superior performance across all evaluation metrics for both single-step and multi-step predictions in hydraulic support pressure forecasting. For single-step prediction, LSTM-PatchTST achieves Root Mean Square Error (RMSE) reductions of approximately 73.36, 72.61, 64.39, 60.43, and 50.17% compared to GRU, LSTM, Informer, PatchTST, and Transformer + LSTM, respectively. Similarly, Mean Absolute Error (MAE) shows substantial reductions of approximately 73.56% 71.21, 64.38, 59.86 and 52.70%, respectively. The Weighted_MAE metric-which assigns higher importance to errors in safety-critical regions—further confirms the proposed model’s effectiveness, with LSTM-PatchTST achieving Weighted_MAE reductions of 75.36, 73.20, 66.83, 62.70%, and 56.05% compared to baseline models for single-step prediction. This superior performance in Weighted_MAE indicates that LSTM-PatchTST not only improves overall prediction accuracy but also enhances reliability specifically in safety-critical scenarios where prediction errors could have severe consequences. In multi-step prediction (using the 12-step horizon as representative), LSTM-PatchTST maintains its substantial advantage with RMSE reductions of approximately 47.22, 48.57, 34.77, 30.00, and 29.41% compared to GRU, LSTM, Informer, PatchTST, and Transformer + LSTM, respectively. The corresponding MAE reductions are approximately 56.66 58.71 43.15, 38.75, and 35.36%, while the Weighted_MAE reductions at the 12-step horizon reach 60.48%, 62.34%, 48.16%, 44.12%, and 41.08%, demonstrating that LSTM-PatchTST’s advantage becomes even more pronounced when specifically considering safety-critical scenarios. These consistent improvements across all metrics and prediction horizons provide strong evidence that LSTM-PatchTST significantly outperforms existing state-of-the-art models in hydraulic support pressure prediction tasks. To visually demonstrate these performance differences, Fig. 8 presents a comparative visualization of the results from Transformer + LSTM, PatchTST, and LSTM-PatchTST for 1-step, 6-step, and 12-step predictions, clearly illustrating the proposed model’s superior tracking capabilities, particularly during periods of pressure fluctuation.

The comparison of PatchTST, Transformer + Lstm and Lstm-PatchTST at 1, 6 and 12 steps.
Based on the graphical analysis, it can be observed that all models perform well in one-step prediction. However, Transformer + LSTM exhibits certain limitations in predicting low pressure points of hydraulic supports (as indicated by black frames), while PatchTST shows constraints in predicting certain high and low points (also marked by black frames). In contrast, LSTM-PatchTST achieves superior prediction results in critical regions (highlighted by red frames), benefiting from its distinctive multidimensional feature extraction and fusion mechanism. When extended to 6-step and 12-step predictions, LSTM-PatchTST demonstrates notably better performance compared to Transformer + LSTM and PatchTST, as clearly reflected in the graphs. In summary, the above comparative analysis under fair and consistent experimental conditions clearly demonstrates the significant advantages of the proposed LSTM-PatchTST model over existing mainstream methods. The superior performance of LSTM-PatchTST, especially in multi-step and extreme condition predictions, highlights its strong capability in multidimensional feature extraction and fusion, as well as its robustness and generalization in complex real-world scenarios. These results confirm the unique contribution and practical value of the proposed approach in advancing the state of the art for hydraulic support pressure prediction.
Comparison of training and prediction times for different models
In time series prediction tasks, the training and prediction times of the model are important factors that affect the efficiency of practical applications. To evaluate the performance of different models in the prediction task, PatchTST, Transformer + LSTM, and LSTM-PatchTST are compared to predict a 12-step length, as shown in Table 3. Bold values represent the best performance.
Based on the tabulated data, the PatchTST model demonstrates optimal performance in terms of training and prediction time, followed by LSTM-PatchTST, while the Transformer + LSTM model requires the longest processing time. Although PatchTST achieves the shortest processing time, LSTM-PatchTST requires only 10 additional seconds while delivering significantly enhanced performance. This marginal time difference is considered acceptable given the substantial performance improvements achieved.
Experiment on adaptability analysis of geological faults
To verify the model’s adaptability to pressure mutations caused by geological faults, we designed systematic fault adapt-ability analysis experiments. We employed a sliding window Z-score method to identify mutation points in pressure time series by calculating local Z-scores to detect anomalous points significantly deviating from statistical characteristics. The window size was set to 15 sampling points, determined based on typical hydraulic support pressure adjustment cycles (10–20 sampling intervals), effectively capturing complete pressure change patterns. The Z-score threshold was set to 2.5, corresponding to approximately 1.2% probability of rare events under normal distribution, consistent with the low-frequency high-risk characteristics of geological fault pressure mutations while effectively filtering general pressure fluctuation interference. As shown in Eq. (18):
where\({Z_t}\) represents the standardized score at time point t,\({x_t}\)represents the original pressure value at time point t,\({\mu _{window}}\)represents the pressure mean within the sliding window, \({\sigma _{window}}\)represents the pressure standard deviation within the sliding window. The window size was set to 15 time steps, and when\(\left| {{Z_t}} \right|>2.5\), the system marked that point as a potential fault point. Taking 6-step prediction as an example, experimental results are shown in Fig. 9.

Adaptability analysis of the LSTM-PatchTST model for predicting pressure changes in hydraulic supports (prediction horizon of 6 time steps) caused by geological faults.
Experimental results demonstrate that the LSTM-PatchTST model successfully detected the main fault point located at time step 323, where the pressure change reached 6.1617 MPa. More notably, the model’s Mean Absolute Error (MAE) in the fault region was 1.3538, while the MAE in the normal region was 1.5408, indicating that the model’s prediction per-formance in the fault region actually outperformed that in normal regions by 12.13%. This counter-intuitive result proves the model’s extremely strong adaptability to pressure mutations, capable of quickly learning new data patterns and making accurate predictions. It should be noted that the weighted MAE metric was not additionally reported in the fault adaptability analysis experiment, primarily because sample weights remain consistent within a single region, making weighted MAE essentially no different from ordi-nary MAE in this context, thus ordinary MAE can adequately reflect model performance.
Performance comparison of alternative datasets in the model
To verify the generalization ability of the model, four subsets were randomly selected from the hydraulic bracket dataset to form the dataset for filtering treatment. The prediction effects of the processed datasets were compared with those of the PatchTST, Transformer + LSTM, and LSTM-PatchTST models at 1-step, 6-step, and 12-step. As shown in Table 4.
As can be seen from the table, the LSTM-PatchTST model consistently demonstrates the best prediction results despite being tested with different datasets. This result indicates that the model has good generalization ability and can effectively adapt to diverse data environments.
Model generalization capability verification
To comprehensively evaluate the generalization capability of the LSTM-PatchTST model, this study introduces a transfer learning36 strategy. Transfer learning aims to transfer knowledge obtained by the model in the source domain (such as a particular mining site dataset) to the target domain (such as another mining site dataset), thereby enhancing the model’s adaptability to different data distributions and generalization performance. In the specific implementation process, we directly applied the optimal model parameters and network structure trained on the original dataset to the hydraulic support pressure dataset from Gengcun Coal Mine in Yima, Henan Province. The relevant prediction results are shown in Fig. 10.

The comparison of PatchTST, Transformer + Lstm and Lstm-PatchTST at 6 steps.
Figure 10 illustrates the pressure prediction performance of various models on the 6-step prediction task. As can be observed, compared to Transformer + LSTM and PatchTST, the LSTM-PatchTST model’s prediction results on the test set closely align with the actual pressure curve, accurately capturing both the overall trend and local fluctuation characteristics of pressure changes. Compared to benchmark models such as GRU, LSTM, PatchTST, Informer, and Transformer + Lstm, the LSTM-PatchTST achieves optimal results in evaluation metrics including Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) across different prediction horizons (6-step, 12-step), demonstrating stronger generalization capability and robustness. As shown in Table 5, LSTM-PatchTST achieves the lowest RMSE and MAE in 1-step, 6-step, and 12-step prediction tasks, significantly outperforming other comparative models, further validating its excellent adaptability to the pressure data from this mining area.
In conclusion, the experimental results confirm that the LSTM-PatchTST model not only performs excellently on the original dataset but also maintains high prediction accuracy and stability when transferred to different mining sites without requiring retraining or parameter adjustments. This indicates that the model possesses strong generalization capability, showing promising prospects for practical application and large-scale deployment in hydraulic support pressure prediction tasks.
Conclusion
This study introduces LSTM-PatchTST, a novel hybrid architecture that advances hydraulic support pressure prediction for coal mining safety applications through multi-dimensional feature dependency fusion. Our approach addresses critical challenges in complex mining environments by making several key theoretical and practical contributions. By strategically integrating LSTM’s sequential dependency modeling with PatchTST’s patch-based feature extraction mechanism, we created a synergistic framework that effectively bridges the gap between temporal dynamics and spatial feature relationships in mining pressure data-a fundamental limitation in previous approaches that typically focused on single feature dimensions.The proposed weighted evaluation framework represents a paradigm shift in assessment methodology for safety-critical industrial applications, prioritizing prediction accuracy in high-risk regions where errors could have catastrophic consequences. Our extensive experimental validation across multiple mining sites reveals two particularly significant findings: first, the counter-intuitive performance improvement of 12.13% in geological fault regions compared to normal regions—challenging conventional assumptions about model degradation during anomalies and suggesting that our architecture’s multi-dimensional feature fusion provides enhanced adaptability precisely when traditional models fail; second, the remarkable generalization capability demonstrated through transfer learning between geographically distinct mining operations, validating the model’s practical utility in diverse real-world scenarios. The synergistic combination of advanced architectures with targeted preprocessing techniques underscores the importance of comprehensive modeling approaches for industrial time series applications, extending beyond mere performance metrics to address fundamental challenges in safety-critical environments. Future research will focus on extending these capabilities through multi-modal data integration from diverse geological formations, developing more sophisticated anomaly characterization mechanisms, and exploring deployment strategies optimized for resource-constrained edge computing environments—ultimately advancing predictive maintenance systems for critical underground infrastructure where early detection of pressure anomalies is essential for preventing catastrophic failures.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Li, T., Wang, J., Zhang, K. & Zhang, C. Mechanical analysis of the structure of Longwall mining hydraulic support. Sci. Prog. 103 (3), 36850420936479. https://doi.org/10.1177/0036850420936479 (2020)
Zhang, L. Application status and development trend of electro-hydraulic control system for hydraulic support. Coal Sci. Technol. 2003 (02) 5–8
Zhang, Q. et al. Structure optimal design research on backfill hydraulic support. J. Cent. South. Univ. 24, 1637–1646 (2017).
Dejun, S. Design of protective hydraulic support used for close-range comprehensive coal mining. Mining & Process. Equipment (2000).
Ge, X. et al. A virtual adjustment method and experimental study of the support attitude of hydraulic support groups in propulsion state, measurement, 158, 2020, 107743, ISSN 0263–2241, https://doi.org/10.1016/j.measurement.2020.107743
Zhang, Y., Zhang, H., Gao, K., Xu, W. & Zeng, Q. New method and experiment for detecting relative position and posture of the hydraulic support, In: IEEE Access 7,181842–181854, (2019).
Tan, T., Yang, Z., Chang, F. & Zhao, K. Prediction of the first weighting from the working face roof in a coal mine based on a GA-BP neural network. Appl. Sci. 9 (19), 4159 (2019).
Shi-tan, G. & Chun-qiu, Wang & Jiang, Bangyou & Tan, Yunliang & Nan-nan, Li. Field test of rock burst danger based on drilling pulverized coal parameters. Disaster Adv. 5 (2012).
Ghasemi, E. & Ataei, M. Application of fuzzy logic for predicting roof fall rate in coal mines. Neural Comput. Applic. 22 (Suppl 1), 311–321. https://doi.org/10.1007/s00521-012-0819-3 (2013).
JIA Yongjie. Predictive analysis of incoming pressure step and strength of working face with hard top slab in wild green tuff. Coal Chem. Ind. (2022) 45(12) 1–7
Zhang, J. et al. Realistic fault detection of li-ion battery via dynamical deep learning. Nat. Commun. 14, 5940. https://doi.org/10.1038/s41467-023-41226-5 (2023).
Zhao, F. M. et al. Application of state of health Estimation and remaining useful life prediction for lithium-ion batteries based on AT-CNN-BiLSTM. Sci. Rep. 14, 29026. https://doi.org/10.1038/s41598-024-80421-2 (2024).
Zheng, W., Xiao, H. & Pei, W. Distributed-regional photovoltaic power generation prediction with limited data: A robust autoregressive transfer learning method. Appl. Energy. 380, 0306–2619. https://doi.org/10.1016/j.apenergy.2024.125058 (2025).
Wang, R., Wu, J., Cheng, X., Liu, X. & Qiu, H. Adaptive expert fusion model for online wind power prediction, neural networks, 184, 107022, ISSN 0893–6080, (2025). https://doi.org/10.1016/j.neunet.2024.107022
Cortez, P., Rio, M., Rocha, M. & Sousa, P. Multi-scale internet traffic forecasting using neural networks and time series methods. Expert Syst. 29, 143–155. https://doi.org/10.1111/j.1468-0394.2010.00568.x (2012).
Yujun, Y., Yimei, Y. & Jianping, L. Research on financial time series forecasting based on SVM, 13th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 2016, 346–349, (2016). https://doi.org/10.1109/ICCWAMTIP.2016.8079870
Multilevel ensemble transform particle filtering, Gregory, A., Cotter, C. J. & Reich, S. SIAM J. Sci. Comput. 38 3, A1317–A1338, (2016)
Lim, J., Kim, H. S. & Park, H. M. Minimax particle filtering for tracking a highly maneuvering target. Int. J. Robust Nonlinear Control. 30 (2), 636–651 (2020).
Zhu, S. Junping Du. Visual tracking using max-average pooling and weight-selection strategy. J. Appl. Math. (SI25) 1–10, 2014. (2014). https://doi.org/10.1155/2014/828907
Lee, C. S., Kuo, Y. H. & Yu, P. T. Weighted fuzzy mean filters for image processing, Fuzzy Sets and Systems, 89, 2, 157–180, ISSN 0165 – 0114, (1997). https://doi.org/10.1016/S0165-0114(96)00075-9
Lai, X., Tu, Y., Yan, B., Wu, L. & Liu, X. A method for predicting ground pressure in Meihuajing coal mine based on improved BP neural network by immune Algorithm-Particle swarm optimization. Processes 12 (1), 147. https://doi.org/10.3390/pr12010147 (2024).
Wang, K., Zhuang, X., Zhao, X., Wu, W. & Liu, B. Roof pressure predic Tion in coal mine based on grey neural network. In IEEE access, 8, 117051–117061, (2020). https://doi.org/10.1109/ACCESS.2020.3001762
Yi-Xin, Z. H. A. O. et al. Deep learning-based mine pressure prediction analysis and model generalization for large mining height working face. J. Coal 2020, 45 (01) 54–65 .https://doi.org/10.13225/j.cnki.jccs.YG19.0903
Qin, C., Zhao, W., Zhong, K., Chen, W. & & & Prediction of Longwall mining-induced stress in roof rock using LSTM neural network and transfer learning method. Energy Sci. Eng. 10 https://doi.org/10.1002/ese3.1037 (2021).
Lu, J., Liu, Z., Zhang, W., Zheng, J. & Han, C. Pressure prediction study of coal mining working face based on Nadam-LSTM, In IEEE Access, 11, 83867–83880, (2023). https://doi.org/10.1109/ACCESS.2023.3302516
LI Zexi. Ensemble learning mining pressure prediction method based on variable time series shift Transformer + LSTM[J]. J. Mine Autom. 2023, 49 (07) 92–98 .
Li, H. J., Fu, X., Qin, Y. F. & Jia, S. F. Application of deep learning classification model for regional evaluation of roof pressure support evolution effects over time in coal mining face. Heliyon 10 (11), e31824. https://doi.org/10.1016/j.heliyon.2024.e31824 (2024).
Jia, H., Pei, Z., Tang, Z. & Li, M. Properties analysis of hydraulic PTO output fluctuation regulating based on accumulator. Actuators 13 (7), 261. https://doi.org/10.3390/act13070261 (2024).
Pang, Y. H. & Zhao, W. H. B. Jian-Jian, Shang, De-Yong, Analysis and prediction of hydraulic support load based on time series data modeling, Geofluids, 8851475, 15 pages, (2020). https://doi.org/10.1155/2020/8851475
Pang, Y. H. & Zhao, W. H. B. Jian-Jian, Shang, De-Yong, Analysis and prediction of hydraulic support load based on time series data modeling, Geofluids, 8851475, 15 pages, (2020).
Sifeng, J. I. A. et al. Dynamic evaluation of support quality of hydraulic support in space-time region. J. Mine Autom. 48 (10), 26–33. https://doi.org/10.13272/j.issn.1671-251x.17992 (2022).
Qin, J., Xiong, J. & Liang, Z. CNN–Transformer gated fusion network for medical image super-resolution. Sci. Rep. 15, 15338. https://doi.org/10.1038/s41598-025-00119-x (2025).
Yuqi Nie, Nam, H., Nguyen, P., Sinthong, J. & Kalagnanam A time series is worth 64 words: Long-term forecasting with Transformers. Preprint at https://arxiv.org/abs/2211.14730, (2022).
Ito, K. & Xiong, K. Gaussian filters for nonlinear filtering problems. IEEE Trans. Autom. Control. 45 (5), 910–927. https://doi.org/10.1109/9.855552 (May 2000).
Wang, Y. Engineering safety management system based on robot intelligent monitoring. Adv. Multimedia 8940678, 10 (2022). https://doi.org/10.1155/2022/8940678
Quan Qian, Q., Wen, R., Tang, Y. & Qin DG-Softmax: A new domain generalization intelligent fault diagnosis method for planetary gearboxes. Reliab. Eng. Syst. Saf. 260, 0951–8320. https://doi.org/10.1016/j.ress.2025.111057 (2025).
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant No. 61601172 and the China Postdoctoral Science Foundation under Grant No. 2018M641287.
Author information
Authors and Affiliations
Contributions
Qiongfang Yu and Chengcheng Sun prepared the main manuscript text, while Yi Yang prepared Fig. 1 and Pengfei Yang prepared Figs. 1 and 2. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, Q., Sun, C., Yang, Y. et al. Hydraulic support pressure prediction via deep learning with multilevel temporal feature integration. Sci Rep 15, 45680 (2025). https://doi.org/10.1038/s41598-025-13089-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-13089-x
