
Abstract
Accurate prediction of the initial production in horizontal wells targeting tight sandstone gas reservoirs (IPHTSG) is critical for assessing the exploitation potential of well locations and identifying reservoir sweet spots. Traditional methods for estimating horizontal well productivity exhibit limited applicability due to reservoir heterogeneity and unfavourable petrophysical properties; therefore, this study proposes the use of machine learning for IPHTSG forecasting by systematically analysing the engineering parameters and production metrics. First, an IPHTSG database is established by categorizing and compiling the collected engineering and production parameters in addition to the classified initial production data. Second, on the basis of the IPHTSG database, prediction models for the IPHTSG are developed by employing various machine learning algorithms. The dimensionality of the input data is reduced via correlation analysis of the feature parameters, and the parameters of each prediction model are optimized using a grid search and 10-fold cross-validation. Finally, the models are applied to make predictions on a test set to validate their reliability, forming a set of methods and procedures for IPHTSG prediction. Then, this work describes a case study that was conducted on the tight gas reservoir of the H8 Member in the Sulige Southeast Field (Ordos Basin). The effective reservoir length, vertical thickness, open-flow capacity, bottom hole pressure, and amount of sand inclusion from 155 horizontal wells were selected as feature parameters, with data from 140 wells used as the training set and data from 15 wells used as the test set. Six machine learning algorithms were utilized to establish models, and the relevant calculation indicators of different models are compared. Ultimately, the XGBoost prediction model, which exhibits superior performance, is selected. This model achieves a training accuracy of 95% and a testing accuracy of 93.33%, with precision, recall, and F1-score values of 95%, 94.12%, and 93.14%, respectively, and it also has a relatively short training time. The method proposed in this paper successfully realizes IPHTSG prediction, providing a decision-making basis for formulating reasonable development plans and optimizing production parameters. This interdisciplinary methodology provides a replicable template for data-intelligent decision-making in tight gas reservoir management.
Similar content being viewed by others


Introduction
With the increasing global energy demand and the gradual depletion of conventional hydrocarbon resources, unconventional tight sandstone gas reservoirs have emerged as pivotal contributors to a sustainable energy supply. However, accurate prediction of the initial production rates remains a critical challenge and has direct implications for development planning, economic evaluation, and reservoir management strategies. The complexity of the reservoir geology, the interaction between fractures, and the dynamic behaviour of fluid flow during production all contribute to the uncertainty in production forecasting. Traditional methods, such as analytical models and empirical correlations, often fail to capture the intricacies of the production process in these unconventional reservoirs, and physics-based approaches typically require precise characterization of complex fracture networks and stress-sensitive permeability variations—parameters that are inherently uncertain in heterogeneous formations1. Furthermore, statistical regression methods, while computationally efficient, frequently fail to capture the nonlinear interactions between geological controls and completion parameters2. In recent years, data-driven methods have gained increasing attention in the field of oil and gas production forecasting, and some scholars have also made certain contributions in this regard3,4,5. These methods leverage large datasets generated from various sources, including well logs, production data, and geophysical surveys, to construct predictive models without relying heavily on physical assumptions or simplifying the current assumptions regarding reservoir behaviour. Machine learning algorithms have demonstrated exceptional ability in terms of handling high-dimensional datasets and identifying complex patterns within unconventional reservoirs in the field of petroleum engineering6,7,8,9,10,11,12,13. Current research efforts have yet to systematically integrate static geological characteristics with dynamic production parameters while simultaneously addressing three critical aspects: (1) statistically robust sample sizes, (2) comparative evaluation of multiple machine learning algorithms, and (3) comprehensive factor analysis14,15,16,17,18. In this study, we aim to investigate the application of data-driven methods to predict the IPHTSG. By analysing a comprehensive dataset including production data, well logs, and reservoir properties, we intend to develop and validate a predictive model that can accurately forecast the initial production of horizontal wells in these unconventional reservoirs. Specifically, we explore the use of machine learning algorithms to build a predictive model based on various features extracted from the dataset. The objectives of this study are twofold: first, to develop a robust and accurate predictive model for the IPHTSG by using data-driven methods, and second, to provide insights into the key factors that influence production in these unconventional reservoirs. The results of this study have the potential to improve production forecasting, optimize well design, and enhance the economic viability of tight sandstone gas reservoir development projects. In the following sections, we present the methodology used to develop the predictive model, the dataset utilized in this study, the results of the model training and validation, and a discussion of the implications and limitations of the findings.
Methodology and workflow
Data Preparation and processing
To predict the IPHTSG, the theoretical or empirical formulas require specified parameters. In actual development processes, various reservoir characteristic parameters or engineering parameters can typically be obtained, and many of these parameters cannot be related to the initial production of horizontal wells via analytical equations. However, machine learning methods can be utilized to explore the relationships among them in detail. Therefore, it is imperative to acquire as many of the characteristic parameters and engineering parameters related to the reservoir encountered during horizontal drilling as possible, thus forming a dataset that is rich in parameter types and sufficient in terms of data volume. Simultaneously, the dataset must be cleaned to remove erroneous, duplicate, and missing data. Second, normalization processing should be applied to the different types of parameters within the dataset. Due to the varying orders of magnitude among different parameter types, eliminating the dimensional differences between features is necessary, as it allows the model to focus more on the intrinsic patterns of the data rather than being distracted by their dimensions. This approach enhances the model’s accuracy and generalizability. Furthermore, normalization makes the model more sensitive to variations in the input data, thereby improving its stability. Finally, correlation analysis of the data is essential, as feature selection is a crucial step in machine learning that can help identify features that are highly correlated with the target variable, which may significantly contribute to the model’s predictive performance. Moreover, features that are weakly correlated with the target variable or highly redundant with other features can be identified and potentially eliminated, simplifying the model and reducing the risk of overfitting. For the target value dataset, and based on the collected characteristic parameters, the IPHTSG can be categorized according to corresponding standards or actual field requirements.
Selection of machine learning algorithms
After data preparation and processing, a predictive model for the IPHTSG was established. Machine learning methods can be used to interpret reservoir characteristics while drilling19,20,21,22, and different algorithms have different effects according to the differences in the amount of sample data and the types of feature parameters. Because the difficulty and complexity of IPHTSG prediction are far greater than those of identifying reservoir characteristics, in this work, we chose the One-Versus-Rest Support Vector Machines (OVR SVMs), One-Versus-One Support Vector Machines (OVO SVMs), Random Forest (RF), Neural Networks (NN), Extreme Gradient Boosting (XGBoost), and Categorical Boosting (CatBoost) algorithms. During the process of model parameter optimization, methods such as grid search and cross-validation are commonly employed, and based the research findings of relevant scholars23,24,25,26, this paper adopts the 10-fold cross-validation method. For each algorithm, all of the parameters other than the optimized parameters specified in the paper were set to their default values.
OVR SVMs
The SVM algorithm was initially developed for binary classification. For multicategory classification, two main methods are employed to construct SVM multiclass classifiers. The direct method modifies the objective function to solve for multiple classification planes simultaneously, but it is computationally intensive and is typically applied only to small problems. Alternatively, the indirect method combines multiple binary classifiers, such as OVR SVMs or OVO SVMs.
In OVR SVMs, each category is classified into one class during training, with the remaining samples constituting the other class. For k categories, k two-class classifiers are constructed; the i-th classifier treats the i-th category as the positive class and all other categories as the negative class. During discrimination, k classifiers produce output values fi(x) = sgn(gi(x)). The input is classified into the category corresponding to the classifier with the largest output, with + 1 indicating a match. However, the decision function may err, and when multiple or no outputs are + 1, the largest output determines the category. However, this method involves a challenge in that training involves only a fraction of the samples, potentially leading to notable deviations influenced by the remaining samples.
OVO SVMs
The SVM is based on the concept of the optimal classification surface for linearly separable data, which aims to correctly separate two sample types while maximizing their classification margin. OVO SVMs represent an extension of SVMs for multiclass classification.
When developing the IPHTSG prediction model based on OVO SVMs, two key parameters are considered: C and γ. The parameter C serves as the penalty coefficient, while γ, defined as \(\:\frac{1}{{\sigma\:}^{2}}\), is a parameter in the kernel function, with σ representing the standard deviation. Following a comparative analysis, the Gaussian kernel function was selected for its high flexibility27.
RF
In the 1980 s, Breiman et al. introduced the classification tree algorithm28, which later evolved into RF in 200129. RF enhances the bagging concept by employing CART decision trees as weak learners and selecting optimal features from a subset of sample features for tree splits, thereby improving model generalization30.
When establishing the IPHTSG prediction model by employing RF, two primary parameters were considered: n_estimators and max_features. n_estimators represents the number of trees in the forest, where increased values improve the performance at the cost of slower execution, while max_features denotes the maximum number of features considered per tree, with smaller subsets accelerating the variance reduction but rapidly increasing bias.
NN
The NN is a mathematical model that draws inspiration from the architecture and functionality of biological neural networks, constituting a nonlinear and adaptive information processing system comprising numerous interconnected nodes, and a classification neural network represents a function that emerges from the composition of multilayer nonlinear functions31. The activation function plays a pivotal role in this system, introducing nonlinearity that enhances the network’s capabilities.
Specifically, a neural network comprises a vast array of simple processing units that are interconnected to form a complex network structure tailored for processing and transmitting information. Neural networks possess the inherent ability to automatically learn intricate data patterns, demonstrating impressive fault tolerance and adaptability. Each neuron within the network receives input signals, processes them via a weighted summation operation followed by an activation function, and subsequently generates output signals. By fine-tuning the connection weights between neurons and selecting the appropriate activation functions, neural networks can effectively learn from and adapt to diverse tasks and datasets. In this study, the sequential module in TensorFlow was employed to construct the neural network model and the number of epochs and batch size were identified as the parameters that require optimization during the model training process.
XGBoost
XGBoost is a boosting algorithm that combines multiple tree models into a robust classifier. It iteratively adds trees, each learning a function to fit the residuals of the preceding prediction. During prediction, each tree outputs a score, with the sample’s predicted value being the aggregate of these scores32. XGBoost regulates the model complexity by adjusting the learning rate of the leaf nodes after each iteration, reducing the tree weights, and enhancing the learning space for subsequent iterations. Additionally, it supports parallelization, accelerating model computation.
When establishing the IPHTSG prediction model using XGBoost, three key parameters are preferred: n_estimators, max_depth, and learning_rate. n_estimators denotes the number of decision trees, or iterations. max_depth represents the maximum depth of each tree; a higher value increases the overfitting risk, while a lower value increases the underfitting risk. learning_rate controls the step size for the weight updates during each iteration, where a smaller value slows the training speed.
CatBoost
CatBoost is a gradient boosting-based decision tree algorithm that is adept at handling datasets with numerous categorical features. It operates within the gradient boosting paradigm, iteratively constructing decision trees to progressively reduce prediction errors. Each subsequent tree is trained on the residuals of the prior trees’ predictions, aiming to rectify errors from earlier models. CatBoost distinguishes itself through its unique handling of categorical features, obviating the need for complex preprocessing, such as one-hot encoding.
This algorithm employs “target statistics” to manage categorical features, computing the category distributions and then utilizing those distributions as numerical features. Furthermore, CatBoost introduces ordered boosting to mitigate prediction shifts. Unlike traditional gradient boosting, which uses the same feature set for all samples, CatBoost randomly orders samples and constructs each tree based on only the feature values from the preceding samples in order. This approach enhances generalization by preventing the model from accessing future data during training.
Construction of model libraries for predicting the IPHTSG
In the process of applying machine learning, the model performance varies with different problems and datasets, and there is no single model that exhibits optimal performance across all data scenarios. Therefore, based on the aforementioned six machine learning algorithms, we optimized the model parameters for actual data, constructed a prediction model library for the initial productivity of horizontal wells in tight sandstone gas reservoirs, and applied these models to predict the test set. By comparing the prediction results for the training set and the test set, we then selected the optimal prediction model.
Workflow
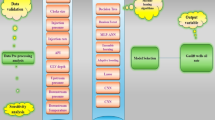
The data-driven workflow for predicting the IPHTSG is illustrated in Fig. 1.
-
(1)
Collect information on the geological and engineering parameters for each horizontal well;
-
(2)
Perform data cleaning, normalization, and correlation analysis on the collected raw data to improve the data quality;
-
(3)
Initialize the IPHTSG prediction model with six algorithms: the OVR SVMs, OVO SVMs, RF, NN, XGBoost and CatBoost;
-
(4)
Train the IPHTSG prediction model on the training set and validation set data, optimize the parameters of each model, and compare the training performance of each model;
-
(5)
Select the optimal model for IPHTSG prediction on the basis of the test set data.

workflow.
Case study
In this study, the He-8 Member of the Shihezi Formation in the southeastern Sulige area of the Ordos Basin was selected as the research area (Fig. 2), with horizontal wells within this region serving as the research subjects. The gas reservoirs in the He-8 Member are characterized by widespread distribution and extensive gas-bearing areas. Against this geological background, the study area has established itself as the largest demonstration base for the development of tight gas horizontal wells in China. However, the He-8 Member reservoir presents several development challenges, including tight reservoir properties, strong heterogeneity, low pressure, and low single-well production rates.
Influenced by the sediment supply from the Yishan Mountains to the north of the basin, the He-8 Member in the northern part of the study area experienced a steep topographic slope during its depositional period, coupled with a gentle depositional basement and a rapid, shallow water depositional environment. This setting primarily fostered the development of a braided river depositional system with frequent lateral shifts, and from north to south, the depositional environment successively transitions from alluvial plain facies through delta plain facies to delta front facies. The primary depositional environment in the study area is the delta plain facies depositional system. The braided channel sand bodies exhibit a broad, repetitive, and extensive north‒south distribution characterized by a high sand‒shale ratio and significant sand body thickness, and the vertically stacked thickness of the sand bodies in the He-8 Member ranges from 10 to 30 m. The developmental scale and geometric morphology of the sand bodies are controlled by the width of the river channels, with variations observed in the internal sand body structures, and the primary storage spaces in the He-8 Member reservoir are dissolved pores, intercrystalline pores, residual intergranular pores, and minor microfractures. Core analysis indicates that the porosity of the He-8 Member reservoir is mainly distributed between 4% and 12%, while the permeability is predominantly within the range of 0.1 mD to 0.4 mD.

Geographical location map of the research area (created by Geomap 3.6 software).
Establishment of a database for predicting the IPHTSG in the study area
Data were collected on the relevant engineering parameters, reservoir characteristics encountered during drilling, and actual initial production capacities for 183 horizontal wells in the tight sandstone gas reservoirs of the He-8 Member, and statistical analysis of the data revealed that the reservoir horizons of these 183 horizontal wells are similar in position and physical properties. Therefore, by using only the average porosity and average permeability of the reservoirs as characteristic parameters has a limited impact in terms of predicting the initial production capacity of horizontal wells. For the engineering and production data related to the reservoirs contained in the horizontal wells, the following parameters were collected: the effective reservoir length (ERL), effective reservoir drilling rate (ERDR), vertical thickness (VT), open-flow capacity (OFC), bottom hole pressure (BHP), amount of fluid entering the ground (AFEG), and amount of sand inclusion (ASI). The ranges of these seven characteristic parameters are presented in Table 1.
After utilizing a data analysis and processing module written in Python to clean the obtained data, a total of 155 sets of valid data were ultimately selected. The feature parameters were then analysed for correlation, as illustrated in Fig. 3, which shows that the ERL-ERDR and AFEG-ASI exhibit strong correlations, exceeding 0.8. Therefore, the ERL, VT, OFC, BHP, and ASI were selected as the feature parameters for model training.

Correlation analysis of 7 kinds of logging data.
The feature parameters were subjected to standardization processing using the fit_transform method provided by the scikit-learn library. The processing formula is \(\:z=\frac{\text{x}-{\upmu\:}}{{\upsigma\:}}\), where x represents the original data, µ is the mean, σ is the standard deviation, and z represents the standardized data. The initial production rates corresponding to the 154 sets of horizontal well feature parameters range from 0.2035 × 104 m³/d to 11.8233 × 104 m³/d. These rates were categorized into six types of target values based on the following intervals: less than 2 × 104 m³/d (I), 2 × 104 m³/d to 4 × 104 m³/d (II), 4 × 104 m³/d to 6 × 104 m³/d (III), 6 × 104 m³/d to 8 × 104 m³/d (IV), 8 × 104 m³/d to 10 × 104 m³/d (V), and greater than 10 × 104 m³/d (VI). Among them, 16 wells were categorized as Type I, 42 as Type II, 50 as Type III, 32 as Type IV, 13 as Type V, and 2 as Type VI. Partial data from the horizontal well initial production capacity database are presented in Table 2. A total of 140 sets of data were randomly selected as the training set, and 15 sets were selected as the test set.
Establishment of the study area IPHTSG prediction model
After the IPHTSG prediction database for the study area was established, the selected machine learning algorithms were employed to develop the IPHTSG prediction models for the study area.
IPHTSG prediction model based on the OVR SVMs algorithm
The Gaussian kernel function was used to establish the OVR SVMs prediction model, and the main parameters C and γ were optimized. The values C = [1, 10, 50, 100, 500], γ= [0.0001, 0.001, 0.01, 0.1, 1] were used to search for the optimal parameter values in 25 combinations of (C, γ) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 4, with the highest prediction accuracy on the training set being 66%, corresponding to the optimal parameter combination of (500, 0.01).

The parameter optimization process in OVR SVMs prediction model.
IPHTSG prediction model based on the OVO SVMs algorithm
The Gaussian kernel function was used to establish the OVO SVMs prediction model, and the main parameters C and γ were optimized. The values C = [1, 10, 50, 100, 500], γ= [0.0001, 0.001, 0.01, 0.1, 1] were used to search for the optimal parameter values in 25 combinations of (C, γ) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 5, with the highest prediction accuracy on the training set being 73%, corresponding to the optimal parameter combination of (500, 0.01).

The parameter optimization process in OVO SVMs prediction model.
IPHTSG prediction model based on the RF algorithm
The main parameters n_estimators and max_features were optimized in the RF algorithm. The values n_estimators = [1, 10, 20, 30, 40, 50, 60], max_features = [1, 2, 3, 4, 5] were set to search for the optimal parameter values in 35 combinations of (n_estimators, max_features) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 6, with the highest prediction accuracy on the training set being 78%, corresponding to the optimal parameter combination of (20, 3).

The parameter optimization process in RF prediction model.
IPHTSG prediction model based on the NN algorithm
The sequential TensorFlow method was used to construct the IPHTSG prediction model for the study area. The main parameters, the number of epochs and batch_size, were optimized. The values epochs = [1, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100], batch_size = [4, 8, 16, 32, 64, 128] were used to search for the optimal parameter values in 66 combinations (epochs, batch_size) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 7, with the highest prediction accuracy on the training set being 70%, corresponding to the optimal parameter combination of (70, 8).

The parameter optimization process in sequential prediction model.
IPHTSG prediction model based on the XGBoost algorithm
During the establishment of the XGBoost prediction model, three main parameters needed to be optimized. The values n_estimators = [1, 5, 10, 20, 50], max_depth = [1, 5, 10, 20, 50], and learning_rate = [0.1, 0.3, 0.5, 0.7, 0.9] were set to search for the optimal parameter values in 125 combinations (n_estimators, max_depth, and learning_rate) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 8, with the highest prediction accuracy on the training set being 80%, corresponding to the optimal parameter combination of (50, 1, 0.3).

The parameter optimization process in XGBoost prediction model.
IPHTSG prediction model based on the catboost algorithm
During the establishment of the CatBoost prediction model, three main parameters were optimized. The values iterations = [5, 10, 20, 50], depth = [4, 8, 12, 16], and learning_rate = [0.1, 0.3, 0.5, 0.7, 0.9] were used to search for the optimal parameter values in 80 combinations of (iterations, depth, and learning_rate) using the grid search method and 10-fold cross-validation method. The parameter optimization process is shown in Fig. 9, with the highest prediction accuracy on the training set being 78%, corresponding to the optimal parameter combination of (20, 8, 0.7).

The parameter optimization process in CatBoost prediction model.
Comparison of the prediction results for each prediction model
After establishing the model and optimizing the parameters of the OVR SVMs, OVO SVMs, RF, NN, XGBoost, and CatBoost algorithms for the IPHTSG in the study area, the six models were utilized to make predictions on the test set data. The time consumed during parameter optimization for the six models is illustrated in Fig. 10, and the optimal parameters are presented in Table 3. The training set accuracy, test set accuracy, precision, recall, and F1 score for the six models are shown in Table 4.

Training time of 6 prediction models.
The machine learning models in this case study were trained on hardware equipped with an i7-13700 K 3.40 GHz processor, 32.0 GB of RAM, and a 64-bit Windows operating system. As illustrated in Fig. 10, although the optimal combination of parameters for the prediction models based on the six algorithms is similar, the training time of the models varies significantly. The training time for the NN model is 7894 s and that for the XGBoost model is 27538s. These two models exhibit significantly longer training times than the other models do. Therefore, unless the performance of the NN and XGBoost models is substantially superior to that of the other models, they were preferably not selected in this case study.
An analysis of the performance of the six prediction models was conducted, and a comparison of the accuracies on the training set revealed that all of the models, except for the OVR SVMs prediction model, achieved accuracies exceeding 0.85. Specifically, the RF, NN and CatBoost prediction models attained training set accuracies above 0.99, with CatBoost reaching the highest accuracy at 0.9989. When the accuracy, precision, recall, and F1-score on the test set are compared, it is evident that these four performance metrics are positively correlated for all prediction models. The XGBoost and CatBoost prediction models exhibited identical values for all four performance metrics on the test set, and the ranking of the six prediction models on the test set, from best to worst, is as follows: CatBoost (XGBoost), RF, OVO SVMs, NN, and OVR SVMs. Both the NN and OVR SVMs prediction models demonstrated performance metrics below 0.8 on the test set. Furthermore, a comprehensive comparison of the performance metrics calculated for the training and test sets across all of the prediction models reveals that the NN and OVR SVMs models significantly overfitted the training data, while the OVO SVMs model exhibited relatively stable overall performance but was not optimal. The RF model achieved a high accuracy on the training set; however, when applied to the test set, only the precision exceeded 0.9, with all other performance metrics falling below 0.9, indicating overfitting. Only the XGBoost and CatBoost prediction models consistently displayed high (above 0.9) and relatively stable performance metrics. Considering that the training time of the CatBoost model significantly exceeds that of the XGBoost model, the XGBoost prediction model was selected for initial production prediction in horizontal wells in this case study. We conducted a feature importance analysis of the XGBoost prediction model, and the results are presented in Fig. 11. The degree of influence of each feature on the prediction results, from greatest to least, is as follows: the OFC, ERL, VT, BHP, and ASI.
The confusion matrix (Fig. 12) and Prediction performance for each category (Table 5) for the test set predictions made by the XGBoost prediction model reveal that the model achieves 100% accuracy when predicting horizontal wells with an initial production rate category of I, II, III and IV. For horizontal wells with an initial production rate category of V, the prediction accuracy is 66.7%. For Categories I, II and IV, the precision, recall, and F1-score are all 1. For Category III, the precision is 0.75, the recall is 1, and the F1-score is 0.8571. For Category V, the precision is 1, the recall is 0.6667, and the F1-score is 0.8. Due to the limited amount of data, there is no data for Category VI in the test set. These results indicate that the XGBoost prediction model can accurately predict horizontal wells with an initial production rate less than 8 × 104m³/d in the study area. When the predicted results exceed 8 × 104m³/d, further analysis incorporating other factors may be considered.

Feature importance analysis of XGBoost prediction model.

Confusion matrix for the test set of XGBoost prediction model.
Results and discussion
By conducting a series of comparison experments, we ascertained that the IPHTSG prediction model can be effectively established utilizing a data-driven methodology grounded in engineering and production data. The creation of the IPHTSG database constituted the cornerstone for developing the IPHTSG prediction model, which served as a comprehensive sample database for model training purposes. The precision of this database is thus a critical determinant of the reliability of the IPHTSG prediction model. Consequently, during the database establishment process, meticulous data cleaning, standardization, and correlation analysis on the engineering and production data were imperative to ensure the high application value and integrity of the database33,34,35. Since missing data can lead to a decline in model performance and different machine learning algorithms have varying capabilities when handling missing data, if a dataset contains a large amount of missing data, it may be necessary to select more complex algorithms or perform additional data preprocessing, which increases both the difficulty of algorithm selection and computational costs. Noisy data can also cause model overfitting and reduce its generalizability. Therefore, before initiating model training, we cleaned the data by performing tasks such as correcting erroneous data, deleting duplicate data, and imputing missing data. Additionally, we conducted feature parameter selection through methods such as correlation analysis.
In this study, six widely applied machine learning algorithms were selected to construct the prediction model. Through a comprehensive comparison of the training set accuracy and multiple evaluation metrics for the test set, we found that only the RF, XGBoost, and CatBoost algorithms achieved accuracy rates exceeding 80% on each sample set, thus meeting the stringent requirements of the project. However, the model training time for the CatBoost algorithm is significantly longer than those of the other models, being at least 20 times greater than those of the RF and XGBoost models, which greatly reduces the training efficiency of the model. Compared with the RF model, the XGBoost model exhibits a similar prediction accuracy on the training set, both exceeding 99%. However, its test set performance in terms of the accuracy, precision, recall, and F1-score is 6.67% (93.33%), 3% (95%), 7.39% (94.12%), and 6.14% (93.14%) higher than that of the RF model, respectively. Therefore, for the case study developed in this research, the XGBoost algorithm was chosen to establish the IPHTSG prediction model.
Apart from the accuracy and reliability of the database and the intrinsic performance disparities among the algorithms, another significant factor contributing to the marked differences in the recognition accuracy among the various algorithms is the selection of the feature parameters. Due to certain constraints when obtaining actual field data within the scope of this study, only a subset of the engineering and production data was selected to provide the feature parameters. However, numerous logging data and other engineering parameters can also provide valuable insights into the characteristics of the IPHTSG. If circumstances permit, it is advisable to consider logging data and other engineering parameters concurrently, and to expand the feature parameters for model training to further enhance the model’s predictive performance. In the case study presented in this paper, two parameters, the OFC (the influence weight exceeds 0.4) and the ERL (the influence weight exceeds 0.2), significantly affect the prediction results. The analysis revealed that the ERL of horizontal wells is positively correlated with both the reservoir contact area and the number of seepage channels; as the ERL of horizontal wells increases, both the contact area with the reservoir, and the number of seepage channels increase as well. This phenomenon is more conducive to the flow of natural gas into the wellbore, thereby increasing the initial production rate. Moreover, when the ERL increases, the pressure gradient around the wellbore also changes. A reasonable distribution of the pressure gradient facilitates a more efficient inflow of natural gas into the wellbore, increasing the OFC and consequently boosting the initial production rate.
For the case study in this research, the optimized XGBoost prediction model has relatively poor prediction performance for the samples in the V category. Through analysis, we believe that there are two main reasons for this phenomenon. First, the sample size is insufficient, making it difficult to accurately capture the characteristics of some data. Second, the geological and engineering factors of tight sandstone reservoirs are relatively complex. For wells with higher initial production capacity, the reservoirs in which they are located may have better physical properties and greater degrees of fracture development. However, in this case study, data related to the degree of fracture development were not collected. As a result, comprehensively considering these complex geological factors is challenging. In future research, efforts should be made to collect a wider variety of parameters to achieve data comprehensiveness.
To achieve accurate prediction of the IPHTSG, it is imperative to increase the number of samples in the database and refine the classification step size for the initial production capacity, as a reduced step size facilitates more precise guidance for actual field development and production activities. On the basis of the case study presented, the method proposed in this paper can predict the IPHTSG to a certain extent, thereby offering a novel and innovative technical approach for its prediction and evaluation.
Conclusions
To address the challenge of accurately predicting the IPHTSG, this paper introduces a new data-driven method based on partial engineering and production data, and the feasibility of this method is verified through the application of an actual case. Some meaningful conclusions are listed below.
-
a.
An IPHTSG database for the study area was established, and it ensures one-to-one correspondence between the feature parameters and the target category and provides a sample database for the establishment of the IPHTSG prediction model.
-
b.
An IPHTSG prediction model for the study area was established. By using five feature parameters, namely, the ERL, VT, OFC, BHP, and ASI, as sample data, we established an IPHTSG prediction model employing the OVR SVMs, OVO SVMs, RF, NN, XGBoost, and CatBoost algorithms. The parameters for each model were rigorously optimized through grid search and 10-fold cross-validation methods. On the basis of the recognition accuracy on the training sets and the accuracy, precision, recall, and F1 score evaluation metrics on the test set across the six target categories, the XGBoost prediction model was selected as the optimal model.
-
c.
In this work, prediction of the IPHTSG was achieved, and the proposed method demonstrated feasibility. This approach will aid engineers in terms of formulating more rational development plans based on multiple factors, including geology and engineering. These plans encompass a good location layout, completion methods, and fracturing designs, ultimately enhancing the overall development efficiency and economic benefits. However, the selection of model feature parameters and machine learning algorithms needs to be tailored according to the characteristics of the data in the study area.
-
d.
In the future, this research can be integrated with real-time interpretation of logging-while-drilling data, real-time updating of reservoir geological models, and maximization of horizontal well productivity, thereby further integrating geology and engineering.
Data availability
Data is provided within the manuscript or supplementary information files. The relevant data has been submitted through the system with the file name “train-test-Scientific Reports.xlsx”.
Abbreviations
- IPHTSG:
-
initial production in horizontal wells targeting tight sandstone gas reservoirs
- OVR SVMs:
-
one-versus-rest support vector machines
- OVO SVMs:
-
one-versus-one support vector machines
- RF:
-
random forest
- NN:
-
neural networks
- XGBoost:
-
extreme gradient boosting
- CatBoost:
-
categorical boosting
- C:
-
penalty coefficient
- \(\sigma\) :
-
standard deviation
- \(\sigma\) :
-
the parameter in the kernel function, = 1/^2
- n_estimators:
-
number of decision trees
- max_features:
-
subset of feature sets selected randomly
- max_depth:
-
maximum depth of each decision tree
- learning_rate:
-
controls the step size of each iteration to update the weights
- epochs:
-
the number of times the entire training dataset
- batch_size:
-
the number of samples that are processed simultaneously
References
Warren, J. E. & Root, P. J. The behavior of naturally fractured reservoirs [J]. Soc. Petrol. Eng. J. 3 (3), 245–255 (1963).
Lie, K. A. et al. Open-source MATLAB implementation of consistent discretisations on complex grids [J]. Comput. GeoSci. 16 (2), 297–322 (2012).
Ali, A. et al. Towards more accurate and explainable supervised learning-based prediction of deliverability for underground natural gas storage [J]. Appl. Energy. 327, 120098 (2022).
Ali, A. Data-driven based machine learning models for predicting the deliverability of underground natural gas storage in salt caverns. [J] Energy. 229, 120648 (2021).
Aliyuda, K. et al. Stratigraphic controls on hydrocarbon recovery in clastic reservoirs of the Norwegian continental shelf. [J] Petroleum Geoscience. 27 (2), petgeo2019–petgeo2133 (2021).
AI-Mudhafar, W. J. Integrating Lithofacies and Well Logging Data into Model for Improved Permeability Estimation: Zubair Formation, South Rumaila Oil Field [J]40315–332 (MARINE GEOPHYSICAL RESEARCH, 2019). 3.
Li, H. et al. A comprehensive prediction method for pore pressure in abnormally High-Pressure blocks based on machine learning [J]. PROCESSES 11 (9), 2603 (2023).
Delavar, M. R. & Ramezanzadeh, A. Pore Pressure Prediction by Empirical and Machine Learning Methods Using Conventional and Drilling Logs in Carbonate Rocks [J]56535–564 (Rock Mechanics and Rock Engineering, 2023). 1.
AI-Mudhafar, W. J. & Bayesian and LASSO Regressions for Comparative Permeability Modeling of Sandstone Reservoirs [J], Nat. Resour. Res., 28(1): 47–62. (2019).
Gao, Y. et al. Pore Pressure Prediction Using Machine Learning Method [C]. Offshore Technology Conference Asia. (2024), February 22.
AI-Mudhafar, W. J. & Wood, D. A. Tree-Based Ensemble Algorithms for Lithofacies Classification and Permeability Prediction in Heterogeneous Carbonate Reservoirs [C]. Offshore Technology Conference. (2022), April 25.
Ahmadi, M. A., Ebadi, M. & Hosseini, S. M. Machine learning-based models for predicting permeability in tight carbonate reservoirs [J]. J. Petrol. Sci. Eng. 192, 107273 (2020).
Chen, Y., Zhang, Y. & Zhang, L. A data-driven approach for shale gas production forecasting based on machine learning [J]. Energy 211, 118689 (2020).
Kang, L. et al. Differentiation and prediction of shale gas production in horizontalwells: A case study of the Weiyuan shale gas field. China [J] Energies. 15, 6161 (2022).
Yang, Y. et al. Using a deep neural network with small datasets to predict the initial production of tight oil horizontal wells [J]. Electronics 12, 4570 (2023).
Zhao Wang, H. et al. Production prediction and main controlling factors in a highly heterogeneous sandstone reservoir: analysis on the basis of machine learning [J]. Energy Sci. Eng. 10, 4674–4693 (2022).
Wang, K. et al. New method for capacity evaluation of offshore Low-Permeability reservoirs with natural fractures [J]. Processes 12, 347 (2024).
Gao, M. et al. Production forecasting based on Attribute-Augmented Spatiotemporal graph convolutionttal network for a typical carbonate reservoir in the middle East [J]. Energies 16, 407 (2023).
Sun, J. et al. Recognition method of fracture type dessert in tight sandstone reservoir while drilling [J]. Sci. Technol. Eng. 18 (15), 88–93 (2018).
Sun, J. et al. Optimization of oil-gas-water layer identification while drilling based on machine learning [J]. J. Xi’an Shiyou Univ. (Natural Sci. Edition). 34 (05), 79–85 (2019).
Sun, J. et al. Optimization of models for a rapid identification of lithology while drilling - A win-win strategy based on machine learning [J]. J. Petrol. Sci. Eng. 176, 321–341 (2019).
Sun, J. et al. Optimization of Models for Rapid Identification of Oil and Water Layers During Drilling - A Win-Win Strategy Based on Machine Learning [C]. Society of Petroleum Engineers. (2018), November 12.
AI-Mudhafar, W. J. Incorporation of Bootstrapping and Cross-Validation for Efficient Multivariate Facies and Petrophysical Modeling [C], SPE Low Perm Symposium. (2016), May 05.
Wang, G. et al. Application of Artificial Intelligence on Black Shale Lithofacies Prediction in Marcellus Shale, Appalachian Basin [C], Proceedings of the 2nd Unconventional Resources Technology Conference. (2014).
Rahimi, M. & Riahi, M. A. Reservoir facies classification based on random forest and geostatistics methods in an offshore oilfield [J]. J. Appl. Geophys. 201, 104640 (2022).
Konat´e, A. A. et al. Capability of self-organizing map neural network in geophysical log data classification: case study from the CCSD-MH [J]. J. Appl. Geophys. 118, 37–46 (2015).
Chang, Y. W. et al. Training and testing low-degree polynomial data mappings via linear SVM [J]. J. Mach. Learn. Res. 11 (11), 1471–1490 (2010).
Breiman, L. Bagging predictors [J]. Mach. Learn 24, 123–140 (1996).
Breiman, L. Random forests [J]. Mach. Learn. 45, 5–32 (2001).
Xie, Y. et al. Evaluation of machine learning methods for formation lithology identification: A comparison of tuning processes and model performances [J]. J. Petrol. Sci. Eng. 160, 182–193 (2018).
J. Yu. Machine learning: from axioms to algorithms [M] 07 (Tsinghua University, 2017).
Chen, T. C. Guestrin. XGBoost: A Scalable Tree Boosting System [C]. KDD ‘16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August (2016).
Van den Bossche, J., Bostoen, R. & Ongenae, F. A systematic review on data cleaning for fraud detection [J]. Knowl. Inf. Syst., 60 (1): 139–163. (2019).
Zaki, M. J. & Meira, A. Jr Fundamentals of Data Mining Algorithms[M] (Cambridge University Press, 2011).
Rubicondo, J. G. Jr., Caires, E. & Barbon, S. Data cleaning: A review of literature and case studies [J]. Data Sci. J. 18 (1), 8 (2019).
Acknowledgements
This work is supported by the National Natural Science Foundation of China (NSFC) (No. 52304036) and the Scientific Research Program Funded by Shaanxi Provincial Science and Technology Department (2023-JC-QN-0432).
Author information
Authors and Affiliations
Contributions
J.S. proposed the research method and research framework. J.S. J.G. provided the actual field data. J.G., K.T. and L.R. carried out the computer simulation experiments. Y.Z. and Z.M. provided ideas for analyzing the experimental results. Z.Z. provided the experimental data. J.S. wrote the main manuscript text. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, J., Gao, J., Tang, K. et al. Initial production prediction for horizontal wells in tight sandstone gas reservoirs based on data-driven methods. Sci Rep 15, 28451 (2025). https://doi.org/10.1038/s41598-025-14468-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-14468-0
