
Abstract
This study developed and validated a machine learning (ML) model to predict in-hospital cardiac mortality in 18,727 atrial fibrillation (AF) patients using electronic medical record data. Four ML algorithms—random forest, extreme gradient boosting (XGBoost), deep neural network, and logistic regression—were applied to 79 clinical variables, including demographics, vital signs, comorbidities, lifestyle factors, and laboratory parameters. The XGBoost model achieved the best performance, with an area under the curve of 0.964 ± 0.014 in the training set and 0.932 ± 0.057 in the validation set, alongside precision, accuracy, and recall of 0.909 ± 0.021, 0.910 ± 0.021, and 0.897 ± 0.038, respectively. Shapley Additive Explanations identified key predictors such as thyroid function indices (e.g., total triiodothyronine, total thyroxine), procalcitonin, N-terminal pro-brain natriuretic peptide, and international normalized ratio. This interpretable model holds promise for improving early risk stratification and individualized care in AF patients. Prospective, multi-center validation is needed to confirm its generalizability.
Similar content being viewed by others


Introduction
Atrial fibrillation (AF) is a common cardiac arrhythmia characterized by an irregular and often rapid heart rate, significantly increasing the risk of stroke, heart failure, and other cardiovascular complications1,2. Its prevalence increases with age, making it a leading cause of morbidity and mortality, especially among hospitalized patients3,4. Early identification of patients at high risk for in-hospital cardiac mortality is essential for improving clinical management and patient outcomes.
Traditional predictive models for in-hospital cardiac mortality in AF patients typically rely on statistical methods, which are often constrained by assumptions like linearity and predefined variables. These limitations can hinder their ability to capture complex, nonlinear relationships in the data. Machine learning (ML) models, however, excel at analyzing large, high-dimensional datasets and identifying intricate patterns that traditional approaches might miss5,6. Recent advances in ML have shown its potential in healthcare applications, such as clinical diagnostics and precision medicine7,8.
In this study, we aimed to develop an explainable machine learning model to predict in-hospital cardiac mortality among patients who are already sick enough to require hospitalization and who also carry a diagnosis of atrial fibrillation—whether pre-existing or newly detected during the index admission. We applied four ML algorithms—random forest (RF), extreme gradient boosting (XGBoost), deep neural network (DNN), and logistic regression (LR)—to electronic medical record data from 18,727 hospitalized AF patients. A total of 79 routinely available admission-day clinical variables were screened to identify predictors of in-hospital cardiac death. The Shapley Additive Explanations (SHAP) method was used to pinpoint the most influential features, and internal validation ensured model robustness and reliability. This approach seeks to provide an early warning system for hospitalized AF patients at risk of cardiac mortality, supporting improved clinical decision-making and resource allocation.
Methods
Study population
A retrospective cohort study was conducted involving patients diagnosed with AF at the First Affiliated Hospital of Xinjiang Medical University between January 2012 and June 2023. The inclusion criteria were as follows: (1) patients aged 18 years or older diagnosed with AF during a previous or current hospitalization, confirmed by electrocardiogram (ECG) findings indicating the absence of P waves replaced by irregular, varying F waves on a single-lead ECG (lasting ≥ 30 s) or a 12-lead ECG (lasting ≥ 10 s) with absolutely irregular RR intervals9; (2) patients with documented in-hospital mortality status, as captured reliably in the electronic medical record system. The exclusion criteria were: (1) patients with incomplete medical records, defined as those with more than 3% missing values across the selected clinical variables, were excluded; (2) patients whose in-hospital death was attributable to non-cardiac causes, such as malignancy, severe infection, end-stage organ disease, accident, or self-inflicted injury. This study received approval from the Ethics Committee of the First Affiliated Hospital of Xinjiang Medical University (Approval No: 231124-05). Given the retrospective nature of the study, informed consent was waived by the Ethics Committee of the First Affiliated Hospital of Xinjiang Medical University, and this study was conducted in accordance with the relevant guidelines and regulations.
Variable selection and preprocessing
Clinical data were retrieved from the hospital information system, initially containing a considerable amount of noise. During preprocessing, missing values and outliers in continuous variables were identified and treated as missing data. We retained only continuous variables with less than 3% missing data, and missing values were imputed using the median. In addition, categorical and laboratory variables were retained only if their overall missing rate across all patients was less than 3%. Variables exceeding this threshold were excluded prior to model construction. A complete overview of missingness by variable is provided in Supplementary Table 1 and Supplementary Fig. 1. This process resulted in the selection of 79 variables for analysis, encompassing demographic information, vital signs, comorbidities, lifestyle factors, and a broad spectrum of laboratory parameters. The key variables considered in the study include demographic details (e.g., sex, age, ethnicity, educational level), vital signs (e.g., heart rate, blood pressure), comorbidities, lifestyle factors (e.g., smoking, drinking), and various laboratory indices. Detailed information on all 79 variables is provided in Supplementary Material 1.
All variables were collected within the first 48 hours of hospital admission, representing baseline measurements recorded at admission and retrieved from the electronic health record system. Data were matched and anonymized using patient IDs to ensure confidentiality and usability. Prior to further analysis, characteristics with zero or near-zero variance were removed, and highly correlated variables (correlation threshold set at 0.95) were identified. Categorical variables such as gender and ethnicity were numerically coded (e.g., ‘male’ and ‘female’ were coded as 1 and 0, respectively; ‘Han,’ ‘Uighur,’ and ‘other ethnicity’ were coded as 0, 1, and 2, respectively). Binary variables related to comorbidities and habits were also coded as binary digits.
Data preparation and model training
To address the imbalance in the dataset, a downsampling method was employed. The deceased group was used as the positive sample, and an equal number of samples were randomly selected from the surviving group as negative samples. For comparison, each algorithm was also trained on the original imbalanced dataset (and on a class‑weighted variant). The dataset was then partitioned, with 80% of the data used as the training set and the remaining 20% as an independent validation set to evaluate the model’s performance. A fivefold cross-validation technique was utilized to optimize model training, as detailed in Supplementary Fig. 2. Specifically, the training set was divided into five equal parts, each representing 20% of the total data. In each iteration, one part was selected as the test set, while the remaining four were used to train the model. After training the model on the selected training set, it was evaluated on the test set. This process was repeated five times to ensure that each portion of the data had an opportunity to be used as a test set. The average of the results from the five evaluations was calculated to determine the model’s overall performance. The model parameter configurations with the highest average performance were selected to obtain the model with optimal performance. Finally, the model’s generalization ability was tested on the independent 20% validation set to ensure that its predictive ability met the expected performance criteria.
Performance evaluation and model explainability
The test set was used to evaluate the efficacy of the classification model based on statistical parameters, including True Positives, True Negatives, False Positives, and False Negatives. Four key performance metrics were employed to assess the models: accuracy, precision, recall, and area under the curve (AUC). The accuracy and average accuracy metrics were used to assess the correlation coefficient of the true predicted values, a metric particularly useful for handling unbalanced data. The recall metric specifically reflects the model’s effectiveness in detecting positive cases, i.e., the probability of correctly predicting cardiac death. The AUC was calculated based on the ROC curve, providing a comprehensive assessment of the classification model’s performance. To enhance the interpretability of the ML models, a feature importance analysis was conducted on the model with the best predictive performance. SHAP values were calculated for each feature to quantify its contribution to the model’s predictions, thereby providing insights into which variables were most influential in determining outcomes.
Model hyperparameter optimization
After establishing the model structures, hyperparameters were systematically and carefully optimized to enhance model performance. For each model, key parameters such as the number of trees, maximum depth, learning rate, and number of hidden layers were fine-tuned. The optimization process involved exploring a range of configurations for each model, as detailed in Supplementary Material 2.
Statistical analysis
Data analysis was performed using R software version 4.4.0 and Python version 3.11. Measurements that followed a normal distribution were expressed as mean ± standard deviation (x ± s) and were analyzed using the t-test. Non-normally distributed measurements were reported as median (quartiles) and were analyzed using the Mann-Whitney U-test. Categorical variables were expressed as counts and percentages (%) and were compared using either the χ² test or Fisher’s exact test. The receiver operating characteristic (ROC) curve was employed as the primary model evaluation metric. A p-value of less than 0.05 was considered to indicate a statistically significant difference.
Results
Patient characteristics
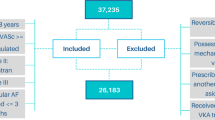
A total of 18,727 patients diagnosed with comorbid AF met the inclusion and exclusion criteria and were included in the study. These patients were used to develop the predictive model, with the study design illustrated in Fig. 1. Among the 18,727 hospitalized patients with atrial fibrillation, 488 (2.61%) died of cardiac-related causes during hospitalization(Supplementary Table 2). Compared with survivors, non-survivors were significantly older (median age: 74.38 [IQR 66.78–80.34] vs. 66.13 [56.29–74.26] years, p < 0.001) and had lower educational levels (median: 7.00 [0.00–13.00] vs. 11.00 [5.00–13.00] years, p < 0.001).The death group showed a lower prevalence of coronary artery disease (67.51% vs. 80.33%, p < 0.001), hypertension (60.35% vs. 65.78%, p = 0.016), and diabetes (32.20% vs. 51.23%, p < 0.001), but a higher prevalence of heart failure (10.44% vs. 1.43%, p < 0.001) and pneumonia (18.03% vs. 12.09%, p < 0.001).In terms of vital signs and laboratory indicators, the death group had higher respiratory rate (20.00 [19.00–22.00] vs. 20.00 [18.00–21.00] breaths/min, p < 0.001) and lower systolic blood pressure (123.00 [107.00–139.00] vs. 130.00 [115.00–146.00] mmHg, p < 0.001). The levels of inflammatory and cardiac injury markers were significantly elevated in the death group, including white blood cell count (WBC: 9.23 vs. 6.62 × 10⁹/L), neutrophils, procalcitonin (2.71 vs. 0.87 ng/mL), D-dimer (1499.05 vs. 462.00 ng/mL), and NT-proBNP (3893.50 vs. 2084.00 pg/mL) (all p < 0.001). Conversely, survivors had higher levels of red blood cell count (RBC: 4.49 vs. 4.05 × 10¹²/L), hemoglobin (136.00 vs. 124.00 g/L), albumin (38.90 vs. 34.58 g/L), and thyroid hormones (TT3, FT3, TT4) (all p < 0.001). No statistically significant differences were observed between the two groups in mean corpuscular hemoglobin concentration (MCHC, p = 0.159), uric acid (UA, p = 0.273), or left ventricular ejection fraction (LVEF, p = 0.171).

Research design technology roadmap.
Characteristics stratified by outcome within the training cohort showed similar patterns of association (Supplementary Table 3). Baseline variables were well balanced between the training and validation sets, with no significant differences observed across clinical or laboratory features (Supplementary Table 4).
Model prediction efficacy and performance
Four ML algorithms—RF, XGBoost, DNN, and LR models—were employed to predict the risk of cardiac death during hospitalization in patients with AF. The results indicated that the XGBoost model exhibited the best performance across all assessment metrics, achieving a mean precision of 0.909 (SD = 0.021), accuracy of 0.910 (SD = 0.021), and recall of 0.897 (SD = 0.038) (Table 1). The analysis of ROC curves further revealed that the XGBoost model was the most effective in predicting in-hospital cardiogenic death risk among AF patients, with the highest predictive capacity (AUC = 0.964 ± 0.014). The XGBoost model outperformed the second-best LR model (AUC = 0.908 ± 0.028) in precision (0.909 ± 0.021), accuracy (0.910 ± 0.021), and recall (0.897 ± 0.038). In comparison, the RF and DNN models demonstrated slightly lower AUCs of 0.879 ± 0.043 and 0.861 ± 0.016, respectively. The XGBoost model exhibited superior precision, accuracy, recall, and discrimination, underscoring its robust predictive capabilities. Independent validation further confirms the clinical utility of XGBoost in predicting cardiac mortality among patients with atrial fibrillation (Fig. 2).

The results of AUC among different ML models in training and validation set. ROC curves for the four models in the training set (A) and validation set (B); RF, random forest; XGBoost, extreme gradient boosting; DNN, deep neural network; LR, logistic regression.
Model explanation
To enhance the interpretability of the model, a SHAP analysis was conducted on the XGBoost model, which demonstrated the optimal predictive performance. A SHAP summary plot was generated (Fig. 3). Figure 3A lists the top 20 features contributing the most to the model, with their contribution values presented in descending order. The horizontal bars on the right rank the top 20 clinical features by the magnitude of their mean absolute SHAP values. Further analysis was performed to determine whether each feature had a positive or negative impact on the model’s prediction results, as shown in Fig. 3B. The twenty most influential variables were identified as total triiodothyronine (TT3), total thyroxine (TT4), free triiodothyronine (FT3), international normalized ratio (INR), procalcitonin (PCT), monocyte count (Mono), red blood cell distribution width (RDW), systolic blood pressure (SBP), lactate dehydrogenase (LDH), magnesium (Mg2+), lymphocyte count (Lym), N-terminal pro-brain natriuretic peptide (NT-ProBNP), glucose (Glu), diastolic blood pressure (DBP), albumin-to-globulin ratio (ALB/GLO), thyroid-stimulating hormone (TSH), ethnicity, mean corpuscular hemoglobin (MCH), Platelet percentage (Pct), and prothrombin activity (PTA).

Training set SHAP summary plot. (A) Beeswarm plots for the XGBoost model. These plots generate SHAP values for each variable and reveal its relationship with in-hospital cardiac death in AF patients. (B) Importance ranking plot of variables for XGBoost model.
A force plot was used to elucidate how different features contributed to the prediction for individual patients (Fig. 4). For samples correctly predicted to have died, lower TT3 and TT4 values resulted in SHAP values exceeding the baseline. In contrast, for samples correctly predicted not to have died, higher TT4 and lower PCT values contributed to negative predictions. For false positives, higher TT3 and TT4 increased the likelihood of incorrectly predicting a death that did not occur. Conversely, for false negatives, lower PCT and higher TT4 values increased the likelihood of incorrectly predicting a death that did not occur. Overall, the contributions of each characteristic were consistent with the model’s overall results, highlighting that PCT, TT3, and TT4 were the most significant variables influencing predictions.
Validation of the final model
The model’s generalization capacity was evaluated using an independent validation set (Table 1). The XGBoost model demonstrated superior performance compared to other models, achieving the highest BA, ACC, and recall values on the validation set. The ROC curves for the models on the validation set are illustrated in Fig. 4B, where the XGBoost model exhibited the largest AUC value of 0.932, indicating its exceptional ability to identify the risk of in-hospital death among AF patients. The ROC curve for the validation set closely resembled that of the training set, providing further evidence of the model’s stability.Notably, the ROC curve for the validation set closely resembled that of the training set, providing further evidence of the model’s robustness and stability. To ensure the reliability of this result, we employed rigorous cross-validation techniques and ensured that the validation set was representative of the overall population.

Variables for four patients that influence the output from the base value. A, B, C and D were one of true positive, true negative, false positive and false negative result, respectively.
Discussion
Numerous studies have unequivocally established that AF significantly elevates the risk of cardiac death1,10,11. Indeed, the mortality rate among AF patients is reported to be 1.5–1.9 times higher compared to those without the condition12. This heightened risk is multifactorial, potentially attributable to the combined impact of thromboembolism, an increased likelihood of heart failure, and the presence of additional health complications11,13.
Given the substantial mortality implications associated with AF, innovative approaches are essential for effective disease management. ML, a branch of artificial intelligence renowned for its ability to discern patterns and features within large datasets, offers a promising avenue for detecting non-linear relationships14. In recent years, the application of ML in AF management has surged dramatically, with researchers harnessing its potential to refine diagnostics, predictions, and outcomes analysis. For instance, Khurshid et al.15 demonstrated the efficacy of deep learning algorithms applied to ECGs for predicting clinical risk factors associated with AF. Suzuki et al.16 took this a step further by developing an ML-driven model capable of high-performance AF recognition, showcasing the technology’s precision in identification tasks. Zhao et al.17 expanded the scope of ML applications in AF care by utilizing these methods to forecast the likelihood of left atrial appendage thrombi in AF patients, a critical aspect of stroke prevention. Goto et al.18 introduced an AI model that leverages prothrombin time-international normalized ratio (PT-INR) measurements to predict one-year clinical outcomes in AF patients, including major bleeding, stroke/systemic embolism, and all-cause mortality. Ribeiro et al.19 conducted a comprehensive analysis using a large digital ECG database to evaluate the mortality risks associated with AF, reinforcing the condition’s status as a strong predictor of both cardiovascular and all-cause mortality. Ambale et al.20 employed random survival forests to assess a range of outcomes, including death, stroke, cardiovascular events, heart failure, and AF itself, identifying inflammation, subclinical atherosclerosis, myocardial injury, and chamber pressures as key predictors across these endpoints. Notably, Bisson et al.21 applied ML models to predict one-year mortality risk, with the best-performing model, a DNN, achieving an AUC of 0.785 (95% CI, 0.781–0.789), highlighting the predictive power of ML in assessing AF-related mortality. Essentially, the increased risk of cardiovascular mortality in AF patients, independent of concomitant heart failure19,22,23 underscores the critical need for a holistic approach to cardiovascular event management in AF patients. Our research is dedicated to providing a robust scientific basis for the in-hospital management of AF patients through accurate risk factor identification. Our goal is to advance individualized treatment strategies to improve clinical outcomes.
Recent multi-omics research has further enriched our understanding of AF pathophysiology. For example, Belfiori et al.24 systematically reviewed transcriptomic and proteomic studies and identified key molecular drivers such as PITX2, BMP10, decorin, and pathways involving fibrosis, electrophysiological remodeling, and cardiac structural proteins. These findings support the concept that AF-related outcomes are not only clinically heterogeneous but also biologically diverse. Their insights help contextualize several predictors identified in our model—such as thyroid hormone abnormalities, NT-proBNP, and inflammation-related markers (e.g., PCT, RDW)—which may reflect deeper mechanistic pathways tied to metabolic stress and atrial remodeling. Integrating such omics-based biomarkers with machine learning could further enhance predictive accuracy and clinical relevance in future work.
In this novel study, four ML algorithms were developed and validated, including RF, XGBoost, DNN, and LR, which demonstrated superior integrated learning performance. These algorithms were based on a comprehensive dataset of 79 metrics encompassing clinical features, laboratory indicators, and immunoinflammatory factors. Our aim was to predict the risk of in-hospital cardiac death in patients diagnosed with AF. Among the different ML algorithms compared, the XGBoost model emerged as the superior performer. When combined with automatic parameter tuning and internal cross-validation, the model demonstrated extremely high predictive accuracy, achieving an AUC of 0.964 ± 0.014 for the training set and 0.932 for the validation set. This excellent performance underscores the potential of ML techniques to enhance clinical risk stratification and decision-making in the management of AF.
Traditional risk stratification models, such as the CHA2DS2-VASc score, primarily rely on linear regression techniques and a limited set of variables25,26,27,28. While these models are useful, they often fail to capture the complex interactions between multiple risk factors. The XGBoost model developed in this study demonstrated superior performance in predicting the risk of in-hospital death among AF patients, achieving an AUC of 0.964. This suggests that ML-based prediction models may be more suitable than traditional methods for screening cardiac death risk. A recent study by Wang et al.29 proposed the CRAMB score, a machine learning-based model using XGBoost to predict one-year mortality in AF patients. Although their outcome focus differs from ours, their use of comorbidity and renal function variables (e.g., BUN) echoes our findings, such as the relevance of creatinine and RDW. This further supports the utility of ML in risk stratification for AF-related mortality. However, the “black box” nature of ML models has historically posed a significant barrier to their widespread adoption30. To address this limitation, the SHAP interpretation method, based on the principles of game theory, was applied, successfully quantifying the contribution of each feature to the model’s predictions and significantly enhancing the model’s interpretability31. To improve interpretability, SHAP value analysis was used to rank the most influential features, which fell into five broad categories: thyroid function, hematologic and coagulation parameters, cardiac function, infection markers, and demographic factors (e.g., ethnicity).
In this study, thyroid function indices were among the strongest predictors of in-hospital cardiac mortality in patients with AF. While overt thyrotoxicosis was uncommon in our cohort, the prominence of thyroid-related features in the model likely reflects the impact of low T3 syndrome, rather than hyperthyroidism. This syndrome—also known as euthyroid sick syndrome—is characterized by reduced T3 levels despite normal TSH and is prevalent among critically ill patients. It has been associated with increased mortality in various cardiac populations, including those with heart failure and ischemic heart disease32,33.
The heart is an important target organ for thyroid hormone, with T3 primarily derived from the conversion of T4, considered the biologically active form of thyroid hormone. T3 can enter cardiomyocytes via protein transporters, interact with thyroid receptors to regulate cardiomyocyte function, and influence cardiac contraction34. Additionally, T3 promotes nitric oxide production in vascular smooth muscle and enhances calcium ion recycling in the vasculature, contributing to vasodilation and reducing coronary and systemic vascular resistance35. These mechanisms may contribute to the development and maintenance of AF by inducing dysregulation of atrial sympathetic remodeling and nerve growth factor protein expression36,37. Thyroid hormone deficiency not only inhibits the expression of thyroid hormone-responsive genes but also alters their transcriptional regulation patterns; in low T3 states, the efficiency of the mitochondrial respiratory chain may be reduced, affecting ATP production and consequently reducing myocardial energy supply38,39. Previous population-based cohort studies have shown that low T3 syndrome is associated with an increased risk of sudden cardiac death and all-cause mortality40,41,42. Previous studies have reported that the prevalence of thyroid dysfunction in hospitalized cardiac patients is 10.2%, and thyroid dysfunction has been associated with increased mortality43,44. Iervasi et al. demonstrated that low free T3 was the strongest independent predictor of cumulative and cardiac mortality in a large prospective study of hospitalized cardiac patients33. Similarly, recent reviews underscore that low T3 correlates with adverse outcomes across cardiovascular disease, including AF32.These findings are consistent with our model’s identification of thyroid indices as top predictors of cardiac mortality in AF patients. Our model provides a more comprehensive understanding of the relationship between thyroid function and cardiac death risk by capturing these complex non-linear relationships and suggests that thyroid function testing should be performed in every newly diagnosed AF patient45.
Therefore, the model’s recognition of thyroid function likely reflects the systemic severity of illness—such as worsening heart failure or metabolic decompensation—rather than thyroid disease as a direct cause of death. This interpretation is supported by the observed distribution of cardiac death causes in our cohort, which included heart failure progression, malignant arrhythmias, acute myocardial infarction, and stroke. Thyroid function testing may serve as a non-invasive window into a patient’s physiological reserve and vulnerability to poor outcomes, and could potentially be incorporated into early risk stratification protocols for AF patients.
AF predisposes patients to left atrial thrombosis, significantly increasing the risk of stroke46. Oral anticoagulants are widely used for stroke prevention in AF and may influence prognosis47. INR is a measure of blood coagulation, with current guidelines recommending an INR target of 2.5 (target range 2–3). A high INR indicates over-anticoagulation, increasing the risk of bleeding complications, including potentially fatal intracranial hemorrhage, while a low INR suggests inadequate anticoagulation, leading to an increased risk of thromboembolic events such as stroke and systemic embolism, which can elevate cardiac workload and lead to death46. Achieving an appropriate balance of anticoagulation is essential to prevent thrombotic and bleeding complications in AF patients, directly impacting in-hospital mortality. Available evidence suggests that moderate anticoagulation intensity, with an INR between 2.0 and 2.5, provides optimal protection against stroke and death in patients with non-valvular AF48. This study focused on a population sample between 2012 and 2023. It is noteworthy that during this period, despite the gradual introduction of new oral anticoagulants since 2009, warfarin and other coumarin-based anticoagulants continued to be widely used as the primary oral anticoagulants for AF due to their cost-effectiveness and extensive clinical experience.
PCT is a procalcitonin prohormone involved in calcium metabolism, primarily produced in neuroendocrine C-cells of the thyroid and K-cells of the lung under non-pathological conditions49. Plasma PCT levels are very low in healthy individuals (< 0.1 ng/ml), but bacterial endotoxins are a strong stimulus for PCT production, leading to levels up to 1000 ng/ml in patients with severe sepsis50. PCT has been used as an indicator of poor prognosis in septic patients51and there is a significant correlation between PCT levels and the incidence of coronary events and cardiovascular death52,53. During the COVID-19 pandemic, the risk of death in severe COVID-19 cases was significantly higher in hospitalized patients with comorbid AF, with persistent and sustained AF identified as an independent risk factor for infection-related death54. Early detection and treatment of infections in AF patients are therefore essential to improve prognosis and reduce the risk of in-hospital cardiac death.
In addition to the key variables that significantly impact in-hospital cardiac mortality, several other factors, while not of primary importance, show a nearly linear correlation with in-hospital cardiac mortality. Integrating and analyzing these indicators allows clinicians to more accurately assess the cardiovascular risk of AF patients and design more effective intervention strategies to reduce in-hospital mortality. It is important to note that even if some risk factors are not included in the top 20, they still play an essential role in clinical practice, particularly in disease prevention.In addition to the top-ranking predictors, several hematologic and biochemical markers—such as PTA, Mono, Lym, RDW, MCH, serum magnesium, Pct, ALB/GLO ratio, and blood glucose—were also significantly associated with in-hospital cardiac mortality in AF patients. These markers may reflect systemic inflammation, coagulation imbalance, nutritional status, metabolic stress, and arrhythmic susceptibility. Although not among the top variables by SHAP value, they align with known pathophysiological mechanisms in AF and cardiovascular disease. A detailed discussion of their potential clinical significance is provided in the Supplementary Material 3.
Limitations
Despite the promising results, this study has several limitations. First, it is a single-center retrospective analysis based on data from a tertiary care hospital, which limits the generalizability of our findings to broader healthcare settings. External validation in diverse populations is warranted. Second, although we included a broad range of clinical and laboratory variables, some potentially important predictors—such as medication adherence, prior ablation history, or AF burden—were unavailable. Their absence may influence model performance and interpretability. Third, the outcome of in-hospital cardiac mortality is relatively rare, raising the issue of class imbalance. While we addressed this using appropriate modeling strategies and internal validation, further prospective studies with larger event counts are needed. Fourth, we did not extract structured data on the primary admission diagnosis for each patient, which may limit the specificity of AF’s role in the mortality pathway; AF may have acted as a comorbidity rather than the primary driver of clinical deterioration. Lastly, although SHAP values enhanced model interpretability, the overall complexity of the XGBoost algorithm may still pose challenges for clinical adoption. Future work should aim to derive simplified and interpretable risk scores from this model to support real-world clinical implementation.
Conclusion
In summary, this study demonstrates the potential of an XGBoost-based ML model to accurately predict in-hospital cardiac mortality in AF patients. The SHAP algorithm significantly enhances the model’s interpretability, offering valuable guidance for clinical treatment decisions. Future research should focus on multi-center validation to broaden the applicability of our model. Prospective evaluations will be crucial to integrating the ML model into clinical workflows, thereby enabling dynamic risk assessment and improving patient care.
Data availability
Some or all of the datasets generated and/or analyzed in this study are not publicly available but can be obtained from the corresponding authors upon reasonable request.
References
Ruddox, V. et al. Atrial fibrillation and the risk for myocardial infarction, all-cause mortality and heart failure: A systematic review and meta-analysis. Eur. J. Prev. Cardiol. 24, 1555–1566 (2017).
Stewart, S., Hart, C. L., Hole, D. J. & McMurray, J. J. V. A population-based study of the long-term risks associated with atrial fibrillation: 20-year follow-up of the renfrew/paisley study. Am. J. Med. 113, 359–364 (2002).
Dai, H. et al. Global, regional, and National prevalence, incidence, mortality, and risk factors for atrial fibrillation, 1990–2017: results from the global burden of disease study 2017. Eur. Heart J. Qual. Care Clin. Outcomes. 7, 574–582 (2021).
Jiao, M. et al. Estimates of the global, regional, and National burden of atrial fibrillation in older adults from 1990 to 2019: insights from the global burden of disease study 2019. Front. Public. Health. 11, 1137230 (2023).
Greener, J. G., Kandathil, S. M., Moffat, L. & Jones, D. T. A guide to machine learning for biologists. Nat. Rev. Mol. Cell. Biol. 23, 40–55 (2022).
Choi, R. Y., Coyner, A. S., Kalpathy-Cramer, J., Chiang, M. F. & Campbell, J. P. Introduction to machine learning, neural networks, and deep learning. Transl. Vision Sci. Technol. 9, 14 (2020).
Rauschert, S., Raubenheimer, K., Melton, P. E. & Huang, R. C. Machine learning and clinical epigenetics: a review of challenges for diagnosis and classification. Clin. Epigenetics. 12, 51 (2020).
Goecks, J., Jalili, V., Heiser, L. M. & Gray, J. W. How machine learning will transform biomedicine. Cell 181, 92–101 (2020).
Joglar, J. A. et al. 2023 ACC/AHA/ACCP/HRS guideline for the diagnosis and management of atrial fibrillation: a report of the american college of cardiology/american heart association joint committee on clinical practice guidelines. Circulation 149, e1–e156 (2024)
Fauchier, L. et al. Causes of death and influencing factors in patients with atrial fibrillation. Am. J. Med. 129, 1278–1287 (2016).
Waldmann, V. et al. Association between atrial fibrillation and sudden cardiac death: pathophysiological and epidemiological insights. Circ. Res. 127, 301–309 (2020).
Benjamin, E. J. et al. Impact of atrial fibrillation on the risk of death: the Framingham heart study. Circulation 98, 946–952 (1998).
Staerk, L., Sherer, J. A., Ko, D., Benjamin, E. J. & Helm, R. H. Atrial fibrillation: epidemiology, pathophysiology, and clinical outcomes. Circ. Res. 120, 1501–1517 (2017).
Wegner, F. K. et al. Machine learning in the detection and management of atrial fibrillation. Clin. Res. Cardiol. 111, 1010–1017 (2022).
Khurshid, S. et al. ECG-Based deep learning and clinical risk factors to predict atrial fibrillation. Circulation 145, 122–133 (2022).
Suzuki, R., Katada, J., Ramagopalan, S. & McDonald, L. Potential of machine learning methods to identify patients with nonvalvular atrial fibrillation. Future Cardiol. 16, 43–52 (2020).
Zhao, Y. et al. Medical record data-enabled machine learning can enhance prediction of left atrial appendage thrombosis in nonvalvular atrial fibrillation. Thromb. Res. 223, 174–183 (2023).
Goto, S. et al. New artificial intelligence prediction model using serial prothrombin time international normalized ratio measurements in atrial fibrillation patients on vitamin K antagonists: GARFIELD-AF. Eur. Heart J. Cardiovasc. Pharmacother. 6, 301–309 (2020).
Ribeiro, A. L. P. et al. Tele-electrocardiography and bigdata: the CODE (Clinical outcomes in digital Electrocardiography) study. J. Electrocardiol. 57S, S75–S78 (2019).
Ambale-Venkatesh, B. et al. Cardiovascular event prediction by machine learning: the Multi-Ethnic study of atherosclerosis. Circ. Res. 121, 1092–1101 (2017).
Bisson, A. et al. Prediction of early death after atrial fibrillation diagnosis using a machine learning approach: A French nationwide cohort study. Am. Heart J. 265, 191–202 (2023).
Olier, I., Ortega-Martorell, S., Pieroni, M. & Lip, G. Y. H. How machine learning is impacting research in atrial fibrillation: implications for risk prediction and future management. Cardiovasc. Res. 117, 1700–1717 (2021).
Brady, P. F. et al. Interactions between atrial fibrillation and natriuretic peptide in predicting heart failure hospitalization or cardiovascular death. J. Am. Heart Assoc. 11, e022833 (2022).
Belfiori, M. et al. Proteomics and bioinformatics in atrial fibrillation: A descriptive review. Bioeng. (basel Switz). 12, 149 (2025).
Mu, X. et al. N-terminal pro-B-type natriuretic peptide improves the predictive value of CHA2 DS2 -VASc risk score for long-term cardiovascular events in acute coronary syndrome patients with atrial fibrillation. Clin. Cardiol. 46, 810–817 (2023).
Shuvy, M., Zwas, D. R., Keren, A. & Gotsman, I. Value of the CHA2 DS2 -VASc score for predicting outcome in patients with heart failure. ESC Heart Fail. 7, 2553–2560 (2020).
Kuo, L. et al. Usefulness of the CHA2DS2-VASc score to predict the risk of sudden cardiac death and ventricular arrhythmias in patients with atrial fibrillation. Am. J. Cardiol. 122, 2049–2054 (2018).
Chen, Y. et al. Predicting All-Cause mortality risk in atrial fibrillation patients: A novel LASSO-Cox model generated from a prospective dataset. Front. Cardiovasc. Med. 8, 730453 (2021).
Wang, B., Jin, F., Cao, H., Li, Q. & Zhang, P. Development of a risk score for predicting one-year mortality in patients with atrial fibrillation using XGBoost-assisted feature selection. Kardiol Pol. 82, 941–948 (2024).
Hu, J. et al. Identification and validation of an explainable prediction model of acute kidney injury with prognostic implications in critically ill children: a prospective multicenter cohort study. EClinicalMedicine 68, 102409 (2024).
Chen, H., Lundberg, S. M. & Lee, S. I. Explaining a series of models by propagating Shapley values. Nat. Commun. 13, 4512 (2022).
Soetedjo, N. N. M., Agustini, D. & Permana, H. The impact of thyroid disorder on cardiovascular disease: unraveling the connection and implications for patient care. Int. J. Cardiol. Heart Vasc. 55, 101536 (2024).
Iervasi, G. et al. Low-T3 syndrome: a strong prognostic predictor of death in patients with heart disease. Circulation 107, 708–713 (2003).
Jabbar, A. et al. Thyroid hormones and cardiovascular disease. Nat. Rev. Cardiol. 14, 39–55 (2017).
Bozkurt, B. et al. Current diagnostic and treatment strategies for specific dilated cardiomyopathies: A scientific statement from the American heart association. Circulation 134, e579–e646 (2016).
Liu, L. et al. Atrial sympathetic remodeling in experimental hyperthyroidism and hypothyroidism rats. Int. J. Cardiol. 187, 148–150 (2015).
Cappola, A. R. et al. Thyroid status, cardiovascular risk, and mortality in older adults. JAMA 295, 1033–1041 (2006).
Brent, G. A. Mechanisms of thyroid hormone action. J. Clin. Invest. 122, 3035–3043 (2012).
Takawale, A., Aguilar, M., Bouchrit, Y. & Hiram, R. Mechanisms and management of thyroid disease and atrial fibrillation: impact of atrial electrical remodeling and cardiac fibrosis. Cells 11, 4047 (2022).
Chen, Z., Wan, H., Min, T., Su, S. & Yang, D. G. Thyroid dysfunction in nonvalvular atrial fibrillation and clinical outcomes. Endocrine 86, 239–245 (2024)
Kannan, L. et al. Thyroid dysfunction in heart failure and cardiovascular outcomes. Circ. Heart Fail. 11, e005266 (2018).
Wang, C. et al. Value of FT3/FT4 ratio in prognosis of patients with heart failure: A Propensity-Matched study. Front. Cardiovasc. Med. 9, 859608 (2022).
Frankel, M. et al. Thyroid dysfunction and mortality in cardiovascular hospitalized patients. Cardiovasc. Endocrinol. Metab. 13, e0299 (2024).
Sterenborg, R. B. T. M. et al. Multi-trait analysis characterizes the genetics of thyroid function and identifies causal associations with clinical implications. Nat. Commun. 15, 888 (2024).
Hindricks, G. et al. ESC Guidelines for the diagnosis and management of atrial fibrillation developed in collaboration with the European Association for Cardio-Thoracic Surgery (EACTS). European Heart Journal 42, 373–498 (2021). (2020).
Hart, R. G. et al. Lessons from the stroke prevention in atrial fibrillation trials. Ann. Intern. Med. 138, 831–838 (2003).
Schäfer, A., Flierl, U., Berliner, D. & Bauersachs, J. Anticoagulants for stroke prevention in atrial fibrillation in elderly patients. Cardiovasc. Drugs Ther. 34, 555–568 (2020).
Odén, A., Fahlén, M. & Hart, R. G. Optimal INR for prevention of stroke and death in atrial fibrillation: a critical appraisal. Thromb. Res. 117, 493–499 (2006).
Becker, K. L., Nylén, E. S., White, J. C., Müller, B. & Snider, R. H. Clinical review 167: procalcitonin and the calcitonin gene family of peptides in inflammation, infection, and sepsis: a journey from calcitonin back to its precursors. J. Clin. Endocrinol. Metab. 89, 1512–1525 (2004).
Bateman, R. M. et al. 36th International Symposium on Intensive Care and Emergency Medicine: Brussels, Belgium. 15–18 March 2016. Crit Care 20, 94 (2016).
Shen, K. & Jiang, S. The value of procalcitonin and brain natriuretic peptide in predicting the prognosis of sepsis. Am. J. Transl Res. 15, 1921–1927 (2023).
Schiopu, A. et al. Plasma procalcitonin and the risk of cardiovascular events and death: a prospective population-based study. J. Intern. Med. 272, 484–491 (2012).
Villanueva, M. P. et al. Procalcitonin and long-term prognosis after an admission for acute heart failure. Eur. J. Intern. Med. 26, 42–48 (2015).
Zając, A., Wrona, E. & Kasprzak, J. D. Permanent and persistent atrial fibrillations are independent risk factors of mortality after severe COVID-19. J. Clin. Med. 13, 3112 (2024).
Acknowledgements
Thanks to all the participants in this study.
Funding
This work was supported by grants from the Top Young Scientific and Technological Talents of the Tianshan Talent Cultivation Program in Xinjiang (2022TSYCCX0101).
Author information
Authors and Affiliations
Contributions
H.L. and X.B. conducted the data analyses, developed the ML models, and drafted the manuscript. S.S. and M.W. contributed to data collection. K.W. and Y.L. were involved in the study’s design and coordination. Y.L. and B.T. had primary responsibility for study design, data analyses, data interpretation, and manuscript writing. X.Z. accessed and verified the data. All authors read and approved the final manuscript. H.L. and X.B. contributed equally to this work and are listed as co-first authors. Y.L. and B.T. contributed equally as corresponding authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
This study received approval from the Ethics Committee of the First Affiliated Hospital of Xinjiang Medical University (Approval No: 231124-05). Given the retrospective nature of the study, informed consent was waived by the Ethics Committee of the First Affiliated Hospital of Xinjiang Medical University, and this study was conducted in accordance with the relevant guidelines and regulations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lv, H., Bi, X., Shang, S. et al. Machine learning model for predicting in-hospital cardiac mortality among atrial fibrillation patients. Sci Rep 15, 29554 (2025). https://doi.org/10.1038/s41598-025-14579-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-14579-8
