
Abstract
Change detection is widely utilized across various domains, such as disaster monitoring, where it aids in identifying differences between images captured at different time intervals. However, current methods often lack constraints on intermediate features and fail to comprehensively model the temporal relationships among these features. Additionally, they rely on simplistic fusion mechanisms, leading to suboptimal network performance. In this paper, we propose: (1) a Feature Information Interaction Module (FIIM) based on spatial attention to enhance semantic information; (2) a Feature Pair Fusion Module (FPFM) with dual-branch structure to model bi-temporal relationships; and (3) a Multi-Scale Supervision Method (MSSM) using contrastive learning to better constrain intermediate features. Comparative experiments conducted on the CDD and LEVIR-CD datasets demonstrate the superiority of our proposed network over existing state-of-the-art methods. Code repository: https://github.com/joyeuxni/SNIIF-Net.
Similar content being viewed by others

Introduction
In recent years, advances in remote sensing technology have significantly enhanced our ability to monitor surface conditions and changes, thereby supporting environmental conservation and promoting harmonious co-existence between humans and nature. The widespread application of change detection (CD) techniques has proven to be particularly valuable in disaster prevention, mitigation, and relief efforts. These techniques allow for the assessment of disaster impacts through the analysis of changes in monitored areas, providing crucial support for disaster management and prevention strategies. Therefore, the study of change detection using remote sensing images is of paramount importance in current research.
In the initial phase of CD, traditional methodologies are primarily employed, which can be broadly categorized into algebraic methods1, feature-based methods2, and post-classification comparison methods3. Algebraic methods are known for their simplicity and ease of operation, which provide quick response to changes. Feature-based methods involve the selection of multiple image features, followed by their transformation and fusion to achieve change detection. Unlike the aforementioned approaches, post-classification comparison methods not only detect changes within a specific region but also classify these changes.
Although the above-mentioned traditional CD algorithms have significantly contributed to the advancement of CD tasks and demonstrated remarkable performance, the continuous development of artificial intelligence4,5,6 and deep learning has shifted the focus towards employing deep learning techniques for change detection. The powerful feature extraction capabilities of deep neural networks have substantial potential to improve the overall performance of these tasks.
To extract richer deep features and improve the robustness and generalization capabilities of CD networks, numerous researchers have developed deep learning-based CD networks for various tasks, achieving commendable results. However, these methods, whether based on fully convolutional networks, Siamese networks, or GAN-based CD networks, have certain limitations: (1) Fully convolutional networks with symmetric structures7,8,9,10,11,12 employ diverse feature fusion strategies to enhance information extraction. For example, references7,9 utilized simple skip connection mechanisms on intermediate features, while references8,13 applied various attention mechanisms to fuse deep feature maps and change maps. Despite these achievements, the reliance on simplistic fusion methods limits their ability to capture fine-grained changes and may introduce noise; (2) Siamese CD networks based on UNet aim to enhance network performance through various supervision methods. For example, studies14,15,16 employed contrastive learning to supervise the final output. Although these methods achieved satisfactory results, they neglected effective supervision of intermediate features, leading to a loss of valuable information; (3) References17,18,19 demonstrated good network performance by integrating GANs. However, these methods struggle to model the interdependencies among feature pairs, which is crucial for generating more detailed change maps. Therefore, effective extraction and fusion of features at different time points and proper constraint of these features remain significant challenges in CD tasks.
In response to the limitations of previous research, we propose a novel model to monitor regional changes, termed the Siamese Network Based on Information Interaction and Fusion for Change Detection (SNIIF-Net). SNIIF-Net introduces a Feature Information Interaction Module (FIIM), which leverages a spatial attention mechanism to enhance the semantic information of features. Additionally, a Feature Pair Fusion Module (FPFM) is employed to capture semantic relationships between feature pairs. The FPFM fully utilizes spatial information to obtain richer detail and enhance the edge information of images, thereby improving model performance. Furthermore, we developed a Multi-Scale Supervision Method (MSSM) based on contrastive learning to refine feature pairs obtained from multiple decoder stages. Experimental results and ablation analysis on two benchmark datasets demonstrate that these modules enable SNIIF-Net to achieve state-of-the-art performance.
Our primary contributions are fourfold:
-
We propose a Feature Information Interaction Module (FIIM) that enhances the semantic richness of the features. By integrating this module at each stage, our network captures more comprehensive information.
-
Unlike other methods that merely concatenate or perform sub-operations, we employ a Feature Pair Fusion Module (FPFM) to effectively model semantic relationships between feature pairs. This module enhances edge information and fully leverages the spatial details of the input image pairs to obtain richer detail information.
-
We also introduce a Multi-Scale Supervision Method (MSSM) based on contrastive learning to constrain the feature pairs obtained from the multiple decoder stage. This approach allows unchanged pixel pairs to approach each other in feature spaces at multiple scales, while changing pixel pairs move away from each other, resulting in a more refined change map.
-
Extensive experiments are conducted to demonstrate the effectiveness of our proposed SNIIF-Net and its constituent modules.
Related Works
-
Feature Enhancement and Fusion
The integration of deep convolutional networks with feature fusion techniques20,21,22 has significantly improved the accuracy and robustness of remote sensing CD tasks. Effective fusion of multi-scale features is critical for CD. Zhang et al.23 proposed the BiFA network, which utilizes a dual temporal interaction module for channel-level alignment and combines the adaptive difference flow field module to alleviate spatial misregistration issues caused by changes in perspective. However, this method is sensitive to noise and does not fully exploit the hierarchical differences in multi-scale features. To further optimize the interaction efficiency of multi-scale features, Liu et al.24 proposed the ExNet, which aligns feature distributions using dynamic low-pass filters and strengthens frequency domain features through frequency division enhancement modules, significantly improving detection robustness in complex scenes. However, its model training requires complex hyperparameter tuning, limiting its generalization capabilities. Wang et al.25 proposed the MSGFNet, which is based on Siamese EfficientNetB4 to extract dual-temporal features and dynamically weight different scales of boundary detail features through the multi-scale gated fusion module, significantly improving the CD accuracy for small objects. In addition, methods based on attention mechanisms also enhance the feature information. Noman et al.26 further designed the ELGC-Net, which captures global and local context information through a pooling-transpose attention mechanism and deep convolution, enhancing noise robustness with multi-scale pooling, although its complex feature fusion process limits real-time performance. With the introduction of the UNet and residual connections, the representation ability of multi-scale features has been enhanced. Huang et al.27 designed the MFCF-Net, which uses an encoder to extract features of the adjacent layer and combines dense skip connections and cross-attention mechanisms to fuse global spatial information, effectively alleviating false detection caused by changes in lighting, but its performance is limited by the dependence on annotated data in imbalanced sample scenarios. Ren et al.28 designed a DAGMSANet, which aggregates adjacent scale semantic information during the encoder stage and combines spatial and channel attention to suppress background noise during the decoder stage, performing excellently in imbalanced sample scenes, although at a significant computational cost. Although the above methods have achieved good results, they have insufficient utilization of multi-scale semantic information in the decoder stage and rely on simple feature subtraction operations (such as subtraction), which collectively limit further performance improvement.
-
Distance Metric Learning
In change detection tasks, adopting appropriate distance measurement methods to assess feature information is crucial for evaluating the effectiveness of change detection algorithms. Most algorithms rely on Cross-Entropy Loss or content loss to constrain change maps. Distance metric learning is employed to evaluate the algorithm’s performance by assigning larger values to changing pixel pairs and smaller values to unchanged pixel pairs. Reference29 introduces a distance metric learning method based on contrastive learning, with the aim of reducing the emphasis on invariant feature pairs while increasing the focus on changing ones. Similarly, Reference13 proposes a weighted contrastive learning method to train a twin convolutional network that takes advantage of the distance between feature vectors to detect changes between image pairs, leading to improved results. Reference15 presents a threshold-based contrastive loss method to calculate changes between feature pairs, effectively minimizing the distance between invariant pairs and maximizing the distance between changing pairs. All these methods adopt the contrastive learning constraint approach proposed in Reference29 to learn distance measurement for change features, improving the detection accuracy. In our work, we also employ contrastive learning-based measurement methods to constrain change feature pairs at different scales, thereby improving network performance. Although the above methods improve network performance through specific constraint strategies, they did not apply distance metric constraints based on contrastive learning to different scale feature maps generated by the decoder. Therefore, the model still has room for improvement in fully utilizing multi-scale feature information.
Method
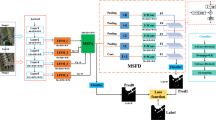
To enhance the use of remote sensing images in monitoring natural disasters and modeling regional changes induced by such events, in this section, we introduce a Siamese Change Detection Network (SNIIF-Net) based on information exchange and fusion. SNIIF-Net is a symmetrically structured network that shares weight parameters and is primarily designed to detect geological and geomorphic changes by analyzing input image pairs. The overall architecture of the proposed SNIIF-Net is illustrated in Fig. 1.

Overall structure of Siamese network based on information interaction and fusion for change detection. The input images \(I_{1}\) and \(I_{2}\) are sourced from the LEVIR-CD dataset30.
Overview
As illustrated in Fig. 1, the SNIIF-Net architecture processes a pair of remote sensing images taken at different times, denoted as \(I_{1}\), \(I_{2}\). These images are initially input into a Siamese convolutional neural network (CNN) to extract the features of remote sensing image feature pairs, represented as \(x_{1}\) and \(x_{2}\). Subsequently, the feature pairs are fed into a symmetric encoder-decoder network that utilizes three encoding stages. Each encoding stage employs two convolutional layers (3\(\times\)3 kernels, stride 1) followed by 2\(\times\)2 max pooling (stride 2), reducing spatial dimensions to (h/2, w/2), (h/4, w/4), and (h/8, w/8), where w and h denote the width and height of the feature map, respectively. In the decoding stage, SNIIF-Net refines feature extraction from different scales using the Feature Information Interaction Module (FIIM), which is based on a spatial attention mechanism to enhance the semantic information of the features. To achieve more precise change features, SNIIF-Net employs the Feature Pair Fusion Module (FPFM) to further process the feature pairs. Additionally, SNIIF-Net integrates residual connections to merge features of various scales, thereby mitigating information loss that may occur during decoding. Finally, SNIIF-Net implements contrastive learning to effectively constrain features of different scales in the decoding stage, thereby enhancing the performance of the change detection network.
Feature information interaction module
The use of multiple downsampling operations in the encoding stage of SNIIF-Net inevitably leads to some information loss, which may impact the accuracy of the final change detection. To mitigate the loss of important information, SNIIF-Net incorporates feature information interaction modules (FIIM) in both symmetric networks. The FIIM module draws inspiration from the Position Attention Module (PAM) in DANet31. While both model spatial dependencies via attention maps, FIIM adapts PAM for change detection by (1) independently processing bi-temporal input features, and (2) integrating residual connections to preserve original features. This module leverages attention mechanisms for feature enhancement, mitigates information loss and can refine change region delineation.

The structure figure of feature information interaction module.
The network structure of the Feature Information Interaction Module (FIIM) is illustrated in Fig. 2. As depicted, the FIIM module first applies a transpose operation to the input feature f. Here, \(f\in \Re ^{C\times H\times W}\) represents the input feature, where C denotes the number of feature channels, while H and W correspond to the height and width of the feature, respectively. Subsequently, the FIIM multiplies the transposed features (of dimension C\(\times\)H\(\times\)W) by the deformed features in a matrix format, followed by a softmax operation to generate a spatial attention relationship map \(M_{s}\in \Re ^{(H\times W)\times (H\times W)}\). The implementation process can be expressed as the following equation.
where \(f_{i}\) and \(f_{j}\) denote features at different positions, and N represents the total number of features. This calculation process allows the determination of the degree of correlation between features located at different positions. Specifically, a stronger correlation between two features corresponds to a higher value of \(M_{s}\).
Subsequently, the FIIM module applies the spatial attention relationship map to the transformed features, resulting in features that incorporate spatial correlation information and are processed in a size of C\(\times\)H\(\times\)W. In particular, to mitigate the potential loss of feature information during this process, the FIIM module employs residual connections to merge features containing spatial information with the original input data, thereby enhancing feature extraction. The final output feature \(f_{s}\) of this feature information interaction module can be represented by the following equation:
where, \(\lambda\) represents the parameter that is automatically optimized by the network. From the above equation, it is evident that the output feature \(f_{s}\) of the feature information interaction module is a weighted sum of the feature information from all positions and the original input feature. Consequently, \(f_{s}\) encompasses rich global contextual information. Furthermore, since the output feature \(f_{s}\) is derived from the spatial attention mechanism, it can adaptively select and aggregate contextual information, model long-term semantic dependencies between features, improve semantic consistency, promote similar semantic features, and ultimately allow SNIIF-Net to more effectively differentiate between changing and unchanged features.
Feature pair fusion module
The effective fusion of bi-temporal features is crucial for change detection tasks utilizing Siamese networks and significantly enhances network performance. Most existing algorithms employ simple subtraction or concatenation methods to refine bi-temporal features. Although these methods can improve the change detection performance to some extent, they often fail to meet high-precision requirements due to spatial position and color shifts in the input images during the feature extraction process. To address this limitation, SNIIF-Net introduces a Feature Pair Fusion Module (FPFM) designed to combine input feature pairs, thus extracting more refined change features. Specifically, the dual-branch design of the FPFM simultaneously captures change magnitude (subtraction branch) and edge consistency (summation branch), with residual connections preserving spatial details. The structure of the FPFM is illustrated in Figure 3.

The structure figure of feature pair fusion module.
As illustrated in Fig. 3, the FPFM module comprises two branches (I and II), with branch I serving as the subtraction branch and branch II functioning as the summation branch. The subtraction branch receives two inputs, \(f_{s1}\) and \(f_{s2}\), which are remote sensing image features extracted at different time points and represented as \(f_{s1},f_{s2}\in \Re ^{C\times H\times W}\). Subsequently, three sequential convolution and ReLU operations are performed to further process the input features, utilizing a convolution kernel size of 3\(\times\)3 and a stride of 2. Additionally, to enhance the output features’ information content, the FPFM module employs multiple residual connection operations (red arrows) to fuse the features during the feature extraction stage. For generating fine-change regions, the FPFM module processes the two features by subtracting one from the other. After applying convolution, batch normalization (BN), and ReLU activation, the output feature \(f_{I}\) of branch I is obtained. The above process can be expressed by the following equation.
where \(F_1\)() represents the operations of convolution, BN and ReLU in the subtraction branch, and \(f_{s i}^{s u b i}\) denotes the features obtained after the i-th convolution and ReLU operations in the subtraction branch, with the input feature \(f_{s i}\).
The summation branch, which runs parallel to branch I, is designed to enhance edge information and mitigate pseudo-change phenomena caused by feature mismatches. Similarly to the subtraction branch, the FPFM module performs a summation operation on the two features after the convolutional layer, resulting in the output feature \(f_{II}\) of the summation branch. The above process can be expressed by the following equation.
where \(F_2\)() represents the operations of convolution, BN and ReLU in the summation branch, and \(f_{s i}^{s u b i}\) denotes the features obtained after the i-th convolution and ReLU operations in the summation branch, with the input feature \(f_{s i}\).
Finally, the chapter employs vector-wise summation to fuse the output features of the two branches, resulting in the final output \(f_{c}\) of the FPFM module. This feature enables the FPFM fusion module to effectively combine multiple features within each branch, resulting in more refined change features. The primary reasons for this approach are as follows: (1) parallel processing of complementary features (change magnitude + edge consistency), and (2) residual connections that mitigate information loss.
Multi-scale supervision method
As shown in Fig. 1, during the decoder stage, we utilize multi-scale features to model changing regions. Solely employing the FPFM module to capture the change information of feature pairs is insufficient for fine change detection tasks based on pixel segmentation. We define changing regions at the same position in different image pairs as positive samples and unchanged regions at the same position in different image pairs as negative samples. Our objective is to assign distinct distance metrics to different categories to enable effective sample separation. A positive sample should exhibit changes, and we aim for the distance between the changing samples to be maximized. In contrast, negative samples, which remain unchanged, should demonstrate significant similarity, which warrants a very small distance value. This implicit distance measure ensures that the unchanged negative samples are as close as possible while maintaining separation between changing positive samples. Based on this concept, we propose a multi-scale supervision method (MSSM) grounded in contrastive learning to assess the distance between feature pairs across various scales. Specifically, we aim to bring unchanged pixel pairs closer together in feature spaces at multiple scales while simultaneously pushing changing pixel pairs apart.
The input for this module consists of feature pairs \((f_{s1}(i,j),f_{s2}(i,j)\in \mathbb {R}^{C\times H\times W}\), where \(1\le i\le H\) and \(1\le j\le W\). These pairs are processed by the FIIM, with \(f_{s1}(i,j)\) representing the intensity vector at the position (i, j) in the image. We define the distance D between feature pairs using the Euclidean distance, which can be expressed by the following equation:
where, m denotes the m-th layer feature in the decoder stage, characterized by a feature scale of \(1/2^{4-m}\). The function D(.) represents the distance function that the network must learn. For clarity in subsequent descriptions, we denote the process described in Equation (5) as \(D_{i,j}\).
To enhance the network’s ability to effectively distinguish information in changing regions and accelerate convergence speed, we require that the distance between positive samples exceeds a specified boundary value (\(\theta\)>0). Only when the distance between positive samples is within this range will the changed pixel pairs influence the loss function. This process is represented by the following equation.
For negative samples, we expect the distance between them to be less than a specified boundary value (\(\varepsilon\)>0). Only when the distance between negative samples falls within this range will unchanged pixel pairs influence the loss function. This process can be expressed by the following equation.
Thus, the loss function of MSSM based on contrastive learning during the decoder stage can be defined as the following equation:
where, \(y_{i,j}^m\) represents the feature of the true label in the decoder stage layer, which is mapped to the input image pair with dimensions H\(\times\)W. When \(y_{i,j}=0\), it indicates that the corresponding pixel pair has not changed; when \(y_{i,j}=1\), it means that the corresponding pixel pair has changed. The parameters \(\lambda _{1}\) and \(\lambda _{2}\) assign different weights to distinct loss functions, addressing the issue of imbalanced positive and negative samples. Using this calculation method, we can derive more detailed change maps in the feature space by applying the distance between features of varying scales.
Loss functions of SNIIF-Net
To take advantage of additional feature information for improved change detection accuracy, we have designed the following loss functions to constrain SNIIF-Net to specific network architectures:
where, \(\ell _{MSSM}\) represents the supervision method of multi-scale contrastive learning, and \(\ell _{change}\) represents the constraint on the final change feature, which can be represented by the following equations:
where, \(X_{hw}^{change}\) denotes the change feature at the pixel position (h, w), \(Y_{hw}\) represents the corresponding label and \(\mathcal {\ell }(\cdot )\) indicates the cross-entropy loss function. To enforce the constraint of changing features, we employ a multi-scale training strategy. By applying this constraint to features at various scales during the decoder stage, we can enhance network performance and ultimately extract more detailed change information.
Experiments and results
Datasets
We first performed training and testing on publicly standard datasets, CDD32 and LEVIR-CD30. The CDD dataset is an open and seasonal remote sensing change detection dataset comprising multi-source remote sensing images and 11 pairs of original images. This includes 7 pairs of change images with dimensions of 4725\(\times\)2200 pixels and 4 pairs of change images measuring 1900\(\times\)1000 pixels, with a spatial resolution ranging from 3 to 100 cm. The CDD dataset was processed and divided into a training set of 10,000 samples, a validation set of 3,000 samples, and a testing set of 3,000 samples, each with a pixel size of 256\(\times\)256. The LEVIR-CD dataset consists of image pairs and semantic and change detection labels for buildings captured at the same location in 2012 and 2016, situated in the area affected by a magnitude 6.3 earthquake in Christchurch, New Zealand, in February 2011. The LEVIR-CD dataset includes 637 pairs of high-resolution images (445 pairs for training) with a spatial resolution of 50 cm and a pixel size of 1024\(\times\)1024.
Experimental settings
The experimental hardware environment comprises an Intel\(\textcircled{R}\) \(\hbox {Core}^{TM}\) CPU at 3.50 GHz and an NVIDIA GeForce GTX TITAN X. The operating system is Ubuntu 16.04, and the compilation environment is Python 3.7, with Python 1.7 selected for specific tasks. Regarding experimental details, SNIIF-Net is configured with a parameter value of \(\theta = 1\), \(\varepsilon = 0.1\), weight decay set to 5e-5, an initial learning rate of 1e-4, 2000 epochs, a batch size of 2, and the Adam optimizer for network optimization. We use the F1 score to evaluate network performance.
Comparisons with other methods
To evaluate the effectiveness of SNIIF-Net, we first compare it with several advanced algorithms using the standard CDD dataset. The results of the quantitative comparison are presented in Table 1, while Fig. 4 provides a visual comparison of various algorithms. Among these, FC-EF7 refers to the concatenation of pairs of input bi-temporal images, treating them as different channels of a single image before processing them through the network for feature extraction. The FC-Siam-con7 employs two parallel branches to process the input bi-temporal images, sharing weight parameters between these branches. Subsequently, convolution operations are applied to combine the two output features using a skip connection approach. The FC-siam-diff7 also utilizes a parallel branch structure typical of Siamese networks. However, unlike FC-Siam-con7, it does not directly concatenate the output of the parallel branches; instead, it computes the absolute value difference between the feature maps of the parallel branches before concatenation.
Table 1 clearly indicates that: (1) Methods based on UNet and Siamese networks7 often utilize simple structures and skip connection mechanisms to process features, which limits their ability to extract rich semantic information. Furthermore, significant detail is lost during the downsampling process, and ineffective supervision of features during upsampling further affects performance; (2) The \(\text {UNet++\_MSOF}\) network8, which employs deep supervision, first utilizes a fully symmetric convolutional network to extract features from the input image and then introduces a differential discrimination network to detect changes in the output feature pairs. This network also incorporates an attention mechanism to fuse depth features and image difference features at various scales. Although \(\text {UNet++\_MSOF}\) with different numbers of channels (16 and 32, representing the number of output channels) performs better than FC-EF, FC-Siam-conc, and FC-Siam-diff, it still relies on a simple skip connection mechanism to fuse intermediate features, which hampers its ability to capture deep features and effectively reconstruct images. Consequently, the F1 score obtained by \(\text {UNet++\_MSOF}\) is relatively low, at 0.062 (16 channels) and 0.020 (32 channels) below the F1 score of SNIIF-Net; (3) DASNet13, which is based on contrastive learning and a dual attention mechanism, improves network performance through the introduction of contrastive learning methods. However, DASNet only supervises the final output features, lacking constraints on intermediate features. Furthermore, the dual attention mechanism increases the burden of the network to some extent, leading to suboptimal performance, with an F1 score that is 0.044 lower than that of SNIIF-Net; (4) SNUNet-CD16, a Siamese network based on UNet, proposes an integrated channel attention fusion method to process intermediate features, outperforming DASNet. However, its use of simple Focal Loss does not adequately supervise the network, resulting in suboptimal performance; (5) Recent methods34,37,38,40,41,45 have achieved high F1 scores through innovative fusion methods or network structures. However, whether leveraging the global feature extraction capabilities of Transformers, employing feature fusion methods with varying attention mechanisms, or utilizing different design approaches based on UNet, these methods often neglect effective constraints on intermediate features, leading to suboptimal performance.

Visual comparison with some algorithms on CDD dataset. Different colors are employed to enhance clarity: white indicates true positives, black represents true negatives, red denotes false positives, and blue signifies false negatives. The input images \(x_{1}\) and \(x_{2}\) are sourced from the CDD dataset32.

Visual comparison with some algorithms on LEVIR-CD dataset. Different colors are employed to enhance clarity: white indicates true positives, black represents true negatives, red denotes false positives, and blue signifies false negatives. The input images \(x_{1}\) and \(x_{2}\) are sourced from the LEVIR-CD dataset30.
In contrast to the aforementioned methods, SNIIF-Net enhances network performance through the innovative design of three modules: the Feature Interaction and Integration Module (FIIM), the Feature Pair Fusion Module (FPFM), and the Multi-Scale Supervision Module (MSSM). This enhancement is primarily attributed to the following factors: (1) the FIIM utilizes attention mechanisms to model contextual information of local features, thus strengthening the interdependence among features and improving the differentiation of change regions; (2) the FPFM effectively leverages spatial and relational information from image pairs to extract more detailed data, enhance edge information, and boost model performance; and (3) the MSSM employs a supervision method based on contrastive learning to effectively constrain intermediate features, enabling the network to generate more refined change maps, which ultimately increases the accuracy of the network.
The visual comparisons presented in Fig. 4 demonstrate that SNIIF-Net outperforms other methods. For example, DASNet lacks effective supervision of intermediate features, which hampers its ability to extract rich semantic information, resulting in coarser change maps and instances of missed detection. In contrast, SNUNet-CD employs a straightforward feature fusion method to generate changing features, inevitably introducing noise that affects the precision of the final change map. In general, SNIIF-Net benefits from contrastive learning-based supervision of intermediate features and incorporates the FIIM and FPFM modules to enhance spatial and semantic relationships. These enhancements improve edge information in the image, making the SNIIF-Net change map more accurate in contour and more closely aligned with the labels, thus more effectively reflecting regional changes compared to those generated by the competing methods.
To further validate the effectiveness of SNIIF-Net, we conducted training and testing on the LEVIR-CD dataset and compared its performance with several algorithms. All experiments used identical settings. Table 2 presents the quantitative comparison results, while Fig. 5 illustrates the visual comparisons of selected algorithms. Similarly to the experimental results obtained from the CDD dataset, SNIIF-Net achieves a better F1 (0.911 vs. 0.910 from M-Swin). The visual results (Fig. 5) show reduced false positives in complex urban areas (e.g., blue pixels in row 2) due to the incorporation of FIIM, FPFM and MSSM.
Ablation study
In this section, we conduct several ablation experiments to evaluate the effectiveness of various components within the SNIIF-Net architecture. The experimental results on the CDD and LEVIR-CD datasets are presented in Table 3, while Figures 6 and 7 illustrate the comparative visualization effects for the two datasets. First, we replace the FIIM module in SNIIF-Net with traditional convolutional operations. Next, we remove the FPFM module using only a simple subtraction operation to process the intermediate features. Finally, we eliminate the MSSM, which is based on contrastive learning, indicating that SNIIF-Net does not employ contrastive learning to supervise the multi-scale output features in the decoder’s intermediate layer.
The experimental results of two datasets indicate the following conclusions: (1) In the absence of the Feature Information Integration Module (FIIM), the SNIIF-Net F1 scores decreased by 0.025 and 0.020, respectively. This finding suggests that replacing the FIIM module with traditional convolution results in a loss of critical detail in the intermediate features extracted. In contrast, employing an attention-based approach to feature extraction enhances the richness of feature information and improves network performance. (2) Replacing the Feature Pyramid Fusion Module (FPFM) with a simple subtraction operation leads to spatial and color shifts during feature extraction and introduces significant noise. In contrast, the application of the FPFM module mitigates the drawbacks of simple subtraction methods and enriches feature information, thus improving accuracy. (3) The absence of the Multi-scale Supervision Module (MSSM) results in the most substantial decrease in network performance, as the MSSM effectively supervises multiple intermediate features and enhances overall network performance. This underscores the MSSM’s critical role in generating fine change maps. Furthermore, comparative analysis of the visualization figures reveals that the contours of the change maps obtained using the aforementioned modules are more refined and closer to the actual labels, yielding better results.

Visual comparison of different ablation settings on CDD dataset. Different colors are employed to enhance clarity: white indicates true positives, black represents true negatives, red denotes false positives, and blue signifies false negatives. The input images \(x_{1}\) and \(x_{2}\) are sourced from the CDD dataset32.

Visual comparison of different ablation settings on LEVIR-CD dataset. Different colors are employed to enhance clarity: white indicates true positives, black represents true negatives, red denotes false positives, and blue signifies false negatives. The input images \(x_{1}\) and \(x_{2}\) are sourced from the LEVIR-CD dataset30.
Finally, we investigate the impact of the Multi-Scale Supervision Module (MSSM) on the performance of SNIIF-Net. The experimental results are presented in Tables 4 and 5, where the values 1/8, 1/4, 1/2, and 1/1 correspond to features on different scales. The data indicate that supervising only a specific scale of features through contrastive learning results in suboptimal network performance. However, utilizing the MSSM to supervise multiple feature layers leads to a gradual improvement in performance. When SNIIF-Net supervises the features across all four scales of the decoder, it achieves the highest F1 score, suggesting that monitoring the features on each scale allows the network to capture more detailed information about the changes, thus enhancing its overall performance.
Conclusion
To address the limitations of previous change detection methods, including inadequate constraints on intermediate features, insufficient modeling of relationships between bi-temporal features, and overly simplistic fusion techniques. We propose SNIIF-Net to improve the precision of change detection tasks. SNIIF-Net significantly improves the semantic richness of features, enhances edge information in images, and boosts model performance through the design of a feature information interaction module and a feature pair fusion module that utilize a spatial attention mechanism. In addition, a contrastive learning-based supervision method effectively constrains intermediate features, allowing the network to generate more detailed change maps. The effectiveness of SNIIF-Net has been validated through experiments conducted on multiple datasets.
Although our approach achieves significant improvements in feature semantics, edge detail preservation, and overall performance, several limitations warrant acknowledgment. The architectural complexity introduced, notably spatial attention mechanisms, may increase computational demands, potentially hindering real-time deployment scenarios. Future research will prioritize: (1) developing lightweight model variants to enhance deployment efficiency; (2) refining multi-scale change detection mechanisms for improved granularity; and (3) strengthening model robustness against environmental perturbations and sensor variations.
Data availibility
The CDD dataset used in this study is publicly available at https://drive.google.com/file/d/1GX656JqqOyBi_Ef0w65kDGVto-nHrNs9. The LEVIR-CD dataset used in this study is publicly available at https://justchenhao.github.io/LEVIR/.
References
Li, L., Li, X., Zhang, Y., Wang, L. & Ying, G. Change detection for high-resolution remote sensing imagery using object-oriented change vector analysis method. In 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2873–2876 (IEEE, 2016).
Celik, T. Unsupervised change detection in satellite images using principal component analysis and \(k\)-means clustering. IEEE geoscience and remote sensing letters 6, 772–776 (2009).
Peiman, R. Pre-classification and post-classification change-detection techniques to monitor land-cover and land-use change using multi-temporal landsat imagery: a case study on pisa province in italy. International journal of remote sensing 32, 4365–4381 (2011).
Shi, P., Dong, X., Ge, R., Liu, Z. & Yang, A. Dp-m3d: Monocular 3d object detection algorithm with depth perception capability. Knowledge-Based Systems 318, 113539 (2025).
Dong, X., Shi, P., Liang, T. & Yang, A. Ctaffnet: Cnn-transformer adaptive feature fusion object detection algorithm for complex traffic scenarios. Transportation Research Record 2679, 1947–1965 (2025).
Dong, X., Shi, P., Qi, H., Yang, A. & Liang, T. Ts-bev: Bev object detection algorithm based on temporal-spatial feature fusion. Displays 84, 102814 (2024).
Daudt, R. C., Le Saux, B. & Boulch, A. Fully convolutional siamese networks for change detection. In 2018 25th IEEE international conference on image processing (ICIP), 4063–4067 (IEEE, 2018).
Peng, D., Zhang, Y. & Guan, H. End-to-end change detection for high resolution satellite images using improved unet++. Remote Sensing 11, 1382 (2019).
Zhang, W. & Lu, X. The spectral-spatial joint learning for change detection in multispectral imagery. Remote Sensing 11, 240 (2019).
Zhao, Y. et al. A triple-stream network with cross-stage feature fusion for high-resolution image change detection. IEEE Transactions on Geoscience and Remote Sensing 61, 1–17 (2023).
Luo, F. et al. Multiscale diff-changed feature fusion network for hyperspectral image change detection. IEEE Transactions on Geoscience and Remote Sensing 61, 1–13 (2023).
Huang, Y., Li, X., Du, Z. & Shen, H. Spatiotemporal enhancement and interlevel fusion network for remote sensing images change detection. IEEE Transactions on Geoscience and Remote Sensing (2024).
Chen, J. et al. Dasnet: Dual attentive fully convolutional siamese networks for change detection in high-resolution satellite images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14, 1194–1206 (2020).
Zhan, Y. et al. Change detection based on deep siamese convolutional network for optical aerial images. IEEE Geoscience and Remote Sensing Letters 14, 1845–1849 (2017).
Guo, E. et al. Learning to measure change: Fully convolutional siamese metric networks for scene change detection. arXiv:1810.09111 (2018).
Fang, S., Li, K., Shao, J. & Li, Z. Snunet-cd: A densely connected siamese network for change detection of vhr images. IEEE Geoscience and Remote Sensing Letters 19, 1–5 (2021).
Gong, M., Niu, X., Zhang, P. & Li, Z. Generative adversarial networks for change detection in multispectral imagery. IEEE Geoscience and Remote Sensing Letters 14, 2310–2314 (2017).
Hou, B., Liu, Q., Wang, H. & Wang, Y. From w-net to cdgan: Bitemporal change detection via deep learning techniques. IEEE Transactions on Geoscience and Remote Sensing 58, 1790–1802 (2019).
Niu, X., Gong, M., Zhan, T. & Yang, Y. A conditional adversarial network for change detection in heterogeneous images. IEEE Geoscience and Remote Sensing Letters 16, 45–49 (2018).
Xu, H., Xu, Y. & Hu, K. A vision-based inspection system for pharmaceutical production line. The Journal of Supercomputing 81, 625 (2025).
Xu, H., Liu, Q., Zhu, J., Dai, H. & Zhang, D. Cslnet: An enhanced yolov8-based approach to defect surface foreign objects in lyophilized powder. Signal, Image and Video Processing 19, 728 (2025).
Xu, H. et al. Esmnet: An enhanced yolov7-based approach to detect surface defects in precision metal workpieces. Measurement 235, 114970 (2024).
Ren, H. et al. Interactive and supervised dual-mode attention network for remote sensing image change detection. IEEE Transactions on Geoscience and Remote Sensing (2025).
Liu, Y., Wang, K., Li, M., Huang, Y. & Yang, G. Exploring the cross-temporal interaction: Feature exchange and enhancement for remote sensing change detection. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2024).
Wang, Y. et al. Msgfnet: Multi-scale gated fusion network for remote sensing image change detection. Remote Sensing 16, 572 (2024).
Noman, M., Fiaz, M., Cholakkal, H., Khan, S. & Khan, F. S. Elgc-net: Efficient local-global context aggregation for remote sensing change detection. IEEE Transactions on Geoscience and Remote Sensing 62, 1–11 (2024).
Huang, B., Xu, Y. & Zhang, F. Remote sensing image change detection based on adjacent-level feature fusion and dense skip connections. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2024).
Ren, H. et al. Interactive and supervised dual-mode attention network for remote sensing image change detection. IEEE Transactions on Geoscience and Remote Sensing (2025).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, 2980–2988 (2017).
Chen, H. & Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sensing 12, 1662 (2020).
Fu, J. et al. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3146–3154 (2019).
Lebedev, M., Vizilter, Y. V., Vygolov, O., Knyaz, V. A. & Rubis, A. Y. Change detection in remote sensing images using conditional adversarial networks. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 42, 565–571 (2018).
Liu, M., Shi, Q., Li, J. & Chai, Z. Learning token-aligned representations with multimodel transformers for different-resolution change detection. IEEE Transactions on Geoscience and Remote Sensing 60, 1–13 (2022).
Chen, H., Qi, Z. & Shi, Z. Remote sensing image change detection with transformers. IEEE Transactions on Geoscience and Remote Sensing 60, 1–14 (2021).
Zhang, C. et al. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS Journal of Photogrammetry and Remote Sensing 166, 183–200 (2020).
Chen, T. et al. A siamese network based u-net for change detection in high resolution remote sensing images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 15, 2357–2369 (2022).
Pan, J. et al. Mapsnet: Multi-level feature constraint and fusion network for change detection. International Journal of Applied Earth Observation and Geoinformation 108, 102676 (2022).
Peng, X., Zhong, R., Li, Z. & Li, Q. Optical remote sensing image change detection based on attention mechanism and image difference. IEEE Transactions on Geoscience and Remote Sensing 59, 7296–7307 (2020).
Lei, T. et al. Ultralightweight spatial-spectral feature cooperation network for change detection in remote sensing images. IEEE Transactions on Geoscience and Remote Sensing 61, 1–14 (2023).
Lei, T. et al. Lightweight structure-aware transformer network for remote sensing image change detection. IEEE Geoscience and Remote Sensing Letters (2023).
Ma, J., Duan, J., Tang, X., Zhang, X. & Jiao, L. Eatder: Edge-assisted adaptive transformer detector for remote sensing change detection. IEEE Transactions on Geoscience and Remote Sensing (2023).
Pan, J. et al. M-swin: Transformer-based multi-scale feature fusion change detection network within cropland for remote sensing images. IEEE Transactions on Geoscience and Remote Sensing (2024).
Ji, Y. et al. Domain adaptive and interactive differential attention network for remote sensing image change detection. IEEE Transactions on Geoscience and Remote Sensing (2024).
Huang, Y., Li, X., Du, Z. & Shen, H. Spatiotemporal enhancement and interlevel fusion network for remote sensing images change detection. IEEE Transactions on Geoscience and Remote Sensing (2024).
Tang, Y., Cao, Z., Guo, N. & Jiang, M. A siamese swin-unet for image change detection. Scientific Reports 14, 4577 (2024).
Miao, R. et al. Dasunet: a deeply supervised change detection network integrating full-scale features. Scientific Reports 14, 12464 (2024).
Chen, H. & Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sensing 12, 1662 (2020).
Zheng, H. et al. Hfa-net: High frequency attention siamese network for building change detection in vhr remote sensing images. Pattern Recognition 129, 108717 (2022).
Miao, L. et al. Snunet3+: A full-scale connected siamese network and a dataset for cultivated land change detection in high-resolution remote-sensing images. IEEE Transactions on Geoscience and Remote Sensing (2023).
Song, S., Zhang, Y. & Yuan, Y. Iterative edge enhancing framework for building change detection. IEEE Geoscience and Remote Sensing Letters 21, 1–5 (2023).
Author information
Authors and Affiliations
Contributions
Conceptualization, Yanni Zhang; methodology, Yanni Zhang; formal analysis, Lei Yang; writing—original draft preparation, Yanni Zhang; writing—review and editing, Caigen Zhou and Jiachen Wen; supervision, Licai Zhu; project administration, Licai Zhu. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Yang, L., Zhou, C. et al. Siamese change detection based on information interaction and fusion network. Sci Rep 15, 29262 (2025). https://doi.org/10.1038/s41598-025-15468-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-15468-w
