
Abstract
Transformer-based approaches have recently made significant advancements in 3D human pose estimation from 2D inputs. Existing methods typically either consider the entire 2D skeleton for global features extraction or break it into independent parts for local features learning. However, capturing the spatial dependencies of the entire 2D skeleton does not effectively facilitate learning local spatial features, while partitioning the skeleton into independent segments disrupts the relevance of individual joints to the whole. In this paper, we propose a novel Origin-centric Part Transformer (OPFormer) block to address this issue through two steps: Skeleton Separation and Skeleton Recombination. Skeleton Separation separates the 2D skeleton into several distinct parts, enabling the extraction of fine-grained local spatial features that accurately reflect the geometric structure of the human body. Secondly, we introduce the concept of a human skeleton Origin, which serves as a central hub to reconnect different parts through Skeleton Recombination. The resulting local features, when fused with global features from the Spatial Transformer Encoder, yield more accurate 3D results. Comprehensive experiments conducted on the Human3.6M and MPI-INF-3DHP benchmark datasets verify that our approach attains state-of-the-art performance. It should be emphasized that OPFormer achieves a Mean Per Joint Position Error (MPJPE) of 37.6mm on the Human3.6M dataset without any additional training data.
Similar content being viewed by others
Introduction
Human pose estimation (HPE) is a critical and challenging task in the field of computer vision (CV), with significant applications in areas such as human-robot interaction1, virtual reality2, and action recognition3. The goal of HPE is to predict the position of each joint from input images or videos. Depending on whether the predicted joint contains depth information, HPE can be categorized into 2D human pose estimation (2D HPE) and 3D human pose estimation (3D HPE). With the advancement of deep learning technology, the field of 2D HPE has matured considerably. The accuracy and generalization of 2D detectors4,5,6,7,8,9 have reached an advanced level. However, the output of these models is limited to 2-dimensional information. In contrast, although 3D HPE faces more challenges, the addition of depth information enables it to provide richer 3D spatial information and a better understanding of human movements and interactions. Consequently, the 2D-to-3D methods of applying the developed 2D detector to the 3D HPE tasks hold significant potential as a monocular solution.
The inherent ambiguity of monocular data allows a single 2D pose to correspond to multiple possible 3D poses, making it challenging to accurately recover 3D poses from single-frame 2D joint position information. Recently, driven by Transformer10 for its ability to capture long-distance dependencies, 2D-to-3D methods11,12,13,14,15,16,17,18 leveraging video frame sequences with temporal motion information have made significant progress. Starting with an input video, the 2D-to-3D methods first detect the 2D keypoints and subsequently infer the 3D joint positions based on the detected 2D keypoints. Among these, PoseFormer11 captures global spatial dependencies from the entire 2D human skeleton and models temporal features from frame sequences to output accurate 3D poses. MixSTE13 further separates the entire human skeleton into multiple joints to model more fine-grained temporal features. However, previous methods overlook the fact that not all human joints are closely related in spatial position, thus capturing the spatial dependencies of the entire 2D skeleton does not effectively facilitate the learning of spatial features.

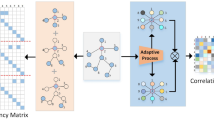
(a) The origin-centric part diagram. The 2D skeleton is separated into multiple parts and an Origin based on the distribution of spatial dependencies, with the corresponding colors from (b) used to draw the joints and connections. (b) The average dependencies within different joint groups in (a). The “Origin” value indicates the average dependency of all joints on the hip joint, while the “Other” value indicates the average dependency between all joints outside the joint groups defined in (a).
To address the above issue, we performed a MixSTE performance analysis in modeling spatial relationships among 17 joints from the Human3.6M19 dataset. We begin by averaging the attention weights of the Spatial Self-Attention modules in MixSTE, resulting in a \(17\times 17\) attention map. Based on the distribution patterns of high-weight regions in the average attention map, the 2D skeleton can be segmented into five joint groups and an Origin, as illustrated in Fig. 1a. Each joint group is represented by a distinct color for clarity, and the corresponding average attention weights between the joints in these groups are visualized with matching colors in Fig. 1b. In addition to the joint groups shown in Fig. 1a, b also illustrates the average attention weights between the hip joint and all other joints (denoted as “Origin”), as well as the average attention weights among all joints outside of the defined joint groups (denoted as “Other”). As shown by the average attention weights associated with the “Other” label in Fig. 1b, joints outside the defined groups show low spatial dependencies, due to their lack of direct anatomical connections and their tendency to move independently. In contrast, joints within the same part exhibit high spatial dependencies, as reflected by the “Right Leg” value, due to their close geometric connections and their synchronized movement. Furthermore, the results indicate that all joints are strongly associated with the hip joint, the root of the human body, and its position subsequently affects the spatial positions of all other joints.
Building on the aforementioned observations, achieving accurate and fine-grained spatial feature modeling is essential for improving the accuracy of 3D human pose estimation. In this paper, we introduce a new Origin-centric and part-based pose decomposition method for more precise spatial feature modeling. Specifically, we propose a novel Origin-centric Part Transformer (OPFormer) block to model fine-grained dependencies through two steps: Skeleton Separation and Skeleton Recombination.
First, the introduction of Skeleton Separation aims to focus the model’s attention on more localized spatial features. This approach is motivated by our observation, as illustrated in Fig. 1a, that spatial dependencies between closely connected joints exhibit higher correlation compared to more distant joints. In light of this, we hypothesize that by isolating these finer-grained local relationships, we can better capture the specific movements and interactions within each body segment. To this end, we divide the 2D skeleton into distinct, independent parts through the process of Skeleton Separation. Each of these parts, such as the legs or arms, is treated as a separate unit, allowing the model to capture local dependencies within each part individually and more effectively. This division not only simplifies the spatial modeling but also improves the granularity of the features learned from closely related joints.
Secondly, we introduce the concept of the hip joint as the Origin of the human skeleton. This Origin plays a critical role as a spatial hub that maintains the overall coherence of the skeleton by reconnecting the separated parts. As shown in Fig. 1b, through the process of Skeleton Recombination, each part is recombined with the Origin, forming what we refer to as Origin-centric Parts (OParts). This process ensures that all parts are not treated as independent isolated regions, but as components whose spatial relationships are maintained relative to the entire body. By establishing this hierarchical relationship, where each OPart remains anchored to the hip joint, we preserve the structural integrity of the skeleton while modeling local spatial dependencies.
Furthermore, although some joint pairs do not belong to the same part, they still exhibit a certain degree of dependency. We adopted the strategy of previous works11,12,13,14,18 to model relationships outside of parts and generate global spatial features that complement local spatial features. Consequently, our proposed OPFormer employs a parallel structural design, with two parallel channels responsible for capturing global and local spatial features, respectively. Finally, after fusing the outputs of the two channels, the temporal block is utilized to obtain the temporal features of each joint over multiple time steps, thereby generating more accurate 3D pose results.
The main contributions of this paper can be summarized in three aspects:
-
We proposed a novel Origin-centric Part Transformer (OPFormer), which models fine-grained local dependencies within each body part through part-level decomposition and utilizes the Origin joint as a central hub to preserve global structural coherence across all parts of the skeleton.
-
We developed an alternative network structure with a dual-channel parallel mechanism to capture spatial features across various ranges. It is complemented by a temporal block to capture temporal features of different joints, and finally it enhanced 3D pose estimation accuracy.
-
We evaluated the proposed model with two benchmark datasets: Human3.6M and MPI INF-3DHP, and the proposed model reached SOAT results without using any extra training data.
Related work
Monocular 3D human pose estimation
Monocular 3D human pose estimation (3D HPE) primarily consists of end-to-end methods and 2D-to-3D methods. Earlier works focused on directly inferring 3D poses from single-view images. Li et al.20 first used convolutional neural networks (CNN21) to regress 3D pose and explored the ability of CNN to encode the relationships of human structure. However, end-to-end methods do not leverage the superior performance of 2D detectors. Chen et al.22 introduced the 2D-to-3D method, dividing 3D HPE into two stages: first estimating a 2D pose and then estimating its depth by matching to a library of 3D poses. However, predicting the 3D pose from the 2D pose cannot avoid inherent depth ambiguity, necessitating additional information for accurate 3D pose estimation. Zhang et al.23 used commercial LiDAR to explore the 3D background and scan neighbors, providing spatial and contextual cues for individual point clouds to improve 3D HPE performance. But hardware-based methods are costly and have stringent environmental requirements, making them challenging to apply in real-world scenarios. Other methods rely on video sequences and use multi-frame image data to predict 3D pose. Earlier video-based methods employed recurrent neural networks (RNN24) to process time series, whereas VideoPose3D25 used a dilated temporal convolution network to process sequences connected by 2D joint coordinates. Compared with RNN-based methods, CNN-based methods can process time series data in parallel. Similar to CNNs, Transformers10 can also process sequence data in parallel and effectively capture long-distance dependencies. Recently, Transformers have become fundamental in natural language processing (NLP), and their application26,27 to visual tasks has achieved advanced performance.
Transformer-based methods
Due to the adoption of self-attention mechanism, Transformer can capture global dependencies across 2D pose sequence. StridedFormer14 reduces the redundancy of 2D pose sequences by replacing the full connection layer in the Vanilla Transformer Encoder (VTE) with Strided Convolution, thereby reducing the data dimension layer by layer. PoseFormerV217 expands the receptive field using frequency domain representation from 2D pose sequences. MotionBERT18 learns human motion representations from large and heterogeneous datasets for downstream tasks like 3D HPE after fine-tuning. MotionAGFormer16 uses Transformer to capture global information and graph convolutional networks (GCNs) to capture local information, ensuring a balanced and comprehensive representation of human motion. In addition, recent methods28,29 leverage Transformer as the backbone of the denoiser within diffusion architectures to achieve more accurate 3D pose estimation. The above methods are rough to use the entire 2D skeleton as the source of spatial features of the model, but we observe that not all human joints are closely related during movement.
Part-aware methods
Some work has also attempted to separate the entire skeleton to investigate new schemes to improve the performance of models. HEMlets Pose30 uses heatmaps of the three joints to represent the relative depth information of the end joints of each part to shorten the gap between 2D observation and 3D interpretation. SRNet31 divides human body into local areas to solve the problem of long-tailed distribution caused by a small number of pose samples. Anatomy3D32 decomposes 3D pose estimation into bone direction and length prediction, leveraging skeletal consistency and a fully convolutional architecture to enhance temporal modeling without recurrent units. PoseAug33 introduced part-aware Kinematic Chain Space to evaluate the rationality of local joint angle for enhanced pose. HSTFormer34 captures temporal features hierarchically, treating joints, parts, and the entire human body as distinct objects to analyze from local to global scales. STCFormer35 divides human body into static parts and dynamic parts, and generates two different Structure-enhanced Positional Embeddings to add to the network structure. While these methods separate the human body into several independent parts, they often neglect the relationships between the parts and the whole. In contrast, our proposed method introduces an Origin-centric Part representation that not only captures fine-grained local dependencies within each part but also preserves global spatial coherence by anchoring all parts to a shared reference joint. This design enables more comprehensive spatial modeling and leads to improved pose estimation accuracy.
Methods

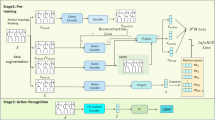
Overview of the network architecture. The proposed network is designed with L stacked loops. Within each loop, the Origin-centric Part Transformer Block and the Spatial Transformer Encoder are arranged in a parallel structure to facilitate feature fusion. Subsequently, these components are integrated with the Temporal Transformer Encoder in a serial structure to enable feature transmission.
The objective of our network is to lift a 2D skeleton sequence generated by a 2D detector into a 3D pose sequence. Figure 2 illustrates the overall network architecture, which consists of five key components. The Origin-centric Part Transformer (OPFormer) Block and the Spatial Transformer Encoder are combined in a dual-channel parallel structure to model spatial dependencies at multiple scales within a single-frame 2D pose. The OPFormer Block, introduced in this work, focuses on capturing intra-part relationships among joints and generating localized spatial features. In line with previous studies11,12,13,14,18, the Spatial Transformer Encoder is employed to model inter-joint relationships across the entire body, producing global spatial features. The outputs of these two channels are adaptively fused to strengthen the network’s ability to capture spatial dependencies at different scales. The fused spatial features are subsequently passed to the Temporal Transformer Encoder, which models temporal dependencies of each joint across sequential frames. The spatial and temporal modeling processes are performed alternately, and the 3D pose sequence is obtained through a Regression Head after L loops. We start with an overview of the computational workflow and then provide a comprehensive explanation of each network component.
Network architecture
As shown in Fig. 2, the input of the model is a 2D skeleton sequence \(X\in {\mathbb {R}}^{T\times J\times C_i}\) with a confidence score, where T is the number of frames, J is the number of joints and \(C_i\) is the number of input channels. The Linear Embedding layer is initially used to project the input to a high-dimensional feature \(F^0\in {\mathbb {R}}^{T\times J\times C_e}\), and then the learnable spatial position embedding \(P_S\in {\mathbb {R}}^{1\times J\times C_e}\) is added. After inputting the prepared features into the parallel channel, we utilize the OPFormer Block to compute the local spatial features \(F_{PS}^l\in {\mathbb {R}}^{T\times J\times C_e}\ \left( l=1,\ldots ,L\right)\), and utilize the Spatial Transformer Encoder to compute the global spatial feature \(F_{GS}^l\in {\mathbb {R}}^{T\times J\times C_e}\ \left( l=1,\ldots ,L\right)\), where L is the depth of the network and \(C_e\) is the number of channels with embedded features. We use adaptive fusion to fuse the output of the two channels to generate a complete spatial feature \(F_S^l\in {\mathbb {R}}^{T\times J\times C_e}\ \left( l=1,\ldots ,L\right)\), this process is defined as:
where \(\odot\) is element-wise production, the adaptive fusion weights \(\alpha _{PS}^l\) and \(\alpha _{GS}^l\) is defined as:
where \(W_A\) is a learnable linear transformation.
Then, the temporal position embedding \(P_T\in {\mathbb {R}}^{T\times 1\times C_e}\) is added to the fused feature \(F_S^l\) and input into the Temporal Transformer Encoder to compute the temporal feature \(F_T^l\in {\mathbb {R}}^{T\times J\times C_e}\ \left( l=1,\ldots ,L\right)\). Finally, a linear Regression Head is applied to \(F_T^L\) to estimate the final 3D pose \(Y\in {\mathbb {R}}^{T\times J\times 3}\), which contains the coordinate values of the three dimensions in the spatial coordinate system.
Origin-centric part transformer block

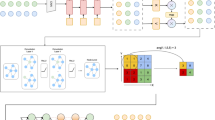
Architecture and computational flow of the origin-centric part transformer block. The input 2D skeleton feature undergoes two key processes: skeleton separation and skeleton recombination, resulting in the generation of OPart features. After each OPart feature is projected into a higher-dimensional space, spatial dependencies are modeled using scaled dot-product attention. Since the origin features span multiple OParts and carry positional dependencies with each part, they are converged into a single feature through a linear transformation module. Finally, the complete skeleton feature is restored via skeleton reconstruction.
The OPFormer Block is designed to compute the local spatial features of a single-frame 2D pose. Unlike previous methods11,13,14 that primarily focus on the global spatial correlations of all human joints, our approach introduces a more localized scope for capturing spatial dependencies.
Skeleton separation and skeleton recombination
As illustrated in Fig. 1a, our method separates the human skeleton into several parts based on spatial dependencies: right leg, left leg, trunk, right arm, and left arm, along with an Origin. Specifically, as shown in Fig. 3, the complete skeleton feature \(F_S\in {\mathbb {R}}^{J\times C_e}\) is segmented into five part features \(F_P^p\in {\mathbb {R}}^{J_p\times C_e}\ \left( p=1,\ldots ,5\right)\) and an Origin feature \(F_O\in {\mathbb {R}}^{1\times C_e}\) via Skeleton Separation, where \(J_p\) denotes the number of joints in the p-th part. Due to stronger spatial dependencies within each part, joints belonging to the same part can provide more fine-grained local spatial representations. However, they lack the implicit positional relationships between different parts. To address this, we recombine each part with the Origin joint to form multiple Origin-centric Parts (OParts). More precisely, for each part, we concatenate the Origin feature \(F_O \in {\mathbb {R}}^{1\times C_e}\) with \(F_P^p \in {\mathbb {R}}^{J_p\times C_e}\) through Skeleton Recombination to generate the OPart feature \(F_{OP}^p\in {\mathbb {R}}^{\left( J_p+1\right) \times C_e}\). The process of skeleton separation and recombination can be denoted as:
Local spatial dependencies modeling
With Origin and joints of the same part included, each OPart is treated as a unit to capture local spatial dependencies, and \(F_{OP}^p\) is then fed into the Scaled Dot-Product Attention (SDPA) mechanism. For computing the query matrix \(Q_{OP}\), the key matrix \(K_{OP}\) and the value matrix \(V_{OP}\), we project \(F_{OP}^p\) by Linear layer:
where \(W_{OP}^Q\), \(W_{OP}^K\), and \(W_{OP}^V\) are projection matrices. The query matrix \(Q_{OP}\), the key matrix \(K_{OP}\) and the value matrix \(V_{OP}\) are then fed into the Scaled Dot-Product Attention (SDPA):
where T is the matrix transpose operation, \(d_K\) is the number of dimensions of the key \(K_{OP}\).
To model relations inside each Origin-centric Part, multi-head self-attention (MSA) mechanism is applied:
where \(W_{OP}^O\) is a learnable linear transformation, H is the number of attention heads. The complete process of local spatial dependencies modeling can be defined as follows:
where MSA represents the multi-head attention, MLP represents the multilayer perceptron and LN is the layer normalization layer.
Skeleton reconstruction
where \(W_O\) is a learnable linear transformation that converges multiple Origin features into a single feature. Through these steps, both local and global spatial dependencies can be accurately captured and used to generate the final 3D pose estimation.
Transformer encoder
Spatial transformer encoder
We utilize Spatial Transformer Encoder (STE) to capture the spatial relationships between the joints outside the parts of a single frame 2D skeleton. The Spatial Multi-Head Self-Attention (SMSA) treats individual joints from the entire body as tokens. Each attention head is computed in a way that follows the scaled dot-product attention. The definition of SMSA and scaled dot-product attention is as follows:
where \(W_S^O\) is a learnable linear transformation, H is the number of attention heads, T is the matrix transpose operation, \(d_K\) is the number of dimensions of the key \(K_S^h\). For computing the query matrix \(Q_S\), the key matrix \(K_S\) and the value matrix \(V_S\), we project spatial feature \(F_S\) by Linear layer:
where \(W_S^{(Q,h)}\), \(W_S^{(K,h)}\), and \(W_S^{(V,h)}\) are projection matrices of the h-th head.
Temporal transformer encoder
We utilize a Temporal Transformer Encoder (TTE) to capture the temporal relationships between different time steps of a single joint. The Temporal Multi-Head Self-Attention (TMSA) treats individual joints from different frames as tokens. Each attention head is computed in a way that follows the scaled dot-product attention. The definition of TMSA and scaled dot-product attention is as follows:
the definition of each parameter in the formula is similar to that in the Spatial Transformer Encoder.
Regression head
A linear Regression Head is employed to estimate the final 3D pose \({\hat{Y}} \in {\mathbb {R}}^{T\times J\times 3}\). We then compute the loss between \({\hat{Y}}\) and GT to train the network from end to end. Since the proposed model processes 2D skeleton sequences at joint-level and frame-level, the final loss function \({\mathscr {L}}\) is composed of two elements:
where \({{\hat{M}}}_t={{\hat{Y}}}_t-{{\hat{Y}}}_{t-1}\), \(M_t=Y_t-Y_{t-1}\), and the constant coefficient \(\lambda _M\) is used to balance position accuracy and motion smoothness.
Experiments
We evaluated our proposed OPFormer model with two benchmark datasets: Human3.6M19 and MPI-INF-3DHP37.
Dataset and evaluation metrics
Human3.6M is a commonly utilized indoor dataset for 3D human pose estimation, comprising 3.6 million video frames. It features 11 professional actors engaged in 15 diverse everyday activities, including actions such as eating, sitting, and walking. Each subject was filmed from four different angles. We followed the protocol of previous works11,25,32,38, training the model on subjects 1, 5, 6, 7, and 8, and testing on subjects 9 and 11.
MPI-INF-3DHP is a comprehensive dataset for 3D human pose estimation, featuring both indoor and outdoor environments. It consists of over 1.3 million frames, capturing 8 categories of activities performed by 8 subjects from 14 camera angles, including a greater variety of poses.
For the Human3.6M dataset, we use MPJPE (Mean Per Joint Position Error) and P-MPJPE (Procrustes-aligned Mean Per Joint Position Error) as metrics to evaluate the performance of OPFormer. MPJPE calculates the average Euclidean distance between the estimated joint and the ground truth. P-MPJPE, on the other hand, computes the MPJPE following rigid alignment between the estimated joint positions and the ground truth, providing greater robustness to single joint prediction errors. We adopt these proven metrics (Percentage of Correct Keypoint with 150 mm, and Area Under the Curve) to evaluate the proposed model in the MPI-INF-3DHP dataset.
Implementation details
Our approach is implemented with PyTorch39 and trained and tested on an NVIDIA RTX 4080 GPU. To ensure a fair comparison, we select specific 2D input lengths for different datasets: Human3.6M (T=27, 81, 243) and MPI-INF-3DHP (T=81). For Human3.6M, we use both the 2D predictions of the Stacked Hourglass7 and the 2D ground truth as inputs to the proposed model, following16,18. Following11,13, the 2D ground truth data is utilized for the MPI-INF-3DHP dataset. During model training, we set the input channel \(C_i\)=3 (including the coordinates of x and y along with confidence scores) following18,40 and use random horizontal flipping as data augmentation following25,32,38. The model is trained for 120 epochs using the Adam41 with an initial learning rate of 0.0002 and a weight decay of 0.99. To address the issue of limited video memory, we use a gradient accumulation strategy. Specifically, we accumulate gradients over batches of size 4 and update the model weights after every 8 such accumulations.
Comparison with state-of-the-art
Table 1 shows the results of our comparison with other methods, including the error and average error for all 15 actions. For the sake of a clear and intuitive presentation of the results, we select only the best results of models without considering variants. To ensure a fair comparison, only the results of models trained without additional pre-training on external data are considered. With the same detector of Stacked Hourglass, our method achieved the best result of average MPJPE of 37.6mm, which outperforms MotionAGFormer16 by 0.8mm (2.4%) MPJPE and MotionBERT18 by 1.6mm (4.8%) MPJPE. It is worth mentioning that our average error is only 0.1mm worse than the pre-trained MotionBERT with extra data. Moreover, OPFormer achieved the best results to date in 9 of the 15 categories. A P-MPJPE of 31.8mm was obtained, which outperforms MotionAGFormer by 0.7mm (2.1%) MPJPE and only 0.1mm worse than HDFormer.
To further evaluate the performance of OPFormer, we used 2D ground truth keypoints as input, allowing for a direct comparison with state-of-the-art methods. The results presented in Table 2 show that by eliminating the error introduced by the 2D pose estimation process, our method achieves an average MPJPE of 15.2mm. This result significantly outperforms all other methods and marks a substantial improvement of 2.6mm (14.6%) over MotionBERT. This considerable enhancement highlights the effectiveness of OPFormer in accurately estimating 3D poses when given precise 2D input data. The removal of 2D estimation errors underscores the inherent robustness and precision of our approach. The experiments conducted with both 2D detected keypoints and 2D ground truth keypoints collectively demonstrate the versatility and reliability of our method across different input types. These findings solidify OPFormer as a highly competitive model in the field of 3D human pose estimation.

The MPJPE distribution on the testset S9 and S11 in Human3.6M. The x-axis and y-axis represents the error interval and poses proportion in a certain interval.

The average joint error for each part across all frames in the Human3.6M testset.
Furthermore, Fig. 4 shows the MPJPE distribution comparisons between OPFormer and two other recent methods, including MotionBERT and MotionAGFormer. With the same input of 2D keypoints from Stacked Hourglass, OPFormer leads to the highest poses proportion with MPJPE less than 30mm, and the lowest poses proportion with MPJPE larger than 40mm. The results demonstrate that our method has fewer errors for difficult actions and higher accuracy for simple actions.
In Fig. 5, we also compare the average joint error for each part with MotionBERT and MotionAGFormer. As shown, the results indicate that the left arm and the right arm exhibit higher detection errors due to more complex movements. The proposed method demonstrates superior accuracy, as evidenced by its performance on each part, particularly in the left and right arms, highlighting its effectiveness in precisely locating joints and handling complex movements.
To verify the generalization of OPFormer on other datasets, we compared it with other methods on MPI-INF-3DHP dataset. As shown in Table 3, with 2D ground truth keypoints as input and a frame number of 81, the proposed model achieves the best results in three evaluation metrics with PCK of 98.7%, AUC of 85.3% and MPJPE of 15.9mm. On MPJPE in particular, the OPFormer is 0.3mm (1.8%) lower than the best previous method MotionAGFormer16. On the other two metrics, our approach also matched the to-data best reported results. These findings demonstrate that OPFormer possesses superior generalization ability and an enhanced capacity for spatial feature modeling when applied to more complex datasets. This robustness across different datasets underscores the effectiveness of OPFormer in 3D human pose estimation.
Ablation study
In order to analyze the impact and performance of each component of the model in depth, we conducted a series of ablation experiments to evaluate their effectiveness. The Stacked Hourglass detector provides 2D keypoints based on the Human3.6M dataset.
As shown in Table 4, since our 3D HPE model is based on video sequences, the Temporal Encoder is a fundamental component. For a fair comparison, we incrementally add modules to the baseline model, which initially includes only the Temporal Encoder, and calculate the MPJPE losses to assess the effect of each component. When only the Spatial Encoder or a simple Part Block is added to the model, the results indicate that more accurate 3D pose estimations cannot be achieved using solely global or local spatial features. However, when we combine these three components, the addition of the Part Block alone only reduces the MPJPE by 0.1 mm, demonstrating that independent local spatial features bring little improvement. The best results (37.6 mm MPJPE) are achieved when we introduce the Origin-centric design to form the OPFormer Block. This addition reduces MPJPE by 2.8mm (6.9%) compared to the baseline model, validating the efficacy of our design.
Table 5 shows how the setting of different hyperparameters impacts the model performance under MPJPE. The proposed model has three main hyperparameters: the depth of the network stack, the dimension of the model, and the number of input frames. To assess the effect of each configuration on the model, we vary each hyper-parameter across three different values while keeping the other two fixed. Referring to the results in Table 5, we select the configuration with Depth=8, Dimension=512, and Frames=243. Table 6 presents the results of an ablation study evaluating the impact of different joint selections as the Origin in our Origin-centric framework. This can be attributed to the hip joint’s anatomical role as the root of the human skeleton, providing a more stable and centrally located reference for modeling spatial dependencies.
Qualitative results
Attention visualization: we visualize the average spatial attention maps for the different layers of the OPFormer Block (top) and the STE (bottom), as illustrated in Fig. 6. From the bottom, the results indicate that the dependencies between all human joints and the hip joint are greatly reduced compared to MixSTE13. As expected, the Spatial Transformer Encoder (SPE) focuses on the spatial relationships of joints outside the part, whereas the dependencies inside the part and the implicit position relationships based on the Origin are transferred to the OPFormer Block. From the top, it is evident that layers 1 to 5 of the OPFormer Block mainly capture the dependencies between different joints within the part, whereas layers 6 to 8 primarily capture the dependencies between the internal joints and the Origin. This clear division of modeling different types of dependencies is due to the OPFormer block and the overall network architecture design. By segmenting the human body structure based on the Origin, our double-channel parallel structure is capable of capturing more fine-grained global and local spatial features. This enhances the model’s ability to comprehensively understand and model the spatial dependencies inherent in human poses.
Qualitative analysis: Figure 7 presents a qualitative comparison between OPFormer and two recent methods: MotionBERT18 and MotionAGFormer16. The examples are selected from the Photo and SittingDown actions in the Human3.6M test set. As highlighted in the blue circled areas, the poses estimated by OPFormer exhibit a closer resemblance to the ground truth compared to the other methods. Importantly, for complex actions such as “SittingDown,” our method achieves significantly more accurate results. This indicates that OPFormer maintains competitive performance even in challenging action categories, demonstrating its robustness and precision in 3D human pose estimation.

Visualization of attention maps in the OPFormer block (top) and the STE (bottom). The x-axis and y-axis correspond to the joint indexes in the part and body. The label indicates which layers the average attention comes from.

Qualitative comparison between OPFormer and the state-of-the-art methods on Human3.6M testset. Red represents the torso and the left, and black indicates the right of the estimated body. The blue circle indicates areas where our method outperforms others.
Conclusion
We propose the OPFormer model for spatial feature modeling that leverages Skeleton Separation and Skeleton Recombination for effective monocular 3D pose estimation. The OPFormer uniquely captures localized joint dependencies within distinct body parts while preserving the structural relevance of each joint to the entire body. Integrated into an innovative network architecture, the OPFormer operates within a parallel and alternating framework, efficiently capturing and fusing spatio-temporal features to enhance performance. Comprehensive experiments on benchmark datasets validate that the proposed model substantially improves the accuracy of 3D HPE, demonstrating robust performance across varying motion patterns. However, our proposed method incurs a relatively higher computational cost compared to some existing approaches. In future work, we plan to explore efficiency-aware variants of our model to reduce computational cost while preserving high accuracy, potentially by sharing Origin embeddings across parts or integrating more efficient attention mechanisms.
Data availability
The data used in this study is sourced from publicly available datasets. Human3.6M dataset URL: http://vision.imar.ro/human3.6m/description.php. MPI-INF-3DHP dataset URL: https://vcai.mpi-inf.mpg.de/3dhp-dataset/.
References
Svenstrup, M., Tranberg, S., Andersen, H. J. & Bak, T. Pose estimation and adaptive robot behaviour for human-robot interaction. In 2009 IEEE International Conference on Robotics and Automation. 3571–3576 (IEEE, 2009).
Mehta, D. et al. Vnect: Real-time 3D human pose estimation with a single rgb camera. ACM Trans. Graph. (TOG) 36, 1–14 (2017).
Zhang, J. et al. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 7, 46–55 (2022).
Cao, Z., Simon, T., Wei, S.-E. & Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7291–7299 (2017).
Chen, Y.et al. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7103–7112 (2018).
Fang, H.-S., Xie, S., Tai, Y.-W. & Lu, C. RMPE: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision. 2334–2343 (2017).
Newell, A., Yang, K. & Deng, J. Stacked Hourglass Networks for Human Pose Estimation. (Springer, 2016).
Sun, K., Xiao, B., Liu, D. & Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5693–5703 (2019).
Xiao, B., Wu, H. & Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV). 466–481 (2018).
Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems (2017).
Zheng, C. et al. 3D human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 11656–11665 (2021).
Li, W., Liu, H., Tang, H., Wang, P. & Van Gool, L. Mhformer: Multi-hypothesis transformer for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13147–13156 (2022).
Zhang, J., Tu, Z., Yang, J., Chen, Y. & Yuan, J. Mixste: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13232–13242 (2022).
Li, W. et al. Exploiting temporal contexts with strided transformer for 3d human pose estimation. IEEE Trans. Multimed. 25, 1282–1293 (2022).
Shan, W. et al. P-stmo: Pre-trained spatial temporal many-to-one model for 3D human pose estimation. In European Conference on Computer Vision. 461–478 (Springer, 2022).
Mehraban, S., Adeli, V. & Taati, B. Motionagformer: Enhancing 3D human pose estimation with a transformer-gcnformer network. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 6920–6930 (2024).
Zhao, Q., Zheng, C., Liu, M., Wang, P. & Chen, C. Poseformerv2: Exploring frequency domain for efficient and robust 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8877–8886 (2023).
Zhu, W. et al. Motionbert: A unified perspective on learning human motion representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 15085–15099 (2023).
Ionescu, C., Papava, D., Olaru, V. & Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 36, 1325–1339 (2013).
Li, S. & Chan, A. B. 3D human pose estimation from monocular images with deep convolutional neural network. In Computer Vision—ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, Singapore, November 1–5, 2014, Revised Selected Papers, Part II 12. 332–347 (Springer, 2015).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Chen, C.-H. & Ramanan, D. 3D human pose estimation= 2D pose estimation+ matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7035–7043 (2017).
Zhang, J., Mao, Q., Hu, G., Shen, S. & Wang, C. Neighborhood-enhanced 3D human pose estimation with monocular lidar in long-range outdoor scenes. Proc. AAAI Conf. Artif. Intell. 38, 7169–7177 (2024).
Elman, J. L. Finding structure in time. Cognit. Sci. 14, 179–211 (1990).
Pavllo, D., Feichtenhofer, C., Grangier, D. & Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7753–7762 (2019).
Carion, N. et al. End-to-end object detection with transformers. In European Conference on Computer Vision. 213–229 (Springer, 2020).
Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Holmquist, K. & Wandt, B. Diffpose: Multi-hypothesis human pose estimation using diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 15977–15987 (2023).
Shan, W. et al. Diffusion-based hypotheses generation and joint-level hypotheses aggregation for 3D human pose estimation. In IEEE Transactions on Circuits and Systems for Video Technology (2024).
Zhou, K., Han, X., Jiang, N., Jia, K. & Lu, J. Hemlets pose: Learning part-centric heatmap triplets for accurate 3D human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2344–2353 (2019).
Zeng, A. et al. Srnet: Improving generalization in 3D human pose estimation with a split-and-recombine approach. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. 507–523 (Springer, 2020).
Chen, T. et al. Anatomy-aware 3D human pose estimation with bone-based pose decomposition. IEEE Trans. Circuits Syst. Video Technol. 32, 198–209 (2021).
Gong, K., Zhang, J. & Feng, J. Poseaug: A differentiable pose augmentation framework for 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8575–8584 (2021).
Qian, X. et al. Hstformer: Hierarchical spatial-temporal transformers for 3d human pose estimation. arXiv preprint arXiv:2301.07322 (2023).
Tang, Z., Qiu, Z., Hao, Y., Hong, R. & Yao, T. 3D human pose estimation with spatio-temporal criss-cross attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4790–4799 (2023).
Chen, H. et al. Hdformer: High-order directed transformer for 3D human pose estimation. arXiv preprint arXiv:2302.01825 (2023).
Mehta, D. et al. Monocular 3D human pose estimation in the wild using improved cnn supervision. In 2017 International Conference on 3D Vision (3DV). 506–516 (IEEE, 2017).
Liu, R. et al. Attention mechanism exploits temporal contexts: Real-time 3D human pose reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5064–5073 (2020).
Paszke, A. et al. Automatic differentiation in pytorch. In NIPS 2017 Autodiff Workshop (2017).
Duan, H., Zhao, Y., Chen, K., Lin, D. & Dai, B. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2969–2978 (2022).
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Acknowledgements
This work was supported in part by the Zhejiang Province Program (2025C01068, 2024C03263, LZ25F020006), and in part by the National Program of China (62172365), and in part by the Macau project: Key technology research and display system development for new personalized controllable dressing dynamic display, and in part by the Ningbo Science and Technology Plan Project (2025Z052, 2025Z062, 2022Z167, 2023Z137), and in part by the Zhejiang Province Regular Undergraduate Universities "14th Five-Year Plan" Higher Education Teaching Reform Project (No. jg20220286).
Author information
Authors and Affiliations
Contributions
J.Y.: Methodology, Validation, Visualization, Writing an original draft. J.C. and Z.L.: Investigation, Resources, Supervision, Reviewing and Editing. J.H. and Y.X.: Formal analysis, Reviewing and Editing. Y.L., L.Z. and W.X.: Conceptualization, Reviewing and Editing. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lin, Z., Yao, J., Huang, J. et al. Origin centric and part based pose decomposition for 3D human pose estimation. Sci Rep 15, 31019 (2025). https://doi.org/10.1038/s41598-025-16381-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-16381-y
