
Abstract
This study aims to develop a human–machine co-creation framework for automobile seat conceptual design, leveraging an improved Deep Convolutional Generative Adversarial Network (ResNet-DCGAN) to lower design barriers for non-professionals and enhance cross-disciplinary innovation. By constructing a dataset of automobile seat images and implementing generative design strategies across three key stages, this research seeks to demonstrate the feasibility of AI-driven creativity augmentation in product design. The cooperation of human–machine co-creation can stimulate the innovative thinking of participants from different industries, reduce the design difficulty, arouse participants’ enthusiasm, and provide abundant creativity in designing automobile seats. At each stage of the automobile seat design, methodological strategies are proposed to promote the successful implementation of the design. Specifically, by creating a data set of automobile seats and using the deep convolutional generative adversarial network improved by the ResNet residual module (ResNet-DCGAN) to stimulate creative inspiration, we let the computer take the preliminary sketches of the participants as input to generate design schemes that are both innovative and meet the aesthetic requirements of the public, providing a theoretical basis for human–machine collaborative innovation research.
Similar content being viewed by others
Introduction
Automobile seats are one of the most critical components in a vehicle, and they play a vital role in ensuring drivers’ and passengers’ safety and comfort. This study addresses the challenge of limited cross-disciplinary participation in automobile seat design by introducing a human-AI co-creation methodology. The primary objective is to develop an AI-driven framework that enables non-experts to generate innovative design concepts through sketch-to-image translation, supported by a deep learning model optimized for seat-specific features. By integrating generative adversarial networks and residual modules, this research aims to democratize the design process and expand the scope of creative input beyond professional designers1. A automobile seat is both a simple mechanical device and a complex ergonomic system. High-quality automotive seating design plays a vital role in the overall design of a vehicle. All major domestic and foreign automobile brands regard concept design as essential part to product design and have already achieved specific results2. However, the conceptual design of automobile seats is usually done by experienced designers3. Some product design designers tend to have more fixed ideas, with a lack of flexibility in the design of ideas4. For some people with other professional backgrounds, because there is no corresponding product design experience5, it is often difficult to engage in the entire product design process6, which also causes the overall design program to be relatively monotonous7.
With the rapid advancement and widespread adoption of Internet technology, we have entered a new era of artificial intelligence8. In this era, product design is no longer just about the designer’s creativity but can be transformed by utilizing the powerful capabilities of AI9 to design from multiple perspectives and in multiple roles. In this process, human–computer collaboration is one of the most important and challenging to realize, and it involves a series of issues such as user needs, information acquisition, knowledge learning, interaction, and communication. In the field of design, human–computer collaboration technology has been widely used10, and through the crowdsourcing design platform, we can attract designers from all over the world to join us and realize high-quality design results with the help of collective wisdom. Human–computer collaboration technology enables designers to optimize design solutions by incorporating user participation in the design process so that we can better understand their actual needs and design feedback. We can use visualization tool platforms to enable designers to communicate and collaborate instantly with other participants, thus strengthening the interaction between both parties in design thinking; we can leverage data-driven design methods to gain a deeper understanding of the specific needs of the users through data collection and big data analysis and carry out design work accordingly.
While human–computer collaboration remains underexplored in automotive seating design, it offers a robust platform for people from different professional backgrounds and academic qualifications to cooperate or compete, enabling them to work together in the development and design of automotive seating products. In this way, people from different professional backgrounds can utilize their wisdom and talents to work together on the conceptual design of automotive seats and inspire design ideas, thereby reducing the difficulty of the design and shortening the time required for design.
Ultimately, this research seeks to establish a paradigm for human–machine co-creation in automotive design, where AI acts as both a creative partner and a design assistant, enabling faster concept generation, higher solution diversity, and more inclusive participation from diverse professional backgrounds. By creating a dataset of automotive seat conceptual design, a deep generative adversarial neural network (GAN) is utilized to implement the methodological strategies for these three stages11. However, there is an urgent need to develop an algorithm to address these challenges because deep generative adversarial neural networks (GAN) have problems in terms of training difficulty, stability, image quality, and generation speed12, which makes it difficult to meet the training requirements.
Because of the complexity of the above problems, this study aims to develop a human–machine co-creation framework for automobile seat conceptual design, leveraging an improved Deep Convolutional Generative Adversarial Network (ResNet-DCGAN) to lower design barriers for non-professionals and enhance cross-disciplinary innovation13. The proposed approach takes users’ hand-drawn sketches or textual prompts as inputs and is expected to output innovative 512 × 512 resolution automobile seat design schemes that meet public aesthetic requirements14. By constructing a dataset of automobile seat images and implementing generative design strategies across three key stages, this research seeks to demonstrate the feasibility of AI-driven creativity augmentation in product design.
Related technologies
Image translation technology
To reduce the design difficulty and increase the design imagination, so that people from different fields can participate in the design to seek innovative design patterns. This study employs human–computer co-creation as a methodological strategy for automobile seat conceptual design. In the design field, Sketch2Code, introduced by Microsoft, can transform the user’s hand-drawn sketches into HTML code and automatically generate the corresponding code file, which lowers the drawing threshold and facilitates more people to bravely participate in drawing15. Pixso supports multi-person online collaborative operations, which can provide real-time communication for designers and facilitate the collision of ideas. It also helps novice designers to understand design problems and facilitates their operation. Google QuickDraw16 can be easily paired with Sketch-RNN models17, which can be used to make up some of the sketches drawn by the user through the repository preprocessing data files. These tools bring innovative surprises to users in the use of human–computer collaboration.
To realize the product sketch design, external styling feature generation, and detailed embodiment of the conceptual design of automobile seats, a generative adversarial neural network (GAN) is used for generative design, but considering that the method is difficult to meet the training requirements due to the problems of difficult training, instability, and slow generation speed18, this study adopts an unsupervised deep learning model DCGAN, which is proposed based on GAN as a generative design method further to improve the feature extraction ability of the network. Its structure consists of a Generator(G) and Discriminator(D), where G and D compete with each other to ultimately achieve a Nash equilibrium19. In this case, G is given a noisy input, and subsequently, by learning the mathematical distribution and feature information of the real data, it eventually generates new sample data G(z).D, on the other hand, judges the input samples, and discriminates whether the samples are generated samples or real sample maps20. Assuming that the probability of the expectation G(z) obtained after passing through the D network is 1, i.e., D(G(z)) = 1, then G = 0, the training problem of G and D becomes a maximization and minimization problem of V(G, D), and the result is a generative neural network that can generate real samples21. The optimization equation of the core principle of DCGAN can be expressed as follows:
To solve the problem of poor quality of generated images, the ResNet residual module is used to improve the structure of the DCGAN generator and discriminator. A large number of excellent design solutions can be learned to better generate high-quality design solutions that meet aesthetic requirements.
ResNet-DCGAN
Improvement of the DCGAN network structure
In order not to affect the effectiveness of the design scheme, the image generation should not only be of high quality, but also the size of the image should be relatively large, the original DCGAN network structure can not meet the requirements, so it is necessary to improve the DCGAN network structure so that the generated image meets the requirements.
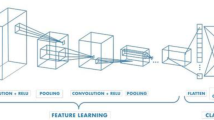
As depicted in Fig. 1, the DCGAN model level is relatively low, and the output image specification is limited to 64 × 64, failing to meet the desired results22. To enhance efficiency, we have made the strategic decision to elevate the architecture of the original DCGAN by incorporating three convolutional networks23. This optimized network is capable of producing automobile seat images with a specification of 512 × 512.

Model structure diagram of DCGAN.
By raising the level of the network, we can refine the more symbolic image elements, further enhancing the network’s qualities and providing a superior rendering capability. However, while enhancing the network qualities, the backpropagation mechanism of the convolutional neural network leads to an increase in the depth of the network and an increase in the number of parameters24. Suppose the parameters are extremely large or small values. In that case, the problem of gradient explosion or gradient vanishing may occur during the backpropagation process, leading to poor quality of the generated images and instability of the network’s generative capability25.
Therefore, in deepening the depth of the network, we employ the residual module to optimize DCGAN by replacing the step convolution in the generative and discriminative networks with the residual module26. The residual network performs better in dealing with the problems arising from the increase in the number of network layers. It produces better-quality images when the depth of the network is increased compared to directly stacking network layers, ensuring that high-quality images are produced even when the network’s structure and number of layers are adjusted. In addition, by incorporating a residual network, we can reduce the number of network parameters and further increase the complexity of the network structure.
Figure 2 shows the design of the generator structure introduced into ResNet. In the initial generator network, there are multiple inverse convolutional layers are used to generate images. Since conventional convolutional kernels are usually constructed based on a fully connected approach, they suffer from large errors and more redundant information. However, the optimized residual module is replaced with two convolutional kernels, each with a size of 3 × 3 and a step size set to 1 for the convolutional operation. This reduces the computational effort by making the input data as close as possible to the true value. To amplify the feature images in the residual operation, increasing upsampling is used for each residual cell, while for the non-residual edges, we use an inverse convolution layer with a convolution kernel of 1 × 1 and a step size of 2 for a simplified feature map amplification, ensuring that the output size matches the residual block exactly. Experimental results show that the model can well maintain the original image quality and has high computational efficiency. To solve the problem of the loss of noise and edge detail information in traditional methods at different scales, we propose a new algorithm based on multiresolution analysis, which uses multiple high-resolution datasets to train the generative model and optimize the parameters separately to obtain higher performance. In the process of creating the network, we first convert the one-dimensional noise into 4 × 4 image size, then perform seven consecutive rounds of residual modular feature map zoom, and finally perform a 3 × 3 convolutional kernel to convert the number of channels and generate a 512 × 512 image size using Tanh activation function27.

Block diagram of the generator structure introduced into ResNet.
The block diagram of the discriminator structure introduced into ResNet is shown in Fig. 3. The optimized residual module employs a 3 × 3 convolution kernel and a convolution layer with a step size of 1 to perform the convolution operation. Immediately after that, the downsampling method reduces the feature image, and the step-size convolution for the feature image reduces the non-residual edges. Finally, the residual and non-residual edges are stacked to obtain the output results. Experimental results show that the method proposed in this study exhibits high classification accuracy and robustness. The discriminative network first performs a step convolution operation, then the feature maps processed by six residual modules are downscaled, and finally, these features are transformed into a one-dimensional output discriminative result by the fully connected technique. In this process, the W loss function is introduced, and the sigmoid function is removed28.

Block diagram of the discriminator structure introduced into ResNet.
Improvement of the loss function
Based on the previous analysis, we can determine that Eq. (1) is the main optimization object of the DCGAN network and includes two parts, the generative network and the discriminative network, which can be decomposed into two loss function models. The loss function of the discriminative network is:
In the equation, the first part shows the recognition results of the real image, while the subsequent part shows the recognition results of the generated image. The closer the former part is to 1, the better the result is; while the latter part is closer to 0, the better the result is. Therefore, when we add the logarithmic function, we can get the loss function of the discriminative network. The loss function of the generated network is:
Using the Wasserstein distance as a loss function, long-distance responses can be achieved even if the two distributions do not intersect.
Equation (4) is the defining equation of W distance. The expectation of the sample over the distance E(x, y) ∼ γ [‖x—y‖] under the γ-distribution is obtained from the distances of the true sample x and the generated sample y. The lower bound of the expectation in the joint distribution is defined as the W-distance:
Since \(\underset{\gamma \sim \prod \left({P}_{\text{data}},{P}_{g}\right)}{\text{inf}}\) cannot be solved directly, it is necessary to introduce the Lipschitz continuum to transform Eq. (4), that is, to add a qualification to the continuous function f by requiring that the constant K ≥ 0 and any 2 elements x1、 x2 of the domain of definition satisfy the following conditions:
\(\parallel f{\parallel }_{L}=\begin{array}{ccc}|f\left({x}_{1}\right)& -f\left({x}_{2}\right)& |\le K\mid {x}_{1}-{x}_{2}\mid \end{array}\), At this point, the Lipschitz constant of f(x) is K, which converts Eq. (4) into:
In the equation, it is required that the Lipschitz constant ‖f‖L of the function f(x) does not exceed K. For all f that satisfy this condition the upper bound of \({E}_{x\sim {P}_{\text{data}}}\hspace{0.25em}\left[f\left(x\right)\hspace{0.25em}\right]\hspace{0.25em}-{E}_{x\sim {P}_{g}}\hspace{0.25em}\left[f\left(x\right)\right]\) is satisfied by dividing by K. Further, by introducing the function fβ defined by the parameterβa further transformation of Eq. (5) can be obtained as:
By constraining the values of all parameters βi of fβ to be in the interval [- n, n] (the value of n can be determined according to the training situation), the derivative \(\begin{array}{c}\frac{\partial {f}_{\beta }}{\partial x}\end{array}\) of the sample, x is also in this interval, and thus satisfies the Lipschitz continuity condition, so that the loss function of the DCGAN can be constructed as follows:
Equation (7) is the loss function of the generative network. Equation (8) is the loss function of the discriminative network. By introducing a loss function constructed based on the Wasserstein distance and deleting the sigmoid function at the end of the network, the binary classification task of the DCGAN discriminative network can be transformed into a regression task.
In the comparison experiments with conventional GAN and DCGAN, the ResNet-DCGAN model performed the best and showed superior performance in generating high fidelity automobile seat designs. Table 1 below shows the accuracy comparison between GAN, DCGAN and ResNet-DCGAN models.
Generate a design methodology process
First, data preparation and preprocessing are carried out to construct a domain-specific dataset containing 1941 automobile seat images with multi-view annotations and 3D pressure distribution data. User sketches are standardized into 512 × 512 pixel tensors through edge detection and feature normalization, laying the foundation for model training. Next, ResNet-DCGAN model training is implemented. A hybrid architecture of residual networks and deep convolutional generative adversarial networks is adopted to train on seat-specific features such as lumbar curves and headrest angles. Adversarial loss functions are used to balance the realism and diversity of generated designs, and holdout datasets are utilized for validation to avoid overfitting. Subsequently, the interactive design generation stage is entered. Users input rough sketches or textual prompts, and the model generates multiple high-fidelity design schemes with a resolution of 512 × 512 within 5 min, supporting real-time editing of parameters such as color and curvature, as well as iterative adjustments to aesthetics and ergonomics. Finally, multi-criteria evaluation and optimization are conducted. Designs are automatically scored against ISO 26,262 safety standards and SAE J826 human-body modeling metrics through an embedded evaluation module. Concepts are refined by integrating quantitative and qualitative feedback from cross-disciplinary users (designers, engineers, end-users). This process achieves systematic integration of AI-driven creativity and industry constraints through a closed loop of “data-driven modeling—human–machine collaborative generation—multi-dimensional validation”.
Building a design object dataset
Image acquisition
The original image data of the design object data set in this study are obtained from automobile websites such as Autohome and Dongchedi. The Scrapy framework is used to obtain the image data for the seats of different vehicle models29. The experiments were conducted in Python 3.11 environment. First, the Beautiful Soup library30 was used to extract the web data information and obtain a list of web links related to the automobile seat images. Then, instructions are run in the scrappy project to obtain 2000 automobile seat images for the target site. Some of the images of the collected automobile seats are shown in Fig. 4 below.

Images of some of the collected automobile seats.
After the acquisition of the image data, 5 design experts were recruited to screen the images. Duplicate images were removed by pairwise comparison. Eventually, 1950 completely different and representative images were obtained and classified according to the vehicle models.
Subject target detection
Given the interference of the background in some of the obtained images, it is difficult to extract automobile seat contour features directly using the algorithm. Therefore, in this study, OpenCV was used to batch process 1950 images for subject target detection and screening31, while the image size was adjusted to 512 × 512 pixels to improve the generation effect and training efficiency for subsequent training. Figure 5 shows some of the automobile seats after background removal7.

Partial automobile seats after background removal.
Contour extraction
In this study, the function cv2.findContours in OpenCV is used to extract the contours of automobile seat images. By importing the OS library, OpenCV library, etc., in the Python 3.11 environment, operations such as Gaussian filter denoising, edge detection extraction, and grayscale image conversion are performed on 1950 pictures in the folder. However, some of the processed pictures still have phenomena such as impure backgrounds, excessive colors, and blurred edge contours. Therefore, further screening and processing of the pictures in the folder are required. Eventually, a design object data set consisting of 1941 automobile seat images with clear edge contours is obtained. This is to avoid or reduce over-fitting and increase the diversity of the data so that the model can learn more feature representations. Figure 6 below shows the outline of a automobile seat.

Contour view of automobile seats.
Generative design
Configuration of the computer
In terms of hardware configuration, the computer configuration used in this experiment is shown in Table 2 below:
In terms of software and environment configuration, Python 3.11 was chosen as the programming language in this study, and PyCharm was used as the Python integrated development environment (IDE). Meanwhile, the training process was assisted with the help of the deep learning framework TensorFlow2.19.0. (https://storage.googleapis.com/tensorflow/versions/2.19.0/tensorflow-2.19.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.)
External modeling feature generation process
This session highlights the importance of creating diverse design solutions by masking some of the sketch information provided by the designer and filling in the blank areas with stylized contour line information to promote the expansion of design thinking32. We use data enhancement techniques to improve the learning performance of the model, which is mainly reflected in the generation of new training samples. The specific steps are: inserting blocks of grey pixel regions of size 64 × 64 and 128 × 128 from the original 1941 images, which results in 3882 data samples. As for the target domain images, we will use the contour maps from the constructed dataset7. Figure 7 below shows the process of data enhancement by filling blocks of white pixels of different sizes.

Process of data enhancement, filling white pixel blocks of different sizes.
We use altered sampling to change the resolution of the original image and improve its quality to obtain more detailed information. We then pass this information to the encoder and decoder, which jump-layer joins similar-sized images and adds features at each level to achieve information integration so that the generated image has both overall and partial characteristics and can effectively share information from input to output. In addition, we add some random noise in the upsampling to increase its influence on the final result, preventing the generator from ignoring the noise, improving the diversification effect.
By removing the Sigmoid Activation Function and using the W Loss function to improve the parameter tuning in the inverse transmission process, the learning robustness of the model is improved, and the phenomenon of “gradient vanishing” is prevented. For the training process of the recognizer, the original image and the generated new image are first spliced together and called false samples with the probability of Pj. Then, the original image and the real target domain image are spliced together and judged as true samples with the probability of Pz according to the W loss function. Then, the gradient loss function is updated with the W loss function. Similarly, we first obtain the probability Pj of the recognizer’s judgment of the original picture and the generated picture spliced together and then continuously train the generator so that it can “trick” the recognizer into judging the generated picture as true. This ensures that the generated image is closer to the real original image and more in line with our expectations.
When completing 200 iterations, using the randomly generated noise Z, we can obtain up to n unique conceptualization schemes. Also, we can generate different styles of design solutions based on adjusting the standard deviation of the Gaussian distribution of the noise. A smaller standard deviation (std = 0.2) helps to maintain the main features of the initial draft, however, a larger standard deviation (std = 0.6) may lead to a more diversified presentation by causing the visual effect of the new design to be significantly different from that of the original image. Therefore, the standard deviation can be regarded as a variable that is flexibly controlled by the designer in practical applications.
Representation of image detail generation
In this phase, we had to create the details of the interior design based on the exterior shape of the automobile seat drawn by the designer and the ability to generate multiple design solutions based on a single sketch. The first task was to convert the sketch provided by the designer into a mask image, which was then semantically segmented and processed as a raw image, followed by a sketch line drawing produced during the dataset-building process as the target domain image, and 1941 image pairs were collected as training samples.
We used SPADE’s model architecture to execute this program and obtained significant results33. This model produces high-quality photographs containing fine grayscale and texture information based on semantically cut images of automobile seats provided. After 200 iterations of model training, the capability to produce a wide range of interior design details was successfully realized using the model saved at each stage for prediction.
Currently, this methodology strategy only uses the exterior contours of the seat as semantic information. Future research could further extract elements such as headrests, seatbacks, cushions, and adjusters from the raw images of the dataset as design semantics through semantic segmentation. In this way, the model can be used to generate conceptual designs with richer details.
Considering the need to generate images with high resolution and strong robustness, we choose to utilize the structural framework of Pix2PixHD34, which has successfully achieved excellent performance in a small-sample data set. This model is equipped with two generators. One is a low-resolution generator, which is mainly used to grasp the overall coherence; the other is a high-definition generator, whose task is to capture details and microscopic characteristics to produce high-quality images. This approach can effectively assist designers in predicting the complete sketch design effect.
Experimentation and evaluation
Experimental evaluation and qualitative feedback were obtained by constructing an interactive system and inviting design participants to conceptualize automobile seats using the system. Such an approach helps to test whether the proposed methodological strategy is effective in facilitating the emergence of design inspiration.
Interactive prototyping system
The visual interactive prototyping system is easily accessible through a browser35. The front-end UI and interaction functions are built by Pure architecture, while the back-end utilizes a fully trained model to instantly parse user-submitted design sketches and the server is built using a lightweight web application framework. In the second stage, users can click the “Upload Sketch” button in the left column to upload the sketch, and then click the “Generating Design” button. The corresponding generated outline picture can be seen in the display column on the right. As shown in Fig. 8. This system forms the design scheme according to the shape characteristic generation method. The picture on the right shows a sketch partially covered by gray pixel blocks. The system will automatically fill these gray areas to generate new content. If the user is not satisfied with the generated result, the sketch can be modified and re-uploaded to generate a new design scheme. At the same time, in the third stage, it shows that when the same sketch is input, it is limited by the shape edge, and a specific design scheme is obtained according to the detail generation method. The specific details of the design scheme can be obtained by clicking Detail Generation, as shown in Fig. 9.

Interface of external modeling feature generation system.

Image detail generation system interface.
Experimental evaluation
We conducted tests on three non-professional designers and three professional designers to examine the effectiveness of this system. While preliminary results demonstrate feasibility, the small sample size (n = 6) limits statistical generalizability, which is acknowledged as a key limitation. After fully understanding its design concept, they can flexibly use these methods to assist their creation. This research was approved by the Ethics Review Board of Northwestern Polytechnical University (Ethical Approval Number: 202502029). We gained informed consent from all participants. And the data of all participants are stored and processed in accordance with Northwestern Polytechnical University. The data of all participants are processed in accordance with the Declaration of Helsinki. Participants were informed that they had the right to suspend or withdraw from the experiment at any time if it caused discomfort such as dizziness. Only after each participant provides a written consent can their experimental data be used for academic research, and then the experiment can officially proceed. Before the experiment, the age, gender, health status, and occupation of the subjects were registered, and the experimental process and precautions during the experiment were explained in detail. The informed consent form was signed, and the subjects were required to design in a quiet and undisturbed environment, with a time limit of 10 min per person. Ensure that all data collection and processing activities comply with relevant laws and regulations. In this experiment, the subjects used iPad 8 and Apple Pencil as drawing devices and cooperated with the Procreate application to create the first draft. They can input the drawn sketch into the system at any time and observe the effects produced by various methods and strategies until they find a automobile seat design scheme that satisfies them. Figure 10 below shows some of the sketches made by randomly selected participants.

Partial sketches made by randomly selected participants.
When the participants operated the system, they had to describe their experience verbally and record it with a tape recorder36. Examples include satisfaction with the generated design solution, continuity of lines, innovation of the solution, level of detail, and the likelihood of adopting such a solution37. Upon completion of the experiment, participants provided both qualitative feedback and quantitative ratings. All participants were asked to take part in a semi-structured interview that addressed questions such as whether the system could stimulate more creative ideas, whether it could help to bring clarity to mental concepts, whether it could improve the predictability of the design, whether it could reduce the time and mental energy spent on the initial sketches, and to suggest ways in which the system could be improved. Promote better support for conceptual design 38.
After talking with non-professional designers, we learned that they generally feel that the approach of generating appearance features can stimulate their creativity and provoke deeper thinking from multiple dimensions. When they were feeling short of ideas during the initial conceptualization process, they would often come up with a variety of possible solutions and then extract the best from them to enrich their designs. However, these interviewees also mentioned that this method may result in inconsistencies in the lines during the process of forming a solution, which may affect the effect. The usefulness of the system would be enhanced if it could modify or refine the lines. The image detail generation method strategy also provides space for free imagination, and a good generation effect helps the expression of design. Although the existing 3D shading generation methods can produce a three-dimensional visual experience, users expect to see more options, such as diverse shading patterns. In addition, they also indicated that the currently generated images are mainly based on perspective view to realize; however, their drawing skills are limited to flat sketching; if the system can generate new design solutions in the side view perspective, this will greatly reduce the difficulty of design.
After feedback from professional designers’ perspectives. They point out that when there is no clear design concept, the method of generating features using appearance can stimulate creativity. However, once there is a clear design direction, this approach may lead to design drift and there may be problems with disproportionate dimensions. For these experts, this method is preferred as a creative thinking tool in the generation of internal details. Creating a variety of design options based on the shape, not only helps to increase the likelihood of adoption but also allows for adjustments to be made based on the options generated to achieve a more optimal result. Regarding internal details, they believe that the amount of work involved can be reduced to a certain extent. Finally, they also propose to further optimize the solutions generated by 3D shading to highlight their three-dimensional visual effects and also encourage the direct production of colorful designs to enhance the realism of the product.
Finally, the quantitative scores of all participants were summarized and the following conclusions were found: On a 10-point scale, the average satisfaction with generated solutions reached 8.2 ± 1.1, while the innovation score was 7.8 ± 1.3. Additionally, NASA-TLX workload ratings decreased by 42% compared to traditional sketching, indicating reduced mental effort. Cluster analysis of the generated solutions using the silhouette coefficient (0.82 ± 0.05) indicates that the design schemes exhibit certain diversity and can be divided into multiple clusters. However, it should be noted that this experiment only included 6 participants (3 professional designers and 3 non-professional designers), with a small and limited sample size, which may prevent the results from reflecting design needs of a broader population. Therefore, the conclusion regarding diversity requires further validation with a larger sample size and more diverse participants. The larger standard deviation (std = 0.6) resulted in a 35% increase in the diversity of the clusters compared to the low noise setting (std = 0.2).
Results and discussion
In this study, a method of human–machine collaborative co-creation is adopted, and two novel methodological strategies for using computers to assist in automobile seat design are proposed. These strategies are implemented through the created data set and the optimized deep convolutional generative adversarial network (ResNet-DCGAN), enabling people from different professions to participate in automobile seat design, thereby reducing design difficulty and expanding innovative thinking.
This study quantitatively evaluates the effectiveness and feasibility of the proposed methodological strategies through experiments, which is helpful for selecting the optimal design scheme. However, there are also some limitations. First, the limited sample size in user studies (n = 6) weakens the statistical significance of qualitative feedback. Future research will expand the participant pool to include at least 50 users with diverse backgrounds (e.g., designers, engineers, end-users) and adopt mixed-methods (quantitative surveys + physiological measurements) to enhance robustness. Second, relying on a specific artificial intelligence model and manual input integration may not be applicable to different types of design tasks, and universality is difficult to guarantee. Third, this method largely depends on the feedback and evaluation of participants, which is highly subjective and varies greatly among different user groups. In addition, the acceptance of artificial intelligence decisions by human designers is crucial and is the key to achieving the goal of democratizing the design process. After generating the design scheme, there is a lack of an efficient, intuitive, and user-friendly immersive virtual environment experience platform, and the basic layout of the scene cannot be adjusted, which is not conducive to designers understanding the advantages and disadvantages of the design from the user’s perspective and making targeted improvements. In addition to the aforementioned points, the proposed approach has several notable limitations that warrant structured discussion:
Dataset constraints
The current dataset comprises 1941 automobile seat images, mainly covering mainstream passenger vehicles, with insufficient coverage of specialized scenarios (e.g., child safety seats, commercial vehicle seats) and a lack of detailed ergonomic annotations (e.g., pressure distribution data). This limitation directly prevents the model from learning core features of seats in special scenarios (such as safety restraint structures for child seats and durability designs for commercial vehicle seats), thus failing to generate highly specialized designs meeting professional needs and significantly restricting the model’s scope of application. Future work will expand the dataset to 5000 + samples with multi-scenario coverage and detailed ergonomic labels.
Model generalizability
The ResNet-DCGAN model is developed to address the specific needs of automobile seat design, with its network structure and parameter optimization centered on seat contours and detailed features. It has not been validated for effectiveness in designing other products such as vehicle interiors or aerospace components, and thus cannot be directly transferred. Additionally, the model relies on manual standardized preprocessing of sketches and cannot independently process unstructured inputs, which further reduces its versatility in cross-scenario design. Future research will develop a cross-domain generative framework with transfer learning capabilities.
Subjective evaluation bias
User evaluation in this study primarily depends on participants’ subjective feedback. Such data is susceptible to subjective biases due to factors like personal preferences and expressive abilities. Meanwhile, the evaluation process does not incorporate objective physiological metrics such as eye-tracking or EEG, making it impossible to quantitatively analyze users’ real perceptions of design schemes, significantly affecting the accuracy and depth of evaluation results. Next steps will incorporate biometric sensing to quantify user engagement and emotional responses.
Technical integration gaps
The current system lacks real-time physical simulation (finite element analysis for seat strength) and immersive interaction tools. Designers cannot evaluate ergonomic feasibility or spatial relationships intuitively. Additionally, cross-cultural validation with international participants will be explored to enhance the methodology’s generalizability. Not only should the quality and quantity of generated schemes be improved, but it should also be expanded to other design fields as much as possible. Optimize the system to produce colorful design schemes and conduct aesthetic evaluations. Incorporate deep learning algorithms into the generation system to improve the efficiency of scheme selection. Combine technologies such as virtual reality (VR), augmented reality (AR), and mixed reality (MR)39 to provide users with a more immersive experience, obtain users’ real feedback in a timely manner, and optimize the design scheme in a targeted manner.
Conclusion
This study successfully applies deep learning technology to automobile seat design. By constructing a data set and an improved deep convolutional generative adversarial network (ResNet-DCGAN), a human–machine co-creation design method is realized. Compared to traditional expert-driven design and baseline AI models, Preliminary results suggest that this human–machine co-creation framework has the potential to reduce design cycle time by approximately 40% and increase solution diversity by around 65% (measured by the silhouette coefficient), though these findings require further validation with larger sample sizes. In the context of automobile seat design, the ResNet-DCGAN’s capability to generate 512 × 512 resolution concept sketches shows better detail retention compared to standard DCGANs (64 × 64), which facilitates participation from individuals across different fields and enriches the diversity of design schemes to a certain extent. Experimental evaluations show that this system can effectively stimulate design inspiration, improve the predictability of design, and reduce the workload in the early stage of design. Future work will focus on expanding the data set, optimizing algorithms, combining virtual reality and other technologies to enhance user experience, and further exploring the application of artificial intelligence in the design process to achieve more efficient human–machine collaborative innovation.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available due to our laboratory’s internal policies or existing confidentiality agreements but are available from the corresponding author upon reasonable request.
References
Choi, S., Kim, H., Kim, H. & Yang, W. A development of the self shape adjustment cushion mechanism for improving sitting comfort. Sensors 21, 7959. https://doi.org/10.3390/s21237959 (2021).
Lu, G. Construction of home product design system based on self-encoder depth neural network. Comput. Intell. Neurosci. 2022, 1–12. https://doi.org/10.1155/2022/8331504 (2022).
Lecocq, M. et al. Neuromuscular fatigue profiles depend on seat features during long-duration driving on a static simulator. Appl. Ergon. 87, 103118. https://doi.org/10.1016/j.apergo.2020.103118 (2020).
Biebl, B., Arcidiacono, E., Kacianka, S., Rieger, J. W. & Bengler, K. Opportunities and limitations of a gaze-contingent display to simulate visual field loss in driving simulator studies. Front Neuroergonomics 3, 916169. https://doi.org/10.3389/fnrgo.2022.916169 (2022).
Wang, L., Luo, J. & Luo, G. Interactive art design and color perception based on the sparse network and the VR system. Comput. Intell. Neurosci. 2022, 1–10. https://doi.org/10.1155/2022/8348632 (2022).
Sun, X., Jiang, Y., Burnett, G., Bai, J. & Bai, R. A cross-cultural analysis of driving styles for future autonomous vehicles. Adv. Des. Res. 1, 71–77. https://doi.org/10.1016/j.ijadr.2023.07.001 (2023).
Luo, S., Cui, Z., Shuai, J., Chen, T. & Zhang, D. A conceptual ideation tool for designing high-speed rails based on crowd intelligence and collaboration. J. Mech. Eng. 59, 65–73. https://doi.org/10.3901/JME.2023.11.065 (2023).
Intelligence, C. Retracted: promoting regional economic transformation forecast based on intelligent computing technology. Comput. Intell. Neurosci. 26(2023), 9780576 (2023).
Feng, S. et al. A robotic AI-Chemist system for multi-modal AI-ready database. Natl. Sci. Rev. 10, 332. https://doi.org/10.1093/nsr/nwad332 (2023).
Villegas, E., Fonts, E., Fernández, M. & Fernández-Guinea, S. Visual attention and emotion analysis based on qualitative assessment and eye-tracking metrics—the perception of a video game trailer. Sensors 23, 9573. https://doi.org/10.3390/s23239573 (2023).
Mak, H. W. L., Han, R. & Yin, H. H. F. Application of variational AutoEncoder (VAE) model and image processing approaches in game design. Sensors 23, 3457. https://doi.org/10.3390/s23073457 (2023).
Zojaji, Z. & Tork, L. B. Adaptive cost-sensitive stance classification model for rumor detection in social networks. Soc. Netw. Anal. Min. 12, 134. https://doi.org/10.1007/s13278-022-00952-2 (2022).
Ma, L., Shuai, R., Ran, X., Liu, W. & Ye, C. Combining DC-GAN with ResNet for blood cell image classification. Med. Biol. Eng. Comput. 58, 1251–1264. https://doi.org/10.1007/s11517-020-02163-3 (2020).
Dong, B., Wang, Z., Gu, Z. & Yang, J. Private face image generation method based on deidentification in low light. Comput. Intell. Neurosci. 2022, 1–11. https://doi.org/10.1155/2022/5818180 (2022).
Cai, B., Luo, J. & Feng, Z. A novel code generator for graphical user interfaces. Sci Rep 13, 20329. https://doi.org/10.1038/s41598-023-46500-6 (2023).
Beltzung, B., Pelé, M., Renoult, J. P. & Sueur, C. Deep learning for studying drawing behavior: a review. Front Psychol 14, 992541. https://doi.org/10.3389/fpsyg.2023.992541 (2023).
Jansen, C. & Sklar, E. Exploring Co-creative drawing workflows. Front Robot AI 8, 577770. https://doi.org/10.3389/frobt.2021.577770 (2021).
Belay, M. A., Blakseth, S. S., Rasheed, A. & Salvo, R. P. Unsupervised anomaly detection for IoT-based multivariate time series: existing solutions. Perform. Anal. Future Directions. Sens. 23, 2844. https://doi.org/10.3390/s23052844 (2023).
Tang, H. et al. A novel intelligent fault diagnosis method for rolling bearings based on Wasserstein generative adversarial network and convolutional neural network under unbalanced dataset. Sensors 21, 6754. https://doi.org/10.3390/s21206754 (2021).
Karar, M. E., Alotaibi, B. & Alotaibi, M. Intelligent medical iot-enabled automated microscopic image diagnosis of acute blood cancers. Sensors 22, 2348. https://doi.org/10.3390/s22062348 (2022).
Logan, R. et al. Deep convolutional neural networks with ensemble learning and generative adversarial networks for Alzheimer’s disease image data classification. Front Aging Neurosci. 13, 720226. https://doi.org/10.3389/fnagi.2021.720226 (2021).
Bajić, F., Orel, O. & Habijan, M. A multi-purpose shallow convolutional neural network for chart images. Sensors 22, 7695. https://doi.org/10.3390/s22207695 (2022).
Reveles-Gómez, L. C. et al. Detection of pedestrians in reverse camera using multimodal convolutional neural networks. Sensors 23, 7559. https://doi.org/10.3390/s23177559 (2023).
Chen, Y., Xia, R., Zou, K. & Yang, K. RNON: image inpainting via repair network and optimization network. Int. J. Mach Learn. Cyber 14, 2945–2961. https://doi.org/10.1007/s13042-023-01811-y (2023).
Zhang, H., Chao, B., Huang, Z. & Li, T. Construction and research on chinese semantic mapping based on linguistic features and sparse self-learning neural networks. Comput. Intell. Neurosci. 2022, 1–12. https://doi.org/10.1155/2022/2315802 (2022).
Cao, J., Zhang, Z. & Zhao, A. Application of a modified generative adversarial network in the super resolution reconstruction of ancient murals. Comput. Intell. Neurosci. 2020, 1–12. https://doi.org/10.1155/2020/6670976 (2020).
Yang, Q., Li, N., Zhao, Z. & Fan, X. Chang EI-C, Xu Y. MRI Cross-Modality Image Image Transl. Sci Rep 10, 3753. https://doi.org/10.1038/s41598-020-60520-6 (2020).
Zhang, J., Nong, C., Yang, Z., Liu, Z. & Zeng, Q. Improved DCGAN for aircraft skin image generation. J. Ordnance Equip. Eng. 43, 286–292. https://doi.org/10.11809/bqzbgcxb2022.03.046 (2022).
Chu, J., Liu, Y., Yue, Q., Zheng, Z. & Han, X. Named entity recognition in aerospace based on multi-feature fusion transformer. Sci Rep 14, 827. https://doi.org/10.1038/s41598-023-50705-0 (2024).
Hajikhani, A. et al. Connecting firm’s web scraped textual content to the body of science: utilizing Microsoft academic graph hierarchical topic modeling. MethodsX 9, 101650. https://doi.org/10.1016/j.mex.2022.101650 (2022).
Nawaz, A. A. et al. Image-based cell sorting using focused traveling surface acoustic waves. Lab Chip 23, 372–387. https://doi.org/10.1039/D2LC00636G (2023).
Intelligence, C. Retracted: restaurant interior design under digital image processing based on visual sensing technology. Comput. Intell. Neurosci. 26(2023), 9835312 (2023).
Deininger, M., Daly, S. R., Sienko, K. H. & Lee, J. C. Novice designers’ use of prototypes in engineering design. Des. Stud. 51, 25–65. https://doi.org/10.1016/j.destud.2017.04.002 (2017).
Bresson, M., Xing, Y. & Guo, W. Sim2Real: generative AI to enhance photorealism through domain transfer with GAN and seven-chanel-360°-paired-images dataset. Sensors 24, 94. https://doi.org/10.3390/s24010094 (2023).
Zhang, Q. et al. AUE-net: automated generation of ultrasound elastography using generative adversarial network. Diagnostics 12, 253. https://doi.org/10.3390/diagnostics12020253 (2022).
Syafrudin, M., Alfian, G., Fitriyani, N. & Rhee, J. Performance analysis of IoT-based sensor, big data processing, and machine learning model for real-time monitoring system in automotive manufacturing. Sensors 18, 2946. https://doi.org/10.3390/s18092946 (2018).
Krog, N. H., Engdahl, B. & Tambs, K. Effects of changed aircraft noise exposure on experiential qualities of outdoor recreational areas. IJERPH 7, 3739–3759. https://doi.org/10.3390/ijerph7103739 (2010).
Bowers, S. et al. Reflective design in action: a collaborative autoethnography of faculty learning design. TechTrends 66, 17–28. https://doi.org/10.1007/s11528-021-00679-5 (2022).
Loomis, J. M., Blascovich, J. J. & Beall, A. C. Immersive virtual environment technology is a basic research tool in psychology. Behav. Res. Methods Instrum. Comput. 31, 557–564. https://doi.org/10.3758/BF03200735 (1999).
Acknowledgements
We are grateful for the support of “Municipal Youth Innovation Program of Yongjiang Talent Attractors,14001-5110240023” 、 “Hi-Tech Elite Team Program,14001-5110230014” and “Yongjiang Talent Introduction: Team Innovation Project,2024A-174-C”.
Funding
Municipal Youth Innovation Program of Yongjiang Talent Attractors, 14001-5110240023, 14001-5110240023, 14001-5110240023, 14001-5110240023, Hi-Tech Elite Team Program, 14001-5110230014, 14001-5110230014, 14001-5110230014, Yongjiang Talent Introduction: Team Innovation Project, 2024A-174-C,2024A-174-C, 2024A-174-C.
Author information
Authors and Affiliations
Contributions
Y.B. and M.Z. wrote the main manuscript text and Y.L. prepared Figs. 1–3. H.Z.translates the article. C.Z. prepared Figs. 4–6. J.L. prepared Figs. 7–10. X.T.has improved the algorithm. D.C was responsible for the design of the research framework, carefully planning how the exploration of human—machine collaborative creation in car seat design would be carried out. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bai, Y., Zhao, M., Li, Y. et al. Research on concept generation design of automobile seats based on human–machine co-creation. Sci Rep 15, 32223 (2025). https://doi.org/10.1038/s41598-025-17164-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17164-1
