
Abstract
This study proposes an efficient fine art image classification method integrating lightweight deep learning to address the limitations of low efficiency and poor generalization in art image classification tasks. The approach designs a lightweight hybrid network, MobileNet-Transformer Hybrid (MTH), that combines depthwise separable convolution with multi-head self-attention mechanisms to achieve efficient fusion of local details and global semantics. A dynamic channel-spatial attention module (DCSAM) adaptively enhances style-sensitive feature responses, while a cross-style feature transfer (CSFT) framework employs contrastive learning to align different style distributions and improve model robustness. Experiments conducted on the ArtBench-10 and WikiArt datasets validate the model’s performance in both classification accuracy and computational efficiency. The results demonstrate: (1) The proposed method enhances local style-discriminative features such as brushstrokes and colors through the DCSAM module, effectively alleviating the misjudgment problem of similar artistic styles. Among them, the CSFT framework constrains the cross-style feature distance through contrastive loss, improving the generalization of rare styles in long-tailed data. (2) The parameter count of the proposed model (1.2 M) is 14.8% of that of EfficientNetV2-S (8.1 million (M)) and 4.2% of that of Swin Tiny (28.3 M). Under this lightweight condition, the proposed model still maintains an ArtBench-10 classification accuracy of 85.2%. Overall, this study provides an efficient solution for art design automation and cultural heritage digitization, offering theoretical innovation and practical application value.
Similar content being viewed by others


Introduction
With the rapid development of digital technologies, art image classification demonstrates substantial application potential in cultural heritage preservation, digital art collection management, and personalized art recommendation systems1. However, traditional image classification methods often face challenges such as poor generalization and low efficiency when processing complex and diverse art images2. Style differences in art images are often reflected in subtle features. For example, the dynamic curves of Baroque style and the static geometry of Neoclassicism are difficult to distinguish by local brushstrokes alone. Meanwhile, scenarios such as mobile art guided tours require real-time responses. The unique stylistic characteristics and rich visual details of art images impose higher requirements on the accuracy and robustness of classification algorithms3. Furthermore, with the widespread adoption of mobile devices and edge computing, achieving efficient real-time classification while maintaining accuracy has become a crucial research direction4,5.
Over the years, researchers have attempted to introduce lightweight networks (such as MobileNet and EfficientNet) into art image classification to reduce model complexity. However, these models are insufficient in capturing the long-range style dependencies unique to art images. At the same time, the global attention mechanism can improve the understanding of the overall artistic semantics. However, its high computational cost hinders deployment on resource-constrained devices. Additionally, existing methods rarely focus on the problems of style diversity and long-tailed distribution that are common in artistic data, which limits the model’s generalization ability in actual complex scenarios. To address these limitations, this study proposes an innovative fine art image classification method by integrating lightweight deep learning techniques. The method achieves innovation through the following key technologies. It directly integrates a lightweight Transformer branch on the shallow feature map of MobileNet (instead of the deep layer or the entire image); it realizes efficient collaborative modeling of local details and global composition while maintaining low computational overhead; it designs a dynamic channel-spatial attention module (DCSAM), which incorporates a channel-spatial joint weight allocation mechanism to adaptively enhance art-sensitive features such as brushstroke textures and color distributions, improving style distinguishability; it adds an art-specific contrastive framework—cross-style feature transfer (CSFT), which alleviates the problem of cross-style feature alignment in artistic data by constructing a contrastive learning strategy for style long-tailed distribution. This study holds important implications for enhancing personalized recommendation systems, promoting cultural heritage digitization, and advancing digital art applications. The study aims to provide an efficient, accurate, and easily deployable solution for art image classification, further expanding the application scope of deep learning in the arts.
The content framework of this study is organized as follows. Section "Literature review" reviews relevant research on art image classification and lightweight deep learning; section "Research model" presents the complete model integrating a lightweight hybrid network, dynamic attention module, and cross-style transfer framework; section "Experimental design and performance evaluation" designs comparative experiments to validate model performance; section "Conclusion" summarizes contributions and outlines future research directions.
Literature review
Current deep learning-based approaches for image classification tasks primarily fall into two categories: Strongly Supervised Learning (SSL) and Weakly Supervised Learning (WSL)6,7. SSL models require precisely labeled data for training, where each target image must have detailed, explicit annotations indicating its category8. WSL models only need broader labeling information without requiring precise annotations for every detail. This characteristic gives WSL greater flexibility and applicability in practical scenarios, particularly when dataset annotation costs are high or accurate labels are difficult to obtain9. Thus, understanding and researching these two approaches can provide more comprehensive solutions and broader application scenarios for image classification tasks.
The SSL method
SSL-based image classification methods heavily rely on costly annotations to establish information exchange between objects10. Guo and Liu (2024) proposed a Part-based Region-Convolutional Neural Network (R-CNN) algorithm. This algorithm overcame these limitations by utilizing deep convolutional features computed from bottom-up region proposals, extending R-CNN to detect objects and localize their key parts while capturing geometric and structural characteristics of the data11. Guo et al. (2024) developed the Pose Normalized CNN model that first calculated object pose estimates and used them to compute local image features and classification. Experimental verification demonstrated that this method achieved high classification accuracy, with further accuracy improvements when labeled bounding boxes were provided during testing12. Rani et al. (2023) introduced a novel end-to-end Mask-CNN model that eliminated the need for fully connected layers in fine-grained image classification. The model consisted solely of a fully convolutional network that could locate specific discriminative parts and generate object-part masks to select useful and meaningful convolutional descriptors13.
The WSL method
At present, great progress has been made in WSL research. With critical features learned from deep learning, WSL plays an increasingly indispensable role in image classification tasks14,15. Qu et al. (2023) avoided expensive annotations like end-to-end bounding boxes or part information by applying visual attention to image classification tasks through deep neural networks (DNNs)16. Li et al. (2023) proposed a part-based R-CNN, building upon the R-CNN framework that utilized DNNs for part detection17. Zheng et al. (2024) developed Constellations, which employed CNN to compute neural activation patterns and identify relationships between information18. Nadamoto et al. (2023) selected multiple useful parts from multi-scale part proposals and used them to compute global image representations for classification19. Aboudi et al. (2023) presented a bilinear model as a novel recognition architecture containing two feature extractors. Its output was calculated using the outer product at each image position, and then aggregated to obtain the image descriptor20. Wang et al. (2024) proposed an object-partial attention model for weakly supervised image classification. Its main novelty lied in integrating the object-partial attention model into two levels of attention mechanisms21. In addition, as an effective self-supervised or weakly supervised representation learning paradigm, contrastive learning has shown strong potential in multiple visual tasks in recent years. For example, Lou et al. (2025) explored a multi-view pixel contrast method to improve the generalization and robustness of image forgery localization22; Zheng et al. (2024) studied heterogeneous contrastive learning, aiming to enhance the ability of base models to process diverse data23. All these works utilize the contrastive relationships between samples or views to learn more discriminative feature representations. In contrast, the proposed CSFT framework also adopts the idea of contrastive learning, but its application scenario and goal are unique. CSFT focuses on solving key challenges in art image classification. Specifically, effectively aligning the feature distributions of different artistic styles improve the model’s robustness to style diversity and long-tailed data distribution. This is a key point that distinguishes art image classification from tasks such as general natural image classification or forgery detection.
Art images and lightweight models
The core difference between art image classification and general image tasks lies in its high dependence on style semantics rather than object semantics. For example, in Van Gogh’s The Starry Night, twisted brushstrokes and vivid colors are more valuable for classification than object semantics such as “starry sky” or “village”. Such tasks require simultaneous modeling of local brushstroke details and global composition rhythm, but general classification models lack targeted designs for this requirement. Most existing studies on artistic images focus on style recognition. For instance, CNN can capture brushstroke textures, but fail to address issues such as model efficiency. Lightweight methods have broad application prospects in the art field. For instance, mobile art education platforms require real-time style recognition, which traditional models struggle to deploy. Deep separable convolution, a current mainstream solution, can compress the number of parameters, but it tends to lose key style features in long-tailed artistic data. Knowledge distillation can reduce model size, yet it weakens the ability to distinguish abstract styles. This contradiction between efficiency and accuracy is the key issue that this study focuses on.
At present, many scholars have also proposed lightweight models for the recognition and analysis of fine art images. For instance, Shen et al. (2024) proposed an instrument indication acquisition algorithm based on a lightweight deep convolutional network and fine-grained features with hybrid attention. By embedding a dual-path hybrid attention module (with channel attention and spatial attention in parallel), the algorithm achieved high image localization accuracy. The inspiration of this study for art image classification lay in its designed cross-scale feature interaction mechanism, which could effectively enhance sensitivity to subtle style differences; meanwhile, its parameter compression strategy provided technical reference for the lightweight design of this study’s MobileNet-Transformer Hybrid (MTH) network24. Shen et al. (2025) developed a lightweight semantic feature algorithm for the detection of ancient mural elements. This algorithm innovatively decomposed mural patterns into combinations of geometric primitives and realized element classification and style decoupling by constructing a hierarchical semantic tree. This method had high robustness in the recognition of incomplete mural elements, which could be transferred to the long-tailed data augmentation of art images. Moreover, it was highly consistent with the cross-style feature alignment goal of this study’s CSFT framework, and had reference value especially in processing artworks with mixed styles25. Shen et al. (2021) proposed a lightweight network for vein recognition. Through shallow feature reuse and dynamic convolution kernel adjustment, this network achieved high accuracy in biometric recognition tasks. Their study verified the feasibility of effectively extracting local detail features with an extremely small number of parameters and confirmed the adaptability of lightweight technology to artistic feature analysis26.
Based on the above literature review and analysis, it can be concluded that current lightweight artistic classification models perform well in general tasks. However, they face the challenge of balancing style sensitivity and computational efficiency. For example, MobileViT-S achieves a low parameter count through a hybrid architecture of CNN and Transformer. Nevertheless, its attention mechanism insufficiently captures style-sensitive features such as local brushstroke textures, leading to a high confusion rate for similar styles; ConvNeXt-T improves feature extraction capability through convolution optimization, but it struggles to handle the long-range brushstroke dependencies of abstract art due to the lack of global composition modeling. These limitations demonstrate the necessity of simultaneously achieving local detail enhancement and global style modeling with a small number of parameters. Based on this, this study proposes the MTH architecture, which integrates lightweight attention for shallow features. Therefore, this study proposes a fine art image classification method incorporating lightweight deep learning to handle these limitations of current approaches.
Research model
A fine Art image classification model based on lightweight deep learning
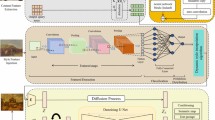
This section provides a detailed description of the proposed fine art image classification model and the design process of its core module architecture. The model consists of three components: the lightweight MTH network, the dynamic channel-spatial attention module (DCSAMD), and the CSFT framework. The following analysis examines the proposed model from four aspects: model design, technical implementation, mathematical modeling, and module interactivity. Figure 1 shows the end-to-end architecture of the model. After the input image undergoes multi-scale feature extraction by the MTH, the DCSAM module enhances the response of style-sensitive regions. Finally, the CSFT framework aligns the cross-style feature distribution and outputs the classification result. The overall design is based on the need to fuse local details and global semantics unique to art images.

Overall architecture of the model.
The lightweight hybrid network
Art image style features exhibit multi-scale characteristics, where both local details and global semantics markedly influence classification results27,28. Traditional CNN, while effective in extracting local features, demonstrates limited capability in modeling long-range dependencies29. Additionally, Vision Transformers (ViT) can capture global context but suffer from high computational complexity, making them unsuitable. for mobile deployment2. Hence, this study proposes a lightweight hybrid architecture that combines MobileNetV3’s Depthwise Separable Convolution (DSC) with Transformer’s global attention mechanism to achieve efficient multi-scale feature extraction and fusion. The specific network structure is presented in Fig. 2.

Lightweight hybrid network structure.
Figure 2 indicates that the constructed lightweight network structure mainly consists of three parts. They are MobileNet backbone, the Transformer branch, and the feature fusion module, respectively.
i. The MobileNet backbone adopts DSC to construct a lightweight feature extractor:
X refers to the input feature map; \(\:{W}_{\text{p}\text{o}\text{i}\text{n}\text{t}\text{w}\text{i}\text{s}\text{e}}\) denotes the pointwise convolution kernel30,31.
ii. The Transformer branch is to apply Multi-Head Self-Attention (MHS) on the shallow feature map \(\:{F}_{1}\in\:{\text{R}}^{H\times\:W\times\:C}\). The input feature F1 is divided into N headers, and the query Q, key K, and value V of each header are calculated as:
The attention output reads:
Finally, the global feature F2 is obtained by concatenation and linear transformation:
dk stands for the key dimension; WO represents the output projection matrix32.
The DCSAM
Art image style differences primarily manifest in feature distribution variations across channel and spatial dimensions33,34. Based on this observation, the DCSAM dynamically allocates weights to adaptively enhance feature responses in critical channels and spatial regions35. The specific structure of this module is revealed in Fig. 3.

The structure of DCSAM.
Figure 3 indicates that the calculation of the proposed DCSAM structure is divided into the following steps:
i. Modeling of the global context.
The input features \(\:{F}_{\text{i}\text{n}}\in\:{R}^{H\times\:W\times\:C}\) are compressed along the spatial dimension to generate a channel description vector:
ii. Calculation of channel attention weights.
The input feature Fin is globally averaged and pooled with the fully connected layer:
σ denotes the Sigmoid function; δ means ReLU; GAP stands for global average pooling.
iii. Extraction of local detail.
Maximum pooling and average pooling are performed along the channel dimension to retain significant spatial information:
iv. Calculation of spatial attention weights
3×3 deep convolution is used to generate spatial weights:
v. Dynamic fusion
The final output feature is the fusion result of channel and space weighting:
The CSFT framework
Current art images exhibit diverse styles, and direct training often leads to model overfitting to specific styles36,37. To address this, the CSFT framework incorporates contrastive learning to align feature distributions across various styles, thus enhancing the model’s generalization ability38, as illustrated in Fig. 4.

The CSFT framework.
In Fig. 4, the calculation method of the contrastive loss function is as follows:
The anchor feature fa, the positive sample fp (same category but different style), and the negative sample fn (different category) are given. Among them, positive samples are selected as image pairs of the same style but different categories (e.g., two works of Baroque style but different categories); negative samples are selected as image pairs of different categories and styles (e.g., a combination of Baroque and abstract style images). This design forces the model to distinguish the independent features of style and content. The loss is defined as:
τ represents the temperature coefficient; its setting follows the general practice of InfoNCE loss, which can avoid the saturation of similarity scores and maintain gradient stability. K refers to the number of samples within the batch.
In addition, the total objective function is calculated by the categorical loss \(\:{L}_{\text{c}\text{l}\text{s}}\) and the contrastive loss:
λ denotes the equilibrium coefficient; β represents the L2 regularization weight39.
The art image classification model proposed in this section integrates a cross-style transfer strategy, a lightweight hybrid architecture, and a dynamic attention mechanism. Among them, MTH is employed to stabilize the image’s local and global features, and the DCSAM model is used to enhance the response of the key areas of the image. Meanwhile, the CSFT strategy utilizes the contrastive learning method to improve the robustness of the style.
Training process of the model
Based on the three parts related to model construction in Sect. 3.1, the model’s training process is plotted in Fig. 5.

Training Process of the model.
Figure 5 outlines the model’s end-to-end training process. (a) The MobileNetV3 backbone and Transformer branch separately extract shallow local features and global semantic features from source and target domain images, with DCSAM adaptively enhancing style-sensitive features; (b) Contrastive learning strategies calculate similarity loss between target and source domain features, forcing feature distribution alignment across artistic styles; (c) Combined classification cross-entropy loss, contrastive loss, and L2 regularization form the total objective function, with backpropagation iteratively optimizing parameters for efficient feature transfer and high-accuracy classification. The complete code implementation, pre-trained model, and key experimental scripts of this study have been open-sourced. The project resources are hosted on the GitHub repository (access link: https://github.com/Gao4253/db-model-analysis).
Experimental design and performance evaluation
Datasets collection
This section details two open-source art image datasets used in experiments: ArtBench-10 (a standardized benchmark for art generation and classification) and WikiArt (a curated collection of classical artworks with balanced distribution). Both datasets contain images of various artistic styles, and the images are all set with annotations and data distributions, which are suitable. for training and evaluating lightweight deep learning models.
ArtBench-10 represents the first standardized dataset specifically designed for art generation and classification. It contains 60,000 high-quality images across 10 styles (Ukiyo-e, Surrealism, Impressionism, etc.), with 6,000 training and 1,000 testing images per style. Sourced from three major art databases (Ukiyo-e.org, WikiArt.org, and Surrealism.website), the dataset undergoes rigorous deduplication, balanced sampling, and preprocessing. Its core advantages include the following three aspects. 1) Weighted sampling balances artist and style distributions to prevent long-tail problems; 2). Style labels extracted from HTML metadata undergo manual verification; 3) It offers 32 × 32, 256 × 256, and original resolution versions, which can be adapted to different model requirements. Figure 6 shows sample images from ArtBench-10.

Sample images of the ArtBench-10 dataset.
The WikiArt dataset comprises curated art images selected from WikiArt.org, encompassing 15 artistic styles (Baroque, Cubism, Abstract Expressionism, etc.) with a total of 100,000 images. Specifically, Baroque and Impressionist style images account for 18.7% and 15.2%; niche styles such as Pointillism and Art Nouveau images account for 3.1% and 2.8%. This study implements the following optimization procedures to address inherent long-tail distribution and noise issues in the raw data. (a). The perceptual hashing algorithm is adopted to remove approximately duplicate images and filter out low-resolution and non-artwork samples; (b). A few styles have been oversampled to ensure that the sample size for each category is no less than 5,000; (c). Random rotation, flipping, and contrast adjustment enhance model generalization. Figure 7 displays representative samples from the WikiArt dataset.

Examples of the WikiArt dataset.
The specific characteristics and division of the datasets are summarized in Table 1.
Experimental environment and parameters setting
This section elaborates in detail on the hardware and software configuration of the experiment, the setting of model parameters, the definition of evaluation indicators, and the basis for selecting the baseline model, ensuring the reproducibility of the experiment and the credibility of the results.
Experimental environment configuration
The experiment is conducted in the following environment, and the hardware and software configurations are outlined in Table 2.
Experimental parameter settings
The parameter settings of the proposed model are listed in Table 3, including the network structure and training hyperparameters.
Experimental evaluation indicators
The experiment uses the following four types of indicators to evaluate the model performance, and the equations are defined as:
i. Accuracy:
ii. Precision:
iii. Recall:
F1 score (\(\:\text{F}1\)):
Among the above several equations, True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN) represent the confusion matrix statistics of the classification results, respectively.
Baseline models
The experiment selects the following five models proposed in the past three years as the baseline models:
-
i.
EfficientNetV2-S: This is a lightweight CNN based on a composite scaling strategy, which balances model depth, width, and resolution.
-
ii.
Swin-Tiny: A hierarchical visual transformer, which reduces computational complexity through the sliding window mechanism;
-
iii.
Convolutional Next-Tiny (ConvNeXt-T): This is a pure convolutional network, which draws on the design concept of the Transformer to improve feature extraction capabilities.
-
iv.
Mobile Vision Transformer-Small (MobileViT-S): A lightweight hybrid architecture that combines MobileNet and ViT;
-
v.
Regularized Network-Y 4GFLOPs (RegNetY-4G): An efficient CNN based on network design space search.
Performance evaluation
This section presents the experimental results of the proposed model in four aspects: validation set performance, confusion matrix analysis, classification performance, and complexity comparison. The data are all based on the ArtBench-10 and WikiArt datasets. All experiments are reproduced three times, and the mean values are taken to eliminate randomness.
Verification set performance (Epoch-Loss)
To validate the model’s training convergence and generalization ability, the pre-partitioned validation set evaluates the model, recording validation loss values every 10 training epochs for both ArtBench-10 and WikiArt datasets. The complete 200-epoch training cycle generates 40 data points. The training results are plotted in Fig. 8.

Validation set performance of the model on various datasets.
Figure 8 demonstrates that the Loss values of both validation sets show a continuous downward trend as training epochs increase from 10 to 200. The first loss decreases from 1.52 to 0.38, while the second declines from 1.89 to 0.39. Rapid loss reduction occurs within the first 50 epochs before gradual stabilization, with both Losses stabilizing below 0.4 by epoch 200. These results indicate that the model’s performance on the validation set gradually improves with the increase in training epochs without significant fluctuations. This confirms that the proposed model has good convergence and generalization ability.
Confusion matrix analysis
Confusion matrices visually represent misclassification patterns of the model in fine-grained style categorization. This experiment is still based on the ArtBench-10 and WikiArt datasets to present the classification results of the main art style categories. It encompasses the number of correctly classified samples (diagonal) and cross-style misclassified samples (non-diagonal). The experimental data are statistically based on 25,000 images in the test set. The final result obtained from the experiment is demonstrated in Fig. 9.

Analysis of the confusion matrix of the model across diverse datasets. (a): Analysis results of the ArtBench-10 dataset; (b): Analysis results of the WikiArt dataset.
Figure 9 reveals that in the ArtBench-10 dataset, the model has a relatively high classification accuracy for the five types of art styles. Realism achieves 895 correct classifications with zero misclassifications, while other styles (Impressionism, Ukiyo-e, Surrealism, Abstraction) exceed 860 diagonal values, with primary confusion occurring between visually similar styles. For the WikiArt dataset, all five styles surpass 1,750 correct classifications, with Baroque achieving optimal performance (1820). However, Abstract Expressionism shows notable. cross-style confusion, and mutual misclassification between Neoclassicism and Baroque (40 vs. 28 cases) remains evident. The confusion matrices of both datasets demonstrate that the model can effectively distinguish most styles, and misclassifications mainly occur between style categories with similar visual features. The above experimental results show that although the proposed model has certain misclassifications in the classification task, it has a good classification performance on the whole.
The classification performance of the model
To verify the comprehensive classification ability of the model in standardized and complex scenarios, the experiment compares the classification effects of the proposed model and five baseline models on the ArtBench-10 and WikiArt datasets. The final results obtained from the experiment are suggested in Fig. 10.

The classification performance of the model in different datasets. (a): Classification performance of ArtBench-10 (%); (b): Classification performance of WikiArt (%).
Figure 10 illustrates that in the ArtBench-10 dataset, the four evaluation indicators of the proposed model (precision: 84.7%, accuracy: 85.2%, recall: 84.9%, F1 score: 84.8%) are significantly superior to those of other baseline models (EfficientNetV2-S, Swin-Tiny, ConvNeXt-T, etc.). In the WikiArt dataset, the proposed model also demonstrates excellent performance compared to other baseline models (precision: 77.5%, accuracy: 78.9%). However, the overall indicators of each model are slightly lower than those in the ArtBench-10 dataset, with RegNetY-4G performing the weakest (F1 score 71.0%) among all baseline models. Experimental results from both datasets indicate that the proposed model has the best classification performance among all compared models.
To further verify the advancement of the model in lightweight art image classification tasks, the study additionally selects two latest lightweight models (EdgeNeXt-XXS and MobileOne-S1) as advanced baselines for quantitative comparison. Table 4 details the comparison results between the proposed model and these two advanced baseline models in terms of key classification indicators (accuracy, F1 score) on the ArtBench-10 test set.
Table 4 presents that the proposed model achieves a Top-1 accuracy of 85.2% and an F1-score of 84.8%, outperforming EdgeNeXt-XXS and MobileOne-S1. This result verifies the model’s advancement in lightweight art image classification tasks; it also indicates that while maintaining lightweight characteristics, the proposed model achieves higher feature discriminative ability through architecture optimization. It is particularly suitable for fine-grained classification scenarios such as artistic style classification.
The complexity of the model
To verify the model’s complexity, experiments are conducted on images with an input resolution of 256 × 256, and comparisons are made across three aspects: parameter count (million (M)), Floating Point Operations Per second (FLOPs), and single-image inference latency (milliseconds (ms)). The specific experimental results are depicted in Fig. 11.

Complexity comparison results between the proposed model and baseline models.
Figure 11 reveals that the proposed model outperforms other baseline models in all three indicators: parameter count, FLOPs (0.8G), and inference latency (12.3ms). Notably, the parameter count of the proposed model is only 1.2 M, which is 14.8% of EfficientNetV2-S (8.1 M) and 4.2% of Swin-Tiny (28.3 M). Among the baseline models, MobileViT-S exhibits the best complexity performance (2.3 M parameters, 1.2G FLOPs, 15.8 ms latency). In contrast, Swin-Tiny and ConvNeXt-T both have parameter counts exceeding 28 M, FLOPs higher than 4G, and inference latencies over 30ms. The complexity indicators of all models show a positive correlation: models with larger parameter counts and FLOPs generally have higher inference latencies, and the proposed model remains optimal across all three dimensions.
Similarly, under the same test environment, the study compares the complexity indicators of the proposed model with those of the two advanced lightweight models (EdgeNeXt-XXS and MobileOne-S1). The results are denoted in Table 5.
Table 5 shows that in the complexity comparison experiment on the ArtBench-10 dataset, the proposed model demonstrates better efficiency. Its parameter count (1.2 M), computational complexity (0.8 GFLOPs), and inference latency (12.3 ms) are all superior to those of EdgeNeXt-XXS and MobileOne-S1. This indicates that the model achieves lower resource consumption and faster real-time response capability through structural optimization. Meanwhile, it is expected to provide a more practical solution for lightweight art image classification tasks.
Ablation experiment and model generalization ability verification
To quantitatively evaluate the contribution of each core module in the proposed model to the final performance, the study conducts systematic ablation experiments on the ArtBench-10 test set. Four model variants are set up for the experiments. They include (1) the complete model; (2) the model without the DCSAM module (w/o DCSAM); (3) the model without the CSFT framework (w/o CSFT); (4) the model retaining only the basic MTH network (Base MTH). All variants maintain the same training settings and hyperparameters. The final results are shown in Table 6.
Table 6 reveals that the complete model outperforms all variants, achieving an accuracy of 85.2% and an F1-score of 84.8%. Removing the DCSAM module leads to a performance decline and a 0.5ms reduction in latency; removing the CSFT framework reduces the metrics by 2.7% with minimal latency change; retaining only the Base MTH results in the largest performance drop but the optimal latency (10.5ms). The above results confirm that the DCSAM and CSFT modules, through their synergy, improve feature selection ability and cross-scale fusion efficiency respectively. Moreover, the performance gains they bring far exceed the slightly increased inference cost.
To evaluate the model’s robustness and generalization ability when facing different, especially visually similar, artistic styles, the study designs the following experiment based on the WikiArt dataset. Five pairs of artistic style categories that are easily confused in visual features (such as Baroque & Neoclassicism, Abstract Expressionism & Futurism) are selected from the dataset. 100 images (50 from each category) are randomly selected for each style pair from the test set to form a “confusable style test subset”. Then, the performance of the complete model is compared with that of the Base MTH network, EdgeNeXt-XXS, and MobileOne-S1 on this subset, with a focus on the models’ ability to correctly classify images into their true styles. The results are demonstrated in Table 7.
Table 7 illustrates that compared with the three baseline models (Base MTH, EdgeNeXt-XXS, and MobileOne-S1), the complete model demonstrates better cross-style classification ability; it achieves an overall accuracy of 75.6% and an average confusion rate of 5.2%. This data indicates that the proposed model effectively reduces the misjudgment rate between visually similar styles through feature decoupling and cross-style relationship modeling. At the same time, this model controls the confusion rate at the best level among models of the same type.
Discussion
This study proposes a fine art image classification method based on lightweight deep learning, which achieves simultaneous improvement in image classification efficiency and accuracy through multi-module collaborative design. The innovation of the proposed lightweight hybrid network (MTH) lies in combining the dual advantages of local details and global semantics. The DSC of MobileNetV3 effectively reduces computational overhead. The Transformer branch captures long-range dependencies through the MHS mechanism, addressing traditional CNN’s insufficient global modeling capability in complex artistic compositions (such as the multi-layered brushstrokes of abstract expressionism and the color gradients of impressionism). The DCSAM notably enhances the expressive ability of style-sensitive features through adaptive weight allocation. In the confusion matrix, the high misclassification rate between “abstract expressionism” and “futurism” reflects their similarity in dynamic composition, while DCSAM alleviates such misclassifications by focusing on local texture differences through spatial attention. The introduction of the CSFT framework endows the model with strong feature learning capabilities. Contrastive learning forces the model to align feature distributions across different styles, enabling it to maintain good robustness in the face of long-tail data. Experimental results reveal that the proposed model achieves F1 scores of 84.8% on ArtBench-10 and 77.6% on WikiArt, verifying its generalization ability. The model’s advantages in complexity (with only 1.2 M parameters) stem from structural optimization and parameter sharing strategies. The shallow feature input of the Transformer branch reduces redundant computations, while the parallel design of dynamic attention avoids information loss during feature fusion. In addition, due to the highly randomized brushstroke distribution of Abstract Expressionism works, the correlation between their local textures and global compositions is weaker than that of traditional schools; this makes it still challenging for the model to capture features of unstructured styles. This limitation indicates that the current attention mechanism still has theoretical deficiencies in analyzing unordered artistic elements. Therefore, the model’s adaptability to other art forms needs to be verified in a differentiated manner. The pixelated features of digital art can be adapted by adjusting the input resolution; for the regional patterns of folk art, cultural prior knowledge needs to be injected into the CSFT framework to improve style decoupling ability. Such scenario-based expansion can provide a new path for cross-art form analysis. To sum up, these designs improve classification accuracy while providing feasibility for edge deployment, thus demonstrating the practical value of lightweight deep learning in art image analysis.
Conclusion
Research contribution
The contributions of this study are as follows:
The MTH network is constructed by effectively fusing the DSC of MobileNet and the MHS mechanism of Transformer. Its innovation lies in applying a lightweight Transformer branch directly to the shallow feature maps extracted by MobileNet (instead of on deep features or the entire image). This design uniquely combines the capabilities of efficient local detail extraction and global semantic modeling; this alleviates the contradiction of traditional CNN in modeling long-range dependencies of art images while reducing the high computational complexity inherent in the standard ViT architecture. Also, it proposes the DCSAM to adaptively enhance feature responses in style-sensitive regions, alleviating misclassification issues caused by artistic style similarities. Moreover, a CSFT framework is designed to break through the constraints of long-tailed data distributions on model generalization for artistic data, providing a new method for robust multi-style modeling.
The proposed model achieves efficient classification at extremely low complexity (1.2 M parameters, 0.8G FLOPs), with an inference latency of only 12.3ms, lower than mainstream baseline models. These strengths offer a feasible solution for real-time art image analysis on mobile and edge devices. Experiments show that the model attains classification accuracies of 85.2% on the standardized dataset (ArtBench-10) and 78.9% on the complex-scene dataset (WikiArt), outperforming the best baseline models. These results validate its practicality in real-world automated artistic design scenarios. This achievement can be widely applied to digital art collection management, personalized art recommendation systems, cultural heritage digital protection, and other fields. Consequently, it can provide technical support for the further development of lightweight deep learning in the arts.
Future works and research limitations
This study still has certain limitations. The model’s classification performance for highly abstract or mixed-style art images leaves room for improvement, primarily because existing attention mechanisms struggle to fully decouple the nonlinear correlations between styles. The coverage of the experimental dataset is limited, and insufficient sample sizes for some niche artistic styles may affect the model’s generalizability. Additionally, the current model is mainly oriented toward static image classification and has not been adapted to the analysis needs of dynamic art forms.
Future work can be carried out in the following directions. Introducing graph neural networks to model the hierarchical relationships between artistic styles can enhance the semantic understanding of mixed-style images. Constructing cross-cultural and multi-modal art datasets, combined with text descriptions and historical context information, can improve classification interpretability. Exploring lightweight temporal modeling methods to extend the model to video art and dynamic design scenarios can promote the multi-dimensional application of intelligent art analysis technologies.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author SungWon Lee on reasonable request via e-mail ascada@deu.ac.kr.
References
Yu, Q. & Shi, C. An image classification approach for painting using improved convolutional neural algorithm. Soft. Comput. 28 (1), 847–873 (2025).
Maurício, J., Domingues, I. & Bernardino, J. Comparing vision transformers and convolutional neural networks for image classification: A literature review. Appl. Sci. 13 (9), 5521 (2023).
Abernot, M. & Todri-Sanial, A. Training energy-based single-layer Hopfield and oscillatory networks with unsupervised and supervised algorithms for image classification. Neural Comput. Appl. 35 (25), 18505–18518 (2023).
Olimov, B. et al. Consecutive multiscale feature learning-based image classification model. Sci. Rep. 13 (1), 3595 (2023).
Datta Gupta, K. et al. A novel lightweight deep learning-based histopathological image classification model for IoMT. Neural Process. Lett. 55 (1), 205–228 (2023).
Patrício, C., Neves, J. C. & Teixeira, L. F. Explainable deep learning methods in medical image classification: A survey. ACM Comput. Surveys. 56 (4), 1–41 (2023).
Yang, Z. et al. A survey of automated data augmentation algorithms for deep learning-based image classification tasks. Knowl. Inf. Syst. 65 (7), 2805–2861 (2023).
Huang, S. C. et al. Self-supervised learning for medical image classification: A systematic review and implementation guidelines. NPJ Digit. Med. 6 (1), 74 (2023).
Ren, Z., Wang, S. & Zhang, Y. Weakly supervised machine learning. CAAI Trans. Intell. Technol. 8 (3), 549–580 (2023).
Senokosov, A. et al. Quantum machine learning for image classification. Mach. Learning: Sci. Technol. 5 (1), 015040 (2024).
Guo, H. & Liu, W. S3L: Spectrum transformer for self-supervised learning in hyperspectral image classification. Remote Sens. 16 (6), 970 (2024).
Guo, H. et al. Improving image classification of gastrointestinal endoscopy using curriculum self-supervised learning. Sci. Rep. 14(1), 6100 (2024).
Rani, V. et al. Self-supervised learning: A succinct review. Arch. Comput. Methods Eng. 30 (4), 2761–2775 (2023).
Chen, J. et al. Weakly-supervised learning method for the recognition of potato leaf diseases. Artif. Intell. Rev. 56 (8), 7985–8002 (2023).
Yang, Z. et al. The devil is in the details: a small-lesion sensitive weakly supervised learning framework for prostate cancer detection and grading. Virchows Arch. 482 (3), 525–538 (2023).
Qu, X. et al. Multi-layered semantic representation network for multi-label image classification. Int. J. Mach. Learn. Cybernet. 14 (10), 3427–3435 (2023).
Li, T. et al. Research on garment flat multi-component recognition based on mask R-CNN. Ind. Textila. 74 (1), 49–56 (2023).
Zheng, Q. et al. A real-time constellation image classification method of wireless communication signals based on the lightweight network mobilevit. Cogn. Neurodyn. 18 (2), 659–671 (2024).
Nadamoto, S., Mori, N. & Okada, M. Constellation identification method using point set data. Artif. Life Rob. 28 (2), 361–366 (2023).
Aboudi, N. et al. Bilinear pooling for thyroid nodule classification in ultrasound imaging. Arab. J. Sci. Eng. 48 (8), 10563–10573 (2023).
Wang, Z. et al. Macaron attention: The local squeezing global attention mechanism in tracking tasks. Remote Sens. 16 (16), 2896 (2024).
Lou, Z. et al. Exploring Multi-View pixel contrast for general and robust image forgery localization. IEEE Trans. Inf. Forensics Secur. 20. (2025).
Zheng, L. et al. Heterogeneous Contrastive Learning for Foundation Models and Beyond (2024).
Shen, J. et al. An instrument indication acquisition algorithm based on lightweight deep convolutional neural network and hybrid attention fine-grained features. IEEE Trans. Instrum. Meas. 73, 1–16 (2024).
Shen, J. et al. An algorithm based on lightweight semantic features for ancient mural element object detection. Npj Herit. Sci. 13 (1), 70 (2025).
Shen, J. et al. Finger vein recognition algorithm based on lightweight deep convolutional neural network. IEEE Trans. Instrum. Meas. 71, 1–13 (2021).
Huang, S. K. et al. Cross-scale fusion transformer for histopathological image classification. IEEE J. Biomedical Health Inf. 28 (1), 297–308 (2023).
Khan, S. et al. A novel cluster matching-based improved kernel fisher criterion for image classification in unsupervised domain adaptation. Symmetry 15 (6), 1163 (2023).
Hasan, M. D. A. et al. Image classification using convolutional neural networks. Int. J. Mech. Eng. Res. Technol. 16 (2), 173–181 (2024).
Asker, M. E. Hyperspectral image classification method based on squeeze-and-excitation networks, depthwise separable Convolution and multibranch feature fusion. Earth Sci. Inf. 16 (2), 1427–1448 (2023).
Hu, Y., Tian, S. & Ge, J. Hybrid Convolutional network combining multiscale 3D depthwise separable Convolution and CBAM residual dilated Convolution for hyperspectral image classification. Remote Sens. 15 (19), 4796 (2023).
Reddi, P. et al. A Multi-Head Self-Attention Mechanism for Improved Brain Tumor Classification Using Deep Learning Approaches 1417324–17329 (Engineering, Technology & Applied Science Research, 2024).
Wang, Y. et al. An attention mechanism module with spatial perception and channel information interaction. Complex. Intell. Syst. 10 (4), 5427–5444 (2024).
Yao, H. et al. Facial expression recognition based on fine-tuned channel–spatial attention transformer. Sensors 23 (15), 6799 (2023).
Zhou, Y. et al. Innovative ghost channel Spatial attention network with adaptive activation for efficient rice disease identification. Agronomy 14 (12), 2869 (2024).
Zhan, G. et al. Unsupervised vehicle re-identification based on cross-style semi-supervised pre-training and feature cross-division. Electronics 12 (13), 2931 (2023).
Liu, J. et al. Semi-supervised medical image segmentation using cross-style consistency with shape-aware and local context constraints. IEEE Trans. Med. Imaging. 43 (4), 1449–1461 (2023).
Liu, X., Zhang, B. & Liu, N. CAST-YOLO: An improved YOLO based on a cross-attention strategy transformer for foggy weather adaptive detection. Appl. Sci. 13 (2), 1176 (2023).
Zhang, J. et al. Learning domain invariant features for unsupervised indoor depth Estimation adaptation, ACM transactions on multimedia computing. Commun. Appl. 20 (9), 1–23 (2024).
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
Kexiang Ma: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation SungWon Lee: writing—review and editing, visualization, supervision, project administration, funding acquisitionXiaopeng Ma: methodology, software, validation Hui Chen: formal analysis, investigation, resources, data curation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics statement
This article does not contain any studies with human participants or animals performed by any of the authors. All methods were performed in accordance with relevant guidelines and regulations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ma, K., Lee, S., Ma, X. et al. Fine art image classification and design methods integrating lightweight deep learning. Sci Rep 15, 33006 (2025). https://doi.org/10.1038/s41598-025-18420-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18420-0
