
Abstract
Probability distributions are widely utilized throughout several domains of life, particularly for studying data sets from environmental science, biology, medicine, economics, insurance, and many more. Standard probability distributions have been utilized in practice for an extended period. In this work, we proposed a continuous probability distribution based on the Ramos Louzada logic called the Ramos Louzada Exponential model with two parameters. The significance of the proposed model lies in its ability to effectively analyze the phenomena observed in nature. Its utility spans multiple disciplines. In particular, these distributions have demonstrated considerable efficacy in data modeling. The study presents some statistical and mathematical characteristics of the new distribution, such as the ordinary moment, the quantile function, the mean, the variance, and the moment generating function. To ensure precise parameter estimation, two estimation methods are evaluated, including maximum likelihood and Bayesian procedures under three suggested loss functions, accompanied by a simulation study that confirmed the reliability and consistency of the two proposed estimators. The performance of the estimators is evaluated through average estimate and mean square error. The utility of the model was demonstrated using three real-life data sets taken from the lifetime and environmental fields. Employing a meticulous comparative evaluation through an array of goodness-of-fit metrics, including Akaike Information Criterion, Correction Akaike Information Criterion (\(\mathcal {CAIC}\)), Hannan-Quin Information Criterion, Bayesian Information Criterion, Kolmogorov-Smirnov (\(\mathcal{K}\mathcal{S}\)) statistics with its associated P-values, the proposed model consistently surpassed traditional competing models such as the generalized Rayleigh, truncated Poisson exponential, alpha power transformed exponential, extended exponential, gamma, Weibull, and two parameters Mira distributions. Based on ((\(\mathcal {CAIC}\)), p-values) [(0.1206,0.5640), (0.1002, 0.62), and (0.1121, 0.2414)] for the three proposed datasets, we observe that the proposed distribution offers optimal fitting compared to other rival distributions.
Similar content being viewed by others

Introduction
Statistical models have been extensively applied in industries such as survival, accounting, actuarial sciences, insurance, and engineering analysis to analyze data patterns. The success of statistical inference is strongly dependent on how well the chosen probability distribution matches the underlying data patterns. However, standard distributions frequently lack the versatility and accuracy required to effectively describe complex information. This constraint has culminated in the development of more adaptive and complex distributional models that better explain real-world data behavior.
Based on existing studies and findings, we can observe that engineering and environmental data sets most often possess a right-tailed distribution. For such types of data sets, probability distributions with heavy-tailed behavior are very competitive models. In this context, many authors have tried to find new statistical models, extending known ones, and better fitting various types of data sets. This flexibility is obtained by adding novel parameters or by some modifications to the classical distribution, increasing its ability to handle complicated scenarios. For more information, one may refer to some recently generated family of distributions, namely, Marshall and Olkin1, progressive type-II censoring Marshall-Olkin distributions2, \(\alpha\)-power transformation3, a new two-parameter mixture family of generalized distributions4, inverse Weibull-G model5, Kumaraswamy-G family6, A new modified cubic transmuted-G family of distributions7, a new power G-family of distributions8, novel odd Type-X family9, Tangent exponential-G family of distributions10, transformed-transformer class of distributions11, exponentiated generalized alpha power family12, Topp-Leone Weibull generated family13, Novel family of probability generating distributions14, mixture Models of the New Topp-Leone-G family15, generalized odd linear exponential family of distribution16, Lomax tangent generalized family of distributions17, new flexible power-X family18, novel compound two components of exponentiated class19, Power Lindley-G family20, sine \(\pi\)-power odd-G family of distributions21, new logarithmic tangent-U family22, new family of upper-truncated distributions23, transformation of the Chen distribution24, modified Weibull distribution25, modified tangent Weibull26, arc cosine-G family27, new logarithmic-G family28, transformed Weibull distribution29, the Fréchet–Power Rayleigh30, and new Topp Leone-G family31.
It is well documented that no particular probability distribution is available to handle every phenomenon, as real-world phenomena are complex, which is the main reason for developing more flexible probability distributions with greater distributional flexibility. Due to this,32 suggested a new methodology for creating a new class of distributions known as the Ramos-Louzada (RL) class of distributions. The derivation of the distributions can be described as follows:
Here, K(x) and k(x) are respectively the cumulative distribution function (CDF) and the probability distribution function (PDF) of the standard distribution. Further, by taking respectively w(t) and W(t) as the PDF and CDF of the RL distribution with the forms
and
The CDF of the RL family of distributions is
Considering the computation of \(\frac{d}{dx} M\left( x\right)\), brings us to the mathematical form of the PDF, denoted as \(m\left( x\right)\), which is represented as follows:
The RL procedure is a novel tool for generalizing a given model, which adds an additional parameter to a distribution. The proposed method has many applications that extend to fitting, especially engineering and environmental areas, and it has an ability to model different kinds of data sets. However, recent works considering the RL technique include33 who proposed the discrete RL distribution,34 defined the generalization of the RL model using the exponentiated method, and35 introduced the inverse power RL with medicine and geology applications.
To our knowledge, the exponential (Exp) distribution is a flexible one-parameter distribution. The Exp model can be utilized in various sectors, including survival, hydrology, insurance, and energy theory. Let Y follows the Exp distribution. The corresponding CDF and PDF are, respectively, given by
and
In research, the Exp distribution has emerged as a well-known survival distribution. In engineering data modeling, this distribution has received a lot of attention, for example, see45,46,47. While there are several generators to attain adaptability, this can make estimation and interpretation difficult. To address this, we are motivated in this study to offer a new form of the Exp distribution based on the approach discussed in Eq. (1), which is intended to give increased flexibility by introducing an additional parameter. The resultant distribution is named the Ramos Louzada Exponential (RL-Exp) model. It is interesting because it offers a broad range of density shapes, including symmetric, skewed, and heavy-tailed forms while also allowing for a variety of failure rate behaviors, and it blends simplicity in definitions, enabling accurate mathematical understanding and effective data modeling. Such versatility renders it appropriate for a variety of statistical and reliability applications. Further, the n parameter offers increased versatility in analyzing the tail behavior of the specified density function. The following objectives of this study can be described as follows:
-
Defined a novel two-parameter generalization of the Exp model by applying the RL tool, which can be enhanced in flexibility, robustness, and applicability to different data scenarios, and established its mathematical properties.
-
Two estimation methods, namely, the maximum likelihood estimator (MLE) and Bayesian estimators based on:
-
1.
Square error (SE) loss function proposed by38, and it measures the discrepancy between predicted and true values by taking the square of their difference.
-
2.
Linex (LI) loss function presented by39, and it is an asymmetric function.
-
3.
General entropy (GE) defined by40, and is also an asymmetric loss function
These loss functions can be apply to compute the cost of errors in parameter estimates.
-
1.
-
Three real data sets are applied from engineering and environmental fields to demonstrate the utility of the proposed RL-Exp model in application. For more reading see36,37,48
The further study is organized as follows: The recommended RL-Exp is defined in “Ramos Louzada-exponential distribution” with some distributional properties. In “Characterization of the RL-Exp model”, various mathematical properties of the new model are established. Section “Statistical inference” demonstrates the estimation of the model parameters based on two different proposed methods. Section “Simulation study and algorithms” delineates the efficacy of the estimations using a Monte Carlo simulation, and three distinct real data sets taken from the engineering and environmental fields are applied to show the results of the application of the RL-Exp model. Section 7 offers final observations.
Ramos Louzada-exponential distribution
A random variable Z is said to follow the RL-Exp model with two parameters \(\alpha\) and \(\beta\) if its CDF and PDF are of the form
and
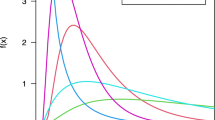
The plots of the CDF and PDF functions under some selected parameter values are shown in Fig. 1, which might have a declining trend, unimodal, and right-skewed PDF shapes. Further, when \(\alpha =1\), we obtained the Ramos Lozuada (RL) distribution.

The CDF and PDF curves of the RL-Exp model are based on some choices of parameters.
The survival function (SF) and hazard rate function (HRF) are formulated, respectively, as:
and
The graphical behavior of the SF and HRF for several selected parameters is sketched in Fig. 2 of the RL-Exp model. For the HRF, it has decreasing and unimodal shapes according to the parameter values.

The SF and HRF curves of RL-Exp model are based on some choices of parameters.
Characterization of the RL-Exp model
Quantile function and and random number generation
The quantile function serves a significant purpose in producing random numbers from a probability model, which are essential for executing a simulation study. The quantile function \(z_p\) associated with the RL-EXP MODEL is written in the following manner:
where W(.) represents the Lambert function with the positive branch.
Proof: For \(0<u<1\), we can define the quantile function of Z as follows:
From Eq. (10), we can be obtain the median value of the proposed RL-Exp model by setting \(u=0.5\), and it is given as
Concerning the RL-Exp distribution, the skewness (\(\mathcal {SKW}\)) and kurtosis (\(\mathcal {KUR}\)) metrics are, receptively, given in the following way:
and
Ordinary moments
Assume that Z is a random variable following the RL-Exp distribution. The \(k^{th}\) moment of Z can be obtained as
where \(\Gamma (n+1)=n!\), \(n=0,1,2,\ldots\).
The mean and variance of Z can be obtained in special case from Eq. (11), and they are in the following form:
and
The index of dispersion of Z is derived as bellow
Moment generating function
Let the random variable Z has a RL-Exp model. Hence, the associated moment generating function (MGF) can be provided in the following form:
Table 1 demonstrates different mathematical properties of the recommended RL-Exp model using various selected parameter values, and Fig. 3 is the 3-dimensional plots of the proposed statistical properties of the new distribution. It can be seen that as \(\beta\) increase and for fixed values of \(\alpha\), the values of \(\mu '_{1}\), \(V_{Z}\), \(I_Z\), \(\mathcal {SKW}\), and \(\mathcal {KUR}\) increase. Further, for fixed values of \(\beta\) and as \(\alpha\) increase the values of \(\mu '_{1}\) and \(V_{Z}\) decrease, where the values of \(I_Z\), \(\mathcal {SKW}\) and \(\mathcal {KUR}\) are constant. In addition, multiple non-monotonic forms are seen, which confirms that the explored RL-Exp model is an adaptable model that accommodates larger data sets.

The plots of mean, variance, skewness and kurtosis for the RL-Exp.
Order statistics
Let a random sample \(z_1,z_2\ldots z_m\) represent the RL-Exp model. The PDF of the \(j^{th}\) order statistic can be expressed as follows
Specially, the PDF of the highest order statistics \(f_{(m:m)}(z)\) is obtained as setting \(j=m\) in Eq. () to get:
Similarly, the PDF of the lowest order statistics \(f_{(1:m)}(z)\) is obtained as setting \(j=1\) in Eq. ()
Furthermore, the \(j^{th}\) CDF of the order statistic of the RL-Exp model can be given by
Statistical inference
Maximum likelihood estimation
In this section, we estimate model parameters \(\rho =(\alpha , \beta )\) using MLE technique based on complete data. Assume that \(\{z_1, z_2, \ldots , z_m\}\) is a random sample follows the equation given in Eq. (9). The likelihood function can be represented as
Using Eqs. (9) in (13), we get that:
The corresponding log-likelihood function is given by
The first partial derivatives of log-likelihood function in Eq. (15) with respect to \(\alpha\) and \(\beta\) provide likelihood equations given as
The maximum likelihood estimates of unknown parameters \(\rho =(\alpha , \beta )\) can now be obtained by solving the above two equations. We adopt a numerical method like the Newton-Raphson or secant methods to evaluate these estimates, as the above equations are nonlinear in nature. The well-known statistical programs for maximizing the log-likelihood function are the R package (Adequacy- Model), the Ox program (subroutine-Max-BFGS), and SAS (PROC-NLMIXED). In this study, we applied the R script with the function (optim), employing the method = L-BFGS-B.
Bayesian estimation
In contrast to the maximum likelihood estimation approach, Bayesian estimation is a more efficient approximation. Taking into consideration past data and samples, it calculates the interest parameters that have not been stated. From a Bayesian standpoint, there is no hard and fast method for choosing priors because one cannot clearly assert that one prior is superior to another. When there is insufficient interpretive information about the unknown parameter, a non-informative prior is frequently adopted. In contrast, if considerable information about the parameter(s) is available, an informative prior is generally more effective. Let the parameters \(\alpha\) and \(\beta\) have, respectively, the prior gamma distributions (Gamma\((a_1, b_1)\) and Gamma\((a_2, b_2)\). The main motivation for the Gamma prior is usually to constrain the random variables to positive values. This is especially useful when dealing with random variables that represent the variance of another distribution. Next, let define the joint priors for the parameters \(\rho =(\alpha , \beta )\) as follows:
The posterior density of \(\rho\) has the following form
The joint posterior distribution of \(\rho\) is given by
The marginal posterior of the \(\alpha\) and \(\beta\) are obtained to be
and
Hence, the Bayes \(\phi (\rho )\) based on SE loss function is
Next, we provide other loss functions, including LI and GE functions. The Bayes estimators based on these loss functions can be formulated, respectively, as \(\tilde{\phi }_{LI}(\rho )=-\frac{1}{q}\text {log}\left( E_{\rho }\left( e^{-q\Pi (\rho )} \mid z\right) \right)\) and \(\tilde{\phi }_{GE}(\rho )=\left( E_{\rho }\left( (\Pi (\rho ))^{-q} \mid z\right) \right) ^{-\frac{1}{q}}\).
By obtaining the joint prior, the posterior function, which is not from a well-known distribution may be determined. Due to this, we are unable to create samples from it; hence, we will employ the Metropolis-Hastening method.
Metropolis hasting method
-
1.
Start with initial values \(\alpha ^{(0)}=\hat{\alpha },\beta ^{(0)}=\hat{\beta }\).
-
2.
Let \(m=1\) define the first iteration.
-
3.
obtain \(\alpha ^*,\beta ^*\), respectively, from a proposal distribution.
-
4.
Compute \(H_\alpha =\min \left[ 1, \dfrac{\pi ^{*}(\alpha ^*\mid \beta ^{m-1})}{\pi ^{*}(\alpha ^{m-1}\mid \beta ^{m-1})}\right]\), \(H_\beta =\min \left[ 1, \dfrac{\pi ^{*}(\beta ^*\mid \alpha ^{m-1})}{\pi ^{*}(\beta ^{m-1}\mid \alpha ^{m-1})}\right]\).
-
5.
For \(1\ge j \ge 2\), generate random samples \(Q_j\), where \(Q_j\sim U(0, 1)\).
-
6.
If \(Q_1\le H_\alpha , \ Q_2\le H_\beta\), then \(\alpha ^{(m)}=\alpha ^{*}, \ \beta ^{(m)}=\beta ^{*}\), else \(\alpha ^{(m)}=\alpha ^{m-1}, \ \beta ^{(m)}=\beta ^{m-1}\).
-
7.
\(m=m+1\).
-
8.
For M repeat of process, the steps (3) to (7) are repeated, and finally, we obtain \(\alpha ^{(m)}\), \(\beta ^{(m)}\) for \(m=1,\ldots , B\).
At the end, the Bayes estimators of \(\alpha\) and \(\beta\) using the Metropolis-Hastening algorithm under the proposed loss error functions can be given as
and
where B denotes the burn-in period.
Interval estimation
Credible interval
In this subsection, we construct the credible confidence intervals of parameters of \(\rho = (\alpha , \beta )\) using the Metropolis-Hastening technique. To cancel the issue of the initial guess, we delete B initial samples (burn-in period). Furthermore, applying the idea of Chen and Shao41, and generating posterior samples, we can compute the credible intervals. Consequently, the \(100(1-p)\%\) Cred Int of \(\Xi =(\delta , \eta )\) is defined by
where, \(i_1^*<i_2^*,\ i_1^*,i_2^*\in \{1,2,\dots ,D\}\) and \(M^*=D-B\).
Bootstrap confidence intervals
In this section, we discuss the construction of bootstrap-percentile (boot-p) and bootstrap-t (boot-t ) confidence intervals. Step-by-step algorithms are provided below for the two methods:
(A) Boot-p
-
1.
Obtain the estimate \(\tilde{\rho }\) based on complete data generated by considering the true parameter as \(\rho\).
-
2.
Obtain the updated estimate \(\tilde{\rho }^{*}\) using \(\tilde{\rho }\) as the true parameter.
-
3.
Repeat step 2, desired \(N_{B}\) number of times.
-
4.
Let \(\tilde{F}_{1}(z) = P(\tilde{\rho }^{*}\le z)\) is the CDF of \(\tilde{\rho }^{*}\), then obtain \(\tilde{\rho }_{B_{p}}(z) = \tilde{F}_{1}^{-1}(z)\). An approximate \(100(1-p)\%\) confidence interval for \(\eta\) is now given by
$$\begin{aligned} \left( \tilde{\rho }^{*}_{B_{p}}\left( \frac{p}{2}\right) ,\tilde{\rho }^{*}_{B_{p}}\left( 1-\frac{p}{2}\right) \right) . \end{aligned}$$
(B) Boot-t
-
1.
Obtain \(\tilde{\rho }^{*}\) using the boot-p method as discussed in the above algorithm.
-
2.
Compute the statistic \(T = \frac{\tilde{\rho }^{*}-\tilde{\rho }}{\sqrt{\tilde{V}(\tilde{\rho }^{*})}}.\)
-
3.
Repeat step 2, \(N_{B}\) number of times.
-
4.
Let \(\tilde{F}_{2}(z) = P(\tilde{T}\le z)\) is the CDF of \(\tilde{T}\), then obtain \(\tilde{\rho }_{B_{t}}(z) = \tilde{\rho } + \sqrt{\tilde{V}(\tilde{\rho })} \tilde{F}_{2}^{-1}(z)\). Further, the approximate \(100(1-p)\%\) confidence interval for \(\eta\) is evaluated as
$$\begin{aligned} \left( \tilde{\rho }^{*}_{B_{p}}\left( \frac{p}{2}\right) ,\tilde{\rho }^{*}_{B_{p}}\left( 1-\frac{p}{2}\right) \right) . \end{aligned}$$
Simulation study and algorithms
In this subsection, we examine the performance of MLE and Bayes under the three loss functions estimators considering a finite number of samples. In the context of the RL-Exp distribution, sampling is performed by selecting random samples such as \(n = 20, 40, 70, 100\). The samples are obtained through the application of the quantile function, given by
The simulation study is conducted for two different sets of \(\rho =(\alpha ,\beta )\). The values pertaining to these combinations are indicated as follows: \(\rho =(0.5,2)\), and Set2: \(\rho =(1.75, 2.3).\) multiple repetitions were performed and yielded consistent results. \(N=1000\) random samples from the RL-Exp distribution are generated and different criteria including average estimates (Mean) and mean square error (MSE) are applied to asses the simulation results. Multiple repetitions were performedsuch as (\(\rho =(2.5, 3.75)\) and \(\rho =(4, 4.5)\)) and yielded consistent results. The proposed criteria can be defined as below
The simulation process is conducted by using the R language software with the optim function. It is well noted that for the Bayes estimator using the MCMC procedure, the obtained estimators are computed with conditions \(q=0.5\), \(D=10000\), the burn-in period \(B=2000\), and the values of prior distribution \(a_1=b_1=a_2=b_2=1\). Figs. 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 and 19 plotted the histogram, trace, the auto-correlation function (ACF), cumuplots function, and Gelman-Rubin diagnostic curves of the unknown parameters \(\alpha\) and \(\beta\) to assess MCMC convergence.
On the other hand, the CIs are constructed using the three proposed techniques with 95% confidence level. We computed the average interval length (ALs) and coverage probabilities (CPs) for each method. The results are presented in numerical form in Tables 4 and 5.
After that, to compare the performance of the two estimation approaches, we have assigned the values of the number of iterations (NI) and MSEs on the basis of their value in decreasing order for the two estimation methods corresponding to the same sample size. From these results obtained in Tables 2 and 3, we can observe that for all recommended estimators, the average parameter estimations approach the actual parameter values. Further, the MSEs decrease in size as m increases, which ensures that the obtained estimated parameter values are consistent and asymptotically unbiased. Moreover, we observed that Bayes estimation under the SE loss function appears as the best estimation method for the RL-Exp model with minimum MSE as compared to other methods mentioned. Figures 4, 5, 6 and 7 confirm this result. In addition, as the value of m continues to rise, the ALs of \(\rho\) ultimately decrease for all suggested techniques. Also, the Boot-t method has greater CPs among credible and Boot-p techniques.

Box plots for the MSEs based on proposed estimators using Set 1.

Box plots for the MSEs based on proposed estimators using Set 2.

Box plots for the MSEs based on proposed estimators at \(\rho =(2.5, 3.75)\).

Box plots for the MSEs based on proposed estimators at \(\rho =(4, 4.5)\).

MCMC convergence plots of RL-Exp model for Table 2 at \(m=100\).

MCMC convergence plots of RL-Exp model for Table 3 at \(m=100\).

MCMC convergence plots of RL-Exp model for \(\rho =(2.5, 3.75)\).

MCMC convergence plots of RL-Exp model for \(\rho =(4, 4.5)\).

Gelman-Rubin diagnostic plots of \(\alpha\) and \(\beta\) for Table 2 at \(m=100\).

Cumuplot function of \(\alpha\) and \(\beta\) for Table 2 at \(m=100\).

Gelman-Rubin diagnostic plots of \(\alpha\) and \(\beta\) for Table 3 at \(m=100\).

Cumuplot function of \(\alpha\) and \(\beta\) for Table 3 at \(m=100\).

Gelman-Rubin diagnostic plots of \(\alpha\) and \(\beta\) for \(\rho =(2.5, 3.75)\).

Cumuplot function of \(\alpha\) and \(\beta\) for \(\rho =(2.5, 3.75)\).

Gelman-Rubin diagnostic plots of \(\alpha\) and \(\beta\) for \(\rho =(4, 4.5)\).

Cumuplot function of \(\alpha\) and \(\beta\) for \(\rho =(4, 4.5)\).
Application of the RL-Exp model to life events
This section demonstrates the RL-Exp distribution as a practical tool, demonstrating its efficiency through the application of real data sets, with a specific focus on case studies in engineering and environmental fields.
First data
The first data set defined the failure times of product reliability during the design phase for 50 elements. It is studied by42 and the values are presented in Table 6.
Second data
The second data set provided 56 yearly records of the highest amounts of rainfall in Karachi, Pakistan, from 1953 to 2009, which offers a comprehensive view of the city’s precipitation patterns. This data set was previously considered43. The values of the data set are summarized in Table 7.
Third data
The third data consisted of the length of the intervals between the periods in which cars pass a spot on a road. The proposed data was sourced from Jorgensen44, and its values were reported in Table 8.
Table 9 summarizes the statistical description of all the proposed data sets, and visual comparisons, including scaled total time on the test (TTT), probability-probability (P-P), and box plots are sketched in Fig. 20 drawn from the three recommended data sets. These representations help in studying the historical performance of the engineering and environmental sectors.

Several descriptive plots of the proposed data set.
Note that the RL-Exp model is applied for the three data sets, with the following initial parameters:
-
1.
Data I: \(\alpha =0.2, \ \ \beta =3.8\).
-
2.
Data II: \(\alpha =0.05, \ \ \beta =2.1\).
-
3.
Data III: \(\alpha =0.95, \ \ \beta =18\).
Now, the proposed model is compared with some renowned distributions, generalized Rayleigh (GR), zero-truncated Poisson exponential ( ZTP-Exp), alpha power transformed exponential (APT-Exp), Weibull (Wei), extended exponential (Ex-Exp), moment exponential (M-Exp), Gamma, XLindley, and two parameters Mira (TPM) distributions for fitting the three data sets.
Hence, several goodness-of-fit metrics like log likelihood function (\(\mathcal {LLF}\)), Akaike Information Criterion (\(\mathcal {AIC}\)), Correction Akaike Information Criterion (\(\mathcal {CAIC}\)), Hannan-Quin Information Criterion(\(\mathcal {HQIC}\)), Bayesian Information Criterion (\(\mathcal {BIC}\)), Kolmogorov-Smirnov (\(\mathcal{K}\mathcal{S}\)) statistics with its associated P-values, Anderson Darling (\(\mathcal {A}\)), and Cramer-Von Mise (\(\mathcal {W}\)) to select the best appropriate model for the two data sets. For a particular probability model, the distribution with the least value of these measures and a greater P-value offers the best fit for modeling a given real-life data set. The parameter estimates of all distributions with goodness-of-fit metrics for the proposed data are given in Tables 10 and 11. To verify whether the obtained estimate actually converges to the MLEs, we have tried the grid search algorithm with some other initial estimates also, and it converges to the same set of estimates. Moreover, we have conducted an extensive grid search method with a grid size of 0.001, and it is noticed that they coincide, which guarantees that the final estimates converge to the MLEs. The statistical software utilizes the R package (AdquacyModel) and the “BFGS” algorithm to perform all of these calculations. Obviously, the numerical values of Tables 10 and 11 demonstrate that the RL-Exp model fits the three data sets better than other fitted distributions, as indicated by the p value. Figures 21, 22, 23, 24, 25 and 26 present the fitted functions for the RL-Exp with the fitting models, including the PDF, CDF, SF, and P-P plots for the applied data sets. These plots further support the findings from Tables 10 and 11, offering a very close fit to each data set as compared to the other contender distributions.

Fitted PDF, CDF, and SF plots of RL-Exp model for the first data set.

Fitted PDF, CDF, and SF plots of RL-Exp model for the second data set.

Fitted PDF, CDF, and SF plots of RL-Exp model for the third data set.

P–P plots of the fitting distributions using data I.

P–P plots of the fitting distributions using data II.

P–P plots of the fitting distributions using data III.
Finally, the three recommended data sets are evaluated by applying the Bayes estimators under SE, LI, and GE loss functions. The obtained results are summarized in Table 12. In addition, the histogram, trace, and ACF plots of the RL-Exp distribution for the MCMC technique are illustrated in Figs. 27, 28 and 29. All the codes used exist in Sect. 8.

MCMC Convergence results using data I.

MCMC Convergence results using data II.

MCMC Convergence results using data III.
Conclusion
The article introduces a new probabilistic model, the Ramos Louzada exponential model, specifically designed for engineering and environmental analysis applications. The proposed model can fit real-world data with ambiguity; our exploration of the RL-Exp model has demonstrated its ability to handle ambiguity and data ambiguity. The proposed model provides insight into reliability properties, moment functions, and order statistics and demonstrates its versatility as a powerful tool for decoding complex, skewed, and symmetric data sets. Using a wide range of methods, we can handle statistical analysis of the RL-Exp model and its unknown parameters. Therefore, we concluded that the Bayesian approach under the SE loss function is superior to the conventional estimating method since it consistently produces lower values for the MSE and number of iterations. We applied the proposed distribution to real-world data sets to verify its practical importance, comparing it directly with well-known classical distributions. The analysis results showed unequivocally that the RL-Exp model outperformed its classical counterpart in capturing the complex nuances of the underlying data, indicating its potential as a superior modeling tool in various fields. Henceforth, to best-fitting capability, the RL-Exp mode has certain disadvantages. For example, it has a non-closed form for the quantile function, and the cost of Bayesian estimates is generally high to compute. For future studies, we can apply the RL-Exp model in other cases, such as bivariate and multivariate versions, regression frameworks, and other statistical inferences, like censored data. Also, the proposed model may be utilized in different areas that require flexible and tractable probabilistic modeling.
Codes used in the paper

Data availability
All data exists in the paper with its related references in the Application section.
References
Marshall, A.W., & Olkin, I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika 84(3), 641–652. https://www.jstor.org/stable/2337585 (1997).
Almetwally, E. M., Khaled, O. M. & Barakat, H. M. Inference Based on Progressive-Stress Accelerated Life-Testing for Extended Distribution via the Marshall-Olkin Family Under Progressive Type-II Censoring with Optimality Techniques. Axioms 14(4), 244. https://doi.org/10.3390/axioms14040244 (2025).
Mahdavi, A. & Kundu, D. A new method for generating distributions with an application to exponential distribution. Commun. Stat. Theory Methods 46(13), 6543–6557. https://doi.org/10.1080/03610926.2015.1130839 (2017).
El-Alosey, A.R., Alotaibi, M.S., & Gemeay, A.M. A new two-parameter mixture family of generalized distributions: Statistical properties and application. Heliyon 10(19). https://doi.org/10.1016/j.heliyon.2024.e38198 (2024).
Hassen, A.S., & Nassr, G.N. The inverse Weibull-G familiy. J. Data Sci. 723–742. https://doi.org/10.6339/JDS.201810_16(4).00004 (2018).
Cordeiro, G. M. & Brito, R. S. The beta power distribution. Braz. J. Probab. Stat. 26(1), 88–112. https://doi.org/10.1214/10-BJPS124 (2012).
Rahman, M.M., Gemeay, A.M., Islam Khan, M.A., Meraou, M.A., Bakr, M.E., Muse, A.H., Hussam, E. & Balogun, O.S. A new modified cubic transmuted-G family of distributions: Properties and different methods of estimation with applications to real-life data. AIP Adv. 13(9). https://doi.org/10.1063/5.0170178 (2023).
Gemeay, A. M., Alharbi, W. H. & El-Alosey, A. R. A new power G-family of distributions: Properties, estimation, and applications. PLoS ONE 19(8), e0308094. https://doi.org/10.1371/journal.pone.0308094 (2024).
Shah, Z., Almetwally, E. M., Khan, D. M. & Jamal, F. A novel odd Type-X family of distributions: Model, theory, and applications to medical, insurance, and engineering data sets. J. Radiat. Res. Appl. Sci. 18(2), 101451. https://doi.org/10.1016/j.jrras.2025.101451 (2025).
Hussam, E., Sapkota, L. P. & Gemeay, A. M. Tangent exponential-G family of distributions with applications in medical and engineering. Alex. Eng. J. 105, 181–203. https://doi.org/10.1016/j.aej.2024.06.034 (2024).
Alzaatreh, A., Lee, C. & Famoye, F. A new method for generating families of continuous distributions. Metron 71(1), 63–79. https://doi.org/10.1007/s40300-013-0007-y (2013).
ElSherpieny, E. A. & Almetwally, E. M. The exponentiated generalized alpha power family of distribution: Properties and applications. Pak. J. Stat. Oper. Res. 18(2), 349–367. https://doi.org/10.18187/pjsor.v18i2.3515 (2022).
Elbatal, I. A., Helal, T. S., Elsehetry, A. M. & Elshaarawy, R. S. Topp-Leone Weibull Generated Family of Distributions with Applications. J. Bus. Environ. Sci. 1(1), 183–195. https://doi.org/10.21608/jcese.2022.270143 (2022).
Ahmad, A. et al. Novel family of probability generating distributions: Properties and data analysis. Phys. Scr. 99(12), 125007. https://doi.org/10.1088/1402-4896/ad8821 (2024).
AL-Dayian, G. R., EL-Helbawy, A., & Abd EL-Maksoud, F.,. Bayesian and Maximum Likelihood Estimation for Mixture Models of the New Topp-Leone-G Family. J. Bus. Environ. Sci. 4(2), 210–253. https://doi.org/10.21608/jcese.2024.330538.1084 (2025).
Jamal, F., Handique, L., Ahmed, A. H. & Khan, S. The generalized odd linear exponential family of distributions with applications to reliability theory. Math. Comput. Appl. 27(4), 55. https://doi.org/10.3390/mca27040055 (2022).
Zaidi, S.M., Mahmood, Z., Atchadé, M.N., Tashkandy, Y.A., Bakr, M.E., Almetwally, E.M., Hussam, E., Gemeay, A.M., & Kumar, A. Lomax tangent generalized family of distributions: Characteristics, simulations, and applications on hydrological-strength data. Heliyon 10(12). https://doi.org/10.1016/j.heliyon.2024.e32011 (2024).
Almetwally, E. M. et al. A new flexible power-X family of distributions: Applications to reliability engineering data. J. Radiat. Res. Appl. Sci. 18(2), 101525. https://doi.org/10.1016/j.jrras.2025.101525 (2025).
Abd EL-Maksoud, F. G., AL-Dayian, G. R., & EL-Helbawy, A. A., A new mixture of two components of exponentiated family with applications to real life data sets. Comput. J. Math. Stat. Sci. 3(2), 316–340. https://doi.org/10.21608/cjmss.2024.262548.1038 (2024).
Hassan, A. S. & Nassr, S. G. Power Lindley-G Family of Distributions. Ann. Data. Sci. 6, 189–210. https://doi.org/10.1007/s40745-018-0159-y (2019).
Sapkota, L. P. et al. Sine \(\pi\)-power odd-G family of distributions with applications. Sci. Rep. 14(1), 19481. https://doi.org/10.1038/s41598-024-69567-1 (2024).
Alsolmi, M. M. A new logarithmic tangent-U family of distributions with reliability analysis in engineering data. Comput. J. Math. Stat. Sci. 4(1), 258–282. https://doi.org/10.21608/cjmss.2025.342223.1090 (2025).
Hassan, A. S., Sabry, M. A., Elsehetry, A. M. A new family of upper-truncated distributions: properties and estimation. Thailand Stat. 18(2), 196–214. https://ph02.tcithaijo.org/index.php/thaistat/article/view/240229 (2020).
Tabassum, N. S., Ehab, M. A., Anum, S. & Tahani; A. A. Theory, simulation, and application of the entropy transformation of the Chen distribution to enhance interdisciplinary data analysis. J. Radiat. Res. Appl. Sci. 18(2), 101472. https://doi.org/10.1016/j.jrras.2025.101472 (2025).
Almazah, M. M. A. et al. Estimation of parameters for the modified Weibull distribution under step-stress accelerated life testing with application to aircraft windshields data. Sci. Rep. 15, 25137. https://doi.org/10.1038/s41598-025-95469-x (2025).
Tianqing, L. et al. A new asymmetrical probability model: Its empirical exploration using the price quotations of the ceramic products. Alex. Eng. J. 117, 66–80. https://doi.org/10.1016/j.aej.2025.01.003 (2025).
Ahmad, A., Rather, A. A., Alqasem, O.A. et al. Introducing novel arc cosine-\(\Psi\) class of distribution with theory and data evaluation related to coronavirus. Sci. Rep. 15. https://doi.org/10.1038/s41598-025-95084-w (2025).
Ahmad, A. et al. A study on the new logarithmic-G family with statistical properties, simulations, and different data analysis. Sci. Rep. 15, 15069. https://doi.org/10.1038/s41598-025-99525-4 (2025).
Sindhu, T. N. et al. Distributional properties of the entropy transformed Weibull distribution and applications to various scientific fields. Sci. Rep. 14, 31827. https://doi.org/10.1038/s41598-024-83132-w (2024).
Ahmad, A. et al. Exploring the Fréchet-Power Rayleigh Distribution with Statistical Properties and Medical Data Insights. Lobachevskii J. Math. 45, 6209–6223. https://doi.org/10.1134/S1995080224607550 (2024).
Hassan, A. S., El-Sherpieny, E. A. & El-Taweel, S. A. New Topp Leone-G Family with Mathematical Properties and Applications. Int. Conf. Appl. Pract. Sci. ICAPS 1860, 012011. https://doi.org/10.1088/1742-6596/1860/1/012011 (2021).
Okutu, J. K., Frempong, N. F., Appiah, S. K. & Adebanji, A. O. A New Generated Family of Distributions: Statistical Properties and Applications with Real-Life Data. Computat. Math. Methods 2023, 9325679. https://doi.org/10.1155/2023/9325679 (2023).
Eldeeb, A. A discrete Ramos-Louzada distribution for asymmetric and over-dispersed data with leptokurtic-shaped: properties and various estimation techniques with inference. AIMS Math. 7(2), 1726–1741. https://doi.org/10.3934/math.2022099 (2022).
Al-Mofleh, H., & Afify, A. Z. A generalization of Ramos-Louzada distribution: Properties and estimation, arXiv, https://arxiv.org/abs/1912.08799 (2019).
Al Mutairi, A. et al. Inverse power Ramos-Louzada distribution with various classical estimation methods and modeling to engineering data. AIP Adv. 13, 095117. https://doi.org/10.1063/5.0170393 (2023).
Riad, F. H., Hussam, E., Gemeay, A. M., Aldallal, R. A. & Afify, A. Z. Classical and Bayesian inference of the weighted-exponential distribution with an application to insurance data. Math. Biosci. Eng. 19(7), 6551–6581. https://doi.org/10.3934/mbe.2022309 (2022).
Hassan, A. S., Mohamd, R. E., Elgarhy, M. & Fayomi, A. Alpha power transformed extended exponential distribution: properties and applications. J. Nonlinear Sci. Appl 12(4), 239–251. https://doi.org/10.22436/jnsa.012.04.05 (2019).
Varian, H. R. A Bayesian approach to real estate assessment (Studies in Bayesian Econometrics and Statistics in Honor of Leonard J, Savage, 1975).
Doostparast, M. & Akbari, M. Bayesian analysis for the two-parameter Pareto distribution based on record values and times. J. Stat. Comput. Simul. 81(11), 1393–1403. https://doi.org/10.1080/00949655.2010.486762 (2011).
Calabria, R. & Pulcini, G. Point estimation under asymmetric loss functions for left-truncated exponential samples. Commun. Stat. Theory Methods 25(3), 585–600. https://doi.org/10.1080/03610929608831715 (1996).
Chen, M. H. & Shao, Q. M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 8(1), 69–92. https://doi.org/10.1080/10618600.1999.10474802 (1999).
Anabike, I. C. et al. A New Weibull-Exponential Distribution with Properties and Applications. Asian J. Math. Comput. Res. 31(3), 40–52. https://doi.org/10.56557/ajomcor/2024/v31i38787 (2024).
Bhatti, F. A., Hamedani, G., Ali, A., & Ahmed, M. On the generalized log Burr III distribution: development, properties, characterizations and applications. Pak. J. Stat 35(1), 25–51 (2019).
Jorgensen, B. Statistical properties of the generalized inverse gaussian distribution, Springer-Verlag. Heidelberg https://doi.org/10.1007/978-1-4612-5698-4 (1982).
Sapkota, L. P. et al. Fitting Real Data Sets by a New Version of Gompertz Distribution. Mod. J. Stat. 1(1), 25–48. https://doi.org/10.64389/mjs.2025.01109 (2025).
Noori, N. A., Abdullah, K. N. & khaleel, M. A. Development and Applications of a New Hybrid Weibull-Inverse Weibull Distribution. Mod. J. Stat. 1(1), 80–103. https://doi.org/10.64389/mjs.2025.01112dd (2025).
Gazar, A. M., Ramadan, D. A., ElGarhy, M. & El-Desouky, B. S. Estimation of Parameters for Inverse Power Ailamujia and Truncated Inverse Power Ailamujia Distributions Based on Progressive Type-II Censoring Scheme. Innov. Stat. Probab. 1(1), 76–87. https://doi.org/10.64389/isp.2025.01106 (2025).
Orji, G. O. et al. A New Odd Reparameterized Exponential Transformed-X Family of Distributions with Applications to Public Health Data. Innov. Stat. Probab. 1(1), 88–118. https://doi.org/10.64389/isp.2025.01107 (2025).
Acknowledgements
The authors extend their appreciation to Taif University, Saudi Arabia, for supporting this work through project number (TU-DSPP-2024-162).
Funding
This research was funded by Taif University, Saudi Arabia, project No. (TU-DSPP-2024-162)
Author information
Authors and Affiliations
Contributions
Fatma and Amirah did the writing, Meraou, Eslam , Wafa, Zakiah, Abdisalam did the mathematics and formal analysis, and Abeer, Hassan did the programming, and editing the language
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Aljohani, H.M., Zaghdoun, F.M., Meraou, M.A. et al. A novel extension of the exponential distribution with application in modeling complex lifetime and environmental data. Sci Rep 15, 33581 (2025). https://doi.org/10.1038/s41598-025-18711-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18711-6
