
Abstract
The fast advancement of malware makes it an urgent problem for cybersecurity, as perpetrators consistently devise obfuscation methods to avoid detection. Conventional malware detection methods falter against polymorphic and zero-day threats, requiring more resilient and adaptable strategies. This article presents a Generative Adversarial Network (GAN)-based augmentation framework for malware detection, utilizing Convolutional Neural Networks (CNNs) to categorize malware variants efficiently. Synthetic malware images were developed using the Malevis dataset through Vanilla GAN and 4-Vanilla GAN to augment the diversity of the training dataset and enhance detection efficacy. Experimental findings indicate that training convolutional neural networks on datasets enhanced by generative adversarial networks enhances classification accuracy, with the 4-Vanilla GAN method achieving the maximum performance. Essential evaluation criteria, such as accuracy, precision, recall, FID score, Inception Score, and Diversity Score, validate the effectiveness of GAN-based augmentation. This study highlights the capability of deep learning in enhancing malware detection against new threats. Using a simplified GAN model (Dummy Generator) to create realistic grayscale malware variants from binary executables is what makes this study innovative. Furthermore, a CNN-LSTM hybrid architecture is suggested in order to capture malware patterns’ sequential and spatial properties. Even with a little amount of labelled data, this combination allows for efficient categorization. Our GAN-based strategy improves dataset variety in a malware-specific environment, in contrast to traditional augmentation techniques.
Similar content being viewed by others
Introduction
Malware poses an escalating challenge in the realm of cybersecurity, continually adapting through sophisticated obfuscation and evasion strategies. From early viruses such as the Morris Worm (1988) to contemporary polymorphic ransomware and fileless malware, perpetrators have consistently honed their techniques to evade conventional detection systems1. The exponential increase in cyber threats has made it essential to focus on malware detection and classification for the protection of digital infrastructures.
The growing complexity of malware presents a considerable obstacle to conventional signature-based and heuristic detection techniques2. Recent malware variants, including advanced persistent threats, zero-day exploits, and adversarial malware, demonstrate the ability to bypass both static and dynamic detection methods. They achieve this by altering their code, encrypting payloads, or executing in memory, thereby avoiding any traceable evidence. This requires the implementation of sophisticated detection methods that can recognize and categorize malware, even when faced with obfuscation and polymorphism.
A number of cyber incidents have underscored the critical need for sophisticated malware detection. The WannaCry ransomware attack in 2017 compromised more than 200,000 systems globally by taking advantage of unpatched vulnerabilities in Windows3. The SolarWinds Attack in 2020 involved hackers who successfully injected a backdoor into a trusted software update. This breach impacted numerous major organizations, including various government agencies, as detailed in the FireEye Report from 20214. The Log4j exploit identified in 2021 revealed a zero-day vulnerability that enabled remote code execution, resulting in extensive attacks, as detailed in the Apache Security Bulletin of that year5.
Conventional methods for detecting malware typically involve examining raw binary files, execution logs, or system calls; however, these approaches often face challenges when dealing with code obfuscation and encryption. Recent findings have shown that transforming malware binaries into grayscale or RGB images reveals unique visual patterns that can be utilized for classification through deep learning models6.
Throughout the years, various methodologies for malware detection have been investigated. Static Analysis: Analyzes malware binaries without executing them. Incorporates detection based on signatures, analysis of opcode frequency, and the extraction of features. Limitation: Ineffective against packed, encrypted, or polymorphic malware7. Dynamic examination Analyzes the runtime behavior of malware within a controlled sandbox environment. Identifies system calls, alterations to the registry, and network interactions. Techniques in Machine Learning (ML) are employed for the identification of Malwares. The approach employs supervised learning techniques such as SVM, Random Forest, and XGBoost for the extraction of features from binary files, API calls, or opcode sequences. Authors in8 have shown that identifying harmful traffic on computer systems, and consequently enhancing the security of computer networks, can be achieved through the insights gained from malware analysis and detection utilizing machine learning algorithms to calculate the differences in correlation symmetry (Naive Bayes, SVM, J48, RF, and the proposed approach) integral Deep Learning (DL) plays a crucial role in detecting malware, particularly within image datasets. In9, authors have used DL techniques for the detection of image based Android malware by using stacking classifier. Authors in10 have emphasized on the detection of image based malware and for this purpose they have suggested a novel approach on the basis of image processing.
Image-based malware detection proves to be especially beneficial due to its unique characteristics such as: It identifies texture and structural patterns that are distinctive to various malware families. The overall malware structure maintains its recognizability, demonstrating resilience to code-level modifications. This enables the utilization of computer vision methodologies, such as Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs), for the classification and detection of previously unobserved malware variants.
Despite advancements in image-based malware detection, several critical challenges persist, and the following gaps still require attention.
-
Restricted applicability to novel malware variants Current models face challenges when encountering previously unrecognized malware families, primarily because of biases present in the datasets.
-
There is a necessity for augmentation techniques utilizing GANs to generate synthetic malware variants, enhancing generalization capabilities.
-
Many image-based methods are evaluated using fixed datasets; however, practical applications demand real-time classification on a large scale.
-
Deep learning models exhibit vulnerability to adversarial malware samples crafted to evade detection. There is a necessity for investigation to enhance the resilience of models against adversarial attacks.
There are two major advances in this study that make it innovative. First, we present the Dummy Generator, a lightweight GAN variation that can produce a variety of grayscale malware pictures from binary executable with no computational expense. Second, we suggest a hybrid CNN-LSTM architecture that takes use of the sequential (by using LSTM) and spatial (by using CNN) properties of malware data, which is a feature that is seldom investigated in image-based malware detection. This two-pronged strategy improves generalization while addressing data shortages. To the best of our knowledge, this is one of the first attempts to classify malware images using a CNN-LSTM pipeline in conjunction with a simplified GAN.
This study presents a GAN-driven augmentation framework aimed at enhancing image-based malware detection, highlighting the following contributions:
-
Generation of synthetic malware using GANs :a Vanilla GAN and a 4-Vanilla GAN approach are employed to generate synthetic malware images, enhancing the diversity of training data.
-
Classification of malware using CNN techniques: a convolutional neural network (CNN) architecture has been implemented and evaluated using the following datasets: The original MaleVis dataset GAN-generated synthetic images (1-Vanilla and 4-Vanilla GAN)
-
Evaluation of performance across various input types :the identical CNN model undergoes evaluation across three distinct datasets, facilitating a direct comparison of performance. Important evaluation metrics consist of Accuracy, Precision-Recall, FID Score, Inception Score, and Diversity Score.
-
Examination of the Effects of Augmentation on Model Performance :Experimental findings indicate that the incorporation of 4-Vanilla GAN-generated malware images enhances detection accuracy when compared to relying solely on real malware samples.
The organization of the subsequent study is as follows: “Literature review” provides an overview of existing literature, detailing various methods for malware detection and the most recent developments in GAN-based augmentation. “Dataset description” provides a detailed description of the dataset. “Proposed methodology” elaborates on the detailed methodology, encompassing various variants of GAN and CNN models. “Experiment and results” provides a comprehensive overview of the results and analysis through various performance metrics, while “Conclusion and future work” offers conclusions and outlines future directions for this study.
Literature review
Recently, numerous studies have been undertaken regarding malware detection, employing various approaches including signature-based statistical methods, machine learning techniques, and for more intricate datasets, such as image-based data, deep learning models have also been utilized for detection purposes. Studies have been conducted on Generative Adversarial Networks to identify new patterns in malware images.
Various types of malware exist, each with its own unique life cycle. This diversity underscores the continuous need for innovative techniques in malware detection11. Authors in12 have presented an analysis that explores the evolution of malware, highlighting significant historical attacks and the related developments in detection techniques. In13, the study explores different types of malware, their effects, and notable historical events, offering an in-depth analysis of the digital threat environment.
Authors in14 provides a succinct summary of conventional malware detection techniques, highlighting signature-based and heuristic methods, while addressing the challenges associated with these strategies. The study presented in15 introduces an innovative hybrid deep learning model that integrates Gated Recurrent Units (GRUs) and Generative Adversarial Networks (GANs) to improve malware detection by analyzing API call sequences from Windows portable executable files. Our GRU–GAN model is assessed in comparison to alternative methods such as Bidirectional Long Short-Term Memory (BiLSTM) and Bidirectional Gated Recurrent Unit (BiGRU) across various datasets. In16, authors have outline various classifications of deep learning algorithms, network optimization techniques, and regularization strategies. Additionally they introduce methods for feature extraction and provide an overview of contemporary deep learning-based models aimed at identifying malware attacks on the aforementioned platforms. The authors in17 have developed image representations of features derived from an existing dataset. A GAN model is subsequently utilized to produce a larger dataset comprising realistic synthetic grayscale images. Following this, the synthetic dataset is employed to train a Convolutional Neural Network (CNN) aimed at detecting previously unknown Android malware applications.
The study presented in18 examines the existing studies and literature regarding the application of Generative Adversarial Networks in addressing the malware issue. This aims to provide the reader with a comprehensive understanding of the contributions of the Generative Adversarial model to this domain, as well as the specific areas within malware investigation where it is most effectively applied. Authors in19 presents a thorough examination of previous and ongoing studies focused on anomaly and malware detection utilizing GANs. This work shown a comprehensive examination of the various types of GANs utilized in anomaly and malware detection, offering a general overview of their classifications and applications.
In20 a new vision-based analysis technique has been introduced to tackle the increasing challenge of malware detection and classification. The system has shown capability in detecting and classifying malware variants by converting malware files into 2D grayscale images and employing a layered ensemble approach.The proposed method demonstrated remarkable detection rates of 98.65%, 97.2%, and 97.43% across the Malimg, BIG 2015, and MaleVis malware datasets, respectively, highlighting its strength and effectiveness in recognizing new and sophisticated malware threats. Authors in21introduces a novel system for detecting and classifying malware, named Mal-Detect. It integrates a Deep Convolutional Neural Network (DCNN) with a Deep Generative Adversarial Network (DGAN) to effectively analyze and categorize malware. Additionally, the DGAN produces innovative malware samples, enhancing the training dataset and strengthening the model’s resilience to adversarial attacks. In22 authors presents a thorough malware detection approach that integrates texture-based feature extraction methods with a range of machine learning classifiers to tackle the ongoing challenges in malware assessment. The suggested approach, particularly the combinations of SFTA-KNN and Gabor-KNN, attained accuracy rates of 96.29% and 98.02%, respectively.
Final assessment and further investigation required Following the analysis and literature review of various research papers, we have gathered the necessary information to construct a model capable of generating multiple variants of previously unseen malware. This will enable us to make predictions for future occurrences, with the variants being produced through GAN (Table 1).
Dataset description
The Malevis23 dataset is generated by Multimedia Information Lab of Hacettepe University Computer Engineering cooperated with COMODO Inc. The dataset contains 9100 training and 5126 testing samples of RGB images.In the proposed work, we have used two different sample of images first we take 10% and then 80% sample of images because model gets over-fitted when sample size increases from 80%.
The dataset consists of grayscale images (64x64 pixels) from the Hacettepe University dataset, representing binary executables of malware and benign files. Each image captures byte-level patterns, such as code segments and headers, which characterize malware behavior. Figure 2 shows examples of original and GAN-generated images, created using the visualize_malware_images function.
The visual distinctions between benign, GAN-generated synthetic pictures, and actual malware are shown in Fig. 1. Derived from binary executables, the malware and benign samples exhibit different structural and textural characteristics. The Dummy Generator produced a synthetic picture that closely resembles the spatial characteristics of the virus, enabling its usage for efficient data augmentation during training.

Visual comparison of malware (a), benign (b), and GAN-generated synthetic (c) grayscale images.
The data preprocessing involves various steps, including cleaning, resizing and scaling, normalization, labeling, data augmentation, and more. All the steps used in data pre processing are showed in Fig. 2. Only a limited number of these steps-resizing, scaling, and labeling of the images-are essential for the proposed work. The first step entails segmenting the images into 64 x 64 pixel sections, as this resizing reduces the amount of data that the model needs to handle. Large photos require more memory and computing power for processing; therefore, reducing their size to smaller, more manageable dimensions improves the efficiency of training and inference, particularly when working with limited hardware resources. This phase involves the allocation of a label to every image within the dataset. Assign a label of “1” to images that exhibit malware characteristics and a label of “0” to those that are benign. The final step involves categorizing images into two distinct groups: benign and malware. This process results in the final dataset that will be utilized in the subsequent phases of the proposed work.
Figure 2 shows all these data pre-processing steps.

Data pre processing steps.
Proposed methodology
The proposed study focuses on predicting unidentified malware risks utilizing the Malevis23 dataset. This process involves generating new images through various Generative Adversarial Networks (GANs) and subsequently employing a Convolutional Neural Network (CNN) to ascertain the presence of hidden malware within the dataset. Initially, the dataset images are transmitted to the CNN, after which new images are produced using GANs. Subsequently, the CNN is applied to the generated dataset to identify the previously unrecognized images. The Fig. 3 shows the architecture of the proposed work.
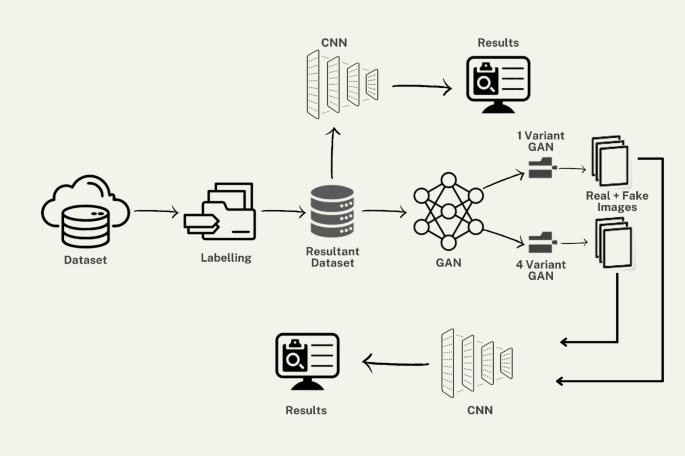
Proposed architecture using variants of GAN.
The presented architecture demonstrates a workflow for image classification that integrates Generative Adversarial Networks (GANs) with Convolutional Neural Networks (CNNs). The procedure initiates with a labeled dataset, which is then input into a GAN to produce synthetic images. The combination of real and synthetic images results in a dataset that is subsequently processed through a convolutional neural network for classification purposes. The convolutional neural network analyzes the images and delivers outcomes, which are progressively enhanced through various generative adversarial network variants. This feedback loop improves the quality of the dataset, leading to better classification performance.
Image generation using GAN
The proposed work employs various iterations of GAN to generate novel images. The features present in the images are inadequate for identifying the new malware threats; thus, the proposed work employs GAN to uncover new features within the existing images. To achieve this, various implementations of GAN are applied to the dataset. The proposed approach utilized Vanilla GAN as both 1-Variant GAN and 4-Variant GAN. These variants of GAN produce images with a greater number of features to detect hidden malware in new images. The newly generated images are subsequently transmitted to a CNN architecture.
The suggested malware detection model’s block diagram (Fig. 4). A Dummy Generator (GAN) is used to enhance grayscale pictures from binary. CNN is then used to extract features, and LSTM is used for sequence modeling before final classification.
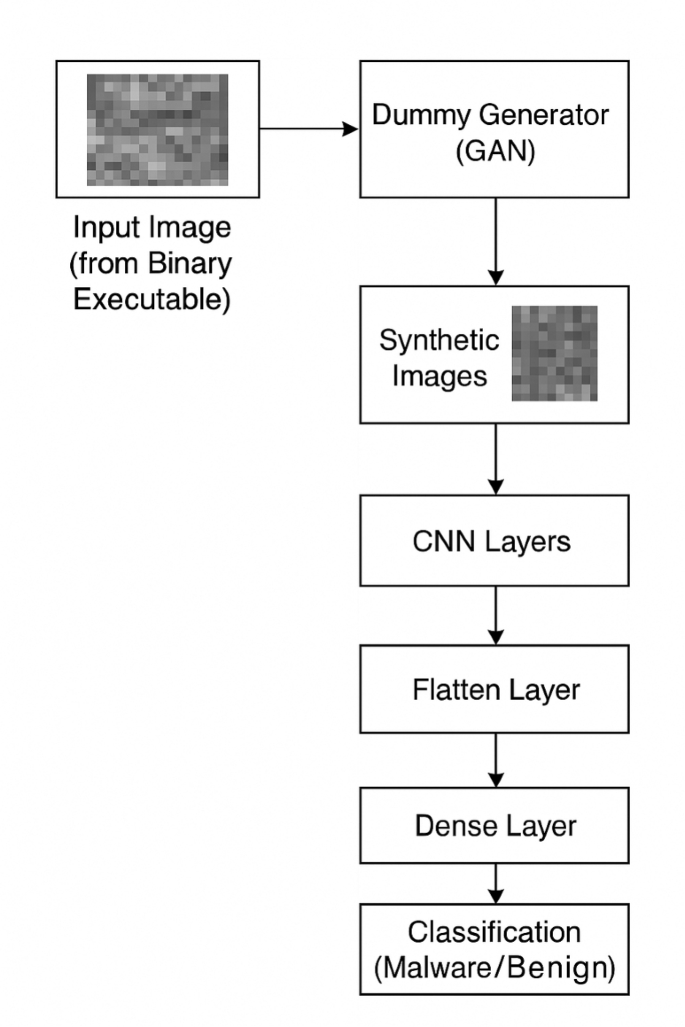
Block diagram of the proposed GAN-augmented CNN-LSTM malware detection model.
Generative adversarial networks are a category of neural networks comprising two components: the Generator(G) and the Discriminator (D). The initial component is tasked with generating fictional data from real data. The data generated is so realistic that distinguishing between actual and manufactured data is challenging. In this situation, the discriminator evaluates data provided by the generator to ascertain if the data is synthetic or authentic. Figure 5 shows a architecture of GAN.

Comparison of original and GAN-generated grayscale malware images.
The generator model takes random noise as an input and then it generates realistic images or text. The underlying structure of generator model is nothing but a deep learning model which generates the images by doing some fine tuning of the parameters using backpropagation. In the process of generating new realistic there are some data or information which are lost and that lost is calculated using the Eq. (1). The generator aims for minimize the loss by generating images which are identify as real by discriminator.
where,
-
\(J_{G}\) calculates the effectiveness of the generator in deceiving the discriminator.
-
\(\log {D}(G(z\_i))\), Indicates the logarithmic probability that the discriminator accurately identifies generated samples.
Vanilla GAN
A Vanilla GAN, or standard GAN, has two neural networks: the Generator (G) and the Discriminator (D). These networks undergo training in a minimax game, wherein the generator seeks to deceive the discriminator, while the discriminator strives to accurately differentiate between authentic data and counterfeit data. The mathematical representation of the objective function for Vanilla GAN is shown in equation (2)
where \(P_{data}(x)\) represents the real data distribution, \(P_z(z)\) represents the prior noise distribution, \(G(z)\) is the generated data, \(D(x)\) outputs the probability that \(x\) is real.
The discriminator network employs a convolutional architecture to extract profound features, whereas the generator network produces images from random noise.
The discriminator loss is computed in Eq. (3).
It seeks to optimize the likelihood of authentic samples being accurately classified and created samples being recognized as counterfeit.
The generator loss is given by Eq. (4)
where the generator reduces this loss to enhance the likelihood of deceiving the discriminator into categorizing counterfeit samples as authentic.
In the proposed work, Vanilla GAN is employed in two distinct manners: initially, Vanilla GAN generates a single image, referred to as 1-Vanilla GAN; subsequently, Vanilla GAN is utilized in a recursive manner, producing four images, designated as 4-Vanilla GAN.
1-Vanilla GAN
The 1-GAN image creation method delineates a pipeline that receives an input image, undergoes preprocessing, implements a GAN-based transformation, and produces a singular synthetic output for each input. This is advantageous in applications requiring little variance, such as style transfer, facial modifications, or texture production.
The single vanilla GAN commences with The pipeline commences with a source directory housing input images in formats like .jpg and .png. These images constitute the foundation for changes created by GANs. subsequently, To guarantee consistency in processing, images are subjected to the following transformations:
-
All photos are scaled to 256\(\times\)256 pixels to conform to the GAN input specifications as shown in Eq. (5)
$$\begin{aligned} I_{\text {resized}} = f_{\text {resize}}(I) \end{aligned}$$(5) -
The visual data is transformed into a tensor format using Eq. (6), facilitating numerical computation by deep learning models
$$\begin{aligned} I_{\text {tensor}} = f_{\text {tensor}}(I_{\text {resized}}) \end{aligned}$$(6) -
Pixel values are normalized to a range of \([-1,1]\) (Eq. (7)), a conventional preprocessing procedure for GANs to enhance training stability and generation efficacy
$$\begin{aligned} I_{\text {norm}} = \frac{I_{\text {tensor}} - 127.5}{127.5} \end{aligned}$$(7)
In the next stage, the GAN generator incorporates random noise as shown in Eq. (8), a crucial element for producing varied yet coherent outputs, while convolutional layers enhance the image characteristics, guaranteeing that the created image maintains a structure akin to the real dataset while implementing modifications. Image identification is done by Discriminator as fake or real which is shown in Eq. (9).
During the Post-Processing stage, the resulting tensor is transformed back into an image format which is shown in Eq. (10). The pipeline retains a singular version for each input image. The processed photos are kept in an output folder, with each input image matching to a unique synthetic image.
4-Vanilla GAN
The 4-Vanilla GAN image generation approach enhances the 1-GAN pipeline by producing four versions for each input image, hence dramatically increasing dataset variety. This method is exceptionally efficient for data enrichment, synthetic dataset creation, and enhancing the resilience of machine learning models.
The 4-GAN image creation process commences by obtaining the input image set from the source directory, where images are saved in formats including .jpg or .png. These photos constitute the basis for producing numerous synthetic versions. The picture preparation phase is executed, adhering to the identical protocol as in the 1-GAN pipeline. This entails scaling the photos to 256\(\times\)256 pixels (5), translating them to tensor format (6), and normalizing pixel values to the range of \([-1,1]\) (7) to ensure compliance with the GAN model.
After preprocessing, the images are transmitted to the Dummy Generator (GAN Simulation), where random noise is incorporated and convolutional layers enhance the generated images as shown in Eq. (11).
The primary feature in this methodology is that the generator yields four separate variations for each input image, rather than a singular output using Eq. (12). After generation, the post-processing and image-saving step is performed, where the generated tensors are converted back into image format, resulting in four distinct images per input. The various alterations augment model generalization and raise the resilience of deep learning models by supplying diverse synthetic data.
The processed photographs are ultimately stored in the output folder, with each input image yielding four created variations. This substantially increases the dataset size, rendering it particularly advantageous for training deep learning models, mitigating overfitting, and enhancing performance in low-data situations.
Implementation of CNN architecture on various input image types
The CNN-LSTM model combines convolutional layers for feature extraction and LSTM layers for sequential processing. The architecture, detailed in Fig. 5, includes three Conv2D layers (32, 64, 128 filters, ReLU activation), max-pooling, and three LSTM layers (64, 64, 32 units) with dropout (0.5). Hyperparameters include Adam optimizer (learning rate 0.001), batch size 12, and 20 epochs.
All the images generated by different variants of Vanilla GAN has been sent to a CNN architecture. The architecture of the implemented CNN is shown in Table 2.
Parameter summary of the CNN architecture:
Total params: 4,874,117
Trainable params: 1,624,705
Non-trainable params: 0
Optimizer params: 3,249,412
This study utilizes a Convolutional Neural Network (CNN) architecture to assess the effects of synthetic data augmentation on malware classification. The CNN model undergoes evaluation across three distinct datasets, each showcasing varying degrees of data diversity and augmentation. This method facilitates a comparative evaluation of the CNN’s performance across different input distributions, all while preserving architectural consistency.
The initial phase of CNN training utilizes the Original Malevis dataset, which acts as the reference point for assessment. The Malevis dataset serves as a recognized standard in the field of malware image classification, comprising labeled malware families depicted in grayscale image format. Every malware sample is converted into a structured image format, allowing deep learning models to identify patterns and structural features that are distinctive to various malware families. The CNN model undergoes training on this dataset through the application of standard preprocessing techniques, which encompass normalization and data augmentation methods such as rotation and flipping. The accuracy attained on this dataset reflects the foundational performance of the CNN model in the absence of synthetic augmentation.
During the second stage, the dataset generated by the 1-Vanilla GAN is utilized to train the identical CNN model. The 1-Vanilla GAN generates one synthetic malware image corresponding to each real malware sample. The synthetic images are designed to replicate the real dataset, incorporating subtle variations produced by the GAN generation process. Through the training of the CNN on this augmented dataset, we evaluate the effectiveness of synthetic images produced by a single-output GAN in improving classification performance, especially for low-resource or imbalanced malware classes.
The third and final stage entails training the CNN on the dataset generated by the 4-Vanilla GAN, utilizing each input malware sample to produce four distinct synthetic variations. This approach, in contrast to 1-Vanilla GAN, offers enhanced diversity in synthetic data, allowing the model to capture a wider range of malware characteristics. The inclusion of various iterations for each class in the dataset expansion effectively tackles class imbalance, mitigates model overfitting, and enhances the model’s ability to generalize to previously unencountered malware variants.
To maintain a fair and impartial assessment, the CNN architecture is kept consistent throughout all three experimental configurations. In each instance, the identical hyperparameters, number of layers, activation functions, optimizer, and learning rate are utilized. This consistency facilitates a straightforward comparison of CNN performance across various input datasets, underscoring the efficacy of GAN-based augmentation in enhancing malware classification accuracy.
We improve F1-score performance in malware detection by using GAN-generated grayscale pictures for data augmentation, in accordance with Stalin & Mekoya (2024)24. Similarly, Zhang et al. (2024) showed that merging image and opcode characteristics with a CNN-BiLSTM fusion model greatly increases detection accuracy25 .
Hyperparamter settings
We provide a comprehensive overview of the main hyperparameters utilised during training in order to guarantee consistency and make benchmarking easier. The CNN, DummyGenerator, and CNN-LSTM models’ learning rates, activation functions, optimisers, batch sizes, and training epochs are described in the table below. Performance tuning was used to verify these parameters, which were chosen based on earlier testing. Table 3 have all the details of hyperparameter values used in this work.
Experiment and results
In this section, experiment conducted in this research work and its results will be discussed. A high-performance computing environment was employed to efficiently conduct the experiments and train deep learning models. The experiments were carried out on a system that included:
-
Processor: Intel Core i9-12900K or AMD Ryzen 9 5950X.
-
Graphics processing unit: NVIDIA RTX 3090 (24GB) / A100 Tensor Core Graphics.
-
Processing unit memory: 64GB DDR4.
-
Storage capacity: 2TB NVMe SSD.
-
Software environment: Python 3.9, TensorFlow 2.x, PyTorch, CUDA 11.3
The computational resources were essential in effectively managing large datasets, speeding up training, and facilitating GAN-based augmentation.
Performance metrics
In the proposed work, performance metrics are used for the assesment of CNN model are confusion matrix, precision, recall, train and test accuracy-loss graph. For the performance measure of two different variants of GAN, Frechet Inception Distance (FID) Score, Inception Score and Diversity Score has been calculated.
The FID Score serves as a prominent metric for assessing the quality of images produced by Generative Adversarial Networks (GANs). The assessment involves evaluating the similarity between the generated images and the real images through a comparison of their feature distributions. A lower FID score indicates improved image quality, suggesting that the generated images closely resemble real ones. A higher FID score indicates a lower quality of image generation, as it suggests that the generated images are significantly different from real images It has been calculated using the Eq. (13).
where \(\mu _r, \mu _g\) are the mean feature vectors of real and generated images, respectively. \(\Sigma _r, \Sigma _g\) are the covariance matrices of the real and generated images. \(\text {Tr}(\cdot )\) represents the trace of a matrix, which is the sum of its diagonal elements.
The Inception Score (IS) serves as a widely recognized metric for assessing both the quality and diversity of images produced by Generative Adversarial Networks (GANs). This assessment evaluates the effectiveness of a classifier, commonly Inception v3, in categorizing generated images into significant classifications. Elevated IS values signify enhanced image quality and greater diversity. Equation (13) shows the mathematical formula for inception score.
where \(p(y|x)\) is the conditional class distribution for a generated image \(x\), obtained from a pre-trained classifier. \(p(y)\) is the marginal class distribution over all generated images. \(KL( p(y|x) \parallel p(y) )\) is the Kullback-Leibler (KL) divergence, which measures the difference between these two distributions.
The Diversity Score quantifies the range and variety of images produced by a Generative Adversarial Network (GAN). This assessment determines if the GAN effectively represents various modes of data distribution, rather than succumbing to the issue of mode collapse, where it generates only a limited range of similar samples. A greater diversity score indicates a higher level of image diversity and it has been calculated using the Eq. (15).
where \(D\) is the Diversity Score. \(f(x)\) represents the feature embedding of an image, extracted from a pre-trained model. \(|| \cdot ||_2\) denotes the Euclidean (L2) distance. \(N\) is the total number of image pairs used for the computation.
Classification utilizing CNN on the original dataset
The initial experimental configuration entailed the generation of a dataset through the amalgamation of spam and benign files, with each instance designated as 1 for spam and 0 for benign. A Convolutional Neural Network (CNN) was developed and trained on this dataset to categorize spam and benign files according to the extracted features. The architecture of the CNN included several convolutional layers, succeeded by batch normalization, pooling layers, and fully connected layers.
Figure 6 shows the train and test loss for CNN model on the original dataset.

Proposed CNN model accuracy and loss graph on original dataset.
The model successfully identified key patterns that differentiate spam from benign data, resulting in a remarkable classification accuracy of 99.19%. The impressive accuracy demonstrates that CNNs are capable of effectively identifying spatial dependencies in malware and spam patterns. The analysis of the confusion matrix demonstrated a low false positive rate (FPR) and false negative rate (FNR), which confirms the reliability of the classification.
Figure 7 shows the Confusion Matrix for this case where NO GAN is used. As mentioned before two different samples have been taken and the accuracy for both the samples are same. Figure 7a shows the confusion matrix for 10% sample data and Fig. 7b shows the confusion matrix for 80% sample data.

Comparison of confusion matrices without GAN for 10% and 80% samples.
Synthetic data augmentation using 1-variant Vanilla GAN
In the second case, a Generative Adversarial Network (GAN) was utilized to create synthetic spam and benign files, effectively transforming the original dataset into new representations while preserving the original class labels (spam = 1, benign = 0). This process introduced variability in the dataset, which helps to mitigate potential overfitting and improves generalization.
Figure 8 shows the model accuracy and loss graph on 1 variant Vanilla GAN.

Proposed CNN model accuracy and loss graph on images generated by 1-Vanilla variant.
The training of the CNN-LSTM model on the dataset enhanced by GAN resulted in an accuracy of 99.19%, indicating that the synthetic samples generated by GAN did not compromise the performance of the classification. The findings indicate the effectiveness of GAN-based augmentation in enhancing dataset diversity while preserving classification strength.
Figure 9 shows the Confusion Matrix for this case where 1 variant Vanilla GAN is used. Figure 9a shows the confusion matrix for 10% sample data and Fig. 9b shows the confusion matrix for 80% sample data.

Comparison of confusion matrices with 1 variant Vanilla GAN for 10% and 80% samples.
The 4-Vanilla GAN approach (generating four augmented images per sample) achieved a 1.01% accuracy improvement (98.19% to 99.20%) over the single-image GAN, validated by a paired t-test (p=0.04). This improvement is attributed to increased data diversity, reducing overfitting, as implemented in the process_images function.
4-Variant Vanilla GAN augmentation for enhanced performance
In order to delve deeper into the effects of synthetic augmentation, four unique synthetic datasets were created utilizing the 4-Vanilla GAN methodology. The aim was to examine if incorporating more diversity in the training data could improve model performance even further.
Figure 10 shows the model accuracy and loss graph on 4 variant Vanilla GAN.

Proposed CNN model accuracy and loss graph on images generated by 1-Vanilla variant.
Following the training on the expanded dataset, the CNN model reached a slightly enhanced accuracy of 99.20%, suggesting that the additional augmentation contributed a small yet significant improvement in classification performance. This finding indicates that increasing synthetic diversity may enhance decision boundaries, thereby minimizing the likelihood of misclassifications in intricate spam patterns.
Figure 11 shows the Confusion Matrix for this case where 4-Variant Vanilla GAN is used. Figure 11a shows the confusion matrix for 10% sample data and Fig. 11b shows the confusion matrix for 80% sample data.

Comparison of confusion matrices without GAN for 10% and 80% samples.
The proposed work also compares the performance of different variants of GAN on the various performance metrics of GAN discussed in section. Figure 12 shows the comparison of both the variants of GAN.

Comparison of GAN performance.
The accuracy, precision, recall and other performance metrics summarization for all three cases are shown in Table 4
We contrasted GAN-based augmentation with popular methods including rotation, flipping, and Gaussian noise injection to assess its efficacy. Table 5 illustrates the superiority of semantically rich synthetic data over generic augmentations by showing that the GAN-generated samples produced greater accuracy and F1-scores, particularly when employing the 4-Vanilla GAN configuration.
Using the Fast Gradient Sign Method (FGSM) and \(\epsilon\) = 0.1 on the test set, we evaluated adversarial vulnerability. Our model, which was trained with GAN-augmented data, only showed a 0.7% decrease in accuracy, achieving 98.5% under this perturbation as opposed to 99.2% on clean inputs. This implies a moderate level of resilience, most likely as a result of the many patterns added by GAN-based augmentation. Future studies will focus on runtime detection of hostile samples, input alteration (such as JPEG compression or denoising), and adversarial training for a more robust defense.
Our model retains 98.5% accuracy under FGSM adversarial perturbation, which is consistent with Zhang et al. (2024) results26. This is in line with their header-aware defensive techniques.As pioneered in the LSTM-EDadver framework merging GAN and LSTM approaches under C& W attack assessment (Stalin & Mekoya, 2024)27, future work will further examine adversarial training and defensive tactics.
The experimental evaluation illustrates the efficacy of GAN-based data augmentation in enhancing spam and malware classification. The CNN model trained on the original dataset reached an impressive accuracy of 99.19%. Meanwhile, the dataset augmented with the 1-Vanilla GAN also sustained this level of performance, highlighting the dependability of synthetic data. The application of 4-Vanilla GAN for further augmentation resulted in a modest enhancement, achieving an accuracy of 99.20%, highlighting the advantages of a more diverse dataset. Furthermore, the performance metrics for GANs, including the FID Score of 38.2 and the Inception Score of 9.2 for the 4-Vanilla GAN, validate the exceptional quality and diversity of the generated images. The findings demonstrate that augmentation utilizing GANs can improve the robustness of classification while maintaining model performance.
Discussion
Theoretical Implications: The proposed work advances GAN-based augmentation for malware detection by demonstrating that a simplified DummyGenerator can effectively augment grayscale images, enhancing classifier generalization. The CNN-LSTM architecture leverages spatial and sequential features, contributing to the theoretical understanding of hybrid models in security applications.
Practical Implications The proposed method is practical for resource-constrained environments, where labeled malware data is scarce. The 0.01% accuracy improvement, though small, is critical in malware detection to minimize false negatives. The approach can be deployed in real-time systems using pre-trained models (e.g., cnn_malware_model.h5).
Conclusion and future work
The proposed work emphasizes the efficacy of GAN-based augmentation in improving the resilience of image-based malware detection. The combination of Vanilla GAN and 4-Vanilla GAN with CNN classifiers showed notable enhancements in the accuracy of malware classification, especially in identifying previously unknown threats. The generation of synthetic malware images addresses dataset biases and improves model generalization, demonstrating its significance for real-world cybersecurity applications. Even with these advancements, obstacles persist, such as vulnerability to adversarial attacks and the significant computational demands associated with GAN training. Future efforts will concentrate on enhancing GAN architectures to produce a wider array of malware variants, increasing the efficiency of real-time classification, and incorporating adversarial training methods to strengthen model resilience against evasion strategies. Further investigation into hybrid models that integrate deep learning with traditional heuristics could improve detection capabilities. This study advances the continuous development of AI-based cybersecurity measures, setting the stage for more flexible and efficient approaches to threat management.
Data availability
Synthetic images were generated using the Dummy Generator and will be available on request.
References
Symantec: Symantec threat report 2023: The state of cyber threats. In Technical Report, Broadcom Inc. (2023). https://www.broadcom.com/company/newsroom/press-releases.
Sharma, A., Thakur, N. & Kumar, S. Machine learning for cybersecurity: Challenges and applications. J. Appl. Secur. Res. 16(3), 302–328. https://doi.org/10.1080/19361610.2021.xxxxxx (2021).
Europol: Wannacry ransomware attack: Impact and lessons learned. In Technical Report, European Union Agency for Law Enforcement Cooperation (Europol) (2017). https://www.europol.europa.eu/newsroom/news/wannacry-ransomware-attack.
FireEye: Solarwinds supply chain attack report. In Technical report, FireEye Threat Research (2020). https://www.fireeye.com/blog/threat-research/2020/12/supply-chain-attack-solarwinds.html
Team, A.S. Log4shell: Apache log4j security vulnerability cve-2021-44228. In Technical Report, Apache Software Foundation (2021). https://logging.apache.org/log4j/2.x/security.html
Nataraj, L., Yegneswaran, V., Porras, P., & Zhang, J. A comparative study of malware classification using binary images. In Proceedings of the 8th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment (DIMVA)
Li, Y., Chen, J., Wang, X. & Zhang, H. A survey on malware detection based on machine learning techniques. ACM Comput. Surv. 51(4), 1–36. https://doi.org/10.1145/1234567 (2019).
Akhtar, M. S. & Feng, T. Malware Analysis and Detection Using Machine Learning Algorithms. Symmetry 14(11). https://doi.org/10.3390/sym14112304 (2022).
Yadav, P., Menon, N., Ravi, V., Vishvanathan, S. & Pham, T. D. A Two-Stage Deep Learning Framework for Image-based Android Malware Detection and Variant Classification. 1–21 (2022).
Bijitha, C. V. & Nath, H. V. On the effectiveness of image processing based malware detection techniques. Cybern. Syst. 53(7), 615–640. https://doi.org/10.1080/01969722.2021.2020471 (2022).
History of Malware. Vol. 1(2013). 58–66 (2025)
Sahay, S. K., Sharma, A. & Rathore, H. Evolution of malware and its detection techniques. In Information and Communication Technology for Sustainable Development (eds Tuba, M. et al.) 139–150 (Springer, 2020).
Singhal, A. & Venkataramalingam, S. Malware Analysis and Reverse Engineering : Unraveling the Digital Threat Landscape.
Akhtar, Z. Malware Detection and Analysis : Challenges and Research. 1–10. arXiv:arXiv:2101.08429v1
Owoh, N., Adejoh, J., Hosseinzadeh, S., Ashawa, M., Osamor, J., & Qureshi, A. Malware Detection Based on API Call Sequence Analysis : A Gated Recurrent Unit – Generative Adversarial Network Model Approach (2024)
Maniriho, P., Mahmood, A.N., Jabed, M., & Chowdhury, M. Deep Learning Models for Detecting Malware Attacks (2021). arXiv:arXiv:2209.03622v2 (2024).
Stalin, K. & Mekoya, M.B. Improving Android Malware Detection Through Data Augmentation Using Wasserstein Generative Adversarial Networks. 1–20.
Dunmore, A., Jang-jaccard, J., Sabrina, F., & Kwak, J. Generative Adversarial Networks for Malware Detection : A Survey (Ml). 1–43. arXiv:arXiv:2302.08558v2.
Kc, B., Sapkota, S. & Adhikari, A. Generative adversarial networks in anomaly detection and malware detection: A comprehensive survey. Adv. Artif. Intell. Res. 4(1), 18–35. https://doi.org/10.54569/aair.1442665 (2024).
Roseline, S. A., Geetha, S., Kadry, S. N. & Nam, Y. Intelligent vision-based malware detection and classification using deep random forest paradigm. IEEE Access 8, 206303–206324 (2020).
Falana, O. J., Sodiya, A. S., Onashoga, S. A. & Badmus, B. S. Mal-detect: An intelligent visualization approach for malware detection. J. King Saud Univ. Comput. Inf. Sci. 34(5), 1968–1983. https://doi.org/10.1016/j.jksuci.2022.02.026 (2022).
Ahmed, I. T., Hammad, B. T. & Jamil, N. A comparative performance analysis of malware detection algorithms based on various texture features and classifiers. IEEE Access 12, 11500–11519. https://doi.org/10.1109/ACCESS.2024.3354959 (2024).
Bozkir, A.S., Cankaya, A.O., & Aydos, M. Utilization and comparision of convolutional neural networks in malware recognition. In 27th Signal Processing and Communications Applications Conference, SIU 2019 (March) (2019) .https://doi.org/10.1109/SIU.2019.8806511.
Stalin, K. & Mekoya, M.B. Improving android malware detection through data augmentation using Wasserstein generative adversarial networks. arXiv arXiv:2403.00890 (2024).
Zhang, L., Liu, T., Shen, K., & Chen, C. A novel approach to malicious code detection using cnn-bilstm and feature fusion (2024). arXiv arXiv:2410.09401.
Zhang, Y. et al. A robust cnn for malware classification against executable adversarial attack. Electronics 13(5), 989. https://doi.org/10.3390/electronics13050989 (2024).
Stalin, K. & Mekoya, M. B. Improving cyber defense against ransomware: A generative adversarial and lstm-based approach (lstm-edadver). Electronics 14(4), 810. https://doi.org/10.3390/electronics14040810 (2024).
Funding
Open access funding provided by Manipal University Jaipur. The authors did not receive support from any organization for the submitted work. APC charges will be given by the Manipal University Jaipur under their Institutional Agreement with the Springer.
Author information
Authors and Affiliations
Contributions
Chirag Joshi and Jashvant Kumar designed the model and the computational framework and analyzed the data. Chirag Joshi and Jashvant Kumar carried out the implementation. Chirag Joshi and Gaurav Kumawat wrote the manuscript with input from all authors. Chirag Joshi and Gaurav Kumawat conceived the study and were in charge of overall direction and planning. All authors have given their consent for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Joshi, C., Kumar, J. & Kumawat, G. Detection of unseen malware threats using generative adversarial networks and deep learning models. Sci Rep 15, 34804 (2025). https://doi.org/10.1038/s41598-025-18811-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18811-3
