
Abstract
Diffuse nitrate (NO₃−) contamination is a critical environmental concern threatening the quality of coastal groundwater resources, particularly in regions undergoing agricultural intensification and rapid land use changes. This study presents an explainable deep learning framework for predicting nitrate concentrations and identifying areas at risk of elevated contamination. The framework integrates key hydrochemical parameters electrical conductivity (EC), chloride (Cl−), organic matter (OM), and fecal coliforms (FC) with remote-sensing derived indicators, including the Normalized Difference Vegetation Index (NDVI) and land use/land cover (LU/LC). Two deep learning models were evaluated in this study: a Multilayer Perceptron (MLP) and TabNet, a novel attention-based architecture for interpretable tabular data. TabNet outperformed MLP, achieving an overall accuracy of 81.60% and a Macro-averaged recall of 84.13%, while providing transparent feature attribution. LASSO regression identified FC (0.52) and EC (0.48) as dominant predictors, highlighting the combined influence of domestic wastewater and agricultural runoff on nitrate contamination. The output risk maps revealed spatially heterogeneous contamination patterns, with hotspots concentrated in agricultural and peri-urban areas. This research highlights the importance of integrating explainable AI with geospatial analysis to guide targeted groundwater monitoring and management strategies. This approach is transferable to other vulnerable coastal aquifers, supporting sustainable groundwater governance under diffuse pollution conditions.
Similar content being viewed by others

Introduction
The deterioration of groundwater quality poses a major environmental concern, directly affecting human health and overall societal well-being1. Safeguarding groundwater quality is strategically vital, given its central role in supporting agriculture, household consumption, industrial activities, and other fundamental demands2,3. Groundwater quality has a direct bearing on public health, food security, ecological balance, and the trajectory of socio-economic development4. Nevertheless, the sustainability of groundwater resources is increasingly jeopardized by accelerated urbanization, industrial growth, changing agricultural practices, and shifting land use patterns4,5. As a result, environmental transformations coupled with human-induced pressures have substantially impacted groundwater quality, endangering both human well-being and the long-term viability of aquifer systems6,7,8. The quality of groundwater is governed by recharge mechanisms, geological and hydrological settings, water rock interactions, and anthropogenic influences9. Analyzing groundwater chemistry offers valuable insights into the fundamental processes driving the hydrogeochemical evolution of aquifer systems10. This knowledge is important for ensuring the sustainable management and protection of groundwater resources4.
Nitrate (NO₃−) contamination in groundwater is a widespread issue, predominantly attributed to anthropogenic activities11,12. It arises from both point sources, such as septic tanks and livestock waste, and diffuse sources, including agricultural fertilizers, pesticide applications, and atmospheric deposition13. High nitrate concentrations impair local water quality and may trigger eutrophication processes in surrounding aquatic environments14. Prolonged ingestion of nitrate-contaminated groundwater presents serious health hazards, notably increasing the risk of methemoglobinemia in infants15. Nitrate (NO₃−) monitoring and health risk assessment are crucial for informing groundwater protection strategies, as evidenced by numerous studies across diverse environmental contexts16. Several studies have also reported that nitrate contamination often coincides with elevated levels of other dissolved constituents, such as salts, nutrients, and metals, derived from both natural processes and human activities17. In addition, changes in land use and land cover (LU/LC) have been extensively investigated for their influence on groundwater quality, particularly in arid and semi-arid environments18,19,20. Recent urban expansion has modified natural LU/LC configurations, affecting groundwater flow regimes and contributing to water quality deterioration through the influx of various contaminants21. Groundwater degradation is driven by population growth, intensified agriculture, mining operations, and shifts in land management practices22,23. Elevated NO₃− concentrations are commonly reported in agricultural zones as a result of excessive manure use, and in urban areas due to the discharge of organic wastes24,25.
Numerous studies have integrated land cover (LC) assessments with hydrochemical analyses to enhance the understanding of groundwater quality dynamics26,27. In recent years, remote sensing indices such as NDVI (vegetation), NDBI (urbanization), and NDWI (surface moisture) have been increasingly utilized in the management of water resources28. Studies reveal that ion responses vary with changes in NDVI, prompting the growing use of AI techniques, such as machine learning and deep learning, for modeling water quality29,30,31,32. These approaches can model complex, nonlinear relationships among variables without requiring prior domain knowledge by utilizing large datasets33,34. Algorithms like Random Forest (RF), Artificial Neural Networks (ANN), and Logistic Regression (LR) have demonstrated strong performance in forecasting groundwater contamination35,36. This research applies advanced deep learning techniques, integrating feature selection, MLP-ANN, and TabNet architectures, to predict nitrate (NO₃−) concentrations. These methods effectively handle complex datasets by isolating key physicochemical indicators and accurately modeling the relationships between inputs and expected outcomes37. In contrast to traditional machine learning methods, TabNet and MLP-ANN models are capable of capturing complex patterns within high-dimensional feature spaces, while offering enhanced robustness, noise resistance, and fault tolerance38.
The aquifer under investigation, situated in a region characterized by intensive agriculture, is impacted by nitrate (NO₃−) contamination, primarily resulting from (LU/LC) alterations and the absence of coordinated management of human-induced pressures39,40. This diffuse contamination, driven by the interplay of natural conditions and anthropogenic activities, remains difficult to model with conventional methods, which often struggle to represent the nonlinear behavior and spatial variability of the underlying processes41,42. To tackle this challenge, the present study employs two deep learning models, the Multilayer Perceptron Artificial Neural Network (MLP-ANN, implemented in Keras) and the attention based TabNet architecture (developed in PyTorch), to predict and map the spatial distribution of nitrate (NO₃−) concentrations. Model calibration was performed using key environmental predictors, including electrical conductivity (EC), chloride (Cl−), organic matter (OM), and fecal coliforms (FC), alongside land-use/land-cover data and vegetation indices (NDVI) derived from remote sensing. The MLP-ANN demonstrated a strong capacity to model complex multivariate relationships within high-dimensional datasets43,44,45 TabNet facilitates adaptive feature selection while maintaining transparency and interpretability throughout the prediction process46. These methods outperform conventional statistical models by offering greater accuracy, resilience to noise, and improved management of class imbalance. The present study aims to advance sustainable groundwater governance by proposing an intelligent risk mapping framework specifically designed for the proactive monitoring of vulnerable aquifers in semi-arid regions.
This study adopts an integrated framework to achieve three primary objectives: to accurately characterize the hydrogeochemical composition of groundwater and generate high-resolution spatial maps of nitrate (NO₃−) concentrations; to assess the influence of land use changes, particularly agricultural intensification, on groundwater quality; and to implement advanced deep learning models namely the Multilayer Perceptron Artificial Neural Network (MLP-ANN, Keras) and the attention-based TabNet algorithm (PyTorch) for robust prediction of NO₃− levels. By addressing these interconnected goals, the study offers novel insights into the dynamics of diffuse anthropogenic pollution and introduces a high-performance, interpretable modeling framework that supports sustainable and evidence-based groundwater management, particularly in semi-arid coastal regions facing increasing environmental pressures.
Materials and methods
Study area
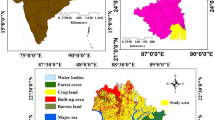
The study focuses on the Rmel coastal aquifer, located in the Lower Loukkos Basin in north-western Morocco, near the city of Larache. It covers an area of approximately 245 km², between longitudes 5°40′W and 5°30′W and latitudes 35°04′N and 34°58′N (Fig. 1). This predominantly agricultural area exhibits diverse topography, with elevations ranging from 0 to 174 m, gradually decreasing from the southeast to the northwest39,47. The highest altitudes are found in the southeastern sector, while the central and eastern parts are characterized by moderate elevations (50 to 120 m). The low-lying coastal areas, characterized by flat terrain, are prone to seawater intrusion and groundwater resurgence. The region has a Mediterranean climate with oceanic influence, receiving annual rainfall between 600 and 800 mm, with moderate temperatures (18–20 °C) and high winter humidity (70–80%). The hydrographic network includes four main watercourses: the perennial Loukkos River in the north, Sakh Soukh in the central zone, Smid Al Ma in the east, which enhances infiltration, and El Kihel in the southeast, which contributes to irregular recharge. Geologically, the aquifer is composed of permeable Quaternary and Pliocene formations overlying a Miocene marl base. Groundwater flows from southeast to northwest, guided by topographic gradients, surface drainage pathways, and diffuse recharge inputs48,49. The aquifer is hydrogeologically bounded by the Loukkos plain to the north, the Atlantic Ocean to the west, the Lalla Mimouna formations to the south, and the Ouled Ogbane aquifer to the east. Piezometric data from December 2024 indicate levels exceeding 67.8 m in the south, with steep declines toward the coastline, reflecting active seaward flow (Fig. 1). The central and northern parts of the aquifer consist of porous Quaternary sands, grey dunes, and weakly cemented sandstones. In contrast, the southern sector comprises heterogeneous Miocene - Pliocene deposits, notably low-permeability blue marls and fossiliferous limestones that act as aquitards. Pliocene-Pleistocene limestone outcrops in the southwest further constrain permeability. The area’s Mediterranean climate with oceanic influence (Csa, Köppen–Geiger) is marked by wet, mild winters (> 110 mm/month = 14 °C) and hot, dry summers (< 2 mm/month; 25 °C), based on data from the Larache station (1963–2025). A net annual water deficit of − 253 mm restricts effective aquifer recharge to the November-April period.

Geographical location of the Rmel aquifer.
Sampling and hydrochemical analysis
Groundwater sampling was conducted throughout the study area as part of a regional monitoring initiative led by the Water Quality Department of the Loukkos Hydraulic Basin Agency. Twenty wells were selected within the coastal aquifer using a stratified grid approach to ensure spatial representativeness, particularly in zones affected by agricultural intensification and potential seawater intrusion. The geographic coordinates (X, Y) of each sampling site were recorded using GPS to facilitate spatial analysis in a GIS environment. Groundwater samples were analyzed following standard protocols to quantify key hydrochemical parameters, including salinity indicators (electrical conductivity [EC, µS/cm], chloride [Cl−, mg/L]), chemical pollutants (nitrate [NO₃−, mg/L], organic matter [OM, mg/L]), and microbial contamination (fecal coliforms [FC, CFU/100 mL]). EC was measured in situ using a calibrated portable device, while chloride was analyzed from non-acidified, refrigerated samples. Nitrate samples were acidified with sulfuric acid (1 mL/L, pH < 2) for stabilization. Organic Matter analysis involved filtration or acidification depending on the method. Fecal coliforms were assessed from sterile, chilled samples processed within 24 hours. All samples were transported in insulated, light-protected containers and analyzed in compliance with national QA/QC standards. Additionally, Landsat-8 imagery (USGS Earth Explorer) was used to derive LU/LC information surrounding the sampling sites. This combined field remote sensing framework supports the spatial modeling of nitrate contamination influenced by anthropogenic land use dynamics, utilizing both statistical and deep learning techniques. All Maps (Figs. 1 and 2, and 4) generated by the author using ArcGIS version 10.8 (Esri Inc., Redlands, CA, USA; https://www.esri.com/en-us/arcgis/about-arcgis/overview)”.
Cross-analysis of nitrate concentrations and land use patterns
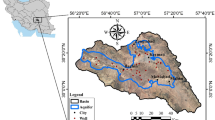
Nitrate (NO₃−) concentrations in groundwater were categorized into five classes: 1.4–4.7, 4.7–7.9, 7.9–12.1, 12.1–24.8, and 24.8–31.2 mg/L (Fig. 2). These values were spatially integrated with a land use/land cover (LU/LC) map produced through supervised classification of Landsat-8 imagery acquired in May–June 2024, coinciding with the active agricultural season and the groundwater sampling campaign. Four dominant LU/LC types were identified: agricultural land, forested areas, bare soils, and urban zones. The overlay analysis revealed clear spatial correlations between land use categories and nitrate concentration levels. Although remaining below the World Health Organization (WHO) guideline of 50 mg/L, the highest nitrate concentrations (≥ 24.8 mg/L) were primarily observed in the southern part of the aquifer, where irrigated agriculture and intensive crop rotation are prevalent. This spatial cross-analysis highlights the significant role of anthropogenic land use in shaping patterns of nitrate contamination and provides a robust basis for incorporating LU/LC variables into the deep learning models developed in this study, enhancing spatially explicit prediction and impact evaluation.

Nitrate (NO₃-) Distribution Overlaid with Land Cover (LU/LC).
Machine learning modeling
Data pre-processing
Before training the MLP and TabNet models, the dataset underwent preprocessing to improve data quality and comply with neural network requirements, including the removal of missing and duplicate entries to ensure stable and reliable learning using (Eq. 1).
This step guarantees data consistency and helps minimize potential biases during the backpropagation process50. A set of environmentally significant and statistically uncorrelated variables was selected to construct the explanatory variable vector as in (Eq. 2):
The target variable\(\:\:y\in\:\{\text{1,2},\text{3,4},5\}\) corresponds to the ordinal nitrate class, defined according to five increasing levels of pollution. To meet the structural requirements of neural network architectures, particularly MLP implemented with Keras/Tensor Flow, the class labels were converted using One-Hot encoding, as defined using (Eq. 3):
One-Hot encoding converts each class into a five-dimensional binary vector, ensuring compatibility with MLP-based architectures for multiclass classification51. Conversely, TabNet uses integer label encoding, mapping ordinal classes to consecutive integers as defined using (Eq. 4):
For MLP training, input data must be statistically standardized to ensure stable stochastic gradient descent52,53. Each variable xj was standardized using Z-score normalization to center and scale the data, as defined by Eq. 5.
This transformation ensures that each variable follows a standardized distribution N (0, 1), thereby reducing the risk of instability associated with exploding gradients or vanishing gradient phenomena54,55. Although TabNet can handle raw inputs via its attention mechanism, normalization was applied for consistency across models. The dataset was then split into training (Dtrain) and testing (Dtest) subsets using stratified sampling to maintain class proportions, as defined using (Eq. 6):
This step limits overfitting, ensures stable gradients, and supports reproducible results by aligning data properties with the requirements of deep learning.
Nitrate prediction using multilayer perceptron (MLP-ANN)
An MLP model implemented in Keras (with TensorFlow backend) was employed to predict ordinal classes of nitrate (NO₃−). Its fully connected architecture enables the modeling of complex nonlinear relationships within environmental datasets56. The MLP architecture comprises: (i) an input layer incorporating five standardized features (NDVI, EC, Cl−, OM, FC); (ii) two hidden layers with 64 and 32 neurons, respectively, using ReLU activation and dropout rates of 0.3 and 0.2; and (iii) an output layer with five neurons activated by Softmax to classify nitrate (NO₃−) levels57. Input features were standardized using Z-score normalization, and target labels were encoded as One-Hot binary vectors. The model was trained on 80% of the data, with stratified cross-validation on the remaining 20% to Maintain class balance. It was compiled using the Adam optimizer and categorical cross-entropy, which is appropriate for multiclass classification, and trained for over 50 epochs with a batch size of 32. MLP-ANN performance was evaluated using overall accuracy, macro-weighted recall, error rate, and AUC, highlighting its strong ability to capture nonlinear patterns associated with nitrate contamination. Compared to the Extremely Randomized Trees (ERT) model, the MLP demonstrated greater sensitivity to complex interactions among environmental variables, particularly in the medium- to high-concentration classes58,59.
Nitrate classification with tabular data network (TabNet)
TabNet is a deep learning architecture designed explicitly for tabular data, utilizing a sequential self-attention mechanism and iterative feature masking to dynamically and hierarchically select relevant variables at each decision step60,61. This model combines fully connected layers with entropic regularization, promoting sparsity and interpretability while mitigating the risk of overfitting62. The dataset consisted of five standardized environmental predictors (NDVI, EC, Cl−, OM, FC) and an ordinal target variable divided into five nitrate concentration classes. Stratified sampling was employed to maintain class balance between the training and testing subsets. The target variable was encoded using Label Encoding to align with model requirements. Model optimization relied on the categorical cross-entropy loss function, with early stopping applied to ensure stable convergence during training63,64. Training involved a sufficient number of decision steps to effectively explore the representation space, while virtual mini batches were employed to optimize memory usage. TabNet’s performance was assessed using four key metrics: overall accuracy, macro-weighted recall, error rate, and AUC65. In addition to its classification performance, TabNet offers intrinsic interpretability via attention mechanisms, enabling precise identification of the most influential predictive variables66. The combination of strong predictive accuracy and inherent interpretability makes TabNet a valuable tool for environmental monitoring and strategic modeling of groundwater quality.
Hyperparameter tuning
The hyperparameters of the TabNet and MLP-ANN models were optimized using an approach combining insights from the literature, empirical exploration, and 10-fold stratified cross-validation67. This strategy aimed to maximize performance while limiting the risk of overfitting associated with the small dataset size (20 samples). For TabNet, the selected parameters were: 5 decision steps (a compromise between accuracy and computational time), learning rate = 0.02, batch size = 256, virtual batch size = 128, entropic regularization, sequential attention mechanism, StepLR scheduler with 10% learning rate reduction every 10 iterations, and early stopping after 20 epochs without improvement68. For MLP-ANN, the configuration included two hidden layers (64 and 32 neurons, ReLU activation) with dropout rates of 0.3 and 0.2, a learning rate = 0.001 (Adam optimizer), and training for 50 epochs, in line with validation curves showing stable convergence. These choices reflect a balance between model complexity and adaptation to the constraints of a small sample, while ensuring the ability to model complex nonlinear relationships between environmental variables and NO₃− classes.
Applying deep learning to a limited dataset
Although the sample size is relatively small, the analytical quality and representativeness of the dataset were ensured through standardized field protocols, rigorous quality control, and spatial coverage targeting areas of primary hydrogeochemical concern69. The selected predictors (NDVI, EC, Cl−, OM, and FC) were chosen based on a dual criterion combining scientific relevance and statistical independence. This independence was quantitatively verified by imposing absolute Pearson correlation coefficients (∣r∣ < 0.70) and variance inflation factors (VIF) < 5, thereby ensuring maximum explanatory power while limiting redundancy70. The Python implementations (MLP under TensorFlow/Keras and TabNet under PyTorch) were optimized for this constrained context by favouring lightweight architectures, an MLP with two hidden layers (64 and 32 neurons) using ReLU activation and dropout rates of 0.3 and 0.2, respectively; and TabNet configured with a sparse sequential attention mechanism and entropic regularization. Overfitting was mitigated through Z-score normalization using Eq. 7:
a stratified train/test split (80/20), early stopping after nₚₐₜiₑₙcₑ = 20 epochs without improvement, and 10-fold stratified cross-validation, where the mean accuracy serves as a robust estimator of generalization performance using Eq. 8.
Accurately modeling nonlinear interactions between parameters is essential for predicting groundwater quality. As demonstrated by71 even with a limited dataset, machine learning or deep learning models, when combined with rigorous variable selection, appropriate regularization, and strict cross-validation, can achieve high accuracy while significantly reducing predictive uncertainty, often quantified by the standard deviation of the cross-validation folds using Eq. 9:
Leveraging feature selection masks and attention weights in TabNet
Unlike the Multi-Layer Perceptron (MLP), which lacks any structural prioritization mechanism and processes all variables equally at each layer thus operating as a black box with limited ability to disentangle the importance or concrete impact of individual variables TabNet incorporates a sequential attention mechanism at its decision steps72. At each stage, it generates sparse feature selection masks that may assign a value of zero to certain variables, adapting the selection of the most relevant features for each instance and progressively revealing the model’s reasoning73. This design offers a dual level of interpretability: local, through instance-specific masks, and global, through the aggregation of masks across the entire dataset74. Such a duality makes TabNet inherently more transparent than a conventional MLP, which provides no structured internal representation to assess the influence of variables75.
LASSO variable importance
The Least Absolute Shrinkage and Selection Operator (LASSO) is a penalized linear regression technique that performs both dimensionality reduction and automatic selection of the most relevant explanatory variables76. This method addresses multicollinearity and high-dimensional data by minimizing a cost function combining mean squared error and an L₁ penalty, which shrinks irrelevant coefficients to zero. In this study, ordinal nitrate (NO₃−) classes were modeled using environmental predictors as explanatory variables77. The regularization parameter controls variable selection in LASSO. The model was implemented using the Lasso module from scikit-learn, following prior standardization of input features with Standard Scaler. The regularization parameter (λ, or α in scikit-learn) was tuned using Lasso CV to balance bias and variance and reduce overfitting. LASSO stabilized the model and selected key predictors, enabling the development of a concise and interpretable nitrate pollution model.
Statistical performance indicators
The classification performance of deep learning models predicting nitrate (NO₃−) concentrations was evaluated using four robust metrics: Accuracy (overall correctness), Recall (sensitivity to true positives), Error Rate (proportion of misclassified instances), and AUC, which measures the model’s ability to distinguish between classes independent of the decision threshold78. AUC values approaching 1 denote high discriminatory power. To address class imbalance in the multiclass context, macro-averaged recall was employed using Eqs. 7–10.
where TP represents true positives, TN true negatives, FP false positives, and FN false negatives.
Cross-validation and CI estimation
The predictive performance of the two Deep Learning architectures TabNet (PyTorch) and MLP-ANN (Keras/TensorFlow) was evaluated using stratified k-fold cross-validation (k = 10), ensuring that the proportions of each of the five nitrate classes were preserved in both the training and testing sets. This procedure reduces estimation variance and ensures balanced representativeness. For a given performance metric M, let mi denote the value obtained for fold i, with i = 1, 2,……, k. The empirical mean and the unbiased standard deviation are defined as:
Under the assumption of an approximately normal distribution of the mi, the 95% confidence interval is given by:
Where t (1-α/2, k-1) is the critical value from the Student’s t-distribution for k −1 degrees of freedom (here, α = 0.05 and t0.975,9≈ 2.262t), a non-parametric bootstrap was also applied, with the 2.5% and 97.5% percentiles of the bootstrapped means defining the lower and upper CI bounds, respectively. This combined approach improves the robustness of the estimation, particularly in the presence of asymmetric distributions. All predictors were Z-score standardized before modeling. For MLP-ANN, One-Hot encoding was used, with two hidden layers (64 and 32 neurons, ReLU activation, dropout = 0.3 and 0.2), a 5-neuron Softmax output, and Adam optimization (learning rate = 0.001) with early stopping. For TabNet, consecutive integer encoding (Label Encoding) was applied, with a sparse sequential attention mechanism, entropic regularization, Adam optimization (learning rate = 0.02), batch size = 256, virtual batch size = 128, StepLR scheduler, and early stopping.
Results
Influence of land use on groundwater contamination
The spatial overlay between land cover categories (forest, bare soil, urban, and agriculture) and hydrochemical indicators reveals a strong correlation between land use and groundwater quality (Fig. 3). Agricultural zones consistently showed the highest concentrations across all five parameters (EC, Cl−, NO₃−, OM, FC). Over 60% of samples from cultivated areas fell into the upper nitrate concentration classes, with the highest class corresponding to 24.8–31.2 mg/L, while no forested samples exceeded 13.3 mg/L. More than half of the agricultural samples recorded Cl− concentrations above 175.8 mg/L, and EC values ranged from 1130 to 1630 µS/cm in 80% of cases, indicating Substantial mineralization likely driven by irrigation and fertilizer inputs. Organic Matter exceeded 3.5 mg/L in 65% of agricultural samples, compared to less than 15% in forest areas. Fecal coliforms (FC) were markedly higher in agricultural and urban zones (14.4–118 CFU/100 mL), while forested sites remained microbiologically unpolluted. These results underscore the cumulative impact of intensive land use, particularly unregulated agriculture, on groundwater quality degradation.

Spatial patterns of key hydrochemical parameters across land cover types.
Nitrate (NO₃-) risk prediction using deep learning
The MLP-ANN model, developed using Keras, demonstrated strong capacity to capture complex nonlinear interactions among environmental variables, yielding reliable predictions even with incomplete or sparsely distributed data. The resulting nitrate risk map exhibits a distinct spatial gradient, with lower concentrations in the northern coastal zone and elevated levels in the central and southeastern regions, where anthropogenic pressures are most intense. In terms of classification, the “Moderate” risk category prevails (34%), followed by “High” (26%) and “Low” (18%), while “Very Low” and “Very High” account for 12% and 10%, respectively (Figs. 4 and 5). TabNet, a newer architecture with adaptive attention mechanisms, dynamically identifies the most influential predictors at each decision step, offering enhanced robustness in handling heterogeneous and noisy hydrogeological data. Its classification output reveals a more refined spatial segmentation, with minimal nitrate concentrations in the northwestern coastal fringe and elevated risks concentrated in agricultural and peri-urban zones in the central, eastern, and southeastern sectors. The resulting classification reflects a similar distribution: “Moderate” (35%), “High” (28%), “Low” (18%), while “Very Low” and “Very High” represent 12% and 7%, respectively (Figs. 4 and 5). This improved delineation supports the identification of priority zones for targeted groundwater management.

Nitrate Contamination Risk Maps Generated by Deep Learning Models: (a) MLP-ANN and (b) TabNet.

Predicted distribution of nitrate risk classes using MLP-ANN and TabNet Models.
Identification of variables governing nitrate concentrations
The standardized coefficients obtained from the LASSO regression applied to the nitrate prediction model reveal a clear ranking of the explanatory variables (Fig. 6). These coefficients, scaled between 0 and 1, indicate the relative contribution of each variable to model performance. Fecal coliforms (FC) emerged as the dominant predictor (0.52), underscoring a strong link between microbiological contamination and nitrate presence, likely driven by the infiltration of domestic wastewater and livestock effluent. Electrical conductivity (EC) followed closely (0.48), confirming its relevance as a proxy for mineralization associated with intensive fertilizer application. Organic matter (OM) showed moderate influence (0.19), reflecting its role in organic nitrogen transformation via nitrification. The Normalized Difference Vegetation Index (NDVI), with a coefficient of 0.09, indirectly captured agricultural activity and its influence on nitrate recharge. Chloride (Cl−) exhibited minimal weight (0.03), indicating a weak association with nitrate concentrations in this setting.

Relative contribution of predictors in the LASSO-based nitrate prediction model.
MLP-ANN vs. TabNet performance for nitrate prediction
The comparative evaluation of MLP-ANN and TabNet models for classifying nitrate concentrations reveals TabNet’s overall superiority across multiple performance metrics (Fig. 7). Achieving an accuracy of 81.60% compared to 78.88% for MLP-ANN, TabNet more effectively captures nonlinear interactions among predictors (NDVI, EC, Cl−, OM, FC) and nitrate classes. Its Macro-averaged recall reaches 84.13%, slightly exceeding that of MLP-ANN (82.65%), indicating improved balance in classifying both frequent and rare categories. TabNet also exhibits a lower error rate (18.40% vs. 21.12%), underscoring its robustness in predicting intermediate classes, which are often critical in environmental assessments. Although MLP-ANN shows a marginally higher AUC (96.51% vs. 96.34%), this does not outweigh TabNet’s overall advantage in accuracy, recall, and class balance. These findings highlight TabNet as a particularly effective algorithm for complex environmental tabular datasets, enabling reliable and detailed nitrate risk assessments.

Comparative Performance of MLP-ANN and TabNet Models in Nitrate Concentration.
CI & robustness analysis
As shown in (Table 1), cross-validation results clearly highlight the Superior performance of the TabNet model compared to the MLP in the multiclass classification of nitrate concentrations. TabNet achieved an average accuracy of 0.8229 (95% bootstrap CI: [0.8207–0.8257]) and a Macro-recall of 0.8463 ([0.8440–0.8486]), outperforming the MLP (accuracy: 0.8133; 95% CI: [0.8098–0.8180]; Macro-recall: 0.8379; 95% CI: [0.8349–0.8416]). TabNet’s particularly high one-vs-rest AUC (0.9650) demonstrates its strong ability to accurately discriminate between different concentration classes, whereas the MLP did not yield usable AUC values. Class-wise predictive distribution also confirms TabNet’s robustness, as it closely replicates the actual distribution of observations: 29.49% (class 1), 25.24% (class 2), 28.08% (class 3), 17.19% (class 4), and 0% (class 5). In comparison, the MLP tends to overestimate class 1 (30.57%) and underestimate class 2 (24.73%), while Maintaining similar values for classes 3 and 4.
Discussion
This study demonstrated the effectiveness of deep learning (DL) models, specifically the Multilayer Perceptron Artificial Neural Network (MLP-ANN, Keras) and the attention-based TabNet model (PyTorch), for predicting nitrate (NO₃−) concentrations in groundwater affected by diffuse pollution. Both architectures successfully captured complex nonlinear relationships between environmental and hydrochemical variables79,80. TabNet achieved higher predictive performance, with an accuracy of 81.60%, a Macro-recall of 84.13%, and a reduced error rate of 18.40%, particularly excelling in the classification of intermediate nitrate levels often misrepresented by traditional methods. To enhance interpretability, a LASSO regression identified key predictors fecal coliforms (0.52) and electrical conductivity (EC) (0.48) jointly explaining over 80% of the variance in (NO₃−) levels, with additional contributors including organic matter (OM) (0.19), NDVI (0.09), and chloride (0.03). Spatial outputs revealed pronounced heterogeneity across the aquifer, with low concentrations in forest-influenced recharge zones in the northwest, and high contamination levels in central and southeastern sectors characterized by intensive agriculture, poorly regulated irrigation, and limited wastewater infrastructure.
High pollutant levels in agricultural zones highlight the usefulness of interpretable deep learning for groundwater management in sensitive areas81,82,83. When compared with simpler methods such as Random Forest, SVM, and Logistic Regression, TabNet not only outperformed MLP-ANN but also achieved superior accuracy, macro-recall, and AUC. Comparable results were reported by Elzain et al.32. in a similar coastal aquifer, where a two-level ensemble (Bagging, Extra Trees, CatBoost) reached R² = 0.995, NSE = 0.996, and MSE = 0.0002. Although our study focuses on nitrates (NO₃−) and theirs on TDS, both confirm the value of advanced models for complex coastal environments32. also showed that SL-DL stacking can improve accuracy and stability; our findings indicate that even without stacking, optimized DL architectures can surpass conventional SL approaches. These conclusions align with84 for the Wadi Guenniche aquifer, where salinization results from natural and anthropogenic interactions, although our analysis underscores the predominant role of intensive agriculture in elevating NO₃- levels, with a strong correlation to market gardening areas.
Recent advances in DL have shown considerable promise in modeling nitrate dynamics under complex, data-scarce, or spatially heterogeneous conditions85,86,87. demonstrated the effectiveness of LSTM networks trained on high-frequency datasets to estimate daily NO₃− concentrations at 42 monitoring stations in Iowa, achieving a median NSE of 0.75 and RMSE of 1.53 mg/L. The same authors88 applied LSTM to low frequency datasets, outperforming traditional models Such as LOADEST and WRTDS-Kalman in 67% of cases (NSE > 0.70)89. expanded this approach with a hybrid CNN-LSTM model that accurately predicted hourly nitrate levels using routine parameters, achieving NSE values between 0.60 and 0.83 without direct NO₃− measurements. In Mediterranean contexts90, applied supervised learning models (Random Forest, XGBoost) and found that spatial location alone accounted for up to 87% of NO₃− variance (r = 0.93)91. modeled ammonium nitrogen dynamics with LSTM, improving temporal granularity and predictive accuracy for real-time water quality assessment. This growing body of work underscores the value of combining spatial data with interpretable AI, such as TabNet, for nitrate prediction under complex land-use pressures.
Our findings align with research in Morocco’s semi-arid regions92: identified intensified agriculture and poor irrigation as major drivers of nitrate pollution, consistent with our maps showing the impact of fertilizers and irrigation93. reported significant groundwater degradation in the Saïs Basin (Fes-Meknes) due to excessive nitrogen fertilizer use and inefficient irrigation practices. In similar coastal contexts94, identified agriculture, livestock farming, and leakage from poorly sealed wells as major nitrate sources, as seen on Jeju Island. Regarding predictive modeling95, highlighted that “entity-aware” models perform well under internal calibration but struggle with extrapolation to poorly monitored areas, stressing caution in generalizing models in data-limited contexts.
Several methodological and data-related limitations must be acknowledged. The approach used remains essentially correlational, without explicitly representing hydrogeochemical processes96,97. To address this, future work will incorporate the analysis of stable isotopes2H18, O) and tritium to trace groundwater origin, identify nitrate sources, and quantify nitrogen transformation processes. These isotopic approaches will be coupled with rigorous hydrochemical analyses following standardized protocols98. The integration of recent climatic data, notably derived from satellite imagery47,99,100,101,102,103,104will enhance model relevance. Combined with advanced machine learning algorithms, in line with hybrid modeling strategies in environmental sciences (Elzain et al., 2023), these indicators will enable the transition from a purely correlational approach to a framework explicitly integrating physical processes, thereby improving causal interpretation, simulation capabilities, and operational applicability.
The dataset remains constrained by a lack of spatial detail and key agricultural variables105,106as well as a limited number of wells, restricting the generalizability of the results95,107. Although prediction intervals were used, the sensitivity of complex models reduces their interpretability66,108and architectural or hyperparameter choices may introduce bias. Furthermore, the model remains static and unvalidated over time, limiting its robustness to seasonal variations, land use changes, or climatic fluctuations.
Despite these limitations, the study provides operational recommendations for managing nitrogen pollution in Mediterranean contexts. The predictive maps generated serve as decision-support tools for planning in coastal areas vulnerable to nitrates, thereby contributing to agricultural resilience and the protection of rural health. Future research avenues include temporal analysis using recurrent models (LSTM, CNN-LSTM) to track nitrate dynamics, hybridization with physical models such as HELM to improve accuracy, and the integration of agricultural data to enhance pollutant transport traceability and modeling. Applying this methodology to other neighboring aquifers, such as the Gharb109 and Ouled Ogbane47would allow for an assessment of its generalizability. Finally, rigorous uncertainty quantification using Bayesian inference, SHAP, and PDP is essential to strengthen interpretability and operational value for decision-makers.
Conclusion
This study developed an innovative and interpretable deep learning framework to estimate nitrate (NO₃−) concentrations in the Rmel coastal aquifer in northwestern Morocco by integrating land use data with key hydrochemical indicators. Among the tested models, the attention-based TabNet algorithm outperformed the MLP-ANN, achieving an overall accuracy of 81.60%, a Macro recall of 84.13%, and a reduced error rate of 18.40%, demonstrating its robustness for nitrate risk Mapping. LASSO regression analysis further enhanced interpretability by identifying fecal coliforms and electrical conductivity as the most influential predictors, together explaining over 80% of the variance in NO₃− concentrations. A distinct spatial gradient of contamination was observed, with lower nitrate levels in forested recharge zones and higher concentrations in agricultural and peri-urban areas, highlighting the critical role of land use in degrading groundwater quality. The generated predictive maps serve as valuable decision-support tools, helping to identify pollution hotspots, guide monitoring strategies, and support the implementation of targeted nitrogen load reduction and land management policies. This framework showcases the potential of interpretable deep learning for advancing sustainable groundwater governance, particularly in semi-arid regions where traditional methods often fall short due to the complexity of diffuse pollution processes. Future research should focus on incorporating temporal dynamics through time-series models such as LSTM and CNN-LSTM to capture seasonal variations in nitrate levels. Additionally, integrating high-resolution agricultural, climatic, and isotopic data can enhance source attribution and process-based understanding of nitrogen transport. Expanding the application of this framework to other vulnerable coastal aquifers and incorporating uncertainty quantification techniques such as SHAP, Bayesian inference, and partial dependence plots will further improve the generalizability, reliability, and policy relevance of data-driven groundwater quality models.
Data availability
Data will be available on the reasonable request from the 1st author.
References
Ratandeep et al. Unravelling groundwater contamination and health-related implications in semi-arid and cold regions of India. J. Contam. Hydrol. 261, 104303 (2024).
Feng, T., Xiong, R. & Huan, P. Productive use of natural resources in agriculture: the main policy lessons. Resour. Policy. 85, 103793 (2023).
Gavrilescu, M. Water, soil, and plants interactions in a threatened environment. Water (Switzerland) 13, (2021).
Ullah, Z. et al. Groundwater contamination through potentially harmful metals and its implications in groundwater management. Front. Environ. Sci. 10, 1–13 (2022).
Rashid, A. et al. Groundwater quality, health risk assessment, and source distribution of heavy metals contamination around chromite mines: application of GIS, sustainable groundwater management, geostatistics, PCAMLR, and PMF receptor model. Int J. Environ. Res. Public. Health 20, 1–13 (2023).
Dao, P. U. et al. The impacts of climate change on groundwater quality: A review. Sci. Total Environ. 912, 169241 (2024).
Jat Baloch, M. Y. et al. Hydrogeochemical mechanism associated with land use land cover indices using geospatial, remote sensing techniques, and health risks model. Sustain 14, 1–14 (2022).
Sajjad, M. M. et al. Assessing the impacts of groundwater depletion and aquifer degradation on land subsidence in lahore, pakistan: A PS-InSAR approach for sustainable urban development. Remote Sens 15, 1–12 (2023).
Jude, N. N., Wotany, E. R., Agyingi, C. & Nelson, M. A. Geological influence on groundwater quality in volcanic aquifers of Eastern Mount cameroon, West of the Penda Mboko river. Discov Appl. Sci 6, 1–10 (2024).
Subba Rao, N., Dinakar, A. & Sun, L. Estimation of groundwater pollution levels and specific ionic sources in the groundwater, using a comprehensive approach of geochemical ratios, pollution index of groundwater, unmix model and land use/land cover – A case study. J. Contam. Hydrol. 248, 103990 (2022).
Ding, K. et al. Tracing nitrate origins and transformation processes in groundwater of the Hohhot basin’s Piedmont strong runoff zone through dual isotopes and hydro-chemical analysis. Sci. Total Environ. 919, 170799 (2024).
Zheng, J. et al. Source apportionment and health risks of nitrate pollution in shallow groundwater in the agricultural Northern xiaoxing’ an mountains region of China. J. Hydrol. Reg. Stud. 59, 102394 (2025).
Nuruzzaman, M., Bahar, M. M. & Naidu, R. Diffuse soil pollution from agriculture: impacts and remediation. Sci. Total Environ. 962, 178398 (2025).
Choudhary, S., Subba Rao, N., Chaudhary, M. & Das, R. Assessing sources of groundwater quality and health risks using graphical, multivariate, and index techniques from a part of rajasthan, India. Groundw. Sustain. Dev. 27, 101356 (2024).
Preethi, B. et al. Health risks due to Geogenic and anthropogenic influences on groundwater quality in Southern india’s hard rock terrain. J. Geochemical Explor. 274, 107762 (2025).
Boumaiza, L., Stotler, R. & Frape, S. A review of the major chemical and isotopic characteristics of groundwater in crystalline rocks of the Canadian shield. Chem. Geol. 669, 122366 (2024).
Adimalla, N., Qian, H. & Tiwari, D. M. Groundwater chemistry, distribution and potential health risk appraisal of nitrate enriched groundwater: A case study from the semi-urban region of South India. Ecotoxicol. Environ. Saf. 207, 111277 (2021).
Akshitha, V., Balakrishna, K. & Udayashankar, H. N. Impact of land use/land cover on groundwater resources in tropical unconfined aquifers of south-western India. Environ. Res. 218, 114994 (2023).
Chen, W. et al. Letter to the editor regarding Li. Identifying ecosystem service bundles and the spatiotemporal characteristics of trade-offs and synergies in coal mining areas with a high groundwater table, Liu et al. (2021) Ecosystem service multifunctiona. Sci. Total Environ. 829, 154717 (2022). (2022).
ullah, A. et al. Integrated assessment of groundwater quality dynamics and land use/land cover changes in rapidly urbanizing semi-arid region. Environ. Res. 260, 119622 (2024).
Ahmadi, H. et al. Assessing the impacts of Landuse-Landcover (LULC) dynamics on groundwater depletion in kabul, afghanistan’s capital (2000–2022): A Geospatial Technology-Driven investigation. Geosci 14, 1–16 (2024).
Ferreira, C. S. S., Seifollahi-Aghmiuni, S., Destouni, G., Ghajarnia, N. & Kalantari, Z. Soil degradation in the European mediterranean region: processes, status and consequences. Sci. Total Environ. 805, 150106 (2022).
Subba Rao, N., Das, R., Sahoo, H. K. & Gugulothu, S. Hydrochemical characterization and water quality perspectives for groundwater management for urban development. Groundw. Sustain. Dev. 24, 101071 (2024).
Madjar, R. M., Scăețeanu, V. & Sandu, M. A. G. Nutrient water pollution from unsustainable patterns of agricultural systems, effects and measures of integrated farming. Water (Switzerland) 16, 1–9 (2024).
Madrigal-Solís, H. et al. A multidisciplinary approach using hydrogeochemistry, δ15NNO3 isotopes, land use, and statistical tools in evaluating nitrate pollution sources and biochemical processes in Costa Rican volcanic aquifers. Sci Total Environ 951, 1–14 (2024).
Chowdhuri, I. & Pal, S. C. Hydrochemical properties of groundwater and land use and land cover changes impact on agricultural productivity: an empirical observation and integrated framework approaches. J. Geochemical Explor. 258, 107402 (2024).
Rajmohan, N., Senthilkumar, M. & Alqarawy, A. M. Hydrogeochemistry and its relationship with land use pattern and monsoon in hard rock aquifer. Appl. Water Sci. 15, 1–18 (2025).
Zheng, Y., Tang, L. & Wang, H. An improved approach for monitoring urban built-up areas by combining NPP-VIIRS nighttime light, NDVI, NDWI, and NDBI. J. Clean. Prod. 328, 129488 (2021).
Sheik, A. G. et al. Machine Learning-Based monitoring and design of managed aquifer rechargers for sustainable groundwater management: scope and challenges. In Environmental Science and Pollution Research (Springer, 2024). https://doi.org/10.1007/s11356-024-35529-3.
Xie, Z. et al. Machine learning approaches to identify hydrochemical processes and predict drinking water quality for groundwater environment in a metropolis. J. Hydrol. Reg. Stud. 58, 102227 (2025).
Elzain, H. E. et al. ANFIS-MOA models for the assessment of groundwater contamination vulnerability in a nitrate contaminated area. J. Environ. Manage. 286, 112162 (2021).
Elzain, H. E. et al. An innovative approach for predicting groundwater TDS using optimized ensemble machine learning algorithms at two levels of modeling strategy. J. Environ. Manage. 351, 119896 (2024).
Aghaabbasi, M. & Chalermpong, S. Machine learning techniques for evaluating the nonlinear link between built-environment characteristics and travel behaviors: A systematic review. Travel Behav. Soc. 33, 100640 (2023).
Chakraborty, C., Bhattacharya, M., Pal, S. & Lee, S. S. From machine learning to deep learning: advances of the recent data-driven paradigm shift in medicine and healthcare. Curr. Res. Biotechnol. 7, 100164 (2024).
Nafouanti, M. B., Li, J., Mustapha, N. A., Uwamungu, P. & AL-Alimi, D. Prediction on the fluoride contamination in groundwater at the Datong basin, Northern china: comparison of random forest, logistic regression and artificial neural network. Appl. Geochem. 132, 105054 (2021).
Rodriguez-Galiano, V., Mendes, M. P., Garcia-Soldado, M. J., Chica-Olmo, M. & Ribeiro, L. Predictive modeling of groundwater nitrate pollution using random forest and multisource variables related to intrinsic and specific vulnerability: A case study in an agricultural setting (Southern Spain). Sci. Total Environ. 476–477, 189–206 (2014).
Chlingaryan, A., Sukkarieh, S. & Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status Estimation in precision agriculture: A review. Comput. Electron. Agric. 151, 61–69 (2018).
Abbas, H. et al. Multilayer perceptron and Markov chain analysis based hybrid-approach for predicting land use land cover change dynamics with Sentinel-2 imagery. Geocarto Int 38, 1–13 (2023).
Chahid, M., Messari, S. E., Hilal, J. E. & Aqnouy, M. I. Application of the DRASTIC-LU/LC method combined with machine learning models to assess and predict the vulnerability of the Rmel aquifer (Northwest, Morocco). Groundw Sustain. Dev 27, 1–11 (2024).
Chahid, M. et al. Assessment and modeling of the hydrochemical evolution of the Rmel aquifer (NW Morocco): geostatistical approaches and machine learning for sustainable management. Mediterr. Geosci. Rev. 7, 341–362 (2025).
Domínguez, A. et al. Science of the total environment development of land use regression, dispersion, and hybrid models for prediction of outdoor air pollution exposure in Barcelona. Environment International. 954, (2024).
Ma, X. et al. A comprehensive review of the development of land use regression approaches for modeling Spatiotemporal variations of ambient air pollution: A perspective from 2011 to 2023. Environ. Int. 183, 108430 (2024).
Maier, H. R. et al. Exploding the myths: an introduction to artificial neural networks for prediction and forecasting. Environ Model. Softw 167, 1–14 (2023).
Vakitbilir, N. et al. Multivariate modelling and prediction of High-Frequency Sensor-Based cerebral physiologic signals: narrative review of machine learning methodologies. Sensors 24, 1–25 (2024).
Bolan, S. et al. Impacts of climate change on the fate of contaminants through extreme weather events. Sci Total Environ 909, 1–15 (2024).
Mursil, M. et al. Interpretable deep neural networks for advancing early neonatal birth weight prediction using multimodal maternal factors. J. Biomed. Inf. 166, 104838 (2025).
Chahid, M. et al. Comparison of groundwater pollution vulnerability assessments via the DRASTIC-LU and DRASTIC-LU-NO3 – methods in the Ouled Ogbane aquifer, Northwest Morocco. Environ. Sci. Pollut Res. https://doi.org/10.1007/s11356-025-36677-w (2025).
El Hamidi, M. J., Larabi, A. & Faouzi, M. Modeling and Mapping of coastal aquifer vulnerability to seawater intrusion using SEAWAT code and GALDIT index technique: the case of the Rmel aquifer – Larache, Morocco. E3S Web Conf. 298, (2021).
El Hamidi, M. J., Larabi, A., Faouzi, M. & Essafi, R. Development of HIS to improve technical knowledge on the reservoir and hydrodynamic functioning of the Rmel aquifer (Morocco). Rev. Des. Sci. L’Eau. 32, 147–162 (2019).
Lones, M. A. Avoiding common machine learning pitfalls. Patterns 5, 101046 (2024).
Dahouda, M. K. & Joe, I. A. Deep-Learned embedding technique for categorical features encoding. IEEE Access. 9, 114381–114391 (2021).
Shadkani, S. et al. Comparative study of multilayer perceptron-stochastic gradient descent and gradient boosted trees for predicting daily suspended sediment load: the case study of the Mississippi river, U.S. Int. J. Sediment. Res. 36, 512–523 (2021).
Yakoubi, S. et al. Recent advances in delivery systems optimization using machine learning approaches. Chem. Eng. Process. - Process. Intensif. 188, 109352 (2023).
Huang, X., Kandris, K. & Katsou, E. Training stiff neural ordinary differential equations in data-driven wastewater process modelling. J. Environ. Manage. 373, 123870 (2025).
Hammad, M. M. Deep Learning Activation Functions: Fixed-Shape, Parametric, Adaptive, Stochastic, Miscellaneous, Non-Standard, Ensemble. (2024). https://doi.org/10.48550/arXiv.2407.11090
Su, J., Lin, Z., Xu, F., Fathi, G. & Alnowibet, K. A. A hybrid model of ARIMA and MLP with a grasshopper optimization algorithm for time series forecasting of water quality. Sci. Rep. 14, 23927 (2024).
Meng, Z., Zhao, F. & Liang, M. Ss-mlp: A novel spectral-spatial Mlp architecture for hyperspectral image classification. Remote Sens. 13, 1–25 (2021).
Thanh, H. V., Dai, Z. & Rahimi, M. Data-driven explainable machine learning approaches for predicting hydrogen adsorption in porous crystalline materials. J. Alloys Compd. 1028, 180709 (2025).
Malik, S. et al. Hybrid metaheuristic optimization for detecting and diagnosing noncommunicable diseases. Scientific Reports 15, 1–11 (2025).
Hira, M. T., Razzaque, M. A. & Sarker, M. Ovarian cancer data analysis using deep learning: A systematic review. Eng. Appl. Artif. Intell. 138, 109250 (2024).
Wang, S. & Zhang, X. Credit Rating Model Based on Improved TabNet. (2025).
Du, K. L., Zhang, R., Jiang, B., Zeng, J. & Lu, J. Understanding machine learning principles: learning, inference, generalization, and computational learning theory. Mathematics 13, 1–57 (2025).
Venkatraj, V. et al. Toward the application of a machine learning framework for Building life cycle energy assessment. Energy Build. 297, 113444 (2023).
Almadhor, A. et al. Transfer learning for Securing electric vehicle charging infrastructure from cyber-physical attacks. Sci. Rep. 15, 1–20 (2025).
Ali, Y., Hussain, F. & Haque, M. M. Advances, challenges, and future research needs in machine learning-based crash prediction models: A systematic review. Accid. Anal. Prev. 194, 107378 (2024).
Salvi, M. et al. Explainability and uncertainty: two sides of the same coin for enhancing the interpretability of deep learning models in healthcare. Int. J. Med. Inf. 197, 105846 (2025).
Algül, E. et al. A comparative study of advanced transformer learning frameworks for water potability analysis using physicochemical parameters. Appl. Sci. 15, 1–22 (2025).
Elzain, H. E. et al. Modeling of aquifer vulnerability index using deep learning neural networks coupling with optimization algorithms. Environ. Sci. Pollut Res. 30–45. https://doi.org/10.1007/s11356-021-14522-0 (2021).
Islam, M. T. et al. Integrated GIS, statistical modeling, and CMIP6-based assessment of groundwater irrigation quality in north-central Bangladesh for sustainable management. Results Eng. 27, 106496 (2025).
Zhang, X., Ramos, B. A. & Cladera, J. R. Research on key influencing factors of ecological environment quality in Barcelona metropolitan region based on remote sensing. Remote Sensing 16, 1–12 (2024).
Elzain, H. E. et al. Comparative study of machine learning models for evaluating groundwater vulnerability to nitrate contamination. Ecotoxicol. Environ. Saf. 229, 113061 (2022).
Liu, X., Tang, Z. & Wei, J. Multi-Layer perceptron model integrating Multi-Head attention and gating mechanism for global navigation satellite system positioning error Estimation. Remote Sens 17, 1–10 (2025).
Jia, W., Sun, M., Lian, J. & Hou, S. Feature dimensionality reduction: a review. Complex. Intell. Syst. 8, 2663–2693 (2022).
Shi, Z., Meng, Z., Tuo, H. & Tan, C. Attribution-based interpretable classification neural network with global and local perspectives. Sci. Rep. 15, 1–18 (2025).
Zhao, Y. et al. Privacy-Preserving and interpretable grade prediction: A differential privacy integrated TabNet framework. Electron 14, 1–18 (2025).
Fira, M., Goras, L. & Costin, H. N. Evaluating sparse feature selection methods: A theoretical and empirical perspective. Appl. Sci. 15, 1–20 (2025).
Banerjee, A., Ó’Domhnaill, A., Creedon, L., Jones, N. & Gharbia, S. A land use regression model to explain the Spatial variation of nitrate concentration – A regional scale case study in the north-west of Ireland. J. Contam. Hydrol. 270, 104528 (2025).
Thölke, P. et al. Class imbalance should not throw you off balance: choosing the right classifiers and performance metrics for brain decoding with imbalanced data. Neuroimage 277, 1–10 (2023).
Samper-Pilar, J., Samper-Calvete, J., Mon, A., Pisani, B. & Paz-González, A. Machine learning analysis of hydrological and hydrochemical data from the Abelar pilot basin in Abegondo (Coruña, Spain). Hydrology 12, 1–25 (2025).
Usman, A. G. et al. Optimized SVR with nature- inspired algorithms for environmental modelling of Mycotoxins in food virtual-water samples. Scientific Reports. 1–17 (2025).
Chang, Y. W. et al. Advanced groundwater level forecasting with hybrid deep learning model: tackling water challenges in taiwan’s largest alluvial fan. J. Hydrol. 655, 132887 (2025).
Mallick, J., Alqadhi, S., Alsubih, M., Ahmed, M. F. M. & Abdo, H. G. Automated interpretation of deep learning-based water quality assessment system for enhanced environmental management decisions. Appl Water Sci 15, 1–11 (2025).
Ye, Z., Yin, S., Cao, Y. & Wang, Y. AI-driven optimization of agricultural water management for enhanced sustainability. Sci. Rep. 14, 25721 (2024).
Abidi, J. H. et al. Integrated approach to understand the multiple natural and anthropogenic stresses on intensively irrigated coastal aquifer in the mediterranean region. Environ. Res. 252, 118757 (2024).
Yang, X. et al. Large-stream nitrate retention patterns shift during droughts: seasonal to sub-daily insights from high-frequency data-model fusion. Water Res. 243, 120347 (2023).
Zarnaghsh, A., Kelly, M., Burgin, A. & Husic, A. Revealing nitrate uptake and dispersion dynamics using high-frequency sensors and two-dimensional modeling in a large river system. Adv. Water Resour. 187, 104693 (2024).
Saha, G. K., Rahmani, F., Shen, C., Li, L. & Cibin, R. A deep learning-based novel approach to generate continuous daily stream nitrate concentration for nitrate data-sparse watersheds. Sci Total Environ 878, 1–10 (2023).
Saha, R. et al. Urban aquifer health assessment and its management for sustainable water supply: an innovative approach using machine learning techniques. Groundw. Sustain. Dev. 25, 101130 (2024).
Hu, Y., Liu, C., Wollheim, W. M., Jiao, T. & Ma, M. A hybrid deep learning approach to predict hourly riverine nitrate concentrations using routine monitored data. J. Environ. Manage. 360, 121097 (2024).
Dorado-Guerra, D. Y., Corzo-Pérez, G., Paredes-Arquiola, J. & Pérez-Martín, M. Á. Machine learning models to predict nitrate concentration in a river basin. Environ Res. Commun 4, 1–11 (2022).
Wang, X. et al. Deep-Learning-Based water quality monitoring and early warning methods: A case study of ammonia nitrogen prediction in rivers. Electron 12, 1–12 (2023).
Sanad AH, Alsaegh AS, Abdulla HM, Mohamed AJ, Alqassab A, Sharaf SMA, Abdulla MH, Khadem SA. Perceptions of Artificial Intelligence in Medicine Among Newly Graduated Interns: A Cross-Sectional Study. Cureus. 16(10), e71216 (2024). https://doi.org/10.7759/cureus.71216. PMID: 39525111; PMCID: PMC11549944.
Jaddi, H. et al. Predicting nitrate levels in the Saïss water table: A comparative study of machine learning methods. BIO Web Conf. 115, 1–8 (2024).
Kwon, E. et al. Nitrate vulnerability of groundwater in Jeju volcanic island, Korea. Sci. Total Environ. 807, 151399 (2022).
Heudorfer, B., Liesch, T. & Broda, S. On the challenges of global entity-aware deep learning models for groundwater level prediction. Hydrol. Earth Syst. Sci. 28, 525–543 (2024).
Kim, J., Kim, H., Kim, H. G., Lee, D. & Yoon, S. A comprehensive survey of deep learning for time series forecasting: architectural diversity and open challenges. Artif Intell. Rev 58, 1–10 (2025).
Shakeri, R., Amini, H., Fakheri, F., Lam, M. Y. & Zahraie, B. Comparative analysis of correlation and causality inference in water quality problems with emphasis on TDS Karkheh river in Iran. Sci. Rep. 15, 2798 (2025).
Selvam, S. et al. Assessment of groundwater from an industrial coastal area of South India for human health risk from consumption and irrigation suitability. Environ. Res. 200, 111461 (2021).
El Hafyani, M., Essahlaoui, N., Essahlaoui, A., Mohajane, M. & Van Rompaey, A. Generation of climate change scenarios for rainfall and temperature using SDSM in a mediterranean environment: a case study of Boufakrane river watershed, Morocco. J. Umm Al-Qura Univ. Appl. Sci. 9, 436–448 (2023).
Hafyani, M. et al. Assessing regional scale water balances through remote sensing techniques: A case study of Boufakrane river watershed, meknes region, Morocco. Water (Switzerland) 12, 1–8 (2020).
Abderrahmane, B., Chahid, M., Aqnouy, M., Milewski, A. M. & Lahcen, B. Evaluating time series models for monthly rainfall forecasting in arid regions: insights from Tamanghasset (1953–2021), Southern Algeria. Geosci 15, 1–16 (2025).
Khalid, E., Aqnouy, M., Bouadila, A. & Et-takaouy, C. Assessment of three satellite precipitation products for hydrological studies in a Data-Scarce context: Ouarzazate basin, Southern Morocco. (2025). https://doi.org/10.1016/j.nhres.2025.02.008
Et-Takaouy, C., Aqnouy, M., Boukholla, A., Stitou, E. & Messari, J. E. Exploring the spatio-temporal variability of four satellite-based precipitation products (SPPs) in Northern morocco: a comparative study of complex Climatic and topographic conditions. Mediterr. Geosci. Rev. 6, 123–144 (2024).
En-Nagre, K. et al. Assessment and prediction of meteorological drought using machine learning algorithms and climate data. Clim. Risk Manag. 45, 100630 (2024).
Karimanzira, D. et al. Application of machine learning and deep neural networks for Spatial prediction of groundwater nitrate concentration to improve land use management practices. Front Water 5, 1–10 (2023).
Suárez-Castro, A. F. et al. Evaluating the suitability of large-scale datasets to estimate nitrogen loads and yields across different Spatial scales. Water Res 268, 1–11 (2025).
Alali, A. M., Abughaban, M. F., Aman, B. M. & Ravela, S. Hybrid data driven drilling and rate of penetration optimization. J. Pet. Sci. Eng. 200, 108075 (2021).
Shi, Y., Wei, P., Feng, K., Feng, D. C. & Beer, M. A survey on machine learning approaches for uncertainty quantification of engineering systems. Machine Learning for Computational Science and Engineering (Springer International Publishing, doi:https://doi.org/10.1007/s44379-024-00011-x. (2025).
Hilal, I. et al. Groundwater Vulnerability Mapping Using the Susceptibility Index (SI) Method and Tritium Isotopes: A Case Study of the Gharb Aquifer in Northwestern Morocco. E3S Web Conf. 489, (2024).
Acknowledgements
Special thanks to the Drâa Oued Noun Hydraulic Basin Agency, Morocco for supporting this research by providing basic data for this study. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R673), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R673), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Morad Chahid: Conceived and designed the experiments; Performed the experiments; Analyzed and interpreted the data; Contributed reagents, materials, analysis tools or data; Wrote the paper. Jamal Eddine Stitou El Messari: Wrote the paper. Ismail Hilal: analysis tools or data; Wrote the paper. Nouhayla Abdi: Wrote the paper. Tarig Ali: Wrote the paper. Rabin Chakrabortty: Aqil Tariq: Wrote the paper. supervision, funding; Wrote the paper. Mourad Aqnouy: analysis tools or data; Wrote the paper.
Corresponding authors
Ethics declarations
Competing interest
The authors declare no competing interests.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Software
All Maps (Figs. 1 and 2, and 4) generated by the author using ArcGIS version 10.8 (Esri Inc., Redlands, CA, USA; https://www.esri.com/en-us/arcgis/about-arcgis/overview)”.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chahid, M., El-Messari, J.E.S., Hilal, I. et al. Deep learning framework for mapping nitrate pollution in coastal aquifers under land use pressure. Sci Rep 15, 34946 (2025). https://doi.org/10.1038/s41598-025-18996-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18996-7
