
Abstract
Graph Convolutional Networks (GCNs) have emerged as a leading approach for human skeleton-based action recognition, owing to their capacity to represent skeletal joints as adaptive graphs that effectively capture complex spatial relationships for feature aggregation. However, existing methods predominantly emphasize either spatial context within individual frames or holistic temporal sequences, often overlooking the interplay of spatial topology across multiple temporal scales. This limitation hinders the model’s ability to fully understand complex actions, especially those involving interactions that vary across different temporal phases. To address this challenge, we propose a Hierarchical Intertwined Graph Learning Framework (HI-GCN), which comprises two key modules: Intertwined Context Graph Convolution and Shifted Window Temporal Transformer. The former module integrates spatial–temporal information from adjacent frames at various temporal scales, thereby refining spatial relationship representations and capturing subtle topological variations that conventional GCNs tend to miss. The latter module advances temporal dependency modeling by applying shifted temporal windows with multi-scale receptive fields. Experimental results demonstrate that HI-GCN surpasses current state-of-the-art methods on multiple skeleton-based action recognition benchmarks, achieving accuracies of 93.3% on NTU RGB+D 60 (cross-subject), 90.3% on NTU RGB+D 120 (cross-subject), and 97.0% on NW-UCLA.
Similar content being viewed by others
Introduction
Skeleton-based human action recognition (HAR) has emerged as a significant advancement in the field of computer vision due to its ability to mitigate the challenges associated with traditional RGB-based approaches. Unlike RGB data, whose variations can heavily influence lighting, environmental conditions, and clothing, skeleton-based data remains robust, capturing only the skeletal structure and motion of the human body. This invariance to extraneous factors enables more consistent and reliable action recognition in a wide range of real-world applications, including intelligent surveillance systems1, health monitoring2,3, and video processing4. The versatility of skeleton-based HAR is further exemplified by its ability to operate effectively in environments with variable conditions, making it increasingly relevant for tasks requiring high accuracy and adaptability.
Graph Convolutional Networks (GCNs) have played a transformative role in skeleton-based human action recognition (HAR) by offering a principled framework to model the structured relationships among human joints5. Unlike conventional deep learning models that treat skeleton sequences as unstructured data, GCNs exploit the inherent graph topology of the human body, representing joints as nodes and their physical or semantic relationships as edges. This enables the model to capture complex spatial dependencies and interaction patterns among body parts, leading to more expressive and semantically rich representations of human motion. The seminal work ST-GCN6 laid the foundation for this paradigm by introducing a spatial–temporal graph structure that combines convolution across both joints and time. However, ST-GCN relies on a fixed, heuristically defined graph based on physical connectivity, which limits its ability to model non-local joint correlations and adapt to diverse action patterns. To overcome this limitation, subsequent research has focused on learning the graph topology adaptively from data7,8. These methods leverage attention mechanisms or other relational reasoning strategies to infer dynamic and context-aware connections among joints, thereby enhancing the flexibility and representational capacity of GCNs. Notably, recent approaches9,10,11,12 have extended adaptive topology modeling by incorporating temporal sensitivity into graph construction. Some methods generate globally shared graphs across the entire action sequence, while others focus on dynamically building frame-specific or phase-specific topologies. These efforts reflect an increasing emphasis on modeling spatial configurations that evolve over time.

Conceptual illustration of the intertwined context topology. This work focuses on capturing the nuanced relationships between joints by leveraging multiple temporal scales with intertwined spatial contexts. Dashed lines between joints depict the key connections, while colored borders highlight the context during different action phases.
Despite recent advances in topology adaptation for skeleton-based action recognition (HAR), existing methods still face considerable challenges in accurately modeling the complex spatiotemporal dynamics of human motion. Current approaches generally fall into three categories: (1) inferring a shared topology across the entire temporal sequence, (2) learning a frame-specific topology at each time step, and (3) explicitly modeling temporal-wise topology by treating temporal frames as graph nodes and directly encoding temporal relationships through graph structures. Sequence-level topology adaptation enables the modeling of global joint dependencies, offering a macro-structural understanding of the action. However, this global abstraction inherently fails to account for transient, frame-level variations in joint interactions that are critical for fine-grained recognition. For example, as illustrated in Fig. 1, in the action “Jump,” a fixed topology inferred over the whole sequence may encode the general relationship between the knees and upper limbs but fails to emphasize localized interactions such as the knee–knee coordination during the take-off phase or the subtle torso-knee dynamics during landing. On the other hand, frame-wise topology learning enhances local dynamic representation by tailoring the joint connectivity to the spatial configuration at each time step. While this enables finer temporal resolution, it lacks a coherent view of how relationships evolve across frames, resulting in a fragmented understanding of long-term dependencies. Such limitations become particularly evident in complex, multi-phase actions (e.g., “Sit Down” \(\rightarrow\) “Rest” \(\rightarrow\) “Stand Up”), where critical cues span across distant frames and cannot be captured by single-frame contexts alone. Moreover, most existing methods overlook the need for temporal hierarchy, adopting a flat temporal modeling paradigm that fails to leverage information at multiple time scales. They typically rely on a uniform temporal granularity, either focusing on instantaneous posture or summarizing entire sequences, without capturing intermediate phases that bridge short-term and long-term dynamics. This absence of temporal scale diversity leads to suboptimal modeling of phase transitions, making it difficult to distinguish between semantically similar but temporally distinct sub-actions. For instance, although the posture at time \(T_i\) in a “Jump” may resemble both the take-off and landing phases, the surrounding temporal context, such as ascending or descending joint trajectories, carries critical information that is lost in static or shallow temporal models. These challenges underscore the need for a more expressive framework that simultaneously captures localized spatial configurations and their evolution across multiple temporal resolutions, thereby enabling robust recognition of complex, temporally structured human actions.
To address the limitations of existing approaches in capturing multi-scale spatial–temporal dynamics, we propose a Hierarchical Intertwined Graph Learning Framework (HI-GCN). The core motivation of HI-GCN is to bridge the gap between frame-specific adaptability and sequence-level contextual awareness by simultaneously enhancing intra-frame spatial perception and inter-frame temporal modeling across multiple temporal scales. Unlike prior approaches that operate either on a fixed topology or a narrow temporal context, HI-GCN is designed to capture the hierarchical and dynamic nature of human actions through two dedicated modules: Intertwined Context Graph Convolution (IC-GC) and Shifted Window Temporal Transformer (SW-TT).
The IC-GC module serves as a spatial reasoning component that adaptively constructs topologies by intertwining the spatial structure of each frame with multi-scale temporal information from adjacent frames. Rather than relying solely on the current frame’s joint configuration, IC-GC integrates temporally local and semi-global motion cues to infer context-aware topological structures. This enables the model to maintain the adaptability of frame-level graph construction while incorporating structural refinements driven by action-phase context. For example, during a “Jump” action, IC-GC allows the model to emphasize the knee–upper limb interaction in a crouching posture while dynamically shifting focus to bilateral knee coordination during the take-off phase. Such intertwined graph construction captures nuanced phase-dependent joint relationships that are often neglected in conventional spatial modules. Complementing this, the SW-TT module addresses temporal modeling through a hierarchical transformer operating on shifted temporal windows. Instead of processing the entire sequence uniformly or relying on local convolutions, SW-TT divides the temporal sequence into overlapping segments and applies attention-based modeling within and across these windows. This design enables effective aggregation of both short-term transitions (e.g., from crouching to mid-air) and long-term dependencies (e.g., full cycle of jump, including take-off and landing). By introducing temporal hierarchy and window-shifting, SW-TT avoids the boundary effects of fixed windowing and enriches the model’s sensitivity to varying motion rhythms. Together, IC-GC and SW-TT synergistically enable HI-GCN to learn expressive spatial-temporal representations that are adaptable, phase-aware, and hierarchically structured, leading to significant improvements in recognizing complex human actions. Extensive experiments demonstrate the effectiveness of HI-GCN in the domain of skeleton-based action recognition. Comparative evaluations on three benchmark datasets-NTU RGB+D 6013, NTU RGB+D 12014, and Northwestern-UCLA15-show that HI-GCN consistently achieves state-of-the-art performance in recognition accuracy,achieving 93.3% on NTU RGB+D 60 (cross-subject), 90.3% on NTU RGB+D 120 (cross-subject), and 97.0% on NW-UCLA.
The main contributions in this paper are summarized as follows:
-
We propose HI-GCN, a hierarchical intertwined graph learning framework designed to address the limitations of existing methods in modeling both frame-specific spatial adaptivity and long-range temporal dependencies. It captures nuanced inter-frame spatial relationships and multi-scale temporal structures essential for recognizing complex human actions.
-
HI-GCN consists of two key components: Intertwined Context Graph Convolution (IC-GC), which adaptively constructs frame-wise topologies enriched with multi-scale temporal context, and Shifted Window Temporal Transformer (SW-TT), which hierarchically models temporal dependencies through shifted attention windows.
-
Comprehensive evaluations on three benchmark datasets-NTU RGB+D 60, NTU RGB+D 120, and Northwestern-UCLA-highlight the superior performance of HI-GCN. It consistently surpasses previous state-of-the-art approaches, setting new standards in recognition accuracy with 93.3% on NTU RGB+D 60 (cross-subject), 90.3% on NTU RGB+D 120 (cross-subject), and 97.0% on NW-UCLA.
Related works
In the domain of skeleton-based action recognition, graph neural networks have become a significant tool for modeling the spatial and temporal relationships among human joints. ST-GCN6 has initiated the application of graph convolution to effectively capture human joint connectivity and temporal motion patterns, thereby establishing a foundation for task-driven graph modeling. Nevertheless, ST-GCN encounters limitations regarding the efficiency of information propagation, particularly for high-order neighboring nodes, which arise from the constraints inherent in adjacency matrix-based aggregation. In response to this, AS-GCN16 has introduced the notion of the action-link, which enhances the representation of cooperative behavior among non-skeleton-connected joints. MS-G3D17 has further refined feature extraction by incorporating a multi-scale aggregation scheme that mitigates irrelevant interactions between nodes.
With the introduction of attention mechanisms, dynamic topology learning has become a promising direction. ST-TR18 attempts to enhance the joint modeling of spatial and temporal features through self-attention mechanisms. However, it neglects the dynamic nature of temporal information, resulting in decreased accuracy in action prediction. Dynamic GCN19 employs a Context Enhancement Network (CeN) to construct adaptive skeletal topologies, thereby enabling more flexible relational modeling. Despite such advances, many GCN-based methods still suffer from a lack of explicit hierarchical structure, which adversely impacts the precision of temporal modeling. In response, some methods combine self-attention-based graph convolution with context-aware topology modeling to improve adaptability to dynamic contexts. Nonetheless, these approaches typically rely on extensive prior knowledge and introduce considerable complexity during spatial graph embedding, which increases the difficulty of capturing diverse temporal dynamics within a single action, ultimately limiting their overall recognition performance.
Meanwhile, recent studies have introduced explicit temporal-wise topology modeling approaches, where temporal frames are treated as graph nodes and their inter-frame relations are directly learned. TD-GCN20 proposes a temporal decoupling strategy by learning frame-specific and channel-specific adjacency matrices, enabling the network to flexibly capture temporal dependencies across different stages of an action. DSTSA-GCN21 further advances this idea by integrating semantic-aware spatio-temporal topology modeling through grouped temporal/channel convolutions and multi-scale temporal modeling. These methods demonstrate the effectiveness of temporal topology modeling in improving fine-grained motion representation and form a critical foundation for our proposed HI-GCN.
Related works such as TSMGA22 and FSCMF23 demonstrate the effectiveness of multi-scale spatio-temporal graph attention and frequency-spatial cross-modal fusion, respectively. Specifically, TSMGA employs multi-scale graph attention for effective spatio-temporal feature extraction in remote sensing change detection, while FSCMF introduces a dual-branch frequency-spatial network for visible and infrared image fusion by combining CNN and Transformer modules to enhance cross-modal representation. These approaches provide valuable insights for improving temporal-wise topology modeling and modality fusion in skeleton-based action recognition.
Building upon these developments, recent studies have further expanded the modeling dimensions, particularly from the perspectives of multi-scale structure and modality fusion. LG-SGNet24 proposed a graph neural framework that jointly models local and global spatial structures. By combining channel-specific global modeling with channel-shared local modeling, the network effectively extracts multi-level spatial features. It further incorporates multi-head self-attention for global temporal modeling and dilated convolutions for local temporal modeling, along with frame-level weighting to focus on key frame dynamics, achieving state-of-the-art performance on the NTU dataset series. Meanwhile, HMSFT25 addresses issues such as jitter and temporal instability in 3D pose estimation by constructing a hierarchical multi-scale spatial-frequency-temporal collaborative Transformer. This framework models fine-grained motion patterns across joint, body-part, and full-body levels through spatial motion-aware modules, frequency-adaptive encoding blocks, and multi-scale temporal modeling, providing a new paradigm for skeleton-based action recognition. Despite these advances, achieving a balanced trade-off between modeling efficiency, global temporal dependency capture, and fine-grained local motion detail remains a fundamental challenge in this domain.
Preliminaries
Skeleton-based graph
In the domain of human action recognition, the skeletal structure is represented as a graph \({\mathscr {G}} = \left( {\mathscr {V}}, {\mathscr {E}} \right)\), with \({\mathscr {V}} = \left( v_1, v_2,\ldots ,v_N \right)\) constituting the set of N joints, each represented as a vertex. The connections between these joints, akin to bones, form the edge set \({\mathscr {E}}\) and are encoded in an adjacency matrix \(\textrm{A} \in {\mathbb {R}}^{N \times N}\), where \(\textrm{A}_{i,j} = 1\) signifies a bone connecting joint \(v_i\) to joint \(v_j\). The sequence of skeletal frames is denoted by \(\textrm{X} \in {\mathbb {R}}^{T \times N \times C}\), where T represents the temporal length of the sequence, encompassing the number of frames, and C is the dimensionality of the features associated with each joint \(v_i\).

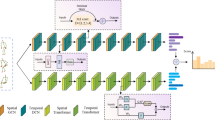
(a) The architecture of HI-GCN. (b) IC-GC aggregates joint information. (c) Illustration of the spatial context of multiple temporal scales intertwining in the Intertwined Unit.
Methods
Framework
As illustrated in Fig. 2a, the HI-GCN framework is designed to hierarchically model the spatial–temporal dynamics of skeleton-based graph sequences for human action recognition. The input skeleton sequence is represented as a three-dimensional tensor of size \(T \times N \times 3\), where T denotes the number of frames, N signifies the number of skeletal joints, and 3 corresponds to the spatial coordinates. Initially, a linear graph embedding layer projects this input into a feature space of size \(T \times N \times C\). The architecture subsequently comprises three sequential stages, each incorporating a stack of HI-GCN blocks (specifically 2, 4, and 3 blocks, respectively). Interposed between these stages are temporal pooling layers (max pooling with kernel size 2 and stride 2) which effectively halve the temporal resolution while doubling the channel dimension, resulting in intermediate feature maps of sizes \(T/2 \times N \times 2C\) and \(T/4 \times N \times 4C\). This progressive downsampling in the temporal domain, in conjunction with increasing feature dimensionality, empowers the framework to capture multi-scale temporal dynamics. Ultimately, global average pooling is applied over both the spatial and temporal dimensions, followed by a linear layer incorporating softmax activation to yield the final action category prediction.
The fundamental building blocks of each stage are the Intertwined Context Graph Convolution (IC-GC) and the Shifted Window Temporal Transformer (SW-TT). The IC-GC module effectively addresses the challenge of learning adaptive spatial topologies across temporal scales by integrating spatial dependencies within individual frames alongside contextual information derived from neighboring frames. This approach facilitates the refinement of frame-specific graph structures while maintaining inter-frame spatial consistency. Conversely, the SW-TT module is introduced to proficiently model temporal dependencies in a hierarchical manner. By segmenting the temporal axis into fixed-size, non-overlapping windows, the SW-TT captures localized temporal dynamics while enabling deeper stages to aggregate a broader temporal context. Together, these two modules are responsible for capturing intricate spatial configurations and the complex temporal evolution inherent in human motion, thereby allowing HI-GCN to construct robust spatial–temporal representations that enhance the accuracy of action recognition.
Intertwined context graph convolution module
The Intertwined Context Graph Convolution (IC-GC) module, as shown in Fig. 2b, operates within each block of the HI-GCN framework to refine the spatial feature representation by dynamically inferring adaptive topologies. The IC-GC module begins by processing the input features through a graph convolution operation that is weighted by an adjacency matrix, which represents the graph structure of the skeleton. The feature update process at each layer is governed in Eq. (1).
where \(\textrm{X}_t^l\) denotes the features of the skeleton at frame t and layer l, and \(\textrm{W}^l \in {\mathbb {R}}^{C_l \times C_{l+1}}\) is a learnable weight matrix that transforms the features. The adjacency matrix \(\textrm{A}\) is used to perform message passing between the joints of the skeleton, enabling the aggregation of neighboring joint information. This iterative process allows for the refinement of spatial feature representations as the model progresses through each layer, dynamically updating the graph and capturing complex spatial dependencies between joints over time. This structure enables the IC-GC to model spatial relationships that evolve across different action phases, maintaining topological adaptability in varied contexts.
In addition to the standard graph convolution operation, IC-GC integrates a self-attention mechanism to refine the adjacency matrix adaptively, further enhancing the flexibility of the learned topologies. The self-attention mechanism26 dynamically computes the adjacency matrix \(\textrm{A}_t\) for each frame t by considering the relationships between all joints, with the attention map computed in Eq. (2).
where \(\textrm{W}_Q, \textrm{W}_K \in {\mathbb {R}}^{C \times C'}\) are learnable projection matrices that transform the input features into queries and keys, respectively. The denominator \(\sqrt{D'}\) serves as a scaling factor to normalize the attention scores. The resulting matrix \(\textrm{A}_t\) represents a context-aware attention map that captures dynamic inter-joint dependencies within each frame. This mechanism allows the IC-GC module to focus on the most semantically relevant joint interactions for each specific action phase, enabling the model to generate refined, context-sensitive topologies. By incorporating self-attention, IC-GC effectively adapts to complex and variable human motions, facilitating improved recognition of diverse and intricate action patterns.
Intertwined context topology modeling
To enhance the spatial modeling capacity of IC-GC, we propose an Intertwined Context Topology Modeling mechanism that integrates frame-level spatial representations with sequence-level context to more accurately capture joint dependencies across different action phases. Traditional approaches often overlook the evolving semantics of joint interactions throughout a motion sequence, leading to rigid or context-agnostic topologies. To address this, we introduce an Intertwined Unit that operates on the query and key matrices, Q and K, used for adjacency learning. As illustrated Fig. 2c, a low-rank temporal pooling is first performed to extract compact sequence-level spatial context. For instance, the query context matrix \(Q_s\) is computed by averaging \(Q_t\) across all temporal frames in Eq. (3).
where \(\textrm{X}^{t}\) denotes the skeletal features at frame t, and \(W_Q\) is a learnable projection matrix that maps the spatial features into the query space. The resulting \(Q_s\) encapsulates the global motion pattern across the sequence, offering a broader perspective beyond local frame-level interactions. To infuse this global context back into each frame while preserving computational efficiency, we employ a low-rank gating mechanism inspired by Squeeze-and-Excitation networks27. This mechanism generates a contextual modulation matrix \(Q_c\) through a two-layer bottleneck transformation in Eq. (4).
where \(\textrm{W}_{1} \in {\mathbb {R}}^{C' \times \frac{C'}{r}}\) and \(\textrm{W}_{2} \in {\mathbb {R}}^{\frac{C'}{r} \times C'}\) are the weights of two fully connected layers, and r is the reduction ratio (set to 4) to reduce parameter count. The nonlinearity sequence ReLU–Tanh, followed by an absolute value, ensures that the gating preserves positivity while maintaining expressiveness. This gate \(Q_c\) captures discriminative global context, which is then broadcast-multiplied onto each frame-level query \(Q_t\) to emphasize informative features conditioned on the entire action sequence.
The modulated queries and keys are utilized to compute the intertwined context topology \({\mathscr {I}}_{t}\) using cosine-based attention in Eq. (5), which accounts for angular similarity rather than raw dot-product alignment.
where \(\odot\) denotes element-wise multiplication, \(\textrm{cos}(\cdot ,\cdot )\) computes the cosine similarity between vectors, and \(\sqrt{d'}\) represents a learnable scaling factor used to normalize the similarity scores. This formulation enables the spatial topology of each frame to be dynamically adjusted based on both local joint relationships and global action semantics, allowing the IC-GC module to model phase-aware spatial dependencies more effectively. Unlike standard dot-product attention, we utilize cosine similarity to emphasize angular relationships between skeleton joints, as their relative orientations are more discriminative for action recognition than magnitude-based features. This normalization inherently enhances robustness to anatomical variations (e.g., bone lengths) while preserving kinematic dependencies critical for modeling skeletal motion.

Architecture of the Shifted Window Temporal Transformer. (a) SW-TT aggregates temporal information across different windows. (b) Illustration of the shifted temporal window operation, highlighting the dynamic adjustment of window positions.
Feature aggregation
After obtaining the \({\mathscr {I}}\) topology, which captures phase-aware spatial dependencies by incorporating both local joint relationships and global action semantics, the IC-GC module performs feature aggregation using a cosine-based attention mechanism. This mechanism modulates the queries and keys, allowing the computation of \({\mathscr {I}}_{t}\) and prioritizing angular similarity over raw dot-product alignment. The topology \({\mathscr {I}}_{t}\) is dynamically updated, thereby enhancing the spatial expressiveness of each frame by encoding subtle contextual variations across different action phases.
In addition to \({\mathscr {I}}_{t}\), a shared learnable adjacency matrix \(\textrm{A}^{p} \in {\mathbb {R}}^{N \times N}\), initialized from the human skeletal prior, is introduced. This adjacency matrix serves as a structural regularizer, encoding inherent joint connectivity that complements the dynamic topology \({\mathscr {I}}_{t}\). The aggregated feature representation for each joint is computed in Equation 6.
where \(\odot\) denotes element-wise multiplication and \(\textrm{W}_{P} \in {\mathbb {R}}^{C \times C}\) is a learnable linear projection for channel-wise transformation. To prevent feature degradation across layers, a residual learning path with a linear transformation is further added, facilitating the learning of deeper and more discriminative representations.
Shifted window temporal transformer
The (SW-TT) module,as illustrated in Fig. 3a, is designed to enhance temporal feature representation following spatial encoding by the IC-GC module. Unlike conventional temporal convolutions with limited receptive fields, SW-TT employs a larger temporal receptive field whose window configuration is explicitly aligned with that of the IC-GC, thus ensuring compatibility and continuity in multi-scale temporal modeling. This alignment contrasts with prior multi-scale temporal convolution approaches17,28, enabling the model to comprehensively capture long-range temporal dependencies while preserving temporal sequence continuity.
To encode positional information within the temporal dimension more effectively, SW-TT replaces standard positional embeddings with a learnable depthwise convolution operation applied to the input sequence \(\textrm{X}^l \in {\mathbb {R}}^{T \times N \times C}\). As illustrated in Fig. 3b, before convolution, \(\textrm{X}^l\) is rearranged to \({\mathbb {R}}^{C \times T \times N}\) to conform with the convolutional kernel shape, and the output \(\textrm{X}_p^l\) is reverted back to \({\mathbb {R}}^{N \times T \times C}\) after processing. This operation is in Eq. (7).
where \(\textrm{DPConv}\) denotes a \(3 \times 1\) depthwise convolution. This convolutional positional encoding introduces an inductive bias that reinforces temporal locality, thereby facilitating more accurate and robust attention calculations over the sequence.
To address the inherent limitation of independent window processing and to enable cross-window temporal context integration, SW-TT incorporates a shifted window mechanism inspired by the Swin Transformer29. Specifically, odd-numbered blocks maintain the original temporal window partitioning, while even-numbered blocks shift the window start backward by half the window size. This temporal shift enhances the connectivity between neighboring windows, enabling smoother information flow and richer temporal modeling across boundaries.
Within each temporal window, attention weights are computed via cosine similarity to maintain consistency with the IC-GC’s spatial attention paradigm. The updated feature representation \(\textrm{X}^{l+1}\) is in Eq. (8).
where \(\textrm{W}_Q, \textrm{W}_K \in {\mathbb {R}}^{C \times C'}\) are learned projection matrices mapping the input to queries and keys, \(\sqrt{d'}\) is a learnable scaling factor normalizing the attention scores, and \(\textrm{W}_P \in {\mathbb {R}}^{C \times C}\) refines the aggregated features. The cosine similarity function explicitly encodes angular correlations between joints across the temporal window. Finally, a residual connection with a linear transformation envelops the SW-TT module to stabilize feature learning and facilitate the flow of gradients during training. By integrating SW-TT with the IC-GC module, the model effectively captures intricate spatial-temporal dependencies and subtle phase-aware joint relationships, resulting in significantly improved representation for skeleton-based human action recognition.
Experiment
Datasets
NTU RGB+D 60 dataset13 represents a foundational benchmark in skeleton-based action recognition, comprising 56,880 action sequences spanning 60 distinct human activity classes. Captured using three synchronized Microsoft Kinect v2 sensors from multiple viewpoints, it features complex daily, health-related, and interactive actions (e.g., “brushing teeth,” “falling,” “pushing”). The dataset’s standardized evaluation protocols-Cross-Subject (X-Sub), which splits 40 subjects for training and 20 for testing, and Cross-View (X-View), utilizing two camera views for training and a third for testing-rigorously assess model generalizability across human subjects and camera perspectives. Its comprehensive motion capture (25 joints per skeleton) and scale established it as the first large-scale benchmark for 3D human activity analysis.
NTU RGB+D 12014 constitutes the largest skeleton action dataset with 114,480 sequences across 120 action classes, including challenging fine-grained interactions (e.g., “threading needle,” “shuffling cards”). Collected from 106 subjects under 32 setup configurations, it introduces novel challenges through its expanded taxonomy of activities requiring precise hand-object coordination. The evaluation protocols include Cross-Subject (X-Sub) with 53 subjects each for training/testing, and Cross-Setup (X-Setup) where samples from even setup IDs train on odd-ID recorded samples. This dataset’s scale and complexity (particularly in capturing subtle motion differences between similar classes like “writing” vs. “typing”) make it essential for stress-testing model robustness.
Northwestern-UCLA dataset15 provides a critical multi-view benchmark with 1,494 sequences across 10 action classes performed in natural environments (e.g., “picking up,” “carrying,” “throwing trash”). Each sequence captures three distinct Kinect viewpoints (frontal, left, and right) of 10 subjects performing activities, enabling rigorous cross-view validation. Annotated with 20-joint skeletons, it emphasizes viewpoint invariance challenges-actions exhibit significant visual variations across perspectives (e.g., “hand waving” appears laterally compressed in profile views). Despite its smaller scale, its realistic settings and precise joint annotations (including finger-level details for object interactions) make it indispensable for evaluating view-agnostic representation learning in controlled environments.
Experiment setting
The proposed HI-GCN is implemented in PyTorch and trained on an NVIDIA RTX 3090 GPU using the SGD optimization algorithm with a momentum of 0.9. For the NTU RGB+D 60 and 120 datasets, the model employs an initial learning rate of 0.1 with batch size 64, while Northwestern-UCLA uses 0.01 and 16, respectively. All input sequences are resized to 64 frames for the NTU datasets and 52 frames for Northwestern-UCLA through established pre-processing pipelines. The temporal modeling component utilizes sliding windows spanning 16 frames for NTU sequences and 13 frames for Northwestern-UCLA, representing approximately 25% of each dataset’s standardized sequence length. The training protocol incorporates a 5-epoch warm-up phase followed by cosine learning rate decay, balancing computational efficiency with model convergence across datasets of varying scales—from NTU’s extensive 56,880 samples to Northwestern-UCLA’s more limited 1494 sequences. This configuration maintains methodological consistency with prior works while optimizing resource allocation for each dataset’s specific characteristics.
Evaluation of human action recognition
Table 1 demonstrates the performance evaluation across three benchmark datasets (NTU RGB+D 60, NTU RGB+D 120, and Northwestern-UCLA) using joint (J), bone (B), and four-stream (4S) modalities, where 4S represents the fused results of joint, bone, joint motion, and bone motion features. HI-GCN achieves state-of-the-art results, surpassing existing methods by significant margins: On NTU 60 Cross-Subject (X-Sub), HI-GCN’s 93.3% in 4S outperforms BlockGCN by 0.2%, while its 96.0% in joint modality exceeds CTR-GCN by 1.2%. For the more complex NTU 120 dataset, HI-GCN’s bone modality accuracy of 88.8% in Cross-Subject surpasses InfoGCN by 1.5%, and its Cross-Setup 4S performance of 91.6% outperforms FR-GCN by 0.7%. On Northwestern-UCLA, HI-GCN achieves 97.0% in 4S, matching the best published result while demonstrating superior efficiency. These consistent gains across all modalities and datasets-particularly the 1.8% advantage over FR-GCN in NTU 120 Cross-Setup bone modality-validate HI-GCN’s effectiveness in integrating structural and dynamic skeletal features through its hierarchical recurrent-feedback architecture.
Ablation study
Effectiveness of IC-GC
Table 2 demonstrates the ablation study of our IC-GC module, evaluating both its architectural configurations and core components. When examining the Parting Temporal Window (PTW) operation, where window sizes were aligned with the temporal sequence length while maintaining SW-TT’s configuration from “Experiment setting” section. The PTW employs adaptive window sizing synchronized with the temporal sequence length to enable hierarchical feature extraction, where larger windows capture coarse action phases while smaller windows preserve fine motion details. By dynamically adjusting the receptive field across temporal scales, PTW effectively resolves the inherent trade-off between long-range dependency modeling and local motion pattern preservation in skeleton action recognition. From Table 2, we observed that removing PTW caused a consistent performance degradation (0.3% X-Sub, 0.2% X-Set), validating its critical role in enabling multi-scale temporal pooling within the Intertwined Unit (IU). Similarly, eliminating the IU led to more substantial drops (1.1% X-Sub, 0.7% X-Set), confirming its effectiveness in dynamically processing sequence spatial context. The complete HI-GCN architecture, integrating both PTW’s flexible window-based temporal modeling and IU’s adaptive spatial reasoning, achieves optimal performance (87.2% X-Sub, 88.6% X-Set), surpassing the baseline by 3.4% and 2.7% respectively. These results empirically demonstrate that PTW’s multi-scale temporal aggregation and IU’s context-aware spatial modeling operate synergistically, where PTW’s windowing mechanism enhances IU’s ability to capture action-phase-specific joint relationships. IU’s dynamic topology learning compensates for PTW’s potential over-smoothing of fine-grained motions.
Effectiveness of SW-TT
Table 3 presents the ablation study of classification accuracies for HI-GCN with different window sizes of the SW-TT on the NTU-RGB+D 120 dataset. The results show the effect of varying window sizes on both the X-Sub and X-Set classification accuracies. The optimal performance is achieved when the window size is set to F/4, where the X-Sub accuracy reaches 87.2% and X-Set accuracy reaches 88.6%. Comparing these results with other window sizes, setting the window to F/2 yields slightly lower performance (86.5% for X-Sub and 87.6% for X-Set), while F/8 and F/16 window sizes show a gradual decline, with accuracies of 85.6% (X-Sub) and 86.9% (X-Set) for F/8, and 84.4% (X-Sub) and 85.8% (X-Set) for F/16. These results suggest that smaller window sizes (F/2) capture fewer temporal dynamics, while larger windows (F/8, F/16) may lead to overfitting or excessive smoothing, confirming that F/4 is the most optimal choice for balancing temporal resolution and model generalization.
Table 4 illustrates the efficacy of the Shifted Window Temporal Transformer (SW-TT) within the HI-GCN framework through a comprehensive ablation study, comparing it with Multi-Scale Temporal Convolution (MS-TC). The findings demonstrate that SW-TT attains superior classification accuracy relative to MS-TC, with enhancements of 0.8% (X-Sub) and 1.1% (X-Set). Component-wise analysis reveals that the Parting Temporal Window (PTW) and Shifted Window (SWin) operations contribute positively to the model’s performance, whereas depthwise convolution exerts minimal influence. Specifically, the removal of SWin results in a decrease of 0.4% (X-Sub) and 0.6% (X-Set) in accuracy, while the omission of PTW causes a reduction of 0.2% (X-Sub) and 0.5% (X-Set). These results suggest that the design of SW-TT, which integrates window-based attention with temporal partitioning, more effectively captures temporal dependencies in skeleton sequences in comparison to traditional temporal convolutions. The complete HI-GCN architecture, incorporating both SW-TT and IC-GC, achieves accuracies of 87.2% (X-Sub) and 88.6% (X-Set), thereby demonstrating superior performance relative to existing methodologies.

The visualization of the spatial posture of three frames uniformly sampled from “Pushing” data in NTU RGB+D 60 (Top), and the normal Spatial Topology that w/o sequence spatial context (Middle), the Intertwined Context Topology (Bottom), respectively. All shown topologies are from the first head of attention.
Computational complexity with other models
Table 5 demonstrates the computational efficiency and performance advantages of HI-GCN compared to existing GCN-based approaches on the NTU-120 X-Sub joint stream dataset. The results show that HI-GCN achieves the highest accuracy (87.2%) while maintaining competitive model complexity (1.67 M parameters) and computational efficiency (1.73G FLOPs). Notably, HI-GCN outperforms frame-level context models (InfoGCN, HD-GCN) by 1.5–2.1 percentage points and sequence-level approaches (CTR-GCN) by 2.3 percentage points, despite using fewer FLOPs than all compared methods. The integration of both frame-level (F) and sequence-level (S) contexts in HI-GCN yields improved performance over models employing either context type alone, as evidenced by the 1.5% accuracy gain over HD-GCN (frame-only) and 2.3% improvement over CTR-GCN (sequence-only). These results validate that HI-GCN’s hierarchical architecture successfully combines the complementary strengths of both temporal granularities while maintaining computational efficiency, achieving state-of-the-art performance with 13.6% fewer FLOPs than 2s-AGCN and 12.2% fewer than CTR-GCN. The balanced trade-off between accuracy and efficiency positions HI-GCN as a practical solution for skeleton-based action recognition tasks.
Although HI-GCN uses multiple temporal hierarchical spatial contexts to construct the topologies, it does not cause high complexity because it necessitates just a single attention calculation like the single hierarchical spatial contexts approach. Comparisons of computational and model complexity with other GCN-based models are shown in Table 5. We perform experiments in a consistent environment by keeping all hyperparameters fixed. This indicates that HI-GCN is a performance-driven model that attains state-of-the-art accuracy by innovatively intertwining multiple temporal hierarchical spatial contexts to infer topology. Furthermore, it showcases competitive efficiency when compared to similar models.
Visualization
Dynamic topology learning in HI-GCN
Figure 4 provides a compelling visualization of HI-GCN’s dynamic topology learning mechanism through the “Pushing” action sequence from NTU RGB+D 60. The three sampled frames (top row) demonstrate progressive postural changes during the push movement, while the corresponding Normal Spatial Topology (middle row) and Intertwined Context Topology (bottom row) reveal how joint correlations evolve. The IC Topology, derived from attention matrices Q and K, shows distinct frame-specific adaptations: while maintaining fundamental anatomical connections (evident in persistent diagonal patterns), it dynamically strengthens action-relevant cross-body links (e.g., left elbow to right ankle) and weakens irrelevant ones (e.g., right wrist to thumb). This adaptive behavior reflects HI-GCN’s capacity to modulate joint relationships based on both spatial configuration and temporal context, effectively balancing biomechanical constraints with action-specific requirements.

Action recognition results of HI-GCN on skeleton-based sequences. The model demonstrates robust performance across diverse action categories including: (a) object manipulation tasks (juggle table tennis ball, play magic cube), (b) sports motions (tennis bat swing, shoot at basket), (c) tool usage (shoot with gun, play guitar), and (d) human–computer interactions (use laptop, type on keyboard). The skeletal overlays highlight HI-GCN’s ability to capture both fine-grained hand-object interactions and full-body coordination patterns.
The observed topology adjustments align precisely with the biomechanical demands of pushing. In the initiation phase (left frame), HI-GCN strengthens connections between the pushing arm (left) and stabilizing leg (right) to model force generation, while reducing weights for the passive right arm. During the main push (center frame), cross-body correlations between torso and lower limbs intensify to represent balance maintenance. Notably, the follow-through phase (right frame) shows diminished upper-body connections as the action concludes. These modifications demonstrate HI-GCN’s ability to: (1) identify and prioritize functionally critical joints for each action phase, (2) suppress noise from inactive body parts, and (3) preserve essential anatomical relationships. Such nuanced adaptation explains HI-GCN’s superior performance in modeling complex, phase-dependent actions compared to fixed-topology approaches.
Performance visualization
Figure 5 demonstrates the action recognition capabilities of HI-GCN through skeletal sequence visualizations across eight representative actions, showcasing its proficiency in modeling both object interactions and full-body kinematics. The framework accurately captures: (1) fine-grained hand-object coordination in tool-based tasks (precise finger positioning when shooting with a gun, strumming patterns during guitar play), (2) dynamic sports motions (wrist snap in tennis swings, arm extension during basketball shots), and (3) subtle human–computer interactions (finger-key alignment while typing, palm orientation over laptop touchpads). Notably, HI-GCN’s hierarchical attention mechanism resolves challenging cases like the magic cube manipulation, where it distinguishes between idle hand positions and active rotation gestures through joint relationship modeling. The skeletal overlays reveal consistent tracking of both major limbs (shoulder-elbow-wrist chains) and delicate end-effectors (fingertips during table tennis juggling), validating its multi-scale spatiotemporal representation learning.
Discussion
While HI-GCN demonstrates compelling performance in skeleton-based action recognition by effectively capturing multi-scale spatial-temporal dependencies, there are still areas for improvement. The current framework is primarily designed for single-person scenarios with high-quality skeleton data, which limits its robustness in real-world settings involving noisy inputs, occlusion, or multiple interacting subjects. Additionally, the model relies solely on structural and motion cues without incorporating semantic-level supervision, which may affect its generalizability to fine-grained or ambiguous actions. Addressing these limitations by introducing semantic guidance, noise-resilient topology learning, and multi-person interaction modeling will be important directions for future research.
Conclusion
This work introduces the HI-GCN, which advances skeleton-based action recognition by effectively modeling complex spatial-temporal dependencies through the integration of IC-GC and SW-TT. By capturing nuanced joint relationships across multiple temporal scales and enhancing temporal feature aggregation with shifted window attention, HI-GCN significantly improves the representation of phase-aware spatial-temporal dynamics. Future work will investigate adaptive graph topology learning guided by semantic action information and extend the framework to handle more challenging scenarios such as multi-person interactions and cross-domain action recognition.
Data availability
The data supporting the findings of this study are publicly available from the following benchmark datasets:
The NTU RGB+D 60 and NTU RGB+D 120 datasets can be accessed at: https://rose1.ntu.edu.sg/dataset/actionRecognition/. The Northwestern-UCLA dataset is available at: https://wangjiangb.github.io/my_data.html. All datasets are freely accessible for academic use and typically require a standard request or registration process.
References
Li, J. et al. Efficient and secure outsourcing of differentially private data publishing with multiple evaluators. IEEE Trans. Depend. Secure Comput. 19, 67–76 (2022).
Dong, C.-Z. & Catbas, F. N. A review of computer vision-based structural health monitoring at local and global levels. Struct. Health Monit. 20, 692–743 (2021).
Pang, Y. et al. Slim unetr: Scale hybrid transformers to efficient 3d medical image segmentation under limited computational resources. IEEE Trans. Med. Imaging 43, 994–1005 (2023).
Senior, A. et al. Enabling video privacy through computer vision. IEEE Secur. Privacy 3, 50–57 (2005).
Pang, Y. et al. Graph-based contract sensing framework for smart contract vulnerability detection. IEEE Trans. Big Data 1, 1 (2025).
Yan, S., Xiong, Y., Lin, D. & Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32 (2018).
Pang, Y. et al. Online self-distillation and self-modeling for 3d brain tumor segmentation. IEEE J. Biomed. Health Inform. 1, 1–13 (2025).
Pang, Y. et al. Efficient breast lesion segmentation from ultrasound videos across multiple source-limited platforms. IEEE J. Biomed. Health Inform. 1, 1–15 (2025).
Huang, J., Wang, Z., Peng, J. & Huang, F. Feature reconstruction graph convolutional network for skeleton-based action recognition. Eng. Appl. Artif. Intell. 126, 106855 (2023).
Huang, J., Huang, T., Dong, C., Duan, S. & Pang, Y. Hierarchical network with local-global awareness for ethereum account de-anonymization. IEEE Trans. Syst. Man Cybern. Syst. 55, 5839–5852 (2025).
Lee, J., Lee, M., Lee, D. & Lee, S. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 10444–10453 (2023).
Huang, T., Huang, J., Dong, C., Duan, S. & Pang, Y. Samamba: Structure-aware mamba for ethereum fraud detection. IEEE Trans. Inf. Forensics Secur. 20, 7410–7423 (2025).
Shahroudy, A., Liu, J., Ng, T.-T. & Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1010–1019 (2016).
Liu, J. et al. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 42, 2684–2701 (2019).
Wang, J., Nie, X., Xia, Y., Wu, Y. & Zhu, S.-C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2649–2656 (2014).
Li, M. et al. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 3595–3603 (2019).
Liu, Z., Zhang, H., Chen, Z., Wang, Z. & Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 143–152 (2020).
Plizzari, C., Cannici, M. & Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Pattern Recognition. ICPR International Workshops and Challenges: Virtual Event, January 10–15, 2021, Proceedings, Part III 694–701 (Springer, 2021).
Ye, F. et al. Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia 55–63 (2020).
Liu, J., Wang, X., Wang, C., Gao, Y. & Liu, M. Temporal decoupling graph convolutional network for skeleton-based gesture recognition. IEEE Trans. Multimedia 26, 811–823 (2023).
Cui, H., Huang, R., Zhang, R. & Hayama, T. Dstsa-gcn: Advancing skeleton-based gesture recognition with semantic-aware spatio-temporal topology modeling. Neurocomputing 637, 130066 (2025).
Zhang, X. et al. Tsmga: temporal–spatial multi-scale graph attention network for remote sensing change detection. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 1, 1 (2025).
Zhang, X. et al. Fscmf: A dual-branch frequency-spatial joint perception cross-modality network for visible and infrared image fusion. Neurocomputing 1, 130376 (2025).
Wu, Z., Ding, Y., Wan, L., Li, T. & Nian, F. Local and global self-attention enhanced graph convolutional network for skeleton-based action recognition. Pattern Recogn. 159, 111106 (2025).
Zhang, H., Hu, Z., Bi, S., Di, J. & Sun, Z. Hmsft: Hierarchical multi-scale spatial-frequency-temporal collaborative transformer for 3d human pose estimation. Pattern Recogn. 164, 111562 (2025).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 1 (2017).
Hu, J., Shen, L., Albanie, S., Sun, G. & Wu, E. Squeeze-and-excitation networks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 7132–7141 (2017).
Chen, Y. et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 13359–13368 (2021).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) 9992–10002 (2021).
Shi, L., Zhang, Y., Cheng, J. & Lu, H. Non-Local Graph Convolutional Networks for Skeleton-Based Action Recognition (2018).
Shi, L., Zhang, Y., Cheng, J. & Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 29, 9532–9545 (2019).
Shi, L., Zhang, Y., Cheng, J. & Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 12026–12035 (2019).
Chen, Z., Li, S., Yang, B., Li, Q. & Liu, H. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition. Proc. AAAI Conf. Artif. Intell. 35, 1113–1122 (2021).
Song, Y.-F., Zhang, Z., Shan, C. & Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 45, 1474–1488 (2022).
Chi, H. et al. Infogcn: Representation learning for human skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 20186–20196 (2022).
Zhou, Y. et al. Blockgcn: Redefining topology awareness for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024).
Author information
Authors and Affiliations
Contributions
Xi Zhang conceived the research idea, led the project, and wrote the main manuscript text. Caiyan Tan implemented the HI-GCN framework and conducted the experiments. Yuan Yuan contributed to the model design and data analysis. Jiexing Yan provided critical revisions and theoretical guidance. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Clarification
All individuals depicted in the current version of Fig. 5 are adult co-authors of the study. Each individual has provided informed consent for the publication of their image in an online open-access publication. We confirm that all identifying images were captured within the context of research-related activities, and consent was obtained prior to their inclusion.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, X., Tan, C., Yuan, Y. et al. Hierarchical intertwined graph representation learning for skeleton-based action recognition. Sci Rep 15, 35447 (2025). https://doi.org/10.1038/s41598-025-19399-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-19399-4
