
Abstract
Investigating the recorded response of a structure to dynamic loads is an efficient method for understanding and describing its current status. In the present paper, the ability of different Convolutional Neural Network (CNN) algorithms using time-frequency images and the performance of a voting ensemble of the models have been investigated in classifying various types of structural damage. The time-frequency images fed into CNNs were generated from acceleration responses obtained from undamaged and damaged conditions of experimental and real-world structures. The structural damages considered in the case studies encompassed various types, severities, and locations, highlighting the variation in the damaged conditions. The findings indicated that employment of a soft voting ensemble learning method, with an average prediction accuracy of 98.5%, Yielded appropriate outcomes. Moreover, in the evaluation of different CNN architectures assessed, DenseNet-based models exhibited superior performance in three distinct considered structures, while VGG-based models exhibited the highest performance across all CNNs in one specific case study focused on the location of damages, respectively. Additionally, an examination was carried out to evaluate the impact of factors that could influence the prediction accuracy of the algorithms. The results showed that increasing the duration of each acceleration record led to an improvement in the final accuracy by about 4% in the investigated structure. Furthermore, the usage of Bump mother wavelet gave rise to the highest performance.
Similar content being viewed by others


Introduction
The deterioration of civil structures and infrastructures stems from factors such as excessive loading, environmental conditions, and natural disasters, often resulting in substantial financial losses1,2. Both short- and long-term structural damages contribute to a decrease in structural lifetime, highlighting the monitoring process’s crucial importance3,4. Conventional methods of SHM, which rely on visual inspection, necessitate the services of certified structural inspectors to evaluate buildings and establish maintenance plans; however, these approaches are demanding, subjective, and susceptible to errors5.
Machine Learning (ML) methodologies have significantly advanced, particularly in the areas of system identification, damage detection, and risk assessment6,7. Additionally, Deep Learning (DL) techniques have garnered significant interest, and particularly, their ability for automatic extraction of complex features in high-dimensional data has led to their widespread adoption across various application fields8,9. Zhang et al10. carried out a study proposing an innovative DL technique to model and predict seismic response, which depends on a Long Short-Term Memory (LSTM) recurrent neural network. Qu et al11. presented the rough set theory and an LSTM network to monitor safety in concrete dams. They also developed single-point and multipoint concrete dam deformation prediction algorithms utilizing LSTM. Furthermore, a novel assessment framework was suggested for a predictive model to forecast the deformation of concrete dams. Mao et al12. conducted a study in which a data anomaly detection approach was presented by employing generative adversarial networks and auto-encoders. Pathirage et al13. carried out a study suggesting an approach for damage detection based upon auto-encoders. The results indicated that the method was capable of discerning patterns between the modal information. Bui-Tien et al.14 introduced a novel framework using the Electric Eel Foraging Optimization algorithm to optimize a DL model combining 1DCNN, Gated Recurrent Units, and Residual Networks, enhancing accuracy and efficiency in bridge damage detection.
CNNs, known for their practicality in processing images15,16 and signals17,18,19have been consistently used to examine the behaviors of various structural systems20,21. In this context, CNNs have been frequently used to assess defects in pavement22,23 and structures24,25. Structural cracks are identified as significant parameters that can influence the performance of structures particularly when subjected to repetitive loads26. In a study, Ali et al27. used eight datasets to assess the effectiveness of five DL models, including a suggested CNN model, for crack localization and detection in structures made of concrete. Kim et al28. utilized an architecture based on CNNs for the purpose of identifying cracks on concrete surfaces, verified using 40,000 images. The outcomes have demonstrated a maximum peak accuracy of 99.8%. Yuan et al29. introduced a methodology for measuring the length of fatigue crack, and the effectiveness of the suggested approach was empirically verified using a compact tensile specimen fatigue test. The outcomes substantiated the approach’s ability to accurately and efficiently measure the length of crack. In addition, new CNNs for the classification of pavement cracks utilizing three-dimensional pictures were suggested in a work by Li et al30.. Pavement patches were categorized into five groups using the suggested CNNs, and of the different suggested CNNs, the total accuracies exceeded 94%.
Another application of CNNs observed in articles involved employing this method to analyze time-frequency images31,32. A study by Jamshidi and El-Badry33investigated the use of CNNs in classifying damage severity. The study used time-frequency representations of acceleration data from multiple sensors for CNN damage identifiers. The evaluation of the CNN-based classifier involves employing a dataset containing the response of a concrete beam subjected to impact hammer tests. It was demonstrated that the utilized method could accurately classify damage at different intensities, ranging from slight to severe. Wang et al34. presented a novel approach to structural damage identification in their study, utilizing the IASC-ASCE SHM benchmark. The abilities of deep neural networks and the Hilbert-Huang Transform were combined in the method. The strategy used in the paper showed advantages in accuracy when compared to SVM and ANN.
Typically, predictions in DL are made using a single model. However, by employing ensemble learning, which integrates multiple models, the accuracy of these predictions can be significantly enhanced. The fundamental principle of ensemble learning is to merge several models, resulting in a more resilient and reliable predictive system. Asghari et al35. introduced an innovative deep ensemble learning approach for detecting structural damages. Lie and Zhao36 introduced a technique to enhance the effectiveness of concrete damage detection by utilizing ensemble learning across various semantic segmentation networks. Their approach involved employing five distinct networks to identify coarse concrete cracks and spalling.
While CNN algorithms have shown promising results in damage detection using time-frequency images obtained from wavelet transform of signals, the studies conducted in this area remain insufficient, as numerous CNN algorithms and factors affecting their performance have not been thoroughly investigated in this field; consequently, these studies need to become more comprehensive. Therefore, the objective of this study is to evaluate and compare the efficacy of multiple fine-tuned CNN algorithms in identifying various types of structural damage, aiming to determine which algorithm achieves the highest prediction accuracy. Moreover, this study proposes a novel application of a voting ensemble of CNN models using time-frequency images for structural damage detection. In this study, acceleration data from different case studies, including an actual bridge in Japan, an experimental steel frame, a grandstand simulator, and a benchmark bridge, is utilized. In conclusion, a thorough parametric investigation is carried out regarding factors influencing prediction accuracy. These factors encompass the type of mother wavelet, the number of input images used to train the algorithms, and the duration of records converted to RGB images.
Methodology
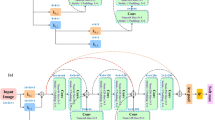
A comprehensive depiction of this research methodology and the algorithms utilized in this investigation is illustrated in Fig. 1. An assortment of CNN-based architectures, including DenseNet 121-based, DenseNet 169-based, DenseNet 201-based, ResNet 50-based, ResNet 101-based, ResNet 152-based, VGG 16-based, and VGG-19-based models, has been employed with the aim of examining the overall capabilities of voting ensemble learning and individual CNNs, as well as contrasting the prediction accuracy of different algorithms for detecting structural damages using time-frequency images derived from wavelet transforms of acceleration response of structures. It should be noted that a dense layer with 1024 neurons was added to well-known CNN architectures before the final output layer. Furthermore, each experiment was repeated Multiple times with different images in training and testing datasets to obviate the necessity for assurance, and the average of them will be presented in the following sections.

An exhaustive overview of the present study.
Wavelet transform
Typically, the initial signals are collected in the time domain and sometimes require transformation for subsequent analysis; moreover, the primary objective of employing mathematical transformations is to discern the generative process of the signal by obtaining information within an alternate functional space37. The Wavelet Transform (WT) is a robust technique for investigating the properties of non-stationary signals38. By employing the WT, the signal in the time domain can be transformed into the time-frequency domain, providing further information about both time and frequency characteristics39. The core concept involves employing a mother wavelet \(\:{\varphi\:}\left(\text{t}\right)\).
where \(\:{\uptau\:}\) and \(\:{\upalpha\:}\) represent the translation parameter and scale parameter, respectively. Continuous Wavelet Transform (CWT) of a signal \(\:\text{f}\left(\text{t}\right)\) can be given by the following equation40.
In this article, CWT is employed to convert the structural response data, obtained from various conditions of the structure, including healthy and various damaged states, into time-frequency images. These images serve as inputs for training the CNN models. By transforming the raw structural response into time-frequency representations, the CWT enables the extraction of detailed features from different states of the structure, facilitating the training process of CNN models to accurately differentiate between different conditions.
Image preprocessing and dataset
Numerous RGB images, each sized 224 × 224 × 3, have meticulously been generated with the utilization of the CWT. These visual representations were derived from the responses extracted from accelerometers positioned within the structures. The quantity of time-frequency images and the specific duration of each record vary and will be elaborated upon extensively in the section dedicated to each considered structure.
Convolutional neural networks
The concept of CNN, a DL method, takes inspiration from the principles of visual neuroscience; furthermore, the CNN architecture typically comprises phases for extracting features and carrying out classification41,42. CNN uses the weight-sharing procedure within its convolutional layers and can lower the quantity of training parameters32. In a convolutional layer, the input layer is convolved with kernels, resulting in the generation of intermediate feature maps through the following process.
where, \(\:{\text{X}}_{\text{i}}^{\text{L}}\) and \(\:{{\upomega\:}}_{\text{i}\text{j}}^{\text{L}}\) indicate the i-th channel of layer L and the i‐th channel of filter j in layer L, respectively. Moreover, S is called the activation function and \(\:{\text{b}}_{\text{j}}^{\text{L}}\) is the bias parameter43. Frequently, a pooling layer is used among a series of consecutive convolutional layers, to mitigate the potential for overlearning44. The size of the input is gradually reduced through pooling layers; furthermore, the pooling layer lowers the quantity of parameters and calculations in the network45. Fully connected layers establish connections connecting each neuron in a particular layer to every individual neuron in a subsequent layer46. Despite the feature extraction role of convolutional and pooling layers in processing input images, it is the fully connected layers taking the responsibility of classifying47,48.
CNNs have evolved with various architectures, each offering unique advantages for image classification. Given the excellent performance of VGG, ResNet, and DenseNet models in image classification, as demonstrated in numerous research papers, these architectures have been chosen for this article. Each of these CNN models has been widely recognized in the field of computer vision. The selection of these architectures in this article is driven by their proven effectiveness across various image classification challenges, aiming to leverage their complementary strengths to achieve state-of-the-art performance.
Fine tuning
Either from scratch or by transfer learning, a CNN model is able to be trained. Transfer learning offers a potent technique to mitigate the reliance of DL approaches on the quantity of available data. Using small-scale datasets or datasets consisting of similar samples, CNNs trained from scratch might experience overfitting, whereas transfer learning is able to mitigate this problem. The utilization of fine-tuning can boost classifier accuracy by transferring knowledge from domains with huge amounts of data49,50. Weights of the model were assigned according to a pre-trained algorithm in the fine-tuning of CNNs, with the exception that a number of the final blocks were left unfrozen to allow for weight adjustments during the training procedure51. In this investigation, all blocks of considered CNNs were frozen except two final blocks.
In the given architecture, the fully connected layer with 1024 neurons is placed before the final classification layer. Additionally, a dropout layer is applied after this dense layer to reduce overfitting by randomly deactivating a subset of neurons during training. After global average pooling compresses the spatial dimensions of the deep features into a vector, this dense layer introduces non-linearity and additional depth, allowing the model to learn more expressive and task-specific feature representations.
Ensemble learning
Ensemble learning refers to a method in ML that various models are combined to create a unified model52. This method boosts the precision and reliability of predictions by integrating multiple models, making it ideal for datasets with small samples and imbalanced distributions53; moreover, it is highly preferred in engineering prediction tasks because of its robustness and superior performance compared to individual models54. Ensemble learning takes advantage of the benefits that different models provide on different data to enhance overall performance53.
A voting classifier functions as a classifier that consolidates the outputs of different ML models, whether they are identical or conceptually diverse, using a majority vote to determine the final prediction55. The voting classifier primarily operates with two techniques, including hard voting and soft voting. In hard voting, the final outcome is determined by counting the class votes from each individual model. The class that garners the majority of votes from the base learners is selected as the final prediction56. Soft voting generates the final prediction by analyzing the probability outputs from each base model. The technique determines the final class by summing the weighted prediction probabilities provided by all classifiers for each possible class. The class with the greatest overall probability is selected as the output label57.
Metrics
The confusion matrix is commonly employed to illustrate how successfully classification algorithms perform. Every component within the matrix denotes the overall number of times the experiments are classified in the related anticipated category. As can be seen, the following equations provide the formula of metrics used to assess the efficacy of different identification models in this paper58.
where TP, FP, FN, and TN stand for true positive, false positive, false negative, and true negative, respectively.
Sensitivity analyses
In the process of determining the damage type through the approach detailed in this study, it becomes apparent that distinct parameters hold varying degrees of influence on the predictions. This section focuses on investigating the impact of three specific parameters using University of Central Florida (UCF) benchmark structure as a case study. By analyzing these parameters in detail, this article aims to gain an understanding of how they affect the overall predictive performance of the proposed method.
University of central Florida benchmark structure
Numerical simulation makes it possible to calculate the solutions of the models computationally, providing a way to replicate real-world physical behavior59. The bridge model, created at the UCF, was employed in this section to assess the effect of three parameters on the performance of considered individual CNN algorithms60,61. The bridge has been made of two 5.49 m long girders, seven 1.83 m long beams, and six 1.07 m tall columns. The cross sections of all beams and columns correspond to S3 × 5.7 and W12 × 26, respectively. Each structure component was joined by a simple, hinged, fixed, or semi-fixed restraint62. The schematic of the considered structure, is illustrated in Fig. 2.

Schematic of the UCF benchmark model, drawn with the aid of SeismoStruct v202563, website: https://www.seismosoft.com.
The structure’s acceleration responses were analyzed in an intact state and five different damaged conditions. These damages involved modifications to the connections between the longitudinal and transverse components, adjustments to the deck’s boundary conditions, and Changes in the stiffness of springs positioned at the supports of the bridge. A force of 10 kN was applied to Node 170 to simulate dynamic excitation, and six accelerometers were utilized to capture the data. The arrangement of sensors, damaged points, and the place of the applied load can be observed in Fig. 3. Furthermore, Table 1 provides comprehensive details on all the states that have been taken into account.

Location of sensors, damages, and the loading.
The networks were trained using time-frequency images generated by CWT with the Bump mother wavelet. The responses were split into 1200 matrices for each condition, with each matrix containing 15 s of acceleration data. An RGB image is generated using one matrix for each condition. Figure 4 provides a representation of the responses of all states, accompanied by their respective time-frequency images.

Samples of the UCF benchmark bridge time-frequency images.
Results
In each of the experiments, the algorithms underwent both training and testing with about 80% and 20% of all images, respectively. The average values of accuracy, precision, F1 score, and recall across all experiments conducted for each algorithm have been calculated and are visually represented in Fig. 5.

The outcomes of the various architectures in the UCF benchmark bridge.
Figure5 makes it clear that DenseNet201-based algorithm outperformed with the highest accuracy at 99% in predicting the types of damages. Furthermore, the three DenseNet-based methods, boasting an average accuracy of 98.8%, demonstrated superior predictive capabilities for types of damages compared to the others.
Evaluating the influence of number and duration of input acceleration records
The training procedure, computational cost, and accuracy of predictions can be strongly affected by the quantity of input images. A larger dataset can provide richer information, allowing the model to be trained better and make more accurate predictions. However, it is crucial to consider that collecting a huge amount of data entails substantial costs; moreover, it is probable that sufficient data in some structures might not be accessible. Consequently, the network might face difficulties in training correctly with limited image data, impacting its accuracy in recognizing various structural damage types. Furthermore, the duration of records converted to time-frequency images could have an impact on the extent to which the method is capable of accurately anticipating the results. Records with a longer duration may contain more comprehensive information; however, accumulating a significant amount of data still face the same issues previously mentioned. This section concentrates on how variations in record duration and number can affect the algorithms’ outcomes.
In this part, the efficiency of the considered network in forecasting the proper state is evaluated using various Quantities of input images acquired from acceleration responses of the UCF benchmark bridge with different durations. Consequently, the network has been given 100%, 90%, 80%, 70%, 60%, and 50% of the entire dataset, which equals 2400 images in every state, in order to be fine-tuned. It should be noted that each dataset consists of images derived from record with durations of either 6-, 9-, 12-, and 15-second employing Amor mother wavelets. Figure 6 (a) illustrates a three-dimensional representation of the changes in prediction accuracy regarding this matter. Moreover, Fig. 6 (b) shows the radar plot of the prediction accuracy of records with different periods in detecting damage types. Each vertex represents the number of images in each state used in the training and testing process, and each grid indicates the prediction accuracy. It is important to highlight that DenseNet121-based model was utilized in this section, given its proper performance observed in the results and its low number of parameters.

The influence of the number and duration of records on accuracy.
Based upon Fig. 6 (a), as the duration of recorded data extends, there is a notable improvement in the accuracy of the results. This trend suggests that longer recording durations provide more comprehensive information, which enhances the performance of the model. Additionally, increasing the number of images used for fine-tuning enhances the precision of the outcomes. With a larger set of images, the model can more effectively identify and learn from patterns and variations, leading to stronger and more precise predictions. However, it is essential to acknowledge the impact of reducing these factors. On average, a shorter duration of records results in an accuracy loss of approximately 4.3%. Similarly, a reduction in the number of input images used for fine-tuning leads to an average accuracy loss of around 2.7%. Figure 6 (b) demonstrates that as the duration of each recording increases, the impact of the number of images on the algorithm’s performance lessens. Specifically, when each recording is 6 s long, increasing the number of images improves performance by 3.6%. However, when the recording length extends to 15 s, this impact drops to 1.7%.
Mother wavelet’s impact on time-frequency images
The deployment of different types of mother wavelet not only leads to changes in the time-frequency images but also might possess an influence on performance of the algorithms. This section examines the effect of changes in mother wavelet types on the outcomes. Accordingly, three different types of commonly used mother wavelet, including Morse, Amor, and Bump, were employed in order to transform the acceleration responses gathered by sensors placed in the UCF benchmark bridge into images. Figure 7 displays the results of this investigation using average prediction accuracy. It is crucial to point out that, based on the superior performance noted in the Sect. “University of central florida benchmark structure”, DenseNet169-based and DenseNet201-based models were selected for use in this section.

The effect of various mother wavelet types on the performance of the considered algorithms.
As delineated by the data presented in Fig. 7, the utilization of Bump and Amor mother wavelets yields the highest and lowest values, respectively. Moreover; the Bump mother wavelet appeared to perform slightly better, possibly because of its ability to focus more clearly on relevant frequency bands. Additionally, the results highlight that DenseNet201-based algorithm exhibits less sensitivity to changes in the choice of mother wavelet. Given the beneficial effect of the Bump mother wavelet, this mother wavelet has been used to convert the acceleration responses into time-frequency images in the following case studies.
Case studies
In this part, the potency of the mentioned CNN algorithms, along with the voting ensemble learning method in detecting the damage types has been thoroughly verified through conducting assessments on three different structures, including a steel truss bridge placed in Japan, an experimental five-story steel frame, and Qatar University’s Grandstand Simulator (QUGS). Each structure offers different challenges and conditions, making the assessments comprehensive and reliable in verifying the models’ capabilities.
The old ADA steel truss Bridge
The acceleration responses of the Old ADA bridge in Japan have been utilized in this section in order to verify the efficacy of different algorithms in a real-world bridge64,65. The dimensions of the main span of the bridge, which was erected in 1959 and demolished in 2012, are 59.2 m in length and 3.6 m in width. Prior to the removal of the bridge, different types of damages were artificially simulated, and environmental vibrations were recorded66.
Four various structural health states were taken into account, which are: case I, Intact structure; case A, at the mid-span of the structure, one of the vertical elements was cut to half of its initial section area; case B, the mentioned element was cut entirely; case C, at the 5/8th span, one vertical truss element was wholly cut after reparation of the element mentioned in last cases. In Fig. 8, the damage scenarios are depicted67.

Visualization of damage locations.
Responses collected from accelerometers were categorized into four groups, consisting of 672, 456, 584, and 568 five-second segments, respectively, with regard to the availability of data. Figure 9 illustrates examples of the acceleration responses and time-frequency images for the mentioned states.

Samples of the Old ADA bridge time-frequency images.
Results
In all of the conducted experiments, the authors utilized 80% of the dataset, which was gathered from all available sensors, for both the training and validation phases. This portion of the data was used to fine-tune the models and ensure they were properly adjusted for optimal performance. The remaining 20% of the dataset was set aside exclusively for testing purposes, allowing for the evaluation of the algorithms’ performance on unseen data. Table 2 provides a clear comparison of the performance of different algorithms in predicting damage types and contains the averages of accuracy, precision, F1_score, and recall of conducted experiments.
Table 2 distinctly reveals that voting ensemble method, with accuracy rates of 97.5% and 97%, effectively demonstrates its capability in predicting damage types. Additionally, the DenseNet201-based algorithm set itself apart by achieving the highest accuracy of 96.3%, outperforming other CNNs in the case study. Furthermore, Fig. 10 (a) visually presents the confusion matrix from one of the analyses conducted with hard voting ensemble learning, while Fig. 10 (b) displays the ROC curve generated from one of the experiments employing each of the CNN architectures.
In this case study, the recorded training times per epoch showed that DenseNet121-based, DenseNet169-based, and DenseNet201-based models took about 4, 6, and 7 s, respectively. Models based on VGG16 and VGG19 required around 3 and 4 s per epoch, respectively. Similarly, ResNet50-based model completed each epoch in around 3 s, while ResNet101-based and ResNet152-based models required about 6.5 and 9 s, respectively. It is worth noting that these training times were measured during one of the training processes for each model using CNN-based architectures with the Adam optimizer, categorical cross-entropy loss function, and a batch size of 32.
It should be noted that given the differences in the number of images across classes, techniques such as over-sampling, under-sampling, or class weighting were not applied, since classification performance was consistently high and no significant bias toward majority classes was observed.

Results of classifying types of structural damage in the Old ADA bridge: (a) Confusion matrix of test dataset; (b) ROC curve.
The experimental five-story steel structure
A detailed laboratory experiment was conducted on a five-story steel frame structure to evaluate its behavior under impact loading conditions. The mentioned study involved capturing various vibration responses, including acceleration, strain, and excitation force, with data being recorded at a sampling rate of 500 Hz for intact state and different damaged scenarios. The structure was built utilizing columns that measure 8 mm by 8 mm and beams that are 6 mm by 6 mm, with twenty of each element included in the design. These elements were assembled into a three-dimensional framework using 40 joints to interconnect them. At the ends of the beams and columns, C-shaped joint mechanisms were used68,69. An image of that experiment is shown in Fig. 11 (a).

(a) The experimental five-story steel structure; (b) Locations and directions of accelerometers and forcing69.
To simulate damage, a healthy beam on the third floor of the frame was substituted with a damaged member in each case. Force measurements were obtained using an impact hammer, and acceleration responses of the experimental frame were recorded utilizing 12 accelerometers. Figure 11 (b) illustrates the locations and directions of the accelerometers and that of the applied forces69. The considered beam experienced three different types of structural anomalies:
Case H: The beam’s cross-section was altered to 8 mm by 8 mm.
Case L: The cross-section was further reduced to 4 mm by 4 mm.
Case R: Partial damage was introduced by decreasing the cross-section by 1 mm in both width and depth, in a portion of the beam.
The results from each accelerometer were segmented into 5-second intervals that encompassed the force application period for each case. These segments were then converted into time-frequency images. Figure 12 presents samples of acceleration responses from various states, along with their time-frequency images.

Samples of the experimental Five-Story steel structure time-frequency images.
Results
The entire dataset, which included a total of 2200 time-frequency images, was divided into training and testing subsets. Specifically, 80% of the images were used for training purposes, while 20% were set aside for validation and testing. Detailed results from the experiments conducted with each algorithm are outlined in Table 3.
Table 3 reveals that the DenseNet121-based algorithm attained the highest accuracy in predicting damage types. Furthermore, the performance of both soft and hard voting ensemble learning methods, which achieved accuracy rates of 98.9% and 98.5% respectively, demonstrates a substantial improvement over the individual algorithms. In this case study, which focuses on various conditions taken place in a beam of the three-dimensional frame, the DenseNet-based models generally demonstrate superior performance compared to the ResNet-based and VGG-based models. In Fig. 13 (a), the confusion matrix is represented, stemming from an analysis that employed hard voting ensemble learning. Meanwhile, Fig. 13 (b) depicts the ROC curve produced from an experiment utilizing each of the considered CNNs.
In one of the training procedures using CNN-based architectures with the Adam optimizer, categorical cross-entropy loss function, and a batch size of 32, the approximate training time per epoch for each CNN architecture was measured independently. DenseNet121-based, DenseNet169-based, and DenseNet201-based models required approximately 5, 7, and 9 s per epoch, respectively. VGG16-based and VGG19-based models completed each epoch in about 4 and 5 s, while ResNet50-based model took 4 s. The deeper ResNet models, namely ResNet101-based and ResNet152-based models, required around 8 and 11.5 s per epoch, respectively.

Results of classifying types of structural damage in the experimental 5-story steel frame: (a) Confusion matrix of test dataset; (b) ROC curve.
Qatar university grandstand simulator
It is essential to experimentally test the newly-introduced methods in a controlled laboratory setting before they are applied to real-life structures; QUGS, illustrated in Fig. 14, has been built for this purpose70. This structure, with dimensions of 4.2 m by 4.2 m in plan, was engineered to accommodate 30 spectators. The steel frame is composed of 8 main girders and 25 filler beams, all supported by 4 columns. The 8 girders measure 4.6 m in length, while the 5 filler beams in the lower section are approximately 1 m long. The remaining 20 beams each have a length of 77 cm. The two long columns are about 1.65 m in length71,72,73.

QUGS (Light green represents the girders, whereas the filler beams are depicted in dark green.).
In this case study, the structural damage was created by loosening the connection bolts which resulted in a slight change in rotational stiffness at the connections74,75; moreover, different bolts were loosened to create various slight damage cases in the benchmark structure17. It should be noted that a shaker was used to dynamically excite the structure, and an accelerometer placed at each beam-to-girder intersection measured and recorded the vibration response for undamaged and damaged conditions. Six damage conditions, resulting from loosening bolts at one joint of the structure, were randomly selected to evaluate the performance of the considered algorithms. Figure 15 illustrates the locations where these considered damages occurred.

Placement of considered damages in QUGS.
The recorded results from each accelerometer were meticulously divided into 25 segments, with each segment consisting of 10-second recordings corresponding to every individual case. To perform the training procedure, these segments were subsequently transformed into time-frequency images by employing the Bump mother wavelet. This transformation was carried out as it leads to the extraction of both time and frequency information. Figure 16 presents samples of the acceleration responses, accompanied by their corresponding time-frequency images.

Samples of the QUGS time-frequency images.
Results
It should be borne in mind that the dataset comprised a total of 5,250 images across all cases. Of these, approximately 4,200 images were set aside for training and validation purposes, allowing the models to learn effectively; furthermore, the remaining images were specifically reserved for the testing phase, which facilitates an evaluation of the models’ performance on previously unseen data. Table 4 details the outcomes obtained from all experiments conducted using each algorithm.
Table 4 clearly indicates that soft voting ensemble learning achieved an accuracy of 99%, reflecting its highly favorable performance in predicting different damage conditions. Among the individual algorithms assessed, VGG16-based algorithm distinguished itself by achieving the highest accuracy, making it the top performer in this evaluation. In this case study that different damage scenarios featured the same type of damage occurring in various locations within the structure, VGG-based models excelled in accurately identifying different states in comparison to DenseNet-based models and ResNet-based models. In Fig. 17 (a), the confusion matrix is illustrated, derived from an analysis using soft voting ensemble learning, and, Fig. 17 (b) shows the ROC curve obtained from an experiment that evaluated the considered CNNs. In one of the training processes using CNN-based architectures with the Adam optimizer, categorical cross-entropy loss function, and a batch size of 64, the approximate average training time per epoch for each CNN model was recorded to assess computational demand during model fitting. DenseNet121-based and ResNet50-based models each required roughly 6.5 s per epoch. DenseNet169-based and DenseNet201-based models took about 9.5 and 13 s, respectively, reflecting the increased complexity in their deeper architectures. VGG16-based and VGG19-based models required approximately 7 and 9 s, respectively. ResNet101-based and ResNet152-based models, showed around 14 and 20 s per epoch, respectively.

Results of classifying types of structural damage in the QUGS: (a) Confusion matrix of test dataset; (b) ROC curve.
Conclusions
The principal goal of the present study is to evaluate the robustness of voting ensemble learning and examine the efficacy of various CNNs utilizing time-frequency images in classifying the health status of structures. To validate the results derived from different algorithms in detecting types of damage, the acceleration responses obtained from three structures were converted into time-frequency images through wavelet transformation. The subsequent step involved training different algorithms using the transformed images. The findings demonstrated that within the considered structures, the utilization of voting ensemble learning, including hard and soft methods, gave rise to average prediction accuracy of 98.2%. Furthermore, in a comparison of various individual CNN architectures, DenseNet201-based algorithm demonstrated the best performance in two case studies, which analyzed different types of damage conditions. Specifically, this algorithm achieved 96.3% and 99% accuracy, respectively, outscoring all other models considered. In the experimental five-story steel structure, which considered damage scenarios within one location, DenseNet121-based algorithm excelled with a 95.4% prediction accuracy, outperforming all other models in this specific structure. The VGG16-based algorithm demonstrated outstanding performance in the last case study, which focused on a single damage type across multiple locations, achieving a 96.2% prediction accuracy and surpassing all other models.
Prior to investigating the mentioned case studies, a comprehensive sensitivity analysis was carried out to assess the parameters that might impact the performance of the algorithms. First, the examination of the final results investigated the utilization of mother wavelets, including Morse, Amor, and Bump. The outcomes showed that the utilization of Bump mother wavelet consistently led to demonstration of the highest accuracy across the considered structure. Additionally, the impact of varying the duration of each record, converted into each RGB image, on prediction accuracy was evaluated, and the investigation revealed that employing records with a duration of 15 s Yielded the highest accuracy compared to durations of 6, 9, and 12 s. Finally, the influence of the quantity of input time-frequency images on accuracy of outcomes was explored, and the findings indicated that a reduction in the number of input data correlated with a decrease in prediction accuracy.
Data availability
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request.
References
Ali, R. & Cha, Y. J. Subsurface damage detection of a steel Bridge using deep learning and uncooled micro-bolometer. Constr. Build. Mater. 226, 376–387 (2019).
Tran-Ngoc, H. et al. Damage assessment in structures using artificial neural network working and a hybrid stochastic optimization. Sci. Rep. 12, 4958 (2022).
Avci, O. et al. A review of vibration-based damage detection in civil structures: from traditional methods to machine learning and deep learning applications. Mech. Syst. Signal. Process. 147, 107077 (2021).
Chen, H. & Ni, Y. Structural Health Monitoring of Large Civil Engineering Structures (Wiley, 2018). https://doi.org/10.1002/9781119166641
Santaniello, P. & Russo, P. Bridge damage identification using deep neural networks on Time–Frequency signals representation. Sensors 23, 6152 (2023).
Kouchaki, M., Salkhordeh, M., Mashayekhi, M., Mirtaheri, M. & Amanollah, H. Damage detection in power transmission towers using machine learning algorithms. Structures 56, 104980 (2023).
Han, Q., Ma, Q., Dang, D. & Xu, J. Modal Parameters Prediction and Damage Detection of Space Grid Structure under Environmental Effects Using Stacked Ensemble Learning. Struct. Control Health Monit. 1–24 (2023). (2023).
Deng, C. et al. Detection of Rupture Damage Degree in Laminated Rubber Bearings Using a Piezoelectric-Based Active Sensing Method and Hybrid Machine Learning Algorithms. Struct. Control Health Monit. 6694610 (2025). (2025).
Mousavimehr, S. M. & Kavianpour, M. R. A non-stationary downscaling and gap-filling approach for GRACE/GRACE-FO data under Climatic and anthropogenic influences. Appl. Water Sci. 15, 91 (2025).
Zhang, R. et al. Deep long short-term memory networks for nonlinear structural seismic response prediction. Comput. Struct. 220, 55–68 (2019).
Qu, X., Yang, J. & Chang, M. A Deep Learning Model for Concrete Dam Deformation Prediction Based on RS-LSTM. J. Sens. 1–14 (2019). (2019).
Mao, J., Wang, H. & Spencer, B. F. Toward data anomaly detection for automated structural health monitoring: exploiting generative adversarial Nets and autoencoders. Struct. Health Monit. 20, 1609–1626 (2021).
Pathirage, C. S. N. et al. Structural damage identification based on autoencoder neural networks and deep learning. Eng. Struct. 172, 13–28 (2018).
Bui-Tien, T., Nguyen-Chi, T., Le-Xuan, T. & Tran-Ngoc, H. Enhancing Bridge damage assessment: adaptive cell and deep learning approaches in time-series analysis. Constr. Build. Mater. 439, 137240 (2024).
Cha, Y. J., Choi, W. & Büyüköztürk, O. Deep Learning-Based crack damage detection using convolutional neural networks: deep learning-based crack damage detection using CNNs. Comput. -Aided Civ. Infrastruct. Eng. 32, 361–378 (2017).
Zhang, L., Xie, Q., Wang, H., Han, J. & Wu, Y. Deep-Learning‐Based Crack Identification and Quantification for Wooden Components in Ancient Chinese Timber Structures. Struct. Control Health Monit. 9999255 (2024). (2024).
Abdeljaber, O. et al. 1-D CNNs for structural damage detection: verification on a structural health monitoring benchmark data. Neurocomputing 275, 1308–1317 (2018).
Kiranyaz, S., Ince, T., Abdeljaber, O., Avci, O. & Gabbouj, M. 1-D Convolutional Neural Networks for Signal Processing Applications. in ICASSP –2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 8360–8364 (IEEE, Brighton, United Kingdom, 2019). 8360–8364 (IEEE, Brighton, United Kingdom, 2019). (2019). https://doi.org/10.1109/ICASSP.2019.8682194
Chamangard, M., Ghodrati Amiri, G., Darvishan, E. & Rastin, Z. Transfer learning for CNN-Based damage detection in civil structures with insufficient data. Shock Vib. 2022, 1–14 (2022).
Mantawy, I. M. & Mantawy, M. O. Convolutional neural network based structural health monitoring for rocking Bridge system by encoding time-series into images. Struct Control Health Monit 29, 1-18 (2022).
Amanollah, H., Asghari, A., Mashayekhi, M. & Zahrai, S. M. Damage detection of structures based on wavelet analysis using improved AlexNet. Structures 56, 105019 (2023).
Hoang, N. D. & Nguyen, Q. L. A novel method for asphalt pavement crack classification based on image processing and machine learning. Eng. Comput. 35, 487–498 (2019).
Cao, M. T., Tran, Q. V., Nguyen, N. M. & Chang, K. T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inf. 46, 101182 (2020).
Li, S. & Zhao, X. Image-Based Concrete Crack Detection Using Convolutional Neural Network and Exhaustive Search Technique. Adv. Civ. Eng. 1–12 (2019). (2019).
Katsigiannis, S., Seyedzadeh, S., Agapiou, A. & Ramzan, N. Deep learning for crack detection on masonry façades using limited data and transfer learning. J. Build. Eng. 76, 107105 (2023).
Nikkhoo, A., Karegar, H., Karami Mohammadi, R. & Hajirasouliha, I. An acceleration-based approach for crack localisation in beams subjected to moving oscillators. J. Vib. Control. 27, 489–501 (2021).
Ali, L. et al. Performance evaluation of deep CNN-Based crack detection and localization techniques for concrete structures. Sensors 21, 1688 (2021).
Kim, B., Yuvaraj, N. & Preethaa, S. Arun pandian, R. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 33, 9289–9305 (2021).
Yuan, Y. et al. Crack length measurement using convolutional neural networks and image processing. Sensors 21, 5894 (2021).
Li, B., Wang, K. C. P., Zhang, A., Yang, E. & Wang, G. Automatic classification of pavement crack using deep convolutional neural network. Int. J. Pavement Eng. 21, 457–463 (2020).
Chen, J. & Shang, G. Localization and imaging of internal hidden defects in concrete slabs based on deep learning of vibration signals. J. Build. Eng. 76, 107087 (2023).
Zhu, Y. et al. Intelligent fault diagnosis of hydraulic piston pump based on wavelet analysis and improved AlexNet. Sensors 21, 549 (2021).
Jamshidi, M. & El-Badry, M. Structural damage severity classification from time-frequency acceleration data using convolutional neural networks. Structures 54, 236–253 (2023).
Wang, X., Zhang, X. & Shahzad, M. M. A novel structural damage identification scheme based on deep learning framework. Structures 29, 1537–1549 (2021).
Asghari, A., Ghodrati Amiri, G., Darvishan, E. & Asghari, A. A novel approach for structural damage detection using Multi-Headed stacked deep ensemble learning. J. Vib. Eng. Technol. https://doi.org/10.1007/s42417-023-01116-y (2023).
Li, S. & Zhao, X. A. Performance improvement strategy for concrete damage detection using stacking ensemble learning of multiple semantic segmentation networks. Sensors 22, 3341 (2022).
Burud, N. & Kishen, J. C. Damage detection using wavelet entropy of acoustic emission waveforms in concrete under flexure. Struct. Health Monit. 20, 2461–2475 (2021).
Alizadeh, M. J., Nourani, V., Mousavimehr, M. & Kavianpour, M. R. Wavelet-IANN model for predicting flow discharge up to several days and months ahead. J. Hydroinformatics. 20, 134–148 (2018).
Wei, P., Li, Q., Sun, M. & Huang, J. Modal identification of high-rise buildings by combined scheme of improved empirical wavelet transform and hilbert transform techniques. J. Build. Eng. 63, 105443 (2023).
Chen, Z., Wang, Y., Wu, J., Deng, C. & Hu, K. Sensor data-driven structural damage detection based on deep convolutional neural networks and continuous wavelet transform. Appl. Intell. 51, 5598–5609 (2021).
Pamuncak, A., Zivanovic, S., Adha, A., Liu, J. & Laory, I. Correlation-based damage detection method using convolutional neural network for civil infrastructure. Comput. Struct. 282, 107034 (2023).
Guzmán-Torres, J. A. et al. Deep learning techniques for multi-class classification of asphalt damage based on hamburg-wheel tracking test results. Case Stud. Constr. Mater. 19, e02378 (2023).
Tang, Z., Chen, Z., Bao, Y. & Li, H. Convolutional neural network-based data anomaly detection method using multiple information for structural health monitoring. Struct. Control Health Monit. 26, e2296 (2019).
Alaeddine, H. & Jihene, M. Deep network in network. Neural Comput. Appl. 33, 1453–1465 (2021).
Chang, S. & Zheng, B. A lightweight convolutional neural network for automated crack inspection. Constr. Build. Mater. 416, 135151 (2024).
Wang, S. et al. Cerebral micro-bleeding identification based on a nine‐layer convolutional neural network with stochastic pooling. Concurr Comput. Pract. Exp 32, 1-16 (2020).
Liu, Y. H. Feature extraction and image recognition with convolutional neural networks. J. Phys. Conf. Ser. 1087, 062032 (2018).
Sony, S., Dunphy, K., Sadhu, A. & Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 226, 111347 (2021).
Xie, W., Wei, S., Zheng, Z., Jiang, Y. & Yang, D. Recognition of defective carrots based on deep learning and transfer learning. Food Bioprocess. Technol. 14, 1361–1374 (2021).
Azimi, M. & Pekcan, G. Structural health monitoring using extremely compressed data through deep learning. Comput. -Aided Civ. Infrastruct. Eng. 35, 597–614 (2020).
Lee, K. S. et al. Evaluation of scalability and degree of Fine-Tuning of deep convolutional neural networks for COVID-19 screening on chest X-ray images using explainable deep-Learning algorithm. J. Pers. Med. 10, 213 (2020).
Moussa, H., Elabeidy, A. B. & Akçaoğlu, T. Predicting the compressive strength of rubberized concrete containing silica fume using stacking ensemble learning model. Constr. Build. Mater. 449, 138254 (2024).
Tao, K. et al. Unlocking potential of pyrochlore in energy systems via soft voting ensemble learning. Small 2402756 https://doi.org/10.1002/smll.202402756 (2024).
Yaghoubzadehfard, A., Lumantarna, E., Herath, N., Sofi, M. & Rad, M. Ensemble learning-based structural health monitoring of a Bridge using an interferometric radar system. J. Civ. Struct. Health Monit. https://doi.org/10.1007/s13349-024-00789-7 (2024).
Javed, A. R., Usman, M., Rehman, S. U., Khan, M. U. & Haghighi, M. S. Anomaly detection in automated vehicles using multistage Attention-Based convolutional neural network. IEEE Trans. Intell. Transp. Syst. 22, 4291–4300 (2021).
Verma, R., Chandra, S. & RepuTE A soft voting ensemble learning framework for reputation-based attack detection in fog-IoT milieu. Eng. Appl. Artif. Intell. 118, 105670 (2023).
Akyol, K., Uçar, E., Atila, Ü. & Uçar, M. An ensemble approach for classification of tympanic membrane conditions using soft voting classifier. Multimed Tools Appl. 83, 77809–77830 (2024).
Wu, D. et al. An edge information fusion perception network for curtain wall frames segmentation. J. Build. Eng. 88, 109070 (2024).
YiFei, L. et al. Metamodel-assisted hybrid optimization strategy for model updating using vibration response data. Adv. Eng. Softw. 185, 103515 (2023).
Yi, T. H., Zhou, G. D., Li, H. N. & Wang, C. W. Optimal placement of triaxial sensors for modal identification using hierarchic wolf algorithm: Optimal placement of triaxial sensors using HWA. Struct. Control Health Monit. 24, e (2017). (1958).
Burkett, J. L. Benchmark Studies for Structural Health Monitoring Using Analytical and Experimental Models (University of Central Florida, 2005).
Luo, Y. et al. Unsupervised structural damage detection based on an improved generative adversarial network and cloud model. J. Low Freq. Noise Vib. Act. Control. 146134842211508 https://doi.org/10.1177/14613484221150804 (2023).
SeismoSoft. SeismoStruct – A computer program for static and dynamic nonlinear analysis of framed structures.
Quqa, S., Lasri, O. & Landi, L. Bridge monitoring using Vehicle-Induced vibration. In European Workshop on Structural Health Monitoring Vol. 254 (eds Rizzo, P. & Milazzo, A.) 59–67 (Springer International Publishing, 2023).
Chang, K. C. Old_ADA_Bridge-damage_vibration_data. Mendeley https://doi.org/10.17632/SC8WHX4PVM.2 (2021).
Zhou, X., Kim, C. W., Zhang, F. L., Chang, K. C. & Goi, Y. Bayesian Model Updating of a Simply-Supported Truss Bridge Based on Dynamic Responses. in Experimental Vibration Analysis for Civil Engineering Structures (eds. Wu, Z., Nagayama, T., Dang, J. & Astroza, R.) vol. 224 59–72Springer International Publishing, Cham, (2023).
Kim, C. W., Zhang, F. L., Chang, K. C., McGetrick, P. J. & Goi, Y. Ambient and Vehicle-Induced vibration data of a steel truss Bridge subject to artificial damage. J. Bridge Eng. 26, 04721002 (2021).
Hoda Armanul, M. Time history response and numerical models of a 3D shear frame. Mendeley https://doi.org/10.17632/BXMD7C78ZF.4 (2022).
Hoda, M. A., Kuncham, E. & Sen, S. Response and input time history dataset and numerical models for a miniaturized 3D shear frame under damaged and undamaged conditions. Data Brief. 45, 108692 (2022).
Abdeljaber, O., Avci, O., Kiranyaz, S., Gabbouj, M. & Inman, D. J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 388, 154–170 (2017).
Avci, O., Abdeljaber, O., Kiranyaz, S. & Inman, D. Structural damage detection in real time: implementation of 1D convolutional neural networks for SHM applications. Struct. Health Monit. Damage Detect. Vol. 7, 49–54. https://doi.org/10.1007/978-3-319-54109-9_6 (2017).
Avci, O., Abdeljaber, O., Kiranyaz, S., Hussein, M. & Inman, D. J. Wireless and real-time structural damage detection: A novel decentralized method for wireless sensor networks. J. Sound Vib. 424, 158–172 (2018).
Avci, O., Abdeljaber, O., Kiranyaz, S. & Inman, D. Convolutional Neural Networks for Real-Time and Wireless Damage Detection. in Dynamics of Civil Structures, Volume 2 (ed. Pakzad, S.) 129–136Springer International Publishing, Cham, (2020). https://doi.org/10.1007/978-3-030-12115-0_17
Kiranyaz, S. et al. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal. Process. 151, 107398 (2021).
Avci, O. et al. A new benchmark problem for structural damage detection: bolt loosening tests on a Large-Scale laboratory structure. In Dynamics of civil structure., 2. Grimmelsman K). 15–22. https://doi.org/10.1007/978-3-030-77143-0_2 (2022).
Author information
Authors and Affiliations
Contributions
H.A., R.K.M., and A.G. designed the methodology, analyzed the data, and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Amanollah, H., Mohammadi, R.K. & Ghorbani-Tanha, A.K. Structural damage detection using voting ensemble of fine-tuned convolutional neural networks and time-frequency images. Sci Rep 15, 36199 (2025). https://doi.org/10.1038/s41598-025-19933-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-19933-4
