
Abstract
In hazy weather, the quality of aerial images suffers severe degradation, which affects the imaging capabilities of advanced remote sensing applications. Most existing learning-based dehazing algorithms utilize manually designed deep structures to enhance model performance. However, these deep networks often contain redundant branches, leading to a significant decrease in computational efficiency. To address this issue, we first conduct experiments to explore the distribution of haze and introduce an improved dehazing strategy in the YUV space. Subsequently, we propose a Runge-Kutta (RK) method-inspired aerial image dehazing network called RKNet, which consists of two parts: luminance (Y) domain haze removal and chrominance (U,V) enhancement. From the perspective of dynamical systems and based on the 3rd-order RK method, we design an RK3 block and incorporate it into RKNet to improve computational accuracy. Experimental evaluations on both synthetic and real-world benchmarks demonstrate that RKNet outperforms current haze removal algorithms and achieves superior performance. In addition, RKNet can improve the detection accuracy and capability of high-level vision algorithms and is also applicable to the processing of sandstorm images and underwater images.
Similar content being viewed by others

Introduction
Hazy weather is a common atmospheric phenomenon that adversely effects on both human activities and machine vision systems. When captured in foggy conditions, images generally appear visually hazy and blurred. Such degraded images are unsuitable for applications that necessitate accurate environmental information for safe operation1, such as unmanned aerial drones, autonomous vehicles, and intelligent infrastructure. As a result, there has been a growing interest in single-image haze removal as a critical low-level computer vision task in recent years. The atmospheric scattering model provides a simplified approximation for the haze imaging process, which is written as:
To restore the haze-free image, the atmospheric scattering model can be converted into the following form:
where I(x) and J(x) denote the haze image and clear image respectively; t(x) is the transmission, \(\beta\) is the scattering coefficient of the atmosphere, d(x) is the scene depth; A represents the global atmosphere light value.
The main challenge in atmospheric scattering model-based haze restoration algorithms is how to estimate the transmission map t(x) and atmospheric light A accurately. Existing approaches generally calculate the intermediate parameters via the prior knowledge2,3,4. However, these methods are limited as prior knowledge can not accurately describe the characteristics of the scenes, which will lead to inaccurate estimation of the parameters, resulting in the issues of blurring and color distortion in outputs.
Recent years have witnessed the significant success of convolutional neural networks (CNN) in high-level computer vision applications5,6,7. Building on the prior work, Cai et al.8 introduced a CNN-based dehazing algorithm. Since then, CNN has become the predominant method in the field of image haze removal9,10,11. While efforts have been made to improve performance, there are still some limitations in current dehazing methods. Firstly, many studies prioritize performance over computation overhead, leading to the algorithms that may be too computationally intensive for practical deployment. Secondly, training deeper networks requires more advanced numerical instability avoidance techniques. Thirdly, unlike high-level visual tasks such as image segmentation and object detection that extract semantic features through CNN, image dehazing requires prediction of fine-grained pixel-level details, making direct use of state-of-the-art (SOTA) CNN suboptimal.

The dehazing results of the proposed method. (a) Aerial haze images; (b) The enhanced results of RKNet.
Actually, compared with RGB space, YUV space can provide a more accurate description of haze degradation characteristics12. To address the aforementioned issues, we first analyze the haze distribution and explore the feasibility of the dehazing strategy in YUV space. Then, we integrate the Runge-Kutta (RK) method-inspired scheme into haze removal network designs and name the model as RKNet. Experimental results on benchmarks demonstrate that RKNet outperforms existing SOTA methods, achieving a superior balance between computing cost and performance. Figure 1 presents the dehazing results of RKNet on LHID dataset13, and it can be seen that compared with the original haze image, the reconstructed image has a significant improvement in visual clarity. To our best knowledge, this is the first attempt to directly incorporate an RK method-inspired scheme into the design of image dehazing network.
The main contributions of this study are summarized as follows:
-
We explore the distribution characteristics of haze in YUV space and propose a joint processing method for Y-channel dehazing and UV-channel enhancement.
-
Inspired by the Runge-Kutta method, we introduce a novel aerial image dehazing network named RKNet, which achieves a remarkable balance between performance and computational cost.
-
Extensive experiments are performed on both synthetic and real-world haze images, demonstrating the superiority of the proposed RKNet over the current SOTAs.
Related work
Image haze removal
Single image haze removal as a classical computer vision task has garnered significant interest from researchers. Existing dehazing algorithms can be broadly categorized into two groups: prior knowledge-driven methods and CNN-based methods.
Prior knowledge-driven methods
The prior knowledge-driven methods are the reverse procedure of the atmospheric scattering model described as Eq. (2). They estimate the necessary parameters in atmospheric scattering model by using the prior assumptions which are derived from the statistical characteristics of the haze images. He et al.2 established the dark channel prior (DCP) theory, which is built on a statistical observation that there are some dark pixels close to zero in at least one color channel within the non-sky area of an outdoor haze-free image. Bui et al.3 introduced the color ellipsoid prior (CEP), where they construct color ellipsoids that are statistically fitted to haze pixel clusters in RGB space. They then calculate the transmission values based on the geometry of these color ellipsoids. Yadav et al.14 proposed a hazy image restoration method, which estimates the approximate depth map of hazy images to derive scene-specific dark channels and transmissions, incorporates histogram normalization for post-processing to enhance image quality. Kaur et al.4 proposed the gradient channel prior (GCP), which estimates the transmission map via the image gradient. Liu et al.15 presented a straightforward method for estimating the transmission map based on the rank-one prior (ROP). Following the proposed ROP theory, they16 took the foreground and the background into consideration, developing ROP\(^+\) to further improve the performance of the algorithm.
Although these algorithms can improve the clarity of haze images to some extent, there are still some issues worth considering. Prior knowledge-driven methods rely on fixed assumptions grounded in mathematical statistics, which may not be effective in some real-world scenarios. In addition, inaccurate parameter estimation will lead to artifacts, halos, and color distortion in the restored results.
CNN-based methods
Early CNN-based dehazing algorithms still rely on the atmospheric scattering model17,18,19. These methods employ CNN to estimate the transmission map and atmospheric light value from haze images, which are then used to inversely infer the model and obtain clear restored images. For instance, Cai et al.8 proposed a dehazing network embedded with bilateral rectified linear units to estimate the medium transmission map. Ren et al.20 developed a coarse-to-fine multiscale deep neural network to predict the refined transmission map. Su et al.21 proposed a fusion network integrating a physical model and image translation for image dehazing, incorporating the estimation of the transmission map through a deep network to guide image translation. Zhang et al.22 introduced a pyramid densely connected transmission map estimation network based on generative adversarial networks (GAN). However, the transmission map is susceptible to noise interference, which will weaken the robustness of the algorithms.
To address the issue, researchers are starting to focus on end-to-end image dehazing methods that directly establish the mapping between haze images and clear images without relying on the physical model. Qin et al.23 introduced a feature attention module (FA) that combines channel attention with pixel attention mechanism, embedding it into the dehazing network. Wu et al.9 proposed an autoencoder-like dehazing network inspired by contrastive learning. Wang et al.24 introduced an unsupervised contrastive learning paradigm called UCL-Dehaze for image dehazing, which leverages unpaired real-world hazy and clean images through adversarial training and a new pixel-wise self-contrastive perceptual loss. Bai et al.11 extracted feature information from the haze image itself to guide network training. Su et al.25 proposed an ent-to-end dehazing network with a parameter-shared architecture that trains on synthetic and real haze images simultaneously, using multi-prior pseudo clean image and a physical-model-guided domain transfer mechanism to reduce domain gaps. Although CNN-based haze removal methods have shown some performance success, the SOTA designs heavily rely on empirical structure, involving numerous attempts and tricks. Image enhancement as a foundational low-level vision task, hinges on recovering fine-grained details like edges, contours, and textures obfuscated by haze, and over-reliance on abstract high-level features undermines sharpness and clarity, making preservation of shallow low-level features critical for visually faithful results26,27. We thus consider that simplifying the dehazing algorithm into a low-level work would be a beneficial approach.
ODE-inspired network design
With the advancement of CNN, scholars have started to explore the theoretical properties of CNN from the perspective of ordinary differential equations (ODE). Weinan et al.28 were the first to observe the connection between residual network (ResNet)29 and ODE. They demonstrated that deep neural networks can be treated as discrete dynamical systems, and established the similarities between ResNet and the discretization of ODE. Chang et al.30 went beyond mere explanation and utilized numerical ODEs to construct reversible neural networks while conducting stability analysis. Inspired by the linear multi-step method for solving ODEs, Lu et al.31 proposed a linear multi-step architecture (LM-architecture). They integrated the LM-architecture into ResNet and ResNeXt32, and observed significantly improved accuracy compared to the original network on public benchmarks.

Comparisons of clear image and RS haze image in RGB and Y, U, V spaces. (a) Clear image in RGB space; (b) Y component of clear image; (c) U component of clear image; (d) V component of clear image; (e) Haze image in RGB space; (f) Y component of haze image; (g) U component of haze image; (h) V component of haze image.
In the field of low-level image translation, recent studies33,34,35,36 have established a connection between ResNet and the explicit/implicit Euler method approximation of ODE. However, the research on ODE-based dehazing algorithms is still in its infancy, and there are numerous issues that warrant further exploration. Given that image haze removal is a low-level computer vision task with the constraint of the highly similar structure between haze and haze-free images, it often relies on intuitive approaches. Building on the inspiration from the aforementioned work, we introduce a simple yet effective image dehazing algorithm.
The proposed method
The progress in single image dehazing can be attributed to the advancements in deep learning, which provides a powerful framework for nonlinear calculations in haze removal algorithms. In general, CNN-based algorithms consist of multiple cascaded layers and can effectively transform complex information flow after iterative training. In a dynamical system, there exists a fixed rule that describes the evolution of input states in a geometric space over time. Similarly, the adaptively selected layers in a CNN can be treated as time nodes in a dynamical system, with the final output state constrained by the ground truth (GT). Previous work28 has characterized this as a controllable issue and conducted a simplified analysis of the low-dimensional version, concluding that a solution can be obtained using numerical methods if the issue is sufficiently smooth. Encouraged by this, we apply the Runge-Kutta (RK) method to our haze removal network design from the perspective of the dynamical system. In this section, we will first analyze the distribution of haze in YUV space and then discuss the details of RKNet.
YUV space analysis and the improved strategy
In accordance with the prescribed guidelines outlined in the ITU-R BT.601-7 standards established by the Radio Communication Division of the International Telecommunication Union (ITU-R), the conversion from RGB to YUV in full range37 is outlined as follows:
Recent research has proved that YUV space can provide a more effective way for image dehazing12. Specifically, they separated the luminance (Y) and chrominance (UV) components and found that the energy of the haze is concentrated in Y channel, while UV channel is less affected. Figure 2 presents a comparison of indicators in RGB and YUV space for RS haze images from the SateHaze1k dataset. In the upper and lower rows, from left to right, are the RGB space views of clear and haze images respectively, along with the corresponding decomposed views of the Y, U, and V components. It can be observed that the RGB haze images suffer from low contrast and local texture blur. The peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) between the clear and degraded images are 13.31dB and 71.92\(\%\), respectively. Converting the images to the YUV space and computing objective quality metrics for each component reveals that the pixel and structural differences caused by haze are predominantly manifested in the Y component. The PSNR and SSIM for the Y component are 14.67dB and 75.02\(\%\), respectively. Through visual comparison, it can be seen that the brightness of the Y channel in haze images is higher, presenting an overall misty appearance, while the UV color channels are less affected, evidenced by their higher objective metric values.

Demonstration of color quantification differences. (a) Clear image; (b) Haze image; (c) Concatenated image; (d) Color quantization of clear image; (e) Color cluster of clear image; (f) Color quantization of haze image; (g) Color cluster of haze image; (h) Color quantization of concatenated image; (i) Color cluster of concatenated image.
On the basis of the preceding analysis, the method38 only remove the haze in Y channel and retain the UV channel of the original image. Such Y-channel-based strategy can accurately extract the haze distribution via the variations of luminance component, achieving superior dehazing performance. However, existing Y-channel dehazing algorithms are not the optimal strategies. In detail, enhancing only Y channel and directly inheriting UV channel information from the original image may disrupt the synergy between Y, U, V channels. That will weaken the chromaticity feature and compress the image’s contrast.
When we concatenate Y channel of the clear image presented in Fig. 3 (a) with the UV channel of the haze image presented in Fig. 3 (b) and convert it to an RGB image, we obtain a low-colorful haze-free image shown in Fig. 3 (c). It is evident that Fig. 3 (a) and Fig. 3 (c) have significant differences. To further visualise the distances, we perform color quantization on them and applied K-means clustering on the quantized results to extract the main 15 color points of the images. Compared to Fig. 3 (d), Fig. 3 (f) and Fig. 3 (h) have a more concentrated quantization distribution due to lower color richness and contrast. To further discuss the impacts of haze, we conduct a mathematical analysis of the atmospheric scattering model to elucidate the degradation characteristics observed in Y channel and UV channel. We consolidate Eqs.(4)-(6) into the matrix expression form:
The expression of Eq. (1) can be reformulated as:
As the scattering coefficient of the atmosphere \(\beta\), exhibits minimal variation across channels, we can effectively disregard the distance component and consider t (i.e., \(e^{-{\beta }d}\)) as a constant. In the case of a color-balanced haze image, where the principle \(A_R\approx A_G\approx A_B\) is consistently observed39, upon substituting Eq. (7) into Eq. (8), we can derive the mapping relationship by rearranging the expressions:
Eq. (9) reveals that the atmospheric light A is exclusively associated with the luminance component Y, while the chrominance components U and V are subject to linear attenuation by the transmission map t and have no direct dependence on A. This result arises naturally from the mathematical derivation which is rooted in color space transformations and the atmospheric scattering model rather than being an a priori assumption. It aligns with the physical nature of haze: atmospheric light primarily contributes to the visual haze-like characteristics such as overall brightness obscuration and lacks significant chromaticity2, and this is consistent with the observed behavior of chrominance components in hazy scenes as visualized in Figure 2. We then depict the conversion process between haze image \(I_{YUV}\) and its corresponding clear image \(J_{YUV}\) as follows:
As discussed, haze-induced alterations in luminance are global, driven by atmospheric light, whereas chrominance degradation stems from transmission-dependent attenuation. This analysis underscores that an effective YUV-based dehazing algorithm must address haze interference in the Y channel while accounting for the collaborative dynamics across the three channels.
RK method inspired dehazing network
As illustrated in Fig. 4, the proposed RKNet consists of two parts: haze removal and chrominance enhancement. The haze removal sub-net utilizes a pyramid structure, performing 2x upsampling and 2x downsampling on the original luminance component \(I_Y\in \mathbb {R}^{H\times W\times 1}\), that aims to capture both local and global distribution features of the haze in Y domain. We embed the RK3 block in each scale branch to calculate the mapping relationship between state nodes in latent space, following which the pixel attention module23 is employed to adaptively allocate weights for the output status of RK3 block. Finally, the feature information flow from the three branches is integrated using element-wise addition, resulting in the haze-free map \(J^{\prime }_{Y}\in \mathbb {R}^{H\times W\times 1}\).

The architecture of the proposed RKNet.
For the attenuated chrominance component \(I_{UV}\in \mathbb {R}^{H\times W\times 2}\), if we directly splice it with \(J^{\prime }_{Y}\), the channels feature may not be well fused. The converted RGB image will suffer from color degradation and visually tend towards greyscale. To address the issue, we introduce the chrominance enhancement (CE) block to balance the chromaticity component. Specifically, we embed the RK3 block and the channel attention module23 into CE block to dynamically assign the weight ratios for the associated representations. The output of CE block is marked as \(J^{\prime }_{UV}\in \mathbb {R}^{H\times W\times 2}\), and we finally splice it with \(J^{\prime }_{Y}\) and convert the spliced result back to RGB space. Overall, the proposed RKNet has a significantly concise structure without redundant branches. Such single-channel haze removal strategy greatly reduces the computational complexity of the algorithm and presents a promising direction for future lightweight dehazing research.
Converting RK method to component block
The explicit RK method is a common approach used in numerical ODE, the following formulas can describe arbitrary s stages of it mathematically:
where G is the adaptively selected nonlinear representation unit; h is the stride length; c, \(\beta\) and \(\lambda\) are the constants, and can be calculated by the Taylor-expansion formula.
In the Runge-Kutta framework, higher-order methods generally reduce local truncation errors by incorporating more intermediate computations but at the expense of increased computational load40,41. The 3rd-order Runge-Kutta (RK3) method emerges as an optimal compromise. It balances the need for accuracy, offering substantially lower truncation errors than lower-order alternatives, with computational efficiency, avoiding the excessive computational demands of higher-order schemes. This balance makes RK3 particularly well-suited for applications where both precision and computational feasibility are critical. Based on Eq. (11), the mathematical expression of the RK3 method can be formulated as:
We transform Eqs.(13, 14) into an intuitive network module. As depicted in Fig. 5, we denote the input state at the current moment as \(y_k\), using \(y_{k+1}\) to represent the output state after a series of numerical computations. The specific structure of G will be further discussed in section "Discussion on the structure of G".

The framework of RK3 block based on the 3rd-order explicit Runge-Kutta method. G1, G2 and G3 are the pre-defined G.
Overall loss function
To optimize RKNet, we employ a combination of the \(\mathcal {L}_{1}\) loss and the contrastive regularization loss9 as the objective function. \(\mathcal {L}_{1}\) loss is commonly employed in low-level vision tasks, given N training sampling \(\{{I}_i,{J}_i\}_{i=1}^N\), we describe it as:
Furthermore, we incorporate the contrastive regularization loss at the perceptual level to enhance the network’s capability in extracting latent representations. Mathematically, it can be expressed as:
here \(\Phi\) denotes the fixed pre-trained VGG19 model adopted to extract the perceptual features; M is the number of the hidden layer; \(\alpha _i\) is the trade-off weights; D(x, y) indicates the \(\mathcal {L}_{1}\) distance between x and y.
Based on the above considerations, the total loss function of RKNet is formulated as the following:
here \(\lambda _1\), \(\lambda _2\) are the hyperparameters for balancing the pixel loss and contrastive regularization loss.
Experiments
Implementation details
In the training stage, we adopt 5000 pairs of synthetic haze images from RESIDE42 as the training data. All the inputs of the network are cropped to a size of \(256\times 256\times 3\), and their pixel values are normalized. The training process is performed using PyTorch 1.9.0 on an NVIDIA GeForce RTX2070 GPU, and the network is trained for a total of 100 epochs. To optimize RKNet, we set \(\lambda _1\) and \(\lambda _2\) to 0.7 and 0.3, respectively. The trade-off weights \(\alpha _i\) are determined using the approach proposed in9. We utilize the Adam optimizer with an initial learning rate of \(1\times 10^{-3}\) to update the network parameters throughout the training process. It’s worth noting that the conversion from RGB to YUV spaces is fully reversible, ensuring the valuable feature of the input is preserved.

Comparison with SOTA algorithms
Evaluating on synthetic datasets
We compare the proposed RKNet with several SOTA haze removal algorithms involving CEEF44, BCDP45, FADE46, PMD-Net47, T-Net48, and IHRNet49. The experiments are performed on two synthetic hazy benchmarks, including RICE43 and RESIDE42. The visual comparison on general daytime haze images is presented in Fig. 6. It is evident that CEEF44 exhibits underexposure, BCDP45 exposes color distortion issues in the sky area, and the results of FADE46 appear visually dimmed. As the learning-based methods, PMD-Net47, T-Net48, and IHRNet49 fail to effectively eliminate the haze effect.
Figure 6 provides the visual comparison on aerial haze images. It is evident that previous algorithms have primarily focused on general scenes, which may not be well-suited for aerial haze images. CEEF44 is capable of eliminating the haze effect; however, excessive enhancement leads to a lack of visual hierarchy in the results. The contrast of BCDP’s results45 is suppressed, and the outputs of FADE46 lose many color features. PMD-Net47 and IHRNet49 exhibit varying degrees of residual haze in a visually grey-masked manner. T-Net48 performs poorly on aerial haze images, displaying evident color shift issues in its outputs. The visual comparison on general daytime haze images is presented in Fig. 7. It is evident that CEEF44 exhibits underexposure, BCDP45 exposes color distortion issues in the sky area, and the results of FADE46 appear visually dimmed. As the learning-based methods, PMD-Net47, T-Net48, and IHRNet49 fail to effectively eliminate the haze effect. Compared to these algorithms, RKNet can effectively eliminate haze interference while preserving the original brightness and color feature of the images. That is credited to the reasonable design of the improved dehazing strategy in YUV space.

The visual comparison on daytime haze images42. Please zoom in for a better illustration.
To evaluate the performance of the algorithms, three evaluation metrics are utilized: PSNR, SSIM, and CIEDE2000. These metrics are responsible for measuring the pixel error, structure error, and color error of the images, respectively. Higher values of PSNR and SSIM, and lower values of CIEDE2000 indicate better algorithm performance. The metrics on RICE43 as shown in Table 1. And the results of objective metrics on RESIDE42 are presented in Table 2. For comparison purposes, the best metrics are marked in bold and the second-best are underlined. Remote sensing images generally exhibit complex and diverse texture patterns, which makes the task of aerial image haze removal more challenging. Comparing Table 1 and Table 2, we notice that the overall performance of the algorithms on RICE is relatively lower. For T-Net48, the metrics are not satisfactory due to its limited generalisation ability. In contrast, RKNet demonstrates better adaptability to various scenarios and achieves optimal performance in the quantitative evaluation.
Evaluating on real-world haze images
Despite being trained on synthetic datasets, RKNet demonstrates excellent generalization performance on real-world haze images. Figure 8 showcases the visual comparison of the algorithms. Although CEEF44, BCDP45, and FADE46 can partially remove haze, their over-enhancement tends to distort color feature of the outputs. In the bottom row of Fig. 8, T-Net48 and IHRNet49 expose aberrant color blocks in the sky region, along with residual haze remaining. In comparison, RKNet not only comprehensively eliminates haze but also generates visually-natural results with fewer artifacts.

The visual comparison on real-world haze images42.
Time complexity analysis
In this section, we conduct experiments to analyze the time complexity of the methods. Table 3 presents the multiply–accumulate operations (MACs) and the number of parameters of the algorithms. Among the comparison models, RKNet has the lowest value of MACs and the fewest number of parameters. To further evaluate the computational efficiency, we then perform time-consuming experiment on a PC with an Intel(R) Core (TM) i5-9400 CPU@2.90GHz, 16GB RAM, and GPU@NVIDIA GeForce RTX2070. As is depicted in Table 4, we calculate the average time-consuming by the methods in handling 540p, 720p, and 1080p haze images. One can see that compared with the prior algorithms, RKNet demonstrates higher computational efficiency.
Discussion on the structure of G
As the adaptively selected nonlinear representation unit, there is a considerable space for exploring the structure of G. In this section, we aim to explore the performance of RKNet by experimenting with different designs of G.
Figure 9 illustrates the three structural schemes we considering for the ablation study. Each scheme consists of two convolutional layers, and the structure of the versions is defined by adjusting the position of the convolution and activation function. To determine the optimal strategy, we evaluate the candidates and calculate the objective indicators based on RESIDE42. As shown in Table 5, RKNet(v3) achieves the best metrics while maintaining the same computational complexity and number of parameters. Therefore, we incorporate G-v3 as the adaptively selected nonlinear representation unit in RKNet.

The candidate structures of G, where ’Conv’ denotes the convolutional layer and ’PReLU’ represents the activation function.

The visual comparison of the dehazing strategies. (a) Haze images. (b) Only processing Y-channel. (c) Co-processing YUV channel. (d) Separate processing Y-channel and UV-channel.
Discussion on the dehazing strategy in YUV space
To explore the optimal dehazing strategy in YUV space, we conduct the ablation experiment in this section. Specifically, we mainly focus on these candidate schemes: 1) Enhancing Y-channel using the haze removal network and inheriting the UV-channel from the inputs. 2) Training the haze removal network to directly reconstruct haze-free images by taking Y, U, V channels as inputs. 3) Enhancing Y-channel using the haze removal network and refining the UV-channel via CE block, and then doing channel splicing.
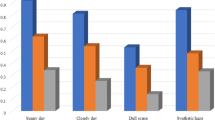
Figure 10 presents the visual comparison of the candidate strategies. In Fig. 10 (b), when we exclusively remove the haze in the Y-channel while directly inheriting the UV-channel from the original images, the visual results appear dim and colorless. Figure 10 (c) indicates that by cooperatively processing the Y, U, V channels as inputs for the haze removal network, the brightness features are compromised, leading to visually darker outputs. Figure 10 (d) demonstrates that the strategy of independently enhancing the Y and UV channels can generate visually more natural results with richer color information. We employed BIQI, NIQE, and SSEQ as objective metrics to quantitatively analyze the average performance of the three schemes on 200 real haze images, where lower metric values indicate better algorithmic performance. As shown in Table 6, the scheme that performs dehazing on the Y channel and collaborative enhancement on the UV channels achieved optimal performance in quantitative evaluations.

The structure of the ODE-inspired components. (a) Residual block. (b) RK2 block.
Comparative analysis of ODE-inspired component
To investigate the influence of different ODE-inspired architectures on network outputs, we conduct the ablation study by individually incorporating two more candidate blocks into the backbone model. As shown in Fig. 11 (a), the Residual block is a classic residual structure interpretable as a discrete approximation of ODE; the RK2 block’s structure, presented in Fig. 11 (b), is constructed based on the second-order Runge-Kutta method to model continuous feature evolution via iterative updates.
Visual comparisons of these ODE-inspired components on real haze images are provided in Fig. 12. Specifically, Fig. 12 (b) shows that the network with embedded Residual blocks fails to effectively mitigate the effects of haze, resulting in visually obscure and blurry outputs. In Fig. 12 (c), although the network with embedded RK2 blocks reduces haze to some extent, the corresponding outputs exhibit noticeable artifacts, particularly in sky regions. Figure 12 (d) demonstrates that the proposed RK3 module not only effectively removes haze but also balances the synergistic relationship between brightness and chromaticity, yielding visually more natural reconstructed results.

Visual comparison of the components with different ODE-inspired structures in real-world haze images. (a) Haze images. (b) Results of the backbone model with embedded Residual blocks. (c) Results of the backbone model with embedded RK2 blocks. (d) The results of the backbone model with embedded RK3 blocks.
Extension applications
Application in object detection
In hazy weather, the low-quality images captured by imaging facilities seriously affect the accuracy of high-level vision algorithms. Here, we present an experimental analysis to demonstrate the effectiveness of incorporating RKNet in improving the accuracy of object detection algorithm under hazy conditions. To conduct this experiment, we utilized the popular object detection algorithm YOLOv750 as the baseline for our evaluation.

Effect of RKNet on the performance of YOLOv750. (a) Detection results of the haze images. (b) Detection results of the clear images reconstructed by RKNet.
Figure 13 (a) shows the object detection results in hazy scenes, while Fig. 13 (b) displays the detection results after being processed by RKNet. It is observed that the number of detected objects increased noticeably, indicating that the removal of haze boosted the visibility and made previously undetectable objects discernible. The results are particularly significant in high-density haze regions, where objects were previously completely obscured by the haze. Furthermore, the probabilities for dehazed objects exhibits overall improved, reflecting enhanced confidence of the algorithm in the detected object categories. This enhancement can be attributed to RKNet effectively eliminating the visual artifacts caused by haze, resulting in more accurate object detection outcomes. The experimental results underscore the potential of RKNet in addressing the challenges posed by hazy weather conditions in real-world object detection applications.

The reconstructed examples of sandstorm images39 using the fusion strategy, where (a) are the original sandstorm images, (b) are the color balanced images and (c) are the clear images enhanced by RKNet.
Sandstorm image reconstruction
Fusion strategy51 has been proven to be feasible for sandstorm image enhancement task. Following that line, we conduct a simple color equalization pre-processing51 and explore the feasibility of utilizing RKNet as the dust removal module in fusion strategy-based sand-dust image enhancement method. Given the sandstorm images as shown in Fig. 14 (a), we can see from Fig. 14 (b) that the color equalization method effectively balances the hue of the images and eliminates the interference of sand, but the dust still exists. In Fig. 14 (c), RKNet can further improve the clarity of the images by eliminating dust interference while retaining the local details.
Underwater image enhancement
Although the proposed algorithm is designed for haze image reconstruction, it has potential applications in complex underwater environments. As shown in Fig. 15, we provide several enhanced examples of underwater images. The top row is the original underwater images and the bottom row is the enhanced results using the proposed method. It is evident that RKNet successfully eliminates the haziness in the images and restores the color characteristics of the scene. From the aesthetic perspective, RKNet can effectively improve the visual quality of the degraded underwater images.

The enhanced examples of underwater images52 using RKNet, where (a) are the underwater images and (b) are the clear images reconstructed by RKNet.
Conclusion
In this paper, we first analysed the weaknesses in current YUV-based dehazing methods and introduced an improved haze removal strategy in YUV space. Following the optimised strategy, we proposed a novel image dehazing network called RKNet, which consists of Y domain haze removal and UV domain chrominance enhancement two parts. Based on the 3rd-order Runge-Kutta method, we designed a RK3 block and integrated it into RKNet to reduce parameter redundancy and computational costs. The experimental results on synthetic and real-world benchmarks demonstrate that RKNet outperforms the SOTA algorithms both qualitatively and quantitatively. Moreover, the proposed algorithm has the potential to improve the performance of object detection model and also generalizes well in other low-level image processing tasks, such as sandstorm image reconstruction and underwater image enhancement.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Singh, D. & Kumar, V. Comprehensive survey on haze removal techniques. Multimed. Tools Appl. 77, 9595–9620 (2018).
He, K., Sun, J. & Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 33, 2341–2353 (2010).
Bui, T. M. & Kim, W. Single image dehazing using color ellipsoid prior. IEEE Trans. Image Process. 27, 999–1009 (2017).
Kaur, M., Singh, D., Kumar, V. & Sun, K. Color image dehazing using gradient channel prior and guided l0 filter. Inf. Sci. 521, 326–342 (2020).
Wan, D. et al. Yolo-hr: Improved yolov5 for object detection in high-resolution optical remote sensing images. Remote Sens. 15, 614 (2023).
Xiao, J. et al. Tiny object detection with context enhancement and feature purification. Expert Syst. Appl. 211, 118665 (2023).
Dong, X. et al. Attention-based multi-level feature fusion for object detection in remote sensing images. Remote Sens. 14, 3735 (2022).
Cai, B., Xu, X., Jia, K., Qing, C. & Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 25, 5187–5198 (2016).
Wu, H. et al. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10551–10560 (2021).
Si, Y., Yang, F. & Chong, N. A novel method for single nighttime image haze removal based on gray space. Multimed. Tools Appl. 81, 43467–43484 (2022).
Bai, H., Pan, J., Xiang, X. & Tang, J. Self-guided image dehazing using progressive feature fusion. IEEE Trans. Image Process. 31, 1217–1229 (2022).
Fang, F., Wang, T., Wang, Y., Zeng, T. & Zhang, G. Variational single image dehazing for enhanced visualization. IEEE Trans. Multimed. 22, 2537–2550 (2020).
Zhang, L. & Wang, S. Dense haze removal based on dynamic collaborative inference learning for remote sensing images. IEEE Trans. Geosci. Remote Sens. 60, 1–16 (2022).
Yadav, A. C., Bose, S. & Kolekar, M. H. Image enhancement by defogging utilizing scene specific dark channel prior. In 2024 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), 1–6 (IEEE, 2024).
Liu, J., Liu, W., Sun, J. & Zeng, T. Rank-one prior: Toward real-time scene recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14802–14810 (2021).
Liu, J., Liu, R. W., Sun, J. & Zeng, T. Rank-one prior: Real-time scene recovery. IEEE Trans. Pattern Anal. Mach. Intell. 45, 8845–8860 (2023).
Ling, Z., Fan, G., Wang, Y. & Lu, X. Learning deep transmission network for single image dehazing. In 2016 IEEE international conference on image processing (ICIP), 2296–2300 (IEEE, 2016).
Kim, S. E., Park, T. H. & Eom, I. K. Fast single image dehazing using saturation based transmission map estimation. IEEE Trans. Image Process. 29, 1985–1998 (2019).
Yang, D. & Sun, J. Proximal dehaze-net: A prior learning-based deep network for single image dehazing. In Proceedings of the european conference on computer vision (ECCV), 702–717 (2018).
Ren, W. et al. Single image dehazing via multi-scale convolutional neural networks. In 14th European Conference on Computer Vision, ECCV 2016, 154–169 (Springer Verlag, 2016).
Su, Y. Z., He, C., Cui, Z. G., Li, A. H. & Wang, N. Physical model and image translation fused network for single-image dehazing. Pattern Recognit. 142, 109700 (2023).
Zhang, H. & Patel, V. M. Densely connected pyramid dehazing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, 3194–3203 (2018).
Qin, X., Wang, Z., Bai, Y., Xie, X. & Jia, H. Ffa-net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI conference on artificial intelligence, 11908–11915 (2020).
Wang, Y. et al. Ucl-dehaze: Toward real-world image dehazing via unsupervised contrastive learning. IEEE Trans. Image Process. 33, 1361–1374 (2024).
Su, Y. et al. Real scene single image dehazing network with multi-prior guidance and domain transfer. IEEE Transactions on Multimedia 1–16 (2025).
Zhang, X., Wang, T., Wang, J., Tang, G. & Zhao, L. Pyramid channel-based feature attention network for image dehazing. Comput. Vis. Image Underst. 197, 103003 (2020).
Wei, J. et al. Shallow feature matters for weakly supervised object localization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5993–6001 (2021).
Weinan, E. A proposal on machine learning via dynamical systems. Commun. Math. Stat. 1, 1–11 (2017).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Chang, B. et al. Reversible architectures for arbitrarily deep residual neural networks. In Proceedings of the AAAI conference on artificial intelligence, 2811–2818 (2018).
Lu, Y., Zhong, A., Li, Q. & Dong, B. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In International Conference on Machine Learning, 3276–3285 (PMLR, 2018).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1492–1500 (2017).
Bai, Y., Liu, M., Yao, C., Lin, C. & Zhao, Y. Ode-inspired image denoiser: An end-to-end dynamical denoising network. In Pattern Recognition and Computer Vision: 4th Chinese Conference, PRCV 2021, Beijing, China, October 29–November 1, 2021, Proceedings, Part III 4, 261–274 (Springer, 2021).
Yang, Y. et al. Dynamical system inspired adaptive time stepping controller for residual network families. In Proceedings of the AAAI Conference on Artificial Intelligence, 6648–6655 (2020).
He, X. et al. Ode-inspired network design for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1732–1741 (2019).
Shen, J., Li, Z., Yu, L., Xia, G.-S. & Yang, W. Implicit euler ode networks for single-image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 218–219 (2020).
BT, R. I.-R. et al. Studio encoding parameters of digital television for standard 4: 3 and wide-screen 16: 9 aspect ratios. International Radio Consultative Committee International Telecommunication Union, Switzerland, CCIR Rep (2011).
Wang, W., Wang, A. & Liu, C. Variational single nighttime image haze removal with a gray haze-line prior. IEEE Trans. Image Process. 31, 1349–1363 (2022).
Si, Y., Yang, F., Guo, Y., Zhang, W. & Yang, Y. A comprehensive benchmark analysis for sand dust image reconstruction. J. Vis. Commun. Image Represent. 89, 103638 (2022).
Zhu, M., Chang, B. & Fu, C. Convolutional neural networks combined with runge-kutta methods. Neural Comput. Appl. 35, 1629–1643 (2023).
Casas-Ordaz, A., Oliva, D., Navarro, M. A., Ramos-Michel, A. & Pérez-Cisneros, M. An improved opposition-based runge kutta optimizer for multilevel image thresholding. J. Supercomput. 79, 17247–17354 (2023).
Li, B. et al. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 28, 492–505 (2018).
Zhou, X., Lin, D. & Junyi, L. Rice: A dataset and baseline for cloud removal in remote sensing images. J. Comb. Math. Comb. Comput. 120, 107–124 (2024).
Liu, X., Li, H. & Zhu, C. Joint contrast enhancement and exposure fusion for real-world image dehazing. IEEE Trans. Multimed. 24, 3934–3946 (2022).
Zhao, X. Single image dehazing using bounded channel difference prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 727–735 (2021).
Li, Z. et al. Fast region-adaptive defogging and enhancement for outdoor images containing sky. In 2020 25th International Conference on Pattern Recognition (ICPR), 8267–8274 (IEEE, 2021).
Ye, T. et al. Perceiving and modeling density for image dehazing. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIX, 130–145 (Springer, 2022).
Zheng, L., Li, Y., Zhang, K. & Luo, W. T-net: Deep stacked scale-iteration network for image dehazing. IEEE Trans. Multimed. 25, 6794–6807 (2023).
Si, Y., Li, C. & Yang, F. Ihr-net: image haze removal network based on improved yuv spatial strategy. Meas. Sci. Technol. 36, 0161b7 (2025).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7464–7475 (2023).
Si, Y., Yang, F. & Liu, Z. Sand dust image visibility enhancement algorithm via fusion strategy. Sci. Rep. 12, 13226 (2022).
Li, C. et al. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 29, 4376–4389 (2020).
Funding
This work is supported by the Wuxi University Research Start-up Fund for High-level Talents(2025r028).
Author information
Authors and Affiliations
Contributions
Y.S. conducted the experiments and wrote the draft; J.C. prepared the Figures and Tables; W.R. carried out checks and revisions on the manuscript; C.L. analyzed the feasibility of the algorithm and managed the project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Si, Y., Chen, J., Rao, W. et al. Runge-kutta method inspired aerial image dehazing network in YUV space. Sci Rep 15, 38332 (2025). https://doi.org/10.1038/s41598-025-22213-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-22213-w
