
Abstract
There is a long debate about how the meaning of words cues our spatial attention. For implicitly spatial words such as “ROOF” or “BASEMENT”, it was recently shown that processing both the cue word and a subsequent spatial target stimulus was necessary for spatial congruity effects to emerge. Here we challenge this work by documenting that word cues alone suffice to induce congruity effects if they are processed deeply. Sixty-three healthy adults detected vertically displaced targets after looking at centrally presented cue words under three counterbalanced instructions, imposing increasing processing depth: Lexical decision, non-spatial categorization, and spatial categorization. Target detection speed revealed spatial congruity effects for both spatial and non-spatial categorization but not for lexical decision. An interpretation in terms of covert attention deployment was corroborated by concomitant vertical displacements of eye gaze. Our results reveal minimal requirements for covert and overt semantic cueing of spatial attention.
Similar content being viewed by others
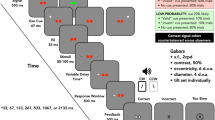

Introduction
Words have denotations and connotations; for example, the word “UP” explicitly denotes upper space but also implies “positive” (as in “thumbs up”). Furthermore, the concept of upper space can be activated implicitly through the use of words with spatial connotations, such as “CLOUD” or “GOD”1 (for review, see2. Similarly, research on metaphor comprehension revealed spatial congruency effects in abstract conceptual domains like emotion and time, such as “happy is up” and “the future lies ahead”3,4. This indirect spatial cognitive activation from word processing has frequently been documented with a visual detection task by applying an attentional cueing paradigm (e.g.5,6,7,8,9,10. We briefly explain this approach because it will be applied in the present study to resolve an open issue in the current debate around the mechanisms involved in semantic cueing of visual attention.
First and fundamentally, the sudden appearance of visual objects tends to capture people’s attention through an orienting response that is mediated through well-defined brain mechanisms11,12. In a visual detection task, observers press a button as soon as they notice a visual target object that randomly appears at various lateralized locations on a screen in front of them (e.g., up, down, left, right). The speed of each button response is measured to the nearest millisecond, establishing a reaction time (RT), i.e. the time interval from target onset to button press13.
The attentional cueing paradigm inserts into this procedure an object (called a visual cue) before the target and measures whether that cue affects RTs, in order to examine how the cue directs the observer’s spatial distribution of “covert attention”. Covert attention is generally believed to be a cognitive resource that facilitates visual-spatial processing in the absence of overt orienting of the eyes, head or body towards the source of stimulation13,14. The absence of such overt movements is often merely assumed on plausibility grounds (because presenting targets randomly at opposing screen locations discourages such anticipatory movements) but can be verified through objective movement monitoring (e.g., per eye tracking).
Among many other objects that have been examined in this way, popular visual cues have been lateralized flashes that explicitly mark a location, or centrally presented arrows that explicitly denote space by pointing to one side15, or small and large numbers that are implicitly associated with space16,17, and also words that either explicitly denote or implicitly connote spatial regions8,9,10. Explicit examples for upper space are “UP” or “ABOVE”, implicit examples are “ROOF” or “CLOUD”. If one such cue leads to relatively fast RTs in response to subsequent targets appearing at peripheral screen locations, then it can be inferred that the observer’s covert attention was aligned at the location of the target, reflecting the use of spatial information contained in the cue (called a valid or congruent trial). A typical example would be faster responses to targets at the upper screen location in response to targets following our previous example cues. Conversely, if a cue leads to relatively slow RTs, then it can be inferred that the cue shifted the observer’s covert attention elsewhere, and that it needed to be re-aligned with the target location as part of its detection process (called an invalid or incongruent trial). The attention-based spatial congruity effect induced by a cue can be quantified by subtracting RT incongruent – RT congruent, usually yielding a positive difference of several tens of milliseconds that captures the time needed for attentional shifts through visual space.
We now turn to an ongoing debate about the underlying mechanisms for this behavioural signature. In semantic cueing studies, when the word cues explicitly denote a spatial region, then the congruity effect is reliable and strong2,5,6,8. Interestingly, when the word cues only implicitly connote space, then the congruity effect depends on the amount of attention the observer invests in the task. This was documented in a recent series of studies with implicitly vertical spatial words (e.g., “CLOUD”, “CARPET”) that we now briefly review.
Shaki and Fischer9 presented vertically connotative cues followed by vertically lateralized targets and compared attention effects under three task instructions: In task 1, observers had to detect all targets and thus could ignore all cues; in task 2, they had to respond only to targets in one location and again could ignore all cues; and in task 3, observers again had to respond to targets in one location but only when the cue word had a specific spatial meaning. In all conditions, the spatial relationship between implicit cue meaning and target location was either congruent or incongruent. With this design, the authors found that attention effects only emerged when both the spatial connotation of the cues and the location of the targets were processed (in task 3).
While this study indicated a combined role for spatial processing of both cues and targets, it remained unclear if spatial processing of the vertically connotative cue words together with non-spatial processing of the targets was sufficient to generate the congruency effect. This was investigated by Shaki and Fischer10 who compared spatial congruency effects under two task instructions: In task 1, observers had to respond only to targets of a specific shape (X or O, discrimination task) and could ignore the cue words; in task 2, they also had to respond to targets of a specific shape but only when the cue words had a specific spatial connotation. As in the previous study, the spatial relationship between implicit cue meaning and target location was either congruent or incongruent. With this design, the authors found that attention effects only emerged when both the spatial connotation of the cues and the identity of the targets were processed (in task 2).
Together, these two studies advanced our understanding of the necessary and sufficient conditions for attentional effects of spatially connotative words. They indicated that both cue and target processing are needed to generate this effect. Specifically, whenever cues were processed in our previous work, the subsequent targets had to be either localized9 or discriminated10. Yet, a fundamental question still remains unanswered: Is processing the cue alone perhaps sufficient to bring about the spatial congruency effect in a target detection task? This important question about the minimal requirements for semantic cueing was answered in the present study by adopting a simple target detection task while manipulating processing depth of the previously studied word cues in three different tasks (see Table 1).
In task 1 (lexical decision), observers were told to respond to targets only when the preceding cue was a word. This assessed the congruency effect when observers were not required to process the specific meaning of the cues. In task 2 (non-spatial categorization), observers also detected targets, but only if the cue word represented an inanimate object. This required observers to process the denotation of the words. In task 3 (spatial categorization), observers again detected targets according to a categorization rule, but now only when cue words connoted a specific vertical area. Hence, this instruction required participants to explicitly process the spatial connotation of the words, resulting in two possible response rules that were examined in separate blocks (respond to target if cue implies up; respond to target if cue implies down).
The key manipulation here is that spatially connoted cue words are activated to different degrees under various task requirement, ranging from lexical decision (task 1) to non-spatial categorization (task 2) to spatial categorization (task 3). Importantly, we expected the congruency effect generated by word processing to depend on the degree of activation of their spatial connotation. The novel prediction to be examined here is that processing of the cue alone might suffice to generate the spatial congruency effect between cue meaning and target location.
Our present study adds a second methodological improvement to the study of semantic cueing effects. Specifically, the above work on lexically induced congruency effects has inferred covert attention shifts from RT differences. However, RTs only provide indirect evidence of attention deployment in space, as explained above. This situation can be improved by measuring a spatial behaviour that might spontaneously occur during our task: Eye movements are known to be closely coupled with covert attention shifts15,18 and can therefore serve as proxy for the hidden cognitive process of spatial attention deployment.
Moreover, it is possible that, in the previously published studies on the congruency effect, observers actually moved their eyes anticipatorily in response to the cues and therefore directly fixated the targets in congruent trials while they had to process targets through peripheral vision in incongruent trials. This would have been possible because previous work inserted stimulus onset asynchronies (SOAs) between 400 and 600 ms between cue and target to determine the time course of the attention effect (cf9,10. , which is sufficient to plan and execute eye movements (e.g19. , . This suspected eye movement strategy would trivialize the above findings because shorter afferent delays of foveal stimuli to cortical areas compared to peripheral stimuli could explain the congruency effects (e.g.20. For these two reasons we recorded eye movements in the present study (see also21,22. We expected overt attention to closely follow the covert attention signature.
Methods
Participants
An a priori power analysis was conducted using MorePower Ver. 6.023 to determine the minimum sample size required for the planned analyses. The analysis targeted the detection of a two-way interaction (Cue × Target) and a three-way interaction (Task × Cue × Target) in a repeated measures ANOVA. Based on partial η² of 0.096 reported in Shaki and Fischer9 for the three-way interaction, α = 0.05, and a desired power of 0.80, the results indicated that at least 48 participants would be required to reliably detect the expected effects. This sample size was proven sufficient in another study by Shaki and Fischer10 who obtained a partial η2 of 0.184 for the three-way interaction and a partial η2 of 0.301 for the two-way interaction with a sample of 46 participants. Because eye-tracking studies often involve data loss due to blinks or calibration difficulties, we recruited slightly more participants than the minimum suggested.
A total of 63 native Hebrew-reading Israeli adults were recruited from the student population of Ariel, Israel. There were 19 males and 44 females with ages ranging from 20 to 32 years (mean: 23.5 years). Exclusion criteria were: (a) reported history of learning disabilities/brain injuries/memory decrease/visual impairments/prescription glasses; (b) consumption of drugs on the day of the experiment; and (c) wearing eye makeup, such as mascara and eye-liner, to ensure good quality eye tracking. All participants received course credit in exchange for their participation.
Stimuli
The stimuli set was informed by previous work and consisted of three Hebrew words associated with upper locations (meaning: hat, roof, tower) and three Hebrew words associated with lower locations (meaning: carpet, floor, basement). All Hebrew words were 4 letters long and shown in black Arial font with 35-point size on white background. The lexical frequencies for the two sets of cue words were tested using the M1 corpus by the National Institute for Testing and Evaluation24. The lexical frequencies of words associated with upper locations (mean = 22.46, SD = 4.85) and words associated with lower locations (mean = 17.35, SD = 3.79) were similar. Three additional non-word letter sequences with similar lengths were used in the lexical decision task. Five additional words of animated objects with similar lengths were used in the non-spatial categorization task (sheep, woman, donkey, snake, bird). Cues were displayed at the centre of the screen, while the target letter (“X”) in a 20-point “Times New Roman” font appeared 8° vertically above or below the centre of the display (cf9,10. Responses were made by pressing the space bar of a QWERTY keyboard centred in front of the screen with the dominant hand. All other keyboard keys were covered.
Apparatus
The experiment was programmed using the EyeLink Experiment Builder software package (SR Research Ltd., version 2.4.77). Eye tracking was performed binocularly using the EyeLink Portable Duo eye-tracker (SR Research Ltd., Ontario, Canada) at a sampling rate of 500 Hz. The signals of horizontal and vertical gaze positions from both eyes were averaged across all selected non-blink samples in a current bin. The stimuli were displayed on an AOC 2470 W 23-inch display screen (1920 × 1080 pixels resolution and 60 Hz refresh rate). The presentation of task instructions, stimuli, event timing and response recording was controlled by Experiment-Builder software.
Design
In task 1 (lexical decision) there were 72 trials, comprising 24 catch trials (12 ‘real’ words without target and 12 non-words) and 48 experimental trials (66.7% go trials). These latter trials reflected the complete crossing of two SOAs (500 and 700 ms), two target locations (above, below), and six cue words. These 24 trials were randomly presented twice with randomly chosen exemplars of each prime type.
In task 2 (non-spatial categorization) there were also 72 trials, comprising 24 catch trials (12 spatial connotative words without target and 12 animal names) and 48 experimental trials (66.7% go trials). These latter trials reflected the complete crossing of two SOAs, two target locations, and six prime words. These 24 trials were randomly presented twice with randomly chosen exemplars of each prime type.
In task 3 (spatial categorization) there were 144 trials, due to two response rules in separate counterbalanced blocks, reflecting the two prime meanings. In each block there were 72 trials, of which 24 were catch trials (12 go-words without target and 12 no-go words) and 48 experimental trials (66.7% go trials). Go trials reflected two SOAs, two target locations and three cue words. These 12 trials were randomly presented four times in each of the two rule conditions.
These three tasks were administered in a counterbalanced order to benefit from a statistically advantageous within-participant design. As a result, there were relatively few trials per task to prevent exhaustion of participants in this attention testing study. The potential concern about reduced statistical power was compensated by the large sample size (see above).
Procedure
This study was approved by the Ethics Committee of Ariel University (reference number AU-SOC-SS-20190204-1). The research procedure complied with the guidelines and regulations based on the Declaration of Helsinki. Informed consent was obtained from all participants prior to their involvement in the study. Personal data were collected only for administrative purposes (awarding course credit) and kept confidential. Published data are fully anonymized, ensuring no personal information was disclosed. The experiment was conducted in the Cognition Lab at Ariel University in a room with controlled lighting (but no natural light). The distance from the participant’s eye to the display screen was 78 cm while using a chin rest to ensure maximum accuracy. Before the task began, each participant was instructed to gaze toward five drifting points on the screen for eye tracker calibration. After completing the calibration, a one-point drift correction was performed after the task instructions had appeared on the screen but before data collection started. Participants were instructed to quickly and accurately make a go/no-go decision in each trial according to the response rule (see Table 1). All participants worked on the three tasks in a counterbalanced order, always beginning with eight practice trials.
All trials consisted of two successive visual onsets: a lexical cue at fixation, to which participants did not overtly react; and a vertically displayed target to which they made their decision depending on the go rule (see Table 1).
Each trial was initiated by a central fixation dot presented for 250 ms. Then, the cue was presented for 250 ms and disappeared. Finally, the target was presented after one of two different randomly chosen SOAs (500 or 700 ms) and remained visible until the participant’s response or 2000 ms had elapsed (also in no-go trials). Reaction time (RT) was defined as the time from target onset until the participant’s response on the space bar. No feedback was given, regardless of whether the response was correct or not.
Analysis
A total of 63 participants were tested but one did not complete all sessions and was excluded from analyses. Practice and no-go trials were not analysed. Considering manual responses, 246 trials (1.4%) reflected anticipatory responses in catch trials and 814 trials (4.5%) reflected omitted responses in go trials. Eight participants with more than 20% errors were excluded. Error trials of the remaining 54 participants ranged only from 0% to 17%. Finally, RTs for go trials outside of the mean and 2.5 standard deviations from the group mean were excluded (26 trials). After this data trimming to ensure high-quality results, the remaining trials were analysed with repeated measures analyses of variance (ANOVA) that evaluated the effects of 3 Task Instructions (lexical decision, non-spatial categorization, spatial categorization; see Table 1), 2 Implied Cue Directions (down, up), 2 Target Locations (down, up) and 2 SOAs (500 and 700 ms) on correct RTs. Congruent cue-target relations (up-up and down-down) were subtracted from incongruent cue-target relations (up-down, down-up) to compute congruency effects. Results appear in Fig. 1 (upper panels).
Considering eye movement data, these were stored as .EDF files in the EyeLink Data Viewer 4.3.21 (SR Research Ltd., Oakville, Ontario, Canada) and later exported to Excel. We wrote a MATLAB code (The MathWorks Inc., 2019) to pre-process the eye position recordings in five steps: First, trials with more than 25% of recordings missing were excluded from the analysis (291 trials). Second, recordings for which manual RTs fell outside of the mean and 2.5 standard deviations from the group mean were excluded (26 trials, as above). Third, we excluded recordings in which eye position of either eye fell outside the screen (25 trials). Fourth, we created 50-millisecond bins to evaluate eye positions during the inter-stimulus interval when the screen was blank (for either 250 ms in the 500 ms SOA; or 450 ms in the 700 ms SOA). We converted eye position data into gaze shifts, corresponding to the difference in average gaze position between subsequent bins (cf25. For each trial, the sum of gaze shifts along the Y-axis (in pixels) was calculated from the cue word disappearance to the appearance of the target, thus reflecting the vertical eye position change over 5 or 11 averages, respectively (for the two SOA conditions). For example, if the average vertical fixation coordinates from two adjacent bins were 10 and 50, respectively, the resulting gaze shift would be + 40, indicating an upwardly displaced start and further upward displacement of eye position at the beginning of the blank screen interval. Positive values corresponded to upward shifts, and negative values corresponded to downward shifts of eye position. It is important to note that we did not analyse eye movements along the X-axis because both cues and targets appeared horizontally centred on the screen. In order to calculate gaze shifts, we need to compare successive eye positions to the position of the eye at the beginning of the blank screen. Therefore, we excluded trials with missing eye position data from the first bin (2 trials or 0.02%). Fifth and last, we linearly interpolated the remaining data to fill in the missing data caused by blinks or random data loss (64 trials or 2.65%). In the lexical decision, non-spatial, and spatial categorization tasks, 92.37%, 91.92% and 92.94% of all fixations fell on the lexical cues, respectively, indicating close overt attention to the cues and thus task compliance in all conditions. Importantly, no cases were removed from the data set so that RT results and gaze results come from the same set of participants.
After this data trimming to ensure high-quality results, the remaining trials were analysed with repeated measures analysis of variance (ANOVA) that evaluated the effects of 3 Task Instructions (lexical decision, non-spatial categorization, spatial categorization; see Table 1), 2 Implied Cue Directions (down, up) and 2 SOAs (500 and 700 ms) on gaze shifts. Given that all eye data were collected prior to target onsets (which would trivially capture overt attention), no meaningful congruency computation was possible. Results appear in Fig. 1 (lower panel). All results were statistically evaluated with SPSS version 29. All raw data, the analysis script, and result tables are available at https://osf.io/y8ntm/.
Results
Reaction times
There was a significant main effect of Task Instructions, F(2, 106) = 21.1304, p < .001, ηp2 = 0.285. Average RTs for the lexical decision, non-spatial categorization, and spatial categorization tasks were 436 ms, 492 ms, and 470 ms, respectively. Post-hoc t-tests showed that the lexical decision task was performed significantly faster than the other two tasks, t(53) = -6.247, p < 001; and t(53) = -3.923, p < .01, respectively. In addition, RT in the non-spatial categorization task was significantly slower than the spatial categorization task, t(53) = 2.617, p = .006.
The main effect of SOA was significant, F(1, 53) = 7.956, p = .007, ηp2 = 0.131, with slower average RT for shorter SOAs (472 ms) than for longer SOAs (460 ms). This decrease of RT with longer SOAs reflects a typical fore-period effect (cf26.
More importantly, there was a significant interaction between Implied Cue Direction and Target Location, F(1, 53) = 5.828, p = .019, ηp2 = 0.099. This result was modulated by processing depth, as indicated by the triple interaction with Task Instructions, F(2, 106) = 9.547, p < .001, ηp2 = 0.153. Post-hoc t-tests on the congruency effect in the three tasks revealed that neither lexical decision nor non-spatial categorization yielded any congruency effect (-0.830 ms, t(53) = -0.300, and 0.738 ms, t(53) = 0.191, respectively). However, spatial categorization incurred a reliable congruency effect (17.133 ms, t(53) = 4.456, p < .001), reflecting the advantage of congruent relations between target locations and connotative spatial meaning of the cues. All other main effects and interactions were non-significant, all p-values > 0.068.
Gaze shifts
There was a significant main effect of Implied Cue Direction, F(1, 53) = 16.709, p < .001, ηp2 = 0.240, with downward cues inducing gaze shifts of 1.258 pixels and upward cues inducing gaze shifts of 4.632 pixels. This result was modulated by processing depth, as indicated by the interaction with Task Instructions, F(2, 106) = 3.408, p = .037, ηp2 = 0.060.
Post-hoc t-tests on the congruency effects in the three tasks revealed that lexical decision did not yield any congruency effect (0.371 pixels, t(53) = 0.534), consistent with the chronometric results above. However, both non-spatial and spatial categorization incurred small but reliable congruency effects (1.911 pixels, t(53) = 2.731, p = .004, and 2.779 pixels, t(53) = 4.337, p < .001, respectively). These two congruency effects were not reliably different from each other (t < 1).
In addition, the main effect of SOA was significant, F(1, 53) = 9.387, p = .003, ηp2 = 0.150, with small SOA inducing gaze shifts of 0.433 pixels and long SOA inducing gaze shifts of 5.457 pixels. Moreover, SOA interacted reliably with Implied Cue Direction, F(1, 53) = 17.797, p < .001, ηp2 = 0.251, due to larger upward gaze shifts for long compared to short SOAs when implied cue direction was upward, t(53) 3.958, p < .001, while no such effect existed for downward connoted cue words, t(53) = 1.478, p > 005 (see lower panel of Fig. 1). Finally, this interaction was further modulated by processing depth, as indicated by the triple interaction of Task, Implied Cue Direction, and SOA, F(1, 106) = 3.307, p = .041, ηp2 = 0.059. Comparing across the lower panels of Fig. 1 shows that participants’ average late gaze position had shifted upwards by the largest amount with upward implied cue direction and spatial meaning extraction, t(53) = 4.543, p < .001, while there was no such shift in the control condition, t < 1. However, the non-spatial condition also showed this late upward shift, t(53) = 2.82, p < .01, which did not statistically differ from the gaze position with spatial meanings, t(53) = 1.11, p > .27. No other ANOVA results were reliable, all p - values > 0.77.

Reaction times (upper panels) and gaze shifts (lower panels) in the three tasks. Error bars reflect 1 SEM. Statistical significance indicated by p < .05 (*), p < .01 (**), and p < .001 (***). For task descriptions see Table 1.
Discussion
Our main goal in this study was to determine the depth of processing at which a word can induce spatial shifts of attention in the semantic cueing paradigm8,9,10. For this, we presented observers with sequences of cue words followed by detection targets. We manipulated the response instructions and recorded reaction times, as well as eye positions, as performance measures. Reaction times are an indirect measure of (covert) attention deployment while eye positions directly indicate (overt) attention in space. Performance measures for trials with congruent cue-target relations (up-up and down-down) were subtracted from those with incongruent cue-target relations (up-down, down-up) to compute spatial congruency effects. We hypothesized that reliably positive scores would indicate that spatially connoted cue words succeeded in directing attention towards locations of subsequent targets. We obtained several clear results from our task manipulation.
Considering first the lexical decision task, we found that it is not enough to recognize the lexical status of the cue word for spatial congruency effects to obtain: There were no reliable congruency effects in the lexical decision task. This result rules out a purely automatic triggering of spatial biases from lexical processing. Consistent with this inference from RT results, there were also no reliable deviations of the eyes from the initial gaze position on those cue words during the wait for the targets. Thus, neither covert nor overt spatial attention shifts were induced by mere lexical decisions.
Secondly, in the non-spatial categorization task, where participants had to process the animacy status of cues, we also obtained no reliable evidence for a covert shift of spatial attention, although the pattern of means suggests the expected trend. However, overt gaze behaviour already showed a reliable congruency effect (cf21,22. Thus, overt attention shifts were statistically dissociated from covert attention shifts in the present results. Given the significant slowing of RTs in this compared to the spatial categorization task (discussed next), we suspect that attentional resources were partly occupied by a known tendency to monitor the animacy status of appearing stimuli: Words (as well as pictures) denoting animate objects recruit more attention at encoding than non-animate objects (animacy monitoring hypothesis, cf27,28. This effect may have biased our intended comparison somewhat and should be avoided in future work.
Our third task was spatial categorization of cue words and clearly showed that it is necessary to understand spatial connotations in order to obtain spatial congruency effects. This is evidenced by the reliable spatial congruency effect emerging in both the manual response times and the gaze data. Moreover, while it was required to process the spatial connotation of cue words, it was not necessary to also process the targets -- the congruency effect resulted with mere target detection. This important result answers our initial question by showing that semantic cueing can emerge without differential target processing.
This insight challenges our previous reports9,10 where we compared effects of differential target processing demands and concluded that both cue and target processing are necessary to obtain spatial congruency effects in semantic cueing of attention. We now understand that, whenever the spatial aspect of lexical cues is processed, attention will be shifted accordingly. Whether and how these results generalize across other conceptual domains remains to be seen. For example, it is currently assumed that spatial congruency effects with time concepts require explicit semantic processing of such concepts29.
A clear pattern in gaze positions is that they tended to drift upward rather than downward over time, regardless of cue connotation or task. This is not surprising in light of a general advantage of the upper compared to the lower visual field for saccade generation (e.g.30,31. More interesting is the tentative evidence of a modulation of this trend by cognitive task, with both non-spatial and spatial semantic processing augmenting the bias (Fig. 1, lower panels). This suggests that allocating cognitive resources to meaning extraction reduces their availability for fixational control, consistent with the view that fixating is also a cognitive task19,32. The present results imply that implicit spatial word processing is enough to bias cognition as long as there is a spatial task to measure the resulting bias. However, now a new fundamental question emerges: Is the mere presentation of spatially connotative words without a subsequent spatial task sufficient to shift spatial attention to the implied location? This question about a further deconstruction of the congruency-generating cognitive mechanism still awaits an answer. Thus, future work should assess the presence of spatial attention shifts under conditions without explicit spatial task. This can be accomplished, for example, by measuring spontaneous changes in pupil diameter on split-screen displays; (cf33. or by recording early components of event-related brain potentials (cf34,35. In conclusion, more work needs to be done to understand how we habitually map meaning onto space.
Data availability
All data obtained in this study are available on the Open Science Framework ( [https://osf.io/y8ntm/](https:/osf.io/y8ntm) ).
References
Chasteen, A. L., Burdzy, D. C. & Pratt, J. Thinking of god moves attention. Neuropsychologia 48 (2), 627–630. https://doi.org/10.1016/j.neuropsychologia.2009.09.029 (2010).
Petrova, A. et al. Spatial congruency effects exist, just not for words: looking into Estes, Verges, and Barsalou (2008). Psychol. Sci. 29 (7), 1195–1199. https://doi.org/10.1177/0956797617728127 (2018).
Santiago, J., Ouellet, M., Román, A. & Valenzuela, J. Attentional factors in conceptual congruency. Cogn. Sci. 36 (6), 1051–1077. https://doi.org/10.1111/j.1551-6709.2012.01240.x (2012). https://psycnet.apa.org/doi/
Malyshevskaya, A. et al. Keeping track of time: horizontal spatial biases for hours, days, and months. Mem. Cognit. 52 (4), 894–908. https://doi.org/10.3758/s13421-023-01508-1 (2024).
Amer, T., Gozli, D. G. & Pratt, J. Biasing spatial attention with semantic information: an event coding approach. Psychol. Res. 82 (5), 840–858. https://doi.org/10.1007/s00426-017-0867-5 (2018).
Estes, Z. & Barsalou, L. W. A comprehensive meta-analysis of spatial interference from linguistic cues: beyond Petrova et al. (2018). Psychol. Sci. 29 (9), 1558–1564. https://doi.org/10.1177/0956797618794131 (2018).
Gibson, B. S. & Bryant, T. A. Variation in cue duration reveals top-down modulation of involuntary orienting to uninformative symbolic cues. Percept. Psychophys. 67 (5), 749–758. https://doi.org/10.3758/BF03193530 (2005).
Logan, G. D. Linguistic and conceptual control of visual Spatial attention. Cogn. Psychol. 28 (2), 103–174. https://doi.org/10.1006/cogp.1995.1004 (1995).
Shaki, S. & Fischer, M. H. How does Language affect Spatial attention? Deconstructing the prime-target relationship. Mem. Cognit. 51 (5), 1115–1124. https://doi.org/10.3758/s13421-022-01390-3 (2023a).
Shaki, S. & Fischer, M. H. Language directs Spatial attention differently in explicit and implicit tasks. Plos One. 18 (11), e0291518. https://doi.org/10.1371/journal.pone.0291518 (2023b).
Von Helmholtz, H. Handbuch der physiologischen optik. Handb. Physiol. Opt. 9, 145. https://doi.org/10.3931/e-rara-21259 (1867).
Sokolov, E. N., Spinks, J. A., Näätänen, R. & Lyytinen, H. The Orienting Response in Information Processing (Lawrence Erlbaum Associates, 2002). https://doi.org/10.4324/9781410601490.
Wolfe, J. M. et al. Sensation and Perception (4th edition) ( Sinauer Associates, 2015). https://doi.org/10.1086/683738.
Kahneman, D. Attention and Effort 218–226 (Prentice-Hall, 1973). https://doi.org/10.2307/1421603.
Posner, M. I. Orienting of attention. The VIIth Sir Frederic Bartlett lecture. Q. J. Exp. Psychol. 32, 3–25. https://doi.org/10.1080/00335558008248231 (1980).
Fischer, M. H., Castel, A. D., Dodd, M. D. & Pratt, J. Perceiving numbers causes spatial shifts of attention. Nat. Neurosci. 6 (6), 555–556. https://doi.org/10.1038/nn1066 (2003).
Shaki, S. & Fischer, M. H. How do numbers shift Spatial attention? Both processing depth and counting habits matter. J. Exp. Psychol. Gen. 153 (1), 171. https://doi.org/10.1037/xge0001493 (2024).
Klein, R. M. Is covert spatial orienting embodied or disembodied cognition? A historical review. Q. J. Exp. Psychol. 73 (1), 20–28. https://doi.org/10.1177/1747021819889497 (2020).
Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 124 (3), 372–422. https://doi.org/10.1037/0033-2909.124.3.372 (1998).
Pease, V. P. & Sticht, T. G. Reaction time as a function of onset and offset stimulation of the fovea and periphery. Percept. Mot. Skills. 20 (2), 549–554. https://doi.org/10.2466/pms.1965.20.2.549 (1965).
Gozli, D. G., Chow, A., Chasteen, A. L. & Pratt, J. Valence and vertical space: saccade trajectory deviations reveal Metaphorical Spatial activation. Visual Cogn. 21 (5), 628–646. https://doi.org/10.1080/13506285.2013.815680 (2013).
Ostarek, M., Ishag, A., Joosen, D. & Huettig, F. Saccade trajectories reveal dynamic interactions of semantic and Spatial information during the processing of implicitly Spatial words. J. Exp. Psychol. Learn. Mem. Cogn. 44 (10), 1658–1670. https://doi.org/10.1037/xlm0000536 (2018).
Campbell, J. I. & Thompson, V. A. MorePower 6.0 for ANOVA with relational confidence intervals and Bayesian analysis. Behav. Res. Methods 44 (4), 1255–1265 (2012). https://www.proquest.com/scholarly-journals/morepower-6-0-anova-with-relational-confidence/docview/1470090528/se-2?accountid=40023
NITE NLP Tools. (Version 15.06.23) Corpus. Jerusalem: National Institute for Testing and Evaluation. https://hlp.nite.org.il/WebCorpora.aspx.
Felisatti, A., Ranzini, M., Blini, E., Lisi, M. & Zorzi, M. Effects of attentional shifts along the vertical axis on number processing: an eye-tracking study with optokinetic stimulation. Cognition 221, 104991. https://doi.org/10.1016/j.cognition.2021.104991 (2022).
Luce, R. D. Response Times: their Role in Inferring Elementary Mental Organization (Oxford University Press, 1991). https://doi.org/10.1093/acprof:oso/9780195070019.001.0001.
Bugaiska, A. et al. Animacy and attentional processes: evidence from the Stroop task. Q. J. Experimental Psychol. 72 (4), 882–889. https://doi.org/10.1177/1747021818771514 (2018).
Komar, G. F. et al. The animacy effect on free recall is equally large in mixed and pure word lists or pairs. Sci. Rep. 13, 11499. https://doi.org/10.1038/s41598-023-38342-z (2023).
von Sobbe, L., Scheifele, E., Maienborn, C. & Ulrich, R. The space–time congruency effect: a meta-analysis. Cogn. Sci. 43 (1), e12709. https://doi.org/10.1111/cogs.12709 (2019).
Fischer, M. H., Deubel, H., Wohlschläger, A. & Schneider, W. X. Visuomotor mental rotation of saccade direction. Exp. Brain Res. 127 (2), 224–232. https://doi.org/10.1007/s002210050792 (1999).
Previc, F. H. Functional specialization in the lower and upper visual fields in humans: its ecological origins and neurophysiological implications. Behav. Brain Sci. 13 (3), 519–542. https://doi.org/10.1017/S0140525X00080018 (1990).
Munoz, D. P. & Everling, S. Look away: the anti-saccade task and the voluntary control of eye movement. Nat. Rev. Neurosci. 5 (3), 218–228. https://doi.org/10.1038/nrn1345 (2004).
Salvaggio, S., Andres, M., Zénon, A. & Masson, N. Pupil size variations reveal Covert shifts of attention induced by numbers. Psychon. Bull. Rev. 29 (5), 1844–1853. https://doi.org/10.3758/s13423-022-02094-0 (2022).
Pinto, M. et al. Visualising numerals: an erps study with the attentional SNARC task. Cortex 101, 1–15. https://doi.org/10.1016/j.cortex.2017.12.015 (2018).
Baier, D. & Ansorge, U. Can subliminal Spatial words trigger an attention shift? Evidence from event-related-potentials in visual cueing. Visual Cogn. 28 (1), 10–32. https://doi.org/10.1080/13506285.2019.1704957 (2020).
Acknowledgements
This work was supported by funding from ISF 1398/24 to SS and from DFG 1915/12-1 “Boundary conditions of conceptual spaces” to MHF.
Author information
Authors and Affiliations
Contributions
S.S. and M.F. conceptualized the study and methodology, performed the statistical analysis, and wrote the main manuscript text. O.P. designed and conducted the experiments, contributed to the Methods and Results sections, and prepared the figures. All authors provided revisions and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shaki, S., Pitem, O. & Fischer, M.H. Lexical priming of space depends on how deeply you think about it. Sci Rep 15, 38410 (2025). https://doi.org/10.1038/s41598-025-22265-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-22265-y
