
Abstract
This study developed a Python-based framework to predict the ultimate bearing capacity of shallow foundations on cohesionless soil, employing machine learning (ML) and deep learning (DL) techniques. Utilizing a comprehensive dataset of 116 footing experiments, Eleven ML models (Gaussian Process Regression (GPR), Extreme Gradient Boosting (XGBoost), Gradient Boosting Machine (GBM), Random Forest (RF), Categorical Boosting (CatBoost) etc.) and five DL models (Artificial Neural Network (ANN), Deep Neural Network (DNN), etc.) trained and compared against traditional methods. Input parameters included foundation dimensions and soil properties. Results demonstrated that ML and DL models significantly outperformed traditional equations, achieving higher accuracy. Ensemble methods like GPR, XGBoost, GBM, RF, and CatBoost exhibited superior performance, with a Coefficient of Determination (R2) values above 0.988 and a Mean Absolute Percentage Error (MAPE) below 5.07%. Conversely, traditional methods showed lower accuracy, with R2 values ranging from 0.684 to 0.82 and MAPE exceeding 19.63%. Taylor diagram analysis confirmed the improved performance of ML and DL. Additionally, a SHapley Additive exPlanations (SHAP) analysis highlighted foundation depth and soil friction angle as the most influential parameters, consistent with geotechnical principles.
Similar content being viewed by others

Introduction
The ultimate bearing capacity (qu) and allowable settlement are crucial factors in designing shallow foundations. The ultimate bearing capacity is influenced by the soil’s shear strength and is typically estimated to be using theories developed by Terzaghi1, Meyerhof2, Hansen3, Vesić4, and others5,6. However, there are notable differences among the equations used to calculate bearing capacity. Additionally, these theories rely on several assumptions that simplify the complexities of the problem7.
Beyond analytical techniques for estimating bearing capacity, several scholars have investigated semi-empirical approaches for assessing foundation bearing capacity ). Although footing load tests provide the most accurate means of directly measuring the ultimate bearing capacity of foundations at a specific site, practical constraints related to cost and time often prevent their use. Typically, experimental studies are carried out on smaller-scale models in laboratory settings, which are considerably smaller than actual foundations8. Furthermore, Finite element method is a highly effective numerical technique for studying soil-structure interaction behavior. Numerous studies have utilized this technique to evaluate the ultimate bearing capacity of shallow foundations, and the accuracy of the results has been validated by comparisons with experimental data9,10,11.
The twenty-first century has witnessed the rapid expansion of Artificial Intelligence (AI), driven by its capacity to process distorted, incomplete, or fuzzy data. This ability to manage input uncertainty renders it a powerful tool for geotechnical problem-solving. Each AI method presents unique characteristics, benefits, and drawbacks, enabling researchers to explore diverse approaches to determine optimal solutions. AI techniques have been applied to a broad spectrum of geotechnical engineering areas, including deep foundations12,13,14,15,16, shallow foundations17,18,19,20,21,22, rock strength prediction23,24, slope stability25,26, soil strength forecasting27,28,29, landslide identification30,31, tunneling32,33, and soil liquefaction34,35. Furthermore, numerous studies have provided state-of-the-art reviews on AI applications in geotechnical engineering36,37,38,39,40,41.
Intelligent systems such as machine learning (ML), and deep learning (DL) are commonly employed to model complex interactions between inputs and outputs or to identify patterns within available data. AI-based methods excel in capturing inherent nonlinearity and intricate interactions among variables across various domains. These approaches can learn the relationships between soil mechanical properties, foundation geometry, and bearing capacity without needing prior knowledge of42,43,44. Recently, researchers have utilized various AI techniques to tackle the ultimate bearing capacity (qu) problem in shallow foundations. Techniques such as artificial neural networks (ANN)45,46,47,48,49,50,51, adaptive neuro-fuzzy inference systems (ANFIS)50,52,53,54, Deep Neural Network (DNN)45,55,56,57,58, Convolutional Neural Network (CNN)59,60, Recurrent Neural Networks (RNN)59,61, Feedforward Neural Networks (FFNN)62,63, Long short-term memory (LSTM)59,60,64, support vector regression (SVR)20,56,58,65, least squares SVR (LSSVR)47,66,67, random forests (RF)59,68,69, gradient boosting machine (GBM)42,47, gaussian process (GPR)55,56,70,71, k-nearest neighbors (KNN)65, decision tree (DT)65,69,72,73, ensemble tree (ET)69,71,72,73, Light Gradient Boosting Machine (LightGBM)60,74,75, Bagging Regressor (BR)47,76, Categorical Boosting (CatBoost)77,78, Ada Boost (AdaBoost)72,79, and extreme gradient boosting (XGBoost)60,65,72 have all shown success in estimating the ultimate bearing capacity of shallow foundations on soil.
This study develops a user-friendly Python framework to estimate the ultimate bearing capacity of shallow foundations, automating key steps and making advanced machine learning (ML) and deep learning (DL) techniques accessible to geotechnical professionals. Using a dataset of 116 footing experiments and input parameters like foundation dimensions and soil properties, the study trains and compare eleven ML models (including GPR, XGBoost, etc.) and five DL models (ANN, CNN, etc.) against traditional theoretical equations, aiming to improve the accuracy and efficiency of ultimate bearing capacity prediction.
Methodology
This study employed a comprehensive approach, utilizing a robust and diverse dataset of 116 footing experiments, as listed inTable 1, compiled from a wide range of prior research. The primary goal was to develop advanced machine learning (ML) and deep learning (DL) models capable of accurately predicting the bearing capacity (qu) of shallow foundations in cohesionless soil. To achieve this, the study incorporated key factors identified through an extensive review of the literature. These factors, namely foundation width (B), foundation depth (D), length-to-width ratio (L/B), soil unit weight (γ), and internal friction angle (φ), served as the input variables. The output variable was the ultimate bearing capacity (qu). Understanding the influence of these parameters is crucial for accurate qu prediction.
This study utilized eleven machine learning (ML) models: Gaussian Process (GPR), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LGBM), Gradient Boosting Machine (GBM), Random Forest (RF), Categorical Boosting (CatBoost), Ada Boost (AdaBoost), K-Nearest Neighbors (KNN), Bagging Regressor (BR), Decision Tree (DT), and Support Vector Regression (SVR). Additionally, five deep learning (DL) models were used: Artificial Neural Network (ANN), Deep Neural Network (DNN), Convolutional Neural Network (CNN), Recurrent Neural Networks (RNN), and Feedforward Neural Network (FFNN). All models were implemented using the Python programming environment, alongside well-known equations by Terzaghi, Meyerhof, Vesić, Hansen, Eurocode 7 (EC7), and Egyptian Code (ECP).
Soft computing approaches
Machine learning (ML) and deep learning (DL) models are a core component of artificial intelligence, focusing on algorithms that learn from data to make predictions without explicit programming. I utilized a range of these models, broadly categorized into ensemble methods and traditional ML algorithms. The ensemble methods, including Gaussian Process Regressor (GPR), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LightGBM), Gradient Boosting Machines (GBM), Random Forest (RF), Categorical Boosting (CatBoost), Adaptive Boosting (AdaBoost), K-Nearest Neighbors (KNN), Bagging Regressor (BR), Decision Trees (DT), Support Vector Machine (SVM), Artificial Neural Network (ANN), Deep Neural Network (DNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Feedforward Neural Network (FFNN) to comprehensively evaluate various approaches to predicting ultimate bearing capacity.
A comparison of various ML and DL algorithms, including their type, strengths, weaknesses, best use cases, performance and computational cost are listed in Table 1 and Table 2, respectively.
Theoretical bearing capacity equations
Terzaghi1, applied Prandtl’s86 plastic failure theory to formulate a method for determining the bearing capacity of shallow foundations, considering soil cohesion, effective stress, and the angle of internal friction. Later, Meyerhof2, Hansen3, Vesić4 The European Code (EC7: Geotechnical Design6, and the Egyptian Code for Soil Mechanics and Foundation Design and Implementation (ECP-202: Part 4-Deep Foundations5 extended Terzaghi’s equation by incorporating shape and depth factors, among others. As shown in Table 3, the fundamental structure of these classical equations remained consistent with Terzaghi’s. However, these traditional methods, despite being supported by extensive in situ and laboratory data, are limited by their reliance on simplifying assumptions, leading to potential inaccuracies in bearing capacity predictions87,88.
Were \({q}_{u}\) ultimate bearing capacity of footing; c soil cohesion; \(\gamma\) effective unit weight of the soil below and around the foundation; B footing width; L footing length; D foundation depth; \({N}_{c}\), \({N}_{q}\), and \({N}_{\gamma }\) non-dimensional bearing capacity factors as exponential functions of \(\varphi\); \(\varphi\) internal friction angle; \({s}_{c}\), \({s}_{q}\), and \({s}_{\gamma }\) non-dimensional shape factors; \({d}_{c}\), \({d}_{q}\), and \({d}_{\gamma }\) non-dimensional depth factors; and \({K}_{p}\) is the passive earth pressure.
Database and modeling
Input selection
For shallow foundations on granular soils, numerous studies emphasize the importance of foundation geometry (width B, length L, depth D), soil friction angle (φ), and unit weight (γ) in determining ultimate bearing capacity. These factors directly influence stress distribution and failure mechanisms, which are crucial for solving bearing capacity problems. Foundation depth (D) significantly impacts bearing capacity, while soil friction angle (φ) is considered the most influential parameter. Uncertainty analyses by Foye et al.89 reinforce the key roles of B, L, D, φ, and γ. Consequently, this study employs these parameters to predict the ultimate bearing capacity of shallow foundations on granular soil.
Dataset
Data quantity and quality are essential for improving modeling accuracy. This study utilized 116 data points sourced from publications by Golder et al.90, Eastwood91, Subrahmanyam92, Muhs et al.93, Weiß94, Muhs and Weiß95,96, Briaud and Gibbens97,98, Gandhi99, and Cerato and Lutenegger87. The dataset comprised 64 small-scale and 52 large-scale experiments. Table 4 comprehensively lists the literature sources and parameter ranges for each footing. Despite variations in testing conditions, the combined dataset provides a substantial volume of diverse data, reflecting various simulations of footing bearing capacity in cohesionless soil in real-world scenarios. Statistical characteristics and the distribution charts of the values of different parameters in the database are depicted in Fig. 1 and summarized in Table 5.

Correlation matrix for the bearing capacity databases.
To facilitate model training and unbiased evaluation, the dataset was partitioned into two distinct subsets: a training set, comprising 70% of the data, and a testing set, comprising the remaining 30%. The training set was utilized to construct the ML and DL models, whereas the testing set, held separate during model development, was exclusively used to assess the models’ predictive performance on unseen data.
Correlation analysis
Figure 1 provides a detailed visual and statistical analysis of the relationships between variables. The diagonal plots, featuring histograms with fitted curves, show the individual distribution of each variable. The off-diagonal scatter plots illustrate the linear relationship between pairs of variables, with a red regression line to highlight the trend72. Crucially, each of these scatter plots includes two key metrics: Pearson’s r, which measures the strength and direction of the linear correlation (e.g., the strong positive relationship between B and D with an r of 0.9383), and R2, which indicates how well the regression line fits the data. Analyzing these values reveals important insights, such as the moderate negative correlation between B and φ (r≈ − 0.4426) and the very weak relationship between L/B and γ (r≈0.1813). The plots in the final row, which compare all other variables against qu, are particularly useful for understanding which factors are most influential. Overall, this single visualization effectively summarizes the data, allowing for a quick and clear assessment of variable dependencies.
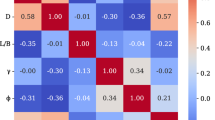
Figure 2 illustrates the correlation matrix as a heatmap, providing a quantitative assessment of the relationships between B, D, L/B, γ, φ, and qu. The intensity of the heatmap’s colors corresponds to the magnitude of the correlation coefficients, with darker red indicating strong positive correlations and darker blue representing strong negative correlations. The diagonal elements naturally show a perfect correlation for each variable with itself.

Heatmap correlation matrix.
The correlation between B (foundation width) and D (foundation depth) is the strongest (0.79), indicating that wider footings tend to have greater foundation depths. The correlation with qu (ultimate bearing capacity) is also strong (0.51), suggesting that an increase in foundation width is strongly associated with an increase in the ultimate bearing capacity of the footing. The correlations with L/B (length L to width B) and φ (soil friction angle) are moderately negative at (− 0.3) and (− 0.44), respectively, while γ (unit weight) has the weakest correlation at (− 0.18).
D shows weak correlations with other variables, except with B, as already mentioned, and a strong positive correlation with qu at (0.71), indicating that an increase in foundation depth is strongly associated with an increase in the ultimate bearing capacity of the footing. The correlations with L/B and γ are moderately negative at (− 0.21) and (− 0.12), respectively, while φ has a weaker correlation at (− 0.42).
L/B has a slight positive correlation with γ (0.18), and its correlation with φ is nearly zero (0.018), suggesting no significant linear relationship. Additionally, the correlation with qu is weakly negative (− 0.22), indicating that longer footings tend to have slightly lower ultimate bearing capacity, in addition to the previously mentioned correlations with B and D.
γ shows a slight positive correlation with φ (0.17). Furthermore, the correlation with qu is weakly negative (− 0.23), Besides the previously mentioned correlations with B, D, and L/B.
Besides the already mentioned correlations with B, D, L/B, and γ, the correlation between φ and qu is nearly zero at (0.079), suggesting no significant linear relationship.
In summary, qu, the ultimate bearing capacity of the footing, exhibits various levels of correlation with the input variables. The strongest positive correlation is with B at (0. 79), highlighting the significant impact of the footing width on the ultimate bearing capacity. qu also shows strong correlations with D (0.71), indicating that footing with greater depths tends to have higher ultimate bearing capacity. Correlations between qu with both L/B and γ are weakly negative (− 0.22) and (− 0.23), respectively, while φ is nearly zero at (0.079), suggesting no significant linear relationship.
Tuning hyperparameters of machine learning models
To enhance machine learning model performance, this study employed Bayesian optimization (BO) for hyperparameter tuning, addressing the limitations of traditional grid and random search methods. Specifically, a fivefold cross-validation (CV) integrated with BO (BO + 5CV) was implemented to mitigate overfitting and ensure robust, generalizable predictions. Utilizing Optuna’s Bayesian optimization, the process aimed to maximize the cross-validated R2 score by iteratively exploring hyperparameter combinations for parameters such as n_estimators, learning_rate, and depth across 1000 iterations. This approach defined an objective function that trains the model with suggested hyperparameters, evaluates its performance through fivefold CV, and returns the mean R2, ultimately identifying the optimal hyperparameter set and corresponding maximum R2 value, as detailed in Table 6.
The skopt.gp_minimize method was utilized for hyperparameter tuning of a Gaussian Process Regressor (GPR) to optimize its intricate kernel function. The objective was to minimize the negative mean squared error obtained from cross-validation. This approach, called Bayesian Optimization, effectively explores the optimal combinations of parameters within the kernel’s components.
The Recurrent Neural Network (RNN) model does not include hyperparameter tuning. It evaluates a single, fixed set of hyperparameters for an LSTM model using k-fold cross-validation. While it saves the best-performing model from those cross-validation runs, it does not systematically search for the optimal values for parameters like the number of LSTM units, epochs, or batch size. This makes it a model evaluation script rather than a hyperparameter optimization one.
Model evaluation
Evaluating machine and deep learning models for predicting complex outcomes, like foundation bearing capacity, requires a comprehensive approach. It’s not enough to just train a model; you must also verify its ability to generalize new, unseen data using a testing dataset. This ensures the model’s predictions are reliable for real-world applications. A robust evaluation combines both visual diagnostics, such as scatter plots, to identify systematic errors, and quantitative metrics to precisely measure performance. The standard metrics used include the Coefficient of Determination (R2) to assess how well the model fits the data; Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), and Root Mean Square Error (RMSE) to quantify the magnitude of prediction errors; Mean Bias Error (MBE) to reveal any prediction bias. Additionally, metrics like the A20 Index provide the percentage of predictions within an acceptable ± 20% error margin, while the Scatter Index (SI) and Agreement Index (d) offer more normalized and robust measures of overall model accuracy and reliability. The A20 Index directly measures a model’s reliability by indicating the percentage of predictions that fall within a precise ± 20% error margin, with higher values showing a greater number of reliable predictions. The SI quantifies the dispersion of predictions relative to actual values; a low value signifies highly precise predictions with minimal scatter. Lastly, the Agreement Index (d) assesses the overall agreement between predicted and observed values on a scale from 0 to 1, where a value closer to 1, reflects a strong alignment between the model’s output and real-world data. Together, these methods provide a thorough and reliable assessment of a model’s predictive capabilities78,89. These metrics are defined as follows:
where \({y}_{i}\) is the actual value, \(\widehat{y}\) is predicted value, \(\overline{y }\) is the mean of the actual values, and \(\overline{\overline{y}}\) is the mean of the predicted values.
Also, Taylor diagrams were used to provide a detailed statistical comparison between predicted and observed values, incorporating metrics such as correlation, RMSE, and normalized standard deviation. This allowed for a more nuanced understanding of model performance and error sources. To ensure robustness, uncertainty analysis was also incorporated.
A comprehensive evaluation framework, encompassing both visual and quantitative analyses, allows for a thorough and balanced assessment of model performance. This robust approach validates the scientific integrity of predictions and ensures their practical applicability in real-world scenarios.
Results
Performance and results of ML and DL models
The performance of various ML and DL models in predicting ultimate bearing capacity for footings with different cross-sectional shapes in sand is visualized in scatter plots, Fig. 3 through Fig. 5. The close clustering of training (70%) and testing (30%) data points around the diagonal line for the ML and DL models indicates strong agreement between predictions and experimental results in most cases, demonstrating the models’ reliability and accuracy. Table 7 presents evaluation metrics used to assess the performance of the established ML and DL models. These metrics include the Coefficient of Determination (R2), Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), Mean Bias Error (MBE), Root Mean Square Error (RMSE), A20 Index (A20), Scatter Index (SI), and Agreement Index (d). Figure 3 through Fig. 5, along with Table 7, compare the predicted and actual values for each model, illustrating their correlation and statistical performance. The performance analysis of the various ML and DL models provides significant insights into their capabilities, particularly regarding the metrics R2, MAPE, MAE, MBE, and RMSE, A20, SI, and d.

Scatter plots between actual and predicted ultimate bearing capacity values based on (a) GPR, (b) XGBoost, (c) LightGBM, (d) GBM, (e) RF, (f) CATBoost, (g) AdaBoost, (h) KNN.
Gaussian Process Regressor (GPR) (Fig. 3(a)) excels with a training R2 of 0.9996, indicating an excellent fit, and a low MAPE of 2.26%, showcasing high accuracy. However, during testing, it shows a decline with a test R2 of 0.972 and an MAPE of 11.27%. The MAE increases from 5.84 in training to 44.21 in testing, with an RMSE of 86.20, indicating a significant rise in prediction errors. The A20 Index remains strong at 88.57%, indicating that most predictions fall within the acceptable ± 20% error margin. The SI of 0.195 suggests moderate scatter, while the Agreement Index (d) of 0.993 reflects strong agreement with actual values. Likewise, Extreme Gradient Boost machine (XGBoost) (Fig. 3(b)) also performs remarkably, achieving a training R2 of 0.9999 and an impressively low MAPE of 0.65%. Its test performance remains robust with a test R2 of 0.9771 and an MAPE of 13.14%. The MAE rises from 1.53 to 42.62, and RMSE increases from 3.75 to 77.86, indicating some loss of accuracy. The A20 Index is at 80%, showing a good proportion of predictions within ± 20%. The SI of 0.176 suggests low scatter, and the Agreement Index (d) of 0.994 indicates strong agreement.
In contrast, Light gradient boosting Machine (LightGBM) (Fig. 3(c)), despite a solid training R2 of 0.9760, struggles in testing with an R2 of 0.9277 and a high MAPE of 26.86%. The MAE escalates from 33.68 in training to 84.03 in testing, with an RMSE of 138.33. Its A20 Index drops to 51.43%, indicating that a significant number of predictions fall outside the acceptable error margin. SI of 0.313 shows increased scatter, and the Agreement Index (d) of 0.982 reflects reasonable agreement. Both Gradient Boosting Machine (GBM) (Fig. 3(d)) and Random Forest Regressor (RF) (Fig. 3(e)) show excellent training performance, with R2 values of 0.9999 and low MAPEs (0.38%). However, they experience increased testing errors, with GBM recording a test R2 of 0.976 and an MAPE of 10.65%, while RF shows a test R2 of 0.9589 and an MAPE of 15.15%. The MAE for GBM rises to 43.02, and for RF, it increases to 56.66. Their A20 Indices remain high at 88.57% and 80%, respectively, indicating a good proportion of accurate predictions.
Both models have low SI values, showing minimal scatter, and strong Agreement Indices (d) of 0.993 for GBM and 0.988 for RF. Categorical Boosting (CATBoost) (Fig. 3(f)) delivers a training R2 of 0.9996 but shows a test R2 of 0.958 and an MAPE of 15.26%. The MAE increases from 7.46 to 56.54, with an RMSE of 105.79. Its A20 Index is 74.29%, indicating some predictions fall outside the acceptable range, while the SI of 0.239 indicates moderate scatter, and the Agreement Index (d) of 0.988 suggests strong alignment with actual values. In addition, Ada Boost Regressor (AdaBoost) (Fig. 3(g)) achieves a training R2 of 0.9995 but declines to 0.942 in testing, with an MAPE of 16.99%. The MAE rises from 6.57 to 70.61, and RMSE increases to 123.71. Its A20 Index is at 68.57%, showing a significant number of predictions outside the acceptable margin. The SI of 0.28 indicates moderate scatter, while the Agreement Index (d) of 0.983 reflects good agreement. K-Nearest Neighbors Regression (KNN) (Fig. 3(h)) maintains a training R2 of 0.9999 but drops to 0.9704 in testing, with an MAPE of 20.23%. The MAE increases from 0.85 to 56.38, and the RMSE is at 88.45. The A20 Index is 62.86%, indicating that a considerable proportion of predictions fall outside the ± 20% range. The SI is 0.20, showing moderate scatter, and the Agreement Index (d) is 0.9919, reflecting strong agreement with actual values.
BR (Fig. 4(a)) demonstrates strong performance with a training R2 of 0.9967 and an MAPE of 5.14%, indicating a good fit to the training data. In the test set, it also performs well, achieving a test R2 of 0.9490 and an MAPE of 18.56%. However, the MAE increases from 16.94 to 64.81, and the RMSE rises from 30.29 to 116.18, suggesting a significant increase in prediction errors. Its A20 Index is 62.86%, the SI is 0.263, and the d is 0.9851, showing a significant number of predictions outside the acceptable margin. On the other hand, Decision Trees (DT) (Fig. 4(b)) achieve excellent training metrics with an R2 of 0.9988 and a low MAPE of 3.65%. It also maintains a strong test performance, with a test R2 of 0.9580 and an MAPE of 17.00%. The MAE increases from 8.42 to 61.89, and the RMSE rises from 17.84 to 105.42. With an A20 Index of 71.43%, a low SI of 0.239, and a high Agreement Index (d) of 0.9884, Decision Trees indicate some predictions fall outside the acceptable range. In addition, Support Vector Machines (SVM) (Fig. 4(c)) perform exceptionally well, with a training R2 of 0.9992 and an MAPE of 4.61%. Its test performance is among the best, achieving a high test R2 of 0.9752, an MAPE of 13.13%, an MAE of 44.96, and an RMSE of 81.06. The A20 Index stands at 80%, the SI is 0.184, and the Agreement Index (d) is 0.9937, highlighting its strong predictive capabilities and low scatter. Neural network models also showcase strong performance.

Scatter plots between actual and predicted ultimate bearing capacity values based on (a) BR, (b) DT, (c) SVM, (d) ANN, (e) DNN, (f) CNN, (g) RNN, (h) FFNN.
Artificial Neural Networks (ANN) (Fig. 4(d)) have a training R2 of 0.9991 and an MAPE of 6.18%. They generalize well to the test set, achieving a test R2 of 0.9753 and an MAPE of 14.37%. The MAE is 45.05, the RMSE is 80.85, the A20 Index is 82.86%, the SI is 0.183, and the Agreement Index (d) is 0.9934, indicating a highly reliable model. The Deep Neural Network (DNN) (Fig. 4(e)) model also performs well, with training metrics of R2 = 0.9969 and MAPE = 9.09%. It maintains a respectable test R2 of 0.9635, though with a higher MAPE of 16.73%. Its A20 Index of 68.57% and SI of 0.223 indicate a significant number of predictions outside the acceptable margin.
Both Convolutional Neural Networks (CNN) (Fig. 4(f)) and Feedforward Neural Networks (FFNN) (Fig. 4(g)) exhibit strong performance. CNN, despite a lower training R2 of 0.9934 and a higher MAPE of 15.38%, achieves a good test R2 of 0.9624 and an MAPE of 22.06%. FFNN shows similar results, with a training R2 of 0.9941 and an MAPE of 10.75%, as well as a test R2 of 0.9673 and an MAPE of 22.33%. Lastly, the Recurrent Neural Network (RNN) (Fig. 4(h)) has a significantly lower training R2 of 0.9664 and a high MAPE of 19.48%. Its performance declines in testing as well, recording a test R2 of 0.9403 and a high MAPE of 26.21%, indicating it is less effective at this prediction task compared to the other models.
The ultimate bearing capacity predictions of footings by the proposed equations were compared with existing code formulas, including Terzaghi, Meyerhof, Vesić, Hansen, ECP, and EC7, for different types of footings in sand. Terzaghi (Fig. 5(a)), Meyerhof (Fig. 5(b)), Vesić (Fig. 5(c)), Hansen (Fig. 5(d)), ECP (Fig. 5(e)), and EC7 (Fig. 5(f)) exhibited comparatively the lowest values, with R2 values ranging from 0.684 to 0.82 and CC values from 0.9 to 0.921, respectively. These models also exhibited the highest errors (RMSE: 221.65 to 293.49 kN/m2, MAE: 115.88 to 142.84 kN/m2, MBE: − 23.08 to 116.30 kN/m2) with an MAPE of more than 19.63%.

Scatter plots between actual and predicted ultimate bearing capacity values based on (a) Terzaghi, (b) Meyerhof, (c) Vesić, (d) Hansen, (e) EC7, (f) ECP.
The analysis reveals that advanced models generally outperform traditional code formulas. Models such as GPR, XGBoost, GBM, DT, SVM, and ANN stand out as top performers, demonstrating excellent training and testing metrics. For instance, XGBoost achieves an exceptionally high training R2 of 0.9999 and a low MAPE of 0.65%, which translates to a robust test performance with an R2 of 0.9771 and an MAE of 42.62. Similarly, GPR and SVM also maintain high test R2 values of 0.972 and 0.9752, respectively, along with low error metrics and high A20 Index values, indicating reliability and strong generalization. In contrast, models like LightGBM, RNN, AdaBoost, and BR show a more significant performance drop from training to testing, with LightGBM recording a test R2 of 0.9277 and a high MAPE of 26.86%, while RNN’s performance declines to a test R2 of 0.9403 and a MAPE of 26.21%, indicating that a significant number of predictions fall outside the acceptable error margin. The traditional formulas, including those from Terzaghi, Meyerhof, Vesić, Hansen, ECP, and EC7, exhibit the weakest performance overall, with the lowest R2 values (ranging from 0.684 to 0.82) and the highest error metrics (RMSE from 221.65 to 293.49 and MAE from 115.88 to 142.84), confirming that ML and DL approaches are significantly more accurate for this task.
While the GPR, XGBoost, GBM, DT, and SVM models demonstrate notably better performance than other models, deriving a clear design formula from them is difficult. Although DL models can yield precise and explicit formulas for strength prediction, applying these networks in engineering design may be impractical because of the complex and lengthy formulas they produce100.
The regression error characteristics curve
Figure 6 presents the Regression Error Characteristics (REC) curve, which is used to evaluate the predictive robustness of the models during both the training and testing phases73,78. The curves illustrate the accuracy of each model in estimating the ultimate bearing capacity. In the training phase, shown in Fig. 6(a), XGBoost, GBM, and RF exhibited the highest predictive accuracy, with CATBoost and GPR following closely behind. In contrast, LightGBM demonstrated the weakest performance. During the testing phase, XGBoost and GBM maintained their position as the most accurate models. GPR, RF, and CATBoost performed similarly, while LightGBM again showed the least robust performance, indicating a consistent lack of reliability. As shown in Fig. 6(b) for the training phase, the KNN model achieved the highest predictive accuracy, followed closely by AdaBoost, SVM, and DT. The BR model, however, lagged with the poorest performance. In the testing phase, all models performed comparably, except for BR, which consistently displayed the lowest performance, indicating a persistent lack of robustness. In the training phase illustrated in Fig. 6(c), the ANN model produced the highest predictive accuracy, followed by DNN, then CNN and FFNN, while the RNN model exhibited the weakest performance. During the testing phase, all models performed similarly, except for RNN, which again showed the lowest performance, suggesting a continual lack of robustness in the RNN model. These results reinforce the findings previously presented.


REC curves illustrate the performance of the adopted models during the training and testing (a) GPR, XGBoost, LightGBM, GBM, RF, CATBoost; (b) AdaBoost, KNN, BR, DT, SVM; (c) ANN, DNN, CNN, RNN, FFNN.
Score analysis
The score analysis presents a detailed ranking of 16 machine learning algorithms based on their performance in both training and testing datasets, as illustrated in Fig. 7. For each algorithm, a composite score was calculated by summing its ranks across 16 key performance metrics (eight from the training set and eight from the testing set). These metrics include the Coefficient of Determination (R2), Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), Mean Bias Error (MBE), Root Mean Square Error (RMSE), A20 Index (A20), Scatter Index (SI), and Agreement Index (d). A higher total score indicates better overall performance. This analysis includes various performance metrics derived from the following 16 machine learning algorithms: GPR, XGBoost, LightGBM, GBM, RF, CATBoost, AdaBoost, KNN, BR, DT, SVM, ANN, DNN, CNN, RNN, and FFNN. The final score for each algorithm reflects the sum of its ranks across all 16 metrics.

Score analysis indicates the performance of 16 ML and DL models.
The Gradient Boosting Machine (GBM) emerged as the top performer, excelling in both the training and testing datasets with a score of 225. XGBoost and Gradient Boosting Regression (GPR) closely followed in second and third places, with scores of 216 and 203, respectively. These models demonstrated strong robustness and excellent generalization capabilities for new, unseen data. In contrast, the Recurrent Neural Network (RNN), with a score of 21, and LightGBM, with a score of 39, experienced significant drops in performance from the training to the testing phase, indicating potential overfitting issues.
The ranking methodology adhered to several key principles. Each of the eight performance metrics was evaluated based on its ideal value (higher R2), while lower RMSE values are desirable. For the Mean Bias Error (MBE), which can take both positive and negative values, models were ranked according to the absolute values of their scores to ensure fairness between over-prediction and under-prediction biases. Additionally, a two-step sorting process was employed to break ties: first by metric value and then alphabetically by the algorithm’s name. An algorithm’s performance on the training dataset reflects its ability to learn effectively from the data provided. The ranks for each algorithm across the eight metrics for both training and testing sets ranged from 16 (best) to 1 (worst).
This analysis provided valuable insights into model behavior. A clear distinction emerged between models that merely memorized the training data and those that generalized effectively. Models that exhibited significant declines in performance from training to testing displayed signs of overfitting. The top three algorithms, GBM (225), XGBoost (216), and GPR (203), consistently performed well across both datasets, making them the most reliable choices for predictive tasks. The results are consistent with the previous findings.
Performance assessment via Taylor diagram
Using a Taylor diagram (Fig. 8), the study compared machine learning, deep learning models, and traditional equations to experimental footing bearing capacity, evaluating normalized standard deviation, Correlation Coefficient (CC), and Normalized Root Mean Square Error (NRMSE). The machine and deep learning models consistently outperformed the traditional equations. Specifically, they demonstrated high CC values (mostly > 0.99), low NRMSE (mostly < 0.13), and normalized standard deviations exceeding 0.95, while the traditional equations showed lower CC (~ 0.9), higher NRMSE (~ 0.5), and lower normalized standard deviations (~ 0.65). LightGBM and RNN exhibited slightly lower performance within the machine learning models. As observed, XGBoost and GBM models demonstrated slightly better overall prediction accuracy than the other models.

Taylor diagram indicating the performance of 23 models.
Feature importance analysis
To explore how input parameters influence the ultimate bearing capacity of footings with different shapes on cohesionless soil, this study utilized Shapley Additive Explanation (SHAP) analysis. Figure 9(a, f) present the SHAP analysis for GBM and XGBoost models. Specifically, Fig. 9(a, b) summarize the effects and relative importance of each feature on the model’s bearing capacity predictions. Figure 9(c, d) present the SHAP feature importance for each input variable, where positive values indicate a positive correlation with bearing capacity and negative values a negative correlation. Figure 9(e, f) feature SHAP decision plots that illustrate the intricate decision-making processes of these machine learning models, offering insights into the global prediction behavior depicted in the summary plots. Analysis of the SHAP features reveals a high degree of similarity between the GBM and XGBoost models. Foundation depth is the most important design parameter, with the angle of internal friction having a significant impact, followed by soil unit weight and foundation width. In contrast, the length-to-width ratio has the least impact.

SHAP decision plots for footings database.
The relationships identified by the machine learning models are consistent with established engineering principles, reinforcing their value as tools for improving design intuition and practical decision-making. For example, the positive correlation between foundation depth and ultimate bearing capacity aligns with geotechnical theory, as greater foundation depth inherently supports a higher ultimate bearing capacity before failure. Similarly, the effects of the angle of internal friction and soil unit weight on ultimate bearing capacity predictions are well recognized within geotechnical engineering. The significant role of foundation dimensions (width and length-to-width ratio) in these predictions underscores their importance in enhancing load resistance and reducing footing settlement, a concept well understood in geotechnical engineering. The insights generated by the model regarding these relationships improve interpretability and provide geotechnical engineers with a deeper understanding of how individual parameters affect geotechnical behaviour, ensuring that the model functions as a valuable tool that connects advanced computation with fundamental engineering principles.
Conclusions
In this study, we evaluated the performance of various machine learning (ML) and deep learning (DL) models for predicting the ultimate bearing capacity (qu) of shallow foundations in cohesionless soil using a dataset of 116 footing experiments. The dataset comprised 64 small-scale and 52 large-scale experiments. The following are the key findings and contributions of this research.
Results demonstrate that advanced ML and DL models are significantly superior to traditional theoretical equations (Terzaghi, Meyerhof, Vesić, Hansen, ECP, EC7), consistently providing predictions that align closely with experimental data. Ensemble methods like XGBoost and GBM emerged as the top performers, with XGBoost showing the highest test R2 (0.9771) and the lowest prediction errors, while GBM achieved the lowest test MAPE (10.65%) and the highest A20 Index (88.57%). The SHAP analysis reinforced these findings by revealing that foundation depth (D) was the most influential parameter, which aligns with established geotechnical principles. This consistency enhances the models’ interpretability and trustworthiness for engineering applications.
This research is primarily based on a dataset that, while including large-scale experiments, is still limited in its overall size and diversity. The performance of the developed models is highly dependent on the quality and representativeness of the specific data used. Consequently, their effectiveness may vary when applied to different data or conditions outside the scope of this study, and the models’ generalizability needs to be further assessed.
The primary advantage of this study is the significant improvement in the accuracy and reliability of predicting shallow foundation bearing capacity compared to conventional methods. The use of explainable AI techniques like SHAP analysis provides valuable insights into the relationships between input parameters and the models’ predictions, bridging the gap between advanced computational methods and fundamental engineering understanding. Furthermore, making the developed Python tool available upon request will facilitate the reproduction of our methodology and support future research in the field.
To validate and broaden the applicability of these findings, future research should focus on a few key areas. First, it is essential to validate these models using full-scale experimental data. Second, expanding the dataset with more extensive and diverse experimental data will enhance the reliability and generalizability of the models. Finally, exploring more advanced feature engineering techniques and continuing to improve the interpretability of complex models are promising avenues for future work.101,102,103
Data availability
All data supporting the findings of this study are available from the corresponding author upon reasonable request.
Abbreviations
- AI :
-
Artificial intelligence
- ML :
-
Machine learning
- DL :
-
Deep learning
- SHAP :
-
SHapley additive exPlanations
- GPR :
-
Gaussian process regressor
- XGBoost :
-
Extreme gradient boost machine
- LGBM :
-
Light gradient boosting machine
- GBM :
-
Gradient boosting machine
- RF :
-
Random forest regressor
- CatBoost :
-
Categorical boosting
- AdaBoost :
-
Ada boost regressor
- KNN :
-
K-Nearest neighbors regression
- BR :
-
Bagging regressor (Bootstrap aggregating)
- DT :
-
Decision tree regressor
- SVR :
-
Support vector machine
- ANN :
-
Artificial neural network (MLP)
- DNN :
-
Deep neural network
- CNN :
-
Convolutional neural network
- FFNN :
-
Feed forward neural network
- RNN :
-
Recurrent neural networks
- R 2 :
-
Coefficient of determination
- MAPE :
-
Mean absolute percentage error
- MBE :
-
Mean bias error
- MAE :
-
Mean absolute error
- RMSE :
-
Root mean square error
- NRMSE :
-
Normalized root mean square error
- CC :
-
Correlation coefficient
- A20:
-
A20 Index
- SI :
-
Scatter Index
- d :
-
Agreement Index
- q u :
-
Ultimate bearing capacity
- c :
-
Soil cohesion
- \(\gamma\) :
-
Effective unit weight of the soil
- B :
-
Footing width
- L :
-
Footing length
- D :
-
Foundation depth
- \({N}_{c}\), \({N}_{q}\), \({N}_{\gamma }\) :
-
Non-dimensional bearing capacity factors
- \(\varphi\) :
-
Internal friction angle
- \({s}_{c}\), \({s}_{q}\), \({s}_{\gamma }\) :
-
Non-dimensional shape factors
- \({d}_{c}\), \({d}_{q}\), \({d}_{\gamma }\) :
-
Non-dimensional depth factors
- \({K}_{p}\) :
-
Passive earth pressure
References
Terzaghi K (1943) Theoretical soil mechanics. Wiley, Hoboken. 10.1002%2F9780470172766
Meyerhof, G. G. Some recent research on the bearing capacity of foundations. Can. Geotech. J. 1(1), 16–26 (1963).
Hansen JB (1970) A revised and extended formula for bearing capacity. Geoteknisk Institut, Copenhagen.
Vesić, A. S. Analysis of ultimate loads of shallow foundations. J. Soil Mech. Found Div. 99(1), 45–73. https://doi.org/10.1061/JSFEAQ.0001846 (1973).
Egyptian Code for Soil mechanics (ECP 202) (2001) Design and implementation of foundations-part four: deep foundations. The National Center for Housing and Building Research, Cairo.
EN 1997–1:2003 (2003) Eurocode 7 geotechnical design-Part 1: general rules.
Das, B. & Sivakugan, N. Principles of foundation engineering 9th edn. (Cengage learning, 2019).
Padmini, D., Ilamparuthi, K. & Sudheer, K. Ultimate bearing capacity prediction of shallow foundations on cohesionless soils using neurofuzzy models. Comput. Geotech. 35(1), 33–46. https://doi.org/10.1016/j.compgeo.2007.03.001 (2008).
Acharyya, R. Finite element investigation and ANN-based prediction of the bearing capacity of strip footings resting on sloping ground. Int. J. Geo.Eng. 10(1), 5. https://doi.org/10.1186/s40703-019-0100-z (2019).
Ebid, A. M., Onyelowe, K. C. & Salah, M. Estimation of bearing capacity of strip footing rested on bilayered soil profile using FEM-AI-coupled techniques. Adv. Civ. Eng. 2022, 804755. https://doi.org/10.1155/2022/8047559 (2022).
Zhang, W., Gu, X. & Ou, Q. Bearing capacity and failure mechanism of strip footings lying on slopes subjected to various rainfall patterns and intensities. Geol. J. https://doi.org/10.1002/gj.4882 (2023).
Al-Atroush, M., Aboelela, A. & Hemdan, E. Beyond p-y method: A review of artificial intelligence approaches for predicting lateral capacity of drilled shafts in clayey soils. J. Rock Mech. Geotech. Eng. 16(9), 3812–3840. https://doi.org/10.1016/j.jrmge.2024.03.017 (2024).
El Gendy, M. Reliable prediction of bored pile load-settlement response using machine learning and Monte Carlo simulations. Geotech. Geol. Eng. https://doi.org/10.1007/s10706-025-03397-4 (2025).
Mohanty, R., Suman, S. & Das, S. K. Prediction of vertical pile capacity of driven pile in cohesionless soil using artificial intelligence techniques. Int. J. Geotech. Eng. 12(2), 209–216 (2018).
Pham, T. & Tran, V. Developing random forest hybridization models for estimating the axial bearing capacity of pile. PLoS ONE 17(3), 0265747. https://doi.org/10.1371/journal.pone.0265747 (2022).
Suman, S., Choudhary, S. & Burman, A. Risk analysis of pile foundations using an improved hybrid ensemble paradigm coupled with Monte Carlo and subset simulations. Transp. Infrastruct. Geotech. 12, 117. https://doi.org/10.1007/s40515-025-00569-w (2025).
Alzabeebee, S., Alshkane, Y. & Keawsawasvong, S. New model to predict bearing capacity of shallow foundations resting on cohesionless soil. Geotech. Geol. Eng. 41, 3531–3547. https://doi.org/10.1007/s10706-023-02472-y (2023).
Mohammed, M., Sharafati, A., Al-Ansari, N. & Yaseen, Z. M. Shallow foundation settlement quantification: Application of hybridized adaptive neuro-fuzzy inference system model. Adv. Civ. Eng. 2020, 1–14 (2020).
Ray, R. et al. Application of soft computing techniques for shallow foundation reliability in geotechnical engineering. Geosci. Front. 12(1), 375–383. https://doi.org/10.1016/j.gsf.2020.05.003 (2021).
Samui, P. Support vector machine applied to settlement of shallow foundations on cohesionless soils. Comput. Geotech. 35(3), 419–427. https://doi.org/10.1016/j.compgeo.2007.06.014 (2008).
Shahin, M. A. A review of artificial intelligence applications in shallow foundations. Int. J. Geotech. Eng. 9(1), 49–60. https://doi.org/10.1179/1939787914Y.0000000058 (2015).
Zhang, R. & Xue, X. Determining ultimate bearing capacity of shallow foundations by using multi expression programming (MEP). Eng. Appl. Artif. Intell. 115, 105255. https://doi.org/10.1016/j.engappai.2022.105255 (2022).
Ali, M. & Lai, S. H. Artificial intelligent techniques for prediction of rock strength and deformation properties–A review. Structures. 55, 1542–1555. https://doi.org/10.1016/j.istruc.2023.06.131 (2023).
Mahmoodzadeh, A. et al. Machine learning techniques to predict rock strength parameters. Rock Mech. Rock Eng. 55(3), 1721–1741. https://doi.org/10.1007/s00603-021-02747-x (2022).
Khajehzadeh, M., Taha, M. R., Keawsawasvong, S., Mirzaei, H. & Jebeli, M. An effective artificial intelligence approach for slope stability evaluation. IEEE Access 10, 5660–5671. https://doi.org/10.1109/ACCESS.2022.3141432 (2022).
Lin, S., Zheng, H., Han, C., Han, B. & Li, W. Evaluation and prediction of slope stability using machine learning approaches. Front. Struct. Civ. Eng. 15(4), 821–833. https://doi.org/10.1007/s11709-021-0742-8 (2021).
Ly, H.-B., Nguyen, T.-A. & Pham, B. T. Estimation of soil cohesion using machine learning method: A random forest approach. Adv. Civ. Eng. 2021, 1–14 (2021).
Pham, B. T., Hoang, T.-A., Nguyen, D.-M. & Bui, D. T. Prediction of shear strength of soft soil using machine learning methods. CATENA 166, 181–191. https://doi.org/10.1016/j.catena.2018.04.004 (2018).
Zhang, W., Wu, C., Zhong, H., Li, Y. & Wang, L. Prediction of undrained shear strength using extreme gradient boosting and random forest based on bayesian optimization. Geosci. Front. 12(1), 469–477. https://doi.org/10.1016/.gsf.2020.03.007 (2021).
Fang, Z., Wang, Y., Peng, L. & Hong, H. Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping. Comput. Geosci. 139, 104470. https://doi.org/10.1016/j.cageo.2020.104470 (2020).
Wang, H., Zhang, L., Yin, K., Luo, H. & Li, J. Landslide identification using machine learning. Geosci. Front. 12(1), 351–364. https://doi.org/10.1016/j.gsf.2020.02.012 (2021).
Jitchaijaroen, W. et al. Machine learning approaches for stability prediction of rectangular tunnels in natural clays based on MLP and RBF neural networks. Intell. Syst. Appl. 21, 200329 (2024).
Zhang, P., Wu, H.-N., Chen, R.-P. & Chan, T. H. Hybrid meta-heuristic and machine learning algorithms for tunneling-induced settlement prediction: a comparative study. Tunn. Undergr. Space Technol. 99, 103383. https://doi.org/10.1016/j.tust.2020.103383 (2020).
Kumar, D., Samui, P., Kim, D. & Singh, A. A novel methodology to classify soil liquefaction using deep learning. Geotech. Geol. Eng. 39, 1049–1058. https://doi.org/10.1007/s10706-020-01544-7 (2021).
Ozsagir, M., Erden, C., Bol, E., Sert, S. & Özocak, A. Machine learning approaches for prediction of fine-grained soils liquefaction. Comput. Geotech. 152, 105014. https://doi.org/10.1016/j.compgeo.2022.105014 (2022).
Baghbani, A., Choudhury, T., Costa, S. & Reiner, J. Application of artificial intelligence in geotechnical engineering: A state-of-the-art review. Earth Sci. Rev. 228, 103991. https://doi.org/10.1016/j.earscirev.2022.103991 (2022).
Fatehnia, M. & Amirinia, G. A review of genetic programming and artificial neural network applications in pile foundations. Int. J. Geo.-Eng. 9(1), 2. https://doi.org/10.1186/s40703-017-0067-6 (2018).
Khajehzadeh, M. & Keawsawasvong, S. Artificial intelligence for bearing capacity evaluation of shallow foundation: An Overview. Geotech. Geol. Eng. 42, 5401–5424. https://doi.org/10.1007/s10706-024-02863-9 (2024).
Phoon, K. K. Z. & W.,. Future of machine learning in geotechnics. Georisk. Assess Manage. Risk Eng. Syst. Geohazards 17, 7–22 (2023).
Zhang, W. et al. Application of machine learning, deep learning and optimization algorithms in geoengineering and geoscience: Comprehensive review and future challenge. Gondwana Res. 109, 1–17. https://doi.org/10.1016/j.gr.2022.03.015 (2022).
Zhang, W. et al. Application of deep learning algorithms in geotechnical engineering: A short critical review. Artif. Intell. Rev. 54, 1–41. https://doi.org/10.1007/s10462-021-09967-1 (2021).
Dehghanbanadaki, A. & Motamedi, S. Bearing capacity prediction of shallow foundation on sandy soils: A comparative study of analytical, FEM, and machine learning approaches. Multiscale Multidiscip. Model Exper. Des. 7, 1–18 (2023).
Keawsawasvong, S. et al. Soft Computing-based models for estimating the ultimate bearing capacity of an annular footing on Hoek-Brown material. Arab. J. Sci. Eng. 49, 5989–6006. https://doi.org/10.1007/s13369-023-08588-w (2023).
Singh, S. P. & Roy, A. K. Machine learning techniques to predict the dimensionless bearing capacity of circular footing on layered sand under inclined loads. Multiscale Multidiscip. Model Exp. Des. 6, 579–590. https://doi.org/10.1007/s41939-023-00176-7 (2023).
Bagińska, M. & Srokosz, P. E. The optimal ANN Model for predicting bearing capacity of shallow foundations trained on scarce data. KSCE J. Civ. Eng. 23, 130–137. https://doi.org/10.1007/s12205-018-2636-4 (2019).
Lai, V. Q., Shiau, J., Van, C. N., Tran, H. D. & Keawsawasvong, S. Bearing capacity of conical footing on anisotropic and heterogeneous clays using FEA and ANN. Mar. Geores. Geotechnol. 41(9), 1053–1070. https://doi.org/10.1080/1064119X.2022.2113485 (2023).
Li, H. et al. Dimensionless machine learning: Dimensional analysis to improve LSSVM and ANN models and predict bearing capacity of circular foundations. Artif. Intell. Rev. 58, 117. https://doi.org/10.1007/s10462-024-11099-1 (2025).
Omar, M., Hamad, K., Al Suwaidi, M. & Shanableh, A. Developing artificial neural network models to predict allowable bearing capacity and elastic settlement of shallow foundation in Sharjah, United Arab Emirates. Arab. J. Geosci. 11, 1–11. https://doi.org/10.1007/s12517-018-3828-4 (2018).
Rezaei, H., Nazir, R. & Momeni, E. Bearing capacity of thin-walled shallow foundations: An experimental and artificial intelligence-based study. J. Zhejiang Univ.Sci. A 4(17), 273–285. https://doi.org/10.1631/jzus.A1500033 (2016).
Sahu, R., Patra, C., Sivakugan, N. & Das, B. Use of ANN and neuro fuzzy model to predict bearing capacity factor of strip footing resting on reinforced sand and subjected to inclined loading. Int. J. Geosynth. Ground Eng. 3, 1–15. https://doi.org/10.1007/s40891-017-0102-x (2017).
Tran, D. T., Tran, M. N., Lai, V. Q. & Keawsawasvong, S. Advanced FELA-ANN framework for developing 3D failure envelopes for strip foundations on anisotropic clays. Model Earth Syst. Environ. 10, 2375–2392. https://doi.org/10.1007/s40808-023-01906-z (2023).
Cabalar, A. F., Cevik, A. & Gokceoglu, C. Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput. Geotech. 40, 14–33. https://doi.org/10.1016/j.compgeo.2011.09.008 (2012).
Jahed Armaghani, D., Harandizadeh, H. & Momeni, E. Load carrying capacity assessment of thin-walled foundations: An ANFIS–PNN model optimized by genetic algorithm. Eng. Comput. 38, 4073–4095. https://doi.org/10.1007/s00366-021-01380-0 (2022).
Momeni, E., Armaghani, D. J., Fatemi, S. A. & Nazir, R. Prediction of bearing capacity of thin-walled foundation: A simulation approach. Eng. Comput. 34, 319–327. https://doi.org/10.1007/s00366-017-0542-x (2018).
Hataf, N. & Beygi, M. Seismic bearing capacity of strip footing placed on sand layer over Hoek-Brown media using finite element limit analysis and machine learning approach. Trans. Infrastruct. Geotechnol. 11, 406–425. https://doi.org/10.1007/s40515-023-00288-0 (2023).
Hataf, N. & Beygi, M. Seismic bearing capacity of strip footing placed on sand layer over Hoek-Brown media using finite element limit analysis and machine learning approach. Transp. Infrastruct. Geotechnol. 11(1), 406–425. https://doi.org/10.1007/s40515-023-00288-0 (2024).
Pham, T. A., Vu, H.-L.T. & Duong, H.-A.T. Improving deep neural network using hyper-parameters tuning in predicting the bearing capacity of shallow foundations. J. Appl. Sci. Eng. 25(2), 261–273 (2021).
Vali, R. et al. Developing a novel big dataset and a deep neural network to predict the bearing capacity of a ring footing. J. Rock Mech. Geotech. Eng. https://doi.org/10.1016/j.jrmge.2024.02.016 (2024).
Mustafa, R., Samui, P., Kumari, S. & Armaghani, D. J. Appraisal of numerous machine learning techniques for the prediction of bearing capacity of strip footings subjected to inclined loading. Model Earth Syst. Environ. 10, 1–22. https://doi.org/10.1007/s40808-024-02008-0 (2024).
Shen, F. et al. Advanced predictive machine and deep learning models for round-ended CFST column. Sci. Rep. 15, 6194. https://doi.org/10.1038/s41598-025-90648-2 (2025).
Shan, F., He, X., Armaghani, D. J. & Sheng, D. Effects of data smoothing and recurrent neural network (RNN) algorithms for real-time forecasting of tunnel boring machine (TBM) performance. J. Rock Mech. Geotech. Eng. 16(5), 1538–1551. https://doi.org/10.1016/j.jrmge.2023.06.015 (2024).
Narmandakh, D. et al. The use of feed-forward and cascade-forward neural networks to determine swelling potential of clayey soils. Comput. Geotech. 157, 105319. https://doi.org/10.1016/j.compgeo.2023.105319 (2023).
Taherdangkoo, R. et al. An efficient neural network model to determine maximum swelling pressure of clayey soils. Comput. Geotech. 162, 105693. https://doi.org/10.1016/j.compgeo.2023.105693 (2023).
Khatti, J., Grover, K. S., Kim, H.-J., Mawuntu, K. B. A. & Park, T.-W. Prediction of ultimate bearing capacity of shallow foundations on cohesionless soil using hybrid lstm and rvm approaches: an extended investigation of multicollinearity. Comput. Geotech. 165, 105912. https://doi.org/10.1016/j.compgeo.2023.105912 (2024).
Roy, N. & Shree, K. Machine learning prediction tool for seismic bearing capacity of strip footings in rock mass. Transp. Infrastruct. Geotechnol. 11(2), 900–919. https://doi.org/10.1007/s40515-023-00312-3 (2024).
Kumar, D. R. et al. Machine learning approaches for prediction of the bearing capacity of ring foundations on rock masses. Earth Sci. Inf. 16, 4153–4168. https://doi.org/10.1007/s12145-023-01152-y (2023).
Xue, X. & Chen, X. Determination of ultimate bearing capacity of shallow foundations using LSSVM algorithm. J. Civ. Eng. Manag. 25(5), 451–459. https://doi.org/10.3846/jcem.2019.9875 (2019).
Dutta, R. K., Gnananandarao, T. & Sharma, A. Application of random forest regression in the prediction of ultimate bearing capacity of strip footing resting on dense sand overlying loose sand deposit. J. Soft Comput. Civ. Eng. 3(4), 28–40 (2019).
Khatti, J. & Grover, S. Estimation of uniaxial strength of rock: A comparison between bayesian-optimized machine learning models. Min. Metall. Explor. 42, 133–154. https://doi.org/10.1007/s42461-024-01168-y (2025).
Ahmad, M. et al. Prediction of ultimate bearing capacity of shallow foundations on cohesionless soils: A gaussian process regression approach. Appl. Sci. 11(21), 10317. https://doi.org/10.3390/app112110317 (2021).
Khatti, J., Muhmed, A. & Grover, S. Dimensionality analysis in assessing the unconfined strength of lime-treated soil using machine learning approaches. Earth Sci. Inform. 18, 234. https://doi.org/10.1007/s12145-025-01731-1 (2025).
Jangid, A., Khatti, J. & Grover, K. Effect of multicollinearity in assessing the compaction and strength parameters of lime-treated expansive soil using artificial intelligence techniques. Multiscale Multidiscip. Model Exp. Des. 8, 68. https://doi.org/10.1007/s41939-024-00590-5 (2025).
Khatti, J. & Grover, S. Assessment of uniaxial strength of rocks: A critical comparison between evolutionary and swarm optimized relevance vector machine models. Transp. Infrastruct. Geotech. 11, 4098–4141. https://doi.org/10.1007/s40515-024-00433-3 (2024).
Daniel, C. A robust LightGBM model for concrete tensile strength forecast to aid in resilience-based structure strategies. Heliyon 10(20), 39679. https://doi.org/10.1016/j.heliyon.2024.e39679 (2024).
Zhou, Y., Wang, W., Wang, K. & Song, J. Application of lightGBM algorithm in the initial design of a library in the cold area of China based on comprehensive performance. Buildings 12(9), 1309. https://doi.org/10.3390/buildings12091309 (2022).
Sharafati, A., Asadollah, S. B. H. S. & Al-Ansari, N. Application of bagging ensemble model for predicting compressive strength of hollow concrete masonry prism. Ain Shams Eng. J. 12(4), 3521–3530. https://doi.org/10.1016/j.asej.2021.03.028 (2021).
Elshaarawy, M. & Hamed, A. Machine learning and interactive GUI for estimating roller length of hydraulic jumps. Neural Comput. Appl. 37, 4247–4276. https://doi.org/10.1007/s00521-024-10846-3 (2025).
Elshaarawy, M., Zeleňáková, M. & Armanuos, A. Hydraulic performance modeling of inclined double cutoff walls beneath hydraulic structures using optimized ensemble machine learning. Sci. Rep. 15, 27592. https://doi.org/10.1038/s41598-025-10990-3 (2025).
Ghanizadeh, A. R., Amlashi, A. T. & Dessouky, S. A novel hybrid adaptive boosting approach for evaluating properties of sustainable materials: A case of concrete containing waste foundry sand. J. Build. Eng. 72, 106595. https://doi.org/10.1016/j.jobe.2023.106595 (2023).
Elshaarawy, M. & Eltarabily, M. Machine learning models for predicting water quality index: Optimization and performance analysis for El Moghra. Egypt. Water Supply 24(9), 3269–3294. https://doi.org/10.2166/ws.2024.189 (2024).
Sultana, P., Dey, A. K. & Kumar, D. Empirical approach for prediction of bearing pressure of spread footings on clayey soil using artificial intelligence (AI) techniques. Res. Eng. 15, 100489. https://doi.org/10.1016/j.rineng.2022.100489 (2022).
Lai, V. Q. et al. Application of ANN and FELA for predicting bearing capacity of shell foundations on sand. Int. J. Geosynth. Ground Eng. 9(2), 18. https://doi.org/10.1007/s40891-023-00437-y (2023).
Lawal, A. I. & Kwon, S. Development of mathematically motivated hybrid soft computing models for improved predictions of ultimate bearing capacity of shallow foundations. J. Rock Mech. Geotech. Eng. 15(3), 747–759. https://doi.org/10.1016/j.jrmge.2022.04.005 (2023).
Nguyen, D. K., Nguyen, T. P., Ngamkhanong, C., Keawsawasvong, S. & Lai, V. Q. Bearing capacity of ring footings in anisotropic clays: FELA and ANN. Neural Comput. Appl. 35, 10975–10996. https://doi.org/10.1007/s00521-023-08278-6 (2023).
Kumar, M. et al. Prediction of bearing capacity of pile foundation using deep learning approaches. Front. Struct. Civ. Eng. 18, 870–886. https://doi.org/10.1007/s11709-024-1085-z (2024).
Prandtl, L. On the penetrating strengths (hardness) of plastic construction materials and the strength of cutting edges. ZAMM J. Appl. Math. Mech. 1, 15–20. https://doi.org/10.1002/zamm.19210010102 (1921).
Cerato, A. B. & Lutenegger, A. J. Scale effects of shallow foundation bearing capacity on granular material. J. Geotech. Geoenviron. Eng. 133, 1192–1202. https://doi.org/10.1061/(ASCE)1090-0241(2007)133:10(1192) (2007).
Kalinli, A., Acar, M. & Gunduz, Z. New approaches to determine the ultimate bearing capacity of shallow foundations based on artificial neural networks and ant colony optimization. Eng. Geol. 117, 29–38. https://doi.org/10.1016/j.enggeo.2010.10.002 (2011).
Fissha, Y. et al. Predicting ground vibration during rock blasting using relevance vector machine improved with dual kernels and metaheuristic algorithms. Sci. Rep. 14, 20026. https://doi.org/10.1038/s41598-024-70939-w (2024).
Golder, H. et al. The ultimate bearing pressure of rectangular footings. J. Inst. Civ. Eng. 17, 161–174. https://doi.org/10.1680/ijoti.1941.13728 (1941).
Eastwood, W. A comparison of the bearing power of footings on dry and inundated sand. Struct. Eng. Inst. Struct. Eng. Lond. 29, 1–11 (1951).
Subrahmanyam, G. The effect of roughness of footings on bearing capacity. J. Int. Soc. Soil Mech. Found Eng. 6, 33–45 (1967).
Muhs, H., Elmiger, R. & Weiß, K. Sohlreibung und Grenztragfähigkeit unter lotrecht und schräg belasteten Einzelfundamenten. Ernst. (1969).
Weiß K (1970) Der Einfluss der Fundamentform auf die Grenztragfähigkeit flachgegründeter Fundamente. Ernst.
Muhs H (1971) Untersuchungen des Setzungsverhaltens und der Grenztragfähigkeit von flachgegründeten Fundamenten in grobkörnigen Sanden. Ernst.
Muhs H, Weiß K (1973) Inclined load tests on shallow strip footings. In: Proceedings of the 8th international conference on soil mechanics and foundation engineering, II, pp. 173–179
Briaud, J.-L. & Gibbens, R. Large scale load tests and data base of spread footings on sand. Publ. No. FHWA-RD-97–068 (Federal Highway Administration, 1997).
Briaud, J.-L. & Gibbens, R. Behavior of five large spread footings in sand. J. Geotech. Geoenviron. Eng. 125, 787–796. https://doi.org/10.1061/(ASCE)1090-0241(1999)125:9(787) (1999).
Gandhi G (2003) Study of bearing capacity factors developed from lab. Experiments on shallow footings on cohesionless soils. PhD thesis, Shri GS Institute of Technology and Science, Indore.
Megahed, K., Mahmoud, N. S. & Abd-Rabou, S. E. M. Prediction of the axial compression capacity of stub CFST columns using machine learning techniques. Sci. Rep. 14, 2885. https://doi.org/10.1038/s41598-024-53352-1 (2024).
Ding, X., Deng, X., Ou, Q. & Deng, W. Experimental study on the behavior of single pile foundation under vertical cyclic load in coral sand. Ocean Eng. 280, 114672. https://doi.org/10.1016/j.oceaneng.2023.114672 (2023).
Gandhi GN (2001) Study of bearing capacity factors developed from laboratory experiments on shallow footings founded on cohesionless soil. PhD Thesis, Shri G.S. Institute of Tech and Science, India.
Luo, Z.-g, Ding, X.-m, Ou, Q. & Fang, H.-q. Bearing capacity and deformation behavior of rigid strip footings on coral sand slopes. Ocean Eng. 267, 113317. https://doi.org/10.1016/j.oceaneng.2022.113317 (2023).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooper ation with The Egyptian Knowledge Bank (EKB). The authors declare that they did not receive any funding or grants for this study.
Author information
Authors and Affiliations
Contributions
M. El Gendy: investigation, methodology, formal analysis, writing-original draft, methodology, formal analysis, writing-review & editing, supervision, validation, reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
El Gendy, M. A comparative machine and deep learning approach for predicting ultimate bearing capacity of shallow foundations in cohesionless soil. Sci Rep 15, 40402 (2025). https://doi.org/10.1038/s41598-025-22812-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-22812-7
