
Abstract
We propose a neural network (NN)-based surrogate modeling framework for photonic device optimization, especially in domains with imbalanced feature importance and high data generation costs. Our framework, which comprises physics-based transfer learning (PBTL)-enhanced surrogate modeling and scalarized multi-objective genetic algorithms (GAs), offers a generalizable solution for photonic design automation with minimal data resources. To validate the framework, we optimize quantum cascade laser (QCL) structures consisting of two regions: active and injection, which have different levels of feature importance. The optimization targets include five key QCL performance metrics, resulting in multiple local optimum structures. To address the challenge of multiple local optima in the output latent space, we integrate a deep neural network total predictor (DNN-TP) with a GA. By replacing computationally expensive numerical simulations with the DNN-TP model, the optimization achieves a speed-up of over 80,000 times, allowing large-scale exploration of the design space. To improve model generalization with limited data, we introduce PBTL, which transfers knowledge from a DNN core predictor (DNN-CP) trained on active-region structures. This approach yields a 0.69% increase in prediction accuracy, equivalent to a 50% reduction in training data requirements, and leads to generate more feasible device structure with 60% improvement in evaluation metric during optimization.
Similar content being viewed by others


Introduction
The recent advancement of artificial intelligence (AI) has significantly accelerated the design and optimization processes across various photonic systems. Deep neural networks (DNNs) have shown remarkable capability in capturing the complex nonlinear relationship between input parameters and output responses. As a result, there is growing consensus that DNNs are well-suited for modeling and optimizing photonic architectures, enabling both forward prediction and inverse design of system behavior1,2,3,4.
Quantum cascade lasers (QCLs) represent one of the most challenging classes of photonic devices to optimize due to their highly sensitive, quantum-scale structural dependencies. Typically comprising 20–30 alternating quantum wells and barriers with nanometer or sub-nanometer precision, the energy states and wave-functions in QCLs are strongly influenced by the thickness of each layer. This, in turn, affects critical device characteristics such as emission wavelength, longitudinal optical (LO) phonon scattering, and interface roughness scattering5,6,7,8. Predicting this behavior generally requires solving the Schrödinger equation, which is computationally intensive.
Metaheuristic algorithms such as genetic algorithm (GA) and particle swarm optimization have been widely used to optimize QCL structures under specific performance constraints9,10,11,12. GAs mimic the natural evolutionary process, exploring a wide range of structural candidates and often yielding a variety of valid design solutions. However, due to the need to evaluate a large population of candidate structures over hundreds of generations, these methods become prohibitively expensive when paired with traditional physics-based simulators. Moreover, given the multi-modal nature of QCL performance metrics such as modal gain, emission wavelength, and energy level alignment, the objective function landscape often contains numerous local optima. Escaping these local optima requires increasing the population size, which further exacerbates the computational burden.
To address this issue, we propose to replace the conventional numerical simulator with a DNN-based surrogate model that significantly reduces the computational cost of optimization. By training the surrogate model on data generated from the Schrödinger equation, we construct a virtual environment that approximates the quantum behavior of QCLs. Integrating this surrogate model into the GA framework allows us to efficiently explore the vast design space (with over 10¹⁵ possible configurations) while preserving the natural evolutionary dynamics of the optimization process. Owing to its simplicity and high parallelizability, the surrogate-based GA achieves a speedup of 80,000 times over conventional approaches.
However, training an accurate surrogate model generally requires a large number of labeled databases that become increasingly challenging in high dimensional design spaces. To mitigate this, we propose a novel transfer learning approach of so-called physics-based transfer learning (PBTL) that leverages domain-specific knowledge about QCL operation. Unlike generic transfer learning (GTL) methods13,14, PBTL utilizes a pre-trained model that captures the essential physical behavior of QCLs in a reduced latent space. This knowledge is then transferred to the target model, improving learning efficiency without sacrificing physical interpretability.
In this work, we present efficient training methodologies for DNN surrogate model of photonic device, which is governed by Schrödinger equation. By applying domain knowledge of the devices, we first developed a surrogate model of a DNN core predictor (DNN-CP) trained on active-region structures, which has high representation for core QCL functionality. Then, two different transfer approaches of PBTL and GTL methodologies are applied to obtain a high quality of a DNN total predictor (DNN-TP) trained on active and injector regions of the QCL. The PBTL ensemble surrogate model has higher accuracy and showed high optimization success ratio compared to GTL ensemble model. In addition, we demonstrate that our surrogate-assisted GA can discover novel QCL structures that satisfy multi-objective constraints much faster than conventional methods.
Methods
Figure 1a illustrates the overall flowchart of the proposed method. The process begins with the generation of a training dataset by solving the Schrödinger equation using numerical algorithms. The input features for the training dataset are the thickness values of 24 superlattice layers in a QCL structure. The output features include the peak emission wavelength (λ), maximum modal gain (G₄₃), homogeneous broadening linewidth (Γ), effective injection energy (Einj), and effective extraction energy (Eext). The five output features are strongly correlated with a specific superlattice region, particularly the injection and active regions. Figure 1b shows the spatial regions and their associated energy levels and wave functions of the QCL structure. By computing energy level differences between wave functions, we can define key modalities such as the emission wavelength, effective injection and extraction energy. Additionally, the optical modal gain spectrum is calculated using the eigenvalues and eigenfunctions obtained from the Schrödinger equation. Figure 1c presents an example of the final modal gain spectrum.
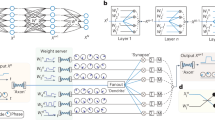
Since the structure of active regions contains essential information regarding QCLs operation, we first create a training dataset composed of various active region configurations while keeping the injection layers fixed. Using this dataset, we trained a model that captures the core operating principles of QCLs. Figure 2a shows a surrogate model of the DNN-CP, which has 8-layer active region superlattice input features and five different output features. Afterward, a second training dataset consisting of full QCL structures with both injection and active regions considered is generated. This dataset is used to train comprehensive surrogate models of the DNN-TP, which are designated in (Figure. 2b–d). Notably, DNN-TP is trained with either direct learning (DL) or transfer learning (TL) methodologies for comparison. Figure 2b shows a schematic diagram of the DNN-TP with DL, where the weights of the DNN-TP are trained without TL. Figure 2c,d show the network structures of DNN-TPs implemented with two different TL methodology of GTL and our proposed PBTL, respectively. Once trained, the DNN-TP model is used as a surrogate simulator to evaluate candidate QCL structures during the optimization process in (Figure. 1a). This dramatically reduces computational time while maintaining physical accuracy, enabling scalable and efficient exploration of high-dimensional design spaces.

(a)Overall procedure of methodology, categorized to training dataset generation process (green), training of the DNN surrogate models (blue), optimization process of the QCLs (gray), and optimization result (red). (b) The wave functions, energy levels and (c) modal gain spectrum of a QCL superlattice structure, where 43/18/9/55/11/53/12/47/22/43/15/38/16 /34/18/30/21/28/25/27/32/27/36/25 with thicknesses are in angstroms. The InAlAs barriers’ thicknesses are bold, while the InGaAs wells are in normal face.

(a) Structure of the DNN-CP with 8-layer active region superlattice input features and five different output features, (b) structure of the DNN-TP based on DL with 24-layer total QCL structure and five different output feature, (c) structure of the DNN-TP based on the GTL where the pretrained weights of the DNN-CP are transferred, (d) structure of the DNN-TP based on our proposed PBTL of which the first hidden layer is divided into two parts that can process thickness of active and injector layers, respectively.
Numerical modelling of QCLs
To generate high quality training dataset, various numerical algorithms were employed to accurately capture the physical behavior of mid-infrared (mid-IR) QCLs. In this study, we consider mid-IR QCLs structures, which are composed of alternating layers of In0.53Ga0.47As/In0.52Al0.48As lattice-matched to an InP substrate. The conduction band (CB) discontinuity between the well and barrier materials is set to 0.51 eV. The total superlattice consists of 24 layers, with a four-well (4QW) active region and an eight-well (8QW) injection region, designed based on the double phonon resonance principle.
Given material properties, the initial potential is defined and used as an input to solve the Schrödinger equation. Because the upper lasing states in the active region are located far from the CB edge, the nonparabolicity (NPB) of the CB must be considered for accurate modeling. To this end, we employ an effective two-band model to incorporate CB nonparabolicity and solve the Schrödinger equation at the zone center15. To solve the equation, numerical QR algorithm is used.
From the calculated energy levels and wave functions, key physical output parameters such as a peak emission wavelength (λ), an effective injection energy level (Einj), and an effective extraction energy (Eext) are obtained. To compute the optical gain spectrum, the intersubband optical dipole moment, intersubband longitudinal optical (LO) phonon scattering rate16, and intrasubband interface roughness (IFR) scattering rate17,18,19 are calculated using Simpson’s 1/3 rule. The detailed theoretical modeling process for the mid-IR QCL is presented in Algorithm 1. Details of numerical modeling process is presented in Sect. 1 of Supplementary Information (SI).
Figure 1b depicts the reference superlattice structure along with its corresponding energy levels and wave functions15. The optical transition between state 4 and state 3 is responsible for lasing while the three lower electron states (Φ₁, Φ₂, Φ₃), which are approximately separated by one LO phonon energy, facilitate efficient carrier extraction. The left-hand side of the injector region enables electron injection from the Φinj into Φ4 in the active region, and extraction from Φ₁ to Φext in the subsequent period. Owing to low effective injection and extraction energies, an intense population inversion is expected between states 4 and 3, resulting in high optical modal gain. As shown in Figure. 1c, the reference structure indeed exhibits a high gain spectrum, confirming its optimized lasing behavior.

Numerical modeling process of the mid-IR QCL.
Training of the DNN surrogate models with PBTL
The objective of training the DNN model is to adjust the weights of the NNs in order to predict output features of the given QCL structures. Figure 2a, b illustrate the NN structure of DNN-CP and DNN-TP. The size of training dataset plays a crucial role in determining the representation capability of the model. In general, as the dimensionality of the input feature space increases, significantly larger datasets are required to achieve a comparable level of accuracy. Given that generating training dataset involves computationally intensive quantum mechanical simulation, it is essential to maximize model generalization ability while minimizing training dataset size.
To this end, we first train the DNN-CP with DL method using a dataset focused on the active region, where physical phenomena most critical to lasing occur. DL means updating the network parameters using training dataset exclusively. In this dataset, the thickness of the injection layers is fixed while only the active region layers are varied. This dimensionality reduction effectively decreases the number of possible input combinations from 10¹⁵ to approximately 5 × 10⁹. As a result, a compact dataset of 35,000 samples is sufficient to encode the fundamental quantum operation of QCLs into the DNN-CP. For training the DNN-TP, which predicts the behavior of the full QCL structure, we generate a dataset of 100,000 samples. This size reflects a practical trade-off between improved representational accuracy and the computational cost of dataset preparation (see Sects. 2 and 3 of SI).
During dataset generation, input structures are initially sampled uniformly from predefined thickness ranges (see Table S1 and S2 in Sect. 2 of SI). However, since functioning QCL structures constitute a sparse subset of the entire design space, random sampling often results in non-operational devices. To address this, we employ a supplementary strategy: previously validated QCL designs are selected and randomly perturbed to generate additional realistic training examples that maintain population inversion conditions essential for laser operation.
To improve the representation ability of the model efficiently, we applied TL approach. Figure 2c shows a network structure of the GTL-based DNN-TP, where the weights of the first hidden layer cannot be transferable due to the mismatch of the input data dimension (8 for DNN-CP and 24 for DNN-TP). On the other hand, our proposed PBTL-based DNN-TP, shown in (Figure. 2d), can take the exact same input dimension of eight as the DNN-CP. Depending on the number of transferred hidden layers up to five, the first few hidden layers of the PBTL-based DNN-TP are split into two parts, corresponding to the active and injector regions, and the remaining non-transferred layers have the common hidden layers. The accuracy of the two DNN-TP neural networks in (Figure. 2c,d) depend on the structure of transferring hidden layers. We determine the optimal transfer-learning structures based on the grid search results of the accuracy of the respective DNN-TP neural networks with respect to transferring layers (see Figure S3 of SI). This ensures that the migration weights only retain core physical information related to the entire structure rather than introducing redundant knowledge unique to the active region.
Optimization of QCLs with surrogate-assisted GA
The optimization process begins by randomly generating QCL candidate structures within a predefined design space. Each candidate is evaluated using the DNN-TP surrogate model to predict key performance metrics. Based on the predicted objective values, high-performing candidates—referred to as elites—are selected as parent structures for crossover, producing offspring structures for the next generation. This process represents exploitation, as it leverages knowledge from previously successful designs. In parallel, exploration is maintained through mutation, in which new structures are randomly generated with a mutation rate of 10%.
Algorithm 2 illustrates the overall procedure of this surrogate-assisted GA. The fitness of each candidate structure is evaluated using a composite objective function, which is defined as
In (6), ti denotes the vector of superlattice layer thicknesses. Each term in the objective function corresponds to a specific performance metric—modal gain, linewidth, emission wavelength, and injection/extraction energies—and is normalized to have a maximum value of 1, ensuring balanced evaluation across all objectives. Due to the multi-objective nature of the problem, the design space contains multiple local optima. To avoid premature convergence and ensure sufficient exploration, we generate 2,000 candidate structures per generation with a mutation rate of 10%. The algorithm is run for 50 generations, yielding a total of 100,000 evaluations per optimization run. Using conventional numerical solvers would make such a computational scale impractical, as each evaluation would require the Schrödinger equation to be solved. To address this challenge, we replace time-consuming numerical evaluation with the DNN-TP surrogate model, which provides fast and accurate predictions of QCL performance. This approach enables efficient and scalable optimization of complex QCL structures while preserving the benefits of nature-inspired evolutionary search.

mid-IR QCL optimization with surrogate-assisted GA.
Result and discussion
Impact of PBTL on surrogate model training
Training a regression DNN model to accurately interpret complex physical phenomena is heavily influenced by the dimensionality of the input feature space. A higher input dimensionality implies a more complex mapping between input and output features, which in turn requires a significantly larger training dataset to achieve comparable accuracy. In our case, the DNN-CP and DNN-TP models differ substantially in their input dimensionality—8 versus 24, respectively. This increase leads to an estimated 10¹⁷ fold increase in the size of the design space, making the training of DNN-TP notably more challenging.
Figure 3a illustrates this trend: the minimum validation loss of DNN-CP is approximately an order of magnitude lower than that of DNN-TP. It is important to note that these models were trained on different dataset sizes—35,000 samples for DNN-CP and 100,000 samples for DNN-TP—reflecting the differences in problem complexity. Although increasing the dataset size improves the performance of DNN-TP, it is computationally impractical to generate significantly larger datasets due to the high cost of numerical simulations (see Figure S1 of SI). To mitigate this challenge, we apply a TL approach, reusing the rich physical representations learned by the DNN-CP. Figure 3b presents the UMAP (uniform manifold approximation and projection) distribution of the input feature spaces for both datasets. UMAP is a dimensionality reduction technique that preserves the local and global structure of high-dimensional data, allowing intuitive comparison of latent distributions. As shown in Figure. 3b, the input features of DNN-CP dataset are narrowly distributed in latent space. This indicates that the DNN-CP more effectively captures fundamental operation principle. In addition, since both models are trained under the same governing Schrödinger equation and share a similar input latent space, we hypothesize that transfer learning can effectively enhance the generalization capability of the DNN-TP.
Figure 4a compares the training and validation loss curves of DNN-TP trained using three methods: DL, GTL, and PBTL. The Figure shows the three models can be well trained without severe overfitting problems. The minimum training loss follows the trend of PBTL < GTL < DL, indicating that both TL approaches help in learning the input–output mapping more efficiently than training from scratch. However, in Figure. 4b, the validation loss shows a different trend: PBTL < DL < GTL, indicating that GTL, despite the improved training performance, negatively affects generalization. This degradation is further evidenced in the weight distribution analysis. In Figure. 4c, the weight distribution of the GTL-trained model deviates significantly from a normal distribution, implying that the transferred weights are misaligned with the target task and hinder the model’s representational capability. In contrast, the PBTL-trained model maintains a stable and Gaussian-like weight distribution, supporting its superior generalization performance.
To quantitatively evaluate model performance, we calculate the Pearson correlation coefficient (PCC) and the coefficient of determination (R2 score) for each output feature. Table 1 presents the evaluation metrics for models trained using three methodologies: DL, GTL, and PBTL. All models achieve a PCC greater than 0.90 across the five modalities, indicating reliable prediction performance even on unseen structures. Importantly, the PBTL-based model consistently outperforms the DL model across all output features, with the most significant improvement observed in modal gain prediction.
This result highlights the effectiveness of knowledge transfers from the DNN-CP, which is trained on a compact latent space where the active region design and modal gain are strongly correlated. In the case of GTL, improvements in evaluation metrics are not significant, and some output modalities even show degraded performance compared to the DL baseline. This suggests that indiscriminate transfer of learned weights, without considering the underlying physical correspondence, may harm model generalization. In contrast, PBTL effectively transfers domain knowledge from DNN-CP, resulting in a 0.69% improvement in overall accuracy. Based on our learning curve analysis, this accuracy level would require training with approximately 150,000 samples if DL is used. Therefore, the proposed PBTL framework can reduce the computational burden of training dataset generation by nearly 50%, without compromising model performance (see Figure S1 of SI).

(a) Loss curve of two models to compare the performance between DNN-CP vs. DNN-TP with DL. The solid lines represent the training losses and the dashed lines indicate validation losses. (b) Training dataset distribution of active dataset and total dataset, which are projected by UMAP.

(a) Loss curves of DNN-TP models trained using three different methodologies of DL, GTL, and PBTL. Solid lines represent training loss while dashed lines indicate validation loss. (b) Validation loss trajectories and the minimum loss values for each model. (c) Distribution of weight values across the different models.
Utility of DNN surrogate model
We evaluate the DNN-TP surrogate model, which is trained with PBTL methodology, in terms of both prediction accuracy and computational efficiency, as required for its integration within the optimization framework. To be useful during multi-objective optimization, the surrogate model must reliably predict key QCL performance metrics across a diverse range of input structures.
To assess the model’s generalization ability, the DNN-TP trained with the proposed PBTL methodology is tested on a separate test dataset, unseen during training. Figure 5a shows scatter plots comparing the DNN-TP predictions with ground-truth values obtained from numerical simulations. A strong linear correlation is observed across all output features, confirming the model’s ability to accurately infer key QCL behaviors. However, some deviations from the ideal linear trend are noticeable, particularly for more intricate output features such as modal gain and linewidth. This can be explained by the physical complexity of these properties. While the emission wavelength and effective energy levels (injection and extraction) are directly determined by the energy level differences in the superlattice, the linewidth and gain are affected by additional mechanisms—such as IFR and LO-phonon scattering—which involve interactions among multiple energy states and wavefunctions. This added complexity results in relatively higher prediction errors for these two modalities.
During the QCL optimization process, the surrogate model is used to evaluate thousands of candidate structures in each generation. Given the multi-objective nature of the task, the solution space contains many locally optimal structures that satisfy only a subset of the design targets. To escape these local optima and ensure sufficient exploration, it is necessary to evaluate a large population of candidates. However, applying conventional numerical solvers to such a large design pool is infeasible due to their serial nature and high computational cost. The DNN-TP surrogate model addresses this limitation by leveraging matrix multiplication and vectorized operations, which are highly parallelizable. As shown in Figure. 5b, the computational time of the numerical solver increases linearly with the number of evaluated structures, requiring approximately 160 s to evaluate 100 QCL candidates. In contrast, DNN-TP evaluates the same number of structures in only a few hundred milliseconds, and its runtime remains effectively constant.

(a) Scatter plot between actual and predicted output characteristics of QCLs. (b) Optimization time comparison between DNN-TP surrogate model and numerical model in linear scale (upper), and logarithm scale (below).
This efficiency gain translates into a dramatic acceleration of the optimization process. For example, in a GA configured with 50 generations and 2,000 candidates per generation, a numerical solver would require approximately 160,000 s (∼44 h) to complete a single optimization run. In contrast, the surrogate-assisted GA completes the same process in just a few seconds. Overall, the use of the DNN-TP surrogate model leads to a speedup of ∼80,000 times while maintaining comparable accuracy to full-physics simulation. This allows for extensive design space exploration and effectively mimics the natural evolutionary process underlying genetic algorithms. Furthermore, the low computational cost of surrogate model has advantage in Uncertainty quantification (UQ). Assessing the robustness of designs against manufacturing process variations is crucial for practical applications. UQ, often performed using computationally intensive Monte Carlo analysis20, is a standard method for this assessment. The low computational cost and parallel processing capabilities of our DNN surrogate model offer a significant advantage, making large-scale UQ analysis practical and enabling the optimization of designs for high robustness.
Although we used GA as a one example, this effectively trained DNN-simulator can be integrated with various optimization algorithms like deep reinforcement learning calibration21 and self-calibrating method22. Especially, when the simulator is computationally expensive or the optimization algorithm has high computation cost, the utility of DNN simulator and our PBTL methodology would be a powerful solution. In our framework, the DNN-CP is defined as an expert model of a performance-critical subcomponent. For our QCL, this is the active region where lasing physics occurs. This concept extends to other platforms23,24,25,26. For a microring resonator (MRR)23, the DNN-CP would model the resonant cavity; for a Mach-Zehnder interferometer (MZI)24, it would model the phase shifter. Crucially, the DNN-CP is trained on a single device instance with fixed structural parameters (a specific radius for a microring). Its purpose is to master the mapping from dynamic control parameters (heater power) to optical performance (transmission). The PBTL methodology then transfers this learned core physics to a more general full-device predictor (DNN-TP). The DNN-TP is designed to predict performance across a broader design space where the structural parameters themselves are treated as input variables. By leveraging the pre-trained knowledge from the DNN-CP, the DNN-TP can be trained far more efficiently than learning from scratch. While our PBTL methodology itself is general, the process including training a device specific DNN-CP, transferring its knowledge to a general DNN-TP, must be repeated for each new platform.
QCLs optimization with surrogate-assisted GA
The optimization is carried out with the following target objectives: a modal gain of 25 cm⁻¹, a spectral linewidth of 24 meV, and injection (Einj) and extraction (Eext) energy level differences of 26 meV each. Figure 6a illustrates the distribution of QCL candidate structures across the optimization process. Initially, the population is widely dispersed across the latent design space. However, as optimization proceeds, the population gradually converges into a narrow region around an optimal solution. This implies that to find the optimal structure, the algorithm must be capable of identifying such a narrowly confined region.
Given that GA is a stochastic optimization algorithm, it carries the inherent risk of converging to local optima if exploration capability is insufficient. Since we observe the optimal structures lie within extremely narrow region in latent space, an extensive population must be evaluated to ensure proper convergence in multi-objective optimization. Figure 6b presents the impact of population size on optimization performance. The aggregated objective score reaches its maximum value (~ 5) when the population size is increased to 2,000 per generation. While the increment of population promotes better global optimization ability, it also requires significantly more computational resources, particularly if numerical solvers are used for evaluation. This challenge motivates the use of a DNN surrogate model to enable more efficient exploration.
Since surrogate predictions do not guarantee physical validity, we validate the optimized structures using a physics-based numerical simulator. To quantify model effectiveness, we compare the pass@128 ratio—defined as the number of physically valid structures among the top 128 candidates—between DNN-TP models trained via DL and PBTL. Figure 6c reveals that even a small difference in model accuracy can result in large disparities in optimization outcomes. Notably, although the DNN-TP-assisted GA shows a high pass ratio initially, the ratio declines as the population size increases. This can be attributed to the reduced selection pressure in large populations, allowing more diverse but potentially unreliable candidates to pass through generations.

Optimization and evaluation results of the surrogate-assisted genetic algorithm for QCL design. (a) Convergence curve of the total objective score over generations for three different DNN training strategies: DL, GTL, and PBTL. (b) Pass@128 ratio comparison for each model, showing a significant improvement in optimization quality with PBTL. (c) Latent space visualization of the candidate structures throughout optimization, illustrating convergence from a dispersed to a compact distribution. (d) Histogram of L1 distances between the optimized and closest training dataset structures, indicating generation of novel designs beyond the training distribution.
While high exploration supports global search, it also increases the likelihood of out-of-distribution (OOD) queries, which can exacerbate the discrepancy between surrogate predictions and ground-truth physics. This observation underscores the importance of balancing exploration and surrogate model reliability in data-driven optimization. This efficiency enables extensive exploration of the design space while implementing a nature-inspired evaluation process into the photonic device optimization workflow—a key step toward biologically motivated optimization in quantum photonics.
To investigate the novelty of the optimized designs, we calculate the L1 distance between each optimized structure and its closest counterpart in the training dataset. As shown in Figure. 6d, the average L1 distance for 100 verified optimized structures is approximately 43, with the minimum distance being 30. These results confirm that the surrogate-assisted GA is not merely reproducing training data but is capable of discovering genuinely novel QCL designs that extend beyond the training distribution.
Finally, the performance of one verified optimized structure is illustrated in (Figure. 7a,b). The structure achieves a peak emission wavelength of 7.72 μm, a modal gain of 37.9 cm⁻¹, a linewidth of 12.5 meV, and effective injection and extraction energy levels of 11.42 meV and 4.98 meV, respectively. Compared to reference structure, the modal gain is 54% increased and all the other parameters are within the operating range. These results confirm that the surrogate model, in conjunction with GA, can identify QCL designs that satisfy multi-objective criteria and maintain physical validity.

(a) Calculated energy levels and wavefunctions of a representative optimized QCL superlattice structure 48/19/23/50/14/51/9/48/17/41/17/39/15 /34/20/36/21/29/27/28/29/24/35/24 with thicknesses are in angstroms. The InAlAs barriers’ thicknesses are bold, while the InGaAs wells are in normal face. (b) Modal gain spectrums of the optimized structure and reference structure. The optimized structure showing a peak near the target wavelength.
Conclusion
We proposed NN-based surrogate modeling framework to efficiently optimize mid-IR QCL structures with five objectives. Given that the output latent space contains multiple local optima, a large population size per generation is required to ensure sufficient exploration. In this setting, the DNN-TP-assisted GA leverages a simple and parallelizable computation process, achieving over 80,000 times faster optimization compared to conventional numerical simulators. To train the DNN-TP model, we introduced a novel transfer learning strategy, PBTL, which incorporates domain-specific physical knowledge grounded in QCL operation principles. By training a core model (DNN-CP) in a reduced latent space, which contains compressed operation principle of the QCL emission process and transferring the learned representations to DNN-TP, we achieved a 0.69% improvement in prediction accuracy, corresponding to a 50% reduction in required training data (50,000 samples). While the numerical gain appears minor, it significantly affects optimization outcomes; notably, the pass@128 ratio of the PBTL model was 60% higher than that of the directly trained model.
Furthermore, we evaluated the L1 distance between physically verified optimized structures and their nearest neighbors in the training dataset, finding a minimum distance of approximately 30. This result demonstrates the surrogate model’s capacity to generate novel and physically consistent designs beyond the training distribution, indicating a learned understanding of underlying quantum physics rather than simple memorization.
Although our method was demonstrated on QCL structures, it is broadly applicable to domains where feature importance is highly imbalanced, and data generation is expensive. The proposed framework—comprising a scalarized multi-objective GA, PBTL-based surrogate modeling, and biologically inspired optimization dynamics—offers a scalable and generalizable solution for real-time photonic design automation.
Data availability
The datasets presented in this paper are not publicly available at this time but may be available from the corresponding author upon reasonable request.
References
Park, J. et al. Free-form optimization of nanophotonic devices: from classical methods to deep learning. Nanophotonics 11, 1809–1845 (2022).
Chen, W. et al. Empowering nanophotonic applications via artificial intelligence: pathways, progress, and prospects. Nanophotonics 14, 429–447 (2025).
So, S. et al. Deep learning enabled inverse design in nanophotonics. Nanophotonics 9, 1041–1057 (2020).
Kim, G. et al. Compact classification using the biomimetic properties of ultrafast spiking microlaser neurons. Neuromorph Comput. Eng. 5, 024021 (2025).
Faist, J. et al. Quantum cascade laser. Science 264, 553–556 (1994).
Sirtori, C. et al. Quantum cascade unipolar intersubband light emitting diodes in the 8–13 µm wavelength region. Appl. Phys. Lett. 66, 4–6 (1995).
Ferreira, R. et al. Evaluation of some scattering times for electrons in unbiased and biased single- and multiple-quantum-well structures. Phys. Rev. B. 40, 1074–1086 (1989).
Hartig, M. et al. Femtosecond luminescence measurements of the intersubband scattering rate in Alx Ga1 – xAs/GaAs quantum wells under selective excitation. Phys. Rev. B. 54, R14269–R14272 (1996).
Mueller, D. & Triplett, G. Development of a multi-objective evolutionary algorithm for strain-enhanced quantum cascade lasers. Photonics 3, 44 (2016).
Ashok, P. et al. Particle swarm optimization approach to identify optimum electrical pulse characteristics for efficient gain switching in dual wavelength quantum cascade lasers. Optik 171, 786–797 (2018).
Dashkov, A. S. & Goray, L. I. QCL design engineering: automatization vs. classical approaches. Semiconductors 54, 1823–1825 (2020).
Franckié, M. & Faist, J. Bayesian optimization of Terahertz quantum cascade lasers. Phys. Rev. Appl. 13, 034025 (2020).
Qu, Y. et al. Migrating knowledge between physical scenarios based on artificial neural networks. ACS Photonics. 6, 1168–1174 (2019).
Fan, Z. et al. Transfer-learning-assisted inverse metasurface design for 30% data savings. Phys. Rev. Appl. 18, 024022 (2022).
Cho, G. & Kim, J. Effect of conduction band non-parabolicity on the optical gain of quantum cascade lasers based on the effective two-band finite difference method. Semicond. Sci. Technol. 32, 095002 (2017).
Kim, J. et al. Theoretical and experimental study of optical gain and linewidth enhancement factor of type-I quantum-cascade lasers. IEEE J. Quantum Electron. 40, 1663–1674 (2004).
Unuma, T. et al. Intersubband absorption linewidth in GaAs quantum wells due to scattering by interface roughness, phonons, alloy disorder, and impurities. J. Appl. Phys. 93, 1586–1597 (2003).
Tsujino, S. et al. Interface-roughness-induced broadening of intersubband electroluminescence in p-SiGe and n-GaInAs/ AlInAs quantum-cascade structures. Appl Phys. Lett 86, (2005).
Wittmann, A. et al. Intersubband linewidths in quantum cascade laser designs. Appl Phys. Lett. 93, (2008).
Shields, M. D. et al. Refined stratified sampling for efficient Monte Carlo based uncertainty quantification. Reliab. Eng. Syst. Saf. 142, 310–325 (2015).
Yan, Q. et al. Multi-wavelength optical information processing with deep reinforcement learning. Light Sci. Appl. 14, 160 (2025).
Xu, X. et al. Self-calibrating programmable photonic integrated circuits. Nat. Photonics. 16, 595–602 (2022).
Ouyang, H. et al. Parallel edge extraction operators on chip speed up photonic convolutional neural networks. Opt. Lett. 49, 838–841 (2024).
Huang, Y. et al. Parallel photonic acceleration processor for matrix–matrix multiplication. Opt. Lett. 48, 3231–3234 (2023).
Xu, X. et al. 11 TOPS photonic convolutional accelerator for optical neural networks. Nature 589, 44–51 (2021).
Wu, B. et al. Chip-encoded high-security classical optical key distribution. Nanophotonics 13, 3717–3725 (2024).
Acknowledgements
This work was supported by the Basic Science Research Program (NRF-2021R1F1A1062591) through the National Research Foundation of Korea (NRF).
Funding
Basic Science Research Program (NRF-2021R1F1A1062591).
Author information
Authors and Affiliations
Contributions
Gibaek Kim - Conceptualization, Methodology, Software, Visualization, Writing—original draft, Writing—review & editing. Jungho Kim - Conceptualization, Methodology, Visualization, Writing—original draft, Writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kim, G., Kim, J. Efficient nanophotonic devices optimization using deep neural network trained with physics-based transfer learning methodology. Sci Rep 15, 39854 (2025). https://doi.org/10.1038/s41598-025-23519-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-23519-5
