
Abstract
In the domain of heterogeneous graph representation learning, traditional methodologies often rely excessively on manually crafted meta-paths and neighbor aggregation mechanisms when faced with diverse node types and complex relationships. This dependence makes it challenging for models to adaptively optimize in situations of information scarcity or insufficient neighbors, frequently resulting in excessive information smoothing and inadequate representational capacity, which in turn affects the distinctiveness of node representations and the effectiveness of tasks. To address these limitations, this paper proposes a framework named GraphFlow, grounded in information flow optimization and potential neighbor selection mechanisms, with the aim of enhancing the learning of inter-node associations through optimized information propagation. Our framework transcends the conventional fixed reliance on neighbors by dynamically optimizing information flow paths and adaptively selecting potential neighbors, enabling it to flexibly and effectively capture latent yet highly relevant neighbors within the graph, even in contexts of information scarcity or a lack of direct neighbors. Specifically, by integrating HodgeRank ranking and adaptive meta-path generation, our approach not only effectively refines the neighbor selection process but also allows for the adaptive modeling of deep semantic relationships among nodes within a multi-level, multi-relational graph structure. This significantly enhances the distinctiveness of node representations and facilitates the effective dissemination of information flow. Extensive experiments conducted on multiple publicly available heterogeneous graph datasets validate that the proposed GraphFlow method outperforms the best baseline performances in tasks such as node classification and link prediction across most evaluation metrics. Notably, it demonstrates exceptional performance on heterogeneous graph datasets characterized by complex node types and multiple relationships, markedly improving the model’s distinctiveness and generalization capabilities.
Similar content being viewed by others

Introduction
Graph data1,2 is a structured data format that plays a crucial role in various fields such as social networks, recommendation systems, knowledge graphs, and bioinformatics. The non-Euclidean structure of graphs enables them to effectively represent complex relationships between entities, such as user interactions in social networks, entities and relationships in knowledge graphs, and interactions between users and items in recommendation systems.With the growing recognition of graph neural networks (GNNs)2,3 in graph data, they have become an important tool for analyzing and learning graph data, especially in tasks such as node classification2, graph classification4, link prediction5, and recommendation6, where they have achieved significant results. GNNs enable traditional graph algorithms to be effectively applied to large-scale and high-dimensional graph data through their powerful representation capabilities.
However, with the increasing application of heterogeneous graphs, existing graph neural network methods7,8,910 have exposed a series of critical issues. Heterogeneous graphs consist of multiple types of nodes and edges, and the relationships between nodes and between edges are diverse and complex, resulting in a graph structure that is hierarchical, heterogeneous, and multi-semantic.Although existing heterogeneous graph representation learning methods7 have achieved some success, they still face many challenges, particularly in modeling the semantic information of complex multi-type nodes and multi-relationship edges, addressing information over-smoothing, and selecting potential neighbors.
The prevailing approaches in heterogeneous graph representation learning indeed heavily rely on meta-paths to capture high-order semantic relationships between nodes. Meta-paths, by specifying relational paths between different node types, effectively encode the complex semantic information inherent in graphs. For instance, The core concept of DIARec8 is to deconstruct the entire session into a series of temporally evolving, fine-grained user intents, rather than treating it as a singular entity. This approach allows for dynamic item recommendations based on the current intent. HAN9 was designed as a unified model capable of automatically learning latent contextual information, discerning item attributes, and distinguishing between short-term session-level user preferences and long-term global-level preferences. This design endows HAN with greater flexibility and adaptability when handling complex heterogeneous graphs. GCORec10 aims to break free from the narrow focus on predicting the next item solely based on the current sequence. Instead, it argues that optimization should not be confined to this localized objective but should simultaneously target a broader goal that captures the global collaboration relationships among all items.
However, despite the promising results achieved by meta-path-based methods in certain scenarios, they still exhibit notable limitations.
First, existing meta-path methods mostly rely on artificially designed meta-paths. This design lacks flexibility and is difficult to adapt to dynamic changes in graph structures, such as an increase in node types or complex edge relationships. Especially in large-scale graph data, artificially designed meta-paths often cannot comprehensively cover all complex relationships, resulting in the model being unable to adaptively adjust, thereby affecting its universality and adaptability. Second, graph neural network methods based on neighbor aggregation are one of the core mechanisms of current graph neural networks. Node representations are learned by aggregating the features of neighboring nodes. However, traditional neighbor aggregation mechanisms face serious information over-smoothing issues when dealing with heterogeneous graphs.As the number of convolutional layers increases, node representations gradually lose their personalized features, leading to a decrease in the discriminative power of node representations. This is particularly pronounced in heterogeneous graphs with multi-type nodes and multi-type edges, where simple neighbor aggregation methods fail to effectively preserve the differences between different nodes, thereby impairing the model’s learning ability and prediction accuracy.
To overcome these issues, this paper proposes an innovative framework that combines information flow optimization with neighbor selection mechanisms. Using the theory of information flow optimization, we introduce a method based on potential neighbor selection, which can adaptively optimize the information propagation paths. This allows the model to effectively choose the most influential neighbors, even in cases where information is insufficient or nodes lack direct neighbors. Furthermore, we incorporate the HodgeRank ranking algorithm to enhance the neighbor selection process, improving the discriminability of node representations. Finally, by combining adaptive meta-path generation with a multi-layer graph convolutional network, we model multi-relational information, effectively avoiding the over-smoothing issue present in traditional methods. The main contributions of this paper are as follows:
-
We proposed an information flow optimization and neighbor selection mechanism, which solves the performance bottlenecks caused by information scarcity and the lack of direct neighbors for nodes, thereby significantly improving the quality of node representation.
-
An adaptive meta-path generation mechanism and multi-layer graph convolution module were designed, effectively improving the modeling ability of multi-level relationships in heterogeneous graphs and enhancing the model’s multi-relationship learning ability.
-
Through theoretical analysis and experimental verification on multiple public datasets, our method achieves significant performance improvements in tasks such as node classification and link prediction, especially on public datasets with complex heterogeneous structures and multi-level relationships, such as IMDB and DBLP, outperforming existing benchmark methods.
Related work
With the rapid development of Graph Neural Networks (GNNs), heterogeneous graphs, which consist of multiple types of nodes and edges, have become an important research focus in the field of graph representation learning. However, processing eterogeneous graphs11,12,13,14 still presents numerous challenges, primarily in effectively modeling the complex relationships between nodes, integrating information from different types of nodes and edges, and enabling efficient information propagation in situations where direct neighbors are lacking in the graph. To address these issues, various methods have been proposed in the academic community, but existing heterogeneous graph representation learning methods still exhibit significant limitations.
Meta-path-based heterogeneous graph representation learning methods are among the earliest classical approaches applied to heterogeneous graphs. PathSim14introduced a meta-path-based similarity measure, laying the foundation for modeling relationships between nodes in heterogeneous graphs. Subsequently, Metapath2Vec combined random walks with meta-paths to effectively guide node embedding learning, pioneering a new paradigm in heterogeneous graph representation learning. While these methods have achieved good results on simple graphs, they overly rely on manually designed meta-paths and lack adaptive capabilities. As a result, they struggle to fully capture the complex, multi-level relationships in the graph, particularly in cases with information scarcity or insufficient neighbors, leading to poor flexibility and adaptability in complex tasks. For instance, ESim15 and HERec16 optimize node embeddings based on meta-paths, but these methods still fail to effectively address changes in graph structure and the scarcity of neighbor information.
To address the static nature of meta-path design, the Graph Transformation Network (GTN)11 introduced an adaptive meta-path generation method. GTN automatically identifies and generates meta-paths, eliminating the dependency on domain knowledge and enhancing the model’s flexibility and adaptability when processing heterogeneous graphs. This method strengthens the graph’s expressive power through multi-level graph learning and soft selection of composite relationships, showing promising results, especially when dealing with multi-level, complex heterogeneous relationships. However, despite the breakthrough in adaptive meta-path generation, the generated meta-paths still lack a deep understanding of domain-specific semantics, which limits their ability to capture complex relationships accurately in certain complex application scenarios, thereby affecting the model’s performance. Seongjun Yun12 further improved GTN by learning a soft selection mechanism for edge types and composite relationships, generating multi-hop connections to further enhance the model’s expressive power and flexibility. The enhanced GTN can generate meta-paths of different types, adapting to various combinations of length and edge types, thus better capturing complex relationships within the graph. Meanwhile, Müller et al.13 introduced the self-attention mechanism from Transformers into graph data, proposing a new graph learning framework that utilizes self-attention to better capture global dependencies between nodes, thereby improving the model’s representational power. While these methods effectively alleviate the bottleneck of over-reliance on local information in traditional methods, an excessive focus on global information may neglect the importance of local structures. This could potentially lead to performance degradation, especially in tasks where local structure is crucial.
Compared with the above methods, the meta-path-free approach also provides a new solution for processing heterogeneous graph information. Yang et al.17 simplified the architecture of heterogeneous graph neural networks (HGNNs) to uniformly process different node/edge types, avoiding complex meta-path designs, thereby reducing computational complexity while maintaining model performance. Zhang et al.18 sought to break free from the reliance on meta-paths in traditional heterogeneous graph embedding to achieve more flexible embedding learning. They generated node sequences via random walks, used the Skip-gram model to learn embeddings, distinguished node types during negative sampling to avoid cross-type noise, and jointly optimized node similarity and type prediction tasks.
Recommendation systems have introduced various innovative approaches. For instance, DIARec models “dynamic intents,” yet these intents are represented as automatically learned vectors devoid of explicit semantics. Once constructed, GCORec’s core component, the Global Item Graph, remains static throughout the training and evaluation processes. HAN (Hierarchical Attention Network) incorporates a hierarchical structure, multiple attention mechanisms (item-level, session-level, and attribute-level), as well as latent context modeling; however, it lacks a neighbor filtering mechanism, thereby rendering it an exceedingly complex and highly parameterized model. Such intricacy necessitates substantial amounts of data for training, increasing the likelihood of overfitting.
In heterogeneous graphs with multi-type nodes and multi-level relationships, heterogeneous graph neural network (HGNN) methods have shown strong performance. For example, HAN19 introduces a hierarchical attention mechanism that models both node-level and semantic-level structures. While this method effectively captures semantic information in heterogeneous graphs, it focuses only on same-type meta-paths, leading to the loss of intermediate node information, which in turn affects the retention of global information. MAGNN20 further models structural information in meta-paths through both intra-path and inter-path aggregation, effectively alleviating the information loss issue. However, although these methods enhance the model’s representational power by aggregating information from different types of nodes, they still face limitations in expression when direct neighbors are lacking. Methods such as HGT21 and HetSANN22 use multi-head attention mechanisms to fuse information from different types of neighbors, yet they fail to fully leverage potential neighbors, limiting their performance on complex heterogeneous graphs. GCC23, which focuses solely on local structural similarity, ignores global semantic relationships, resulting in poor generalization in heterogeneous graph environments.Meanwhile, neighbor aggregation-based graph convolution networks play a crucial role in heterogeneous graph representation learning. R-GCN24 introduces edge-type weights to aggregate neighbor information, allowing the model to handle the impact of multi-type edges on nodes. However, R-GCN still faces challenges related to neighbor scarcity and insufficient information flow, particularly when there are not enough neighbors in heterogeneous graphs, leading to suboptimal performance. The pathless method does indeed reduce human dependence, but at the cost of model capacity and interpretability. For example, the SeHGNN method is sensitive to meta-path length and difficult to automatically select the optimal scale; the SR-RSC method alleviates gradient vanishing through relationship-level residuals, but does not utilize node attribute differences, resulting in limited expressive power on attribute-rich heterogeneous graphs.
Discussion
The limitations of existing methods are summarized as follows:
-
Static nature and limitations of metapath design: Most existing methods rely on manually designed meta-paths or fixed neighbor aggregation strategies, such as MAGNN and HetSANN. While these approaches effectively leverage diverse types of neighbor sets, they struggle to accommodate the dynamic changes in graph structures and scenarios of information scarcity, resulting in poor adaptability and insufficient flexibility of the models.
-
Information Over-smoothing Issue: Traditional neighbor aggregation methods tend to cause information over-smoothing as the number of convolution layers increases. This results in the loss of distinctiveness between nodes, undermining the model’s ability to differentiate node representations.
-
Insufficient Potential Neighbor Exploration: Existing methods typically assume that the relationships between nodes depend solely on direct neighbors, failing to strike a balance between global and local perspectives. For instance, GTN can generate various types of meta-paths, accommodating combinations of different lengths and edge types, thereby enhancing the ability to capture the intricate relationships within the graph. However, it overlooks the significant information conveyed through multi-hop paths and inter-type edges between nodes, resulting in insufficient distinctiveness of node representations.
Problem formulation and analysis
Definition 1
Heterogeneous Graph: A heterogeneous graph \({\mathcal {G}}\) consists of a set of nodes, a set of edges, and their relationships composed of multiple types of relationships. The definition is as follows:
Let \(\mathcal {V}\) represent the set of nodes in the graph, indicating all the nodes within the graph. Let \(\mathcal {E}\) represent the set of edges, indicating all the connections between nodes. \(\mathcal {T}=\{t_1,t_2,...,t_k\}\) denotes the set of node types, \(\mathcal {R}=\{r_1,r_2,...,r_m\}\) representing the types of all edges in the graph.
Definition 2
Metapath: A path that describes high-order relationships between nodes in a heterogeneous graph, consisting of alternating node and edge types. Formal definition is:
Here, \(\nu _i\in \mathcal {I}\) represents the node type, \(r_i\in \mathcal {R}\) represents the edge type, and n denotes the length of the meta-path. The meta-path captures cross-type relationships between nodes by constructing multi-level connections.
Definition 3
Node and Neighbor: The core of node representation learning lies in the aggregation of neighbor information. In this context, we define a node’s neighbors as both direct neighbors and potential neighbors (Before each hop of message passing, the model selects the top k neighbor nodes most likely to carry valid semantic information through HodgeRank scoring).
Direct Neighbors: The set of direct neighbors \(\mathcal {N}(\nu )\) of a node \(\varvec{v}\) includes all the nodes that are directly connected to \(\varvec{v}\) through edges of types in \(\mathcal {R}\).
Potential Neighbors: The set of potential neighbors \(\mathcal {N}_{\text{lat}}(\nu )\) of a node \(\varvec{v}\) includes nodes that are not directly connected to \(I(\nu ,u)\), but can effectively influence its node representation through indirect paths or edges of different types. Formally, it is defined as:
Here,\(I(\nu ,u)\) represents the information flow between node \(\varvec{v}\) and node \(\varvec{u}\). Let \(\varvec{v}\) and \(\varvec{u}\) be two nodes within the graph. In the context of representation learning, each node is typically associated with an embedding vector. The information flow metric \(I(\nu ,u)\) is grounded in the principle of mutual information, serving to quantify the degree of interdependence or information sharing between two random variables, which in this case are the nodes themselves. The calculation of \(I(\nu ,u)\) assesses the mutual information between the embedding representations of nodes \(\varvec{v}\) and \(\varvec{u}\) . This metric effectively measures the extent to which knowing the representation of one node reduces the uncertainty regarding the representation of the other node.
Definition 4
Information Flow and Neighbor Selection Mechanism: The information flow optimization problem aims to select the most influential neighbors by optimizing the information flow paths, thereby enhancing the quality of node representations. Let \(I(\nu ,u)\) represent the information flow between node \(\varvec{v}\) and node \(\varvec{u}\) , then the objective of information flow optimization is:
This objective optimizes neighbor selection by maximizing the information flow paths, thereby improving the quality of node representations. We further analyze the error lower bounds of GraphFlow in comparison to GCN, HAN, and others, as detailed in Analysis:
Error Lower Bound Analysis: First, we begin with the definition of the error metric. For each node \(\varvec{v}\), the error between its embedding representation \(\text{h}_{\nu }\) and its true label \(\text{y}_{\nu }\) is defined as:
The error of the entire graph is defined as the sum of all node errors:
In traditional GCN methods, the representation of a node is obtained by aggregating the features of its neighboring nodes. The representation \(\text{h}_{\nu }\) of node \(\varvec{v}\) is updated as the weighted sum of its neighboring nodes’ representations:
Here, \(\text{W}^{(l)}\) is the trainable weight matrix, and \(\text{N}^{(v)}\) is the set of neighbors of node \(\varvec{v}\). Due to the over-smoothing problem in the GCN model, as the number of layers increases, the node representations lose their distinguishability, and consequently, the error may increase with the number of layers. In deriving the error lower bound, we combine the characteristics of neighbor aggregation and the similarity of node representations, defining the total error as:
Here, \(\text{h}_{\nu }^{(L)}\) represents the node representation at the L-th layer. To avoid over-smoothing of the information, we introduce a smoothing coefficient \(\alpha\) to measure the impact of neighbor aggregation. To alleviate excessive smoothing, a mechanism is needed to balance fitting accuracy (i.e. minimizing prediction error) and representation smoothness. The smoothing coefficient \(\alpha\) is used to measure the degree of influence of neighbor aggregation and control the trade-off between smoothing and fitting. Using the Lagrange multiplier method, transform the constrained problem into an unconstrained problem: minimize \(\sum _{\nu \in \mathcal {V}}\parallel \textbf{h}_\nu ^{(L)}-\textbf{y}_\nu \parallel _2+\alpha \sum _{\nu \in \mathcal {V}u\in \mathcal {N}(\nu )}\parallel \textbf{h}_\nu ^{(L)}-\textbf{h}_u^{(L)}\parallel _2\), where \(\alpha\) is the Lagrange multiplier (i.e. smoothing coefficient), ignoring the constant c, The error lower bound can be written as:
HAN employs a graph attention mechanism to model the relationships between nodes at both the node level and the semantic level. Specifically, HAN utilizes different types of meta-paths to model heterogeneous graphs. However, due to its reliance on fixed meta-path designs and the lack of dynamic adaptation, HAN is also susceptible to the over-smoothing problem. In HAN, the update formula for node representations is:
Here, \(\alpha _{\nu u}\) is the weight calculated through the attention mechanism, reflecting the strength of the relationship between node \(\varvec{v}\) and node \(\varvec{u}\). Similarly, for HAN, the node representation is not just the weighted average of neighboring information, but also incorporates the varying importance assigned by the attention mechanism. Therefore, the error lower bound is:
Among them, \(\beta\) is the smoothing coefficient, which controls the influence of attention mechanism on errors.
The GraphFlow method introduces a latent neighbor selection mechanism and information flow optimization, aiming to optimize node representations and avoid information over-smoothing. Unlike GCN and HAN, GraphFlow dynamically optimizes neighbor selection and information flow paths, effectively capturing the deeper relationships between nodes. In GraphFlow, the node representation not only depends on the information from direct neighbors but also utilizes the information flow optimization mechanism to select latent neighbors. The information flow metric \(I(\nu ,u)\) measures the similarity between nodes, and the latent neighbor set \(\mathcal {N}_{\text{lat}}(\nu )\) is selected through information flow optimization. Therefore, the derivation of the error lower bound is:
Here, \(\lambda\) is the regularization coefficient, which controls the impact of information flow optimization on the error. By maximizing the information flow paths, GraphFlow effectively selects latent neighbors, thereby reducing the error and improving the quality of node representations. Ultimately, we derive the error lower bound formulas for different methods. In summary: GCN:The error lower bound primarily arises from the aggregation of neighbor information and the smoothing effect caused by the increase in the number of layers.
GraphFlow: By leveraging information flow optimization and a latent neighbor selection mechanism, it significantly reduces the error and avoids over-smoothing.
Through the above analysis, we have demonstrated the differences in the error lower bounds of GCN, HAN and GraphFlow. GraphFlow, through its latent neighbor selection and information flow optimization mechanisms, effectively avoids the issue of over-smoothing and provides a more flexible approach to node representation learning.
Methodology
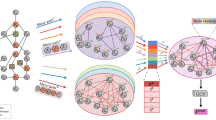
When the immediate neighbors are insufficient to construct high-quality meta-paths, utilizing indirect neighbors of the target node as alternative direct neighbors becomes a natural choice. However, current studies have yet to jointly consider both direct and indirect neighbors for generating meta-paths. To address this issue, this chapter introduces an adaptive meta-path-based heterogeneous graph representation learning model, termed GraphFlow. The core objective of this model lies in dynamically learning multi-layer semantic relationships between nodes by optimizing information flow paths, selecting potential neighbors, and leveraging a multi-layer graph convolutional network. The overall framework of the model is illustrated in Fig. 1. Specifically, GraphFlow begins by employing the Random Walk with Restart (RWR) algorithm to generate random walk paths, from which indirect neighbors are extracted as candidates for direct neighbors. Subsequently, through information flow optimization and the HodgeRank ranking mechanism, the most relevant potential neighbors are selected to enrich the neighborhood information of the target node. Finally, leveraging the enhanced adjacency tensor and a multi-layer graph convolutional network, the model effectively captures cross-layer semantic relationships between nodes and addresses the complex interactions between long and short paths. Regarding its training strategy, GraphFlow adopts both unsupervised and semi-supervised learning approaches, validating the model through link prediction and node classification tasks. This methodology not only enhances the model’s generalization capabilities but also provides a solid foundation for future practical applications.

Heterogeneous graph representation learning model for adaptive meta-path multi level subgraph aggregation.
Meta-path based subgraph generation module
Connections between heterogeneous and non-heterogeneous nodes have different semantics, and by analyzing existing studies, ignoring node differences between isomorphic and heterogeneous neighbors leads to loss of useful information in the graph. Therefore, in order to capture the node differences between isomorphic and heteromorphic neighbors, the heteromorphic graph is decomposed into multiple isomorphic and heteromorphic subgraphs (i.e., relational subgraphs) through metapath sets. Different meta-paths have different semantics, so the generated heterogeneous and isomorphic subgraphs need to be treated differently. Metapaths are first categorized into two types based on the type of subgraphs they can generate, as shown in the following formula:
Where ho and he refer to the meta-paths for generating isomorphic and isomorphic subgraphs, respectively, and the corresponding subgraphs are subsequently generated through the meta-paths, as shown in the following equations:
\(\mathcal {G}^{ho}\) is a homomorphic subgraph and \(\mathcal {G}^{he}\) is a heteromorphic subgraph. For a particular type of node, it carries different semantic information in different subgraphs. Therefore, each subgraph can be considered as an interaction graph with specific semantic information. The model needs to learn node features independently from homogeneous and heterogeneous subgraphs to retain more useful information.
Candidate direct neighbor generation
In this section, we systematically redefine the candidate direct neighbor generation mechanism from the perspective of information flow optimization. The goal is to establish neighborhood information that is richer in semantic meaning and structurally complete by mining potential higher-order neighbors and performing importance evaluation. This lays the foundation for subsequent latent neighbor selection and adaptive information flow path optimization. Specifically, consider a given heterogeneous graph \(\mathcal {G}=({\mathcal {V}},\mathcal {E},\mathcal {T},\mathcal {R})\), where \(\text{V}\) represents the nodes, \(\text{E}\) represents the edges, \(\text{V}\) and \(\text{R}\) denote the node types and relationship types, respectively. Ach node \(\nu \in \mathcal {V}\) has an initial feature matrix \(\textbf{X}\in \mathbb {R}^{|\mathcal {V}|\times d}\), where \(\text{d}\) is the feature dimension. To fully mine the potential important neighbors of node \(\varvec{v}\), we first perform a random walk process on the graph \(\mathcal {G}\). Let the transition matrix during the random walk be defined as:
where \(\text{A}_{\text{norm}}\) is the normalized adjacency matrix, \(\textbf{I}\) is the identity matrix, and \(\alpha \quad \in \quad (0,1)\) is the transition probability parameter. Each random walk starting from node \(\varvec{v}\) generates a node path sequence \(\mathcal {P}_i(\nu )=(\nu _0=\nu ,\nu _1,\nu _2,...,\nu _l)\), where \(\text{l}\) is the path length. Through multiple random walks, the walk paths corresponding to node \(\varvec{v}\) can be represented as:
where \(\text{k}\) is the number of generated paths. Based on the walk paths \(\mathcal {P}(\nu )\), the candidate neighbors \(\mathcal {N}_{\text{cand}}(\nu )\) of node \(\varvec{v}\) are defined as:
Here, all nodes that appear in any of the random walk paths, excluding the starting node \(\varvec{v}\) itself, are included in the candidate neighbor set. It is important to note that \(\mathcal {N}_{\text{cand}}(\nu )\) not only contains the traditional first-order neighbors but also includes higher-order neighbors indirectly connected through multi-hop paths, thereby greatly enriching the potential semantic context of the node.
To measure the potential information flow strength between the candidate neighbor nodes and the target node \(\varvec{v}\), we further introduce the node pair co-occurrence frequency matrix \(\mathbb {C}\in \mathbb {R}^{|\mathcal {V}|\times |\mathcal {V}|}\), which is defined as:
where \(\mathbb {I}(\bullet )\) is the indicator function, which takes the value 1 when node \(\nu _{j}\) appears in the path \(\mathcal {P}\), and 0 otherwise. The co-occurrence frequency matrix \(\text{C}\) effectively captures the number of times nodes co-occur during the random walk process, providing a quantitative basis for the subsequent importance ranking of potential neighbors.
Considering that the distance of a node from the starting node in the path varies, a reasonable hierarchical decay should be applied to the importance of nodes. Let \(\gamma \in (0,1)\) be the step decay factor. Then, the importance score \(s(u\mid \nu )\) of candidate neighbor \(\varvec{u}\) to node \(\varvec{v}\) is defined as:
where \(\mathcal {P}[j]\) represents the \(\text{j}\)-th node in path \(\mathcal {P}\). This weighting mechanism ensures that candidate nodes closer to the target node receive higher scores, which aligns with the natural law of diminishing intensity as information flows through the graph. Ultimately, the importance scores of all candidate neighbors of node \(\varvec{v}\) can be integrated into a vector:
Through the aforementioned candidate neighbor generation and weighting model, GraphFlow systematically expands the potential information flow receivers within the local neighborhood of node \(\varvec{v}\). Compared to traditional methods that rely on static direct neighbors, this mechanism can dynamically uncover potential nodes that are closely related to the target node and have rich semantic context, even in complex graph environments with missing information or sparse neighbors.
Potential neighbor screening
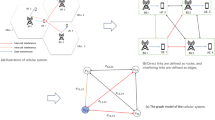
Once the candidate neighbor set \(\mathcal {N}_{\text{cand}}(\nu )\) is constructed, the key challenge in GraphFlow’s information flow optimization system is to accurately select the most information-rich nodes from this set. Directly incorporating too many low-quality or redundant neighbors not only exacerbates the over-smoothing of node features but can also lead to the collapse of the node representation space. Therefore, this section proposes a potential neighbor selection method based on local ranking theory. Using the HodgeRank ranking model, we systematically optimize the relevance evaluation of candidate neighbors to maximize the discriminative power of node representations and the effectiveness of information flow. In order to more reasonably utilize partial order to filter candidate neighbors, this section needs to sort the relevance of candidate nodes to the target node, and then select the important candidate nodes to be added to the candidate neighbor set of the target node. To this end, it is necessary to find a suitable graph sorting method to sort the candidate nodes. For graph sorting tasks, many methods have been proposed, such as PageRank and HITS. However, these methods are primarily designed for global sorting of nodes across the entire graph, and the most important nodes in the entire graph may not have sufficient influence on the given target node. Compared to sorting based on global topology, sorting based on the local topology structure around the target is more suitable for potential neighbor expansion, as shown in Fig. 2:

Candidate direct neighbor generation.
As shown in Fig. 2, assuming \(\nu _t\) is the target node, random walks along different paths starting from \(\nu _t\) yield two walk paths \(\nu _t-\nu _4-\nu _{11}-\nu _5\) and \(\nu _t-\nu _5-\nu _{11}-\nu _4--\nu _9\). From the first path, we know node \(\nu _4>\nu _5\), while in the second path, the opposite \(\nu _5>\nu _4\) holds true. Therefore, a reasonable candidate neighbor sorting strategy is needed that can maximize compatibility with all partial order relations.
Considering the node co-occurrence information embedded in the path \(\mathcal {P}(\nu )\) generated by random walks, we can further extract a set of node pairs with local partial order relationships, denoted as \(\mathcal {O}(\nu )\), defined as:
Where \(u_i\prec u_j\) indicates that node \(u_{i}\) is closer to the target node \(\varvec{v}\) in a particular random walk path. Each pair of nodes \((u_i,u_j)\) can be viewed as a local partial order comparison, reflecting the relative importance between the node pair. Based on the partial order node set \(\mathcal {O}(\nu )\), we define the partial order graph \(\mathcal {G}_\text{order}(\nu )=(\mathcal {N}_\text{cand}(\nu ),\mathcal {O}(\nu ))\), where the node set consists of the candidate neighbors and the edge set represents the partial order relations. Furthermore, to quantify the importance of each partial order edge, we introduce a confidence weight matrix \({\text{W}}\in {\mathbb {R}^{|\mathcal {N}_{\text{cand}}(\nu )|\times |\mathcal {N}_{\text{cand}}(\nu )|}}\), defined as:
That is, the weight of a node pair is the inverse of the relative frequency of their co-occurrence across all paths. The higher the frequency, the smaller the weight, emphasizing strong associations within the sparse relationships. To obtain the optimal global ranking score in the presence of inconsistent or conflicting partial order relationships, GraphFlow introduces a local ranking optimization model based on Hodge theory. Specifically, let the node importance score vector be \(\textbf{s}\in \mathbb {R}^{|\mathcal {N}_{\text{cand}}(\nu )|}\), then the overall ranking problem can be formalized as a weighted least squares optimization problem:
Where \(s(u_i)\) represents the global importance score of node \(\varvec{u}\). Ideally, for each partial order node pair \((u_i,u_j)\), we should have \(s(u_i)>s(u_j)\), and the difference between them should be close to 1. The above optimization problem can be transformed into solving a standard linear system. Let \(\text{D}\in \mathbb {R}^{|\mathcal {O}(\nu )|\times |\mathcal {N}_{\text{cand}}(\nu )|}\) be the finite difference matrix, where each row corresponds to a partial order relation, defined as:
The weighted Laplacian matrix is:
Where \(\text{W}\) is the diagonal weight matrix. Finally, the closed form solution of the node importance score vector \(\text{s}\) is:
Where \(\epsilon >0\) is a regularization term to ensure the numerical stability of the matrix, and 1 is the vector of ones.
By solving the above optimization problem, we can obtain the global importance score s(u) for each node in the candidate neighbor set. Nodes with higher scores contribute more to the information flow transmission toward the target node \({\varvec{\nu }}\). It is important to note that HodgeRank not only maximizes the compatibility with consistent partial order relations in local paths, but also effectively suppresses the inevitable local conflicts and noise in random walks. This ensures, theoretically, the robustness of the ranking and the consistency of the information flow direction.
After obtaining the importance scores, GraphFlow determines the final potential neighbors \(\mathcal {N}_{\text{lat}}(\nu )\) based on the following selection criteria:
Where \(\tau (\nu )\) is a dynamic threshold based on the scores of the original direct neighbors of the target node \({\varvec{v}}\). Specifically, let the original direct neighbors of \({\varvec{\nu }}\) be \(\mathcal {N}(\nu )\), then:
Only retain nodes with scores at least better than the weakest among the original direct neighbors, ensuring that the introduced new neighbors have a significant advantage in information contribution.

Potential neighbor selection.
For example, in Fig. 3, after applying HodgeRank, the indirect neighbor \(\nu _{11}\) ranks higher than some of the direct neighbors \((\nu _1,\nu _2,\nu _3)\) in terms of global score. This ranking result is intuitively reasonable: node \(\nu _{11}\) has more common neighbors with the target node \(\nu _{11}\) than nodes \((\nu _1,\nu _2,\nu _3)\) and it appears in multiple random walk paths. To some extent, \(\nu _{11}\) is indeed more influential than \((\nu _1,\nu _2,\nu _3)\), since these latter nodes only have one path leading to the target node. Therefore, according to the strategy of constructing a potential direct neighbor set, node \(\nu _{11}\) is selected to enhance the direct neighborhood of the target node.
Adjacency tensor enhancement
After the potential neighbors are selected based on HodgeRank, GraphFlow not only redefines the effective neighborhood of each target node, but also lays the foundation for further constructing heterogeneous information flow channels. Therefore, this section focuses on how to systematically integrate the selected potential neighbors into the original heterogeneous graph structure, proposing an adjacency tensor enhancement mechanism to support the subsequent steps of adaptive meta-path generation and multi-layer information aggregation.
Consider the initial heterogeneous graph \(\mathcal {G}=(\mathcal {V},\mathcal {E},\mathcal {T},\mathcal {R})\), where each edge type \(r\in \mathcal {R}\) corresponds to an adjacency matrix \(\textbf{A}^{(r)}\in \{0,1\}^{|\mathcal {V}|\times |\mathcal {V}|}\), and all \(\textbf{A}^{(r)}\) are organized into an adjacency tensor \(\mathcal {A}\in \mathbb {R}^{|\mathcal {V}|\times |\mathcal {V}|\times |\mathcal {R}|}\). In traditional heterogeneous graph modeling, this tensor reflects the direct connection information between nodes based on various types of relationships. However, the direct neighbor information is often insufficient due to issues such as sparsity and insufficient sampling, which limits the construction of meta-paths. To address this, GraphFlow proposes an enhanced adjacency tensor \(\textbf{A}^{+}\), which systematically reconstructs the potential connectivity patterns between nodes by incorporating latent direct neighbor information.
Specifically, for each relationship type \(r\in \mathcal {R}\), the enhanced adjacency matrix \(\textbf{A}^{(r)}+\) is constructed based on the original adjacency matrix \(\textbf{A}^{(r)}\). Let the target node be \(\mathcal {V}\), and the latent direct neighbors of node \(\nu \in \mathcal {V}\) in the \(\text{r}\)-th subgraph be denoted as \(\mathcal {N}_{\text{lat}}^{(r)}(\nu )\). The update rule for \(\textbf{A}^{(r)}+\) is defined as follows:
Where \(\mathcal {E}^{(r)}\) represents the edges formed by the original \(\text{r}\)-type relationships. Specifically, for each node \({\varvec{v}}\), the latent direct neighbor \({\varvec{u}}\) is added to the set of connecting edges based on the original edges, and assigned a binary label of 1. This mechanism ensures that for each relationship type, nodes can have richer neighborhood information that has been filtered based on importance.After stacking all the enhanced subgraph adjacency matrices, the enhanced adjacency tensor \(\mathcal {A}^+\in \mathbb {R}^{|\mathcal {V}|\times |\mathcal {V}|\times |\mathcal {R}|}\) is obtained, which can be formally expressed as:
It is important to note that the enhanced adjacency tensor \(\textbf{A}^{+}\) is not merely a simple expansion of edges. More importantly, by integrating the HodgeRank-based latent neighbor selection mechanism, each newly added connection corresponds to an optimally selected result within the local partial order structure. As a result, this mechanism effectively mitigates the risk of introducing noise from irrelevant nodes, while significantly enhancing the coverage of potential higher-order semantic information between nodes. Furthermore, to model the weight differences between node pairs across various relationship types, GraphFlow introduces a learnable relationship importance matrix \(\textbf{W}_r\) based on \(\textbf{A}^{+}\), defined as follows:
Here, \(\text{MLP}_r(\bullet )\) represents a layer-specific Multi-Layer Perceptron (MLP) for each relationship type \(\text{r}\), and \(\textbf{X}_{u}\), \(\textbf{X}_{v}\) are the initial features of nodes \({\varvec{v}}\) and \({\varvec{u}}\), respectively. By introducing \(\textbf{W}_r\), not only is the connection information between nodes recorded, but the model is also able to capture the variability in connection strength across different semantic relationships.
Multi-layer convolutional module
The GraphFlow multi-layer graph convolution module combines GCN graph convolution networks to adaptively obtain meta-paths and utilize message passing mechanisms to learn high-order and low-order semantic information on heterogeneous graphs. Take a two-layer GCN as an example to describe how the model captures meta-path information. For a single-layer GCN, the formula is shown in Equation 35:
\(\mathrm {H^{(l)}\in \mathbb {R}^{n\times d}}\) is the feature representation of the node at layer l, \(\mathrm {X\in \mathbb {R}^{n\times d}}\) is the feature vector of the target node, \(\text{W}^{(1)}\in \mathbb {R}^{\mathrm {m\times d}}\) is the model adaptive parameter matrix. This article adopts the advanced idea of SGC model, abandoning the activation function and directly training the parameters. The node features obtained through two-layer convolution are shown in formula 36:
\(\mathrm {W^{(2)}\in \mathbb {R}^{m\times d}}\) is the learnable parameter matrix of the second layer. To obtain a longer heterogeneous meta path, it can be extended to the \(\textit{l}\) layer, as shown in formula 37:
The multi-relation aggregation in the GraphFlow model is inspired by FAME. Experiments show that the optimal weight matrices for node embeddings obtained from meta-paths of different lengths are not the same. In GTN, similar to FAME, meta-paths of different lengths use the same weight matrix (i.e., W) for learning, which leads to weight conflicts during model training and limits performance improvement. Therefore, the GraphFlow model adopts independent weight learning matrices for each meta-path length to capture the varying impacts and importance of meta-paths of different lengths on node representation learning. Additionally, to further enhance efficiency, GraphFlow simplifies the GCN architecture by removing the nonlinear activation functions, as shown in Equation 38:
Where \(A^{l}\) represents the aggregated adjacency matrix of meta paths of length \(\textit{l}\) , and \(\beta _{r}\) is the independent weight matrix of adjacency matrix \(\mathbb {A}_r\) of type \(\textit{r}\) .
The proposed GraphFlow model utilizes the adjacency matrix product to obtain meta-paths of different lengths. However, initial experiments and result analysis reveal that this approach introduces conflicts regarding the importance of different meta-paths. As shown in Fig. 4, this is a user-item network containing two types of nodes (users and items) and four types of edge relationships between nodes (click, purchase, add to cart, and favorite). For example, as illustrated in Fig. 4a, this is a meta path with \(I_1\overset{buy}{{{\longrightarrow }}}U_1\overset{click}{{{\longrightarrow }}}I_2\) length of 2. Assuming that the meta paths \(I_1\overset{buy}{{{\longrightarrow }}}U_1,U_1\overset{click}{{{\longrightarrow }}}I_2\) with a length of 1 and their corresponding weights \(\beta _{buy}\) and \(\beta _{click}\) are important, their weights are relatively large (ranging from 0 to 1, closer to 1). Since the weight of the meta path with length 2 is calculated by multiplying the meta path with length 1 through the adjacency matrix, when both meta paths with length 1 are important, the meta path with length 2 composed of them should also be important. The weight of result \(I_1\overset{buy}{{{\longrightarrow }}}U_1\overset{click}{{{\longrightarrow }}}I_2\) calculated by \(\beta _{buy}\cdot \beta _{click}\) is actually smaller. This result will have a negative impact on the model, ultimately leading to a decrease in its influence. And as shown in Fig. 4b, assuming that \(I_1\overset{buy}{{{\rightarrow }}}U_1\) is important and \(I_3\overset{cart}{{{\rightarrow }}}U_1\) is not important, but meta path \(I_1\overset{buy}{{{\longrightarrow }}}U_1\overset{click}{{{\longrightarrow }}}I_2\) is important, this leads to \(I_3\overset{cart}{{{\rightarrow }}}U_1\) also being important, resulting in conflicting assumptions. The same applies to Fig. 4c. Therefore, in order to learn the weights of meta paths of different lengths, the multi-layer graph convolution of the GraphFlow model requires the use of completely independent aggregation weight parameters.

Explanation of contradictory elemental paths.
By completely independent aggregation, weight dependencies between different meta paths can be eliminated, thereby completely resolving weight conflicts between meta paths. The resulting adjacency matrices of different lengths are shown in formula 39:
In completely independent aggregation, a total of \(\Sigma _{i=1}^l|R|^l\) learnable parameters are used to aggregate different relationships, resulting in a combined adjacency matrix, and the weights of all meta paths of different lengths are completely independent. The final node embedding is represented by formulas 40 and 41:
\(\mathrm {H^l}\) represents the node representation of length \(\text{l}\), and \(\text{H}\) represents the final node representation.
Algorithm flow
In the GraphFlow framework, to fully leverage the advantages of information flow optimization and latent neighbor selection mechanisms, the model training phase must adopt flexible learning paradigms based on the characteristics of different tasks, including unsupervised learning and semi-supervised learning. This paper provides a detailed explanation of the overall training process and the specific implementation steps of each module, ensuring that information flow maximization and node embedding optimization proceed simultaneously. Please refer to Algorithm 1 for specific details: First, in the unsupervised learning scenario, GraphFlow employs a negative sampling strategy to optimize node representations, with the goal of minimizing the binary cross-entropy loss function based on node pairs. Specifically, given a target node \({\varvec{v}}\) and its potential positive neighbor \(u^{+}\) and negative neighbor \(u^{+}\), the unsupervised loss \(\mathcal {L}_{\text{unsup}}\) is defined as follows:
Here, \(\sigma (\bullet )\) represents the Sigmoid activation function, and \(\sin (\cdot ,\cdot )\) denotes the similarity measure between the feature vectors of node pairs, typically using either inner product or cosine similarity. In the semi-supervised learning scenario, the model incorporates node label supervisory signals and optimizes using the cross-entropy loss function \(\mathcal {L}_{\sup }\). This is defined as follows:
Here, \(V_{l}\) represents the set of labeled nodes, \(\text {c}\) is the number of classes, and \(\mathcal {Y}_{\nu c}\) is the indicator variable for the true label of node \({\varvec{v}}\) in class \(\text {c}.\)

The overall process of GraphFlow.
Experimental results and analysis
Dataset
Six publicly available real datasets were used in the experimental evaluation. The statistical data of these six datasets are shown in Table 1.
-
Amazon: A dataset focused on product categories, where there is only one type of product (electronic) and the relationships between nodes are limited to two types: query and purchase.
-
Alibaba: A dataset composed of user and product nodes. The relationships between the nodes include four types: click, purchase, add to cart, and favorite. Product categories serve as the labels for nodes in classification tasks.
-
AMiner: A citation network dataset in the computer science field, consisting of nodes representing authors (A), papers (P), and conferences (C).
-
DBLP: A bibliographic network consisting of 4057 authors (A), 14528 papers (P), 7723 terms (T), and 20 conferences (C).
-
IMDB: A subset of data collected from an online movie database, used in this section to extract relationships between actors, movies, and directors.
-
Retailrocket: A dataset generated by the online shopping site Retailrocket over 4 months, documenting three types of user behavior: purchase, page view, and add to cart.
Baseline model
Heterogeneous Graph Embedding Methods:
-
Metapath2vec (M2V)25 : A heterogeneous graph embedding method that performs meta-path-based random walks and uses the skip-gram model to embed heterogeneous graph feature information.
-
R-GCN24 : Considers the influence of different edge types on nodes and applies weight sharing and coefficient constraints in heterogeneous graphs.
-
HAN19 : A graph attention network applied to multiplex networks, using manually selected meta-paths to learn node embeddings.
-
NARS26 : Decouples heterogeneous graphs based on edge types and then aggregates neighbor features on decoupled subgraphs.
-
MAGNN27 : A meta-path aggregation GNN for heterogeneous graphs that considers intermediate node feature information within meta-paths.
-
HPN28 : Designs a semantic propagation mechanism to alleviate semantic confusion and a semantic fusion mechanism to integrate rich semantics.
Multi-Path Heterogeneous Graph Embedding Methods:
-
PMNE15 : Includes three different models to combine multiplex networks, generating an overall embedding for each node, represented as PMNE-n, PMNE-r, and PMNE-c.
-
MNE29 : Combines high-dimensional general embeddings with low-dimensional hierarchical embeddings to obtain the final embedding.
-
GATNE30 : Includes two variants, GATNE-T and GATNE-I, that learn complex semantic information in heterogeneous graphs.
-
GTN11 : Converts a heterogeneous graph into multiple meta-path graphs and then learns node embeddings on these meta-path graphs using GCN.
-
DMGI31 : Integrates node embeddings from multiple graphs by introducing a consensus regularization framework and a universal discriminator.
-
FAME32 : A heterogeneous information network embedding method based on random projection, using spectral graph transformation to capture meta-paths and improve efficiency through random projection.
-
HGSL33 : An advanced heterogeneous GNN that performs parallel heterogeneous graph structure learning and GNN parameter learning to achieve classification tasks.
-
HGTN34 : Uses hypergraphs to capture heterogeneous information in heterogeneous information networks.
Meta-path-free embedding Methods :
-
SeHGNN17 : Achieve efficient and accurate heterogeneous graph node representation through “single-layer, long-range paths,” “parameter-free neighbor aggregation,” and “Transformer semantic fusion.”
-
SR-RSC18 In heterogeneous graph convolutions, we introduce “relationship-level residual connections” to solve the common problems of over-smoothing and gradient vanishing in deep networks.
For a fair comparison, the embedding dimension of all the above models was set to 256 and the number of training rounds was set to 200. all the models were trained independently by the Adam optimizer so that each baseline model would yield the best performance. For the random-walk based approach, the walk length of each node was set to 100 for 1000 iterations, the window size was set to 5, the number of negative samples was set to 7, and the number of walks per node was set to 40. For the homomorphic graph embedding approach, the training was performed by ignoring the heterogeneity of the nodes and edges. The other base models are set according to the hyperparameters recommended in the original paper and tuned to the best. In the potential direct neighbor selection step, the set of candidate nodes within h hops from the target node is obtained, where h is set from 1 to 5, and all these paths are converted to ordinal pairs and the ordinal pairs occurring in repeated paths are retained.For the proposed GraphFlow method, the model layer is set to 3 and the number of training rounds is set to 200.
Node classification
For node classification, the training set consists of 80% of data nodes, with the remaining 20% used as the training and validation sets. The experiment was repeated 10 times and the average was taken as the node classification prediction result. The detailed results are shown in Table 2:
The experimental results are shown in Table 2, with the best results highlighted in bold, and the best results in the baselines underlined. The first eight baselines are unsuper- vised learning methods, while the remaining methods are semi-supervised.
1.GraphFlow vs Traditional Heterogeneous Graph Methods, Unlike traditional heterogeneous graph methods, GraphFlow shifts from neighbor feature aggregation to information flow path optimization. Essentially, GraphFlow maximizes the effective information flow between the target node and its potential neighbors, dynamically selecting the most contributive relational paths. This significantly enhances the discriminative power of node feature representations.
2.Efficient Neighbor Discovery and Node Information Reconstruction, graphFlow combines random walks with HodgeRank ranking to systematically explore potential high-efficiency neighbors, reconstructing the local information network of nodes. Additionally, during the multi-layer graph convolution phase, GraphFlow assigns independent weight matrices for meta-paths of different lengths and relationships. This avoids cross-relation conflicts and feature interference, further enhancing the semantic hierarchy and relational discriminability of node representations.
3.Optimization of Node Representation Alignment. GraphFlow is designed with the core objective of minimizing the lower bound of node representation error. Theoretically, through the dual mechanism of latent neighbor expansion and information flow optimization, it significantly strengthens the alignment between node features and neighborhood structures. Compared to traditional approaches that rely on static meta-path designs or single neighbor aggregation, GraphFlow’s systematic information flow-driven paradigm significantly improves the quality of node representation information.
4.The GraphFlow model performs well on most datasets, yet its performance on the DBLP dataset is inferior to the best baseline. This phenomenon may stem from the fact that the design of the GraphFlow model focuses on mining potential neighbors, while relatively weakening the relationship between edges. In datasets with a large number of edges, this characteristic may affect the model’s performance to some extent.
Link prediction
For link prediction, this paper randomly selects 85%, 5%, and 10% of the edges as the training, validation, and test sets, respectively. Simultaneously, an equal number of negative node pairs (i.e., node pairs that are not connected) are randomly sampled and added to the training, validation, and test sets. The edge types between the negative node pairs are predicted using all edge types in the dataset. The experiment is repeated 10 times, and the average results are reported. The experimental results are shown in Tables 3 and 4:
1.Information Flow Maximization: GraphFlow centers around maximizing information flow, using HodgeRank to select potential neighbors, effectively addressing the issue of local information fragmentation present in traditional neighbor sampling. Unlike fixed neighbor aggregation or static meta-path methods, GraphFlow dynamically identifies the most influential neighbors around a node, restructuring the local network based on the distribution of information flow. This neighbor optimization strategy, which focuses on the effectiveness of information rather than simple topological connectivity, significantly improves the semantic consistency and structural discriminability of node embeddings in link prediction tasks.
2.Enhanced Neighbor Discovery and Multi-Relation Path Encoding. GraphFlow leverages an augmented adjacency tensor following latent neighbor expansion to systematically encode multi-order, multi-relational path information. Through a multi-layer convolutional network, it gradually refines node representations. Meta-path interactions of different relation types are adaptively weighted, effectively preventing issues of relation noise and excessive coupling. This results in fine-grained semantic fusion and multi-scale structural awareness within heterogeneous graphs. Compared to traditional manually designed meta-paths, GraphFlow significantly enhances the automatic search and optimization of meta-path combinations, ensuring that node representations fully capture potential higher-order patterns.
3.Theoretical Basis and Generalization Across Graphs. Theoretically, GraphFlow aims to minimize the lower bound of node representation error, emphasizing the consistency-enhancing effect of latent neighbor selection and information flow reconstruction in feature learning. By analyzing and ranking local partial order information using HodgeRank, it avoids the inconsistencies and noise that might arise during latent neighbor selection, ensuring stability in the training process and consistency in optimization direction. This mechanism has not only achieved high prediction accuracy in complex heterogeneous environments like Alibaba and IMDB, but also demonstrated significant performance advantages in general heterogeneous graphs like DBLP with multiple node types. This fully validates the universality and strong generalization capabilities of the GraphFlow model.
Analysis of ablation experiment
This section further validates the effectiveness of each module in the model through ablation experiments. The following variants are considered:
-
\(GF_R\): This variant does not consider the importance of different relations , the weight \(\beta _{\text{r}}\) is set to 1.
-
\(GF_L\): This variant uses only two layers of GCN to obtain node feature representations, thus capturing only meta-paths of length 2.
-
\(GF_{NOL}\): This variant does not use independent aggregation parameters in the convolutional layers.
-
\(GF_{NOH}\): This variant does not use the HodgeRank algorithm to expand the candidate neighbor set.
-
\(\text{GF}_{\text{AVT}}\): This variant uses activation functions to test performance.
-
GF NONH: This variant does not use neighbor tensor enhancement.
Table 5 presents the results of the ablation study on three node classification datasets. From the results, it is clear that neglecting the importance of relations, using fewer layers to train the model, and not utilizing independent aggregation parameters all limit the model’s performance, reducing its performance ceiling. Additionally, not using the HodgeRank algorithm to rank and filter the candidate node set leads to the model performing the worst among the variants.
The experimental results also demonstrate the effectiveness and rationale behind the proposed GraphFlow model. The comparison of \(GraphFlow_NOH\) and GraphFlow reflects the importance of the HodgeRank latent direct neighbor selection module. A non-discriminatory selection of candidate nodes results in learned node features that lack discriminability and introduce considerable noise, adversely affecting model performance. Comparisons between \(GraphFlow_R\), \(GraphFlow_L\), \(GraphFlow_NOL\), and GraphFlow reflect the significance of the proposed multi-layer graph convolution module. This indicates that the multi-layer graph convolution module can effectively and adaptively learn both short and long meta-paths, fully exploring the heterogeneous graph structure to learn global feature attributes and providing richer information sources for the target node’s features.
Parameter sensitivity analysis
Finally, this paper investigates the sensitivity of the GraphFlow model to the parameters of random walk path length p, node feature dimension d, and training epochs. Figure 4 presents the Macro-F1 scores for the node classification task with different parameter settings across four datasets.

Parameter sensitivity analysis.
-
(1)
Analysis of Random Walk Path Length: The experimental results shown in Fig. 5a reveal that the performance of the GraphFlow model initially improves as the random walk path length p increases. However, when \(\mathrm {p\geqslant 30}\), the performance starts to slightly decline, though the impact is minimal. From the analysis, it can be concluded that increasing the walk path length improves performance because longer path walks allow for a more comprehensive exploration of the target node’s neighborhood, leading to the selection of more and higher-quality candidate neighbors. However, the performance does not significantly improve with excessively long paths because the most influential neighbors for the target node are those within its immediate neighborhood. Exploring distant neighborhoods does not bring performance gains. Additionally, the use of the HodgeRank algorithm for proper global ranking ensures that the model can distinguish useful nodes as potential neighbors, preventing significant performance drops due to inappropriate path lengths.
-
(2)
Analysis of Node Feature Dimensions: The experimental results shown in Fig. 5b indicate that as the feature dimension d increases, the performance of GraphFlow first gradually improves and then slightly decreases. The best performance is achieved when d = 200 across all four datasets. This is because when the feature dimension d is too small, the features of all nodes are compressed into a small vector space, making it difficult to retain the feature proximity between all node pairs. On the other hand, larger dimensions cause the distance between node features to increase, introducing noise into the feature learning process. This noise prevents an accurate representation of the proximity between the target node and candidate nodes.
-
(3)
Training round analysis: Figure 5c illustrates the performance of the proposed GraphFlow in terms of the number of training epochs. It can be concluded that the proposed model converges quickly and efficiently, achieving stable performance within 80 epochs across nearly all test datasets. This also reflects the high efficiency of the model.
The regularization coefficient \(\lambda\) plays a crucial role in information flow optimization and potential neighbor selection to avoid information oversmoothing. To evaluate the importance of \(\lambda\), node classification experiments were conducted on two datasets (DBLP and IMDB):

Hyperparametric sensitivity of the node classification regularization factor \(\lambda\).
The experimental results show that the optimal \(\lambda\) setting of the proposed model varies from dataset to dataset (As shown in Fig. 6). The best performance is obtained when \(\lambda\) = 0.7 on DBLP and \(\lambda\) = 0.6 on IMDB. In this paper, we observe that the optimal setting of \(\lambda\) is usually greater than 0.5 and the learned node representations provide better discrimination. In addition, the experimental results for all datasets with \(\lambda\) at its maximum and minimum are not optimal, which suggests that the model in this chapter obtains the best results by considering the isomorphic and heterogeneous subgraph information in a relatively balanced way, which again demonstrates the effectiveness of this strategy.
Calculate cost analysis
The computational overhead associated with the generation of potential direct neighbors arises from two primary steps: the generation of candidate neighbors and the selection of potential direct neighbors. The computational cost of these components primarily stems from random walk sampling and the HodgeRank ranking of node pairs. Notably, the cost of random walk sampling is not significantly greater than that of the random walk variants employed by other heterogeneous models, such as HetGNN and HGT. Furthermore, in practice, the HodgeRank scores can be readily computed using linear least squares regression. For linear least squares problems, not only is there an analytical solution, but several efficient numerical algorithms also exist. Specifically, for each given target node, the scale of the corresponding least squares problem is determined by the number of candidate nodes, which is typically quite small, thus keeping the computational overhead minimal.Moreover, when the proposed potential direct neighbor generation is applied to large-scale heterogeneous graphs, both random walk sampling and HodgeRank operations need to be executed only once and can be pre-computed. Additionally, the generation of candidate neighbors and the computation of HodgeRank scores for the target nodes operate independently of other target nodes. This independence allows for the potential utilization of distributed computing techniques to further accelerate these two processes and reduce computational costs. In summary, when the methodology presented in this paper is employed in large-scale heterogeneous graphs, the computational costs remain manageable.
The multi-layer graph convolution module consists primarily of two computational components: the subgraph generation module and the multi-layer graph convolution module. The time complexity of the subgraph generation module is denoted as \(\mathcal {O}(|R|n^2)\), while the time complexity of the graph convolution is represented as \(\mathcal {O}(n^{2}dl+mdn+nd^{2}(l-1))\). Consequently, the overall time complexity of the GraphFlow is characterized as \(\mathcal {O}(n^2(|R|^n+ndl)^n+mdn^n+nd^2(l^n-1))\). This chapter also compares the efficiency of the proposed model with other GNN baseline models in the context of semi-supervised node classification. Notably, the proposed model demonstrates rapid convergence within 80 training epochs, indicating that it does not necessitate the 200 epochs set for assessment in conventional training experiments, thereby achieving greater efficiency.
Conclusion
In this paper, we propose GraphFlow, a novel framework for learning node representations on heterogeneous graphs. The method presented in this chapter first generates indirect neighbors as candidates through random walks. Then, using HodgeRank, high-correlation candidate nodes are selected as potential neighbors to supplement the target node’s neighborhood relationships. Finally, based on the adjacency tensor reconstructed from the potential neighbors, GraphFlow leverages a multi-layer graph convolution module to adaptively learn the interactions between long and short meta-paths across multiple semantics. It uses fully independent parameter aggregation to resolve weight conflicts between different meta-paths, ensuring that the node feature learning is both more meaningful and more distinguishable. Experiments on six real-world datasets successfully validate the superiority of the proposed GraphFlow in link prediction and node classification tasks.In future work, we will aim to reduce the computational overhead associated with model runtime. While the proposed model is suitable for large-scale datasets, it is constrained by hardware limitations. The multi-layer convolution model entails substantial computational demands, leading to an increase in the size of the resultant matrices, which consequently extends the runtime. In subsequent phases, we plan to utilize servers equipped with superior hardware to further validate the algorithm’s performance35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50.
Data availability
The datasets in this article are all publicly available datasets. ACM, DBLP, and Freebase all originate from the HGB benchmark (https://github.com/THUDM/HGB). If you need any code, you can contact the author Wu Yufei, to obtain the data.
References
Song, X. et al. Bi-CLKT: Bi-graph contrastive learning based knowledge tracing. Knowl. Based Syst. 241, 108274 (2022).
Song, X. et al. Jkt: A joint graph convolutional network based deep knowledge tracing. Inform. Sci. 580, 510–523 (2021).
Gao, H. & Ji, S. Graph U-Nets. In ICML 2083–2092 (2019).
Zhang, M., Cui, Z., Neumann, M. & Chen, Y. An end-to-end deep learning architecture for graph classification. In AAAI 4438–4445 (2018).
Kipf, T. N. & Welling, M. Variational graph auto-encoders. arXiv preprint (2016). arXiv:1611.07308.
Rex, J. Y. & Leskovec. J. Position-aware graph neural networks. In ICML 7134–7143 (2019).
Schlichtkrull, M. et al. Modeling relational data with graph convolutional networks. In European Semantic Web Conference 593–607 (Springer, 2018).
Vaghari, H., Aghdam, M. H. & Emami, H. DIARec: Dynamic intention-aware recommendation with attention-based context-aware item attributes modeling. J. Artif. Intell. Soft Comput. Res. 14(2), 171–189 (2024).
Vaghari, H., Aghdam, M. H. & Emami, H. HAN: Hierarchical attention network for learning latent context-aware user preferences with attribute awareness. IEEE Access (2025).
Vaghari, H., Hosseinzadeh Aghdam, M. & Emami, H. Group attention for collaborative filtering with sequential feedback and context aware attributes. Sci. Rep. 15(1), 10050 (2025).
Yun, S. et al. Graph transformer networks. Adv. Neural Inf. Process. Syst. 32 (2019).
Yun, S. et al. Graph Transformer Networks: Learning meta-path graphs to improve GNNs. Neural Netw. 153, 104–119 (2022).
Müller, L. et al. Attending to graph transformers. arXiv preprint arXiv:2302.04181 (2023).
Sun, Y., Han, J., Yan, X., Yu, P. S. & Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 4(11), 992–1003 (2011).
Defferrard, M., Bresson, X., & Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems vol. 29 (2016).
Dong, Y., Chawla, N. V., & Swami, A. Metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 135–144 (2017).
Yang, X. et al. Simple and efficient heterogeneous graph neural network. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 37 (2023).
Zhang, R., Zimek, A. & Schneider-Kamp, P. A simple meta-path-free framework for heterogeneous network embedding. Proceedings of the 31st ACM International Conference on Information & Knowledge Management (2022).
Wang, X. et al. Heterogeneous graph attention network. In WWW 2022–2032 (2019).
Fu, X. et al. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. Proceedings of the Web Conference 2331–2341 (2020).
Wu, Z. et al. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 32(1), 4–24 (2020).
Goyal, P. & Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl.-Based Syst. 151, 78–94 (2018).
Qiu, J. et al. GCC: Graph contrastive coding for graph neural network pre-training. In KDD 1150–1160 (2020).
Wang, X. et al. Dynamic heterogeneous information network embedding with meta-path based proximity. IEEE Trans. Knowl. Data Eng. 34(3), 1117–1132 (2022).
Dong, Y., Chawla, N. V. & Swami, A. Metapath2vec: Scalable representation learning for heterogeneous networks. in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 135–144 (2017).
Zhang, C., Swami, A. & Chawla, N. V. Shne: Representation learning for semantic-associated heterogeneous networks. in Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining 690–698 (2019).
Zhang, C., Song, D., Huang, C., Swami, A., & Chawla, N. V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2018).
Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9(11), 2579–2605 (2008).
Jing, B., Park, C. & Tong, H. Hdmi: High-order deep multiplex infomax. in Proceedings of the Web Conference 2021 2414–2424 (2021).
Kipf, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (2017).
Park, C., Kim, D., Han, J. & Yu. H. Unsupervised attributed multiplex network embedding. In AAAI 5371–5378 (2020).
Hamilton, W., Ying, Z., & Leskovec, J. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems vol. 30 (2017).
Zhang, Q., Wu, X., Yang, Q., Zhang, C. & Zhang, X. Few-shot heterogeneous graph learning via cross-domain knowledge transfer. in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2450–2460 (2022).
Bruna, J., Zaremba, W., Szlam, A., & LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv preprint arXiv:1312.6203 (2013).
Fan, W. et al. Graph neural networks for social recommendation. In WWW 417–426 (2019).
Ying, R. et al. Graph convolutional neural networks for web-scale recommender systems. In SIGKDD 974–983 (2018).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. in International Conference on Machine Learning 1597–1607 (PMLR, 2020).
Fan, S. et al. Metapath-guided heterogeneous graph neural network for intent recommendation. In SIGKDD 2478–2486 (2019).
Fan, Y., Hou, S., Zhang, Y., Ye, Y. & Abdulhayoglu. M. Gotcha - Sly Malware!: Scorpion A Metagraph2vec Based Malware Detection System. In SIGKDD 253–262 (2018).
Wang, X. et al. A survey on heterogeneous graph embedding: Methods, techniques, applications and sources. IEEE Trans. Big Data (2022).
Sun, Y. & Han, J. Mining heterogeneous information networks: A structural analysis approach. SIGKDD Explor. 2012, 20–28 (2012).
Wang, X., Liu, N., Han, H., & Shi, C. Self-supervised heterogeneous graph neural network with contrastive learning. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining 1726–1736 (2021).
Zhou, M. & Gong, Z. GraphSR: A data augmentation algorithm for imbalanced node classification. Proceedings of the AAAI Conference on Artificial Intelligence 37(4), 4954–4962 (2023).
Li, Q., Ni, H. & Wang, Y. NHGMI: Heterogeneous graph multi-view infomax with node-wise contrasting samples selection. Knowl.-Based Syst. 289, 111520 (2024).
Zhang, C., Song, D., Huang, C., Swami, A. & Chawla, N. V. Heterogeneous graph neural network. in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 793–803 (2019).
Lin, W. & Li, B. Status-aware signed heterogeneous network embedding with graph neural networksIEEE Trans. Neural Netw. Learn. Syst. (2022).
Shen, X. et al. Neighbor contrastive learning on learnable graph augmentation. Proceedings of the AAAI Conference on Artificial Intelligence 37(8), 9782–9791 (2023).
Veličković, P. et al. Graph attention networks. In International Conference on Learning Representations (2018).
Tang, J. et al. Line: Large-scale information network embedding. in Proceedings of the 24th International Conference on World Wide Web 1067–1077 (2015).
Yu, L. et al. Heterogeneous graph representation learning with relation awareness. IEEE Trans. Knowl. Data Eng. (2022).
Acknowledgements
This paper is based on the research project hky25002 of technical service for analyzing power load data in typical industries and universities in Hebei Province and Basic Research Funds for Universities in Hebei Province in 2025 Project 2025YBTD02, Research on Theoretical Methods of Graph Representation Learning Based on Random Walk and Meta-Path Aggregation.
Author information
Authors and Affiliations
Contributions
[Yufei Wu]: Conceptualization, Methodology, Formal analysis, Investigation, Data Curation, Writing-Original Draft, Visualization. [Xiumei Wen]: Resources, Supervision, Project administration, Funding acquisition, Writing – Review & Editing. [Wei Chen]: Investigation, Data Curation, Writing-Original Draft. [Yingxue Mu]: Supervision, Writing – Review & Editing, Funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, Y., Wen, X., Chen, W. et al. Information flow optimization for adaptive neighbor selection graph embedding. Sci Rep 15, 40108 (2025). https://doi.org/10.1038/s41598-025-23811-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-23811-4
