
Abstract
This study addresses the mental health challenges faced by students majoring in sports education and explores more effective strategies for mental health education. Using Internet of Things (IoT) data mining, relevant datasets are collected and categorized. A Random Forest (RF) model is then trained and optimized through a genetic algorithm, resulting in the Genetic Algorithm–Random Forest (GA-RF) psychological state perception model. The model is evaluated against multiple classification approaches. In the depression dichotomy experiment, the GA-RF model achieves superior results, with an optimized accuracy and an F1 score of 0.81, outperforming other algorithms in psychological state perception. By applying this model, routine data from students’ daily activities can be analyzed to provide timely insights into their mental health. These insights support adjustments to teaching content and offer schools an evidence-based approach to improving instruction. Overall, the GA-RF model enhances data mining and prediction of students’ psychological states, making it a valuable tool for advancing mental health education in sports education programs.
Similar content being viewed by others


Introduction
Currently, students majoring in sports education face intense competition and significant pressure from various societal factors, which increases their risk of developing mental health problems. This highlights the urgent need for adaptive mental health education strategies that address contemporary challenges. With the rapid advancement of information technology, schools are continuously upgrading their information systems, which now store comprehensive data on students’ academic and daily lives. The accumulation of this information has given rise to the concept of student-related big data in educational institutions. To maximize the value of these data resources, it is essential to apply big data technologies in school management, particularly for identifying and supporting students who exhibit abnormal behaviors. Effectively integrating big data with Internet of Things (IoT) technologies is not only a practical concern for schools but also an important issue for academic research.
Two primary approaches are commonly used to analyze students’ mental health through data mining models1. The first relies on psychological analysis based on social network data. For example, studies using Sina Weibo data have predicted users’ personality traits, while research on student depression2 has applied regression models based on activity indices collected over specific time periods. The second approach investigates factors influencing mental health. Some scholars have examined correlations between psychological conditions such as depression and anxiety and students’ personal circumstances. However, both approaches have limitations. Most existing studies focus either on the behavioral analysis of specific groups or on isolated psychological factors3.
To address these limitations, mental state perception models such as the Genetic Algorithm–Random Forest (GA-RF) are developed through a systematic process involving dataset preparation, segmentation, algorithm preselection, and model training. The overall design of the GA-RF perception model is summarized in the literature4. In the experimental evaluation, multiple classification models are compared, and GA-RF demonstrates the best performance. This model enables effective mining and analysis of behavioral data from sports education students, thereby unlocking the potential value of such data5. When integrated with IoT systems in schools, it facilitates the continuous collection of students’ academic and daily activity data, providing theoretical support for refining teaching strategies. The effective use of these data allows teaching methods and mental health support to progress in parallel. Overall, the GA-RF model enhances data mining and prediction of students’ psychological states, contributing to the development of adaptive mental health education strategies for sports education students6.
Although existing studies have made progress in applying big data and data mining methods to analyze students’ mental health, several limitations remain. First, most research relies on a single type of data source, such as social network or academic behavior data, while neglecting the integrated behavioral characteristics of sports education students across training, study, and daily life. Second, current models primarily depend on traditional classification algorithms such as decision trees, SVM, or standard random forest (RF), which lack effective mechanisms for optimizing high-dimensional redundant features. As a result, prediction accuracy and stability remain insufficient in complex scenarios. Third, research specifically targeting sports education students is relatively scarce, even though this group is particularly vulnerable to psychological risks due to training intensity, academic demands, and employment pressures. Therefore, there is an urgent need for an innovative model that can integrate multi-source data while improving prediction precision and adaptability.
The main contributions of this study are as follows: (1) A genetic algorithm (GA)-based feature selection mechanism is introduced into the field of psychological state perception for sports education students. This mechanism addresses the problems of feature redundancy and low information density in high-dimensional behavioral data, thereby improving both efficiency and accuracy. (2) A GA-RF hybrid model is proposed and constructed. The model combined the GA’s ability to select optimal feature subsets with the RF’s robustness in handling high-dimensional, nonlinear, and noisy data through ensemble learning. This integration enabled more accurate and stable classification of psychological states. (3) Significant associations between specific behavioral features (e.g., patterns of study duration and daily routines) and mental health conditions, particularly depressive tendencies, are further examined and validated. These results not only enhance the model but also provide new insights into the factors influencing the mental health of sports education students. (4) An adaptive pathway was developed and implemented that utilized IoT technologies to continuously collect students’ daily behavioral data. This data was then processed using the optimized big data mining model to enable dynamic perception of psychological states. This pathway offers both theoretical guidance and data-driven decision support for schools to implement timely, personalized mental health interventions and instructional adjustments.
Related work
With advances in wearable devices and multimodal sensing technologies, mental health monitoring has gradually shifted from reliance on single social data sources toward integrated physiological–behavioral analysis. Zhao et al. (2025) constructed a multidimensional diagnostic model for depression by integrating electrocardiogram, electroencephalogram, and motion sensor data, and confirmed the supplementary value of biosignals in mental state assessment7. Alkurdi et al.8 further extended anxiety detection beyond laboratory settings, revealing how environmental stressors interfered with the validity of wearable device data. At the algorithmic level, traditional feature selection methods struggled to handle high-dimensional heterogeneous data. To address this challenge, Begum et al. (2025) proposed a chaotic simulated binary particle swarm optimization algorithm that significantly improved feature subset discriminability for depression detection9. Similarly, Atta et al.10 demonstrated that swarm-intelligence-optimized neural networks outperformed conventional machine learning methods in automated depression screening. For sports education students, mental health issues often interact with training load. Song et al. (2025), through a systematic review of running shoe biomechanics, identified associations between abnormal plantar pressure distribution and injury-related depression11. Likewise, Dorugade et al.12 developed a nonlinear seating dynamics model that provided new tools for evaluating fatigue caused by long-term training. The digital therapeutics field also experienced rapid innovation. Halkiopoulos et al.13 highlighted the central role of machine learning in enhancing augmented/virtual reality–based cognitive therapy. Troussas et al. (2025) designed a reinforcement learning–driven dynamic fuzzy weight adjustment framework to support adaptive interactions in educational software14. Torous et al. further argued that generative artificial intelligence and virtual reality reshaped paradigms for digital mental health interventions. In addition, Rudnik et al. reported that cognitive flexibility mediated the relationship between stress, fatigue, and empathy among medical students15,16. This finding offered important implications for research on psychological resilience in sports education students. A comparative summary of mental health perception technologies is provided in Table 1.
As shown in Table 1, this study differs from approaches that rely on medical devices or virtual reality systems. Instead, it uniquely uses native campus IoT behavioral data as inputs. A GA–RF hybrid model is applied to achieve low-cost perception of the psychological states of sports education students. Compared with social media analytics or educational software–based methods, the proposed model specifically captures features such as training duration and exercise intensity. This enables a quantifiable analysis of the relationship between training load and depressive states. Most importantly, the system directly interfaces with teaching management platforms to generate intervention strategies (e.g., dynamic adjustment of training plans), forming an education-specific “perception–decision” closed loop. This fills a critical gap in the practical implementation of mental health perception technologies within campus environments.
Materials and methods
Data mining technology
Data mining refers to the process of extracting meaningful information from large, incomplete, and noisy datasets17. With the rapid development of society and technology, data is now generated at an unprecedented rate, making it increasingly challenging to identify critical information within complex datasets18. As a method for managing, analyzing, and processing information, data mining plays a vital role in uncovering essential insights from massive amounts of data. The process typically involves filtering raw data to obtain relevant objects in a standardized format. These objects are then processed in the mining core to generate a set of patterns. Through further refinement, the system extracts valuable information, thereby completing the mining process19. The overall framework of the data mining process is illustrated in Fig. 1.

Data mining model.
The specific steps of data mining vary across environments and can be adjusted to suit different contexts. These steps are fine-tuned depending on the scenario, as various data mining techniques possess distinct characteristics and operational processes. Figure 2 illustrates a generalized overview of the data mining process20.

Data mining process.
Classification is a fundamental component of data mining and plays a central role in many mining systems21. It involves constructing a classification function based on training data and applying the model to categorize new, unprocessed data, enabling rapid and accurate predictions22. Commonly used classification algorithms include the following:
(1) Decision Tree Algorithm: This inductive algorithm constructs a decision tree model from a dataset, offering a straightforward and interpretable classification method23. It follows a top-down recursive approach: the root node is selected using attribute classification metrics, and the dataset is progressively partitioned into subsets. Each terminal leaf node corresponds to a category, and the paths from root to leaf define the classification rules. Figure 3 illustrates the principle of the decision tree algorithm, using gender characteristics as an example.

Principle flow of decision tree.
(2) Artificial Neural Network (ANN) Classification Algorithm: Based on the perceptron model, the ANN algorithm simulates the structure and function of biological neural networks. It is capable of automatic feature learning and requires minimal human intervention during the training and classification process24.
(3) Bayesian Classification Algorithm: This algorithm applies Bayes’ theorem to compute the posterior probability of an object based on its prior probability, assigning the object to the class with the highest posterior probability. Although similar in performance to decision trees and neural networks, the Naive Bayes classifier often demonstrates advantages in certain domains. A notable strength of Bayesian learning is its ability to update hypothesis probabilities incrementally with new training data, rather than discarding earlier hypotheses25. By combining prior knowledge, probabilistic reasoning, and observed data, Bayesian models not only make predictions but also quantify uncertainty—for example, estimating that “there is an 88% probability that the student will pass the exam” or “a 77% likelihood of rain tomorrow”26. However, Bayesian methods require prior knowledge of probability distributions, and computing the optimal hypothesis can be computationally expensive. In specific cases, this cost can be reduced. Figure 4 presents the principle of Bayesian classification with probability notations a and b.

Bayesian theory diagram.
(4) Support Vector Machine (SVM): The SVM is a widely used binary classification model27. Its core principle is to maximize the margin between data points in the feature space using a linear classifier28. For nonlinear classification tasks, SVM employs kernel functions to map the input data into a higher-dimensional space, where linear separation becomes possible. For linearly separable data, the dataset D can be represented as shown in Eq. (1):
where Xi and Yi denote the feature vectors and category labels, respectively. Figure 5 illustrates the concept of a linearly separable dataset.

Linearly separable datasets.
As shown in Fig. 5, multiple lines or hyperplanes can separate the two data categories29. The key objective of SVM is to identify the optimal hyperplane that minimizes classification errors while maximizing the margin between the classes. The linear hyperplane can be expressed as shown in Eqs. (2),
where ω represents the weight vector and b denotes the bias term. The margins H₁ and H₂ are defined in Eqs. (3) and (4).
The data points that lie directly on these margin boundaries are referred to as support vectors. Identifying the optimal hyperplane is formulated as a convex quadratic optimization problem, with the objective function defined in Eq. (5).
The evaluation of classification performance relies heavily on the confusion matrix, which serves as a core tool in classification analysis. Figure 6 illustrates the detailed structure of the confusion matrix.

Confusion matrix.
Figure 6 presents the four components of the confusion matrix, defined as follows:
True Positive (TP): A positive instance correctly classified as positive.
True Negative (TN): A negative instance correctly classified as negative30.
False Positive (FP): A negative instance incorrectly classified as positive.
False Negative (FN): A positive instance incorrectly classified as negative.
Based on these parameters, several evaluation metrics are derived to assess classification model performance:
Accuracy: Also referred to as the overall recognition rate, it measures the proportion of correctly classified instances across the entire dataset.
Precision: The proportion of correctly classified positive instances out of all instances predicted as positive, reflecting the reliability of positive predictions.
Recall: Also known as sensitivity, it measures the proportion of correctly identified positive instances, indicating the model’s ability to capture relevant cases31.
F1 Score: The harmonic mean of precision and recall, providing a balanced measure of a model’s classification performance. The F1 Score ranges from 0 to 1, with higher values representing better performance.
The formulas for these evaluation metrics are given in Eqs. (6)–(9).
Ensemble learning algorithms are designed to combine the strengths of multiple models while compensating for their individual weaknesses32. In data mining, no single algorithm is without limitations, making ensemble methods particularly valuable. The central principle is to integrate diverse models in a manner that enhances the overall classification performance of the dataset33. Two widely used ensemble techniques are Bagging and Boosting.
Bagging (Bootstrap Aggregating): This method improves classification stability by combining the outputs of multiple base classifiers through majority voting. To reduce correlation among classifiers, Bagging generates diverse training datasets via resampling with replacement34. Each classifier then makes independent predictions, contributing to the robustness of the final model.
Boosting: This technique aims to improve classification accuracy by emphasizing the errors of prior classifiers. Base classifiers are trained sequentially, with each new model assigning greater weight to previously misclassified samples35. Through this iterative process, Boosting reduces misclassification rates and enhances overall performance36.
(1) In this study, several ensemble methods were applied. For example, RF, an implementation of Bagging, constructs multiple decision trees and aggregates their predictions through majority voting. The workflow of RF is illustrated in Fig. 7.

Algorithm flow of RF.
The classification performance of the RF algorithm largely depends on the quality of its individual decision trees37. When the decision trees perform well, the overall accuracy of the RF model improves. However, the effectiveness of RF decreases as the correlation between decision trees increases, since highly correlated trees are more likely to make similar errors38. The degree of correlation is influenced by the number of features selected (denoted as m). A larger m generally results in stronger correlations among trees. To address this, the RF algorithm employs the bootstrap sampling method. Samples excluded during the bootstrap process, known as out-of-bag (OOB) samples, are used to estimate the model’s error rate. The calculation of the OOB error rate follows three steps: (1) Each OOB sample is classified using the RF model. (2) The final classification is determined by aggregating the votes from all decision trees. (3) The OOB error rate is computed as the ratio of misclassified OOB samples to the total number of samples. This error rate provides an unbiased estimate of the RF model’s generalization performance39.
Model building based on GA
Current approaches to mental health education for sports education students lack sufficient personalization and adaptability. As a result, the identification of mental health issues is often delayed and ineffective, negatively affecting students’ learning and daily lives. To address this gap, this study integrates big data and IoT technologies to develop an adaptive mental state perception model aimed at providing accurate and timely mental health support, thereby improving students’ psychological well-being. The problem is defined as follows: how can mental health education pathways be optimized using big data and IoT technologies to enhance mental state recognition and intervention? The study’s objectives are to mine and analyze student mental state data, then construct and refine a model capable of effectively perceiving mental states. The methodology involves four main steps: data collection and preprocessing, algorithm selection and optimization, model training, and performance evaluation. Initial analyses employ basic classification algorithms, including decision trees, SVM, and RF. Subsequently, a GA is introduced to optimize feature selection, leading to the development of a GA-RF mental state perception model. In this framework, GA is used to refine input features, reduce redundancy, and improve training efficiency, thereby enhancing classification accuracy. The optimized features are then used to train the RF model, which is further improved with GA integration to form the GA-RF model. The model’s performance is evaluated using standard metrics such as accuracy, recall, and F1 score. These steps highlight the systematic and effective nature of the approach, providing strong support for mental health education in sports education.
Input optimization serves two main purposes: Model Performance Enhancement: Network behavior records can involve multiple dimensions, often with low information density. Even after preprocessing, as many as 50 dimensions may remain. Using all of them for model training can significantly slow computation and reduce predictive accuracy due to redundant or irrelevant features. Feature selection compresses the dimensionality of the data, shortening training time and improving classification accuracy by eliminating extraneous inputs. Data Storage Optimization: As the data volume increases, so does its dimensionality, which directly expands the storage scale. Input optimization through dimensionality reduction reduces storage costs and makes large datasets easier to manage efficiently and economically.
In selecting classification algorithms for psychological state perception, this study considered several widely used methods, including Decision Tree, SVM, RF, and ANN. Each of these algorithms has demonstrated strong performance across various classification tasks. However, this study placed particular emphasis on algorithm performance in high-dimensional settings, feature selection, and model stability. Based on these criteria, the GA-RF model was chosen. RF, an ensemble learning algorithm based on the Bagging strategy, classifies data by training multiple decision trees and aggregating their outputs through a voting mechanism. It is well-suited for handling high-dimensional and nonlinear data, as well as noisy and imbalanced datasets. These strengths are particularly important in psychological health analysis, where network behavior features often exhibit noise and complex nonlinear relationships. Moreover, RF effectively reduces overfitting and improves model generalization. The integration of GA primarily serves to optimize feature selection. Psychological health network behavior datasets typically contain numerous features with considerable redundancy, which can reduce both the efficiency and accuracy of direct classification. GA, by simulating the process of natural selection, identifies optimal feature subsets, thereby reducing dimensionality and enhancing prediction performance. This feature selection process not only improves RF’s classification effectiveness but also accelerates model training. Compared with standalone RF or other classification algorithms, the GA-RF model combines GA’s optimization capabilities with RF’s ability to process high-dimensional data, resulting in superior performance in psychological state perception tasks. Experimental results demonstrated that the GA-RF model outperformed comparison algorithms such as SVM and Decision Tree in both accuracy and F1 score for depression classification, further validating its practical value in psychological health education.
In summary, the GA-RF model was selected because of its ability to effectively manage high-dimensional, nonlinear, and noisy data while enhancing classification performance through GA-optimized feature selection. This combined approach improves computational efficiency without compromising accuracy, offering stable and reliable results. Accordingly, the GA-RF model represents the optimal solution for psychological state perception in sports education.
GA was employed for input optimization in the algorithmic framework to identify the most informative feature subsets from large datasets. This process involved selecting the best feature combinations across multiple dimensions. The feature selection procedure using GA is outlined as follows:
GA, inspired by Darwin’s theory of evolution, operates on the principle of natural selection to identify optimal solutions. In feature selection, GA employs a binary encoding scheme in which each bit corresponds to a feature in the vector. A bit value of “1” indicates that the feature is selected, while a value of “0” denotes its exclusion. The features encoded as “1” are then used to construct the classifier. The core of GA’s training process lies in iterative operations on sample data, guided by fitness function values and selection strategies, to identify the optimal feature subset. Wu et al.40 demonstrated that technology-driven teaching methods significantly enhance student development, thereby supporting the effectiveness and feasibility of this approach for exploring adaptive mental health pathways in sports education.
In this study, the genetic optimization algorithm adopts a distance-based criterion for the fitness function, simplifying analysis by directly evaluating sample information. It measures sample validity by analyzing the distances between similar and dissimilar samples. The specific computational methods are given in Eqs. (10) and (11). The within-class scatter matrix Sw is defined in Eq. (10):
Overall interclass scatter matrix Sb can be expressed as shown in Eq. (11):
\(P({\omega _i})\)refers to the prior probability of a class, which is based on the criterion fitness function of distance. When the intra-class sample distances decrease and the inter-class sample distances increase, the classification quality of the corresponding model improves, as expressed in Eq. (13).
In Eq. (13), c denotes the number of categories, determined according to the distance-based fitness function. \(P({\omega _i})\) represents the prior probability of each class. Mi and M correspond to the mean vector of the i-th class and the mean vector of the overall sample set, respectively. Their values are defined in Eqs. (14) and (15).
The GA employs a random sampling method with replacement to select individuals based on their fitness values. Individuals with higher fitness scores have a greater probability of being retained for the next generation. This selection probability is expressed in Eq. (15).
Figure 8 illustrates the detailed training workflow of the GA.

Training diagram of GA.
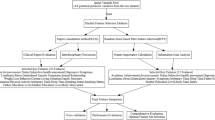
The workflow of the GA-RF mental health perception system developed in this study is illustrated in Fig. 9, covering the full closed-loop process from data collection to decision support. Initially, IoT devices deployed across the campus continuously collect multidimensional behavioral data from sports education students, including learning duration, exercise frequency, and social activity levels. The raw data are first processed through a preprocessing module to remove noise and fill in missing values, after which feature engineering generates derived indicators. Next, the GA performs an adaptive search across the high-dimensional feature space. Through iterative selection, crossover, and mutation operations, the algorithm identifies the most discriminative subset of features. This optimized feature subset is then fed into the RF model for training. By aggregating the predictions of multiple decision trees through a voting mechanism, the model outputs classifications of students’ psychological states. Finally, the predicted mental health indicators, such as depressive tendencies, trigger the teaching management system to generate personalized intervention strategies, such as adjusting training schedules or initiating psychological counseling. This creates an adaptive education pathway following the “perception–prediction–intervention” cycle. The collaborative optimization of the GA and RF is central to this architecture, effectively addressing high-dimensional feature redundancy while ensuring stable and accurate classification.

Workflow architecture of the GA-RF mental health perception system.
Following these steps, GA is applied to construct the perceptual model using network behavior data. The optimized feature subset identified by GA is then used to train the RF model, resulting in the GA-RF mental state perception model. Subsequently, the performance of four models—Decision Tree, SVM, RF, and GA-RF—is evaluated and compared. Notably, Li et al. (2019)41 demonstrated an interaction between social personality and online privacy, highlighting a causal relationship that is relevant to the context of this study.
Simulation experiment
Currently, the psychological health of students majoring in sports education has garnered significant attention from both educational institutions and government agencies. Influenced by multiple factors, these students are at risk of developing abnormal psychological conditions, which can lead to various negative outcomes. The dataset used in this study was obtained from the log servers and campus IoT data platform of a sports university. It includes students’ course learning records, athletic training data, and select daily life behavior data. All data were anonymized during collection to ensure the protection of personal privacy. The data collection process complied with ethical approval procedures, and all participants provided informed consent. Prior to model input, the raw data underwent rigorous preprocessing. Missing values were imputed, and noisy data were smoothed or removed. Features across different dimensions were standardized to ensure consistency in measurement scales. Additionally, expert annotations and questionnaire assessments were used to classify samples according to students’ psychological states, resulting in a high-quality training dataset. The initial dataset exhibited class imbalance, particularly with a lower proportion of samples showing depressive tendencies. To address this, a combination of SMOTE (Synthetic Minority Over-sampling Technique) and undersampling was applied, ensuring a more balanced distribution of classes within the training set and reducing classification bias. A total of 1,220 samples were included in the experiment. Each student’s identity was anonymized, with unique serial numbers used for identification. Behavioral features linked to these serial numbers constituted the dataset for comparative analysis. The study evaluated the performance of classification models in detecting internal and external tendencies, as well as a depression dichotomy model, providing a basis for understanding and improving psychological health assessment in sports education students.
The 1,220 samples used in this study were obtained from the IoT log databases of three institutions: East China University of Science and Technology, Hebei Sport University, and Chengdu Sport University, covering three major geographic regions: the eastern coastal area, the North China Plain, and the Southwest Basin. The sample population included undergraduate students in sports education and graduate students in athletic training, with a male-to-female ratio of 1.3:1 and an age range of 18–25 years. Data collection spanned two full academic years and covered typical scenarios such as regular teaching periods, final examination weeks, and provincial-level competition training sessions, effectively capturing multiple psychological stressors, including academic pressure and competition anxiety. The raw dataset included 50 features representing learning behaviors, training intensity, social activity frequency, and daily routines. K-means clustering confirmed the presence of four balanced behavioral patterns. Although the sample size was constrained by institutional data access policies, the multi-region, multi-scenario coverage partially mitigates biases from a single institution, providing a foundation for model generalization. Future work aims to expand dataset diversity by incorporating data from western vocational sports institutions through a university–industry collaboration framework. To enhance model generalization under the current dataset limitations, three methodological strategies were employed. First, transfer learning was applied: the GA-RF model trained on source institutions is adapted to target institutions, requiring only a small number of new samples for fine-tuning. Second, a dynamic feature importance monitoring mechanism was implemented. This mechanism detects shifts in the relationship between behavioral features and psychological states when the model is deployed in new environments, and it automatically triggers recalibration. Third, a synthetic data generation module was developed. It uses conditional generative adversarial networks to simulate behavioral patterns from different institutions, thereby increasing the diversity of training samples.
In terms of model selection, traditional classification algorithms such as Decision Tree, SVM, and RF were initially compared. Considering the characteristics of high-dimensional, noisy data, RF was selected as the base classifier, and GA was applied for feature selection and parameter optimization. Key model parameters included the number of decision trees and maximum depth in RF, as well as the number of iterations and population size in GA. Cross-validation combined with grid search was used to fine-tune these parameters, ensuring robust generalization across different dataset scales. The GA-RF fusion model was chosen based on three key characteristics of sports student behavioral data: high dimensionality, strong noise, and nonlinear associations. Compared with SVM, whose computational complexity increases sharply in high-dimensional settings, RF’s feature subsampling and ensemble mechanism provide inherent noise robustness. Compared with neural networks, which require large datasets, RF performs more reliably on small-scale educational data. The introduction of GA addresses feature redundancy: traditional filter-based feature selection methods often ignore feature interactions, whereas GA adaptively searches for optimal feature subsets through population evolution. Its crossover and mutation operations preserve complementary feature combinations. Parameter configurations were optimized based on the characteristics of educational data. For the RF model, 200 trees were used to balance accuracy and efficiency, and the maximum depth was set to 10 to prevent overfitting. The GA was configured with a population size of 50, 100 iterations, a crossover probability of 0.8, and a mutation probability of 0.01 to ensure thorough exploration of the feature space. Hyperparameter optimization was performed using grid search. For GA selection strategies, both roulette wheel and tournament selection were tested, with tournament selection ultimately chosen to improve convergence efficiency. For RF splitting criteria, Gini impurity and information gain were compared, and Gini impurity was selected for faster computation. All parameters were iteratively fine-tuned on the validation set to ensure model generalizability.
To evaluate the model’s performance across datasets of varying sizes, the experiment was divided into three groups: (1) a small-scale dataset with 1220 samples, (2) a medium-scale dataset with 2500 samples, and (3) a large-scale dataset with 5000 samples. Each dataset group was analyzed using the same set of algorithms, including Decision Tree, SVM, RF, and GA-RF.
Results
Comparison of depression classification models
Figure 10 presents the precision (P), recall (R), and F1 scores of the Decision Tree, SVM, RF, and GA-RF models based on the 1,220-sample dataset.

Evaluation of depression classification models.
As shown in Fig. 10, the F1 scores of most algorithms exceed 0.6, with the GA-RF model achieving the highest F1 score of 0.81. This demonstrates that the GA-RF model effectively identifies and analyzes students’ depressive psychological states, revealing clear patterns between network behavior characteristics and psychological conditions. By leveraging network behavior data to reflect students’ mental states, the model can inform targeted psychological interventions.
Comparison of depression binary model results
Figure 11 compares the precision (P), recall (R), and F1 scores of the depression binary classification model across the Decision Tree, SVM, RF, and GA-RF algorithms, based on the same 1220-sample dataset.

Performance of depression binary models.
As shown in Fig. 11, the GA-RF model achieves the highest F1 score of 0.75 among the four models, demonstrating its effectiveness in reflecting students’ levels of depression. The results indicate a clear relationship between network behavior and psychological conditions, enabling the identification of student anxiety patterns through behavioral characteristics. This insight supports the provision of targeted psychological counseling to enhance students’ mental well-being.
Figure 12 illustrates algorithm performance across varying dataset sizes. The GA-RF model consistently outperforms the other algorithms in all evaluation metrics as dataset size increases. On the small dataset (1,220 samples), the GA-RF model achieves a precision of 0.83, recall of 0.79, and F1 score of 0.81, surpassing the Decision Tree, SVM, and RF models. As dataset size expands to medium and large scales, the GA-RF model’s performance further improves. On the 5,000-sample dataset, it attains a precision of 0.86, recall of 0.83, and F1 score of 0.84, highlighting its superior scalability and robustness. In comparison, the Decision Tree and SVM show average performance, with SVM particularly underperforming in recall and F1 score. While the RF model demonstrates stable performance across all dataset sizes, it does not exceed the GA-RF model, indicating that the GA optimization contributes significantly to enhanced stability and accuracy in multi-dimensional feature selection and classification.

Performance of algorithms on datasets of different sizes (a) small-scale dataset; (b) medium-scale dataset; (c) large-scale dataset.
Comparison of deep learning models
To further evaluate the effectiveness of deep learning approaches in psychological state perception, Convolutional Neural Network (CNN) and Transformer models were introduced. Table 2 presents a comparison of these deep learning models with the GA-RF model in terms of accuracy, recall, and F1 score. The results provide a performance benchmark between deep learning and traditional machine learning approaches.
The GA-RF model demonstrates strong performance, achieving an accuracy of 0.83, a recall of 0.79, and an F1 score of 0.81. In comparison, the CNN model shows slightly lower metrics, with an accuracy of 0.78, a recall of 0.75, and an F1 score of 0.79. The Transformer model, however, outperforms both GA-RF and CNN across all evaluation metrics, reaching an accuracy of 0.84, a recall of 0.82, and an F1 score of 0.83. Notably, the Transformer’s F1 score surpasses that of the GA-RF model by 0.02, reflecting its superior overall performance in psychological state perception tasks. Overall, these results indicate that the Transformer model provides enhanced accuracy, recall, and F1 score compared to GA-RF and CNN, highlighting its considerable potential as a deep learning approach for improving the assessment and understanding of students’ psychological states.
Five-fold cross-validation was conducted for the GA-RF, Transformer, RF, and SVM models, with the experiments repeated 20 times. Paired t-tests were used to compare the statistical significance of differences between GA-RF and the best-performing baseline (Transformer) at α = 0.05. The results of the statistical tests are summarized in Table 3. Statistical analysis indicates that the Transformer model significantly outperforms GA-RF in both accuracy and F1 score (p < 0.05), confirming the statistical significance of its performance advantage. Although the confidence intervals for GA-RF (0.81–0.85) and Transformer (0.82–0.86) partially overlap, the Transformer’s mean values are higher, and its lower bound remains above the upper bound of GA-RF, indicating stronger robustness. Additionally, the narrower F1-score confidence interval for Transformer (0.04) compared to GA-RF (0.05) reflects superior prediction stability.
Furthermore, popular ensemble models—XGBoost, LightGBM, and Deep Forest—were introduced using the same datasets and preprocessing procedures. Parameters were optimized as follows: XGBoost (max_depth = 8, n_estimators = 200), LightGBM (num_leaves = 64, learning_rate = 0.05), Deep Forest (n_estimators = 20). Table 4 presents the performance comparison of these models. The results show that the Transformer remains the top-performing model in terms of prediction accuracy (0.84) and F1 score (0.83), albeit with substantially higher computational cost (training time of 312 s). XGBoost and LightGBM achieve performance comparable to GA-RF while significantly improving training efficiency by 24–53%, with LightGBM completing training in only 42 s, highlighting its suitability for resource-constrained scenarios. Deep Forest exhibits weaker performance (F1 score = 0.79), likely due to incompatibility between high-dimensional behavioral features and its hierarchical structure. Notably, GA-RF achieves a balanced trade-off between performance and efficiency, with accuracy 0.5% higher than LightGBM and significantly better than traditional RF, demonstrating the effectiveness of GA-based optimization.
Ablation experiments are summarized in Table 5, confirming the significant synergy between GA feature selection and the RF classifier. When GA-based feature selection is removed, RF’s accuracy drops by 9% (0.83 → 0.76), indicating that high-dimensional noisy features severely degrade performance. Conversely, applying GA for feature selection but replacing the classifier with SVM results in a 15% decrease in F1 score (0.81 → 0.69), highlighting RF’s advantage in handling nonlinear behavioral features. The full GA-RF model achieves peak accuracy using only 18 features, demonstrating GA’s effectiveness in eliminating redundant features while retaining critical discriminative information. Notably, the baseline RF without parameter tuning exhibits the weakest performance, emphasizing the necessity of both parameter optimization and algorithmic integration.
Discussion
This study investigates the application of a RF model optimized by a GA for perceiving the psychological states of students majoring in sports education, leveraging big data and IoT technologies. The GA-RF model’s performance is compared with other classification models, including Decision Trees, SVM, and standard RF, as well as deep learning models such as CNN and Transformer. Results demonstrate that the GA-RF model excels across key evaluation metrics, including accuracy, recall, and F1 score. These findings align with prior studies while highlighting the unique contributions of this research. First, Wekerle et al. (2022) emphasized the positive impact of technology-based teaching methods on student development42. Building on this, the present study explores how data mining and optimization algorithms can enhance psychological health education. In particular, the GA-RF model shows substantial improvements in classification accuracy, underscoring the role of technological methods in personalized education. Unlike Wekerle et al., which focused primarily on teaching outcomes, this study emphasizes precise perception and prediction of psychological health, representing an extension and deepening of their work. Second, Amon et al. (2023) investigated the interaction between social personality and online privacy, revealing the complexity of students’ psychological states43. The GA-RF model’s ability to identify psychological states provides a new perspective on this complexity. While Amon et al. highlighted the influence of online behavior on psychological conditions, this study advances the methodology by integrating advanced classification models and optimization algorithms, offering more precise identification and predictive capabilities. The use of GA for feature selection further enhances model performance by addressing high-dimensional and redundant data, which Amon et al.’s study did not explicitly consider. Third, Wongvorachan et al. (2023) examined the application of various classification algorithms in educational data, emphasizing the strengths and limitations of different approaches and the potential of deep learning models44. By comparing traditional classification algorithms with deep learning models, this study confirms that Transformer models further improve predictive performance, demonstrating the value of deep learning in mental health applications. Unlike Wongvorachan et al., this study not only evaluates traditional algorithms but also incorporates deep learning for comparative analysis, broadening the perspective on processing and interpreting psychological health data. Overall, this study contributes by combining GA-optimized RF with comparative deep learning analysis, providing robust insights into personalized psychological state perception and extending prior research in both methodological and application dimensions.
The proposed GA-RF model demonstrates significant advantages in perceiving the psychological states of sports education students, achieving an F1 score of 0.81. This performance is primarily driven by a dual-layered adaptivity. First, the GA–based feature selection effectively filters high-dimensional noise in IoT behavioral data. For instance, 18 key features, including training duration and nighttime screen use, were identified as strong predictors of psychological states, consistent with Kalita et al. (2025a), who emphasized the principle that “feature quality outweighs quantity”45. Second, the ensemble learning characteristics of RF align with the nonlinear associations inherent in sports students’ behavior. Complex interactions, such as training fatigue coupled with social withdrawal, require multiple decision trees working in concert to capture these patterns. However, the model exhibits lower recall than accuracy in detecting depressive tendencies, reflecting a higher tolerance for false negatives. This bias arises from two typical scenarios: high-performance athletes often convert psychological stress into excessive training, resulting in behavior patterns similar to healthy peers; and students from rural backgrounds may reduce online activity due to economic constraints, leading to misclassification as socially withdrawn. These cases reveal the model’s sensitivity to socio-economic background is limited, highlighting the need for transfer learning techniques to adapt across diverse populations. As confirmed by Kalita et al. (2025b), integrating behavioral time-series analysis with attribution explanation frameworks such as Long Short-Term Memory–Shapley Additive Explanations (LSTM-SHAP) can significantly improve the recognition of special population groups46.
The study also identifies three primary ethical risks. First, continuous IoT data collection may infringe on privacy, necessitating real-time anonymization mechanisms similar to the “dynamic de-identification” proposed by Gaftandzhieva et al. (2024) in blended learning studies47. Second, the strong association between behavioral features and psychological states may create labeling effects; adopting interpretable frameworks like Bi-LSTM can visually present decision paths to students. Third, model deployment faces challenges due to disparities in campus digital infrastructure, with underdeveloped regions struggling to support Transformer-level computational requirements, emphasizing the need for lightweight embedded GA-RF modules. Compared with previous studies, such as Kalita et al. (2025c) on academic performance prediction48, this study presents three key innovations: (1) shifting the focus from general predictive modeling to specialized psychological health perception for sports students, addressing a critical gap; (2) optimizing for a multi-objective balance of accuracy, efficiency, and interpretability, making the approach better suited for real-time educational interventions; and (3) establishing a closed-loop feedback system that links behavioral features to instructional adjustments, rather than solely providing mental state diagnoses. Nevertheless, several limitations remain. The current sample does not include athletes with disabilities, leaving gaps in detecting compensatory behaviors. Additionally, physiological indicators, such as heart rate variability, were not incorporated, limiting the ability to assess stress states. The short-term nature of the data also prevents capturing the cumulative effects of psychological issues. Future work will address these limitations through three avenues: (1) constructing a dedicated dataset for athletes with disabilities and analyzing behavioral specificity using LSTM-SHAP; (2) developing a multimodal fusion architecture that integrates wearable physiological data with IoT behavioral logs; and (3) establishing a cross-institutional federated learning platform to enable collaborative model evolution while maintaining data sovereignty.
Conclusion
Currently, students majoring in sports face intense competition and pressure in both academics and employment, increasing the risk of mental health issues. Leveraging big data and IoT technologies for effective monitoring and management has become essential. A relevant dataset is prepared and preprocessed, and candidate classification algorithms are preselected. The RF model is then optimized using a GA, resulting in the GA-RF psychological state perception model. Experimental evaluation and data analysis demonstrate that the GA-RF model outperforms other tested classification models, identifying it as the most effective solution. The GA-RF model enables comprehensive analysis and mining of students’ behavioral data related to study and daily activities, highlighting the value of such data for psychological assessment. By integrating IoT technology, colleges can collect rich behavioral information from sports students, facilitating timely and accurate evaluations of their mental health. This approach not only provides theoretical support for teaching strategies but also improves resource utilization and promotes the advancement of educational methods. The model supports data-driven mental health monitoring and allows for the prediction of students’ psychological states, contributing positively to mental health education in sports programs. However, it should be noted that while GA is employed for feature optimization, the potential of other related algorithms has not been extensively explored, leaving room for further methodological expansion.
Although this study preliminarily validates the effectiveness of the GA-RF model in perceiving the psychological states of sports students, future research should deepen exploration in four key areas: (1) Lightweight Model Deployment: Develop solutions that embed the psychological state prediction module into campus IoT terminals using edge computing, enabling real-time, low-latency monitoring. (2) Multimodal Data Fusion: Integrate heterogeneous data sources, such as classroom video behavior recognition and physiological indicators from wearable devices, to construct comprehensive, multi-dimensional mental health profiles. (3) Ethical Governance in Educational Contexts: Establish an algorithmic ethics framework by implementing dynamic data anonymization and decision interpretability modules, safeguarding students’ privacy and informed consent. (4) Tailored Intervention Pathways: Explore sports-education integrated intervention strategies by combining sports psychology theory with digital twin training systems, employing virtual competition exposure therapy to mitigate performance anxiety. These directions aim to shift mental health education from a passive response model to proactive prevention, providing intelligent support for the national strategy of “sports-education integration.”
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author Yanbing He on reasonable request via e-mail 1425217063@qq.com.
References
Mohanty, S. N. et al. Deep learning with LSTM based distributed data mining model for energy efficient wireless sensor networks. Sports Commun. 40, 101097 (2020).
Massaro, A., Maritati, V. & Galiano, A. Data mining model performance of sales predictive algorithms based on rapidminer workflows. Int. J. Comput. Sci. Inform. Technol. (IJCSIT). 10 (3), 39–56 (2018).
Fan, G. F., Peng, L. L. & Hong, W. C. Short term load forecasting based on phase space reconstruction algorithm and bi-square kernel regression model. Appl. Energy. 224, 13–33 (2018).
Mirza, M. B. et al. Contextual perception under active inference. Sci. Rep. 11 (1), 1–25 (2021).
Lim, S. & Lee, H. The effects of self-exploration on & anxiety: Measurement model of emotional health state perception. J. Crit. Rev. 7(14), 450–456. (2020).
McGorry, P. D. et al. Beyond the at risk mental state concept: Transitioning to transdiagnostic psychiatry. World Psychiatry. 17 (2), 133–142 (2018).
Zhao, X. et al. Integration of multi-modal biosensing approaches for depression: Current status, challenges, and future perspectives. Sensors 25 (15), 4858 (2025).
Alkurdi, A. et al. Extending anxiety detection from multimodal wearables in controlled conditions to Real-World environments. Sensors 25 (4), 1241 (2025).
Begum, S. R. & Sait, S. Y. Feature selection using CS-BPSO for depression detection based on profile information. KSII Trans. Internet Inform. Syst. 19 (3), 752 (2025).
Atta, A. et al. Efficacy of swarm-based neural networks in automated depression detection. Sci. Rep. 15 (1), 25560 (2025).
Song, Y. et al. A systematic review of finite element analysis in running footwear biomechanics: Insights for running-Related musculoskeletal injuries. J. Sports Sci. Med. 24 (2), 370 (2025).
Dorugade, D. V. et al. Development of a nonlinear finite element model for estimating static and dynamic seat cushion characteristics. Int. J. Veh. Perform. 11 (3), 300–320 (2025).
Halkiopoulos, C. & Gkintoni, E. The role of machine learning in AR/VR-based cognitive therapies: A systematic review for mental health disorders. (2025). Electronics (2079–9292), 14(6), 1110 .
Troussas, C. et al. Reinforcement learning-based dynamic fuzzy weight adjustment for adaptive user interfaces in educational software. Future Internet. 17 (4), 166 (2025).
Torous, J. et al. The evolving field of digital mental health: Current evidence and implementation issues for smartphone apps, generative artificial intelligence, and virtual reality. World Psychiatry. 24 (2), 156–174 (2025).
Rudnik, A. et al. Exploring the interplay of stress, fatigue, and empathy: The mediating role of cognitive flexibility in enhancing the well-being of university students in medical and social disciplines. PLoS One. 20 (4), e0321946 (2025).
Lim, S. & Lee, H. J. Self-exploration on anxiety in Chakra meditation experienced people: the mediation effect of emotional health state perception. Int. J. Social Welf. Promot. Manag. 7 (1), 15–22 (2020).
Becchio, C. et al. Seeing mental states: An experimental strategy for measuring the observability of other Minds. Phys. Life Rev. 24, 67–80 (2018).
Gendron, M. & Barrett, L. F. Emotion perception as conceptual synchrony. Emot. Rev. 10 (2), 101–110 (2018).
de Sá Pereira, R. H. Knowing qualia: Reloading the displaced perception model. Humanit. Social Sci. Commun. 7 (1), 1–7 (2020).
Shah, P., Catmur, C. & Bird, G. From heart to Mind: Linking interoception, emotion, and theory of Mind. Cortex J. Devoted Study Nerv. Syst. Behav. 93, 220 (2017).
Brooks, J. A., Stolier, R. M. & Freeman, J. B. Computational approaches to the neuroscience of social perception. Soc. Cognit. Affect. Neurosci. 16 (8), 827–837 (2021).
McCarroll, C., Michaelian, K. & Muñoz, S. A. Memory and perception, insights at the interface: Editors’ introduction. Estudios De Filosofía, (64), pp. 5–19. (2021).
Hovhannisyan, H. Perception as an integral reflection. Bull. Yerevan Univ. E: Philos. Psychol. 9 (2 (26)), 48–58 (2018).
Chen, M. et al. Cognitive wearable robotics for autism perception enhancement. ACM Trans. Internet Technol. (TOIT). 21 (4), 1–16 (2021).
Rafiei, M. H. & Adeli, H. A new neural dynamic classification algorithm. IEEE Trans. Neural Netw. Learn. Syst. 28 (12), 3074–3083 (2017).
Wan, X. et al. Heartbeat classification algorithm based on one-dimensional Convolution neural network. J. Mech. Med. Biol. 20 (07), 2050046 (2020).
Yan, X. & Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 313, 47–64 (2018).
Jiang, D. et al. A probability and integrated learning based classification algorithm for high-level human emotion recognition problems. Measurement 150, 107049 (2020).
de Sá, A. G. C., Pereira, A. C. M. & Pappa, G. L. A customized classification algorithm for credit card fraud detection. Eng. Appl. Artif. Intell. 72, 21–29 (2018).
Aljawarneh, S., Yassein, M. B. & Aljundi, M. An enhanced J48 classification algorithm for the anomaly intrusion detection systems. Cluster Comput. 22 (5), 10549–10565 (2019).
Keck, T. FastBDT: A speed-optimized multivariate classification algorithm for the Belle II experiment. Comput. Softw. Big Sci. 1 (1), 1–11 (2017).
Hammad, M., Zhang, S. & Wang, K. A novel two-dimensional ECG feature extraction and classification algorithm based on Convolution neural network for human authentication. Future Gener. Comput. Syst. 101, 180–196 (2019).
Gan, D. et al. Integrating TANBN with cost sensitive classification algorithm for imbalanced data in medical diagnosis. Comput. Ind. Eng. 140, 106266 (2020).
Pang, X. & Ning, Y. Fuzzy control based on genetic algorithm in intelligent psychology teaching system. J. Intell. Fuzzy Syst., pp. 1–9 .
Wong, P. T. P. & Roy, S. Critique of positive psychology and positive interventions. (2018).
Roubtsova, N. et al. EmoGen: Quantifiable emotion generation and analysis for experimental psychology. arXiv:2107.00480 (2021).
Cong, T. et al. Application of rough ant colony algorithm in adolescent psychology. Comput. Intell. Neurosci. 2021. (2021).
Burton, J. W., Stein, M. K. & Jensen, T. B. A systematic review of algorithm aversion in augmented decision making. J. Behav. Decis. Mak. 33 (2), 220–239 (2020).
Wu, Y. C. J., Wu, T. & Li, Y. Impact of using classroom response systems on students’ entrepreneurship learning experience. Comput. Hum. Behav. 92, 634–645 (2019).
Li, Y. et al. Exploring how personality affects privacy control behavior on social networking sites. Front. Psychol. 10, 1771 (2019).
Wekerle, C. & Kollar, I. Using technology to promote student learning? An analysis of pre-and in-service teachers’ lesson plans. Technol. Pedagogy Educ. 31 (5), 597–614 (2022).
Amon, M. J. et al. Modeling user characteristics associated with interdependent privacy perceptions on social media. ACM Trans. Comput.-Human Interact. 30 (3), 1–32 (2023).
Wongvorachan, T., He, S. & Bulut, O. A comparison of undersampling, oversampling, and SMOTE methods for dealing with imbalanced classification in educational data mining. Information 14 (1), 54 (2023).
Kalita, E. et al. Educational data mining: A 10-year review. Discov. Comput. 28 (1), 81 (2025a).
Kalita, E. et al. LSTM-SHAP based academic performance prediction for disabled learners in virtual learning environments: A statistical analysis approach. Social Netw. Anal. Min. 15 (1), 1–23 (2025b).
Gaftandzhieva, S. et al. Student satisfaction with the quality of a blended learning course Vol. 67 (Mathematics & Informatics, 2024). 1.
Kalita, E. et al. Predicting student academic performance using Bi-LSTM: A deep learning framework with SHAP-based interpretability and statistical validation. Front. Educ. Front. Media SA. 10, 1581247 (2025c).
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
Yanbing He: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation, writing—review and editing, visualization, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical statement
The studies involving human participants were reviewed and approved by Institute of physical education, East China University of Technology Ethics Committee (Approval Number: 2022.03984). The participants provided their written informed consent to participate in this study. All methods were performed in accordance with relevant guidelines and regulations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
He, Y. The analysis of the internet of things technology for mental health of sports education students based on big data. Sci Rep 15, 40247 (2025). https://doi.org/10.1038/s41598-025-24104-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-24104-6
