
Abstract
In social interactions, we often encounter situations where a partner’s face is (partially) occluded, e.g., when wearing a mask. While emotion recognition in static faces is known to be less accurate under such conditions, we investigated whether these detrimental effects extend to empathic responding, mentalizing (i.e., Theory of Mind), and prosociality in more naturalistic settings. In four studies (Ntotal = 157), we presented short video clips of narrators recounting neutral and emotionally negative autobiographical stories, with their faces shown in four conditions (two per experiment): fully visible, eyes covered, mouth covered, and audio-only. Participants then responded to questions assessing affect, mentalizing performance, and willingness to help. Affect ratings were slightly lower when the narrator’s mouth was covered, and participants were less willing to help narrators with covered eyes. Importantly, however, empathic responding and mentalizing performance remained robust across visibility conditions. Thus, our findings suggest that social understanding – specifically, empathizing and mentalizing – is not substantially impeded by partial or complete facial occlusion, when other cues, such as vocal information, can be used to compensate. These insights may help contextualize concerns about detrimental effects of face coverage in social interactions.
Similar content being viewed by others

Introduction
As long as humans have been interacting, they have encountered circumstances that prevent them from fully perceiving those they are engaging with. The ancient myth of Pyramus and Thisbe describes the star-crossed couple whispering love confessions through a crack in the wall to evade their feuding families1. We, too, as citizens of the less romantic 21st century sometimes find ourselves engaging with others whose face is partially covered, whether by face masks or sunglasses. Does this impair our ability to empathize with them and to correctly understand their beliefs and intentions? After all, Pyramus and Thisbe met a tragic end that was (in some way) caused by a misunderstanding. And during the Covid-19 pandemic many worried about a decline in social understanding due to the widespread use of protective masks2,3. With only part of the facial information available, people might fail to recognize the feelings and needs of the ones surrounding them, ultimately fostering a lack of connection and maybe even prosocial behavior. Addressing this concern, we sought to investigate whether partially or fully occluding a target person’s face does in fact have a detrimental impact on empathy, mentalizing, and prosociality.
Numerous studies have examined how the reduction or absence of face cues impacts emotion recognition. While pre-pandemic experiments utilized pieces of cardboard4, different types of headdress5,6, sunglasses7, as well as bars and other geometric shapes7 to reduce the visibility of facial features, many studies from 2020 onward specifically focused on face masks8,9,10,11,12,13,14,15,16,17. Throughout these studies, a consistent pattern emerged: When parts of the face were covered, emotional expressions were recognized with significantly lower accuracy, affecting both the categorization of the emotions and the assessment of their intensity. Visibility of the mouth area, in particular, was identified as crucial for accurate recognition18,19, although the informative value of different face areas varies depending on the specific emotion20,21,22,23. In addition to impeding emotion recognition, occluding parts of the face seems to impair face identification10,15,24 and reduce assessments of interpersonal closeness11,25. Taken together, these findings indicate that a lack of available facial cues may impair social understanding, aligning with concerns regarding face mask usage.
However, almost all of the referenced studies employed static images or very short video stimuli with little or no context (for an exception see25). While there may be some real-world scenarios where these conditions apply, such as briefly glimpsing the masked face of a person driving by, they do not match the complexity of most meaningful real-life interactions26,27. Facial expressions, although prominent23,28,29,30, are not the only manifestations of emotions, and affective states are also conveyed through vocal31,32,33, bodily34,35,36, and olfactory37,38,39 cues. Given this plethora of abundant (and redundant40) signals, it is not far-fetched to assume that humans are able to compensate for a lack of visual information in realistic interaction settings. On the contrary, it is hard to imagine that one would not understand and feel for a heartbroken friend burying their head in a pillow, while still seeing their trembling shoulders and hearing the anguish in their voice as they talk about the barriers separating them from their soulmate.
Besides anecdotal experience, there is considerable empirical support for humans’ capability to flexibly infer another person’s mental state from signals other than facial information. Motion cues, for example, appear to hold the potential to compensate for incomplete or compromised information in emotion recognition (for a review see30). With regard to face masks specifically, the aforementioned negative effects on emotion recognition were largely mitigated when the person’s full body was visible41. Moreover, studies using longer video clips of masked and unmasked target persons talking about themselves and their (emotional) experiences found no reduction in social connectedness and empathic accuracy42,43. This suggests that in dynamic, contextualized, and multimodal settings – more closely mirroring real-life interactions – the detrimental effects of face masks are much less severe or even absent. In these scenarios, the voice of one’s interaction partner might provide valuable insights into their inner workings both through the content of their words and the manner of speaking. While combining face and voice information typically leads to the best emotion recognition performance44,45,46, accuracy rates are still high when using voice-only cues31,47,48 and audio stimuli can effectively evoke empathic responses and accurate mentalizing49. In studies presenting videotaped conversations, verbal information was identified as the most essential source for accurate understanding, especially when inferring a person’s thoughts (rather than their feelings)50,51. Some researchers even suggested that voice-only communication enhances empathic accuracy by reducing cognitive load and enabling a more effective focus on highly informative cues provided by the voice52.
The opposing findings and conclusions may seem difficult to reconcile at first, but they can be at least partially understood by considering the differences in methodology. We have already pointed out the use of static, isolated cues compared to longer and contextually enriched stimuli, which offer less experimental control but higher ecological validity. Social cognitive processes like the perception of (emotional) faces are known to vary between naturalistic and more controlled experimental settings53,54, with real-life approaches frequently suggesting conclusions that differ from those originally assumed based on less ecologically valid paradigms55. In addition, the referenced studies addressed social understanding by means of a wide range of dependent variables, from basic emotion identification to complex measures of empathy and mentalizing, also referred to as Theory of Mind (ToM). This distinction is critical, as reduced face visibility may impede the quick recognition of prototypical emotion expressions, but not the tendencies to empathize, mentalize, and behave appropriately – arguably the most crucial aspects in real-life interactions. In our study, we employed dynamic video clips resembling realistic social interactions, implementing varying levels of face occlusion, and focused on two central functions of social understanding that go beyond emotion recognition: empathizing, defined in our context as the sharing of another person’s emotions56,57, and mentalizing (or, used interchangeably, ToM), which encompasses cognitive reasoning about a person’s thoughts, beliefs, and intentions58,59. The inclusion of affective as well as cognitive components enables us to draw more nuanced conclusions about which facets of social understanding (if any) are affected by a lack of facial information. Furthermore, we consider these two functions highly relevant due to their influence on prosociality, as both empathy and ToM have been linked to costly helping, donations, and other forms of cooperative and prosocial behavior60,61,62,63,64.
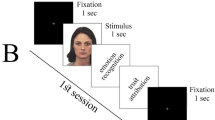
The objective of our study was to investigate if and how partial or complete occlusion of an interaction partner’s face affects empathizing, mentalizing, and prosociality, in a task using naturalistic, dynamic, and multimodal stimuli. Following the established EmpaToM paradigm65, participants watched video clips of narrators recounting brief autobiographical stories (for a schematic depiction of the experimental procedure see Fig. 1; for example narrations see Supplement S1) about either neutral or negative experiences (Valence: neutral vs. negative), that either did or did not require ToM (ToM Requirement: noToM vs. ToM). After each clip, we assessed: (i) participants’ current affective state (affect rating), interpreting the difference in ratings between neutral and negative narrations as empathic responding; (ii) their accuracy (question accuracy) and – as a complementary measure – response time (question RT) in answering a question about the narration, which either required factual reasoning (in noToM trials) or mentalizing (in ToM trials); and (iii) their willingness to invest (hypothetical) resources to help the person in the video (prosociality rating).
Critically, we manipulated Visibility of the narrator’s face across four experiments with a total sample size of N = 157 (for an overview of the experiments, see Table 1). Each experiment compared two of a total of four conditions: In the full visibility condition, participants saw the narrator’s face without any restrictions, replicating the original EmpaToM. In the mouth covered condition, we added a black bar to obstruct the visibility of the mouth area. In the eyes covered condition, we did the same for the eye area. Finally, in the no visibility condition, participants saw a blank screen and could only hear the narration (audio-only). We opted for the somewhat artificial coverage using black bars over more naturalistic obstructions like masks and sunglasses in order to maintain high comparability across conditions and to prevent the type of coverage and associated attitudes from influencing the results8,66. Therefore, any effects emerging in our data can be solely attributed to the visibility manipulation.
Based on the mixed state of research, we considered several plausible result patterns (for more detailed hypothesis derivations, see also the following preregistration, which was created as part of a student project for two of the experiments: https://doi.org/10.17605/OSF.IO/DS4VE): If the reduction of available facial information significantly impairs the components of social understanding, as evidenced for emotion recognition4,9,11,67, we would expect diminished empathic responses – reflected in smaller affect rating differences between neutral and negative narrations – as well as reduced mentalizing performance (especially response accuracy), and prosociality under conditions of limited facial visibility. The extent of this reduction might be contingent on the degree of coverage – the less facial information available, the higher the impact – or on the specific face areas covered. One possibility is that occluding the mouth, frequently considered the most diagnostically informative feature of the face18,19, could particularly present difficulties. Alternatively, one could hypothesize that within our study, it is more detrimental to cover the eye area, given that the predominant emotion in the negatively valenced narrations is sadness – an emotion for which the eyes are assumed to provide the most informative cues21,23,68. However, an entirely different prediction presents itself if one takes into account that humans are highly proficient in deducing another person’s thoughts and feelings from a variety of signals – vocal cues in particular32,40,51 – and can compensate for the missing visual input in multimodal settings. With this in mind, we would not expect differences in empathic responding, mentalizing accuracy, and prosociality as a function of face visibility. Lastly and given the established differentiation between empathy and ToM69,70, it is plausible that the results could vary between these functions. For instance, face occlusion might more severely impact empathic responses, where emotion recognition is crucial71,72,73. Determining which of these hypothesized patterns emerges in our data will offer more comprehensive and nuanced insights into the potential impairment of social understanding when facial cues are absent or only partially available.

Schematic depiction of the experimental procedure and conditions. The narrations were either emotionally neutral or negative (Valence) and either required ToM or factual reasoning to answer the question they prompted (ToM Requirement). In each experiment, clips were presented in two of four Visibility conditions. Exp.1: full visibility vs. eyes covered, Exp.2: full visibility vs. mouth covered, Exp.3: eyes covered vs. mouth covered, Exp.4: full visibility vs. no visibility (audio-only). Each participant completed 48 trials in a fully crossed 2 × 2 × 2 within-subjects design. The individual in the recreated video stills provided informed consent for publication of the images in an online open-access publication.
Results
For each of the four experiments, we computed linear mixed models (LMMs) with fixed effects for Valence (neutral vs. negative), ToM Requirement (noToM vs. ToM), and Visibility (Exp.1: full visibility vs. eyes covered; Exp.2: full visibility vs. mouth covered; Exp.3: eyes covered vs. mouth covered; Exp.4: full visibility vs. no visibility). We assessed four dependent variables: Affect rating, question accuracy, question response time (RT; in correctly answered trials), and prosociality rating (in Exps. 1, 2 and 4). These analyses deviate from our initial plan (see, e.g., preregistration https://doi.org/10.17605/OSF.IO/DS4VE) which proposed conducting separate analyses of variance (ANOVA) for each experiment and then pooling the data for combined LMMs. In retrospect, we determined that computing experiment-wise LMMs would be a more robust approach, allowing us to maximize power and better account for variability in the data. However, we also report the originally planned analyses in Supplement S3. Notably, results across the different analysis approaches were largely consistent and did not alter our conclusions.
Our analysis focused on several key effects that were central to addressing our research question: An impairment of empathic responding would be reflected in a reduced affect rating difference between neutral and negative narrations when faces were (partially) covered. Statistically, this would manifest as a significant interaction between Visibility and Valence while the main effect of Visibility – reflecting general differences in mood – was not directly relevant to our hypotheses. For accuracy and RTs in the single-choice questions, a significant main effect of Visibility would suggest a general impairment of understanding when the full face was not visible. A significant interaction between Visibility and ToM Requirement, on the other hand, could indicate specific difficulties related to ToM (or noToM). Finally, for prosociality rating, we examined both the main effect of Visibility (indicating overall reduced willingness to help), as well as the interaction between Visibility and Valence (specifically addressing prosocial response towards individuals in need).
Affect rating
Estimated marginal means for affect ratings (on a scale from 0 to 10, with symbolic anchors at the endpoints and midpoint) are displayed in Fig. 2. In addition to the random intercepts for participants and narrations, the final models for Experiments 1, 2, and 4 included random slopes for Valence and ToM Requirement, whereas the final model for Experiment 3 only featured a random slope for Valence. Note that the computation of these models deviated from the preregistered plan (see 4.4 ‘Design and Analyses’). Across the four experiments, participants reported lower affect following negative narrations compared to neutral ones (estimated marginal means Exp.1: 2.71 vs. 5.99; Exp.2: 2.95 vs. 5.95; Exp.3: 2.26 vs. 5.84; Exp.4: 2.40 vs. 6.15), confirming the effectiveness of our valence manipulation and replicating previous findings from the original task49,64,65,74, bs < −3.01, ts < −10.63, ps < 0.001. While affect ratings did not differ between ToM conditions after negative narrations (ts < |0.32|, ps > 0.753, ds < |0.06|), participants rated their affect slightly lower after neutral ToM compared to neutral noToM narrations (ts > 2.73, ps < 0.009, ds > 0.52), as indicated by significant (or in the case of Exp. 2, marginally significant) Valence x ToM Requirement interactions, bs > 0.69, ts > 1.86, ps < 0.068, and main effects of ToM Requirement, bs < −0.38, ts < −1.99, ps < 0.052. While they are not central to our research questions, these patterns also replicate earlier findings49,65.
For the critical Visibility x Valence interaction – reflecting a potential moderation of empathic responses by narrator visibility – no significant effect was observed in any of the experiments, bs < |0.12|, ts < |1.25|, ps > 0.210. Hence, what part of the narrators’ faces were visible did not significantly influence participants’ empathy with the narrators. The main effect of Visibility was significant in Experiment 2, b = −0.16, ts = −3.33, ps < 0.001, but not in Experiment 3, b = −0.10, t = −1.86, p = 0.063, or in Experiments 1 and 4, bs < |0.06|, ts < |1.09|, ps > 0.274: Participants rated their affective state slightly lower overall when the narrator’s mouth was covered compared to when the face was fully visible (Exp.2 – mouth covered: 4.37 vs. full visibility: 4.53; Exp.3 numerical difference: mouth covered: 4.00 vs. eyes covered 4.10). No further main effects or interactions reached significance, bs < |0.33|, ts < |1.49|, ps > 0.136.

Estimated marginal means for affect rating in Experiments 1–4. Differences between the rated affect after negative versus neutral narrations were interpreted as empathic responding. Error bars represent standard errors. On the x-axis, the different combinations of Valence and ToM Requirement are displayed. Bar colors and patterns denote Visibility condition (full visibility: white; eyes covered: dots; mouth covered: diagonal stripes; no visibility: black). Significant differences between Visibility conditions within each Valence x ToM Requirement combination are marked with horizontal brackets. *: p <.05.
Question accuracy
Estimated marginal means for question accuracy (in %) are presented in Fig. 3. The final models (computed in deviation from the preregistered plan, see above) for Experiments 1 and 2 did not feature any random slopes, while for Experiments 3 and 4, the best-fitting models included random slopes for ToM Requirement. Accuracy was slightly higher for ToM questions than for noToM questions (Exp.1: 80.6% vs. 78.8%; Exp.2: 80.4% vs. 80.1%; Exp.3: 78.8% vs. 74.0%; Exp.4: 78.8% vs. 77.1%), although the difference did not reach statistical significance in any experiment, bs < 0.05, ts < 1.31, ps > 0.196. In Experiments 1, 2, and 4, questions following negative narrations were answered with higher accuracy compared to neutral narrations as reflected in significant main effects of Valence, bs > 0.09, ts > 2.06, ps < 0.045 (Exp.1: 84.6% vs. 74.8%; Exp.2: 85.2% vs. 75.3%; Exp.4: 82.5% vs. 73.5%). In Experiment 4, the significant three-way interaction, b = 0.14, t = 2.02, ps = 0.044, indicated that the valence effect was stronger in noToM trials with fully visible narrators (t(64.9) = −2.22, p = 0.030, d = −0.48) compared to the other Visibility x ToM Requirement combinations (ts < |1.56|, ps > 0.125, ds > |0.35|).
Most importantly for our hypotheses, there were no significant main effects of Visibility, bs < |0.02|, ts < |0.91|, ps > 0.365, and Visibility x ToM Requirement interactions, bs < |0.05|, ts < |1.55|, ps > 0.122, in any of the experiments. Thus, we found no evidence that mentalizing performance was affected by which part of the narrators’ faces participants could see. No other main effects or interactions reached significance, bs < |0.60|, ts < |1.51|, ps > 0.131.

Estimated marginal means for question accuracy in Experiments 1–4. Error bars represent standard errors. On the x-axis, the different combinations of Valence and ToM Requirement are displayed. Bar colors and patterns denote Visibility condition (full visibility: white; eyes covered: dots; mouth covered: diagonal stripes; no visibility: black). Significant differences between Visibility conditions within each Valence x ToM Requirement combination are marked with horizontal brackets. *: p <.05.
Question response time
As a complementary analysis, we also examined the time it took participants to give correct responses in the single-choice questions, although interpretability is limited due overall long response durations (which included reading time) and the emphasis on accuracy over speed in the instructions. The best-fitting models for RTs (in seconds) did not include random slopes but only the random intercepts for participant and narration. Analyses of these models revealed one significant effect, which was the interaction between Visibility and ToM Requirement in Experiment 2, b = 0.91, t = 2.15, p = 0.032. It took participants slightly longer to respond to ToM questions when the narrator’s mouth was covered compared to fully visible (16.8 s vs. 16.3 s; marginally significant: t(1424) = −1.89, p = 0.059, d = −0.13), while there was no comparable difference for noToM questions (16.0 s vs. 16.4 s, t(1424) = 1.15, p = 0.249, d = 0.08). Apart from that, no further main effects of Visibility or interactions between Visibility and ToM Requirement reached significance, bs < |0.33|, ts < |1.24|, ps > 0.215. The same applied to all remaining main effects and interactions, bs < |2.38|, ts < |1.98|, ps > 0.053.
Prosociality rating
Estimated marginal means for prosociality ratings (on a scale from 0 to 10) in the three experiments that measured this dependent variable (Exps. 1, 2, 4) are shown in Fig. 4. The final models (derived from analyses deviating from the preregistration, see above) for Experiments 1 and 2 included random slopes for Valence, while for Experiment 4, incorporating random slopes for all three factors (Visibility, Valence, ToM Requirement) led to the best model fit. In line with earlier findings63,74, a significant main effect of Valence indicated that participants were willing to invest more resources to help a narrator recounting a negative experience compared to a neutral one (Exp.1: 6.45 vs. 3.46; Exp.2: 6.94 vs. 4.41; Exp.4: 6.92 vs. 3.84), bs > 2.53, ts > 7.42, ps < 0.001. Additionally, in Experiment 1, prosociality ratings were significantly higher following ToM compared to noToM narrations (5.21 vs. 4.69), b = 0.53, t = 2.06, p = 0.045.
The main effect of Visibility, which was central to our hypotheses, reached significance in Experiment 1, b = −0.22, t = −3.21, p = 0.001: Participants were less willing to invest resources to help a person whose eyes were covered compared to when they were fully visible (4.84 vs. 5.06). In Experiments 2 and 4, on the other hand, visibility had no effect on prosociality, bs < 0.09, ts < 1.46, ps > 0.143, indicating that impaired visibility of narrators’ mouths (Exp.2) or complete faces (Exp.4) did not significantly reduce participants’ willingness to invest resources. The remaining main effects and interactions did not reach statistical significance bs < |0.54|, ts < |1.90|, ps > 0.063, including the interaction between Visibility and Valence, bs < |0.13|, ts < |1.09|, ps > 0.278.
To explore the relationship between empathizing, mentalizing, and willingness to help, we computed correlations between affect ratings und prosociality ratings as well as between accuracy and prosociality ratings on the interindividual level across Experiments 1, 2, and 4. For negatively valenced narrations, we observed a strong negative correlation between affect ratings and prosociality ratings, r = −0.42, p < 0.001, while no significant correlation was found in the neutral condition, r = 0.10, p = 0.290. This suggests that participants were more willing to invest (hypothetical) resources if they empathized strongly with a narrator recounting a negative experience. The correlation between accuracy and prosociality did not reach significance for either ToM questions, r = 0.16, p = 0.080, or noToM questions, r = 0.03, p = 0.731.

Estimated marginal means for prosociality rating in Experiments 1, 2, and 4. Error bars represent standard errors. On the x-axis, the different combinations of Valence and ToM Requirement are displayed. Bar colors and patterns denote Visibility condition (full visibility: white; eyes covered: dots; mouth covered: diagonal stripes; no visibility: black). Significant differences between Visibility conditions within each Valence x ToM Requirement combination are marked with horizontal brackets. *: p <.05.
Bayes factors
Given that our LMM analyses revealed mostly null effects for the key comparisons relevant to our hypotheses, we conducted additional Bayesian analyses to quantify the strength of evidence for the absence of effects. Specifically, we performed Bayesian t-tests on the raw data (separate from the LMM framework) to compute Bayes Factors in favor of the null hypothesis (BF₀₁), using a standard Cauchy prior of 0.707.
For empathic responding, we calculated the difference in affect ratings between negative and neutral narrations within each visibility condition and then compared these differences across conditions. According to common classifications of Bayes Factor75,76 all four experiments provided moderate support for the null hypothesis (Exp. 1: BF₀₁ = 4.06; Exp. 2: BF₀₁ = 3.59; Exp. 3: BF₀₁ = 5.88; Exp. 4: BF₀₁ = 5.59).
For accuracy, Bayesian t-tests again indicated moderate evidence for no difference in performance between visibility conditions (Exp. 1: BF₀₁ = 4.63; Exp. 2: BF₀₁ = 4.97; Exp. 3: BF₀₁ = 5.41; Exp. 4: BF₀₁ = 5.69). With respect to the interaction between Visibility and ToM Requirement on accuracy, Bayes Factors provided moderate support for the null in all experiments, with the exception of Experiment 2, which showed only anecdotal evidence (Exp. 1: BF₀₁ = 4.55; Exp. 2: BF₀₁ = 1.52; Exp. 3: BF₀₁ = 4.43; Exp. 4: BF₀₁ = 5.73).
For prosociality, the significant visibility effect observed in the LMM for Experiment 1 was accompanied by anecdotal evidence for the alternative hypothesis (BF₀₁ = 0.45). In contrast, Experiments 2 and 4 yielded anecdotal to moderate evidence for the null (Exp. 2: BF₀₁ = 2.07; Exp. 4: BF₀₁ = 5.09). Finally, for the interaction between Visibility and Valence on prosociality, all relevant comparisons provided moderate support for the null hypothesis (Exp. 1: BF₀₁ = 5.63; Exp. 2: BF₀₁ = 4.23; Exp. 4: BF₀₁ = 5.43).
Discussion
While the challenge of interacting with individuals whose faces are (partly) covered is not new, the widespread use of protective masks during the Covid-19 pandemic has intensified discussions about the impact of reduced face visibility. In this context, numerous studies have reported impaired emotion recognition when parts of the face were occluded9,11,14,15. The goal for our study was to investigate whether similar detrimental effects would emerge for more complex aspects of social understanding – specifically, empathizing and mentalizing – as well as social decision making when provided with realistic and contextual cues that might enable compensation for the reduced visual information41,42,77. In a video-based paradigm65, we presented short autobiographical narrations of either neutral or negative valence, followed by questions about the participant’s affective state, understanding, and willingness to help. The clips were manipulated to show the narrator’s face in different visibility conditions: fully visible, with black bars covering either their eyes or mouth, or with only the narrator’s voice audible.
Across four experiments, consistent patterns emerged for all variables of interest. Firstly, the affect ratings provided by the participants after each narration showed that our stimuli successfully elicited empathic responding, in line with previous studies using this task64,65,78. Interestingly, participants reported slightly lower overall affect when the narrator’s mouth was covered. However, the effect of narration valence – i.e., the difference in affect between neutral and negative narrations – did not significantly vary between visibility conditions. Hence, critical to our main hypothesis, the extent of empathic responding was not influenced by whether participants could see the narrator’s full face, their upper face, their lower face, or nothing at all.
Secondly, participants generally performed well on questions about the narrations’ content, achieving a mean accuracy of around 80% both for mentalizing and factual reasoning. This finding aligns with the accuracy levels reported in prior studies49,65,74 and suggests that ceiling effects are unlikely to affect our results. Importantly, accuracy rates did not indicate any disadvantage for mentalizing performance when the narrator’s face was partially or fully obscured. We additionally analyzed response times for correct answers, though this provides complementary rather than central insights as response times were relatively high (due to the time required to read the question) and instructions prioritized accuracy over speed. Similar to accuracy, response times were not substantially affected by the visibility manipulation, with a single exception: In one of the experiments, participants took slightly longer to answer Theory of Mind questions when the narrator’s mouth was covered versus fully visible, while no such delay emerged for factual reasoning questions.
Finally, prosociality was – in line with Lehmann et al.63 – associated with empathic responding: Participants who reported lower affect after negative narrations were more willing to help the narrator compared to participants whose affect was less diminished while we did not observe a significant correlation between accuracy and prosociality ratings. Our main analysis revealed that participants were more willing to (hypothetically) invest resources to help narrators who recounted a negative autobiographical story compared to a neutral one, as in previous studies63,74. This valence effect remained consistent across visibility conditions, indicating that the increase in prosociality after learning about someone’s bad experiences (compared to neutral experiences) was not significantly affected by facial feature visibility. However, overall prosociality – irrespective of emotional valence – was lower when the narrators’ eyes were covered compared to when their faces were fully visible. Since no similar effects were observed when the mouth or the full face (including the eyes) was covered, this likely does not reflect a general reluctance to help individuals whose faces are not fully visible. Instead, it may point to more specific effects for covered eyes or even the particular type of coverage used in the study (as we discuss later).
Integrating all these results, we found that participants’ social understanding (i.e., empathy and ToM) was not substantially impaired by limited visibility of the speaker’s face, as levels of empathizing and mentalizing were maintained across conditions in all four experiments. Perhaps most strikingly, even removing visual input completely in one of our experiments did not significantly impair social understanding compared to unobscured face visibility. This contrasts with prior findings on the detrimental effects of (partial) face coverage4,7,9 as well as the differential importance of eye and mouth visibility for emotion recognition18,20,21. It is apparent that participants in our study utilized other cues and modalities to compensate for the reduced visibility of the narrator. For example, when the narrator’s mouth or eyes were covered, participants might have instead concentrated on other areas of the face or on body posture41. However, since even these signals were unavailable in the no visibility condition, the narrator’s voice likely served as the most important source of information, both non-verbal and verbal. Numerous prior studies have documented humans’ ability to interpret tone of voice and other vocal cues, observing high levels of emotion recognition even in the absence of accompanying visual information31,48. Additionally, the verbal content of our study’s narrations offered extensive contextual information about the narrator’ affective state. As demonstrated by McCrackin and Ristic77, providing even a single line of context can significantly mitigate the negative impact of facial coverage. It therefore seems plausible that in our study, the narrator’s voice provided sufficient information to compensate for the lack of facial cues. While it is possible that part of this compensation was a voluntary effort by participants to give socially desirable answers for the affect and prosociality ratings, critically, the same is impossible for mentalizing given the performance-based nature of its assessment. Consequently, our data provide substantial support for the possibility of unimpaired empathizing and mentalizing, even when the interaction partner’s face is partially or fully covered. The dynamic and multimodal nature of our stimuli likely played a pivotal role in shaping these findings. While studies using static and artificial stimuli have overwhelmingly reported detrimental effects of face masks, research employing more naturalistic procedures has found no significant impact on empathy and connectedness42,43. Our results align well with these latter findings, which more closely represent real-life interactions, thereby underscoring the importance of ecological validity when studying social cognition.
Even though these findings are encouraging in terms of the potential for compensation in less-than-ideal circumstances, it would certainly be an overreach to conclude that (partial) face coverage does not have any adverse effects on social interactions. In fact, there seems to be some evidence for this in our own data. First, there is the decrease in prosociality towards individuals whose eyes were not visible, as observed in one of the experiments. Participants may have felt less closeness and connectedness to these narrators, especially given the cover story that they intentionally wanted their identity to be concealed. This effect may have been further intensified by our choice of “neutral” coverage using black bars: In everyday contexts, black bars over the eyes are often associated with anonymizing individuals in criminal investigations. If this imagery evoked associations with untrustworthy or suspicious people, it could explain why participants were less willing to help the narrators in this condition. Alternatively, the decrease in prosociality may reflect that in the eyes covered condition, participants felt less watched and, consequently, were less self-aware and concerned about social expectations79,80,81. To distinguish between these potential explanations (dependent either on the coverage itself or the specific type of coverage) it could be helpful to replicate our experiment using a more naturalistic form of coverage (e.g., adding sunglasses to the narrators’ faces) in the future. Another potential detrimental effect of face coverage is that while people may not be objectively worse at understanding their interaction partner when they cannot see their full face, they might still find it less pleasant or more effortful82. This could explain the slightly more negative affect reported by participants when the narrator’s mouth area was covered as well as participants taking slightly more time to think about questions requiring Theory of Mind (while giving equally accurate responses) in one of the experiments. Interestingly, a similar discrepancy between objective performance and subjective judgments has been reported in previous studies investigating the effect of masks on emotion recognition41,83. For example, Ross and George41 found that participants were less confident in their emotion recognition performance for masked faces, despite no actual decrease in accuracy. Additionally, the face occlusion in our experiments might have been perceived as a sign of unapproachability, disconnectedness or untrustworthiness, contributing to the negative affective response11,82,84.
It is also important to keep in mind that our experimental setup in many ways provided optimal circumstances for compensation. Even though our task is quite challenging, as narrators recount relatively complex autobiographical stories in a short time period (12–15 s), the audio tracks offered contextual information, delivered with articulatory clarity and high-quality sound. In contrast, real face masks create a physical barrier that can occasionally impede not only visibility but also clarity of speech82,85,86. In addition, there were no other cues vying for the participants’ attention in our paradigm, such as background noises or additional tasks. As most people can probably attest, it is notably more challenging to discern another person’s inner workings when they are squeezed next to you in a crowded subway than when you are sitting in the peace of your living room. It is therefore plausible that the ability to compensate for missing information reaches a limit when environmental factors are disadvantageous and attentional resources are otherwise engaged. The specific threshold for this limit could also vary between individuals. For example, persons with sensory impairments or symptoms of dementia are likely to be more severely affected by reduced visual information8,82,87,88. Exploring whether and how our pattern of results might change under particularly challenging conditions, such as additional distractions, could further enhance understanding of the underlying processes.
Another aspect potentially influencing our results might be the respective comparison conditions of visibility in each experiment. Since practical constraints (such as maintaining sufficient trials per condition) prevented us from comparing all four visibility conditions in a single within-subject experiment, we cannot rule out that the stimuli were evaluated differently depending on the condition they were contrasted against. For instance, covering the eyes might be perceived as an obstructive blocking of information when contrasted with fully visible faces but less so when compared to faces where other regions are occluded in a similar manner. This effect might have been exacerbated by the instructions framing the different types of coverage with distinct justifications (e.g., anonymizing narrators, investigating language comprehension) which potentially introduced motivational or emotional biases. A related limitation applies to our emotional valence conditions, which contrasted only neutral and negative narrations. The omission of other valence conditions (such as positive narrations) may have created specific contrast effects that do not fully represent the broader pattern of empathic responding, particularly positive empathy. There might have also been contrast effects within the experiment, e.g., when multiple trials of the same condition were presented consecutively, although exploratory analyses did not suggest that carry-over effects significantly affected our main results (see Supplement S4).
Despite the limitations discussed above, we believe that – considering the four experiments in combination – our results clearly demonstrate the human ability to flexibly compensate when visual information in social interactions is reduced. Without explicitly delving into evolutionary theories, it seems intuitively plausible that humans, at some point, developed strategies to cope with limited facial information. Such adaptations would have been crucial for effective communication with conspecifics over distances, at night, or in densely vegetated areas, even without considering artificial obstacles like brick walls and sunglasses. We believe that acknowledging this potential for compensation could shift the focus from solely emphasizing impairments in split-second emotion recognition, towards exploring social understanding in conditions that more closely reflect the complex, dynamic, and multimodal nature of naturalistic interactions27,89,90,91. A better insight into the mechanisms and prerequisites for successful compensation could, in turn, help create conditions that facilitate it, particularly in interactions where accurate understanding and empathizing are essential. For instance, in a clinical setting where masks are indispensable, this could involve setting up a calm, distraction-free space for discussing sensitive topics. Or, in everyday interactions like talking to a co-driver, it might simply mean being careful to provide ample verbal context when making arrangements without visual contact to avoid misunderstandings.
In essence, our findings demonstrate robust empathizing and mentalizing even when an interaction partner’s face is partially or fully occluded. This suggests that participants in our study effectively compensated for the missing facial information by relying on other available signals, particularly vocal cues. We observed a slight reduction in prosociality when the interaction partner’s eyes were covered (but not for mouth or full-face occlusion), possibly hinting at effects of specific types of coverage on social decision making but not suggesting a general reduction in willingness to help when facial visibility is reduced. Taken together, we argue that it is important to acknowledge not only the adverse effects of masks and other visual barriers but also the adaptive abilities that can mitigate these challenges in naturalistic settings. Adopting this balanced perspective would help to promote a more comprehensive view of social understanding49,92,93, one that reflects the remarkable flexibility inherent in human social cognition.
Methods
Sample
A total of 165 individuals participated in one of four experiments that took place between September 2021 and October 2022. Recruitment was conducted through university online platforms (University of Hannover, University of Würzburg), online posts, and private contacts. Data from eight participants were excluded from the analyses because their error rates were more than two standard deviations above the mean of their respective experiment. Consequently, the final sample sizes for the experiments ranged from 38 to 41 participants (total N = 157). The mean sample age varied from 21.6 to 27.1 years, with female participants representing between 70.7% and 81.6% of the samples. Table 1 summarizes demographic characteristics for Experiments 1–4. Participants received either monetary compensation, course credit, or bookstore vouchers for their participation. The procedure complied with the ethical standards of the 1964 Declaration of Helsinki regarding the treatment of human participants in research. The paradigm employed in this study (EmpaToM task) has been approved by ethics committees (Ethikkommission des Institutes für Psychologie der Humanwissenschaftlichen Fakultät der Julius-Maximilians-Universität Würzburg, GZEK 2017-04).
Stimulus material
In the course of the study, we presented video clips of different narrators recounting autobiographical episodes, which were taken and adapted from the validated EmpaToM paradigm65. Each video clip lasted approx. 15 s and featured a male or female individual whose face and upper body were shown from a frontal perspective in 4:3 format. The narrations dealt either with neutral experiences, such as work and leisure activities, or emotionally negative events, such as losing a loved one or getting injured (manipulation of Valence: neutral vs. negative). A total of 12 narrators (six female and six male, of different age groups) were selected for the study. Each narrator was featured in four videos, two neutral and two negatively valenced. Within each valence condition, one narration gave rise to a question that required mentalizing (e.g., recognizing ironic subtext, reading “between the lines”) while the other involved purely factual reasoning (manipulation of ToM Requirement: noToM vs. ToM). Two sets of narrations and associated questions are provided as examples in the supplements (Supplement S1).
The EmpaToM videos were displayed unaltered in the full visibility condition, while modifications were made for three additional conditions, varying which parts of the narrator’s face were visible to the participant (manipulation of Visibility: full visibility vs. eyes covered vs. mouth covered vs. no visibility). In the eyes covered and mouth covered condition, we added black bars, approximately 1/4th of the video’s width and 1/7th of the video’s height, and placed them over either the eye or the mouth area, respectively. Throughout each clip, the bar remained stationary and did not follow the narrators’ head movements. However, the relevant region (eye area/mouth area) was concealed at all times. In the no visibility condition, we isolated the audio from each video and played it over a blank screen. Each participant encountered all clips from one narrator in the same Visibility condition, with the assignment of narrators to conditions counterbalanced between participants.
Procedure
The experiment was designed and conducted with PsychoPy94. Data collection took place at the Julius-Maximilians-Universität Würzburg (Exps. 1, 2, 4) and the Leibniz Universität Hannover (Exp.3), with up to four individuals participating simultaneously. After giving their informed consent, participants were seated in front of a computer monitor with a standard German keyboard and over-ear headphones. They received both written and verbal instructions about the experimental procedure. Depending on the specific experiment, different cover stories were provided to explain the Visibility conditions. For the eyes covered condition, participants were told that a bar was placed over the eye area, because the narrators in the respective video wished to remain anonymous (Exps. 1 and 3). The feigned reason for covering the mouth was either to test the dependence of language comprehension on mouth visibility (Exp.2) or to create a control condition for the narrators with covered eyes (Exp.3). Finally, it was explained that the audios in the no visibility condition were sourced from earlier studies, with video footage available only for the “more recently recorded” narrations (Exp.4).
To familiarize themselves with the task, participants completed two practice trials. After confirming that there were no remaining questions, they proceeded to complete 48 trials in randomized order. During these trials, each participant encountered all possible narrations in one of the two visibility conditions included in their experiment. The study took about 40 min, with a break after half of the trials. Each trial began with a fixation cross (2 s), followed by the narrator’s name (2 s), and then the narration (15 s) presented in the respective Visibility, Valence, and ToM Requirement condition (a schematic depiction of the experimental procedure is provided in Fig. 1; the individual in the example images provided informed consent for their publication in an online open-access publication). After each clip, participants were first asked to rate their own affective state (affect rating: “How are you feeling?”, in German: “Wie fühlst du dich?”) on a scale with three marked anchors: A sad emoji face at the left end, a neutral face in the center, and a happy face at the right end. Participants used the arrow keys on the keyboard to move the marker across the scale in increments of one-tenth of the scale length and confirmed their selection by pressing Enter. After that, another fixation cross appeared, followed by a single-choice question about the content of the narration with three response options. In the noToM condition, the questions started with “It is true that…” (in German: “Es stimmt, dass…”), while in the ToM condition, questions were prefaced by “[Name] thinks that…” (in German: “[Name] denkt, dass…”). Participants were required to press one of three marked keys to select the option which they believed to be a correct statement based on the presented narration. They were given no time restriction and instructed to work conscientiously rather than quickly. Accuracy and RTs for correct responses were collected as measures of the participants’ ToM and factual reasoning performance (question accuracy, question RT). While the trial ended at this point in Experiment 3, all other experiments additionally recorded a rating for prosociality (preceded by another fixation cross). For this last rating, participants were asked to indicate their willingness to help the narrator (prosociality rating: “How much resources would you be willing to invest to help the person?”, German: “Wie viele deiner Ressourcen würdest du investieren, um der Person zu helfen?”) on a 10-point rating scale. The ends of the scale were labeled “nothing at all” and “a lot” (German: “gar nichts” – “sehr viel”), from left to right. In the initial instructions, it was emphasized that “resources” could refer to financial as well as emotional or practical support, depending on the narrator’s needs. After completing the trials, participants filled out a questionnaire that collected their demographic data, asked them what they thought the objective of the study was, and gave them the opportunity to leave additional comments about any issues that occurred during the experiment. Participants were then debriefed and thanked for their participation.
Design and analysis
We chose to divide our study into four experiments to avoid an overly large number of trials and to reduce potential suspicions regarding the experimental manipulation. Each experiment compared two of the overall four visibility conditions: Exp. 1: full visibility vs. eyes covered; Exp. 2: full visibility vs. mouth covered; Exp. 3: eyes covered vs. mouth covered; Exp. 4: full visibility vs. no visibility (audio-only). Combined with the Valence (neutral vs. negative) and ToM Requirement (noToM vs. noToM) manipulation of the EmpaToM, this resulted in a 2 × 2 × 2 within-subjects design per experiment. We conducted separate analyses for each experiment, applying linear mixed models (LMMs). Our initial analysis plan (see e.g., preregistration https://doi.org/10.17605/OSF.IO/DS4VE) had been to calculate repeated-measures ANOVAs for each experiment and to subsequently pool the data from multiple experiments to compute combined LMMs. The results of these planned analyses are available in the supplements (Supplement S3). However, to enhance statistical power and better account for variance associated with different participants and stimuli, we ultimately decided to apply LMMs (instead of ANOVAs) to the data of each experiment. While we did not have specific hypotheses regarding the random effects, their inclusion allowed us to account for structured variability in our data, thereby improving model fit and reducing unexplained noise. Note, however, that the overall pattern of results remained consistent across the different analytical approaches and supported the same conclusions.
Analyses were conducted for four dependent variables: (1) Affect rating (0–10 on a scale with ten increments where the midpoints and endpoints were anchored), where we were mainly interested in the effect of face visibility on empathic responding, as reflected in the difference between affect in neutral and negative trials (i.e., the Visibility x Valence interaction). (2) Question accuracy (in %), where differences could be observed specifically for ToM questions (reflected in a Visibility x ToM Requirement interaction) or for overall understanding. (3) Question RT (in seconds), with a similar focus as accuracy. For RT analyses, we included only trials with correct responses and additionally removed those with exceptionally high RTs, defined as more the 3 SDs above the experiment mean (1.5% of the trials with correct responses). (4) Prosociality rating (on a scale from 0 to 10), examining both the overall effect of Visibility as well as its interaction with Valence. Prosociality was only assessed in Experiments 1, 2 and 4.
For each of these dependent variables we fitted LMMs to the trial-wise data per experiment, employing Maximum Likelihood estimation and Satterthwaite approximation for the degrees of freedom (packages ‘lme4’95 and ‘lmerTest’96 in R, version 4.3.197). The LMMs included Level 1 fixed effects for Valence (coded as neutral = −0.5, negative = 0.5) and ToM Requirement (noToM = −0.5, ToM = 0.5). Additionally, we modeled Visibility as a Level 1 factor (Exp.1: full visibility = −0.5, eyes covered = 0.5; Exp.2: full visibility = −0.5, mouth covered = 0.5; Exp.3: eyes covered = −0.5, mouth covered = 0.5; Exp.4: full visibility = −0.5, no visibility = 0.5).
Each model began with a baseline structure including only the fixed effects and random intercepts for participants and narrations. We then incrementally added random slopes for Visibility, Valence, and ToM Requirement by participant and conducted Likelihood Ratio Tests for model comparison. Only random slopes that significantly improved model fit without causing singularity issues were retained. In the Results section, we report findings from the best-fitting model for each dependent variable and experiment. To ensure robustness, we also conducted supplementary analyses using both a minimal model (random intercepts only) and a maximal model (including all random slopes, as recommended by98). These alternative models produced no meaningful differences in results. Full details of all LMMs are available in the supplements (Supplement S2).
In the Results section, we report unstandardized coefficients (b) and the associated t- and p- values as calculated by the ‘lmerTest’96 package in R. For post-hoc comparisons, we provide estimated marginal means and t-tests computed with the ’emmeans’99 package. Cohen’s d was estimated based on the resulting t-value, sample size and the correlation between the repeated measures100.
In addition to our primary analyses, we conducted supplementary Bayesian analyses for the comparisons most relevant to our hypotheses. Specifically, we performed paired-samples Bayesian t-tests on the raw (unmodeled) data to compute Bayes Factors (BF₀₁), which quantify the likelihood of the data under the null hypothesis relative to the alternative. All Bayesian analyses were conducted using the R package ‘BayesFactor’101, with the default Cauchy prior of 0.707. We interpreted the resulting Bayes Factors following standard classifications75,76, with values of BF₀₁ between 3 and 10 indicating moderate evidence for the null. These analyses were applied to the key comparisons for affect rating (interaction Visibility x Valence), accuracy (main effect Visibility, interaction Visibility x ToM Requirement), and prosociality (main effect Visibility, interaction Visibility x Valence) across all experiments.
To investigate interindividual differences in the association between empathy and prosociality, we computed Pearson correlations between the participant-wise means for affect rating and prosociality rating, separated by valence condition (Exps. 1, 2, 4). Similarly, we examined the correlation between question accuracy and prosociality rating – separately for the ToM and noToM condition – to explore the potential association between accurate mentalizing and prosociality.
Data availability
The raw data and the R script used for the analyses are available on the Open Science Framework repository (https://osf.io/ndbwy/?view_only=42ab4f9690634eb78032d8c648372113).
References
Ovidius Naso, P. & Innes, M. M. The Metamorphoses of Ovid (Penguin Books, 1979).
Fortin, J. Masks keep us safe. They also hide our smiles. The New York Times (2020). https://www.nytimes.com/2020/06/23/style/face-mask-emotion-coronavirus.html
Max-Planck-Institut für Kognitions- und Neurowissenschaften. Trotz Schutz: Wie uns Corona-Masken Emotionen schlechter erkennen lassen. (2021). https://www.cbs.mpg.de/trotz-schutz-wie-uns-corona-masken-emotionen-schlechter-erkennen-lassen
Bassili, J. N. Emotion recognition: the role of facial movement and the relative importance of upper and lower areas of the face. J. Pers. Soc. Psychol. 37, 2049–2058. https://doi.org/10.1037/0022-3514.37.11.2049 (1979).
Kret, M. E. & De Gelder, B. Islamic headdress influences how emotion is recognized from the eyes. Front. Psychol. 3, Article 110. https://doi.org/10.3389/fpsyg.2012.00110 (2012).
Kret, M. E. & Fischer, A. H. Recognition of facial expressions is moderated by Islamic cues. Cogn. Emot. 32, 623–631. https://doi.org/10.1080/02699931.2017.1330253 (2018).
Roberson, D., Kikutani, M., Döge, P., Whitaker, L. & Majid, A. Shades of emotion: what the addition of sunglasses or masks to faces reveals about the development of facial expression processing. Cognition 125, 195–206. https://doi.org/10.1016/j.cognition.2012.06.018 (2012).
Aguillon-Hernandez, N., Jusiak, R., Latinus, M. & Wardak, C. COVID-19 masks: A barrier to facial and vocal information. Front. Neurosci. 16, 982899. https://doi.org/10.3389/fnins.2022.982899 (2022).
Carbon, C. C. Wearing face masks strongly confuses counterparts in reading emotions. Front. Psychol. 11, 566886. https://doi.org/10.3389/fpsyg.2020.566886 (2020).
Fitousi, D., Rotschild, N., Pnini, C. & Azizi, O. Understanding the impact of face masks on the processing of facial identity, emotion, age, and gender. Front. Psychol. 12, 743793. https://doi.org/10.3389/fpsyg.2021.743793 (2021).
Grundmann, F., Epstude, K. & Scheibe, S. Face masks reduce emotion-recognition accuracy and perceived closeness. PLOS ONE. 16, e0249792. https://doi.org/10.1371/journal.pone.0249792 (2021).
Langbehn, A. T., Yermol, D. A., Zhao, F., Thorstenson, C. A. & Niedenthal, P. M. Wearing N95, surgical, and cloth face masks compromises the perception of emotion. Affect. Sci. 3, 105–117. https://doi.org/10.1007/s42761-021-00097-z (2022).
Marini, M., Ansani, A., Paglieri, F., Caruana, F. & Viola, M. The impact of facemasks on emotion recognition, trust attribution and re-identification. Sci. Rep. 11, 5577. https://doi.org/10.1038/s41598-021-84806-5 (2021).
McCrackin, S. D., Capozzi, F., Mayrand, F. & Ristic, J. Face masks impair basic emotion recognition: group effects and individual variability. Soc. Psychol. 54, 4–15. https://doi.org/10.1027/1864-9335/a000470 (2023).
Noyes, E., Davis, J. P., Petrov, N., Gray, K. L. H. & Ritchie, K. L. The effect of face masks and sunglasses on identity and expression recognition with super-recognizers and typical observers. R Soc. Open. Sci. 8, 201169. https://doi.org/10.1098/rsos.201169 (2021).
Swain, R. H., O’Hare, A. J., Brandley, K. & Gardner, A. T. Individual differences in social intelligence and perception of emotion expression of masked and unmasked faces. Cogn. Res. Princ Implic. 7, Article 54. https://doi.org/10.1186/s41235-022-00408-3 (2022).
Tsantani, M., Podgajecka, V., Gray, K. L. H. & Cook, R. How does the presence of a surgical face mask impair the perceived intensity of facial emotions? PLOS ONE. 17, e0262344. https://doi.org/10.1371/journal.pone.0262344 (2022).
Blais, C., Roy, C., Fiset, D., Arguin, M. & Gosselin, F. The eyes are not the window to basic emotions. Neuropsychologia 50, 2830–2838. https://doi.org/10.1016/j.neuropsychologia.2012.08.010 (2012).
Kim, G., Seong, S. H., Hong, S. S. & Choi, E. Impact of face masks and sunglasses on emotion recognition in South Koreans. PLOS ONE. 17, e0263466. https://doi.org/10.1371/journal.pone.0263466 (2022).
Beaudry, O., Roy-Charland, A., Perron, M., Cormier, I. & Tapp, R. Featural processing in recognition of emotional facial expressions. Cogn. Emot. 28, 416–432. https://doi.org/10.1080/02699931.2013.833500 (2014).
Eisenbarth, H. & Alpers, G. W. Happy mouth and sad eyes: scanning emotional facial expressions. Emotion 11, 860–865. https://doi.org/10.1037/a0022758 (2011).
Schurgin, M. W. et al. Eye movements during emotion recognition in faces. J. Vis. 14, 14. https://doi.org/10.1167/14.13.14 (2014).
Wegrzyn, M., Vogt, M., Kireclioglu, B., Schneider, J. & Kissler, J. Mapping the emotional face. How individual face parts contribute to successful emotion recognition. PLOS ONE. 12, e0177239. https://doi.org/10.1371/journal.pone.0177239 (2017).
Carragher, D. J. & Hancock, P. J. B. Surgical face masks impair human face matching performance for familiar and unfamiliar faces. Cogn. Res. Princ Implic. 5, 59. https://doi.org/10.1186/s41235-020-00258-x (2020).
Kastendieck, T., Zillmer, S. & Hess, U. Un)mask yourself! Effects of face masks on facial mimicry and emotion perception during the COVID-19 pandemic. Cogn. Emot. 36, 59–69. https://doi.org/10.1080/02699931.2021.1950639 (2022).
Redcay, E. & Moraczewski, D. Social cognition in context: A naturalistic imaging approach. NeuroImage 216, 116392. https://doi.org/10.1016/j.neuroimage.2019.116392 (2020).
Risko, E. F., Laidlaw, K., Freeth, M., Foulsham, T. & Kingstone, A. Social attention with real versus reel stimuli: toward an empirical approach to concerns about ecological validity. Front. Hum. Neurosci. 6, 143. https://doi.org/10.3389/fnhum.2012.00143 (2012).
Adolphs, R. Recognizing emotion from facial expressions: psychological and neurological mechanisms. Behav. Cogn. Neurosci. Rev. 1, 21–62. https://doi.org/10.1177/1534582302001001003 (2002).
Ekman, P. & Oster, H. Facial expressions of emotion. Annu. Rev. Psychol. 30, 527–554. https://doi.org/10.1146/annurev.ps.30.020179.002523 (1979).
Krumhuber, E. G., Kappas, A. & Manstead, A. S. R. Effects of dynamic aspects of facial expressions: A review. Emot. Rev. 5, 41–46. https://doi.org/10.1177/1754073912451349 (2013).
Johnson, W. F., Emde, R. N., Scherer, K. R. & Klinnert, M. D. Recognition of emotion from vocal cues. Arch. Gen. Psychiatry. 43, 280–283. https://doi.org/10.1001/archpsyc.1986.01800030098011 (1986).
Russell, J. A., Bachorowski, J. A. & Fernández-Dols, J. M. Facial and vocal expressions of emotion. Annu. Rev. Psychol. 54, 329–349. https://doi.org/10.1146/annurev.psych.54.101601.145102 (2003).
Schirmer, A. & Kotz, S. A. Beyond the right hemisphere: brain mechanisms mediating vocal emotional processing. Trends Cogn. Sci. 10, 24–30. https://doi.org/10.1016/j.tics.2005.11.009 (2006).
Dael, N., Mortillaro, M. & Scherer, K. R. Emotion expression in body action and posture. Emotion 12, 1085–1101. https://doi.org/10.1037/a0025737 (2012).
De Gelder, B., De Borst, A. W. & Watson, R. The perception of emotion in body expressions. WIREs Cogn. Sci. 6, 149–158. https://doi.org/10.1002/wcs.1335 (2015).
Wallbott, H. G. Bodily expression of emotion. Eur. J. Soc. Psychol. 28, 879–896. https://doi.org/10.1002/(SICI)1099-0992(1998110)28:6%3C879::AID-EJSP901%3E3.0.CO;2-W (1998).
Calvi, E. et al. The scent of emotions: A systematic review of human intra- and interspecific chemical communication of emotions. Brain Behav. 10, e01585. https://doi.org/10.1002/brb3.1585 (2020).
Chen, D. & Haviland-Jones, J. Human olfactory communication of emotion. Percept. Mot Skills. 91, 771–781. https://doi.org/10.2466/pms.2000.91.3.771 (2000).
De Groot, J. H. B. et al. A Sniff of happiness. Psychol. Sci. 26, 684–700. https://doi.org/10.1177/0956797614566318 (2015).
Esposito, A. The perceptual and cognitive role of visual and auditory channels in conveying emotional information. Cogn. Comput. 1, 268–278. https://doi.org/10.1007/s12559-009-9017-8 (2009).
Ross, P. & George, E. Are face masks a problem for emotion recognition? Not when the whole body is visible. Front. Neurosci. 16, 915927. https://doi.org/10.3389/fnins.2022.915927 (2022).
Knowles, M. L. & Dean, K. K. Do face masks undermine social connection? Soc. Personal Psychol. Compass. 17, e12889. https://doi.org/10.1111/spc3.12889 (2023).
Scheibe, S., Grundmann, F., Kranenborg, B. & Epstude, K. Empathising with masked targets: limited side effects of face masks on empathy for dynamic, context-rich stimuli. Cogn. Emot. 37, 683–695. https://doi.org/10.1080/02699931.2023.2193385 (2023).
Bänziger, T., Grandjean, D. & Scherer, K. R. Emotion recognition from expressions in face, voice, and body: the multimodal emotion recognition test (MERT). Emotion 9, 691–704. https://doi.org/10.1037/a0017088 (2009).
Kreifelts, B., Ethofer, T., Grodd, W., Erb, M. & Wildgruber, D. Audiovisual integration of emotional signals in voice and face: an event-related fMRI study. NeuroImage 37, 1445–1456. https://doi.org/10.1016/j.neuroimage.2007.06.020 (2007).
Vroomen, J., Driver, J. & De Gelder, B. Is cross-modal integration of emotional expressions independent of attentional resources? Cogn. Affect. Behav. Neurosci. 1, 382–387. https://doi.org/10.3758/CABN.1.4.382 (2001).
Rutherford, M. D., Baron-Cohen, S. & Wheelwright, S. Reading the Mind in the voice: A study with normal adults and adults with asperger syndrome and high functioning autism. J. Autism Dev. Disord. 32, 189–194. https://doi.org/10.1023/A:1015497629971 (2002).
Scherer, K. Vocal communication of emotion: A review of research paradigms. Speech Commun. 40, 227–256. https://doi.org/10.1016/S0167-6393(02)00084-5 (2003).
Landmann, E., Krahmer, A. & Böckler, A. Social Understanding beyond the familiar: disparity in visual abilities does not impede empathy and theory of Mind. J. Intell. 12, Article 2. https://doi.org/10.3390/jintelligence12010002 (2024).
Gesn, P. R. & Ickes, W. The development of meaning contexts for empathic accuracy: channel and sequence effects. J. Pers. Soc. Psychol. 77, 746–761. https://doi.org/10.1037/0022-3514.77.4.746 (1999).
Hall, J. A. & Schmid Mast, M. Sources of accuracy in the empathic accuracy paradigm. Emotion 7, 438–446. https://doi.org/10.1037/1528-3542.7.2.438 (2007).
Kraus, M. W. Voice-only communication enhances empathic accuracy. Am. Psychol. 72, 644–654. https://doi.org/10.1037/amp0000147 (2017).
Zhao, N., Zhang, X., Noah, J. A., Tiede, M. & Hirsch, J. Separable processes for live in-person and live zoom-like faces. Imaging Neurosci. 1, 1–17. https://doi.org/10.1162/imag_a_00027 (2023).
Hsu, C. T., Sato, W. & Yoshikawa, S. Enhanced emotional and motor responses to live versus videotaped dynamic facial expressions. Sci. Rep. 10, 16825. https://doi.org/10.1038/s41598-020-73826-2 (2020).
Ravreby, I. et al. The many faces of mimicry depend on the social context. Emotion https://doi.org/10.1037/emo0001445 (2024).
De Vignemont, F. & Singer, T. The empathic brain: How, when and why? Trends Cogn. Sci. 10, 435–441. https://doi.org/10.1016/j.tics.2006.08.008 (2006).
Gallese, V. The roots of empathy: the shared manifold hypothesis and the neural basis of intersubjectivity. Psychopathology 36, 171–180. https://doi.org/10.1159/000072786 (2003).
Frith, C. D. & Frith, U. Theory of Mind. Curr. Biol. 15, R644–R645. https://doi.org/10.1016/j.cub.2005.08.041 (2005).
Saxe, R. & Kanwisher, N. People thinking about thinking people: the role of the temporo-parietal junction in theory of Mind. NeuroImage 19, 1835–1842. https://doi.org/10.1016/S1053-8119(03)00230-1 (2003).
Eisenberg, N., Eggum, N. D. & Di Giunta, L. Empathy-related responding: associations with prosocial behavior, aggression, and intergroup relations. Soc. Issues Policy Rev. 4, 143–180. https://doi.org/10.1111/j.1751-2409.2010.01020.x (2010).
Eisenberg, N. & Miller, P. A. The relation of empathy to prosocial and related behaviors. Psychol. Bull. 101, 91–119. https://doi.org/10.1037/0033-2909.101.1.91 (1987).
Hein, G., Silani, G., Preuschoff, K., Batson, C. D. & Singer, T. Neural responses to ingroup and outgroup members’ suffering predict individual differences in costly helping. Neuron 68, 149–160. https://doi.org/10.1016/j.neuron.2010.09.003 (2010).
Lehmann, K., Böckler, A., Klimecki, O., Müller-Liebmann, C. & Kanske, P. Empathy and correct mental state inferences both promote prosociality. Sci. Rep. 12, 16979. https://doi.org/10.1038/s41598-022-20855-8 (2022).
Tusche, A., Böckler, A., Kanske, P., Trautwein, F. M. & Singer, T. Decoding the charitable brain: Empathy, perspective taking, and attention shifts differentially predict altruistic giving. J. Neurosci. 36, 4719–4732. https://doi.org/10.1523/JNEUROSCI.3392-15.2016 (2016).
Kanske, P., Böckler, A., Trautwein, F. M. & Singer, T. Dissecting the social brain: introducing the empatom to reveal distinct neural networks and brain–behavior relations for empathy and theory of Mind. NeuroImage 122, 6–19. https://doi.org/10.1016/j.neuroimage.2015.07.082 (2015).
Leder, J., Koßmann, L. & Carbon, C. C. Perceptions of persons who wear face coverings are modulated by the perceivers’ attitude. Front. Neurosci. 16, 988546. https://doi.org/10.3389/fnins.2022.988546 (2022).
Kotsia, I., Buciu, I. & Pitas, I. An analysis of facial expression recognition under partial facial image occlusion. Image Vis. Comput. 26, 1052–1067. https://doi.org/10.1016/j.imavis.2007.11.004 (2008).
Bombari, D. et al. Emotion recognition: the role of featural and configural face information. Q. J. Exp. Psychol. 66, 2426–2442. https://doi.org/10.1080/17470218.2013.789065 (2013).
Kanske, P., Böckler, A., Trautwein, F. M., Lesemann, P., Singer, T. & F. H. & Are strong empathizers better mentalizers? Evidence for independence and interaction between the routes of social cognition. Soc. Cogn. Affect. Neurosci. 11, 1383–1392. https://doi.org/10.1093/scan/nsw052 (2016).
Völlm, B. A. et al. Neuronal correlates of theory of Mind and empathy: A functional magnetic resonance imaging study in a nonverbal task. NeuroImage 29, 90–98. https://doi.org/10.1016/j.neuroimage.2005.07.022 (2006).
Besel, L. D. S. & Yuille, J. C. Individual differences in empathy: the role of facial expression recognition. Personal Individ Differ. 49, 107–112. https://doi.org/10.1016/j.paid.2010.03.013 (2010).
Preston, S. D. & De Waal, F. B. M. Empathy: its ultimate and proximate bases. Behav. Brain Sci. 25, 1–20. https://doi.org/10.1017/S0140525X02000018 (2002).
Shamay-Tsoory, S. G. The neural bases for empathy. Neuroscientist 17, 18–24. https://doi.org/10.1177/1073858410379268 (2011).
McDonald, B., Böckler, A. & Kanske, P. Soundtrack to the social world: emotional music enhances empathy, compassion, and prosocial decisions but not theory of Mind. Emotion 22, 19–29. https://doi.org/10.1037/emo0001036 (2022).
Lee, M. D. & Wagenmakers, E. J. Bayesian Cognitive Modeling: A Practical Course (Cambridge University Press, 2014). https://doi.org/10.1017/CBO9781139087759
Jeffreys, H. Theory of Probability (Oxford University Press, 1961).
McCrackin, S. D. & Ristic, J. Emotional context can reduce the negative impact of face masks on inferring emotions. Front. Psychol. 13, 928524. https://doi.org/10.3389/fpsyg.2022.928524 (2022).
Lantos, D. et al. Introducing the english empatom task: A tool to assess empathy, compassion, and theory of Mind in fMRI studies. Neuroimage Rep. 3, 100180. https://doi.org/10.1016/j.ynirp.2023.100180 (2023).
Haley, K. J. & Fessler, D. M. T. Nobody’s watching? Subtle cues affect generosity in an anonymous economic game. Evol. Hum. Behav. 26, 245–256. https://doi.org/10.1016/j.evolhumbehav.2005.01.002 (2005).
Nettle, D. et al. The watching eyes effect in the dictator game: it’s not how much you give, it’s being seen to give something. Evol. Hum. Behav. 34, 35–40. https://doi.org/10.1016/j.evolhumbehav.2012.08.004 (2013).
Conty, L., George, N. & Hietanen, J. K. Watching eyes effects: when others Meet the self. Conscious. Cogn. 45, 184–197. https://doi.org/10.1016/j.concog.2016.08.016 (2016).
Saunders, G. H., Jackson, I. R. & Visram, A. S. Impacts of face coverings on communication: an indirect impact of COVID-19. Int. J. Audiol. 60, 495–506. https://doi.org/10.1080/14992027.2020.1851401 (2021).
Grenville, E. & Dwyer, D. M. Face masks have emotion-dependent dissociable effects on accuracy and confidence in identifying facial expressions of emotion. Cogn. Res. Princ Implic. 7, Article 15. https://doi.org/10.1186/s41235-022-00366-w (2022).
Oldmeadow, J. A. & Gogan, T. Masks wearing off: changing effects of face masks on trustworthiness over time. Perception 53, 343–355. https://doi.org/10.1177/03010066241237430 (2024).
Corey, R. M., Jones, U. & Singer, A. C. Acoustic effects of medical, cloth, and transparent face masks on speech signals. J. Acoust. Soc. Am. 148, 2371–2375. https://doi.org/10.1121/10.0002279 (2020).
Rahne, T., Fröhlich, L., Plontke, S. & Wagner, L. Influence of surgical and N95 face masks on speech perception and listening effort in noise. PLOS ONE. 16, e0253874. https://doi.org/10.1371/journal.pone.0253874 (2021).
Poon, B. T. & Jenstad, L. M. Communication with face masks during the COVID-19 pandemic for adults with hearing loss. Cogn. Res. Princ Implic. 7, 24. https://doi.org/10.1186/s41235-022-00376-8 (2022).
Schroeter, M. L., Kynast, J., Villringer, A. & Baron-Cohen, S. Face masks protect from infection but May impair social cognition in older adults and people with dementia. Front. Psychol. 12, 640548. https://doi.org/10.3389/fpsyg.2021.640548 (2021).
Schilbach, L. Eye to eye, face to face and brain to brain: novel approaches to study the behavioral dynamics and neural mechanisms of social interactions. Curr. Opin. Behav. Sci. 3, 130–135. https://doi.org/10.1016/j.cobeha.2015.03.006 (2015).
Schilbach, L. et al. Toward a second-person neuroscience. Behav. Brain Sci. 36, 393–414. https://doi.org/10.1017/S0140525X12000660 (2013).
Shamay-Tsoory, S. G. & Mendelsohn, A. Real-life neuroscience: an ecological approach to brain and behavior research. Perspect. Psychol. Sci. 14, 841–859. https://doi.org/10.1177/1745691619856350 (2019).
Hessels, R. S. How does gaze to faces support face-to-face interaction? A review and perspective. Psychon Bull. Rev. 27, 856–881. https://doi.org/10.3758/s13423-020-01715-w (2020).
Wieser, M. J. & Brosch, T. Faces in context: A review and systematization of contextual influences on affective face processing. Front. Psychol. 3, Article 471. https://doi.org/10.3389/fpsyg.2012.00471 (2012).
Peirce, J. et al. PsychoPy2: experiments in behavior made easy. Behav. Res. Methods. 51, 195–203. https://doi.org/10.3758/s13428-018-01193-y (2019).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear Mixed-Effects models using lme4. J. Stat. Softw. 67, 1–48. https://doi.org/10.18637/jss.v067.i01 (2015).
Kuznetsova, A., Brockhoff, P. B. & Christensen, R. H. B. LmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26. https://doi.org/10.18637/jss.v082.i13 (2017).
R Core Team. R: A language and environment for statistical computing. (2023). https://www.R-project.org/
Barr, D. J., Levy, R., Scheepers, C. & Tily, H. J. Random effects structure for confirmatory hypothesis testing: keep it maximal. J. Mem. Lang. 68, 255–278. https://doi.org/10.1016/j.jml.2012.11.001 (2013).
Lenth, R. V. emmeans: Estimated marginal means, aka least-squares means. (2024). https://CRAN.R-project.org/package=emmeans
Dunlap, W. P., Cortina, J. M., Vaslow, J. B. & Burke, M. J. Meta-analysis of experiments with matched groups or repeated measures designs. Psychol. Methods. 1, 170–177. https://doi.org/10.1037/1082-989X.1.2.170 (1996).
Morey, R. D. & Rouder, J. N. BayesFactor: Computation of Bayes Factors for common designs. (2024). https://CRAN.R-project.org/package=BayesFactor
Acknowledgements
We would like to thank the students that helped with adjusting the stimuli and collected data for the experiments: Malin Sappa, Annika Plenker, Alin Termure, Carolina De Assis, Laura Schneider, and Mustafa Baraka. We also want to thank André Forster for his valuable input on the computation of LMMs. This work was supported by an Emmy Noether grant provided by the German Research Foundation (grant number BO 4962/1–1).
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was supported by the German Research Foundation under Grant number BO 4962/1–1. Deutsche Forschungsgemeinschaft.
Author information
Authors and Affiliations
Contributions
All authors contributed to the conception of the study, which was supervised by AB. IFS carried out the majority of data collection. EL, IFS, and AB were responsible for analyzing the results. EL wrote the original draft of the manuscript, which was revised and added to by AB. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Landmann, E., Straub, I.F. & Böckler, A. No evidence for disruption of empathy and mentalizing by face coverage in multimodal settings. Sci Rep 15, 43281 (2025). https://doi.org/10.1038/s41598-025-25393-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25393-7
