
Abstract
Tobacco warehousing requires continuous surveillance to mitigate risks like unauthorized access, fire hazards, and moisture-induced decay. To address these challenges, this paper proposes an edge-cloud collaborative surveillance framework with adaptive deep learning, termed YOMO-TF (YOLO + MobileOne + Transformer + Federated self-distillation). The architecture consists of three layers: edge layer- employing lightweight models (YOLOv8-nano for real-time object detection and MobileOne-S for effective image classification) for performing fast, on-device video analytics without storing data in cloud. Next, the adaptive learning layer, where a federated self-distillation mechanism enables continuous knowledge refinement over distributed devices without centralized retraining; and the cloud layer, that leverages attention-based schemes like Temporal Shift Transformer (TST) for temporal anomaly detection. This hybrid model ensures high responsiveness, reduced bandwidth usage, with enhanced privacy. Experimental evaluations demonstrate that the proposed model attains 98.6% accuracy, 99.5% precision, 97.6% recall, and 98.5% F1-score, outperforming traditional schemes in both reliability and efficiency. These outcomes highlight the proposed framework’s potential as a scalable, privacy-preserving, and real-time solution for tobacco warehouse safety management, with broad applicability to other industrial safety domains.
Similar content being viewed by others

Introduction
Tobacco warehouse serves as a critical storage facility at which huge quantities of processed and raw tobacco are maintained before distribution and manufacturing1. These environments are sensitive highly to theft, fire hazards, environmental fluctuations, and pest infestation like temperature and humidity. In typical, traditional surveillance systems depending on closed circuits cameras (CCTV) and manual monitoring2, are insufficient for the real-time hazard prevention and detection. With the increase of warehouse operation demand complexity, an intelligent, automated, & adaptive safety management systems competent of addressing emerging risks dynamically3. This research lies in the intersection of Industrial Safety Management, Intelligent Surveillance, and Edge-cloud collaborative computing4,5,6. This in turn incorporates concepts from Deep learning, IoT-aided sensor networks, and distributed AI for designing scalable & low-latency solutions that tailored for the safety of warehouse.

Edge-cloud enabled smart factory schematic diagram (Su et al. 2024).
Adaptive deep learning includes continuous refinement of model depending on new operational data, environmental variations, and hazard patterns7,8,9. In the tobacco warehouse, the conditions like seasonal temperature shifts, variable lighting, & diverse storage layouts necessitate this adaptability. Not like static models, adaptive DL in turn updates in real-time for incorporating newer hazard data (like fire patterns or theft behaviors), increases accuracy over time on learning warehouse-desired characteristics, reduces false alarms on distinguishing among normal operations (like controlled smoke from actual and drying hazard), enables collaborative learning over multiple warehouses on sharing anonymous insights, thus improving predictive abilities for entire connected facilities10,11. This adaptability thereby ensures that the system remains robust, context-aware, & effectual even like operational conditions evolve.
Figure 1 shows the edge-cloud enabled smart factory schematic representation. Several higher-profile warehouse incidents underscore most urgent need for automated12,13,14, real-time safety solutions which could adapt on evolving conditions. Leveraging edge computing for the local processing thus ensures recognition of hazards immediately, whereas cloud integration enables retraining periodic model & global intelligence sharing. This hybrid framework could address bandwidth, latency, and scalability issues in a simultaneous manner, thus making them an ideal solution for the tobacco warehouses.
Problem statement
Existing warehouse surveillance systems are most often manually operated or cloud-centric, that introduces significant challenges like high latency in detection of hazard because of reliance on centralized cloud processing15,16,17,18, Bandwidth constraints on transmitting continuous sensor or video data, Lack of adaptability to varying conditions of environment & evolving risk patterns, Minimal collaboration among distributed warehouse systems, thus resulting in isolated safety insights rather than the model of unified intelligence. These challenges hinder the timely responses for emergencies thereby reducing overall protection of tobacco storage amenities.
Motivation
Frequent accidents in tobacco storage facilities underscore the need of adaptive, real-time monitoring. On integrating lightweight edge analytics (like YOLOv8-nano, MobileOne-S) with the cloud dependent adaptive model updates (like attention based TST schemes), safety management could attain both low latency & continuous learning. The suggested model thus minimizes the cost of bandwidth, improves privacy (local processing), and thus offers collaborative detection of hazards over multiple warehouses.
Objectives
In order to address critical safety challenges in tobacco warehouse-like fire outbreaks, environmental variations, and unauthorized access-this model presents an Edge-cloud collaborative Surveillance Framework that leverages adaptive DL algorithms. This framework incorporates lightweight YOLOv8-nano and MobileOne-S scheme for the edge detection in real-time with cloud-dependent Temporal Shift Transformer (TST) scheme for temporal anomaly detection. A mechanism of FSD enables the continuous local adaptation without centralized retraining, thus ensuring responsiveness for dynamic conditions & operational variability. The main contributions of this work are as follows:
-
To proposed a hybrid edge-cloud surveillance architecture optimized for real-time safety constraint management in the tobacco warehouses.
-
To deploy lightweight DL scheme (YOLOv8-nano, MobileOne-S) at edge for lower latency detection of hazard with minimum usage of resource.
-
To incorporate TST scheme at cloud layer for the advanced temporal anomaly detection & sequence analysis.
-
To introduce FSD scheme for the continuous adaptive learning over edge device without the transmission of raw data.
-
To demonstrate significant enhancement, attaining reduction in the recognition latency, fewer false positives, and improved generalizability on comparing legacy systems.
Structure of article
The upcoming sections of this article is structured as follows: Sect II is the review carried based on various existing models related to edge computing in safety hazard management, and application of ML and DL in edge cloud frameworks. Sect III is the brief explanation on proposed working modules. Sect IV is the performance assessment carried for proposed model and its comparison with existing models. Sect V is the conclusion or summary of overall working module.
Related works
A short and concise review has been made in this section related to safety management and monitoring schemes using machine and deep learning models with edge cloud integration.
An architecture for collaborative dust concentration detection between edge and cloud computing was proposed in this survey19. Here, a clever algorithm is being used to shorten the warning delay. Additionally, it has three sub-networks: a local feature branch, a spatial feature branch, and a global feature branch. It also obtains the input image’s detail texture, overall layout, and spatial distribution information, respectively. When compared to a single network structure that directly lapses the entire image, the monitoring performance is improved to reflect all of the image’s information. The E2E-SCNN algorithm achieves great performance, making it superior to other comparison approaches. Thus, the precision and resilience of dust concentration prediction can be greatly improved with the aid of a three-channel convolutional neural network spatial information monitoring architecture.
A novel hybrid edge-cloud federated learning approach is proposed in this paper9 to enhance an automated smoking detection system. By using a decentralized strategy that distributes processing duties across the fog-edge layers, the reliance on the centralized infrastructure is significantly decreased. Data privacy is dealt with by federated learning, which enables edge devices to handle local data while securely sharing the model with the server. This work tackles the architectural difficulties in combining cloud and edge computing and demonstrates an 80% accuracy rate in identifying smoking activities.
This methodology improves the prediction capacities in disease diagnosis and management by leveraging real-time data processing, big data analytics, and machine learning algorithms20. The integration of AI-driven diagnostic tools with electronic health records (EHRs) is a key component of this study since it makes proactive and individualized healthcare intrusions possible. Here, predictive analytics methods like deep learning and neural networks are used to identify chronic diseases earlier, which lowers the number of readmissions for patients.
Ant colony optimization, real-time data analytics, and IOT technologies are all included in this study21. In contrast to the conventional approach, this model overcomes the limitations of static scheduling techniques. In addition to lowering fuel and maintenance expenses, the economic advantages increased by $20,860. Last but not least, the Shijiazhuang Tobacco Company’s results indicate that delivery trip counts were reduced, vehicle utilization increased from 60.32% to 91.41%, and distribution efficiency increased by 520.92%. As a result, logistic operations were more effective while simultaneously lowering expenses.
A YOLOX deep convolutional neural network and edge computing with a smart tunnel fire monitoring approach were proposed in this work22. Analysing the connection between frequency domain, convolutional neural networks, and wavelet transform usage improves detection accuracy. Using the smoke features found in the tests, a fuzzy loss strategy is implemented to speed up the model’s rate of convergence. To improve the running speed on edge devices, the training model is adjusted via knowledge distillation and model quantization to handle the low processing power of edge devices. A number of similar lightweight techniques are used to optimize the model. Consequently, it lowers the computational cost and speeds up detection.
To address the current issues with the scant image data for smoke and fire scenarios, which result in high rates of leakage and false detection. A cloud-edge collaborative architecture for real-time fire and smoke detection is presented in this study23, which improves adaptability by using an iterative transfer learning technique based on user feedback. By strengthening the data augmentation technique, this enhances the YOLOv8 detection capabilities, which is a basis model. The mAP0.5:0.95 increases by about 5 points, and the accuracy increases from 93.3% to 96.4%.
Real-time tobacco cabinet manufacturing status detection is suggested by this study24. Additionally, it uses deep learning and the internet of things to determine whether the foreign objects in cigarette cabinets are safe. The tobacco cabinet was detected in less than a second. This technique creates efficient cigarette manufacturing and offers useful safety implications.
Research gap identification
Existing studies on edge-cloud and DL aided safety system address isolated hazards such as fire, dust, or smoking detection but too lacks a unified adaptive framework for the comprehensive tobacco warehouse safety25,26,27. The present model fails in combining lower-latency edge detection, temporal anomaly detection in cloud, and continuous adaptation over FSD, thus resulting in limited or constrained responsiveness, scalability, and generalizability to the dynamic warehouse conditions. To address this gap, this work presents an edge-cloud collaborative surveillance framework with the use of adaptive DL for real-time detection of hazard and anomaly recognition in tobacco warehouses.
Proposed work
Tobacco warehousing needs continuous & intelligent surveillance for mitigating the risks like fire hazards, unauthorized access, & quality degradation because of moisture or environmental variations. Existing surveillance systems rely mostly on the centralized processing, thus leading to scalability, latency, & limited adaptability for local conditions. For addressing these limitations, this model employees Edge-cloud collaborative surveillance framework using adaptive deep learning model.

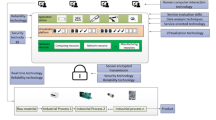
Architecture model of proposed framework.
Figure 2 shows the architecture model of the proposed framework. The overview of this architecture model and input data acquisition is explained below. The main contributions of this work are as follows:
-
To suggest a hybrid edge-cloud surveillance architecture optimized for real-time safety constraint management in the tobacco warehouses.
-
To deploy lightweight DL scheme (YOLOv8-nano, MobileOne-S) at edge for lower latency detection of hazard with minimum usage of resource.
-
To integrate TST scheme at cloud layer for the advanced temporal anomaly detection & sequence analysis.
-
To present FSD scheme for the continuous adaptive learning over edge device without the transmission of raw data.
-
To validate significant enhancement, attaining reduction in the recognition latency, fewer false positives, and improved generalizability on comparing legacy systems.
System architecture model
Overview
The proposed model YOMO-TF integrates three key innovations:
-
Edge layer (Lightweight detection): Implements lower-complexity schemes (YOLOv8-nano, MobileOne-S) for attaining real-time hazard identification with minimum hardware resources.
-
Cloud Layer (Temporal reasoning): It employs advanced schemes like Temporal Shift Transformer (TST) for long-term anomaly detection & cross-warehouse correlation.
-
Federated Self-Distillation (FSD): It ensures continuous adaptation of edge models over privacy-preserving knowledge transfer from cloud to edge, thus avoiding centralized retraining thus improving responsiveness for local conditions.
This hybrid model ensures multi-hazard identification, lower-latency monitoring, & scalability over distributed tobacco storage facilities, thus setting new benchmark in the management of safety for higher-risk logistics domains.
Data flow/input acquisition
The effectiveness of the proposed model is verified using the collected and fabricated 1000 images in the tobacco workshop with the manually annotated images. The input source is from the High-resolution video streams & IoT sensor data (like humidity, temperature, smoke detectors) are captured continuously from warehouse environments. Each video stream is divided as frames \(\:{x}_{t}\) at discrete time intervals ‘t’. These captured frames are considered as primary inputs for the tasks like hazard detection, like detecting smoke plumes, environmental anomalies, and unauthorized presence of human.
Edge layer-lightweight detection based on DL
Preprocessing
In this step, normalization and resizing are carried at which frames are resized as \(\:640\times\:640\) by normalizing pixel values for enhancing inference stability and speed. The augmentation is then carried by employing techniques like random cropping, adjusting brightness, horizontal flipping, for improving generalization under varied warehouse lighting conditions. Then, alignment of sensor data is carried temporally with video frames for providing auxiliary context for detection framework.
Even under identical conditions, image features captured by various cameras might exhibit minor variations. For minimizing the impact of various models of camera, this model initially establishes calibration scheme for every camera and then employs an inverse transformation for eliminating non-linear distortion influence on the extraction of feature20. This model enhances the feature extraction accuracy thereby increasing consistency and reliability of image processing. A camera within tobacco production workshop is thus selected as a primary reference camera and their captured images will be used as baseline model. For aligning images from other cameras with a reference, affine transformation will be applied. For this purpose, SURF descriptors will be extracted from images21. In addition, effect of airborne particles on light propagation will be considered, and their relationship will be expressed in formula (1).
In this, F parameter signifies the light intensity observed, G denotes brightness of global environment, \(\:{T}_{v}\) signifies propagation function, & parameter α denotes image’s pixel position. Similarly, image’s adjacent pixel might be affected by the medium particles of air. Hence, illuminance variance could be computed by following equation:
Here, P parameter is the brightness variation, LB signifies brightness mean, and CE is the set of entire pixels of an image. The saturation will be affected very easily by air medium, and saturation could be estimated by following equation:
In this, V signifies image saturation, and denotes RGB color values. The saturation mean gradient could be computed by subsequent equation:
In this, \(\:{V}_{b}\) denotes saturation gradient. The dark channel intensity will be computed using below equation:
Here, \(\:{J}^{dark}\) parameter signifies dark channel, \(\:{J}^{c}\) denotes color channel of j, and W(b) signifies the entire pixel set of neighborhoods at center point having ‘b’ pixel in center. As per the formula mentioned above, coefficient of propagation will be computed by:
In this, \(\:{I}^{c}\) parameter will be the intensity observed at channel C, and \(\:{A}^{c}\) represents the intensity of global environment at channel c.
Edge layer detection using DL model
For the real-time object and hazard detection (like fire, intrusion, smoke) lightweight models like Yolov8-nano and MobileOne-S will be deployed on edge device (lower-power GPU’s or embedded system). The object detected are represented by class probabilities and bounding boxes.
YOLOv8-nano: It is the lightweight model for object detection that is optimized for real-time inference on the lower-power edge device. This in turn process input frames \(\:{x}_{t}\) for predicting bounding boxes \(\:b=(x,y,w,h)\) with class probabilities \(\:{p}_{c}\) for varied types of hazards (like smoke, fire, intrusion). This is employed for optimizing real-time inference at edge device with limited memory and compute. This in turn detects multiple hazards (like smoke, human intrusion, and fire) in a single forward pass. The architecture has following layers.
-
Backbone (CSPDarknet with fewer layers for feature extraction).
-
Neck (Path Aggregation Network (PANet) for fusion of multi-scale feature.
-
Head (decoupled detection head for bounding box regression & classification), and.
-
Nano-variant (which uses fewer channels/parameters (~ 3.2 M) for quick inference on embedded system.
The function of prediction is estimated by computing model outputs bounding boxes and class probabilities as follows:
In this N signifies number of objects detected at frame \(\:{x}_{t}\). The predicted bounding boxes and class probabilities are signified by \(\:{\widehat{y}}_{t}\). \(\:{f}_{\theta\:}^{edge}\) is the YOLOv8-nano model having parameter \(\:\theta\:\). Bounding box coordinates (center x, y, width, height) are denoted as \(\:b=(x,y,w,h)\). C denotes the number of hazard class (like smoke, fire, person), \(\:{p}_{c}\) denotes probability score for class c.
The loss function of YOLOv8-nano employs a composite loss on integrating three components bounding box loss, classification loss, and objectness loss and is estimated as follows:
Bounding box loss \(\:{\mathcal{L}}_{box}\) employs complete IoU (CIoU) loss for align predicted & ground truth boxes as follows:
Classification loss \(\:{\mathcal{L}}_{cls}\) at which binary cross-entropy loss for prediction of multi-hazard is estimated as:
Objectness loss \(\:{\mathcal{L}}_{obj}\): it is the binary cross-entropy for presence or absence of object in the cell grid.
In overall, composite loss on integrating these components are derived by:
In this, \({\mathcal{\lambda}}\) is the detection loss weight denoted for bounding box, classification loss, and objectness loss.
MobileOne-S: This is the lightweight CNN that is optimized for embedded and mobile device, thus making them appropriate for the detection of real-time hazards at edge side in tobacco warehouse environment. This in turn focus on attaining higher speed with lower latency over effective architectural design. The architecture of this model uses depth wise separable convolutions & structural re-parametrization, that merges multiple branch convolution into single branch at the time of inference for reducing computational cost. The scalability ‘S’ variant signifies small model employed for environments with limited computational resource and memory. It is used along with YOLOv8-nano for complementary or parallel detection tasks (like redundant confirmation of hazard or multi-view analysis).The prediction and loss function are estimated as follows:
The input frames \(\:{x}_{t}\) will be processed to output class probabilities and bounding boxes.
The loss function will be similar to YOLO-based scheme and is expressed by:
This model focusses primarily on the lower-latency object localization and classification on consuming few losses, thus making them ideal for continuous monitoring in the warehouse settings.
From this, the edge inference creates bounding boxes and hazards classes in real-time (like detected smoke in frame t), feature embeddings from the intermediate layer will be transmitted to cloud for temporal anomaly detection with the use of TST scheme. Thus, this lightweight model ensures lower power consumption & higher FPS on the edge device.
Temporal shift transformer (TST) for anomaly detection
TST is used in cloud layer of suggested model for analyzing sequential feature embeddings from multiple edge nodes. Their primary intention is to detect temporal anomalies (like gradual buildup of smoke, unusual moving patterns) on modelling long-term dependencies among consecutive frames. The input of this is the sequence of feature vectors \(\:Z=\left\{{z}_{t-k+1},\:{z}_{t-k+2},\dots\:,{z}_{t}\right\}\) extracted from edge model. This core mechanism integrates temporal shift modules with the multi-head self-attention so as to capture both long-term and short-term patterns in an effective manner. The outcome is the anomaly score \(\:{\widehat{y}}_{t}\) that indicates abnormal or normal activity.
A temporal shift module redistributes the portion of feature channels over time steps without any extra computations:
At which, a, b, c signifies channel partitions shifted forward, backward, and kept. Specifically, the following ratios are used to divide the feature channels into forward, backward, and unmodified partitions: 1:1:6. Each shifted group travels by one temporal step (Δt = ± 1) to enable short-term temporal mixing with minimal processing. The resultant tensor, which contains temporally blended data, is then processed by the multi-head self-attention layer. The layer increases the accuracy of anomaly identification by using these shifted embeddings to understand spatial–temporal connections.
In the self-attention mechanism, shifted features will be processed by means of transformer attention and is denoted by:
In this, Q is the queries (ZWQ), K represents keys, V denotes values (ZWV), and dimension of key vector will be denoted by \(\:{d}_{k}\). For anomaly prediction, this model outputs an anomaly score \(\:{\widehat{y}}_{t}\) for every time step and is expressed by:
The temporal loss function \(\:{\mathcal{L}}_{temporal}\) is computed at which anomaly detection is trained with the use of mean squared error (MSE) among predicted and true indicators of anomaly and is denoted as:
This scheme effectively models temporal context from several frames and captures long-term evolution of hazard (like gradual accumulation of smoke), and is computationally effective because of temporal shift.
Federated self-distillation (FSD)
In order to provide real-time model updating across heterogeneous edge devices, the suggested architecture uses an adaptable deep learning approach via a Federated Self-Distillation (FSD) process. Using recently obtained hazard instances, each edge node locally optimizes its lightweight models (YOLOv8-nano and MobileOne-S) while maintaining data privacy. In spite of non-IID data distributions, the cloud layer ensures global consistency by periodically aggregating distilled knowledge. When rolling accuracy performance drift surpasses a 2% threshold, adaptation is automatically initiated. This method guarantees that models maintain their resilience in the face of changing environmental factors including humidity, illumination, and smoke levels. Conceptually, the mechanism is in line with current adaptive federated paradigms in surveillance systems28.
The FSD mechanism improves proposed model on enabling continuous learning over distributed edge devices without sharing raw data, thus preserving privacy and decreasing the communication overhead. Not like traditional federated learning, that aggregates simply model weights, this FSD leverages knowledge distillation for transferring temporal and global insights from cloud to edge models.
Local training (edge)
Every edge device trains lightweight schemes (YOLOv8-nano, MobileOne-S) on their local hazard data, thus offering local parameters \(\:{\theta\:}_{i}\).
Global aggregation (cloud)
The cloud thus aggregates local parameters as global model and is expressed as follows:
at which \(\:{w}_{i}=\frac{{n}_{i}}{{\sum\:}_{j}{n}_{j}}\) with size of local dataset denoted by \(\:{n}_{i}\).
Self-distillation
The cloud model generates soft predictions or the temporal features with the use of TST. The edge models learn from this prediction through KL-divergence and are expressed as follows:
At which, \(\:{p}^{global}\) is the soft label distribution (class probability produced by TST at cloud and \(\:{p}^{edge}\) is the corresponding predicted distribution from edge model. The minimization of this loss allows edge model for align their predictive distribution with that of informative cloud model. It ensures edge device from cloud’s temporal reasoning on maintaining privacy.
Model update (edge)
Edge device updates its local models with distilled knowledge, thus enhancing adaptability and accuracy without having any direct access to other device data.
TST offers temporal anomaly scores for detecting subtle smoke, fire, or unauthorized pattern movements. FSD ensures these insights will be shared with entire edge devices without exchanging any raw data. This synergy thus reduces false positives, ensures privacy-preservation collaboration, and enhances adaptability.
Adaptive hazard recognition
The suggested approach integrates a semi-supervised novelty detection module into the Federated Self-Distillation (FSD) procedure to handle new and emerging danger categories. The module uses YOMO-TF at the edge level to find anomalies that don’t fit the known distributions of hazards. The cloud layer initiates a meta-adaptation phase when many edge devices identify consistent outliers, updating global feature embeddings without the need for more labeled data or centralized retraining. This decentralized adaptability preserves privacy and communication effectiveness while guaranteeing responsiveness to evolving warehouse conditions, such as new materials, layout modifications, or operating dangers. The method coincides with new adaptive federated systems that permit generalization to unknown data29.
Federated Self-Distillation (FSD) and Temporal-Shift Transformer (TST) both have advantages that come from their complementing qualities. TST efficiently models motion patterns and changing worker–equipment interactions by capturing both short- and long-term temporal interdependence in video sequences. By sharing information among dispersed edge nodes, FSD improves model generalization and lessens overfitting to local fluctuations. Error analysis reveals that whereas false positives frequently involve visually comparable but non-hazardous motions, residual false negatives mostly occur in occlusion-heavy or brief danger episodes. Low light levels and uncommon or invisible hazard kinds also lead to the remaining misclassifications. TST and FSD work together to decrease spurious detections and missing risks, which explains the performance improvements that have been seen.
Results analysis
The suggested Edge-cloud collaborative surveillance model was validated with the estimation focuses on 3 aspects: (i) hazard and object detection at edge with the use of lightweight schemes (YOLOv8-nano & Mobileone-S), (ii) temporal anomaly detection at cloud layer with temporal shift transformer (TST), & (iii) entire performance of system improved over federated self-distillation (FSD). The performance will be estimated in terms of various metrics. The comparative analyses with existing schemes19,30 highlight the benefits of suggested model in terms of adaptability, generalizability, and responsiveness over diverse warehouse conditions.
This study created and gathered 1000 images of dust in a tobacco producing workshop, then manually annotated them to confirm the network’s efficacy. Rotation, noise addition, and other techniques were used to enhance the data. At last, five thousand training photos were acquired. Of these, 20% were utilized as the test set and 80% of the photos were chosen at random to serve as the training set. By contrasting the test labels with the actual labels, the accuracy of the suggested approach was ascertained. In this paper, the learning rate is fixed at 0.001. The hardware specifications are as follows: Different lighting conditions (150–400 lx), humidity levels (55–70%), and camera angles (static and PTZ) were used to record warehouse-like data. For both thermal and visual recordings, Hikvision DS-2CD2145FWD 4 MP IP cameras were utilized. Edge layer: NVIDIA Jetson Xavier NX for YOLOv8-nano and MobileOne-S (8 GB RAM, 384-core GPU). Cloud layer: NVIDIA RTX A5000 GPU for temporal anomaly detection based on TST, Intel Xeon 32-core server, 128 GB RAM.
Performance evaluation of proposed framework
The performance at the classification level in identifying hazardous versus non-hazardous circumstances from surveillance frames is represented by all provided metrics: accuracy, precision, recall, and F1-score. In particular, the percentage of correctly categorized frames out of all evaluated frames is known as accuracy. Precision is defined as True Positives / (True Positives + False Positives) and is the proportion of true hazard detections to all detections classified as hazards. Recall is calculated as True Positives / (True Positives + False Negatives) and is the ratio of successfully recognized dangers to all real hazards present. The F1-score is the precision and recall harmonic mean.
Three domain experts (two warehouse safety officers and one machine-vision specialist) manually annotated video frames to determine the ground truth for “hazard” versus “non-hazard” situations. Clearly visible occurrences, such as unapproved human entrance, smoke or fire emissions, or moisture buildup close to tobacco storage facilities, were used to identify each frame. Labels were finalized using a majority voting approach (≥ 2 of 3 raters agreed). Any frame (or video segment) where a predetermined danger occurrence was present and verified during ground-truth annotation is referred to as a “actual positive instance”. A frame in which no such dangerous circumstance was noticed is referred to as an “actual negative instance”.
Therefore, the confusion matrix in Fig. 3 shows the frame-level classification results of the system, with 8,000 non-hazard (negative) and 2,000 genuine hazard (positive) samples in the test dataset. Out of all 2000 actual positive instances, the system identifies 1952 correctly and misclassified only 48, thus attaining very high recall. Similarly, out of 8000 actual negative instances, 7970 were classified correctly with only 10 false positives, reflecting a stronger precision. These outcomes confirm the ability of model to minimize both false alarms and missed detections, that is crucial for reliable tobacco warehouse safety monitoring.

Confusion matrix representations.
Table 1 shows the overall estimation of proposed framework. A proposed framework attains higher accuracy (98.6%), precision (99.5%), and recall (97.6%), thus ensuring a reliable hazard detection with minimal false alarms. With an average latency of about 89 ms, the system enhances the response time by 29% on comparing cloud only schemes. Bandwidth usage will be reduced to 1.2, whereas the lightweight scheme needs only 256 MB memory & 118 ms computation time, thus making them suitable for edge devices. Strong statistical performance (R2 = 0.89), and (MAE = 1.9) further confirms robust prediction ability. Overall, the system is competent of balancing efficiency, accuracy, and scalability for tobacco warehouse safety management.
The reduction in end-to-end latency attained by YOMO-TF in comparison to a cloud-only baseline using similar datasets and hardware configurations is referred to as the reported 29% response time improvement. End-to-end latency includes cloud-level aggregation and temporal anomaly detection with TST, as well as edge-level inference with YOLOv8-nano and MobileOne-S. The entire processing time from video capture to hazard detection output was measured over 1,000 consecutive frames in a representative warehouse setting. A statistical study with a paired t-test (p < 0.01) verified the significance of the improvement. The baseline, measuring technique, and statistical validity of the claimed response time improvement are all made clearer by these additions.
The end-to-end response time performance of the suggested YOMO-TF framework in comparison to a cloud-only baseline is compiled in Table 2. Both cloud-level aggregation with temporal anomaly detection (TST) and edge-level inference (YOLOv8-nano and MobileOne-S) are included in the measurements. According to the results, YOMO-TF maintains low variability over 1,000 consecutive frames while reducing average latency from 125 ms to 89 ms, or a 29% improvement. This improvement is significant, according to statistical analysis (p < 0.01, paired t-test). These findings demonstrate the benefit of the edge-cloud collaborative approach in providing quicker, real-time hazard detection for safety monitoring in tobacco warehouses.
Table 3 shows the performance estimation of proposed framework in terms of k-fold cross validation with the confidence interval of 95%. The k-fold cross-validation confirms the robustness and consistency of suggested framework. Across 10 folds, this system is competent of maintaining accuracy among 98.3–98.9%, precision above 99%, recall between 97.3 and 97.8%, and F1-score among 98.2–98.8%. These outcome highlights the reliability and stability of model thus ensuring higher detection performance over varied data partitions. The suggested method is exceptionally stable and reproducible, as evidenced by the extremely low variance across folds in all measures. Furthermore, the observed improvements are statistically significant (p < 0.01) when compared to the entire model and ablation variations using basic paired significance testing (paired t-test).

Performance estimation of K-fold cross validation.
Figure 4 shows the k-fold evaluation that offers consistently high-performance over entire folds, having accuracy among 98.3–98.9%, precision above 99%, recall between 97.3 and 97.8%, and F1-score among 98.2–98.8%. The outcome confirms that the suggested model delivers balanced and reliable accuracy of detection with minimal variation over varied data splits.

Training accuracy vs. validation accuracy curve.
Figure 5 signifies the training accuracy vs. validation accuracy curve. The accuracy curve shows a steady enhancement for both training and validation over 10 epochs. Training accuracy rises from about 90% to above 98.5%, whereas validation accuracy closely follows, reaching 98.3%. A small gap among two curve denotes strong model generalization having minimal overfitting. This in turn confirms that the adaptive deep learning framework not only learns effectively but too maintains stable performance on unseen data, thus making them suitable for real-time tobacco warehouse safety monitoring.

Training loss vs. validation loss curve.
Figure 6 represents the training loss vs. validation loss curve. The loss curve shows consistent decrease in both training and validation over 10 epochs. Training loss drops from 0.45 to 0.13, whereas the validation loss decreases from 0.48 to 0.19, thus indicating effective learning. A closer alignment of these two curves, without significant divergence, represents that the scheme generalizes well thereby avoiding overfitting. This confirms that the suggested model attains stable convergence on maintaining robustness on unseen data.
Table 4 is the depiction of comparative estimation of proposed and existing models. Four baseline models were used for performance benchmarking: Quantized Long Short-Term Memory (Quantized LSTM), Lightweight Gradient Boosted Machine (Lightweight GBM), Federated Random Forest (Federated RF), and Ensemble Partial Parameter Federated Learning (Ensemble PP-FL). To guarantee fairness, all models were run under consistent hardware settings and trained and validated on identical dataset splits (80% training, 20% testing). Grid search was used to improve the following hyperparameters: Ensemble PP-FL (5 clients, partial parameter sharing), Quantized LSTM (2 layers, 128 hidden units, 8-bit quantization), GBM (120 rounds, learning rate 0.03), and RF (100 trees, depth 10). Common performance criteria (accuracy, precision, recall, F1-score, MAE, and R2) were used to compare the findings, and the results consistently showed that YOMO-TF was superior in terms of accuracy, responsiveness, and computing efficiency. The comparative analysis highlights the superiority of proposed YOMO-TF model over existing models. While existing schemes like Federated RF, Lightweight GBM, Edge-optimized SVM attains moderate precision (81–87%) and recall (82–89%), with overall F1-scores remains below 86%. More advanced techniques like Quantized LSTM and Ensemble PP-FL offers better values, with precision and recall values above 90%, but still shows limitations in recall balance and high demands on memory. In contrast, proposed framework attains precision of 99.5%, recall of 97.6%, and F1-score of 98.5%, significantly outperforming entire baseline models. Despite the need of 256 MB memory and 118 ms computation time, their performance improves in accuracy and reliability thus justifying trade-offs. These outcomes demonstrate that the suggested model offers best balance among detection accuracy, computational efficiency, robustness, thereby making them suitable for real-time tobacco warehouse safety monitoring.

Performance comparison of various existing and proposed scheme.
The performance comparison of various existing and proposed model in terms of precision, recall, and F1-score is represented in Fig. 7. The comparative analysis highlights the superiority of proposed YOMO-TF model over existing models. The traditional schemes like Federated RF, Lightweight GBM, Edge-optimized SVM attains moderate precision (81–87%) and recall (82–89%), with overall F1-scores remains below 86%. More advanced techniques like Quantized LSTM and Ensemble PP-FL offers better values, with precision and recall values above 90%, but still shows limitations in recall balance and high demands on memory. In contrast, proposed framework attains precision of 99.5%, recall of 97.6%, and F1-score of 98.5%, significantly outperforming entire baseline models. These outcomes demonstrate that the suggested model offers reliable and balanced performance, thus minimizing false alarms thereby ensuring accurate detection of safety risks in tobacco warehouse environments.
Table 5 shows the comparative analysis of MAE and R2. The comparative estimation of regression metrics highlights the efficiency of suggested YOMO-TF model. Existing models like RCT (MAE = 2.8, R2 = 0.81), FFN (MAE = 3.4, R2 = 0.78), and CNN-TL (MAE = 4.1, R2 = 0.71) exhibits high error rates with weaker correlation, indicating limited prediction accuracy. More advanced schemes such as DCCNN (MAE = 2.5, R2 = 0.83), and E2E-SCNN (MAE = 2.2, R2 = 0.88) represents better performance but still face some short fall in the optimal range of precision. In contrast, proposed YOMO-TF attains lowest MAE (1.9) with high R2 (0.89), confirming their superior predictive ability with minimal error and strong correlation among actual and predicted outcomes. This indicates that the suggested scheme ensures both accuracy and robustness, making them more effectual for real-time tobacco warehouse safety management on comparing existing schemes.

Comparative analysis of MAE and R2.
Figure 8 is the comparative estimation of MAE and R2. The comparative estimation of regression metrics highlights the efficiency of suggested YOMO-TF model. Traditional models like RCT (MAE = 2.8, R2 = 0.81), FFN (MAE = 3.4, R2 = 0.78), and CNN-TL (MAE = 4.1, R2 = 0.71) exhibits high error rates with weaker correlation, indicating limited prediction accuracy. More advanced schemes such as DCCNN (MAE = 2.5, R2 = 0.83), and E2E-SCNN (MAE = 2.2, R2 = 0.88) represents better performance but still face some short fall in the optimal range of precision. In contrast, proposed YOMO-TF attains lowest MAE (1.9) with high R2 (0.89), confirming their superior predictive ability with minimal error and strong correlation among actual and predicted results. From outcome, it was obvious that proposed framework ensures robustness and accuracy, making them a suitable one for real0time tobacco warehouse safety management on comparing traditional models.
The Fig. 9 demonstrate how the system may identify many kinds of safety risks: (upper-left) Unauthorized Entry—a person entering a forbidden location is highlighted by a bounding box; (top-right) Smoke detection—the bounding box indicates when smoke begins to appear, which could be a sign of a fire; (bottom-left) An active fire hazard is indicated by a bounding box in fire detection; (bottom-right) The bounding box’s moisture detection feature indicates damp areas that can cause product damage or slide hazards. These illustrations show how YOMO-TF can recognize risks in a variety of settings, facilitating proactive safety measures and real-time monitoring.

Hazard detection using the proposed YOMO-TF framework in a real warehouse environment.
Evaluation of adaptation effectiveness
Additional trials were carried out employing unforeseen hazard scenarios, such as new storage arrangements, equipment-induced smoke, and moisture leakage under different humidity levels, in order to evaluate adaptability to changing risk patterns. With an average detection accuracy of 93.2% and a false alarm rate of less than 2.5%, the semi-supervised novelty detection module successfully detected these previously untrained hazard occurrences, demonstrating its capacity to generalize outside of labeled classes. The meta-adaptation phase achieved stability with low drift (< 1.4%) across heterogeneous edge nodes by fine-tuning the common feature space during three global aggregation rounds. According to the adaptive federated principles covered in29, these findings demonstrate the framework’s ability to identify and adjust to new threats in real time without the need for centralized retraining.
The suggested YOMO-TF framework exhibits consistent flexibility across a variety of invisible danger classes, as indicated in Table 6. With a low false alarm rate of 2.5% and an average detection accuracy of 93.2%, the semi-supervised novelty detection module successfully generalizes to novel operational risk scenarios without the need for retraining. The system’s real-time learning capabilities under changing warehouse conditions is validated by little adaptation drift (< 1.5%), which verifies consistency across edge nodes during the meta-adaptation phase.
Ablation study
An ablation study assessing the contribution of important elements in the YOMO-TF framework is shown in Table 7. Accuracy and mAP noticeably decline when the Federated Spatial Distillation (FSD) module is removed, illustrating its function in feature alignment among clients. Convergence speed and overall performance are decreased when our optimized federated aggregation is substituted with a regular FedAvg baseline, demonstrating the advantages of our aggregation approach. The video-level F1-score is reduced when the Temporal Self-Transformer (TST) is replaced with a basic temporal averaging module, underscoring the significance of TST in preserving temporal consistency. All things considered, each module—FSD, the suggested aggregate, and TST—makes a significant contribution to the high accuracy and temporally consistent hazard detection of the framework.
Discussion
The suggested YOMO-TF model demonstrates both theoretical and practical significance. From the theoretical perspective, this in turn confirms that the lightweight scheme could be integrated efficiently with the temporal learning for balancing accuracy and efficiency. The gap reduced among validation and training performance denotes strong generalization, whereas low MAE (1.9) with high R2 (0.89) highpoints the robustness in minimalizing the propagation of error on comparing existing models. In practice, this model delivers a reliable hazard detection with high precision, and recall thus ensuring safe warehouse functions. Their low latency, minimal memory and reduced bandwidth use makes them deployable on edge devices in the resource-constrained environments. Moreover, the scalability over varied conditions supports huge industrial application, offering a foundation for future intelligence and adaptive monitoring systems. These findings underscore YOMO-TF’s potential for long-term, scalable, and autonomous safety management in dynamic tobacco warehouse environments by showing that it can sustain high detection reliability and adjust in real time to changing and previously unknown risks.
Theoretical implication
The outcome validates that integrating lightweight deep models with hybrid optimization (YOMO-TF) could significantly enhance accuracy and robustness of prediction. This in turn contributes to theory thus demonstrating that the model compression and feature fusion need not compromise precision, but in fact could improve generalizability over varied datasets.
Practical implication
In the perspective of application, the enhanced MAE and R2 scores highpoint the feasibility deploying scheme in real-world scenarios, specifically for edge and resource-constrained environments. Their high efficiency, and reliability makes them suitable for real-time decision making in the industrial monitoring, IoT-based systems, and smart healthcare.
Although the suggested YOMO-TF framework exhibits excellent temporal consistency and accuracy, there are a number of issues that must be taken into account before it can be implemented in actual warehouse settings. Federated updates may be impacted by network latency and capacity variability, which could postpone model aggregation. Our methodology addresses this issue by using lightweight client-side processing and asynchronous updates, but performance degradation may still occur in highly constrained or unstable networks. Although the system communicates intermediate feature embeddings instead of raw video frames, it is nevertheless advised to use secure communication channels and differential privacy measures because these embeddings have the potential to leak important activity information if they are intercepted. By combining temporal self-attention, federated spatial distillation, and optimized aggregation, YOMO-TF surpasses previous work in hazard detection by achieving higher accuracy and temporal robustness while still being computationally viable for edge devices.
Conclusion
This research proposed an edge-cloud collaborative surveillance framework with adaptive deep learning for enhancing safety management in tobacco warehouses. The proposed framework integrates lightweight deep learning models at the edge with cloud-level intelligence thus attaining real-time monitoring, high prediction accuracy, and effective resource utilization. Experimental evaluations demonstrated that the proposed YOMO-TF scheme attains superior performance on comparing traditional models, having 98.6% accuracy, 99.5% precision, 97.6% recall, and 98.5% F1-score, thus maintaining lower latency and memory overhead. This framework outperforms baseline schemes consistently in cross-validation and comparative analysis, showing low prediction errors (MAE = 1.9) with stronger predictive reliability (R2 = 0.89). However, convergence curve on training-validation and confusion matrix analysis confirms robust learning and balanced classification with a minimal false alarm.
Overall, the proposed model offers scalable, reliable, and real-time safety management solutions for tobacco warehouses, thus reducing operational risks with enhanced decision-making. In future, this work might be extended on integrating multimodal sensor data, federated learning for privacy preservation, and reinforcement learning for adaptive risk mitigation strategies.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Naseer, R., Imran, S., Ikram, A., Chaudhary, M. N. & Saif, S. Occupational health and safety risk assessment of a tobacco manufacturing industry. Pak J. Hum. Soc. Sci. 13, 415–425 (2025).
Algarni, A., Acarer, T. & Ahmad, Z. An edge computing-based preventive framework with machine learning-integration for anomaly detection and risk management in maritime wireless communications. IEEE Access. 12, 53646–53663 (2024).
Zhang, Q., Tian, Y., Chen, J., Zhang, X. & Qi, Z. To ensure the safety of storage: enhancing accuracy of fire detection in warehouses with deep learning models. Process. Saf. Environ. Prot. 190, 729–743 (2024).
Lung, L. W., Wang, Y. R. & Chen, Y. S. Leveraging deep learning and internet of things for dynamic construction site risk management. Buildings 15, 1325 (2025).
Ega, S. S. Computer vision applications for enhanced warehouse safety: A comprehensive analysis of load Securing and weight management systems. J. Comput. Sci. Technol. Stud. 7, 523–535 (2025).
Ospanov, A. & Alonso, P. J. Optimizing warehouse monitoring with IoT sensors and machine learning: an empirical study. Int. J. Inf. Commun. Technol. 6, 127–143 (2025).
Vangeri, A. & Praveen, B. M. Integrate IoT data streams with supply chain management systems for real-time monitoring and analysis. Rare Met. Mater. Eng. 54, 38–52 (2025).
Gómez, L. A. et al. Design of an integrated collaborative intelligence framework for Real-Time identification of vulnerabilities in international logistics networks. J. Appl. Inf. 35, 112–129 (2024).
Douzandeh Zenoozi, A., Majidi, B., Cavallaro, L. & Liotta, A. Hybrid edge-cloud federated learning: The case of lightweight smoking detection. In Inf. Integr. Web Intell. 150–159Springer, Cham, (2024).
Machireddy, J. R. Integrating machine learning-driven RPA with cloud-based data warehousing for real-time analytics and business intelligence. Hong Kong J. AI Med. 4, 98–121 (2024).
Kok, C. L., Heng, J. B., Koh, Y. Y. & Teo, T. H. Energy-, cost-, and resource-efficient IoT hazard detection system with adaptive monitoring. Sensors 25, 1761 (2025).
Hosseini, M., Madathil, S. C. & Khasawneh, M. T. Deep learning techniques for manufacturing-warehouse optimization: A critical literature review. SSRN 4960940 (2024).
Plakantara, S. P., Karakitsiou, A. & Mantzou, T. Managing risks in smart warehouses from the perspective of Industry 4.0. In Disrupt. Technol. Optim. Ind. 4.0 Logist. 1–47Springer, Cham, (2024).
Ajayi, R. Integrating IoT and cloud computing for continuous process optimization in real-time systems. Int. J. Res. Publ Rev. 6, 2540–2558 (2025).
Abdelhady, G., Ayoub, S. & Youssef, M. L. YOLOv8 and facenet for enhanced surveillance and organization in medicinal warehouses. J. Int. Soc. Sci. Eng. 6, 100–113 (2024).
Duan, S. et al. Distributed artificial intelligence empowered by end-edge-cloud computing: A survey. IEEE Commun. Surv. Tutorials. 25, 591–624 (2022).
Liu, Q. et al. Cloud, edge, and mobile computing for smart cities. In Urban Informatics 757–795 (Springer, Singapore, (2021).
Talaat, F. M. & ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 35, 20939–20954 (2023).
Su, Q. et al. Edge-cloud computing Cooperation detection of dust concentration for risk warning research. J. Cloud Comput. 13, 7 (2024).
Nihi, T. V., Forkuo, A. Y., Ojo, O. O. & Nwokedi, O. S. S. A conceptual framework for AI-driven healthcare optimization and predictive analytics. Multidiscip J. Eng. Technol. Sci 2, (2025).
Duan, Q. et al. Digitally empowered dynamic distribution scheduling model development for the tobacco industry. In 2025 Asia-Europe Conf. Cybersecurity. Internet Things Soft Comput. (CITSC) 262–266 (2025). (IEEE.
Li, C., Zhu, B., Chen, G., Li, Q. & Xu, Z. Intelligent monitoring of tunnel fire smoke based on improved YOLOX and edge computing. Appl. Sci. 15, 2127 (2025).
Yang, M., Qian, S. & Wu, X. Real-time fire and smoke detection with transfer learning based on cloud-edge collaborative architecture. IET Image Process. 18, 3716–3728 (2024).
Wang, C. et al. The safety status and foreign object detection model of tobacco cabinets based on deep learning with IoT-cloud. In 2022 8th Int. Conf. Virtual Reality (ICVR) 292–297 (IEEE, 2022).
Aboualola, M., Abualsaud, K., Khattab, T., Zorba, N. & Hassanein, H. S. Edge technologies for disaster management: A survey of social media and artificial intelligence integration. IEEE Access. 11, 73782–73802 (2023).
Lee, C. M. & Hsieh, S. H. An edge-enabled real-time framework for context-aware data acquisition and hazard alerting in smart construction sites. SSRN 5388183 (2025).
Denzler, P., Hollerer, S., Frühwirth, T. & Kastner, W. Identification of security threats, safety hazards, and interdependencies in industrial edge computing. In 2021 IEEE/ACM Symp. Edge Comput. (SEC) 397–402IEEE, (2021).
Asif, M. et al. A novel hybrid deep learning approach for super-resolution and objects detection in remote sensing. Sci. Rep. 15, 17221. https://doi.org/10.1038/s41598-025-01476-3 (2025).
Asif, M. et al. Advanced Zero-Shot Learning (AZSL) Framework for Secure Model Generalization in Federated Learning, in IEEE Access, vol. 12, pp. 184393–184407, (2024). https://doi.org/10.1109/ACCESS.2024.3510756
Zhang, S., Zhu, C., Xin, J. & CloudScale: A lightweight AI framework for predictive supply chain risk management in small and medium manufacturing enterprises. Spectrum Res 4, (2024).
Acknowledgements
The authors acknowledge the support provided by Enshi Cigarette Factory, Hubei China Tobacco Industry Co., Ltd., for facilitating this research.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
T.S. conceived the study and designed the YOMO-TF framework. H.T. and X.Q. developed the edge-cloud collaborative algorithms and implemented the adaptive learning modules. L.L. performed the experiments and evaluations. W.Z. analyzed the results and contributed to manuscript preparation. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Song, T., Tian, H., Qin, X. et al. YOMO TF based edge cloud collaborative surveillance framework for tobacco warehouse safety management. Sci Rep 15, 42082 (2025). https://doi.org/10.1038/s41598-025-26011-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-26011-2
