
Abstract
Object detection in remote sensing images is a major challenge because of the complex background and diverse appearance of remote sensing images. At the same time, targets may have different sizes and densely distributed targets in the image. To address these challenges, we propose an enhanced YOLOv8 model that integrates three key components: dynamic convolution (DyConv), which replaces the ordinary convolutional layer in the C2F module in the backbone network, and adaptively adjusts the convolution filter according to the input features to enhance the model’s ability to deal with objects of different scales and appearance. Dual level Routing Attention (BRA) was used to process the high-level features of the backbone network, suppress irrelevant background information, emphasize effective features and establish semantic correlation. Asymptotic Feature Pyramid Network (AFPN) improves multi-scale feature fusion to ensure the effective fusion of small object details in the low level and high-level semantic information. Through experiments on the Remote Sensing Object Detection (RSOD) dataset, our improved YOLOv8 model shows significant performance improvement over the original model, achieving 65.4% of the mAP50-95 score, an improvement of 3.3%. Compared with the mainstream single-stage, two-stage and DETR models, our proposed model achieves the improvement of detection accuracy while ensuring computational efficiency.
Similar content being viewed by others
Introduction
Remote sensing is essential for various applications, such as identifying vehicles, aircraft, and buildings in images1,2,3,4,5. The data in remote sensing images have very special characteristics, that is, the size of the same target is different, the large and small targets coexist, the targets are densely arranged, and the image background is complex. Therefore, the analysis of remote sensing data is a great challenge. A key aspect of analyzing remote sensing data is the accurate and rapid detection of small objects (SOD)6,7,8,9,10. Small objects, which occupy limited pixel space in images, present a significant challenge in computer vision. Object detection algorithms often struggle with these small items because their features can become less prominent during the convolution process. Factors such as poor visibility, limited contextual information, blurred features, and complex backgrounds further complicate SOD11,12,13,14. Another key aspect is the coexistence and dense arrangement of object sizes. The convolution process of different depths maintains the features and semantics of objects of different sizes.
Object detection technology has made significant progress, from the traditional two-stage detector to the single-stage framework, and in recent years, the DETR object detection architecture based on the attention mechanism has been developed. Early object detection systems predominantly utilized two-stage methods, such as R-CNN15 and its successors Fast R-CNN16 and Faster R-CNN17. These approaches initially generate region proposals before classifying each proposal and performing bounding box regression. While this methodology achieves high detection accuracy, its computationally intensive nature limits its applicability for real-time processing.
To address the speed limitations of two-stage models, one-stage detectors emerged as a more efficient alternative. Notable examples include SSD18 and the YOLO series19. These one-stage models predict class scores and location coordinates directly from the input image without the need for pre-generated candidate bounding boxes. This approach significantly enhances detection speed, making real-time applications feasible. However, early one-stage models often exhibited lower accuracy compared to their two-stage counterparts, particularly when dealing with small or densely packed objects. The direct prediction mechanism, while fast, initially struggled to match the precision achieved by the more computationally intensive two-stage methods in challenging scenarios.
With the further development of deep learning, the Transformer architecture has been introduced into the field of object detection. Building upon traditional convolutional neural networks, the Transformer-based detector DETR (Detection Transformer)20 proposes a completely new end-to-end paradigm for object detection. DETR models object detection as a set prediction problem, directly outputting object bounding boxes and categories through the encoder-decoder architecture of the Transformer. The core of DETR lies in its attention mechanism, which can capture long-range dependencies between pixels in an image, effectively addressing the limited receptive field issue of traditional convolutional neural networks. However, DETR faces specific challenges in remote sensing image object detection: firstly, the attention calculation leads to high computational complexity; secondly, DETR performs poorly in detecting small objects because the features of small objects are easily overwhelmed by large objects or background information during global attention computation; finally, DETR’s training convergence is slow, requiring longer training cycles to achieve optimal performance. In addition to object detection models, some methods have been developed in recent years to enhance image processing by preprocessing detection images, such as super-resolution21 and brightness enhancement22. These methods can improve the accuracy of object detection to a certain extent, but often increase the amount of calculation.
In recent years, the continuous advancement of deep learning has simultaneously driven the rapid development of remote sensing image analysis technology. The Mamba-DCAU23proposed by Cui and Zhang employs a state space dual attention mechanism and demonstrates excellent performance in hyperspectral image classification. The TBNet24 developed by Li et al. specifically addresses the detection of small and weak targets in remote sensing images through texture and boundary awareness mechanisms. The YGNet25proposed by Song and Gao is a lightweight remote sensing object detection model that enhances detection accuracy while maintaining computational efficiency. Wang et al.26 investigated active object detection algorithms, improving remote sensing image detection performance through adaptive attribute adjustment. The EFCNet27 by Wang et al. focuses on small object detection and achieved 75.9% mAP on the DOTA dataset. The Sf-YOLOv59 by Liu et al. proposes an improved feature fusion mechanism for more efficient feature extraction, suitable for small object detection in resource-constrained environments.
Although these methods have made significant progress in their respective fields, they still have limitations when dealing with comprehensive challenges such as the coexistence of multi-scale objects, dense arrangements, and complex background interference in remote sensing images under complex backgrounds. In such scenarios, In such scenarios, extracting features from objects of different scales, effectively leveraging high-level semantics and features, and fusing multi-level features are critical issues that need to be addressed in remote sensing image object detection.
In this paper, we propose an enhanced architecture derived from the original YOLOv828 model, specifically tailored for achieving real-time and accurate object detection in remote sensing environments. We utilize the real-world remote sensing image dataset RSOD for model training and validation, which encompasses typical characteristics of remote sensing image data, including complex background interference and multi-scale dense targets. Additionally, we conducted ablation studies on the modified model to demonstrate its capability to significantly improve the detection accuracy of objects across different scales in remote sensing while maintaining real-time processing performance. This improved approach effectively satisfies the demands for efficient and precise object detection in remote sensing applications.
The contributions of this work are:
-
1.
Dynamic Convolution (DyConv)30: In the backbone network, we replace the convolutional layers in the C2F module with dynamic convolution to achieve adaptive adjustment of the convolutional filter. This enhancement enhances feature extraction capabilities for objects of different scales, orientations, and appearances with only a minimal increase in model parameters.
-
2.
Bi-Level Routing Attention (BRA)29: In the last layer of the backbone network, we add a bi-level routing attention module, which uses lightweight attention mechanism calculation to emphasize high-level features and establish semantic correlation, suppress irrelevant background interference, and optimize high-level input of feature fusion.
-
3.
Asymptotic Feature Pyramid Network (AFPN)31: AFPN replaces the traditional PAFPN structure in the Neck part of the model, which ensures that the most relevant information is emphasized at different feature levels. Especially when fusing features across levels, more low-level detail features are retained, enhancing the multi-scale feature fusion capability.
These enhancements collectively provide a powerful solution for real-world applications, where both precision and speed are critical. By integrating BRA, Dynamic Convolution, and AFPN, our model achieves superior performance in handling complex scenarios, thereby setting a new benchmark for small object detection in remote sensing images.
Methods
In this section, we provide a detailed description of the enhancements proposed for the YOLOv8 model to improve its performance in object detection within remote sensing images. We begin by briefly reviewing the original YOLOv8 architecture and analyzing its limitations when applied to object detection in remote sensing scenarios. Subsequently, we introduce a novel architectural modification designed to optimize the model’s ability to detect multi-scale and densely distributed objects in remote sensing contexts. These modifications are aimed at enhancing feature extraction capabilities, improving attention mechanisms, refining multi-scale feature fusion, and preserving real-time processing efficiency.
The overview of YOLOv8 model
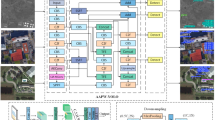
YOLOv8 represents a significant advancement in the YOLO (You Only Look Once) series, designed to achieve state-of-the-art performance in object detection while maintaining efficiency. The architecture of YOLOv8 is meticulously crafted to enhance both accuracy and speed, making it particularly suitable for real-time applications. Its main structure is shown in Fig. 1.

YOLOv8 architecture.
The core of YOLOv8 is its backbone network, which is responsible for extracting rich feature representations from the input images. The backbone network adopted an improved architecture based on CSPDarknet. CSP Bottleneck with 2 Convolutions (C2F) module was used to replace the traditional Cross Stage Partial module. The fluidity and reusability of model features are enhanced, and richer gradient flow information is obtained while ensuring the model is lightweight. At the end of the backbone network, the Spatial Pyramid Pooling-Fast (SPPF) module was used to further expand the receptive field of each spatial location under the high-level features to capture the context information.
The feature enhancement network of Neck in YOLOv8 plays a crucial role in refining these extracted features. The model uses PAFPN structure for multi-scale feature fusion, where FPN transfers semantic information from top to bottom, and PAN transfers detailed feature information from bottom to top. The two synergistically enhance the fusion expression of features at different scales.
The detection head part of the model is improved from the original coupled detection head to the decoupled detection head, which is used to process the multi-level feature map (P3, P4, P5) input from Neck. The detection head at each level has two tasks, one is to output the detection box position and scale through two sets of CBS modules and a 1 × 1 convolutional layer, and the other is to identify the type through two sets of CBS modules and a 1 × 1 convolutional layer output. Corresponding to the output of the detection head, the classification loss of the target and the regression loss of the detection box are used to pull the training of the entire YOLOv8 model.
Overall, through the combination of an optimized backbone, a powerful feature enhancement network, and an efficient detection head, YOLOv8 achieves remarkable performance in object detection, setting new benchmarks in terms of accuracy, speed, and robustness.
However, YOLOv8 model still has limitations in object detection of remote sensing images. First, small targets in remote sensing only account for a small number of pixels, and the detail information is diluted by the downsampling operation of deep convolution. The existing adjacent layer fusion mechanism of PAFPN is difficult to fully retain the features of small targets. Second, The complex background interference will lead to an increase in false alarm rate. Targets in remote sensing images are often densely arranged around these backgrounds, and the model lacks a mechanism to show the semantic differences between the modeling target and the background, which may lead to the extraction of false information and the flooding of key information. Third, the static convolution kernel is difficult to adapt to the differences in scale, rotation and other characteristics of remote sensing targets, and remote sensing targets with various appearance changes are very unfriendly to the static convolution process.
Proposed architectural changes
The above limitations restrict the accuracy of YOLOv8 in remote sensing scenes. To this end, this paper introduces Dynamic Convolution (DyConv), Bi-level Routing Attention (BRA) and Progressive Feature Pyramid (AFPN) modules to optimize feature extraction, enhance semantic discrimination and improve multi-scale fusion. This subsection will introduce the main three modifications of the model to further improve the detection accuracy of objects with different scales and dense arrangements in remote sensing complex backgrounds under the premise of a small increase in the computational complexity of the model. Figure 2 shows the improved yolov8 structure in this paper.

The Network Structure of the Improved YOLOv8 algorithm.
Bi-level routing attention
One of the key improvements of our enhanced YOLOv8n model is the introduction of the Bi-level Routing Attention (BRA) mechanism. The method flowchart of BRA module is shown in Fig. 3. The traditional attention mechanism used in the field of object detection can effectively capture the spatial dependence in the image, emphasize the target features, establish the target semantic correlation information, and suppress the background information. However, due to the complexity of image information, performing global attention calculations on image vectors leads to significant memory usage and computational costs. Therefore, directly introducing traditional attention mechanisms into object detection would inevitably result in a substantial increase in model parameters and computational requirements. Since the effective information of targets in remote sensing images is not necessarily global, we decided to apply sparse attention calculations in the model to avoid the high computational costs introduced by global attention calculations.

Bi-level routing attention module.
The BRA method is a typical approach for sparse attention in images. BRA obtains the adjacency matrix of the inter-region affinity map by averaging the query and key vectors in regions, and then constructs the index routing by obtaining the indices of the top-k elements in each row. The process of obtaining the top-k index corresponding to the query of a single region is shown in Fig. 4. Finally, it uses the query vector and the routed key and value vectors to complete the attention calculation. Unlike other sparse attention methods, the routing design of BRA avoids the non-adaptive problem of manually crafted sparse attention, and all query-corresponding routed key-value pairs are relatively independent and do not interfere with each other.

The process of getting top-k index for single region query.
We designed the BRA module at the topmost layer of the backbone network, after the SPPF module. Our considerations are as follows: First, the deep feature maps of the backbone network contain high-level semantic information and retain the spatial features of large targets. We hope to achieve semantic association in space through BRA, establish semantic dependencies between different targets, emphasize the feature representation of real targets, and suppress irrelevant background interference, providing pure high-level semantic features for the Neck. Second, although BRA optimizes the computation compared to global attention, its computational complexity is still \(O\left( {{{\left( {HW} \right)}^{\frac{4}{3}}}} \right)\). To ensure the lightweight nature of the model, we only perform BRA calculations on the high-level features of the backbone network and discard the attention calculations of low-level features.
Asymptotic feature pyramid network
Another improvement strategy of the model is to use Asymptotic Feature Pyramid Network (AFPN) as the feature fusion network of Neck in YOLOv8. In the original model, PAFPN was used for cross-level feature fusion. FPN passed high-level features to low-level features through a top-down path to enhance the expression ability of low-level features, and PAN made up for the lack of low-level feature details in the high-level feature map through a bottom-up path. PAFPN integrates the high-level level and the low-level level interactively through two paths. However, PAFPN has the following limitations in remote sensing image target detection: First, the feature fusion strictly adopts the progressive fusion of adjacent layers, and the cross-level features still need to be passed multiple times to fuse, and the respective feature information will inevitably be lost in the bottom-up transmission process, which is not conducive to the feature preservation of low-level small targets. Second, after up-sampling/down-sampling, the feature maps of different levels are concatenate with the feature maps of adjacent levels directly, which lacks consideration of processing the semantic differences between different levels.
AFPN has the following characteristics for feature fusion at different levels: First, it uses a progressive feature fusion method. The semantic gap between non-adjacent level features is large, and the high-level features and low-level features cannot be directly fused. AFPN gradually transitions from the fusion of adjacent low-level features to the fusion of high and low levels (as shown in Fig. 2), alleviating the semantic gap between cross-level features, making low-level detail features integrated into other levels, and allowing cross-level feature fusion to avoid information loss caused by layer by layer transmission. The other is to use adaptive spatial fusion (ASF). For example, the above, middle and lower three levels of features are fused to the middle level (as shown in Fig. 5). After different levels are adjusted to the same scale by up/down sampling, the spatial weights of each level at the middle level are obtained by convolution and Softmax, and the spatial fusion is realized by weighted summation. ASF realizes AFPN to dynamically learn the weights between different levels in the fusion process and suppress conflicting semantics.

AFPN module.
Dynamic Convolution
The third improvement of the model is to replace the convolutional layers of the C2F module in the backbone network with dynamic convolutions (DyConv). In the backbone network of YOLOv8, deep feature extraction is mainly performed at a fixed scale through the C2F module. However, the convolution layer calculation uses a static convolution kernel, which is difficult to adapt to different target morphology and texture features, such as different illumination, rotation Angle and scaling of the image, resulting in reduced target sensitivity. As shown in Fig. 6, DyConv can adaptively adjust the weight of the convolution kernel according to the input image. Specifically, the feature map is first passed through an attention module composed of global average pooling, fully connected layer and Softmax to obtain the weights of k convolution kernels. Then, k convolution kernels with the same scale and number of channels are set to perform weighted summation through the attention weights, and finally the convolution kernel parameters of the layer are obtained.

Dynamic Convolution module.
In remote sensing image detection, we introduce DyConv mainly to improve the adaptability of the model to texture, scale and rotation. By dynamically allocating convolution kernel weights and adaptively adjusting the function of the overall convolution kernel, the network can better deal with the changes in object scale, orientation and appearance, so as to further improve the feature extraction ability of the model.
Loss function
For the loss function of the model, we use the native loss calculation combination of YOLOv8. The total loss calculation is divided into two types of loss, which are classification loss and bounding box regression loss. The bounding box regression loss is divided into CIoU loss and distribution focal loss.
For object classification loss, the model uses binary cross-entropy (BCE) to calculate the loss. This is applied independently to each class, allowing the model to handle multi-label classification scenarios. The loss for a single class is:
where N is the number of samples, \({y_i}\) is the ground-truth label (0 or 1), and \({p_i}\) is the predicted probability for the class.
For bounding box regression loss, first the model uses complete intersection over union (CIoU) to calculate the loss. The CIoU loss takes into account not only the overlap area between the predicted and true boxes and the distance between their centers, but also their aspect ratio consistency. It is defined as follows:
where \(IoU\) is standard intersection over union, \(\rho\) is the Euclidean distance between the centers of the predicted box b and the ground-truth box \({b^{gt}}\), c is the diagonal length of the smallest enclosing box covering the two boxes, v measures the aspect ratio consistency, and \(\alpha\) is a weighting function.
To enhance localization accuracy, model incorporates distribution focal loss (DFL). Instead of directly regressing the box coordinates, it models the bounding box location as a discrete probability distribution over a range of values. DFL focuses on learning this distribution by maximizing the probabilities around the true value:
where y represents the position continuous value of a single edge on some real box, \({y_i}\) and \({y_{i+1}}\) are its two nearest discrete neighbors in the distribution, and \({S_i}\), \({S_{i+1}}\) are their corresponding predicted probabilities. This approach provides a more refined and robust mechanism for bounding box regression.
Finally, the total loss function \({L_{total}}\) of the model is the weighted sum of the losses of the above three parts:
Experimental results
In this section, we discuss the remoting sensing datasets, training environment, and performance evaluation indicators. Thereafter, we verify the superiority of the proposed method through several experiments.
Dataset description
In this work, the Remote Sensing Object Detection (RSOD) dataset32,33 is utilized to validate the performance of the proposed enhanced YOLO model. The dataset follows the PASCAL VOC (Visual Object Classes) format, it offers a comprehensive collection of 976 images, encompassing a diverse set of 6950 objects across 4 categories: airplane, oil tank, playground, and highway overpass. The image resolutions typically fall around 1075 × 923 pixels. These objects pose significant challenges while being essential for automatic scene interpretation and object recognition from a bird’s-eye view. In our experiments, we compare our proposed model against state-of-the-art methods using the RSOD dataset, demonstrating substantial improvements in both accuracy and efficiency.
Data augmentation
To improve training performance, data augmentation is adopted to enrich the dataset. This strategy enhances the robustness and generalization capabilities of object detection models. In this work, we utilize an x8 augmentation method, which includes rotations (90°, 180°, 270°), horizontal and vertical flips, and translations. These transformations increase the diversity of the training data, helping the model recognize objects under different conditions. By simulating various orientations, positions, and angles, the augmented dataset not only expands the training set but also improves the model’s ability to generalize, leading to better accuracy and reliability in real-world scenarios.
Training setup
The hardware environment comprises NVIDIA RTX 4070 GPU. The software environment consisting of Python 3.10, Pytorch 2.1 and CUDA 12.1. SGD optimizer is used for dynamically tuning the learning rate and updating the model parameters through the training procedure. The remaining hyperparameters are shown in Table 1.
The hyperparameters are set as: learning rate initialized to 0.01, batch size to 16, the momentum to 0.9, the weight decay to 0.001, the number of epoch to 500 with patience to 50. In terms of data preprocessing, all images were resized to a uniform resolution of 640 × 640 pixels during the train process. The remaining configurations are the same as to the original YOLOv8n model.
Evaluation metrics
In this paper, we evaluate the performance of the proposed model using two primary metrics: mean average precision (mAP) and computational efficiency. The mean average precision (mAP) refers the capability of detection over all kind of objects, is the most common evaluation index used to evaluate the detection performance of the network. mAP considers both Precision (P) and Recall (R), which are defined in Eqs. (7) and (8), respectively.
where TP, FP and FN refer the number of True Positive, False Positive and False Negative samples. The average precision (AP) is defined using the Precision Recall (PR) curve under a give threshold. Intersection over union (IoU) is the degree of overlap between the predicted box and the actual box, which is set to higher than 0.5. The mAP is the average of all of AP over all classes, defined in Eq. (9) as belows:
where n refers the total number of object class, \({{{\bar {R}}}_{k,k+1}}\) refers the averaged value of R in the region between k and k + 1, \({{\text{P}}_i}{{(}}{{{\bar {R}}}_{k,k+1}})\) refers the measured \({{\text{P}}_i}\) at \({{{\bar {R}}}_{k,k+1}}\)for the ith class of object. Specifically, we utilize mAP at an Intersection over Union (IoU) threshold of 0.5 (denoted as mAP50) and mAP averaged over IoU thresholds ranging from 0.5 to 0.95 with a step size of 0.05 (denoted as mAP50-95) to measure the recognition accuracy. These metrics provide a comprehensive assessment of the model’s precision across different levels of object localization.
To quantify the computational cost, we employ two key indicators: Frames Per Second (FPS) and Giga Floating-point Operations Per Second (GFLOPs). FPS measures the number of frames that can be processed per second, which is a direct indicator of the model’s real-time performance. GFLOPs, on the other hand, represents the number of floating-point operations per second, providing an estimate of the computational complexity of the model. By considering both FPS and GFLOPs, we aim to provide a balanced evaluation of the model’s efficiency in terms of both speed and computational resources.
Effectiveness of the proposed model
To visually demonstrate the detection performance of improved YOLOv8, some of the detection results of improved YOLOv8 and original YOLOv8 on RSOD dataset are illustrated in Fig. In addressing high similarity among objects and densely scenarios, the original YOLOv8 model exhibits varying degrees of missed detection and misdetection. Specifically, in Fig. 7 (a), the original YOLOv8 model misidentifies the jet bridge on the left side of the image as aircraft due to their similarity to the background. This phenomenon is also observed in the oil tank detection in Fig. 7(b), where the YOLOv8 model similarly misidentifies background elements as oil tanks. However, the improved model effectively mitigates the issue of misidentification and demonstrates superior performance in addressing the missed detection problem illustrated in Fig. 7(d)(D). In a word, these experimental results illustrate the practical advantages of our proposed improvements.

Detection results for YOLOv8 and our improved model on the RSOD dataset. (a-d) The original model (A-D) The improved model. The satellite images are from the RSOD open dataset (Long et al., 2017, DOI: https://doi.org/10.1109/TGRS.2016.2645610; GitHub repository: https://github.com/RSIA-LIESMARS-WHU/RSOD-Dataset-).
Ablation study of the proposed model
To evaluate the impact of the proposed enhancement strategy on the performance of the original YOLOv8 model on object detection in remote sensing images, we conduct a series of ablation studies. On the basis of YOLOv8 algorithm, each improvement is tested independently and in combination. The results are shown in Table 2, and the model can achieve the highest performance when the three improvements we proposed are used in combination.
The results of different improved detection accuracy are analyzed below. Under the improvement of individual modules: The AFPN module effectively integrates low-level small target detail features with high-level semantic features through progressive cross-layer processing, and improves the positioning accuracy under strict IoU threshold (mAP50-95 by 2.1%). BRA module includes part of the potential target area when filtering the background through the routing mechanism, which decreases the recall rate (decreases in mAP50), but improves the retained target localization accuracy (increases 0.9% in MAP50-95). When the DyConv module is used alone in the backbone network, the two detection accuracy indicators decline, which indicates that dynamic convolution needs more training data to play its adaptive advantage, and it is easy to lead to overfitting under limited data.
Under the improvement of the combination module: when AFPN and DyConv are combined, the dynamic kernel of DyConv adapts to different scale targets, which can provide more balanced multi-scale features for AFPN, and the mAP50 and MAP50-95 indicators are improved. When AFPN and BRA are combined, the mAP50 index is increased by 4.2%compared with BRA alone, but it does not achieve the effect of AFPN alone, indicating that the cross-level feature fusion of AFPN makes better use of multi-level features and semantic information, but BRA still has an impact on the filtering of potential targets. When BRA and DyConv are combined, the mAP50 index is improved by 1.8% compared with the BRA module alone but not as good as the effect of DyConv alone, but the MAP50-95 index reaches 64.3%, which is higher than the baseline model and the model using two modules alone, indicating that DyConv can extract more fine-grained features. The backbone network is assisted to separate the background and object features, and BRA is assisted to effectively suppress the background and emphasize the object of the high-level feature map.
Finally, the enhanced model, which integrates the interconnection of the three modules, achieves the highest target detection accuracy (mAP50 reaches 98.4%, mAP50-95 reaches 65.4%). These three modules collectively form a comprehensive action chain: DyConv dynamically adapts and extracts target features within the backbone network. The BRA module conducts spatial semantic association and emphasizes high-level features while suppressing irrelevant background information. The AFPN module deeply fuses multi-level features while preserving low-level feature details. Through the synergistic improvements of these three modules, there is a concurrent enhancement in both target localization accuracy (corresponding to the mAP50-95 index) and target recall rate (also corresponding to the mAP50-95 index).
Comparison with other detection models
To validate the effectiveness of the proposed model, we compare it with mainstream detection models on the RSOD dataset. As shown in Table 3; Fig. 8, our improved YOLOv8 achieves a mAP50-95 of 65.4%, surpassing all compared models. The performance differences stem from distinct architectural designs and feature extraction strategies.
Among one-stage models, classical detectors like RetinaNet35 and EfficientDet36 rely on fixed convolutional kernels and adjacent-level feature fusion, which struggle to adapt to the scale and orientation diversity of remote sensing objects. For example, RetinaNet achieves only 31.0% mAP50-95 with high computational costs (153 GFLOPs). TOOD37 further improves accuracy via task-aligned heads (63.2% mAP50-95), yet its parameter size (32.0 M) and GFLOPs (147) remain impractical for real-time scenarios. While YOLO-series models (e.g., YOLOv8n: 62.1% mAP50-95, 8.1 GFLOPs) improve efficiency, their limited feature extraction and multi-scale fusion optimization have restricted the accuracy of target detection in the background of remote sensing images.
Two-stage models, such as Faster R-CNN17 and Cascade R-CNN38, enhance precision through region proposal mechanisms but suffer from excessive computational complexity. Additionally, feature fusion strategies lack explicit optimization of low-level feature details and high-level semantics, resulting in suboptimal performance.
Transformer-based models face unique challenges: DETR’s20 global attention mechanism causes slow convergence on small datasets (46.2% mAP50-95) and discards critical low-level features, while Deformable DETR’s39 sparse attention reference points bias toward high-contrast regions (19.8% mAP50-95), failing in complex backgrounds. Both models also exhibit high computational costs (e.g., Deformable DETR: 144 GFLOPs), limiting real-time applicability.
In contrast, our improved model addresses these limitations through the synergy of three kinds of modules. DyConv performs adaptive features such as target scale, BRA dynamically routes key features and suppresses background interference, and AFPN progressively fuses cross-scale features to preserve small target details and promote cross-level feature fusion. With only 0.3 M more parameters than YOLOv8n, the model achieves 3.3% mAP50-95 improvement (62.1% to 65.4%) while maintaining real-time efficiency (65.7FPS). Experimental results show that the proposed algorithm successfully balances accuracy and computational efficiency, making it very suitable for real-time remote sensing applications.

Performance comparison of different models on RSOD dataset.
Conclusion
In this paper, an enhanced YOLOv8 model for object detection in remote sensing images is proposed. The three main improvements of the model are as follows: DyConv in the backbone network adaptively adjusts the convolution filter according to the input feature map to enhance the ability of the model to deal with objects of different scales and appearances. BRA module selectively highlights the high-level features of the backbone network through routing and attention calculation, establishes the semantic correlation between effective features, and suppresses irrelevant background interference. AFPN improves multi-scale feature fusion and retains more low-level detail features on cross-scale feature fusion to promote the deep fusion of high-level semantics and low-level features. Through a large number of experiments on the RSOD dataset, the improved YOLOv8 model achieves 65.4% of the mAP50-95 score, an increase of 3.3%. Compared to state-of-the-art models, our method achieves superior accuracy with a FPS of 65.7 while maintaining computational efficiency. These results highlight the effectiveness of the proposed improvements in balancing accuracy and efficiency. Although our model achieves significant improvement in object detection in remote sensing images, there are still some limitations. For example, the computational complexity of AFPN can be further reduced to improve the real-time performance. Moreover, current models may face challenges in detecting very small objects with very limited pixel information. Addressing these limitations will be an important direction for future research. Future work will focus on further optimizing the computational efficiency of the model to make it more suitable for real-time applications on edge devices. In addition, we plan to explore the fusion of multi-modal data, such as combining optical and SAR images, to enhance the robustness of small object detection in complex environments. In addition, the proposed method is extended to other types of remote sensing images, such as high-resolution urban scenes and farmland, to verify its generalization ability.
Discussion
This paper introduces an improved object detection model framework based on YOLOv8, which is specially designed to deal with the characteristics of remote sensing images. The structure design of the improved model is basically driven by the specific challenges related to object detection in remote sensing images, such as remote sensing complex background interference, the coexistence of large and small scale targets, and the dense arrangement of targets. Through a series of targeted architecture optimization, the proposed model improves the detection accuracy as a whole while meeting the computational efficiency, which is helpful for the image data analysis of satellite remote sensing to the earth.
The performance improvement of YOLOv8 model in this paper is attributed to three task-oriented architecture enhancements. Firstly, DyConv was used to replace the static volume base in the C2F module in the backbone network, which enhanced the adaptability of the model to different scale, rotation, brightness and other features of the target type, and improved the target feature extraction ability. Secondly, the BRA module is added to the end of the backbone network to emphasize target features, establish target semantic association and suppress background interference through dynamic routing and attention calculation. Thirdly, AFPN is used as the multi-level feature fusion network of the Neck region of the model, and the deep fusion of low-level detailed features and high-level semantic features is realized through progressive fusion and cross-level feature fusion.
In the ablation experiment, when the three improvements are used in combination, the detection accuracy of nonlinear superposition is enhanced, but when DyConv and BRA are used alone, some accuracy indicators are decreased, which indicates that the three improvements proposed in this paper interact with each other and form a mutual improvement chain: DyConv adapts to different appearance features of the target and extracts separately, BRA receives the feature map extracted by depth for spatial semantic association, emphasizes target features and suppresses irrelevant background, and provides more effective high-level features for the feature fusion network. AFPN ensures the least information loss when high-level features interact with low-level features, and fully integrates multi-level feature information. The three improvements jointly achieve the improvement of the accuracy index in remote sensing image target detection. At the same time, in the experiments comparing single-stage detector, two-stage detector and DETR type detector, the proposed model still maintains strong competitiveness in detection accuracy performance.
The proposed model outperforms mainstream models in remote sensing image detection accuracy, but it still has the following limitations: First, for tiny targets with a very low proportion of pixels, even if AFPN retains detailed features, the model may still miss detection. This is due to the nature of information loss in the down-sampling process, which needs to be further optimized by combining super-resolution preprocessing or high-frequency feature enhancement strategies. Second, although the cross-level fusion of AFPN improves the accuracy, it increases the computational complexity by 16.7GFLOPs (+ 106% compared with the baseline). When deploying edge devices (such as on-board processors), channel pruning or quantization compression should be used to reduce the computation time. Third, the current experiment only focuses on the four types of targets of the RSOD dataset. In more complex urban scenes (such as dense buildings) or dynamic targets (such as vehicles), the model needs targeted data augmentation or transfer learning strategies to ensure the reliability of the detection task.
In general, the model in this paper verifies its competitiveness in dealing with remote sensing background challenges through a dataset of remote sensing images. Although the calculation of the improved model is more than twice that of the baseline model, it can still maintain 65.7 FPS on the mainstream graphics card RTX 4070, indicating that the model can ensure the real-time performance of image processing on edge devices and cloud devices with good performance. The proposed model architecture is theoretically applicable to other target detection tasks with complex backgrounds, large changes in target appearance, and dense arrangement of targets, such as disaster detection and damage assessment. We will migrate the proposed model to the above scenarios to verify our conjecture in future work. And we plan to explore multi-modal data fusion to deal with extreme object detection challenges such as tiny objects and environmental occlusion objects in remote sensing images.
Data availability
All data generated or analysed during this study are included in this published article.
References
Bai, T. et al. Deep learning for change detection in remote sensing: a review. Geo-spatial Inform. Sci. 26, 262–288 (2023).
Cheng, G., Xie, X., Han, J., Guo, L. & Xia, G. S. Remote sensing image scene classification Meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 13, 3735–3756 (2020).
Hong, D. et al. More diverse means better: multimodal deep learning Meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 59, 4340–4354 (2020).
Yuan, Q. et al. Deep learning in environmental remote sensing: achievements and challenges. Remote Sens. Environ. 241, 111716 (2020).
Zhang, L. & Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geoscience Remote Sens. Magazine. 10, 270–294 (2022).
Liu, Y., Sun, P., Wergeles, N. & Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 172, 114602 (2021).
Wu, X., Hong, D., Chanussot, J. & UIU-Net U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 32, 364–376 (2022).
Sun, W., Dai, L., Zhang, X., Chang, P. & He, X. RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring. Appl. Intell. 52, 8448-8463 (2022).
Liu, H., Sun, F., Gu, J. & Deng, L. Sf-yolov5: A lightweight small object detection algorithm based on improved feature fusion mode. Sensors. 22, 5817 (2022).
Yang, C., Huang, Z. & Wang, N. QueryDet: cascaded sparse query for accelerating high-resolution small object detection, In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13668–13677.
Wang, G. et al. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 23, 7190 (2023).
Zhang, H. et al. Construction of a feature enhancement network for small object detection. Pattern Recogn. 143, 109801 (2023).
Deng, C., Wang, M., Liu, L., Liu, Y. & Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimedia. 24, 1968–1979 (2021).
Zhang, Y., Zhang, H., Huang, Q., Han, Y. & Zhao, M. DsP-YOLO: an anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst. Appl. 241, 122669 (2024).
Girshick, R. et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In: IEEE Comput. Soc. 580-587 (2014).
Girshick, R. Fast-RCNN. in: Proceedings of the IEEE international conference on computer vision. 1440–1448 (2015).
Ren, S. et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39 (6), 1137–1149 (2017).
Liu, W. et al. SSD: Single shot multibox detector. In: Computer vision-ECCV 21–37(2016) (2016).
Redmon, J. et al. You only Look Once: unified, real-time Object Detection (Computer Vision & Pattern Recognition IEEE, 2016).
Carion., Nicolas, M. et al. End-to-end object detection with transformers. lecture notes in computer science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Vol.12346: 213–229 (2020).
Zhang, L., Li, Y., Zhou, X. & Gu, S. Transcending the limit of local window: advanced super-resolution transformer with adaptive token dictionary. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2856–2865 (2024).
Sun, Y. et al. Low-light enhancement method with dual branch feature fusion and learnable regularized attention. Front. Optoelectron. 17, (1), 28 (2024).
Cui, X., Zhang, L. & Mamba -DCAU: state space dual attention center-sampling U-Net for hyperspectral image classification. Int. Jounarl Remote Sens. 46 No, 15: 5523–5547 (2025).
Li, Z. et al. TBNet: A texture and boundary-aware network for small weak object detection in remote-sensing imagery. Pattern Recogn. 158, 110976 (2025).
Song, X., Gao, E. & YGNet A lightweight object detection model for remote sensing. IEEE Geosci. Remote Sens. Lett. 22, 1–5 (2025).
Wang, J. et al. An active object-detection algorithm for adaptive attribute adjustment of remote-sensing images. Remote Sens. 17 (5), 818 (2025).
Wang, Y. et al. EFCNet for small object detection in remote sensing images[J]. Sci. Rep. 15 (1), 20393 (2025).
Glenn, J., Ayush, C. & Jing, Q. Ultralytics YOLOv8. GitHub, (2023). https://github.com/ultralytics/ultralytics.
Zhu, L. et al. BiFormer: vision transformer with bi-level routing attention, 2023 IEEE/CVF Conference on Computer Vision and (CVPR), 10323–10333 (2023).
Chen, Y. et al. Dynamic Convolution: attention over Convolution kernels. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). 11027-11036 (2020).
Yang, G. et al. AFPN: asymptotic feature pyramid network for object detection, 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2184–2189 (2023).
Long, Y., Gong, Y., Xiao, Z. & Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 55 (5), 2486–2498. https://doi.org/10.1109/TGRS.2016.2645610,link (2017).
Xiao, Z., Liu, Q., Tang, Q. & Zhai, X. Elliptic fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 36(2), 618-644 (2015).
Glenn, J. Ultralytics YOLOv5. GitHub, (2020). https://github.com/ultralytics/yolov5.
Lin, T. Y. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42 (2), 318–327 (2020).
Tan, M., Pang, R. & Le, V. EfficientDet: scalable and efficient object detection. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (2020).
Feng, C. et al. TOOD: Task-aligned one-stage object detection. Proceedings of the IEEE International Conference on Computer Vision: 3490–3499 (2021).
Cai, Z., Nuno, V. & Cascade, R-C-N-N. Delving into high quality object detection. IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2018).
Zhu, X. et al. Deformable DETR: Deformable transformers for end-to-end object detection. 9th International Conference on Learning Representations, ICLR 2021 (2021).
Author information
Authors and Affiliations
Contributions
Z.H. and W.C. conceived of the study, designed the methodology, conducted the experiments, and completed the article. D.Y. constructed the prototype of the paper, prepared the experimental software and compared and verified the model. Z.W. prepared the experimental data set and assisted in revising the paper. P.W. directed the experiment and completed the graphical work. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hu, Z., Chen, W., Yang, D. et al. Enhancing object detection in remote sensing images with improved YOLOv8 model. Sci Rep 15, 42488 (2025). https://doi.org/10.1038/s41598-025-26536-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-26536-6
