
Abstract
This study introduces a Jellyfish optimization technique integrated with a Multi-Layer Perceptron, specifically a Feedforward Neural Network (FNN) model, for remaining useful life (RUL) prediction of lithium-ion batteries (LIBs). A multiple battery with multi-input (MBMI) profile is utilized to create 91-dimensional data features for model training. A systematic sampling approach is employed to extract relevant data features. Results show that the proposed JFO-based FNN model outperforms the traditional FNN model’s accuracy. The Mean Square Error (MSE) is used as the objective function to determine optimal model hyperparameters. The research utilizes the NASA LIB database, which includes four datasets. For LIB cell B5, the proposed model achieved an MSE of 3.9494*10− 4. The model’s accuracy and efficiency are further validated using particle swarm optimization. However, the LIBs B6 and B18 showed higher error results due to capacity regeneration issues. The MIT-Stanford LIB datasets demonstrated high applicability when validating the JFO-FNN model’s outcomes. The novelty of this work lies in using a JFO-optimized FNN model trained on systematically sampled, multi-battery LIB datasets to improve predictive accuracy, generalization, and robustness. Overall, the developed RUL prediction framework appears to be fast, effective, and yields promising results.
Similar content being viewed by others

Introduction
Presently, a wide range of industries, including communication, energy management systems, electric cars, and aircraft, use lithium-ion batteries (LIBs)1,2,3. Low voltage drop, high energy density, high electromotive force, ease of handling, and a broad operational temperature range are just a few of the benefits that LIBs offer in a variety of applications4,5. Repeated charge and discharge cycles already lead to the aging of LIBs and reduced health. It leads to serious consequences, including degradation through failure of the system, breakdown, and economic loss6. It is emphasized to be necessary for the control and maintenance of the LIBs health to deliver efficient performance throughout its life7. The controlled operations of the LIBs avoid problems of degradation, however, it is necessary to predict the remaining useful life of the LIB precisely to reduce the risk of unexpected LIB failure, optimize resources, and thereby get effective and reliable LIB performance8.
The use of LIBs in different applications decreases their capacity. The LIB is replaced for safety reasons when the capacity nears a threshold limit set at around 70% to 80% of the rated original capacity9. Therefore, it is imperative to closely predict the remaining useful life of the LIB to ensure the safe and reliable operation of the energy storage system (ESS). The accurate evaluation mitigates safety concerns and ensures that LIB functions reliably and efficiently. The RUL prediction is the number of charging and discharging cycles that the LIB can undergo before it arrives at the threshold level and is calculated using its present cycle.
There are two main approaches to forecasting the RUL i.e. model-based and data-driven methods. Mathematical modelling and derivations that require empirical and experimental validation are considered with model-based methods9. These techniques use different sets of equations to define the LIBs’ behavior and calculate the RUL. In10, the authors proposed the RUL prediction algorithm using the unscented particle filter (PF). The issue with sample degeneracy associated with UPF was minimized with the implementation of the Markov Chain Monte Carlo method. Furthermore, three models were reported by Walker et al.11 including nonlinear least squares, particle filter, and unscented Kalman filter. The models correctly predict RUL, whereas model-based methods need some degree of information that can precisely describe the internal workings to enhance RUL prediction accuracy.
The data-driven approaches for estimating the RUL derive parameters, such as capacity, impedance, voltage and current. Data-driven models outperform model-based models in accuracy, speed, and simplicity12. For instance, a Support Vector Machine (SVM) model to assess the LIB’s health and prognosis was proposed13. This model combined with the PF technique to show the LIB’s degradation profile. Yet, the SVM-PF model’s training used only capacity data, resulting in low-dimensional training data and less precise RUL results. Liu et al.14 later introduced the Relevance Vector Machine (RVM) algorithm, which incorporates an online training method to improve RUL prediction accuracy using the NASA database. Using an ANN model, Ansari et al.15 employed the back propagation neural network (BPNN) model to predict the RUL. The model training was performed with data collected through a mathematical sampling technique. Nevertheless, the execution time was high and further requires human experience in choosing the appropriate model parameters. In16, this issue was addressed by appropriately selecting the model parameters using a bat-based PF model. The method demonstrated effective outcomes and versatility to varying dynamic trends. Table 1 delivers a comparative evaluation of literature research. Additionally, Ansari et al.17 introduced a new RUL prediction algorithm consisting of bio-inspired jellyfish optimization (JFO) and FNN model. The JFO selects the FNN model parameter to achieve satisfactory results, nonetheless, LIB datasets with varying characteristics were not considered to validate the developed model.
The aforementioned studies fall short in accuracy due to the absence of data variety from multiple operational profiles, resulting in the inability to accurately predict the RUL. Moreover, the model parameters were inadequately chosen for training. Henceforth, this study presents the RUL prediction of the LIB using an optimized model with systematic sampling to precisely attain the data and accomplish accurate model training and further validate the proposed model with the LIB database with dynamic characteristics. Furthermore, in contrast to other studies that focus on single battery single input (SBSI) profiles and single inputs18,19, this approach considers MBMI profile factors. These include the acquisition of data parameters from multiple LIBs to attain higher data dimensionality. The mathematical sampling process is applied to select 30 samples of the LIB parameters like voltage, current, and temperature (VIT). Additionally, the capacity data is added to develop the proposed MBMI data framework. Lastly, the FNN model parameters are accurately optimized with the JFO. The key novelty of the paper is as follows:
-
Implementation of the JFO algorithm for selecting optimal model hyperparameters, including hidden neurons and learning rate, to enhance predictive accuracy and computational efficiency.
-
Utilization of multi-battery parameters to construct a comprehensive and suitable data framework for efficient model training and generalization across different LIB datasets.
-
30 data samples are carefully selected using the systematic sampling (SS) technique to ensure optimal representation and accuracy in model training.
-
The optimized FNN model is trained with various LIB datasets to enhance its predictive performance and robustness, across different LIB characteristics.
The paper’s structure is as follows: Section II discusses LIB data acquisition. Section III delivers the methodology and proposed framework for the RUL prediction. Section IV details the experimental results, with the conclusion in Section VI.
Lithium-ion battery data acquisition
The experimental LIB dataset is sourced from the NASA Prognostics Centre of Excellence Data Repository, which offers four datasets from Li-ion 18,650-sized rechargeable LIBs23. The LIB parameters are analyzed, and their data structure is established using the constant current and constant voltage (CCCV) method. Three distinct operating profiles (charge, discharge, and electrochemical impedance spectroscopy) were applied to LIBs at varying temperatures. Various current load levels were used during discharges before the LIBs voltage dropped to predetermined thresholds.
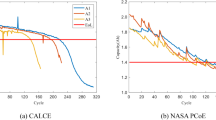
Additionally, the JFO-FNN model is validated with the MIT-Stanford LIB dataset from two batches i.e. ‘2017-05-12’ and ‘2018-04-20’20. Each LIB cell has a nominal capacity and nominal voltage of 1.1 Ah and 3.3 V. For batch ‘2017-05-12’, all cells were charged in cycles using either a one-step or two-step procedure. The range of the charging time is around 8 to 13.3 min (0–80% SOC). Except for 3.6 C (80%), two cells are typically tested per policy. A rest period of 1 min and 1 s was implemented after achieving 80% state of charge during charging and after the discharging operation. The LIB cells were cycled to 0.88 Ah, or 80% of their nominal capacity. Whereas, for the batch ‘2018-04-12’, every LIB cell was cycled using a two-step charging operation. A 10-minute charging duration is set for each cell. A 5-second rest time was applied after four operations i.e. before and after discharging, after internal resistance test and after attaining 80% SOC while charging. A random selection of the cell based on the previously accomplished work is undertaken and the dataset from four cells namely c33, c34, c35 and c36 is acquired from two batches21,22. It is noted that the MIT-Stanford dataset shows dynamic features whereas, the NASA dataset is constructed under non-dynamic operating conditions. On the other hand, the current value fluctuates rapidly over time during the discharging operation, making it difficult to accurately obtain the LIB data parameters. Additionally, because no preassigned methods are used throughout the discharging operation, the LIB parameters exhibit a considerable degree of unpredictability. The LIB parameters from the discharge profile are not taken into account because of this concern23. The capacity degradation profile of the NASA and MIT-Stanford LIB dataset is shown in Fig. 1. Additionally, the specifications of the LIB cells with their source, charging/discharge protocol and cycle rate is presented in Table 2.

Capacity degradation curve of NASA and MIT-Stanford LIB dataset (Two batches i.e. ‘2017-05-12’ and ‘2018-02-20’).
Rul prediction methodology and framework
The presented methodology and framework were constructed using the FNN model, a bio-inspired algorithm named the JFO technique and the SS method. First, the FNN model is used in a wide range of applications, including face recognition, simulation modelling, and time series prediction, to mention a few. The popularity of these applications has generated interest in creating effective training techniques that have quick convergence and strong generalization capabilities24. Recently, the JFO approach has been designed and has been used in numerous research projects25. The JFO approach demonstrates an excellent ability to solve optimization problems and is simple to use. Currently, the JFO technique has not been used to a greater extent for state estimation of the LIB but except few works published21,26. Consequently, the JFO technique is taken into consideration when developing the suggested RUL prediction framework to appropriately select the FNN model parameters. Finally, systematic sampling is employed to identify the precise data characteristics of key parameters to establish a suitable data structure.
Multilayer perceptron-based feedforward neural network
The Multilayer perceptron (MLP) based FNN model is commonly applied in machine learning systems because of its easy implementation and nonlinear response27. The paper proposes a three-layer FNN model consisting of the input layer, hidden layer and output layer as depicted in Fig. 2. The input layer takes the constructed 91-dimensional data, the hidden layer is optimized and the output layer delivers the estimated capacity to attain the required RUL prediction results. Moreover, the Levenberg-Marquardt Algorithm for training the FNN model is considered15. The FNN model has an input layer, which considers the input from the selected LIB parameters. The JFO technique determines the hidden neurons and learning rate in the FNN model. However, selecting the conventional FNN model parameters is undertaken with a trial-and-error technique. Parameters such as learning rate, hidden neurons, number of epochs and iterations are selected with a trial-and-error technique. Table 3 depicts the selection of the conventional FNN model hyperparameters. The selection of the model hyperparameters is considered with the training dataset as B6, B7 and B18 while the testing dataset is taken as B5. It was examined that minimum RMSE was achieved with a hidden neuron of 5, learning rate of 0.01, number of epochs as 500 and number of iterations as 50 respectively. The learning rate i.e. 0.01 indicates the slow learning ability of the FNN model but with better accuracy and prediction outcomes.

Proposed MLP based FNN model for the RUL prediction.
The anticipated capacity is the only neuron that the FNN model’s output layer contains. The output and hidden layers are regarded as processing layers in the FNN model. These layers can be activated using a hyperbolic tangent sigmoid function. The activation function is expressed as follows:
The hidden layer in the FNN model is expressed as follows:
refers to the number of hidden neurons. The expression of the output based on the output layer of the FNN model can be expressed as:
where, n denotes the hidden neurons, \(\mathop W\nolimits_{{j,k}}^{o}\) is the weight between the \(jth\) hidden neuron and output neuron, \(\mathop b\nolimits_{k}^{o}\) express the threshold value for \(kth\) output neuron.
Bio-inspired jellyfish optimization (JFO) technique
The bio-inspired algorithm i.e. JFO technique was invented in the year 2020 and depicts the jellyfish movement to search best outcomes. The JFO techniques find the solutions by considering many factors such as ocean currents, jellyfish movement, time control mechanisms, and jellyfish bloom. The JFO was selected due to its dynamic balance between exploration and exploitation phases, inspired by real biological behavior, which is particularly effective for non-convex and high-dimensional search spaces such as hyperparameter tuning in neural networks. Unlike Genetic Algorithms, JFO requires fewer control parameters and avoids premature convergence. Compared to Bayesian Optimization, which is computationally expensive due to surrogate modeling, JFO offers a light but competitive alternative. Additionally, Grid Search, while thorough, is not practical in high-dimensional or continuous spaces. Consequently, JFO strikes a good balance between efficiency and effectiveness in optimizing the learning rate and hidden neurons of the suggested FNN model. The JFO algorithm follows three search operational principles, namely:
-
1)
Ocean current
The abundance of food in the ocean currents attracts jellyfish. The average of all vectors from jellyfish to jellyfish at the ideal point is used to illustrate the ocean trend.
where, \(df=\mathop e\nolimits_{c} \mu\) and is the deviation between the mean location of all jellyfish and their current ideal position, \(\mathop n\nolimits_{{pop}}\) denotes jellyfish population,\(\mathop X\nolimits^{*}\) indicates the ideal location within the swarm, \(\mu\)is the mean position of the jellyfish and \(\mathop e\nolimits_{c}\)is a factor controlling pull and.
-
2)
Jellyfish swarm
The collective jellyfish movement starts as passive (Type A) and, over time, accelerates into active movement (Type B). In their passive state, jellyfish are assumed to move in a circling pattern around their current positions, and the updated position is given by:
where \(\mathop H\nolimits_{b}\)and \(\mathop L\nolimits_{b}\)express the maximum and minimum limits of the boundary conditions in the search space. The coefficient of motion is \(\delta\)> 0.
-
3)
Time control mechanism
The jellyfish’s movement and timing are modeled using a time control mechanism that governs its motion in ocean currents. This mechanism consists of a time-dependent function, c(t), and a constant. The function c(t) is random and takes on values between 0 and 1 over time, and it is expressed as:
The described structure is well in place, JFO techniques used for selecting the most appropriate FNN model hyperparameters, obeying optimization constraints. It utilizes a correlated search space for identifying the optimal FNN parameters, with this space limited by the minimum and maximum values set for the parameters to be optimized. Establishing accurate boundaries is crucial for selecting the proper hyperparameters; otherwise, deviations may occur, resulting in suboptimal predictions. Nonetheless, the effectiveness of the JFO technique is evaluated with Mean Square Error (MSE) as the objective function and denoted as:
where \(ck\) represents the real capacity data samples, \(\mathop {ck}\nolimits^{\Delta }\) denotes the predicted capacity data samples. Table 4 shows the model parameters applied to the proposed JFO-FNN model are presented. The selection of the parameters such as number of epochs, iterations and population size is determined using the trial-and-error method. It is examined that the model hyperparameters of FNN should be carefully selected. For instance, a model with a high learning rate could miss the optimal values, whereas a low learning rate could lead to slow convergence. Overfitting might result from using too many layers, while modeling difficult data wouldn’t be possible with too few.
The lowest and maximum values of the model’s hyperparameters that need to be carefully optimized define the boundaries of the search space used for choosing the optimal FNN parameters. For instance, a boundary condition [1 40] was assigned for hidden neurons whereas, [0 1] was assigned to achieve an optimized learning rate. It is crucial to choose the hyperparameters with an appropriate boundary; otherwise, the results might diverge significantly and produce unsatisfactory prediction results. The selection of the different JFO parameters is shown in Table 5.
The evaluation to choose the JFO parameters is performed on the preliminary studies, where B5 is selected as a testing dataset and batteries B6, B7, and B18 were training datasets. Henceforth, the precise selection of the optimization parameters is crucial as it leads to better model training with higher generalization and lower computational complexity. Figure 3 illustrates the fundamental structure of the FNN model training with JFO. The movement of each jellyfish inside the swarm is updated using the time control mechanism. The updating continues until the best objective function is attained. The optimized hyperparameters of the FNN model are generated by JFO. The objective function determined by the FNN model is returned as the fitness value for the JFO. The best jellyfish within the operation is the ideal result, and the FNN model makes use of it.

Training process of the JFO-FNN to achieve optimized weight and bias.
Data extraction with a mathematical sampling method
The mathematical sampling method applied in this work is referred to as systematic sampling (SS). The SS method is considered to extract the features/samples by considering an equal time interval from a large dataset28. The equal time interval is the sampling interval and is obtained by dividing the total data features/samples by a suitable sampling size. The sample size is selected by considering the model’s operation, constraints and outcomes. It is important to understand the suitable selection of the data sample size. A large number of data samples could result in low sampling error and computational complexity whereas, a small data size may lead to non-sampling error. The selected data samples from the parameter profile show the approximate characteristics of the parameter. However, some relevant features having a strong correlation with the parameter characteristics may be left unnoticed. Therefore, the sample size in the SS technique should be accurately calculated so that important parametric features are attained. The SS method reduces the likelihood of utilizing filter methods to eliminate the unwanted/noisy data and avoids the need for clustered data19.
In the proposed work, the SS method is utilized to attain 30 data samples from each parameter i.e. VIT and one sample from capacity data. The initial evaluation with different data features suggested the accurate data feature size as 30. The combined 30 samples from VIT and a single capacity sample formed a 91-dimensional data structure. The proposed 91-dimensional data framework created with the SS technique is as follows:
where, a, b and n represents the cycle 1, cycle 2 and last cycle. For \(\:\left\{\frac{{V}^{a}}{30}*1,\frac{{V}^{a}}{30}*2\dots\:\frac{{V}^{a}}{30}*30\right\}\), \(\:\frac{{V}^{a}}{30}*1\:\)represents the first voltage feature, \(\:\frac{{V}^{a}}{30}*2\) is the second data feature and \(\:\frac{{V}^{a}}{30}*30\) is last voltage sample from first charging cycle. Similarly, the data samples are extracted from the temperature and current profiles. Additionally, \(\:{C}_{a}\), \(\:{C}_{b}\:\)and \(\:{C}_{n}\:\)are the first, second and last extracted capacity samples. The proposed developed data framework depicts the input data samples as I and target data samples i.e. C for proposed JFO-FFN model can be shown as:
where \(\:\left\{\frac{{V}^{1}}{30}*1,\frac{{V}^{1}}{30}*2\dots\:\frac{{V}^{1}}{30}*30\right\}\:\)denotes the voltage samples from cycle 1, cycle 2 and the last cycle. A similar method is applied to the temperature and current parameters. \(\:C1,\:C2\dots\:Cn\) signifies estimated capacity from cycle one to cycle n i.e. last cycle.
Table 6 depicts the conducted analysis to select the 30 data samples from each charging cycle for different LIB parameters. A trade-off curve illustrating the relationship between RMSE and training time, based on various data features (5, 10, 15, 20, 25, 30 and 35), is depicted in Fig. 4. The trade-off curve involving RMSE and training time indicates that the careful choice of data features is essential. The computational complexity is low when the data features are minimal. It produces less accurate findings, though. On the contrary, adding additional data attributes increases computing complexity. As a result, choosing the right data characteristics is essential to achieving accurate results with the least amount of computational complexity.

Trade-off between RMSE and training time considering data sample size.
The JFO-FNN method may be divided into three tiers, as shown in Fig. 5: data acquisition and preparation level, training level and lastly prediction level. The initial step is obtaining appropriate parameters by analyzing the LIB datasets. The LIB parameters such as VIT and discharge capacity are selected and further, the SS method is applied to construct a 91-dimensional data framework. The SS method suitably selects 30 data samples from VIT with a single data sample from capacity. The developed data framework is appropriately applied for carrying out the model training in the second level. During JFO-FNN testing for each LIB, the model training was performed on the dataset from the other three LIBs. The JFO-FNN model parameters such as iterations, epochs, and jellyfish population are attained using the trial-and-error method, however, the FNN model parameters, i.e. learning rate and hidden neurons are selected by utilizing the JFO technique. In the final stage, the RUL prediction is performed by analyzing the cycle number i.e. threshold capacity level. The JFO-FNN training is examined through error indices i.e. RMSE and MAPE which are equated as:
In addition, the RUL error is estimated with the true RUL and predicted RUL as shown as:
where, the negative \(\mathop {RUL}\nolimits_{{error}}\)denotes that \(\mathop {RUL}\nolimits_{{predicted}}\)is smaller than \(\mathop {RUL}\nolimits_{{true}}\)and vice versa.

Proposed RUL prediction framework with hybrid JFO-FNN algorithm and MBMI profile.
Results and discussion
A JFO-FNN-based RUL prediction framework is developed using different MBMI profiles. The constructed data framework is developed using different LIBs and their related parameter showing high correlation with the output capacity curve. Model training and testing are performed on different training and testing datasets. Table 7 shows the evaluation of the charging/discharging profile to select the best profile for LIB parameter selection. Due to the rapid current fluctuations and no preset protocols, the initial outcomes to predict the LIB show high error with the discharge profile as compared with the charging profile.
Analysis of the LIB dataset from the NASA database
The JFO-FNN model is trained and validated with a traditional FNN model and PSO-FNN technique to predict the RUL of LIBs as presented in Table 8. In this work, each LIB dataset is regarded as a testing dataset, while the remaining three LIB datasets provide 70% of the training dataset. The RUL prediction is analyzed starting from cycle one. This is assumed as a complete single LIB dataset is applied for model testing, hence plots the capacity curve from cycle one. The initial capacity for B5, B6, B7 and B18 is assigned as 1.96, 2.04, 1.89 and 1.86 Ah whereas, the threshold capacity or the knee point for B5, B6, B7 and B18 is 1.41, 1.39, 1.51 and 1.41 Ah. The performance indicates that the JFO-FNN model consistently outperforms FNN and PSO-FNN in terms of accuracy and reliability for RUL prediction across all batteries. JFO-FNN achieves the lowest RMSE, MSE, and MAPE values, demonstrating superior predictive accuracy. For instance, in B5, JFO-FNN records an RMSE of 0.0292 compared to 0.5961 for FNN and 0.1299 for PSO-FNN. Additionally, JFO-FNN maintains minimal RUL errors and stable predictions. However, this improved performance comes with a trade-off in terms of computational cost. Specifically, the JFO-FNN model incurs a notably higher training time ranging from 173.84 to 192.74 s primarily due to the iterative nature and exploration–exploitation balance of the Jellyfish Optimization algorithm. Despite this increased training overhead, the inference latency of JFO-FNN remains competitive, with an average of ~ 0.46 milliseconds, which is only marginally higher than that of PSO-FNN and baseline FNN. This demonstrates that while JFO-FNN may not be ideal for real-time online learning scenarios, it is well-suited for offline training followed by real-time inference in battery management systems, where fast and accurate RUL predictions are essential. Figure 6 shows the box plot for different models executed with the NASA database. The box plot compares the performance of FNN, JFO-FNN, and PSO-FNN for RMSE and MAPE showing high variability, especially in PSO-FNN and the FNN model.

Box plot curve showing the error indices for the RUL prediction models with the NASA LIB datasets.
Despite this, its improved accuracy justifies the increased computational cost, confirming JFO-FNN’s robustness in RUL prediction for the LIBs. The RUL prediction outcomes for LIB datasets are presented on Fig. 7. The degradation curve for every LIB demonstrates the effectiveness of the JFO-FNN model compared to standard FNN and PSO-FNN approaches.
In all cases, the JFO-FNN consistently provides predictions that closely align with the actual capacity trends, particularly during the critical phases near the threshold capacity. The inset highlights areas of rapid capacity degradation, showing that JFO-FNN outperforms other models by maintaining better accuracy and tracking. For B5, JFO-FNN captures the discharge capacity pattern with minimal deviation. Similarly, in B6 and B7, JFO-FNN maintains a tighter fit to the actual capacity, especially in regions with sudden drops. PSO-FNN and standard FNN show larger deviations, particularly in critical prediction phases. These results validate the JFO-FNN’s robustness and precision in forecasting RUL across diverse datasets, highlighting its ability to provide reliable predictions in both stable and fluctuating capacity cycles. Furthermore, the effect of capacity regeneration phenomena is more dominant in B6. Due to this, the error indices outcome for B6 was comparatively high compared with the other tested LIB datasets.

Degradation profile curve to predict the RUL for the LIBs with MCMI profile data.
Validation with the MIT-Stanford dataset
LIB datasets from batch ‘2017-05-12’
The JFO-FNN model is validated with the MIT-Stanford dataset from batch ‘2017-05-12’. The JFO-FNN model showed high accuracy and robustness during training with validated LIB datasets owing to the high volume of the training dataset. Table 9 shows the performance indices for the proposed JFO-FNN model, PSO-FNN model and conventional FNN model for different datasets obtained from the MIT-Stanford database. The cycle number for c33, c34, c35 and c36 is stated as 870, 842, 709 and 876 whereas, the initial capacity is mentioned as 1.0877, 1.0790, 1.0799 and 1.0946 Ah and the threshold capacity or the knee point is assigned as 0.94 Ah.
The performance indices for batteries C33–C36 from batch ‘2017-05-12’ indicate that the JFO-FNN model consistently surpasses both FNN and PSO-FNN in predictive accuracy and reliability. JFO-FNN achieves the lowest RMSE and MSE across all datasets, reflecting superior generalization and precision in RUL estimation. However, this comes at the expense of increased training time, with values ranging from approximately 119 to 140 s. This is significantly higher than the baseline FNN (sub-second) and PSO-FNN (ranging from 63 to 155 s), indicating that the JFO-based optimization introduces a considerable computational burden during model training. In contrast, inference latency for JFO-FNN remains within a narrow and acceptable range of 0.46–0.48 milliseconds only slightly higher than FNN and PSO-FNN demonstrating that once the model is trained, it can still deliver near-instantaneous predictions suitable for real-time deployment. This trade-off suggests that JFO-FNN is best leveraged in settings where offline training is feasible, and real-time inference accuracy is critical, such as in BMS applications for EVs.

Degradation profile curve to predict the RUL for the LIBs from batch ‘2017-05-12’ with MCMI profile data.
Additionally, the prediction curve for the MIT-Stanford dataset is shown in Fig. 8. The JFO-FNN model was successful in reconstructing the capacity curve due to the right selection of the features and an optimized FNN model network. A high error was achieved with dataset C36 because of capacity regeneration phenomena, which resulted in inaccurate reconstitution of the predicted capacity curve as well. For instance, the RMSE value under C33, C34 and C35 with the JFO-FNN model was 0.0486, 0.0201 and 0.0815. However, the RMSE value with C36 was 0.1839 which is comparatively higher than other datasets because of capacity regeneration. The least execution time among the three models was taken by the traditional FNN model with an average time of 0.37s while the average execution time for the proposed JFO-FNN model is estimated as 131.445 s and the PSO-FNN model was 119.57 s respectively.
LIB dataset from batch ‘2018-04-12’
The JFO-FNN algorithm is trained and validated with datasets from other batch ‘2018-02-20’. The validation with other batches was conducted to demonstrate the applicability and effectiveness of the JFO-FNN model as shown in Table 10. The cycle number for the LIB cell c33, c34, c35 and c36 is stated as 2189, 824, 988 and 1027 whereas, the initial capacity is mentioned as 1.0650, 1.0452, 1.0601 and 1.0710 Ah and the threshold capacity or the knee point is assigned as 0.98 Ah for c33 and 0.93 Ah for c34, c35 and c36. The performance indices highlight the superior predictive accuracy of the JFO-FNN model compared to FNN and PSO-FNN for RUL estimation across all datasets. JFO-FNN consistently achieves lower RMSE, MSE, and MAPE values, indicating its robustness in minimizing prediction errors. Specifically, JFO-FNN outperforms in C34 and C35, where it demonstrates a significant reduction in error while maintaining stable RUL predictions. However, in case of c33, the JFO-FNN technique showed high error compared with other validated models demonstrating the need to use specialized feature techniques. The high error could be due to the capacity regeneration or irregular degradation pattern during experimental protocols. The training time for JFO-FNN ranges from approximately 150 to 224 s, which is notably longer than PSO-FNN (93–170 s) and much higher than the lightweight FNN (under 1 s in all cases). This highlights the added computational burden introduced by the JFO optimizer during model training. However, inference latency remains within a tight and practical range for all models, with JFO-FNN requiring 0.45–0.48 milliseconds, only marginally higher than FNN and PSO-FNN. Although FNN shows faster training times, its predictive accuracy is notably lower. PSO-FNN displays moderate performance but suffers from higher error rates, especially in complex datasets. These results underscore JFO-FNN’s efficiency in delivering precise RUL forecasts while effectively balancing computational complexity.
The RUL prediction curves for batteries c33, c34, c35 and c36 from batch ‘2018-02-20’ illustrate the superior predictive accuracy of the JFO-FNN model over standard FNN and PSO-FNN as depicted in Fig. 9. JFO-FNN consistently aligns closely with the actual capacity, particularly near the critical threshold regions, as highlighted in the insets. For instance, in C33 and C34, JFO-FNN minimizes deviation during rapid degradation phases, outperforming other models in tracking dynamic capacity changes. In contrast, FNN and PSO-FNN exhibit significant errors and instability in high-degradation cycles, as evident in C35. These results confirm JFO-FNN’s robustness and precision in providing reliable RUL estimates across varying degradation profiles.

Degradation profile curve to predict the RUL for the LIBs from batch ‘2018-04-20’ with MCMI profile data.

Box plot curve showing the error indices for the RUL prediction models with MIT-Stanford LIB datasets from batch ‘2017-05-12’ and batch ‘2018-04-12’.
Figure 10 illustrates the RMSE and MAPE distributions for FNN, JFO-FNN, and PSO-FNN using MIT-Stanford battery datasets from batches ‘2017-05-12’ and ‘2018-04-12’. The JFO-FNN exhibits the lowest errors, indicating better performance, while PSO-FNN shows higher variability, particularly in RMSE, suggesting instability in predictions. The average training time and inference latency of the trained JFO-FNN model were measured as 170 s and 0.46 ms per sample on an Intel i7 CPU, indicating suitability for real-time BMS deployment scenarios with sub-10 ms response requirements. From the above results, it is evident that selecting appropriate LIB parameters and identifying critical data features are essential for ensuring accurate predictions. In this study, a LIB parameter was selected from the charging profile and additionally, accurate selection of data samples was conducted to enhance prediction accuracy. It was observed that, with the NASA dataset, the error was primarily due to local fluctuations from capacity regeneration. Whereas the dynamic features of the LIB parameters with the MIT-Stanford dataset influenced prediction outcomes. By using the SS technique, it was possible to reconstitute the capacity curve. The rapid variation in parameter features, however, renders optimized models like JFO-BPNN incapable of reconstructing the estimated degradation curve.
Furthermore, the operational profile analysis in this work to extract the LIB dataset was limited to charging profile only and therefore, further research analysis could be performed to conduct a comprehensive analysis of the based on the discharging process. Moreover, other parameters such as time and impedance maybe acquired to train state of the art models for RUL prediction which remains unaddressed in this work.
Comparative analysis of the outcome with other models
In this study, the JFO-FNN model is trained with the NASA dataset and tested using the MIT-Stanford dataset. Additionally, the results are compared with previously conducted research considering state-of-the-art models, as presented in Table 11. To provide an unbiased comparison, the LIB dataset B5 was considered. The analysis is performed by considering execution factors such as model implementation, error indices (i.e., RMSE), and existing research gaps. A deep neural network (DNN) model was applied which delivered satisfactory outcomes with the RMSE of 3.42729. In another work30, optimized SVR model was applied for RUL prediction which shows the RMSE as 0.0307. Ansari et al.15 utilized the BPNN model which attains a higher RMSE as 0.0819 due to the inappropriate selection of model parameters. A stacked autoencoder (SAE) model was used for RUL prediction which delivered the RMSE as 0.65 depicting high error. With the GRU model31, the RMSE achieved was 0.97% which could be further improved with the utilization of the right amount of data and suitable model parameters.
Conclusion
This work proposes an integrated RUL prediction framework comprising the FNN model and JFO. The JFO-FNN model is trained with key LIB parameters, which strongly shows a correlation with the output. are extracted. A data framework with high dimensionality, consisting of 91 data features, is constructed. The training of the JFO-FNN model with developed data with the MBMI profile outperforms the PSO-FNN model and conventional FNN models considering different error indices. With B5, the MSE, RMSE, and MAPE are 3.9494 × 10⁻⁴, 0.1987, and 0.0828, respectively, which are significantly more accurate compared to 2.4646, 0.0607, and 1.1752 in B6. Compared with the PSO-FNN model and conventional FF model, the proposed JFO-FNN model is more accurate and has better capacity reconstitution ability. Further, the capacity regeneration effect showed high influence in the LIB such as B6 and B18, respectively, delivering a higher error in terms of MSE, MAPE and RMSE compared to the other LIBs such as B5 and B7. The JFO-FNN model is validated with the MIT-Stanford dataset and shows good results based on low error and high accuracy. The suggested work would facilitate regulated management by substituting the LIBs before reaching the threshold of RUL prediction.
It is important to note that this study primarily focuses on the implementation and evaluation of the JFO algorithm for hyperparameter tuning in battery RUL prediction models. While the findings highlight the algorithm’s effectiveness in improving predictive accuracy, training time, and inference latency, the scope of this work does not extend to real-time deployment scenarios in production EV battery management systems. Future research will address scalability and integration challenges in embedded environments to evaluate the algorithm’s performance under real-time constraints. This work could be further extended to LIB applications for charging/discharging in future EVs and LIB swapping stations. Furthermore, the integration of JFO with advanced hybrid architectures (e.g., recurrent–convolutional models) and domain-specific feature engineering will be explored to enhance RUL prediction performance further. Lastly, the parameter selection should be carefully analyzed to achieve more accurate prediction outcomes.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Hu, X., Zou, C., Zhang, C. & Li, Y. Technological developments in batteries: A Survey of Principal Roles, Types, and Management Needs. IEEE Power Energy Mag 2023: 42–44 .
Gong, X., Xiong, R. & Mi, C. C. A Data-Driven Bias-Correction-Method-Based Lithium-Ion battery modeling approach for electric vehicle applications. IEEE Trans. Ind. Appl. 52, 1759–1765. https://doi.org/10.1109/TIA.2015.2491889 (2016).
Swornowski, P. J. Destruction mechanism of the internal structure in Lithium-ion batteries used in aviation industry. Energy 122, 779–786. https://doi.org/10.1016/j.energy.2017.01.121 (2017).
Zhang, J. & Lee, J. A review on prognostics and health monitoring of Li-ion battery. J. Power Sources. 196, 6007–6014. https://doi.org/10.1016/j.jpowsour.2011.03.101 (2011).
He, W., Williard, N., Osterman, M. & Pecht, M. Prognostics of lithium-ion batteries based on Dempster-Shafer theory and the bayesian Monte Carlo method. J. Power Sources. 196, 10314–10321. https://doi.org/10.1016/j.jpowsour.2011.08.040 (2011).
Chen, L., Xu, L. & Zhou, Y. Novel approach for Lithium-Ion battery On-Line remaining useful life prediction based on permutation entropy. Energies 11, 820. https://doi.org/10.3390/en11040820 (2018).
Tan, Y., Tan, Y., Zhao, G. & Zhao, G. Transfer learning with long short-term memory network for state-of-health prediction of lithium-ion batteries. IEEE Trans. Ind. Electron. 67, 8723–8731. https://doi.org/10.1109/TIE.2019.2946551 (2020).
El Mejdoubi, A., Chaoui, H., Sabor, J. & Gualous, H. Remaining useful life prognosis of supercapacitors under temperature and voltage aging conditions. IEEE Trans. Ind. Electron. 65, 4357–4367. https://doi.org/10.1109/TIE.2017.2767550 (2018).
Liao, L. & Köttig, F. Review of hybrid prognostics approaches for remaining useful life prediction of engineered systems, and an application to battery life prediction. IEEE Trans. Reliab. 63, 191–207. https://doi.org/10.1109/TR.2014.2299152 (2014).
Zhang, X., Miao, Q. & Liu, Z. Remaining useful life prediction of lithium-ion battery using an improved UPF method based on MCMC. Microelectron. Reliab. 75, 288–295. https://doi.org/10.1016/j.microrel.2017.02.012 (2017).
Walker, E., Rayman, S. & White, R. E. Comparison of a particle filter and other state Estimation methods for prognostics of lithium-ion batteries. J. Power Sources. 287, 1–12. https://doi.org/10.1016/j.jpowsour.2015.04.020 (2015).
Bamati, S. & Chaoui, H. Developing an online Data-Driven state of health Estimation of Lithium-Ion batteries under random sensor measurement unavailability. IEEE Trans. Transp. Electrif. 9, 1128–1141. https://doi.org/10.1109/TTE.2022.3199115 (2023).
Nuhic, A., Terzimehic, T., Soczka-Guth, T., Buchholz, M. & Dietmayer, K. Health diagnosis and remaining useful life prognostics of lithium-ion batteries using data-driven methods. J. Power Sources. 239, 680–688. https://doi.org/10.1016/j.jpowsour.2012.11.146 (2013).
Liu, D., Zhou, J., Liao, H., Peng, Y. & Peng, X. A health indicator extraction and optimization framework for lithium-ion battery degradation modeling and prognostics. IEEE Trans. Syst. Man. Cybern Syst. 45, 915–928. https://doi.org/10.1109/TSMC.2015.2389757 (2015).
Ansari, S., Ayob, A., Lipu, M. S. H., Hussain, A. & Saad, M. H. M. Multi-Channel profile based artificial neural network approach for remaining useful life prediction of electric vehicle Lithium-Ion batteries. Energies 14, 1–22 (2021).
Wu, Y., Li, W., Wang, Y. & Zhang, K. Remaining useful life prediction of lithium-ion batteries using neural network and bat-based particle filter. IEEE Access. 7, 54843–54854. https://doi.org/10.1109/ACCESS.2019.2913163 (2019).
Ansari, S. et al. Optimized Data-Driven Network for Remaining Useful Life Prediction of Lithium-ion Batteries. IEEE Int. Conf. Energy Technol. Futur. Grids, Wollongong, Australia: 2023, 1–6. (2023).
Zhang, Y., Xiong, R., He, H. & Liu, Z. A LSTM-RNN method for the lithuim-ion battery remaining useful life prediction. Proc. 2017 Progn Syst. Heal Manag Conf. PHM-Harbin 2017. https://doi.org/10.1109/PHM.2017.8079316 (2017).
Wang, C., Lu, N., Wang, S., Cheng, Y. & Jiang, B. Dynamic long short-term memory neural-network- based indirect remaining-useful-life prognosis for satellite Lithium-ion battery. Appl. Sci. 8. https://doi.org/10.3390/app8112078 (2018).
Severson, K. A. et al. Data-driven prediction of battery cycle life before capacity degradation. Nat. Energy. 4, 383–391. https://doi.org/10.1038/s41560-019-0356-8 (2019).
Ansari, S. et al. Optimized data-driven approach for remaining useful life prediction of Lithium-ion batteries based on sliding window and systematic sampling. J. Energy Storage. 73, 109198. https://doi.org/10.1016/j.est.2023.109198 (2023).
Ansari, S., Ayob, A., Hossain Lipu, M. S., Hussain, A. & Saad, M. H. M. Particle swarm optimized data-driven model for remaining useful life prediction of lithium-ion batteries by systematic sampling. J. Energy Storage. 56, 106050. https://doi.org/10.1016/j.est.2022.106050 (2022).
Park, K., Choi, Y., Choi, W. J., Ryu, H. Y. & Kim, H. LSTM-Based battery remaining useful life prediction with Multi-Channel charging profiles. IEEE Access. 8, 20786–20798. https://doi.org/10.1109/ACCESS.2020.2968939 (2020).
Yang, J. & Ma, J. Feed-forward neural network training using sparse representation. Expert Syst. Appl. 116, 255–264. https://doi.org/10.1016/j.eswa.2018.08.038 (2019).
Chou, J. S. & Truong, D. N. Multiobjective optimization inspired by behavior of jellyfish for solving structural design problems. Chaos Solitons Fractals. 135, 109738. https://doi.org/10.1016/j.chaos.2020.109738 (2020).
Ansari, S., Ayob, A., Hossain Lipu, M. S., Hussain, A. & Md Saad, M. H. Jellyfish optimized recurrent neural network for state of health Estimation of lithium-ion batteries. Expert Syst. Appl. 238, 121904. https://doi.org/10.1016/j.eswa.2023.121904 (2024).
Hagan, M. T. & Menhaj, M. B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Networks. 5, 989–993. https://doi.org/10.1109/72.329697 (1994).
Saavedra-Nieves, A. Assessing systematic sampling in estimating the Banzhaf–Owen value. Oper. Res. Lett. 48, 725–731. https://doi.org/10.1016/j.orl.2020.08.015 (2020).
Khumprom, P. & Yodo, N. A data-driven predictive prognostic model for lithium-ion batteries based on a deep learning algorithm. Energies 12, 1–21. https://doi.org/10.3390/en12040660 (2019).
Wang, Y. et al. A method based on improved ant Lion optimization and support vector regression for remaining useful life Estimation of lithium-ion batteries. Energy Sci. Eng. 7, 2797–2813. https://doi.org/10.1002/ese3.460 (2019).
Wei, M. et al. Remaining useful life prediction of lithium-ion batteries based on Monte Carlo dropout and gated recurrent unit. Energy Rep. 7, 2862–2871. https://doi.org/10.1016/j.egyr.2021.05.019 (2021).
Wei, M., Ye, M., Wang, Q. & Xinxin-Xu, Twajamahoro, J. P. Remaining useful life prediction of lithium-ion batteries based on stacked autoencoder and Gaussian mixture regression. J. Energy Storage. 47, 103558. https://doi.org/10.1016/j.est.2021.103558 (2022).
Chen, J. C., Chen, T. L., Liu, W. J., Cheng, C. C. & Li, M. G. Combining empirical mode decomposition and deep recurrent neural networks for predictive maintenance of lithium-ion battery. Adv. Eng. Inf. 50, 101405. https://doi.org/10.1016/j.aei.2021.101405 (2021).
Acknowledgements
The work acknowledges the grant received from Universiti Kebangsaan Malaysia (UKMKPU-2023-008).
Author information
Authors and Affiliations
Contributions
Md Ibrahim and Shaheer Ansari conceptualized, wrote the main file and prepared files. Afida Ayob supervised the work and provided the funding. M S Hossain Lipu, Maher G M Abdolrasol, Abdul Waheed Khwaja, Muhammad Amir Khalil and Daniel Ioan Stroe reviewed the file and delivered appropriate suggestion.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ibrahim, M., Ansari, S., Ayob, A. et al. Hybrid optimized remaining useful life prediction framework for lithium-ion batteries with limited data samples. Sci Rep 15, 39126 (2025). https://doi.org/10.1038/s41598-025-26743-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-26743-1
