
Abstract
With the growing availability of short video platforms such as TikTok and Bilibili, patients with diabetic kidney disease (DKD) are increasingly seeking health information through these channels. However, the quality and user engagement of DKD-related content on these platforms have not been systematically evaluated. This exploratory cross-sectional study assessed the quality and reliability of DKD-related short videos and examined predictors of user engagement. On April 4, 2025, the top 100 DKD-related videos were collected from each platform. Content quality and reliability were assessed using the Global Quality Score (GQS), the modified DISCERN (mDISCERN), and the Medical Quality Video Evaluation Tool (MQ-VET). An eXtreme Gradient Boosting (XGBoost) model was employed to predict the number of likes and identify associated predictors. Despite being shorter in length, TikTok videos received significantly more likes, saves, shares, and comments than those on Bilibili (all p < 0.001), and scored higher on GQS and MQ-VET, with no significant difference in mDISCERN scores. Videos uploaded by professionals generally showed higher quality. Follower count, video length, and days since upload were the strongest predictors of engagement. Overall, TikTok videos exhibited higher quality and engagement than those on Bilibili; however, given the algorithm-driven sampling, uploader-level clustering, and tool adaptation, these findings should be interpreted as descriptive and exploratory rather than causal.
Similar content being viewed by others

Introduction
Diabetic kidney disease (DKD) is a common microvascular complication of diabetes and a major cause of end-stage renal disease1. With the global rise in diabetes prevalence, the incidence of DKD has also increased, occurring in approximately 30–40% of patients with diabetes2,3,4. In China, DKD has surpassed glomerulonephritis-related chronic kidney disease as the leading cause of chronic kidney disease5. Although integrated management strategies can delay progression, no curative therapy is currently available6,7,8. Therefore, it is crucial to raise public awareness of early DKD detection and self-management.
In the digital era, the widespread adoption of the internet and the rapid emergence of short video platforms have granted the public unprecedented access to health information, substantially enhancing health literacy9,10,11. A study has shown that about 80% of internet users use online sources to obtain health information12. TikTok and Bilibili, two of the leading short video platforms in China, have become important channels for disseminating medical and health knowledge to the public12,13. Owing to their wide reach, speed, and interactivity, these platforms offer considerable opportunities for health education and public engagement14. However, because videos can be freely uploaded without filtering, these platforms often feature low-quality and unreliable content, with some even conveying misleading or deceptive information15,16. This issue is particularly concerning for chronic diseases like DKD, which require long-term management. Exposure to inaccurate or incomplete information may impair patients’ understanding and reduce treatment adherence.
Although previous studies have assessed the quality of health information in short videos on topics such as liver cancer15, cervical cancer17, gastroesophageal reflux disease18, and schizophrenia19, systematic investigations focusing on DKD-related content remain scarce. Most research emphasizes content quality while neglecting user engagement, and few studies have quantitatively assessed or predicted behaviors such as likes. This gap limits both understanding of DKD-related content and insights into the factors shaping user engagement.
Given this, the present study focuses on health videos related to DKD on TikTok and Bilibili. A cross-sectional design was employed to systematically assess the quality and reliability of video content using standardized assessment tools. Additionally, the XGBoost algorithm was applied to model video characteristics and user engagement metrics. This study was designed as an exploratory evaluation of DKD-related health information on China’s leading short video platforms, focusing on video quality, reliability, and factors associated with user engagement.
Materials and methods
Search strategy and data collection
This exploratory cross-sectional study analyzed DKD-related short videos on TikTok and Bilibili. On April 4, 2025, we systematically searched the Chinese versions of TikTok and Bilibili using the keyword “糖尿病肾病” (DKD in Chinese) in the search bar. To minimize personalized recommendations, we cleared the browsing history, conducted the searches in anonymous mode, and manually set the sorting method to comprehensive ranking; however, some algorithm-dependent bias could not be entirely eliminated. Videos were excluded if they were advertisements, entirely in English, duplicates (only the first video retained), or unrelated to the theme (as defined in Supplementary Table S1), until the top 100 relevant videos were identified. The sample size was based on previous cross-sectional studies of short videos, which have demonstrated good representativeness and statistical stability15,20.
Data collection was completed on April 5, 2025, encompassing basic information for all selected videos. The study conducted a quantitative analysis of video data across several dimensions, including user interaction metrics such as likes, comments, saves, and shares, as well as content features like background music (BGM), dietary management, subtitle settings, and video length. Additionally, uploader-related information was recorded, including whether the uploader was a patient, whether the account was verified, the number of followers, and the total number of videos published.
Video classification
Each video was assigned a classification label based on its style and uploader attributes, which facilitated subsequent analyses. Video styles were categorized into five types: (1) solo narration, (2) PPT/classroom-style explanation, (3) animation/action, (4) clinical setting, and (5) TV show/documentary. Uploader identity was classified into four categories: (1) professional institution, (2) professional individual, (3) non-professional institution, and (4) non-professional individual. This classification framework was adapted from the standards established by Zheng15. To further refine uploader attributes, a secondary classification for “verified” accounts was implemented. Detailed classification criteria are provided in Supplementary Tables S2-S4.
Video quality and reliability assessments
Three established tools were used to assess video quality and reliability. Although originally developed for websites or written health materials, mDISCERN and GQS have been increasingly applied in studies evaluating health-related videos on platforms such as TikTok and Bilibili13,21,22,23. The GQS employs a 5-point scale to evaluate overall content quality, focusing on dimensions such as content flow, information completeness, and clinical applicability24. In contrast, mDISCERN emphasizes scientific accuracy and reliability, providing a content quality framework based on five dimensions: information accuracy, evidence reliability, balance of viewpoints, clarity of information sources, and expression of uncertainty25. The MQ-VET integrates patient education and clinical applicability, offering a more detailed and structured evaluation through four modules: content accuracy, educational effectiveness, comprehensibility, and applicability, with a total of 15 specific criteria assessed across these modules26. Detailed descriptions of these tools can be found in Supplementary Tables S5-S8. Prior to scoring, two assessors with medical backgrounds (JJ and LS) underwent standardized training and calibration tests. In case of discrepancies, a nephrology expert (ZH) with extensive clinical experience intervened to resolve inconsistencies and ensure the reliability of the assessments.
XGBoost-Based prediction of likes
To further examine user engagement with DKD-related short videos, the dataset of 200 samples was randomly divided into training and testing sets at a 7:3 ratio for XGBoost model development and performance evaluation. Likes, as the most immediate and simplest form of feedback, reflect viewers’ instant recognition and emotional resonance with the content27. A previous study has shown that videos with higher like counts are more likely to be recommended to users, as likes consistently demonstrate a positive correlation with diverse engagement metrics and serve as a key indicator of content popularity28. Therefore, likes were selected as the outcome variable, with video and creator features such as follower count, BGM, subtitle availability, certification status, video length, the number of topics, uploader type, and days since upload as predictors. Given the skewed distribution and presence of zero values in the like count, a log (1 + x) transformation was applied to normalize the data and improve model fit. The model was developed using the “xgboost” package, with three-fold cross-validation to assess robustness and grid search for hyperparameter tuning to prevent overfitting. Feature importance was visualized, and SHapley Additive exPlanations (SHAP) values were used to interpret the impact of each variable on the predicted like count. Finally, the model results were integrated into a Shiny application framework for interactive web-based visualization.
Statistical analysis
All statistical analyses were performed using IBM SPSS Statistics (version 27.0) and R (version 4.4.3). Continuous variables were tested for normality using the Shapiro-Wilk test. For normally distributed data, results were presented as mean ± standard deviation, and comparisons were made using the independent samples t-test. For non-normally distributed data, results were presented as median and interquartile range (IQR), and comparisons were performed using the Mann-Whitney U test. Categorical variables were presented as frequencies and percentages, and group comparisons were conducted using the chi-square test or Fisher’s exact test. To ensure the reliability of the assessments, inter-rater consistency was quantified using the intraclass correlation coefficient (ICC)29. To address potential non-independence among videos from the same uploader, uploader-level ICCs were calculated to quantify clustering. Random-intercept multilevel linear models were additionally fitted, where appropriate, to examine whether the main results remained consistent after adjusting for this clustering. A p-value < 0.05 was considered statistically significant.
Results
Video characteristics
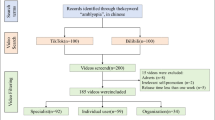
Initially, 141 videos were identified on TikTok and 143 on Bilibili. After applying standardized inclusion and exclusion criteria, 41 TikTok videos (24 irrelevant, 17 duplicates) and 43 Bilibili videos (28 irrelevant, 13 duplicates, 1 in English, 1 advertisement) were excluded. Ultimately, 100 eligible videos were retained per platform, yielding 200 videos for analysis (Fig. 1).

Flowchart of DKD-related video selection on TikTok and Bilibili.
As shown in Table 1, user engagement data revealed that TikTok significantly outperformed Bilibili in terms of likes, saves, shares, and comments (all p < 0.001). Additionally, the two platforms differed in video length (p < 0.001) and days since upload (p < 0.001). TikTok videos were generally more up-to-date and shorter. Regarding content presentation, Bilibili videos predominantly featured PPT/classroom-style explanation (47.0%) and solo narration (26.0%), while TikTok videos primarily featured solo narration (66.0%) (Supplementary Figure S1). Compared to Bilibili, TikTok videos made greater use of technical elements, with 49.0% incorporating BGM and 97.0% including subtitles. In terms of content, both platforms focused on “symptoms and diagnosis” (Bilibili: 74.0%; TikTok: 72.0%) and “treatment and prevention” (Bilibili: 69.0%; TikTok: 63.0%). The radar chart in Supplementary Figure S2 illustrated that Bilibili covered a broader range of topics, particularly in core medical areas such as “pathogenesis,” “epidemiology,” and “treatment and prevention.” Content related to dietary management was underrepresented on both platforms, with coverage below 30.0% (Table 1).
Uploader characteristics
This study included 127 video uploaders, with 67 on Bilibili and 60 on TikTok. Table 2 showed that TikTok uploaders had a median follower count of 111,500 and posted more videos than those on Bilibili. On TikTok, 95.0% of uploaders were professional individuals, a significantly higher proportion than Bilibili’s 49.3%. In contrast, non-professional individuals made up the second largest group on Bilibili, accounting for 29.8%. Among verified uploaders, the majority were healthcare professionals on both platforms (TikTok: 98.3%; Bilibili: 82.6%).
Video quality and reliability assessment
The ICC values were all > 0.8 (Supplementary Table S9), ensuring the reliability of the subsequent data analysis. As shown in Fig. 2, TikTok outperformed Bilibili in both GQS and MQ-VET scores (GQS: p < 0.001, MQ-VET: p = 0.013). Specifically, the median GQS score for TikTok was 4.0 (IQR: 3.0–4.0), higher than Bilibili’s median of 3.0 (IQR: 2.0–4.0). The median MQ-VET score for TikTok was 45.5 (IQR: 41.0–49.0), also higher than Bilibili’s median of 42.0 (IQR: 40.0–46.0). In contrast, there was no significant difference between the two platforms in mDISCERN scores, with both platforms having a median score of 2.0 (IQR: 2.0–2.0).

Distribution and comparison of quality and reliability scores of DKD-related short videos between TikTok and Bilibili. Note: (A) Distribution of GQS scores for TikTok and Bilibili; (B) Comparison of GQS scores between the two platforms; (C) Distribution of mDISCERN scores for TikTok and Bilibili; (D) Comparison of mDISCERN scores between the two platforms; (E) Distribution of MQ-VET scores for TikTok and Bilibili; (F) Comparison of MQ-VET scores between the two platforms. ns, not significant; *p < 0.05, ****p < 0.0001.
To further investigate the impact of uploader background on the scores, we conducted subgroup analyses. Uploaders were categorized into two groups based on their background: the professional group (comprising professional individuals and institutions) and the non-professional group (comprising non-professional individuals and institutions). As shown in Fig. 3 and Supplementary Table S10, videos from the professional group generally scored higher than those from the non-professional group across GQS, mDISCERN, and MQ-VET, suggesting that professional background may be associated with improved informational quality and reliability.

Comparison of quality and reliability scores of DKD-related videos from professional and non-professional uploaders on Bilibili and TikTok. Note: (A) Comparison of GQS scores between professional and non-professional videos on Bilibili; (B) Comparison of GQS scores between professional and non-professional videos on TikTok; (C) Comparison of mDISCERN scores between professional and non-professional videos on Bilibili; (D) Comparison of mDISCERN scores between professional and non-professional videos on TikTok; (E) Comparison of MQ-VET scores between professional and non-professional videos on Bilibili; (F) Comparison of MQ-VET scores between professional and non-professional videos on TikTok. *p < 0.05, **p < 0.01, ***p < 0.001, ****p < 0.0001.
Sensitivity and clustering assessment
Evidence of uploader-level clustering was observed for video quality scores on both platforms (Supplementary Table S11), suggesting some degree of within-uploader correlation. After adjustment for random effects using multilevel linear models, the positive association between uploader professionalism and video quality remained statistically significant on both platforms. Videos from professional creators generally achieved higher GQS, mDISCERN, and MQ-VET scores than those from non-professionals (Supplementary Tables S12–S13). Although clustering may have influenced the precision of estimates to a limited extent, the overall pattern of associations appeared broadly consistent after adjustment.
When comparing engagement metrics between platforms, ICCs for likes, saves, shares, and comments ranged from 0.062 to 0.132 (Supplementary Table S14), indicating weak clustering at the uploader level. After accounting for this dependence, TikTok videos generally received more likes (p = 0.006), saves (p = 0.004), and shares (p = 0.029) than Bilibili videos, while the difference in comments approached significance (p = 0.057). These findings suggest that accounting for uploader-level clustering had limited impact on the observed platform differences in engagement (Supplementary Table S15).
Like-count prediction model
We successfully developed a like-count prediction model, achieving an R² of 0.833 in the training set, indicating a good fit (Fig. 4A). As shown in Fig. 4B, follower count, video length, and days since upload were the primary factors influencing the number of likes, with follower count showing the strongest association. In contrast, certification status and BGM contributed less to the prediction, indicating their relatively limited influence on user engagement. The beeswarm plot further revealed a negative correlation between video length and like count (Supplementary Figure S3). To enhance the model’s interpretability and practical application, we developed an interactive visualization platform based on the Shiny framework (https://mdyy.shinyapps.io/dkdvedio0/), which allows real-time prediction of like counts based on the characteristics of DKD-related short videos and dynamically displays the influence of each variable on the predicted outcome (Fig. 4C).

XGBoost-based prediction of like counts and web application deployment. Note: (A) Scatter plot showing the performance of the XGBoost model in predicting like counts; (B) Feature importance ranking of predictors in the model; (C) Web-based application interface for predicting like counts of DKD-related short videos based on input features.
Discussion
Principal findings
This study found that TikTok outperformed Bilibili in both GQS and MQ-VET scores, while the two platforms showed similar performance in mDISCERN scores. Although the overall video quality on TikTok was higher than that on Bilibili, both platforms exhibited varying degrees of deficiencies in content depth, evidence-based support, and the structural integrity of the information. Subgroup analysis revealed that uploaders with a medical background significantly outperformed non-professional uploaders in terms of scores. This trend persisted after adjusting for uploader-level clustering, suggesting that professionalism may be associated with more accurate and comprehensible content, though this relationship should be interpreted with caution.
Video quality and reliability
The study found that the proportion of DKD-related short videos citing authoritative references in the mDISCERN scores was extremely low, indicating that these videos still lack sufficient evidence-based support. Additionally, the “content accuracy” module in the MQ-VET tool received significantly lower scores compared with other modules, further reflecting the videos’ limitations in terms of information reliability. Most videos did not specify recording dates, update times, or references, which weakened the verifiability and timeliness of the content. These issues are not unique to DKD-related videos. Prior research has reported similar concerns, showing that many health-related videos on short video platforms fail to provide credible references or balanced perspectives, thereby increasing the risk of misinformation12,30. For example, Mueller et al. reported that 48.0% of atopic dermatitis–related short videos contained potentially harmful information, and more than two-thirds of psoriasis-related videos disseminated misleading claims31,32.
Several factors may contribute to this problem. First, citing authoritative sources requires substantial time and effort for searching, screening, and verification, which increases the workload for content creators. Second, even medical professionals often prefer simplified, accessible language in public health communication to facilitate comprehension and engagement33. Third, the short and fast-paced format of videos, particularly solo narration, makes it difficult to systematically reference clinical guidelines or research evidence.
Association between uploader background and video quality
Videos uploaded by professionals tended to show higher quality and reliability than those from non-professionals, in line with previous findings22,34. Healthcare professionals often possess stronger medical knowledge and are trained to follow evidence-based guidelines, which may enhance the accuracy and credibility of their content. Moreover, professional creators are more likely to disclose their authorship transparently, a factor that may contribute to higher mDISCERN scores.
The difference between professional and non-professional uploaders was particularly pronounced on TikTok (Fig. 3). TikTok enforces stricter verification standards for professional uploaders, such as requiring physicians to be licensed at tertiary hospitals and hold at least the title of attending physician22. In contrast, Bilibili applies more lenient entry criteria, allowing non-professionals easier access to publish health-related content, which may contribute to greater variability in quality22.
In our study, we also noted that some uploaders identified themselves as healthcare professionals but lacked verified credentials. This raises the possibility that certain individuals may present themselves as medical experts to increase credibility and attract viewers20,35. While such cases appear relatively uncommon, they highlight the need for caution when interpreting online health information, particularly in the absence of clear verification.
Factors influencing engagement
In the XGBoost model, follower count was emerged as the strongest predictor of likes, accounting for 60.6% of the model’s feature importance. This finding is consistent with previous studies indicating that creators with larger audiences generally achieve greater visibility and engagement on video-sharing platforms27,28. Once users follow a creator, they are more likely to receive updates and encounter that creator’s videos in their feed, thereby having more opportunities to engage than non-followers28. A larger follower base may also provide broader initial exposure, which in turn increases the likelihood of accumulating user interactions. Although the correlation between follower base and engagement appears robust, the present analysis cannot establish a definitive causal relationship.
This study revealed a negative association between video length and likes. Longer videos were linked to lower viewing ratios and fewer views, with each additional minute estimated to reduce viewership by nearly one-sixth28. Because users’ attention spans are limited and expectations are high, longer videos are less likely to sustain viewing or generate engagement28. Other factors, including certification status and background music, contributed only marginally to predicting likes. Although uploader verification has been recognized as an important factor for enhancing the credibility of health-related videos20,36, its impact on immediate engagement in our dataset was limited. Similarly, while background music may improve the overall viewing atmosphere, it does not appear to be a major factor influencing user engagement27,37.
Limitations
This study has several limitations. First, restricting the sample to the top 100 videos on TikTok and Bilibili may have introduced algorithm-driven selection bias and excluded other relevant content. Second, the quality assessment tools (GQS and mDISCERN), although widely used in prior research, were not specifically designed for short-form videos and may not fully capture their characteristics. Third, multiple videos from the same uploader could lead to clustering effects and reduce the independence of observations. Fourth, subgroup analyses were limited by small sample sizes and should be regarded as exploratory and hypothesis-generating. Finally, as a cross-sectional study based on data collected on a single day, the findings represent only a snapshot of platform content. Given the algorithm-driven dynamics and cultural specificity of TikTok and Bilibili, the representativeness and generalizability of the results are limited. Future studies should incorporate multi-platform and multi-time-point sampling, as well as patient perspectives and guideline concordance, to provide a more comprehensive evaluation.
Conclusion
This exploratory study offers an overview of the current landscape of DKD–related short videos on TikTok and Bilibili. Overall video quality was suboptimal, particularly regarding information accuracy and source attribution. Videos from professional uploaders were generally of higher quality, and follower count appeared to be associated with greater user engagement. Considering the algorithm-driven sampling, potential clustering among uploaders, and the limited adaptability of evaluation tools to short-form content, these findings should be interpreted as descriptive observations rather than causal inferences, offering a reference point for future systematic and longitudinal research.
Data availability
All data will be available from the corresponding author upon reasonable request.
Abbreviations
- DKD:
-
Diabetic kidney disease
- GQS:
-
Global Quality Score
- mDISCERN:
-
modified DISCERN
- XGBoost:
-
Extreme Gradient Boosting
- MQ-VET:
-
Medical Quality Video Evaluation Tool
- ESRD:
-
End-stage renal disease
- BGM:
-
Background music
- SHAP:
-
SHapley Additive exPlanations
- IQR:
-
Interquartile range
- ICC:
-
Intraclass correlation coefficient
References
Sagoo, M. K. & Gnudi, L. Diabetic Nephropathy: An Overview. Methods Mol Biol 3–7, (2067). https://doi.org/10.1007/978-1-4939-9841-8_1 (2020).
Worldwide trends in. Diabetes prevalence and treatment from 1990 to 2022: a pooled analysis of 1108 population-representative studies with 141 million participants. Lancet 404, 2077–2093. https://doi.org/10.1016/s0140-6736(24)02317-1 (2024).
Harjutsalo, V. & Groop, P. H. Epidemiology and risk factors for diabetic kidney disease. Adv. Chronic Kidney Dis. 21, 260–266. https://doi.org/10.1053/j.ackd.2014.03.009 (2014).
Gupta, S., Dominguez, M. & Golestaneh, L. Diabetic kidney disease: an update. Med. Clin. North. Am. 107, 689–705. https://doi.org/10.1016/j.mcna.2023.03.004 (2023).
Zhang, L. et al. Trends in chronic kidney disease in China. N Engl. J. Med. 375, 905–906. https://doi.org/10.1056/NEJMc1602469 (2016).
Lin, Y. C., Chang, Y. H., Yang, S. Y., Wu, K. D. & Chu, T. S. Update of pathophysiology and management of diabetic kidney disease. J. Formos. Med. Assoc. 117, 662–675. https://doi.org/10.1016/j.jfma.2018.02.007 (2018).
Yamout, H. & Bakris, G. L. Diabetic nephropathy: SGLT2 inhibitors might halt progression of diabetic nephropathy. Nat. Rev. Nephrol. 12, 583–584. https://doi.org/10.1038/nrneph.2016.109 (2016).
Yu, J., Liu, Y., Li, H. & Zhang, P. Pathophysiology of diabetic kidney disease and autophagy: A review. Med. (Baltim). 102, e33965. https://doi.org/10.1097/md.0000000000033965 (2023).
Zhao, B. Y. et al. Digital health literacy and associated factors among internet users from china: a cross-sectional study. BMC Public. Health. 24, 908. https://doi.org/10.1186/s12889-024-18324-0 (2024).
Zhao, Y. & Zhang, J. Consumer health information seeking in social media: a literature review. Health Info Libr. J. 34, 268–283. https://doi.org/10.1111/hir.12192 (2017).
Madathil, K. C., Rivera-Rodriguez, A. J., Greenstein, J. S. & Gramopadhye, A. K. Healthcare information on youtube: A systematic review. Health Inf. J. 21, 173–194. https://doi.org/10.1177/1460458213512220 (2015).
Tu, J., Zhang, C., Zhang, H., Liang, L. & He, J. Evaluating the reliability and quality of knee osteoarthritis educational content on TikTok and bilibili: A cross-sectional content analysis. Digit. Health. 11, 20552076251366390. https://doi.org/10.1177/20552076251366390 (2025).
Wang, H., Zhang, H., Cao, J., Zhang, F. & Xiong, W. Quality and content evaluation of thyroid eye disease treatment information on TikTok and bilibili. Sci. Rep. 15, 25134. https://doi.org/10.1038/s41598-025-11147-y (2025).
Zhu, W. et al. Information quality of videos related to esophageal cancer on tiktok, kwai, and bilibili: a cross-sectional study. BMC Public. Health. 25, 2245. https://doi.org/10.1186/s12889-025-23475-9 (2025).
Zheng, S. et al. Quality and reliability of liver Cancer-Related short Chinese videos on TikTok and bilibili: Cross-Sectional content analysis study. J. Med. Internet Res. 25, e47210. https://doi.org/10.2196/47210 (2023).
Niu, Z. et al. Quality of pancreatic neuroendocrine tumor videos available on TikTok and bilibili: content analysis. JMIR Form. Res. 8, e60033. https://doi.org/10.2196/60033 (2024).
Zhang, J. et al. Short video platforms as sources of health information about cervical cancer: A content and quality analysis. PLoS One. 19, e0300180. https://doi.org/10.1371/journal.pone.0300180 (2024).
Cai, Y. et al. The status quo of short video as sources of health information on gastroesophageal reflux disease in china: a cross-sectional study. Front. Public. Health. 12, 1400749. https://doi.org/10.3389/fpubh.2024.1400749 (2024).
Zhang, W. et al. Evaluation of the content and quality of schizophrenia on tiktok: a cross-sectional study. Sci. Rep. 14, 26448. https://doi.org/10.1038/s41598-024-75372-7 (2024).
Sun, F., Zheng, S. & Wu, J. Quality of information in gallstone disease videos on tiktok: Cross-sectional study. J. Med. Internet Res. 25, e39162. https://doi.org/10.2196/39162 (2023).
Kong, W., Song, S., Zhao, Y. C., Zhu, Q. & Sha, L. TikTok as a health information source: assessment of the quality of information in Diabetes-Related videos. J. Med. Internet Res. 23, e30409. https://doi.org/10.2196/30409 (2021).
Liu, Z. et al. YouTube/ Bilibili/ TikTok videos as sources of medical information on laryngeal carcinoma: cross-sectional content analysis study. BMC Public. Health. 24, 1594. https://doi.org/10.1186/s12889-024-19077-6 (2024).
Bernard, A. et al. A systematic review of patient inflammatory bowel disease information resources on the world wide web. Am. J. Gastroenterol. 102, 2070–2077. https://doi.org/10.1111/j.1572-0241.2007.01325.x (2007).
Wang, J. et al. Assessing the content and quality of GI bleeding information on Bilibili, TikTok, and youtube: a cross-sectional study. Sci. Rep. 15, 14856. https://doi.org/10.1038/s41598-025-98364-7 (2025).
Sahin, E. & Seyyar, M. Assessing the scientific quality and reliability of YouTube videos about chemotherapy. Med. (Baltim). 102, e35916. https://doi.org/10.1097/md.0000000000035916 (2023).
Guler, M. A. & Aydın, E. O. Development and validation of a tool for evaluating YouTube-based medical videos. Ir. J. Med. Sci. (1971 -). 191, 1985–1990. https://doi.org/10.1007/s11845-021-02864-0 (2022).
Zhang, R. et al. Analyzing dissemination, quality, and reliability of Chinese brain tumor-related short videos on TikTok and bilibili: a cross-sectional study. Front. Neurol. 15, 1404038. https://doi.org/10.3389/fneur.2024.1404038 (2024).
Yang, S., Brossard, D., Scheufele, D. A. & Xenos, M. A. The science of youtube: what factors influence user engagement with online science videos? PLoS One. 17, e0267697. https://doi.org/10.1371/journal.pone.0267697 (2022).
Koo, T. K. & Li, M. Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 15, 155–163. https://doi.org/10.1016/j.jcm.2016.02.012 (2016).
Liu, H. et al. Assessment of the reliability and quality of breast cancer related videos on TikTok and bilibili: cross-sectional study in China. Front. Public. Health. 11, 1296386. https://doi.org/10.3389/fpubh.2023.1296386 (2023).
Mueller, S. M. et al. Fiction, Falsehoods, and few facts: Cross-Sectional study on the Content-Related quality of atopic Eczema-Related videos on YouTube. J. Med. Internet Res. 22, e15599. https://doi.org/10.2196/15599 (2020).
Mueller, S. M. et al. The absence of evidence is evidence of Non-Sense: Cross-Sectional study on the quality of Psoriasis-Related videos on YouTube and their reception by health seekers. J. Med. Internet Res. 21, e11935. https://doi.org/10.2196/11935 (2019).
Warde, F. et al. Plain Language communication as a priority competency for medical professionals in a globalized world. Can. Med. Educ. J. 9, e52–e59 (2018).
Xu, R., Ren, Y., Li, X., Su, L. & Su, J. The quality and reliability of short videos about premature ovarian failure on bilibili and tiktok: Cross-sectional study. Digit. Health. 11, 20552076251351077. https://doi.org/10.1177/20552076251351077 (2025).
Guan, J. L. et al. Videos in Short-Video sharing platforms as sources of information on colorectal polyps: Cross-Sectional content analysis study. J. Med. Internet Res. 26, e51655. https://doi.org/10.2196/51655 (2024).
Gong, X., Dong, B., Li, L., Shen, D. & Rong, Z. TikTok video as a health education source of information on heart failure in china: a content analysis. Front. Public. Health. 11, 1315393. https://doi.org/10.3389/fpubh.2023.1315393 (2023).
Shi, A. et al. Mpox (monkeypox) information on tiktok: analysis of quality and audience engagement. BMJ Glob Health. 8 https://doi.org/10.1136/bmjgh-2022-011138 (2023).
Acknowledgements
We gratefully acknowledge the content uploaders on TikTok and Bilibili whose publicly available videos made this study possible.
Funding
This study was supported by the Startup Fund for Scientific Research, Fujian Medical University (Grant No. 2019QH1217), and the Fujian Provincial Health Commission Scientific Research Plan Project (Grant No. 2021QNA076).
Author information
Authors and Affiliations
Contributions
Shuo Lin: Writing – original draft, Visualization, Resources, Data curation. Jianjie Ju: Writing – original draft, Methodology, Conceptualization, Data curation. Zhouhua Wang: Writing - original draft, Writing – review & editing, Funding acquisition, Conceptualization, Data curation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This study uses publicly available videos from TikTok and Bilibili, which do not involve personal data or sensitive information, thus ethical review is not required.
Consent for publication
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lin, S., Ju, J. & Wang, Z. Information quality assessment and user engagement prediction of short videos about diabetic kidney disease on TikTok and bilibili. Sci Rep 15, 43572 (2025). https://doi.org/10.1038/s41598-025-27650-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27650-1
