
Abstract
Over the last decade, significant progress has been made in image dehazing, particularly with the advent of deep learning-based methods. However, many of the existing dehazing approaches face critical limitations such as relying on assumptions that fail under complex atmospheric conditions. This results in poor visibility restoration. To address this, this study proposes Dehaze-Attention, an improved image dehazing model designed to handle variable haze densities while preserving essential structural information. The proposed model introduces several contributions. First, it employs advanced feature extraction through convolutional layers to capture foundational details from hazy images. Second, an attention mechanism is integrated into architecture, enabling the model to dynamically focus on relevant features and reduce information loss. Third, a multi-scale network structure is incorporated to process haze across different densities by combining global and local feature analysis. The model was evaluated on a synthesized set of hazy images derived from the UDTIRI dataset under diverse atmospheric conditions. Experimental results demonstrated that the proposed Dehaze-Attention model achieves state-of-the-art performance, with significant improvements in both quantitative metrics (PSNR and SSIM) and subjective evaluations compared to baseline models. The results highlight that the improved model can be used for applications in aerial imaging, autonomous systems, and remote sensing.
Similar content being viewed by others

Introduction
The presence of haze, a common atmospheric phenomenon, significantly reduces the visibility of images, thus degrading the performance of computer vision systems. Image dehazing is a critical preprocessing step in many vision-based applications, from autonomous driving and traffic monitoring to remote sensing and outdoor surveillance1. Haze results from atmospheric particles scattering light, which diminishes the clarity, color fidelity, and contrast of captured images2. Effective image dehazing is crucial as the demand for high-quality visual data in various applications grows. This is particularly relevant in fields such as autonomous navigation and remote sensing, where the accuracy of image data is paramount for decision-making and analysis3.
Despite the advancements in image dehazing techniques, current methods still face significant challenges that limit their practical utility. Many dehazing models trained on synthetic datasets struggle to perform well on real-world images due to the domain shift between synthetic and real atmospheric conditions4,5. These methods often fail to restore image quality effectively under varying environmental conditions, particularly in situations with dense fog or when dealing with dynamic scenes6. Additionally, many existing dehazing algorithms struggle with high computational costs, making them unsuitable for real-time applications7.
Existing dehazing methods, including those based on deep learning, have made substantial progress over the last decade2,8,9,10. Nevertheless, they exhibit several limitations. Many algorithms rely on assumptions that do not hold in complex atmospheric conditions, leading to poor restoration of visibility and color fidelity11. Dehazing methods often result in the loss of important details, which is particularly detrimental in applications such as object detection where precision is crucial.
To overcome existing limitations this paper proposes, Dehaze-Attention, an improved image dehazing model with the capability to handle variable densities of fog while preserving important structural information. The architecture combines convolutional layers and attention mechanisms to extract features from the input hazy image. The contributions of this research are as follows:
-
(I)
Implementation of multi-scale feature extraction using convolutional layers to extract visual features from hazy images across varying spatial scales. This provides the model with a robust, hierarchical representation of hazy image contents for more effective dehazing.
-
(II)
Implementation of a channel attention mechanism to focus on the most salient image features. This improves dehazing quality by reducing irrelevant features and information loss.
-
(III)
Integration of a multi-scale processing structure to capture both local details and global structures from hazy images. This multi-scale approach enhances the model’s ability to restore clarity across variable haze densities.
This paper is organized as follows. Section “Related studies” discusses related studies on image dehazing methods. Section “Dehaze-attention model for improved image dehazing” presents the Dehaze-Attention model and its components. Section “Experimental results and analysis” presents experimental results, comparisons with existing methods, and a detailed “Discussion” of findings. Section “Conclusion” concludes the paper with a summary of results and potential areas for future research.
Related studies
Dehazing techniques are essential in the field of image processing, particularly for enhancing the visibility of images captured in adverse weather conditions such as fog, smog, or mist. Image dehazing techniques have evolved significantly, driven by advancements in computational methods and the increasing need for clear visual data in various applications. The following sections provide a literature review of recent studies categorized by their primary focus and innovations in image dehazing.
Deep neural architectures for image dehazing
Recent deep learning-based approaches have demonstrated remarkable success in automatically learning the features and dynamics required for effective dehazing12,13,14,15. Notable models include DEA-Net8,16, DehazeNet10 and AOD-Net17 providing frameworks that directly learn the mapping from hazy to clear images. DehazeNet is designed to directly estimate the transmission map from hazy images using a deep neural network. It adopts a non-linear regression model that learns the relationship between hazy inputs and their corresponding transmission maps. This approach bypasses the need for explicit atmospheric light estimation, streamlining the dehazing process16.
AOD-Net employs a deep CNN takes a hazy image and a predefined Point Spread Function (PSF) as inputs to produce a clearer output image17. The network architecture consists of two main components: a multi-scale processing module and an adaptive deblurring module. The structure of AOD-Net is illustrated in Fig. 1 (with the left image showing the AOD-Net network structure and the right image depicting the K-value estimation module). The multi-scale processing module in AOD-Net addresses the issue of scale variability in haze density. The adaptive deblurring module dynamically adjusts its parameters based on the input image characteristics.

AOD-net network structure.
AOD-Net has the advantage of being lightweight and fast, making it suitable for real-time applications. It integrates the estimation of transmission and atmospheric light into a single process, improving the efficiency of the network17. Recent developments have also emphasized novel neural network architectures to enhance the performance of image dehazing. For instance, Dwivedi and Chakraborty18 proposed an extended local dark channel prior approach that computes the dark channel from all three RGB channels rather than a single channel. They demonstrated improved accuracy over state-of-the-art methods and deep learning models across synthetic and real-world datasets.
Attention mechanism for image dehazing
Attention mechanisms can be used to enhance feature learning in deep neural networks for image dehazing19,20. Attention allows models to focus on the most salient parts of an image by selectively emphasizing informative features and suppressing irrelevant ones9,21. This capability is crucial for handling the complex degradation characteristics of hazy images, where visibility can vary significantly across different regions22. Recent studies have shown that attention-based architectures yield substantial improvements in dehazing quality and efficiency. For instance, MixDehazeNet introduced by Lu et al. 10 integrates a Mix Structure Block Network that strategically prioritizes essential features for effective dehazing through a well-structured attention framework. Similarly, Cui et al. 9 designed the Enhanced Context Aggregation Network (ECANet), which utilizes both spatial and channel attention to extract discriminative features for dehazing. Furthermore, Zhang et al. 22 implemented attention blocks within a Dual Multi-Scale Dehazing Network to capture details and semantics.
The application of attention mechanisms extends beyond single-scale models to more complex multi-stage and multi-scale frameworks. For instance, Wang et al. 21,23 proposed Feature Decoupled Autoencoder which decomposes hazy images into feature representations and refines them using attention. Moreover, the Multistage Progressive Dehazing Network developed by Yin and Yang24 employs a strategy of cross-scale and cross-stage attention. This approach allows for the selective aggregation of complementary features, enhancing the network’s ability to reconstruct high-quality haze-free images from severely degraded inputs. Integrating multi-head attention mechanisms with advanced recurrent neural units were also shown to substantially enhance feature representation and robustness, especially under small-sample or noisy conditions25,26.
Other studies include Li et al. 27 who proposed FAPANet, a deep learning network that utilizes a Feature Attention Parallel Aggregation approach to recalibrate and enhance the most relevant features for image clarity. Guo et al. 28 proposed an image Dehazing Transformer that can handle large contexts and dense haze scenarios. Multiscale networks such as Multiscale Depth Fusion Networks and Dual Multi-Scale Dehazing Networks integrate multiple scales of processing to handle variations in haze density22,29. Furthermore, lightweight architectures such as Lightweight Dual-Attention Network and Shift Interactive Perception Network (SIP-Net) focus on efficient attention mechanisms for robust dehazing10,19. These approaches demonstrate the ongoing evolution in dehazing technology, merging traditional dehazing methods with modern computational techniques. Recent studies have further demonstrated the effectiveness of combining transformer-based attention mechanisms with convolutional neural network (CNN) for image restoration tasks, including super-resolution, leading to improved quantitative and perceptual outcomes30,31. These advancements highlight the dynamic capabilities of attention mechanisms in addressing the diverse challenges posed by image dehazing, paving the way for more robust and efficient dehazing solutions.
Generative adversarial networks (GANs) for image dehazing
GANs have emerged as a powerful tool for improving single-image dehazing by generating more realistic and visually appealing outputs. GANs are particularly good at recovering fine details and textures lost due to haze, leading to higher-quality restorations that are often indistinguishable from real, haze-free images32,33. GAN based methods typically consist of a generator that produces dehazed images and a discriminator that evaluates the quality of these images34,35. Recent GAN-based approaches have pushed the boundaries of image enhancement and restoration tasks related to adverse weather and lighting conditions. For instance, Bose et al.36 introduced LumiNet, a multispatial attention GAN designed for backlit image enhancement. Jaisurya and Mukherjee37 reported significant improvement by implementing an attention based GAN network for single image dehazing .
Despite their advantages, GAN-based approaches face several challenges. GANs require careful tuning of hyperparameters, such as learning rates and loss weightings, as well as a balanced training schedule to achieve optimal performance38. The training of GANs can be unstable and often leads to mode collapse where the generator produces limited varieties of outputs. Additionally, GANs require careful tuning of hyperparameters and training dynamics to achieve optimal results39. Recent advancements, such as Cycle-SNSPGAN, address this issue by introducing unsupervised learning strategies in an attempt to improve the generalization ability of dehazing models on real-world hazy images40. For instance, DehazeDNet41 incorporates CycleGAN into its framework to ensure the dehazing model not only translates images effectively but also respects the physical characteristics of haze.
Reinforcement learning for image dehazing
Reinforcement learning (RL) has been explored as a novel approach to adaptively select the processing steps required for dehazing based on the state of the input image. Unlike static models, RL allows for dynamic adaptation to varying degrees of haze, potentially providing customized dehazing that is optimized for each specific image. Yu et al. 42 proposed an RL-based framework which extends the DehazeNet model16 to a multi-scale architecture. This framework employs a multi-agent RL system where each pixel agent can select the most appropriate dehazing method for different regions of the image. In another study by Wang et al. 43, RL was applied to underwater image enhancement for object detection, demonstrating the flexibility of RL in configuring visual enhancement algorithms. Their approach used underwater image features as states and object detection score increments as rewards to train the RL agent.
Despite its potential, RL-based dehazing frameworks face several challenges. A significant limitation is the requirement for extensive training, as RL models must explore a wide range of states and actions to learn effective policies44. This process is computationally intensive and demands carefully curated datasets that reflect real-world haze conditions. Moreover, the design of the reward function is critical to the success of RL models. The reward must accurately represent the quality of dehazing to guide the agent’s learning process effectively. An improperly designed reward can lead to suboptimal policies or even degrade the model’s performance. For instance, Ye et al. 45 incorporated reinforcement learning into a low-quality image enhancement framework by designing a reward function based on object detection results. This approach bypassed the need for manual labeling and retraining and has demonstrated effectiveness in enhancing low-quality images, including foggy conditions. However, it underscored the sensitivity of RL models to the reward design and dataset variability.
Dehaze-attention model for improved image dehazing
This section discusses the dehaze-attention model, and the improvements made to the original AOD-Net architecture aimed at addressing its limitations. The proposed model particularly focuses on handling variable haze densities and preserving image details. The improved model features a multi-scale network structure, integrated advanced attention mechanisms, and an improved K-value estimation process. These enhancements are designed to improve the model’s efficiency and effectiveness in dehazing images under a broader range of atmospheric conditions, thereby increasing its applicability in critical areas. Major elements of the improved model are discussed as follows.
Multi-scale network structure
To handle the varying density and scale of haze across an image, a multi-scale processing approach is proposed. As shown in Fig. 2, the model incorporates both global and local scale analysis for robust dehazing.

Architecture of the Dehaze-attention model.
The specific implementation steps are as follows. First, the input is down-sampled to increase the receptive field and extract high-level features. The smaller scale input then passes through a compact K-value estimation module to analyze haze content. This module uses reduced 64 × 64 resolution and 6 channels to improve efficiency.
The initial K-values are used to produce a small dehazed image via the clean image generation module. Next, up-sampling restores the original resolution. Finally, this preprocessed result combines with the original input to feed into the base AOD-Net model for full-scale dehazing. This multi-scale approach allows global haze estimation through the down-sampled path, along with refined local dehazing on the original image.
Enhanced K-value estimation
The K-value estimation module is critical for assessing haze depth and density, which directly impacts dehazing accuracy. K-value is responsible for accurately estimating the depth and degree of fog. Thus, the accuracy of K-value estimation directly affects the quality and precision of the final dehazing outcome.

K-value estimation module.
As shown in Fig. 3, the redesigned module contains five convolutional layers with tailored filters. The filters vary in receptive field sizes, enabling multi-scale haze feature extraction. Small 3 × 3 kernels capture fine particulate haze, while larger 5 × 5 kernels handle dense fog areas. This multi-field approach allows a comprehensive analysis of the haze distribution. The improved K-value estimation approach provides clearer haze-free outputs across images with complex haze variations.
Integration of attention mechanism for effective feature learning
Haze effects are uneven, making certain inputs more valuable. Thus, in image dehazing, a model’s ability to focus on informative features while suppressing less relevant ones is critical. We integrate an attention mechanism to focus on the most informative features for dehazing. An attention mechanism allows the model to dynamically modulate its sensitivity to different input characteristics. Specifically, a squeeze-and-excitation (SE) module is added, as depicted in Fig. 4. We selected the SE module as the attention mechanism due to its simplicity and effectiveness in enhancing channel-wise feature representations with minimal computational cost46. This allows us to retain a lightweight model architecture, whereas more complex attention variants such as CBAM or Transformer-based attention were not adopted to preserve model efficiency.

SE channel attention structure.
The Squeeze operation reduces the dimensionality of the feature map, transforming it from a three-dimensional shape of C×H×W into a 1 × 1×C feature vector, which decreases the model’s computational load and the number of parameters in the feature map, making the module more efficient in learning and utilizing the relationships between different channels to enhance the model’s performance. The Excitation operation then converts the feature vector into a richer channel vector, assigning corresponding weights to each channel of the feature map. Finally, the weights are multiplied by the original feature map channels to obtain the final feature map information. The SE module is placed after initial feature extraction. This allows attention-driven refinement of subsequently processed representations to emphasize features most affected by haze.
Modified loss function
In image dehazing, the selection and modification of the loss function are crucial for training the model to generate clearer and more realistic images. This involves measuring the difference between the model’s predicted output and the actual dehazed image and minimizing this difference. Different loss functions affect how the algorithm processes various details in the image, such as contrast, brightness, and edges. In this study, we use a Multi-scale SSIM (MS-SSIM) loss function which decomposes the image at different scales. It then computes the SSIM metric at each scale, averaging these metrics to obtain a final similarity score47. The MS-SSIM loss function is defined by Eq. (1):
Combining the strengths of MS-SSIM and L1 loss functions, this study proposes a hybrid loss function to modify the original L2 loss function, defined as follows in Eq. (2):
Where \(\alpha\) is a scaling factor, based on multiple training rounds, an optimal value of 0.8 for\(~\alpha\) has been determined. This hybrid approach aims to retain color and brightness while effectively preserving texture and edge details in the image, addressing common issues of color shifts or dimming encountered in other loss functions.
Evaluation metrics
The effectiveness of the proposed dehazing model is evaluated using both subjective and objective methods. Subjective Evaluation involves visually inspecting the dehazed images, and assessing various aspects such as texture, contrast, saturation, and blurriness. The advantages of this method include its low threshold, requiring no specialized knowledge or experience, making it suitable for small datasets with significant color variations. However, its drawbacks include variability in evaluations by different observers, making quantification difficult, and slower evaluation speeds, rendering it unsuitable for large datasets. Objective evaluation calculates numerical values for each image using parameters such as Peak signal-to-noise ratio (PSNR)48 and Structural Similarity Index (SSIM)49, providing a direct assessment of the quality of a dehazed image. PSNR and SSIM are defined mathematically in Eqs. (3) and (5), evaluating image quality by assessing pixel errors and structural similarities, respectively. PSNR essentially measures the peak signal level of noise, with larger values indicating lower image distortion.
where MSE (Mean-Square Error) represents the mean squared error between the pixel values of two images.
The SSIM index primarily assesses three features of images: brightness, contrast, and structure, defined mathematically as follows:
where \(l\left( {x,y} \right)\) represents the luminance comparison function, \(c\left( {x,y} \right)\) represents the contrast comparison function, and \(s\left( {x,y} \right)\) represents the structure comparison function. The parameters \(\alpha\), \(\beta\), and \(\gamma\) represent the weights of different features in the SSIM index, and when all are set to 1, we have:
In general, both PSNR and MSE are used to assess image quality by evaluating the global size of pixel errors between the output and original images. A higher PSNR value indicates that the signal part of the image is more prominent relative to the noise, resulting in better image quality, while a lower MSE value indicates that the reconstructed image is closer to the original, thus also reflecting better quality.
Experimental results and analysis
Dataset description
We conduct experiments using synthesized hazy images derived from the UDTIRI dataset50, a widely used benchmark for aerial and atmospheric image processing. The dataset includes high-resolution aerial images captured under varying weather and lighting conditions. To simulate haze, a synthetic haze generation process was applied to clean images using Koschmieder’s model51. This approach introduces controlled levels of haze, enabling precise testing of the dehazing algorithm under diverse atmospheric conditions, including light haze, moderate haze, and dense haze. The haze synthesis process is governed by the Eq. (6):
Where I(x) is the observed hazy image, J(x) is the haze-free image, t(x) is the transmission map which simulates the haze density and A is the global atmospheric light. Haze in real-world scenarios can range from light (e.g., slight fog) to dense (e.g., heavy pollution or thick fog). Categorizing images ensures your model generalizes well across all these conditions. To simulate varying haze densities, we applied the following parameters for the transmission map t(x) and atmospheric light A, as illustrated in Table 1.
An example of the synthetic haze generation process is illustrated in Fig. 5. This systematic variation of transmission values ensures that the synthesized dataset covers a diverse range of haze densities. This dataset provides a comprehensive benchmark for comparing dehazing algorithms under controlled and challenging conditions. This allows robust evaluation of the proposed dehazing model.
Baseline setting
We use the following baseline methods to evaluate the Dehaze-Attention model’s performance on benchmark datasets.
-
(i)
AOD-Net17: An end-to-end CNN model that estimates transmission map and atmospheric light jointly. It utilizes normalized episodic training to handle varying haze densities. AOD-Net was chosen as it represents a standard end-to-end CNN baseline for the task.
-
(ii)
EDN-GTM52: An enhanced U-Net architecture utilizing spatial pyramid pooling, Swish activation function, and Dark Channel Prior (DCP). The modifications aim to improve feature extraction and restoration capability. EDN-GTM was selected as a baseline due to its utilization of U-Net architecture which is widely adopted for image restoration tasks.
-
(iii)
FFA-Net53: A multi-scale attention feature fusion network, employing attention mechanisms to focus on haze-relevant regions. It fuses features from different scales to handle varying haze densities. FFA-Net was included given its use of attention mechanisms, providing a relevant baseline for comparison with the proposed model’s attention modules.
Model training
The model was trained on the 600 training images from the UDTIRI dataset, while the 100 validation images were used for hyperparameter tuning, and the 300 testing images were reserved for performance evaluation. To enhance the model’s robustness and prevent overfitting, data augmentation techniques such as random cropping, flipping, and rotation were employed. These augmentations ensured better generalization across diverse image conditions.

Training and validation loss of dehaze-attention for light, moderate, and dense haze images.
The model was implemented in PyTorch using NVIDIA RTX 3090 GPU with 32GB RAM. The training process utilized the Adam optimizer with a learning rate of 0.0001, and a batch size of 16, and was conducted over 100 epochs to ensure convergence. To address the risk of overfitting on a relatively small dataset, we combined several strategies in addition to data augmentation. These include early stoppage based on validation loss, weight regularization (L2 penalty), and optimization of key hyperparameters through cross-validation54. The training also utilized a hybrid loss function that combines MS-SSIM and L1 loss, as defined in Eq. (2), to balance structural similarity and pixel-level accuracy. Figure 5 illustrates the training and validation losses of the Dehaze-Attention model across Light, Moderate, and Dense Haze conditions. The decreasing trend in both training and validation losses demonstrates the model’s ability to generalize well and minimize errors across different levels of haze intensity.
Results analysis
Quantitative performance comparison
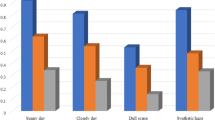
To evaluate the effectiveness of the proposed model, a comparative analysis was conducted using synthesized hazy images. The performance of the proposed model was quantitatively assessed using PSNR and SSIM indices. PSNR measures the peak signal-to-noise ratio between the dehazed image and the ground truth image, with higher values indicating better restoration quality. SSIM on the other hand evaluates the quality of dehazed images by measuring structural similarity to the ground truth based on pixel-wise differences55. The results of the Dehaze-Attention model are compared with the three baslines: AOD-Net, EDN-GTM52 and FFA-Net53. Table 2 presents the quantitative performance metrics across light, moderate, and dense haze conditions.
The comparison highlights the significant improvements achieved by the Dehaze-Attention model in handling variable haze densities. Table 2 presents the quantitative performance metrics across light, moderate, and dense haze conditions, demonstrating the superior performance of the proposed model in terms of both PSNR and SSIM.
Particularly, the Dehaze-Attention model demonstrated superior performance across all haze conditions, achieving a PSNR of 29.11 dB and an SSIM of 0.940 in light haze, 23.16 dB and 0.763 in moderate haze, and 21.47 dB and 0.681 in dense haze. These improvements indicate that the model’s attention mechanism and multi-scale feature extraction effectively focus on haze-relevant features while preserving structural details.In contrast, EDN-GTM, which employs spatial pyramid pooling and modifications to the U-Net architecture, achieves competitive results under light haze (PSNR = 27.27, SSIM = 0.925). FFA-Net and AOD-Net exhibit limited effectiveness in handling hazy images.
Analysis by haze condition
A visual comparison was performed to illustrate the enhancements in image quality by the Dehaze-Attention model compared to other baseline models across varying haze densities. In light haze conditions (Fig. 6), the Dehaze-Attention was able to recover more detailed textures and maintaining natural color fidelity compared to baseline models.

Visual comparison of light haze dehazing.
Similarly, for moderate (Fig. 7) and dense (Fig. 8) hazy condition, the Dehaze-Attention model demonstrated enhanced performance. It effectively reduces haze while preserving image details better than baseline models. Furthermore, these visual comparisons across all haze conditions provide a comprehensive view of each model’s capabilities. The Dehaze-Attention model consistently offers clearer, more detailed, and naturally colored images compared to the others. These visual results corroborate the quantitative data and highlight the effectiveness of the Dehaze-Attention model in handling various atmospheric disturbances.

Visual comparison of moderate haze dehazing.

Visual comparison of dense haze dehazing.
In addition to restoration quality, we evaluated the average inference time per image for each haze condition using an RTX 3090 GPU. The Dehaze-Attention model achieved average inference times of 113.49 ms for light haze, 5.26 ms for moderate haze, and 2.71 ms for dense haze. The variation in inference time is primarily due to differences in input image sizes across haze categories, with denser haze conditions requiring less time due to reduced visibility necessitating less image detail processing.
Ablation study
To evaluate the effects of individual components of the model architecture, an ablation study was conducted by selectively removing the multi-scale network structure, attention mechanism, and K-value improvements. This process was aimed at isolating and evaluating their individual effects on the model’s performance. The study was specifically conducted under light haze conditions to ensure a controlled complexity, allowing for clearer observation of how each component contributes under minimally challenging conditions. This approach also facilitates a baseline performance assessment, highlighting even subtle improvements attributable to each component without the overwhelming effects of dense haze. The results of the ablation study are summarized in Table 3.
The results demonstrate the significance of each component in enhancing the dehazing process. Particularly, the absence of the multi-scale network resulted in a PSNR decrease to 19.51 dB and SSIM to 0.492. This highlights the critical role of the multi-scale network in capturing features at multiple resolutions to handle complex haze patterns effectively. Similarly, the absence of the attention mechanism results in a PSNR dropping to 21.76 dB and SSIM to 0.521, emphasizing its importance in focusing on critical regions of the image, such as densely hazed areas. The exclusion of K-value enhancements, which adjust key parameters within the model, had a comparatively smaller impact, indicating their supportive rather than critical role in the dehazing process. These findings reinforce that the multi-scale network and attention mechanism are pivotal for the model’s success in dehazing under varied conditions.
Discussion
The experimental results demonstrate that the proposed Dehaze-attention model significantly outperforms existing dehazing methods in both objective and subjective evaluations. The model consistently outperformed across a wide range of metrics, which demonstrates its ability to address the limitations of traditional approaches. One of the key strengths of the proposed model lies in its robustness to haze density. The integration of a multi-scale network structure allows the model to address varying haze densities, from light to dense, by performing both global and local haze estimation. This ensures that the model maintains high dehazing performance regardless of the atmospheric conditions, producing images that are clear and natural-looking.
Another critical improvement is the model’s enhanced feature learning capability, enabled by the integration of an attention mechanism. This mechanism allows the model to focus on haze-affected regions and prioritize the most informative features, leading to enhanced image quality. The attention mechanism ensures better preservation of fine details, sharper edges, and improved contrast in dehazed images. The redesigned K-value estimation module further contributes to the model’s performance by accurately estimating haze depth and density. Its multi-scale convolutional layers capture fine and coarse haze features, enabling precise haze removal across diverse conditions. Additionally, the use of a hybrid loss function, which combines Mean Structural Similarity (MS-SSIM) and L1 loss, further enhances the model’s ability to preserve global structures while refining local details. This balance ensures that the dehazed images are not only visually appealing but also structurally accurate, making the proposed model a significant advancement in image dehazing. Furthermore, the ablation study demonstrated the importance of the multi-scale network, attention mechanism, and K-value estimation in achieving the observed performance improvements, providing valuable insights into the design of advanced dehazing architectures.
Theoretical contribution
This study makes several theoretical contributions. It introduces a novel theoretical framework that integrates attention mechanisms and multi-scale features to address the problem of robust image dehazing under variable atmospheric conditions. This framework not only consolidates existing dehazing techniques but also opens new avenues for theoretical exploration in image restoration56. Our framework provides a comprehensive theoretical understanding of how attention and multi-scale processing can be effectively harnessed to manage diverse haze densities. It offers insights that challenge existing dehazing models and pave the way for further theoretical refinement. Moreover, the incorporation of attention mechanisms into dehazing architecture not only enriches current discussions on role of attention mechanisms but also guides future research in image processing domain.
Practical implications
The proposed image dehazing algorithm has significant practical implications across diverse fields, including aerial imaging, autonomous vehicles, surveillance, remote sensing and medical diagnosis. These sectors depend on high quality, clear images for optimal performance, making the presence of haze detrimental to their operations. Images captured under hazy conditions contain atmospheric particles such as aerosols and molecules, which diminish visibility and impact the effectiveness of these applications. For instance, surveillance videos recorded in hazy weather exhibit reduced clarity, hampering investigative efforts. Similarly, in transportation, hazy conditions lead to poor visibility for drivers, increasing the risk of accidents. Improving visibility in hazy conditions enhances safety for drivers and reduces perceptual errors.
In remote sensing, the algorithm preprocesses satellite and aerial imagery to reduce visual distortions caused by atmospheric haze, thereby enhancing the accuracy of data used in environmental monitoring and land surveying. For medical imaging, particularly in procedures such as endoscopy, haze removal restores clarity to images, significantly aiding in more accurate diagnosis and better patient outcomes.
Moreover, the model can also be incorporated into consumer devices such as digital cameras and smartphones to improve photo quality under hazy conditions for everyday users. Additionally, in the entertainment industry, the ability to selectively remove haze in post-production offers filmmakers and visual artists new creative freedoms to enhance the visual appeal of their works without the need for extensive manual adjustments.
Limitations and future work
Although the proposed Dehaze-attention model demonstrates significant advancements in image dehazing, it is not without its limitations. One of the primary constraints is its susceptibility to extremely variable atmospheric conditions, where the presence of very dense or unevenly distributed fog can affect its performance. The model’s reliance on certain preset parameters, which are optimized for average haze conditions, may not be as effective in these extreme scenarios. Moreover, while the model excels in handling typical haze situations, its adaptability to other forms of atmospheric disturbances, like smog or mist, which might have different particulate compositions and behaviors, has not been thoroughly explored.
To these limitations, future research should focus on several strategic areas. Firstly, developing adaptive algorithms that dynamically adjust parameters based on real-time atmospheric assessments would ensure the model maintains high performance under extreme and variable conditions. Secondly, it is important to broaden testing conditions. Extending model testing to encompass a wider range of atmospheric disturbances could help evaluate and potentially broaden the model’s applicability. Lastly, integrating the dehazing model with other technologies, such as predictive weather modeling tools, could lead to the creation of a more robust system. Such a system would be capable of making proactive adjustments based on predicted environmental changes, thereby enhancing overall performance and utility in diverse operational contexts.
Conclusion
This study presented Dehaze-Attention model, an advanced deep learning framework for image dehazing for efficient image dehazing. Evaluated using the synthesized hazy images from the UDTIRI dataset, the model demonstrated superior performance, supported by robust quantitative metrics and qualitative evaluations. The enhancements in performance are attributed to several key innovations: a multi-scale network structure that effectively handles varying haze densities, an attention mechanism that sharpens focus on critical regions, and a redesigned K-value estimation module for precise haze depth analysis. These features collectively enable the production of clearer, more detailed, and natural-looking images.
The findings of this study highlight the versatility and effectiveness of the Dehaze-Attention model for a wide range of applications, including aerial imaging, autonomous vehicles, and remote sensing. The model’s robustness to diverse haze densities and its ability to preserve fine details and natural colors make it a significant contribution to the field of image dehazing. However, there is still room for further exploration. Future research should focus on reducing computational complexity to enable real-time deployment of low-power devices. Additionally, semi-supervised learning approaches to reduce dependence on synthesized data and improve generalization to real-world scenarios should be investigated.
Data availability
The ground truth image datasets used and analyzed in this study are available from the following URLs: [https://www.kaggle.com/datasets/jiahangli617/udtiri](https:/www.kaggle.com/datasets/jiahangli617/udtiri) and [https://udtiri.com/](https:/udtiri.com) . The implementation codes can be requested from the corresponding author and will be provided upon reasonable request.
References
Song, Y., He, Z., Qian, H. & Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 32, 1927–1941 (2023).
Wang, X. et al. A modified atmospheric scattering model and degradation image clarification algorithm for haze environments. Opt. Commun. 560, 130489 (2024).
Ahmed, M. et al. Vision-Based autonomous navigation for unmanned surface vessel in extreme marine conditions. In 2023 IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS). 7097-7103 (2023). https://doi.org/10.1109/IROS55552.2023.10341867.
Yu, H. et al. ACM, Lisboa Portugal, source-free domain adaptation for real-world image Dehazing. In Proceedings of the 30th ACM International Conference on Multimedia 6645–6654 (2022). https://doi.org/10.1145/3503161.3548410.
Yang, A. et al. Visual-quality-driven unsupervised image dehazing. Neural Netw. 167, 1–9 (2023).
Wang, X. et al. Decoupling degradation and content processing for adverse weather image restoration (2023). https://doi.org/10.48550/arXiv.2312.05006.
Agrawal, S. C. & Jalal, A. S. A comprehensive review on analysis and implementation of recent image dehazing methods. Arch. Computat. Methods Eng. 29, 4799–4850 (2022).
Chen, Z., He, Z. & Lu, Z. M. DEA-Net: single image dehazing based on Detail-Enhanced Convolution and Content-Guided attention. IEEE Trans. Image Process. 33, 1002–1015 (2024).
Cui, Z. et al. ECANet: enhanced context aggregation network for single image dehazing. SIViP 17, 471–479 (2023).
Lu, L., Xiong, Q., Xu, B. & Chu, D. MixDehazeNet mix structure block for image dehazing network. In International Joint Conference on Neural Networks (IJCNN) 1–10 (2024). https://doi.org/10.1109/IJCNN60899.2024.10651326.
Liu, P. J. Enhance dehazed images rapidly without losing restoration accuracy. IEEE Access. 12, 40795–40808 (2024).
Frants, V., Agaian, S. & Panetta, K. QCNN-H: Single-Image dehazing using quaternion neural networks. IEEE Trans. Cybernetics. 53, 5448–5458 (2023).
Song, Y., Li, J., Wang, X. & Chen, X. Single image dehazing using ranking convolutional neural network. IEEE Trans. Multimedia. 20, 1548–1560 (2018).
Ma, Q., Wang, S., Yang, G., Chen, C. & Yu, T. A novel bi-stream network for image dehazing. Eng. Appl. Artif. Intell. 136, 108933 (2024).
Liu, X., Chau, K. Y., Zheng, J., Deng, D. & Tang, Y. M. Artificial intelligence approach for detecting and classifying abnormal behaviour in older adults using wearable sensors. J. Rehabilitation Assist. Technol. Eng. https://doi.org/10.1177/20556683241288459 (2024).
Cai, B., Xu, X., Jia, K., Qing, C. & Tao, D. DehazeNet: an end-to-end system for single image haze removal (2016). https://doi.org/10.48550/arXiv.1601.07661.
Li, B., Peng, X., Wang, Z., Xu, J. & Feng, D. AOD-Net: all-in-one dehazing network. In IEEE International Conference on Computer Vision (ICCV) 4780–4788 (2017). https://doi.org/10.1109/ICCV.2017.511.
Dwivedi, P. & Chakraborty, S. Single image dehazing using extended local dark channel prior. Image Vis. Comput. 136, 104747 (2023).
Hua, Z., Hua, Z., Li, J. & LWDA-Net a lightweight dual-attention network for single image dehazing. In 4th International Conference on Neural Networks, Information and Communication (NNICE) 415–420 (IEEE, 2024). https://doi.org/10.1109/NNICE61279.2024.10499091.
Ren, D., Li, J., Han, M. & Shu, M. DNANet dense nested attention network for single image dehazing. In ICASSP –2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2035–2039 (IEEE, 2021). https://doi.org/10.1109/ICASSP39728.2021.9414179.
Wang, N., Cui, Z., Su, Y. & Li, A. RGNAM: recurrent grid network with an attention mechanism for single-image dehazing. J. Electron. Imag 30, 1452 (2021).
Zhang, S., Zhang, X. & Shen, L. Dual Multi-Scale dehazing network. IEEE Access. 11, 84699–84708 (2023).
Wang, J., Wang, F. & Yin, D. Feature decoupled autoencoder: semi-supervised learning for image dehazing. In IEEE International Conference on Multimedia and Expo (ICME) 01–06 (IEEE, 2022). https://doi.org/10.1109/ICME52920.2022.9859652.
Yin, H. & Yang, P. Multistage progressive single-Image dehazing network with feature physics model. IEEE Trans. Instrum. Meas. 73, 1–12 (2024).
Chen, L. et al. IWOA-Optimized deep learning for bearing fault diagnosis under noisy and variable conditions. IEEE Trans. Instrum. Meas. 74, 1–18 (2025).
Chen, L. et al. Siamese CNN-BiMGRU integrating multihead attention mechanism and its application to multipart covers fault detection under small-scale samples condition. Struct. Health Monit. 2025, 14759217251370360. https://doi.org/10.1177/14759217251370360 (2025).
Li, C., He, Y. & Li, X. Feature attention parallel aggregation network for single image haze removal. IEEE Access. 10, 15322–15335 (2022).
Guo, C. et al. Image dehazing transformer with transmission-aware 3D position embedding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 5802–5810 (IEEE, 2022). https://doi.org/10.1109/CVPR52688.2022.00572.
Yin, X., Tu, G. & Chen, Q. Multiscale depth fusion with contextual hybrid enhancement network for image dehazing. IEEE Trans. Instrum. Meas. 72, 1–12 (2023).
Talreja, J., Aramvith, S. & Onoye, T. D. H. T. C. U. N. Deep hybrid transformer CNN U network for Single-Image Super-Resolution. IEEE Access. 12, 122624–122641 (2024).
Talreja, J., Aramvith, S. & Onoye, T. X. T. N. S. R. Xception-based transformer network for single image super resolution. Complex. Intell. Syst. 11, 162 (2025).
Su, Y. Z. et al. Prior guided conditional generative adversarial network for single image dehazing. Neurocomputing 423, 620–638 (2021).
Kolekar, M. H., Bose, S. & Pai, A. SARain-GAN: Spatial attention residual UNet based conditional generative adversarial network for rain streak removal. IEEE Access. 12, 43874–43888 (2024).
Goodfellow, I. et al. Generative adversarial nets. In Advances in Neural Information Processing Systems vol. 27 (Curran Associates, Inc., 2014).
Manu, C. M. & Sreeni, K. G. GANID: a novel generative adversarial network for image dehazing. Vis. Comput. 39, 3923–3936 (2023).
Bose, S., Nawale, S., Khut, D. & Kolekar, M. H. LumiNet: multispatial attention generative adversarial network for backlit image enhancement. IEEE Trans. Instrum. Meas. 72, 1–14 (2023).
Jaisurya, R. S. & Mukherjee, S. AGLC-GAN Attention-based global-local cycle-consistent generative adversarial networks for unpaired single image dehazing. Image Vis. Comput. 140, 104859 (2023).
Arjovsky, M., Chintala, S., Bottou, L. & Wasserstein, G. A. N. (2017). https://doi.org/10.48550/arXiv.1701.07875.
Dong, Y., Liu, Y., Zhang, H., Chen, S. & Qiao, Y. FD-GAN: generative adversarial networks with fusion-discriminator for single image dehazing (2021). https://doi.org/10.48550/arXiv.2001.06968.
Wang, Y. et al. Cycle-SNSPGAN: towards Real-World image dehazing via cycle spectral normalized soft likelihood Estimation patch GAN. IEEE Trans. Intell. Transp. Syst. 23, 20368–20382 (2022).
Rupesh, G., Singh, N. & Divya, T. DehazeDNet: image dehazing via depth evaluation. SIViP 18, 9387–9395 (2024).
Yu, J., Liang, D., Hang, B. & Gao, H. Aerial image dehazing using reinforcement learning. Remote Sens. 14, 5998 (2022).
Wang, H., Sun, S., Bai, X., Wang, J. & Ren, P. A reinforcement learning paradigm of configuring visual enhancement for object detection in underwater scenes. IEEE J. Oceanic Eng. 48, 443–461 (2023).
Guo, T. & Monga, V. Reinforced depth-aware deep learning for single image dehazing. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 8891–8895 (2020). https://doi.org/10.1109/ICASSP40776.2020.9054504.
Ye, J., Wu, Y. & Peng, D. Low-quality image object detection based on reinforcement learning adaptive enhancement. Pattern Recognit. Lett. 182, 67–75 (2024).
Zeng, C. et al. Squeeze-and-Excitation Self-Attention mechanism enhanced digital audio source recognition based on transfer learning. Circuits Syst. Signal. Process. 44, 480–512 (2025).
Wang, Z., Simoncelli, E. P. & Bovik, A. C. Multiscale structural similarity for image quality assessment. In The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003 1398–1402 (2003). https://doi.org/10.1109/ACSSC.2003.1292216.
Cheng, S. & Yang, B. An efficient single image dehazing algorithm based on transmission map Estimation with image fusion. Eng. Sci. Technol. Int. J. 35, 101190 (2022).
Bakurov, I., Buzzelli, M., Schettini, R., Castelli, M. & Vanneschi, L. Structural similarity index (SSIM) revisited: a data-driven approach. Expert Syst. Appl. 189, 116087 (2022).
Guo, S. et al. UDTIRI: An Online Open-Source Intelligent Road Inspection Benchmark Suite (2024). https://doi.org/10.48550/arXiv.2304.08842.
Kar, A., Dhara, S. K., Sen, D. & Biswas, P. K. Zero-Shot single image restoration through controlled perturbation of koschmieder’s model. Vis. Comput. 2021, 16205–16215 (2021).
Tran, L. A. & Park, D. C. Encoder-decoder networks with guided transmission map for effective image dehazing. Vis. Comput. https://doi.org/10.1007/s00371-024-03330-5 (2024).
Qin, X., Wang, Z., Bai, Y., Xie, X. & Jia, H. FFA-Net: feature fusion attention network for single image dehazing. Proc. AAAI Conf. Artif. Intell. 34, 11908–11915 (2020).
Moradi, R., Berangi, R. & Minaei, B. A survey of regularization strategies for deep models. Artif. Intell. Rev. 53, 3947–3986 (2020).
Li, S., Lin, J., Yang, X., Ma, J. & Chen, Y. BPFD-Net: enhanced dehazing model based on Pix2pix framework for single image. Mach. Vis. Appl. 32, 124 (2021).
Goyal, B. et al. Recent advances in image dehazing: formal analysis to automated approaches. Inform. Fusion. 104, 102151 (2024).
Acknowledgements
This work was funded by a project under the Research Matching Grant Scheme: Smart Space - Intelligent Smart Cities Management and IoT Analytics Platform (Project Code: 700007). The authors would also like to acknowledge the support from the Innovation and Technology Fund (ITF) of Hong Kong Special Administrative Region, China (Ref.: ITS/123/21FP).
Author information
Authors and Affiliations
Contributions
Conceptualization, Hao Huang and Yuk Ming Tang; methodology, Hao Huang and Yuk Ming Tang; validation, GTS Ho, MW Geda, and Minghao Li; formal analysis, Hao Huang; investigation, Hao Huang; resources, Hao Huang; data curation, MW Geda; writing—original, draft preparation, Hao Huang; visualization, Minghao Li; writing-review and editing, GTS Ho and MW Geda; supervision, Yuk Ming Tang; project administration, Minghao Li.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huang, H., Ho, G.T.S., Geda, M.W. et al. Dehaze-attention: enhancing image dehazing with a multi-scale, attention-based deep learning framework. Sci Rep 15, 44191 (2025). https://doi.org/10.1038/s41598-025-27959-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27959-x
