
Abstract
Accurately predicting the unconfined compressive strength (UCS) of microsilica-lime stabilized sulfate sand (MSLSS) is critical for the safe and efficient design of infrastructure in arid regions, yet it remains challenging due to the highly nonlinear relationships among influencing factors. This study pioneers the development of hybrid machine learning (ML) models, integrating the Sparrow Search Algorithm (SSA) with XGBoost (XGB), Random Forest, and Decision Tree, for predicting UCS of MSLSS. These models were trained and tested on experimental datasets incorporating input variables: lime content, microsilica content, curing days, curing condition, optimum moisture content (OMC), and maximum dry density. Comprehensive performance evaluation using metrics such as R2, MAE, MSE, and MRE demonstrated that SSA optimization markedly enhanced the predictive accuracy and generalization capability of all base models, with the RF model exhibiting the most substantial improvement. The hybrid XGB-SSA model achieved the highest overall predictive accuracy, yielding excellent performance on the testing set (R2 = 0.982, MAE = 1.358). The standard XGB model also displayed competitive results, presenting a practical alternative when model complexity is a concern. SHAP-based interpretability analysis revealed OMC and microsilica content as the most influential input variables. This study provides valuable support for geotechnical design and engineering applications in relevant contexts.
Similar content being viewed by others

Introduction
Stabilization techniques for sulfate sand subgrade materials are becoming increasingly crucial for transportation infrastructures in desert and arid regions across countries along the Belt and Road such as China, Iran, and Saudi Arabia, etc.1,2. In cases of sulfate sand, traditional calcium-based stabilizers (cement and lime) would react with sulfates and generate ettringite minerals, causing significant volumetric expansion during hydration and bring heaving and cracking of subgrades3,4,5,6. Additionally, the production of cement also arouses increasing concerns in terms of high energy consumption, carbon emission, and environmental risk7,8. microsilica, a by-product of silicon metal production, poses significant risks to human health and the environment if not handled properly. Recently, the combination of microsilica and lime as mixed stabilizers has shown promise for sulfate soil stabilization9,10,11,12,13,14,15,16. By mixing microsilica and lime in the presence of water, the environmental pH value increases and the active silica reacts with calcium hydroxide, forming calcium silicate hydrated gels17,18 and results in better performance of microsilica-lime stabilized sulfate sand (MSLSS), with high strength and less hydration expansion.
Despite this potential, accurately modeling the relationships between the strength of MSLSS and its multiple influencing factors remains a challenge hindering its broader application. The mechanical properties of MSLSS are governed by several key factors, including the proportions of lime and microsilica, curing age, and compaction conditions, etc.19,20. A thorough understanding of the relationship between them is essential for advancing the utilization of MSLSS. Conventional laboratory testing provides a direct approach but is time-intensive and costly, especially for this multi-variable system. On the other hand, the accuracy capability of conventional empirical formula by regression analyses becomes doubtful as regression coefficients increasingly introduced to mimic the highly nonlinear relationship. As a result, it is imperative to propose a method with high robustness, accuracy and generalization capabilities in predicting the mechanical properties of MSLSS.
In recent years, machine learning (ML) has emerged as a transformative tool in civil engineering, enabling data-driven modeling of complex material behaviors and geotechnical properties that are otherwise challenging to characterize using traditional empirical or physical approaches21,22. The application of ML techniques has demonstrated remarkable success in predicting mechanical properties such as unconfined compressive strength (UCS), stiffness, permeability, and liquefaction potential of soils and construction materials23,24,25,26,27,28,29. For instance, Jas et al.30 developed an explainable ML model using LightGBM and SHAP analysis to evaluate liquefaction potential in gravelly soils, achieving a balance between accuracy and interpretability, while Kang et al.31 integrated Lattice Boltzmann Methods with ML algorithms to predict permeability in porous media, reporting R2 values exceeding 0.9. In the realm of strength prediction, Nasiri et al.32 employed SHAP-based explainable AI to model UCS and Young’s modulus of rocks, emphasizing model transparency, and Nawaz et al.33,34 used Gene Expression Programming (GEP) and ANN to estimate UCS and stiffness modulus in clayey soils, achieving high accuracy (R2 up to 0.98) through sensitivity analysis. Similarly, Zhang et al.35 applied Extreme Gradient Boosting (XGBoost) to predict compressive strength of cement-stabilized soft soil, identifying key features such as cement content and curing age. Further advancing the field, Khawaja et al.36 compared GEP, ANN, and Multi-Expression Programming for predicting resilient modulus of subgrade soil, while Jafri et al.37 used GEP to model rock cutting performance. Moreover, recent works by Sun et al.38 and Yao et al.39 have optimized alkali-activated concrete and solid waste-cement stabilized soils using Random Forest and XGBoost models, respectively, further reinforcing the potential of ML in sustainable construction practices. These advancements collectively illustrate the superiority of single ML models over conventional empirical formulas, particularly in handling nonlinearity and high-dimensional interactions, paving the way for more reliable and efficient engineering solutions.
A common drawback of ML approaches is that researchers often either dedicate substantial time to manually adjusting hyperparameters or rely on default settings, which may be far from optimal40. To address this, scholars are increasingly leveraging intelligent optimization algorithms (sparrow search algorithm41, genetic algorithm42, whale optimization algorithm43, particle swarm optimization44, grey wolf optimizer45, Artificial bee colony46, etc.) to optimize ML model hyperparameters during training and improve prediction accuracy. Among them, the sparrow search algorithm (SSA), a biologically inspired heuristic approach, has an edge of simple structure, fast speed, and strong search ability, leading to its extensive application in optimization tasks47,48. Recently, some scholars have successfully applied the SSA optimization model to hydrological management and disaster prevention. Liu et al.49, Hu et al.50 and Song et al.51 successfully produced groundwater potentiality prediction and water quality prediction by hybrid artificial intelligence methods, integrating SSA with machine learning methods. Zheng et al.52, Shui et al.53, and Wang et al.54 adopted SSA to optimize ML models for slope stability prediction.
Despite these advances, the prediction of strength in stabilized sulfate-rich soils, a critical concern for infrastructure development in arid regions, remains underexplored. The complex physicochemical interactions between lime, microsilica, and sulfate sands present challenges for conventional modeling approaches. Notably, the potential of SSA-optimized hybrid machine learning models for predicting geotechnical properties of MSLSS represents a significant research gap. This study addresses this void by pioneering the integration of metaheuristic optimization with interpretable ML frameworks, ultimately contributing to intelligent, data-informed geotechnical design for sustainable infrastructure.
To achieve this goal, hybrid prediction models with hyperparameters tuned by the sparrow search algorithm are developed for predicting the unconfined compressive strength (UCS) of MSLSS. Firstly, a dataset containing the results of compaction test and UCS test of MSLSS was collected. Secondly, six ML models were proposed and evaluated: three hybrid models (XGB-SSA, RF-SSA, DT-SSA) and their corresponding single models (XGB, RF, DT). During model training, the hyperparameters of the hybrid models were optimized using SSA, while the single models used default settings. Model performance was assessed using indicators including R2, MAE, MSE, and MRE. This study represents the first application of hybrid ML models optimized by SSA to forecast the UCS of MSLSS, contributing to the advancement of ML applications in soil modification.
Methodology
Methodology conception
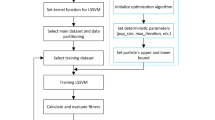
Figure 1 illustrates the methodology flowchart for developing both hybrid ML models integrated with SSA and single ML models. The main steps of the prediction model development are as follows:
-
(1)
A dataset containing experimental UCS data for MSLSS was compiled from the literature9,20. Initial exploratory data analysis included generating scatter plots and calculating Pearson correlation coefficients to investigate relationships between variables.
-
(2)
Data splitting and normalization. For hybrid prediction models, the dataset was partitioned into a training set (70%), a validation set (10%), and a testing set (20%). For single models, the dataset was partitioned into a training set (80%) and a testing set (20%).
-
(3)
Models training. For the hybrid models, the base ML models (XGB, RF, DT) were initially trained using the training set. Subsequently, the validation set was input into these preliminarily trained models under different hyperparameter configurations. For the single models, the models were trained directly using the training set with their default hyperparameter settings.
-
(4)
Models validating. The testing set was used to evaluate the predictive accuracy and generalization capabilities of the final models.

Methodology flowchart.
Data collection and analysis
The experimental dataset utilized in this study, comprising a total of 96 data points, was sourced from the work of Ghorbani et al.9 and Karimi et al.20, specifically focusing on the UCS of MSLSS. The dataset encompasses key parameters influencing UCS, including lime content (L), microsilica content (MS), curing days (CD), curing condition (CC), optimum moisture content (OMC), and maximum dry density (MDD).
In this work, these six parameters are considered independent variables, while UCS is the response variable. Table 1 outlines the statistical distribution of each input and output variable within the compiled databank. Scatter plots depicting the relationships between each input variable and UCS, along with linear fit lines, are presented in Fig. 2. The scatter plots indicate a positive correlation between UCS and L, MS, and OMC, while a negative correlation is observed with MDD. Notably, all variables exhibit considerable dispersion, suggesting inherent randomness and complex, potentially nonlinear, interrelationships. This complexity precludes accurate description using conventional polynomial models, motivating the use of ML approaches.

Scatter plots of input variables versus output UCS: (a) L-UCS; (b) MS-UCS; (c) CC-UCS; (d) CD-UCS; (e) OMC-UCS; (f) MDD-UCS.
Figure 3 depicts the Pearson correlation matrix, with blue and red hues denoting negative and positive coefficients, respectively. The input variables exhibit two striking relationships: OMC-L (PCC = 0.91) and MDD-MS (PCC = – 0.91). The simultaneous rise in OMC and fall in MDD originates from the intrinsically lower bulk densities and higher hydrophilicity of microsilica and lime. The incorporation of microsilica and lime dilutes the overall matrix density, directly reducing MDD, while their affinity for water elevates the water demand during compaction, increasing OMC. Despite reducing density and increasing water content, microsilica and lime act as effective cementitious agents: after compaction, their pozzolanic reactions stiffen the soil skeleton55,56. This results in a counterintuitive negative relationship between MDD and UCS, alongside significant positive correlations of UCS with OMC (PCC = 0.65) and with L (PCC = 0.62).

Matrix of Pearson correlation coefficient for all variables.
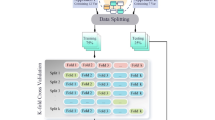
Data splitting and normalization
To mitigate overfitting risks, we employed a combination of cross-validation techniques and learning curve analysis. The dataset is split into five folds. Each fold in turn serves as the testing set while the remaining four folds are used for training and validating, yielding five training-validation runs. Specifically, the dataset was partitioned into training (70%), validation (10%), and testing (20%) sets for hybrid models, and training (80%) and testing (20%) sets for single models, using systematic sampling to maintain data distribution consistency. The final performance is reported as the average of the five validation results.
Prior to model training, all input variables were normalized to the interval [0, 1]. This preprocessing step ensures uniform influence of each feature on the predicted response and significantly accelerates the convergence and enhances the numerical stability of the subsequent iterative optimization process.
Machine learning models
The DT model is a supervised ML model commonly used for classification and regression. It is structured as a tree, where leaves represent outcomes (predicted values) and branches represent decision rules leading to those outcomes57. The DT model is characterized in nature by nonlinearity and is easy to interpret and visualize. Its drawback that needs attention is its proneness to overfitting, especially since the tree-growth is without constraints.
The RT model is a widely used ensemble ML method that integrates multiple DTs. Figure 4 presents a schematic of the RF model. To enhance precision and efficiency, each DT is trained independently on a distinct bootstrap sample (with replacement) of the training data58. The final outcome is determined from the average or most-voted results of each DT, and the problems of overfitting and noisy or outlier data points can be mitigated by aggregating the results of these multiple DTs. RF also excels at handling high-dimensional data without requiring dimensionality reduction. Due to its robustness and versatility, RF is one of the most commonly used ML methods.

Schematic representation of RF model.
The XGB model is a typical ensemble ML method derived from traditional GBDT methodology, which integrates gradient-boosting techniques to achieve more precise final predictions59. The model schematic map of XGB is illustrated in Fig. 5. As shown in this figure, XGB can minimize loss function by sequentially training DT based on the residual between the predicted- and measured- value of the previous DT. Through multiple iterations, the accuracy of the XGB model was progressively enhanced. The results of each DT are weighted for the final prediction result. This sequential learning approach enables XGB to effectively model complex data relationships, enhancing both performance and generalizability.

Schematic representation of XGB model.
Optimization algorithm
The SSA is a novel meta-heuristic optimization algorithm taking inspiration from the hunting and anti-predation behavior of sparrows40. It operates independently of gradient information, boasts excellent parallel processing capabilities, and achieves convergence at a rapid pace. In this study, SSA was used in this study to optimize the parameters of ML models.
The process of constructing the optimization model based on SSA is presented as follows;
-
(1)
Initialize sparrow population, iterations, and proportion of finders and followers. Calculate and sort the fitness of all sparrows.
-
(2)
Update the position of finders. Finders (typically 10%-20% of the population), responsible for scouting food sources, update their positions according to:
$$X_{nd}^{g + 1} =_{{}} \left\{ {\begin{array}{*{20}c} {X_{nd}^{g} \cdot \exp (\frac{ - n}{{\alpha \cdot g_{\max } }}), \, R_{2} < ST} \\ {X_{nd}^{g} + Q \cdot L, \, R_{2} \ge ST} \\ \end{array} } \right.$$(1)
where g and \(g_{\max }\) denotes the present number of iterations and the maximum iteration, respectively;\(X_{n,d}^{g}\) represents the d-th dimension of the n-th sparrow in the present iteration; \(R_{2}\) and ST denotes the alarm value and the threshold for triggering the alarm.
Update the position of followers. Followers (the remaining population) update their positions by moving towards the finders:
where \(X_{p}^{g}\) denotes the optimal position occupied by the finder, \(X_{{{\text{worst}}}}^{g}\) indicates global worst position; \(A^{ + }\) is a matrix in which each element is randomly assigned as 1 or -1.
The formula for the sparrows that are randomly chosen to exhibit scouting and warning behaviors is:
where \(X_{best}^{g}\) signifies the best position; β is a parameter controlling step size; \(f_{n}\) refers to the present fitness-value, \(f_{g}\), and \(f_{w}\) refers to the fitness values of the best and worst position.
Performance evaluation
To evaluate the performance of the hybrid model and other models, several statistical metrics were utilized, including mean squared error (MSE), R-squared (R2), mean absolute error (MAE), and mean relative error (MRE). In regression analysis, R2 quantifies the proportion of variance explained by the model, while metrics such as MAE, MSE, and MRE provide complementary measures of prediction error magnitude60. The formulas for these metrics are:
where, \(y_{i}\), \(y_{ip}\) and \(\overline{y}_{i}\) represents the tested-, predicted-, and mean-value of UCS for MSLSS, respectively. In present work, a comprehensive ranking method was utilized for model performance evaluation61,62.
where score represents the average performance of the model, m represents the number of performance indicators, and \(Rank_{i}\) is the ranking of each model based on the performance indicators.
Results and discussion
Three hybrid ML models and their single counterparts were utilized to capture the intricate, nonlinear correlations between the UCS of MSLSS and its significant influencing factors (i.e., L, MS, CD, CC, OMC, MDD). To assess the efficacy of the hybrid models, the predictions of the hybrid models (XGB-SSA, DT-SSA, RF-SSA), the models without hyperparameter optimization (XGB, DT, RF), and conventional empirical models were thoroughly compared and evaluated. Two empirical formulas (EF) were also evaluated. Similar to ML model training, 80% of the experimental data were used as the training set for regression analysis, yielding the following formulas:
Empirical formula (I):
Empirical formula (II):
Construction of hybrid models
ML models are often initially trained using default hyperparameter values, which frequently lead to suboptimal performance. To enhance results, SSA was employed to iteratively update the models by minimizing the mean MAE from fivefold cross-validation, thereby searching for optimal hyperparameters. The iteration curves for the SSA-hybridized ML models are shown in Fig. 6. Table 2 presents the optimal parameters for each hybrid ML model (XGB-SSA, DT-SSA, RF-SSA) after 250 iterations. It is observed that different ML models exhibit distinct optimization speeds and fitness values, indicating variations in SSA effectiveness and overall hybrid model performance. The XGB-SSA model achieved the lowest fitness value, demonstrating the best validation set performance. Over iterations, the fitness value decreased from 1.06 to 1.04 for XGB-SSA, from 2.97 to 1.29 for RF-SSA, and from 3.83 to 3.57 for DT-SSA. Consequently, the validation set performance ranking (strongest to weakest) is: XGB-SSA > RF-SSA > DT-SSA. Although XGB achieved the best overall performance, it showed the smallest improvement when integrated with SSA. In contrast, the RF model exhibited the most substantial performance enhancement through SSA optimization.

Identifying the optimum parameters.
Indicators of model performance
To develop high-performance prediction models, both ML models and empirical models were trained and evaluated using four performance indicators: R2, MAE, MSE, and MRE. Their predictive capabilities were compared across both training and testing datasets. The results are visually summarized in a radar chart (Fig. 7) and detailed numerically in Table 3. A model is considered to perform better in predicting the unconfined compressive strength (UCS) of MSLSS as the R2 value approaches 1.0, and the MAE, MSE, and MRE values approach zero.

Radar chart of evaluation indexes for models: (a) R2; (b) MAE; (c) MSE; (d) MRE.
As illustrated, all models except EF(I) and EF(II) demonstrate strong performance on the training set, with R2 values exceeding 0.90. The inferior performance of the empirical formulas arises from their limited capacity to capture the nonlinear relationships between input variables and the target UCS. Ranked in ascending order of training set performance, the models are: EF(II), RF, DT-SSA, DT, RF-SSA, XGB, and XGB-SSA. The hybrid XGB-SSA model consistently outperformed all others across every evaluation metric and dataset. On the training set, XGB-SSA achieved the lowest MAE (0.491), MSE (0.557), and MRE (0.167), alongside the highest R2 (0.998). This superior performance extended to the testing set, where XGB-SSA again yielded the best results: MAE (1.358), MSE (3.846), R2 (0.982), and MRE (1.046). The standard XGB model ranked second overall, exhibiting strong and competitive results close to those of XGB-SSA, particularly on the testing set (MAE = 1.581, MSE = 5.494, R2 = 0.974).
SSA optimization significantly enhanced the predictive performance of the base ML models (XGB, RF, DT). The improvement was most pronounced for RF-SSA, which significantly reduced the testing MSE from 40.819 to 8.876 and increased R2 from 0.813 to 0.959. Moreover, the SSA-optimized models exhibited improved generalization ability, showing less overfitting compared to their non-optimized counterparts. For example, the RF-SSA model maintained robust performance on the testing set (R2 = 0.959), despite an increase in MAE from training to testing. In contrast, the base RF model suffered from substantial overfitting, with a notable decline in R2 from 0.903 on the training set to 0.813 on the testing set. These results demonstrate that SSA optimization not only boosts predictive accuracy but also effectively mitigates overfitting. Conversely, the empirical models fundamentally underfit, failing to capture the underlying complexities of the dataset in both training and testing phases.
Prediction performance and comparative analysis
A score ranking method was employed to quantitatively evaluate the prediction capabilities of the ML models. As illustrated in Fig. 8, models were compared based on this scoring approach, with higher scores indicating better predictive performance. The overall ranking of model performance is as follows: XGB-SSA > XGB > RF-SSA > DT-SSA > DT > RF > EF(II) > EF(I).

Score ranking of models.
The XGB-SSA consistently achieves the best performance across all datasets, while the standard XGB model closely followed, ranking second. This comparable performance can be attributed to XGB’s inherent ensemble learning mechanism and advanced optimization algorithms, which reduce the necessity for additional hyperparameter tuning via SSA. Therefore, depending on practical constraints, the direct application of XGB may serve as an efficient and competitive alternative. In contrast, the RF model demonstrated relatively inferior performance, likely due to overfitting. However, its hybrid version, RF-SSA, ranked third overall, indicating that SSA optimization significantly enhances RF’s prediction capability by improving hyperparameter selection. This observation aligns with the empirical findings of Wang & Zhao63, who reported that metaheuristic optimization via SSA led to the most substantial improvement in RF model efficacy compared to conventional tuning methods. It is also noteworthy that all ML models consistently outperformed the empirical models, underscoring the strength of ML approaches in capturing nonlinear and complex relationships within data.
Scatter plots in Fig. 9 compare the experimental UCS of MSLSS against predictions from all eight models. Five reference lines indicate error margins of 0%, ± 10%, and ± 20%. Predictions from the EF(I) model show considerable volatility, with approximately 78% of the training data points lying outside the ± 20% error bounds. Although EF(II) and the RF model exhibit tighter clustering around the ideal line (y = x) on the training set, their testing errors increase significantly, reflecting poor generalization. In comparison, the XGB and hybrid ML models (especially XGB-SSA) achieve higher accuracy with lower error rates. During training, about 85% of the data points generated by XGB-SSA and XGB fall within the ± 20% error range. More importantly, during testing, the majority of predictions lie close to the ideal 45° line, with the remainder confined within the ± 20% error boundaries. These results emphasize the superior generalization ability of the hybrid XGB-SSA model over both standalone ML and empirical models.

Scatter plots exhibition: (a) XGB-SSA; (b) RF-SSA; (c) DT-SSA; (d) XGB; (e) RF; (f) DT; (g) EF(I); (h) EF(II).
The Taylor diagram64 offers a concise and integrated visualization of model accuracy by summarizing performance statistics (R, RMSE, standard deviations) through the spatial positioning of model markers. In such diagrams, the proximity of a point to the reference point reflects the model’s predictive idealness. As illustrated in Fig. 10, which is based on error analyses from Table 3 for both training and testing datasets, the XGB-SSA model is positioned markedly closer to the reference point than all other models. It is closely followed by XGB, RF-SSA, and DT-SSA, thereby robustly confirming its superior predictive performance among the evaluated approaches.

Evaluation of model performance by Taylor diagram: (a) training set; (b) testing set.
Figure 11 further displays the residual error distributions of all models during the testing phase. The RF and empirical models demonstrated notably poor predictive accuracy, with EF(I) exhibiting the widest residual range. The residual spans of EF(II) and the RF model were only exceeded by EF(I), underscoring their substantial instability in predicting UCS. By contrast, the residuals of the XGB-SSA and XGB models were tightly clustered near zero. The relative frequencies of residuals within the interval [− 2, 2] reached 0.63 for XGB-SSA and 0.47 for XGB, indicating significantly higher stability and reliability compared to other models.

Residual error distribution of models: (a) curve plots; (b) violin plots.
Feature importance
Although the XGB-SSA model demonstrates superior predictive performance for UCS estimation of MSLSS, the inherent complexity of XGB’s multi-layered decision tree architecture limits the interpretability of feature-outcome relationships. To gain deeper insights into global feature importance and their specific contributions to UCS predictions, Shapley Additive Explanations (SHAP) analysis was employed. For each specimen, SHAP values quantify the relative contribution of each input feature relative to a baseline average prediction.
Figure 12a and b present the SHAP-based feature importance analysis and the summary plot, respectively, for the six input variables used in predicting the UCS of MSLSS. Feature importance is represented by the mean absolute SHAP value, with higher values indicating greater predictive influence. As illustrated in Fig. 12a, a clear feature hierarchy emerges: OMC, MS, and CD are the dominant parameters, with SHAP contributions of 0.196, 0.095, and 0.055, respectively. The variable L exhibits a secondary yet statistically significant impact (0.021), while the influences of CC and MDD are minimal. The SHAP analysis identified OMC as the most influential parameter, which aligns with geotechnical principles where moisture content critically affects compaction efficiency and strength development in stabilized soils. This phenomenon is due to the closely correlation between OMC and lime content (PCC ≈ 0.91), reflecting the role of lime in altering the soil’s water retention properties and facilitating pozzolanic reactions with microsilica.

SHAP values of different feature values: (a) feature importance; (b) summary plot.
The SHAP summary plot in Fig. 12b visualizes the distribution of feature effects across individual specimens. Features are categorized along the vertical axis, and the horizontal alignment corresponds to the magnitude of SHAP values. A color gradient reflects feature values, with red indicating high values and blue denoting low values.
Figure 12b clearly indicates a positive correlation between OMC and UCS. Pearson correlation analysis (Fig. 3) further reveals that OMC exhibits a strong positive correlation with L (PCC ≈ 0.91) and a weaker positive correlation with MS (PCC ≈ 0.32). This increase in OMC, typically associated with the addition of lime and microsilica, enhances hygroscopicity through pozzolanic reactions and modifies the pore structure65. These mechanisms collectively contribute to the improvement of UCS. In contrast, the relationship between MS and UCS exhibits a parabolic trend, peaking near the median value. Initial strength gains are attributed to high reactivity and pore-filling effects of microsilica. However, beyond an optimal threshold, excessive MS content leads to over-densification and increased viscosity, which hinders uniform binder distribution and may induce internal stresses and micro-cracking due to uncontrolled hydration, ultimately reducing soil strength66.
Conclusions
In this study, machine learning (ML) models integrated with the intelligent Sparrow Search Algorithm (SSA) were employed to predict the strength of MSLSS. Three hybrid models (XGB-SSA, RF-SSA, DT-SSA) were developed by coupling SSA with the XGB, RF, and DT algorithms, respectively. Their performance was evaluated and compared using four metrics (R2, MAE, MSE and MRE) to identify the most effective predictive model. Finally, the SHAP method was applied to interpret the influence of input variables. The superiority of the proposed models was established through comparisons with both standalone ML models and empirical formulas. The main conclusions are summarized as follows:
-
(1)
Integrating SSA with base ML models markedly improved their predictive accuracy for the UCS of MSLSS. The hybrid models (XGB-SSA, RF-SSA, DT-SSA) consistently outperformed their non-optimized counterparts (XGB, RF, DT) as well as conventional empirical models (EF(I) and EF(II)) across all evaluation metrics (R2, MAE, MSE, MRE) on both training and testing sets. This underscores the vital role of intelligent hyperparameter optimization in enhancing the accuracy and generalization ability of ML models for complex geotechnical engineering problems.
-
(2)
Among all evaluated models, the XGB-SSA hybrid model achieved the highest predictive accuracy and robustness. It delivered exceptional performance on the testing set (R2 = 0.982, MAE = 1.358, MSE = 3.846, MRE = 1.046), demonstrating a strong capability to capture complex nonlinear relationships. The standard XGB model also exhibited high performance, ranking second overall. In contrast, conventional empirical regression models displayed fundamental limitations due to underfitting, resulting in the poorest predictive outcomes.
-
(3)
Based on the SHAP analysis of the optimal XGB-SSA model, OMC, MS, and CD are identified as the most influential parameters affecting the prediction of UCS. Among these, OMC exhibits the strongest positive contribution, which can be attributed to its association with increased lime and microsilica content. These components enhance pozzolanic reactivity and improve microstructural density, thereby strengthening the material. In contrast, the relationship between MS content and UCS is nonlinear: while moderate amounts of MS improve strength through pore-filling and heightened reactivity, exceeding an optimal threshold leads to excessive densification and disrupted binder distribution, ultimately reducing overall strength.
In summary, the developed hybrid predictive model offers significant potential for saving resources and time by enabling preliminary strength assessments, thereby reducing the reliance on extensive experimental work while maintaining scientific rigor. However, the reliance on a limited dataset from specific regions may constrain generalizability across diverse soil types and environmental conditions. Therefore, it should be used as a complementary tool alongside laboratory testing for critical geotechnical designs, particularly in preliminary stages and mix optimization processes. Furthermore, the current model does not fully incorporate long-term durability factors such as wet-dry cycles and sulfate attack resistance. Future research should focus on expanding the database to include more diverse soil conditions and chemical compositions.
Data availability
All data generated or analyzed during this study are included in this published article.
Abbreviations
- UCS:
-
Unconfined compressive strength
- ANN:
-
Artificial neural network
- SVR:
-
Support vector regression
- DT:
-
Decision tree
- RF:
-
Random forest
- XGB:
-
EXtreme gradient boosting
- SSA:
-
Sparrow search algorithm
- XGB-SSA:
-
XGBoost model with SSA
- RF-SSA:
-
RF model with SSA
- DT-SSA:
-
DT model with SSA
- MDD:
-
Maximum dry density
- OMC:
-
Optimum moisture content
- MSLSS:
-
Microsilica-lime sulfate sand
- L:
-
Lime percentage/content
- MS:
-
Microsilica percentage/content
- CC:
-
Curing condition* (*Curing conditions indicate whether the sample is flooded or not. If it is flooded, it is 1, otherwise it is zero)
- CD:
-
Curing days
- MAE :
-
Mean absolute error
- RMSE :
-
Root mean square error
- R 2 :
-
Coefficient of determination
- MRE :
-
Mean relative error
- MSE :
-
Mean squared error
References
Zakeri, J. & Forghani, M. Railway route design in desert areas. J. Environ. Eng. https://doi.org/10.5923/j.ajee.20120202.03 (2012).
Zhu, B. Q. & Yang, X. P. The origin and distribution of soluble salts in the sand seas of northern China. Geomorphology https://doi.org/10.1016/j.geomorph.2010.07.001 (2010).
Liu, K. et al. Effect of aluminate content in cement on the long-term sulfate resistance of cement stabilized sand. Mar. Georesour. Geotec. https://doi.org/10.1080/1064119X.2019.1635235 (2020).
Zhang, M. et al. Calcium-free geopolymer as a stabilizer for sulfate-rich soils. Appl. Clay Sci. https://doi.org/10.1016/j.clay.2015.02.029 (2015).
Cerato, A. B., Miller, G. A., Madden, M. E., Varnier, M. C., & Adams, A. Calcium-based stabilizer induced heave in Oklahoma sulfate-bearing soils. Oklahoma. Dept of Transportation. https://rosap.ntl.bts.gov/view/dot/23202/dot_23202_DS1.pdf (2011).
Rao, S. M. & Shivananda, P. Impact of sulfate contamination on swelling behavior of lime-stabilized clays. J. ASTM Int. https://doi.org/10.1520/JAI13063 (2005).
Zhang, M., Guo, H., Tahar, E. K., Zhang, G. P. & Tao, M. J. Experimental feasibility study of geopolymer as the next-generation soil stabilizer. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2013.06.01 (2013).
Chen, S., Hou, X., Luo, T., Yu, Y. & Jin, L. Effects of MgO nanoparticles on dynamic shear modulus of loess subjected to freeze-thaw cycles. J. Mater. Res. Technol. https://doi.org/10.1016/j.jmrt.2022.05.013 (2022).
Ghorbani, A., Hasanadehshooiili, H., Karimi, M., Daghigh, Y. & Medzvieckas, J. Stabilization of problematic silty sands using microsilica and lime. Balt. J. Road Bridge E. https://doi.org/10.3846/bjrbe.2015.08 (2015).
Sandra, G. & Huriye, B. Characterization of volume change and strength behavior of microsilica and lime-stabilized Cyprus clay. Acta Geotech. https://doi.org/10.1007/s11440-020-01060 (2021).
Moayed, R. Z., Izadi, E. & Heidari, S. Stabilization of saline silty sand using lime and micro silica. J. Cent. South Univ. https://doi.org/10.1007/s11771-012-1370-1 (2012).
Ebailila, M., Kinuthia, J., Oti, J. & Al-Waked, Q. Sulfate soil stabilisation with binary blends of lime–silica fume and lime–ground granulated blast furnace slag. Transp. Geotech. https://doi.org/10.1016/j.trgeo.2022.100888 (2022).
Ebailila, M., Kinuthia, J. & Oti, J. Suppression of sulfate-induced expansion with lime–silica fume blends. Materials. https://doi.org/10.3390/ma15082821 (2022).
Chakraborty, S., Puppala, A. J. & Biswas, N. Role of crystalline silica admixture in mitigating ettringite-induced heave in lime-treated sulfate-rich soils. Géotechnique. https://doi.org/10.1680/jgeot.20.P.154 (2022).
Moayyeri, N., Oulapour, M. & Haghighi, A. Study of geotechnical properties of a gypsiferous soil treated with lime and silica fume. Geomech Eng. https://doi.org/10.12989/gae.2019.17.2.195 (2019).
Fattah, M. Y., Al-Saidi, A. A. & Jaber, M. M. Consolidation properties of compacted soft soil stabilized with lime-silica fume mix. Int. J. Sci. Eng. Res. https://www.researchgate.net/publication/264825661 (2014).
Demir, I. & Baspinar, M. S. Effect of silica fume and expanded perlite addition on the technical properties of the fly ash–lime–gypsum mixture. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2007.01.011 (2008).
Lin, R. B., Shih, S. M. & Liu, C. F. Characteristics and reactivities of Ca (OH) 2/silica fume sorbents for low-temperature flue gas desulfurization. Chem. Eng. Sci. https://doi.org/10.1016/s0009-2509(03)00222-7 (2003).
Ghorbani, A. & Hasanzadehshooiili, H. Prediction of UCS and CBR of microsilica-lime stabilized sulfate silty sand using ANN and EPR models; application to the deep soil mixing. Soils Found. https://doi.org/10.1016/j.sandf.2017.11.002 (2018).
Karimi, M., Kia, S. & Daghigh, Y. Stabilization of silty sand soils with lime and microsilica admixture in presence of sulfates. In Proceedings of the 14th Pan-American Conference on Soil Mechanics and Geotechnical Engineering. (2011).
Mozumder, R. A. & Laskar, A. I. Prediction of unconfined compressive strength of geopolymer stabilized clayey soil using artificial neural network. Comput. Geotech. https://doi.org/10.1016/j.compgeo.2015.05.021 (2015).
Hammoudi, A., Moussaceb, K., Belebchouche, C. & Dahmoune, F. Comparison of artificial neural network (ANN) and response surface methodology (RSM) prediction in compressive strength of recycled concrete aggregates. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2019.03.119 (2019).
Nawaz, M. N. et al. A robust prediction model for evaluation of plastic limit based on sieve# 200 passing material using gene expression programming. PLoS ONE https://doi.org/10.1371/journal.pone.0275524 (2022).
Kumar, A., Sinha, S., Saurav, S. & Vinay, B. C. Prediction of unconfined compressive strength of cement–fly ash stabilized soil using support vector machines. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00833-9 (2024).
Ceryan, N., Okkan, U. & Kesimal, A. Prediction of unconfined compressive strength of carbonate rocks using artificial neural networks. Environ. Earth Sci. https://doi.org/10.1007/s12665-012-1783-z (2013).
Mozumder, R. A., Laskar, A. I. & Hussain, M. Empirical approach for strength prediction of geopolymer stabilized clayey soil using support vector machines. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2016.12.012 (2017).
Rezaei, M. & Asadizadeh, M. Predicting unconfined compressive strength of intact rock using new hybrid intelligent models. J. Min. Environ. https://doi.org/10.22044/jme.2019.8839.1774 (2020).
Baghbani, A., Nguyen, M. D., Kafle, B., Baghbani, H. & Faradonbeh, R. S. AI grey box model for alum sludge as a soil stabilizer: An accurate predictive tool. Int. J. Geotech. Eng. https://doi.org/10.1080/19386362.2023.2258749 (2023).
Onyelowe, K. C., Jalal, F. E., Iqbal, M., Rehman, Z. U. & Ibe, K. Intelligent modeling of unconfined compressive strength (UCS) of hybrid cement-modified unsaturated soil with nanostructured quarry fines inclusion. Innov. Infrastruct. So. https://doi.org/10.1007/s41062-021-00682-y (2022).
Jas, K., Mangalathu, S. & Dodagoudar, G. R. Evaluation and analysis of liquefaction potential of gravelly soils using explainable probabilistic machine learning model. Comput. Geotech. https://doi.org/10.1016/j.compgeo.2023.106051 (2024).
Kang, Q., Li, K. Q., Fu, J. L. & Liu, Y. Hybrid LBM and machine learning algorithms for permeability prediction of porous media: a comparative study. Comput. Geotech. https://doi.org/10.1016/j.compgeo.2024.106163 (2024).
Nasiri, H., Homafar, A. & Chelgani, S. C. Prediction of uniaxial compressive strength and modulus of elasticity for Travertine samples using an explainable artificial intelligence. Results Geophys. Sci. https://doi.org/10.1016/j.ringps.2021.100034 (2021).
Nawaz, M. N. et al. Estimating the unconfined compression strength of low plastic clayey soils using gene-expression programming. Geomech. Eng. 25, 69–86. https://doi.org/10.12989/gae.2023.33.1.001 (2023).
Nawaz, M. N., Akhtar, A. Y., Hassan, W., Khan, M. H. A. & Nawaz, M. M. A sustainable approach for estimating soft ground soil stiffness modulus using artificial intelligence. Environ. Earth Sci. https://doi.org/10.1016/j.trgeo.2024.101262 (2023).
Zhang, C. et al. Efficient machine learning method for evaluating compressive strength of cement stabilized soft soil. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2023.131887 (2023).
Khawaja, L. et al. Development of machine learning models for forecasting the strength of resilient modulus of subgrade soil: genetic and artificial neural network approaches. Sci. Rep. https://doi.org/10.1038/s41598-024-69316-4 (2024).
Jafri, T. H. et al. Predicting the rock cutting performance indices using gene expression modeling. Model Earth Syst. Env. https://doi.org/10.1007/s40808-024-02097-x (2024).
Sun, Y. et al. Prediction & optimization of alkali-activated concrete based on the random forest machine learning algorithm. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2023.13151 (2023).
Yao, Q. L., Tu, Y. L., Yang, J. H. & Zhao, M. J. Hybrid XGB model for predicting unconfined compressive strength of solid waste-cement-stabilized cohesive soil. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2024.138242 (2024).
Michael, L., Joana, P., Marj, T., Gonzalez, P. M. & Mikhail, K. Wildfire susceptibility mapping: Deterministic vs. stochastic approaches. Environ. Modell. Softw. https://doi.org/10.1016/j.envsoft.2017.12.019 (2018).
Xue, J. K. & Shen, B. A novel swarm intelligence optimization approach: sparrow search algorithm. Syst. Sci. Control Eng. https://doi.org/10.1080/21642583.2019.1708830 (2020).
Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks: Theory and Applications (pp. 43–55). Cham: Springer International Publishing. (2018).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. https://doi.org/10.1016/j.advengsoft.2016.01.008 (2016).
Kennedy, J., & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95-international conference on neural networks. IEEE. https://doi.org/10.1109/ICNN.1995.488968 (1995).
Seyedali, M., Mohammad, M. S. & Andrew, L. Grey wolf optimizer. Adv. Eng. Softw. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Karaboga, D. Artificial bee colony algorithm. Scholarpedia https://doi.org/10.4249/scholarpedia.6915 (2010).
Wang, P., Zhang, Y. & Yang, H. W. Research on economic optimization of microgrid cluster based on chaos sparrow search algorithm. Comput. Intel. Neurosc. https://doi.org/10.1155/2021/5556780 (2021).
Zhang, C. L. & Ding, S. F. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl-Based. Syst. https://doi.org/10.1016/j.knosys.2021.106924 (2021).
Liu, R. et al. Spatial prediction of groundwater potentiality using machine learning methods with Grey Wolf and Sparrow Search Algorithms. J. Hydrol. https://doi.org/10.1016/j.jhydrol.2022.127977 (2022).
Hu, Y. K., Li, L. Y., Wang, N., Zhou, X. L. & Fang, M. Application of machine learning model optimized by improved sparrow search algorithm in water quality index time series prediction. Multimed. Tools Appl. https://doi.org/10.1007/s11042-023-16219-7 (2024).
Song, C. G., Yao, L. H., Hua, C. Y. & Ni, Q. H. Comprehensive water quality evaluation based on kernel extreme learning machine optimized with the sparrow search algorithm in Luoyang River Basin, China. Environ. Earth Sci. https://doi.org/10.1007/s12665-021-09879-x (2021).
Zheng, B. et al. A new, fast, and accurate algorithm for predicting soil slope stability based on sparrow search algorithm-back propagation. Nat. Hazards. https://doi.org/10.1007/s11069-023-06210-8 (2024).
Shui, K., Hou, K. P., Hou, W. W., Sun, J. L. & Sun, H. F. Optimizing slope safety factor prediction via stacking using sparrow search algorithm for multi-layer machine learning regression models. J. Mt. Sci-Engl. https://doi.org/10.1007/s11629-023-8158-7 (2023).
Wang, M., Zhao, G. Y. & Wang, S. F. Hybrid random forest models optimized by Sparrow search algorithm (SSA) and Harris hawk optimization algorithm (HHO) for slope stability prediction. Transp. Geotech. https://doi.org/10.1016/j.trgeo.2024.101305 (2024).
Kalhor, A., Ghazavi, M., Roustaei, M. & Mirhosseini, S. M. Influence of nano-SiO2 on geotechnical properties of fine soils subjected to freeze-thaw cycles. Cold Reg. Sci. Technol. https://doi.org/10.1016/j.coldregions.2019.03.011 (2019).
Chen, S. F., Ni, P. F., Sun, Z. & Yuan, K. K. Geotechnical properties and stabilization mechanism of nano-MgO stabilized loess. Sustainability. https://doi.org/10.3390/su15054344 (2023).
Myles, A. J., Feudale, R. N., Liu, Y., Woody, N. A. & Brown, S. D. An introduction to decision tree modeling. J. Chemom. J. Chemom. Soc. https://doi.org/10.1002/cem.873 (2004).
Breiman, L. Random forests. Mach. learn. https://doi.org/10.1023/a:1010933404324 (2001).
Chen, T. Q. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939785 (2016).
Sadik, L. Developing prediction equations for soil resilient modulus using evolutionary machine learning. Transp. Infrastruct. Geotechnol. https://doi.org/10.1007/s40515-023-00342-x (2024).
Zorlu, K., Gokceoglu, C., Ocakoglu, F., Nefeslioglu, H. A. & Acikalin, S. Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng. Geol. https://doi.org/10.1016/j.enggeo.2007.10.009 (2008).
Xi, B., He, J. T. & Li, H. G. Integration of machine learning models and metaheuristic algorithms for predicting compressive strength of waste granite powder concrete. Mater. Today Commun. https://doi.org/10.1016/j.mtcomm.2023.106403 (2023).
Wang, M., Zhao, G. Y., Liang, W. Z. & Wang, N. A comparative study on the development of hybrid SSA-RF and PSO-RF models for predicting the uniaxial compressive strength of rocks. Case Stud. Constr. Mat. https://doi.org/10.1016/j.cscm.2023.e02191 (2023).
Taylor, K. E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. https://doi.org/10.1029/2000JD900719 (2001).
Kim, M. A., Rosa, V., Neelakantan, P., Hwang, Y. C. & Min, K. S. Characterization, antimicrobial effects, and cytocompatibility of a root canal sealer produced by pozzolan reaction between calcium hydroxide and silica. Materials. https://doi.org/10.3390/ma14112863 (2021).
Yang, X., Hu, Z. Q., Li, L., Wang, X. L. & Zhou, X. Strength properties, microstructural evolution, and reinforcement mechanism for cement-stabilized loess with silica micro powder. Case Stud. Constr. Mat. https://doi.org/10.1016/j.cscm.2023.e02848 (2024).
Funding
This research is supported by the National Natural Science Foundation of China (No. 12102367 to SC); the Special Fund for the Launch of Scientific Research in Xijing University (No. XJ23T01 to SC); China Postdoctoral Science Foundation (No. 2024MD764012 to JN). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
Conceptualization, Shufeng Chen; Data curation, Boli Liu; Formal analysis, Boli Liu; Funding acquisition, Shufeng Chen; Investigation, Boli Liu; Methodology, Shufeng Chen and Boli Liu; Validation, Shufeng Chen and Boli Liu; Visualization, Boli Liu; Writing—original draft, Shufeng Chen and Boli Liu; Writing—review & editing, Huanhuan Li and Jingjing Nan.
Corresponding author
Ethics declarations
Competing interests
The authors have declared that no competing interests exist.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, S., Liu, B., Li, H. et al. Predicting the strength of microsilica lime stabilized sulfate sand using hybrid machine learning models optimized with sparrow search algorithm. Sci Rep 15, 44118 (2025). https://doi.org/10.1038/s41598-025-27974-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27974-y
