
Abstract
Zero-shot learning enables the recognition of images from unseen classes by leveraging auxiliary semantic information. Traditional methods typically learn either the relationship between the visual features and the semantic vectors or that between the seen and the unseen semantic vectors. However, their zero-shot recognition performances are not ideal for scene images due to large intra-class variations. To address this challenge, we propose a novel approach combining semantic autoencoders (SAEs) and visual relation transfer (VRT), termed SAEVRT. Specifically, we learn two semantic autoencoders for both the seen and the unseen scene classes, which help to alleviate the domain shift between the visual and the semantic spaces. Considering that semantic vectors (no attribute vectors available) are less effective than visual features for scene images, we propose an interpretable seen and unseen visual relation transfer method to learn more effective unseen semantic vectors. By combining SAEs and VRT in a unified learning framework, we exploit both the visual-semantic and seen-unseen relationships. Extensive experiments on four scene datasets demonstrate the superior performance of SAEVRT, achieving recognition accuracies of 63.77\(\%\), 67.75\(\%\), 58.68\(\%\), and 53.26\(\%\) on Scene15, MIT67, UCM21, and NWPU45, respectively.
Similar content being viewed by others

Introduction
Traditional scene recognition tasks have achieved great success due to the development of deep learning technology1,2. However, they need a large number of training images and fail to recognize test images from an unseen class3. Benefiting from auxiliary semantic information, zero-shot learning is capable of recognizing new images from an unseen class. Therefore, in this paper, we explore zero-shot learning in scene recognition to tackle zero-shot scene recognition.
The key to zero-shot learning is how to build the relationship between the visual features and the semantic vectors. Accordingly, many researchers make great efforts to learn this relation, which can be divided into the following three embedding categories. (1) Visual\(\rightarrow\)Semantic Embedding learns an embedding function that projects the visual features to the semantic vectors. Representative methods are the Semantic AutoEncoder (SAE) method4 and variants5,6 thereof. (2) Semantic\(\rightarrow\)Visual Embedding learns an embedding function that projects the semantic vectors to the visual features. Based on the vision transformer framework, the Cross Attribute-Guided Transformer (CAGT) method7 devises an attribute-guided transformer network to refine visual features. (3) Visual\(\rightarrow\)Common Space\(\leftarrow\)Semantic Embedding learns two embedding functions that project the semantic vectors and the visual features to a common space. For example, to address the domain shift problem, the simple Discriminative Dual Semantic Autoencoder (DDSA) method8 learns two bidirectional mappings in an aligned space.
Learning the relationship between the visual features and the semantic vectors is conducive to promote the zero-shot recognition performance. However, it neglects the relationship between the seen and the unseen scene classes, which leads to the domain shift problem between these two groups of classes. To overcome this problem, researchers have began to exploit the relationship between the seen and the unseen classes using the unseen semantic information9. One of the representative methods is the Relational Knowledge Transfer (RKT) method10, which extracts the relational knowledge between the seen and the unseen semantic vectors using sparse coding theory. Following this line of research, the Transferring Knowledge and preserving Data Structure (TKDS) method11 directly transfers knowledge from the seen domain to the unseen domain, relieving the domain shift to some extent. With the help of the unseen semantic information, the Zero-Shot Learning based on Class Prototype and dual Latent Subspace learning with Reconstruction (ZSL-CPLSR) method12 builds a relationship between the seen and unseen classes, aiming to learn the unseen class prototypes and facilitate the subsequent subspace learning. Although these methods help to relieve the domain shift issue in zero-shot learning, their zero-shot recognition performances are not ideal for scene images due to large intra-class variations. To address this challenge, more performant zero-shot learning methods are still anticipated for scene recognition.
In this paper, in order to take advantage of the above two kinds of relationships, we propose to combine semantic autoencoders and visual relation transfer to tackle zero-shot scene recognition. Concretely, we first learn the relationship between the visual features and the semantic vectors by two semantic autoencoders for both the seen and the unseen scene classes. Then, considering that the semantic vectors (no attribute vectors available) are less effective than the visual features for scene images, we propose to learn the relationship between the seen and the unseen visual features and transfer this relational knowledge to generate unseen semantic vectors. Finally, we combine semantic autoencoders and visual relation transfer in a unified learning framework. Consequently, the proposed SAEVRT method is beneficial to generate more effective unseen semantic vectors and align the visual features and the semantic vectors in a better way, thereby enhancing the performance of zero-shot scene recognition. Our contributions are summarized as follows:
-
(1)
We propose to combine semantic autoencoders and visual relation transfer in a unified framework to tackle zero-shot scene recognition. To the best of our knowledge, we are the first to take advantage of both the visual-semantic and seen-unseen relationships.
-
(2)
Different from the seen and unseen semantic relation transfer, we propose an interpretable seen and unseen visual relation transfer method, which directly transfers the visual relation knowledge from the visual space to the semantic space, and hence learns more representative unseen semantic vectors.
-
(3)
An iterative optimization algorithm is devised for the proposed unified learning framework. Comprehensive experiments on four public scene datasets demonstrate that the proposed method achieves a superior zero-shot recognition performance.
The remainder of this paper is structured as follows. Section “Related work” reviews the related work. Section "Combining semantic autoencoders and visualrelation transfer" introduces the proposed SAEVRT method for zero-shot scene recognition. Section “Experiments” presents the experimental results. Section “Conclusion” concludes this paper.
Related work
Zero-shot learning
Zero-shot learning has been attracting increasing attention as its powerful ability of recognizing new images from an unseen class13,14. In the early years, most researchers focused on learning more effective attribute vectors, since auxiliary semantic information plays the dominant role in zero-shot learning. For example, Lampert et al15. introduced attribute-based classification, where objects are classified based on the semantic attributes. Yazdanian et al16. used different kinds of descriptions to learn new discriminative attributes, which helps to improve the zero-shot recognition performance. Having obtained representative semantic vectors, researchers make great efforts to learn the relationship between the visual features and the semantic vectors. Li et al17. developed a Dual Visual-Semantic Mapping Paths(DMaP) method, which helps to train the visual-semantic mapping between the visual space and the semantic embedding space. Instead of inductive learning, Li et al18. proposed a transductive zero-shot learning method for zero-shot learning based on knowledge graph, where the relationship between the visual features and the semantic vectors is exploited in a graph convolutional network. Moreover, benefiting from the powerful ability of Generative Adversarial Nets (GANs), researchers are able to generate a sufficient number of seen images, and then transfer zero-shot classification into traditional classification tasks19. Xian et al20. integrated the Wasserstein GAN with a classification loss, which aims to produce sufficient and discriminative deep features. Tang et al21. proposed a Structure-Aligned Generative Adversarial Network (SAGAN) framework to improve the performance of zero-shot learning. However, these methods may generate some noisy images, resulting in a degenerated performance22.
Recently, considering that the visual and semantic feature alignment plays a critical role in zero-shot learning, Cheng et al23. proposed a Discriminative and Robust Attribute Alignment(DRAA) method, which improves the discrimination power of the learned attribute embedding by contrastive learning. Given that the attribute vectors and the visual features contain complementary information, Hu et al24. proposed a complementary semantic information learning method, which consists of two branches: the Attribute Refinement by Localization branch and the Visual-Semantic Interactionbranch. Yao et al25. proposed a Deep Semantic Canonical Correlation Embedding(DSCCE) model, which learns the visual and semantic feature interaction in an embedding reconstruction manner. From the perspective of contrastive learning, Jiang et al26. designed a Dual Prototype Contrastive Network (DPCN). However, the above methods neglect the relationship between the seen and the unseen spaces, which fails to promote the zero-shot recognition performance for scene images. For this reason, we focus on learning not only the relationship between the visual and the semantic spaces, but also the relationship between the seen and the unseen spaces.
Zero-shot scene recognition
Scene recognition has been widely used in many latent computer vision applications27. With the great success of deep learning and massive labelled images, the performance of traditional scene recognition has reached a saturation point. However, in real-world applications, the number of labelled images is insufficient. The extreme case is that the number of labelled images is zero, called zero-shot learning. To deal with this situation, Li et al28. first introduced zero-shot scene classification in the remote sensing community. Considering that there are no attribute vectors available, the authors used the natural language processing model Word2Vec to project the name of scene classes to the semantic vectors. In addition, they learned the relationship between the seen and the unseen scene classes by constructing a semantic-directed graph. Since then, more and more researchers have paid their attention to zero-shot remote sensing scene classification. For instance, Li et al29. introduced the Locality-Preserving Deep Cross-Modal Embedding Network(LPDCMEN), which helps to tackle the problem of class structure inconsistency in an end-to-end way. Quan et al30. proposed a semi-supervised Sammon embedding method to learn semantic prototypes, allowing to align a consistent class structure between the visual and the semantic prototypes. Different from these methods, other researchers utilize generative networks to generate unseen class samples for the zero-shot scene classification task. Ma et al31. proposed to augment the Variational Autoencoder(VAE) models with the GAN model to deal with zero-shot remote sensing image scene classification. Liu et al32. used two VAEs to project the visual features of image scenes and the semantic features of scene classes into a shared latent space. However, these generative networks face challenges in generating high-quality scene images19. Therefore, it is necessary to explore more refined zero-shot scene recognition methods.
Combining semantic autoencoders and visual relation transfer
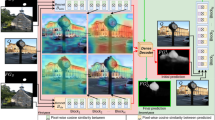
In order to take advantage of both the visual-semantic and seen-unseen relationships, we propose to combine semantic autoencoders and visual relation transfer to tackle zero-shot scene recognition. The framework of our proposed SAEVRT method is illustrated in Fig. 1. First, we learn semantic autoencoders for both the seen and the unseen scene classes, which helps to build the visual-semantic relationship. Then, we construct the seen visual relation and transfer it into unseen classes, which helps to build the seen-unseen relationship. Third, we combine the above objectives into a unified learning framework. Subsequently, an alternating iterative strategy is devised for our unified learning framework, which generates more effective unseen semantic vectors. Finally, we can predict these unseen semantic vectors into the ground truth class prototypes, which achieves improved zero-shot learning performance.

The framework of the proposed SAEVRT method. The visual features and the semantic vectors are extracted based on the CNN backbone and the Word2Vec model, respectively. In the training phase, we learn two semantic autoencoders for both the seen and the unseen scene classes and transfer the seen visual relation into unseen classes, which are formulated in a unified learning framework, generating effective unseen semantic vectors. In the testing phase, we compare these unseen semantic vectors with ground truth class prototypes, yielding the final zero-shot learning results. Three unknown matrices that are learned based on the seen classes are marked with red colors. Note: three seen images and three unseen images in this figure are from the MIT67 dataset (https://web.mit.edu/torralba/www/indoor.html).
Notation
For the \(N_s\) seen scene images, we denote the visual features as \({\textbf {X}}^s=[{\textbf {x}}^{s}_1,{\textbf {x}}^{s}_2,\) \(\ldots ,{\textbf {x}}^{s}_{N_s}]\in \mathbb {R}^{d\times N_s}\), the semantic vectors as \({\textbf {S}}^s=[{\textbf {s}}^{s}_1,{\textbf {s}}^{s}_2,\ldots ,{\textbf {s}}^{s}_{N_s}]\in \mathbb {R}^{r\times N_s}\), and the label values as \({\textbf {y}}^s=[y^s_1,y^s_2,\ldots ,y^s_{N_s}]\in \mathbb {R}^{1\times N_s}\), where d and r represent the dimension of the visual features and the semantic vectors, respectively. For the \(N_u\) unseen scene images, we denote the visual features as \({\textbf {X}}^u=[{\textbf {x}}^{u}_1,{\textbf {x}}^{u}_2,\ldots ,{\textbf {x}}^{u}_{N_u}]\in \mathbb {R}^{d\times N_u}\), the semantic vectors as \({\textbf {S}}^u=[{\textbf {s}}^{u}_1,{\textbf {s}}^{u}_2,\ldots ,{\textbf {s}}^{u}_{N_u}]\in \mathbb {R}^{r\times N_u}\), and the class labels as \({\textbf {y}}^u=[y^u_1,y^u_2,\ldots ,y^u_{N_u}]\in \mathbb {R}^{1\times N_u}\). In zero-shot learning, the class labels in \({\textbf {y}}^u\) are totally different from those in \({\textbf {y}}^s\), i.e., \({\textbf {y}}^s\cap {\textbf {y}}^u=\emptyset\). Note that in the training phase, the seen visual features \({\textbf {X}}^s\), the seen semantic vectors \({\textbf {S}}^s\), the seen label values \({\textbf {y}}^s\) and the unseen visual features \({\textbf {X}}^u\) are known, which are jointly used to learn the unseen semantic vectors \({\textbf {S}}^u\). In the testing phase, we can use the learned \({\textbf {S}}^u\) to classify an unseen test image.
Formulation
1) Semantic autoencoders for both the seen and the unseen scene classes: Semantic autoencoders learn the relationship between the visual features and the semantic vectors, which helps to alleviate the domain shift between the visual and the semantic spaces. For the seen scene classes, in order to take the advantage of the semantic autoencoder, we use it to align the visual features and the semantic vectors, i.e.,
here, \({\textbf {E}}^s\in \mathbb {R}^{r\times d}\) represents the seen encoder matrix, and \(\alpha\) is a hyperparameter. Our previous work33 has demonstrated the necessity of training another semantic autoencoder for the unseen classes, since it helps to address the domain shift between the unseen visual features and the unseen semantic vectors. Consequently, we formulate the unseen semantic autoencoder as follows:
where \({\textbf {E}}^u\in \mathbb {R}^{r\times d}\) represents the unseen encoder matrix, and \(\beta\) is a hyperparameter.
According to Eqs. (1) and (2), \({\textbf {E}}^s\) learns the relational knowledge of the seen domain, while \({\textbf {E}}^u\) learns the relational knowledge of the unseen domain. Since these two encoder matrices come from two different domains, \({\textbf {E}}^s\) is different from \({\textbf {E}}^u\) to some extent. To address this issue, we minimize the discrepancy between \({\textbf {E}}^s\) and \({\textbf {E}}^u\), i.e.,
This minimization problem aims to align the seen encoder matrix \({\textbf {E}}^s\) and the unseen encoder matrix \({\textbf {E}}^u\).
2) Seen and unseen visual relation transfer: Relational knowledge transfer learns the relationship between the seen semantic vectors and the unseen semantic vectors, which helps to alleviate the domain shift issue between the seen and the unseen spaces, thus generating more effective unseen visual features. However, when we apply this method to zero-shot scene recognition, the performance is not optimal. The main reason lies in that the semantic vectors of scene images extracted by the word2vec model (no attribute vectors available) are less effective than the visual features trained by the deep CNN models. To this end, we propose an interpretable seen and unseen visual relation transfer, which learns the relationship between the seen visual features and the unseen visual features, and transfers this knowledge to obtain more effective unseen semantic vectors.

The motivation of the proposed visual relation transfer method, where the values on the line represent the distances between two different samples. Generally, the greater the distances between the seen and the unseen visual features, the greater the distances between the seen and the unseen semantic vectors. Note: three seen images and two unseen images in this figure are from the MIT67 dataset (https://web.mit.edu/torralba/www/indoor.html).
The motivation of the proposed visual relation transfer method is shown in Fig. 2. Basically, the greater the distances between the seen and the unseen visual features, the greater the distances between the seen and the unseen semantic vectors. Motivated by this, in order to transfer seen and unseen visual relation knowledge to the semantic space, we expect that the seen images with large distances to the unseen images (in the visual space) should have the smallest influence to represent the unseen images (in the semantic space). Therefore, the transfer weight coefficient is defined as:
where \(\sigma\) is a predefined non-negative value. One can see that this coefficient is inversely proportional to the distance between the seen and the unseen visual features, which is consistent with our expectation. Thus, we can use the corresponding transfer weight matrix \({\textbf {V}}^{su}\in \mathbb {R}^{N_s\times N_u}\) to represent the unseen semantic vectors, i.e.,
This representation helps to generate unseen semantic vectors by transferring the visual relationship between the seen and the unseen classes. It is reasonable for a seen semantic vector to have a relatively large weight for a neighbor unseen semantic vector and a correspondingly small weight for other unseen semantic vectors.
3) Combining semantic autoencoders and visual relation transfer: Semantic autoencoders learn the relationship between the visual features and the semantic vectors, while visual relation transfer learns the relationship between the seen visual vectors and the unseen visual vectors. In order to promote the zero-shot recognition performance for scene images with large intra-class variations, we take advantage of not only the relationship between the visual and the semantic spaces, but also the relationship between the seen and the unseen spaces, and propose to combine these two relationships in a unified learning framework. To that end, we formulate the optimization problem of the proposed SAEVRT method by combining Eqs. (1)–(3) and (5) as follows:
where \(\lambda _1\) and \(\lambda _2\) are two hyperparameters. The equality constraint in Eq. (6) being difficult to satisfy, we relax it as:
Thus, Eq. (6) can be further recast as:
where \(\lambda _3\) is a hyperparameter.
It is noted that the proposed SAEVRT method has three advantages: (1) semantic autoencoders allows to address the domain shift issue between the visual and the semantic spaces; (2) visual relation transfer helps to address the domain shift issue between the seen and the unseen spaces; (3) by combining semantic autoencoders and visual relation transfer, we can transfer two kinds of relationships to generate more effective unseen semantic vectors, thereby improving the zero-shot scene recognition result.
Optimization
Considering that the proposed objective function in Eq. (8) is not jointly convex in \({\textbf {E}}^s\), \({\textbf {E}}^u\) and \({\textbf {S}}^u\), an alternating iterative strategy is devised for our unified learning framework. The update of \({\textbf {E}}^s\) depends on the calculation of \({\textbf {E}}^u\), the update of \({\textbf {E}}^u\) depends on the calculation of \({\textbf {E}}^s\) and \({\textbf {S}}^u\), and the update of \({\textbf {S}}^u\) depends on the calculation of \({\textbf {E}}^u\). Therefore, we first need to initialize \({\textbf {E}}^u\). Since the semantic vectors of the unseen scene classes are unknown in zero-shot learning, the initialization of \({\textbf {E}}^u\) depends on that of \({\textbf {E}}^s\).
Initializing \({\textbf {E}} ^s\) and \({\textbf {E}} ^u\): In the training procedure, the visual features and semantic vectors of the seen scene classes are known, thus we can initialize \({\textbf {E}}^s\) by learning the seen semantic autoencoder,
Then, we take the derivative of Eq. (9) w.r.t. \({\textbf {E}}^s\) and set it to 0, i.e.,
Eq. (10) is a Sylvester equation, and it has the closed-form solution by using the Bartels–Stewart algorithm34. As an illustration, let \({\textbf {A}} = {\textbf {S}}^s({\textbf {S}}^s)^\text {T}\), \({\textbf {B}}=\alpha {\textbf {X}}^s({\textbf {X}}^s)^\text {T}\), \({\textbf {C}}=(1+\alpha ){\textbf {S}}^s({\textbf {X}}^s)^\text {T}\), then the seen encoder matrix \({\textbf {E}}^s\) is calculated as:
In Matlab, we can implement this step with the sylvester function.
By transferring the encoder knowledge from the seen space to the unseen space, we can initialize \({\textbf {E}}^u\) with the help of \({\textbf {E}}^s\),
Calculating \({\textbf {S}} ^u\): With fixed \({\textbf {E}}^s\) and \({\textbf {E}}^u\), the objective function in Eq. (8) is recast as:
We take the derivative of Eq. (13) w.r.t. \({\textbf {S}}^u\) and set it to 0, i.e.,
here, \({\textbf {I}}\) means the identity matrix.
Updating \({\textbf {E}} ^u\): With fixed \({\textbf {E}}^s\) and \({\textbf {S}}^u\), the objective function in Eq. (8) is recast as:
We take the derivative of Eq. (15) w.r.t. \({\textbf {E}}^u\) and set it to 0, i.e.,
Let \({\textbf {A}}^{*} = \lambda _1{\textbf {S}}^u({\textbf {S}}^u)^\text {T}+\lambda _2{\textbf {I}}\), \({\textbf {B}}^{*}=\lambda _1\beta {\textbf {X}}^u({\textbf {X}}^u)^\text {T}\), \({\textbf {C}}^{*}=\lambda _1(1+\beta ){\textbf {S}}^u({\textbf {X}}^u)^\text {T}+\lambda _2{\textbf {E}}^s\). The unseen encoder matrix \({\textbf {E}}^u\) can be updated as:
Updating \({\textbf {E}} ^s\): With fixed \({\textbf {E}}^u\) and \({\textbf {S}}^u\), the objective function in Eq. (8) is recast as:
We take the derivative of Eq. (17) w.r.t. \({\textbf {E}}^s\) and set it to 0, i.e.,
Let \({\textbf {A}}^{**} = {\textbf {S}}^s({\textbf {S}}^s)^\text {T}+\lambda _2{\textbf {I}}\), \({\textbf {B}}^{*}=\alpha {\textbf {X}}^s({\textbf {X}}^s)^\text {T}\), \({\textbf {C}}^{**}=(1+\alpha ){\textbf {S}}^s({\textbf {X}}^s)^\text {T}+\lambda _2{\textbf {E}}^u\). The seen encoder matrix \({\textbf {E}}^s\) can be updated as:
Finally, we detail the pseudo-code for solving the proposed optimization problem in Algorithm 1.

SAEVRT
Classification
Having obtained the unseen encoder matrix \({\textbf {E}}^u\), we are able to use it to classify an unseen test image. Let \({\textbf {x}}^u_i\) represent the visual features of the i-th unseen test image, and \({\textbf {P}}^u= [{\textbf {p}}^u_1,{\textbf {p}}^u_2,\ldots ,{\textbf {p}}^u_{C_u}]\in \mathbb {R}^{r\times C_u}\) (\(C_u\) is the number of unseen scene classes) represent the unseen class prototypes extracted from the unseen scene classes. After that, the predicted class label of the unseen image \({\textbf {x}}^u_i\) can be conducted in the semantic space (\(\mathcal {S}\)) or in the visual space (\(\mathcal {V}\)).
(1) \(\mathcal {S}\): The unseen visual features \({\textbf {x}}^u_i\) can be encoded onto the unseen semantic space as:
Then, the predicted class label is obtained by calculating the cosine distance (\(\text {d}_\text {cos}({\textbf {x}},{\textbf {y}})= 1-\frac{{\textbf {x}}\cdot {\textbf {y}}}{\Vert {\textbf {x}}\Vert \Vert {\textbf {y}}\Vert }\)),
(2) \(\mathcal {V}\): The unseen class prototypes \({\textbf {p}}^u_j\) can be decoded back onto the unseen visual space as:
Then, the predicted class label is obtained by calculating the cosine distance,
Convergence and computational complexity analysis
In Algorithm 1, with initialized encoder matrices \({\textbf {E}}^s\) and \({\textbf {E}}^u\), the calculation of \({\textbf {S}}^u\) guarantees the closed-form solution. In additional, the updates of \({\textbf {E}}^s\) and \({\textbf {E}}^u\) have closed-form solutions by solving the corresponding Sylvester equations. To this end, with the iterative update rule, the SAEVRT method is able to converge to a local optimum.
For the computational cost of the proposed SAEVRT method, we only take the three iteration steps into account (the other steps could be pre-calculated). First, the main computational cost of calculating \({\textbf {S}}^u\) depends on computing the inverse matrix, i.e., \(O(r^3)\). Second, the main computational cost of updating \({\textbf {E}}^u\) and \({\textbf {E}}^s\) depends on calculating the Sylvester equation4, i.e., \(O(d^3+r^3)\). To sum up, the total computational cost of Algorithm 1 is \(O(T(2d^3+3r^3))\) (T indicates the total number of iteration steps).
Experiments
Datasets and set-up
Scene1535: This dataset contains 4,485 images from 15 indoor and outdoor scene classes, and each class contains 200 to 400 images. We show some example images in Fig. 3. Some scene classes present a high between-class similarity, which leads to greater difficulties in classifying unseen scene images. For the splits of seen/unseen classes, we randomly select 10 seen classes and 5 other classes as unseen classes.

Example indoor and outdoor scene images from the Scene15 dataset (https://github.com/TrungTVo/spatial-pyramid-matching-scene-recognition).
MIT6736: This dataset contains 15,620 images from 67 indoor scene classes, and the number of images varies with at least 100 images per class. We show some example images in Fig. 4. Most indoor scene images consist of multiple objects and present large visual variations, which results in a degenerated zero-shot recognition performance. For the splits of seen/unseen classes, we randomly select 57 seen classes and 10 other classes as unseen classes.

Example indoor scene images from the MIT67 dataset (https://web.mit.edu/torralba/www/indoor.html).
UCM2137: This dataset contains 2,100 images from 21 remote sensing scene classes, and each class contains 100 images. We show some example images in Fig. 5. This is a widely-used scene dataset in the remote sensing community. For the splits of seen/unseen classes, we randomly select 16 seen classes and 5 other classes as unseen classes.

Example remote sensing scene images from the UCM21 dataset (http://weegee.vision.ucmerced.edu/datasets/landuse.html).
NWPU4538: This dataset contains 31,500 images from 45 remote sensing scene classes, and each class contains 700 images. We show some example images in Fig. 6. This is the most challenging large-scale remote sensing scene dataset. For the splits of seen/unseen classes, we randomly select 35 seen classes and 10 other classes as unseen classes.

Example remote sensing scene images from the NWPU45 dataset (https://gcheng-nwpu.github.io/).
Visual features: In order to obtain a better zero-shot recognition performance, we extract the visual features of all scene images by using the ResNet method39 (pre-trained on the large-scale Places dataset40), which results in a 2048-dimensional vector.
Semantic vectors: Since there are no attribute vectors available for scene images, we extract semantic vectors of all scene classes by using the Word2Vec method (pre-trained on the large-scale Google News Corpus), which results in a 300-dimensional vector. When a class contains multiple words, we calculate the mean of the individual semantic vectors to obtain the final semantic vector41.
We repeat all experiments 25 times under a random seen/unseen split and report the average recognition results. In our experiments, we discover that the zero-shot recognition performance in the visual space is superior to that in the semantic space, therefore, we only report the recognition accuracies in the visual space. For the five parameters, we first fix \(\alpha\) and \(\beta\) at appropriate values, since they are relatively independent of the three other parameters. Then, we tune \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) (with one of them fixed) by a grid search. As a result, on the four scene datasets, we set the values of these five hyperparameters as in Table 1. In Sect. "Parameter sensitivity analysis", we will discuss the parameter sensitivity in detail. The source code is available online at https://github.com/chenchenwang93/SAEVRT.
Comparison experiments
(1) Comparison with SAE-based methods: To investigate the effectiveness of the proposed SAEVRT method, we first compare it with four widely-used SAE-based methods. SAE4 trains an encoder to project the visual features into the semantic space and sets a decoder (based on the encoder) to reconstruct the visual space; DDSA8 learns two semantic autoencoders to project the visual features and the semantic vectors to a shared and discriminative space; CAE42 learns two semantic autoencoders for both the seen and the unseen classes. Different from the CAE method, DIPL5 uses the nearest unseen class to learn the unseen semantic autoencoder. To make a fair comparison, we conduct the experiments in the same settings. The experimental results are reported in Table 2. Inspecting these results, we have the following conclusions. (1) On the four scene datasets, CAE and DIPL achieve a superior performance compared with SAE and DDSA, since the first two methods take the unseen classes into consideration. (2) The proposed method provides a better performance than the four other SAE-based methods. Since SAEs solely build the relationship between the visual features and the semantic vectors, they fail to build the relationship between the seen and the unseen classes. VRT significantly compensates this inherent limitation in SAEs, which helps to learn more effective unseen semantic vectors, thus improving the zero-shot recognition performance.
(2) Comparison with RKT-based methods: Considering that SAEVRT combines semantic autoencoders and visual relation transfer, we also compare it with three RKT-based methods. RKT10 learns the relational knowledge between the seen semantic vectors and the unseen semantic vectors based on sparse coding theory; TKDS11 directly transfers knowledge from the seen domain to the unseen domain; ZSL-CPLSR12 builds the relationship between the seen classes and the unseen classes to learn the unseen class prototypes. We conduct the these experiments in the same settings. The experimental results are presented in Table 3. Inspecting these results, we draw two conclusions. (1) ZSL-CPLSR performs better than RKT and TKDS. This is because that ZSL-CPLSR contains two stages, i.e., class prototype learning by using RKT and dual latent subspace learning with the help of reconstruction. (2) On the four scene datasets, the proposed method performs better than ZSL-CPLSR, since the visual relation transfer uses the more effective visual features rather than the semantic vectors.
(3) Comparison with state-of-the-art methods: We also compare the proposed SAEVRT method with some state-of-the-art (SOTA) zero-shot learning methods. Two baselines are the SAE and RKT methods; SSE43 learns similarity functions to project the unseen domain samples into the seen semantic space; DMaP17 learns the intrinsic connection between the manifold structure and the transferability of the mapping between the visual features and the semantic vectors; WDVSc44 learns three categories of visual structure constraint to address the domain shift for transductive zero-shot learning; moreover, VSOP45 exploits the shared subspace using both the visual and the semantic features. Based on GAN, LsrGAN46 transfers knowledge from the seen classes to the unseen classes by leveraging semantic information; SAGAN21 introduces a structure-aligned module to explore the structural consistency between the visual and the semantic spaces. Moreover, three recently proposed zero-shot learning methods, i.e., DSCCE25, DRAA23 and ZGLR47, are used for comparison for the Scene15 and MIT67 scene datasets; two recently proposed zero-shot scene classification methods, i.e., Ma et al31. and Liu et al32., are used for comparison for the UCM21 and NWPU45 remote sensing scene datasets.
To fully evaluate the effectiveness of the SAEVRT method, we conduct comparison experiments under different splits. For the four scene datasets, the experimental results are reported in Tables 4–7. Observing these results, we obtain the following three conclusions. (1) SAE achieves a better performance than RKT. For example, the performance of SAE increases 4.37\(\%\), 1.19\(\%\) and 6.66\(\%\) points compared to RKT under three different splits for the Scene15 dataset. (2) LsrGAN and SAGAN perform better than two baseline zero-shot learning methods (SAE and RKT). The main reason is that the GAN-based methods help to generate more appropriate unseen samples with the relationship between the visual features and the semantic vectors, or the relationship between the seen classes and the unseen classes. (3) The recently proposed methods achieve a better performance than the generative network methods. For example, the performance of DRAA is 2.54\(\%\) points higher than that of SAGAN under the split of 57/10 for the MIT67 dataset; the performance of the method of Liu et al. is 2.21\(\%\) points higher than that of LsrGAN under the split of 35/10 for the NWPU45 dataset. (4) SAEVRT obtains the highest recognition accuracy among the other zero-shot learning methods. By combining SAEs and VRT in a unified learning framework, we exploit both the visual-semantic and seen-unseen relationships, which generates more effective unseen semantic vectors, thereby improving the zero-shot scene recognition accuracy.

Confusion matrices of the zero-shot learning results for the Scene15 dataset.

Confusion matrices of the zero-shot learning results for the MIT67 dataset.

Confusion matrices of the zero-shot learning results for the UCM21 dataset.

Confusion matrices of the zero-shot learning results for the NWPU45 dataset.
To further discuss the zero-shot recognition results for each unseen scene class in detail, we present the confusion matrices of the proposed SAEVRT method. Here, we conduct experiments under the seen/unseen splits illustrated in Section 4.1. For the Scene15 dataset, when the five unseen classes are ‘Kitchen’, ‘Tall building’, ‘Inside city’, ‘Mountain’, and ‘Street’, the experimental results are reported in Fig. 7. Most of the images in the class ‘Inside city’ are misclassified onto the class ‘Street’. For the MIT67 dataset, when the ten unseen classes are ‘Computer room’, ‘Elevator’, ‘Laboratory wet’, ‘Church inside’, ‘Bowling’, ‘Warehouse’, ‘Corridor’, ‘Shoe shop’, ‘Buffet’, and ‘Children room’, the experimental results are reported in Fig. 8. Most of the images in the class ‘Corridor’ are misclassified onto the class ‘Elevator’, since these two classes share some semantic information. For the UCM21 dataset, when the five unseen classes are ‘Mobile home park’, ‘Golf course’, ‘Runway’, ‘Airplane’, and ‘River’, the experimental results are reported in Fig. 9. The recognition accuracies for the classes ‘Mobile home park’ and ‘Golf course’ almost reach the maximum. For the NWPU45 dataset, when the ten unseen classes are ‘Wetland’, ‘Overpass’, ‘River’, ‘Mobile home park’ ‘Cloud’, ‘Rectangular farmland’, ‘Baseball diamond’, ‘Railway station’, ‘Church’, and ‘Mountain’, the experimental results are reported in Fig. 10. The recognition accuracy for the class ‘Railway station’ almost reaches the maximum, whereas the recognition accuracies for the classes ‘Mobile home park’ and ‘Church’ are rather poor. The main reason is that the remote sensing scene images in these two classes have complex backgrounds.
Ablation study
In order to observe the influence of each term in the proposed optimization problem on the zero-shot recognition results, we evaluate three variants of SAEVRT. First, we remove the third term in the objective function (\(\lambda _1=0\) in Eq. (8)) and record it as SAEVRT-\(\lambda _1\). Second, we remove the fourth term in the objective function (\(\lambda _2=0\) in Eq. (8)) and record as SAEVRT-\(\lambda _2\). Third, we remove the fifth term in the objective function (\(\lambda _3=0\) in Eq. (8)) and record as SAEVRT-\(\lambda _3\). The experimental results are reported in Table 8. Overall, we can observe that the zero-shot recognition results of SAEVRT are consistently higher than those of the other variants. More specifically, for the Scene15 dataset, when removing the third term, the recognition result drops 7.22\(\%\) points; when removing the fourth term, the recognition result drops 2.04\(\%\) points; when removing the fifth term, the recognition result drops 4.31\(\%\) points. For the UCM21 dataset, when removing the third term, the recognition result drops 6.59\(\%\) points; when removing the fourth term, the recognition result drops 1.06\(\%\) points; when removing the fifth term, the recognition result drops 1.79\(\%\) points. These experimental results demonstrate that combining semantic autoencoders and visual relation transfer is helpful to exploit not only the relationship between the visual and the semantic spaces, but also the relationship between the seen and the unseen spaces. For the two other scene datasets, we obtain the similar results. Therefore, we can confirm that the three terms play a positive role in improving the performance of zero-shot scene recognition.

Recognition accuracies with different values of \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) for the Scene15 dataset.

Recognition accuracies with different values of \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) for the MIT67 dataset.

Recognition accuracies with different values of \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) for the UCM21 dataset.

Recognition accuracies with different values of \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) for the NWPU45 dataset.
Parameter sensitivity analysis
The proposed SAEVRT method contains three important hyperparameters \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\). Parameter \(\lambda _1\) adjusts the importance of the seen and the unseen semantic autoencoders; \(\lambda _2\) controls the consistency of the seen and the unseen encoder matrices; and \(\lambda _3\) controls the importance of the visual relation transfer. In order to fully explore how the hyperparameters impact the recognition performance, we use the four scene datasets to conduct parameter sensitivity analysis. For the Scene15 dataset, we first fix parameter \(\lambda _1\) at \(10^2\) and observe the recognition accuracies when varying the two other parameters \(\lambda _2\) and \(\lambda _3\). Then, we fix parameter \(\lambda _2\) at \(10^3\) and observe the recognition accuracies when varying the two other parameters \(\lambda _1\) and \(\lambda _3\). Finally, we fix parameter \(\lambda _3\) at 1 and observe the recognition accuracies when varying the two other parameters \(\lambda _1\) and \(\lambda _2\). The experimental results are presented in Fig. 11 (a)–(c). We can notice that when the value of \(\lambda _1\) is gradually increased, the recognition results fist improve and then decline. Moreover, when the value of \(\lambda _2\) is greater than or equal to \(10^3\), this has an important influence on the recognition accuracies; when the value of \(\lambda _3\) is less than or equal to 1, this also has an important influence on the recognition accuracies. For the three other datasets, the experimental results are presented in Figs. 12,13,14, where similar trends can be observed. Therefore, \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) play a crucial role to compromise the importance of these objective functions in the unified learning framework.
Discussion
Examining Tables 4–7, on the four scene datasets, the proposed SAEVRT method obtains the best zero-shot recognition result among all competing methods under standard splits, i.e., 63.77\(\%\), 67.75\(\%\), 58.68\(\%\), and 53.26\(\%\) on Scene15, MIT67, UCM21, and NWPU45, respectively. However, SAEVRT may be inferior to the other methods under different splits. For example, on the Scene15 dataset, SAEVRT achieves a recognition accuracy of 42.05\(\%\) under the 8/7 split, while DRAA achieves a recognition accuracy of 42.32\(\%\) under the same split. On the MIT67 dataset, SAEVRT achieves a recognition accuracy of 78.58\(\%\) under the 62/5 split, while ZGLR achieves a recognition accuracy of 78.73\(\%\) under the same split. The reason may be that the proposed visual relation transfer method cannot effectively exploit the seen-unseen relationship under a relatively small or large seen/unseen split, which fails to transfer the visual relation knowledge from the visual space to the semantic space, thus degenerating the zero-shot learning recognition result. Therefore, it is not convincing to evaluate zero-shot recognition performance based on a fixed split.
In addition, we can observe that almost all standard deviations are quite large. Actually, when conducting the randomized experiments, we find that if the randomly chosen unseen scene classes are significantly different from the seen scene classes, the zero-shot recognition performance declines sharply, since it is difficult for knowledge transfer. Accordingly, we should pay more attention to some unseen scene classes that are significantly different from seen scene classes.
Conclusion
In this paper, we have proposed a novel zero-shot scene recognition method by combining semantic autoencoders and visual relation transfer. By learning two semantic autoencoders for both the seen and the unseen classes, our proposed method has alleviated the domain shift problem between the visual features and the semantic vectors. By transferring the visual relationship from the seen classes to the unseen classes, our proposed method is able to generate more effective unseen semantic vectors, and align the visual features and the semantic vectors in a better way. Comprehensive experiments on four public scene datasets have confirmed the effectiveness of the proposed SAEVRT method, achieving recognition accuracies of 63.77\(\%\), 67.75\(\%\), 58.68\(\%\), and 53.26\(\%\) on Scene15, MIT67, UCM21, and NWPU45, respectively.
Zero-shot scene recognition assumes that the test images solely come from the unseen scene classes. However, this assumption in not really practical, since the real scene images may come from both the seen scene classes and the unseen scene classes. To overcome this shortcoming, generalized zero-shot learning (GZSL)48,49 has been introduced. In our future work, we will try to extend the proposed method to tackle this generalized zero-shot scene recognition task.
Data availability
This study used four scene image datasets Scene15, MIT67, UCM21, and NWPU45, which ares available at https://github.com/TrungTVo/spatial-pyramid-matching-scene-recognition, https://web.mit.edu/torralba/www/indoor.html, http://weegee.vision.ucmerced.edu/datasets/landuse.html, and https://gcheng-nwpu.github.io/, respectively. The source code of this study is available online at https://github.com/chenchenwang93/SAEVRT.
References
Xie, L., Lee, F., Liu, L., Kotani, K. & Chen, Q. Scene recognition: A comprehensive survey. Pattern Recognition. 102, 107205 (2020).
Wang, C., Peng, G. & De Baets, B. Deep feature fusion through adaptive discriminative metric learning for scene recognition. Information Fusion. 63, 1–12 (2020).
Pourpanah, F. et al. A Review of Generalized Zero-Shot Learning Methods. IEEE Transactions on Pattern Analysis and Machine Intelligence. 45(4), 4051–4070 (2023).
Kodirov, E., Xiang, T. & Gong, S. Semantic Autoencoder for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4447–4456 (2017).
Zhao, A., et al. Domain-invariant projection learning for zero-shot recognition. In Advances in Neural Information Processing Systems. 1019–1030 (2018).
Han, X. et al. Design of a turbo-based deep semantic autoencoder for marine Internet of Things. Internet of Things. 28, 101393 (2024).
Chen, S. et al. TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence. 45(11), 12844–12861 (2023).
Liu, Y., Li, J. & Gao, X. A Simple Discriminative Dual Semantic Auto-encoder for Zero-shot Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 940–941 (2020).
Yao, H., Zhang, C., Wei, Y., Jiang, M. & Li, Z. Graph Few-Shot Learning via Knowledge Transfer. In Proceedings of the AAAI Conference on Artificial Intelligence. 6656–6663 (2020).
Wang, D., Li, Y., Lin, Y. & Zhuang, Y. Relational knowledge transfer for zero-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence. 2145–2151 (2016).
Li, X., Fang, M. & Wu, J. Zero-shot classification by transferring knowledge and preserving data structure. Neurocomputing. 238, 76–83 (2017).
Zhao, P., Zhang, S., Liu, J. & Liu, H. Zero-shot Learning via the fusion of generation and embedding for image recognition. Information Sciences. 578, 831–847 (2021).
Fang, J. et al. Zero-shot learning via categorization-relevant disentanglement and discriminative samples synthesis. The Visual Computer. 40, 3889–3901 (2024).
Chen, S., Hong, Z., You, X. & Shao, L. Semantics-Conditioned Generative Zero-Shot Learning via Feature Refinement. International Journal of Computer Vision. 133, 4504–4521 (2025).
Lampert, C. H., Nickisch, H. & Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence. 36(3), 453–465 (2014).
Yazdanian, R., Shojaee, S.M. & Baghshah, M.S. An attribute learning method for zero-shot recognition. In Proceedings of the Iranian Conference on Electrical Engineering. 2235–2240 (2017).
Li, Y., Wang, D., Hu, H., Lin, Y., & Zhuang, Y. Zero-shot recognition using dual visual-semantic mapping paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3279–3287 (2017).
Li, Q., Sun, X. & Dong, J. Transductive zero-shot learning via knowledge graph and graph convolutional networks. Scientific Reports. 15, 28708 (2025).
Xu, B., Zeng, Z., Lian, C. & Ding, Z. Generative Mixup Networks for Zero-Shot Learning. IEEE Transactions on Neural Networks and Learning Systems. 36(3), 4054–4065 (2025).
Xian, Y., Lorenz, T., Schiele, B. & Akata, Z. Feature Generating Networks for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5542–5551 (2018).
Tang, C., He, Z., Li, Y. & Lv, J. Zero-Shot Learning via Structure-Aligned Generative Adversarial Network. IEEE Transactions on Neural Networks and Learning Systems. 33(11), 6749–6762 (2022).
Wang, Y., Hong, M., Huangfu, L., & Huang, S. Data Distribution Distilled Generative Model for Generalized Zero-Shot Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence. 5695–5703 (2024).
Cheng, D. et al. Discriminative and Robust Attribute Alignment for Zero-Shot Learning. IEEE Transactions on Circuits and Systems for Video Technology. 33(8), 4244–4256 (2023).
Hu, X., Wang, Z. & Li, J. Learning complementary semantic information for zero-shot recognition. Signal Processing: Image Communication. 115, 116965 (2023).
Yao, Z., Jiang, Q., Zhong, W. & Gu, X. Deep Semantic Canonical Correlation Embedding for Zero-Shot Industrial Process Fault Diagnosis. IEEE Transactions on Systems, Man, and Cybernetics: Systems. 55(7), 4458–4471 (2025).
Jiang, H. et al. Dual Prototype Contrastive Network for Generalized Zero-Shot Learning. IEEE Transactions on Circuits and Systems for Video Technology. 35(2), 1111–1122 (2025).
Wang, C., Peng, G. & De Baets, B. Joint global metric learning and local manifold preservation for scene recognition. Information Sciences. 610, 938–956 (2022).
Li, A., Lu, Z., Wang, L., Xiang, T. & Wen, J. R. Zero-shot scene classification for high spatial resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing. 55(7), 4157–4167 (2017).
Li, Y., Zhu, Z., Yu, J. G. & Zhang, Y. Learning Deep Cross-Modal Embedding Networks for Zero-Shot Remote Sensing Image Scene Classification. IEEE Transactions on Geoscience and Remote Sensing. 59(12), 10590–10603 (2021).
Quan, J., Wu, C., Wang, H., & Wang, Z. Structural alignment based zero-shot classification for remote sensing scenes. In Proceedings of the IEEE International Conference on Electronics and Communication Engineering. 17–21 (2018).
Ma, S., Liu, C., Li, Z. & Yang, W. Integrating Adversarial Generative Network with Variational Autoencoders towards Cross-Modal Alignment for Zero-Shot Remote Sensing Image Scene Classification. Remote Sensing. 14(18), 4533 (2022).
Liu, C., Ma, S., Li, Z., Yang, W. & Han, Z. Mining Contrastive Relations Between Cross-Modal Features for Zero-Shot Remote Sensing Image Scene Classification. IEEE Geoscience and Remote Sensing Letters. 21, 1–5 (2024).
Wang, C., Peng, G. & De Baets, B. A distance-constrained semantic autoencoder for zero-shot remote sensing scene classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. 14, 12545–12556 (2021).
Bartels, R. H. & Stewart, G. W. Solution of the matrix equation AX+ XB= C [F4]. Communications of the ACM. 15(9), 820–826 (1972).
Lazebnik, S., Schmid, C., & Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Vision and Pattern Recognition. 2169–2178 (2006).
Quattoni, A. & Torralba, A. Recognizing indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 413–420 (2009).
Yang, Y. & Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. 270–279 (2010).
Cheng, G., Han, J. & Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proceedings of the IEEE. 105(10), 1865–1883 (2017).
He, K., Zhang, X., Ren, S., & Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 770–778 (2016).
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A. & Torralba, A. Places: A 10 million Image Database for Scene Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. 40(6), 1452–1464 (2018).
Sumbul, G., Cinbis, R. G. & Aksoy, S. Fine-grained object recognition and zero-shot learning in remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing. 56(2), 770–779 (2018).
Sun, G., Wu, S., Gao, G., Wu, F. & Jing, X.Y. Coupled autoencoders learning for zero-shot classification with domain shift. In Proceedings of the International Conference on Progress in Informatics and Computing. 66–70 (2017).
Zhang, Z. & Saligrama, V. Zero-shot learning via semantic similarity embedding. In Proceedings of the IEEE International Conference on Computer Vision. 4166–4174 (2015).
Wan, Z., et al. Transductive zero-shot learning with visual structure constraint. In Advances in Neural Information Processing Systems. 9972–9982 (2019).
Wu, H. et al. Joint Visual and Semantic Optimization for zero-shot learning. Knowledge-Based Systems. 215, 106773 (2021).
Vyas, M.R., Venkateswara, H. & Panchanathan, S. Leveraging seen and unseen semantic relationships for generative zero-shot learning. In Proceedings of the European Conference on Computer Vision. 70–86 (2020).
Wang, Q., Mou, H., Wang, J., Wei, C. & Zhou, Y. Zero-shot learning based on the fusion of global and local representations. Measurement Science and Technology. 36(3), 035905 (2025).
Verma, V.K., Arora, G., Mishra, A. & Rai P. Generalized zero-shot learning via synthesized examples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4281–4289 (2018).
Chen, Y. & Zhou, Y. Incorporating attribute-level aligned comparative network for generalized zero-shot learning. Neurocomputing. 573, 127188 (2024).
Acknowledgements
The authors gratefully acknowledge the editors and reviewers for their insightful comments and constructive suggestions, which have significantly enhanced the quality of this work.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62301373, and in part by the Natural Science Foundation of Hubei Province under Grant 2023AFB279. BDB received funding from the Flemish Government under the “Onderzoeksprogramma Artificiële Intelligentie (AI) Vlaanderen” programme.
Author information
Authors and Affiliations
Contributions
Chen Wang contributes to Writing–original draft, Validation, Methodology, Data curation. Man Wang contributes to Writing–review and editing, Validation, Methodology. Guohua Peng contributes to Writing–review and editing, Methodology. Bernard De Baets contributes to Writing–review and editing, Validation, Supervision. Xiong Pan contributes to Writing–review and editing, Supervision. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, C., Wang, M., Peng, G. et al. Enhancing zero-shot scene recognition through semantic autoencoders and visual relation transfer. Sci Rep 15, 44213 (2025). https://doi.org/10.1038/s41598-025-28158-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28158-4
