
Abstract
Transitioning from pre-university studies to a bachelor’s degree can be quite challenging, as students often have to choose from a wide range of programs without knowing their academic compatibility. This lack of information can lead to poor performance or even dropout. To tackle this issue, we conducted a study at a Spanish university using machine learning (ML) algorithms on academic data from 2010 to 2022 (about 72,000 records) to develop a degree recommendation tool aligned with pre-university profiles. Our results show an average accuracy of 70% for the top 5 predictions and 90% for the top 10. Moreover, explainability techniques allowed us to identify profiles according to bachelor’s degree programs and observe relationships between pre-university subjects and chosen degrees. For example, students who take Geography in their access proofs are less likely to choose Computer Engineering, while Mathematics, English, and Physics negatively affect recommendations for Education degrees. The tool is designed to assist school counselors by providing comprehensive and accurate guidance, considering students’ academic profiles, interests, and socioeconomic factors. This is expected to improve academic performance and reduce dropout rates. Future work includes expanding the number of academic records, incorporating additional universities, and introducing new ML algorithms to enhance our results.
Similar content being viewed by others


Introduction
University guidance plays a significant role in students’ decision-making and academic success. Choosing a university program is a critical moment in the lives of pre-university students, with substantial implications for their academic and professional futures. It is important to note that high school graduates in Spain have selected one of four modalities (General, Arts, Science and Technology, Humanities and Social Sciences), while their transition to university involves choosing from dozens of university programs about which they have little detailed knowledge regarding academic demands or suitability for their profile. As a result, they may be uncertain about which university program to pursue upon completing their studies, making this an important decision for their professional development and, ultimately, their life plans1.
Student success can be understood in basic terms as students entering and staying in university until they obtain a bachelor’s degree or certificate2. Many factors influence students’ success in higher education. According to Hailikari, Tuononen, and Parpala3 the factors vary greatly depending on the study profiles (how they manage their time and effort) of the students. For Ruohoniemi and Lindblom-Ylänne4 there are differences in students’ performance depending on the role of the practical part of studies and the importance of self-discipline. Hailikari et al.3, explain these differences by the non-vocational orientation of the humanities and social sciences, where less emphasis is placed on the practical side of studies.
Appropriate guidance plays a key role in providing the necessary support to make informed choices and thus aligning students’ skills, interests and aspirations with the most appropriate degrees for them5. However, this process can be complex and challenging due to the diversity of academic options. Multiple factors influence career choice; for students, these include interest, life ambition, the challenging nature of the career, the prestige of the profession, intellectual ability, high salary potential, and the prospects of job opportunities6. On the other hand, career congruence between parents and adolescents and the role of counselors influence the career orientation of their students or children7. For that reason, and to improve student success, an increasing number of vocational education and training institutions are implementing various actions, such as the Netherlands and its career guidance programmes2. In fact, schools that implement guidance programmes with more comprehensive models give students better career information, prepare them better for their future, and students obtain higher grades and have a more positive climate in their schools8.
It remains a challenge to accurately determine the skills required for students to successfully undertake specific undergraduate degrees, beyond mere stereotypes. For instance, how can one provide evidence-based answers to the following questions: What level of mathematics proficiency is recommended for bachelor’s degrees in Computer Engineering, Multimedia Engineering, or Robotics Engineering, and for bachelor’s degrees in Primary Education or Early Childhood Education? It is important to note that this information cannot be directly obtained from institutional academic guides, as the level of demand often depends on the instructors teaching the courses, the department responsible for them3, or even the degree program itself9. Therefore, obtaining this information is difficult without continuous and structured student surveys correlated with their profiles10. An alternative approach could be to analyze the profiles of students who have successfully completed a degree program, or at least the first academic year, which is typically the most critical and sees the highest dropout rates11. This is the approach we propose in this study.
A logical way to address this challenge is by employing machine learning, an area of Artificial Intelligence that is increasingly applied across various fields, including health12,13, industry14,15, economics16,17, and education18,19. The primary reason why machine learning models have seen limited application in data analysis thus far is their complex interpretability, often referred to colloquially as “black boxes”20.
However, recent advancements in Explainable Artificial Intelligence (XAI)21 enable the extraction of useful and comprehensible information from predictive models. Specifically, post-hoc techniques offer a unified approach to explaining the predictions made by any machine learning model. One such tool is SHAP (SHapley Additive exPlanations)22, which is based on game theory and can extract information about the impact or importance of variables at both global and local levels.
The primary objective of this article is the development of a predictive recommendation system that encompasses all undergraduate degree programs, emphasizing the importance of tailoring machine learning algorithms to the specific needs of higher education profiles.
The research questions posed are as follows:
-
RQ1: What level of quality could a machine learning-based university bachelor’s degree recommendation system achieve?
-
RQ2: Could student profiles be extracted to provide evidence on the skills recommended for different bachelor’s degrees?
The article is structured as follows. Section “State of the art” reviews the most relevant research that has used artificial intelligence to guide students in their choice of studies. Section “Methodology” presents the analysis methodology used. Section “Results” shows the results obtained from the training and validation of the predictive models. Finally, “Discussion” discusses the results and “Conclusions and future work” draws the main conclusions of this research as well as proposals for future work.
State of the art
The application of recommendation systems in education has gained significant traction in recent years, particularly in higher education. While still in its early stages compared to other domains like learning analytics, these systems show promise in guiding students towards optimal academic paths. This section reviews the existing literature on personalized recommendation systems for students, with a focus on higher education and major selection.
Evolution of educational recommendation systems
The concept of using recommendation systems in educational contexts was first explored by Recker et al. 23 with their “Altered Vista” system. Although pioneering, this system focused on recommending general web resources rather than specific academic content for university programs.
Subsequent research by Lemire et al. 24 demonstrated the viability of applying recommendation systems in academia, focusing on recommending supplementary materials for university students using collaborative filtering techniques. However, their work did not address the crucial aspect of guiding students in course or program selection.
Course and program recommendation systems
The first significant attempts to apply recommendation systems to university course selection were made by Bendakir and Aïmeur25 and Farzan and Brusilovsky26. These studies introduced systems like CourseAgent and RARE (Recommender system based on Association RulEs), which aimed to guide students based on their interests, academic history, and association rules combining data mining with user ratings.
A more recent and promising approach is presented by Tavakoli et al.27 with their AI-driven recommendation system, eDoer. While primarily focused on continuous education, their methodology of analyzing job market demands and recommending relevant educational resources offers valuable insights for university program recommendations.
Collaborative filtering and its limitations
Collaborative Filtering, a widely used approach in recommendation systems28, has been successfully applied in various domains. For instance, Fareed et al. 29 utilized social networks for movie recommendations, while Yan30 employed it for recommending English text readings. However, these systems often face the “cold start” problem, where new users with no interaction history receive only generic recommendations.
Machine learning approaches in educational recommendations
Given the limitations of collaborative filtering for new users, our proposal focuses on a supervised machine learning approach. This method utilizes pre-university student profiles and their subsequent university performance, combined with explainability techniques for transparency. This approach aligns with trends in educational data mining and learning analytics31.
Recent studies have shown the potential of machine learning in predicting academic success and providing personalized recommendations. For example, Iatrellis et al.32 developed a machine learning-based system for predicting student performance and providing personalized learning path recommendations in higher education. Similarly, Moreno-Marcos et al.33 explored the use of machine learning techniques for early prediction of student performance in MOOCs, demonstrating the potential of these approaches in educational contexts.
Advantages of our proposed approach
Our proposed system offers several advantages:
-
Objectivity: Utilizes quantifiable academic data from university entrance exams and actual student performance.
-
Risk reduction: Potentially decreases dropout rates and major changes by basing recommendations on profiles of successful students.
-
Reduced subjective bias: Less influenced by personal perceptions often present in preference surveys or personality questionnaires.
-
Scalability: Can incorporate a large number of profiles and be updated for more precise recommendations.
As a case study, we aim to distinguish the profiles of 48 university bachelor’s degree programs offered at the University of Alicante. Our goal is to propose an ideal list of bachelor’s degree programs for future students based on their probability of success, using pre-university and university academic profiles.
Currently, there is no available application that encompasses all university bachelor’s degree programs of an institution based on these student profiles. Our research aims to fill this gap, providing a valuable tool for both school counselors and potential students.
Methodology
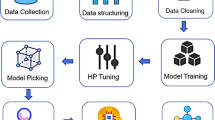
This methodology outlines a comprehensive approach to evaluate the effectiveness of machine learning-based recommendations for bachelor’s degree selection. It begins with the careful gathering and preparation of data, ensuring its relevance and quality for analysis. Subsequently, robust evaluation metrics are employed to validate the model’s performance, providing insights into its accuracy and reliability. The choice of an appropriate machine learning algorithm is especially important for effectively aligning student profiles with suitable academic programs. Finally, techniques to enhance transparency are applied, allowing for a clearer understanding of the decision-making process behind the recommendations.
Data collection and preprocessing
The data used to train our predictive model consists of the complete set of anonymized academic records available at a Spanish university. The variable selection process was straightforward and conditioned by the nature of this data; as no additional information, such as socioeconomic or psychometric data, was available, all available academic variables were selected for the study. This dataset includes the chosen university degree program, gender, average grade in pre-university studies, pre-university background (high school, vocational training, entrance exam for those over 25, access as a university graduate), the results of university entrance exams with their respective grades, and the credits passed during the first year of the bachelor’s degree program, given that it is the most important year and sees the highest dropout rate34,35. This decision, therefore, reflects the entirety of the academic information the university holds on record for incoming students, resulting in the 37 predictor variables detailed in Sect. 4.1. All methods were performed in accordance with the relevant guidelines and regulations.
As part of the preprocessing, we will select samples to avoid missing or unknown values. We will also select students whose background is high school, as this is the majority class and they have taken the university access exams.
Metrics and model validation
Given that we will base our recommendation system on a supervised machine learning classification approach, the metrics we will use are accuracy based on the top 5 (acc-5) and top 10 (acc-10) recommendations, respectively. That is, the recommendation will be considered correct if the actual bachelor’s degree chosen by the student is included in the list of top 5 or top 10 recommendations.
To validate the results of the models, we will use the widely adopted 10-fold cross-validation scheme. By using these 10 results and applying a statistical hypothesis test, we can determine which models perform better in terms of predictive performance.
Selection of a machine learning algorithm
To identify patterns characterizing the behavior of various student profiles within bachelor’s degree programs, we employed multiple machine learning (ML) algorithms to predict the bachelor’s degrees that best align with students’ profiles.
We evaluated several machine learning methodologies to ascertain which algorithms are capable of extracting more accurate patterns for prediction. This approach seeks to establish associations between input variables and the target outcome. Our selection encompassed algorithms from diverse regression families, including linear regression, decision trees, neural networks, support vector machines, and neighborhood-based models, with the aim of assessing and pinpointing the most effective one. The baseline model predicts the most common outcome variable value. Naive Bayes36 operates as a classification method grounded on the theorem of the same name, assuming conditional independence among each pair of variables. Decision trees37 for classification typically construct binary trees from training data and make predictions based on the path within the tree. Random Forest38 amalgamates predictions from multiple trees to enhance robustness. AdaBoost39 sequentially constructs regressors, adjusting weights to minimize errors. XGBoost40, Light Gradient Boosting Machine (LGBM)41, CatBoost42, Histogram Gradient Boosting (Histogram GBC)43 utilize boosting with gradient descent for optimization in a different way. Neural networks, particularly multilayer perceptrons44, fully connect all layers. Lastly, Nearest Neighbors45 make predictions using the k nearest samples, with different values of k tested in our study (i.e., 1, 3, 5, 7, and 9).
To ensure a fair and reproducible comparison, we evaluated a range of classical machine learning algorithms. For each algorithm, we performed a limited hyperparameter sweep using values commonly considered effective in similar studies. Table 1 lists the specific hyperparameters that were varied for each model during our evaluation. For models where a single set of parameters is shown, these represent the default, widely-used configurations from the Scikit-learn library, which served as our baseline for those algorithms.
Application of explainability techniques
The most accurate predictions often come from complex models, often referred to as “black boxes”46. Post-training, explaining these models coherently can be achieved through several approaches. While methods like permutation-based feature importance exist38, we chose to employ a more advanced technique rooted in game theory: SHAP (SHapley Additive exPlanations). SHAP values (Fig. 1) enhance the precision of the latter approach by equally distributing benefits and costs among variables. Originally designed for economic contexts with unequally contributing partners, Shapley values represent the expected average marginal contribution of a variable, ensuring local accuracy and consistency. Despite the internal non-linearities of most machine learning models, this linear approach sheds light on their behavior.

General scheme of the post-hoc explicability of the machine learning models.
An extension of Shapley values was introduced by Lundberg and Lee47,48, enabling the distribution of marginal contributions at various levels —individual, group, or overall— based on a unified approach to explain predictions made by any trained ML model. The SHAP (SHapley Additive exPlanations) tool, developed by Lundberg22, facilitates these calculations, emphasizing the growing importance of SHAP values in understanding and interpreting complex machine learning models.
Results
Below, we present the results obtained from the training and validation of the predictive models, including performance metrics such as the accuracy rate using the top 5 or top 10 recommendations, as well as error analysis and visualizations of the results.
Dataset and feature selection
To construct the data set, we requested anonymized student data from a Spanish university for the past several years. To this end, we held several meetings with technicians and directors of the IT services responsible for the administration of the university’s IT processes and data custody. We gathered as much information as possible related to the student profiles. The obtained anonymized information includes gender, the order of chosen bachelor’s degree programs and the one in which the student enrolled, pre-university pathways chosen, pre-university study center, the number of credits enrolled in during the first year of the university bachelor’s degree program and how many of them were passed, subjects evaluated in the university entrance exams, and averages of the access grades and pre-university studies.
Based on these variables, a selection process was conducted. This process was guided by several criteria: data availability (since profiles may contain unknown values), their influence on prediction (determined through preliminary tests), and the aim to maintain the smallest number of variables possible. This last point is extremely important, as a large number of variables negatively affects data representation, a phenomenon known as the ‘curse of dimensionality’49. This phenomenon can lead to undesired results that negatively impact the performance of predictive models. However, it is also important to find a balance so that the selected variables are sufficiently representative to ensure good prediction results.
Specifically, the variables we selected for our study are as follows. These initial variables are common to all profiles: Gender (Male or Female), Year of Enrollment (2010–2022), and Average Pre-university Studies. The reason for including Year of Enrollment in the study is to understand the temporal evolution of the bachelor’s degree program and its importance in the recommendation of degree programs. If this variable is relevant for a bachelor’s degree program, it indicates strong external and non-academic influences on the profiles of students who have pursued it, which can be explained by the year of enrollment. It is also worth noting that the average of pre-university studies was chosen to represent the student’s average performance, rather than the university entrance exam score, because the former is more general and a school counselor can easily estimate it by knowing the student’s trajectory. The university entrance exam score is more difficult to estimate, as it depends on both the average of pre-university studies and the subjects evaluated in the entrance exams, including both mandatory and optional subjects.
The following list of selected variables consists of all subjects that a student can be evaluated on in the university entrance exams in Spain, specifically in the Valencian Community. Each student must be evaluated on 5 mandatory subjects, with a final score ranging from 0 to 10. It is also possible to achieve a higher final score by being evaluated on additional optional subjects to obtain up to 4 additional points (the final score would range from 0 to 14), thereby qualifying for university bachelor’s degree programs where the number of places is limited and selection is based on the order of the best scores of the applicants. In the Spanish system of university entrance exam evaluation, the possible subjects to choose from are: Applied Mathematics in Social Sciences, Art Fundamentals, Art History, Artistic Drawing, Audiovisual Culture, Biology, Chemistry, Design, Economics, Electrotechnics, Environmental Earth Sciences, Geography, Geology, Greek, History of Music and Dance, History of Philosophy, Industrial Technology, Languages (English, German, French, Italian, Portuguese, Valencian), Latin, Literature, Mathematics, Musical Analysis, Performing Arts, Physics, Plastic and Graphic Expression Techniques, Practical Music Language, Spanish History, Spanish Language and Literature, and Technical Drawing. In summary, we considered a total of 37 variables, with the majority being numerical, such as subject grades and the year of enrollment, and only one categorical variable, Gender.
The provided data corresponds to the years from 2010 to 2022, with a sample size of 72,041 students, of which 21,616 took their university access exams, who will be the focus of this study. In Table 2, we can observe the number of students available per year, and in Table 3, we have a summary by bachelor’s degree program with their access exam average (a higher entrance exam average implies some with better grades).
Finally, and to ensure the highest possible quality in the results and avoid noise in the profiles as much as possible, the students who exceeded the credits of the first year with greater comfort were selected. For this, we have chosen those whose value of exceeding credits is equal or greater than to the median according to the chosen bachelor’s degree, resulting in a final size of the total data set of 13,066 samples for 48 bachelor’s degrees.
Model performance
Below, we present the results corresponding to the 10-fold cross-validation mean based on accuracy metrics for the top 5 (acc-5) and top 10 (acc-10) recommendations. Figure 2 summarizes the aforementioned results.

Results of 10-fold cross-validation according to the metrics of whether the recommendation is in the top 5 or top 10 recommended grades. The gain with respect to the base model is shown in parentheses (algorithm acc/baseline acc).
We observe that the most effective algorithms are those based on gradient descent and boosting applied to decision trees, excelling in both acc-5 and acc-10. The algorithm that stands out as the best performer in both metrics is CatBoost, achieving 70% and 88% accuracy, with improvements ratios of 1.85 and 1.58 over the Baseline, respectively. Additionally, Neural Net ranks second with a respectable accuracy rate of 69% and 88%, respectively.

Average results of 10-CV sorted by the acc-5. Green bullets indicate the Y-axis algorithm is significantly better than X-axi.
Figure 3 depicts pairwise comparisons within the context of our case study. Comparisons were conducted using the Wilcoxon signed-rank test50, employing the standard 95% confidence level51 with Holm’s adjustment52. This non-parametric statistical test does not assume a normal distribution of means. The results suggest that gradient-based tree and neural network models significantly outperform others (as indicated by the green bullets). However, given CatBoost’s slight edge over Neural Net, we will henceforth select it as the preferred algorithm for conducting explainability tests.
Examples of explainability
Next, we will analyze the results of the impacts of the input variable values on the model using the SHAP tool. To do this, we first need to choose a bachelor’s degree program, which is a category of the target variable, and in this way, we can extract the general profiles associated with each one to interpret them.
Given that there are 48 bachelor’s degree programs grouped into different faculties, and considering the affiliation of the authors of this study and the know-how acquired during our years as educators, we have selected bachelor’s degree programs that appear to be similar to compare the profiles extracted using the SHAP explainability tool for machine learning. Thus, we have selected two engineering degree programs belonging to the Polytechnic School, and two Master’s degree programs in Education belonging to the Faculty of Education.
Example profiles: bachelor’s degree in robotics engineering vs. computer engineering
As mentioned earlier, these degrees may seem similar in content except for the application to the field of robotics. Figure 4 shows, in graphical format, the first variables according to their importance in two engineering degrees.

Comparison of explainability with SHAP values for the Degree in Robotics Engineering and Computer Engineering. The variables are arranged from left to right in order of decreasing importance. The average SHAP impact is indicated in parentheses.
These scatter plots for each variable represent the impact on the model’s prediction of a sample’s value (student)—all of them are calculated as part of a test in the 10-fold cross-validation, meaning they are part of the prediction and not the training, to avoid the undesired effect of overfitting—. If this sample is situated above y = 0 (dashed line), the algorithm will positively value similar samples for recommending the degree, and conversely, if the impact is below 0, the tendency will be not to recommend this degree. The greater the distance of these impacts from y = 0, the greater their contribution to the final positive or negative decision.
If we interpret the trends in the Degree in Robotics Engineering for each feature, we observe that:
-
Mathematics is the most relevant variable with an average impact of 0.621. The higher the grade in this subject, the more likely it is that this degree will be recommended. Positive recommendations start around a value of 3.
-
Year of Enrollment ranks second, with particular relevance for the years between 2015 and 2017, during which there were more enrollments.
-
Physics is in third place, and similar to mathematics, the higher the grade, the greater the probability of recommending the degree.
-
There is a clear gender gap, with the male gender having the most positive impact.
-
In fifth place is the variable Average Pre-university Studies; this system considers that starting from an 8, the probability of recommendation will be positive.
Regarding studies in computer engineering, we highlight that:
-
Firstly, we have Gender. Typically, in engineering fields, there is a gender gap, and in this case, similar to the previous engineering degree, there is a higher probability that the male gender will study it, with an average impact of 0.704.
-
The second variable is Geography, with an average impact of 0.581. If this subject has been evaluated in the entrance exams and high grades have been achieved, it is less likely that this degree will be studied.
-
In third place is the subject of Mathematics, commonly assumed to be important in engineering. In this instance, positive recommendations are established around a value of 2 or higher.
-
Physics, similar to Robotics, is in fourth place, and the higher the grade, the more likely it is to be recommended.
-
In this case, Applied Mathematics in Social Sciences ranks fifth, and similar to Geography, the relationship is inverse, meaning that the higher the grade, the lower the probability of recommending this degree program.
Example profiles: degree in primary education vs. early childhood education
In this new example, we will compare the degree in Early Childhood Education and Primary Education. Figure 5 shows the impacts of the SHAP values according to the input variables of the model.

Comparison of explainability with SHAP values for the Bachelor’s Degree in Early Childhood Education and the Bachelor’s Degree in Primary Education. The variables are arranged from left to right in order of decreasing importance. The average SHAP impact is indicated in parentheses.
Just as we commented on the plots corresponding to the two engineering degrees, we will proceed to interpret the impact plots corresponding to these two education degrees. We will start with Early Childhood Education:
-
The first notable variable is Gender, with a strong impact of 1.019. In this case, there is a gender gap oriented towards the female sex, where it clearly has a greater impact on the recommendation of these studies.
-
The second variable is the subject English, with an impact of 0.286, where an inverse relationship is observed. That is, the higher the grade in this subject, the less likely the model is to recommend these studies.
-
Similar to the previous trend, Mathematics has an inverse impact relationship.
-
On the other hand, Geography has a direct, non-linear relationship, and with grades above 2.5, a positive recommendation begins.
-
In fifth place is Average Pre-university Studies, also with an inverse relationship. Thus, the trend is that if a grade below 7 is obtained, this bachelor’s degree program would be recommended, and with higher grades, it would not.
Regarding studies in Primary Education, we will comment on each of the variables that appear in the graph:
-
The first variable in importance corresponds to Applied Mathematics in Social Sciences, with an impact of 0.259, where the relationship is direct but with a non-linear effect. The impact of the recommendation increases with values above 3, stabilizes around 7, and decreases again until reaching 10.
-
Similar to the previous degree program, the variable Gender establishes a gender gap. In this case, with an impact of 0.246, which is lower than the previous degree program (the impacts are closer to y = 0) and is in the second position in importance.
-
In third place, we find Geography with a behavior similar to the previous degree.
-
In fourth place is Physics, with an inverse relationship. Practically, if this subject has been evaluated in the entrance exams, the higher the grade obtained, the less likely it is that Primary Education will be studied.
-
Mathematics is in fifth place with a behavior also similar to the previous degree program but with a lower impact of 0.218.
Recommender tool
Finally, with the aim of facilitating access to and usage of our university bachelor’s degree recommendation system, we have developed a simple yet functional and efficient tool for this purpose. We have utilized the Jupyter Notebooks technology of Python with the online service of Google Colab.
We have chosen this method of access due to its free availability and ease of use, requiring only a web browser.
This tool has been developed as a proof-of-concept and has been shared with guidance counselors to demonstrate its potential for assisting in the personalized attention to students in their respective educational institutions, and it could also serve as an example or foundation for other developments, as its source code is accessible.
Discussion
This section presents general considerations, key findings, and limitations of our study, as outlined in the following subsections.
General considerations
The studies by Delogu et al.34 and Vaarma & Li35 present machine learning-based approaches to detect student dropout in different contexts. Delogu et al. analyze Italian universities, considering academic and socioeconomic factors, and find that low academic performance and unfavorable socioeconomic situations are related to dropout. Vaarma & Li study academic records, demographic data, and data on the use of a learning management system (LMS) in a Finnish university, concluding that low academic performance and low LMS usage are determining factors for dropout. We observe how, in different contexts, academic performance is an important factor for the successful completion of higher education.
Our study is based on these findings to relate pre-university academic data with academic success profiles in university. Through this relationship, we hope that students will choose bachelor’s degree programs compatible with their profiles, thereby reducing the risk of dropout. We also consider the role of school counselors important, as they should also evaluate sociodemographic and socioeconomic variables along with our recommendations to provide comprehensive support to students.
Findings
It is important to contextualize the performance of our model. While some fields of predictive analytics may strive for accuracy thresholds upwards of 95%, the goal of this system is not to deterministically predict a student’s fate, but to provide recommendations. In the context of educational guidance, a top-10 recommendation list with an accuracy of nearly 90% represents a powerful tool for exploration, significantly narrowing down the 48 available degrees to a manageable and relevant subset. The aim is to augment the counselor’s expertise, not to replace it, by providing data-driven starting points for conversation.
We have observed some interesting characteristics in the recommendations thanks to the explainability of the ML models, which are not obvious to experts. In the analysis of examples from both engineering and education bachelor’s degrees, we have found relationships between the subjects taken and the recommendations for the bachelor’s degree programs. For example, there are inverse relationships with the subject of Geography and the Bachelor’s Degree in Computer Engineering. This can be understood in two ways: if a student takes this subject and achieves a good grade, it is unlikely that they will decide to study this degree; or, on the other hand, students who have chosen computer engineering with good performance (we have selected only those students whose credits passed in the first year are equal to or greater than the median in that degree program) have not taken this subject. We also observe the same effect in the Bachelor’s Degrees in Education with subjects such as Mathematics, English, or Physics, where having taken these subjects or having obtained good grades in them negatively affects the decision to recommend these degree programs.
We have also observed other relationships that seem more logical, such as Mathematics having a positive relationship with engineering degrees, as would be expected, and that there is a gender gap favoring males. In the Bachelor’s Degrees in Education, there is also a gender gap, in this case favoring females, and in this case, the subject of Geography has a positive relationship between the grade obtained and the probability of recommending these degree programs.
Limitations
We have used the available data from a single public higher education institution, a Spanish university, which provided this anonymized information following a formal request reviewed by the Vice-Rectorate of Technology and the ethics committee. While this study is confined to a single institution, this focus provides a unique level of specificity. The model captures particular success factors inherent to the university itself, such as its specific curriculum, teaching methodologies, and evaluation criteria. A student’s success is influenced by these local nuances, meaning that the profile for a successful engineering student at the University of Alicante might differ from that at another institution. Therefore, rather than a limitation, the single-university scope should be seen as a feature that makes the tool’s recommendations highly contextualized and relevant for students considering this specific university.
We understand that this study lacks emotional and socioeconomic context information related to the students, as this information does not currently exist and is not possible to obtain given the large volume of students we have analyzed, which includes 13 academic years. However, our proposal for the university is to use a widely utilized personality test such as the Big Five53 to obtain useful information in the future that will impact the students themselves. Additionally, the amount of data on student profiles could be expanded by attempting to obtain additional information managed by public institutions such as the Consellería de Educación in the Valencian Community to cross-reference the data with students enrolled in the university during the studied periods and thus obtain, in an anonymized manner, all complete academic records of pre-university studies, which would likely positively impact the improvement of the training of our ML model and the precision of its recommendations.
Finally, a major limitation of our study is the lack of a formal user-centric evaluation. We frame this as an important next step for future work, which must involve usability testing and qualitative feedback from counselors.
Ethical considerations and responsible AI
A more significant limitation, however, is the absence of a formal evaluation of the developed tool with its intended end-users: school counselors. The current research focuses on the technical validation of the machine learning model, but a user-centric evaluation is a critical next step. Future work must include usability testing and qualitative feedback from counselors to assess the tool’s real-world effectiveness. Furthermore, the model relies solely on academic records, lacking psychometric or socioeconomic data for a more holistic view. Future iterations could be enhanced by incorporating validated personality assessments, such as the Big Five model, to capture non-academic traits correlated with student success.
The development of AI-based recommendation systems in education, while promising, raises significant ethical questions. The primary concern is not whether such a system can be built, but whether it should be used without a deep understanding of its potential societal impact. The use of algorithmic systems in high-stakes decisions like education is a topic of intense debate, with scholars warning about the risks of “automating inequality"54.
The Risk of Reinforcing Stereotypes: Our SHAP analysis (Figs. 4 and 5) clearly reveals that the model identifies and learns existing societal biases from the historical data. The strong correlation between gender and certain degree programs (e.g., males with Engineering, females with Education) is a stark example. This is a well-documented phenomenon in machine learning, where models trained on biased data inevitably reproduce, and can even amplify, those biases55. If used naively, the recommendation tool could perpetuate these harmful stereotypes, discouraging female students from pursuing STEM fields and male students from education, thus undermining decades of effort to promote diversity and equity in these areas56.
Inductive Reasoning and the Is-Ought Problem: The system operates on the principle of inductive reasoning, analyzing past trends (“what is”) to recommend future choices. As the philosopher David Hume noted, this approach can be problematic in the social sciences. By recommending degrees based on profiles of previously successful students, the system inherently favors the status quo. It risks creating a feedback loop where the model’s predictions influence user choices, and those choices then generate data that confirms the model’s original biases57. This process can reduce the diversity of the student population over time and fail to identify potential in students who do not fit traditional molds, thus reproducing the current demographic landscape (“what is”) rather than helping to create a more inclusive one (“what ought to be”).
AI Literacy and Over-reliance: A critical factor for the responsible deployment of this tool is the promotion of AI literacy among its users58. Counselors must be trained to understand the system’s limitations, its probabilistic nature, and its inherent biases. The tool should be viewed as a supplementary instrument for augmenting professional judgment, not as an infallible oracle. Over-reliance on its outputs, a phenomenon known as automation bias, could lead to a reduction in the quality of guidance, narrowing down student options prematurely and discouraging exploration59. Therefore, the tool is intentionally designed for professional counselors, who can apply their own judgment, rather than for direct use by students.
Therefore, any future deployment of this tool must be accompanied by a robust framework for responsible AI. This includes: (1) regular audits of the model for bias and fairness using established frameworks60, (2) clear communication of the system’s capabilities and limitations to all stakeholders, and (3) comprehensive training for counselors on its ethical use.
Conclusions and future work
Different machine learning algorithms with cross-validation have been applied to obtain the best predictions and thus build a bachelor’s degree recommender for a Spanish university, which has served as a case study. Using the CatBoost algorithm, we achieved a total of 70% accuracy with the first 5 predictions and 90% using the first 10 predictions. Additionally, we applied explainability techniques to understand in detail the trends in the profiles of students across all bachelor’s degree programs, allowing us to take corrective measures if necessary. We considered two examples from engineering and education fields to interpret the results of the explainability, noting direct and inverse relationships between some subjects and their possible recommendations. Also, a simple recommendation tool has been created to test the system.
For future work, it would be beneficial to apply recent ML techniques such as classification using graph algorithms with deep neural networks and compare results. Additionally, we aim to expand the dataset with profiles from upcoming courses and collaborate with other universities to enable a broader bachelor’s degree recommendation based on evidence from various institutions.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Al Ahmar, M. A. A prototype rule-based expert system with an object-oriented database for university undergraduate major selection. Proceeding Int. J. Appl. Inf. Syst. IJAIS 1–5 (2012).
te Wierik, M. L. J., Beishuizen, J. & van Os, W. Career guidance and student success in Dutch higher vocational education. Stud. High. Educ. 40, 1947–1961 (2015).
Hailikari, T., Tuononen, T. & Parpala, A. Students’ experiences of the factors affecting their study progress: differences in study profiles. J. Furth. High. Educ. 42, 1–12 (2018).
Ruohoniemi, M. & Lindblom-Ylänne, S. Students’ experiences concerning course workload and factors enhancing and impeding their learning – a useful resource for quality enhancement in teaching and curriculum planning. Int. J. Acad. Dev. 14, 69–81 (2009).
Vista, A. & Alkhadim, G. S. Pre-university measures and university performance: a multilevel structural equation modeling approach. in Frontiers Education 7 723054 (Frontiers, (2022).
Ogowewo, B. O. Factors influencing career choice among secondary school students: implications for career guidance. Int J. Interdiscip Soc. Sci 5, (2010).
Suryadi, B., Sawitri, D. R., Hayat, B. & Putra, M. D. K. The influence of Adolescent-Parent career congruence and counselor roles in vocational guidance on the career orientation of students. Int. J. Instr. 13, 45–60 (2020).
Lapan, R. T., Gysbers, N. C. & Sun, Y. The impact of more fully implemented guidance programs on the school experiences of high school students: A statewide evaluation study. J. Couns. Dev. 75, 292–302 (1997).
Parpala, A., Lindblom-Ylänne, S., Komulainen, E., Litmanen, T. & Hirsto, L. Students’ approaches to learning and their experiences of the teaching–learning environment in different disciplines. Br. J. Educ. Psychol. 80, 269–282 (2010).
Trigwell, K. Routledge,. Scholarship of teaching and learning. In University teaching in focus 286–303 (2021).
Schneider, M. & Preckel, F. Variables associated with achievement in higher education: A systematic review of meta-analyses. Psychol. Bull. 143, 565 (2017).
Javaid, M. et al. Evolutionary trends in progressive cloud computing based healthcare: Ideas, enablers, and barriers. Int. J. Cogn. Comput. Eng. 3, 124–135 (2022).
Oliver-Roig, A., Rico-Juan, J. R., Richart-Martínez, M. & Cabrero-García, J. Predicting exclusive breastfeeding in maternity wards using machine learning techniques. Comput. Methods Programs Biomed. 221, 106837 (2022).
Carter, B. Understanding the Cost of Healthcare Inpatient Services: Prediction of of Medicare Inpatient Hospital Costs of Diagnosis-Related Groups (Truman State University, 2023).
Llorca-Schenk, J., Rico-Juan, J. R. & Sanchez-Lozano, M. Designing porthole aluminium extrusion dies on the basis of eXplainable artificial intelligence. Expert Syst. Appl. 222, 119808 (2023).
Liu, T. et al. Optimizing green supply chain circular economy in smart cities with integrated machine learning technology. Heliyon 10, (2024).
Rico-Juan, J. R. & de La Paz, P. T. Machine learning with explainability or Spatial hedonics tools? An analysis of the asking prices in the housing market in Alicante, Spain. Expert Syst. Appl. 171, 114590 (2021).
Rico-Juan, J. R., Gallego, A. J. & Calvo-Zaragoza, J. Automatic detection of inconsistencies between numerical scores and textual feedback in peer-assessment processes with machine learning. Comput. Educ. 140, 103609 (2019).
Zheng, L. et al. Evolutionary machine learning builds smart education big data platform: Data-driven higher education. Appl. Soft Comput. 136, 110114 (2023).
Koh, P. W. & Liang, P. Understanding black-box predictions via influence functions. In International conference on machine learning 1885–1894PMLR, (2017).
Arrieta, A. B. et al. Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion. 58, 82–115 (2020).
Lundberg, S. SHAP (SHapley Additive exPlanations). (2019).
Recker, M. M., Walker, A. & Lawless, K. What do you recommend? Implementation and analyses of collaborative information filtering of web resources for education. Instr Sci. 31, 299–316 (2003).
Lemire, D., Boley, H., McGrath, S. & Ball, M. Collaborative filtering and inference rules for context-aware learning object recommendation. Interact. Technol. Smart Educ. 2, 179–188 (2005).
Bendakir, N. & Aïmeur, E. Using association rules for course recommendation. In In Proceedings of the AAAI workshop on educational data mining vol. 3 1–10 (2006).
Farzan, R. & Brusilovsky, P. Social navigation support in a course recommendation system. in Adaptive Hypermedia and Adaptive Web-Based Systems (eds Wade, V. P., Ashman, H. & Smyth, B.) (vol 4018 91–100 (Springer Berlin Heidelberg, Berlin, Heidelberg, (2006).
Tavakoli, M. et al. An AI-based open recommender system for personalized labor market driven education. Adv. Eng. Inf. 52, 101508 (2022).
Koren, Y., Rendle, S. & Bell, R. Advances in collaborative filtering. Recomm Syst. Handb 91–142 (2021).
Fareed, A., Hassan, S., Belhaouari, S. B. & Halim, Z. A collaborative filtering recommendation framework utilizing social networks. Mach. Learn. Appl. 14, 100495 (2023).
Yan, K. Optimizing an english text reading recommendation model by integrating collaborative filtering algorithm and fasttext classification method. Heliyon (2024).
Baker, R. S., Martin, T. & Rossi, L. M. Educational data mining and learning analytics. in The Handbook of Cognition and Assessment (eds (eds Rupp, A. A. & Leighton, J. P.) 379–396 (John Wiley & Sons, Inc., Hoboken, NJ, USA, doi:https://doi.org/10.1002/9781118956588.ch16. (2016).
Iatrellis, O., Savvas, I. Κ., Fitsilis, P. & Gerogiannis, V. C. A two-phase machine learning approach for predicting student outcomes. Educ. Inf. Technol. 26, 69–88 (2021).
Moreno-Marcos, P. M., Alario-Hoyos, C., Muñoz-Merino, P. J. & Kloos, C. D. Prediction in moocs: A review and future research directions. IEEE Trans. Learn. Technol. 12, 384–401 (2018).
Delogu, M., Lagravinese, R., Paolini, D. & Resce, G. Predicting dropout from higher education: evidence from Italy. Econ. Model. 130, 106583 (2024).
Vaarma, M. & Li, H. Predicting student dropouts with machine learning: an empirical study in Finnish higher education. Technol. Soc. 76, 102474 (2024).
Bayes, T. Naive Bayes classifier. Artic Sources Contrib 1–9 (1968).
Breiman, L. Classification and Regression Trees (Routledge, 2017).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55, 119–139 (1997).
Chen, T. & Guestrin, C. XGBoost: A Scalable Tree Boosting System. CoRR abs/1603.02754, (2016).
Ke, G. et al. LightGBM: A highly efficient gradient boosting decision tree. in Advances Neural Inform. Process. Systems 3149–3157 (2017).
Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: gradient boosting with categorical features support. ArXiv Prepr. ArXiv181011363 (2018).
Pedregosa, F. et al. Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Hinton, G. E. Connectionist learning procedures. in Machine Learning, Volume III 555–610Elsevier, (1990).
Cover, T. M. & Hart, P. E. Nearest neighbor pattern classification. Inf. Theory IEEE Trans. On. 13, 21–27 (1967).
Adadi, A. & Berrada, M. Peeking inside the Black-Box: A survey on explainable artificial intelligence (XAI). IEEE Access. 6, 52138–52160 (2018).
Lundberg, S. M. & Lee, S. I. Consistent feature attribution for tree ensembles. ArXiv Prepr. ArXiv170606060 (2017).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. in Advances Neural Inform. Process. Systems 4765–4774 (2017).
Bellman, R. Dynamic programming. Science 153, 34–37 (1966).
Wilcoxon, F. Individual comparisons by ranking methods. Biom Bull. 1, 80–83 (1945).
Stapor, K., Ksieniewicz, P., García, S. & Woźniak, M. How to design the fair experimental classifier evaluation. Appl. Soft Comput. 104, 107219 (2021).
Holm, S. A simple sequentially rejective multiple test procedure. Scand J. Stat 65–70 (1979).
John, O. P., Donahue, E. M. & Kentle, R. L. Big Five Inventory. (2012). https://doi.org/10.1037/t07550-000.
Eubanks, V. Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor. (Macmillan + ORM, (2025).
Verma, S. Weapons of math destruction: how big data increases inequality and threatens democracy. Vikalpa J. Decis. Mak. 44, 97–98 (2019).
D’ignazio, C. & Klein, L. F. Data Feminism (MIT Press, 2023).
Ensign, D., Friedler, S. A., Neville, S., Scheidegger, C. & Venkatasubramanian, S. Runaway feedback loops in predictive policing. in Conference on fairness, accountability and transparency 160–171PMLR, (2018).
Long, D. & Magerko, B. What is AI Literacy? Competencies and Design Considerations. in Proceedings of the CHI Conference on Human Factors in Computing Systems 1–16 (ACM, Honolulu HI USA, 2020). HI USA, 2020). (2020). https://doi.org/10.1145/3313831.3376727.
Skitka, L. J., Mosier, K. & Burdick, M. D. Accountability and automation bias. Int. J. Hum. -Comput Stud. 52, 701–717 (2000).
Morley, J., Floridi, L., Kinsey, L. & Elhalal, A. From what to how: an initial review of publicly available AI ethics Tools, methods and research to translate principles into practices. Sci. Eng. Ethics. 26, 2141–2168 (2020).
Funding
This work has been partially funded by Intralab 2023, project IDA23 for the promotion of digital transformation at the University of Alicante.
Author information
Authors and Affiliations
Contributions
J. R.-J. has participated in: Data curation; Formal analysis; Investigation; Methodology; Project administration; Resources; Software; Supervision; Validation; Visualization; Roles/Writing - original draft; and Writing - review & editing.M. P.-F. has participated in: Conceptualization; Investigation; Methodology; Supervision; Roles/Writing - original draft; and Writing - review & editing in English.A. J.-M. has participated in: Conceptualization; Investigation; Methodology; Supervision; Roles/Writing - original draft; and Writing - review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics
All methods were performed in accordance with the relevant guidelines and regulations. This research has been granted by the Ethics Committee of the University of Alicante, in ordinary session of March 29, 2025, approved the Research Protocol entitled: “System of orientation to undergraduate studies at the University of Alicante using machine learning and explainability for students coming from baccalaureate” Code UA-2025-05-27. Informed consent was obtained from all human research participants.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rico-Juan, J.R., Pertegal-Felices, M.L. & Jimeno-Morenilla, A. Using explainable AI to align pre-university profiles with bachelor’s degree success. Sci Rep 15, 44373 (2025). https://doi.org/10.1038/s41598-025-28179-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28179-z
