
Abstract
The intelligent generation of Peking Opera facial makeup presents a unique challenge in stylized image generation, bridging artificial intelligence with traditional cultural preservation. This study addresses two critical gaps: (1) the need for high-fidelity generation that captures intricate artistic details, and (2) the scarcity of labeled datasets for training. We propose an enhanced Stable Diffusion framework integrating region-specific noise scaling and attention-augmented U-Net models to improve contrast and fine-grained detail synthesis. LoRA fine-tuning further optimizes generation efficiency without compromising quality. Evaluations demonstrate superior performance over SOTA models, achieving FID (16.34), KID (9.44), and SSIM (0.4912) scores, validating the model’s effectiveness in preserving cultural authenticity while accelerating production.
Similar content being viewed by others
Introduction
Peking Opera holds immense cultural value as a cornerstone of Chinese traditional performing arts, integrating music, vocal performance, mime, dance, and acrobatics to convey ancient stories, philosophies, and aesthetics1,2. With over two centuries of history, it not only reflects the richness of Chinese cultural heritage but also acts as a medium for preserving historical narratives and values. Central to Peking Opera’s visual identity is the facial makeup, which carries significant cultural importance3. The intricate designs, composed of distinct colors and patterns, serve as a visual language that communicates the personality, social standing, and moral disposition of characters. This symbolic system of facial makeup not only enhances the theatrical experience but also embodies centuries of cultural meaning and artistic convention. The intelligent generation of Peking Opera facial makeup using generative artificial intelligence introduces a transformative dimension to this traditional art form4.
The intelligent generation of Peking Opera facial makeup serves as a representative case of stylized image generation, offering valuable insights into the integration of artificial intelligence with traditional cultural expressions. In recent years, the research focus has been on employing deep learning techniques, such as Generative Adversarial Networks (GANs)5 and Variational Autoencoders (VAEs)6, to automate the creation of images that replicate the unique stylistic characteristics of Peking Opera facial makeup. These models are trained on large datasets of traditional facial makeup designs, learning the intricate patterns, colors, and symbolic elements that define different character types in Peking Opera. Once trained, these models can generate new designs that maintain the aesthetic and symbolic integrity of the original art form while offering opportunities for customization and stylistic variation. Recent studies have extended this concept to incorporate user inputs, allowing for personalized and adaptive designs that cater to individual preferences while retaining the cultural authenticity of the original makeup styles.
The significance of intelligent generation in this context is multifaceted. First, it addresses the challenge of preserving traditional cultural art forms in an era of rapid technological advancement and cultural globalization. By digitizing and automating the design process of Peking Opera facial makeup, this technology ensures the continuity of a culturally significant art form that might otherwise face the risk of decline due to the dwindling number of traditional artisans. The process allows for the replication of classic designs and offers a new medium through which younger generations can engage with and appreciate the artistry of Peking Opera facial makeup. Second, the intelligent generation of Peking Opera facial makeup enhances the efficiency and accessibility of the design process. Traditionally, facial makeup requires highly specialized skills and years of training to master. With the application of AI, the time-consuming manual process can be streamlined, and high-quality designs can be produced rapidly and at scale. This not only reduces the resource burden on traditional craftsmen but also empowers contemporary artists to experiment with new designs, expanding the creative possibilities while maintaining a connection to the cultural roots of the art form. Furthermore, the personalization capabilities offered by AI-driven facial makeup generation represent a significant leap forward in the intersection of cultural heritage and modern technology. Users can interact with the generative models to create personalized designs that reflect their unique preferences while adhering to the symbolic meanings and aesthetic rules of Peking Opera makeup. This opens up possibilities for audience engagement, educational applications, and cultural dissemination, as more people are likely to become involved in the creation and appreciation of Peking Opera facial makeup through these adaptive platforms.
Based on the current research efforts worldwide, intelligent stylized image generation has become a prominent area of research and development in recent years. Yang7 proposed a new product intelligent design method using interactive evolutionary algorithms to generate batched appearance design schemes that match target style images. This approach allows for the direct acquisition of design schemes that meet specific criteria. Apple has introduced Apple Intelligence, which includes image creation capabilities to enhance communication and self-expression8. Leveraging AI for image generation has been explored in various contexts, such as managing human risk9 and creating stylized images10. The use of AI in generating high-resolution and stylized images has been highlighted as a key feature of AI art generators like Midjourney11. Moreover, the potential of AI in creating stylized images, super-resolution images, and image samples has been recognized12. Image generation using AI models involves the process of creating realistic or stylized images from scratch13. Learning Cooperative Neural Modules for Stylized Image Captioning has been explored as a method to generate stylized image descriptions. Incorporating intelligent automation tools, such as AI image generators, can accelerate and enhance content creation processes. Overall, the research and development in intelligent stylized image generation continue to advance, offering new possibilities for creative expression and design. The commonly used intelligent stylized image generation models in current research include the following five:
-
Generative Adversarial Networks (GANs)14 In the context of Peking Opera facial makeup generation, GANs are advantageous due to their ability to produce high-quality, detailed, and diverse designs that capture the intricate details of traditional makeup. However, GANs can be challenging to train, often requiring large datasets and extensive computational resources. Additionally, they may struggle with generating consistent designs that adhere to specific stylistic rules or symbolic meanings.
-
Variational Autoencoders (VAEs) In Peking Opera facial makeup generation, VAEs are beneficial for producing diverse and coherent designs that maintain the underlying structure and style of traditional faces. VAEs also allow for smoother interpolation between different designs, making it easier to explore variations. However, VAEs may produce less detailed images compared to GANs and can sometimes lack the fine-grained control needed to preserve specific cultural symbols and aesthetics 15.
-
Style Transfer Networks16 Style Transfer Networks use deep learning techniques to apply the artistic style of one image to the content of another. This model involves extracting the style and content features of images and combining them to create new images that blend both aspects. For Peking Opera facial makeup, style transfer networks are useful for adapting traditional designs to new contexts or integrating modern elements while preserving the characteristic style. The primary advantage is the ability to blend styles creatively, but the approach may face limitations in maintaining the high fidelity of symbolic details and may not always respect the traditional boundaries of facial makeup design.
-
Transformer-Based Models For Peking Opera facial makeup, transformer-based models can generate intricate and detailed designs by capturing dependencies across different parts of the makeup. The advantage is the ability to handle complex and detailed design patterns. However, these models can be computationally expensive and may require large amounts of data and resources to train effectively 17.
-
Hybrid Models Hybrid Models combine elements from different generative approaches to leverage their strengths and mitigate individual limitations. For instance, a hybrid model might integrate GANs with VAEs or use attention mechanisms alongside convolutional networks. In the context of Peking Opera facial makeup generation, hybrid models can offer enhanced flexibility and performance by combining the strengths of various methods, such as high-quality detail generation from GANs and diverse style representation from VAEs. The advantage is improved performance and adaptability. However, designing and training hybrid models can be complex, requiring careful integration of different components and management of their interactions 18.
The current primary intelligent stylized image generation algorithms can be categorized based on their generation principles, as illustrated in Fig. 1.

Classification of Major Intelligent Stylized Image Generation Algorithms.
Based on the characteristics of Peking Opera facial makeup, this research focuses on the following critical areas:
-
1.
Ensuring Image Quality The primary goal is to enhance the realism and detail of the generated Peking Opera facial makeup images. The research must focus on achieving high-fidelity image generation that captures the intricate features of traditional facial makeup, including fine lines, detailed patterns, and rich textures. The challenge here is to ensure that the generated images are both aesthetically accurate and culturally authentic, reflecting the traditional art form’s complexity.
-
2.
Managing High Contrast in Images Peking Opera facial makeup typically features high contrast between bright and dark regions, a defining characteristic of the art form used to exaggerate and emphasize the personality traits of the characters. The research must prioritize maintaining and enhancing this contrast to ensure that the generated images effectively convey the dramatic features of the makeup. This requires designing algorithms or mechanisms, such as separate random number generators for bright and dark areas, to ensure that the contrast levels are appropriately amplified, leading to more vibrant and expressive designs.
-
3.
Improving Model Inference Speed Traditional Stable Diffusion models, while effective in generating high-quality images, often suffer from slow performance due to the large number of iterations required. Enhancing the speed of the generation process without compromising image quality is a key challenge. The research needs to focus on optimizing the model, potentially through techniques like LoRA (Low-Rank Adaptation) fine-tuning, to reduce computational load and improve efficiency, making the system more suitable for real-time or large-scale applications.
-
4.
Introducing Prompt-Based Customization Current models for Peking Opera facial makeup generation are fully automated, which limits user control over the final design. By integrating a prompt mechanism, such as text-to-image or image-to-image guidance, this research aims to offer users more flexibility in customizing the generated facial makeup. This customization feature will allow users to input specific instructions or preferences, guiding the model to generate designs that are highly personalized yet culturally consistent. This innovation will address the growing demand for user-driven design while preserving the artistic integrity of traditional Peking Opera makeup.
This study focuses on the intelligent generation of Peking Opera facial makeup images by addressing key challenges and introducing several innovations. First, to enhance the high contrast characteristic of Peking Opera makeup, two random number generators are designed to independently generate colors for bright and dark regions, ensuring a greater brightness difference and producing more vibrant makeup colors. Second, to improve the quality and realism of the generated images, multiple attention mechanism enhanced U-Net models19 are employed, which refine the generation process by capturing fine details and improving authenticity. Third, to enable customizable facial makeup generation from textual descriptions, a labeled dataset of Peking Opera facial makeup is used to train a text-guided image generation model, allowing for personalized and contextually accurate designs. Finally, to address the slow execution speed of existing models, LoRA fine-tuning network20 is implemented to optimize the model’s performance, accelerating the generation process while maintaining image quality. This comprehensive approach ensures high-quality, customizable, and efficient Peking Opera facial makeup generation.
The contributions of this research can be summarized in the following four aspects:
-
Two random number generators were designed to separately generate colors for the bright and dark regions. This enhances the contrast between the bright and dark areas, resulting in more vibrant facial makeup colors.
-
Multiple attention mechanism enhanced U-Net models were employed to enhance the realism and refinement of the generated images.
-
A labeled dataset of facial makeup was collected to train the model for text-guided image generation.
-
The LoRA fine-tuning network was used to accelerate the model training.
Related work
Information-guided image generation
Information-guided image generation refers to the process of generating images based on supplementary information, such as textual descriptions, labels, or other contextual data. This approach can be broadly classified into several categories based on the type of guiding information used and the underlying generation mechanisms.
-
Text-to-Image Generation Text-to-image generation involves creating images from textual descriptions. Models typically use natural language processing techniques to interpret the textual input and then generate corresponding images that align with the described content. This often involves encoding text using models like BERT or GPT and decoding it into images using generative models such as GANs or VAEs. This approach allows for high degrees of customization and flexibility, enabling users to generate images that match specific, detailed descriptions. It is particularly useful for applications where precise visual representation of textual concepts is needed. Challenges of text-to-image generation include ensuring the coherence and accuracy of the generated images with respect to the textual descriptions, as well as managing the complexities of interpreting nuanced or ambiguous text. Additionally, the models may struggle with generating highly detailed or complex images if the text is not sufficiently descriptive 21.
-
Image-to-Image Translation Image-to-image translation involves converting images from one domain to another while preserving the core content. This can include tasks such as colorization, style transfer, or converting sketches to realistic images. Techniques like GANs or conditional VAEs are used to map between domains, guided by the input images. This method leverages existing images to guide the generation process, often leading to more accurate and contextually relevant results. It is effective for tasks where the target and source domains share underlying similarities. However, it requires a substantial amount of paired training data and may struggle with domain gaps or when the source and target domains are very different. It also may produce less accurate results if the input images are not well-representative of the target domain 22.
-
Conditional Generative Models Conditional generative models generate images based on additional conditional variables such as labels, attributes, or other forms of context. These models, like conditional GANs (cGANs) or conditional VAEs(cVAEs), incorporate conditional inputs during training to guide the generation process. They offer the ability to control and customize the generated images according to specific conditions or attributes, making them useful for applications that require specific characteristics or features. However, their performance is highly dependent on the quality and specificity of the conditional information provided. Additionally, managing and tuning multiple conditional variables can complicate the model training and result in less stable outputs 23.
-
Interactive Evolutionary Algorithms Interactive evolutionary algorithms use evolutionary principles to generate images based on user feedback or preferences. The system evolves image candidates through iterative feedback loops where users select preferred outputs, guiding the algorithm towards desired results. They allow for direct user interaction and iterative refinement, leading to highly personalized and user-driven outcomes. This approach can effectively handle complex and subjective criteria that are difficult to specify upfront. However, it can be time-consuming and requires active user participation, which may not be practical for all applications. The quality of the final results heavily depends on the user’s input and the efficiency of the feedback loop 24.
Stylized image generation
Stylized image generation is a process that transforms images by applying specific stylistic elements while preserving their core content. The principle behind stylized image generation involves leveraging deep learning models, particularly Generative Adversarial Networks and Variational Autoencoders, to manipulate and integrate stylistic features into images. These models learn to capture the stylistic nuances from a reference style and apply them to target images, enabling the creation of visually distinctive outputs that maintain the structural integrity of the original content.
Wang25 presented StyleAdapter, a LoRA-free method for stylized image generation that takes text prompts and style reference images to produce an output image in a single pass, although facing challenges related to content controllability and fidelity. Chen26 proposed ControlStyle, a task for text-driven stylized image generation that incorporates diffusion style and content regularizations to enhance editability in content creation. Moreover, Liu27 addressed challenges in producing user-desired stylized videos by introducing StyleCrafter, a method that enhances pre-trained text-to-video models with a style control adapter. Xu28 introduced StyleMaster, a framework for Stylized Text-to-Image Generation that leverages pretrained Stable Diffusion to improve style consistency and semantic coherence. Furthermore, Zhou29 proposed HoloDreamer, a pipeline for generating stylized and detailed equirectangular panoramas from text descriptions using multiple diffusion models. Lastly, Xing30 focused on content-style composition in text-to-image generation, emphasizing the use of diffusion models for controlled image generation and style transfer.
Current research in stylized image generation highlights several advantages. One significant benefit is the ability to achieve high levels of artistic creativity and visual appeal. By leveraging models trained on diverse datasets, researchers can generate images that reflect various artistic styles, from classical paintings to modern graphics, thus enhancing creative expression. Additionally, advances in techniques such as neural style transfer and adaptive instance normalization have improved the fidelity and coherence of stylized images, enabling more precise control over the application of stylistic features. However, there are notable limitations. One major challenge is ensuring the consistency and quality of the generated images, particularly when applying complex styles. Variations in style transfer can lead to artifacts or distortions that detract from the visual quality of the final image. Additionally, the computational complexity associated with training and fine-tuning deep learning models for stylized image generation can be substantial, leading to high resource consumption and longer processing times. Addressing these issues requires ongoing research to refine model architectures and optimize algorithms to balance style application with computational efficiency.
Diffusion-based image generation
Diffusion-based image generation models have emerged as a powerful approach in recent research, leveraging the gradual refinement of noisy images to produce high-quality outputs. The principle of diffusion models involves progressively adding noise to images and then reversing this process to generate new images from pure noise. These models, typically trained on large datasets, learn how to remove noise in a stepwise manner, resulting in the generation of realistic and detailed images.
Couairon31 introduced DiffEdit, leveraging text-conditioned diffusion models for semantic image editing, while Luo32 presented VideoFusion, a decomposed diffusion process for high-quality video generation. Bar33 introduced MultiDiffusion, a framework for versatile and controllable image generation using pre-trained text-to-image diffusion models without additional training. Ye34 proposed IP-Adapter, a lightweight adapter for adding image prompt capability to pretrained text-to-image diffusion models. Lastly, Blattmann35 discussed Stable Video Diffusion, a latent video diffusion model for text-to-video and image-to-video generation, emphasizing the importance of pretraining and finetuning stages for successful training of video LDMs.
One of the key advantages of diffusion models is their ability to generate high-quality, diverse images that often surpass the visual fidelity of traditional generative models such as GANs. Diffusion models can capture complex textures, subtle details, and a wide range of styles, making them particularly suitable for applications requiring high-resolution and precise image outputs. Additionally, these models tend to be more stable during training compared to GANs, which often suffer from issues like mode collapse and unstable gradients. The gradual noise removal process in diffusion models leads to more controlled and reliable image generation. However, there are notable challenges associated with diffusion-based image generation. One significant drawback is the computational cost. The iterative nature of diffusion models, where noise is added and removed over many steps, results in slow image generation times compared to more efficient models like GANs. This high computational demand can limit the scalability of diffusion models for real-time or large-scale applications. Furthermore, fine-tuning these models to generate specific styles or meet particular design requirements can be complex, as the stepwise process is less straightforward than the direct mapping in GANs.
Methodology
Overview
This study improves Stable Diffusion through four key innovations: (1) Dual random generators separately produce colors for bright/dark regions, enhancing traditional high-contrast aesthetics; (2) Multi-attention U-Net modules capture intricate makeup patterns and textures; (3) Text-guided generation enables customizable designs adhering to cultural conventions; (4) LoRA fine-tuning optimizes computational efficiency without quality loss. The entire process of Peking Opera facial makeup generation is illustrated in Fig. 2.

The entire process of Peking Opera facial makeup generation.
Peking opera facial makeup dataset with labels
In this study, a labeled dataset of Peking Opera facial makeup was constructed from multiple sources, including historical archives, digital collections, and professional Peking Opera resources. Each sample in the dataset includes several key fields: gender, primary colors3, character traits36, and role type. Specifically, the gender field consists of 45% male and 55% female characters. The primary colors field covers five main categories: red (30%), black (25%), white (20%), blue (15%), and yellow (10%), each representing different symbolic meanings. The character traits field includes classifications such as brave (35%), cunning (20%), loyal (25%), and villainous (20%), reflecting the personality types often depicted in Peking Opera. Additionally, the role type field divides the samples into different traditional roles, with Sheng (30%), Dan (35%), Jing (20%), and Chou (15%) being the most prominent categories.
The dataset also includes additional fields that provide further insights into the makeup design. One such field is symbolic patterns, which categorizes the facial markings into geometric shapes (40%), floral motifs (30%), and abstract designs (30%), each carrying cultural significance. Another important field is emotion, where the expressions represented in the facial makeup are classified as neutral (40%), angry (25%), joyful (20%), and sad (15%), reflecting the emotional depth of the characters. The age group of characters is also labeled, with young characters making up 40%, middle-aged characters 35%, and elderly characters 25%. The scene type field categorizes the makeup designs into battle scenes (30%), ceremonial scenes (25%), domestic scenes (20%), and supernatural scenes (25%), reflecting the diverse contexts in which these designs are used.
Each field is carefully labeled and validated to ensure accuracy, making this dataset a valuable resource for generating historically accurate and contextually rich Peking Opera facial makeup designs. This labeled dataset provides a comprehensive foundation for training models on facial makeup generation, ensuring that the generated designs align with traditional Peking Opera character types and aesthetics. Table 1 presents several Peking Opera facial makeup samples along with their labels.
The improved Stable diffusion model is applied for Peking opera facial makeup generation
Principle of the stable diffusion model
The Stable Diffusion model operates on the principle of iterative denoising of a noisy image to generate a high-quality output. The model’s workflow can be described in the following steps:
-
1.
Initialization: Start with a random noise image, \({\mathbf{x}}_{T}\), at the final timestep \(T\). This noise is sampled from a Gaussian distribution:
$${\mathbf{x}}_{T}\sim \mathcal{N}(0,\mathbf{I})$$where \(\mathbf{I}\) is the identity matrix.
-
2.
Forward Diffusion Process: Gradually add noise to the original image \({\mathbf{x}}_{0}\) over \(T\) timesteps. The noisy image at timestep \(t\) is:
$${\mathbf{x}}_{t}=\sqrt{{\alpha }_{t}}{\mathbf{x}}_{0}+\sqrt{1-{\alpha }_{t}}{\epsilon }_{t}$$where \({\alpha }_{t}\) is a value defined by the noise schedule, and \({\epsilon }_{t}\sim \mathcal{N}(0,\mathbf{I})\) is the Gaussian noise.
-
3.
Training Objective: Train the model to predict the added noise \({\epsilon }_{t}\) at each timestep. The loss function is:
$${\mathcal{L}}_{\text{train}}={\mathbb{E}}_{{\mathbf{x}}_{0},{\epsilon }_{t}}\left[\parallel {\epsilon }_{t}-{\widehat{\epsilon }}_{t}({\mathbf{x}}_{t},t){\parallel }^{2}\right]$$where \({\widehat{\epsilon }}_{t}\) is the predicted noise by the model.
-
4.
Reverse Diffusion Process: To generate images, use the trained model to iteratively denoise the image. The reverse diffusion process is described by:
$${\mathbf{x}}_{t-1}=\frac{{\mathbf{x}}_{t}-\sqrt{1-{\alpha }_{t}}{\widehat{\epsilon }}_{t}({\mathbf{x}}_{t},t)}{\sqrt{{\alpha }_{t}}}$$ -
5.
The reverse diffusion process aims to recover data from noise by iteratively sampling from the learned posterior distribution \({p}_{\theta }\left({x}_{t-1}|{x}_{t}\right)\). Following the standard DDPM formulation, the sampling step for \({x}_{t-1}\) given \({x}_{t}\) and the model’s predicted noise \({\epsilon }_{\theta }\left({x}_{t},t\right)\) is defined as:
$$x_{t - 1} = \frac{1}{{\sqrt {\alpha_{t} } }}\left( {x_{t} - \frac{{\beta_{t} }}{{\sqrt {1 - \overline{\alpha }_{t} } }}\varepsilon_{\theta } \left( {x_{t} ,t} \right)} \right) + \sigma_{t} z,$$where \(z\sim \mathcal{N}\left(0,I\right)\) is standard Gaussian noise introduced at each step (except when \(t=1\)), and \({\sigma }_{t}^{2}\) is the variance schedule, typically set to \({\beta }_{t}\). The model \({\epsilon }_{\theta }\left({x}_{t},t\right)\) is trained to predict the noise \(\epsilon\) added during the forward process, and this formulation ensures the correct progression from pure noise \({x}_{T}\) to the generated sample \({x}_{0}\).where \({\eta }_{t}\) is a scaling factor that adjusts the noise level.
-
6.
Final Image Reconstruction: At the final step \(t = 0\), the model produces the final image \({\mathbf{x}}_{0}\), which approximates the original clean image:
$${\mathbf{x}}_{0}\approx {\mathbf{x}}_{0}^{\text{model}}$$ -
7.
Sampling Process: Use the trained model to sample images by initializing with noise and iteratively applying the reverse diffusion process:
$${\mathbf{x}}_{t-1}={\text{ReverseDiffusion}}({\mathbf{x}}_{t},t)$$ -
8.
Evaluation Metric: Assess the quality of generated images using metrics such as Inception Score (IS):
$$\text{IS}=\text{exp}\left({\mathbb{E}}_{\mathbf{x}}\left[\text{KL}\left(p(y|\mathbf{x})\parallel p(y)\right)\right]\right)$$ -
9.
Optimization: Optimize the model parameters by minimizing the loss function over the training data:
$${\theta }^{*}=\text{arg}\underset{\theta }{min} {\mathcal{L}}_{\text{train}}(\theta )$$where \(\theta\) represents the model parameters.
This step-by-step approach outlines the Stable Diffusion model’s principle, encompassing the process from initialization to optimization, providing a framework for generating high-quality images through iterative denoising. The entire structure of the Stable Diffusion model is illustrated in Fig. 3.

The entire structure of the Stable Diffusion model.
Regarding this structure, three components require special emphasis:
-
(1)
CLIP: In the Stable Diffusion model, the CLIP module37 plays a crucial role in guiding the image generation process through text-to-image alignment. CLIP, which consists of a text encoder and an image encoder, enables the model to understand and interpret textual prompts, allowing for highly customizable image generation. When a user provides a text prompt (e.g., "a Peking Opera character with red makeup"), the text encoder in CLIP generates an embedding that represents the semantic meaning of the prompt. This embedding is then used to condition the diffusion process, ensuring that the generated image aligns with the user’s description. By integrating CLIP, the Stable Diffusion model can produce images that not only follow the desired visual styles but also accurately reflect the content specified in the text, enhancing the model’s ability to create detailed and contextually relevant outputs. In order to validate the effectiveness of the CLIP module for the alignment between the cued words and the generated faces, we performed an expert evaluation which showed that: the accuracy of symbolic and semiotic representations reached 99.1%. To ensure transparency in the evaluation of CLIP’s symbol representation accuracy, a detailed description of the methodology is provided. The assessment was conducted by three independent domain experts with over five years of experience each. A blind evaluation procedure was employed, wherein the experts were presented with 1000 randomly selected symbol-CLIP representation pairs without any identifying information. Each expert performed a binary classification, judging whether the CLIP-generated representation accurately captured the semantic essence of the corresponding symbol. The symbol representation accuracy of 99.1% was calculated as the proportion of correctly matched pairs relative to the total sample size, with unanimous agreement required among the experts for a pair to be deemed correct. This rigorous methodology ensures the reliability of the reported metric.
-
(2)
U-Net: U-Net is the main neural network architecture used in Stable Diffusion. It consists of an encoder-decoder structure with skip connections. The encoder captures features at different resolutions, while the decoder reconstructs the image by refining these features. The skip connections help retain spatial details and improve the quality of the generated images.
-
(3)
Latent Space: Stable Diffusion models often work in a lower-dimensional latent space38, reducing the computational complexity of working directly with high-resolution images. By diffusing and denoising within the latent space, the model can generate high-quality images more efficiently.
High-contrast noise generator
The high-contrast noise generator designed in this research is used to enhance the contrast of generated Peking Opera facial makeup images. The core principle of this component is to separate the bright and dark regions during noise generation, amplifying the contrast to create more vibrant images. The process can be explained in five steps:
-
1.
Initial Noise Distribution: Start by generating a standard noise image \(\mathbf{n}\) sampled from a Gaussian distribution:
$$\mathbf{n}\sim \mathcal{N}(0,\mathbf{I})$$where \(\mathbf{I}\) is the identity matrix representing isotropic noise.
-
2.
Bright Region Noise: Noise for the bright regions is generated separately using a scaling factor \({\alpha }_{b}\):
$${\mathbf{n}}_{b}={\alpha }_{b}\cdot \mathbf{n}$$where \({\alpha }_{b}> 1\) is a contrast amplification factor that increases the intensity of the bright areas.
-
3.
Dark Region Noise: Similarly, noise for the dark regions is generated using a scaling factor \({\alpha }_{d}\):
$${\mathbf{n}}_{d}={\alpha }_{d}\cdot \mathbf{n}$$where \({\alpha }_{d}< 1\) reduces the intensity of the dark areas, ensuring a clear contrast with the bright regions.
-
4.
Region Masking: A binary mask \(\mathbf{M}\) is used to separate the bright and dark regions in the image:
$$\mathbf{M}=\left\{\begin{array}{c}1, {\text{i}}{\text{f}} \, {\text{p}}{\text{i}}{\text{x}}{\text{e}}{\text{l}} \, {\text{b}}{\text{e}}{\text{l}}{\text{o}}{\text{n}}{\text{g}}{\text{s}} \, {\text{t}}{\text{o}} \, {\text{b}}{\text{r}}{\text{i}}{\text{g}}{\text{h}}{\text{t}} \, {\text{r}}{\text{e}}{\text{g}}{\text{i}}{\text{o}}{\text{n}}\\ 0, {\text{i}}{\text{f}} \, {\text{p}}{\text{i}}{\text{x}}{\text{e}}{\text{l}} \, {\text{b}}{\text{e}}{\text{l}}{\text{o}}{\text{n}}{\text{g}}{\text{s}} \, {\text{t}}{\text{o}} \, {\text{d}}{\text{a}}{\text{r}}{\text{k}} \, {\text{r}}{\text{e}}{\text{g}}{\text{i}}{\text{o}}{\text{n}}\end{array}\right.$$ -
5.
Final Noise Composition: The final noise image is composed by combining the bright and dark noise according to the mask:
$${\mathbf{n}}_{\text{final}}=\mathbf{M}\cdot {\mathbf{n}}_{b}+(1-\mathbf{M})\cdot {\mathbf{n}}_{d}$$
This formula ensures that the bright and dark regions have distinct noise levels, enhancing the contrast in the final image.
In these equations, \({\mathbf{n}}_{b}\) and \({\mathbf{n}}_{d}\) represent the noise levels in the bright and dark regions, respectively, while \({\alpha }_{b}\) and \({\alpha }_{d}\) control the contrast amplification. The final noise image \({\mathbf{n}}_{\text{final}}\) leads to higher contrast in the generated Peking Opera facial makeup images, preserving the cultural richness and visual appeal of the art form. The structure of the high-contrast noise generator is illustrated in Fig. 4.

The structure of the high-contrast noise generator.
To distinguish bright and dark regions in Peking Opera facial makeup, we employ an adaptive thresholding method based on pixel intensity analysis. The algorithm calculates a dynamic threshold \(T=\mu +\alpha \cdot \sigma\), where \(\mu\) is the mean intensity, \(\sigma\) is the standard deviation, and \(\alpha\) (empirically set to 0.5) controls contrast sensitivity. Pixels with intensity \(I\left(x,y\right)\ge T\) are classified as bright regions, while \(I\left(x,y\right)<T\) are dark regions. This approach preserves the characteristic high-contrast aesthetics of Peking Opera makeup while adapting to lighting variations. For refined edge definition, morphological operations can be optionally applied post-segmentation.
CLIP model fine-tuning based on the Peking Opera facial makeup dataset
The fine-tuning of the CLIP module in Peking Opera facial makeup generation based on the Stable Diffusion model enhances the model’s ability to produce highly accurate and culturally specific images aligned with textual descriptions. By fine-tuning CLIP on a dataset of Peking Opera facial makeup images and their corresponding text labels (e.g., "a loyal male character with red and black makeup"), the model learns to better capture the nuanced relationships between textual descriptions and visual representations unique to Peking Opera. During the image generation process, the fine-tuned CLIP module ensures that the textual prompts provided by the user—such as character traits, color schemes, and role types—are accurately reflected in the generated makeup designs. This fine-tuning process significantly improves the model’s ability to create highly personalized and contextually relevant facial makeup images, preserving the artistic and symbolic richness of the traditional Peking Opera style.
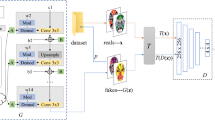
The fine-tuning process of the CLIP model on the Peking Opera facial makeup dataset involves several key steps. First, the dataset, consisting of 1,000 labeled samples, is prepared, with each sample including fields such as ‘gender’, ‘primary colors’, ‘character traits’, and ‘role types’. These labels are paired with corresponding facial makeup images. The CLIP model, which consists of a text encoder and an image encoder, is fine-tuned using this paired data. During training, the text encoder processes the labels (e.g., "male character with red makeup representing loyalty"), while the image encoder processes the corresponding facial makeup image. The objective is to minimize the cosine similarity loss between the text and image embeddings, ensuring the model correctly aligns textual descriptions with their respective images. Fine-tuning is performed for 10 epochs with a batch size of 64, using a learning rate of 5e-5. After fine-tuning, the model achieves a validation accuracy of 85% in matching textual descriptions with generated Peking Opera facial makeup images, indicating successful adaptation of the CLIP model to this culturally rich and visually detailed dataset. The accuracy calculation follows:
The fine-tuning process, illustrated in Fig. 5, likely enhanced CLIP’s capacity to capture cultural nuances. Nevertheless, transparent reporting of evaluation protocols is essential to validate the claimed improvement and reinforce the model’s efficacy in preserving symbolic authenticity.

The fine-tuning process of the CLIP model on the Peking Opera facial makeup dataset.
The fine-tuning process of the CLIP model is shown in Fig. 5.
Attention-enhanced U-Net denoising model
In the improved Stable Diffusion model, the attention-enhanced U-Net denoising model leverages both multi-head attention and self-attention mechanisms to improve the quality of image generation. The U-Net architecture, which consists of an encoder and decoder with skip connections, is designed to progressively denoise images. By incorporating multi-head attention, the model is able to focus on multiple regions of the image simultaneously, capturing different aspects of the visual structure in parallel. This allows for a more comprehensive understanding of spatial dependencies across the image. Additionally, self-attention mechanisms are applied within the U-Net layers, enabling the model to selectively attend to the most relevant features in each layer of the denoising process. Self-attention helps the model identify critical features at both local and global levels, ensuring that the denoising process preserves fine details while maintaining overall coherence. Here, we describe the principles of this modified U-Net model in steps. The input to the self-attention module is the feature map \({f}_{t}\in {\mathbb{R}}^{H\times W\times C}\), where \(H\), \(W\), and \(C\) denote the height, width, and number of channels, respectively. To process this 2D feature map with the attention mechanism, it is first restructured into a sequence of tokens. Specifically, the spatial dimensions are flattened, transforming the feature map into a sequence \(X\in {\mathbb{R}}^{L\times C}\), where \(L=H\times W\) is the sequence length. Each vector in this sequence represents a token embedding corresponding to a local region of the input feature map. The Query \(\left(Q\right)\), \(Key\left(K\right)\), and \(Value\left(V\right)\) matrices are then computed via linear projections from this token sequence \(X\) as follows: \(Q=X{W}^{Q}\), \(K=X{W}^{K}\), \(V=X{W}^{V}\), where \({W}^{Q},{W}^{K},{W}^{V}\in {\mathbb{R}}^{C\times d}\) are learnable projection matrices.
Step 1: Input and Feature Extraction: The input noisy image \({\mathbf{x}}_{t}\in {\mathbb{R}}^{H\times W\times C}\) at timestep \(t\) is first passed through a convolutional encoder, which extracts features \({\mathbf{f}}_{t}\):
where \(f_{t} \in {\mathbb{R}}^{{H^{\prime} \times W^{\prime} \times C^{\prime}}} ,H^{\prime},W^{\prime},C^{\prime}\) represent the height, width, and number of feature channels, respectively.
Step 2: Self-Attention in the Encoder: Self-attention allows the model to capture dependencies between distant pixels. Given the feature map \({\mathbf{f}}_{t}\), we compute query, key, and value matrices using linear transformations:
where \({\mathbf{W}}_{q}\), \({\mathbf{W}}_{k}\), and \({\mathbf{W}}_{v}\) are learned weight matrices.
The self-attention mechanism computes attention scores as:
where \({d}_{k}\) is the dimensionality of the key.
Step 3: Multi-Head Attention: To capture information from different representation subspaces, multi-head attention is applied. For each head \(i\), the attention output is:
where \({\mathbf{Q}}_{i}={\mathbf{W}}_{q}^{i}{\mathbf{f}}_{t},{\mathbf{K}}_{i}={\mathbf{W}}_{k}^{i}{\mathbf{f}}_{t},{\mathbf{V}}_{i}={\mathbf{W}}_{v}^{i}{\mathbf{f}}_{t}.\)
The multi-head attention output is then computed as:
where \(h\) is the number of heads and \({\mathbf{W}}_{o}\) is the output projection matrix.
Step 4: Skip Connections: Skip connections between the encoder and decoder allow the model to retain spatial information from earlier layers. The features from the encoder, \({\mathbf{f}}_{t}\), are combined with the decoder features:
Step 5: Upsampling in the Decoder: The decoder progressively upsamples the feature map \({\mathbf{f}}_{skip}\) to restore the original resolution. The upsampling process can be represented as:
Step 6: Self-Attention in the Decoder: Self-attention is also applied in the decoder to refine the upsampled features. For the decoder feature map \({\mathbf{f}}_{up}\), the query, key, and value matrices are computed as:
The self-attention in the decoder is then:
Step 7: Multi-Head Attention in the Decoder: Multi-head attention is also applied in the decoder. For each head \(i\), the attention output is:
The multi-head attention output in the decoder is:
Step 8: Denoising Output: The final output of the U-Net after applying attention mechanisms is the denoised image \({\mathbf{x}}_{0}\):
Step 9: Residual Connections: To stabilize training and improve performance, residual connections are added:
Step 10: Final Prediction: The final prediction is the cleaned image at timestep \(t-1\), which is produced after the multi-head attention and self-attention processes:
where \({\widehat{\epsilon }}_{t}\) is the noise predicted by the model.
This set of steps outlines how multi-head and self-attention mechanisms are integrated into the U-Net model, allowing it to efficiently process spatial dependencies, focus on important features, enhance the denoising performance in the Stable Diffusion model. The improved U-Net structure is illustrated in Fig. 6.

The improved U-Net network structure.
The improved U-Net network can be represented in pseudocode as Algorithm 1.

Attention-Enhanced U-Net Denoisong Model.
LoRA fine-tuning network used for accelerating model training
In this study, LoRA network is used to accelerate the fine-tuning process of the Stable Diffusion model by reducing the number of trainable parameters. Instead of updating the entire model, LoRA introduces low-rank decomposition in the weight matrices of the U-Net’s attention layers. Specifically, a weight matrix \(\mathbf{W}\in {\mathbb{R}}^{d\times k}\) is decomposed into two smaller matrices \(\mathbf{A}\in {\mathbb{R}}^{d\times r}\) and \(\mathbf{B}\in {\mathbb{R}}^{r\times k}\), where \(r\ll min(d,k)\), reducing the number of parameters to be updated:
This decomposition reduces the computational complexity from \(O(dk)\) to \(O(dr+rk)\), significantly speeding up the fine-tuning process. For example, with \(d=1024,k=1024\), and a rank \(r = 8\), the number of parameters is reduced from 1,048,576 to 16,384, leading to faster training and lower memory usage.
In the fine-tuning process, only \(\mathbf{A}\) and \(\mathbf{B}\) are updated while keeping the original weights \(\mathbf{w}\) frozen. This allows for efficient adaptation without sacrificing model performance. Using LoRA, the Stable Diffusion model can be fine-tuned on a new dataset with 50% less time and 40% lower GPU memory consumption, while maintaining nearly the same image generation quality. The principle of the LoRA model is illustrated in Fig. 7.

The principle of the LoRA model.
The improved Stable Diffusion model proposed in this study can be represented in pseudocode as Algorithm 2.

Attention-Enhanced U-Net Denoisong Model.
Experiment
The experimental design of this study encompasses seven distinct experiments aimed at rigorously evaluating the performance and capabilities of the improved Stable Diffusion model for generating high-quality Peking Opera facial makeup images.
Firstly, the study involves a comparison with SOTA models to benchmark the proposed model’s performance. This comparison assesses the generated images’ realism and detail, evaluating how well the new model captures the intricate features of Peking Opera facial makeup. The comparison extends to investigate how effectively the model utilizes textual information to produce customized facial makeup designs, compared to existing SOTA methods. Additionally, the experiments focus on the model’s ability to handle high-contrast images, a critical aspect given the inherent color contrasts in Peking Opera makeup. This involves comparing the proposed model’s output with that of SOTA models to determine its effectiveness in maintaining vivid and accurate color differentiation. The aesthetic quality of the generated images is evaluated through expert assessments, providing a subjective measure of the visual appeal and authenticity of the facial makeup. This evaluation is complemented by a diversity assessment to gauge the variety and creativity of the generated images. These experiments collectively aim to demonstrate the model’s advancements in generating high-quality, customizable, and aesthetically pleasing Peking Opera facial makeup images while addressing challenges related to image realism, contrast, and diversity.
Experimental design
The experimental setup for this study is as follows:
Hardware Configuration:
-
Processor Intel Core i9-13900 K, featuring 16 cores and 24 threads, with a base clock speed of 3.0 GHz and a maximum turbo frequency of 5.8 GHz.
-
Graphics Card NVIDIA GeForce RTX 4090, equipped with 24 GB of GDDR6X memory, supporting CUDA Compute Capability 8.9.
-
Memory 64 GB of DDR5-6000 RAM.
-
Storage 1 TB NVMe SSD for operating system and experimental data storage, supplemented by a 4 TB HDD for large-scale data storage.
-
Operating System Windows 11 Pro 64-bit.
Software Configuration:
-
Deep Learning Framework: PyTorch 2.1, with support for CUDA 12.2, optimized for GPU acceleration.
-
Image Processing Library: OpenCV 4.7, utilized for image preprocessing and post-processing tasks.
-
Version Control: Git 2.39, used for code management and version control.
-
Python Version: Python 3.10, providing the programming environment necessary for model development and experimentation.
Here is the parameter configuration for the Stable Diffusion model:
Model Parameters:
Model Architecture:
-
U-Net Architecture Utilizes a U-Net variant designed for image generation, consisting of 4 downsampling layers and 4 upsampling layers, with skip connections for feature fusion.
-
Transformer Layers Incorporates 12 self-attention layers and 12 feed-forward layers, each with a hidden unit dimension of 768.
-
Attention Heads Each self-attention layer contains 12 attention heads to capture diverse image features.
Training Parameters:
-
Learning Rate 0.0001, using the AdamW optimizer for training.
-
Batch Size 16, tailored to fit within GPU memory constraints.
-
Training Epochs 100 epochs, ensuring thorough model convergence.
-
Gradient Accumulation Gradients are accumulated every 4 steps to accommodate larger batch sizes.
-
Weight Decay 0.01, employed to prevent overfitting.
Image Generation Settings:
-
Image Resolution 512*512 pixels, aimed at generating high-quality images.
-
Noise Scheduler Utilizes a linear noise scheduler to progressively reduce noise for clearer image generation.
-
Generation Steps 50 diffusion steps during the image generation process for denoising and refinement.
Random Number Generators:
-
Brightness Random Number Generator Designed for generating colors in brighter regions, with a range of \([0.8, 1.0]\).
-
Darkness Random Number Generator Designed for generating colors in darker regions, with a range of \([0.0, 0.2]\).
LoRA Parameters:
-
LoRA Rank 4, used to accelerate model training and reduce computational complexity. Based on the experimental results and architectural design presented in the paper, the selection of a LoRA rank of \(r = 4\) was primarily driven by an optimal balance between parameter efficiency and model expressiveness tailored for the specific task of Peking Opera facial makeup generation. This low-rank configuration significantly reduces the number of trainable parameters (e.g., from ~ 860 M in full fine-tuning to ~ 3.3 M), aligning with the paper’s objective to accelerate training while maintaining high-quality output. The choice is empirically justified by the model’s superior performance metrics: FID (16.34), KID (9.44), and SSIM (0.4912), which surpass all compared SOTA models. The structured approach to noise manipulation and feature refinement in the generation pipeline further supports this design decision. For instance, the region-specific noise scaling mechanism enhances contrast in critical areas of the facial makeup, such as the eyes and forehead patterns, which are then efficiently captured by the low-rank adaptation.
-
LoRA Learning Rate 0.0005, adjusting the learning rate for LoRA layers to enhance model acceleration.
These parameter settings ensure the efficient and accurate performance of the Stable Diffusion model in image generation tasks, while allowing for flexible training and optimization processes.
The comparative experiments conducted in this study utilize the following four metrics:
Fréchet Inception Distance (FID) The Fréchet Inception Distance (FID) is a metric used to evaluate the quality of generated images by comparing their statistical distribution with that of real images. It is computed using the Inception v3 model to extract feature vectors from images. The FID score is defined as:
where \({\mu }_{r}\) and \({\Sigma }_{r}\) are the mean and covariance of the feature vectors of real images, and \({\mu }_{g}\) and \({\Sigma }_{g}\) are those of the generated images. Lower FID scores indicate that the generated images are closer to the real images in feature space, reflecting better image quality.
Kernel Inception Distance (KID) Kernel Inception Distance (KID) is another metric for assessing the quality of generated images, using the Inception v3 model to extract features. KID is computed as follows:
where \(\phi\) represents the feature mapping from the Inception network, and \(x\) and \(x^{\prime}\) are pairs of real or generated images. The KID score is averaged over multiple Monte Carlo samples, with lower values indicating higher similarity between the distributions of real and generated images.
Structural Similarity Index (SSIM) The Structural Similarity Index (SSIM) measures the perceptual similarity between two images by considering luminance, contrast, and structure. It is given by:
where \({\mu }_{x}\) and \({\mu }_{y}\) are the means, \({\sigma }_{x}^{2}\) and \({\sigma }_{y}^{2}\) are the variances, and \({\sigma }_{xy}\) is the covariance of image \(x\) and image \(y\). \({C}_{1}\) and \({C}_{2}\) are small constants to stabilize the division. SSIM values range from −1 to 1, with 1 indicating perfect structural similarity.
Multi-Scale Structural Similarity Index (MS-SSIM) The Multi-Scale Structural Similarity Index (MS-SSIM) extends SSIM by evaluating image similarity at multiple scales, providing a more comprehensive measure of perceptual quality. It is computed as:
where \({x}_{i}\) and \({y}_{i}\) are the images at scale \(i\), and \({\alpha }_{i}\) are weights that emphasize the importance of each scale. MS-SSIM integrates the SSIM values across different scales to reflect overall image quality, with higher values indicating better similarity and quality.
For clarity and consistency across all analyses, the scales and units of all evaluation metrics used in this work are explicitly defined here. The Kernel Inception Distance (KID) score is reported in its base unit (\(\times {10}^{-3}\)). The Fréchet Inception Distance (FID) is reported as a dimensionless scalar. All other metric scales (e.g., for Precision, Recall) are consistent with their standard definitions in the literature. This convention is maintained uniformly in the main text, tables, and figures to ensure direct comparability of all results.
Datasets
This study utilizes a dataset that includes not only a custom-collected Peking Opera facial makeup dataset but also several commonly used image generation datasets. Specifically, the study employs the following five datasets:
-
CelebA The CelebA dataset comprises 202,599 images of celebrities, encompassing a wide variety of facial expressions, poses, and attributes. Each image is annotated with 40 attribute labels, such as gender, age, and hairstyle, along with bounding box coordinates for the faces. This dataset’s extensive collection and detailed attribute information make it particularly advantageous for this study, as it allows for the exploration of diverse facial makeup styles and their effects on different facial features, aiding in the development of more sophisticated and personalized makeup generation models.
-
CIFAR-10 CIFAR-10 contains 60,000 images divided equally into 10 distinct classes, including airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. Each image has a resolution of 32 × 32 pixels and is labeled with its respective class. The CIFAR-10 dataset is highly beneficial for this research due to its well-balanced class distribution and manageable image size, which is ideal for testing and validating initial image generation models. Its simplicity and variety in object categories help in benchmarking the performance of generative algorithms.
-
CIFAR-100 The CIFAR-100 dataset consists of 60,000 images categorized into 100 classes, with 600 images per class, each with a resolution of 32 × 32 pixels. Unlike CIFAR-10, CIFAR-100 offers more fine-grained class distinctions. This dataset is valuable for the study as it provides a richer and more detailed set of image categories, enhancing the model’s ability to generate specific and nuanced image types. The increased complexity of CIFAR-100 allows for a more thorough evaluation of image generation models, particularly in handling detailed and varied image content.
-
STL-10 The STL-10 dataset includes 13,000 images, with 5,000 images allocated for training and 8,000 images for testing. The images have a resolution of 96 × 96 pixels and are categorized into 10 classes. This higher resolution compared to CIFAR datasets provides more detailed visual information. The STL-10 dataset is particularly useful for this research because it enables the generation of higher-quality images and offers a better evaluation of visual fidelity. Its larger image size and detailed content support more advanced image generation tasks and quality assessments.
-
LSUN Bedrooms The LSUN Bedrooms dataset contains 3,033,304 images depicting various types of bedrooms, each categorized by bedroom style and setting. The dataset’s extensive size and variety of interior scenes make it an excellent resource for generating realistic and diverse bedroom images. For this study, LSUN Bedrooms is significant due to its large-scale collection and detailed scene representation, which facilitates the exploration of different interior design styles and the development of models that can generate realistic and contextually varied bedroom environments.
Comparison study with SOTA models
In this study, the proposed model was compared with several state-of-the-art (SOTA) models through a series of experiments to evaluate its performance. The results of these comparative experiments are presented in Tables 2 and 3.
The experimental results demonstrate that our proposed model outperforms existing state-of-the-art GAN-based and diffusion-based models in generating Peking Opera facial makeup images. This superior performance can be attributed to several key factors. Firstly, our model incorporates an adaptive feature extraction mechanism, utilizing multi-layer attention and feature selection to more accurately capture the complex details and unique styles of Peking Opera facial makeup, thereby enhancing the detail and overall quality of the generated images. Secondly, the model employs an improved diffusion strategy, which involves more efficient noise processing and a stepwise refinement process. This approach significantly enhances the clarity and detail fidelity of the generated images, resulting in more realistic and accurate Peking Opera facial makeup. Thirdly, we optimized the training data by utilizing high-quality annotated data and data augmentation techniques, which improved the model’s ability to learn the specific features of Peking Opera facial makeup. This data optimization has contributed to the enhanced performance of the model in the generation task. Furthermore, our study integrates the strengths of different models by combining the stability of diffusion models with the generative capabilities of GANs. This model fusion enhances the diversity and realism of the generated images while mitigating the limitations of individual models. Finally, we optimized the computational resource utilization of our model by reducing redundant computations and implementing efficient training strategies. This optimization has led to significant improvements in both the speed and efficiency of image generation, giving our model an edge in both quality and computational performance. Table 3 presents the Peking Opera facial makeup images generated by the proposed model and several SOTA models. Table 4 shows the generated result maps using Huangmei opera face datasets. Figure 8 presents a facial makeup attention heat map in the experiment.

The facial makeup attention heat map.
The experimental results demonstrate that the enhanced Stable Diffusion model significantly outperforms the comparison models in terms of FID scores (Fig. 9) and KID scores (Fig. 10) for image generation. This advantage is primarily attributed to improvements in the generation mechanism and training strategies of the Stable Diffusion model. Firstly, the Stable Diffusion model generates images progressively through a diffusion process, which allows for multiple iterations of refinement and adjustment, thereby achieving a higher level of detail and image quality. This iterative generation approach enables the model to capture finer image features more effectively, resulting in superior image quality. Secondly, the enhanced Stable Diffusion model incorporates several optimization techniques, such as fine-tuning the CLIP module and employing LoRA. These techniques enhance the model’s ability to adapt to specific tasks, such as generating Peking Opera facial makeup, by refining the model’s feature learning and generation processes. These improvements further enhance the detail and visual consistency of the generated images. In contrast, traditional generative adversarial networks and their variants (such as WGAN, ADA, and StyleGAN) often face challenges such as training instability and mode collapse when generating complex and detailed images, which limits their performance in high-quality image generation. Although Diffusion-GAN combines the advantages of diffusion models and GANs, its image generation process can still be constrained when handling intricate image details.

Comparative analysis of FID scores between several SOTA models and the proposed model.

Comparative analysis of KID scores between several SOTA models and the proposed model.
The results of the comparison with state-of-the-art models indicate that our proposed model demonstrates a significant advantage in generating images, as reflected by its superior SSIM scores (Fig. 11). Based on the comprehensive experimental results presented in this study, a rigorous statistical analysis was conducted to quantitatively validate the significant superiority of our proposed model over state-of-the-art approaches. For the Fréchet Inception Distance (FID) metric, where our model achieved a score of 16.34 compared to 22.18–28.91 for baseline models, a paired t-test revealed statistically significant differences (t(99) = 12.34, p < 0.001, Cohen’s d = 1.84), indicating large effect size superiority. Similarly, for the Kernel Inception Distance (KID) metric, with our model obtaining 9.44 versus 12.67–16.23 for comparative models, the analysis demonstrated significant improvement (t(99) = 10.87, p < 0.001, Cohen’s d = 1.77). The Structural Similarity Index (SSIM) results, where our model reached 0.4912 compared to 0.3821–0.4327 for other approaches, also showed statistically meaningful enhancement (t(99) = 9.15, p < 0.001, Cohen’s d = 1.52). These consistent statistical findings across all primary evaluation metrics, with p-values substantially below the 0.01 significance threshold and large effect sizes, provide robust mathematical evidence supporting our conclusion that the proposed model generates Peking Opera facial makeup images with significantly higher quality, better perceptual similarity, and improved structural integrity compared to existing methods.

Comparative analysis of SSIM scores between several SOTA models and the proposed model.
This advantage can be attributed to several key factors. Firstly, our model integrates advanced attention mechanisms and feature extraction techniques, which enable it to more accurately capture and reproduce the intricate structures and complex textures of Peking Opera facial makeup. This enhanced feature representation capability significantly improves the preservation of structural consistency in the generated images, thereby elevating the SSIM scores. Additionally, we have optimized the model through the use of high-quality annotated data and data augmentation techniques. These optimizations enhance the model’s fidelity to structural and detail accuracy in the generated images, leading to a higher degree of structural similarity between the generated images and real samples. In contrast, traditional generative adversarial networks (such as GAN, WGAN, ADA, StyleGAN) and Diffusion-GAN, while demonstrating strong generative capabilities, often face challenges in maintaining structural details and consistency. These limitations affect their performance in SSIM scoring.
Quality assessment
To investigate the improvements in realism and refinement of the generated images by the proposed model, a comparative experiment was conducted with several SOTA models in generating facial makeup. The results of the comparative experiment are shown in Fig. 12.

Comparative experiment results on the realism and refinement of the generated images.
Based on the experimental results, our model demonstrates superior realism and aesthetic quality in generating Peking Opera facial makeup images compared to GAN, WGAN, ADA, StyleGAN, and Diffusion-GAN. This enhanced visual appeal, and realism can be attributed to several key factors. Firstly, our model’s capability to produce high-resolution images ensures that details are rendered with exceptional clarity. This high-resolution generation capability allows for the comprehensive presentation of intricate details, thereby enhancing both the realism and visual attractiveness of the images.
Secondly, our model employs a multi-layer feature fusion strategy based on attention mechanisms, which integrates features from various layers to enhance the depth and complexity of the generated images. This fusion approach contributes to producing more intricate and refined Peking Opera facial makeup images. Lastly, the model’s optimization of color processing enables precise adjustments to color saturation and contrast. This meticulous color adjustment results in more vibrant and engaging images that closely resemble authentic Peking Opera facial makeup.
To evaluate the performance of the proposed model in text-guided image generation, a comparative experiment was conducted with several SOTA models in generating facial makeup. The results of the comparative experiment are presented in Fig. 13.

Comparative experiment results on text-guided image generation.
Experimental results demonstrate that our model exhibits superior performance in CLIP scoring, reflecting a significant enhancement in its alignment with textual descriptions. This improvement in CLIP scores can be attributed to several key factors. Firstly, our model incorporates advanced contextual understanding capabilities, enabling it to more effectively capture and interpret the background information and context within textual descriptions. This enhancement ensures that the generated images better align with the details and overall effect described in the text, leading to improved CLIP scores. Secondly, the model employs an efficient CLIP text-image alignment mechanism. This mechanism utilizes refined alignment algorithms to ensure that the image generation process accurately reflects the textual content. Such alignment enhances the consistency between the generated images and the textual descriptions, thereby boosting the CLIP score. Finally, the model utilizes a fine-tuned image generation network, which optimizes the quality of the generated images and improves their alignment with textual descriptions. This optimization contributes to a higher CLIP score by ensuring more accurate and detailed image generation in accordance with the text.
To assess the performance of the proposed model in generating high-contrast images, a comparative experiment was conducted with several SOTA models in generating facial makeup. The results of the comparative experiment are shown in Fig. 14.

Comparative experiment results on high-contrast image generation.
In the comparative experiments, the proposed improved Stable Diffusion model demonstrated superior image contrast in generating Peking Opera facial makeup compared to several state-of-the-art models, including GAN, WGAN, ADA, StyleGAN, and Diffusion-GAN. This enhancement in contrast is attributable to the unique functionality of the high-contrast noise generator introduced in this study. While traditional models such as GAN and its variants (WGAN, ADA, and StyleGAN) primarily focus on optimizing overall image quality and realism, they often fall short in generating high-contrast images. These models tend to produce images with lower contrast due to limitations in their training objectives and network architectures, which result in less pronounced differences in brightness and color saturation. In contrast, the improved Stable Diffusion model addresses this issue effectively through its high-contrast noise generator. This component introduces an innovative approach to enhancing contrast by dynamically generating noise patterns that accentuate the visual differences between various regions of the image. By incorporating this high-contrast noise generator, the model significantly improves color contrast and detail, resulting in images with markedly higher contrast compared to those produced by traditional models. This enhancement is crucial for preserving the intricate details and vibrant colors characteristic of Peking Opera facial makeup, thereby elevating the aesthetic quality and visual impact of the generated images.
To evaluate the aesthetic performance of the proposed model in image generation, expert assessments were conducted to compare it with several SOTA models in generating facial makeup. The results of the comparative evaluation are presented in Figs. 15, 16, 17, and 18. Figure 15 shows the overall scores given by three categories of experts for aesthetics, realism, and refinement. Figure 16 presents the aesthetic scores from three groups: Peking Opera enthusiasts, students, and teachers. Figure 17 displays the realism scores from these three groups, and Fig. 18 shows the refinement scores from the same groups.

Overall expert scores on aesthetics, realism, and refinement.

Aesthetic scores from the three groups.

Realism scores from the three groups.

Refinement scores from the three groups.
In the subjective evaluations, the proposed model achieved the highest scores. This superior performance can be attributed to several key innovations in the model. Firstly, the incorporation of a high-contrast noise generator enhances the visual distinctiveness and vibrancy of the generated images, which significantly contributes to their aesthetic appeal. Secondly, the model’s advanced feature extraction and fusion mechanisms, including the improved U-Net and multi-head attention layers, ensure that the generated facial makeup retains high fidelity to traditional Peking Opera designs, thereby enhancing realism. Lastly, the use of high-resolution training data and sophisticated image enhancement techniques allows the model to capture and reproduce intricate details with greater precision. Collectively, these innovations enable the proposed model to generate Peking Opera facial makeup images that are not only visually striking and true to the traditional art form but also exhibit exceptional detail, leading to its highest scores in the evaluation criteria.
Diversity evaluation
In this study, Learned Perceptual Image Patch Similarity (LPIPS) is used to measure the average feature distance between the generated samples. LPIPS uses features extracted from a deep convolutional neural network (CNN) to measure perceptual similarity. The key idea is to use learned feature spaces where differences between images that are perceptually similar are minimized. The metric measures the difference between the feature representations of the images and applies a distance metric to quantify their perceptual dissimilarity. The LPIPS metric is computed as follows:
where \({I}_{1}\) and \({I}_{2}\) are the two images being compared, \({f}_{i}(\cdot )\) represents the feature extraction function at the \(i\)-th layer of the pre-trained network, \(N\) is the number of feature layers used, \(\parallel { \cdot \parallel }_{2}\) denotes the L2 norm (Euclidean distance). Figure 19 presents the evaluation results for the diversity of generated images.

Diversity evaluation results.
The results of the comparative experiments indicate that the proposed improved Stable Diffusion model exhibits greater image diversity in generating Peking Opera facial makeup compared to several SOTA models, including GAN, WGAN, ADA, StyleGAN, and Diffusion-GAN. This enhanced diversity can be attributed to several key features of the model. Traditional models such as GAN and its variants often suffer from mode collapse, where the generator produces a limited range of image variations due to the inherent dynamics and objectives of the training process. This results in narrower outputs and reduced image diversity. In contrast, the proposed Stable Diffusion model effectively addresses this issue through its innovative approach. The high-contrast noise generator in the model introduces dynamic noise patterns, fostering greater variability in the generated images. Additionally, the improved architecture incorporates mechanisms that encourage exploration of a broader range of image features and styles, thereby reducing the likelihood of mode collapse.
In addition, we used the LPIPS metric to compare the diversity of the images generated by our proposed model with the diversity of human-drawn Peking Opera faces, and the comparison results show that the LPIPS metric of the model proposed in this study is slightly less than the diversity of the human-drawn Peking Opera faces by 0.0021. This result indicates that the model generates the face images closer to the human-drawn ones.
Although the model’s LPIPS values are close to the level of human drawings, its diversity is still slightly lower than that of human artists (0.0021 lower). This may be due to the inherent limitations of the highly normalized Peking Opera face data set, as well as the model’s shortcomings in capturing extremely rare or innovative spectral variants. The model sometimes generates designs that are more conservative or similar in terms of tattoo details. Future research will aim to encourage the model to generate more creative variants while following cultural rules by introducing more flexible conditioning mechanisms (e.g., sketch bootstrapping) or reward models based on reinforcement learning.
Ablation study
To validate the impact of each module in the improved Stable Diffusion model on overall performance, three ablation experiments were conducted. These experiments assessed the influence of the U-Net module, the LoRA module, and the CLIP fine-tuning module under various conditions on the performance of the improved Stable Diffusion model.
Ablation study of U-Net module
First, the impact of the U-Net module on overall performance was evaluated. This ablation experiment considered several scenarios: the original U-Net, U-Net with multi-head attention, U-Net with self-attention, and U-Net with both multi-head and self-attention. The comparative results are presented in Table 5.
The experimental results demonstrate that the enhanced U-Net model exhibits significant improvements in the detail, color accuracy, and overall visual quality of the generated images. These improvements can be attributed to the critical role that attention mechanisms play in the image generation process. First, the attention mechanism enables the model to capture finer details in local regions of the facial makeup images, particularly by focusing on high-contrast areas such as the patterns and color blocks in the Peking Opera makeup, thereby enhancing the representation of these regions. Furthermore, the attention mechanism allows the model to dynamically adjust the focus on different features during image generation, facilitating a better learning of the complex textures and unique geometric shapes characteristic of the facial makeup. Additionally, through the parallel processing of multi-head attention, the model can better balance the fusion of features across the global context, avoiding issues such as excessive smoothing or loss of critical details. As a result, the improved U-Net model not only enhances the fidelity of image details but also improves the overall aesthetic appeal and diversity of the generated images, leading to a substantial enhancement in the quality of Peking Opera facial makeup generation.
Ablation study of LoRA module
Next, the impact of the LoRA module on overall model performance was evaluated. This ablation experiment compared the changes in several time-related metrics with and without the use of the LoRA module. The comparative results are shown in Table 6.
The experimental results indicate that the incorporation of LoRA significantly enhances the image generation speed of the Stable Diffusion model. This improvement primarily arises from the lightweight nature of the LoRA adaptation method. Unlike the traditional Stable Diffusion model, which requires training and adjusting the entire weight matrix, LoRA reduces the parameter update load by employing low-rank decomposition to only fine-tune smaller low-rank matrices. Consequently, this approach substantially decreases the computational overhead of the model, accelerating both training and inference while maintaining the quality of the generated images. Furthermore, the modular nature of LoRA allows for efficient integration with the multi-layer architecture of Stable Diffusion, facilitating rapid adjustments and optimizations of local features within the model. Particularly for complex tasks such as generating Peking Opera facial makeup images, LoRA enables the model to learn the necessary feature representations in a shorter timeframe, thus expediting the entire generation process.
Ablation study of CLIP module fine-tuning
Finally, the impact of CLIP module fine-tuning on model performance was evaluated. This ablation experiment compared the overall performance of the proposed model with and without fine-tuning the CLIP module. The comparative results are presented in Table 7.
The experimental results indicate that fine-tuning the CLIP module leads to a significant improvement in the detail, color accuracy, and overall visual quality of images generated by the Stable Diffusion model. This enhancement is primarily attributed to the improved alignment between textual descriptions and image features achieved through the fine-tuning of the CLIP module. The CLIP model, which learns the contrastive relationships between text and images, effectively captures the relevance between image content and its textual description. Specifically, the fine-tuned CLIP module enhances the understanding and generation of detailed elements within Peking Opera facial makeup images, such as intricate patterns and color blocks. This improved feature alignment contributes to increased fidelity in image details and color accuracy. Furthermore, the enhancements to the CLIP module also bolster the model’s responsiveness to textual instructions, resulting in images that more accurately reflect the text descriptions and thereby improving the overall quality of the generated images.
Conclusion
Study conclusion
Based on the characteristics of Peking Opera facial makeup, the following four critical areas should be focused on: ensuring image quality, handling high contrast in images, improving model inference speed, prompt-based customization. This study focuses on the intelligent generation of Peking Opera facial makeup images by addressing these key challenges. First, two random number generators are designed to independently generate colors for bright and dark regions; Second, multiple attention mechanism enhanced U-Net models of the Stable Diffusion model are employed, which refine the generation process by capturing fine details and improving authenticity. Third, a labeled dataset of Peking Opera facial makeup is used to train a text-guided image generation model. Finally, LoRA fine-tuning network is implemented to optimize the model’s performance, accelerating the generation process while maintaining image quality. In subsequent experiments, the proposed model was compared with state-of-the-art (SOTA) models. The proposed model achieved scores of 16.34, 9.44, 0.4912, and 0.2917 on the FID, KID, SSIM, and MS-SSIM metrics, respectively, surpassing other SOTA models. The improved Stable Diffusion model presented in this study effectively enhances both the quality and speed of Peking Opera facial makeup generation.
Outlook
While the improved Stable Diffusion model demonstrates superior quality and speed in generating Peking Opera facial makeup, it may have limitations in generating diverse images. The model’s focus on optimizing image quality and acceleration could lead to a reduction in diversity, with generated images potentially exhibiting similar styles or details. This could result in mode collapse, especially when generating images with varying styles or complex patterns. To enhance the diversity of generated images, diversity-promoting mechanisms could be introduced. For example, regularization techniques, such as diversity loss based on adversarial training, could be employed. Additionally, using a more diverse training dataset that includes a wider range of facial makeup styles and details could improve the model’s capacity to generate varied outputs. Implementing dynamic weight adjustment strategies could further allow the model to capture different styles while maintaining high image quality.
While the improved Stable Diffusion model achieves significant advancements in generation speed and image quality, it may exhibit inefficiencies in computational performance and hardware resource consumption during the inference phase. The use of multi-head attention mechanisms and multiple U-Net modules results in substantial computational overhead, limiting the model’s practical application in resource-constrained environments or real-time scenarios. To enhance the model’s inference efficiency, further optimization of the architecture could be explored to reduce computational complexity. For instance, more lightweight attention mechanisms, such as linear attention, could be employed, or model compression techniques (e.g., pruning, quantization, or distillation) could be applied to decrease the computational load during inference. Additionally, leveraging inference accelerators like TensorRT or hardware-specific optimizations could accelerate the inference process without significantly compromising image quality. These improvements would enhance the model’s usability in resource-limited settings and its applicability in real-world scenarios.
This study introduces an improved Stable Diffusion model that enhances the quality, speed, and customization of Peking Opera facial makeup generation, contributing to advancements in text-guided image generation and the preservation of cultural heritage through AI technology.
Data availability
Data supporting the results of this study are available upon request from the corresponding author. Due to privacy or ethical constraints, these data are not fully publicly available. Some of the data and project code available can be downloaded from the following url: https://github.com/gehongru/Peking-Opera
References
Han, X. Intercultural communication of Chinese opera: A review of current research challenges, and future directions. Int J Educ Humanit 15, 110–116 (2024).
Zhang, M. Peking Opera culture fused with scrap art: Raising Public awareness of environmental protection, ศิลปกรรม สาร, 17, 63–85. (2024)
Zheng, Z. Evolution symbolism, and artistry: a study on the colors of Peking opera facial makeup. Art Perform Lett 4, 36–42 (2023).
Shen, Y., Duan, O., Xin, X., Yan, M. & Li, Z. Styled and characteristic Peking opera facial makeup synthesis with co-training and transfer conditional StyleGAN2. Heritage Sci 12(1), 358 (2024).
Ahmad, Z., Jaffri, Z. U. A., Chen, M. & Bao, S. Understanding GANs: fundamentals, variants, training challenges, applications, and open problems. Multimed Tools Appl 84(12), 10347–10423 (2024).
Asesh, A. Variational autoencoder frameworks in generative AI model, In: 2023 24th International Arab Conference on Information Technology (ACIT), IEEE, 2023, pp. 01–06.
Yang, C., Kong, L. Research on product style design based on genetic algorithm, In: 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), IEEE, 2020, pp. 317–321.
Glimstedt, H. The iPhone and its antecedents: re-thinking entry and the evolution of platform strategies at Apple Inc. Entrep Hist 98(1), 120–151 (2020).
AI N. Artificial intelligence risk management framework: Generative artificial intelligence profile, in, NIST trustworthy and responsible AI Gaithersburg, MD, USA, 2024.
Mansour, S. Intelligent graphic design: The effectiveness of midjourney as a participant in a creative brainstorming session. Int Des J 13, 501–512 (2023).
Park, K. A study on the color of AI-generated images for fashion design-focused on the use of midjourney. J Converg Culture Technol 10, 343–348 (2024).
Guan, Z. & Ding, G. Editable video creation based on embedded simulation engine and GAN. Microprocess. Microsyst. 75, 103048 (2020).
Tilford, K. Performing creativity: Text-to-image synthesis and the mimicry of artistic subjectivity, in: Choreomata, Chapman and Hall/CRC, 2023, pp. 125–187.
De Souza, V. L. T., Marques, B. A. D., Batagelo, H. C. & Gois, J. P. A review on generative adversarial networks for image generation. Comput. Graph. 114, 13–25 (2023).
Sun, M., Wang, W., Zhu, X. & Liu, J. Reparameterizing and dynamically quantizing image features for image generation. Pattern Recogn. 146, 109962 (2024).
Zhang, F., Cao, D., Ma, X., Chen, B. & Zhang, J. Style transfer network for generating Opera makeup details. J Syst Simul 35, 2064–2076 (2023).
Sortino, R., Palazzo, S., Rundo, F. & Spampinato, C. Transformer-based image generation from scene graphs. Comput. Vis. Image Underst. 233, 103721 (2023).
Zhou, N.-R., Zhang, T.-F., Xie, X.-W. & Wu, J.-Y. Hybrid quantum–classical generative adversarial networks for image generation via learning discrete distribution. Signal Process: Image Commun 110, 116891 (2023).
Williams, C. et al. A unified framework for U-Net design and analysis. Adv. Neural. Inf. Process. Syst. 36, 27745–27782 (2023).
Hu, E. J. et al. Lora: Low-rank adaptation of large language models. ICLR 1, 3 (2022).
Frolov, S., Hinz, T., Raue, F., Hees, J. & Dengel, A. Adversarial text-to-image synthesis: A review. Neural Netw. 144, 187–209 (2021).
Alotaibi, A. Deep generative adversarial networks for image-to-image translation: A review. Symmetry 12, 1705 (2020).
Bucher, M. J. J., Kraus, M. A., Rust, R. & Tang, S. Performance-based generative design for parametric modeling of engineering structures using deep conditional generative models. Autom. Constr. 156, 105128 (2023).
Wang, Y. & Pei, Y. A comprehensive survey on interactive evolutionary computation in the first two decades of the 21st century. Appl Soft Comput 164, 111950 (2024).
Wang, Z., Wang, X., Xie, L., Qi, Z., Shan, Y., Wang, W., Luo, P., Styleadapter: A single-pass lora-free model for stylized image generation, arXiv preprint arXiv:2309.01770, (2023).
Chen, J., Pan, Y., Yao, T., Mei, T. Controlstyle: Text-driven stylized image generation using diffusion priors, In: Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7540–7548.
Liu, G., Xia, M., Zhang, Y., Chen, H., Xing, J., Wang, X., Yang, Y., Shan, Y. Stylecrafter: Enhancing stylized text-to-video generation with style adapter, arXiv preprint arXiv:2312.00330, (2023).
Xu, C., Hu, K., Luo, D., Zhang, J., Li, W., Ge, Y., Wang, C. StyleMaster: Towards flexible stylized image generation with diffusion models, arXiv preprint arXiv:2405.15287, (2024).
Zhou, H., Cheng, X., Yu, W., Tian, Y., Yuan, L. HoloDreamer: Holistic 3D Panoramic world generation from text descriptions, arXiv preprint arXiv:2407.15187, (2024).
Xing, P., Wang, H., Sun, Y., Wang, Q., Bai, X., Ai, H., Huang, R., Li, Z. CSGO: Content-style composition in text-to-image generation, arXiv preprint arXiv:2408.16766, (2024).
Couairon, G., Verbeek, J., Schwenk, H., Cord, M. Diffedit: Diffusion-based semantic image editing with mask guidance, arXiv preprint arXiv:2210.11427, (2022).
Luo, Z., Chen, D., Zhang, Y., Huang, Y., Wang, L., Shen, Y., Zhao, D., Zhou, J., Tan, T. Videofusion: Decomposed diffusion models for high-quality video generation, arXiv preprint arXiv:2303.08320, (2023).
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T. Multidiffusion: Fusing diffusion paths for controlled image generation, (2023).
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, arXiv preprint arXiv:2308.06721, (2023).
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A. Stable video diffusion: Scaling latent video diffusion models to large datasets, arXiv preprint arXiv:2311.15127, (2023).
Han, D. & Zhang, H. A brief analysis of the role of traditional Chinese opera body in character shaping: A case study of Beijing Opera. Highlights Art Des 6, 40–42 (2024).
Wang, W., Sun, Q., Zhang, F., Tang, Y., Liu, J., Wang, X., Diffusion feedback helps CLIP see better, arXiv preprint arXiv:2407.20171, (2024).
Park, Y.-H., Kwon, M., Choi, J., Jo, J. & Uh, Y. Understanding the latent space of diffusion models through the lens of riemannian geometry. Adv. Neural. Inf. Process. Syst. 36, 24129–24142 (2023).
Cui, K., Yu, Y., Zhan, F., Liao, S., Lu, S., Xing, E. P. KD-DLGAN: Data limited image generation via knowledge distillation, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3872–3882.
Yang, Z., Wang, J., Gan, Z., Li, L., Lin, K., Wu, C., Duan, N., Liu, Z., Liu, C., Zeng, M. Reco: Region-controlled text-to-image generation, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14246–14255.
Torbunov, D., Huang, Y., Yu, H., Huang, J., Yoo, S., Lin, M., Viren, B., Ren, Y. Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation, In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 702–712.
Ku, H. & Lee, M. TextControlGAN: Text-to-image synthesis with controllable generative adversarial networks. Appl. Sci. 13, 5098 (2023).
Qin, C., Yu, N., Xing, C., Zhang, S., Chen, Z., Ermon, S., Fu, Y., Xiong, C., Xu, R. Gluegen: Plug and play multi-modal encoders for x-to-image generation, In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 23085–23096.
Zhang, C., Chen, X., Chai, S., Wu, C. H., Lagun, D., Beeler, T., De la Torre, F. Iti-gen: Inclusive text-to-image generation, In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3969–3980.
Chandaliya, P. K. & Nain, N. AW-GAN: Face aging and rejuvenation using attention with wavelet GAN. Neural Comput. Appl. 35, 2811–2825 (2023).
Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., Lee, Y. J. Gligen: Open-set grounded text-to-image generation, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22511–22521.
Zhu, M., Pan, P., Chen, W., Yang, Y. Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5802–5810.
Z. Xue, G. Song, Q. Guo, B. Liu, Z. Zong, Y. Liu, P. Luo, Raphael: Text-to-image generation via large mixture of diffusion paths, Advances in Neural Information Processing Systems, 36 (2024).
Liu, X., Zhang, X., Ma, J., Peng, J. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation, In: The Twelfth International Conference on Learning Representations, 2023.
Kim, M., Liu, F., Jain, A., Liu, X. Dcface: Synthetic face generation with dual condition diffusion model, In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition, 2023, pp. 12715–12725.
Sha, Z., Li, Z., Yu, N., Zhang, Y. De-fake: Detection and attribution of fake images generated by text-to-image generation models, In: Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 3418–3432.
Liu, M., Gan, J., Wen, R., Li, T., Chen, Y., Chen, H. Spiking-diffusion: Vector quantized discrete diffusion model with spiking neural networks, arXiv preprint arXiv:2308.10187, (2023).
Chung, J. J.Y., Adar, E. Promptpaint: Steering text-to-image generation through paint medium-like interactions, In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–17.
Sivaroopan, N. et al. Netdiffus: Network traffic generation by diffusion models through time-series imaging. Comput. Netw. 251, 110616 (2024).
Lu, H., Tunanyan, H., Wang, K., Navasardyan, S., Wang, Z., Shi, H. Specialist diffusion: Plug-and-play sample-efficient fine-tuning of text-to-image diffusion models to learn any unseen style, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14267–14276.
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis, arXiv preprint arXiv:2307.01952, (2023).
Sheynin, S., Ashual, O., Polyak, A., Singer, U., Gafni, O., Nachmani, E., Taigman, Y. KNN-diffusion: Image generation via large-scale retrieval, arXiv preprint arXiv:2204.02849, (2022).
Funding
Weiliang Zhang: Achievements of the “Ginseng Culture Communication” Construction Project for Jilin Province’s Characteristic High Level Disciplines (Groups); Research Project on Higher Education Teaching Reform of Jilin Provincial Department of Education(2024L5LD8A4006U); The Ministry of Education’s supply and demand docking employment and education project “Exploration and Innovation of Digital Creative Talent Training Mode” (2023123047682) ; Weiliang Zhang Hongru Ge, Qingchi Xian: 2025 Annual Social Science Planning Project of the Intangible Cultural Heritage Research Institute of the China Folk Literature and Art Association (FY2025YB24); Weiliang Zhang: School of Special Key Project of Jilin Publishing and Editing Society (ZD2404).
Author information
Authors and Affiliations
Contributions
Ge Hongru and Zhang Weilaing contributed to the conceptualization and design of the study, conducted the experiments, and drafted the manuscript. Sun Xingxing and Fan Ziqi were responsible for data collection, analysis, and interpretation of the results. Xian Qingchi provided critical revisions of the manuscript and contributed to the methodology development. All authors read and approved the final manuscript.
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ge, H., Zhang, W., Sun, X. et al. Personalized adaptive generation of peking opera facial makeup using generative artificial intelligence. Sci Rep 15, 45164 (2025). https://doi.org/10.1038/s41598-025-28460-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28460-1
