
Abstract
Efficient estimation of crop water requirements (ETc) is important for sustainable agricultural water management, particularly under increasing climate variability. Traditional methods lack a comprehensive analysis of dynamic patterns associated with crop evapotranspiration factors. To address these limitations, we propose a dynamic graph-based Dual-Graph Semantic Fusion (DG-DGSF) for ETc estimation. The multivariate time series is decomposed into trend and seasonal parts. This decomposition enables us to attain two dynamic graphs, Seasonal Dynamic Graph (SDG) and Trend Dynamic Graph (TDG), with their semantic characteristics extracted through Dual-Graph Semantic Fusion (DGSF). Each model is incorporated with the Dynamic Graph Learner (DGL) model and Graph Convolutional based on Recurrent Unit (GC-GRU) to analyse the trend and seasonal components. The DGL receives the trend or seasonal information to produce dynamic graphs, while GC-GRU combines the dynamic graph characteristics with the original series data. To effectively combine and extract the semantic characteristics from the trend and seasonal parts, a contrastive learning model is designed, followed by a supervised prediction model based on a multi-layer perceptron. The proposed DG-DGSF model was tested on data collected over two years (2023–2024) in Prince Edward Island, Canada. Three experimental locations were selected within the research farm: Location 1 consisted of loam, Location 2 featured sandy loam, and Location 3 contained loamy sand. The DG-DGSF model is compared with state-of-the-art models, including BiLSTM, GRU, GCN, BiGRU, LSTNet, DGDL, TPA-LSTM, and GCN-LSTM. The performance of the DG-DGSF is evaluated using numerous visual, statistical and probability metrics. The results demonstrated that the DG-DGSF model outperformed the benchmark models with the lowest forecasting error and highest ETc prediction rates, RMSE = 0.0469, MAPE = 0.120, NRMSE = 0.0431, KGE = 0.977, NSE = 0.963.
Similar content being viewed by others
Introduction
Climate change is one of the most complicated global issues which greatly impacts ecological systems and raises considerable in estimating crop water requirements1,2,3. The sustainability and availability of water sources have been limited due to changing precipitation patterns, increasing temperatures, and extreme weather events4,5,6. These climatic conditions affect key factors like evapotranspiration (ET, soil moisture, humidity, and crop maturity stages, lowering predictable irrigation water applications in crop fields7,8. As a result, advanced data-driven approaches are essential for delivering timely and precise water use recommendations to support efficient irrigation systems9. Consequently, there is a high demand for accurate daily ET prediction systems to optimize real-time irrigation scheduling and provide resilient agricultural water management strategies10,11,12,13.
Potato cultivation has great importance in Prince Edward Island (PEI), Canada, as it is the leading agro economy of the province and contributes significantly to the overall economy and rural livelihoods14,15,16,17,18,19. PEI is well known for producing high-quality potatoes due to its mild climate, favourable soil properties, and regular precipitation during the growing period20,21,22,23,24,25. However, recent climate change, including droughts and rising temperatures has negatively affected potato yield and quality26. As a result, supplementary irrigation has become important in this region for the optimum moisture level of the soil, which minimizes water stress during key growth periods and guarantees tuber quantity and quality of potato tuber27,28. In this context, accurately estimating the water demand of potato production systems is a challenging task to improve irrigation practices, sustainable agriculture, and sustainable water resource management in PEI under varied climatic conditions25,29,30,31,32,33,34,35,36,37.
Precise estimation of ETc and crop coefficients (Kc) is particularly important for high water-demand crops like potatoes38,39. Although traditional models require extensive meteorological inputs, they struggle to simulate the nonlinear and dynamic behaviour of agro-climatic systems40. Emerging ML and deep learning (DL) techniques offer more adaptable and efficient alternatives41,42. Several studies have explored DL approaches for ETc estimation43. For example, Nayak et al44. compared several machines learning algorithms, including LSTM, SVR, and RF models using limited weather data, for daily reference evapotranspiration (ETc) estimation. Authors that LSTM outperformed classic approaches, with an R2value of up to 0.98. Similarly, El-Kenawy et al45. tested both LSTM and Gated Recurrent Unit (GRU) models. Hybrid models integrating Convolutional Neural Networks (CNNs) with recurrent algorithms have also been employed widely46,47. For example, a CNN-GRU-LSTM model was designed to predict water stress in Saudi Arabia48. They achieved an average of R2 = 0. 99.
In addition, graph-based learning approaches have been increasingly adopted to investigate complex relationships in water management systems49,50. Graph neural networks (GNNs) were applied by51to predict water shortage52,53. Employed graph-based deep learning approaches to predict crop ETc and Kc using time series data.
Despite the promising results of these studies, they often failed to generalize across different soil types for monitoring Etc which play a crucial role in water management systems54,55,Z.-Y2,3.. Figure 1 demonstrates the motivation for utilising dynamic relation-based graphs for ETc prediction. Figure 1 depicts how the relationships among variables such as soil moisture, temperature, and rainfall change over time, as shown in different graph structures across time intervals. Traditional prediction approaches assume static correlations among time series variables; however, those models fail to extract such temporal variations54,55,56. In contrast, dynamic graph base methods can represent and learn dependencies, leading to more accurate prediction. This adaptability is important factor for predicting ETc, where variables interactions shift due to seasonal and trend factors. As a result, predicting future values of ETc effectively requires understanding and modelling dynamic relationships among time series data.

Modelling time series as dynamic graphs.
As a result, developing a dynamic graph-based Dual-Graph Semantic Fusion (DG-DGSF) method can effectively address these limitations. This proposed model is designed to represent trend and seasonal information as dynamic graphs, enabling it to capture varying dependencies among time series variables. Additionally, it can learn both long-term and short-term patterns influencing these variables, thereby improving the accuracy of ETc predictions across different soil types. Such advancements will contribute to more efficient and precise irrigation practices for potato cultivation.
In contrast to traditional models that rely on meteorological data or fixed crop coefficients, our approach incorporates key hydrological and soil parameters, including soil texture, seasonal variability, field capacity, wilting point, soil moisture, rainfall, irrigation, and leaching soil moisture storage change. The proposed approach is designed to capture both long-term and short-term evapotranspiration patterns, allowing it to track changes in water consumption. Its ability to model the dynamic interactions between soil and plant processes, along with fluctuating weather conditions, is expected to significantly improve the accuracy and resolution of ETc predictions.
A comprehensive investigation is conducted to examine the performance of the DG-DGSF model. To the best of our knowledge, this is the first attempt to integrate LOESS (locally estimated scatterplot smoothing), dynamic graph, and contrastive graph learning for estimating crop water in the context of soil–plant-atmosphere continuum, specifically for potato production. This study is relevant under the variable climatic and hydrological conditions typical of regions such as Prince Edward Island. This study specifically aims to:
-
Capture the complex spatial and dynamic relationships among key hydrological and soil parameters, including soil texture type, field capacity, wilting point, soil moisture, rainfall, irrigation, periodic fluctuations within the growing season, leaching, and change in soil moisture storage that influences potato crop water demand.
-
Apply graph-based contrastive learning to enhance feature representation and inter-variable dependency modelling for improved generalization under variable field conditions.
-
Incorporate the STL (Seasonal and Trend decomposition using Loess) model LOESS to decompose the time series data into trend and season parts and use them as inputs to the proposed DG-DGSF model.
-
Design a DGL and a GC-GRU to analyse the trend and season parts.
-
Suggest the DGSF model to integrate and fuse the trend and season dynamic graphs. The DGSF combined spatial and temporal dependencies extracted from trend and season information. The DGSF is used to bridge this information of trend and season by regulating and aligning this semantic information across the seasonal trend information.
-
Leverage contrastive learning to align semantic characteristics of dynamic graphs, which are then processed through an MLP for prediction.
Materials and methods
Experimental setup
This study was conducted over two years (2023–2024) at the Canadian Centre for Climate Change and Adaptation in St. Peter’s Bay, Prince Edward Island, Canada, as shown in Fig. 2. The experimental period spanned the typical potato growing season, starting on June 1st and ending on October 8th each year. The region has a humid continental climate and is widely recognized for its extensive potato cultivation. Three experimental locations were selected within the research farm to ensure coverage of the primary soil textures found in Prince Edward Island and maintain consistency in environmental conditions. Each site was designated a unique, representative soil type: Location 1 consisted of loam, Location 2 featured sandy loam, and Location 3 contained loamy sand. Three replicate lysimeter plots were built at each soil type, producing nine samples across all soil textures. This structure was created to comprehensively compare soil–water interactions and crop water demands across diverse soil conditions.

Experimental location.
Lysimeter design and crop planting
Lysimeters are designed to mimic the field situation in a controlled environment so that exact measurement of water movement related to crops can be taken57. The dimensions of each lysimeter utilized in the investigation were 122 cm in length, 61 cm in breadth, and 61 cm in depth. The lysimeters were filled with soil and planted with potatoes to resemble the natural field situation as much as possible and at the same time make accurate measurements of all water inputs and outputs.
The Russet Burbank potato cultivar, a widely cultivated variety in Prince Edward Island, was chosen to be planted in the lysimeters. Before planting, representative soil samples were collected from each soil type for laboratory analysis at the PEI Analytical Services. These composite samples were analysed to ascertain the bulk density, organic matter levels, and soil texture. The recognized soil classifications were loam, sandy loam, and loamy sand, exhibiting corresponding bulk density values of 1.36, 1.44, and 1.68 g/cm3. The analysis revealed specific ratios of sand, silt, and clay and organic matter content to enhance comprehension of the soil’s physical characteristics. The site was prepared by digging the soil in each plot to a depth of roughly 15–20 cm to improve drainage and establish optimal conditions for root and tuber development. Certified seed tubers were utilized to mitigate disease risk and maintain uniform crop quality. Each seed piece was pruned to a weight of 45–60 g and included a minimum of one discernible bud. Planting took place on June 1st, 2023. Each lysimeter unit is comprised of a single row of three plants, with individual seed pieces placed 40 cm apart and a 30 cm buffer from the lysimeter edge to mitigate boundary effects.
This configuration facilitated optimal tuber development and was established in collaboration with local potato cultivators and agricultural consultants in PEI58. Pre-plant tillage was used to control the impact of weeds, and then regular cultivation was conducted. A visual representation of crop development stages within the lysimeter units is provided in Fig. 3. The required irrigation depth was first converted into an equivalent water volume, which was then measured using graduated cylinders. As shown in Fig. 3, water was precisely quantified before application. The measured volumes were subsequently delivered manually to each lysimeter (Fig. 3), ensuring uniform distribution and consistency across replicates. This method allowed precise control over irrigation amounts and provided high accuracy in water balance calculations.

Crop development phases within the lysimeter units, St. Peter’s Bay, Prince Edward Island, Canada.
Data collection and monitoring
A Spectrum Technologies WatchDog 1400 Micro Station was installed to monitor soil conditions and facilitate precise irrigation planning for the Russet Burbank potato variety. The moisture levels at various soil strata were captured by embedding three WaterScout SM100 soil moisture sensors manufactured by Spectrum Technologies Inc. in each lysimeter at depths of 15 cm, 22.5 cm, and 30 cm. Before data collection, the FieldScout 350 TDR system and the manufacturer’s recommended procedures were implemented to enhance the accuracy of measurements. Volumetric soil water content and weather information were automatically recorded every 30 min to monitor changes that influence root development and plant water absorption. To inform daily irrigation decisions, soil moisture data for all lysimeter plots were examined each morning at 9:30 AM. These parameters facilitated the assessment of the need for irrigation on that day.
Irrigation time and volumes were estimated based on the soil moisture retention curves developed for each soil texture utilized in the study, as described by26. The irrigation depth was modified to correspond with the projected active root zone during the development cycle to provide efficient water distribution. The objective was to maintain soil moisture around the field capacity without creating water stress or leaching. Observations of potato crop progression were conducted in a proximate field utilizing uniform planting and management techniques. This facilitated precise monitoring of growth stages, encompassing seedling emergence, initiation of tuber formation, and physiological maturity.
Estimation of reference evapotranspiration (ET0)
Reference evapotranspiration (ET₀) denotes the potential water loss from a properly irrigated grass surface under ideal conditions and is a benchmark for estimating crop water requirements. ET₀ was estimated by the FAO Penman–Monteith equation59 from data collected at two meteorological stations. To this end, an automated weather station (iMETOS IMT300-USW) was deployed on-site for the duration of the study. This station recorded a full set of the meteorological variables, including precipitation, air temperature, relative humidity, solar radiation, wind speed, dew point temperature, vapour pressure deficit, wind direction and gust intensity. All sensors displayed data, which was sent to the FieldClimate platform without interruption during the trial. Additional daily weather data were collected from a nearby weather station in St. Peter’s Bay (coordinates: 46.45°N, 62.58°W) located 350 m away from the main experimental plots. For each year, these datasets were employed in the computing of ET₀ on daily basis (using standard PM-56 calculator)59.
where \({R}_{n}-G\) is the net balance of energy available at the surface \(\left[\frac{\text{MJ}}{{\text{mm}}^{2}{\text{d}}}\right],\left({e}_{s}-{e}_{a}\right)\) indicates the vapour pressure deficit of air at the reference height kPa \(,\Delta\) reflects the slope of the relationship between saturation vapour pressure and temperature at the mean air temperature Kpa/o C \(, \gamma\) is the psychometric constant Kpa/oC, and U2 is wind speed m/s at 2 m height.
Estimation of crop evapotranspiration (ETc)
ETc is the total amount of water that can be lost from the crop to the atmosphere by the combined processes of soil evaporation and crop transpiration. This value varies according to the crop type, phenological stage, and current weather conditions. In this study, ETc for potato was directly calculated from data obtained by the lysimeter blocks, according to the following formula60,61:
where ETc = crop evapotranspiration (mm/day), I = irrigation applied (mm/day), R = rainfall received (mm/day), DP = water lost through deep percolation (mm/day), ΔS = change in soil water storage (mm/day). The water entering the lysimeter from rain or irrigation was closely monitored. The surplus water from precipitation or excessive irrigation that extends beyond the root zone was collected in a container at the base of each lysimeter, known as deep percolation. This approach enabled accurate plant water uptake assessment for different stages of plant growth, soil types and climatic conditions.
Problem definition
The proposed model in this study aims to predict ETc. The problem of detection is defined as follows: a multivariate time series is defined as \(X\in {R}^{N}xM\) where \(T\) refers to the length of time series data, \(M\) is the number of variables { irrigation, rainfall, water lost, change in soil water storage} in \(X.\) All variable \(M\) are defined as \(G=(V,E, A)\), where \(V\) denotes the number of nodes, \(E\) is the number of edges, and \(A\) refers to the adjacency matrix. Suppose each variable \(M\) is represented by \(s\) a sequence of datapoints, so we referred to the values of all variables at time \(t\) as \({S}^{t}\).
Over time, a sequence of graphs is created the evolving graph forms a sequence of graphs: \(G = \left\{ {G}_{1},{G}_{2}, ..., {G}_{T} \right\}.\) The learning mapping function is defined as
Using the dynamic graphs graph deep learning, the model \(\xi\) learns from network behaviour to predict \({ET}_{C}\).
Proposed framework for ETc prediction
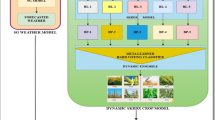
Figure 4 depicts the proposed model for ETc prediction. The collected multivariate time series \(X\) is decomposed into seasonal parts and trend parts \({X}_{s}^{t}, {X}_{T}^{t}\), using the STL model LOESS. This procedure of decomposition enables us to attain two dynamic graphs, the Seasonal Graph and the Trend Graph, with their semantic characteristics through DGSF. The proposed DGSF model is divided into three parts: trend dynamic graph and seasonal dynamic graph, denoted as SDG and TDG, respectively, and contrastive learning based MLP. Each part of SDG, and TDG includes two modules: DGL and GC-GRU. The DGL receives the trend or seasonal information to produce dynamic graphs, while GC-GRU combines the dynamic graph characteristics with the original series data. To effectively combine and extract the semantic characteristics from the trend and seasonal time series data, a contrastive learning model is designed, followed by a supervised prediction model. The contrastive learning is employed to align semantic characteristics, and then they are sent to an MLP for prediction.

The proposed model for ETC prediction.
Time series decomposition
As the agriculture time series exhibits a high nonlinearity and complex behaviour, several machine learning models fail to capture the hidden and influential characteristics. Consequently, in recent years, much work has involved decomposition models to pre-process time series data. Those decomposition models can effectively reveal the important and hidden characteristics of the data as well as improve the predictive accuracy of the model. In the present study, we adopted a seasonal and trend decomposition model named STL model LOESS (locally estimated scatterplot smoothing) to decompose the time series data into trends, seasonality, and residuals62. For more details, the LOESS model is explained in Liu et al63.. We applied STL model to capture the seasonal changes and long-term trends in potato crop evapotranspiration time series. Suppose a multivariate time series is defined as \(X\in {R}^{N}xM\) where T refers to the length of time series data, M is the number of variables in X \(.\) Each variable \(Y=\{{y}_{1}, {y}_{2}, \dots {y}_{T}\}\) where \(T\) is the number of datapoints. The LOESS model decomposes the \(y\) into trends, seasonality, and residuals.
where: \({Y}_{t}\) = the original time series, \({T}_{t}\) refers to the trend component, \({S}_{t}\) denotes the seasonal component, \({R}_{t}\) is the residual/noise (random fluctuations). Figure 5 shows that Leaching, rainfall, irrigation, and change in storage are decomposed into trend and season components. The data for the year 2023 is taken as an example.

Time series is being decomposed into trend and season parts.
DG-DGSF framework
In this section, a dynamic graph learner (DGL) is introduced to analyse trend and season parts. To process both current time features and historical information, multi-head attention layer (MHAL) is employed in this paper. The DGL model is derived as:
where \({\ddot{H}}^{t}\in {\mathbb{R}}^{Nxh}, h\) is the hidden size, \(V, Q, F\) are key, value, query matrices, \({\Gamma }^{t}\) is either \({X}_{s}^{t}, {X}_{T}^{t}\) season or trend features extracted in Sect. 4.1.
The \({\ddot{H}}^{t}\) is further fused with node embedding \({NE}^{(t-1)}\in {\mathbb{R}}^{Nxe}\), where \(e\) represents the number of embedding dimensions. A gated fusion approach proposed by64,65 is adopted in this paper to integrate the spatial and temporal features. The gated fusion approach could learn important information from different data sources. The gated fusion approach is applied as
where \(\sigma\) denotes the Sigmoid activation function, \(\odot\) Hadamard product, z, r, c are the update gate, the reset gate, and the memory cell.
Adjacency matrix producer
To construct an adjacency matrix for each dynamic graph, we followed the study in66. To obtain the Adjacency matrix, the learnable weight tensor and node embedding are integrated using the following formula:
where \(\circledast_{1}, {\circledast}_{1}\) are the training parameters, \(\alpha\) is regulated parameter for \(ReLU\)
Dual-graph semantic fusion (DGSF)
In ETc Prediction, a short-term fluctuation due to rainfall, temperature changes, and long-term trends associated with soil moisture depletion play significant roles. These characteristics evolve at different temporal scales; however, they are inherently interdependent. To effectively extract this information, cross-scale dependencies, we suggest DGSF to improve the prediction ability of the proposed model. The DGSF is employed to integrate spatial and temporal dependencies extracted from trend graphs and season graphs. As we decomposed the multivariate time series into seasonal and trend features and transferred them into dynamic graphs, the DGSF is suggested to bridge this information by regulating and aligning this semantic information across the seasonal trend information66. Firstly, the proposed DGSF identified nodes with global or local spatial information in each graph by computing mutual information (MI) among aligned nodes’ embeddings over time,
The \({Adj}^{t}\) calculated value in the previous section reflects the correlation between the node \({v}_{t}[i]\) and other nodes in the graphs. This matrix can be represented as a one-to-many relationship to depict the spatial semantics of node \({v}[i]\) at time t. As a result, each entity in \({Adj}^{t}\) is mapped as the rest (OvR) relationship to generate a vector of OvR for each node. Then, the matrix AA is generated to represent OvR relationship of all nodes. Then, AA and \({Adj}^{t}\) are concatenated to form spatial semantic state matrix (\(SSM\)).
where \(FCS\) denotes the full connected layer, each entity in \(SSM[i]\) refers to the semantic relationship between node \(i\) and other nodes. In ETc modelling, some variables, such as rainfall and irrigation, influence the spatial behaviour of the demand for water over time. These impacts are not static; however, some nodes exhibit stable behaviour.
In other words, the trend and seasonal information evolve separately; however, in fact, the seasonal patterns and trend patterns interact. Learning them in isolation phases could miss these dependencies. To solve this issue, we calculated the cosine similarity between these two semantic states \({SSM}^{1}, {SSM}^{2}\) is calculated to measure how each node’s spatial semantics change over time.
Nodes with the Top K highest similarities are considered to produce global spatial patterns, while the remaining \(non Top K\) nodes are assumed to exhibit local, time-sensitive behaviours. The mutual information is calculated as follows:
where \(M\) refers to the index mask, \(MI\) computing approach, then the \({L}_{max}, \text{and} {L}_{max}\) are maximized and minimized \(MI\) during the training phase. The MI measures the similarity between two variables by identifying how much information is shared between them.
Graph convolutional based on GRU (GC-GRU)
Graph convolutional neural network models have been widely applied in time series prediction issues. Recently, several studies have effectively integrated GCN with LSTM to improve the ability of GCN to capture and learn complex representations of the multivariate time series data, leading to a more advanced prediction model compared to using either LSTM or GCN. As temporal and spatial dependencies vary across different domains of multivariate time series, and for better integration between temporal dependencies and spatial dependencies, in this paper, the GCN is integrated with GRU67.
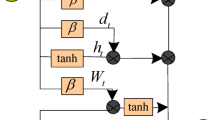
where \(\odot\) Hadamard product, \(\vartheta {*}_{G}\) denotes the propagation layer, \(\beta\) refers to the hyperparameters which is used to adjust the percentage of temporal information to the spatial information, \(\sigma\) is the Sigmoid activation function, \(z, r, c\) are the update gate, the reset gate, and the memory cell.
Dual-view contrastive learner with MLP (CLM-MLP)
To improve the semantic interaction between \({SSM}_{trend}\) and \({SSM}_{season}\) characteristics, we designed a contrastive learning model (CLM). This proposed CPM model aims at aligning the local and global semantics characteristics extracted from the seasonal and trend graphs. The model receives the node embedding \(N{E}_{season}^{t}\) and \(N{E}_{trend}^{t}\) extracted from the season graph and trend graph. This contrastive learning model keeps highly impacted feature representations. The main formula of the CLM is:
let \({X}_{season}\), and \({X}_{trend}\) represent the node embeddings \(N{E}_{season}^{t}\) and \(N{E}_{trend}^{t}\) obtained from \(SG\) and \(TG\)
These two features are aligned using CLM using \(Info\_loss\) function
where \(coss\) is the cosine similarity, \(\tau \in \{0.1, 0.2, 0.5\}\) denotes the hyperparameters, then the fused representation \(FusX\) is defined:
The fused features are transferred into a prediction MLP to generate the final target value \({\ddot{x}}^{t}\):
The total training objective \({L}_{total}\) is computed as the sum of the supervised losses and contrastive.
Model Development and optimisation
The proposed DG-DGSF model aims at ETc prediction which is defined as the total amount of water that can be lost from the crop. The data was collected from the period of 2023 to 2024. The collected dataset was carefully divided into the training set, which includes the data during the growing season from June 1, 2023, to October 8, 2023, and the testing and validation sets, which contain the data from the growing season from June 1, 2023, to October 8, 2024.The proposed model (DG-DGSF) was evaluated against GRU68, BiGRU67, BiLSTM and graph-based methods including Graph Convolutional network (GCN) (He et al., 2020), GCN based LSTM (GCN-LSTM)69, Dynamic Based Graph Deep Learning (DGDL)65 ), Long-Short-term Network (LSTNet)66, TPA-LSTM66. All models were implemented using Python 3.13. All simulation results were conducted on a computer with the following specification: Intel(R) Iris(R) Xe Graphics, CPU 12th Gen Intel(R) Core (TM) i7-1260U, 1100 MHz, 10 Core(s), 12 Logical Processor(s). The model DG-DGSF development process includes six phases, ensuring a comprehensive model and accurate prediction abilities based on two years data collected from three fields.
-
Phase 1: Data collection The data was collected over two years (2023–2024) at the Canadian Centre for Climate Change and Adaptation in St. Peter’s Bay, Prince Edward Island, Canada. Figure 3 shows the data collection process. Three experimental locations were chosen in this research. The three experimental locations were selected within the research farm to ensure coverage of the primary soil textures found in Prince Edward Island and maintain consistency in environmental conditions. Each location was designated a unique, representative soil type: Location 1 consisted of loam, Location 2 featured sandy loam, and Location 3 contained loamy sand.
-
Phase 2: Data decomposition- in this paper a seasonal and trend decomposition model called STL model LOESS (locally estimated scatterplot smoothing) was employed to decompose the time series data into trends, seasonality, and residuals components. The STL model LOESS can improve the performance of the prediction model by exhibiting the nonlinearity and complex behaviours in crop time series data. Each variable in the time series data was passed through the STL model LOESS model and three components were extracted including trends, seasonality, and residuals representations. Figure 5 shows the decomposition process of different variables.
-
Phase 3: DG-DGSF model The DG-DGSF model was designed to analysis trend and season parts extracted in phase 4 and predict ETc values. The trend and seasonal components were transferred into dynamic graph (DG). As a result, two dynamic graph models were constructed named trend dynamic graph model and seasonal dynamic graph model. Each model was included dynamic graph learner (DGL), and Graph Convolutional based on GRU (GC-GRU) to extract representative information from trend and season components. To combined dynamic graph representation extracted from trend dynamic graph and seasonal dynamic graphs, we developed Dual-Graph Semantic Fusion (DGSF). The DGSF integrates spatial and temporal representations extracted from trend graphs and season graphs. The DGSF produced \({SSM}_{trend}\) and \({SSM}_{season}\) characteristics to predict ETc.
-
Phase 4: prediction phase: Dual-View Contrastive Learner with MLP (PCM-MLP) To improve the semantic interaction between the extracted features in Phase 3, a contrastive learning model was suggested to merge the \({SSM}_{trend}\) and \({SSM}_{season}\) characteristics, This contrastive learning model aims at aligning the local and global semantics characteristics extracted from the seasonal and trend graphs. The model receives the node embedding \(N{E}_{season}^{t}\) and \(N{E}_{trend}^{t}\) extracted from the season graphs and trend graphs. Then it fused final features into the prediction MLP model to generate the final target value \({\ddot{x}}^{t}\):
-
Phase 5: Training models: the proposed DG-DGSF model and all benchmark models were trained using the time series data from June 1, 2023, to October 8, 2023, and they were tested and validated using the data from the growing season from June 1, 2024, to October 8, 2024. Different metrics were used to evaluate the performance of the proposed model against the benchmark models. In this paper, we ensured that all the models were trained on a comprehensive set of data, integrating extensive historical data to make accurate predictions about future ETc values.
-
Phase 6: Optimisation and parameters selections All models parameters were selected carefully and optimized during the validation phase. All model parameters were selected carefully and optimized during the training phase. The hyperparameters of the proposed model and benchmark models were reported in Tables 1, and 2. The baseline models were divided into two classes: classic models named GRU BiGRU, BiLSTM and graph-based methods including Graph Convolutional network (GCN), GCN based LSTM (GCN-LSTM), Dynamic Based Graph Deep Learning (DGDL), Long-Short-term Network (LSTNet), TPA-LSTM.
Evaluation metrics
We employed several probability and statistical metrics to evaluate the proposed model. according to the previous studies, the following metrics were considered the most effective evaluation metrics: Root Mean Square Error (\(RMSE\)), Correlation coefficient (\(r\)), and Normalised RMSE (\(NRMSE\)), Mean Absolute Percentage Error (\(MAPE\)), Normalised Root Mean Square Error (\(NRMSE\)), Kling–Gupta Efficiency (\(KGE\)), Nash–Sutcliffe Efficiency (\(NSE\)), Coefficient of Variation (\(CV\)), Fractional Bias (\(FB\)), Prediction Interval Normalized Average Width metric (PINAWM) and Winkler Score (WS).
Experimental results
Numerical assessment
In this section, we quantify predictive performance using RMSE (mm·day⁻1), Root Mean Square Error (\(RMSE\)), Mean Absolute Percentage Error (\(MAPE\)), Correlation coefficient (\(r\)), and Normalised RMSE (\(NRMSE\)). This study focuses on predicting ETc, which refers to the total water loss from a crop through both soil evaporation and plant transpiration. The proposed model (DG-DGSF) was compared against nine models, including graph-based models and standard DL models, including BiLSTM, GRU, GCN, BiGRU, LSTNet, DGDL, TPA-LSTM, GCN-LSTM to predict Crop evapotranspiration (\(ETc\)). Table 3 reports the results in terms of \(NRMSE\), \(MAP E\), \(NRMSE\), and \(r\).
Obviously, the proposed DG-DGSF model demonstrated superior performance against the graph-based approaches and standard models, achieving the highest prediction rates across all four locations categorized by the highest \(r=0.993\) and lowest \(RMSE=0.0669\) values, compared to other graph deep learning and standard models. The proposed model outperformed the graph deep learning models, for example, the DGDL achieved lower prediction results \(r, and RMSE\), compared to our DG-DGSF model the \(r=0.920\) \(RMSE=0.173\). The GCN-LSTM, and GCN also scored lower results than the proposed model for GCN-LSTM \(r=0.8943\) \(RMSE=0.321\), and for GCN \(r=0.863\) \(RMSE=0.432\). The results confirmed that the performance of the proposed DG-DGSF model outperformed the standard dynamic graph deep learning techniques.
The standard deep learning models GRU, BiLSTM, BiGRU, TPA-LSTM, and LSTNet showed lower performance compared to graph-based deep learning models. The LSTNet, and TPA-LSTM recorded the highest \(RMSE\) and \(r\) among the standard deep learning models for TPA-LSTM and LSTNet \(r=0.903, \text{and} 0.887\) respectively. These results of all standard models underscore the superior performance of the proposed model (DG-DGSF). In addition, there was no noticeable fluctuation in the \(r\) values of the proposed DG-DGSF model for all three locations. The proposed DG-DGSF attained \(r\) values of 0.992, 0.979, 0.982 for location, location 2, and location 3, respectively. Compared to BiLSTM, GRU, GCN, BiGRU, LSTNet, DGDL, TPA-LSTM, GCN-LSTM, the DG-DGSF model delivered more accurate \(ETc\) predictions for three locations, highlighting its efficacy over these models. The noteworthy improvement in \(ETc\) prediction accuracy confirmed the advantage of the proposed DG-DGSF.
Table 3 further reports the performance of all prediction models in terms of Mean Absolute Percentage Error (\(MAPE\)) and Normalised Root Mean Square Error (\(NRMSE\)). The \(NRMSE\) calculates the standard deviation of prediction errors relative to the range of observed values, making it an effective metric for comparing prediction model performance across different data scales. While \(MAPE\) evaluates the average absolute percentage difference between actual and precited values, delivering a clear percentage-based indication of accuracy. Lower values of both \(NRMSE\) and \(MAPE\) metrics reflect a higher predictive accuracy. The obtained results based on \(NRMSE\) and \(MAPE\) revealed that the proposed DG-DGSF model showed a consistent and significant improvement in performance compared to previous models. Compared DG-DGSF \(NRMSE\) and \(MAPE\) values for three locations, it can be noticed that there was a decrease in both values compared to BiLSTM, GRU, GCN, BiGRU, LSTNet, DGDL, TPA-LSTM, and GCN-LSTM. The proposed DG-DGSF scored the lowest values of \(NRMSE=0.043, 0.0452, 0.0475.\) and \(MAPE=0.120, 0.112, 0.125\) for location 1, location 2 and location 3 respectively. The obtained results highlighted the robustness and efficacy of the proposed model as a superior tool for \(ETc\) prediction.
For further assessment, we adopted four metrics named Kling–Gupta Efficiency (\(KGE\)), Nash–Sutcliffe Efficiency (\(NSE\)), Coefficient of Variation (\(CV\)), and Fractional Bias (\(FB\)). Table 4 summarises the perfume evaluation of the proposed DG-DGSF model compared to previous approaches using \(KGE\), \(CV\), \(NSE\), \(FB\) . Our DG-DGSF model achieved a remarkable \(KGE=0.976, 0.967, 0.975\), and \(NSE=0.985, 0.966, 0.976\) for three locations confirming its superior capability to capture the dynamic patterns of observed data compared to state-of-the-art models. These are high values of \(KGE\), and \(NSE\) showed a significant advantage in extracting trends and behaviours associated with the observed data that are not visible for other models. However, the graph-based deep learning models scored a range of \(NSE\) values: GCN (0.851), DGDL (0.932), GCN-LSTM (0.889) for location one, GCN (0.841), DGDL (0.928), GCN-LSTM (0.865) for location two, and GCN (0.837), DGDL (0.910), GCN-LSTM (0.876) for location three. While the graph-based deep learning models showed reasonable performance, the DG-DGSF model consistently outperformed them in all three locations. The variation in performance intensifies further with the standard model GRU (0.831), BiGRU (0.865), BiLSTM (0.873). The \(KGE\) further emphasize the DG-DGSF model exceptional performance. The DG-DGSF model achieved the highest \(KGE\) for three stations, highlighting its efficiency in capturing the important patterns of observed data. The consistently high KGE, and NSE values across three locations confirmed its ability to capture trends and seasonal patterns.
Further evaluation using CV, and FB delivers complementary analysis into potential variability and biases in the model’s predictive results. The DG-DGSF model scored a lower \(FB=0.0081\) and \(CV=0.342\) compared to the state of the models, demonstrating good performance in terms of reducing both variability and bias. The lower \(CV\), and \(FB\) values of the DG-DGSF model highlight its outstanding facility to produce predictions with low bias and variability, in addition, confirming its robustness as a \(ETc\) prediction tool.
Visual evaluation of the proposed model
While the results in Tables 3 and 4 provided valuable quantitative evaluation of prediction model performance, those metrics might not always expose limitations and potential shortcomings. To provide a more thorough understanding of the proposed DG-DGSF mode behaviour for the \(ETc\) prediction. In this experiment, several plots were utilized as a complementary analysis approach. These visual plots offer valuable evaluation that numerical measures might ignore. Figure 6 displays scatterplots for all models, comparing the predicted with actual \(ETc\) values. Each plot includes the coefficient of determination (\({R}^{2} \in [\text{0,1}]\) ) with the linear fit equation (y = mx + c). A higher \({R}^{2}\) value indicates stronger relationship between the actual values and the predicted model. Figure 6 shows that the proposed model DG-DGSF mode behaves very closely to the actual values. It scored the highest \({R}^{2}\) compared to the state-of-the-art models. The visual results in Fig. 6 align with the previous observations from Tables 3 and 4, where the graph-based models and standard models achieved lower performance values compared to the DG-DGSF model. The scatterplot for the DG-DGSF mode produced patterns that are closely equivalent to the y = x line. The results indicated there was a strong alignment between the DG-DGSF model and actual \(ETc\) values. These visual results support our findings in Tables 3 and 4 to demonstrate the exceptional performance of the proposed model in predicting \(ETc.\) Figure 7 employs violin plots to report the absolute forecasting Error (FE) for DG-DGSF model and the state-of-the-art models. The violin plots utilize an inverted probability density function to show the error distribution of prediction models. The DG-DGSF model violin plots demonstrated slight bias|. The limit range of errors in the DG-DGSF model plot refers to its strength in handling various data points, even for complex predictions. Presenting the distribution of errors using violin plots supports the findings attained by previous metrics and proves the DG-DGSF model’s suitability for \(ETc\) prediction. The superior performance of the proposed DG-DGSF in reducing prediction errors made it a suitable choice for practical applications in this agricultural domain.

Scatter plots of each location for models’ performance comparison.

Prediction Errors using Violin plots generated by the proposed model against comparing models.
The efficiency of DG-DGSF was assessed using visualized Taylor plots in Fig. 8. Taylor plots are a graphical measure which provides a summary of how well the predicted model matches the actual values in terms of correlation, root mean square difference and ratio of variance. Figure 8 shows the Taylor diagrams of the proposed model as well as the baselines. From the results, it can be observed that the behaviour of the proposed DG-DGSF model was satisfactory and very close to the actual data. The proposed DG-DGSF demonstrated a strong relationship with the ETc across three locations. In addition, the DGDL model also showed a high performance and scored high regression values compared to other graph-based models.

Taylor diagrams of all three locations generated by the proposed model against comparing models.
Evaluation based on statistical approaches
Statistical assessment was adopted for further evaluation of the proposed models. In this experiment, the Diebold Mariano (DM) approach was employed to evaluate the proposed DG-DGSF model against the state-of-the-art methods. Using this approach, a statistical examination was conducted to identify whether the prediction errors of the two approaches differ significantly. In other words, DM verify if the predictions of the proposed DG-DGSF model are statistically more accurate than other approaches. Figure 9 displays a heatmap for three locations using DM. A negative number in a cell means that the model in the row performs better than models in the column by producing lower prediction errors, while a positive value indicates that the column model outperforms the row model. The results demonstrate that the proposed DG-DGSF model has a compelling advantage over the state of the art. The proposed DG-DGSF model consistently produced negative values in the entire heatmap, showing its efficiency compared to other models. Conversely, some standard and graph-based models, such as GRU and GCN models, produced positive values toward other models, signifying that their predictions are statistically not accurate enough.

Heating map of DM metric for all three locations generated by the proposed model against comparing models.
For further evaluation, we applied a residual-based bootstrapping, which is a statistical measure employed to assess the distribution of possible prediction errors of the predictive models. This approach involves resampling the residuals from the training sample. Then, it subsequently evaluates models using these resampled samples. In this paper, we resampled the time series data 100 times, and the resulting residuals were kept calculating the probabilistic measures shown in Fig. 9. The average of PICP for the three locations was presented in Fig. 10. The proposed DG-DGSF model showed extraordinary performance, scoring PICP of 0.99, proving that approximately 0.99% of true values lay within its predicted intervals. The results demonstrated that the proposed DG-DGSF model showed a high degree of confidence by capturing most of the actual values. Furthermore, the graph-based models such as DGDL and GCN-LSTM also showed promising performances, and they achieved an average of PICP of 0.93.
Prediction Interval Normalized Average Width metric (PINAWM) and Winkler Score (WS) are also adopted in this paper, which calculates the average width of the data’s variability relative to prediction intervals. Figures 10, 11 and 12 present a comparison evaluation in terms of \(PINAWM, PINAWM, WS\) . The model with lower values of PINAWM refers to narrower intervals and accurate predictions. Based on the results, the proposed DG-DGSF model outperforms the state-of-the-art models, scoring PINAWM of 0.15. Although DGDL and GCN-LSTM models recorded slightly lower PINAWM 0.18 and 0.22, respectively, they scored lower PICP compared to the proposed DG-DGSF model, obtaining an average of 0.93.

Model evaluation using PCIP criteria

The PINAWM score for model evaluation

Model assessment based on WS
Based on the obtained results using PINAWM, WS, and PICP, the proposed model delivered itself as a superior model for ETc prediction. As it showed reliable predictions with lower uncertainty. This exceptional performance of the proposed model in Table 5 supports the findings in Figs. 9, 10, 11 and 12, showing the proposed DG-DGSF model demonstrated a strong prediction capability across different evaluation metrics. In the section, a deeper investigation was made by employing the following metrics: F-Index, Coverage Width (\(CW\)), and Average Coverage Error (\(ACE\)). The proposed DG-DGSF model demonstrated strong performance across these measures. The proposed DG-DGSF model scored the lowest value of \(CW\)=17.34F-Index = 25.22, and \(ACE\)=4.56 for location 1. The results indicated that the proposed DG-DGSF model significantly produced narrower prediction intervals compared to the state-of-the-art models. This designed DG-DGSF model offers more accurate predictions.
Performance evaluation based on nested cross validation
We also adopted nested, chronological cross-validation to further evaluate and assess the generalisation of the proposed DG-DGSF model. The time-series data were divided into folds such that each outer fold held out a strictly future test block. Within each outer fold, hyperparameters and early stopping were tuned only on earlier training data using rolling or blocked validation. The future test block was not used for tuning. All preprocessing steps were fitted on training windows only and applied forward to validation and test samples to eliminate information leakage. We report performance only on outer test folds, using \(RMSE (\text{mm} {\text{day}}^{-1})\),
\(MAPE\) (%), and \(NSE\) (%), \(KGE\), \(CV\) (%).
Across the five outer test folds, the model maintains stable predictive accuracy with \(RMSE\)= 0.05 \(\pm\) 0.002 mm·day⁻1 and \(MAPE\) = 0.128 \(\pm\) 0.003, \(KGE\)=0.9622 \(\pm\) 0.006, \(NSE\)=0.9502 \(\pm\) 0.008 demonstrating consistent performance under a time-aware protocol that mirrors deployment (train on past → predict future). The results indicate that predicted and observed ETc values were very close across all folds. Overall, the nested, chronological cross-validation confirms that the proposed model generalises well across the evaluated time periods (Table 6).
Conclusion, future direction, and limitations
This study introduces a novel dynamic graph-based methodology (DG-DGSF), designed to enhance the prediction accuracy of potato crop evapotranspiration amidst changing climatic conditions, particularly pertinent for agricultural water management in Prince Edward Island. The suggested methodology employs seasonal and trend decomposition using LOESS smoothing (STL), augmenting the model’s ability to identify intricate temporal patterns in multivariate agricultural datasets. The integration of DGL and GC-GRU, along with dual-view semantic fusion and contrastive learning frameworks, facilitated the thorough modelling of complex spatio-temporal interactions in soil–water-plant relationships.
While our validation on PEI showed promising results, wider applicability requires testing under varied soils, climates, and management practices. We are currently working on collecting a multi-site dataset that covers Atlantic maritime, humid temperate, Prairie semi-arid, and continental interior conditions, with a range of soil textures and farming systems cross Canada. Future work will use region-held-out and climate-stratified evaluation protocols. We will also evaluate the proposed model on additional crops to assess crop-specific transferability. Together, these steps aim to demonstrate the model’s robustness and universality beyond the current setting.
The DG-DGSF model was evaluated comprehensively over three soil textures (loam, sandy loam, and loamy sand), exhibiting the variety of agricultural circumstances within the research area. Quantitative evaluations indicated that DG-DGSF surpassed multiple benchmark models, including advanced graph-based methods such as GCN-LSTM and DGDL, as well as traditional deep learning techniques like BiLSTM and GRU. Metrics such as RMSE, MAPE, NSE, KGE, and correlation coefficients repeatedly demonstrated the enhanced predictive capabilities of the proposed model. The quantitative findings were supported by extensive visual analyses, including scatterplots, Taylor diagrams, violin plots, and Diebold-Mariano statistical tests, all affirming the model’s efficacy in identifying underlying patterns and reducing prediction mistakes and biases.
The proposed DG-DGSF model substantially outperformed the state-of-the-art models in ETc prediction. The obtained results based on visual approaches, such as forecasting error plots and Taylor plots, demonstrated that the DG-DGSF model has a lower prediction error compared to all benchmark models. Also, based on Taylor and scatter plots, the results showed that the proposed DG-DGSF model produced very close values to actual values.
The DG-DGSF model has considerable potential, although several constraints must be recognized to clarify its applicability and scope. The main limitation is the reliance on high-quality, regularly monitored data from lysimeters and automated meteorological stations. Moreover, although this model has undergone rigorous validation under specific experimental conditions in Prince Edward Island, its applicability to significantly diverse climatic zones, soil types, or agricultural systems remains minimally examined. Therefore, careful application is advised when evaluating differences from the examined contexts.
An additional significant factor is the intrinsic complexity and computing demands of the DG-DGSF system. The complex amalgamation of dynamic graph structures, semantic fusion processes, and contrastive learning modules requires substantial computational resources. Moreover, the intricacy of the model may pose challenges to stakeholders and practitioners, potentially hindering acceptance or practical utility unless accompanied by enhanced interpretability mechanisms.
The model’s complexity may present difficulties for stakeholders and practitioners, potentially obstructing acceptance or practical use unless supported by improved interpretability mechanisms. Practices include variable fertilizer applications, diverse cropping systems, rotating techniques, and targeted pest or disease management protocols that may affect evapotranspiration rates and soil–water dynamics, introducing additional factors not comprehensively incorporated into the existing framework.
To improve deplorability of the proposed model under limited resources, we will consider model tuning as a multi-objective issue: keep prediction error low while also reducing time complexity including FLOPs, latency, and memory usage. We will examine several metaheuristic policies such as Genetic Algorithms (GA) and Particle Swarm Optimisation (PSO) to discover the key settings of the proposed model including window length, decomposition, and graph parameters. In parallel, we will investigate the effects of model compression on the results with knowledge distillation to produce compact student models that run faster with less memory. For hyperparameter selection, our plan will be considered Bayesian search to minimise tuning time while maintaining accuracy. Together, these techniques aim to retain accuracy at low cost and deliver robust, lightweight models suitable for stakeholders with constrained hardware.
Future research must focus on overcoming these constraints while enhancing the robustness and application of the DG-DGSF model. A prompt approach involves the incorporation of extensive datasets that include various geographic regions, climate variables, and agricultural management practices. Comprehensive cross-validation of worldwide datasets, especially from areas with diverse soil types and climatic variations, would enhance the model’s robustness and universality. Additional research into sophisticated optimization methods and computational simplifications may help reduce computational limitations. Methods such as metaheuristic optimization, ensemble forecasting, and model pruning may reduce processing requirements while maintaining prediction accuracy. These strategies would improve the model’s accessibility, especially for stakeholders with constrained computational resources, thereby expanding their usefulness.
Later studies could examine the effects of climate change scenarios on model efficacy and irrigation methodologies. Integrating climate projection data from global climate models (GCMs) across different emission scenarios (e.g., Representative Concentration Pathways—RCPs) would facilitate evaluating future evapotranspiration patterns and irrigation requirements. Such assessments would be essential for long-term agricultural planning and resource distribution, enabling proactive initiatives for climate change adaptation and resilience.
Notwithstanding its constraints, the suggested framework signifies a substantial progression in agricultural water management, presenting encouraging opportunities for additional improvement. Future research will enhance the DG-DGSF model’s utility as a decision-support tool for sustainable agricultural water management by tackling computational challenges, broadening data diversity, improving model interpretability, and integrating socio-economic and climate change factors.
Data availability
The datasets generated and/or analysed during the current study are not publicly available as the authors are not allowed to share the data on public domains but are available from the corresponding author on reasonable request.
References
Dzvene, A. R., Zhou, L., Slayi, M. & Dirwai, T. L. A scoping review on challenges and measures for climate change in arid and semi-arid agri-food systems. Discov. Sustain. 6, 151 (2025).
Yang, Y. et al. Characterization of greenhouse gas emissions and water requirement of farmland in China’s main grain-producing areas under future climate scenarios. Agric. Syst. 225, 104293 (2025).
Yang, Z.-Y. et al. A comprehensive review of deep learning applications in cotton industry: from field monitoring to smart processing. Plants 14, 1481 (2025).
AlZaatiti, F., Halwani, J. & Soliman, M. R. Climate change impacts on flood risks in the Abou Ali river basin, Lebanon: A hydrological modeling approach. Results Eng. 25, 104186 (2025).
Borah, G. Urban water stress: Climate change implications for water supply in cities. Water Conserv. Sci. Eng. 10, 20 (2025).
Granata, F., Di Nunno, F. Financing the future of water: unlocking investment, innovation, and governance for resilient infrastructure in a changing climate. Earth Syst. Environ. 1–25 (2025).
Adebayo, O., Singh, A., Bista, P., Angadi, S., Ghimire, R. Compost addition improves soil water storage and crop water productivity in cover crop integrated sorghum production system under a limited irrigation management. Irrig. Sci. 1–15 (2025).
Tang, Z. et al. Farmland mulching and optimized irrigation increase water productivity and seed yield by regulating functional parameters of soybean (Glycine max L.) leaves. Agric. Water Manage. 298, 108875 (2024).
Togneri, R., Prati, R., Nagano, H. & Kamienski, C. Data-driven water need estimation for IoT-based smart irrigation: A survey. Expert Syst. Appl. 225, 120194 (2023).
Et-taibi, B. et al. Enhancing water management in smart agriculture: A cloud and IoT-Based smart irrigation system. Results Eng. 22, 102283 (2024).
Cheema, S.J., Karbasi, M., Randhawa, G.S., Liu, S., Esau, T.J., Grewal, K.S., Abbas, F., Zaman, Q.U., Farooque, A.A. A state-of-the-art novel approach to predict potato crop coefficient (Kc) by integrating advanced machine learning tools. Smart Agric. Technol. 100896 (2025).
Bhatti, A. Z. et al. Climate change impacts on rainfed agriculture and mitigation strategies for sustainable agricultural management: A case study of Prince Edward Island, Canada. World Water Policy 8, 142–179. https://doi.org/10.1002/WWP2.12083 (2022).
Farooque, A. A. et al. How can potatoes be smartly cultivated with biochar as a soil nutrient amendment technique in Atlantic Canada?. Arab. J. Geosci. 13, 1–9 (2020).
Bhatti, A. Z. et al. An overview of climate change induced hydrological variations in Canada for irrigation strategies. Sustain https://doi.org/10.3390/SU13094833 (2021).
Bhatti, A. Z. et al. Climate change impacts on precipitation and temperature in Prince Edward Island, Canada. World Water Policy 7, 9–29. https://doi.org/10.1002/WWP2.12046 (2021).
Bhutto, R.A., Khanal, S., Wang, M., Iqbal, S., Fan, Y., Yi, J. Potato protein as an emerging high-quality: Source, extraction, purification, properties (functional, nutritional, physicochemical, and processing), applications, and challenges using potato protein. Food Hydrocoll. 110415 (2024).
Doorenbos, J., Pruitt, W.O. Guidelines for predicting crop water requirements (1977).
Economou, F. et al. Life cycle assessment of potato production in insular communities under subtropical climatic conditions. Case Stud. Chem. Environ. Eng. 8, 100419 (2023).
Hu, T., Zhang, X., Khanal, S., Wilson, R., Leng, G., Toman, E.M., Wang, X., Li, Y., Zhao, K. Climate change impacts on crop yields: A review of empirical findings, statistical crop models, and machine learning methods. Environ. Model. Softw. 106119 (2024).
Ierna, A. Water management in potato, in: Potato Production Worldwide. Elsevier, pp. 87–100 (2023).
Ishak, N. F. & Mazlan, Z. Key challenges and potentials of potato (Solanum tuberosum L.) farming in Malaysia: A mini review. Potato Res. 1–16 (2025).
King, B.A., Stark, J.C., Neibling, H. Potato Irrigation Management. Potato Prod. Syst. 417–446. (2020) https://doi.org/10.1007/978-3-030-39157-7_13
Nayak, L., Barik, M., Tiwari, R.K., Kumar, R., Kumar, A., Lal, M.K. Overview of underground vegetable crops, in: Abiotic Stress in Underground Vegetables. Elsevier, pp. 3–11 (2025).
Nyawade, S. O., Karanja, N. N., Gachene, C. K. K., Schulte-Geldermann, E. & Parker, M. Effect of potato hilling on soil temperature, soil moisture distribution and sediment yield on a sloping terrain. Soil Tillage Res. 184, 24–36 (2018).
Piekutowska, M. & Niedbała, G. Review of methods and models for potato yield prediction. Agriculture 15, 367 (2025).
Cheema, S. J. et al. A comprehensive analytical and computational assessment of soil water characteristics curves in Atlantic Canada: Application of a novel SelectKbestbased GEP model. Agric. Water Manag. 298, 108868 (2024).
Adekanmbi, T. et al. Assessing future climate change impacts on potato yields—A case study for prince Edward island. Canada. Foods 12, 1176 (2023).
Danielescu, S. et al. Crop water deficit and supplemental irrigation requirements for potato production in a temperate humid region (Prince Edward Island, Canada). Water 14, 2748 (2022).
Rajendran, S., Domalachenpa, T., Arora, H., Li, P., Sharma, A., Rajauria, G. Hydroponics: Exploring innovative sustainable technologies and applications across crop production, with Emphasis on potato mini-tuber cultivation. Heliyon (2024).
Tekle, S. L., Bonaccorso, B. & Naim, M. Simulation-based optimization of water resource systems: a review of limitations and challenges. Water Resour. Manag. 39, 579–602 (2025).
Velten, B. & Stegle, O. Principles and challenges of modeling temporal and spatial omics data. Nat. Methods 20, 1462–1474 (2023).
Zeghina, A., Leborgne, A., Le Ber, F., Vacavant, A. Deep learning on spatiotemporal graphs: A systematic review, methodological landscape, and research opportunities. Neurocomputing 127861 (2024).
Ren, W., Jin, N. and OuYang, L. Phase space graph convolutional network for chaotic time series learning. IEEE Trans. Ind. Inform. (2024).
Yang, Q., Yao, W., Liu, W. and Liu, H. An Enhanced TPA-LSTM Method for PMU Data Recovery and Prediction. In 2024 21st International conference on harmonics and quality of power (ICHQP) (pp. 614–618). IEEE (2024).
Zheng, W. & Chen, G. An accurate GRU-based power time-series prediction approach with selective state updating and stochastic optimization. IEEE Trans. Cybern. 52(12), 13902–13914 (2021).
She, D. & Jia, M. A BiGRU method for remaining useful life prediction of machinery. Measurement 167, 108277 (2021).
Kim, J. and Moon, N. BiLSTM model based on multivariate time series data in multiple field for forecasting trading area. J. Ambient Intell. Human. Comput, pp.1–10 (2019).
Sharma, D. N. & Tare, V. Assessment of irrigation requirement and scheduling under canal command area of Upper Ganga Canal using CropWat model. Model. Earth Syst. Environ. 8, 1863–1873 (2022).
Zhang, F. et al. Coupling effects of irrigation amount and fertilization rate on yield, quality, water and fertilizer use efficiency of different potato varieties in Northwest China. Agric. Water Manag. 287, 108446 (2023).
Fu, C. et al. Combining the FAO-56 method and the complementary principle to partition the evapotranspiration of typical plantations and grasslands in the Chinese Loess Plateau. Agric. Water Manag. 295, 108734 (2024).
Ajith, S., Vijayakumar, S. & Elakkiya, N. Yield prediction, pest and disease diagnosis, soil fertility mapping, precision irrigation scheduling, and food quality assessment using machine learning and deep learning algorithms. Discov. Food 5, 1–23 (2025).
Hailegnaw, N. S. et al. Integrating machine learning and empirical evapotranspiration modeling with DSSAT: Implications for agricultural water management. Sci. Total Environ. 912, 169403 (2024).
Xue, Y., Zhang, Z., Li, X., Liang, H., Yin, L. A review of evapotranspiration estimation models: advances and future development. Water Resour. Manag. 1–17 (2025).
Nayak, A.K., Sarangi, A., Pradhan, S., Panda, R.K., Jeepsa, N.M., Satpathy, B.S., Kumar, M. Estimation of daily reference evapotranspiration using machine learning and deep learning techniques with sparse meteorological data (2024).
El-Kenawy, E.-S.M., Alhussan, A.A., Khodadadi, N., Mirjalili, S., Eid, M.M. Predicting potato crop yield with machine learning and deep learning for sustainable agriculture. Potato Res. 1–34 (2024).
Gündüz, A., Orman, Z. Hyperspectral image classification using a hybrid RNN-CNN with enhanced attention mechanisms. J. Indian Soc. Remote Sens. 1–17 (2024).
Mahmoud, A. & Mohammed, A. Leveraging hybrid deep learning models for enhanced multivariate time series forecasting. Neural Process. Lett. 56, 223 (2024).
Elabd, E., Hamouda, H. M., Ali, M. A. & Fouad, Y. Climate change prediction in Saudi Arabia using a CNN GRU LSTM hybrid deep learning model in al Qassim region. Sci. Rep. 15, 1–19 (2025).
Han, D., Wang, P., Tansey, K., Zhang, Y. & Li, H. A graph-based deep learning framework for field scale wheat yield estimation. Int. J. Appl. Earth Obs. Geoinf. 129, 103834 (2024).
Saravanan, K. S. & Bhagavathiappan, V. Innovative agricultural ontology construction using NLP methodologies and graph neural network. Eng. Sci. Technol. an Int. J. 52, 101675 (2024).
Ghayekhloo, M. & Nickabadi, A. Supervised contrastive learning for graph representation enhancement. Neurocomputing 588, 127710 (2024).
Li, X., Wang, Y., Wang, Y. & An, X. Graph contrastive learning for recommendation with generative data augmentation. Multimed. Syst. 30, 170 (2024).
Xia, J., Wu, L., Chen, J., Hu, B. & Li, S. Z. Simgrace: A simple framework for graph contrastive learning without data augmentation. Proc ACM Web Conference 2022, 1070–1079 (2022).
Wang, L., Chen, Z., Liu, W. & Huang, H. A temporal-geospatial deep learning framework for crop yield prediction. Electronics 13, 4273 (2024).
Wang, D. et al. Dynamic travel time prediction with spatiotemporal features: using a GNN-based deep learning method. Ann. Oper. Res. 340(1), 571–591 (2024).
Huang, D., Liu, H., Bi, T. & Yang, Q. GCN-LSTM spatiotemporal-network-based method for post-disturbance frequency prediction of power systems. Global Energy Interconnection 5(1), 96–107 (2022).
Zsembeli, J., Czellér, K., Sinka, L., Kovács, G., Tuba, G. Application of lysimeters in agricultural water management. Creat. a Platf. to address Tech. used Creat. Prot. Environ. Econ. Manag. Water Soil 5–21 (2019).
Strange, P. C. & Blackmore, K. W. Effect of whole seed tubers, cut seed and within row spacing on potato (cv. Sebago) tuber yield. Aust. J. Exp. Agric. 30, 427–431 (1990).
Allen, R. G., Pereira, L. S., Raes, D. & Smith, M. FAO Irrigation and drainage paper No 56. Rome Food Agric. Organ. United Nations 56, e156 (1998).
Rana, G. & Katerji, N. Measurement and estimation of actual evapotranspiration in the field under Mediterranean climate: A review. Eur. J. Agron. 13, 125–153 (2000).
Srinivas, B. & Tiwari, K. N. Determination of crop water requirement and crop coefficient at different growth stages of green gram crop by using non-weighing lysimeter. Int. J. Curr. Microbiol. Appl. Sci. 7, 2580–2589 (2018).
He, R., Zhang, L. & Chew, A. W. Z. Modeling and predicting rainfall time series using seasonal-trend decomposition and machine learning. Knowl.-Based Syst. 251, 109125 (2022).
Liu, X. and Zhang, Q. Combining seasonal and trend decomposition using LOESS with a gated recurrent unit for climate time series forecasting. IEEE Access (2024).
Liang, Z., Li, W., Wang, Z., Zheng, X. and Pang, B. SSSLN: Multivariate time series forecasting via collaborative dynamic graph learning. Neural Netw, p.107485 (2025).
Islam, M.I.K., Saifuddin, K.M., Hossain, T. and Akbas, E. Dygcl: Dynamic graph contrastive learning for event prediction. In 2024 IEEE International Conference on Big Data (BigData) (pp. 559–568). IEEE (2024).
Georgousis, S., Kenning, M. P. & Xie, X. Graph deep learning: State of the art and challenges. IEEe Access 9, 22106–22140 (2021).
Shang, C., Chen, J. and Bi, J. Discrete graph structure learning for forecasting multiple time series. (2021) arXiv preprint arXiv:2101.06861.
Zhang, Z., Cui, P. & Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 34(1), 249–270 (2020).
Bhatti, U. A., Tang, H., Wu, G., Marjan, S. & Hussain, A. Deep learning with graph convolutional networks: An overview and latest applications in computational intelligence. Int. J. Intell. Syst. 2023(1), 8342104 (2023).
Acknowledgements
Authors would also like to thank the Sustainable Agriculture Research Group at UPEI’s Canadian Center for Climate Change and Adaptation for their assistance during experimentation.
Funding
This research was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) Alliance Sustainable Agriculture Research Initiative Grant.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cheema, S.J., Diykh, M., Ali, M. et al. Dynamic graph learning framework based seasonal and trend decomposition approach for potato crop evapotranspiration prediction. Sci Rep 15, 45732 (2025). https://doi.org/10.1038/s41598-025-28592-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28592-4
