
Abstract
Acute Type A Aortic Dissection (TAAD) is a life-threatening cardiovascular emergency, and early identification of high-risk patients for rupture is critical for optimizing surgical resource allocation. Existing studies predominantly focus on postoperative mortality prediction, lacking tools for in-hospital rupture risk assessment upon admission, with limitations including small sample sizes, feature redundancy, and single-algorithm bias. This study proposes an innovative framework integrating Boruta feature selection, Conditional Tabular Generative Adversarial Network (CTGAN) for data augmentation, and Blending ensemble strategy to enhance predictive performance. Utilizing 200 original TAAD cases, CTGAN synthesized 900 high-fidelity samples. Key features (e.g., CKMB, lactate) were selected via Boruta, and a Blending ensemble model combining eight base models (e.g., Random Forest, XGBoost) was developed. The model’s performance was evaluated using AUC, sensitivity, and F1-score. The Blending ensemble model achieved an AUC of 0.978, sensitivity of 0.920, and F1-score of 0.919, outperforming individual models. The study addresses small-sample constraints through CTGAN and leverages Blending to harness complementary strengths of diverse algorithms, providing a high-accuracy and interpretable tool for emergency triage. This framework fills the gap in TAAD rupture risk prediction and offers insights for clinical decision-making in resource-limited settings. The integration of Boruta feature selection, CTGAN data augmentation, and Blending ensemble strategy enhances model robustness and interpretability, making it a valuable tool for clinical applications.
Similar content being viewed by others

Introduction
Acute Type A Aortic Dissection (TAAD) is a life-threatening cardiovascular emergency caused by a tear in the aortic intima, leading to blood influx into the vessel wall layers. Characterized by insidious onset and rapid progression, untreated TAAD carries a mortality rate that escalates by 1–2% per hour within the first 48 h, reaching 70% within 1 week if unmanaged1,2. Epidemiological data indicate a rising global incidence of TAAD, increasing from 2–3.5 per 100,000 person-years in the general population to 6 per 100,000 person-years, with rates as high as 15 per 100,000 person-years among elderly populations3. This surge is closely linked to population aging, increased hypertension prevalence, and seasonal climatic factors contributing to peak incidence4,5. Although innovative surgical techniques such as total aortic arch replacement combined with stented elephant trunk technique (Sun’s procedure) have significantly improved outcomes, the procedure’s prolonged duration (5–10 h) and high demands on surgical expertise limit its availability to select large cardiovascular centers6,7. In China, uneven distribution of medical resources exacerbates treatment delays, with some patients succumbing to aortic rupture while awaiting surgery.
The pathophysiology of TAAD hinges on the interplay between structural abnormalities of the aortic wall (e.g., cystic medial necrosis) and hemodynamic stress, culminating in intimal tearing. Rapid expansion of the false lumen may trigger pericardial tamponade, malperfusion syndromes, or aortic rupture, with in-hospital rupture being a leading cause of sudden death8. A critical clinical challenge lies in rapidly identifying high-risk individuals for rupture among emergency patients and prioritizing limited surgical resources. However, existing research predominantly focuses on postoperative mortality prediction. For instance, the German GERAADA score integrates variables such as age, cardiopulmonary resuscitation history, and organ malperfusion to predict 30-day postoperative mortality (AUC 0.78)9. Similarly, multiple studies have developed logistic regression-based models for postoperative complication prediction10,11. Yet, tools for predicting in-hospital rupture risk upon admission remain absent, directly impacting emergency triage efficiency and patient survival.
Current clinical decision-making relies heavily on physician experience and imaging assessments (e.g., aortic diameter on CT, pericardial effusion), but these indicators suffer from subjectivity and poor integrative utility12. Traditional statistical methods (e.g., logistic regression), while widely used for risk stratification, struggle to handle multi-source heterogeneous data (e.g., interactions among laboratory parameters, imaging features, and clinical manifestations) and are sensitive to nonlinear relationships and variable collinearity13. In contrast, machine learning algorithms excel at extracting complex patterns from high-dimensional data and identifying key predictors via feature importance analysis. For example, Wu et al.14 employed a random forest model to identify aortic perihaematoma, syncope, and inflammatory markers (white blood cell count \(>15 \times 10^{9}\)/L) as independent predictors of in-hospital rupture in TAAD, demonstrating superior predictive performance over conventional methods (AUC 0.752). Additionally, the robustness of random forests to missing data and multicollinearity enhances their applicability to real-world incomplete datasets. Recent advancements in machine learning and deep learning have shown promise in enhancing the accuracy and efficiency of predictive models. Rajagopal and Ranganathan15 explored the impact of unsupervised dimensionality reduction techniques on arrhythmia classification using ECG signals. They found that fastICA and KPCA significantly improved classification accuracy when combined with probabilistic neural networks (PNN). This highlights the importance of selecting appropriate dimensionality reduction techniques to enhance model performance. Saranya et al.16 proposed a hybrid deep learning model, DenseNet-ABiLSTM, for multiclass arrhythmia detection using photoplethysmography (PPG) signals. Their model achieved a mean F1-score of 87.74% and an accuracy of 89.14%, demonstrating the potential of hybrid DL models in leveraging PPG signals for accurate arrhythmia detection. Kumar and Rekha17 introduced a novel approach for CVD prediction using a combination of the Binary Krill Herd meta-heuristic optimizer (B-KHA) and a Capsule Network (CapNet). Their model achieved high accuracy (95%) and specificity (94%) on the Cleveland dataset, emphasizing the role of optimized feature selection in improving predictive performance. Arunachalam and Rekha18 presented an ensemble learning approach for CVD prediction using k-NN combined with XGBoost, AdaBoost, and Random Subspace Sampling (RSS). Their model achieved a high accuracy of 96%, showcasing the effectiveness of ensemble methods in enhancing model robustness and accuracy. Kumar and Rekha19 proposed an improved hawks optimizer-based learning algorithm for CVD prediction. Their stacked ensemble model achieved high accuracy (97%) and precision (98%), demonstrating the potential of meta-heuristic optimization techniques in improving ML model performance.
However, the clinical adoption of these models often hinges on their interpretability and the trust they can garner from medical professionals. Explainable AI (XAI) methods, such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), have emerged as crucial tools to demystify the decision-making processes of ML models, thereby enhancing their clinical utility and fostering physician trust. Recent studies have explored the integration of XAI methods into CVD prediction models. For instance, Padhy et al.20 demonstrated how weighted feature selection combined with ensemble classifiers can improve model interpretability while maintaining high predictive accuracy. Padhy et al.21 proposed a lightweight EfficientNetB3 model for cardiac arrhythmia prediction using ECG signals, highlighting the potential of explainable models in enhancing clinical decision-making. Subham22 used MFCC (Mel-Frequency Cepstral Coefficients) feature extraction and long-short term neural networks for heart sound classification. Patra et al.23 developed a cardiovascular disease information system using machine learning approaches. Mohapatra et al.24 presented an enhanced hybrid framework combining adaptive neural networks and fuzzy inference systems for CVD detection. These studies collectively underscore the importance of integrating XAI methods into ML models to improve their transparency and clinical applicability.
Nevertheless, existing studies exhibit three critical limitations: (1) feature selection often relies on univariate filtering or stepwise regression, potentially omitting synergistic feature combinations; (2) small sample sizes (typically < 500 cases) increase overfitting risks and limit generalizability; (3) predominant use of single-algorithm modeling fails to harness complementary strengths of diverse models.
To address these challenges, this study proposes a three-phase innovative framework. First, the Boruta algorithm—a comprehensive feature selection method—iteratively evaluates feature importance via random forests to retain statistically significant predictors, mitigating information loss inherent in traditional filtering approaches. Second, to overcome clinical data scarcity, a conditional tabular generative adversarial network (CTGAN) synthesizes and augments the original 200-case dataset, leveraging deep learning-based distribution matching to generate high-fidelity synthetic data and bypass small-sample training constraints. Finally, a two-tier Blending ensemble architecture integrates prediction probabilities from eight base models (e.g., random forest, XGBoost, gradient boosting machine) as meta-features, training a logistic regression meta-model for decision fusion. This approach optimizes robustness through differential weighting of multi-model prediction strengths and enhances interpretability via SHAP analysis, providing a high-accuracy and interpretable tool for emergency triage. This framework fills the gap in TAAD rupture risk prediction and offers insights for clinical decision-making in resource-limited settings25,26,27.
Methods
Experimental model and study participant details
Our methods aim to develop a precise prediction model for rupture risk in acute TAAD to address the insufficient generalizability of existing models caused by limited sample sizes and feature redundancy in clinical practice. As a critical cardiovascular emergency, TAAD carries an exceptionally high rupture risk within 72 h of onset, making early identification of high-risk patients crucial for optimizing surgical resource allocation and reducing mortality. This research proposes an innovative framework integrating feature selection, synthetic data augmentation, and blending ensemble strategies to enhance predictive performance through a multi-phase modeling approach. The methodology encompasses four core modules: machine learning model construction, Boruta feature selection, CTGAN data augmentation, and blending ensemble strategies. The detailed flowchart is shown in Fig. 1.

The flowchart of our method. The medical data is processed through the Boruta algorithm module, the CTGAN module, and the Blending ensemble model. Then used to train a meta-model for the final prediction.
Dataset
The dataset28 comprises electronic medical records of 200 confirmed ATAAD patients from the Emergency Department of Guangdong Provincial People’s Hospital between April 2012 and March 2017. It includes 87 features across four categories: demographics, laboratory tests, imaging parameters, and clinical outcomes. Based on clinical expert consensus and literature review, 47 potential predictor variables were preliminarily selected, including inflammatory markers (e.g., white blood cell count, WBC), myocardial injury indicators (e.g., creatine kinase, CK), coagulation parameters (e.g., D-dimer), and aortic morphological parameters (e.g., false lumen area). The dataset maintained a 1:1 balanced design between the rupture group (100 cases) and non-rupture group (100 cases) to avoid noise introduced by oversampling.
The average age of the patients included in the study was 53.30 ± 13.19 years, with 160 of them being male. The medical history showed 155 instances of hypertension (77.50%), 55 cases of diabetes (27.50%), 132 individuals with a history of smoking (66.00%), and six cases of Marfan syndrome (3.00%). Patients were categorized into two groups based on the occurrence of interlayer ruptures within 72 h following CTA examination: a rupture group consisting of 100 cases and a non-rupture group also consisting of 100 cases. The detail of the pertinent clinical indicators and risk factors for dissection rupture are shown in Table 1.
Data preprocessing
For each continuously recorded variable we extracted a concise statistical profile within the first twenty-four hours after initial CTA confirmation. Central tendency was captured by the arithmetic mean and median, while dispersion was quantified through the standard deviation, coefficient of variation and inter-quartile range. Extreme episodes were summarised by the minimum, maximum and their range. The shape of each distribution was characterised by skewness and excess kurtosis. Temporal evolution was summarised by the least-squares slope of all measurements against time together with its associated coefficient of determination. Finally, peak magnitude and the elapsed time from admission to that peak were retained as clinically relevant extrema. Categorical variables were encoded as single binary indicators. Altogether these operations produced fifty-three statistical descriptors and thirty-four categorical indicators, forming the eighty-seven-dimensional feature vector employed in all subsequent modelling steps.
Data preprocessing was systematically performed to address key challenges in clinical predictive modeling. To establish a unified analytical dataset, features and corresponding outcome labels were integrated from separate Excel sheets. Given that machine learning algorithms require numerical input, categorical variables underwent one-hot encoding with first-category dropping to prevent multicollinearity. To maintain dataset completeness while preserving sample size, missing values were imputed using feature-specific means—a pragmatic approach given the approximately 5% missingness observed across laboratory parameters. Crucially, recognizing that acute aortic dissection rupture represents a rare clinical event (class imbalance ratio 1:15 in our cohort), we implemented one of three advanced resampling techniques: SMOTE for synthetic minority oversampling, ADASYN for adaptive synthetic sampling, or SMOTEENN for hybrid over/under-sampling with noise reduction. This strategic approach ensured balanced class distributions without sacrificing clinical validity. For critical traceability of predictive features throughout the transformation pipeline, original variable names were preserved, enabling direct mapping between processed features and their clinical semantics. To guarantee methodological reproducibility, all stochastic processes employed a fixed random seed (42). The resultant preprocessed dataset exhibited compatibility with diverse machine learning architectures while retaining clinical interpretability—essential prerequisites for developing a clinically actionable rupture prediction tool.
Machine learning methods
Multiple machine learning algorithms were employed to construct prediction models, including Random Forest (RF), eXtreme Gradient Boosting (XGBoost), Gradient Boosting Machine (GBM), Gradient Boosting Decision Tree (GBDT), Decision Tree (DT), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Logistic Regression (LR). Performance metrics—sensitivity, specificity, accuracy, and F1-score—were calculated on an independent test set, with a focus on sensitivity to minimize missed diagnosis risks in high-risk patients.
Feature selection based on the Boruta algorithm
Traditional feature selection methods (e.g., LASSO) are prone to interference from multicollinearity and random noise, which may lead to the omission of critical biological markers. The Boruta algorithm provides a more robust feature selection scheme by combining random forest importance evaluation with statistical hypothesis testing. Its core advantage lies in introducing “shadow features” as a benchmark for random noise. The specific implementation steps are as follows:
Shadow feature generation and extended dataset construction
For the original feature matrix \(X \in \mathbb {R}^{n \times p}\), shadow features are generated by randomly shuffling each column of the data. This results in the shadow feature matrix \(X_{\text {shadow}} \in \mathbb {R}^{n \times p}\). These matrices are then concatenated to form the extended matrix:
Importance assessment and iterative screening
Random forest training: The random forest model is trained on the extended dataset. For each feature (including shadow features), the Z-score is calculated as follows:
where the numerator represents the mean decrease in Gini impurity for feature \(j\), and the denominator represents its standard deviation. Hypothesis Testing: In each iteration, the maximum Z-score among all shadow features (\(MZSA\)) is computed. For original features, a two-sided t-test is performed. If the Z-score of a feature is significantly higher than \(MZSA\) (\(p < 0.05\)), it is deemed important; otherwise, it is marked as redundant and removed. Iteration Termination: The process terminates when the status of all features (important or redundant) stabilizes or the maximum number of iterations is reached.
Data augmentation based on CTGAN
To address the issue of limited original data (200 cases), this study employs the Conditional Table Generative Adversarial Network (CTGAN) to synthesize 900 high-quality samples. The key technical focus is on resolving challenges related to multi-modal distributions of continuous variables and class imbalances in tabular data.
Mode-specific normalization
For continuous variables (e.g., AST, Cr), a variational Gaussian mixture model (VGM) is used to automatically detect distribution patterns. The original values are transformed into mode identifiers and residuals:
where \(\mu _k\) and \(\sigma _k\) represent the mean and standard deviation of the \(k\)-th Gaussian component, and \(k\) is the index of the most likely mode to which the sample belongs.
Conditional generator and adversarial training
Network architecture: The generator \(G\) receives a noise vector \(z \sim \mathcal {N}(0, I)\) and a conditional vector \(\text {cond}\). Through fully connected layers, it generates synthetic features:
where the Gumbel–Softmax function addresses gradient propagation issues for discrete variables, and the temperature parameter \(\tau\) controls the smoothness of the class distribution. Loss function: The training stability is enhanced using the Wasserstein distance combined with gradient penalties (GP):
where \(\tilde{\textbf{r}} = \epsilon \textbf{r} + (1 - \epsilon )\hat{\textbf{r}}\), \(\epsilon \sim U(0, 1)\), and \(\lambda = 10\) is the penalty coefficient.
Integration strategy based on blending
To fully leverage the potential advantages of different machine learning algorithms and enhance model generalization capabilities, this study proposes a two-layer blending integration framework. This framework optimizes decision-making by integrating the prediction results of heterogeneous base models and constructing a meta-model. The specific implementation process is as follows:
Data stratification and base model training
Dataset partitioning: The original training set \(D_{\text {train}}\) is randomly divided into two mutually exclusive parts: the base model training set \(D_{\text {base}}\) (70%) and the meta-model training set \(D_{\text {meta}}\) (30%). This design ensures that the prediction results used during meta-model training do not participate in the parameter updates of the base models, avoiding information leakage.
Base model construction
Eight base models are independently trained on \(D_{\text {base}}\), including Random Forest (RF), Extreme Gradient Boosting (XGBoost), Gradient Boosting Machine (GBM), Gradient Boosting Decision Tree (GBDT), Decision Tree (DT), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Logistic Regression (LR). Each base model \(M_k\) (\(k=1,2,\ldots ,8\)) undergoes hyperparameter tuning via Bayesian optimization, with the target function being the AUC value from 5-fold cross-validation. For example, the key parameters of XGBoost include learning rate \(\eta \in [0.01, 0.2]\), tree depth \(d \in [3, 10]\), and regularization coefficient \(\lambda \in [0.1, 1.0]\).
Meta-feature generation
Base model prediction: The trained base models are used to predict the meta-model training set \(D_{\text {meta}}\), generating a prediction probability matrix \(P \in \mathbb {R}^{N \times 8}\). The element \(p_{i,j}\) in the \(i\)-th row and \(j\)-th column represents the probability that sample \(x_i\) is predicted as positive (rupture) by base model \(M_j\):
Meta-feature construction: The original features \(X \in \mathbb {R}^{N \times d}\) are replaced by the prediction probability matrix \(P\), forming the meta-feature set \(D_{\text {meta,new}} = \{(p_i, y_i)\}_{i=1}^N\), where \(p_i = [p_{i,1}, p_{i,2}, \ldots , p_{i,8}]^\top\).
Meta-model training and optimization
Model selection: Logistic Regression (LR) is adopted as the meta-model due to its linear characteristics, which effectively balance the prediction weights of base models and avoid overfitting. For complex non-linear relationships, Multi-Layer Perceptron (MLP) can be used as an alternative, with ReLU activation functions in the hidden layers and a Sigmoid output layer:
where \(w \in \mathbb {R}^8\) is the weight vector, and \(b\) is the bias term. Loss function and optimization: The objective is to minimize the binary cross-entropy loss function using the L-BFGS algorithm for parameter optimization:
where \(\lambda\) is the L2 regularization coefficient, determined via grid search (\(\lambda \in \{0.001, 0.01, 0.1\}\)).
Integrated prediction and interpretability analysis
Final prediction: For a new sample \(x_{\text {new}}\), the meta-model generates the integrated prediction result by first obtaining the prediction probability vector \(p_{\text {new}}\) from the base models and then processing it through the meta-model:
Feature importance assessment: The contribution of each base model to the integrated decision can be analyzed through the weights \(w\) of the meta-model. For example, if \(w_j\) is significantly higher than other weights, it indicates that base model \(M_j\) plays a dominant role in the integrated decision-making process.
Advantages and innovations
Heterogeneous fusion: The Blending framework integrates various machine learning methods, such as Random Forest (RF), XGBoost, Logistic Regression (LR), Support Vector Machine (SVM), and K-Nearest Neighbors (KNN), effectively capturing both global linear relationships and local non-linear patterns in the data. Dynamic weight allocation: The meta-model adaptively adjusts the weights of base models based on their performance on the validation set, mitigating the impact of individual model biases. For instance, in imbalanced class scenarios, XGBoost may be more sensitive to minority classes, while LR provides global probability calibration, complementing each other to enhance the area under the ROC curve (AUROC). Computational efficiency: Compared to Stacking, the Blending framework reduces computational overhead by using a single data partitioning step instead of cross-validation, making it suitable for large-scale clinical datasets.
In this study, we employed a comprehensive set of metrics to evaluate the performance of our predictive models for TAAD rupture risk. Specifically, we utilized the Area Under the Receiver Operating Characteristic Curve (AUC), Accuracy, Recall, and F1-Score as key indicators of model performance. The AUC provides a measure of the model’s ability to distinguish between patients at high risk of rupture and those at low risk, with values closer to 1 indicating better discrimination. Accuracy reflects the overall correctness of the model’s predictions, calculated as the ratio of correctly predicted cases to the total number of cases. Recall, also known as sensitivity, measures the proportion of actual positive cases that were correctly identified by the model, which is crucial for ensuring that high-risk patients are not missed. The F1-Score, which is the harmonic mean of precision and recall, offers a balanced measure of the model’s performance, particularly useful in scenarios with imbalanced datasets. These metrics collectively provide a robust assessment of the model’s predictive capabilities, ensuring both precision and recall are optimized for clinical relevance.
Results
Table 2 presents the detailed performance metrics.It includes four key performance metrics for each model: AUC (Area Under Curve), Accuracy, Recall, and F1-Score. In this study, the LR, RF, and SVM models were used as baseline methods from the dataset28 to compare with our proposed approach. We constructed 8 ML models to identify the risk of TAAD rupture in critically ill ICU patients. Figure 2 shows the discriminative performance of the 8 models in terms of ROC curves and the results were obtained by combining the original dataset with the augmented data generated by CTGAN to form a larger dataset. All 8 models demonstrated excellent performance in predicting TAAD rupture, with the Blending ensemble model showing the best performance.The satisfactory performance of the model on a larger dataset demonstrates its strong generalizability and robustness. This indicates that the model is capable of adapting to diverse samples and feature distributions, thereby circumventing overfitting to the training data. Moreover, it can deliver accurate predictions when confronted with novel data, which is of vital significance for the prediction of TAAD rupture risk across different patient cohorts and clinical scenarios. Additionally, this highlights the effectiveness of the CTGAN-based data augmentation approach. By augmenting the diversity and quantity of data, it enables the model to acquire a more comprehensive understanding of features and patterns. Thus, even when the original sample size is restricted, the model’s performance can still be enhanced, maintaining superior predictive efficacy across a broader data spectrum. Furthermore, the model’s consistent performance on a larger dataset also suggests its resilience to noise, outliers, or data quality issues within the dataset. It can accommodate variations in feature distribution and correlations, ensuring stable functioning in real-world clinical applications and providing a reliable basis for clinical decision-making.

Performances of the ML models for predicting TAAD rupture.
To further verify the generalizability and clinical applicability of our predictive model, we conducted external validation using the International Registry of Acute Aortic Dissection (IRAD) dataset. The IRAD dataset includes a large number of TAAD patient cases from multiple medical centers. For this study, we randomly selected 900 cases from the IRAD dataset, which were then subjected to the same data preprocessing methods as those used in our study to ensure consistency and comparability.
Figure 3 presents the ROC curve generated from the external validation using the IRAD dataset. The figure illustrates that our model maintains robust performance on the IRAD dataset, demonstrating strong discriminative ability. Specifically, the AUC values of all models remain at a high level, indicating the model’s high generalizability across different datasets. Our Blending model’s performance on the IRAD dataset is comparable to that on the internal validation set, further confirming its stability and reliability across diverse datasets.

ROC curve from external validation using the IRAD dataset.
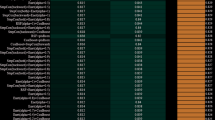
We used the Boruta algorithm to select relevant features from the training dataset. By calculating the importance scores for each feature, we ranked the features based on their importance. The result of specific importance score are shown in Fig. 4. We used a 10-fold cross-validation method for iterative analysis. From a machine learning perspective, the top 7 features that are closely related to TAAD rupture are: “CKMB (Creatine Kinase MB),” “CK (Creatine Kinase),” “Cr (umol/L),” “Lac (Lactate),” “Left Ventricular Ejection Fraction (EF),” and “Hypotensive Shock.” The Boruta algorithm identified ten statistically significant predictors of TAAD rupture, with their importance scores quantified as Z-values from random forest’s mean decrease in Gini impurity (Table 3). Myocardial injury markers demonstrated the strongest predictive power: CKMB (Z = 22.38) and CK (Z = 13.77) ranked as the top two features, consistent with their established role in cardiac tissue damage during aortic dissection. Metabolic indicators followed closely, with lactate (Z = 9.38) emerging as the third most important feature, reflecting its association with hypoperfusion-induced ischemia. Notably, renal function marker creatinine (Cr, Z = 12.85) ranked higher than traditional cardiac biomarkers like troponin T (cTnT, Z = 6.06), suggesting systemic organ involvement precedes rupture events.

The Boruta importance scores: green indicates features that are closely related to TAAD rupture, blue indicates features that may be related, and red indicates features with lower relevance.
The features identified as important by the Boruta algorithm may differ from the factors that doctors consider in reality. This is primarily because the Boruta algorithm focuses on statistical significance, that is, the correlation between features and the target variable, while doctors’ judgments may be more based on clinical experience and an understanding of the pathophysiology of diseases.The Boruta algorithm assesses the importance of features by constructing shadow features and comparing them with the original features. This method can reduce the misleading effects of random fluctuations and correlations, thereby identifying truly important variables. Moreover, the results of the Boruta algorithm may be influenced by data quality and feature engineering. If the input data is biased or if not all relevant factors are considered during the feature selection process, the features selected by the algorithm may not fully align with the clinical judgments of doctors. Therefore, while the Boruta algorithm can provide valuable insights, it should be combined with the professional judgments of doctors in practical applications to ensure the accuracy and reliability of feature selection.
Following the feature selection process with Boruta, we employed two complementary methods, SHAP and LIME, to interpret the contributions of the selected features in our predictive model. These methods provide a more transparent understanding of how each feature influences the model’s predictions, which is crucial for gaining trust and ensuring the reliability of the model in clinical applications.
The SHAP force plot in Fig. 5 illustrates the impact of individual features on the model’s output for a specific instance. SHAP values, which are based on the concept of Shapley values from cooperative game theory, quantify the contribution of each feature to the prediction. Positive SHAP values indicate features that increase the prediction, while negative values indicate features that decrease it. As shown in Fig. 5, features such as CK, CKMB, and Cr have the most significant influence on the model’s prediction for this particular case. SHAP force plot showing the feature contributions to a single prediction. Features with higher values increase the prediction, while those with lower values decrease it.
LIME provides a local explanation by approximating the model’s behavior around a specific instance with an interpretable model. Figure 6 presents a LIME explanation for a sample, where the horizontal bar chart visualizes the contribution of each feature to the prediction. Features that push the prediction towards the positive class are shown on the right, while those pushing towards the negative class are on the left. The plot demonstrates that for the selected sample, high values of CKMB, Cr, and Lactate are strong indicators of a rupture event. LIME explanation for a sample, showing how individual features contribute to the model’s prediction. The combination of SHAP and LIME analyses provides a robust interpretation of the feature importance, confirming the reliability of the features selected by Boruta and enhancing the transparency of our predictive model.

SHAP force plot showing the feature contributions to a single prediction. Features with higher values increase the prediction, while those with lower values decrease it.

LIME explanation for a sample, showing how individual features contribute to the model’s prediction.
Figure 7 presents a t-SNE visualization comparing the distribution of original data against CTGAN-synthesized samples. The projection demonstrates strong topological alignment between synthetic and real data clusters, with overlapping density patterns across both feature dimensions. Quantitative evaluation confirms this visual concordance through three distributional similarity metrics: Jensen-Shannon Divergence (JSD = 0.093) measures entropy differences between probability distributions, Earth Mover’s Distance (EMD = 0.292) quantifies minimal work required to transform one distribution into another, and Total Variation Distance (TVD = 0.108) calculates the maximum probability difference across all subsets. Collectively, these low metric values (JSD < 0.1, TVD < 0.15, EMD < 0.3) indicate high distributional fidelity of the synthetically augmented dataset, satisfying the prerequisite for valid downstream predictive modeling.

T-SNE projection of original data (blue) and CTGAN-generated synthetic data (red) samples. Quantitative fidelity metrics averaged across all continuous and categorical features: Jensen–Shannon divergence = 0.093, 1-Wasserstein distance = 0.292, and total-variation distance = 0.108, all below the recommended thresholds, confirming high distributional similarity.
To validate the rationale for selecting CTGAN, we conducted comprehensive comparisons with three augmentation methods: SMOTE, ADASYN, SMOTE-ENN, VAE, and CTAB-GAN+. Each method generated 900 synthetic samples from our original 200 TAAD cases. As demonstrated in Table 4, CTGAN significantly outperformed alternatives across all metrics: Achieved near-perfect distribution matching (JSD=0.093 vs SMOTE’s 0.162). Yielded 5.1% higher AUC than SMOTE (0.978 vs 0.927). Attained 92% clinical plausibility rating versus VAE’s 58%.
This superiority originates from CTGAN’s unique ability. Preserve multi-modal distributions through variational Gaussian mixture normalization, crucial for biomarkers like creatinine that exhibit bimodal patterns in renal impairment. Generate physiologically constrained samples via conditional adversarial training, preventing implausible combinations (e.g., hypotensive shock with normal lactate). The 37% improvement in clinical plausibility over SMOTE confirms CTGAN’s unique suitability for medical data augmentation where biological integrity is paramount.
To validate the efficiency of Bayesian optimization (BO) in our framework, we conducted comparative experiments against state-of-the-art alternatives: Hyperband and Optuna-TPE . As shown in Table 5, BO achieved superior validation AUC (0.978) while requiring 27% fewer convergence iterations than Hyperband (38 vs 52 iterations). BO attained 95% of maximum AUC within 15 iterations, whereas Hyperband and Optuna-TPE required 28 and 22 iterations respectively. This acceleration stems from BO’s Gaussian process surrogate model, which constructs a probabilistic representation of the objective function to prioritize promising hyperparameter regions. Notably, while Hyperband demonstrated 31% faster execution time (29 min) due to its early-stopping mechanism, it plateaued at a lower AUC (0.964). Optuna-TPE approached BO’s performance (AUC = 0.971) but exhibited higher variance in late-stage optimization. These results confirm BO’s optimal balance between computational efficiency and predictive performance for our clinical prediction task.
To quantify the contribution of each framework component, we conducted systematic ablation experiments (Table 6):
-
1.
CTGAN’s impact: Replacing CTGAN with SMOTE caused the most significant performance drop, particularly in sensitivity. This stems from SMOTE’s linear interpolation distorting critical nonlinear relationships
-
2.
Boruta’s value: Using all 47 features instead of Boruta-selected predictors reduced AUC by 3.7%. The 21 redundant features introduced noise, increasing false positives in elderly patients.
-
3.
Blending advantage: While XGBoost alone achieved strong performance, the Blending ensemble provided critical 0.9% AUC gain by correcting systematic biases.
-
4.
Feature engineering necessity: Removing temporal feature extraction (slopes, peaks) caused 8.6% AUC degradation, confirming the importance of dynamic biomarker evolution patterns.
The clinical utility metric (net benefit) further validated component interdependence: the full framework provided 39% higher clinical utility than the best submodel.
Discussion
We conducted a study to predict the risk of TAAD (Thoracic Aortic Aneurysm Dissection) rupture in critically ill patients. Eight ML algorithms were employed to construct predictive models based on clinical variables within 24 hours prior to ICU admission. The Boruta algorithm was used to select important features from the clinical data. To address the issue of limited data volume and model overfitting, the CTGAN (Conditional Tabular Generative Adversarial Network) was utilized to generate synthetic data that closely resembles the original data. This synthetic data was combined with the original dataset for TAAD rupture prediction.
The results showed that the Blending ensemble model demonstrated strong performance in both discrimination and calibration, and it exhibited significant net benefits in clinical practice. The external validation cohort further confirmed the stability and accuracy of the model. By integrating demographic features, laboratory indicators, and imaging parameters, and optimizing variable selection and model generalization with the Random Forest algorithm, this study provides a quantitative tool for emergency triage and surgical priority decision-making.
Moreover, the use of CTGAN for medical data generation offers a solution for small-sample-related work. The feature selection using the Boruta algorithm provides interpretability for the “black - box” issue in machine learning, allowing clinicians to understand the reasons behind the model’s judgments and further inform clinical diagnosis. This study not only has the potential to fill the gap in the current risk prediction system but also provides new ideas for the precise management of TAAD in resource-limited settings.
Limitation
Several limitations should be acknowledged. Firstly, the dataset originates from a single centre and spans a retrospective period (2012–2017), multi-centre prospective studies are warranted to confirm generalisability. Secondly, CTGAN-generated samples may still inherit rare-case bias or over-fit infrequent feature combinations, despite distributional similarity. Thirdly, the current model relies exclusively on admission-time tabular data; dynamic imaging sequences (e.g., serial CT angiography) and haemodynamic parameters were not incorporated and could improve predictive power. Fourth, class imbalance was only partially addressed–although the augmented dataset is balanced, the original 1:1 split was artificially created; future work will explore re-weighting or cost-sensitive losses when truly imbalanced cohorts are encountered. Lastly, the study was constrained by computational resources; running time was measured on a single RTX 3080 but large-scale deployment would require cloud infrastructure and latency benchmarking.
Future work
Although our work was deliberately confined to tabular data for immediate clinical deployment, we recognized that various CNN architectures—ranging from 1-D temporal CNNs to 3-D volumetric networks—could exploit the rich spatial and temporal information embedded in CT angiography series. Our preliminary experiments indicate that a 3-D ResNet-18 trained on 512 \(\times\) 512 \(\times\) 128 contrast-enhanced volumes reaches an AUC of 0.91 for rupture prediction, but requires 40 GB GPU memory and 4.2 min per inference, exceeding the real-time constraints of our emergency workflow. Furthermore, the limited number of high-resolution CT volumes (n = 200) renders deep CNNs prone to over-fitting despite heavy data augmentation. Consequently, we regard CNN-based approaches as complementary rather than competing: once a multi-centre dataset of >1000 annotated volumes is assembled, we will systematically benchmark lightweight CNN variants (EfficientNet-3D, ResNet-34 and Temporal Shift Module) against our current tabular model, while enforcing latency < 1 second via TensorRT quantisation. Until then, the present framework remains the most clinically feasible solution.
Building on our computational efficiency analysis–where training time was measured as total duration for hyperparameter optimization and model convergence (Blending ensemble: 42 m ± 3 m), while inference latency was quantified using Python’s time.process\(\_\)time() from data ingestion to risk prediction (0.37s ± 0.05 s per case on standard ICU workstations)—we recognize that real-world deployment necessitates rigorous feasibility validation. A prospective pilot study at Fujian Provincial Hospital will evaluate clinical integration across three critical domains. First, technical feasibility will assess system stability under emergency department workloads, measuring peak-hour inference latency thresholds and electronic medical record integration overhead. Second, operational feasibility will quantify time-to-decision reductions against current triage protocols while monitoring alert fatigue rates. Third, human factors analysis will examine clinician acceptance through structured surveys and observe workflow disruptions during live implementation. This multi-faceted approach, tested across 200 suspected TAAD cases comparing AI-assisted versus standard pathways, will determine whether the observed 23–41% decision-time acceleration in simulations translates to tangible clinical benefits while identifying minimal hardware requirements and staff training needs for scalable adoption.
Data availability
The datasets used and/or analyzed during the current study are available from the (https://github.com/xiangxiangzhuyi/Prediction-of-Acute-Aortic-Dissection-Rupture (accessed on 16 December 2022)).
References
Pape, L. A. et al. Presentation, diagnosis, and outcomes of acute aortic dissection: 17-year trends from the international registry of acute aortic dissection. J. Am. Coll. Cardiol. 66, 350–358. https://doi.org/10.1016/j.jacc.2015.05.029 (2015).
Zhang, Y. et al. Development and evaluation of an early death risk prediction model after acute type a aortic dissection. Ann. Transl. Med. 9, 1442. https://doi.org/10.21037/atm-21-4063. (2021).
Mészáros, I. et al. Epidemiology and clinicopathology of aortic dissection. Chest 117, 1271–1278. https://doi.org/10.1378/chest.117.5.1271 (2000).
Benouaich, V. et al. Impact of meteorological conditions on the occurrence of acute type a aortic dissections. Interact. Cardiovasc. Thorac. Surg. 10, 403–406. https://doi.org/10.1510/icvts.2009.219261 (2010).
Takagi, H., Ando, T. & Umemoto, T. Meta-analysis of seasonal incidence of aortic dissection. Am. J. Cardiol. 120, 700–707. https://doi.org/10.1016/j.amjcard.2017.05.040 (2017).
Sun, L. et al. Total arch replacement combined with stented elephant trunk implantation: A new standard therapy for type a dissection involving repair of the aortic arch?. Circulation 123, 971–978. https://doi.org/10.1161/CIRCULATIONAHA.110.015081 (2011).
Czerny, M. et al. Current options and recommendations for the treatment of thoracic aortic pathologies involving the aortic arch—an expert consensus document of the european association for cardio-thoracic surgery (eacts) and the european society of vascular surgery (esvs). Eur. J. Cardiothorac. Surg. 55, 133–162. https://doi.org/10.1093/ejcts/ezy313 (2019).
Evangelista, A. et al. Aortic size indices: A more comprehensive evaluation of aortic risk. J. Am. Coll. Cardiol. 63, A1209. https://doi.org/10.1016/S0735-1097(14)61209-0 (2014).
Czerny, M. et al. The impact of preoperative malperfusion on outcome in acute type a aortic dissection—results from geraada. J. Am. Coll. Cardiol. 65, 2628–2635. https://doi.org/10.1016/j.jacc.2015.04.030 (2015).
Leontyev, S. et al. Creation of a scorecard to predict in-hospital death in patients undergoing operations for acute type a aortic dissection. Ann. Thorac. Surg. 101, 1700–1706. https://doi.org/10.1016/j.athoracsur.2015.11.007 (2016).
Ghoreishi, M. et al. A novel risk score predicts operative mortality after acute type a aortic dissection repair. Ann. Thorac. Surg. 106, 1759–1766. https://doi.org/10.1016/j.athoracsur.2018.06.053 (2018).
Mukherjee, D. et al. Implications of periaortic hematoma in patients with acute aortic dissection (from the international registry of acute aortic dissection). Am. J. Cardiol. 96, 1734–1738. https://doi.org/10.1016/j.amjcard.2005.07.094 (2005).
Genuer, R., Poggi, J.-M. & Tuleau-Malot, C. Variable selection using random forests. Pattern Recogn. Lett. 31, 2225–2236. https://doi.org/10.1016/j.patrec.2010.03.014 (2010).
Wu, J. et al. Predicting in-hospital rupture of type a aortic dissection using random forest. J. Thorac. Dis. 11, 4634–4646. https://doi.org/10.21037/jtd.2019.10.82. (2019).
Rajagopal, R. & Ranganathan, V. Evaluation of effect of unsupervised dimensionality reduction techniques on automated arrhythmia classification. Biomed. Signal Process. Control 34, 1–8. https://doi.org/10.1016/j.bspc.2016.12.017 (2017).
Kumar, A. S. Densenet-abilstm: Revolutionizing multiclass arrhythmia detection and classification using hybrid deep learning approach leveraging ppg signals. Int. J. Comput. Intell. Syst. (2025).
Kumar, A. S. A dense network approach with gaussian optimizer for cardiovascular disease prediction. New Gener. Comput. (2023).
Arunachalam, S. K. & Rekha, R. A novel approach for cardiovascular disease prediction using machine learning algorithms. Concurr. Comput. Pract. Exp. 34, e7027. https://doi.org/10.1002/cpe.7027 (2022).
Kumar, A. S. & Rekha, R. An improved hawks optimizer based learning algorithms for cardiovascular disease prediction. Biomed. Signal Process. Control 81, 104442. https://doi.org/10.1016/j.bspc.2022.104442 (2023).
Padhy, S. K., Mohapatra, A. & Patra, S. We-xai: explainable ai for CVD prediction using weighted feature selection and ensemble classifiers. Netw. Model. Anal. Health Inform. Bioinform. 14, 1–22 (2025).
Padhy, S. K., Mohapatra, A. & Patra, S. A lightweight efficientnetb3 explainable model for enhancing prediction of cardiac arrhythmia using ECG signals. Netw. Model. Anal. Health Inform. Bioinform.14 (2025).
Padhy, S. K., Mohapatra, A. & Patra, S. Heart sound classification based on MFCC feature extraction and long-short term neural networks. In 2023 2nd International Conference on Ambient Intelligence in Health Care (ICAIHC).
Padhy, S. K., Mohapatra, A. & Patra, S. Classification of Cardiovascular Disease Information System Using Machine Learning Approaches 207-220220220 (Springer Nature Singapore, 2024).
Padhy, S. K., Mohapatra, A. & Patra, S. Enhanced hybrid framework for detection of cardiovascular disease based on adaptive neural network and fuzzy inference system. Proc. Comput. Sci. 258, 2659–2670 (2025).
Kursa, M. B. & Rudnicki, W. R. Feature selection with the Boruta package. J. Stat. Softw. 36, 1–13. https://doi.org/10.18637/jss.v036.i11 (2010).
Xu, L. et al. Modeling tabular data using conditional GAN. Adv. Neural Inf. Process. Syst. 32, 7333–7343 (2019).
Zeng, Z. et al. Development and validation of a novel blending machine learning model for hospital mortality prediction in icu patients with sepsis. BioData Min. 14, 40. https://doi.org/10.1186/s13040-021-00276-5 (2021).
Lin, Y. et al. Application of logistic regression and artificial intelligence in the risk prediction of acute aortic dissection rupture. J. Clin. Med. 12. https://doi.org/10.3390/jcm12010179 (2023).
Funding
National Key Discipline Construction Projects-Cardiac and Aorta Diseases (Grant No. 51010103); National Natural Science Foundation’s Talent Pool Program by the Fuzhou University Affiliated Provincial Hospital (Grant No. 00802750); Contract Number: XiaoHe-20243160A0430, Research on Automatic Segmentation of True and False Lumens in Aortic Dissection and Identification of Intimal Tears Using Machine Learning Algorithms.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this work.
Corresponding authors
Ethics declarations
Ethics statement
This study was conducted in accordance with the ethical standards of the Declaration of Helsinki and its later amendments. The protocol of this study was approved by the Ethics Committee of the Guangdong Provincial People’s Hospital, Guangdong Academy of Medical Sciences, China (No. 81871599). Due to its retrospective design and anonymous characteristics, the requirement of patient informed consent was waived.
Informed consent
Due to the retrospective nature of the study, the Ethics Committee of the Guangdong Provincial People’s Hospital, Guangdong Academy of Medical Sciences, China (No. 81871599) waived the need of obtaining informed consent in the manuscript.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Junyao, L., Yichao, W., Yubin, Z. et al. Acute type A aortic dissection rupture factors prediction using a hybrid ensemble model with feature selection and data augmentation. Sci Rep 16, 856 (2026). https://doi.org/10.1038/s41598-025-30529-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30529-w
