
Abstract
This research investigated and optimized the separation of carbon dioxide (CO2) from natural gas in an adsorption column filled with grafted-beam nanofiber adsorbent. The main purpose of using ANN and RSM models in this manuscript is to compare these two methods in predicting the CO2 adsorption capacity. In other words, it was made to find a suitable model that has the highest agreement with the experimental data. Also, the other purpose of using the RSM model is to detect the optimized empirical conditions. Moreover, two common ANN models are applied in this work, including a multilayer perceptron (MLP) and radial basis function (RBF). The novelties of this work are explained as follows: (1) detecting the optimized synthesis factors of NF-PAN/PUGMA sorbent which possess the highest CO2 adsorption capacity with the help of response surface methodology (RSM), (2) studying the simultaneous interaction of synthesis parameters on the CO2 adsorption capacity with the help of both RSM and artificial neural networks (ANNs), (3) testing two types of ANN models including multilayer perceptron (MLP) and radial basis function (RBF) to predict the effect of monomer volume percentage and irradiation dose on the CO2 adsorption capacity. Indeed, finding the best model (ANN or RSM) can help engineers in practical applications predict CO2 adsorption capacity using NF-PAN/PUGMA under different conditions without incurring high-priced chemical materials, electricity, or human resources. The validation results were examined using correlation coefficients (R2) of RSM, RBF, and MLP models. The correlation coefficients for the RSM, RBF, and MLP models were 0.9910, 0.9949, and 0.9968, respectively. Additionally, the average absolute relative deviation (AARD) values for the RBF and MLP models were 0.00046512 and 0.00045511, respectively, indicating that the MLP model is better than the RBF model. To identify the optimal network structure, the trial-and-error method was conducted for MLP and RBF models. The number of neurons was found at 12 and 45 for MLP and RBF, respectively. The optimized effective parameters were obtained using RSM: 25.80% GMA, 66.45% amine, and an irradiation intensity of 28 kGy.
Similar content being viewed by others

Introduction
Global warming is one of the most important challenges in the current century. The release of CO2 gas in the atmosphere is the main reason for global warming. The combustion of fossil fuels for various purposes, such as electricity generation, transportation, oil refining, and cement production, is recognized as the common activities that contaminate the atmosphere with CO2 gas. Over the past decade, there has been a 2.7% increase in CO2 levels, reaching 60% of the 1990 baseline. Despite efforts to reduce greenhouse emissions, these endeavors have proven inadequate to keep pace with rapid population growth and economic development. The gas extracted from natural gas fields comprises a hydrocarbon mixture, predominantly consisting of over 70% methane1. Depending on the geological characteristics of the extraction site, the composition of the extracted gas may vary. Typically, it contains impurities like carbon dioxide, hydrogen sulfide, nitrogen, and a substantial quantity of hydrocarbons such as ethane, propane, butane, and pentane. Therefore, it is essential to eliminate these impurities, like CO2 from natural gas. There are different materials for removing this gas. Among these materials, polymeric ones prove to be appropriate for crafting sorbents with an excellent uptake capability. The Radiation-induced graft polymerization (RIGP) methodology proves to be a suitable approach for introducing functional moieties in the polymer matrix. RIGP takes place when particles of the precursors are subjected to the radiation with intense energy. This process leads to the generation of radicals, initiating reactions among monomer molecules2. This method has been employed to enhance polymeric architectures for trapping pollutants, particularly toxic gases. In addition, Gamma emissions onto the synthesized adsorbents generate advantages such as high performance, the absence of additives, and convenient operation. Glycidyl methacrylate (GMA) can serve in a role of a precursor in RIGP to treat the polymer matrix3. Amine groups can be introduced to various polymers to create immobilized carrier membranes. One such polymer is polyacrylonitrile (PAN), which is a significant commercial polymer known for its solvent stability, thermal, and mechanical resistance4. Since polyacrylonitrile (PAN) comprises active nitrile moieties that undergo chemical modifications through certain reactions5. In this case, some works are explained as follows. Nassef et al. employed the RIGP method and an electron beam accelerator to prepare the adsorbent. During the grafting stage, the joining of glycidyl methacrylate (GMA) to polyethylene-polypropylene has been conducted. The treated sorbent was treated with trimethylamine, which exhibited a CO2 uptake capability of 4.52 mmol/g. Additionally, the current sorbent demonstrated successful regeneration across four steps6. Investigations into the effects of key parameters on the synthesis procedure and application of Response Surface Methodology (RSM) and artificial neural networks (ANN) have been carried out rarely.
RSM is extensively recognized as a valuable concept for assessing the connection between input factors and outputs. Certainly, RSM is a potent mathematical tool for optimizing the involved parameters7. Nihaal et al.8 applied RSM for finding an accurate relation between Nusselt number and other factors, such as Forchheimer number and Thermophoresis parameter, which can be used in optimizing the heat transfer in the nanofluid. Hirematha et al.9 used RSM for optimizing thermal management and enhancing energy efficiency in advanced Magnetohydrodynamics (MHD) systems. According to conclusive data, employing a permeable partition instead of a solid partition leads to a notable enhancement in the mean Nusselt value. Vinutha et al.10 utilized (RSM)'s face-centered Central Composite Design to calculate the transfer of heat flux at the wall. This approach accounts for the interplay between the heat radiation, magnetic parameter, and squeezing number.
In recent decades, ANNs have emerged as powerful tools in various fields, including forecasting, clustering, and regression. ANNs can effectively capture complex relationships within data and learn from patterns, making them well-suited for modeling and predicting CO2 adsorption capabilities. Utilizing ANNs can potentially streamline the process, enhance efficiency, and provide valuable insights for optimizing CO2 capture applications11. In recent years, there has been a substantial increase in the mathematical modeling of adsorption systems3,4,5,6,11,12,13,14,15,16,17. Bararpour et al. probed the CO2 removal using solid sorbents based on potassium carbonate-treated γ-Alumina under various operational conditions. The research specifically focused on assessing the impact of parameters such as carbonating thermal, carbonating period, and H2O/CO2 proportion on the sorption capability of the sorbents12. Streb et al. devised a model for CO2 adsorption from diverse streams using an ANN based on a Multi-Layer Perceptron (MLP) architecture.18. Mahabaleshwar et al.19 used a neural network with the method of the Levenberg–Marquardt backpropagation technique (LMBPT) for studying the heat and mass transport over a non-Newtonian ternary Casson fluid on a radially extending surface with magnetic field and convective boundary conditions. In their study, the PDE equations of heat and mass transfer were converted to the ODE equations with the help of an ANN model. Nihaal et al.20 utilized ANN to model complex nonlinear interactions between several parameters and engineering factors. This ANN-driven framework enhances accuracy and offers predictions in capturing multifactor dependencies, offering a transformative tool for optimizing nanofluid behavior. Vinutha et al.21 used ANN for predicting the effect of magnetic field, activation energy, heat radiation, Maxwell velocity slip, and Smoluchowski thermal slip on the nanofluid motion. In their work, the actual and predicted data for the power index, magnetic field parameter, activation energy parameter, Radiation parameter, and reaction rate for all ranges of values are similar when applying a wavelet neural network.
In this study, the nanofiber surface underwent irradiation with the GMA (glycidyl methacrylate) monomer using Gamma rays. The synthesis method has been optimized with the least number of tests, which was facilitated by the RSM. The resulting optimized electrospun fibers were employed for the adsorption of CO2 in static column adsorption experiments. Besides, the RSM was exploited for finding the optimum values of input variables for synthesizing the adsorbent, which are the Gamma dose, % GMA, and % amine. Also, the ANN approach was used in predicting the CO2 adsorption conditions for the prepared adsorbents. The input parameters in the ANN were Gamma dose, % GMA, and % amine for predicting CO2 adsorption. Two different ANN models, such as MLP and radial basis function (RBF), were selected for this case.
The objectives of this work are explained as follows: (1) detecting the optimized synthesis factors of NF-PAN/PUGMA sorbent which possess the highest CO2 adsorption capacity with the help of response surface methodology (RSM), (2) studying the simultaneous interaction of synthesis parameters on the CO2 adsorption capacity with the help of both RSM and artificial neural networks (ANNs), (3) testing two types of ANN models including multilayer perceptron (MLP) and radial basis function (RBF) to predict the effect of monomer volume percentage and irradiation dose on the CO2 adsorption capacity. One of the main aims of this work is to compare the RSM model with ANN models for selecting the most suitable model for predicting the CO2 adsorption capacity by varying radiation dose, volume percent of amine, and volume percent of monomer. In addition, RSM was also used for finding the optimized parameters. The main purpose of using ANN and RSM models in this manuscript is to compare these two methods in predicting the CO2 adsorption capacity. In other words, it was made to find a suitable model that has the highest agreement with the experimental data. Also, the other purpose of using the RSM model is to detect the optimized empirical conditions.
Because of terrible growth of CO2 gas relative to other gases and its hazardous for human health, the author decided to study the adsorption capacity of this gas.
The main goals and novelties of the current work have been listed as follows: (1) The effect of operational parameters of fiber polymerization, including monomer volume percentage, design irradiation dose, and amine volume percentage to obtain optimal conditions by the experimental method, (2) Comparison of the effects of radiation dose alterations on the gas uptake, (3) The fabricated adsorbent has been utilized to absorb gas in new columns with atmospheric pressure and ambient temperature, (4) Determining the optimal operating values by design- expert software, and (5) Anticipation of CO2 uptake with the MLP-ANN and RBF modeling.
Data collection
The data and information extracted from the thesis of Ali Ahmadizadeh Torzani on the adsorption of CO2 by radiated-grafting nano fiber adsorbent in a packed column. The synthesis and adsorption process are explained as follows. In the initial step of the adsorbent synthesis, a polymeric nanofiber, which was a mixture of PAN and PU, was produced using the electrospinning device. Subsequently, the prepared nanofibers from the electrospinning step were immersed in the GMA solution overnight. In the final step, the fabricated adsorbent was exposed under the irradiation of a Gamma ray to conduct the RIGP process. To eliminate the unreacted particles, the adsorbent was rinsed with methanol continuously. Additionally, the adsorbent was placed in an oven at 45℃ for 4 h to dry completely. The fabricated adsorbent was labeled as NF-PAN/PUGMA. The synthesis details have been comprehensively explained in the work of Deitzel et al.22. In order to incorporate the amine functional groups in the structure of the synthesized adsorbent, they were treated with EA. The amination reaction was carried out by immersing NF-PAN/PUGMA nanofibers in a mixture comprising amine and water. The modified adsorbent with EA was agitated at 65 °C for further processing. The fabrication of the adsorbent for CO2 elimination is displayed in Fig. 1.

The synthesis process of the aminated NF-PAN/PUGMA nanofibers23.
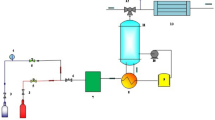
The CO2 sorption was conducted on the NF-PAN/PU utilizing a column with a height of 10 cm and a diameter of 0.8 cm, in which fiberglass was installed at the beginning and end of it. An NDIR (nondispersive infrared sensor) was utilized to show the content of CO2. Two MFCs (Mass Flow Controller) were equipped to make a gas mixture containing CH4 (methane) and CO2 at different percentages. An image of the CO2/CH4 system is displayed in Fig. 2. The sorption capability (q) of CO2 was measured utilizing Eq. (1) 23:

The setup of the CO2 adsorption system23.
Eq. (1) refers to the mathematical formula for calculating the adsorption capacity of CO2 using NF-PAN/PUGMA. According to Eq. (1), several parameters should be known, such as the rate of CO2 stream (F), initial concentration of CO2 gas (Co), saturation time of adsorbent (tq), and mass of adsorbent (W). Indeed, the product of F, Co, and tq gives the adsorbed CO2 on the NF-PAN/PUGMA. The greater value of “q” means a larger amount of CO2 gases are adsorbed in the pores of the NF-PAN/PUGMA. The units of each parameter were brought into the nomenclature.
Response surface methodology
The design of an experiment is a scientific method that involves changing input variables in a process to gain knowledge about the process and achieve a desired input–output relationship. This method has several benefits, such as identifying the critical factors that affect the process, reducing the cost of the process, creating a model of the process, and determining the relationship between input and output variables13. By analyzing the interaction of independent variables and their effects on the dependent variable, the design of an experiment can produce a semi-empirical model that accurately identifies the factors that influence the process and optimizes it while minimizing costs24. RSM is a statistical method used in the design of experiments to predict the relationship between independent and dependent parameters in the form of a surface, and it is a collection of mathematical and statistical techniques that can be employed to enhance, optimize, and analyze various processes by examining the connection between input variables and output responses25,26. Two-factor interaction (2FI) model in the RSM method is according to Eq. (2) 27.
In this equation, y is a function of the predicted response (CO2 adsorption capacity), βₒ, βᵢ and βᵢⱼ is the fixed term, coefficient of the linear components, and the coefficient of the interaction components, respectively. ε0 is the residual error.
The experiments were designed using the RSM approach to optimize the sorption of CO2 with NF-PAN/PU- GMA-EA. Generally, RSM is a multivariate mathematical tool utilized to optimize procedures. In this method, two levels of factorial design are utilized (− 1, + 1), which are then put over the center points (coded 0), and over the star points (-α, + α)28,29. This research used RSM to optimize the CO2 sorption factors using three independent inputs: radiation intensity, GMA content, and amine content. The domain of independent inputs is written in Table 1.
Artificial neural network (ANN)
One of the primary advantages of ANNs is the capability to decrease the cost of tests or save time by establishing relationships among the factors of a modeling system30. ANNs are considered reliable modeling techniques that exhibit a performance similar to the nervous system of people. Indeed, ANN is utilized for modeling systems where the explicit model does not exist to connect the independent factors to the target31. The architecture of ANNs has three layers, which are the input, hidden, and output layers. Neurons are matched to neighboring neurons, and the interconnectivity of neurons facilitates the transfer of output data from one neuron to another32. The mathematical equation of ANNs is written in Eq. (3) 31:
where f, w, and b are the neuron activation function, weights, and bias vector, respectively. In the current research, both MLP and RBF have been utilized to predict the CO2 adsorption capacity. The input parameters for the network included %GMA, %amine, and dose, while the output parameter was the CO2 adsorption capacity. To enhance the learning process of the ANNs, the adsorption variables have been normalized in the domain of − 1 to + 1 using Eq. (4) 33. The values of the R2, MSE, and the AARD were measured regarding the formulations that are brought in Eqs. 5, 6, and 734,35.
MLP network
MLP refers to a specific kind of ANN that may utilize one or more hidden layers to enhance the network’s precision36. In this model, variables are propagated forward (feed-forward), and error quantities are propagated backward (backpropagation) for optimizing the weight and bias quantities. By adjusting the count of neurons and hidden layers, the optimal architecture can be achieved. The trend of the calculation process in this model is written in Eq. 813:
The learning algorithm formula in the MLP model is written in Eq. (9). η is the learning rate, a small positive value that controls the adjustment magnitude. ytrue is the actual value. ypredict is the predicted value. Also, wi+1 and wi refer to the new and old value of the weights, respectively.
In this study, the selection of activation functions for the hidden layer neurons and output layer neurons involved a trial-and-error process, leading to the choice of the tansig function for the hidden layer and the purelin function for the output layer. The general calculation forms for these functions are written in Eqs. 10 and 11, respectively37:
RBF network
RBF is a kind of feed-forward backpropagation method that is better than the other models by exhibiting a higher training rate. The number of neurons in the hidden layer is variable, and the optimal neuron count is typically determined through trial and error. The fundamental aim of the training step in this network is to decrease the MSE value to a specific threshold or achieve a predetermined number of network training epochs38. The Gaussian function and the calculation trend in this model are expressed in Eqs. 12 and 13, respectively31.
Unlike RBF, which has only one hidden layer, MLP can have multiple hidden layers, making it more suitable for solving more complex problems with diverse data. RBF is a stochastic ANN that learns based on the probability distribution of its input set. Meanwhile, MLP maps the input datasets to a set of outputs, where each neuron in the hidden and the output layers is processed using an activation function.
Results and discussion
RSM results
Process optimization and prediction of the corresponding model are carried out using the RSM design program. In this method, the interactions of the experimental inputs and their impacts on the output have been displayed in the diagram template. After introducing the considered variables with their range, and adsorption capacity in the software as a response, the predicted model for the adsorption capacity of CO2 is shown in Eq. (14):
In Eq. (14), A refers to the gamma intensity, B refers to the amount of glycidyl methacrylate, and C refers to the amount of ethanolamine. According to Eq. (14), it can be derived that the gamma intensity (A), amount of glycidyl methacrylate (B), and amount of ethanolamine (C) had a considerable impact on CO2 sorption capability. Equation (14) is a parabolic formula, which means that each effective parameter has an optimum point. This formula also shows the simultaneous interaction of parameters on the adsorption capacity. Moreover, Eq. (14) is a mathematical model that RSM predicts, which can be used in practical applications with similar empirical conditions. The obtained data for the analysis of variance (ANOVA) are given in Table A1. P-values greater than 0.1 imply that factors have no impact on the process. The F-value is calculated as 489.95, which reveals the model is significant. There is only a 0.01% possibility that F-values this large could occur due to noise. The anticipated R2 and adjusted R2 are computed and written in Table 2. The calculated R2 of 0.9910 is in reasonable agreement with the Adjusted R2 of 0.9932. Adequate precision that specifies the signal-to-noise ratio is 61.9596. A ratio more than 4 is good, which implies that the noise to the ratio of the model is put on the appropriate board, and these models can be exploited to navigate the design space. The values of actual R2, adjusted R2, and predicted R2 were more than 0.99, which implies the closeness of real data to calculated data. Also, the mean or average of the predicted data was 2.08. The low standard deviation (0.0691) reveals that the predicted values were gathered around the mean point, and the dispersion of predicted values is very low. As listed in Table A1, the model does not lack fit, which shows that the model is good. The examination using the Pearson correlation coefficient matrix (Fig. 2) indicates that there is no notable linear correlation between the adsorbent and CO2 adsorption capacity. According to Fig. 3, a significant positive correlation between the CO2 adsorption capacity and gamma dose. Additionally, CO2 adsorption capacity demonstrates a moderately negative correlation with the amount of GMA and amine. Statistical dispersion trend of each parameter is displayed in.

The correlation matrix of CO2 adsorption capacity.
3D diagram of CO2 adsorption capacity
The impact of the volume percentage of GMA and amine volume percentage on the CO2 sorption capability at the gamma value of 30kGy. It was observed that the pattern of variation in the adsorbent’s sorption capacity is primarily positive. It is highest at 25% by volume of monomer and 75% by volume of amine. This trend decreases as the volume percentage of monomer and amine increases from 25 to 30 and from 75 to 100%, respectively. The adsorption capacity of CO2 was 1.16 mmol/g at a volume percentage of monomer of 25 and amine volume percentage of 75. The CO2 adsorption capacity has the least value at the corner points, which is zero. Also, the reduction of active sites for the attachment of amino groups at higher volume percentages of monomer decreases the CO2 adsorption capacity. Incorporating a higher amino groups at a higher amount of monomer can fill a large number of pores and cavities, and as a result, can block these pores, which inhibit the penetration of CO2 gas in these pores. It was also derived that the gamma dose and volume percentage of amine on the CO2 sorption capability at a constant value of the volume percentage of GMA, which was 20%. By elevating the gamma intensity from 10 to 30 kGy and the volume percentage of amine from 40 to 75%, the CO2 sorption capability reaches the highest value because the highest number of pores and active sites were created at these values. Indeed, the adsorption capacity of CO2 at the volume percentage of amine of 75 and gamma intensity of 30 kGy has been calculated at 2.25 mmol/g. Thus, it is concluded that the increase of monomer, amine, and gamma radiation cannot always increase the CO2 adsorption capacity, and it is necessary to find the optimum points of each parameter. It can be derived that more gamma radiation can destroy the structure of NF-PAN/PUGMA, which leads to a reduction in adsorption capacity. Elevating the radiation intensity decreased the CO2 uptake, which is owing to the generation of homopolymers and the blocking of the active sites of GMA monomers.
Optimization results
The main aim is to reach the highest CO2 sorption capability. The output levels and factors have been tuned independently, and the fine-tuning method has been used to obtain the best response. The highest CO2 sorption capability has been achieved at a gamma intensity of 28.03 kGy, GMA content around 25.77%, and EA content around 66.45%. Under these optimal conditions, the CO2 adsorption capacity was obtained as 2.95 mmol/g. Some studies on the modeling of adsorption processes using RSM research methods are summarized in Table 3.
ANNs result
Typically, determining the optimal structure of a neural network involves a trial-and-error process with tuning parameters that influence the training step, like the number of neurons, the training function, and the activation function. Hence, assessing the network’s validity involves comparing anticipated quantities with the empirical values to ensure its reliability. Some studies on the modeling of the CO2 adsorption process using ANN are written in Table 4.
To train the MLP network in this work, the normalized data were split into three distinct categories: 70% for network training, 20% for validation, and 10% for testing. The number of datapoints was 463. The number of data points in the training, validation, and testing was 324, 93, and 46, respectively. Diverse learning concepts such as Levenberg–Marquardt (trainlm), Bayesian Regularization (trainbr), and Scaled Conjugate Gradient (trainscg), have been employed. The LM algorithm was first proposed for nonlinear least squares problems by scholars Levenberg and Marquardt. The Levenberg–Marquardt (LM) optimization technique is the best training algorithm for adjusting the MLP model hyperparameters. Indeed, the LM algorithm is defined as a classical gradient-based optimization method used to solve non-linear least squares problems, characterized by its fast convergence speed when provided with an appropriate initial value. In each training algorithm, various sizes of hidden layers and various numbers of neurons have been assessed. The impact of diverse activation algorithms for neurons was also evaluated, with the nonlinear tangent sigmoid (tansig) function selected for hidden layer neurons and the linear function (purelin) chosen for output layer neurons. Notably, the conclusions of the trainbr and trainlm algorithms in the training step are identical, with simply tiny differences in Mean Squared Error (MSE). Consequently, the trainbr has been considered as a training algorithm. After running the MLP network in MATLAB software, the outputs and results of the network for learning functions, the number of layers, and different neurons are shown in Table 5. Besides, it is necessary to determine the best output of the MLP network to find the optimal network. The specifications of the best MLP network outputs for determining the optimal network are brought in Table 6. The accuracy of the network results and comparing the real data with the predicted value, is quite acceptable. The neural network has a low error rate and can calculate the value based on the input variables.
The results of Table 6 were as follows:
• The best result was obtained for a two-layer MLP network with 6 neurons and Trainbr learning function, with MSE equal to 0.00045512.
• The results for Trainbr learning function were better than Trainlm and Trainscg; so that both the R2 value was higher and the MSE was lower.
• The number of Trainlm and Trainscg Epochs was much less than Trainbr.
The schematic of the MLP model is shown in Fig. 4, Fig. 5, 6, 7, and 8 are the outputs for the optimal MLP network with 6 neurons and Trainbr training function. Fig. 7 displays the mean square error of 0.0011969 at the step of 58, which is considered an optimum value of the MLP two-layer. The graph of the histogram displays the normal trend of the neural network (Fig. 10), which proves that the zero error was achieved at bin 9. Regarding Fig. 8 the values of R2 were calculated at 0.99695, 0.9952, and 0.99726 for the steps of training, validation, and testing, respectively, which imply the closeness of empirical variables to the forecasted values.

Schematic graph for the MLP architecture with three hidden layers.

MLP network regression diagram for CO2 adsorption.

MLP model regression diagram at the training step.

MLP network histogram error diagram.

MLP model regression of (a) training, (b) validation, (c) testing variables.
To compare the RBF network with the MLP, it is necessary to increase the neuron value to such an extent that the MSE of the RBF network in Spread is equal to 4 with the MSE of the MLP network. A schematic of the RBF model in this study has been drawn in Fig. 9 . The R2 values of MLP, RBF, and RSM models were attained at 0.99973, 0.99493, and 0.9952, respectively. By comparing the R2 value of the RSM and ANN models, it is concluded that the MLP model is better than the RBF and RSM models because of its higher R2 value. Table 7 shows the dimensions of the outputs and results of the network in MATLAB software for the number of spreads and different neurons. After running the network with different numbers of neurons, it was observed that the MSE of the RBF network with 45 neurons was 0.00020117, which is almost equal to the MSE of the MLP network. , Fig. 10, 11 and 12 show the results of the RBF network. Figure 10 proves the high quantity of R2 at 0.99493. The graph of the histogram displays the normal trend of the neural network (Fig. 12 ), which proves that the zero error was achieved at a bin of 10. Figure 12 reveals that the best performance was seen after 45 steps with the MSE value of 0.000455113. In other word, the most suitable convergence was conducted after 45 runs of the ANN program with the least possible error. According to Table 8, in a certain MSE, the number of neurons for the MLP network was equal to 45, while for the RBF network it was equal to 46 neurons, which shows that the RBF network used many more neurons to achieve this error value compared to the MLP. The three-dimensional diagrams show the effect of important parameters on CO2 adsorption (Figs. 13 and 14). As observed, the variation trend of the CO2 adsorption capacity with changes in irradiation dose and monomer volume percentage is identical in MLP and RBF models. In both Figs. 13 and 14, increasing the gamma dose and monomer volume percentage can promote the CO2 adsorption capacity. In other words, a higher amount of monomer and a higher dose of radiation assist in the adherence of more CO2 molecules in the vacant places of the adsorbent. In other words, the highest CO2 adsorption capacity was observed at a monomer volume percentage of 50 and a gamma dose of 100 kGy. This prediction explains that a larger monomer amount and gamma dose can produce more pores and active sites in the structure of NF-PAN/PUGMA.

Schematic graph of the RBF structure with a single hidden layer.

Regression of experimental data points in RBF for CO2 adsorption capacity.

RBF network histogram error image.

RBF network performance diagram.

The three-dimensional shape of the MLP network for calculating the effect of (a) monomer volume percentage and irradiation dose, (b) amine percentage and irradiation dose, and (c) monomer volume percentage and amine percentage on the adsorption capacity of the adsorbent.

The three-dimensional shape of the RBF network to calculate the effect of (a) amine percentage and irradiation dose, (b) monomer volume percentage and amine percentage, and (c) monomer volume percentage and irradiation dose on the adsorption capacity of the adsorbent.
The accuracy of RSM and ANN models was evaluated using correlation coefficients (R2). The correlation coefficients for the RSM, RBF, and MLP models were 0.9910, 0.9949, and 0.9968, respectively. Indeed, the MLP model has higher agreement with the experimental data. Thus, it is concluded that the MLP model can predict better than the RSM and RBF models.
Conclusion
In this research, the electrospinning procedure was used to fabricate NF-PAN/PU utilizing PAN and PU. Subsequently, radiation emission with GMA and surface treatment with amine were carried out on the synthesized NF-PAN/PU. The influence of factors such as the monomer content, radiation intensity, and amine content were investigated. The optimized factors were 25.80% of GMA, 66.45% of amine, and a radiation value of 28 kGy. In the next step of this research, machine learning was utilized for predicting the CO2 adsorption. ANN models, including MLP and RBF, were used for finding the best model that has a higher adaptation with the experimental data. The other aim of using ANN models is to detect the parameter interactions on the CO2 adsorption capacity. It will assist us in predicting the CO2 adsorption capacity without performing tests in the practical conditions. Also, it was observed that the performance of the MLP model is better than the RBF model because the number of neurons (6) and error (0.00045512) were lower, and its R2 was higher (0.9968). Additionally, the trainbr was used as a training function, and the number of APECs was 300 in the MLP model. Ultimately, MLP and RBF 3D diagrams displayed that increasing the monomer volume percentage and irradiation dose can lead to improved CO2 adsorption capacity.
Some recommendations about the ANN method in the field of CO2 capture can be useful for scientists working in the future. In our opinion, scientists can consider other waves, like ultrasonic or microwave, as inputs. Additionally, other variables, such as additives, activation energy, temperature, and saturation time, can be defined as inputs. It is interesting to probe the combination of PAN with other polymers except PU for testing the CO2 capacity with ANN. Moreover, other outputs, such as absorption efficiency, can also be studied in addition to CO2 solubility. The other recommendation is entering data with the use of molecular dynamics (MD) because of a lack of enough experimental data. It is recommended to apply other ANN methods, such as a support vector machine (SVM), to study CO2 capacity in NF-PAN/PUGMA. One challenge with the ANN method is the need to provide a large amount of input data, which can be solved in the ANN structure by experts in computer and chemical engineering.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Abbreviations
- RIG:
-
Radiation-induced grafting
- q:
-
Adsorption capacity (mg/g)
- F:
-
Flow rate of CO2 gas (L/min)
- Co :
-
Initial concentration of CO2 (mg/L)
- tq :
-
Saturation time of adsorbent (min)
- W:
-
Mass of adsorbent (g)
- EA:
-
Ethanolamine
- PAN:
-
Polyacrylonitrile
- PU:
-
Polyurethane
- GMA:
-
Glycidyl methacrylate
- q:
-
Adsorption capacity
- NVF:
-
N-vinyl formamide
- UHMWPE:
-
Ultra-high molecular weight polyethylene
- ANN:
-
Artificial neural network
- MSE:
-
Mean squared error
- MAE:
-
Mean absolute error
- RMSE:
-
Root mean square error
- Outlier:
-
A point that’s endlessly distinctive from other focuses in a dataset
- Outlier Detection:
-
The method of finding outliers in a dataset
- Neurons:
-
The basic units of the large neural network
- Bias:
-
A constant which helps the model in a way that it can best fitted for fit the data
- Activation function:
-
A mathematical function between the input feeding the current neuron and its output going to the next layer
- Weight:
-
Represents the importance and strengths of the feature/input to the Neurons
- Epoch:
-
In the training process, the inputs are entered in each training step and give an output that is compared with the target to calculate an error. With this process, weights and biases are calculated and modified in each epoch
References
Heydari-Gorji, A., Yang, Y. & Sayari, A. Effect of the pore length on CO2 adsorption over amine-modified mesoporous silicas. Energy Fuels 25(9), 4206–4210 (2011).
Ibrahim, H. M. & Klingner, A. A review on electrospun polymeric nanofibers: Production parameters and potential applications. Polym. Testing 90, 106647 (2020).
Nia, R. H., Ghaedi, M. & Ghaedi, A. Modeling of reactive orange 12 (RO 12) adsorption onto gold nanoparticle-activated carbon using artificial neural network optimization based on an imperialist competitive algorithm. J. Mol. Liq. 195, 219–229 (2014).
Karbalaei Mohammad, N., Ghaemi, A., Tahvildari, K. & Sharif, A. A. Experimental investigation and modeling of CO2 adsorption using modified activated carbon. Iran. J. Chem. Chem. Eng. 39(1), 177–192 (2020).
Amiri, M., Shahhosseini, S. & Ghaemi, A. Optimization of CO2 capture process from simulated flue gas by dry regenerable alkali metal carbonate based adsorbent using response surface methodology. Energy Fuels 31(5), 5286–5296 (2017).
Pashaei, H., Ghaemi, A., Nasiri, M. & Karami, B. Experimental modeling and optimization of CO2 absorption into piperazine solutions using RSM-CCD methodology. ACS Omega 5(15), 8432–8448 (2020).
Khuri, A. I. & Cornell, J. A. Response Surfaces: Designs and Analyses (Routledge, 2018).
Nihaal, K., Mahabaleshwar, U., Swaminathan, N. & Bognar, G. Optimization of heat transfer analysis on an aggregated nanofluid flow over a thin porous needle: Sensitivity analysis approach. Int. J. Thermofluids 27, 101191 (2025).
Hiremath, P. et al. Sensitivity analysis of MHD nanofluid flow in a composite permeable square enclosure with the corrugated wall using response surface methodology-central composite design. Numer. Heat Transf. Part A Appl. 86(20), 7326–7343 (2025).
K. Vinutha, K. Sajjan, J. Madhukesh, G. Ramesh, Optimization of RSM and sensitivity analysis in MHD ternary nanofluid flow between parallel plates with quadratic radiation and activation energy. J. Thermal Anal. Calorimet. 149(4) (2024).
Kianpour, M., Sobati, M. A. & Shahhosseini, S. Experimental and modeling of CO2 capture by dry sodium hydroxide carbonation. Chem. Eng. Res. Des. 90(11), 2041–2050 (2012).
Bararpour, S. T., Adanez, J. & Mahinpey, N. Application of core-shell-structured K2CO3-based sorbents in postcombustion CO2 capture: Statistical analysis and optimization using response surface methodology. Energy Fuels 34(3), 3429–3439 (2020).
Zaferani, S. P. G., Emami, M. R. S., Amiri, M. K. & Binaeian, E. Optimization of the removal Pb (II) and its Gibbs free energy by thiosemicarbazide modified chitosan using RSM and ANN modeling. Int. J. Biol. Macromol. 139, 307–319 (2019).
Dehdashti, B., Amin, M. M., Gholizadeh, A., Miri, M. & Rafati, L. Atenolol adsorption onto multi-walled carbon nanotubes modified by NaOCl and ultrasonic treatment; kinetic, isotherm, thermodynamic, and artificial neural network modeling. J. Environ. Health Sci. Eng. 17(1), 281–293 (2019).
Kareem, F. A. A. et al. Experimental measurements and modeling of supercritical CO2 adsorption on 13X and 5A zeolites. J. Nat. Gas Sci. Eng. 50, 115–127 (2018).
Naeem, S., Shahhosseini, S. & Ghaemi, A. Simulation of CO2 capture using sodium hydroxide solid sorbent in a fluidized bed reactor by a multi-layer perceptron neural network. J. Nat. Gas Sci. Eng. 31, 305–312 (2016).
Amini, Y., Gerdroodbary, M. B., Pishvaie, M. R., Moradi, R. & Monfared, S. M. Optimal control of batch cooling crystallizers by using genetic algorithm. Case Stud. Thermal Eng. 8, 300–310 (2016).
Streb, A. & Mazzotti, M. Performance limits of neural networks for optimizing an adsorption process for hydrogen purification and CO2 capture. Comput. Chem. Eng. 166, 107974 (2022).
Mahabaleshwar, U., Nihaal, K., Zeidan, D., Dbouk, T. & Laroze, D. Computational and artificial neural network study on ternary nanofluid flow with heat and mass transfer with magnetohydrodynamics and mass transpiration. Neural Comput. Appl. 36(33), 20927–20947 (2024).
Nihaal, K., Mahabaleshwar, U., Joo, S. & Bognar, G. Bioconvection and chemical reaction impacts on Casson nanofluid flow on a thin needle: A stochastic approach. Thermal Advances 3, 100042 (2025).
Vinutha, K. et al. Use of wavelet-based neural networks for optimization of heat and mass transfer radiative hybrid nanofluid over a nonlinear stretching surface. Adv. Mech. Eng. 17(9), 16878132251371756 (2025).
Deitzel, J. M., Kleinmeyer, J., Harris, D. & Tan, N. B. The effect of processing variables on the morphology of electrospun nanofibers and textiles. Polymer 42(1), 261–272 (2001).
Tourzani, A. A. et al. Enhancing the formation of eco-friendly CO2 adsorbent through utilizing the RSM technique and implementation of PAN/PU electrospinning and radiation-grafted approaches. J. Clean. Prod. 434, 140213 (2024).
Afzal A, Roy RG, Koshy CP, Abbas M, Cuce E, RK Ar, Shaik S, Saleel CA. Characterization of biodiesel based on plastic pyrolysis oil (PPO) and coconut oil: performance and emission analysis using RSM-ANN approach. Sustain. Energy Technol. Assess. 2023; 56:103046.
Khoshraftar, Z. & Ghaemi, A. Evaluation of pistachio shells as solid wastes to produce activated carbon for CO2 capture: Isotherm, response surface methodology (RSM) and artificial neural network (ANN) modeling. Curr. Res. Green Sustain. Chem. 5, 100342 (2022).
Afzal, A. et al. Response surface analysis, clustering, and random forest regression of pressure in suddenly expanded high-speed aerodynamic flows. Aerospace Sci. Technol. 1(107), 106318 (2020).
Pambi, R. L. & Musonge, P. Application of response surface methodology (RSM) in the treatment of final effluent from the sugar industry using Chitosan. WIT Transac. Ecol. Environ. 16(209), 209–219 (2016).
Masoumi, H., Imani, A., Aslani, A. & Ghaemi, A. Modeling of carbon dioxide absorption into aqueous alkanolamines using machine learning and response surface methodology. Sci. Rep. 14(1), 23967 (2024).
Masoumi, H., Ghaemi, A. & Gilani, H. G. Synthesis of polystyrene-based hyper-cross-linked polymers for Cd (II) ions removal from aqueous solutions: Experimental and RSM modeling. J. Hazard. Mater. 416, 125923 (2021).
Monjezi, A. H., Mesbah, M., Rezakazemi, M. & Younas, M. Prediction bubble point pressure for CO2/CH4 gas mixtures in ionic liquids using intelligent approaches. Emergent Materials 4(2), 565–578 (2021).
Hemmati, A., Ghaemi, A. & Asadollahzadeh, M. RSM and ANN modeling of hold up, slip, and characteristic velocities in standard systems using pulsed disc-and-doughnut contactor column. Separat. Sci. Technol. 56(16), 2734–2749 (2021).
Mashhadimoslem, H. et al. Development of predictive models for activated carbon synthesis from different biomass for CO2 adsorption using artificial neural networks. Ind. Eng. Chem. Res. 60(38), 13950–13966 (2021).
Ghaemi, A., Hemmati, A., Asadollahzadeh, M. & Molaee, M. Hydrodynamic behavior of standard liquid-liquid systems in Oldshue-Rushton extraction column. RSM and ANN Model. Chem. Eng. Process. Process Intensific. 168, 108559 (2021).
Sheikholeslami, M., Gerdroodbary, M. B., Moradi, R., Shafee, A. & Li, Z. Application of neural network for estimation of heat transfer treatment of Al2O3–H2O nanofluid through a channel. Comput. Methods Appl. Mech. Eng. 344, 1–12 (2019).
Amini, Y., Fattahi, M., Khorasheh, F. & Sahebdelfar, S. Neural network modeling the effect of oxygenate additives on the performance of Pt–Sn/γ-Al2O3 catalyst in propane dehydrogenation. Appl. Petrochem. Res. 3(1), 47–54 (2013).
Esfandiari, K., Ghoreyshi, A. A. & Jahanshahi, M. Using artificial neural network and ideal adsorbed solution theory for predicting the CO2/CH4 selectivities of metal–organic frameworks: A comparative study. Ind. Eng. Chem. Res. 56(49), 14610–14622 (2017).
Yulia, F., Chairina, I. & Zulys, A. Multi-objective genetic algorithm optimization with an artificial neural network for CO2/CH4 adsorption prediction in metal–organic framework. Therm. Sci. Eng. Progress. 1(25), 100967 (2021).
Sharifahmadian A. Numerical models for submerged breakwaters: coastal hydrodynamics and morphodynamics. Butterworth-Heinemann; 2015.
Thouchprasitchai, N., Pintuyothin, N. & Pongstabodee, S. Optimization of CO2 adsorption capacity and cyclical adsorption/desorption on tetraethylenepentamine-supported surface-modified hydrotalcite. J. Environ. Sci. 65, 293–305 (2018).
Khalili, S., Khoshandam, B. & Jahanshahi, M. Optimization of production conditions for synthesis of chemically activated carbon produced from pine cone using response surface methodology for CO2 adsorption. RSC Adv. 5(114), 94115–94129 (2015).
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Hadiseh Masoumi: Conception and design of the study, acquisition of data, methodology, validation, visualization, drafting the manuscript, writing-editing, writing-original draft, and approval of the version of the manuscript. Ahad Ghaemi: Conception and design of the study, supervision, acquisition of data, methodology, validation, project administration, and visualization. Pouria Zareei: Conception and design of the study, acquisition of data, software, and methodology. Alireza Hemmati: Methodology, validation, supervision, and visualization.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Masoumi, H., Ghaemi, A., Zareei, P. et al. Study of CO2 capture by synthesized composite and modelling with machine learning and response surface methodology. Sci Rep 16, 981 (2026). https://doi.org/10.1038/s41598-025-30592-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30592-3
