
Abstract
In streaming services such as e-commerce, suggesting an item plays an important key factor in recommending the items. In streaming service of movie channels like Netflix, amazon recommendation of movies helps users to find the best new movies to view. Based on the user-generated data, the Recommender System(RS) is tasked with predicting the preferable movie to watch by utilising the ratings provided. A Dual module-deeper and more comprehensive Dense Neural Network (DNN) learning model is constructed and assessed for movie recommendation using Movie-Lens datasets containing 100k and 1M ratings on a scale of 1 to 5. The model incorporates categorical and numerical features by utilising embedding and dense layers. The improved DNN is constructed using various optimizers such as Stochastic Gradient Descent (SGD) and Adaptive Moment Estimation (Adam), along with the implementation of dropout. The utilisation of the Rectified Linear Unit (ReLU) as the activation function in dense neural networks is employed to mitigate issues such as overfitting, gradient instability, and convergence deceleration. The Dense NN model that has been proposed is subjected to a comparative analysis with pre-existing models. The evaluation of the proposed model is conducted using two widely accepted metrics, namely Mean Squared Error (MSE) and Mean Absolute Error (MAE). The obtained results for the MSE and MAE are 0.16 and 0.33, respectively.
Similar content being viewed by others

Introduction
Online movie streaming has become steadily common as internet use and movie consumption both continue to expand. There are a plethora of movie libraries available to viewers. Users will have a hard time locating compelling videos as a result. Thus, it is important to have a content-based automatic movie recommendation system. There has been a huge development in the two main areas of focus, which are video classification and recommendation. Most currently available movie recommendation systems only base their suggestions on text. The names and descriptions of videos are included in word-based content features1. There exist three distinct categories of video recommender models, including the content-based (CBF) recommendation system, collaborative filtering(CF) recommendation system, and hybrid recommendation system. CF is employed to the word in order to advances the identification of the k-nearest neighbours’ objects. As users number increases, CF faces scalability issues and locating the nearest neighbours in large databases becomes costly. Additionally, users can alter their neighbours. When a user modifies or adds a rating, the similarity between two movies is significantly modified2.
CBF3 take the personal interests of the users into account. Each user profile is constructed using identifiers that represent the attributes of the item. In CBF recommendations, products which are similar that have already been rated by other users are excluded. For instance, a user who views and enjoys Star Wars is more likely to have science fiction films such as Guardians of the Galaxy. Hybrid recommendation systems4 combine collaborative filtering and content-based filtering techniques. Some investigations have combined the results of collaborative filtering and content-based separation. The RS is a component of E-Commerce applications that provide the ability to broadcast online entertainment. Primarily, it collects information about the audience for specific products. With the advancement of information technology, information overflow has already surpassed information switching5.
The challenge in today’s information-overloaded society isn’t so much finding information as it is quickly the process of extracting pertinent and valuable information from massive datasets. It’s built on implementing cutting-edge technology into the movie selection system for optimal results. Deep learning has made greater impacts in the disciplines of computer visualisation, object identification, and recognition, which are the focus of much current research6. Every year, the Deep Learning model got better at both the movie classification system and the recommendation system. Most of the time, study into deep learning looks at things like text, speech, and images. People can recognise graphics data better than other types of data7. It is recommended to use visual data for classification work. In this case, the film is stimulating data for task layout and difficult data domains for classification challenges. In recent years, deep learning has demonstrated gains in image processing, language processing, and speech recognition, and it has gained prominence in artificial intelligence and related domains, particularly machine learning and data mining8. Despite the fact that research into the use of deep learning neural networks for recommendation systems is still in its early phases, it is gaining interest in international academic circles and industry. Many research institutions and universities in the United States and worldwide have conducted extensive research on deep learning-based recommendation systems. Deep learning-based recommendation systems have emerged as a hotspot for recommendation system research.
With the rise of online streaming services, movie recommendation systems have become a standard feature of the modern entertainment industry. Unfortunately, the personalization capabilities of traditional recommendation systems are generally constrained by their reliance on either categorical or numerical data. In order to overcome this shortcoming, a hybrid dual-module technique that utilizes both categorical and numerical datasets to improve the quality of movie suggestions has emerged as a potent alternative.
The prime contributions of the recommended system are as follows:
-
Fusing the numerical and categorical features enhances the accuracy and effectiveness of movie recommendations.
-
Dual module approach with wider and deeper SGD enhanced the movie recommendations.
Related work
Many different techniques have been evolved in the past by researchers with the goal of creating an effective recommendation system, with the most common ones being the collaborative filtering, content-based, and hybrid recommendation models. If the data are cold and sparse, collaborative filtering will have trouble getting started. A content-based model’s performance suffers without a reliable technique for extracting features. Current recommendation approaches are difficult to assimilate with factors from the data series, and they require expertise of the user’s behaviour9. Deep-learning neural network models have specific issues when classifying movie recommendation systems. Radhika et al.9 came up with an an innovative approach to movie recommendation utilising deep reinforcement learning (DRL). The proposed method effectively tackles the issue of data sparsity and incorporates pre-processing techniques. The user’s interests are evaluated through the utilisation of cross-entropy. The proposed methodology enhances both the speed and accuracy of the network. Xia0 et al.6 developed a perturbation approach derived from the user profile to facilitate the recommendation of work using Deep Reinforcement Learning (DRL). The present methodology leverages the susceptibility level data coupled with the selected item and employs it to identify the corresponding movie by using privacy-related information. Sridhar et al.1 introduced a novel approach utilising deep neural networks and probability models to construct a recommendation system for movies. This method was implemented and evaluated using a dataset consisting of 100,000 movie lens records.
The k-nearest neighbour approach was employed to view activation maps with weighted class and cosine similarity indexes. Chen et al.10 conducted an analysis of the diversity within the interests of the user and the user embedding. The user integrated several personal interests and employed a deep neural network to generate movie recommendations. Yuyan et al.11 suggested using visual information like trailers and the Resnet-152 model to forecast the movie genres. Each trailer is divided into sections, produces a brief visual shot, and uses advanced visual effects to promote the film. 25M datasets that were utilised for visual features are here provided by the film. In-depth research is done in on the fresh allied filtering model for movie recommendation that is based on deep learning.
Wang et al.7 employed the LSTM-CNN approach to tackle the problem of movie suggestions. This involved extracting user behaviour data and user rating information. The methodology employed in this study focused on the movie lens dataset and generated a ranked list of films for the testing dataset. Rawat et al.12 employed deep learning methods to analyse the user’s browsing activity and make a movie suggestion. Together, embedding and collaborative filtering form the basis of this method. Nambiar et al.13 addressed accurately forecasting the movie genres based on the movie’s poster and overview. Chavare et al.14 proposed the ConvMF algorithm, an enhanced deep learning approach, for the purpose of movie recommendation. This technique leverages word vector characteristics and incorporates a deep neural network architecture. The Doc2Vec technique is employed to extract the words within a sentence and calculate the similarity vector, which is then utilised in collaborative filtering for the motive of movie recommendation. Numerous scholars have endeavoured to investigate deep neural network models by a comprehensive examination of existing literature. However, they have encountered challenges related to data sparsity, feature selection, overfitting, and algorithm optimisation8. Neural networks have emerged as a potent paradigm for improving movie recommendation systems’ efficacy in recent years. Numerous studies have investigated deep learning-based user preference modeling that incorporates contextual and content data. For example,15 suggested a hybrid strategy that blends graph-based techniques with CNN-based preference prediction, demonstrating notable gains in recall and precision. Similar to this,16 created a hybrid recommendation model that uses artificial neural networks to combine content-based methods and collaborative filtering, resolving cold-start issues and increasing prediction accuracy. Furthermore,17 showed how supplementary textual signals might improve user satisfaction in recommendation systems by integrating sentiment analysis into Neural Collaborative Filtering (NCF) to improve ranking processes.
In order to capture the dynamic and diverse character of user preferences, other contributions concentrate on sequence modeling and multimodal feature integration. In order to process user behavior sequences,18 used deep learning architectures in conjunction with KMeans clustering, reporting improved performance in RMSE and Top-N recommendation metrics. By presenting a multi-modal Transformer framework that integrates textual, visual, and structural aspects of films, including poster attention processes,19,20,21,22advanced this trend. Their methodology emphasizes how crucial it is to include rich contextual information in addition to conventional rating data. Together, these studies show how neural network architectures—whether via multimodal fusion, hybridization, or sequential modeling—have emerged as a key component of the development of next-generation movie recommendation systems.
Proposed approach
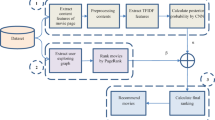
The methodology presented for the development of an advanced and profound model for movie recommendations is illustrated in Fig. 1.

Proposed methodology.
In the course of this research, both 100-K and 1-Million movie-lense data with ratings from 1 to 5 were compiled to use in the construction of a movie RS. These data-sets were compiled as part of a study conducted at the University of Minnesota by grouplens100k23. It has one hundred thousand ratings ranging from one to five stars, with input 1682X943 movies and users data. The user data file has four columns, which include user-id, movie, rating, and timestamp information respectively. The contents of a typical user data file are detailed in Table 1, which may be seen here.
Table 2 illustrates the sample data of ratings. In this table, the value of 1 indicates that a movie belongs to a specific genre, while the 0 indicates that it does not belong to that genre. Movies have the potential to encompass multiple genres simultaneously. The identifiers used to describe movie information correspond to those found in the u.data dataset.
Exploratory Data Analysis (EDA) is applied in order to comprehend the insights of considered datasets. Figure 2 and 3 represents distrubutions of movie ratings for the 100-K and 1-Million movie lens datasets.

Rating Distribution(100-K).

Rating Distribution(1M).
To get a better insights on genres distribution, the number of movies in each genre is plotted in Fig. 4. Table 3 displays the total number of ratings received for each movie with the average rating.

Movies per genre.
Within the datasets, it is observed that certain attributes like name of user and title of the movie title are categorical. In the context of neural networks,the input data must be in numerical form. Therefore, in order to magnify the accuracy, in the model proposed the data is subjected to pre-processing wherein the label encoding technique is employed to convert it into numerical values. The categorical input was encoded numerically and afterwards assessed in the model. In label encoding the categorical attributes are replaced with numericals ranging from 0 to n-1( n is number of clases) followed by construction of the Dense NN. In the context of Neural Networks (NN), the fundamental component is the neuron, which is responsible for the management and regulation of signals within the system. The input vector x, representing signals, propagates via axons and engages in a multiplicative with dendrites (weights w) of another neuron. The data originating from the neurons will be aggregated through a specific threshold, resulting in the transmission of an output, commonly referred to as a prediction.
The activation function(f) represents the firing frequency of each neuron. The f can be ReLu, Tanh and Maxout. The mathematical representation of the sigmoid function, which introduces non-linearity, can be expressed \(\sigma = \frac{1}{1 + e^x}\) . It takes value range from 0 and 1. The function tanh is a sigmoid which is scaled neuron represented as tanh = 2\(\sigma\)(2x) –1 range from [-1;1]. Tanh is a zero centrered and gradient saturated.
The ReLU is mathematically expressed as f(x) = max(0, x). It exhibits faster convergence in acceleration when compared to the sigmoid function due to its linear nature. During the process of training, the weights are updated in both the forward and backward passes. NN mostly operate in a forward manner, where information flows in a unidirectional manner without looping via hidden layers. Additionally, forward layers not provides feedback to preceding layers. To magnify the optimizers of NN model, a wider and deeper architecture is implemented by incorporating dense layers with optimizers and dropout layers. The term dense layer in NN refers to a type of layer where each neuron is fully connected to the neurons in the preceding layers. The Dense NN model performs matrix-vector multiplication to compute the output received from each neuron in its preceding layers. The Dense NN is depicted in Fig. 5.

Dense NN.
Because the Movie-lens 100-k and 1-M datasets contain higher dimensional numerical and categorical variables, embedding and dense layers are integrated to move on to the subsequent levels. The variables that are input have embedding performed on [x1, x2, x3,....... Xn]. The process of embedding involves the conversion of discrete or categorical data into continuous numerical representations. From a deep learning standpoint, embeddings are employed to minimize the dimensionality of discrete variables and serve as an input to the Dense NN. The system of embedding involves identifying the nearest neighbour space, which may then be utilised for recommending goods to users. Additionally, this approach can be employed to establish connections between discrete variables. Figure 6 illustrates the integration of embedding with a Dense NN.

Combining embedding and dense layers in NN.
In the context of DNN, the execution of computationally expensive backpropagation onthe entirety of the training set has been accounted for result in suboptimal optimization. Although batch approaches, such as the limited memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) algorithm, are habitual in training the models on the entire dataset, their computational time increases significantly on a single system when dealing with huge datasets. Additionally, these methods need to be revised when it comes to applying them to fresh data. In order to address the issue of optimization loss, the Dense NN was improved by the incorporation of the Stochastic Gradient Descent (SGD) optimizer. SGD is an iterative approach of optimization that uses stochastic approximation to perform gradient descent. It is utilized to identify both max and min in a given function. SGD has enhanced efficiency in training big datasets, hence resulting in reduced computational time. The algorithm utilizes a limited number of occurrences to do the integration and adapt to the first and second-order approximations of the gradient and loss function. Hence, the challenge associated with achieving comprehensive coverage of the model at the local optimum might be able mitigated.
The dataset can be defined as D \(a_{i}\in \mathbb {R}^{n}\) is an vector of n-dimensional: \(b_{i}\in \{1,m-1\}\)is the \(i^{th}\) sample used for training with categorical variables. The SGD can be defined as follows: Initially, set zero vector to training sample with weighted value \(E_{1}\) and then select training sample randomly \((a_{it},b_{it})\) from the complete training set, where \(i_{t}\in \{1,....,m\}\) is the output value of the given training dataset at the i\(\hat{\hbox {t}}\)h iteration. The target function are as follows:
Calculating the gradient based on the formula will result in a value that can be expressed as
where, \(\alpha _{t}={\left\{ \begin{array}{ll} \begin{array}{c} 1\\ 0 \end{array} & \begin{array}{c} if\,b_{it}(E_{t},a_{it})<1\\ otherwise \end{array}\end{array}\right. }\)
It is possible to update the matrix E as below
where, \(\eta _{t}=\frac{1}{\lambda t}\)
Following is an updated form of the weighted matrix W that may be derived using equations (2) and (3):
The equation 4 in the context of SGD can be employed to calculate the maximum and minimum values throughout each iteration. The construction of a Dense NN with increased depth and width on a limited dataset has the potential to result in overfitting, wherein the model becomes excessively specialised to the training data. The presence of noise in the data might lead to an increase in the generalisation error due to the problem of overfitting. In order to address this issue, dropout interventions are implemented. Dropouts are the anticipated outcomes derived from the weighted average of multiple models. If dropout is implemented randomly, it may result in the exclusion of certain units inside the hidden layer throughout the training process. There is no certainty that two hidden nodes will occur several times in the model, hence the weight updates will not be dependent on the presence of these hidden nodes. The inclusion of a certain feature can help mitigate the inter-dependencies across other features. Figure 7 depicts a comparison between neural networks that incorporate dropout layers and those that do not. In Fig. 7a, it can be observed that each node is connected to other nodes. In Fig. 7b, it can be observed that certain nodes are subject to random omission. The omission of the hidden-layer can lead to reduction in computational expenses. The implementation of these nodes serves to mitigate the issue of overfitting and diminish the strength of coupling.

(a) NN with no drop-out layers (b) NN with drop-out layers.
During the training, it is possible for a neural network to experience a reduction in its width, resulting in a narrower network. To counteract this, while implementing dropout, a wider network is employed by incorporating a greater number of nodes. Dropout is implemented at each layer in a Dense NN. Initially, a probability value of 0.5 is employed to maintain consistency at each output node within the hidden layer nodes. Values in the range of 0.8 to 1.0 are commonly employed for the purpose of maintaining input nodes originating from visible levels as explained in Algorithm 1.

Movie Recommendation using Dual Module Neural Network.
The optimiser in Dense NN Model_2 has been changed to adam; the learning rate is set to 0.001; and the number of epoch has been set to 200. In Dense NN Model_2 SGD optimizer and dropout is utilized. The detailed architecture has been shown in Fig. 8.

Dual module deep learning architecture.
Discussions of results
The implementation of this work was conducted in a Jupyter notebook on a system with GPU capabilities. The Python programming language is commonly employed for the implementation of ensemble learning models. In python tensorflow and keras library is imported to generate the Dense NN models. The tests involved the utilisation of two distinct datasets, namely the 100K and 1M movie lens datasets. The classes, including dense, dropout, embedding, concatenate, activation, and reshape, are imported in TensorFlow Keras to construct the Dense NN. The studies were done using various optimisation algorithms, including Stochastic Gradient Descent (SGD) and Adaptive Moment Estimation (Adam)24.
Adam is a gradient descent optimizer that computes adaptive learning values for each parameter. It is a stochastic optimisation that uses only first order gradients and a little amount of memory.
Three distinct models are constructed utilising several optimisation algorithms, including Stochastic Gradient Descent (SGD) and Adam. In order to execute the created models, the first batch size is set to 128, the number of epochs is set to 100, the verbosity level is set to 1, and the necessary callbacks are configured. The training and validation loss for Model_1, Model_2, and Model_2 are calculated and visually depicted in Fig. 9, Fig. 10, and Fig. 11, correspondingly, using the movie lens 100k dataset. The training and validation loss for Dense NN Model_1, Dense NN Model_2, and Dense NN Model_2 on the 1M movie lens dataset are calculated and visually depicted in Fig. 12, Fig. 13, and Fig. 14, respectively.

Dense NN Model_1 training and validation loss(100-k dataset).

Dense NN Model_2 training and validation loss(100-k dataset.

Dense NN Model_2 training and validation loss(100-k dataset).

Dense NN Model_1 training and validation loss(1M dataset).

Dense NN Model_2 training and validation loss(1M dataset).

Dense NN Model_2 training and validation loss(1M dataset).
In order to assess the effectiveness of the constructed neural network models, the evaluation metrics MSE and MAE are utilised. MSE is calculated by taking the average of the squared differences between the projected score and the actual value score. The mean squared error (MSE) score will be positive due to the squaring operation applied to the values. The equation used to calculate the MSE is as follows:
The Mean Absolute Error (MAE) is computed as the average of all absolute errors. The absolute error is determined by calculating the discrepancy between the experimental value and the original value. The location of the experimented value is unknown, but x represents the original value. The variable N represents the quantity of errors.
Tables 4 and 5 present a comparison of the MSE and MAE between the proposed model and existing models, using datasets of 100k and 1M, respectively.

Comparative graph of proposed models for 100k dataset.

Comparative graph of proposed models for 1M dataset.
The results indicate that the suggested model demonstrated superior performance, with MSE of 0.159284 and MAE of 0.326350 on the 100k dataset. Similarly, on the 1M dataset, the model achieved an MSE of 0.167927 and an MAE of 0.332462. Figures 14 and 15 present a comparison of the MSE and MAE between the proposed model and existing models.
The movie recommendation process involves randomly selecting a user ID from a pool of constructed larger and deeper Dense NN models, and subsequently recommending films to that user. Table 6 presents the film that has been recommended for the user with the identification number 406, along with the top three films that have been listed utilising the proposed deep neural network (DNN) models. According to Table 7, the 1M movie lens dataset suggests the top three films for user id 4169.
Comparative analysis
The proposed model has been compared with recent research works based on deep-learning models such as AutoRec25, Neural Collaborative Filtering26, and LightGCN27. On the similar datasets, our model achieves better results compared to baseline models as indicated in Table 8 and 9.
Conclusion and future enhancements
The integration of numeric and categorical information in the hybrid dual-module approach for movie recommendations provides a comprehensive and tailored user experience. A NN with increased depth and breadth is designed to enhance the movie RS, employing optimised algorithms such as SGD and Adam. Embedding layers are incorporated in order to transform textual data into numerical vectors. The concatenation of the embedding layer and dense layer results in the formation of a densely connected layer. The method under consideration is founded on the concept of dropout, while the optimizers have been adapted through the use of SGD and Adam. Parallelization is achieved by the utilisation of TensorFlow. Ultimately, the output layers are supplemented with the softmax activation function.
Through the integration of the unique capabilities of each module and the provision of customization features, this methodology offers precise and varied suggestions for films, thereby augmenting user contentment and involvement within the dynamic realm of digital entertainment. The film is forecaster via suggested DNN models and assessed based on MAE and MSE. The optimized Dense NN Model_2 exhibited superior performance compared to certain state-of-the-art models. The improvement of this study can be achieved by taking into account of reviews pertaining to the movie, integrating sentiments, multi modal data and reinforcement learning to enhance recommendation accuracy.
Data availability
In the course of this research, both 100-K and 1-Million MovieLens data with ratings from 1 to 5 were compiled to use in the construction of a movie Recommendation System. These datasets were compiled as part of a study conducted at the University of Minnesota by GroupLens and available at https://grouplens.org/datasets/movielens/.
References
Sridhar, S. & Sanagavarapu, S. Extending deep neural categorisation models for recommendations by applying gradient based learning. In: 2021 8th International Conference on Computer and Communication Engineering (ICCCE), pp. 249–254 (IEEE, 2021).
Felfernig, A. et al. Basic approaches in recommendation systems. Recommendation Systems in Software Engineering, 15–37 (2014)
Van Meteren, R. & Van Someren, M. Using content-based filtering for recommendation. In: Proceedings of the Machine Learning in the New Information Age: MLnet/ECML2000 Workshop, vol. 30, pp. 47–56 (Barcelona, 2000).
Shih, Y.-Y. & Liu, D.-R. Hybrid recommendation approaches: collaborative filtering via valuable content information. In: Proceedings of the 38th Annual Hawaii International Conference on System Sciences, pp. 217–217 (IEEE, 2005).
Sama, L., Wang, H. & Makkar, A. Movie recommendation system using deep learning. In: 2021 9th International Conference on Orange Technology (ICOT), pp. 1–4 (2021). IEEE
Xiao, Y. et al. Deep-reinforcement-learning-based user profile perturbation for privacy-aware recommendation. IEEE Internet Things J. 8(6), 4560–4568 (2020).
Wang, H., Lou, N. & Chao, Z. A personalized movie recommendation system based on lstm-cnn. In: 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), pp. 485–490 (IEEE, 2020).
Liu, G. & Wu, X. Using collaborative filtering algorithms combined with doc2vec for movie recommendation. In: 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), pp. 1461–1464 (IEEE, 2019).
Radhika, V. & Swaraj, K. Movie genre prediction and recommendation using deep visual features from movie trailers. In: 2020 International Conference on Power, Instrumentation, Control and Computing (PICC), pp. 1–6 (IEEE, 2020).
Chen, X., Liu, D., Xiong, Z. & Zha, Z.-J. Learning and fusing multiple user interest representations for micro-video and movie recommendations. IEEE Trans. Multimed. 23, 484–496 (2020).
Yuyan, Z., Xiayao, S. & Yong, L. A novel movie recommendation system based on deep reinforcement learning with prioritized experience replay. In: 2019 IEEE 19th International Conference on Communication Technology (ICCT), pp. 1496–1500 (IEEE, 2019).
Rawat, R.M., Tomar, V. & Kumar, V. An embedding-based deep learning approach for movie recommendation. In: 2020 5th International Conference on Communication and Electronics Systems (ICCES), pp. 1145–1150 (IEEE, 2020).
Nambiar, G., Roy, P. & Singh, D. Multi modal genre classification of movies. In: 2020 IEEE International Conference for Innovation in Technology (INOCON), pp. 1–6 (IEEE, 2020).
Chavare, S.R., Awati, C.J. & Shirgave, S.K. Smart recommender system using deep learning. In: 2021 6th International Conference on Inventive Computation Technologies (ICICT), pp. 590–594 (IEEE, 2021).
Gao, X., Ma, Z., Yan, X., Zhang, C. & Li, M. User preference modeling for movie recommendations based on deep learning. Sci. Rep. 15, 12842. https://doi.org/10.1038/s41598-025-93322-y (2025).
Sharma, M. Hybrid recommendation system for movies using artificial neural network. Expert Syst. Appl. 238, 122374. https://doi.org/10.1016/j.eswa.2023.122374 (2024).
Bsoul, R., Al-Saqqa, S., Zayed, A. & Alqudah, A. Enhancing movie recommendation systems with neural collaborative filtering and sentiment analysis. SN Comput. Sci. 6, 142. https://doi.org/10.1007/s42979-025-02946-6 (2025).
Siet, Y., Wang, C., Guo, X. & Hsueh, Y. Enhancing sequence movie recommendation system using deep learning and kmeans. Appl. Sci. 14(21), 9631. https://doi.org/10.3390/app14219631 (2024).
Wang, J., Zhang, Q., Li, Y., Zhang, C. & Yan, J. Movie Recommendation with Poster Attention via Multi-modal Transformer Feature Fusion. arXiv preprint arXiv:2407.08134 (2024).
Parisae, V. & Bhavanam, S. N. Stacked u-net with time–frequency attention and deep connection net for singlechannel speech enhancement. Int. J. Imaging Syst. Technol. 34(2), 255 https://doi.org/10.1142/S0219467825500676 (2024).
Vanambathina, S.D., Nandyala, S.: Speech enhancement using u-net-based progressive learning with squeeze-tcn. In: Advances in Distributed Computing and Machine Learning, pp. 419–432. https://doi.org/10.1007/978-981-97-3523-5_31 (Springer, 2024).
Jannu, C. et al. Single channel speech enhancement using a complex dual-path multi-axial transformer with frequency prompt. Circuits Syst. Signal Process. 44(6), 4224–4257. https://doi.org/10.1007/s00034-025-03010-2 (2025).
GroupLens: Movielens 100k movie ratings. stable benchmark dataset. University of Minnesota http://grouplens.org/datasets/movielens/100k/ (2017). [Accessed on 10th September 2023]
Kingma, D.P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Sedhain, S., Menon, A.K., Sanner, S. & Xie, L. Autorec: Autoencoders meet collaborative filtering. In: Proceedings of the 24th International Conference on World Wide Web (WWW), pp. 111–112 https://doi.org/10.1145/2740908.2742726 (2015).
He, X. et al. Neural collaborative filtering. In: Proceedings of the 26th International World Wide Web Conference (WWW), pp. 173–182 https://doi.org/10.1145/3038912.3052569 (2017).
He, X. et al. Lightgcn: Simplifying and powering graph convolution network for recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pp. 639–648 https://doi.org/10.1145/3397271.3401063 (2020).
Funding
Open access funding provided by B.M.S. College of Engineering. Open access funding provided by B.M.S. College of Engineering, Bull Temple Road, Bengaluru - 560019, KA, India.
Author information
Authors and Affiliations
Contributions
The first author Dr. Raghavendra C K initiated this research work to compare the existing recommendation models with the deep learning-based approach, formulated the problem statement, objectives, and mathematical models. The second author Dr. Srikantaiah K C reviewed the complete work and suggested a few changes in final manuscript. The third author Dr Sunil C K assisted in formulating the methodology and formatting the manuscript in latex template.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
C. K., R., K. C., S. & C. K., S. Dual module- wider and deeper stochastic gradient descent and dropout based dense neural network for movie recommendation. Sci Rep 16, 1210 (2026). https://doi.org/10.1038/s41598-025-30776-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30776-x
