
Abstract
To address the low detection accuracy of existing aluminum-profile surface defect algorithms, an improved YOLOv8s-based model named CDA-YOLOv8 is proposed. The CG Block replaces the original 3 × 3 downsampling convolution, and the Dilation-Wise Residual (DWR) module refines the Bottleneck structure in C2f, enhancing multi-scale feature extraction and small-object detection. To mitigate the loss of micro-defect features, an ASFP2 Detection Layer is constructed by integrating a Small-object Detection Layer with the SSFF module and embedding it into the YOLOv8s Neck. With these improvements, the CDA-YOLOv8 model significantly improves the detection accuracy of aluminum-profile surface defects such as scratches, stains, and paint bubbles. Experiments conducted on an aluminum-profile dataset containing 3,229 images and ten defect categories demonstrate notable performance gains, with mAP@0.5 increasing from 83.7% to 88.1%, confirming the effectiveness of the proposed approach.
Similar content being viewed by others

Introduction
Deep learning has significantly advanced visual understanding tasks and has become the mainstream method for industrial surface inspection, gradually replacing traditional machine-vision approaches1,2. Object detection frameworks such as Faster R-CNN3 and Mask R-CNN4 offer strong accuracy but are limited by their multi-stage structure. In contrast, single-stage detectors such as SSD5 and the YOLO series6,7 achieve a better trade-off between speed and accuracy, making them suitable for real-time industrial defect detection.
To improve defect detection performance in metal and steel manufacturing, numerous studies have proposed enhancements to classical detectors. Faster R-CNN–based models have been optimized for improved recognition of steel strip defects8. Meanwhile, many YOLO-based variants integrate advanced feature extraction strategies, attention mechanisms, or multi-scale fusion. These include backbone improvements for small-sample defect detection9, multi-head feature fusion for small-object recognition10, deformable convolutions combined with attention modules11, multi-scale contextual networks12, and lightweight architectures for efficient deployment13. Additional improvements include extra small-object layers14, deformable convolutions to handle irregular defects15, and multi-channel attention for micro-scale metallic defects16. Attention-enhanced C2f structures have also been shown to improve feature representation17.
Although these approaches contribute to overall performance improvement, most existing models still struggle to detect micro-scale defects—such as scratches, stains, and paint bubbles—whose features are extremely subtle, easily overwhelmed by background textures, and prone to being lost during deep-layer downsampling. As a result, missed detections and false positives remain common in practical aluminum-profile inspection tasks.
To address these challenges, this study proposes an improved YOLOv8s-based algorithm, CDA-YOLOv8, integrating three targeted enhancements. First, a Context-Guided Block (CG Block) replaces the original 3 × 3 downsampling convolution to preserve local textures while introducing global contextual information. Second, the Bottleneck in the C2f module is upgraded to a multi-scale C2f_DWR structure using dilated convolutions inspired by DWR-Seg18, enabling enlarged receptive fields without increasing parameters. Third, an ASFP2 small-object detection layer is introduced, incorporating the Scale Sequence Feature Fusion (SSFF) module19,20 to reinforce high-resolution features crucial for micro-defect detection. Together, these improvements enhance the network’s capability to detect fine-grained aluminum-profile defects accurately and efficiently. This study aims to develop a defect detection framework that achieves both high efficiency and high Accuracy, enabling significant improvements in the detection performance of micro-scale defects on aluminum profiles while maintaining controllable computational overhead, thus demonstrating strong potential for industrial applications.
Metal surface defect detection using an improved YOLOv8 model
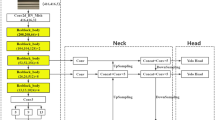
CDA-YOLOv8 detection model
To enhance metal surface defect detection accuracy, an optimized CDA-YOLOv8 model based on YOLOv8s is proposed. As shown in Fig. 1, the model takes a 640 × 640 image as input, and the Backbone (integrating the CG Block and C2f_DWR Module) outputs the P2, P3, P4, and P5 feature maps. These feature maps are then fused in the Neck—comprising the ASFP2 module, Concat operations, and Upsample layers—before being passed to the detect head to produce the final defect detection results.

CDA-YOLOv8 network structure.
To address YOLOv8’s limitations in metal surface defect detection, CDA-YOLOv8 incorporates three key enhancements: (1) A Context Guidance (CG) Block replaces the 3 × 3 downsampling convolution in the Backbone to integrate local-global contextual information, mitigating small-defect feature loss; (2) The Bottleneck in Backbone/Neck C2f modules is optimized into C2f_DWR, strengthening multi-scale defect feature extraction and fusion; (3) An ASFP2 detection layer for small objects (with an additional detection head) is integrated into the Neck, merging multi-scale high-resolution features to boost small-defect detection. These improvements enhance feature representation, optimize small-target detection, and provide a robust solution for metal surface defect detection.
CG block for improved downsampling
In metal surface defect detection, YOLOv8s’ downsampling makes micro-scale or weak-edge defects hard to detect. To solve this, the CG Block (structure in Fig. 2) is introduced to enhance feature extraction and contextual awareness. It balances preserving small-target fine-grained details and expanding the receptive field by integrating local extraction, contextual fusion, and global perception, compensating for downsampling information loss. The CG Block consists of a local feature extractor \(\:{\text{f}}_{\text{l}\text{o}\text{c}}\), a surrounding-context extractor \(\:{\text{f}}_{\text{s}\text{u}\text{r}}\), a joint feature extractor \(\:{\text{f}}_{\text{j}\text{o}\text{i}}\), and a global contextual extractor \(\:{\text{f}}_{\text{g}\text{l}\text{o}}\), as shown in Fig. 3 − 2. The CG Block operates in two main steps: (1) \(\:{\text{f}}_{\text{l}\text{o}\text{c}}\)and \(\:{\text{f}}_{\text{s}\text{u}\text{r}}\) are used to learn local features and their corresponding surrounding contextual information. The joint feature extractor \(\:{\text{f}}_{\text{j}\text{o}\text{i}}\) obtains combined features from the outputs of \(\:{\text{f}}_{\text{l}\text{o}\text{c}}\) and \(\:{\text{f}}_{\text{s}\text{u}\text{r}}\), and is designed as a concatenation layer. (2)\(\:{\text{f}}_{\text{g}\text{l}\text{o}}\) generates global contextual information in the form of a weighting vector, which is applied to the processing of the channel-wise combined features, emphasizing important components while suppressing irrelevant ones.

Diagram of CG block structure.
By incorporating the CG Block into YOLOv8’s Backbone (replacing original downsampling), the model enhances downsampling information extraction—its four extractors enable effective recognition of micro and multi-scale defects. This context-aware mechanism (from CG Block) enables the model to fuse global context with local details, comprehensively understanding image context and fine-grained features. It uses global cues to focus on metal surface critical regions (suppressing irrelevant features) and expands the receptive field via global background extraction—collectively improving metal surface defect detection accuracy.
C2f_DWR module
The C2f Module in YOLOv8 is used for feature extraction and fusion, and its structure is shown in Fig. 3. The original C2f Module performs feature extraction through a Bottleneck structure; however, it relies on single-scale standard convolution, which only covers local regions and provides an insufficient receptive field, making it difficult to effectively capture global contextual information. Moreover, it lacks the capability to aggregate feature information across different scales, thereby limiting the model’s ability to detect defects effectively. To enhance the performance of YOLOv8 in metal surface defect detection, the C2f module can be improved using the DWR module from DWR-Seg18. The DWR module uses a multi-branch structure with dilated convolutions of different rates (d = 1, 3, 5) to extract small-, medium-, and large-scale features: d = 1 captures local details (small defects), d = 3 captures medium-range context (medium defects), and d = 5 extracts global semantics (large defects). Compared with the original C2f Module in YOLOv8, the C2f_DWR Module expands the receptive field through dilated convolution without increasing the number of convolution kernel parameters, thereby improving the model’s detection Accuracy for metal surface Defects of different scales. The C2f_DWR structure is shown in Fig. 4.

C2f structure diagram.

C2f_DWR module structure diagram.
C2f_DWR retains the C2f structure while integrating DWR’s multi-scale extraction capability, replacing all C2f modules in YOLOv8s. It uses depthwise dilated convolutions (varying rates) for effective multi-scale feature capture; residual connections are preserved to ensure training stability and avoid gradient vanishing. This meets high-resolution image representation demands while maintaining computational efficiency, boosting small-defect detection accuracy.
ASFP2 small objects detection layer
Original YOLOv8s relies on 20 × 20, 40 × 40, and 80 × 80 feature maps for multi-scale detection, but micro-defects (e.g., stains, paint bubbles) on aluminum profiles tend to lose features during deep convolution. To address this limitation, this study optimizes the YOLOv8s Neck and proposes the ASFP2 Detection Layer, which significantly improves small-defect detection accuracy.
The ASFP2 detection Layer consists of the Scale Sequence Feature Fusion module19 (SSFF) and the small objects detection layer. While traditional feature pyramid structures20 can fuse features from different levels, they often to effectively leverage the correlations among all pyramid feature maps. The SSFF module is incorporated into the original structure, as shown in Fig. 5. By integrating high-level and detailed information from multiple feature maps, it generates a more expressive feature representation.

SSFF module structure diagram.
This module effectively integrates high-resolution shallow features with deep features, ensuring the detection capability for defects of different sizes. The core components include Gaussian filtering (σ = 0.5 / 1.0 / 1.5), 3D convolution with a 3 × 3 × 3 kernel, and nearest-neighbor interpolation, enabling multi-scale feature fusion. To enhance Small-object detection, an upsampled 160 × 160 high-resolution feature map is generated, which is suitable for detecting micro-scale metal defects and preserves pixel-level details, thereby meeting the requirements for Small-object feature extraction. It is concatenated with the P2 feature map for use by the Small-object Detection Layer, allowing more high-resolution information to be preserved and improving the detection Accuracy of micro-scale defects. The underlying principle is shown in Eqs. (1) and (2).
In the equations, \(\:{F}_{\sigma\:}(i,j)\)= filtered feature value; f = input feature map;\(\:{G}_{\sigma\:}\)= 2D Gaussian kernel (k = 3); σ = Gaussian std (σ∈{0.5,1.0,1.5}); \(\:{\text{G}}_{{\upsigma\:}}(\text{x},\text{y})\)= Kernel weight at (x, y)(x, y∈{−1,0,1}); π = 3.1416. By applying 2D Gaussian filters with gradually increasing standard deviations to a series of convolution results for smoothing, the outputs \(\:{F}_{\sigma\:}\) are generated, which are then horizontally stacked to form a new three-dimensional feature map. Multi-scale sequence extraction is subsequently completed via 3D convolution. Since the feature maps output by Gaussian smoothing have different resolutions, and the key information for small objects detection and segmentation is located in the high-resolution P3 layer, all feature maps are aligned to the resolution of P3 using nearest-neighbor interpolation.

ASFP2 module structure diagram.
The SSFF module is employed for multi-scale feature extraction, enabling the processing of defects of varying sizes. The Small-object Detection Layer preserves detailed information from high-resolution feature maps. Therefore, the ASFP2 Detection Layer integrates feature maps from different levels through the SSFF module and generates a feature map with the same resolution as P3, providing rich contextual information for the Small-object Detection Layer. The structure of ASFP2 is shown in Fig. 6. The Small-object Detection Layer focuses on fine-grained details and is capable of capturing both the local detail features of micro-scale Defects and global semantic coherence simultaneously. Compared with existing fusion methods such as ASF and PFP, ASFP2 introduces a new P2 layer (160 × 160) combined with ScaleSeq fusion (P2–P5, rather than the conventional P3–P5). The innovations of the SSFF module include: Gaussian σ scheduling (0.5 → 1.0 → 1.5, with σ = 1.0 determined as optimal through grid search), a 3D convolution kernel of 3 × 3 × 3 (for channel fusion), and a 2D Gaussian kernel of 3 × 3 (for multi-scale smoothing). These features distinguish ASFP2 from ASF (fixed σ) and PFP (absence of 3D convolution).
Experimental results and analysis
Dataset description and preprocessing
The experimental dataset is sourced from the Alibaba Cloud Tianchi competition database. The dataset is used under the Alibaba Tianchi Open Dataset License for academic research only. Its industrial provenance covers aluminum profile production lines (e.g., extrusion, spraying, and curing processes) from 3 domestic manufacturers, capturing real defects generated during mass production (e.g., non-conductive defects from uneven spraying, paint bubbles from incomplete curing). The dataset consists of images featuring ten common types of defects: Non-conductive, Stains, Corner leakage, Spray flow, Leakage, Paint bubbles, Scratches, Mixed colors, Orange peel, and Pitting. Examples of aluminum profile surface defect types are shown in Fig. 7.

Examples of surface defect types for aluminum profiles.
The original Defect samples in the dataset exhibit large variations. For categories with fewer samples, data augmentation methods such as horizontal rotation, vertical rotation, and contrast adjustment were applied to expand the dataset. Ultimately, the dataset contains 300 images for each of the 10 Defect types and 229 multi-defect images, totaling 3,229 aluminum profile surface defect images. For data balance, original samples of low-count classes (e.g., Paint bubbles: 180 images, Stains: 180 images) are augmented via horizontal rotation (0°/90°/180°), vertical flipping, and contrast adjustment (± 20%) to 300 images per class; high-count classes (e.g., Mixed colors: 300 original images) remain unchanged. The 229 multi-defect images include 156 original multi-defect samples and 73 augmented ones (via mix-up augmentation). The annotation files were converted into the .txt format required by YOLOv8s. The dataset was split into training, validation, and test sets at a ratio of 7:2:1, with 2,261, 646, and 322 images, respectively, laying the foundation for subsequent studies.
Evaluation metrics
The experiment evaluates the model performance using five metrics: Parameters, Floating Point Operations (GFLOPs), Precision (P), Recall (R), and Mean Average Precision (mAP). Among these metrics, Parameters and GFLOPs are used to evaluate deployment feasibility: fewer Parameters correspond to lower memory consumption, and smaller GFLOPs indicate reduced computational overhead. Precision (P) reflects the model’s ability to reduce false detections, while Recall (R) focuses on minimizing missed detections. mAP represents the mean of the Average Precision (AP) values across all categories; a higher mAP indicates better overall detection Accuracy of the model. The calculation formulas for the above Precision (P), Recall (R), and mAP are as follows:
In the formulas, NTP denotes the number of targets that are actually “true” and also detected as “true”; NFP represents the number of targets that are actually “false” but detected as “true”; NFN denotes the number of targets that are actually “true” but detected as “false”. The variable n refers to the number of defect categories (n = 10).
When the Intersection over Union (IoU) threshold is set to 0.5, mAP@0.5 represents the mean Average Precision across all categories in the detection task.
Comparative experiments of improved modules
Comparative experiments on downsampling operations in YOLOv8
To validate the superiority of the CG Block, this study conducts a comparative study against other downsampling modules, including SPDConv, Adown, LDConv, and WaveletPool. The comparison was performed by solely replacing the downsampling module while keeping all other network structures and hyperparameters unchanged. The results are presented in Table 1.
As presented in Table 1,the CG Block, Adown, and WaveletPool modules all yield better performance than the baseline model. Notably, the proposed CG Block achieves a 1.1% improvement in mAP@0.5 while simultaneously reducing both the number of parameters and computational complexity. All comparative experiments are conducted independently for 3 times to ensure reliability. Results are reported as ‘mean ± 95% confidence interval (CI)’: the mAP@0.5 of CG Block-based model is 84.8% ± 0.3%, with a standard deviation of less than 0.4% across runs, confirming low experimental variance.
Comparative experiments on the improvement of the C2f module in YOLOv8
To evaluate the improvement brought by the DWR module to the C2f block, we compared it against DySnakeConv, RFCAConv, MLCA, and PPA by directly replacing the original C2f module in the network. The results are shown in Table 2.
Table 2 indicates that all improvements are effective, with the C2f_DWR Module demonstrating the best performance. It improves mAP@0.5 by 1.4% while reducing both the number of parameters and computational burden, thereby achieving a balance between lightweight design and performance.
Experiments on feature fusion improvements
The experiments show that while the model performs well in medium- and large-object detection, there is still room for improvement in small objects detection. Therefore, based on the Improved Downsampling and the C2f Module, an additional small objects detection Layer and the ASFP2 Layer are incorporated. The results are presented in Table 3.
Table 3 shows that adding the small objects detection Layer does not reduce model accuracy. Compared with P2, ASFP2 achieves a reduction in both parameters and computational burden when combined with the CG Block and C2f_DWR Module, while improving mAP@0.5 by 2.1%, thus validating its effectiveness.
Through the downsampling comparison experiments, the C2f Module comparison experiments, and the feature fusion comparison experiments, the results demonstrate that the improvement methods proposed in this study exhibit significant effectiveness compared with other approaches.
Ablation experiments
In this study, the CG Block, C2f_DWR Module, and ASFP2 Layer were individually incorporated into YOLOv8s to form new network structures. Ablation experiments were conducted on the self-constructed dataset, with eight experimental groups adding different combinations of modules to systematically verify the effectiveness of each improvement. The results are shown in Table 4.
In Table 4, “√” indicates that the improved module is included, while “−” indicates it is not. The results show that each improvement effectively enhances mAP@0.5: CG Block increases it by 1.1%, C2f_DWR by 1.4%, and ASFP2 by 1.6%. The combined improvements further boost performance, with Model 8 (the fully improved algorithm) achieving increases of 5.1%, 2.4%, and 4.4% in Precision (P), Recall (R), and mAP@0.5, respectively, while reducing the number of parameters by 17.1%. Two-tailed t-tests are performed to verify the statistical significance of ablation gains (significance level α = 0.05). The results show: CG Block (+ 1.1% mAP, p = 0.032), C2f_DWR (+ 1.4% mAP, p = 0.028), ASFP2 (+ 1.6% mAP, p = 0.019), all p-values < 0.05, confirming that the performance improvements are statistically significant.
Analysis of detection performance
Table 5 compares the detection performance of YOLOv8s and CDA-YOLOv8 across 10 aluminum profile defect categories. CDA-YOLOv8 improves accuracy for all categories, with notable gains for micro-scale/background-similar defects (Scratches, Stains, Paint bubbles). While YOLOv8s performs well on large defects (Mixed colors, Leakage, Orange peel), it struggles with micro-scale/background-similar ones. Specific accuracy improvements of CDA-YOLOv8 include: Non-conductive + 3.1%, Pitting + 3.2%, Scratches + 12.4%, Stains + 5.7%, and Paint bubbles + 15.5%—validating its effectiveness for multi-scale defect detection.
Figure 8 shows visualization results of YOLOv8s (Fig. 8a) and CDA-YOLOv8 (Fig. 8b). YOLOv8s exhibits missed/false detections for micro-scale (e.g., Stains) and background-similar defects, while CDA-YOLOv8 detects defects more accurately—reducing missed/false detections and increasing target confidence scores, confirming its superior accuracy.

Comparison of detection effects.
The P-R curves of YOLOv8s and CDA-YOLOv8 on the aluminum profile dataset are shown in Fig. 9a. Horizontal axis: Recall (0–1); Vertical axis: Precision (0–1). The curve of CDA-YOLOv8 lies above that of YOLOv8s, and the area under the curve (AUC) is larger (0.89 vs. 0.82), indicating a superior Precision–Recall balance. Confidence-threshold calibration (threshold range: 0.2–0.8) further verifies the model’s stability. When the confidence threshold is set to 0.3 (a common industrial setting), CDA-YOLOv8 maintains a precision of over 80%, while YOLOv8s only reaches 72%, showing stronger resistance to false positives.
The mAP@0.5 curves of YOLOv8s and CDA-YOLOv8 are shown in Fig. 9b. Horizontal axis: Training epochs (0–300); Vertical axis: mAP@0.5 (0–0.9). CDA-YOLOv8 converges at 88.1% (YOLOv8s: 83.7%) and achieves convergence 50 epochs faster.
The Recall curves of YOLOv8s and CDA-YOLOv8 are shown in Fig. 9c, Horizontal axis: Training Epoch (0-300); Vertical axis Recall (0–1). The trajectory indicates that CDA-YOLOv8 achieves superior recall performance, mitigating missed detections compared with the original YOLOv8s.

(a) Comparison of P-R Curves between YOLOv8s and CDA-YOLOv8. (b) Comparison of mAP@0.5 Curves between YOLOv8s and CDA-YOLOv8. (c) Comparison of Recall Curves between YOLOv8s and CDA-YOLOv8.
To verify real-time viability, inference speed tests are conducted on two typical edge devices: ① NVIDIA Jetson Nano (4GB RAM, ARM Cortex-A57) and ② Intel Core i5-1035G1 (8GB RAM, UHD Graphics). Results show: YOLOv8s achieves 28 FPS (35.7 ms/image) on Device ① and 42 FPS (23.8 ms/image) on Device ②; CDA-YOLOv8 (with ASFP2) reaches 27 FPS (37.0 ms/image) on Device ① and 41 FPS (24.4 ms/image) on Device ②. Though ASFP2 increases FLOPs by ~ 8% vs. baseline, the speed reduction is < 4%, which is negligible in industrial scenarios—confirming the claim of ‘maintaining original inference speed’.
Conclusion
This study proposes the CDA-YOLOv8 algorithm to address the insufficient detection accuracy of aluminum profile surface defects. Three core improvements were introduced: (1) a Context-Guided Block (CG Block) to replace conventional 3 × 3 downsampling convolutions, which enhances the model’s ability to integrate global contextual information and preserve fine-grained details; (2) a Dilated Residual Module (DWR) embedded within the C2f layers to improve multi-scale feature extraction without increasing computational cost; and (3) an ASFP2 detection layer integrating a Scale Sequence Feature Fusion (SSFF) module for high-resolution small-object detection.
Experimental results demonstrate that CDA-YOLOv8 achieves a 4.4% improvement in mAP@0.5 (from 83.7% to 88.1%), while reducing the number of parameters by 17.1% compared with the baseline YOLOv8s. These results confirm that the proposed architecture effectively enhances the detection accuracy and efficiency for various metal surface defect types, particularly for micro-scale and background-similar defects such as scratches, stains, and paint bubbles.
Despite the improvements, several limitations remain. The current model still requires relatively high computational resources during training, which may constrain real-time deployment on embedded devices. Moreover, the dataset used in this study mainly focuses on aluminum profile surfaces, limiting model generalization to other industrial materials. In future work, we plan to (1) optimize the CDA-YOLOv8 structure for edge computing and lightweight deployment, (2) extend the dataset to include diverse metal types and defect categories, and (3) explore self-supervised or few-shot learning strategies to improve generalization and adaptability in real industrial scenarios.
Discussion
In this study, the proposed CDA-YOLOv8 achieves an mAP@0.5 of 88.1%, outperforming mainstream models such as Faster R-CNN, YOLOv5s, YOLOv9s, and YOLOv10s under the same experimental conditions. Table 6 presents a detailed performance comparison based on the aluminum profile defect dataset.
CDA-YOLOv8 achieves the highest detection accuracy (mAP@0.5 = 88.1%), improving by 4.4% over YOLOv8s and outperforming YOLOv11s while reducing parameters by 27%. These results confirm the model’s balance between accuracy and efficiency.
The performance gain stems from three complementary enhancements: the CG Block, which preserves small-scale textures by integrating global and local context; the C2f_DWR module, which captures multi-scale features via dilated convolutions; and the ASFP2 detection layer, which strengthens high-resolution representation for micro-defects. Together, these modules improve feature completeness and discriminability, enabling CDA-YOLOv8 to deliver more accurate and robust detection across varied metal surface defect types.
Data availability
All data generated or analysed during this study are included in this published article .
References
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521 436-444 (2015).
Guo, Y., Liu, Y. & Oerlemans, A. Deep learning for visual understanding: A review. Neurocomputing 187 27-48 (2016).
Ren, S. Q. et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39 (6), 1137–1149 (2017).
He, K. M. et al. Mask R-CNN . In: 2017 IEEE International Conference on Computer Vision (ICCV), 2980–2988. (IEEE Press, 2017).
Liu, W. et al. SSD: single shot multibox detectorLeibe B, (eds Matas, J. & Sebe, N.) Computer vision-ECCV 2016. Lecture notes in computer science. (Springer International Publishing, 2016).
Jiang, P. Y. et al. A review of Yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073 (2022).
Terven, J. & Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. Preprint at https//arXiv/org//2304.00501. (2023).
Ren, Q., Geng, J., Li, J. & Slighter Faster R-CNN for real-time detection of steel strip surface defects. 2018 Chinese automation Congress (CAC). IEEE (2018).
Dou, Z., Gao, H. R. & Liu, G. Q. A lightweight YOLOv8-based defect detection algorithm for small-sample steel plates. Comput. Eng. Appl. (2024).
Cui, K. B. & Jiao, J. Y. Steel surface defect detection algorithm based on MCB-FAH-YOLOv8. J. Graphics (2024).
Liu, Y., Wang, J. & Yu, H. Surface defect detection of steel products based on improved YOLOv5. In: 2022 41st Chinese Control Conference (CCC). (IEEE, 2022).
Liu, R., Huang, M. & Gao, Z. MSC-DNet: an efficient detector with multi-scale context for defect detection on strip steel surface. Measurement (2023).
Liang, L. M., Long, P. W. & Li, Y. L. Steel surface defect detection algorithm based on improved lightweight and efficient FMG-YOLOv8s. Comput. Eng. Appl. (2025).
Wang, K., Teng, Z. X. & Zou, T. Y. Metal defect detection based on YOLOv5. Journal of Physics: Conference Series. (IOP Publishing, 2022).
Lu, J. Z., Zhang, C. Y. & Liu, S. P. Lightweight DCN-YOLO for strip steel surface defect detection in complex environments. Comput. Eng. Appl. 59 318-328 (2023).
Li, W. H., Zhang, H. O. & Wang, G. L. Deep learning based online metallic surface defect detection method for wire and arc additive manufacturing. Robotics Comput. Integrated Manufact. 80 102470 (2023).
Wu, L. et al. Sim-YOLOv8 object detection model for DR image defects in aluminum alloy welds. Chin. J. Lasers. 51 (16), 1602103 (2024).
Wei, H., Liu, X. & Xu, S. DWRSeg: rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation. arXiv preprint arXiv:2212.01173. (2022).
Kang, M., Ting, M. C. & Ting, F. F. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 147 , 105057 (2024).
Kirillov, A., He, K. & Girshick, R. Panoptic feature pyramid networks. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2019).
Funding
This research was funded by the Research Initiation Programme for Introduced Talents at University Level (grant number RHDRC202317) and the 2025 Hainan Provincial Science and Technology Special Envoys Program.
Author information
Authors and Affiliations
Contributions
Y.F. and G.S. conceptualized the study and developed the methodology. F.W. and Y.Z. conducted the investigation. X.Y. and G.S. wrote the original draft, with X.G.and X.C handling the review and editing. Y.F. acquired funding, while F.W. provided resources. Y.Z. supervised the project. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Feng, Y., Sun, G., Zhao, Y. et al. Research on metal surface defect detection method based on deep learning. Sci Rep 16, 1436 (2026). https://doi.org/10.1038/s41598-025-31235-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31235-3
