
Abstract
The eastern margin of the Qinghai-Xizang Plateau, as a critical transition zone between the plateau and the Sichuan Basin, poses substantial challenges for geographic regionalization, primarily due to its intricate terrain and climatic heterogeneity. Traditional spatial clustering methods often struggle to balance spatial continuity and attribute similarity, suffering from subjectivity and inadequate representation of topographic complexity. This study proposes a novel mountainous geographic regionalization framework that integrates topographic and climatic characteristics, using Kangding county as a typical case. Principal Component Analysis (PCA) was employed to perform dimensionality reduction on multiple environmental variables and assign relative weights. A Gaussian-weighted function was further applied to adjust attribute distances to capture spatial non-stationarity, while the geographic distance weight was systematically optimized. The partitioning outcomes were evaluated using clustering quality indicators (Davies-Bouldin index, Silhouette index, Calinski-Harabasz index) and spatial autocorrelation indicators (Moran’s I index, Moran’s Z-score). Results indicated that when the number of clusters was set to five and the geographic distance weight was 0.5, the clustering algorithm optimized the trade-off between spatial continuity and attribute similarity (Davies-Bouldin index = 1.14, Silhouette index = 0.30, Calinski-Harabasz index = 25150.91, Moran’s I = 0.97, Moran’s Z-score = 292.28). Compared to the traditional K-means clustering, this approach enhanced intra-cluster similarity (Sil) by 259% and improved spatial continuity (Moran’s I, Moran’s Z-score) by approximately 44%. This method effectively addresses the challenge of coordinating spatial constraints with attribute heterogeneity in mountainous environmental zoning, in a county scale, providing an automated, data-driven approach for geographic partitioning in complex terrains. The findings offer valuable insights for mountain ecosystem management and regional geographic studies. Our study provides a set of effective methods of demarcation of regional boundaries based on raster data, offering important insights for ecological zoning management and regional studies in mountainous environments at a small scale.
Similar content being viewed by others

Introduction
The Qinghai-Xizang Plateau, known as the “Roof of the World,” plays an important role in global climate and environmental systems due to its unique geographic position and dramatic topographic variations1,2. Its eastern edge serves as a key transition zone between the Qinghai-Xizang Plateau and the Sichuan Basin3. This region is characterized by rugged terrain, steep elevation gradients, and diverse landforms, which exerts substantial influence on local climate patterns and hydrological processes4,5. Regional geographic segmentation is vital for comprehensively understanding climatic and geographic characteristics of this area, facilitating the identification of key drivers influencing soil, vegetation, and other environmental elements6,7. However, this process remains challenging due to the region’s complex topography and climate variability.
Spatial clustering is a fundamental geographic technique that partitions areas based on both attribute similarity and spatial continuity8,9. Traditional clustering methods such as K-means and hierarchical clustering primarily focus on attribute-based similarity10,11,12. While spatial clustering integrates geographic relationships to ensure that regions are not only internally homogeneous but also spatially contiguous13,14,15. Traditional clustering methods often overlook spatial dependencies8, leading to fragmented clusters, particularly in complex terrains or climate zones. By integrating spatial constraints, spatial clustering produces more geographically coherent results, making it an essential tool in modern geographical analysis16. This approach has been widely applied across various disciplines, including epidemiology17,18, ecological zoning19,20, geomorphology21,22, and environmental management23.
Spatial clustering incorporates spatial constraints into traditional clustering methods to maintain spatial connectivity, often represented by geographic adjacency24. A straightforward approach extends the traditional K-means algorithm by treating spatial coordinates as attributes and assigning appropriate weights to reflect spatial constraints8. Recent studies have applied spatial distances24 or spatial adjacency relationships16 to construct spatial weight matrices, enabling more precise spatial continuity constraints. However, achieving an optimal balance between spatial continuity and attribute similarity remains a major challenge. Several studies have demonstrated that enforcing spatial continuity often leads to the low attribute similarity within regions8,9, and this trade-off is determined subjectively in most cases. Wolf (2021) have proposed a method that applied multiplicative kernel combinations to adjust the bandwidths of geographic and feature kernels. Nevertheless, these bandwidths are usually determined subjectivity based on prior experience or specific clustering objectives. Therefore, the development of automated and data-driven methods for objectively determining the balance between spatial continuity and attribute similarity remains a crucial challenge in spatial clustering research25.
Distance-based methods are common in spatial clustering26,27,28. The main distance metrics include Euclidean distance, Manhattan distance, and Minkowski distance29,30. Euclidean distance is simple to compute and works well in most31. Manhattan distance is better for cities because movement follows straight paths along a grid32. Minkowski distance is more flexible through parameter adjustments, allowing a smooth transition between Euclidean and Manhattan distances33. However, using these distance metrics alone does not work well in mountainous environments, where critical terrain factors such as slope and elevation are often overlooked despite their importance in spatial partitioning. Recent studies have changed distance measures to include terrain and climate variables34,35. For example, Dehghan et al. (2018) used a weighted Euclidean distance framework that considering climate and geographic attribute35. This method worked better than regular distance measures for spatial clustering. Therefore, developing better distance metrics that effectively capture terrain characteristics is still an important research topic in mountainous regions.
To address these limitations and develop a more reliable method for boundary delineation in small-scale mountainous environments, we propose a spatial clustering framework designed for county-level regions. We selected six key indicators that represent terrain and climate features to calculate attribute distance. Principal Component Analysis (PCA) was applied to simplify the environmental data and determine attribute distance weights based on the variance contribution of each principal component. To capture spatial non-stationarity in complex terrain, attribute distances were further adjusted with Gaussian weighted functions. Furthermore, the optimal weighting combination was systematically examined by fixing attribute distance weights and varying geographic distance weights. The clustering performance was assessed using three clustering metrics (Davies-Bouldin, Silhouette, and Calinski-Harabasz indices) and two spatial autocorrelation metrics (Moran’s I and Moran’s Z score). The most effective geographically weighted distance was then applied to delineate spatial partitions in Kangding county, revealing spatial patterns and providing insights for targeted environmental management and regional analysis at a small spatial scale.
Materials and methods
Study area and datasets
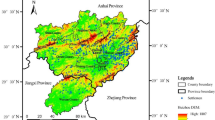
Kangding county lies in the transition zone between the eastern edge of the Qinghai-Xizang Plateau and the Sichuan Basin, encompassing an area of approximately 11,595 km2 (Fig. 1). The region exhibits diverse landforms, including plateau gorges, hilly plateaus, and alpine valleys. The terrain gradually decreases from west to east, averaging 4,002 m. Kangding experiences a monsoon-influenced climate, characterized by an annual average temperature of approximately 7.1 ℃ and an annual precipitation of around 800 mm.Vegetation and soil distributions demonstrate distinct vertical zonation patterns. Vegetation transitions from forests at lower altitudes to shrubs and meadows at higher elevations. Similarly, soil types follow an elevational gradient, ranging from cinnamon soil and brown soil at lower altitudes to alpine meadow soil and frigid frozen soil at higher elevations. The vertical differentiation of the natural environment, driven by topography and climate, serves as a fundamental basis for boundary delineation and spatial partitioning at Kangding county.

Location of the study area in the Qinghai-Xizang Plateau, China. Base map provided by Esri. Administrative boundaries from the Geographic Information Public Service Platform (https://www.tianditu.gov.cn/). Tibetan Plateau boundary from the National Tibetan Plateau Data Center (https://data.tpdc.ac.cn).
The environmental data for this study including 6 variables related to climate and terrain (Fig. 2). Climate data, specifically annual precipitation and temperature, were obtained from the National Tibetan Plateau Data Center (https://data.tpdc.ac.cn) at a spatial resolution of 1 km36,37. The mean annual precipitation and temperature from 2018 to 2022 were computed and incorporated as environmental variables. The Digital Elevation Model (DEM) was acquired from the Shuttle Radar Topography Mission (SRTM) at a resolution of 30 m. Slope, plan curvature, and profile curvature were derived from the DEM using the System for Automated Geoscientific Analyses (SAGA GIS), version 9.10.1, developed by the Department of Physical Geography, University of Hamburg, Hamburg, Germany (https://saga-gis.sourceforge.io/).
To enhance computational efficiency and maintain a consistent spatial resolution, all datasets were resampled. The final dataset comprised 45,647 raster pixels at a spatial resolution of 500 m × 500 m, with all data projected to the CGCS2000 3 Degree GK Zone 34 coordinate system. All data pre-processing was conducted in ArcGIS Pro (Esri, Redlands, USA).

Spatial variability of topographic and climatic variables for principal component analysis (PCA)-driven spatial clustering: (a) Annual precipitation (mm), (b) Mean annual temperature (°C), (c) Elevation (m), (d) Slope gradient (°), (e) Plan curvature, (f) Profile curvature. Maps were generated using ArcGIS Pro.
Clustering methodology
The PCA method
In this study, we used PCA to simplify environmental variables and assign weights to attribute distances. PCA is a common statistical method that converts original variables into fewer principal components while keeping most of the data’s variance35. Before applying PCA, we standardized all environmental variables using Z-score normalization to reduce the effect of different units on the results6,38. In this study, we kept principal components that explained more than 80% of the total variance for clustering analysis. The standardization process and PCA computations were performed in ArcGIS Pro.
Spatial cluster
This study uses the Aggregate coordinate and attributes for spatial cluster (ACA-Cluster) method developed by Dong et al. (2022)39. This method applies the K-means algorithm to combine spatial continuity and attribute similarity in clustering. ACA-Cluster integrates spatial and attribute distances, allowing effective grouping of spatially continuous data. The clustering process uses Euclidean distance to maintain spatial continuity while incorporating attribute distance into the distance matrix. The conceptual framework is shown in Fig. 3. The total spatial distance (D) is calculated as:
Where\(\:{d}_{p}\) is the spatial distance, indicating how close the pixels are; and \(\:{d}_{a}\) denotes the attribute distance, measuring the similarity of attribute between pixels. The spatial distance \(\:{d}_{p}\) is computed as Euclidean distance between pixel i and j:
Where (xi, yi) and (xj, yj) are the coordinates of pixels i and j, respectively. \(\:{d}_{a}\) is formulated as follows:
Where, m represents the number of attribute variables, while aik and ajk denote the attribute values of pixel i and j at the k-th attribute variable. Given the complex mountainous terrain of Kangding County, conventional distance measures often struggle to adequately capture the influence of topography on spatial continuity. To overcome this limitation, we incorporate Gaussian weighting functions into attribute distance computation. This is formulated as follows:
where \(\:{d}_{ij}\) denotes the Euclidean geographical distance, and is the bandwidth parameter that regulates the spread of the Gaussian function. To mitigate the influence of the Gaussian function’s bandwidth on the results, we set β to 0.1. The final spatial distance combines the weighted geographical and attribute distance, computed as follows:
where and ak represent the weights of geographic distance and attribute distances of different principal components, respectively. The term m indicates the number of principal components, while represents the attribute distance of the k-th principal component. In this study, the weights of principal component attribute distances were assigned according to the proportion of eigenvalues, ensuring that their sum equals 1. The geographic distance weights were specified as 0.15, 0.25, 0.50, 0.75, and 1.00 respectively. For each weight combination, clustering analyses were performed with three cluster numbers (k = 3, 5, 8) to evaluate clustering performance and spatial dependency under different configurations.

Technical workflow of the spatial clustering framework integrating PCA and spatial constraints.
Evaluation
Evaluating unsupervised clustering methods is challenging because there is no definitive standard for result assessment10. To address this issue, this study applied two types of metrics to evaluate clustering performance.
The first type measures how well clusters are separated and how compact they are. These metrics help determine the best clustering algorithm and the optimal number of clusters for a dataset40. The selected metrics include the Davies-Bouldin (DB) index, Silhouette score, and Calinski-Harabasz (CH) index. The DB index assesses clustering compactness by comparing intra-cluster and inter-cluster distances across all cluster pairs. A lower DB index indicates better clustering quality34. The Silhouette score evaluates clustering effectiveness by comparing how similar each sample is to its assigned cluster versus other clusters. It ranges from − 1 to 1, with higher values indicating well-separated clusters10. The CH index measures clustering performance by comparing inter-cluster variance to intra-cluster variance, where higher values suggest better clustering quality10.
The second type of metric examines the spatial distribution of clusters. According to Ohana-Levi et al. (2019), well-formed spatial clusters should show strong similarity among nearby points34. Moran’s I index and Moran’s Z-score were used to measure spatial segregation and global spatial autocorrelation in the clustering results. Moran’s I index quantifies global spatial autocorrelation, while Moran’s Z-score evaluates whether the observed clustering pattern differs from a random distribution. Higher values of both metrics indicate stronger spatial autocorrelation and better clustering performance.
Results
Weighting attribute distances using PCA
PCA was used to reduce the dimensionality of variables in the clustering analysis, helping to lower computational complexity41. Table 1 shows the eigenvalues and variance contributions of each principal component. The first four principal components (PC1–PC4) were selected for spatial clustering, as they accounted for over 85% of the total variance. PC1 accounted for 34.07% of the total variance, while PC2, PC3, and PC4 accounted for 20.18%, 19.74%, and 13.31%, respectively (Table 1). To determine the weights of the attribute distances, the variance contributions of these four principal components were normalized, yielding weights of 0.39 (PC1), 0.23 (PC2), 0.22 (PC3), and 0.15 (PC4). In the clustering analysis, the total weight of the four principal component attributes was fixed at 1, while the optimal weight combination was determined by adjusting the weight of geographic distance. Furthermore, Table 2 presents the loadings of different variables in the first four principal components. The results indicate that PC1 is primarily associated with elevation and temperature, PC2 and PC4 are dominated by plan curvature and profile curvature, whereas PC3 is primarily related to rainfall and slope. PC2 and PC4 exhibit a high degree of similarity, both being predominantly influenced by terrain curvature indicators.
Regionalization results of different k and
Figure 3 illustrate the clustering results under different geographic distance weights () when k equals 3, 5, and 8, respectively. The results indicate that clustering based solely on attribute distances tends to result in complex spatial boundaries and fragmented spatial distributions. As increases, the spatial continuity of the clusters gradually improves, and the clustering boundaries become more simplified. However, the influence of on spatial continuity differs with the number of clusters. When k = 3, distinct clustering patterns emerge at = 0.25. In contrast, when k = 5 or 8, clear spatial continuity is observed only when reaches 0.5 or 0.75. Furthermore, as increases, the clustering boundaries progressively simplify, and small fragmented clusters near the boundaries gradually decrease.
Visualizing clustering maps with different k values and selecting an appropriate k based on subjective judgment provides a more intuitive approach42. When k = 3, Kangding county is divided into three spatial clusters: the northeast, central, and southern areas (Fig. 3a). However, this division may result in grouping areas with distinct geographic features into the same cluster. For instance, the central-western region is relatively flat, while the eastern region is characterized by steep terrain, with the two regions also experiencing different climatic conditions. When k = 5, the clustering results reveal more detailed spatial differentiation (Fig. 3b). The central area is divided into eastern and western subregions, whereas the southern area is further split into southeastern and southwestern parts. The southeastern area corresponds to the Gongga Mountain region, which is characterized by high elevation, steep terrain, and increased rainfall. In contrast, the southwestern area lies within the Yalong River Valley, characterized by similarly steep terrain but lower elevation and reduced rainfall. When k = 8, the spatial segmentation becomes even more detailed (Fig. 3c). The Dadu River Valley in the northeastern region, which was previously classified as a single cluster when k = 3 or k = 5, is further subdivided into two distinct clusters: one for the river valley itself and another for the more distant northeastern area.

Spatial clustering partitions under varying cluster numbers (k) and geographic distance weight (): (a) k = 3 with weight configurations: (a-1) only attribute, (a-2) =0.15, (a-3) =0.25, (a-4) =0.50, (a-5) =0.75, (a-6) =1.00; (b) k = 5 with weights analogously assigned (b-1 to b-6); (c) k = 8 configurations (c-1 to c-6).
Clustering performance comparison and analysis
Figure 4 presents the clustering performance and spatial dependence of the model under varying cluster numbers and weight combinations. The results indicate that the DB index, Silhouette score, and CH index reach their optimal values when the geographic distance weight () is set to 0.25. As exceeds 0.25, the clustering performance gradually deteriorates. Among different k values, the clustering performance is optimal when k = 5, yielding a DB index of 1.02, a Silhouette score of 0.33, and a CH index of 29932.99. Moran’s I index and Moran’s Z-score results indicate that the spatial dependence of the clustering results peaks when reaches 0.5. When exceeds 0.5, both Moran’s I index and Moran’s Z-score stabilize. Moreover, a comparison of different cluster numbers reveals that a smaller number of clusters corresponds to higher spatial dependence. Once the spatial structure stabilizes, the performance of k = 3 and k = 5 becomes comparable, whereas that of k = 8 is less effective.

Sensitivity of clustering performance and spatial autocorrelation metrics to geographical distance weights (Wp) across cluster numbers (k = 3, 5, 8): (a) Davies-Bouldin (DB) index, (b) Silhouette score, (c) Calinski-Harabasz (CH) index, (d) Moran’s I index, (e) Moran’s Z-score.
Figure 5 compares the inter-cluster distributions of key attribute (e.g., elevation) under different spatial weights and cluster numbers (k = 3, 5, 8). The results indicate that the variation patterns of attributes among clusters remain generally consistent across different cluster numbers. When clustering relies solely on attribute distances, the differences in attributes among clusters are most pronounced. As the geographic distance weight increases, the differences in attributes among clusters gradually decrease. However, when the geographic distance weight reaches 0.5, the differences in attributes among clusters tend to stabilize. Furthermore, the results indicate that elevation and temperature exhibit the most pronounced differences among clusters, which is consistent with the PCA results showing that PC1 is primarily driven by elevation and temperature (Fig. S2).

Elevation heterogeneity across spatially clustering partitions: Effects of geographic distance weights () and cluster numbers (k). (a) k = 3: (a-1) only attribute, (a-2) =0.15, (a-3) =0.25, (a-4) =0.50, (a-5) =0.75, (a-6) =1.00; (b) k = 5 with analogous configurations (b-1–b-6); (c) k = 8 partitions (c-1–c-6).
Regionalization results
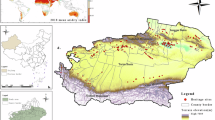
After evaluating clustering performance, spatial continuity, and attribute similarity, we determined that k = 5 and = 0.5 were the optimal parameters for boundary delineation in Kangding county. The corresponding spatial clustering map is presented in Fig. 6. The consistency between cluster boundaries and attribute patterns further reinforces the reliability of the partitioning results. As indicated in Table 3, the environmental characteristics of the five spatial clusters display distinct patterns. Specifically, Cluster 1 represents the Dadu River Valley, which has the lowest average elevation but exhibits the greatest elevation variation, steep slopes, and the highest temperatures in Kangding county. In contrast, Cluster 2 features higher elevations, lower temperatures, and less topographic variation. Cluster 3 represents the Tagong Grassland-Xinduqiao region, characterized by relatively flat terrain and the lowest precipitation. Cluster 4 represents the Gongga Mountain region, which has the highest elevations and considerable elevation variation; it experiences persistent snow cover, leading to the lowest temperatures and the highest precipitation. Cluster 5 represents the Yalong River Valley, characterized by pronounced elevation variation and steep slopes, similar to Cluster 1 (Dadu River Valley).

Optimal spatial partitioning of Kangding county based on spatial clustering (k = 5, =0.50).
Discussion
This study shows that combining Gaussian-weighted attribute distance with geographic distance in spatial clustering performs better than traditional methods that use only attribute distance. This approach is especially effective in maintaining spatial continuity. Traditional clustering methods may create clusters with lower attribute similarity but often result in fragmented spatial partitions, making interpretation difficult. This observation aligns with findings by Gao and Kupfer (2018)13. Additionally, our study finds that increasing the number of clusters worsens spatial fragmentation in traditional clustering results, supporting the conclusions of Rodrigues et al. (2015)43. Adding geographic distance as a constraint significantly improves spatial continuity, making clustering results more consistent with real geographic patterns24. For example, the REDCAP model proposed by Guo (2008) introduced spatial continuity constraints in clustering, improving the coherence of clustered regions14. Building on this, we integrated geographic distance constraints into raster data clustering, further demonstrating the advantage of spatial clustering in defining continuous geographic regions. Moreover, applying Gaussian weighting to attribute distances smooths variations between adjacent regions, reducing the impact of spatial non-stationarity in complex terrain44.
Balancing spatial continuity and attribute similarity is a key challenge in geographic spatial clustering. Spatial continuity keeps neighboring geographic units together, while attribute similarity focuses on clustering based on feature differences. Too much emphasis on spatial continuity can merge clusters with distinct characteristics45, while relying only on attribute similarity can break natural spatial relationships34. Kang et al. (2022) proposed a method that models attribute dependency within subregions using a Markov random field while maintaining cluster boundary continuity through a spatial consistency strategy46. This approach evaluates clustering performance using the Adjusted Rand Index and Macro-F1 score, while spatial continuity is measured using Join Count Statistics, achieving a balance between spatial structure and attribute similarity. In this study, we evaluated clustering performance and spatial autocorrelation under different geographic distance weighting schemes. We prioritized spatial continuity while maintaining attribute differentiation as much as possible. However, as Kupfer et al. (2012) pointed out, in some large-scale geographic classifications, internal homogeneity should be more important than spatial continuity47. Therefore, the role of spatial continuity constraints should be adjusted based on the goals of regionalization to ensure a proper balance between spatial structure and attribute characteristics.
PCA results indicate that elevation and temperature are the main factors driving spatial differences in Kangding County (Table 2). This is largely due to Kangding’s location at the transition between the Hengduan Mountains and the Qinghai-Xizang Plateau. The area’s varied terrain increases the influence of elevation on temperature, shaping natural regional differences. This aligns with previous studies, which have also identified elevation and temperature as key factors in environmental diversity48,49. For example, Wei et al. (2024) highlighted that elevation gradients are crucial in regulating terrestrial ecosystem net primary productivity50. In mountainous areas with significant elevation changes, variations in height affect solar radiation distribution, which in turn influences climate, soil, vegetation, and energy availability49. Our findings support this view. The strong match between clustering boundaries in Kangding and the DEM further confirms the role of elevation in spatial partitioning. Temperature is also a key ecological factor. It affects vegetation diversity, productivity, and soil nutrients, shaping ecosystem characteristics51. This explains the strong link between Kangding’s cluster patterns and its climate. Similarly, Hu et al. (2020) used topographic and temperature variables to study vegetation patterns, identifying the Qinling-Daba Mountain climate transition zone and reinforcing the importance of temperature in regional ecosystems3. In summary, our study confirms that elevation and temperature play a dominant role in spatial differentiation. In complex mountainous landscapes, geographic diversity is mainly shaped by the interaction between these two factors.
This study presents a spatial clustering method that combines geographic distance with Gaussian-weighted attribute distance. This method improves attribute similarity within clusters while maintaining spatial continuity. Applied in the Kangding region, it effectively identifies spatial clusters at a county-level spatial scale in areas with significant topographic variation. To regulate the influence of Gaussian-weighted attribute distance in clustering, the decay coefficient (β) was set at 0.01. While principal component analysis was used to determine attribute weights, the balance between geographical distance and attribute distance remains manually assigned. Future research should explore dynamic optimization of parameters such as β and weights using clustering objectives and advanced algorithms, including Bayesian optimization and adaptive methods. Additionally, this study employed an unsupervised classification method to segment Kangding’s natural geographic environment, considering topography and climate as primary driving factors. This approach could be extended to spatial partitioning in future studies to enhance predictive model performance.
Conclusion
This study introduces a geographically weighted clustering framework that integrates multiple topographic and climatic factors using PCA-based dimensionality reduction and Gaussian spatial weighting functions. Through a joint evaluation mechanism incorporating both clustering performance and spatial autocorrelation, this framework provides a novel, objective method that contributes to geographical regionalization research at a small spatial scale. Compared to traditional spatial clustering methods, the proposed framework enhances attribute similarity while preserving spatial continuity, thereby reducing the subjectivity in weight assignment. The resulting small-scale spatial partitioning in Kangding County distinctly delineates regional environmental characteristics, underscoring the dominant role of topographic gradients in shaping climatic, vegetation, and other natural geographic features. The derived boundary delineation results supports ecological environment management and provides a foundational framework for partition-based models used in prediction and classification tasks. Future research should refine this framework by automating the optimization of geographic and attribute distance weights, enabling adaptive trade-offs between spatial continuity and attribute similarity across diverse research scenarios.
Data availability
The datasets analyzed in this study are publicly available. Climate data were obtained from the National Tibetan Plateau Data Center (https://data.tpdc.ac.cn). The DEM was acquired from the Shuttle Radar Topography Mission (SRTM, https://srtm.csi.cgiar.org/).
References
Yi, J. et al. Mapping human’s digital footprints on the Tibetan plateau from multi-source Geospatial big data. Sci. Total Environ. 711, 134540 (2020).
He, K., Chen, X., Liu, J. & Zhao, D. A multiple-step scheme for the improvement of satellite precipitation products over the Tibetan plateau from multisource information. Sci. Total Environ. 873, 162378 (2023).
Hu, X. & Yuan, W. Evaluation of ERA5 precipitation over the Eastern periphery of the Tibetan plateau from the perspective of regional rainfall events. Int. J. Climatol. 41, 2625–2637 (2021).
Zhao, R., Chen, B., Zhang, W., Yang, S. & Xu, X. Formation mechanisms of persistent extreme precipitation events over the Eastern periphery of the Tibetan plateau: synoptic conditions, moisture transport and the effect of steep terrain. Atmos. Res. 304, 107341 (2024).
Zhou, Y., Li, Y., Zhang, L., Su, Q. & Huang, X. Spatial–temporal characteristics of geological disaster resilience in poverty and disaster-prone areas in china: a case study of Ganzi Prefecture. Environ. Sci. Pollut. Res. https://doi.org/10.1007/s11356-023-28049-z (2023).
Perdinan & Winkler, J. A. Selection of climate information for regional climate change assessments using regionalization techniques: an example for the upper great lakes Region, USA. Int. J. Climatol. 35, 1027–1040 (2015).
Gao, Y., Gao, J., Chen, J., Xu, Y. & Zhao, J. Regionalizing aquatic ecosystems based on the river subbasin taxonomy concept and Spatial clustering techniques. Int. J. Environ. Res. Public. Health. 8, 4367–4385 (2011).
Wang, H., Song, C., Wang, J. & Gao, P. A raster-based Spatial clustering method with robustness to Spatial outliers. Sci. Rep. 14, 1–14 (2024).
Wolf, L. J. Spatially–encouraged spectral clustering: a technique for blending map typologies and regionalization. Int. J. Geogr. Inf. Sci. 35, 2356–2373 (2021).
Zhao, W. et al. Comparison and application of SOFM, fuzzy c-means and k-means clustering algorithms for natural soil environment regionalization in China. Environ. Res. 216, 114519 (2023).
Chauhan, N., Paliwal, R., kumar, V., Kumar, S. & Kumar, R. Watershed prioritization in lower shivaliks region of India using integrated principal component and hierarchical cluster analysis techniques: a case of upper Ghaggar watershed. J. Indian Soc. Remote Sens. 50, 1051–1070 (2022).
Schmidt, G. & Schröder, W. Regionalisation of climate variability used for modelling the dispersal of genetically modified oil seed rape in Northern Germany. Ecol. Indic. 11, 951–963 (2011).
Gao, P. & Kupfer, J. A. Capitalizing on a wealth of Spatial information: improving biogeographic regionalization through the use of Spatial clustering. Appl. Geogr. 99, 98–108 (2018).
Guo, D. Regionalization with dynamically constrained agglomerative clustering and partitioning (REDCAP). Int. J. Geogr. Inf. Sci. 22, 801–823 (2008).
Williams, C. L., Hargrove, W. W., Liebman, M. & James, D. E. Agro-ecoregionalization of Iowa using multivariate geographical clustering. Agric. Ecosyst. Environ. 123, 161–174 (2008).
Liu, Q., Deng, M., Shi, Y. & Wang, J. A density-based Spatial clustering algorithm considering both Spatial proximity and attribute similarity. Comput. Geosci. 46, 296–309 (2012).
Rosbergen, M. T. et al. Cluster-based white matter signatures and the risk of dementia, stroke, and mortality in community-dwelling adults. Neurology. 103, e209864 (2024).
Dupas, M. C. et al. Spatial distribution of poultry farms using point pattern modelling: A method to address livestock environmental impacts and disease transmission risks. PLoS Comput. Biol. 20, e1011980 (2024).
Aho, K., Parsons, S., Castro, A. J. & Lohse, K. A. Mapping socio-ecological systems in idaho: Spatial patterns and analytical considerations. Ecosphere 13, e4242 (2022).
Li, Z., Zhong, J., Yang, J., Zhang, D. & He, S. Assessment framework and empirical analysis of the ecological protection importance for key town agglomerations in China. J. Clean. Prod. 372, 133682 (2022).
Chai, H., Zhou, C., Chen, X. & Cheng, W. Digital regionalization of geomorphology in Xinjiang. J. Geog. Sci. 19, 600–614 (2009).
Fang, W. & Zhang, H. Zonation and scaling of tropical cyclone hazards based on Spatial clustering for coastal China. Nat. Hazards. 109, 1271–1295 (2021).
Chormanski, J. et al. Flood mapping with remote sensing and hydrochemistry: A new method to distinguish the origin of flood water during floods. Ecol. Eng. 37, 1334–1349 (2011).
Aydin, O., Janikas, M. V., Assunção, R. M. & Lee, T. H. A quantitative comparison of regionalization methods. Int. J. Geogr. Inf. Sci. 35, 2287–2315 (2021).
Duque, J. C., Anselin, L. & Rey, S. J. The max-p-regions problem. J. Reg. Sci. 52, 397–419 (2012).
Kisilevich, S., Mansmann, F., Nanni, M. & Rinzivillo, S. in In Data Mining and Knowledge Discovery Handbook. 855–874 (eds Maimon, O. & Rokach, L.) (Springer US, 2010). https://doi.org/10.1007/978-0-387-09823-4_44
Ansari, M. Y., Ahmad, A., Khan, S. S. & Bhushan, G. Mainuddin. Spatiotemporal clustering: a review. Artif. Intell. Rev. 53, 2381–2423 (2020).
Zhang, T., fan, Li, Z., Yuan, Q. & Wang, Y. ning. A Spatial distance-based Spatial clustering algorithm for sparse image data. Alexandria Eng. J. 61, 12609–12622 (2022).
Prasetyo, S. Y., Zain Nabiilah, G., Nabila Izdihar, Z., Prabowo, A. S. & Ash Shiddiqi, H. K-Nearest Neighbor Algorithm for Heart Disease Detection: A Comparative Evaluation of Minkowski and Manhattan Distances. in 2023 6th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI) 237–241IEEE, (2023). https://doi.org/10.1109/ISRITI60336.2023.10467899
Temple, J. T. Characteristics of distance matrices based on Euclidean, Manhattan and hausdorff coefficients. J. Classif. 40, 214–232 (2023).
Murray, A. T. Integrating attribute and space characteristics in choropleth display and Spatial data mining and TUNG-KAI SHYY. Int. j. Geographical Inform. Sci. 14, 649-667 (2000).
Xulu, S., Peerbhay, K., Gebreslasie, M. & Ismail, R. Unsupervised clustering of forest response to drought stress in Zululand region, South Africa. Forests 10, (2019).
Whigham, P. A., De Graaf, B., Srivastava, R. & Glue, P. Managing distance and covariate information with point-based clustering. BMC Med. Res. Methodol. 16, 115 (2016).
Ohana-Levi, N. et al. A weighted multivariate Spatial clustering model to determine irrigation management zones. Comput. Electron. Agric. 162, 719–731 (2019).
Dehghan, Z., Eslamian, S. S. & Modarres, R. Spatial clustering of maximum 24-h rainfall over urmia lake basin by new weighting approaches. Int. J. Climatol. 38, 2298–2313 (2018).
Peng, S. 1-km monthly mean temperature dataset for China (1901–2024). Natl. Tibetan Plateau / Third Pole Environ. Data Cent. https://doi.org/10.11888/Meteoro.tpdc.270961 (2019).
Peng, S. 1-km monthly precipitation dataset for China (1901–2024). National Tibetan Plateau / Third Pole Environment Data Center doi:https://doi.org/10.5281/zenodo.3114194 (2020).
Zhang, Q., feng, Wu, F., qi, Wang, L., Yuan, L. & Zhao, L. shan. Application of PCA integrated with CA and GIS in eco-economic regionalization of Chinese loess plateau. Ecol. Econ. 70, 1051–1056 (2011).
Dong, J. et al. Effects of anthropogenic precursor emissions and meteorological conditions on PM2.5 concentrations over the 2 + 26 cities of Northern China. Environ. Pollut. 315, 120392 (2022).
Xiong, H. & Li, Z. Clustering Validation Measures. in Data Clustering: Algorithms and Applications. Available at: https://api.semanticscholar.org/CorpusID:34792999 (2018).
Córdoba, M., Bruno, C., Costa, J. & Balzarini, M. Subfield management class delineation using cluster analysis from Spatial principal components of soil variables. Comput. Electron. Agric. 97, 6–14 (2013).
Zhang, Y., Moges, S. & Block, P. Optimal cluster analysis for objective regionalization of seasonal precipitation in regions of high spatial-temporal variability: application to Western Ethiopia. J. Clim. 29, 3697–3717 (2016).
Rodrigues, P., Figueira, R., Vaz Pinto, P., Araújo, M. B. & Beja, P. A biogeographical regionalization of Angolan mammals. Mamm Rev 45, 103–116 Preprint at (2015). https://doi.org/10.1111/mam.12036
Yao, X. et al. Affinity zone identification approach for joint control of PM2.5 pollution over China. Environ. Pollut. 265, 115086 (2020).
Rueda, M., Rodríguez, M. Á. & Hawkins, B. A. Towards a biogeographic regionalization of the European biota. J. Biogeogr. 37, 2067–2076 (2010).
Kang, Y. et al. STICC: A multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguity. (2022). https://doi.org/10.1080/13658816.2022.2053980
Kupfer, J. A., Gao, P. & Guo, D. Regionalization of forest pattern metrics for the continental united States using contiguity constrained clustering and partitioning. Ecol. Inf. 9, 11–18 (2012).
Zhang, Y. et al. Vegetation change and its relationship with climate factors and elevation on the Tibetan plateau. Int. J. Environ. Res. Public. Health 16, 4709 (2019).
Sun, R. & Zhang, B. Topographic effects on Spatial pattern of surface air temperature in complex mountain environment. Environ. Earth Sci. 75, 621 (2016).
Wei, D. et al. Elevation-dependent pattern of net CO2 uptake across China. Nat. Commun. 15, 2489 (2024).
Zhao, J., Yang, W., Tian, L., Qu, G. & Wu, G. L. Warming differentially affects above- and belowground ecosystem functioning of the semi-arid alpine grasslands. Sci. Total Environ. 914, 170061 (2024).
Funding
This study was supported by the National Natural Science Foundation of China (42171067),and the National Key Research and Development Program of China (2023YFD1901204).
Author information
Authors and Affiliations
Contributions
Developing the methodology, supervision, validating the results and reviewing were done by Xiaoguo Wang and Bo Zhu. applying the methodology, preparing codes, software, analyzing the data, writing the original draft were done by Xianglong Liu, Desheng Hong, Hongyang Dong and Hangtao Du. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, X., Hong, D., Dong, H. et al. Enhancing demarcation in regionalization in the eastern Qinghai-Xizang Plateau through geographically weighted. Sci Rep 16, 2276 (2026). https://doi.org/10.1038/s41598-025-32098-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32098-4
