
Abstract
Unmanned aerial vehicles enable efficient ground-object recognition under adverse illumination, yet infrared imagery still suffers from low contrast, background clutter, and tiny targets. We present YOLO-IR based on YOLOv7, a lightweight detector that integrates a global-efficient backbone to strengthen global–local thermal-texture modeling, the parameter-free SimAM attention to highlight salient IR structures, an efficient BiFPN for weighted bidirectional multi-scale fusion, and the normalized wasserstein distance for scale-insensitive localization across assignment, regression, and non-maximum suppression. On a UAV thermal dataset, YOLO-IR attains 94.5% precision, 92.9% recall, and 95.7% mAP@0.5, improving over the YOLOv7 baseline by + 4.3% P, + 1.8% R, and + 4.2% mAP, while maintaining real-time throughput on a single GPU. Comprehensive ablations attribute consistent gains to each component, and qualitative results on dense, low-contrast scenes show fewer misses and false alarms. These findings indicate that YOLO-IR delivers accurate and efficient IR road-object recognition from UAV viewpoints.
Similar content being viewed by others


Introduction
As a new remote sensing surveillance platform, drones possess features such as low cost, small size, and high maneuverability. Consequently, they have gained widespread applications in various fields, including transportation, military, search and rescue, as well as scientific research1,2. In conditions of visible light for target detection and recognition, the visibility of objects in the image is high, and the textures are clear. The features of the target to be detected are rich, and favorable lighting conditions facilitate the extraction of high-level abstract features by various target recognition algorithms3. However, the challenges encountered during the target recognition process are often attributed to poor lighting conditions. In low-light environments, captured images are severely degraded by insufficient light4, particularly in nighttime conditions where targets may appear blurry, making feature extraction challenging and posing significant challenges to the task of target detection5,6,7,8,9. Images generated by infrared thermal imaging technology exhibit strong anti-interference capabilities, long detection range, and all-weather detection advantages. This provides an effective approach for target detection and recognition under nighttime conditions10,11. Various research institutes and universities worldwide have conducted highly effective studies on the accuracy of target recognition based on infrared images12.
Features from infrared thermal images can be autonomously learned and extracted by object detection and recognition algorithms based on deep learning, demonstrating superior performance while reducing workloads13,14. Object detection algorithms are primarily categorized into Two-Stage algorithm based on Region Proposal and One-Stage algorithm based on regression problem14,15. The Two-Stage algorithm detects and recognizes the target in two steps, and with the advancement of deep learning, its detection accuracy has increased16 However, the algorithm’s speed gradually encounters a bottleneck due to the need to extract features from a large number of generated candidate regions. One-stage methods remove proposal generation and directly predict boxes and categories, significantly improving throughput at some cost to accuracy—an attractive trade-off for UAV scenes with many targets and a strong need for real-time performance. Within IR-UAV applications, Du et al. proposed FA-YOLO with negative-sample focusing and CBAM17; Jiang et al. validated YOLOv5 on low-altitude IR remote sensing18; Zhao et al. introduced YOLO-ViT (MobileViT + C3PANet with K-means + + anchor optimization) and further improved performance with a different design trade-off19. Jie Wu et al. explored fuzzy comprehensive evaluation to improve recognition under low contrast and blurry boundaries20. Despite these advances, IR-UAV detection still struggles with dense and small targets, monotonous textures, and background clutter21,26.
In parallel, state-of-the-art real-time detectors such as RT-DETRv227 and YOLOv11-based detectors28 as well as YOLOv1229 continue to push the accuracy–efficiency frontier on visible-light benchmarks. To ensure fairness in the IR setting, we adopt a unified training/testing protocol and compare against established YOLO baselines as well as these latest real-time detectors, viewing them as complementary directions for systematic IR-specific evaluation.
We focus on IR-UAV scenes where low thermal contrast, weak/monotonous textures, background clutter, and the top-down viewpoint yield tiny and densely distributed targets, causing recognition difficulty, unstable localization, and stricter real-time requirements21,26. High-resolution IR data are not always available, further limiting the cues that models can exploit. To address these factors, we build on a strong one-stage baseline and propose YOLO-IR, an improved IR target detection and recognition method based on YOLOv7.
To meet real-time constraints while improving robustness to tiny/occluded targets and low contrast, YOLO-IR integrates four targeted components: GENet to strengthen global–local thermal-texture modeling, SimAM to emphasize informative IR structures without additional parameters, BiFPN for weighted bidirectional multi-scale fusion, and NWD to stabilize tiny-object localization across assignment, regression, and NMS. Concretely, GENet—built with FCMAE-pretrained features and 7 × 7 convolutions—enhances long-range context; SimAM provides parameter-free attention with negligible compute; BiFPN adds cross-node connections and weighted fusion to enrich semantics and improve robustness to occlusion/scale changes; and NWD replaces IoU-family metrics to reduce sensitivity to small positional offsets typical of tiny targets.
On this basis, we validate YOLO-IR under a unified training/testing protocol. Our main contributions are:
-
(1)
Global–Efficient backbone (GENet). Replace the ELAN-style stem with a global–local extractor—FCMAE-pretrained features and 7 × 7 convolutions—to reinforce thermal-texture modeling and long-range context.
-
(2)
Parameter-free attention (SimAM). A 3D energy-based, parameter-free attention emphasizes salient IR structures without increasing parameters, improving dense/small-target discrimination.
-
(3)
Efficient BiFPN fusion. A weighted bidirectional FPN enhances multi-scale robustness and mitigates low-contrast failures while preserving real-time inference.
-
(4)
Scale-insensitive localization via NWD. Using NWD for assignment/regression/NMS improves localization stability on tiny IR targets relative to IoU-family metrics.
-
(5)
Comprehensive, reproducible evaluation. Under a unified setup, YOLO-IR achieves 94.5% precision, 92.9% recall, and 95.7% mAP@0.5, surpassing YOLOv7 by + 4.3% P, + 1.8% R, and + 4.2% mAP; on the dense split it reaches 92.7% mAP.
YOLO-IR infrared target recognition algorithm
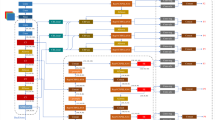
Addressing the issues of complex background information, small target sizes, varied scales, blurry features in low-light or nighttime drone low-altitude infrared remote sensing images, and the current challenges of slow inference speed and low recognition accuracy in existing networks, this paper proposes the YOLO-IR network for infrared remote sensing image target detection and recognition, as illustrated in Fig. 1.

Network architecture diagram of YOLO-IR.
Figure 1 presents the overall YOLO-IR architecture: we retain the YOLOv7 three-scale detection head and modify the backbone, neck, and localization metric. In the backbone, ELAN is replaced by GENet (7 × 7 stem with Fully Convolutional Masked Autoencoder-pretrained features and LayerNorm (LN), GELU, and Global Response Normalization (GRN)), which strengthens global–local representation with only a small increase in complexity. SimAM is inserted after backbone stages to highlight salient IR features without adding parameters. In the neck, PANet is replaced by a bidirectional, weight-fused Bi-directional Feature Pyramid Network (BiFPN) that prunes low-contribution nodes, preserving more detail and improving recognition. For localization, Normalized Wasserstein Distance (NWD) replaces IoU in assignment, regression, and NMS, yielding more stable tiny-object localization and better small-target detection.
Global and efficient feature extraction network
The special characteristics of infrared remote sensing images, and some of the features extracted by ELAN in the original YOLOv7 network are invalid. The convergence speed of the network will be affected by these invalid features; Additionally, the feature information received by ELAN undergoes a series of convolutions. The limited receptive field of these 3 × 3 convolutions proves to be weak, making it difficult to capture sufficient contextual information, consequently resulting in a decrease in model accuracy. Therefore, to enhance the model’s ability to extract effective features and capture contextual information, we constructed GENet based on ConvNeXt V230 to replace ELAN in the Backbone of the original network, using FCMAE as the pre-training framework for GENet. The structure of FCMAE is shown in Fig. 2.

Schematic structure of FCMAE.
FCMAE is a self-supervised learning method, after receiving the input image, FCMAE will randomly mask part of the image, and then let the model try to recover the masked area, which is used to promote the model to learn the local and global features of the image, and improve the model generalization ability. GRN (Global Response Normalization) is a normalization method, different from the traditional BN (Batch Normalization) layer, in which GRN normalizes the feature maps of each channel during the convolution process as a way to improve the feature diversity of the channels. The structure of GENet is shown in Fig. 3.

Structure diagram of GENet.
GENet enhances the feature learning capability of the model with FCMAE as a pre-training framework. The utilization of a 7 × 7 convolutional kernel ensures that the model possesses a larger receptive field compared to a 3 × 3 convolution. LN (Layer Normalization) is incorporated to improve the network’s recognition performance for smaller batch sizes. GELU activation function is employed to mitigate the issue of gradient vanishing. GRN is introduced to enhance channel feature diversity during the convolution process, further improving network performance.
Simple and parameter-free attention mechanism
Attention weights can be generated from both spatial and channel perspectives through the attention mechanism. These weights are then applied to the input features, aiding the feature extraction network in focusing on the most crucial information for the current task within complex data. This enhances the model’s ability to recognize targets. Channel attention can be viewed as one-dimensional attention, where it weights different channels equally across all positions. In contrast, spatial attention can be seen as two-dimensional attention, weighting different positions equally across all channels and refining features in the spatial dimension. Existing attention mechanisms tend to combine spatial attention and channel attention serially and in parallel, which in turn improves the focus of the attention mechanism on key information, channel attention and spatial attention are shown in Fig. 4.

Schematic of channel attention and spatial attention.
The one-dimensional and two-dimensional weights generated by existing attention mechanisms treat feature information in each channel or spatial position equally. This contradicts the neural activity in the human brain when processing visual information. The attention mechanism’s ability to focus on detailed information within the network is hindered by such a limitation. SimAM31 is a simple and efficient attention module. Unlike existing attention mechanisms, three-dimensional attention weights for feature maps in the feature layer can be derived directly based on a custom energy function by SimAM. This is achieved without introducing additional parameters to the original network, thereby compensating for the shortcomings of one-dimensional and two-dimensional weights. To enhance the network’s ability to handle complex background information and extract key feature information in infrared remote sensing images, SimAM is integrated into the Neck of the original network, the schematic of SimAM is shown in Fig. 5.

Schematic of SimAM.
The essence of three-dimensional attention weights is to differentiate feature information within the same channel or spatial position and assign different weights. This process emulates the way the human brain handles input visual information. In visual neuroscience, when the human brain receives input visual information, the discharge patterns of active neurons differ significantly from those of regular neurons. In attention mechanisms, such active neurons should be assigned higher weights. To identify important neurons, an energy function \({e}_{t}^{*}\) is defined by SimAM to measure the importance of neurons. The expression of \({e}_{t}^{*}\) is given by Eq. 1:
where t represents the target neuron in a single channel of the input feature \(X \in R^{C \times H \times W}\); λ is a hyperparameter controlling the regularization strength; \(\hat{\mu }\)and \(\hat{\sigma }^{2}\) represent the mean and variance of all neurons in that channel except the target neuron t. The expressions for \(\hat{\mu }\) and \(\hat{\sigma }^{2}\) are given by Eqs. 2 and 3:
where \(M = H \times W\) represents the number of neurons in a single channel; i is the index in the spatial dimension; xi denotes other neurons in the input feature \(X \in R^{C \times H \times W}\) in a single channel, excluding the target neuron t.
Equation 1 indicates that as \({e}_{t}^{*}\) becomes smaller, the distinction between the target neuron t and other neurons xi increases, making it more crucial in processing visual information. Therefore, 1/\({e}_{t}^{*}\) can be utilized to represent the importance of neurons. According to the definition of the attention mechanism, enhancing the processing of important neurons allows us to obtain three-dimensional attention weights. After integrating SimAM into GENet, the network’s ability to select and focus on feature information is strengthened without introducing additional parameters. This contributes to the network’s learning of target details in infrared remote sensing images, ultimately improving the model’s performance.
Bi-directional feature pyramid network
A specialized network structure is employed by the SSD algorithm to simultaneously predict targets on feature maps at different levels, achieving a balance between detection speed and accuracy. Precisions in object detection are further enhanced by FPN through the construction of a feature pyramid via lateral and top-down connections, extracting multi-scale features from the image. However, these traditional top-down structures are inherently constrained by unidirectional information flow. To address this issue, the bidirectional feature network PANet has been proposed. The structure of the bidirectional feature fusion network is illustrated in Fig. 6.

Schematic diagram of bi-directional feature fusion network. (a) PANet. (b) BiFPN.
As shown in Fig. 6a to alleviate the constraints of unidirectional information propagation, the FPN feature network is extended by PANet through the introduction of the bottom-up pathway aggregation network. This extension reduces the number of convolutions during the propagation process, and reintroduces shallow features to the top layer, thereby preserving more feature information and increasing the representation capability of the fused features. However, PANet exhibits deficiencies in the process of merging input features, leading to the introduction of BiFPN32. As shown in Fig. 6b, the feature fusion network is simplified by BiFPN through the removal of nodes with smaller contributions compared to PANet. Additionally, an additional pathway is introduced between the input and output nodes of the same layer, allowing the network to incorporate more feature information through fusion. Furthermore, the importance of different input features is learned by BiFPN, enabling weighted fusion for features at different resolutions. Taking the example of the P5 output, the weighted fusion calculation formula is expressed as Eqs. 4 and 5:
where P5td represents the output features of the fifth layer in the network’s top-down pathway; P5out represents the output features of the fifth layer in the network’s bottom-up pathway; ω denotes the weights distinguishing between input features of different resolutions; Resize signifies the upsampling or downsampling operation; P5in represents the output of the fifth layer in the forward calculation pathway; ε is a small constant used to prevent numerical instability.
In the Neck of the original YOLOv7, BiFPN is introduced to replace PANet, optimizing the bidirectional structure of the feature fusion network. Nodes with minimal contributions to feature fusion are removed, improving the efficiency of feature fusion. An additional pathway is introduced between the input and output nodes of the same layer, enabling the fusion of more effective features learned by GENet and SimAM. Features from inputs with different resolutions are weighted and fused, enriching the semantic information of the fused features and enhancing the network’s recognition accuracy.
Normalized Wasserstein distance
The IoU series of metrics used in YOLOv7 is too sensitive to targets occupying small pixels, and the positional offset of the small-target Anchor causes drastic fluctuations in the IoU values, which is not a good metric for small targets, and severely degrades the detection performance when used in an Anchor-based detector. To address this issue, a novel small object detection evaluation method based on the Wasserstein distance, NWD33 is chosen. Subsequently, modifications are made to the original algorithm in terms of label assignment, nonmaximum suppression (NMS), and regression loss functions to replace the IoU metric with the NWD metric. NWD employs the Wasserstein distance to compute distributional distance, assessing the similarity between targets through Gaussian distributions corresponding to the targets. For Gaussian distributions Na and Nb modeled by bounding boxes \(A=\left(c{x}_{a},c{y}_{a},{w}_{a},{h}_{a}\right)\) and \(B=\left(c{x}_{b},c{y}_{b},{w}_{b},{h}_{b}\right)\), the second-order Wasserstein distance is defined as Eq. 6:
where ||·||, represents the Frobenius norm, and W22 \((N_{a} ,N_{b} )\) is the second-order Wasserstein distance between bounding boxes A and B. As the obtained W22 \((N_{a} ,N_{b} )\) is a distance metric and cannot be directly used as a similarity metric (similar to IoU, a value between 0 and 1), it is normalized using its exponential form. The new metric is expressed as Eq. 7:
where C is a constant related to the dataset and is set to the average absolute size of the target anchors. After obtaining the formula for NWD, the Anchor is offset along the diagonal direction to verify the sensitivity scales of IoU and NWD to targets of different scales. The deviation curves of IoU and NWD are compared as shown in Fig. 7.

Value-deviation curves for IoU and NWD.
The horizontal axis in the graph represents the pixel offset along the diagonal for anchors, while the vertical axis represents the values of IoU and NWD. It can be observed that NWD is less sensitive to targets of different scales, making it more suitable for measuring similarity between small targets. Using NWD as a new metric for the model can accelerate convergence and enhance the model’s detection performance for small targets.
Results and analysis of experiments
Dataset composition and experimental parameter settings
The currently available HIT-UAV34 infrared remote sensing dataset comprises a total of 2898 thermal infrared images featuring five target types: Person, Car, Bicycle, OtherVehicle, and Dont-Care. Experimental validation of this dataset revealed its limited generalizability, with a predominant focus on campus backgrounds and a significant presence of duplicated images, leading to potential overfitting during training. To enhance algorithm performance, we refined the target categories by removing Bicycle, OtherVehicle, and Dont-Care. We introduced new categories, including Non-motor vehicles, Van, Pushdozer, Construction machine, and Truck. Additionally, we eliminated duplicate or non-target images. To further augment the dataset, we selected additional images from other publicly available datasets and extracted consecutive frames from network videos. The augmented dataset now encompasses seven target categories, totaling 3165 thermal infrared images. A representation of dataset samples is illustrated in Fig. 8.

Sample diagram.
The color of objects in thermal infrared images is correlated with their temperature. In scenarios with low lighting conditions, the use of infrared thermal imaging technology enhances the features of targets. This results in superior detection performance compared to images captured by conventional CCD in low-light settings. Observation of the samples revealed that there were shaded areas that were similar in shape to the contours of the vehicles. This is attributed to the evening time of image acquisition when there is direct sunlight, causing a significant temperature difference between the ground in areas where vehicles are parked and the ground directly exposed to sunlight. In thermal infrared images, this temperature difference forms dark patches that resemble vehicle shapes. Interference in the model’s detection capabilities may be caused by these patches resembling vehicles. Therefore, there is a need to enhance the model’s ability to discern and handle such phenomena.
The experiments were conducted on Ubuntu 18.04 LTS with Python 3.9.21, CUDA 11.7, and NVIDIA cuDNN 8.5.0. The hardware comprised a 12th Gen Intel® Core™ i9-12900 (16 cores [8P+8E]/24 threads) CPU and an NVIDIA GeForce RTX 3090 Ti (24 GB) GPU. We used PyTorch 1.13.0+cu117 and TorchVision 0.14.0+cu117. All experiments were conducted under the same initialization conditions for training and testing. The dataset was partitioned into an 8:2 ratio for training and testing, with a batch size set to 24 for each training batch. The Adam optimizer was chosen, with a momentum of 0.9, weight decay set to 0.0005, label smoothing set to 0.01, and a total of 300 training epochs.
Evaluation indicators
We used standardized metrics for object evaluation. The object detection performance of the model is evaluated using precision (P), recall (R), F1-score (F1), average precision (AP), and mean average precision (mAP). The model’s complexity is measured by the number of model parameters and floating-point operations per second (GFLOPs). The detection speed of the model is reflected by the number of images detected per second (FPS). In particular, model parameters is used to measure the number of parameters to be learned by the model, the more parameters the more complex the model, F1 is utilized to assess the balance between precision and recall of the model, and AP and mAP are the final evaluation metrics for measuring the detection accuracy of the model.
The calculations for P, R, F1, AP, mAP, FPS, and GFLOPs are as follows:
where True Positive (TP), False Positive (FP), and False Negative (FN) represent correctly identified, incorrectly identified, and missed samples; In Eq. 12, N is a variable indicating the number of categories in the dataset, and N = 7 in this experiment; In Eq. 13, NMS, and Infer denote the model post-processing time and inference time. Regarding the number of floating point operations in the convolutional layer, the calculation is shown in Eq. 14:
where H and W represent the height and width of the feature map; Kh and Kw represent the height and width of the convolutional kernel; Cin and Cout represent the number of input and output channels.
Ablation experiment
To verify the effectiveness of the methods proposed in this paper, we conducted ablation experiments for each improvement method using a test set to assess the impact of each improvement method on the model. The ablation experiments were conducted on a total of 6 sets of models with an input image size of 640 × 640, the experimental design and experimental results is shown in Table 1, evaluating the model performance in terms of P, R, mAP, GFLOPs, FPS, and F1.
Model 1 is the original YOLOv7; Model 2 represents the network model with enhanced feature extraction using GENet; Model 3 is the optimized model using the SimAM; Model 4 represents the network model with BiFPN replacing PANet for feature fusion; Model 5 denotes the model optimized using the NWD metric; Model 6 is the final improved YOLO-IR infrared object detection model proposed in this paper.
In Table 1, the performance of the improved network model is significantly improved over the baseline model YOLOv7 under the same experimental setup. Integrating GENet into the backbone, the model mAP improves by 1.9%, indicating that the feature extraction ability of GENet is better than ELAN in the backbone of the baseline model, and it is more suitable for feature extraction of targets in thermal infrared images. Adding the SimAM to the baseline model, the model improves the mAP by 2.4% while increasing the computation by only 1.26%, which verifies the important role of SimAM in feature selection and focusing. Using BiFPN instead of PANet, the mAP of the improved model increased by 2.6%, indicating the effectiveness of the BiFPN jump connection and weighted feature fusion approach. Using NWD instead of the IoU metrics of the baseline model, the model computation is almost the same, but the performance is improved by 0.6%. The improved network YOLO-IR, proposed in this paper, improves mAP by 4.2% and F1 by 3.1% compared to the baseline model, indicating that the model strikes a good balance between the two along with higher precision and recall.
The mAP comparison curve between YOLO-IR and YOLOv7 over 300 iterations is illustrated in Fig. 9. Throughout the iterations, YOLO-IR consistently outperforms and converges faster than the benchmark model. Corroborating the Table 1 improvements.

Sample diagram.
Comparative of validation results of different algorithms
The accuracy of the recognition algorithm is influenced by the number of targets in the image. As the number of targets increases, recognition algorithms need to detect and classify more objects, thus affecting detection accuracy. Moreover, an increase in the number of targets can lead to an expansion in the variety of target types and mutual occlusion among the targets. To further validate the performance of YOLO-IR, the thermal infrared dataset is categorized based on the density of target distribution into three classes: target sparse distribution (number of targets < 5), target moderate distribution (number of targets between 5 and 10), and target dense distribution (number of targets > 10). Different models from the YOLO series are selected to conduct experiments on each dataset category, with the same experimental environment and parameters.
Analysis of target sparse distribution detection results
For target sparsely distributed images, the detection results of different algorithms are shown in Fig. 10.
In the target recognition experiment on images with target sparse distribution, the detection results are shown in Fig. 10: All seven algorithms correctly classify the targets in the images without missing or false positives and achieve relatively ideal recognition rates. This is because in images with few targets, high contrast with the background, so that feature extraction for all algorithms is relatively easy and the recognition difficulty is low. From Fig. 10, it can be observed that YOLOv5 has relatively poor recognition results compared to other methods, with the lowest confidence in the identified targets.

Sample diagram.
Experimental data for different algorithms on this type of image are shown in Table 2. All baseline YOLO models achieve precision higher than 95% and mAP@0.5 above 94.7%, indicating that existing YOLO networks can already obtain good detection performance on sparsely distributed infrared targets. Nevertheless, the improved network proposed in this paper (YOLO-IR) further boosts the accuracy: its mAP@0.5 reaches 99.3%, which is 0.4 percentage points higher than the best competing baseline, and it also achieves the highest F1 score of 97.7%. Therefore, for infrared night-vision images with sparsely distributed targets, YOLO-IR can still provide a noticeable improvement in precision even when YOLOv5–YOLOv12 already obtain strong recognition results.
Analysis of target moderate distribution detection results
For target moderately distributed images, the detection results of different algorithms are shown in Fig. 11.

Recognition results of different algorithms on target moderately distributed images.
In the target recognition experiment on images with target moderate distribution, the detection results are shown in Fig. 11: YOLOv8 exhibits higher precision than YOLOv5 and YOLOv12, but three tend to miss small targets during the recognition process. YOLOv6 successfully identifies small targets, but the precision on this type of image is poor compared to other methods, identifying targets with low confidence, and also misidentifying dark patches and cluttered backgrounds formed by parked vehicles The baseline model YOLOv7 and YOLOv11 misclassifies Non-motor vehicles as Cars, with lower confidence in the identified targets. In comparison to other YOLO series models, the proposed improvement in this paper does not exhibit any instances of missed or false detections. In comparison with the other YOLO-series models, the improved method proposed in this paper does not exhibit any obvious missed or false detections on this dataset.
The experimental data for different algorithms on images with targets moderately distributed are shown in Table 3. Compared with images containing sparsely distributed targets, all YOLO baselines show a noticeable degradation in performance on this more challenging scenario, with reduced mAP@0.5 values and F1 scores. Among the baselines, YOLOv7 achieves the best overall performance with an mAP@0.5 of 96.7% and an F1 score of 93.9%, while YOLOv11 and YOLOv12 obtain competitive precision but still lag behind YOLOv7 and YOLOv8 in terms of mAP@0.5. In contrast, the proposed improved network (YOLO-IR) attains an mAP@0.5 of 97.4%, which is 0.7 percentage points higher than the best competing baseline, and simultaneously achieves the highest F1 score of 95.6%. These results demonstrate that even for images with moderately distributed targets, YOLO-IR maintains a high level of recognition accuracy and exhibits strong robustness.
Analysis of target dense distribution detection results
For target densely distributed images, the detection results of different algorithms are shown in Fig. 12.

Recognition results of different algorithms on target densely distributed images.
In the target recognition experiment on images with target-dense distribution, the detection results are shown in Fig. 12: YOLOv5 is significantly affected by an increase in the number of target types and mutual occlusion between targets, leading to frequent instances of missed detections during the recognition process. YOLOv6 has a relatively low miss rate, but in the presence of a complex background, it tends to incorrectly identify the background multiple times. Additionally, when faced with densely packed targets, YOLOv6 is prone to false positives, making its performance relatively poorer compared to other YOLO series models. The baseline model YOLOv7 exhibits fewer instances of false positives and misses, performing well among the YOLO series algorithms. YOLOv8, similar to YOLOv5, is also significantly affected by an increase in the number of target types and mutual occlusion between targets, resulting in a higher miss rate.
Newly introduced YOLOv11 and YOLOv12 both demonstrate competitive detection results in dense scenarios. YOLOv11 achieves the highest precision (96.5%) and the best F1 score (91.3%) among the baselines, but its mAP@0.5 remains limited to 86.6%, indicating that it still fails to fully detect all valid targets. YOLOv12 improves recall and mAP@0.5 over YOLOv6, yet its overall performance is still inferior to that of YOLOv7 and YOLOv11. In contrast, the improved method proposed in this paper successfully detects all targets in the dense scenes of Fig. 12 without obvious missed or false detections, and achieves the best visual recognition performance.
The quantitative experimental data for each algorithm on densely distributed target images are listed in Table 4. As shown in the table, dense target distributions have a clear negative impact on the performance of all YOLO-based algorithms, leading to a noticeable drop in both mAP@0.5 and F1 compared with sparse or moderately distributed scenarios. However, the proposed method (YOLO-IR) still maintains strong detection capability: its mAP@0.5 reaches 92.7%, which is 3.4 percentage points higher than the highest mAP@0.5 achieved by the baselines (YOLOv7), and its F1 score of 92.5% is 1.2 percentage points higher than that of YOLOv11. These results indicate that the proposed YOLO-IR method continues to exhibit excellent recognition performance and robustness even when dealing with infrared images containing densely distributed targets.
Comprehensive experimental data analysis
After conducting experiments on the infrared dataset divided into three categories based on target distribution density, it was observed that the density of targets and algorithm performance showed an inverse proportional trend. This is because, in densely distributed target scenarios, the contrast with the background is low, making it challenging for algorithms to extract features. Unlike the proposed method in this paper, other models lack attention mechanisms and effective feature extraction networks. Consequently, these algorithms struggle to distinguish more critical features of the targets during the feature extraction process, resulting in poorer performance in target recognition.
To further verify the effectiveness of YOLO-IR, additional experiments were conducted on the entire thermal infrared dataset using Faster R-CNN as a representative two-stage detector, several YOLO-series one-stage detectors, and RetinaNet as a high-precision one-stage baseline. The experimental results are summarized in Table 5.
The data in Table 5 indicates that YOLO-IR has a significant advantage in detecting targets in thermal infrared images of drones. When the input resolution is 640 × 640, Faster-RCNN performs poorly on this dataset since Faster-RCNN is prone to miss detection of small targets; YOLOv5 and YOLOv8 perform well in terms of precision and poorly in terms of recall on this dataset; whereas YOLOv6, although better balanced between precision and recall, still has a low recall; RetinaNet performs well in terms of both precision and recall; Compared with YOLOv5, YOLOv6, YOLOv8, yet its recall is still not satisfactory. RetinaNet performs well in both precision and recall, achieving competitive F1 and mAP@0.5 scores. Among the traditional YOLO baselines, YOLOv7 delivers strong overall performance, while the newly introduced YOLOv11 and YOLOv12 further improve the results: in particular, YOLOv12 attains the best mAP@0.5 (92.6%) and F1 score (90.7%) among all baseline detectors.
In contrast, the proposed YOLO-IR achieves the highest performance across all metrics, with an mAP@0.5 of 95.7% and an F1 score of 93.7%. The F1 value of over 93% indicates that the model achieves an excellent balance between precision and recall, and its overall performance is significantly better than that of the comparison models. Combining the results in Tables 2, 3, 4, and 5, it can be concluded that the mAP@0.5 of the proposed method is consistently higher than that of the other algorithms. This demonstrates that YOLO-IR maintains high detection precision and exhibits strong robustness when recognizing targets in thermal infrared images, even in the presence of complex background clutter and small-scale targets.
Conclusion
This paper addresses the challenges of detecting and recognizing infrared targets in low-altitude UAV infrared remote sensing images under low-light or nighttime conditions. The challenges include complex background information, small target sizes, varying scales, blurred features, and low recognition accuracy with current algorithms. To tackle these issues, the paper proposes a method for infrared target detection and recognition in UAV images, named YOLO-IR. In this paper, our main contributions are as follows:
-
(1)
GENet is constructed to replace ELAN in the Backbone of the baseline model. It employs a self-supervised learning approach to assist the network in learning better feature representations. Simultaneously, the introduction of GRN enhances feature diversity within the channels during the convolution process, thereby improving the model’s generalization ability.
-
(2)
After GENet, we integrated SimAM, which enhances the network’s ability to selectively focus on and gather feature information without introducing additional parameters, strengthening the network’s learning of target feature details.
-
(3)
We introduced BiFPN, which removes nodes with minimal contributions to the feature network, adds crossnode connections to preserve more feature details, and weights the fusion of features from different resolutions to enrich the semantic information of the fused features.
-
(4)
Replaced the IoU metric with NWD, which is more suitable for small objects, enhancing the detection performance of the model on tiny targets.
The experimental results indicate that on the thermal infrared dataset, the model achieves precision, recall, and mAP values of 94.5%, 92.9%, and 95.7%, respectively, with an FPS of 110. Compared to the baseline model, the precision, recall, and mAP have improved by 4.3%, 1.8%, and 4.2%, demonstrating that YOLO-IR can accurately identify multi-scale infrared targets and is suitable for infrared target recognition in UAV scenarios.
Although YOLO-IR has shown strong performance for infrared detection and recognition in UAV imagery under low-light or nighttime conditions, its robustness across different sensors and flight altitudes, as well as under adverse weather (e.g., fog and rain), has not been systematically studied; this remains a gap in current research and will be a key focus of our future work.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Jawaharlalnehru, A. et al. Target object detection from unmanned aerial vehicle (UAV) images based on improved YOLO algorithm. Electronics 11(15), 2343 (2022).
Sommer, L., Schuchert, T. & Beyerer, J. Comprehensive analysis of deep learning-based vehicle detection in aerial images. IEEE Trans. Circuits Syst. Video Technol. 29(9), 2733–2747 (2018).
Dong, Y., Li, Y. & Li, Z. Research on detection and recognition technology of a visible and infrared dim and small target based on deep learning. Electronics 12(7), 1732 (2023).
Yang, S. et al. LightingNet: An integrated learning method for low-light image enhancement. IEEE Trans. Comput. Imaging 9, 29–42 (2023).
Gao, P. et al. GF-detection: Fusion with GAN of infrared and visible images for vehicle detection at nighttime. Remote Sens. 14, 2771 (2022).
Zhang, Q. et al. Multi-object detection at night for traffic investigations based on improved SSD framework. Heliyon 8(11), e11570 (2022).
Jiang, S. et al. Optimized loss functions for object detection and application on nighttime vehicle detection. Proc.Inst. Mech. Eng. Part D J. Automob. Eng. 236(7), 1568–1578 (2022).
Shao, X. et al. Feature enhancement based on CycleGAN for nighttime vehicle detection. IEEE Access 9, 849–859 (2021).
An, W., et al. A nighttime vehicle detection method based on YOLO v8. In 2023 IEEE International Conference on Unmanned Systems (ICUS), Hefei, China 1512–1516 (2023).
Li, Y., et al. Performance analysis of ship target recognition in multi-band infrared images based on deep learning. In 2023 7th International Conference on Transportation Information and Safety (ICTIS), Xi’an, China 432–436 (2023).
Zhang, Y. et al. Electric and fuel car identification based on UAV thermal infrared images using deep convolutional neural networks. Int. J. Remote Sens. 42(22), 8526–8541 (2021).
Ma, J. et al. Infrared dim and small target detection based on background prediction. Remote Sens. 15(15), 3749 (2023).
Bai, C., Bai, X. & Wu, K. A review: Remote sensing image object detection algorithm based on deep learning. Electronics 12(24), 4902 (2023).
Xiao, Y. et al. A review of object detection based on deep learning. Multimed. Tools Appl. 79, 23729–23791 (2020).
Mahaur, B., Singh, N. & Mishra, K. K. Road object detection: A comparative study of deep learning-based algorithms. Multimed. Tools Appl. 81(10), 14247–14282 (2022).
Zhou, M., Wang, J. & Li, B. ARG-mask RCNN: An infrared insulator fault-detection network based on improved mask RCNN. Sensors 22(13), 4720 (2022).
Du, S. et al. FA-YOLO: An improved YOLO model for infrared occlusion object detection under confusing background. Wirel. Commun. Mobile Comput. 2021, e1896029 (2021).
Jiang, C. et al. Object detection from UAV thermal infrared images and videos using YOLO models. Int. J. Appl. Earth Obs. Geoinf. 112, 102912 (2022).
Zhao, X. et al. YOLO-ViT-based method for unmanned aerial vehicle infrared vehicle target detection. Remote Sens. 15(15), 3778 (2023).
Wu, J., He, Y. & Zhao, J. An infrared target images recognition and processing method based on the fuzzy comprehensive evaluation. IEEE Access 12, 12126–12137 (2024).
Li, Y. et al. Multi-object detection for crowded road scene based on ML-AFP of YOLOv5[J]. Sci. Rep. 13(1), 17310 (2023).
Mao, Q.-C. et al. Finding every car: a traffic surveillance multi-scale vehicle object detection method. Appl. Intell. 50(10), 3125–3136 (2020).
Su, X. et al. Research on real-time dense small target detection algorithm of UAV based on YOLOv3-SPP. J. Braz. Soc. Mech. Sci. Eng. 45(9), 488 (2023).
Cao, S. et al. UAV small target detection algorithm based on an improved YOLOv5s model. J. Vis. Commun. Image Represent. 97, 103936 (2023).
Lin, J. et al. Infrared dim and small target detection based on U-Transformer. J. Vis. Commun. Image Represent. 89, 103684 (2022).
Liu, C. et al. Infrared small target detection based on multi-perception of target features. Infrared Phys. Technol. 135, 104927 (2023).
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y. & Chen, J. RT-DETRv2: Improved Real-Time DEtection TRansformer. arXiv preprint arXiv:2407.17140 (2024).
Zhou, X., et al. CSTM-YOLOv11: A real-time object detection algorithm based on YOLOv11 in complex traffic scenarios. In Signal, Image and Video Processing (Springer, 2025). https://doi.org/10.1007/s11760-025-04646-0.
Tian, Y., Ye, Y. & Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv preprint arXiv:2502.12524 (2025).
Woo, S. et al. "ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada 16133–16142 (2023).
Yang, L., et al. SimAM: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the 38th International Conference on Machine Learning 11863–11874 (PMLR, 2021).
Tan, M., Pang, R. & Le, Q. V."EfficientDet: Scalable and efficient object detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 1077810787 (2020).
Xu, C. et al. Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark. ISPRS J. Photogramm. Remote. Sens. 190, 79–93 (2022).
Suo, J. et al. HIT-UAV: A high-altitude infrared thermal dataset for unmanned aerial vehicle-based object detection. Sci. Data 10, 227 (2023).
Acknowledgements
Heartfelt thanks to all the authors for their help. This was crucial for the completion and publication of this research.
Funding
This research was supported by Xi’an Science and Technology Project Program [Grant No. 2024GXFW0020] and Yulin Science and Technology Bureau Project [Grant No. 2024-CXY-160].
Author information
Authors and Affiliations
Contributions
All authors participated in the conception and design of this study. Material preparation was done by X.L., data collection and organization, as well as dataset creation, was done by J.G., conceptualisation was done by H.G., algorithm design and debugging was done by X.L., data analysis, experiments and thesis writing was done by R.S., and all the authors commented on a previous version of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The contact author has declared that none of the authors has any competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, X., Shi, R., Gao, H. et al. An improved algorithm for infrared road object recognition in UAV perspective. Sci Rep 16, 2377 (2026). https://doi.org/10.1038/s41598-025-32314-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32314-1
