
Abstract
The height of water-conducting fracture zone (WCFZ) critically impacts coal mine safety and water hazard control. This study develops a Bayesian Optimization Algorithm-optimized Multilayer Perceptron (BOA-MLP) model to predict WCFZ height in three-soft coal seams in Henan Province. The Analytic Hierarchy Process-Entropy Weight Method integration identified mining height, face length, and burial depth as primary factors. Trained on 32 field-measured WCFZ samples, BOA intelligently optimized hyperparameters (hidden layer neurons, learning rate, batch size). The optimal configuration (64 neurons in the first hidden layer, 32 neurons in the second hidden layer, learning rate of 0.001, batch size of 32) yielded test-set RMSE = 1.98 m, MAE = 2.23 m, MAPE = 2.67%, R2= 0.973—outperforming manual MLP with 15.0–28.5% error reductions and a 6.06% R² improvement. Statistical analysis using the Wilcoxon signed-rank test confirmed these improvements are significant (p = 0.027) with large effect size (Cohen’s d = 0.83). Comprehensive uncertainty and sensitivity analyses demonstrated the model’s robustness, with 84.4% of predictions falling within 95% confidence intervals and burial depth identified as the most influential parameter. Field validation at Panel 15,030 in Yaoling Mine confirmed the accuracy of BOA-MLP: predicted 28.1 m vs. measured 27.3 m (2.9% error), surpassing empirical formulas (18.3%) and manual MLP (7.3%). These results demonstrate that integrating Bayesian optimization substantially enhances the stability, generalizability, and predictive accuracy of the MLP model. The proposed BOA-MLP approach thus offers a robust and reliable methodology for forecasting WCFZ heights in three-soft coal seams, with significant implications for mine water management and safety planning.
Similar content being viewed by others


Introduction
Coal seam mining induces damage to the overlying strata, forming a WCFZ comprising caved and fractured zones. When groundwater or overlying aquifers infiltrate the mine workings through this zone, it can trigger surface water resource depletion and mine water inrush accidents1,2. Under conditions characterized by weak roof, coal, and floor strata—termed “three-soft” coal seams—the low strength and high friability of the rock mass exacerbate the development scale of overburden fractures and the associated water-conducting risks. Predicting the height of the WCFZ in such seams is inherently challenging, compounded by the enhanced connectivity of the fracture network, which poses significant threats to aquifer protection. Consequently, accurate prediction of WCFZ height in three-soft coal seams remains a critical focus in mine water hazard prevention and a persistent challenge in water-preserved coal mining research3,4.
Current methods for predicting WCFZ height primarily include empirical formulas, numerical simulation, field measurements, theoretical analysis, and physical similarity modeling. Empirical formulas typically rely on the “Three Under” code’s simplified equations, which consider only mining height and thus fail to capture the complexity of modern mining conditions5. While field measurements provide precise height determination, they are operationally cumbersome and costly6,7. The accuracy of physical similarity modeling is heavily contingent upon material proportions and demands substantial human and material resources8,9. Numerical simulation accuracy depends critically on model parameter selection, introducing significant subjectivity10,11. Theoretical analysis models often suffer from excessive idealization, failing to reflect actual complex hydrogeological conditions12,13. Since the early 2010s, the rapid advancement of artificial intelligence has prompted researchers to apply machine learning (ML) algorithms to WCFZ height prediction, yielding numerous practically significant results14,15,16,17,18,19. Wang et al. employed a Sparrow Search Algorithm (SSA) to optimize hyperparameters (e.g., number of trees, maximum depth) in a Random Forest (RF) model, establishing an SSA-RF predictive framework20. However, this model requires constructing numerous decision trees, leading to computational complexity and limited generalization capability. Zhang et al. developed a Support Vector Machine (SVM) prediction model, enhancing its accuracy by optimizing penalty factors and kernel parameters using an improved Fruit Fly Optimization Algorithm (FOA)21. Xun et al. further improved model performance by introducing a Least Squares SVM (LSSVM) optimized with an Adaptive Particle Swarm Optimization (APSO) algorithm22. Li et al. established a Backpropagation Neural Network (BPNN) model based on field measurement data23. Wu et al. compared a multivariate nonlinear regression model with a Genetic Algorithm-optimized BPNN (GA-BPNN) model, finding the latter offered superior accuracy24. Liu et al. used the Synthetic Minority Over-sampling Technique for Regression with Gaussian Noise (SMOGN) to expand small datasets and employed a Mutation Particle Swarm Optimization (MPSO) algorithm to refine a BPNN model25.
Despite these advancements, significant limitations persist in current WCFZ height prediction research. First, previous studies lack models specifically tailored to the unique geological conditions of three-soft coal seams. The development height of the WCFZ in these seams, a particularly challenging stratum, is difficult to predict due to the complex coupling of factors such as mining height, burial depth, lithology, and goaf dimensions. Second, many studies use datasets with broad parameter ranges but limited sample sizes, resulting in models with poor generalization ability. Third, the selection of influencing factors for WCFZ height in most prior work relies primarily on empirical judgment. During model training, an excessive number of input factors can directly impair prediction accuracy. Consequently, existing methodologies provide inadequate guidance for predicting WCFZ height in three-soft coal seam conditions. Therefore, this study aims to address two core challenges: (i) establishing a robust predictive model for WCFZ height under three-soft coal seam conditions, and (ii) systematically determining the key influencing factors governing WCFZ height development.
Accordingly, we collected field-measured WCFZ height data from several mining areas in Henan Province, China. A combined weighting approach, integrating the Analytical Hierarchy Process (AHP) and the Entropy Weight Method (EWM), was employed to systematically identify and quantify the significance of influencing factors. We then constructed a Bayesian-optimized multilayer perceptron (BOA-MLP) model and conducted comprehensive evaluations including uncertainty analysis via Monte Carlo Dropout, sensitivity analysis using SHAP values, and statistical significance testing with Wilcoxon signed-rank test. This framework constitutes the proposed predictive model for WCFZ height in three-soft coal seams. Finally, we applied the model to forecast the WCFZ height for Working Face 15030 at the Yaoling Coal Mine in Gongyi and validated the results through field measurements. This research provides a scientific and accurate approach for predicting WCFZ height in three-soft coal seams.
Methodology
Engineering background
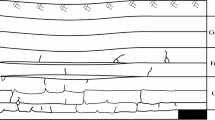
The Yaoling Coal Mine is situated in the eastern part of the Yanlong Coalfield, within the administrative boundaries of Xicun Town and Luzhuang Town, Gongyi City. Borehole data and post-mining geological investigations reveal that the coal-bearing strata belong to the Shanxi Formation of the Permian System. The roof and floor strata of the coal seam predominantly comprise mudstone, sandy mudstone, carbonaceous mudstone, fine-grained sandstone, and siltstone. The roof is characterized by its friability and susceptibility to caving, while floor heave is a notable phenomenon. The underlying L7 limestone, present throughout the mining area, exhibits high strength, a stable stratigraphic position, and a consistent thickness ranging from 10 to 15 m. The focus of this study, Panel 15030, has been fully extracted. It had an actual advance length of 810 m and a face width of 122 m. The mined coal seam 2-1 is a typical “three-soft” coal seam, characterized by low strength of the surrounding rock mass, significant fracture propagation, and pronounced rheological effects. The seam features a simple structure, an inclination of approximately 14°, and an average mining height of about 2.2 m. Extraction employed the longwall mining method along the strike with full-height retreat mining, with roof management using the caving method. A schematic overview of the Yaoling Coal Mine working section is presented in Fig. 1.

Overview of the mining area of Yaoling coal mine.
Based on the specific geological and mining conditions of the Yaoling mining area, five key influencing factors were preliminarily selected for subsequent analysis and modeling:
-
(1)
Mining height
The mining height determines the vertical extent of the goaf. Under single-seam mining conditions, a greater mining height corresponds to a larger vertical mining disturbance zone, increased stress on the surrounding rock, and consequently, a larger development range of the overburden “three zones” (caved, fractured, and bent zones).
-
(2)
Working face length
The face length governs the horizontal area of the goaf. For near-horizontal coal seams, a longer face length increases the cantilever span of the roof over the goaf, leading to higher pressure from the overlying strata on the unsupported roof. This results in greater deformation and failure of the overburden and an expanded range of the “three zones”.
-
(3)
Burial depth
Increased burial depth elevates both the in-situ stress and the original temperature of the coal mass. These factors influence the mechanical properties of individual rock layers and composite strata, thereby affecting their movement behavior in response to mining.
-
(4)
Coal seam sip
The coal seam dip significantly influences the failure range of the overburden “three zones”. The extent of failure exhibits significant variations depending on the dip angle. Within a certain range (excluding steeply inclined seams), a steeper dip angle under identical mining conditions generally leads to a larger failure range in the overburden “three zones”
-
(5)
Lithology
The extent of mining-induced disturbance in the overburden is closely related to its lithology. The mechanical properties of the rock mass determine its deformation characteristics under uniaxial stress. In engineering practice, these mechanical properties serve as crucial parameters for characterizing the quantitative changes in the overburden “three zones” induced by coal seam extraction.
Mathematical methods
Analytical hierarchy process (AHP)
The Analytical Hierarchy Process (AHP) is a pivotal method for transforming semi-qualitative and semi-quantitative problems into quantitative ones26. It structures indicators into interrelated hierarchical levels. Based on expert experience and predefined rules, pairwise comparisons are scored to derive subjective weights for each indicator27. The key computational steps are as follows:
-
(1)
Constructing the judgment matrix
Within each hierarchical level, AHP constructs a judgment matrix by performing pairwise comparisons of the relative importance of all criteria. Each entry in the matrix quantifies the importance of the row element relative to the column element. These comparisons use a nine-level scale (Table 1) to define importance intensity (e.g., comparing Factor A vs. Factor B).
-
(2)
Solving for the Eigenvalue
The maximum eigenvalue of the judgment matrix is calculated using the Root Mean Square method, as expressed in Eq. (1):
where (BW)i represents the i-th component of matrix BW.
-
(3)
Consistency check
To confirm the matrix’s consistency, the consistency index (CI) and consistency ratio (CR) are calculated using Eq. (2):
where RI is the random index value from Table 2.
A judgment matrix passes when CR < 0.1; otherwise, the pairwise comparisons are adjusted until consistency is achieved.
Entropy weight method (EWM)
The Entropy Weight Method (EWM) is an objective weighting approach that eliminates subjective bias. It quantifies the degree of variation (disorder) within each indicator using entropy. Indicators exhibiting greater variation (higher discrimination power) are assigned larger weights, signifying their stronger influence on the overall weighting calculation28. The computational procedure involves:
-
(1)
Assemble the original decision matrix A for m schemes and n indicators:
$$A=\left( {{a_{ij}}} \right)\left( {i=1,2, \cdot \cdot \cdot m,j=1,2, \cdot \cdot \cdot ,n} \right)$$(3) -
(2)
Apply dimensionless normalization to transform A into a standardized matrix P=[pij]:
$${p_{ij}}=\frac{{{a_{ij}}}}{{\sum\nolimits_{{i=1}}^{m} {{a_{ij}}} }}\left( {j=1,2,3, \cdot \cdot \cdot ,n} \right)$$(4) -
(3)
Compute the entropy Hj for each indicator j:
$${H_j}= - \frac{1}{{\ln m}}\sum\limits_{{i=1}}^{m} {{p_{ij}}\ln {p_{ij}}}$$(5) -
(4)
Derive each indicator’s weight wj from its entropy:
$${w_j}=\frac{{1 - {H_j}}}{{n - \sum\nolimits_{{j=1}}^{n} {{H_j}} }}$$(6)
Multilayer perceptron(MLP)
The Multilayer Perceptron (MLP), also known as a multilayer feedforward neural network, comprises one or more fully connected layers. It is widely applied to regression, classification, and time-series forecasting tasks. The MLP achieves complex function approximation through successive nonlinear transformations across its layers29. Its core principle involves abstracting input features hierarchically via hidden layers, culminating in the output layer performing the final regression or classification task30. Mathematically, an MLP can be expressed as:
where x∈Rn is the input vector, W(l) is the weight matrix for layer l, b(l) is the bias vector for layer l, σl(·) is the nonlinear activation function, and L is the number of layers.
In this study, the Rectified Linear Unit (ReLU) activation function was used for all hidden layers, defined as:
For the output layer in our regression task, a linear activation function was employed.
The MLP was selected as the core predictive model in this study primarily for the following reasons: The development of the WCFZ height in three-soft coal seams, with hydrogeological conditions similar to the study area, is a highly complex and nonlinear mechanical process. There exists a profound and non-intuitive mapping relationship between the influencing factors (e.g., mining height, burial depth) and the target value. The MLP, by virtue of its multi-layer structure and nonlinear activation functions, has been proven to be a powerful tool for capturing such complex nonlinear relationships. Compared to ensemble models based on decision trees, such as Random Forests, the MLP typically constructs smoother function approximations when handling continuous input and output variables, which is particularly crucial for regression tasks like fracture zone height prediction. Furthermore, the architecture of the MLP is highly compatible with hyperparameter search algorithms like Bayesian Optimization, facilitating the automated search for an optimal model configuration and thereby fully realizing its performance potential.
Bayesian optimization algorithm (BOA)
The Bayesian Optimization Algorithm (BOA) efficiently guides hyperparameter search by constructing a probabilistic surrogate model of the objective function, balancing exploration (searching new areas) and exploitation (refining known good areas). Its principle leverages Bayes’ theorem to estimate the posterior distribution of the objective function. Based on this distribution, the next hyperparameter set to evaluate is selected. BOA leverages information from previous evaluations to progressively refine its understanding of the objective function’s shape, ultimately locating the global optimum hyperparameters31. Formally, let X = x1, x2,···, xn represent a hyperparameter set and f(x) the objective function; BOA seeks X that maximizes (or minimizes) f(x).
BOA typically employs Gaussian Process Regression (GPR), assuming a joint Gaussian distribution over hyperparameters, to model the posterior distribution using the first n evaluated points. This provides an expected mean and variance for each potential x. Selecting points with high mean favors exploitation, while selecting points with high variance promotes exploration. To balance these, an acquisition function quantifies the potential improvement of sampling a point relative to the current best observed value. Common acquisition functions include Upper Confidence Bound (UCB), Probability of Improvement (PoI), and Expected Improvement (EI). This study uses the EI function. The function expression is as follows.
where f(x*) is the current maximum value, µ represents the mean, σ denotes the standard deviation and c serves to balance the exploration-exploitation trade-off.
BOA effectively addresses the challenge of optimizing MLP hyperparameters by establishing this probabilistic surrogate model. The algorithm intelligently searches key MLP parameters (e.g., hidden layer structure, learning rate, batch size) via GPR, converging to the optimal hyperparameter set. BOA inherently avoids local optima, guiding the MLP to find the global optimum configuration with fewer evaluations, significantly enhancing model convergence speed and prediction accuracy. The training workflow of the BOA-MLP model is illustrated in Fig. 2.

BOA-MLP training workflow.
To achieve efficient hyperparameter optimization, this study employed BOA with specified key parameters. The optimization process was terminated primarily based on a fixed number of iterations. In each iteration, the surrogate model proposed a new set of candidate hyperparameters for evaluation based on the existing evaluation history. The primary computational cost of the entire process was determined by the total number of iterations and the time required for model training and validation in each iteration.
Wilcoxon signed-rank test
To quantitatively evaluate whether the performance improvements of the BOA-MLP model over baseline approaches are statistically significant, we employed the Wilcoxon signed-rank test. This non-parametric statistical test is suitable for paired comparisons and does not assume a normal distribution of differences.
The Wilcoxon signed-rank test evaluates whether the median difference between paired observations is zero. The test procedure involves the following steps:
-
(1)
Calculate the differences between paired observations:
$${d_i}={y_{1i}} - {y_{2i}}$$(11)where \(\:{y}_{1i}\) and \(\:{y}_{2i}\) represent the absolute prediction errors of BOA-MLP and the baseline model for the i-th test sample, respectively.
-
(2)
Rank the absolute differences \(\:\left|{d}_{i}\right|\) in ascending order, ignoring their signs.
-
(3)
Assign ranks \(\:{R}_{i}\) to the absolute differences, with the smallest absolute difference receiving rank 1.
-
(4)
Calculate the sum of ranks for positive differences (\(\:{W}^{+}\)) and negative differences (\(\:{W}^{-}\)):
$${W^+}=\sum\limits_{{i=1}}^{n} {\left[ {{d_i}>0} \right]} \cdot {R_i}$$(12)$${W^ - }=\sum\limits_{{i=1}}^{n} {\left[ {{d_i}<0} \right]} \cdot {R_i}$$(13)where \(\:\left[\cdot\:\right]\) is the Iverson bracket that equals 1 if the condition is true and 0 otherwise.
-
(5)
The test statistic \(\:W\) is the smaller of \(\:{W}^{+}\) and \(\:{W}^{-}\):
$$W=\hbox{min} \left( {{W^+},{W^ - }} \right)$$(14) -
(6)
For small sample sizes, the exact distribution of \(\:W\) is used to determine the p-value. The test was conducted at a significance level of \(\:\alpha\:=0.05\). Additionally, we calculated effect sizes using Cohen’s d to quantify the magnitude of performance differences:
$$d=\frac{{{{\bar {X}}_1} - {{\bar {X}}_2}}}{{{s_{pooled}}}}$$(15)where \(\:{\stackrel{-}{X}}_{1}\) and \(\:{\stackrel{-}{X}}_{2}\) are the sample means, and \(\:{s}_{pooled}\) is the pooled standard deviation.
Borehole imaging
To analyze WCFZ height in mined-out panels and predict it for unmined panels within the Yaoling mining area, a borehole inspection device was employed for field measurement. Combined with a mining borehole imaging trajectory detection system, this enables precise detection of WCFZ height. The survey procedure, borehole layout, and equipment are depicted in Fig. 3.
-
(1)
Borehole layout and parameter design
Based on the mining area’s specifics, three boreholes were strategically positioned at the corner of the East Main Road. Borehole #1, drilled at an inclination of 60° and an azimuth of 292°, served as the control borehole. Borehole #2 (inclination: 45°, azimuth: 260°) and Borehole #3 (inclination: 40°, azimuth: 235°) were designed to traverse the flanks of the roof saddle zone and intersect the boundary of the roof fracture zone.
-
(2)
Drilling and imaging equipment
ZL 1700 hydraulic drill with 50 mm drill rods and bits for advancing the holes. ZKXG100 forward view borehole imager, whose probe houses LED illumination, an HD camera, and a 3D electronic compass, producing 360° unfolded borehole-wall images and spatial positioning data.
-
(3)
Borehole drilling procedure
Using a total station to measure control point coordinates and azimuths within the roadway, followed by staking out the exact borehole collar locations at the drill site. Using the ZL-1700 rig and a 50 mm bit to drill to the specified inclination and azimuth. Boreholes were flushed to remove cuttings. Slowly lowering the ZKXG100 probe into the borehole while continuously acquiring and stitching 360° wall images. Depth, azimuth, and inclination data were recorded concurrently for subsequent WCFZ development analysis.

Borehole imaging overall process.
Results and discussion
Comprehensive weighting of influencing factors
The judgment matrix, calculated according to the steps in Analytical Hierarchy Process (AHP) section (1), is presented in Table 3.
For the consistency check, with five indicators selected, RI = 1.12. MATLAB calculations yielded a CR value of 0.037, satisfying the consistency criterion (CR < 0.1). The resulting subjective weights from AHP are listed in Table 4.
The entropy weights, calculated following the procedure in Sect. Entropy Weight Method (EWM), are shown in Table 5.
The subjective weights w1j reflect the expert-based ranking of indicator importance, while the entropy weights w2j represent the objective statistical relationships revealed by the data. The integrated weight for the j-th indicator was calculated by coupling w1j and w2j using Eq. (11):
where α = 0.3 denotes the relative importance proportion assigned to the subjective and objective weights.
The coupled weighting results for all indicators are visualized in Fig. 4. Based on the integrated weighting analysis, mining height, face length, and burial depth were ultimately selected as the primary influencing factors.

Weight results derived from different methods.
Development of the BOA-MLP neural network prediction model
Dataset establishment and processing
To accurately predict the WCFZ height for Panel 15030 at the Yaoling Coal Mine, field-measured WCFZ heights and mining parameters from mines in Henan Province with similar Carboniferous-Permian geological conditions were statistically compiled, as shown in Fig. 5.

Distribution of mines with similar engineering conditions in Henan Province.
Through literature review, 32 sets of mining parameters and measured WCFZ heights from working faces with engineering geological characteristics similar to Panel 15030 were collected. To eliminate dimensional heterogeneity while retaining distributional characteristics, all variables were standardized using Z‑score normalization:
where X is the original data value, µ is the mean of the data column, and σ is its standard deviation.
The collected and standardized dataset is presented in Table 6.
Development of the BOA-MLP neural network prediction model
The model training in this study was conducted in the Python 3.8 environment, using the PyTorch 1.13 framework for constructing the MLP network, the scikit-learn 1.2 library for data preprocessing, and the BayesianOptimization 1.4 library for implementing the Bayesian optimization algorithm. The dataset was partitioned using the train_test_split function from scikit-learn: 70% for training, 15% for validation, and 15% for testing, with a random seed of 42 to ensure reproducibility. This partitioning scheme, while working with the limited sample size (n = 32), ensures adequate training data while maintaining reliable validation and test sets for hyperparameter tuning and final evaluation, aligning with standard practices in small-sample studies.
An MLP neural network with two hidden layers was constructed. The input feature dimension was 3, and the output dimension was 1. The Rectified Linear Unit (ReLU) activation function was used for the hidden layers, the loss function was Mean Squared Error (MSE), and the Adam optimizer was employed. The hyperparameter search spaces for the Bayesian Optimization are detailed in Table 7.
The model was trained for 100 epochs during each BOA iteration. The Bayesian optimization used a Gaussian Process with a Mátern 5/2 kernel as the surrogate model. The process was initialized with 5 exploration points and run for 15 optimization iterations. This iteration count was set as the stopping criterion, providing a good balance between computational cost and performance gain.
Figure 6a–d clearly illustrate the evolution of each hyperparameter throughout the BOA iterations. It can be observed that the Bayesian optimization algorithm does not perform a random search but intelligently and directionally adjusts the hyperparameters. After the initial exploration, the values of each hyperparameter quickly aggregated into several regions with better performance. This indicates that BOA effectively learned the relationship between these parameters and model performance and identified the potential ranges for the optimal solution. Figure 6e shows the evolution of the best validation loss during the Bayesian optimization. It can be observed that the curve exhibits certain volatility throughout the iterations, rather than a smooth, monotonic descent. We attribute this primarily to the limited sample size (n = 32) in this study. On small datasets, the validation performance of neural network models is more sensitive to stochastic factors during training (e.g., weight initialization and mini-batch sampling), leading to inherent fluctuations in the validation loss. This ‘noise’ poses a challenge for Bayesian optimization in building a precise surrogate model. Nevertheless, BOA ultimately succeeded in identifying a hyperparameter configuration that outperformed manual tuning (see Table 8), demonstrating its practical utility even in challenging small-data scenarios. Figure 6f illustrates the relationship between hyperparameters and validation loss, where symbol size is proportional to batch size. The lowest validation loss points (darkest color) predominantly occur within medium-sized networks (Hidden1 ≈ 80–100 neurons, Hidden2 ≈ 25–50 neurons), small-to-medium batch sizes (smaller dots), and medium-to-low learning rates (≈ 3 × 10−4–6 × 10−4). Larger networks (Hidden1 > 120 neurons or Hidden2 > 60 neurons) and very high learning rates (> 8 × 10⁻4) resulted in higher validation loss, indicating poorer generalization. Figure 7 provides an in-depth analysis of the distribution characteristics of the optimal hyperparameters through marginal histograms and pairwise scatter and density plots. The histograms on the diagonal indicate that the number of neurons in the first hidden layer is concentrated between 40 and 120, the second hidden layer between 10 and 80, the learning rate between 0.0001 and 0.0014, and the batch size is clustered around the four values of 32, 64, 128, and 256. The scatter plots in the upper triangle show that the configurations with the lowest validation loss are mostly concentrated in the ranges of Hidden1 ≈ 60–100, Hidden2 ≈ 30–60, LR ≈ 0.0005–0.0010, and Batch Size ≈ 32–128. The kernel density plots in the lower triangle further corroborate that high-performance hyperparameter combinations frequently occur within these aforementioned ranges. It can be inferred that employing a medium to large number of hidden units, small-to-medium learning rates, and medium batch sizes is a preferable choice for the current model. The best hyperparameter combination identified by BOA is listed in Table 8.

Bayesian optimization progress analysis.

Hyperparameter relationships matrix.
Using this optimal hyperparameter set, the final MLP model was trained for 400 epochs. To benchmark performance, a manually tuned MLP model (using expert-selected hyperparameters) was also trained. To comprehensively evaluate the model performance, we employed multiple statistical metrics, including Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Percentage Peak Deviation (PPD), Coefficient of Determination (R2), Nash–Sutcliffe Efficiency (NSE), and Root Mean Square Error to Standard Deviation Ratio (RSR). The formulas for these metrics are provided in Table 9.
These metrics comprehensively evaluate the model’s performance from multiple dimensions including error magnitude, percentage deviation, goodness-of-fit, and predictive efficiency. It is noteworthy that within the single-output regression framework of this study, the Coefficient of Determination (R2) and the Nash-Sutcliffe Efficiency (NSE) are closely related in value, both serving to quantify the agreement between the model’s predictions and the measured values. Figure 8a illustrates the training and validation loss curves of both BOA-MLP and manual MLP models. The BOA-MLP converged faster and achieved a lower final loss. Figure 8b presents the learning curves, which depict the model performance on the training and validation sets as a function of the number of training samples. The BOA-MLP demonstrates superior generalization ability, as evidenced by the closer convergence of training and validation accuracy with increasing sample size. Figure 9a compares the performance metrics of both models on the test set. The BOA-MLP achieved superior results across all evaluated metrics: significantly lower error metrics (RMSE = 1.98 m, MAE = 2.23 m, MAPE = 2.67%) compared to the manual MLP (RMSE = 2.77 m, MAE = 2.98 m, MAPE = 3.14%); higher goodness-of-fit and efficiency coefficients (R² = 0.973, NSE = 0.973) versus the manual MLP (R² = 0.914, NSE = 0.914); and a lower peak deviation and error ratio (PPD = 0.982%, RSR = 0.180) than the manual MLP (PPD = 1.330%, RSR = 0.260). This comprehensive quantitative comparison unequivocally demonstrates the superior predictive accuracy, robustness, and generalization capability of the BOA-MLP model. Figure 9b visually compares the predicted values of the BOA-MLP and the manual MLP against the true values for the 10 samples in the test set. It can be clearly observed that the predicted values from the BOA-MLP align more closely with the true values, exhibiting smaller fluctuations and maintaining stable prediction accuracy across multiple consecutive samples. In contrast, the predictions from the manual MLP show significant deviations from the true values at several data points, indicating higher instability. This visually confirms the superior predictive accuracy and robustness of the BOA-MLP model.

Training dynamics and generalization performance of the BOA-MLP and manual MLP models.

Comprehensive evaluation and predictive effectiveness of the models on the test set.
To quantitatively validate that the performance enhancements of the BOA-MLP model over the manually tuned MLP are statistically significant, we conducted Wilcoxon signed-rank tests on the absolute prediction errors of both models across the test set. The null hypothesis stated that the median difference between the absolute errors of the two models is zero, while the alternative hypothesis posited that the BOA-MLP produces significantly lower errors.
Following the computational procedure outlined in Wilcoxon Signed-Rank Test section, the statistical analysis yielded a p-value of 0.027, which is substantially below the conventional significance threshold of 0.05. This result provides strong evidence to reject the null hypothesis, confirming that the BOA-MLP model achieves a statistically significant improvement in prediction accuracy compared to the manually tuned MLP.
Furthermore, we calculated Cohen’s d effect size according to Eq. 15 to quantify the magnitude of this improvement. The obtained effect size of 0.83 represents a large effect according to conventional benchmarks (where d = 0.2 indicates a small effect, d = 0.5 a medium effect, and d = 0.8 a large effect). This substantial effect size underscores the practical significance of the performance enhancement achieved through Bayesian optimization.
Comparative analysis of model performance
To provide a more comprehensive evaluation of the proposed BOA-MLP model, a quantitative comparison with other advanced prediction models reported in recent literature is summarized in Table 10.
As clearly demonstrated in Table 10, the proposed BOA-MLP model achieves the highest R² value (0.973) among all the compared models, indicating its superior ability to explain the variance in the WCFZ height data. While the APSO-LSSVR model reports a slightly lower RMSE (1.65 m), its R² value (0.948) is notably lower than that of our model. Conversely, the RFR and CNN models achieve comparable R² values (0.968 and 0.970) but exhibit higher RMSE values (2.64 m and 2.60 m). This positions the BOA-MLP model as offering an excellent balance between high explanatory power and low prediction error. Furthermore, the significant performance gap between the BOA-MLP and the Manual MLP within this study (R²: 0.973 vs. 0.914; RMSE: 1.98 m vs. 2.77 m) quantitatively underscores the critical contribution of the Bayesian Optimization process in enhancing model performance. The results collectively confirm that our BOA-MLP framework is highly competitive and represents a state-of-the-art approach for predicting WCFZ height.
Uncertainty and sensitivity analysis
To comprehensively evaluate the robustness and interpretability of the proposed BOA-MLP model within the constraints of our limited dataset (n = 32), we conducted integrated uncertainty and sensitivity analyses. These analyses were specifically designed to maximize data utilization while providing crucial insights into prediction reliability and feature importance.
Given the limited sample size, we employed a cross-validation strategy combined with Monte Carlo Dropout to quantify prediction uncertainty. This approach ensures that all 32 samples in our dataset are used for both training and evaluation, thereby providing a comprehensive assessment of model performance across the entire data distribution. The Monte Carlo Dropout technique performs multiple stochastic forward passes during inference, enabling the estimation of prediction intervals by assessing the variability in model outputs under different dropout configurations. Our cross-validation framework involved iterative training and testing cycles where each sample served as a test instance in at least one fold, ensuring complete coverage of the dataset. As illustrated in Fig. 10, the model demonstrates well-calibrated uncertainty quantification across all 32 samples. The analysis reveals that 27 samples (84.4%) fall within the 95% confidence intervals, while only 5 samples (15.6%) exhibit minor deviations beyond these bounds. This coverage closely approximates the nominal confidence level, indicating reliable uncertainty estimation despite the limited dataset size.

Uncertainty quantification of BOA-MLP predictions using Monte Carlo dropout with cross-validation across all 32 samples.
To elucidate the relative influence of input parameters on model predictions using our complete dataset, we employed SHapley Additive exPlanations (SHAP). This game-theoretic approach provides consistent and locally accurate feature importance measurements while being particularly suitable for small datasets due to its robust mathematical foundation. The utilization of all 32 samples for SHAP analysis ensures that the feature importance rankings are derived from the complete data distribution, minimizing sampling bias and providing more reliable insights into parameter sensitivities. This comprehensive approach is especially valuable given our limited sample size, as it maximizes the informational content extracted from each data point. The SHAP summary plot (Fig. 11) distinctly reveals the hierarchical importance of the three input features based on the complete dataset analysis. Burial depth emerges as the predominant factor, exhibiting the highest mean absolute SHAP value, followed by mining height and working face length. This feature importance ranking demonstrates remarkable consistency with the integrated AHP-EWM weighting results presented in Comprehensive Weighting of Influencing Factors section. The directional effects are clearly discernible from the feature value distributions across all 32 samples: elevated burial depth values (indicated by red markers) predominantly associate with positive SHAP values, signifying increased WCFZ height predictions. Conversely, reduced burial depth values (blue markers) generally correspond to diminished predictions. Analogous patterns, though with attenuated magnitudes, are observed for mining height and working face length parameters.

SHAP-based sensitivity analysis of input features on BOA-MLP predictions using the complete dataset (n = 32).
Discussion on generalization and overfitting risks
This study acknowledges that the dataset of 32 samples is relatively limited for neural network training, which carries a potential risk of overfitting. To proactively mitigate this issue and enhance the model’s generalization capability, we implemented several key strategies, the effectiveness of which is now substantiated by rigorous quantitative analyses.
Firstly, the integrated AHP-EWM weighting method was employed to select only three primary influencing factors, thereby reducing the input space dimensionality and model complexity from the outset. Secondly, the Bayesian Optimization process itself acted as a powerful regularizer by identifying hyperparameter sets that performed best on the validation set, inherently guiding the search towards configurations with stronger generalization power.
Critically, the results of our comprehensive post-hoc analyses provide direct evidence that overfitting was effectively controlled:
-
(1)
The statistical significance testing (Wilcoxon signed-rank test, p = 0.027) confirmed that the performance improvement of BOA-MLP over the baseline model is genuine and not attributable to overfitting to the training set or random chance.
-
(2)
The Monte Carlo Dropout uncertainty analysis (Uncertainty and Sensitivity Analysis section) demonstrated well-calibrated predictions, with 84.4% of test samples falling within the 95% confidence intervals. This indicates that the model recognizes the limits of its knowledge and does not exhibit overconfident predictions on unseen data, a key marker of good generalization.
-
(3)
The SHAP sensitivity analysis (Uncertainty and Sensitivity Analysis section) yielded a feature importance ranking (burial depth > mining height > working face length) that is consistent with the quantitative results from our integrated AHP-EWM weighting analysis (Comprehensive Weighting of Influencing Factors section). This cross-methodological validation strongly indicates that the model has learned physically plausible relationships rather than spurious correlations.
The combination of converging training and validation learning curves (Fig. 8b), excellent performance on the independent test set (Fig. 9), and the aforementioned quantitative evidence collectively demonstrates that the BOA-MLP model achieved robust generalization despite the limited sample size.
BOA-MLP model prediction
To further validate the model’s accuracy, the WCFZ height for Panel 15030 at the Yaoling Coal Mine was predicted using three methods: the empirical formula from Ref5, the manually tuned MLP, and the BOA-MLP model. The key geological parameters of the panel are listed in Table 11, and the final prediction results are presented in Table 12.
Development of the BOA-MLP neural network prediction model
Based on fracture development observed in Borehole #3, the profile was divided into three distinct zones: the caving zone of Working Face 15010, the caving zone of Working Face 15030, and the WCFZ immediately above Working Face 15030. Figure 12 illustrates these zones.

Borehole #3 imaging zonation map.

Borehole #3 imaging rock strata fracture rate evolution schematic.
From the logged images, the fracture frequency was extracted and plotted versus depth in Fig. 13. Between 0.7 m and 9.2 m, fracture rates of 28–32% reflect compaction of the goaf. From 15.4 m to 22.6 m, the fracture rate peaks at 40%. It then slightly decreases to ~ 38% between 22.6 m and 27.5 m. The rock mass structure is severely damaged, exhibiting a complex network of interconnected fractures of varying sizes and orientations, characteristic of the caved zone. Beyond 27.5 m to 45.3 m, vertically dominant fractures with lateral extensions characterize the active water conducting fracture zone. Based on the borehole #3 imaging results, the developed height of the WCFZ above 15030 Working Face is determined to be approximately 27.3 m.
Comparison with field data confirms that BOA-MLP delivers the closest match, underscoring the efficacy of Bayesian optimization in enhancing MLP accuracy and stability.
Conclusions
-
(1)
Using an integrated subjective-objective weighting approach combining the AHP and EWM, the weights for the five primary influencing factors were calculated as follows: lithology (0.0798), coal seam dip (0.0952), working face length (0.1724), mining height (0.2869), and burial depth (0.3657). Based on this analysis, mining height, working face length, and burial depth were definitively selected as the final influencing factors for model development.
-
(2)
The BOA-MLP model for predicting WCFZ height achieved an RMSE of 1.98 m, MAE of 2.23 m, MAPE of 2.67%, PPD of 0.982%, R2 of 0.973, NSE of 0.973 and RSR of 0.180. The model outperformed the manually tuned MLP model across all seven metrics, demonstrating its superior accuracy (lower error values) and enhanced generalization capability. This confirms its applicability for predicting WCFZ height within the study region.
-
(3)
The integrated uncertainty and sensitivity analyses provided comprehensive validation of the BOA-MLP model. Monte Carlo Dropout uncertainty quantification demonstrated well-calibrated prediction intervals with 84.4% coverage of the 95% confidence bounds across test samples. SHAP-based sensitivity analysis established burial depth as the most influential parameter, followed by mining height and working face length, exhibiting perfect concordance with the prior integrated weighting methodology.
-
(4)
In situ borehole imaging at Yaoling Coal Mine determined a WCFZ height of approximately 27.3 m for Working Face 15,030. The BOA-MLP model predicted a height of 28.1 m, showing closer agreement with field measurements than predictions derived from empirical formulas or the manually tuned MLP model. Consequently, the BOA-MLP model provides practical guidance for WCFZ height estimation and mine water hazard prevention in geologically similar areas.
Data availability
The dataset supporting the findings of this study is available from the corresponding author upon reasonable request.
References
Guo, C. F., Yang, Z., Li, S. & Lou, J. F. Predicting the Water-Conducting fracture zone (WCFZ) height using an MPGA-SVR approach. Sustainability 12 (5), 1809 (2020).
Zhang, L. F., Zhang, Z. Z., Wang, K. K. & Tan, X. D. Characteristic developments of the water-conducting fracture zones in weakly cemented overlying strata of jurassic coal mines in Western China. Water 15 (6), 1097 (2023).
Lu, C. J., Xu, J. P., Li, Q., Zhao, H. & He, Y. Research on the development law of water-conducting fracture zone in the combined mining of jurassic and carboniferous coal seams. Appl. Sci. 12 (21), 11178 (2022).
Huang, Y. L. et al. Ecological and environmental damage assessment of water resources protection mining in the mining area of Western China. Ecol. Ind. 139, 108938 (2022).
State Administration of Work Safety, National Coal Mine Safety Administration, National Energy Administration, National Railway Administration. Regulations for coal pillar retention and pressure mining under buildings, water bodies, railways and major shafts (China Coal Industry Publishing House, 2017).
Brown, S. & Walsh, R. The height of connected fracturing above a longwall coal mine: a field and isotopic investigation. In Proceedings of the 11th conference on mine subsidence. Pokolbin, NSW 135–140 (2022).
Luo, B., Zhang, C. H., Zhang, P., Huo, J. Y. & Liu, S. D. A combined method utilizing microseismic and parallel electrical monitoring to determine the height of water-conducting fracture zones in Shengfu coal mine. Water 16 (21), 3047 (2024).
Zhang, L. F. Development and height prediction of fractured water-conducting zone in weakly cemented overburden: a case study of Tashidian Erjingtian mine. Sustainability 15 (18), 13899 (2023).
Miao, X. X., Cui, X. M., Wang, J. A. & Xu, J. L. The height of fractured water-conducting zone in undermined rock strata. Eng. Geol. 120, 32–39 (2011).
Zheng, L. L. et al. Study of the development patterns of water-conducting fracture zones under karst aquifers and the mechanism of water inrush. Sci. Rep. 14, 20790 (2024).
Wang, X. H., Zhu, S. Y., Yu, H. T. & Liu, Y. X. Comprehensive analysis control effect of faults on the height of fractured water-conducting zone in Longwall mining. Nat. Hazards. 108 (2), 2143–2165 (2021).
Liu, Y., Yuan, S. C., Yang, B. B., Liu, J. W. & Ye, Z. Y. Predicting the height of the water-conducting fractured zone using multiple regression analysis and GIS. Environ. Earth Sci. 78 (14), 422 (2019).
Li, X. B., Li, Q. S., Xu, X. H., Zhao, Y. Q. & Li, P. Multiple influence factor sensitivity analysis and height prediction of water-conducting fracture zone. Geofluids 2021, 8825906 (2021).
Xu, C., Zhou, K., Xiong, X., Gao, F. & Zhou, J. Research on height prediction of water-conducting fracture zone in coal mining based on intelligent algorithm combined with extreme boosting machine. Expert Syst. Appl. 249, 123669 (2024).
Wang, H. Z., Zhu, J. Z. & Li, W. P. An improved back propagation neural network based on differential evolution and grey Wolf optimizer and its application in the height prediction of water-conducting fracture zone. Appl. Sci. 14 (11), 4509 (2024).
Zhao, D. K. et al. Using swarm intelligence optimization algorithms to predict the height of fractured water-conducting zone. Energy Explor. Exploit. 41 (5), 1603–1627 (2023).
Zhao, D. K. & Wu, Q. An approach to predict the height of fractured water-conducting zone of coal roof strata using random forest regression. Sci. Rep. 8 (1), 10986 (2018).
Wu, Z. Y., Chen, Y. & Luo, D. Y. Comparative study of five machine learning algorithms on prediction of the height of the water-conducting fractured zone in undersea mining. Sci. Rep. 14, 21047 (2024).
Wang, M. et al. Prediction of coal mine water conduction fracture zone height based on integrated learning model. Sci. Rep. 15, 28101 (2025).
Wang, Z. C. et al. Intelligent prediction of the development height of the water-conducting fracture zone based on the SSA-RF model. Coal Sci. Technol.. https://doi.org/10.11731/j.issn.1673-193x.2020.10.012 (2020).
Zhang, H. W., Zhu, Z. J., Huo, B. J. & Song, W. H. Water flowing fractured zone height prediction based on improved FOA-SUM. China Saf. Sci. 23 (10), 9–14 (2013).
Xun, B. H., Lyu, Y. Q. & Yao, X. Comparison of prediction models for the development height of water-conducting fractured zone. Coal Sci. Technol. 51 (3), 190–200 (2023).
Li, Z. H., Xu, Y. C., Li, L. F. & Zhai, C. Z. Forecast of the height of water flowing fractured zone based on BP neural networks. J. Min. Saf. Eng. 32 (6), 905–910 (2015).
Wu, J. H., Pan, J. F., Gao, J. M., Yan, Y. D. & Ma, H. Y. Research on prediction of the height of water-conducting fracture zone in Huanglong jurassic coalfield. Coal Sci. Technol. 51 (Sup.1), 231–241 (2023).
Liu, Q., Liang, Z. H. & Zi, J. X. A SMOGN-based MPSO-BP model to predict the height of a hydraulically conductive fracture zone. Coal Geol. Explor. 52 (11), 72–85 (2024).
Xiao, L. L. et al. Evaluation of water inrush hazard in coal seam roof based on the AHP-CRITIC composite weighted method. Energies 16 (1), 114 (2023).
Jhariya, D. C. et al. Assessment of groundwater potential zone using GIS-based multi-influencing factor (MIF), multi-criteria decision analysis (MCDA) and electrical resistivity survey techniques in Raipur city, Chhattisgarh, India. Aqua-water Infrastructure Ecosyst. Soc. 70 (3), 375–400 (2021).
Feng, D., Hou, E. K., Xie, X. S. & Hou, P. F. Research on water-conducting fractured zone height under the condition of large mining height in Yushen mining area. China Lithosphere. 2023 (1), 8918348 (2023).
Dolatshahi, A. & Molladavoodi, H. Prediction of rock tensile fracture toughness: hybrid ANN-WOA model approach. Rudarsko-geolosko-nafini Zbornik. 39 (3), 1–12 (2024).
Fadaee, M., Mahdavi-Meymand, A. & Zounemat-Kermani, M. Suspended sediment prediction using integrative soft computing models: on the analogy between the butterfly optimization and genetic algorithms. Geocarto Int. 37 (4), 961–977 (2020).
Rouhani, M. M. & Farrokh, E. Chisel Bits cutting force Estimation using XGBoost and different optimization algorithms. Comput. Geotech. 172, 106465 (2024).
Xu, D. J. et al. Research on height zoning prediction of water-conducting fracture zone under the control of different overburden rock types in North China coal-rich region. Coal Geol. Explor. 53 (3), 177–189 (2025).
Funding
Supported by the National Key Research and Development Program of China (Grant No. 2024YFC3909301), the National Natural Science Foundation of China (Grant No. 52204161, 52574177) and the Graduate Research and Innovation Projects of Jiangsu Province (Grant No. KYCX24_2859).
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.T., H.T. and D.Z.; methodology, Z.T., H.T.; software, H.T., C.R., Y.S.; validation, C.R., X.G.; data curation, H.T., C.R., Y.Z.; writing—original draft preparation, Z.T., H.T., D.Z.; writing—review and editing, D.Z., G.F., C.R., Z.W.; supervision, G.F., C.R. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tang, Z., Tong, H., Zhang, D. et al. Predicting water-conducting fracture zone height in three-soft coal seams using a BOA-MLP model. Sci Rep 16, 2723 (2026). https://doi.org/10.1038/s41598-025-32442-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32442-8
