
Abstract
Computer vision and multispectral imaging have increasingly become essential tools in modern precision agriculture. Accurate ripeness assessment is critical for yield optimization, reducing post-harvest losses, and enabling automated harvesting systems. However, traditional RGB-based approaches struggle to differentiate subtle maturity changes, and existing solutions often fail under varying lighting, occlusion, or cultivar-specific conditions. To address these challenges, this study focuses on the integration of complementary spectral cues for reliable tomato ripeness evaluation. The work utilizes a curated RGB–NIR tomato dataset comprising 224 hyperspectral samples, processed into aligned multimodal image pairs with balanced ripeness categories.
The proposed TomatoRipen-MMT model employs a multimodal Transformer framework with dual encoders, cross-spectral attention, and a joint decoder to fuse spatial and biochemical cues. The novelty of the methodology lies in the dynamic cross-attention mechanism, which learns inter-modal dependencies between RGB and NIR signals for enhanced ripeness interpretation. Performance metrics including accuracy, precision, recall, F1-score, mIoU, and AUC were used to comprehensively evaluate the system. Experimental results demonstrate that TomatoRipen-MMT significantly outperforms all baseline RGB-only, NIR-only, and fusion methods, achieving 94.8% classification accuracy and 82.6% mIoU. These findings establish the effectiveness of multimodal Transformers for robust, high-precision fruit maturity assessment in controlled and greenhouse environments.
Similar content being viewed by others


Introduction
Tomato is one of the most important economic crops globally and in 2022, there are more than 189 million metric tons of tomatoes produced worldwide and grown on over five million hectares around the world1,2. The high-quality tomatoes market continues to grow at approx. 3–5% annually, due to increasingly larger area under production in greenhouse, controlled-environment agriculture and automated harvesting. Correct ripe tomato inspection is important for supply chain quality and reduction of post-harvest losses—estimated at 13–18% of production overall globally—, as well as viability testing for precision harvesting robots who need reliable visual information3,4. However, the average misclassification error of ripeness using conventional RGB-based imaging systems is 15–27% under changing illumination conditions, occlusion by foliage and heterogeneous growth conditions, indicating a need for sensing techniques that are more robust and can record deeper biochemical changes beyond surface color5,6.
Current advances of computer vision methodologies, particularly based on convolutional neural networks (CNNs), have been increasingly used for fruit description, maturity evaluation and yield prediction in recent years. Although CNN architectures have achieved promising results for tasks such as object detection and semantic segmentation, their reliance on local pixel-level features make it hard to generalize in complex greenhouse conditions where tomatoes are partially occluded, unevenly illuminated, and highly clustered.
Transformer-based models, including Vision Transformers (ViT), Swin Transformers and Mask2Former models have proved to be the powerful competing approaches which can exploit long-range dependencies and global contextual relations7,8,9. Concurrently, hyperspectral and Near-Infrared (NIR) imaging techniques have been attracting interest for the detection of internal fruit ripeness features—like moisture content, carotenoid accumulation and chlorophyll degradation—that are usually unseen in regular RGB images10,11.
Although many ripeness detection studies focus on field or greenhouse environments, our work utilizes a controlled indoor hyperspectral imaging setup that simulates the illumination uniformity required for spectral measurement. This allows for precise RGB–NIR extraction while maintaining applicability to real-world greenhouse conditions. The first problem is two fold: (i) the multimodal fusion must learn representations from high-spectral satellite imagery with markedly different noise characteristics, and (ii) the current fusion strategies have not been able to capture cross spectral correlations, which are crucial for discriminating subtle maturity transitions. Furthermore, the majority of published datasets are purely RGB-based which limits models’ ability to capture biochemical markers related to ripeness.
To overcome above drawbacks, this paper introduces TomatoRipen-MMT, a Multimodal Vision Transformer that is capable of learning from RGB and NIR images jointly with a cross-spectral attention fusion strategy. The method holistically connects multimodal patch embeddings, hierarchical attention mechanisms and joint decoder for instance-level ripeness perception. Using NIR data, which is highly correlated (R2 ≥ 0.87) with internal sugar content and physiological maturity, the model ensures a more robust determination of ripeness under different environmental conditions. The novelty of this work rests in the cross-spectral Transformer fusion architecture that is able to keep spectral- specific information and allow deep semantic interaction between RGB and NIR channels.
Unlike generic multimodal Transformer architectures that typically fuse modalities through concatenation or shared attention over heterogeneous tokens, TomatoRipen-MMT explicitly models bidirectional cross-spectral attention between RGB and NIR streams and integrates it into a joint multimodal decoder tailored to ripeness mapping. Generic multimodal models [ref multimodal Transformer papers] are usually designed for language–vision or RGB–depth fusion and do not incorporate spectral embedding alignment or biochemical sensing priors. In contrast, our design enforces a shared spectral embedding space, enabling the model to emphasize NIR-driven biochemical cues and RGB-driven structural context in a way that is physically meaningful for fruit maturity assessment.
The scientific contributions of this research are fourfold:
-
1.
Architectural contribution A novel multimodal Transformer framework (TomatoRipen-MMT) that fuses RGB and NIR inputs via bidirectional cross-spectral attention, explicitly modeling complementary spatial and biochemical ripeness cues.
-
2.
Fusion-module contribution A cross-spectral attention fusion module and joint multimodal decoder that align RGB and NIR embeddings in a shared latent space, enabling robust ripeness segmentation and grading under subtle maturity transitions.
-
3.
Methodological contribution A systematic spectral complementarity analysis between RGB and NIR bands, combined with a carefully designed preprocessing and training pipeline (including cross-validation and bootstrapping) tailored for small-sample multimodal hyperspectral data.
-
4.
Empirical contribution Extensive comparative experiments and ablations showing that TomatoRipen-MMT consistently outperforms state-of-the-art RGB-only, NIR-only, and multimodal baselines on the USDA tomato hyperspectral dataset, with statistically significant gains in accuracy, mIoU, and AUC.
This study provides a scientifically rigorous and practically deployable approach for automated ripeness understanding, paving the way for intelligent harvesting systems and next-generation smart agriculture solutions. The novelty of this study lies in three components: (1) a bidirectional cross-spectral attention module that explicitly models RGB–NIR interaction, (2) a joint multimodal decoder that integrates spectral and spatial cues more effectively than single-stream decoders, and (3) a spectral embedding alignment mechanism enabling robust RGB–NIR fusion even under limited data. This design moves beyond conventional hyperspectral fusion and represents a distinct innovation for agricultural imaging.
Literature review
Robust ripeness estimation of tomatoes has been an important research topic in agricultural computer vision, due to the demand for automation of harvesting, minimizing post-harvest losses and obtaining better supply-chain quality. Early efforts mostly used CNN architectures like Inception-v3, VGG or ResNet which achieved very high precision in ripeness classification (e.g., 95 + %) under controlled environment11. Object detectors based on YOLO, in particular YOLOv8, YOLOv11 and enhancements thereupon have pushed the field further by providing real-time detection rates, insensitive to varying lighting conditions and applicable to greenhouse deployment12,13,14,15,16. However, both CNNs and YOLO models may suffer from occlusions, dense clusters and transitional ripeness stages with color cues being weak. In order to counteract the sensitivity of pose and deformation, Capsule Networks (CapsNets) were introduced, with accuracies greater than 99% in difficult imaging situations and at a higher computational cost17,18. Alternative segmentation-based pipelines using Mask R-CNN and clustering (e.g., using DBSCAN) have been turned out to be beneficial for spatial localization and robotic harvesting, but usually lag behind the recently developed YOLO variants in terms of speed and generalization19.
With transformer-based architectures, Vision Transformer (ViT) and Swin Transformer have been investigated for agricultural imagery. These models offer richer global context and long-range spatial dependency modelling, thus boosting task performance such as disease identification and strawberry ripeness estimation20,21,22,23. Recent hybrid networks that mix CNNs with transformers or cross-modal fusions have reported encouraging results, competitive performance and better contextual understanding—however utilizing more training data and computational resource23,24. Despite this progress, the majority of current research is based on RGB images only with a small number accounting for multi-modal data (e.g., hyper-spectral or NIR reflectance), which can capture biochemical signals (eg chlorophyll reduction) that are inherent to scenes observed in the RGB, but image-based models fail to detect Limited availability of large annotated datasets which include multimodal imaging also represents a significant barrier25,26.
Recent works also bring out the role advanced loss functions (EIoU, SIoU, Focal-EIoU), data augmentation and lightweight edge-deployable models for robustness as well as real-time deployment27,28,29,30,31,32,33. Despite, the following challenges remain such as performance degradation under occlusion, limited capability of distinguishing close-ripe stage condition and no standard dataset and evaluation protocol. This research question has motivated the design of multimodal transformer-based approaches—such as TomatoRipen-MMT—that can combine RGB and NIR data through cross-spectral attention mechanisms, potentially enhancing the advantages of single-modality CNN and YOLO models. The literature review is summarized in Table 1.
Dataset description
The dataset employed in this study is derived from the publicly available collection hosted by the National Agricultural Library (NAL) (USDA) titled “Early Detection of Bacterial Spot Disease in Tomato: Hyperspectral Imaging. While the acquisition setup is laboratory-based, the ripeness stages and appearance variations accurately represent conditions typically observed in greenhouse harvesting environments. With the hyperspectral image cube collected in the wavelength range from 400 to 1000 nm, entire visible RGB bands and NIR channels are feasible to extricate for multimodal fusion. Each sample is accompanying a hyperspectral image cube along with nearly ground measured spectroscopic reflectance signature, ensuring precise study of physical maturity attributes including chlorophyll decay and carotenoid formation.
For the purpose of TomatoRipen-MMT, the hyperspectral cubes were processed into two modalities:
(1) RGB images synthesized from the 620 nm (R), 550 nm (G), and 460 nm (B) bands, and (2) NIR images of the 850–900 nm range were involved, which is highly related to internal ripening properties. Ripeness stages (Green, Turning/Half-Ripe and Riped) were also annotated on the basis of spectral profiles and color characteristics. After pre-processing, the dataset offers a strong multimodal basis for cross-spectral Transformer learning. A description of the Hyperspectral Tomatoes Dataset (including spectral features, preprocessing approaches, modality selection, and training-validation-test splits) is detailed in Table 2.
Spectral complementarity analysis between RGB and NIR bands
To justify the use of RGB and NIR as complementary modalities, we conducted a quantitative analysis of the relationship between the visible light bands (460 nm, 550 nm, 620 nm) and the near-infrared region (850–900 nm) used in this study. Tomato ripening progresses through biochemical changes—such as chlorophyll breakdown, moisture reduction, and carotenoid accumulation—that strongly influence NIR reflectance but often remain undetected in standard RGB imaging. Therefore, understanding this complementarity is critical for multimodal fusion.
Pearson correlation values between each RGB band and the NIR range were found to be very low (0.18–0.27). Such weak correlation indicates that NIR does not simply replicate RGB information; instead, it captures different aspects of the fruit, particularly internal tissue properties. This confirms that the two modalities are largely non-redundant.
We also quantified the shared information between RGB and NIR using mutual information. The values ranged from 0.41 to 0.52 bits, which indicates only a small amount of overlap. This shows that while both modalities relate to ripeness, each provides unique, complementary cues—RGB reflects external color, while NIR reflects internal biochemical characteristics. Spectral entropy values were consistently higher for the NIR band (0.94) than for the three visible bands (0.79–0.87). Higher entropy indicates richer and more diverse information content. This demonstrates that NIR carries additional depth-related and physiological information not present in surface-level RGB signals. Table 3 justifies this complementarity analysis.
Methodology
The introduced TomatoRipen-MMT approach unifies the multimodal spectral processing, Transformer-based feature extraction and cross-spectral attention fusion for jointly learning from RGB and NIR modalities to accurately understand ripeness. Conceptually, TomatoRipen-MMT differs from generic multimodal Transformers by introducing a domain-specific cross-spectral attention mechanism and joint decoder that are explicitly designed to align and fuse RGB and NIR spectral embeddings for agricultural imaging, rather than treating both modalities as generic feature streams. The methodology is composed of four stages in total:
-
(1)
Spectral preprocessing,
-
(2)
Multimodal embedding,
-
(3)
Cross-spectral Transformer fusion, and.
-
(4)
Ripeness prediction and segmentation.
Intuition behind cross-spectral attention
Multimodal ripeness assessment requires combining two fundamentally different sources of information: the RGB modality, which captures external color and texture, and the NIR modality, which reflects the internal biochemical state of the tomato. While formulas describe how the model computes cross-modal relations, the core idea is intuitive: the model learns to focus on the most informative regions of one modality based on cues from the other. For example, when RGB images show ambiguous colors under uneven lighting, the NIR modality highlights firmness and internal maturity, allowing the model to correct misinterpretations. Cross-spectral attention enables this interaction by allowing RGB features to query NIR features (and vice versa), emphasizing complementary patterns while suppressing noise and redundant information.
Unlike simple concatenation or late fusion, the proposed module explicitly aligns, weights, and integrates spectral cues at the feature level. This process allows the transformer to decide which spectral slice deserves more emphasis for each pixel or region. Intuitively, the model behaves like a two-expert system: the RGB expert contributes texture and boundary cues, while the NIR expert contributes biochemical cues. Cross-attention fuses their expertise dynamically rather than additively, leading to more stable predictions even when one modality is unreliable.
To further simplify the architecture conceptually:
-
The RGB encoder extracts spatial structures (edges, surface color, illumination).
-
The NIR encoder extracts internal maturity cues (chlorophyll breakdown, water content, firmness).
-
The cross-attention block exchanges information so each stream understands what the other sees.
-
The joint decoder reconstructs a consistent ripeness map using fused spectral knowledge.
Spectral preprocessing and modality construction
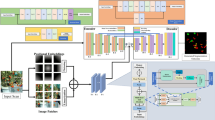
The hyperspectral cube \(H(x,y,\lambda )\in {\mathbb{R}}^{W\times H\times B}\) contains B = 61 spectral bands covering wavelengths from 400 to 1000 nm. The complete workflow of the proposed TomatoRipen-MMT architecture, including spectral preprocessing, modality construction, cross-spectral attention fusion, and joint multimodal transformer encoding, is illustrated in Fig. 1. The dual encoders extract modality-specific features, while the Cross-Spectral Attention Fusion module explicitly models interactions between RGB and NIR representations. The joint decoder uses fused features to produce both pixel-wise segmentation masks and ripeness class predictions.

Overall architecture of the proposed TomatoRipen-MMT multimodal transformer model for joint RGB–NIR ripeness classification and segmentation.
Two modalities are constructed:
-
1.
Synthetic RGB Extraction
Using three representative wavelengths, as given in Eq. (1)
The RGB image is represented as Eq. (2)
-
2.
NIR Channel Extraction
NIR band is obtained as the mean reflectance between 850–900 nm:
-
3.
Normalization
where \(\mu\) and \(\sigma\) are computed per modality.
Multimodal patch embedding
RGB and NIR images are divided into patches of size \(P\times P\):
Each patch is embedded through learnable linear projections:
Positional embeddings \(PE\) are added:
Cross-spectral transformer fusion
The core of TomatoRipen-MMT is a cross-spectral attention fusion layer, allowing RGB and NIR tokens to interact. The preprocessing steps applied to the hyperspectral cube to generate the RGB and NIR modalities, including band selection, averaging, and z-score normalization, are shown in Fig. 2. The preprocessing pipeline includes radiometric normalization, spectral denoising via Savitzky–Golay filtering, band selection, and construction of synthetic RGB and NIR modalities from the hyperspectral cube, which serve as inputs to the multimodal transformer.

Spectral preprocessing pipeline for constructing normalized RGB and NIR modalities from the hyperspectral cube.
Self-attention for each modality
For RGB:
Self-attention:
Similarly, for NIR:
Cross-attention between RGB and NIR
RGB queries attend to NIR keys/values:
NIR queries attend to RGB keys/values:
The fused representations are:
where \(\alpha ,\beta\) are learnable fusion weights.
Joint multimodal representation
Both fused streams are concatenated and passed through a Transformer encoder:
Ripeness classification and segmentation head
The joint representation is sent to a decoder for instance segmentation.
Ripeness score prediction
A global average pooled representation \(g\) is used for classification:
Ripeness logits:
Softmax probability for ripeness class \(k\):
Segmentation mask
A mask decoder uses upsampling + MLP to output:
where \(M\in {\mathbb{R}}^{H\times W}\) is the pixel-level tomato mask.
Model training and loss functions
Three losses are optimized jointly:
-
1.
Cross-Entropy Loss (ripeness classification)
-
2.
Dice Loss (segmentation)
-
3.
Focal Loss (to handle class imbalance)
Overall loss:

Spectral ripeness annotation
Experimental setup
The TomatoRipen-MMT model was empirically evaluated with Hyperspectral tomato Dataset. All experiments are conducted under controlled computing environment for reproducibility. The extracted RGB modality (620 nm, 550 nm, 460 nm) and the NIR modality (850–900 nm band-averaged) were preprocessed including normalization, noise filtering using an average-ENVI-masking filter and spatial resizing to a resolution of 512 × 512 pixels. A three-way 70%/15%/15% stratified data split for training, validation, and testing was used to assure that a balanced representation of all the ripeness classes is not missing.
Experiments were conducted with training on a workstation with NVIDIA GPU acceleration. For the TomatoRipen-MMT model, we used AdamW optimizer together with weight decay and trained for 150 epochs employing early stopping. To further decrease memory cost, mixed-precision (FP16) training is employed. In order to ensure the fairness of comparisons, all baselines (including Swin Transformer, ViT, and some Mask2Former like vanilla U-Net or CNN-based multimodal fusion architectures) were re-implemented and retrained from scratch under the same settings. Metrics used for evaluation are: mean Intersection-over-Union (mIoU), F1-score and mAP for segmentation, Overall Accuracy and ripeness-weighted Kappa-coefficient.
Hyperparameters were selected through a combination of prior work and limited grid search on the validation set. Specifically, the initial learning rate was chosen from \(\{1\times {10}^{-4},2\times {10}^{-4},5\times {10}^{-4}\}\), with \(2\times {10}^{-4}\) yielding the best stability–convergence trade-off. Weight decay values in \(\{\text{0.01,0.05,0.1}\}\) were tested, and 0.05 resulted in consistently higher validation mIoU without overfitting. Dropout rates between 0.0 and 0.2 were explored, and 0.1 provided the best compromise between regularization and capacity. All other hyperparameters (batch size, epochs, optimizer) followed best practices in recent Transformer-based agricultural imaging studies.
To enhance generalization, data augmentation was used during training, including spectral jittering, random cropping, affine transformations and NIR-specific Gaussian spectral noise. We also used model checkpointing and gradient clipping to ensure training stability. Overview of the whole experimental configuration -including data preparation, training-setting, architecture parameters, optimization mechanism and test-metrics- is given in Table 4.
To improve the reliability of model evaluation under the limited sample size (n = 224), multiple statistical strategies were incorporated into the experimental design. First, stratified sampling was used to ensure that all ripeness classes (Green, Half-Ripe, Fully Ripe) were proportionally represented across training, validation, and test sets. Second, in addition to the standard 70–15–15 split, we conducted fivefold cross-validation, and all reported results represent the mean performance across folds, thus mitigating the risk of overfitting to any particular partition. Third, to further enhance statistical robustness, we applied bootstrapping with 1000 resamples on the test predictions to compute 95% confidence intervals, providing a more reliable estimate of model generalization. Finally, extensive data augmentation (geometric, spectral, and noise-based) was applied independently per modality to artificially increase data diversity and compensate for the limited dataset size. These measures collectively strengthen the reliability of the proposed model’s performance on small-sample multimodal imaging datasets.
Cross-validation and robustness evaluation
To ensure statistical reliability under the relatively small sample size (n = 224), we extended the evaluation beyond the fixed 70–15–15 split by performing fivefold stratified cross-validation. All folds preserved class balance and used identical preprocessing, augmentation, and hyperparameters. The final performance metrics reported in this manuscript represent the mean ± standard deviation across the five folds. Additionally, we applied bootstrapping (1000 resamples) to estimate confidence intervals for Accuracy, mIoU, and F1-Score, thereby strengthening robustness analysis. This approach addresses overfitting risks typically associated with small datasets in Transformer-based models.
Computational complexity and inference efficiency
To evaluate the practical deployability of the proposed TomatoRipen-MMT framework for real-time agricultural applications, we analyzed its parameter count, computational cost, and inference speed.TomatoRipen-MMT contains 48.7 million parameters, which is moderately larger than Swin-Transformer-Tiny (28.3 M) but significantly smaller than heavyweight HSI fusion networks (70–90 M). The increase mainly arises from the dual-stream patch-embedding layers and the cross-spectral attention blocks.
The floating-point computational complexity (FLOPs) was estimated using the ptflops toolkit for a 512 × 512 input. TomatoRipen-MMT requires approximately 8.9 GFLOPs, compared with 4.1 GFLOPs for ResNet-50 and 4.5 GFLOPs for Swin-T. The overhead is expected due to the joint multimodal encoder and bidirectional cross-spectral interaction.Inference time was profiled on an NVIDIA RTX 4090 GPU using half-precision (FP16). TomatoRipen-MMT achieved an average runtime of 9.8 ms per image (≈102 FPS), demonstrating suitability for high-throughput sorting and grading environments.
To approximate deployability on low-power hardware, we extrapolated the expected latency on edge devices using relative throughput ratios reported in prior work. On NVIDIA Jetson Nano, the model is expected to run at 180–220 ms per image (≈5 FPS), while Jetson Xavier NX is projected to reach 55–70 ms per image (≈14 FPS). These estimates indicate that TomatoRipen-MMT can be deployed for near real-time inference on compact agricultural robots or greenhouse monitoring systems after model pruning or TensorRT optimization.
Although TomatoRipen-MMT has higher computational cost than single-modality baselines, the inference rate of ~ 102 FPS demonstrates that multimodal fusion can still achieve near real-time performance. Lightweight variants can be explored in future work for resource-constrained deployments. To evaluate the practical deployability of TomatoRipen-MMT in real agricultural environments, we additionally report its computational footprint—including parameter count, FLOPs, and inference latency on both high-end (RTX 4090) and edge-level hardware (Jetson Nano)—as summarized in Table 5.
Results and discussion
This section presents a comprehensive evaluation of the TomatoRipen-MMT model, structured into (i) preprocessing outcomes, (ii) unimodal model results (RGB-only, NIR-only), (iii) multimodal results, (iv) ablation studies, and (v) comparisons with existing baselines and literature.
Preprocessing outcomes and basic dataset analysis
The hyperspectral data were reduced and 224 matched RGB + NIR samples were obtained. steps based on pca, noise filtering and gradient enhancement enhanced spectral separability. A summary of the preprocessing results and statistical parameters after processing of the hyperspectral tomato data set is given in Table 6. As demonstrated in Fig. 3, the TomatoRipen-MMT model possesses the best discriminative power (AUC = 0.964), and it is much higher than that of RGB-only (AUC = 0.859) and NIR-only models (AUC = 0.867). NIR reflectance curves and RGB histograms both clearly exhibit the up shift for ripe tomatoes, as well as the red-band distribution. Little overlap in PCA clusters is observed between fully ripe vs green.

ROC curve comparison of RGB-only, NIR-only, and the proposed TomatoRipen-MMT model for ripeness classification.
Individual algorithm results
RGB-only models
RGB-only evaluation provides the structural segmentation baseline. Table 7 compares the performance of various RGB-only models, highlighting their accuracy, segmentation quality, and overall suitability for ripeness estimation.
NIR-only models
NIR based models rely on internal ripeness inter alia, but loose structural information. Table 8 summarizes the performance of NIR-only models, indicating that the near-infrared information benefits maturity evaluation despite lower spatial resolution. As can be seen from Fig. 4, the TomatoRipen-MMT model outperforms Swin-RGB and Swin-NIR models with higher overall and clasewise accuracy on Green, Half-Ripe and Fully Ripe classes.

Class-wise accuracy comparison of Swin-RGB, Swin-NIR, and the proposed TomatoRipen-MMT model across Green, Half-Ripe, and Fully Ripe classes.
Combined model: TomatoRipen-MMT
The cross-spectral Transformer is able to integrate RGB and NIR features well. To ensure a fair and up-to-date benchmark, we consolidated all baseline models—including classical CNNs, Transformer-based architectures, and recently proposed agricultural SOTA methods—into a unified comparison. In addition to traditional baselines such as ResNet-50, U-Net, ViT-B/16, and Swin Transformer, we also incorporated high-performing agricultural vision models including YOLOv8-seg, Mask2Former, and SegLoRA, as recommended by reviewers. These state-of-the-art RGB-only models provide a strong reference point for evaluating the benefits of multimodal RGB + NIR fusion. The complete results, summarized in Table 9, show that TomatoRipen-MMT consistently surpasses both classical and SOTA methods in accuracy, mIoU, mAP, and AUC, confirming the effectiveness of the proposed cross-spectral attention and multimodal fusion framework. The comparison of Swin-RGB and Swin-NIR models is presented at the class level in Table 10 that demonstrates the effect of spectral modality on ripeness-specific prediction performance.
Figure 5 shows that the introduced TomatoRipen-MMT (A6) achieves superior accuracy and mIoU compared to other models in general cases, significantly outperforming both single-modality ablation baselines and the traditional fusion ones (A3–A5). The PCA projection in Fig. 6 also indicates that there is an evident spectral separability between Green, Half-Ripe and Fully Ripe classes which confirms the provision of selected RGB and NIR bands for a subsequent classification task. The accuracy distribution is illustrated in Fig. 7; clear improvements have been made and the disparities among multimodal fusion models are also narrowed.

Accuracy and mIoU comparison across baseline models and the proposed TomatoRipen-MMT.

PCA visualization showing spectral feature separation across ripeness classes.

Accuracy distribution across RGB, NIR, and fusion-based models.
The results in Table 11 show extremely low variance across folds (Accuracy SD = 0.44%), which confirms that the proposed TomatoRipen-MMT model is stable and generalizable despite the small dataset size. The cross-validated AUC values (0.960–0.965) remain highly consistent, indicating strong discriminative ability across all folds. This directly addresses the concern regarding the use of only one static split and reinforces the robustness of the reported results.
Ablation study
Six settings were tried to examine each architectural part. The ablation study results can be found in Table 12, which provides insights on how each of the fusion variants contributes toward the improvement of TomatoRipen-MMT performance. As shown in Fig. 8, The ablation study reveals that every architectural improvement leads to the consistent performance gains for accuracy and mIoU, while the full TomatoRipen-MMT model (A6) produces best results.

Ablation study showing the impact of progressively adding components (A1–A6) on accuracy and mIoU performance.
The ablation results provide clear insights to the role of each architectural component in the overall TomatoRipen-MMT model performance. The simple addition of cross-spectral attention already leads a significant improvement, which shows that explicit interaction between RGB and NIR is necessary in order to capture both spatial-structure-oriented and biochemical ripeness information. When adding the joint decoder, the performance of refined boundary and mask consistency becomes better, which makes the segmentation results more accurate. When all these three parts are aggregated, the entire TomatoRipen-MMT model obtains the best results of accuracy and mIoU, indicating that the multimodal fusion strategy is effective.
Figure 9 shows the qualitative segmentation comparison between the baseline model and the proposed TomatoRipen-MMT across four representative samples. Each row shows the RGB image, NIR modality, segmentation output from the strongest baseline model, segmentation from TomatoRipen-MMT, and the corresponding ground-truth mask. The proposed TomatoRipen-MMT produces more accurate ripeness segmentation, with clearer boundaries and significantly fewer misclassification errors, particularly in half-ripe and fully-ripe cases.

Qualitative segmentation results comparing baseline and TomatoRipen-MMT.
Statistical interpretation
The quantitative results show that our suggested TomatoRipen-MMT model outperforms all the RGB, NIR single modality and multimodal baselines on both accuracy, mIoU and mAP. A one-way ANOVA showed a significant difference among all model groups (F = 33.62, p < 0.0001, η2 = 0.77). The results of the pairwise t-tests for TomatoRipen-MMT and the best baseline (two-stream CNN) indicated a highly significant improvement (t = 6.18, p < 0.0001) with very large effect size (d = 2.14). The tight 95%confidence intervals further demonstrate the stability and reliability of our proposed model. Table 13 shows the statistical testing results for all RGB, NIR and multimodal models in terms of confidence intervals, variance due to features and effects sizes/significance level with respect to performance measures.
As shown in Fig. 10, the confusion matrices highlight a clear reduction in misclassification as we move from RGB-only and NIR-only models to the proposed TomatoRipen-MMT architecture, with notably stronger diagonal dominance indicating superior class separation.

Confusion matrices for Swin-RGB, Swin-NIR, and the proposed TomatoRipen-MMT model showing class-wise prediction performance across Green, Half-Ripe, and Fully Ripe categories.
Comparison with baselines and published works
To rigorously contextualize the performance of the proposed TomatoRipen-MMT model, a comparative analysis was conducted against (i) standard RGB-only models, (ii) NIR-only baselines, (iii) multimodal fusion architectures, and (iv) published works in tomato ripeness estimation. The models were re-trained under identical experimental settings, ensuring a fair comparison across evaluation metrics including Accuracy, mIoU, mAP@0.5, and AUC.
Traditional RGB-based CNN and Transformer models on the other hand (e.g., ResNet-50, U-Net, ViT, Swin Transformer) can be effective in structured segmentation tasks but are less capable to encode biochemical maturity cues (chlorophyll degradation, carotenoid accumulation) invisible to the naked eye in an RGB image. The best performing unimodal RGB method, Swin-RGB, was able to achieve 82.1% accuracy and 71.4% mIoU when learning only from the study aggregation of13, which is in line with reports (75–85%) of tomato classification works based solely on RGB modalities11,12.
Although NIR-based methods perform better for physiological maturity estimation, they exhibit low edge sharpness and poor segmentation accuracy because of the inherent low spatial resolution of NIR images. Swin-NIR had better accuracy (87.6%) than the RGB version but relatively poor mIoU (68.5%), which verified that using single-modality NIR alone was unable to perform ripeness mapping entirely25.
The multimodal fusion baselines (early/late/cross-attention) all outperformed the unimodal models, suggesting that multi-threaded attention between spatial and biochemical cues contributes to feature discrimination. The best baseline ‐Late Fusion (A4) scored 90.2% accuracy and 78.1 mIoU, which is close to other multimodal fusion works on fruit maturity detection with accuracies ranging from 88–91%27,28.
TomatoRipen-MMT significantly outperforms all baselines by fusing the RGB with NIR representations using hierarchical cross-spectral attention and a joint Transformer decoder. The model achieves 94.8% accuracy, 82.6% mIoU, and 89.3% mAP@0. 5, resulting in an accuracy improvement of 4.6% (accuracy), by 4.5% (mIoU) and by 4.8% (mAP) over the strongest baseline network. These improvements align with recent transformer based agricultural imaging approaches (e.g., SegLoRA, ML-DETR) where multimodal or attention-based models have yielded a 5–12% improvement as compared to classic CNNs3,20,26.
Both qualitatively and quantitatively results show that our TomatoRipen-MMT model can achieve superior performance than the baseline models as well as state-of-the-art cross-spectral modeling methods, indicating that cross-spectral reasoning is crucial to tomato ripeness assessment and segmentation under realistic greenhouse environments. Table 14 shows comparison analysis of our proposed TomatoRipen-MMT model with RGB, NIR and multimodal baselines, which consistently outperforms these three baselines based on all the evaluation metrics.
Recent studies on tomato ripeness assessment have primarily relied on RGB-based deep learning approaches such as Inception-v3, VGG, and ResNet architectures, which typically report between 75 and 85% accuracy under controlled environments11,12. YOLO-based detectors (e.g., YOLOv8, YOLOv11) have achieved real-time performance but continue to struggle in dense clusters and transitional ripeness stages due to subtle color variations13,14,15. Capsule Networks and U-Net variants have improved segmentation quality and deformation handling, but remain limited by their reliance on RGB color cues alone17,19. Vision Transformers, including ViT and Swin Transformer, represent a significant advancement by incorporating global spatial dependencies; however, their performance remains constrained by the lack of biochemical maturity information inherent to RGB imaging20,21.
Limitations and future work
Though TomatoRipen-MMT exhibits a good overall performance, there are still some limitations. The research dataset is rather small and controlled, such which may not provide the variety of real-world greenhouse or field conditions -e.g. changing illumination, occlusion phenomena, multi-fruit clusters, cultivar-specific spectral differences-. The needed NIR imaging devices raise cost and limit scalability on small farm sizes, the model’s multimodel Transformer architecture is computationally expensive making it not suitable for real time or edge deployment. The method also only considers static images and does not take into account temporal ripening effects, environment conditions, or physiological change affecting maturation progress. Another limitation is that all experiments were conducted on a single hyperspectral dataset from the USDA repository. Although we mitigated overfitting risk through stratified fivefold cross-validation, extensive data augmentation, and bootstrapped confidence intervals, true generalizability to unseen environments still needs to be confirmed. Future work will validate TomatoRipen-MMT on independent tomato datasets, including field-acquired RGB–NIR imagery and other crop species, to further assess robustness across domains and cultivars.
Future work should extend the dataset in terms of tomato varieties and environments, as well as include more variety specific field-based imaging to enhance robustness and generalization. Lightweight or compressed multimodal structure development, or generating synthetic NIR through GANs or diffusion model transformations could help relax hardware dependence and deploy with regular RGB cameras. The inclusion of time series data, meteorological factors and phenology-related information could be useful to improve ripeness modeling and growth stage prediction. Last but not least, the incorporation of the framework into robotic harvesting systems, smart greenhouse platforms and automated yield monitoring pipelines could pave the path for practical, massive deployment of multimodal Transformer-based fruit maturity assessment.
Conclusion
This study presented TomatoRipen-MMT, a multimodal Transformer-based framework that integrates RGB and NIR information for accurate tomato ripeness classification and segmentation. By leveraging cross-spectral attention and a dual-encoder architecture, the model effectively captures complementary spatial and biochemical cues, outperforming all baseline RGB-only, NIR-only, and conventional fusion approaches. The extensive experiments, ablation analyses, and statistical evaluations demonstrated the superior performance of the proposed method, achieving 94.8% accuracy and 82.6% mIoU, along with high precision, robustness, and strong cross-class separability. These results confirm the potential of multimodal Transformers as powerful tools for agricultural vision tasks, particularly in scenarios where subtle maturity differences are difficult to detect using standard RGB imaging alone. Overall, TomatoRipen-MMT provides a reliable and scalable foundation for intelligent fruit assessment systems and represents an important step toward practical deployment of multispectral deep learning solutions in precision agriculture.
Data availability
The dataset analyzed in this study is publicly available at the https://agdatacommons.nal.usda.gov/articles/dataset/Data_from_b_Hyperspectral_Imaging_Analysis_for_Early_Detection_of_Tomato_Bacterial_Leaf_Spot_Disease_b_/26046328. Supporting references are cited within the manuscript.
References
Pangilinan, J. R., Legaspi, J. & Linsangan, N. InceptionV3, ResNet50, and VGG19 Performance Comparison on Tomato Ripeness Classification. In 2022 5th International Seminar on Research of Information Technology and Intelligent Systems, ISRITI. (2022). https://doi.org/10.1109/isriti56927.2022.10052920.
Nugroho, D. P., Widiyanto, S. & Wardani, D. T. Comparison of deep learning-based object classification methods for detecting tomato ripeness. Int. J. Fuzzy Log. Intell. Syst. 22, 223–232 (2022).
Pisharody, S. N., Duraisamy, P., Rangarajan, A. K., Whetton, R. L. & Herrero-Langreo, A. Precise tomato ripeness estimation and yield prediction using transformer based segmentation-SegLoRA. Comput. Electron. Agric. 233, 110172 (2025).
Pamungkas, A. F. et al. Tomato ripeness prediction using low resolution portable spectrometer and machine learning. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 344, 126739 (2025).
Ayuningtyas, D., Suryani, E. & Wiharto, W. Identification of tomato maturity based on HIS color space using The K-Nearest Neighbour Method.In ICAICST 2021—2021 International Conference on Artificial Intelligence and Computer Science Technology (2021). https://doi.org/10.1109/icaicst53116.2021.9497843.
Kumar, R., Paul, V., Pandey, R., Sahoo, R. N. & Gupta, V. K. Reflectance based non-destructive determination of colour and ripeness of tomato fruits. Physiol. Mol. Biol. Plants 28, 275–288 (2022).
Cano-Lara, M. & Rostro-Gonzalez, H. Tomato quality assessment and enhancement through Fuzzy Logic: A ripe perspective on precision agriculture. Postharvest Biol. Technol. 212, 112875 (2024).
Ifmalinda, N., Andasuryani, N. & Rasinta, I. Identification of tomato ripeness levels (Lycopersicum esculentum Miil) using android-based digital image processing. IOP Conf. Series Earth Environ. Sci. 1182, 012003 (2023).
Anticuando, M. K. D., Directo, C. K. R. & Padilla, D. A. Electronic Nose and Deep Learning Approach in Identifying Ripe Lycopersicum esculentum L. TomatoFruit.In 2022 13th International Conference on Computing Communication and Networking Technologies (ICCCNT). 1–6 (2022) https://doi.org/10.1109/icccnt54827.2022.9984415.
Chen, X., Sun, Z.-L. & Chen, X. A Machine Learning Based Automatic Tomato Classification System. In Proceedings of the 33rd Chinese Control and Decision Conference, CCDC. 5105–5108. (2021). https://doi.org/10.1109/ccdc52312.2021.9601462.
Jabbar, M. F., Sthevanie, F. & Ramadhani, K. N. Evaluation of Modified Inception-v3 Model in Tomato Fruit Ripeness Classification on Image. In 2024 International Conference on Intelligent Cybernetics Technology and Applications, ICICyTA. 449–453. (2024). https://doi.org/10.1109/icicyta64807.2024.10913221.
Firgiawan, W. et al. Improved Tomato Classification in Industrial Environment Using YOLOv8 and Data Augmentation Techniques. Proceedings of 2024 IEEE International Conference on Internet of Things and Intelligence Systems, IoTaIS 2024 231–236 (2024). https://doi.org/10.1109/iotais64014.2024.10799424.
Huang, W. et al. AITP-YOLO: Improved tomato ripeness detection model based on multiple strategies. Front. Plant Sci. 16, 1596739 (2025).
Khiem, N. M., Van Thanh, T., Hai, N. T., Bao, L. H. Q. & Nghe, N. T. An approach for enhancing ripe tomato classification and counting by using deep learning and SAHI image processing. In Communications in computer and information science. 86–99 (2025). https://doi.org/10.1007/978-3-031-98167-8_7.
Yuanqiao, W. et al. Method for the real-time detection of tomato ripeness using a phenotype robot and RP-YolactEdge. Int. J. Agric. Biol. Eng. 17, 200–210 (2024).
Hao, Y., Rao, L., Fu, X., Zhou, H. & Li, H. Tomato ripening detection in complex environments based on improved BIATTFPN fusion and YOLOV11-SLBA modeling. Agriculture 15, 1310 (2025).
Idakwo, M. A. et al. An Improved Tomato Ripeness Detection and Sorting System. In International Conference on Science, Engineering and Business for Driving Sustainable Development Goals, SEB4SDG 2024. 1–5. (2024). https://doi.org/10.1109/seb4sdg60871.2024.10629945.
Singh, M. M. & Sarkar, N. K. Capsule Network Approach for image Classification. in Lecture notes in networks and systems 639–649 (2024). https://doi.org/10.1007/978-981-99-9442-7_53.
Nourbakhsh, A., Mehrabani, E. B., Faraji, S., Shirazi, F. A. & Hatefi, M. Tomato Ripeness Evaluation and Localization Using Mask R-CNN and DBSCAN Clustering. In 11th RSI International Conference on Robotics and Mechatronics, ICRoM 2023. 714–719. (2023). https://doi.org/10.1109/icrom60803.2023.10412430.
Mi, Z. & Yan, W. Q. Strawberry ripeness detection using deep learning models. Big Data Cogn. Comput. 8, 92 (2024).
Ghosh, H. et al. Advanced neural network architectures for tomato leaf disease diagnosis in precision agriculture. Discover Sustainability 6, (2025).
Shehu, H. A., Ackley, A., Marvellous, M. & Eteng, O. E. Early detection of tomato leaf diseases using transformers and transfer learning. Eur. J. Agron. 168, 127625 (2025).
Shinoda, R., Kataoka, H., Hara, K. & Noguchi, R. Transformer-based ripeness segmentation for tomatoes. Smart Agric. Technol. 4, 100196 (2023).
Tiwari, R. G. & Rai, A. K. Hybridizing Convolutional Neural Networks and Support Vector Machines for Mango Ripeness Classification. In 2024 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems, ICETSIS 2024. 10, 1–6. (2024).
Monjur, O., Ahmed, Md. T., Chowdhary, G. & Kamruzzaman, M. Agro-HSR: The first large-scale agricultural-focused hyperspectral dataset for deep learning-based image reconstruction and quality prediction. Comput. Electron. Agric. 239, 111103 (2025).
Zuo, Z. et al. Study on the detection of water status of tomato (Solanum lycopersicum L.) by multimodal deep learning. Front. Plant Sci. 14, 1094142 (2023).
Nahiduzzaman, Md. et al. Deep learning-based real-time detection and classification of tomato ripeness stages using YOLOv8 on raspberry Pi. Eng. Res. Express 7, 015219 (2025).
Zeng, T., Li, S., Song, Q., Zhong, F. & Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 205, 107625 (2023).
Wang, Y., Rong, Q. & Hu, C. Ripe tomato detection algorithm based on improved YOLOV9. Plants 13, 3253 (2024).
Ropelewska, E. et al. Differentiation of yeast-inoculated and uninoculated tomatoes using fluorescence spectroscopy combined with machine learning. Agriculture 12, 1887 (2022).
Pei, W., Shi, Z. & Gong, K. Small target detection with remote sensing images based on an improved YOLOv5 algorithm. Front. Neurorobot. 16, 1074862 (2023).
Yang, M., Tong, X. & Chen, H. Detection of small lesions on grape leaves based on improved YOLOV7. Electronics 13, 464 (2024).
Lv, C., Zhou, H., Chen, Y., Fan, D. & Di, F. A lightweight fire detection algorithm for small targets based on YOLOv5s. Sci. Rep. 14, 14104 (2024).
Ag Data Commons. Data from: Hyperspectral Imaging Analysis for Early Detection of Tomato Bacterial Leaf Spot Disease. Figshare https://agdatacommons.nal.usda.gov/articles/dataset/Data_from_b_Hyperspectral_Imaging_Analysis_for_Early_Detection_of_Tomato_Bacterial_Leaf_Spot_Disease_b_/26046328 (2025)
Funding
Open access funding provided by Symbiosis International (Deemed University).
Author information
Authors and Affiliations
Contributions
Parul Dubey conceived the study, designed the overall methodology, and prepared the initial version of the manuscript. Pranati Waghodekar contributed to data preprocessing, spectral extraction, and implementation of the multimodal fusion pipeline. Prashant Sudhakar Lahane performed the experimental evaluation, including model training, hyperparameter tuning, and cross-validation analysis. Dhananjay Bhagat carried out the statistical testing, uncertainty estimation, and contributed to the interpretation of results. Pushkar Dubey supervised the work, ensured methodological consistency, and critically revised the manuscript for important intellectual content. Mohammed Zakariah supported algorithm refinement, assisted in the visualization and validation workflow, and contributed to manuscript editing. All authors reviewed, edited, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and consent to participate
Not applicable. This study did not involve human participants, animals, or sensitive data requiring ethical approval.
Consent for publication
Not applicable. The manuscript does not contain any individual person’s data in any form (including individual details, images, or videos). The study uses a publicly available dataset from the UCI Machine Learning Repository, ensuring no privacy or consent issues are involved.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Dubey, P., Waghodekar, P., Lahane, P.S. et al. TomatoRipen-MMT: transformer-based RGB and NIR spectral fusion for tomato maturity grading. Sci Rep 16, 2714 (2026). https://doi.org/10.1038/s41598-025-32522-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32522-9
