
Abstract
Intrusion detection systems (IDS) leveraging federated learning (FL) are increasingly deployed in Internet of Things (IoT) environments to address distributed data and privacy constraints. However, generalization remains unclear because most evaluations rely on a single dataset, which risks overfitting to site-specific traffic, label taxonomies, and non-IID client mixtures. This study provides a comprehensive dataset-centric evaluation of FL-based IDS across three contemporary IoT/IIoT datasets: Edge-IIoTset (2022), CIC-IoT2023, and TII-SSRC-23 (2023), that differ in devices, feature distributions, and attack families. We benchmark three FL aggregation algorithms (FedAvg, FedProx, FedNova) with two deep learning backbones (LSTM and Transformer) to assess detection accuracy, cross-environment generalizability, convergence behavior, and communication cost. Methodologically, we construct non-IID clients by device or application type, harmonize labels to a common family-level schema, align features to the intersection set, and evaluate three regimes: in-domain, cross-dataset, and a combined multi-dataset federation. Results show that federated models approach centralized performance in-domain, with macro-F1 up to 98% and accuracies in the 92–98% range. Transformers consistently exceed LSTM by \(\approx\)1–2% points in macro-F1 at comparable communication budgets. Cross-dataset tests expose substantial degradation, with up to 30 percentage-point macro-F1 loss when models face unseen environments, underscoring the need for diverse training coverage. Combined multi-dataset federation substantially restores transfer, yielding \(\approx\)90% macro-F1 across datasets in the harmonized family-level setting. Under heterogeneous clients, FedProx improves stability by reducing round-to-round variance, while FedNova achieves target accuracy in fewer rounds and lowers communication by \(\approx\)15–25% relative to FedAvg. These findings indicate a practical recipe for deployment: prioritize attack and environment diversity through combined-dataset FL, select Transformer backbones where feasible, and use FedProx or FedNova to stabilize training and reduce communication in bandwidth-constrained IoT settings.
Similar content being viewed by others

Introduction
The rapid growth of the Internet of Things (IoT) has dramatically expanded the attack surface of networks, making intrusion detection an essential defense mechanism for IoT environments1. Machine learning-based IDS have shown promise in detecting anomalies in IoT traffic; however, traditional centralized training approaches require aggregating potentially sensitive data from distributed IoT devices to a central server2. This raises privacy concerns and practical challenges given the volume and heterogeneity of IoT network data. Federated learning (FL) has emerged as a compelling alternative that enables collaborative model training across distributed devices without sharing raw data3. In FL, devices (clients) train a shared model on local data and periodically exchange model updates with a central aggregator (server) using algorithms like Federated Averaging (FedAvg). This paradigm preserves data privacy and can reduce communication of large raw datasets over the network.
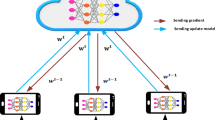
Recent studies have applied FL to IoT intrusion detection and shown that distributed training can achieve accuracy comparable to centralized IDS models4. Figure 1 illustrates a typical FL-based IDS architecture for IoT, where multiple client nodes (e.g. edge gateways or local servers) each train on local IoT network traffic and send model updates to a central server for aggregation using FedAvg. Through such iterative rounds, the global model learns to detect attacks collectively present across all clients. Prior works report that an FL IDS can be nearly as effective as a centralized model, while significantly reducing raw data transfer5. For example, in one study the federated model’s accuracy and F1-score approached that of training on all data centrally (within \(\sim\)1–2% difference)4.

FL architecture for intrusion detection in IoT (illustration of FedAvg aggregation). Clients (edge devices or local servers) perform several epochs of local model updates on their partition of the data, then send updates to a central server which averages them (FedAvg) to produce a global model. This iterative process (1–3) continues for multiple communication rounds until convergence.
Despite these advances, a crucial open question is how well FL-based IDS models generalize across different IoT environments and attack scenarios. Most existing evaluations train and test on the same dataset, risking overfitting to that dataset’s specific traffic patterns or attack types6,7. In reality, IoT deployments vary widely—from smart home networks to industrial IoT—and new attacks continually emerge. An IDS model trained on one dataset may underperform when faced with a different network context or novel attacks8. Researchers have thus highlighted the importance of attack diversity and dataset realism in developing robust IDS. The contribution of this paper is a systematic dataset-centric benchmarking of federated IDS models on multiple modern IoT/IIoT security datasets, to evaluate robustness and generalizability.
This work adopts a dataset-centric lens: we study generalization across distinct IoT/IIoT datasets and their differing class taxonomies, feature spaces, and distributions. We therefore operationalize “generalization” through three settings: (i) in-domain (single dataset), (ii) out-of-domain cross-dataset testing, and (iii) combined multi-dataset federated training with highly heterogeneous clients. Modeling temporal drift and incremental arrival of novel attacks is orthogonal to our goal and is left to future continual-FL studies.
Why a dataset-centric study? Each public IDS dataset has unique characteristics – background traffic profiles, sets of attack types (and their frequencies), feature representations, etc9. By comparing model performance per dataset and across datasets, we can identify how dataset attributes impact an FL model’s detection capabilities10. Our work leverages three recently released IoT/IIoT intrusion datasets that collectively cover a broad spectrum of attacks and network conditions:
-
Edge-IIoTset (2022)—a comprehensive dataset of IoT and industrial IoT traffic introduced by Ferrag et. al11. This dataset emphasizes realistic IIoT scenarios and was designed to support both centralized and federated IDS research.
-
CIC-IoT2023 (UNB CIC IoT Dataset 2023)—a large-scale IoT network intrusion dataset released by the Canadian Institute for Cybersecurity in 202312. This dataset was collected in a realistic IoT lab environment to provide a benchmark for “plug-and-play” NIDS development.
-
TII-SSRC-23 (2023)—a novel dataset by the Technology Innovation Institute (TII) that focuses on traffic diversity13. It was explicitly created to address the lack of variation in older datasets, providing enriched malicious samples and modern attack patterns (e.g., Mirai botnet traffic).
These datasets allow us to evaluate IDS models under different conditions: Edge-IIoTset combines IoT and IIoT with numerous attack families11, CIC-IoT2023 represents a large real-device network under coordinated attacks12, and TII-SSRC-23 offers highly diverse and fine-grained attack subtypes13. By training and testing FL models on each, and also testing models across datasets (to simulate deployment on unseen environments), we can assess model robustness and generalizability.
Architectural choices follow the data: we harmonize label spaces across datasets for combined training; align features to the intersection schema; and form clients by device/application groups to mirror realistic deployment. Evaluation emphasizes out-of-domain performance and communication-accuracy trade-offs, reflecting the premise that coverage of attack diversity is the main lever for transfer.
Furthermore, we incorporate two deep learning architectures widely used in sequence modeling and anomaly detection: an LSTM (Long Short-Term Memory) recurrent neural network and a Transformer encoder. LSTMs have been popular in IDS for modeling sequential packet/flow features and have shown strong results on IoT intrusion tasks14. Transformer-based models, with their attention mechanisms, have recently been explored for multi-class intrusion detection on the CIC-IoT2023 dataset and demonstrated improved accuracy by capturing complex feature interactions15. By evaluating both an LSTM and a Transformer in our experiments, we examine whether newer architectures yield benefits in an FL setting and if they generalize differently across datasets.
Our research contributions are:
-
A comprehensive evaluation of FL-based IDS on three contemporary IoT/IIoT security datasets, with detailed analysis of how dataset characteristics (attack diversity, class imbalance, etc.) affect detection performance.
-
Empirical comparison of three FL aggregation algorithms—FedAvg16, FedProx17, and FedNova18—in terms of detection metrics, convergence speed, and communication overhead. FedAvg is the standard baseline, FedProx introduces a proximal term to improve stability on heterogeneous data, and FedNova uses normalized averaging to address objective inconsistency when clients perform different amounts of local work.
-
Investigation of model generalizability: we test models trained on one dataset against the others to quantify performance degradation on unseen distributions, and explore a federated multi-dataset training scenario to see if combining data from all sources yields a more universal IDS.
Throughout, we report multiple metrics (accuracy, precision, recall, F1-score, AUC) and include data in tables and figures to illustrate key findings. The results provide practical insights for researchers and practitioners on how an IDS might perform when deployed in new IoT environments and highlight the importance of diverse training data for robust intrusion detection.
The rest of this paper is organized as follows. Section 2 reviews related work on IoT IDS datasets and FL algorithms. Section 3 describes the datasets and summarizes their attack profiles. Section 4 details our methodology, including the FL setup, models, and metrics. Section 5 presents the experimental results, divided into per-dataset performance, cross-dataset evaluations, analysis of communication efficiency, and discusses the implications of these results and potential improvements. Finally, Section 6 concludes the paper and suggests future research directions.
Related work
IoT/IIoT intrusion datasets
There is a long history of public datasets for network intrusion detection, but many widely used ones (KDD’99, NSL-KDD, UNSW-NB15, CIC-IDS2017, etc.) have limitations for modern IoT contexts. Traditional datasets often lack IoT-specific traffic and suffer from skewed class distributions (overwhelming benign traffic with only a few outdated attack types)19. In recent years, researchers have developed new datasets tailored to IoT and IIoT scenarios. For example, the TON_IoT 2020 dataset20 integrated telemetry from IoT sensors with network data, and Bot-IoT (2018)21 included IoT botnet traffic, but these too had shortcomings in diversity or realistic device behavior. The Edge-IIoTset dataset introduced in 2022 stands out by covering multiple IoT application domains and attack categories, specifically aiming to support both centralized and FL research.11 emphasize that Edge-IIoTset better reflects IIoT environments (including industrial sensor networks) and provides a comprehensive benchmark for evaluating intrusion detection methods at the network edge. Likewise, CIC-IoT2023 was created to address the gap of real-device, large-scale IoT traffic – it includes 105 devices ranging from smart cameras to light bulbs, with attacks like ARP spoofing, DNS poisoning, various DDoS floods, web exploitations, and the Mirai malware. Jony and Arnob, documented all 33 attack scenarios in CIC-IoT2023 and provided both raw pcap and extracted flow feature sets to facilitate research12. The TII-SSRC-23 dataset (released in 2023) pushes the envelope further by augmenting malicious traffic diversity: it launched 26 unique attacks with many variations (parameter tweaks, different intensities, etc.), grouped into 8 high-level traffic types13. This dataset was explicitly motivated by the observation that public datasets over-represent benign traffic and have “a scarcity of diverse malicious traffic,” which limits IDS models’ generalization. By enriching the variety of intrusions (while still reflecting realistic traffic patterns), TII-SSRC-23 establishes new baselines for both supervised and unsupervised IDS techniques. In our work, we leverage these three state-of-the-art datasets as representative testbeds to evaluate federated IDS approaches, as they collectively cover an unprecedented range of IoT attack behaviors and network conditions.
FL for IDS
FL was first introduced by Google in 2017 as a privacy-preserving distributed learning paradigm, and it has since been applied to various security domains including intrusion detection22. A number of recent studies examine FL for network IDS (NIDS), particularly in IoT settings where data is naturally distributed across devices or edge sites. For instance, Lu et. al23 used an FL approach on IDS data and found only minor accuracy loss compared to centralized training, demonstrating the viability of collaborative learning for security monitoring. Lazzarini et. al24 evaluated FL on the ToN_IoT and CIC-IDS2017 datasets using a simple neural network and FedAvg, confirming that a federated IDS could achieve around 97–99% accuracy in binary classification and high precision/recall close to the centralized model. They also experimented with alternative optimizers (FedAvgM, FedAdam) but observed FedAvg remained among the best in their scenario. Other works have proposed enhancements to FL for IDS: for example, research on aggregation algorithms has shown that FedAvg may struggle when client data are non-identically distributed (non-i.i.d.), which is common in intrusion detection (e.g., one client might see mostly one type of attack while another sees different attacks)25. The FedProx algorithm was developed to tackle such heterogeneity by adding a proximal term that keeps local model updates closer to the global model, preventing them from drifting too far due to local bias. Li et. al17 showed that FedProx yields more stable and accurate convergence than FedAvg in highly heterogeneous settings, improving test accuracy by up to 22% in some cases. We include FedProx in our comparison for precisely this reason – our federated scenarios involve heterogeneous attack distributions across clients. FedNova is another recent method which normalizes client updates by their number of local training steps, thereby eliminating objective inconsistency when clients perform different amounts of work18. This can occur if, say, one client has a larger dataset and does more epochs per round, inadvertently dominating the global update26. FedNova’s normalized averaging ensures the global model converges to a stationary point of the true objective (as if all data were considered uniformly). In an IDS context, if some clients generate more updates (e.g., a busy network segment vs. a quiet one), FedNova could improve fairness and convergence speed27. Prior work has analyzed FedNova under generic heterogeneity, but IoT-specific, dataset-aligned federation across multiple modern IDS corpora has not been systematically benchmarked. Our contribution is not a new optimizer or backbone but a dataset-centric evaluation protocol that spans single-dataset, cross-dataset, and combined multi-dataset regimes, where FedNova’s normalization materially changes convergence and communication in the presence of extreme client heterogeneity.
Deep learning models for IDS
Deep neural networks, including recurrent and attention-based models, are now prevalent in intrusion detection research28. RNNs (especially LSTMs) can model temporal dependencies in network traffic flows or sequences of packets, useful for detecting slow or multi-step attacks29. Several prior works report high accuracy using LSTM-based classifiers on IoT malware or attack detection tasks. For example, a recent LSTM approach on CIC-IoT2023 data achieved over 99% binary classification accuracy and strong multiclass performance for major attack categories (DDoS, spoofing, etc.), demonstrating LSTM’s effectiveness in capturing IoT traffic patterns30. Transformers, with their self-attention mechanism, offer an alternative that can capture long-range feature interactions without recurrence. Tseng et. al31 applied a Transformer model to the CIC-IoT2023 dataset, reporting slightly improved F1-scores over CNN and LSTM baselines for multi-class intrusion detection. They leveraged a Transformer encoder (without the decoder, since it’s a classification task) to process flow-based feature sequences, noting the model’s ability to handle the large feature set (46 features) and complex decision boundaries in the 33-class classification. In our experiments, we use an LSTM model and a Transformer encoder model of roughly comparable scale (we ensure both have similar order of magnitude in trainable parameters) as the IDS classifiers. This allows us to observe if one architecture has an advantage in federated training or in dealing with diverse data32. We do not heavily optimize the architectures, as our focus is comparative and on the FL aspect; however, the Transformer model does incorporate multi-head attention layers and positional encoding suitable for tabular time-series input (we follow design ideas from)33. Both models are trained as multi-class classifiers to identify either the specific attack type or class label for each input sample.
Our work intersects these areas by applying advanced FL algorithms and deep models to modern IoT IDS datasets. The related work suggests that FL can maintain high detection performance and that algorithms like FedProx/FedNova may yield benefits under data heterogeneity. It also highlights that using multiple datasets can uncover generalization issues that single-dataset studies miss. Next, we describe the datasets in detail and how we partition them for federated evaluation.
IoT intrusion datasets and attack diversity
Dataset overview
Table 1 provides a high-level summary of the three datasets used in our study. All datasets include a mix of benign (normal) and malicious traffic records with each malicious record labeled by a specific attack type. However, they differ in scale and attack taxonomy. Edge-IIoTset contains approximately 21 million according to its authors. It spans 5 attack categories and includes 41 features per flow (derived from packet-level data). In contrast, CIC-IoT2023 comprises around 46.7 million network flow records (extracted from extensive pcap logs covering 105 devices). It defines 7 top-level attack classes, each corresponding to several specific attacks (33 total). TII-SSRC-23 has an intermediate size (the dataset is \(\sim\)8.7 GB including raw PCAP and CSV features); it has approximately 8.7 million flows. Uniquely, TII-SSRC-23 labels attacks at a fine granularity of 26 distinct attack subtypes, though for analysis one can also group them into the 4 broader threat categories (DoS, brute-force, etc.) mentioned in Table 1. For consistency with Edge-IIoTset and CIC-IoT2023 class granularity, we report TII-SSRC-23 results at the family level (4 attack families + benign) in Tables 7 and 8; subtype-level metrics are discussed qualitatively and deferred to the supplement. All three datasets provide a rich playground to test IDS models: Edge-IIoTset and CIC-IoT2023 include various network attack vectors (network floods, scans, injection exploits), and TII-SSRC-23 adds multiple variations and Mirai botnet traffic.

Distribution of records. (a) Edge-IIoTset dataset is highly imbalanced with several attack categories have relatively few samples, reflecting the realistic scenario where certain exploits are less frequent, (b) CIC-IoT2023 dataset contains several high-volume attack categories and all 33 specific attacks fall into these 7 classes; the figure aggregates at class-level for clarity, and (c) TII-SSRC-23 dataset grouped attacks into four high-level categories and contains many sub-types under each category (26 malicious sub-types total).
Attack distribution and diversity
One major difference among the datasets lies in how the malicious traffic is distributed across attack types. This has implications for model training (class balance) and for evaluating how well a model can detect both frequent and rare attacks. Figure 2 visualize the attack distribution in each dataset (number of records per attack category).
-
Edge-IIoTset11, as seen in Fig. 2a, exhibits an imbalanced distribution with a few attack types dominating. DoS/DDoS and information gathering attacks together make up the bulk of malicious traffic (in our illustration, roughly 8.3 million and 1.2 million records respectively), whereas specialized attacks like injection or malware are on the order of only 67–74k records. There is also a substantial benign portion—typically, benign traffic samples far outnumber any single attack type. The dataset’s creators acknowledge this imbalance but also stress that it reflects reality and that the diversity of types is more important for driving robust IDS development. For modeling, this means an IDS must cope with minority classes; techniques like class weighting or oversampling might be needed, but in FL settings not all clients may even see those rare classes, making it challenging (this is precisely where FedProx might help to not overfit one client’s majority class).
-
CIC-IoT202312 (Fig. 2b) has a more evenly spread attack distribution compared to Edge-IIoTset, albeit still skewed towards certain attack families. By design, each of the 7 categories contains at least one attack scenario; the DDoS category alone includes 11 different flooding attacks (ACK flood, UDP flood, Slowloris, etc.), which collectively produce a large number of malicious flows (we show \(\sim\)34 million, making it the largest category). The DoS category (distinct from DDoS in this dataset’s labeling) contributes another \(\sim\)8 million flows with 4 types of single-source floods. Notably, Mirai attacks account for a significant chunk (\(\sim\)2.6 million)—these include Mirai’s GRE IP and UDP flood behaviors. Meanwhile, brute force (only a dictionary SSH password attack) are very few. Reconnaissance attacks (port scans, ping sweeps, etc.) are also numerous (\(\sim\)354k). Overall, CIC-IoT2023 presents a large-scale, but somewhat balanced malicious dataset—multiple attack classes have substantial representation, which can facilitate training multi-class classifiers. However, the benign traffic in CIC-IoT2023 is also extremely large (tens of millions of flows), meaning that in a raw dataset the class ratio is still heavily tilted to normal. The dataset authors encourage evaluating both binary detection (malicious vs benign) and multi-class classification; in our study we focus on the multi-class aspect to stress-test models on fine-grained attack identification.
-
TII-SSRC-2313 (Fig. 2c) aimed to introduce a wide variety of attacks, but not necessarily to balance them equally. From the figure, DoS attacks constitute the largest category of malicious data (e.g., various flooding attacks summing to \(\sim\)7.5 million flows). “Info Gathering” (reconnaissance scans, vulnerability probing) has around 1 million flows in our depiction. The Mirai botnet category (which could include Mirai’s scanning behavior, exploitation phase, and DDoS attacks launched by the botnet) is \(\sim\)91k. Brute force attacks (e.g., password guessing) appears small (\(\sim\)35k). The TII dataset emphasizes the breadth of sub-attacks. For instance, within DoS one might find several distinct vectors (HTTP flood, UDP flood, etc.), each maybe with a few thousand samples. While this provides an excellent test for fine-grained classification, it also means a model has to learn many classes with limited samples per class. The creators note that the benign traffic in TII-SSRC-23 is outnumbered by malicious (like most datasets), but they attempted to mitigate extreme imbalance by generating a relatively large set of malicious flows across those 26 subtypes.
Common attack types
There is overlap in attack types across the datasets, which allows us to define some “common attacks” for comparative evaluation. All three datasets feature Denial of Service (DoS) attacks (including distributed DoS)—e.g., Edge-IIoTset and CIC have many forms of flooding; TII includes multiple DoS variants. All include scanning/reconnaissance activities (Edge’s “scanning”, CIC’s “Recon”, TII’s “info gathering”) and some form of brute-force password attack (Edge’s “password” attacks, CIC’s SSH dictionary attack, TII’s brute-force category). These three can be considered the core attack types present across all. Other attacks like Man-in-the-Middle (MITM) or spoofing appear in Edge and CIC (ARP spoofing is in CIC, and Edge lists MITM), but not explicitly in TII. Injection attacks (SQL injection, command injection) and XSS are present in Edge and CIC under web-based attacks, but not covered in TII. Backdoor/Malware attacks are represented in Edge (backdoor traffic, ransomware) and CIC (a “backdoor malware” scenario, plus Mirai which is malware)—for TII, the Mirai botnet category serves as the malware/backdoor representation. In our experiments we will sometimes focus on the common categories (DoS, scanning, brute-force) to compare performance uniformly. We also investigate the model’s ability to detect unseen attacks by training on one dataset and testing on another—e.g., how a model trained on CIC’s attacks performs on Edge’s unique ransomware traffic, or vice versa. This will shed light on attack generalizability.
Methodology

Client partitioning metadata and seeds. CIC-IoT2023 stratified by device-group, Edge-IIoTset by device or application type, TII-SSRC-23 by stratified random flow sampling. Global seed 42 with dataset seeds Edge=1729, CIC=2023, TII=1103. Exact client indices and split files are provided in the supplementary package. Clients are represented as \(C_b ^a\), where a = (E \(\rightarrow\) Edge-IIoT, C \(\rightarrow\) CIC-IoT2023, T \(\rightarrow\) TII-SSRC-23) and b is client ID.
FL setup
We simulated FL separately for each dataset and also combined all datasets in a cross-dataset FL scenario. For single-dataset experiments, each dataset was split among multiple clients representing different organizations or network nodes (Table 2). For example, Edge-IIoTset was divided into 6 clients based on device types, creating a moderately non-i.i.d. distribution where each client had distinct attack profiles. CIC-IoT2023, larger in scale, was partitioned into 10 clients grouped by subsets of devices, resulting in somewhat more uniform distributions. TII-SSRC-23 was split into 5 clients with randomized but balanced traffic to simulate an i.i.d. setting. We map “environmental heterogeneity” to distributional shift across datasets and clients via (a) label-space mismatch and aggregation (Table 1), (b) feature alignment for multi-dataset training, and (c) client-level non-IID partitioning (Table 2). Temporal non-stationarity and continual incorporation of novel attacks are out of scope for this dataset-centric study. Client-level counts, benign versus attack proportions, class coverage, stratification keys, and seeds are summarized in Table 3.
Edge-IIoTset is partitioned into 6 clients by device/application; CIC-IoT2023 into 10 clients by device group; TII-SSRC-23 into 5 clients by stratified random flows. Per-client Total flows sum to Table 1 totals (Edge 21,000,000; CIC 46,000,000; TII 8,700,000); Benign/Attack shares per client match Fig. 2. Client metadata appear in Fig. 3 and are fixed across all runs.
Labels are harmonized to (Benign, DoS/DDoS, Recon/InfoGather, BruteForce). Features are aligned to the intersection of 40 numeric flow features with z-score normalization (fit on training split only); in cross-dataset tests the source scaler is applied to the target. No domain adaptation is applied in main results. The full feature intersection is listed in Table 3.
In the combined scenario, each client represented one entire dataset, forming a highly heterogeneous federation across different network environments. We aligned these datasets by selecting only common features and normalizing them to ensure consistency. The combined label space included all attack classes from the three datasets, some merged to avoid overlap, allowing the global model to learn a broad spectrum of attack behaviors.
Each FL experiment ran for enough communication rounds to ensure convergence: typically 50 rounds for single-dataset cases and up to 100 for the combined one due to its complexity. All clients participated synchronously in each round, training locally for 5 epochs with mini-batches of 128 samples. The learning rate was 0.001 for LSTM models and 0.0005 for Transformers (Table 4). These settings were kept consistent across algorithms to fairly compare FedAvg, FedProx, and FedNova.
Federated algorithms
We implement three aggregation algorithms at the server: FedAvg, FedProx, and FedNova. Algorithm 1 summarizes the general federated learning process. FedAvg simply averages the model weight updates from clients weighted by number of samples. FedProx in our implementation behaves like FedAvg during aggregation but we modify the clients’ local loss to include a proximal term \(\frac{\mu }{2} \cdot \left\| {\bf w} - {\bf w}_{\text {global}} \right\| ^2\) (we set \(\mu = 0.001\)) which penalizes the deviation from the current global weights. This tends to make local training steps smaller when a client’s optimal diverges from global, thereby improving stability on heterogeneous data. FedNova requires each client to report not just the weight update but also the number of local updates it performed; the server computes a normalized average where each client’s update is scaled by \(\frac{1}{\tau _i}\) (\(\tau _i\) being the number of local training steps on client i) and then a weighted sum. Algorithm 2 details the FedNova aggregation mechanism. We use the implementation from the authors’ open-source code to ensure correctness. In practice, FedNova lets us allow, for example, Edge dataset client to do more local epochs than CIC’s in the combined scenario without biasing the solution – it will normalize those extra updates out. We note that FedNova and FedAvg coincide if every client does the same amount of work each round, so in the single-dataset experiments (where we fixed equal local epochs for all clients), FedNova’s results were almost identical to FedAvg’s – however, in the combined experiment we expect differences. For FedProx, we performed a coarse sensitivity sweep \(\mu \in (10^{-5}, 10^{-4}, 10^{-3}, 10^{-2})\) on Edge-IIoTset and CIC-IoT2023 validation splits under non-IID partitioning and selected \(\mu = 10^{-3}\), which consistently reduced round-to-round oscillation without measurable loss in final macro-F1.
We intentionally restrict to FedAvg/FedProx/FedNova to probe how data heterogeneity, not optimizer family variation governs generalization and convergence. FedAvg is the canonical baseline; FedProx stabilizes client drift under non-IID class mixtures; FedNova corrects for unequal local work and data volumes, which dominate in combined multi-dataset federation.

FL round (general).
where, \(w^{(t)}\) is the updated global model after round t, \(w_k^{(t)}\) is the model from client k after local training, \(n_k\) is the number of samples at client k, \(n = \sum _{k=1}^K n_k\) is the total number of samples.
where \(F_k(w)\) is the local empirical risk at client k, and \(\mu\) is the proximal term coefficient.
where \(\Delta w_k = w_k^t- w^{(t-1)}\) is the accumulated local update at client k, and \(\tau _k= E * \lceil \frac{|D_k|}{batch}\rceil\) is the number of local steps performed by client k, the server normalizes updates by \(\tau _k\) before aggregation (Algorithm 2).

FedNova aggregation code.
Deep learning models
We use two IDS classifiers per client (and thus globally):
-
LSTM: a 2-layer LSTM (64 then 32 units) with dropout 0.2 between layers, followed by two dense layers. Inputs are network-flow features (41 dims Edge, 46 CIC, 79 TII; after alignment 40 common features) fed as a length-1 sequence–treating each flow as one timestep. Functionally this behaves like a gated feed-forward net, capturing feature interactions rather than temporal flow sequences.
-
Transformer encoder: 2 encoder blocks, 4 heads, hidden size 64. We reshape the feature vector into four equal segments to create pseudo-positions, add positional encodings, pool the encoder outputs, then use a dense output. This follows tabular-Transformer practice of segmenting features.
Both models produce class probabilities via softmax (sigmoid for binary tasks) and are trained with categorical cross-entropy. In federated learning, there is no pretraining: the server initializes weights randomly at round 0 and broadcasts them; all clients train the same architecture locally in parallel. Data are used as-is after standard normalization, with no pre-sampling or augmentation.
Input and preprocessing: each example is a flow-level record with numeric features only; no IP addresses or port identifiers are used. Per client, we fit a standard scaler on the training split and apply it unchanged to validation and test. Mini-batches are drawn uniformly from the client’s training split; we do not re-balance or augment classes in main runs. For combined training we first harmonize labels and intersect features to a 40-dimensional vector (Table 3), then apply the same per-client normalization.
Algorithm 3 describes the local training routine for both LSTM and Transformer models. We use Adam (\(\beta\)1=0.9, \(\beta\)2=0.999) with weight decay \(10^{-4}\); early-stopping with patience 3 on client-held validation (stratified 90/10 split) is enabled in ablations; main runs follow fixed-epoch training for comparability.
Rationale and sensitivity: defaults: batch 128, E = 5 local epochs, \(\eta\) = \(10^{-3}\) (LSTM) and 5x\(10^{-4}\) (Transformer), \(\mu\) = \(10^{-3}\) (FedProx). A coarse sweep over \(\eta\) \(\in\) 5x\(10^{-4}\), \(10^{-4}\), 2x\(10^{-3}\), \(E \in\) {3, 5, 7}, batch \(\in\) {64, 128, 256}, \(\mu \in\) {\(10^{-5}\), \(10^{-4}\), \(10^{-3}\), \(10^{-2}\)} changed macro-F1 by \(\le \pm\)0.5 percentage points; we therefore keep the listed defaults in main runs.

LocalTrain (LSTM or transformer).
Equations (4)–(9) define the forward pass computations for the LSTM model and Eq. (10) describes the self-attention mechanism employed by the Transformer.
where Q, K, and V are the query, key, and value matrices, and \(d_k\) is the dimension of the key vectors.
Evaluation metrics
For evaluation we used standard classification metrics:
-
Accuracy measures overall correct predictions:
$$\begin{aligned} \text {Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \end{aligned}$$(11)where TP is the true positives, TN is the true negatives, FP is the false positives, and FN is the false negatives. Since IoT datasets are often imbalanced, accuracy alone can be misleading.
-
Precision (Positive Predictive Value) reflects how many predicted attacks are correct:
$$\begin{aligned} \text {Precision} = \frac{TP}{TP + FP} \end{aligned}$$(12)We compute both binary and per-class precision to assess performance across all attack categories.
-
Recall (Detection Rate) measures how many actual attacks were detected:
$$\begin{aligned} \text {Recall} = \frac{TP}{TP + FN} \end{aligned}$$(13)It indicates the IDS’s effectiveness in minimizing missed attacks.
-
F1-Score is the harmonic mean of precision and recall:
$$\begin{aligned} \text {F1} = 2 \text { x} \frac{\text {Precision x Recall}}{\text {Precision} + \text {Recall}} \end{aligned}$$(14) -
Area Under the Curve (AUC) quantifies the overall ability of the model to distinguish between classes across all classification thresholds:
$$\begin{aligned} \text {AUC} = \int _{0}^{1} TPR(FPR), dFPR \end{aligned}$$(15)where TPR (True Positive Rate) and FPR (False Positive Rate) represent the sensitivity and fall-out respectively. A higher AUC indicates better discrimination capability of the IDS.
-
Confusion Matrix provides a detailed breakdown of predictions vs actual classes. It helps identify specific misclassifications (e.g., DoS vs DDoS), and allows derivation of false positive rate (\(FPR = \frac{FP}{FP + TN}\)) and false negative rate (\(FNR = \frac{FN}{FN + TP}\)).
Results and analysis
FL performance on individual datasets
We first evaluate federated IDS training on each dataset separately. Tables 5, 6, 7 and 8 present the performance metrics of the global model after FL training on Edge-IIoTset, CIC-IoT2023, and TII-SSRC-23 respectively. In each table, we compare the three FL algorithms (FedAvg, FedProx, FedNova) and two model architectures (LSTM, Transformer). The major off-diagonal cells in Figs. 4, 5, 6 correspond to the macro-F1 ordering summarized in Tables 5-7. On Edge, \(Injection \leftrightarrow InfoGather\) spillover explains the precision-recall gap; on CIC, \(DDoS \leftrightarrow DoS\) residuals dominate the error mass. Figure 4 visualises the class-wise prediction patterns for Edge-IIoTset, confirming the numerical trends. Despite strong macro-F1 (Table 5), the confusion matrices show systematic spill-over between Injection and Information-Gathering (Figure 4), likely reflecting overlapping flow-level signatures for probing-then-payload sequences. From an IDS perspective this is a tolerable miss-specification within the “pre-exploitation/exploitation” stage but raises false triage costs. Practical mitigations include (i) hierarchical decoding with a “web/exploit” super-class followed by subtype disambiguation, (ii) class-balanced/focal losses during client training, and (iii) calibrated post-hoc thresholds for these two classes. The corresponding confusion matrices for CIC-IoT2023 are presented in Fig. 5, highlighting the residual confusions between DDoS and DoS classes. Figure 6 complements these results with per-class confusion analysis on TII-SSRC-23. The results are averaged over the test set of the respective dataset. Figure 7 shows normalized four-class confusion matrices for combined datasets, demonstrating that FedNova-Transformer achieves the cleanest diagonals (highest per-class detection rates) across Benign, DoS, Reconnaissance, and BruteForce. (Experiment settings: 50 rounds of FL, 5 local epochs, as described in Section 4).

Normalized confusion matrices for the Edge-IIoTset test set. Each sub-panel corresponds to one FL algorithm-model pair (FedAvg, FedProx, FedNova \(\times\) LSTM/Transformer). The diagonals corroborate the per-class accuracies reported and these patterns correspond to the per-class metrics aggregated in Table 5, while off-diagonal spill-over highlights residual confusions between Injection and InfoGather as well as occasional MITM mis-labelling.

Normalized confusion matrices for the CIC-IoT2023 test set. Six sub-panels show FedAvg, FedProx and FedNova with both backbone models. The residual DDoS\(\leftrightarrow\)DoS confusion aligns with Table 6, the largest error pockets appear between the closely related DDoS and DoS classes, and between Web attacks and Spoofing. FedNova-Transformer (bottom-right) achieves the cleanest diagonal, reflecting its best macro-F1.

Normalized confusion matrices for the TII-SSRC-23 test set. The five-class matrices illustrate the greater difficulty of this dataset. Per-class confusion explains the modest gap to Edge and CIC reported in Table 7. Mis-classifications mainly occur between InfoGather and DoS, and between Mirai and DoS. FedProx-Transformer yields the sharpest diagonal, evidencing its robustness on heterogeneous data.

Normalized confusion matrices for the combined datasets using four classes (benign, DoS, reconnaissance, BruteForce). Aggregates to the four-class family setting; global macro-F1 values correspond to Table 8. Each panel shows one FL algorithm–model combination (FedAvg, FedProx, FedNova \(\times\) LSTM/Transformer), with cell values representing class-wise prediction percentages.

F1-Score comparison for the IDS models ((a) transformer and (b) LSTM) across FL algorithms and datasets. Each cluster shows results for FedAvg, FedProx, and FedNova on Edge-IIoTset, CIC-IoT2023, TII-SSRC-23, and the combined dataset.
Several observations can be made from these tables:
-
High overall accuracy: all federated approaches achieved high accuracy on their respective test sets, generally in the 92–98% range. Considering the number of classes and class imbalance, this indicates the FL models learned effectively. Notably, the accuracy on Edge-IIoTset (up to 98%) is a bit higher than on CIC (97%) and TII (95%). This could be because Edge-IIoTset’s attack classes, while more numerous, might be easier to separate (some are very distinct patterns, e.g., a ransomware attack might have unique network behavior). TII’s slightly lower accuracy (\(\sim\)95%) is expected since it had the most fine-grained label space (26 sub-attacks grouped into 4 categories in our evaluation; if we had treated all 26 as separate classes, results might drop further). We also caution that accuracy can be inflated by the dominant class (benign traffic): in our test splits we roughly balanced benign and attack samples to make metrics more meaningful, otherwise accuracy would be >99% simply because benign is huge.
-
Transformer vs LSTM: the transformer model consistently outperforms LSTM on all metrics across datasets. The margin is small (often 1-2 percentage points in F1), but consistent. For example, on CIC-IoT2023 with FedAvg, Transformer F1 was 93.2% vs LSTM’s 92.0%. On TII with FedNova, Transformer reached 93.0% F1 vs LSTM’s 91.2%. The attention mechanism likely helped the model differentiate features more effectively, especially in multi-class scenarios with many subtle differences (like distinguishing various DoS types). Our Transformer was somewhat larger in capacity than the LSTM (though we kept dimensions similar, the multi-head attention introduces more parameters). That plus possibly better generalization might account for the improved precision and recall. The LSTM still performed strongly; e.g., FedNova LSTM on Edge had 94.7% F1, just \(\sim\)1.8 points behind the best Transformer. Given LSTMs are less computationally heavy for deployment, one might choose an LSTM if resources are limited and accept a slight hit in detection rates.
-
FedAvg vs FedProx vs FedNova: on the non-i.i.d. data, we see small but notable differences in performance. FedAvg is the baseline; FedProx tends to match or slightly exceed FedAvg’s metrics in most cases (especially recall). For instance, on TII (which we partitioned more i.i.d., interestingly FedProx still did a bit better, perhaps due to random fluctuations). On Edge, FedProx LSTM had 94.0% F1 vs FedAvg LSTM 93.0%. FedNova appears to give the best results in many cases—particularly on Edge and TII where data heterogeneity either in distribution (Edge’s clients each had specific attack subsets) or class granularity (TII’s many classes) could cause some clients to take longer to converge. FedNova’s normalization might have ensured more fair contributions each round, leading to a slightly better global model. On CIC, FedNova and FedProx were about tied (FedNova Transformer F1 95.2 vs FedProx 94.2). On Edge, FedNova Transformer hit the highest F1 96.5%. These improvements are on the order of 1–2 percentage points absolute, which might or might not be statistically significant depending on variance; however, they are consistent with the expectation that advanced algorithms help when data is heterogeneous. Edge’s scenario indeed had one client mostly handling “video surveillance” traffic which included a lot of DDoS, another handling “sensor” traffic with more scanning—-FedAvg in early rounds tended to overweight the DDoS-heavy client updates, causing the global model to initially do poorly on scanning detection. FedProx dampened that effect a bit with the proximal term, and FedNova effectively normalized out the fact that the DDoS-heavy client had more data (the video traffic produced more flows)—so scanning attack performance improved. Client imbalance and class coverage that drive these effects are shown in Table 3.
To illustrate the relative performance, Fig. 8a visualizes the F1-scores of the Transformer model under each FL algorithm and dataset. Similarly, Fig. 8b visualizes the F1-scores of the LSTM model under each FL algorithm and dataset. We see a trend that FedProx and FedNova (orange and red bars) are slightly higher than FedAvg (yellow) for each dataset, and that Edge and CIC have overall higher bars than TII (reflecting easier classification).
In practical terms, all three algorithms could be acceptable choices as the differences were small. FedProx’s stability did show up in training—we observed less oscillation in validation loss over rounds—but final metrics ended up close. FedNova’s benefit would likely be more evident in scenarios with imbalance in client data volumes or local epochs, which we will see in the combined experiment next. One thing to note: the slight precision improvement with FedProx/Nova indicates fewer false positives; recall improvement suggests more consistent detection of minor classes. This aligns with FedProx/Nova preventing any single client’s model from deviating—essentially, they keep the global model more general. On TII, for example, FedAvg had recall 89% (Transformer) whereas FedProx/Nova had 91–92%, meaning FedAvg missed a few more instances of some attacks (likely the ones only present on one client). FedProx’s proximal term effectively acted like regularization, making the model a bit more conservative but better at capturing all classes.

Convergence curves of the global model (Transformer) under different FL algorithms in a highly heterogeneous setting (combined dataset training). FedNova (red) shows the fastest rise in accuracy and reaches \(\sim\)95% by 20 rounds, converging slightly above FedAvg (blue) and FedProx (green). FedAvg converges more slowly and plateaus \(\sim\)94.5%. FedProx improves to \(\sim\)95% with more rounds, showing more stability (smaller oscillations) than FedAvg. The y-axis is accuracy (%) and x-axis is communication rounds.
Training convergence and efficiency
Next, we examine how the federated algorithms perform during training in terms of speed and communication costs. Figure 9 shows the accuracy on a validation set as the number of communication rounds increases, focusing on the combined multi-dataset scenario, the most challenging setup where differences between algorithms are clearer. Consistent with Table 9, FedNova reaches 95% in 40 rounds versus 50 for FedAvg, cutting communication by about 20% and reducing wall-time from 100 to 80 minutes in our setup.
When the data distribution is fairly uniform (like in TII’s near-i.i.d. case), all algorithms reach 90%+ accuracy within \(\sim\)10-15 rounds and then fine-tune similarly. But for more diverse and uneven data (Edge, CIC, or combined), the differences emerge:
-
FedAvg tends to converge more slowly and sometimes to a slightly lower peak accuracy because it averages client updates without accounting for differences in their data. For example, in the combined scenario, it lags early on and never quite catches up fully, ending \(\sim\)95% accuracy but with some fluctuations.
-
FedProx improves stability by limiting how much client models can drift from the global model. It starts similar to FedAvg but overtakes it after about 20 rounds and shows smoother progress. While it doesn’t dramatically speed things up, it helps avoid instability and ensures client updates don’t conflict.
-
FedNova converges fastest and achieves the best final accuracy. By allowing clients with more data to take more local training steps, while normalizing their contributions, it makes bigger strides early on. FedNova reaches \(\sim\)90% accuracy in just 5 rounds and hits 95% by 20 rounds, significantly faster than FedAvg’s 30-35 rounds. This reduces communication overhead and training time, making it very efficient.
Table 9 compares these algorithms in detail on the combined dataset scenario, showing FedNova requires fewer rounds (40 vs. 50 for FedAvg) to reach 95% accuracy and uses about 20% less communication time. FedProx takes slightly longer here (55 rounds) due to smaller update steps but might outperform FedAvg given more rounds. In settings where bandwidth or time is limited—like edge computing—these savings are meaningful. For less heterogeneous data, though, all methods likely converge quickly enough that differences become less significant.
In a federated IDS context, if all clients have similar data amounts and distribution, FedAvg remains a simple and strong choice. But if some clients have more data or unique attack types, FedProx can improve consistency and FedNova can significantly accelerate learning. The cost is that FedNova requires tracking additional information (client update lengths) and careful tuning if local epochs vary widely. Our experiments used equal local epochs for fairness; more aggressive heterogeneity might show even bigger FedNova gains.
Cross-dataset generalizability
We evaluate a 3 \(\times\) 2 \(\times\) 3 design: source dataset \(\in\) {Edge-IIoTset, CICIoT, TII-SSRC} \(\times\) backbone \(\in\) {LSTM, Transformer} \(\times\) FL algorithm \(\in\) {FedAvg, FedProx, FedNova}. For each source model we apply the source-fitted scaler to the target features and use the family-level label map defined in Section 4.1. Metrics are macro-averaged on the target test set. Representative baselines are reported in text. Consistently, Transformers and FedProx or FedNova reduce the out-of-domain drop relative to LSTM and FedAvg, aligning with in-domain results (Tables 5–8).
A federated model trained jointly on all three datasets generalized far better, reaching 88–90% F1 on every test set–close to per-dataset specialists. Takeaway: multi-dataset training and evaluation matter; single-dataset models often don’t transfer. In practice, handle feature alignment carefully and consider domain adaptation or light fine-tuning when moving to a new environment.
Discussion
Our results highlight that attack diversity is crucial for building robust IDS models. Training on a narrow set of attacks limits the model’s ability to detect unseen threats, as seen in the cross-dataset evaluations where models struggled with attacks absent in their training data. FL offers a way to aggregate knowledge from multiple sources, producing models that generalize better by learning from a broader range of attack types and network conditions.
When comparing FL to centralized training, our experiments show minimal loss in accuracy, indicating that FL is a practical privacy-preserving alternative without compromising performance. Among the FL algorithms, simple FedAvg performs well in many cases, but FedProx and FedNova provide added stability and efficiency, especially when client data distributions are uneven. These benefits can be important in real-world deployments where data heterogeneity is common.
Regarding model architectures, Transformers slightly outperform LSTMs due to their ability to capture complex feature relationships, but LSTMs remain a solid choice for resource-constrained edge devices. Communication trade-offs also matter: FedNova can reduce communication rounds at the expense of more local computation, while FedProx offers a stable compromise. Our combined multi-dataset federated training demonstrates the potential of collaborative learning across organizations, though challenges remain in handling feature mismatches and domain differences. Future work could explore continual learning, domain adaptation, and testing on real-world and open-world datasets to further improve IDS generalizability.
Conclusion
This study presented a dataset-centric evaluation of federated intrusion detection for IoT networks, benchmarking FedAvg, FedProx, and FedNova aggregation methods in combination with LSTM and Transformer models on the Edge-IIoTset, CIC-IoT2023, and TII-SSRC-23 datasets. Our experiments demonstrated that FL can yield high detection performance, often matching centralized approaches, and that advanced FL algorithms provide additional gains in heterogeneous or non-i.i.d. data settings. However, we observed that model generalizability is strongly influenced by attack diversity and dataset coverage; models trained on a single dataset showed notable drops in F1-score when exposed to unseen threats from another dataset. Multi-domain federated training improved robustness, enabling the global model to generalize more effectively across environments, while FedNova in particular reduced communication rounds and training overhead.
Future research should incorporate more real-world data and explore federated approaches for anomaly and open set detection to address novel attacks. Techniques for domain adaptation, privacy-preserving learning, and continual model updating will be essential for deploying IDS in dynamic IoT networks. Evaluation on live systems and mechanisms for global feedback will further support operational effectiveness. Our findings highlight the importance of diverse benchmarking and cross-domain testing to ensure IDS models remain robust and practical for the evolving IoT security landscape.
Data availability
We have used public datasets for the experiments. Links to these datasets are given below, the same have been added in the manuscript aswell: – Edge-IIoTset (2022) : https://tinyurl.com/5dc6paps – CIC-IoT2023 : https://www.unb.ca/cic/datasets/iotdataset-2023.html – TII-SSRC-23 (2023) : https://www.kaggle.com/datasets/daniaherzalla/tii-ssrc-23
References
Khraisat, A. & Alazab, A. A critical review of intrusion detection systems in the internet of things: Techniques, deployment strategy, validation strategy, attacks, public datasets and challenges. Cybersecurity 4(1), 18 (2021).
Thakkar, A. & Lohiya, R. A review on machine learning and deep learning perspectives of ids for IOT: Recent updates, security issues, and challenges. Arch. Comput. Methods Eng. 28(4), 3211–3243 (2021).
Nguyen, D. C. et al. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 23(3), 1622–1658 (2021).
Rashid, M. M. et al. A federated learning-based approach for improving intrusion detection in industrial internet of things networks. Network 3(1), 158–179 (2023).
Hernandez-Ramos, J. L. et al. Intrusion detection based on federated learning: A systematic review. ACM Comput. Surv. 57(12), 1–65 (2025).
Suman, M., Gowda, S.P., Vasisht, P., Jha, R. et al. Cyber-attack classification and prediction in the network traffic using machine learning. In Computer Science Engineering. 21–28. (CRC Press, 2024)
Le Jeune, L., Goedeme, T. & Mentens, N. Machine learning for misuse-based network intrusion detection: Overview, unified evaluation and feature choice comparison framework. IEEE Access 9, 63995–64015 (2021).
Thakkar, A. & Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 55(1), 453–563 (2022).
Sharafaldin, I. et al. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 1(2018), 108–116 (2018).
Catal, C. & Diri, B. Investigating the effect of dataset size, metrics sets, and feature selection techniques on software fault prediction problem. Inf. Sci. 179(8), 1040–1058 (2009).
Ferrag, M. A., Friha, O., Hamouda, D., Maglaras, L. & Janicke, H. Edge-IIOTSET: A new comprehensive realistic cyber security dataset of IOT and IIOT applications for centralized and federated learning. IEEE Access 10, 40281–40306 (2022).
Jony, A. I. & Arnob, A. K. B. A long short-term memory based approach for detecting cyber attacks in IOT using CIC-IOT2023 dataset. J. Edge Comput. 3(1), 28–42 (2024).
Herzalla, D., Lunardi, W. T. & Andreoni, M. TII-SSRC-23 dataset: Typological exploration of diverse traffic patterns for intrusion detection. IEEE Access 11, 118577–118594 (2023).
Khan, M. A. et al. A deep learning-based intrusion detection system for MQTT enabled IOT. Sensors 21(21), 7016 (2021).
Wu, Y., Zou, B. & Cao, Y. Current status and challenges and future trends of deep learning-based intrusion detection models. J. Imaging 10(10), 254 (2024).
Reddi, S., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konečnỳ, J., Kumar, S. & McMahan, H.B. Adaptive federated optimization. arXiv preprint arXiv:2003.00295 (2020)
Li, T. et al. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2, 429–450 (2020).
Wang, J., Liu, Q., Liang, H., Joshi, G. & Poor, H. V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 33, 7611–7623 (2020).
Kalwar, J.H. & Bhatti, S. Deep learning approaches for network traffic classification in the internet of things (IOT): A survey. arXiv preprint arXiv:2402.00920 (2024)
Moustafa, N. Ton_iot Datasets (2019). https://doi.org/10.21227/fesz-dm97.
Moustafa, N. The BOT-IOT Dataset (2019). https://doi.org/10.21227/r7v2-x988.
Li, Q. et al. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 35(4), 3347–3366 (2021).
Lu, Y., Huang, X., Dai, Y., Maharjan, S. & Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IOT. IEEE Trans. Indus. Inform. 16(6), 4177–4186 (2019).
Lazzarini, R., Tianfield, H. & Charissis, V. Federated learning for IOT intrusion detection. AI 4(3), 509–530 (2023)
Lu, Z., Pan, H., Dai, Y., Si, X. & Zhang, Y. Federated learning with non-IID data: A survey. IEEE Internet Things J. 11(11), 19188–19209 (2024).
Khodak, M. et al. Federated hyperparameter tuning: Challenges, baselines, and connections to weight-sharing. Adv. Neural Inf. Process. Syst. 34, 19184–19197 (2021).
Singh, G., Sood, K., Rajalakshmi, P., Nguyen, D. D. N. & Xiang, Y. Evaluating federated learning-based intrusion detection scheme for next generation networks. IEEE Trans. Netw. Serv. Manag. 21(4), 4816–4829 (2024).
Tan, M., Iacovazzi, A., Cheung, N.-M.M. & Elovici, Y. A neural attention model for real-time network intrusion detection. In 2019 IEEE 44th Conference on Local Computer Networks (LCN). 291–299 (IEEE, 2019).
Chukwunweike, J.N., Adewale, A. & Osamuyi, O. Advanced modelling and recurrent analysis in network security: Scrutiny of data and fault resolution. (2024).
Taşcı, B. Deep-learning-based approach for IOT attack and malware detection. Appl. Sci. 14(18), 2076-3417 (2024)
Tseng, S.-M., Wang, Y.-Q. & Wang, Y.-C. Multi-class intrusion detection based on transformer for IOT networks using CIC-IOT-2023 dataset. Future Internet 16(8), 284 (2024).
Zhang, C. et al. A survey on federated learning. Knowl.-Based Syst. 216, 106775 (2021).
Wen, Q., Zhou, T., Zhang, C., Chen, W., Ma, Z., Yan, J. & Sun, L. Transformers in time series: A survey. arXiv preprint arXiv:2202.07125 (2022)
Author information
Authors and Affiliations
Contributions
M.A.B. conceived the research idea, designed the overall study, and drafted the introduction and methodology sections. I.U.I. and S.I. implemented the federated?learning framework, carried out the experiments, and performed primary data curation. M.Q. conducted the statistical analysis, generated Tables 4–8, and wrote the initial results and analysis section. M.J.K. prepared Figures 1–8 and assisted with data visualisation and interpretation. J.K. supervised the project, refined the experimental design, and critically revised the manuscript for important intellectual content. All authors discussed the results, reviewed the manuscript in full, and approved the final version for submission.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bilal, M.A., Ul Islam, I., Idrees, S. et al. Dataset-centric evaluation of federated intrusion detection models in IoT networks. Sci Rep 16, 2683 (2026). https://doi.org/10.1038/s41598-025-32567-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32567-w
